Вычисляемый столбец sql: Производительность вычисляемых столбцов в SQL Server / Хабр
Содержание
Online Documentation for SQL Manager for PostgreSQL
Выводимые поля
На этой вкладке Вы формируете выходную форму запроса.
Вы указываете, какие поля будут отображаться в результате запроса и как они будут отсортированы и сгруппированы. Можно перетащить нужное поле из рабочей области или выбрать его из раскрывающегося списка Source field name. Также, Вы можете создавать вычисляемые поля.
С помощью кнопок Вы можете изменить порядок полей.
-
В столбце Name of output указан псевдоним поля, под которым оно будет выведено в результате запроса.
-
Столбец Aggregate содержит аггрегирующую функцию. -
Source field name содержит настоящие имена столбцов, выводимых в результат запроса. -
Grouping указывает сгруппирован столбец или нет.

Если флажок Select only unique records установлен, то в результате запроса отображаются только неповторяющиеся записи.
Основные действия с полями выполняются при помощи контекстного меню, которое открывается по нажатию на поле правой кнопкой мыши.
С помощью этого меню выполняются следующие операции:
-
удаление выделенного поля — Delete current row, -
вставка вложенного запроса — Insert Query, -
вставка вычисляемого поля — Insert CASE.
Также поля можно отсортировать, щелкнув левой кнопкой мышки на заголовок столбца в котором содержатся поля.
Порядок полей в результате запроса будет соответствовать их последовательности в этой таблице.
Встроенный запрос открывается на отдельной вкладке рабочей области для редактирования и отображается в дереве подзапросов в левой части Визуального конструктора.
|
|
|
|
|
|
|
|
НОУ ИНТУИТ | Лекция | Оператор SELECT
< Урок 29 || Урок 12: 123456
Аннотация: В основе всех действий по выборке данных в окружении Microsoft SQL Server лежит один оператор Transact-SQL, оператор SELECT. В этом уроке вы познакомитесь с наиболее важными компонентами оператора SELECT, а также со способами использования конструктора запросов Query Designer для автоматического построения оператора для вас.
В этом уроке вы познакомитесь с наиболее важными компонентами оператора SELECT, а также со способами использования конструктора запросов Query Designer для автоматического построения оператора для вас.
Воспользовавшись конструктором запросов Query Designer SQL Server, вы можете ввести оператор SELECT непосредственно в панели SQL Pane, либо заставить конструктор запросов сделать это для вас, воспользовавшись панелями диаграмм Diagram Pane или сетки Grid Pane. Одна возможность не исключает другую. Вы можете начать построение запроса путем добавления таблиц в панели диаграмм Diagram Pane, переименовать столбцы в панели сетки Grid Pane и указать порядок, в котором должны располагаться строки, введя фразу ORDER BY непосредственно в панели SQL Pane.
Ключевые слова: синтаксис, множества, базовая, разделы, список, запрос, Transact-SQL, pane, Enterprise Manager, latin-1, percent
Вы научитесь:
- выбирать все столбцы в запросе;
- переименовывать столбцы в запросе;
- создавать вычисляемые столбцы в запросе;
- возвращать первые n строк в запросе;
- возвращать первые n процентов строк в запросе.
