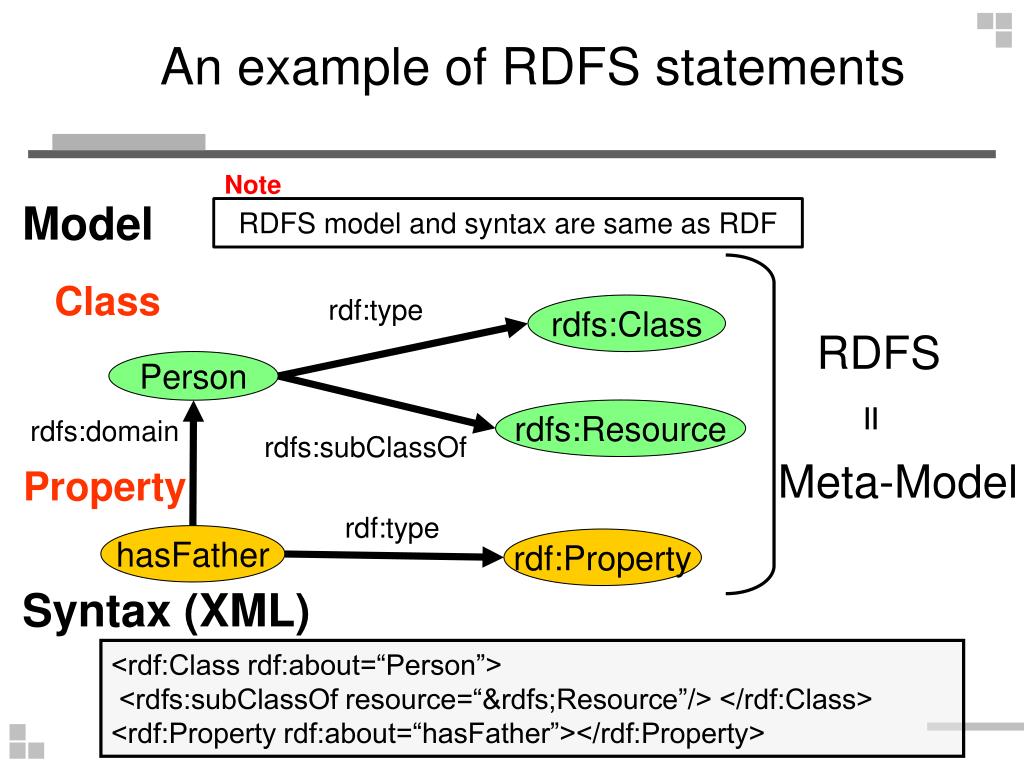
Xml синтаксис: Правила синтаксиса XML
Содержание
Правила синтаксиса XML
Правила синтаксиса XML крайне просты и логичны. Их легко запомнить и легко использовать.
Все XML элементы должны иметь закрывающий тег
В HTML некоторые элементы могут не иметь закрывающего тега:
<p>Это параграф. <br>
В XML нельзя опускать закрывающий тег. Абсолютно все элементы должны закрываться:
<p>Это параграф.</p> <br>
Возможно, вы заметили из предыдущих примеров, что XML декларация не имеет закрывающего тега. Это не ошибка. Дело в том, что декларация не относится к XML документу, поэтому у нее и нет закрывающего тега.
Теги XML регистрозависимы
Теги XML являются регистрозависимыми. Так, тег <Letter> не то же самое, что тег <letter>.
Открывающий и закрывающий теги должны определяться в одном регистре:
<Message>Это неправильно</message> <message>Это правильно</message>
Замечание: «Открывающий и закрывающий теги» иногда еще называют «начальный и конечный теги». Используйте то определение, которое вам более симпатично. По сути это одно и то же.
Используйте то определение, которое вам более симпатично. По сути это одно и то же.
XML элементы должны соблюдать корректную вложенность
В HTML иногда можно наблюдать такую картину:
<b><i>Это жирный и курсивный текст</b></i>
и иногда это даже работает должным образом.
В XML все элементы обязаны соблюдать корректную вложенность:
<b><i>Это жирный и курсивный текст</i></b>
Понятие «корректная вложенность» по отношению к приведенным примерам просто означает, что так как элемент <i> открывается внутри элемента <b>, то и закрываться он должен внутри элемента <b>.