 intuit.ru/2010/edi»>выбирать подмножество столбцов в запросе;
intuit.ru/2010/edi»>выбирать подмножество столбцов в запросе;Использование оператора SELECT
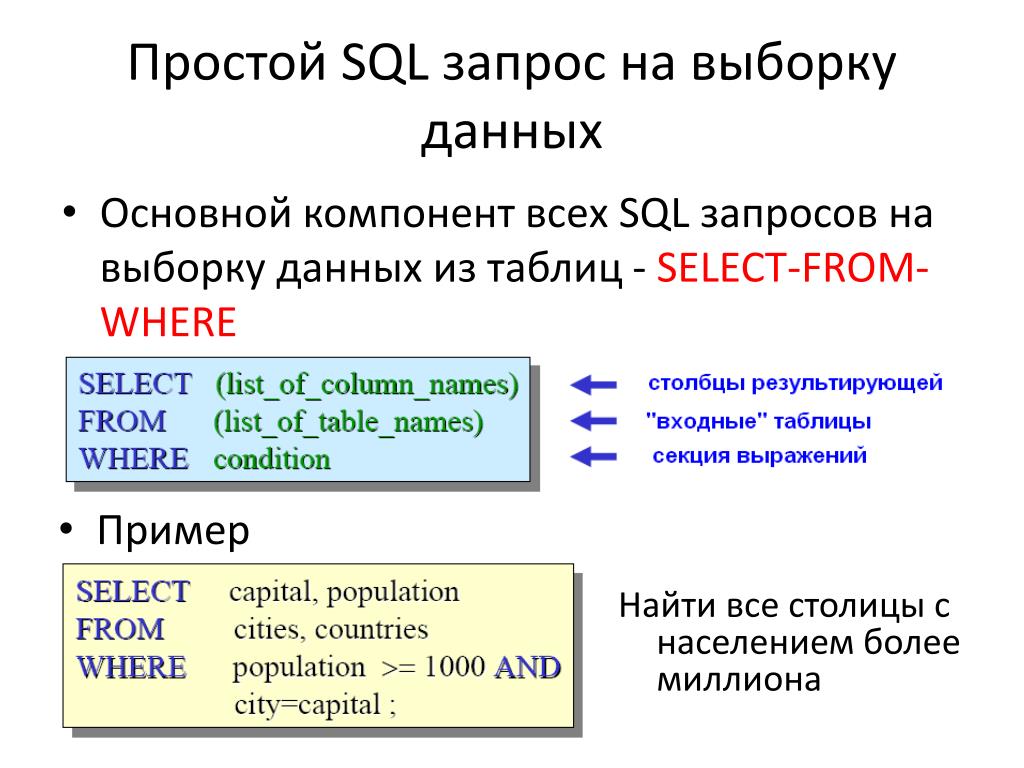
Синтаксис оператора SELECT очень сложен и состоит из множества фраз и ключевых слов, но базовая его структура достаточно проста:
SELECT [TOP n [PERCENT]] список_столбцов FROM список_источников [WHERE условие_поиска] [ORDER BY выражение]
Обязательными являются только первая и вторая фразы (разделы) оператора SELECT. Первая фраза, SELECT список_столбцов, задает столбцы, которые будут возвращены запросом. Список столбцов может содержать реальные столбцы из таблицы и представления (виды), на которых основывается запрос, либо содержать вычисляемые столбцы, получаемые из оригинальных столбцов. Вторая фраза, FROM список_источников, задает таблицы и представления, на которых основывается запрос.
Вторая фраза, FROM список_источников, задает таблицы и представления, на которых основывается запрос.
Выборка всех столбцов
Простейшим случаем использования оператора SELECT является выборка всех столбцов из одной таблицы. Как большинство версий языка SQL, Transact-SQL позволяет вам использовать знак звездочки (*), если вы хотите задать все столбцы, поэтому в этом простом случае оператор будет иметь следующую форму:
SELECT * FROM имя_таблицы
Выберите все столбцы
- Откройте конструктор запросов Query Designer для таблицы Properties, щелкнув правой кнопкой мыши на ее имени в рабочей панели Details Pane Enterprise Manager, открыв меню Open Table (Открытие таблицы) и выбрав Return All Rows (Показать все строки). SQL Server откроет конструктор запросов Query Designer для таблицы.
увеличить изображение
- Измените оператор SQL, чтобы отобразить все столбцы из таблицы Oils.
увеличить изображение
- Нажмите кнопку Run (Выполнить)в панели инструментов конструктора запросов, чтобы выполнить запрос. Конструктор запросов отобразит все записи из таблицы Oils.