У XML документа должен быть корневой элемент
XML документ должен содержать один элемент, который будет родительским для всех других элементов. Он называется корневым элементом.
<корневой>
<потомок>
<подпотомок>... ..</подпотомок>
</потомок>
</корневой>
..</подпотомок>
</потомок>
</корневой>
 ..</подпотомок>
</потомок>
</корневой>
..</подпотомок>
</потомок>
</корневой>
XML пролог
Следующая строка называется XML прологом:
<?xml version="1.0" encoding="UTF-8"?>
XML пролог необязателен. Но если он есть, то это должна быть первая строка XML документа.
В XML документе могут присутствовать международные символы, вроде русских букв, и чтобы не возникало ошибок необходимо указать кодировку, либо сохранить XML файл в формате UTF-8.
UTF-8 — кодировка XML документов по умолчанию.
Значения XML атрибутов должны заключаться в кавычки
Так же, как и в HTML, у XML элементов могут быть атрибуты в виде пары имя/значение.
В XML значения атрибутов должны заключаться в кавычки.
Посмотрите на следующие два примера XML документа. Первый с ошибкой, второй написан правильно:
<note date=12/11/2007> <to>Tove</to> <from>Jani</from> </note> <note date="12/11/2007"> <to>Tove</to> <from>Jani</from> </note>
Ошибка в первом XML документе заключается в том, что значение атрибута date элемента note не заключено в кавычки.
Сущности
Некоторые символы в XML имеют особые значения.
Если вы поместите, например, символ «<» внутри XML элемента, то будет сгенерирована ошибка, так как парсер интерпретирует его, как начало нового элемента.
Так, к ошибке приведет следующая строка XML документа:
<message>если жалование < 1000</message>
Чтобы такая ошибка не возникала, нужно заменить символ «<» на его сущность:
<message>если жалование < 1000</message>
В XML существует 5 предопределенных сущностей:
| Сущность | Символ | Значение |
|---|---|---|
| < | < | меньше, чем |
| > | > | больше, чем |
| & | & | амперсанд |
| ' | ‘ | апостроф |
| " | « | кавычки |
Замечание: Только символы «<» и «&» строго запрещены в XML. Символ «>» допустим, но лучше его всегда заменять на сущность.
Символ «>» допустим, но лучше его всегда заменять на сущность.
Комментарии в XML
Синтаксис комментариев в XML такой же, как и в HTML.
<!-- Это комментарий -->
Использование двух символов тире в середине комментария не допустимо.
Неверно:
<!-- Это -- комментарий -->
Странно, но так можно:
<!-- Это - - комментарий -->
В XML пробелы сохраняются
В HTML несколько последовательных пробельных символов усекаются до одного. В XML документе все пробельные символы сохраняются.
В XML новая строка сохраняется как LF
В приложениях Windows новая строка хранится в следующем виде: символ перевода каретки и символ новой строки (CR+LF).
Unix и Mac OSX используют LF.
Старые Mac системы используют CR.
XML сохраняет новую строку как LF.
Синтаксически верный XML документ
Если XML документ составлен в соответствии с приведенными синтаксическими правилами, то говорят, что это «синтаксически верный» XML документ.
Разметка XML документа. XML атрибуты. Корень XML документа. Декларации в XML. Комментарии в XML. Синтаксис XML документа
Здравствуйте, уважаемые посетители моего скромного блога для начинающих вебразработчиков и web мастеров ZametkiNaPolyah.ru. Сегодня продолжаем говорить о расширяемом языке разметки XML, продолжим разговор о XML тегах, рассмотрим, как писать сокращенные XML теги, поговорим о кодировки в XML документах, так же рассмотрим, что такое корневой элемент или иначе корень XML документа, в этой публикации мы рассмотрим вопрос о комментариях в XML документах, а так же посмотрим какие символы запрещены в XML. Рассмотрим, что такое декларация, а так же для чего нужна декларация в XML документе и как правильно декларировать. Так же мы поговорим, о разметки XML документа. И так, продолжаем разговор о синтаксисе XML документа, начатый в статье Расширяемый язык разметки XML. Синтаксис XML. Структура XML документа. Применение XML.
Синтаксис XML. Структура XML документа. Применение XML.
Синтаксис XML документа, как декларировать XML документ, из чего состоит XML документ. Инструкции XML документа.
Содержание статьи:
- Синтаксис XML документа, как декларировать XML документ, из чего состоит XML документ. Инструкции XML документа.
- Пример XML документа:
- Пример процессинговых инструкций в XML документе:
- XML комментарии, как правильно писать комментарии в XML документе.
- XML теги и XML элементы, правила написания XML тегов.
- XML атрибуты, как правильно писать XML атрибуты
- Пример того как можно составлять XML документ:
- Пример того как нельзя составлять XML документ:
- Так писать XML документы нельзя:
- Пример пустого XML документа:
- Типы данных в XML. CDATA и PCDATA.
- Пролог в XML документе. Кодировка XML документа. Русские XML теги. Кодировка Unicode.
- XML подведение итогов. Well-formed document или хорошо сформированный XML документ.

В первой статье, я как смог, так и объяснил, что такое синтаксис вообще и в XML документе в частности. Теперь предлагаю более подробно остановиться на данном вопросе, а так же рассмотреть, что такое декларация в XML и как декларировать XML документ. Синтаксис в XML на самом деле очень сложный, шаг влево, шаг в право и XML парсер вас уже не поймет.
Для начала, давайте рассмотри из чего состоит XML документ и соответственно рассмотрим синтаксис XML документа.
Пример XML документа:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
<people>
<man>
<name>Василий</name>
<surname>Теркин</surname>
<nationality>Русский</nationality>
<age>30</age>
<growth unit=»см»>185</growth>
</man>
</people>
|
1 2 3 4 5 6 7 8 9 10 11
| <?xml version=»1. <!— Пример XML документа —> <people> <man> <name>Василий</name> <surname>Теркин</surname> <nationality>Русский</nationality> <age>30</age> <growth unit=»см»>185</growth> </man> </people> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>Любой XML документ начинается с пролога или декларации. Что такое пролог в XML документе или иначе декларация XML документа — это начало XML документа, в примере это первая строка, как правило показывается, что это XML документ и указывается версия XML, а так же кодировка XML документа(<?xml version=»1.0″ encoding=»UTF-8″ ?>), на данный момент уже есть XML версии 1.1.
Обратите внимание на конструкцию пролога, так как в XML все очень жестко и структурировано, а именно на начало декларации(<?), любая декларативная команда в XML или команда по обработке всегда начинается с <?, если сказать грубо то эта команда дает указание парсеру начать обрабатывать XML документ. Данная команда не несет никаких данных, но она несет в себе инструкции как эти данные обрабатывать.
Данная команда не несет никаких данных, но она несет в себе инструкции как эти данные обрабатывать.
Так же, помимо декларативных инструкций можно давать процессинговые инструкции или инструкции по обработке XML документа, то есть в XML документе могут находится не только сами данные, но и инструкции по их обработке, то есть указания, что с этими данными делать.
Пример процессинговых инструкций в XML документе:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<?format drive=»d»?>
<document>
Дальше идет сам документ
</document>
|
| <?xml version=»1.0″ encoding=»UTF-8″ ?> <?format drive=»d»?> <document> Дальше идет сам документ </document> |
В этом примере я указал пролог XML документа, затем указал, что необходимо сделать с XML документом, то есть отформатировать диск D, а затем уже пошли данные самого XML документа. Этих инструкций может быть бесконечно много, так как придумываете вы их самостоятельно для решения тех или иных задач. Как и в случае с XML тегами, никаких инструкции в XML не заложено, их ноль, но когда вы решаете определенные задачи вы придумываете эти инструкции самостоятельно.
Этих инструкций может быть бесконечно много, так как придумываете вы их самостоятельно для решения тех или иных задач. Как и в случае с XML тегами, никаких инструкции в XML не заложено, их ноль, но когда вы решаете определенные задачи вы придумываете эти инструкции самостоятельно.