увеличить изображение
 intuit.ru/2010/edi»>Включите панель SQL Pane, щелкнув на кнопке SQL Pane (Панель SQL)в панели инструментов конструктора запросов. Конструктор запросов отобразит панель SQL Pane.
intuit.ru/2010/edi»>Включите панель SQL Pane, щелкнув на кнопке SQL Pane (Панель SQL)в панели инструментов конструктора запросов. Конструктор запросов отобразит панель SQL Pane.увеличить изображение
Совет. Вы можете отобразить большее количество строк в панели результатов Results Pane, перетащив разделительную линию между двумя панелями.
Дальше >>
< Урок 29 || Урок 12: 123456
вычисляемых столбцов в SQL Server
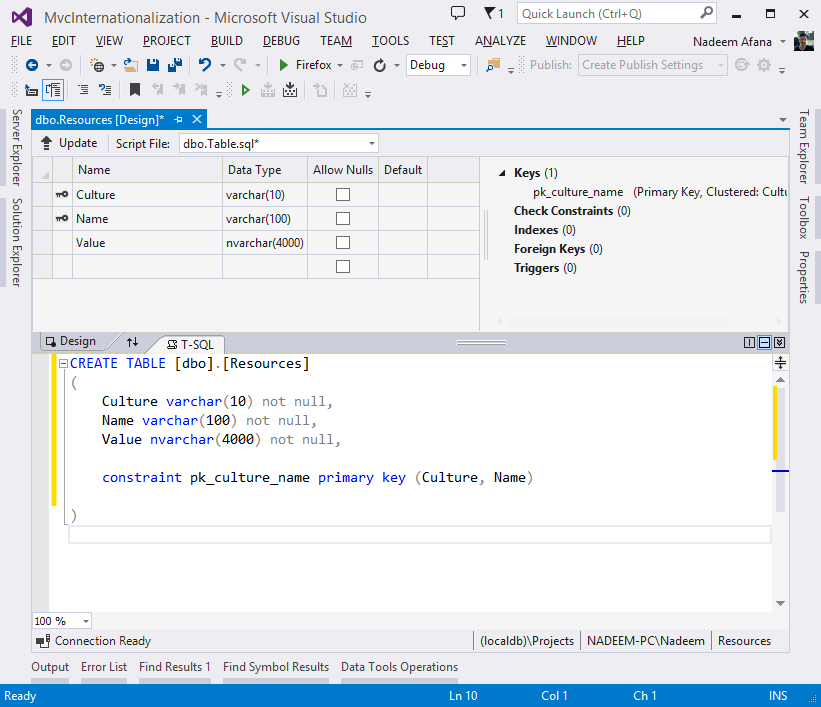
В этой статье вы узнаете о вычисляемых столбцах в SQL Server.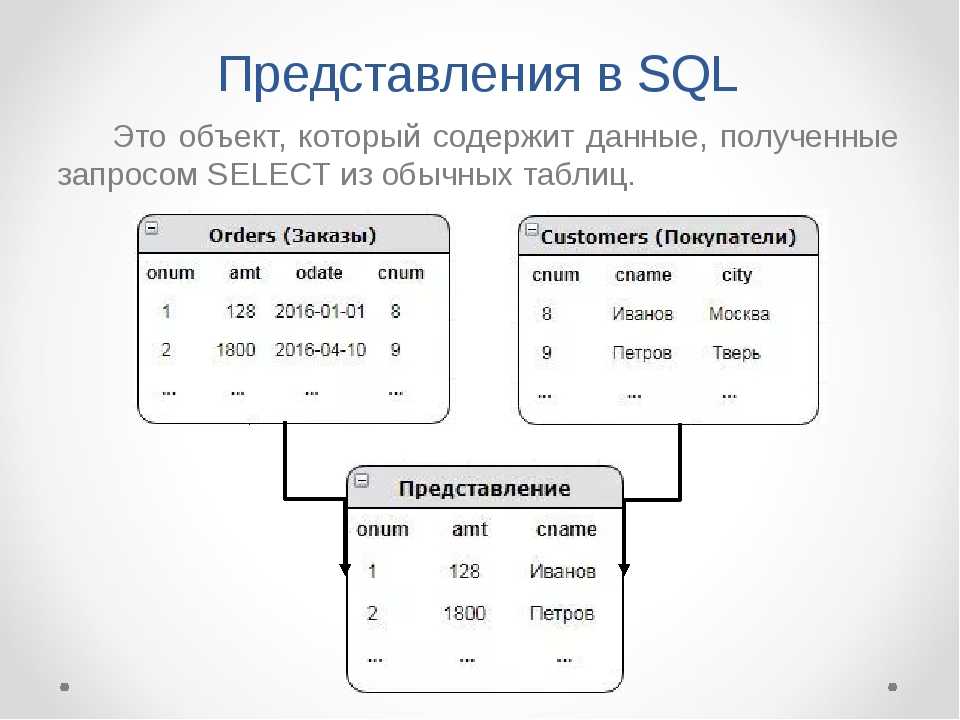 Вычисляемый столбец вычисляется из выражения, которое может использовать другие столбцы в той же таблице. Выражение может быть именем невычисляемого столбца, константой, функцией и любой их комбинацией, соединенной одним или несколькими операторами, но подзапрос не может использоваться для вычисляемого столбца.
Вычисляемый столбец вычисляется из выражения, которое может использовать другие столбцы в той же таблице. Выражение может быть именем невычисляемого столбца, константой, функцией и любой их комбинацией, соединенной одним или несколькими операторами, но подзапрос не может использоваться для вычисляемого столбца.
Например, таблица Employee_Salary содержит столбцы Emp_Id, Basic, HR, Da, Medical, Pf,+ Esi и Total_Salary, а столбец Total_Salary вычисляется, поэтому формула для Total_Salary :
Total_Salary=Basic+HR+Da+Medical+Pf+Esi
Вычисляемые столбцы на самом деле являются виртуальными столбцами, которые физически не хранятся в таблице, если столбец не помечен как PERSISTED. Значения для вычисляемых столбцов пересчитываются каждый раз, когда на них ссылаются в запросе. Значения вычисляемого столбца обновляются при изменении любых столбцов, которые являются частью их вычисления. Пометив вычисляемый столбец как PERSISTED, мы можем создать индекс для вычисляемого столбца. Вычисляемые столбцы, используемые в качестве ограничений CHECK, FOREIGN KEY или NOT NULL, должны быть помечены как PERSISTED.
Вычисляемые столбцы, используемые в качестве ограничений CHECK, FOREIGN KEY или NOT NULL, должны быть помечены как PERSISTED.
Как создать вычисляемый столбец в SQL Server
Мы можем создать вычисляемый столбец либо в запросе на создание, либо с помощью обозревателя объектов, здесь мы читаем об обоих методах.
Используя команду Create
На приведенном выше изображении мы создаем таблицу Employee_Salary, и последний столбец этой таблицы a = является вычисляемым. Теперь проверяем дизайн таблицы для столбца Total_Salary,
Если свойство Persisted отключено, вычисляемый столбец будет просто виртуальным столбцом. Никакие данные для этого столбца не будут храниться на диске, а значения будут вычисляться каждый раз при обращении к ним в сценарии. Если это свойство установлено активным, то данные вычисляемого столбца будут храниться на диске. Если для свойства Persisted установлено значение on, то для вычисляемого столбца можно создать индекс.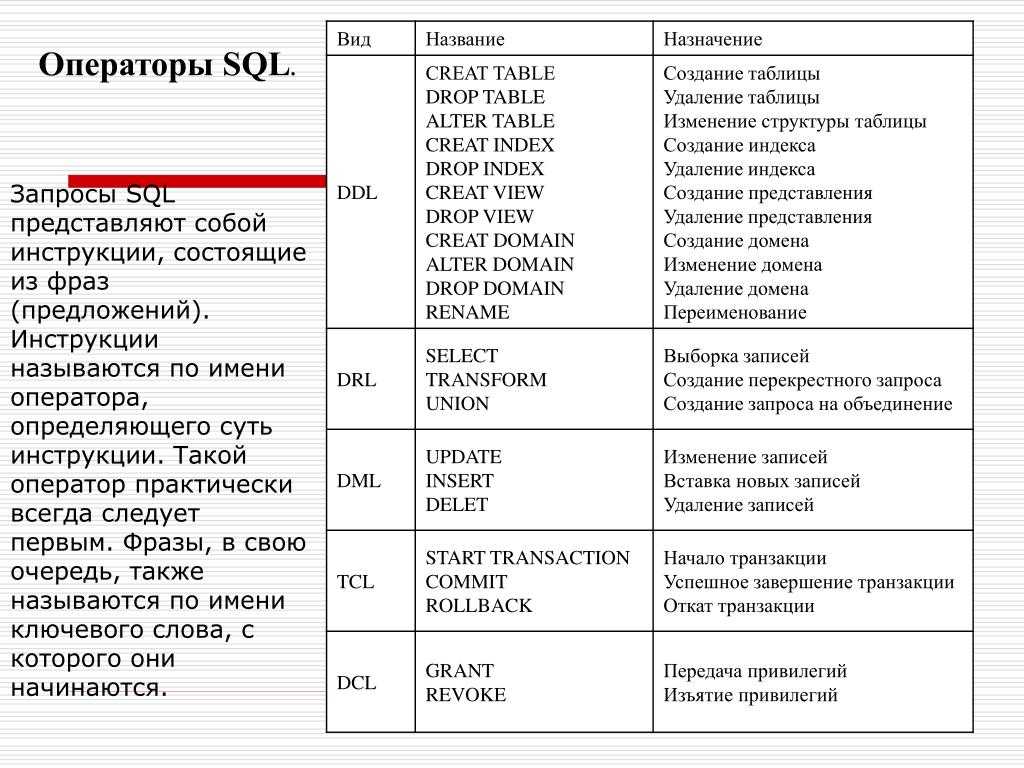