Если скопировать данный пример в текстовый редактор(например, в редактор с подсветкой синтаксиса Notepad++), а затем открыть XML документ в браузере, то ничего не произойдет, так как браузер не поймет данную инструкцию, но если вы напишите программу, которая будет знать эту инструкцию, то после работы с данными находящимися в XML документе она отформатирует диск D. И так, можно сделать вывод, что в XML прологом документа называют все, что предшествует самим данным, то есть декларация XML документа и инструкции по обработке XML документа.
XML комментарии, как правильно писать комментарии в XML документе.
Комментарии, ну наверное вы знаете для чего они нужны, если говорить научным языком, комментарии — это не анализируемая часть текста. На самом деле, в XML комментарии имеют большее значение, они могут иметь смысл, как и XML теги и реально анализироваться программой. Комментарии в XML документе — это еще одна разновидность XML конструкций.
На самом деле, в XML комментарии имеют большее значение, они могут иметь смысл, как и XML теги и реально анализироваться программой. Комментарии в XML документе — это еще одна разновидность XML конструкций.
Естественно, чаще всего используются для того, что бы оставлять для себя и кого-то другого какие-то пометки и указания по самому XML документу. Синтаксис комментариев в XML, такой же как и в HTML комментариях, начинается комментарий с конструкции <!(знак восклицания в XML означает декларацию, то есть мы этим знаком как бы говорим, декларирую комментарий ), а дальше идут два минуса, единственное, что нельзя писать в комментариях — это два минуса, так как два минуса будут символизировать окончание комментариев, в HTML, внутрь комментариев так же нельзя размещать два минуса.
В XML вы никогда не сможете написать вот такой комментарий: <!— ———————— —>, если у вас возникнет необходимость отделить логически одну часть документа от другой используйте символ равно(=): <!— ========== —>. Если же вы попробуете создать XML документ с таким комментарием <!— ———- —>, а затем открыть его в браузере, то обработчик выдаст ошибку, с текстом, «Ошибочный синтаксис в комментарии». То есть получается, что обработчик анализирует, все что находится в комментариях.
Если же вы попробуете создать XML документ с таким комментарием <!— ———- —>, а затем открыть его в браузере, то обработчик выдаст ошибку, с текстом, «Ошибочный синтаксис в комментарии». То есть получается, что обработчик анализирует, все что находится в комментариях.
Два минуса в комментарий размещать нельзя, но отключить целый блок разметки при помощи комментариев можно, это всегда пожалуйста:
Пример XML комментариев:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<?format drive=»d»?>
<!— Пример XML документа —>
<people>
<man>
<name>Василий</name>
<!—<surname>Теркин</surname>
<nationality>Русский</nationality>
<age>30</age>—>
<growth unit=»см»>185</growth>
</man>
</people></pre>
<pre>
|
1 2 3 4 5 6 7 8 9 10 11 12 13
| <?xml version=»1. <?format drive=»d»?> <!— Пример XML документа —> <people> <man> <name>Василий</name> <!—<surname>Теркин</surname> <nationality>Русский</nationality> <age>30</age>—> <growth unit=»см»>185</growth> </man> </people></pre> <pre> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>Блок кода, находящийся между <!— —>, этими символами обрабатываться никак не будет. Таким образом вы можете отключать часть разметки XML документа, если вдруг возникнет необходимость посмотреть, что произойдет, но необходимости удалять код нет.
XML теги и XML элементы, правила написания XML тегов.
Из прошлой статьи, мы выяснили, что теги в XML только парные, то есть существует открывающий тег и обязательный ему закрывающий тег, XML теги регистрочувствительны, не важно в каком регистре вы пишите свой тег, важно, что если вы создали элемент people с открывающим тегом <people>, то закрывающий тег нужно будет писать в том же регистре </people>.
В название XML элементов не может быть пробелов, то есть вы не имеете права написать такой тег <takoi tag>, пробелов в названиях быть не должно. Вместо пробелов можно использовать, дефисы, нижние подчеркивания, точки(<takoi_tag><takoi-tag><takoi.tag>), все эти теги имеют право на существование, но пробелов в название XML тегов быть не должно!
Имя каждого XML элемента всегда должно начинаться с буквы, никаких цифр, минусов, запятых первым символом в название не может быть. Кстати буквы в название XML тега могут быть любыми, хоть русские, хоть китайские, любые. Например, если вы напишите тег <человек> или <男子>, обработчик XML вас прекрасно поймет, главное регистр соблюдайте.