Мы видим, что столбец Total_Salary имеет вычисляемый тип, а также существует формула для этого вычисляемого столбца, и тип столбца сохраняется.
Мы также можем создать вычисляемый столбец с помощью окна обозревателя объектов. Перейдите в свою базу данных, щелкните правой кнопкой мыши таблицы, выберите опцию «Новая таблица». Создайте все столбцы, которые вам нужны, и пометьте любой столбец как вычисляемый, выберите этот столбец и перейдите в окно свойств столбца и напишите свою формулу для вычисляемого столбца.
Теперь мы вставляем некоторое значение в таблицу Employee_Salary и позже изучаем данные таблицы.
Мы видим, что мы не вставляли никаких значений для столбца Total_Salary, но этот столбец содержит значения, потому что столбец Total_Salary имеет вычисляемый тип и вычисляет значение из значений других столбцов.
Обновите содержимое таблицы
Теперь мы обновляем значения столбцов basic и HR и в таблице Employee_Salary и изучаем изменения в значениях столбца Total_Salary.
Запрос
- /*Выбрать значения из таблицы*/
- ВЫБЕРИТЕ * FROM dbo.Employee_Salaryes
- /*Обновить запись*/
- ОБНОВЛЕНИЕ dbo.Employee_Salary
- SET Employee_Salary.Medical=1000,Employee_Salary.HR=1500
- ГДЕ
- Сотрудник_Зарплата.Basic=17000
- /*Выбрать значения из таблицы*/
- ВЫБЕРИТЕ * FROM dbo.Employee_Salaryes
Вывод
На изображении выше мы видим, что значение столбцов Total_Salary для Emp_Id 2 и 5 было изменено. Таким образом, ясно, что если значения любого столбца изменяются, и этот столбец является частью вычисляемого столбца, то значения вычисляемого столбца также изменятся.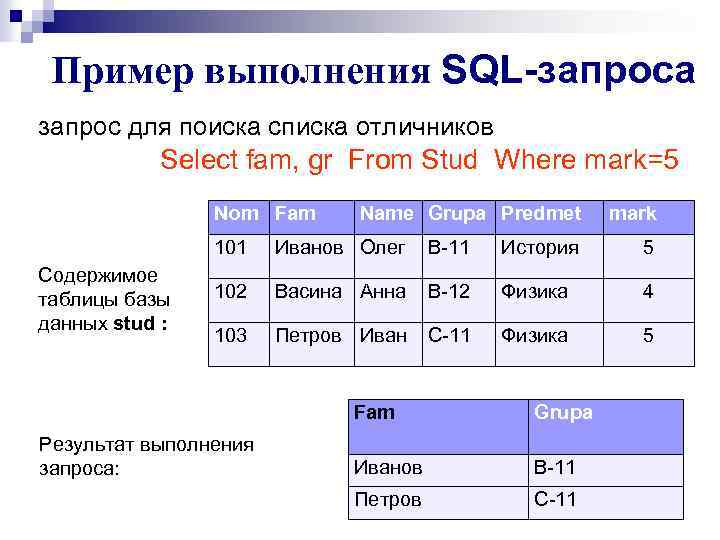
Добавить вычислимый столбец в существующую таблицу
Синтаксис
Альтер Таблица Таблица Add Column_Name AS (write_formula)
Пример
- ALTER TABLE DBO.EM.MAREEE
- ADD Total_Salary AS ([Basic]+([HR]*2)+([Da]*1.5)+([Medical]*1.4)+[Pf]+[Esi])
Изменение любого существующего столбца
Синтаксис
- Изменить таблицу Имя_таблицы Удалить столбец Имя_столбца
- ALTER TABLE Table_Name ADD Column_Name AS (Write_Formula)
Пример
- ALTER TABLE dbo.Employee_Salary DROP COLUMN dbo.Employee_Salary.Total_Salary
- ALTER TABLE dbo.Employee_Salary
- ADD Total_Salary AS ([Basic]+([HR]*2)+([Da]*1.5)+([Medical]*1.4)+[Pf]+[Esi])
Использовать функцию User_Define в вычисляемом столбце
Теперь мы узнаем, как использовать пользовательские функции для вычисляемых столбцов. Сначала мы создаем функцию, которая возвращает рассчитанную зарплату
Сначала мы создаем функцию, которая возвращает рассчитанную зарплату
Функция
- [число])
- ВОЗВРАТ [число с плавающей запятой]
- СО СХЕМОЙ ПРИВЯЗКИ
- КАК
- НАЧАЛО
- DECLARE @Total_Salary [float];
- ЕСЛИ @Employee_Type=1
- НАЧАЛО
- SET @Total_Salary= @basic+@Da*1.2+@Esi*1.4+@Hr*2+@Medical*1.8+@Pf*2.5
- КОНЕЦ
- ИНАЧЕ ЕСЛИ @Employee_Type=2
- НАЧАЛО
- SET @Total_Salary= @basic+@Da*1.3+@Esi*1.5+@Hr*2+@Medical*1.8+@Pf*2.5
- КОНЕЦ
- ЕСЛИ @Employee_Type=3
- НАЧАЛО
- SET @Total_Salary= @basic+@Da*1. 8+@Esi*1.6+@Hr*3+@Medical*1.8+@Pf*2.5
- КОНЕЦ
- ВОЗВРАТ @Total_Salary;
- КОНЕЦ
 8+@Esi*1.6+@Hr*3+@Medical*1.8+@Pf*2.5
8+@Esi*1.6+@Hr*3+@Medical*1.8+@Pf*2.5 Теперь мы используем эту функцию в вычисляемом столбце.
Ограничения вычисляемого столбца
- Вычисляемый столбец не может быть целью инструкции INSERT или UPDATE.
- Мы не можем напрямую ссылаться на столбцы из других таблиц для выражения вычисляемого столбца.
- Обнуляемость значения вычисляемого столбца будет определяться самим ядром базы данных. Результат большинства выражений считается допускающим значение NULL, даже если присутствуют только столбцы, не допускающие значения NULL, поскольку возможные потери значимости или переполнения также приведут к нулевым результатам. Чтобы преодолеть эту проблему, функция COLUMNPROPERTY с Свойство AllowsNull .
а. Подзапрос нельзя использовать в качестве выражения для создания вычисляемого столбца.