По определению в XML не может быть одиночных тегов, любой тег должен быть закрыт. Одиночных тегов в XML нет в принципе, но бывает необходимость, когда по грамматике тег не будет иметь содержимое, то есть пустой элемент. То есть, иногда существует необходимость в XML элементах, в которых по смыслу никогда не будет содержимого, в таких случаях писать такие конструкции нет смысла(<tag></tag>).
Поэтому было придумано сокращение тегов в XML(<tag />), обратите внимание, что это не одиночный тег, а просто сокращение записи(<tag></tag>) . <tag />, такая конструкция в XML называется самозакрывающийся тег, обратите внимание, что слэш стоит справа от названия тега и пробел между название тега и слэшом обязателен. То есть, записи <tag /> и <tag></tag> — это одно и то же, а когда анализатор встроенный в браузер их обработает, он покажет одно и то же, обычно вот так: <tag />.
XML атрибуты, как правильно писать XML атрибуты
Обратите внимание на самый первый пример, у тегов <man> и <growth> имеются атрибуты, id и cm, в первом случае параметром является число-идентификатор, во втором случае единицы измерения роста — сантиметры. Все XML атрибуты вы придумываете самостоятельно(в отличие от HTML атрибутов), семантику и грамматику для XML атрибутов вы придумываете то же самостоятельно, то есть задаете для этих XML атрибутов смысл и правила.
Параметром или значением XML атрибута, может быть все, что угодно, все на что хватит вашей фантазии. А вот синтаксис у XML атрибутов строгий, значение атрибутов всегда должны быть в двойных кавычках, но некоторые парсеры XML допускают вольности и ставить одинарные кавычки, но лучше к данному подходу не привыкать. Как и в случае с XML тегами, XML атрибутов может быть бесконечно много.
Единицы измерения XML. Корневой XML элемент или корень XML документа.
В XML существует очень важное правило, минимальной единицей измерения является документ, один XML элемент это документ, и этот XML элемент является минимальной единицей измерения — всегда! Как это можно понять? XML документ всегда состоит из одного тега или элемента, по буржуйски этот тег называется root или корень XML документа, это означает, что у любого документа должен быть всегда один элемент(один тег), внутри него может быть все, что угодно, но один XML элемент в XML документе должен быть всегда.
В первом нашем примере корневым элементом является, элемент <people>, внутри него можно размещать все, что угодно, делать какие угодно ветвления и вложения, но создавать элемент уровня <people> уже нельзя.
Пример того как можно составлять XML документ:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
<people>
<man>
<name>Василий</name>
<surname>Теркин</surname>
<nationality>Русский</nationality>
<age>30</age>
<growth unit=»см»>185</growth>
</man>
<woman>
<name>Сонька</name>
<surname>Золотая Ручка</surname>
<nationality>Русская</nationality>
<age>26</age>
<growth unit=»см»>176</growth>
</woman>
</people>
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
| <?xml version=»1. <!— Пример XML документа —> <people> <man> <name>Василий</name> <surname>Теркин</surname> <nationality>Русский</nationality> <age>30</age> <growth unit=»см»>185</growth> </man> <woman> <name>Сонька</name> <surname>Золотая Ручка</surname> <nationality>Русская</nationality> <age>26</age> <growth unit=»см»>176</growth> </woman> </people> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>В данном примере, элементы woman и man лежат внутри корневого XML элемента people, поэтому здесь ничего не нарушено и XML документ составлен правильно.
Пример того как нельзя составлять XML документ:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
<people>
<man>
<name>Василий</name>
<surname>Теркин</surname>
<nationality>Русский</nationality>
<age>30</age>
<growth unit=»см»>185</growth>
</man>
<woman>
<name>Сонька</name>
<surname>Золотая Ручка</surname>
<nationality>Русская</nationality>
<age>26</age>
<growth unit=»см»>176</growth>
</woman>
</people>
<animal>
<cat>Большой, толстый кот</cat>
</animal>
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| <?xml version=»1. <!— Пример XML документа —> <people> <man> <name>Василий</name> <surname>Теркин</surname> <nationality>Русский</nationality> <age>30</age> <growth unit=»см»>185</growth> </man> <woman> <name>Сонька</name> <surname>Золотая Ручка</surname> <nationality>Русская</nationality> <age>26</age> <growth unit=»см»>176</growth> </woman> </people> <animal> <cat>Большой, толстый кот</cat> </animal> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>Данный пример по своей сути не правильный и XML обработчик выдаст ошибку, так как у XML документа может быть только один корневой элемент, а в данном примере их два, это people и animal, что противоречит стандарту XML. Еще раз повторюсь, у XML документа может быть только один корневой элемент, внутри которого должны располагаться все остальные элементы. Если же вы все-таки напишите два корневых элемента, анализатор вам так и скажет, «В XML документах, допускается один элемент верхнего уровня».
Если же вы все-таки напишите два корневых элемента, анализатор вам так и скажет, «В XML документах, допускается один элемент верхнего уровня».
Так же не может быть XML документов состоящих только из пролога, в XML документе должен быть хотя бы один XML элемент.
Так писать XML документы нельзя:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
|
| <?xml version=»1.0″ encoding=»UTF-8″ ?> <!— Пример XML документа —> |
Нельзя, потому что внутри XML документа должен быть один тег, а в данном случае нет ни одного тега. XML документа без корня существовать не может. Если вам интересно как создать пустой XML документ, то тут все очень просто.
Пример пустого XML документа:
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
<tag />
|
| <?xml version=»1. <!— Пример XML документа —> <tag /> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>Данный документ пустой и содержит один элемент(tag), то есть корень XML документа, поэтому он удовлетворяет XML стандарту. XML документ это всегда один главный тег, то есть все прологи, процесинговые инструкции, это все не так важно, XML документ — это один тег.
Типы данных в XML. CDATA и PCDATA.
Как я уже говорил, XML работает только с данными, в чистом XML данные одни — текст. XML документ состоит из элементов, внутри которых расположены текстовые данные. Любые данные находящиеся внутри XML документа рассматриваются как PCDATA (Parsed Character Data), это означает, что XML анализатор будет рассматривать данные, как парсируемые, анализируемые текстовые данные, то есть XML парсер анализирует не только теги и атрибуты, но и то что находится внутри них.
С одной стороны это удобно, но допустим если у вас появится желание поместить внутрь XML элемента пример 3+4>2, у вас это не получится, так знак «>» запрещенный символ, всего в XML три запрещенных символа (<, >, &). И если анализатор XML встретит эти символы внутри элемента, он будет их анализировать и естественно ругаться, говоря что вы допустили синтаксическую ошибку.
И если анализатор XML встретит эти символы внутри элемента, он будет их анализировать и естественно ругаться, говоря что вы допустили синтаксическую ошибку.
В связи с этим, в XML ввели еще один тип данных CDATA, которые анализатор XML вообще не трогает никак, грубо говоря мы ему указываем, что от этого места до этого просто текст, с которым ничего делать не надо.Что бы указать XML анализатору, что данные являются CDATA, надо сделать декларацию(<!), затем пишется следующая конструкция [CDATA[, после чего вы можете писать все, что захотите, после того как вы разместили нужные данные конструкция закрывается(]]>)
<?xml version=»1.0″ encoding=»UTF-8″ ?>
<!— Пример XML документа —>
<data>
<new.tag>
<![CDATA[
Внутри этой конструкции можно размещать любые символы, даже
запрещенные(>,<,&)
]]>
</new.tag>
</data>
|
1 2 3 4 5 6 7 8 9 10
| <?xml version=»1. <!— Пример XML документа —> <data> <new.tag> <![CDATA[ Внутри этой конструкции можно размещать любые символы, даже запрещенные(>,<,&) ]]> </new.tag> </data> |
 0″ encoding=»UTF-8″ ?>
0″ encoding=»UTF-8″ ?>Все, что размещено в этой конструкции(<![CDATA[…………]]>), анализатор будет считать обычным текстом и не будет обращать на него внимание. Правильно эта конструкция называется секция CDATA, то есть раздел непарсируемых данных.