б. Если мы используем разные типы данных в нашем выражении, то оператор с более низким приоритетом попытается преобразовать его в тип данных с более высоким приоритетом. Если неявное преобразование невозможно, будет сгенерирована ошибка.

Заключение
Используйте вычисляемый столбец для таблицы, если вы хотите вставить данные в столбец после выполнения вычислений с данными другого столбца. Вы можете использовать скалярное выражение или пользовательскую функцию для вычисляемых столбцов
.
Прочтите дополнительные статьи о SQL Server
sql server — SQL: используйте вычисляемый столбец, только что определенный в последующих вычислениях
Я провел несколько тестов и обнаружил, что на производительность различных решений влияет количество задействованных записей, поэтому они разные сценарии могут быть представлены.
CTE и SUBSELECT на самом деле почти одинаковые, и план такой же. .
.
Double LEAD() всегда должен быть худшим, глядя на план кажется, что LEAD() вычисляется дважды (с сегментом и проектом последовательности) со стоимостью, превышающей скалярное значение cte и subselect.
Но кажется, что Double LEAD() может лучше использовать параллелизм, поэтому общее время выполнения может быть меньше.
Для огромной таблицы с очень большим количеством строк Double LEAD() , вероятно, наихудший вариант, а CTE или SUBSELECT будут лучшими.
Есть еще вариант, можно использовать CTE с ROW_NUMBER() вместо LEAD() .
План запроса действительно уродлив по сравнению с другими, но время выполнения может быть лучше, чем у других решений, оно зависит от версии SQL Server (Express или Standard) и от серверного оборудования (ядер и оперативной памяти) для параллелизма.
Проверить примерно так:
;С
л КАК (
ВЫБЕРИТЕ ID_ChargeCarrier, StoredOn, ROW_NUMBER() OVER (РАЗДЕЛЕНИЕ ПО ID_ChargeCarrier ORDER BY StoredOn) AS row_id
ИЗ MyTable
)
ВЫБРАТЬ
ID_ChargeCarrier, l1. StoredOn, l2.StoredOn AS LeftOn,
l2.StoredOn, l1.StoredOn AS TimeDifference
С л л1
LEFT JOIN l l2 ON l1.ID_ChargeCarrier = l2.ID_ChargeCarrier AND l1.n = l2.n - 1
 StoredOn, l2.StoredOn AS LeftOn,
l2.StoredOn, l1.StoredOn AS TimeDifference
С л л1
LEFT JOIN l l2 ON l1.ID_ChargeCarrier = l2.ID_ChargeCarrier AND l1.n = l2.n - 1
StoredOn, l2.StoredOn AS LeftOn,
l2.StoredOn, l1.StoredOn AS TimeDifference
С л л1
LEFT JOIN l l2 ON l1.ID_ChargeCarrier = l2.ID_ChargeCarrier AND l1.n = l2.n - 1
Для своих тестов я использую эту таблицу, заполненную 3 миллионами записей.
СОЗДАТЬ ТАБЛИЦУ [dbo].[_Memberships](
[MembershipId] [int] НЕ NULL,
[ValidFromDateKey] [дата] НЕ NULL,
[ValidToDateKey] [дата] NULL,
[ColInt] [int] IDENTITY(1,1) NOT NULL,
[ColGUID] [уникальный идентификатор] NULL,
[ColVarChar] [varchar](250) NULL,
[ColChk] AS (контрольная сумма ([ColVarChar])),
ОГРАНИЧЕНИЕ [PK_Memberships] ПЕРВИЧНЫЙ КЛЮЧ КЛАСТЕРИРОВАННЫЙ ([MembershipId] ASC)
WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) НА [ПЕРВИЧНОМ]
ИДТИ
ИЗМЕНИТЬ ТАБЛИЦУ [dbo].[_Memberships] ДОБАВИТЬ ОГРАНИЧЕНИЕ [DF_Memberships_ColGUID] ПО УМОЛЧАНИЮ (newid()) ДЛЯ [ColGUID]
ИДТИ
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС [ix_checksum] ON [dbo].