Пролог в XML документе. Кодировка XML документа. Русские XML теги. Кодировка Unicode.
Как я уже говорил, в XML документе есть пролог, в котором указывается язык XML, его версия и кодировка XML документа, но писать пролог не обязательно и все будет прекрасно работать, до тех пор пока вы не напишите хотя бы одну букву не входящую в латинский алфавит.
Все дело в том, что проблема с кодировкой в XML решена очень грамотно, в XML нет понятия битой кодировки, то есть каракозябры в XML вы никогда не увидите. Если вы не указываете в прологе кодировку, то в XML документе можно использовать только латинские буквы. Если вы в своем документе использовали хотя бы одну букву не латинского алфавита, то вы обязаны декларировать, какую кодировку вы используете, в XML документе кодировки могут быть любые.
Если вы не указываете в прологе кодировку, то в XML документе можно использовать только латинские буквы. Если вы в своем документе использовали хотя бы одну букву не латинского алфавита, то вы обязаны декларировать, какую кодировку вы используете, в XML документе кодировки могут быть любые.
Причем, после того, как вы укажете кодировку, символы из этой кодировки вы можете использовать любые и в любом месте XML документа, в название тегов, атрибутов, значений атрибутов, сами данные и так далее. Кодировку для XML документа, я бы посоветовал использовать UTF-8. Сейчас объясню почему.
Unicode — это универсальное средство, которое позволяет использовать помимо стандартных символов и графики использовать какие-либо частные символы, дополнительные графические элементы, национальные языки и многое другое, универсальность его намного больше, чем однобайтовых кодировках.
Unicode, на самом деле один, но у него есть множество способов кодирования. UTF — это способ кодирования файлов. И вот этих UTF много, порядка 10 штук, можете поискать(UTF-7, UTF-8, UTF-16, UTF-32), цифра показывает минимальное число бит на один символ.
И вот этих UTF много, порядка 10 штук, можете поискать(UTF-7, UTF-8, UTF-16, UTF-32), цифра показывает минимальное число бит на один символ.
И так, нам необходимо указывать кодировку своих документов, причем указывать и для редактора и для анализатора, хорошо, если вы используете какой-нибудь Notepad++, где вы явно указываете кодировку и нет никаких проблем, а если вы используете обычный блокнот windows.
Предлагаю попробовать создать пустой документ, с расширением txt в обычном блокноте. И затем его сохранить. Размер этого документа будет ноль байт.
А теперь попробуйте пересохранить этот же пустой документ, но уже в кодировки Unicode, я выберу способ кодирования UTF-8, а теперь посмотрите, какой размер будет у пустого файла в кодировки UTF-8. Документ в кодировки UTF-8 будет весить 3 байта, но откуда взялись эти 3 байта, в документе по прежнему ничего нет, он пустой.
Так вот, блокноту нужно как-то подсказывать, какая кодировка используется, для этих целей в Unicode придумали Byte Order Mark, или сокращенно BOM, это метка порядка чередования байтов. Идея разработчиков Unicode очень проста. Поскольку в Unicode миллиарды различных символов, включая полную типографику, в которой только с десяток символов пробелов(узкий пробел, широкий пробел, неразрывный пробел, широкий пробел с переносом, неразрывный пробел и так далее). Среди множества этих пробелов есть один хитрый пробел, который называется неразрывный непечатный пробел, он применяется для разделение частей многосложных слов, его невидно, но он есть, как суслик, ты его не видишь, а он есть.
Идея разработчиков Unicode очень проста. Поскольку в Unicode миллиарды различных символов, включая полную типографику, в которой только с десяток символов пробелов(узкий пробел, широкий пробел, неразрывный пробел, широкий пробел с переносом, неразрывный пробел и так далее). Среди множества этих пробелов есть один хитрый пробел, который называется неразрывный непечатный пробел, он применяется для разделение частей многосложных слов, его невидно, но он есть, как суслик, ты его не видишь, а он есть.
И не менее хитрые разработчики Unicode придумали такую штуку, если файл начинается с неразрывного непечатного пробела, программа поймет, во-первых, что вы используете Unicode, а во-вторых, способ кодирования. Неразрывный непечатный пробел и есть BOM, метка, которая показывает какую кодировку вы используете, а при способе кодирования UTF-8 неразрывный непечатный пробел кодируется тремя байтами, поэтому наш пустой документ имеет размер три байта.
Так вот, если этот BOM есть, любая виндовая программа определит, что документ закодирован в Unicode. Некоторые Unix интерпретаторы косячат, когда видят BOM, поэтому старайтесь кодировать все свои документы(не только XML) без BOM.
Некоторые Unix интерпретаторы косячат, когда видят BOM, поэтому старайтесь кодировать все свои документы(не только XML) без BOM.
Для нас же(людей использующих русский язык) наличие BOM в начале XML документа означает, что мы можем использовать любые символы в документе явно не указывая кодировку. То есть парсер поймет какая кодировка у XML документу по наличию BOM, это единственное исключения, когда можно не писать для русского языка кодировку, но лучше не надейтесь на BOM и всегда указывайте кодировку.
XML подведение итогов. Well-formed document или хорошо сформированный XML документ.
И так, расширяемый язык разметки XML, применяется для хранения, обработки и передачи каких-либо данных. Во многих случаях вы даже не догадываетесь, что используется XML. Чистый XML имеет только синтаксис, синтаксис XML очень и очень жесткий, грамматику и семантику XML придумывает разработчик.
Так же мы поговорили про анализатор XML, который прежде чем, что-то делать с документом проверяет его и в случае малейшей ошибки должен отказаться от работы с XML документом. Well-formed document — это первый уровень правильности написания XML документа, грубо говоря — это соблюдение всех синтаксических правил.
Well-formed document — это первый уровень правильности написания XML документа, грубо говоря — это соблюдение всех синтаксических правил.
Любой XML документ считается синтаксически правильно сформированным, если выполняются следующие синтаксические правила в XML документе:
- Документ XML соответствует своей кодировке и кодировка указанна внутри XML документ.
- XML документ имеет только один корневой элемент.
- Все элементы внутри корня XML документа корректно закрыты и вложены.
- Правильно соблюден регистр имен элементов и деклараций
- Значение XML атрибутов заключены в двойные кавычки.
- Внутри одного тега нет повторяющегося атрибута, один и тот же атрибут два раза в одном теге находиться не могут
Если все эти правила соблюдены в XML документе, то первый уровень проверки XML документа пройден — анализатор может его легко обработать, документ считается правильным или валидным. Собственно это и есть весь XML, кроме одной весчи, о которой мы поговорим в следующих статьях
На этом всё, спасибо за внимание, надеюсь, что был хоть чем-то полезен и до скорых встреч на страницах блога для начинающих вебразработчиков и вебмастеров ZametkiNaPolyah. ru
ru
- Возможно, вам будет интересно:
Что такое SEO, определение SEO. Черное SEO. Белое SEO
Заметки о Drupal
Как создать сайт используя Drupal. Установка Drupal на локальный сервер. Локализация Drupal. Как русифицировать Drupal при помощи .po файл. Перевод Друпала при помощи архива
Логическое форматирование HTML-документов. Непосредственное форматирование HTML документов. HTML тэги, часть 3
HTML атрибуты, для чего используются HTML атрибуты, какие бывают HTML атрибуты, синтаксис и назначение атрибутов в HTML
HTML теги, часть 1. Тэг PRE авторское форматирование, тэг BR перенос строк. Пробельные символы
Блочные и строчные элементы. Теги HTML заголовков h2-H6
Структура HTML документа. Тэги html, head, body и title
Что такое теги, какие теги бывают и где их искать
Панель инструментов Google — Google WebMaster Tools. Регистрация и возможности предоставляемые Google WebMaster Tools
Google Analytics — регистрация, установка и получение кода счетчика посещаемости. Работа со статистикой
Работа со статистикой
Что такое RSS лента и поток. Программы для чтения RSS лент — RSS reader. Иконки и кнопки RSS для сайта. Как устроен формат RSS.
Счетчики посещений
Заметки о XML и XLST
Расширяемый язык разметки XML. Синтаксис XML. Структура XML документа. Применение XML
Конфликты в XML. Пространство имен в XML. Способы именования пространства имен в XML. Как использовать HTML теги в XML документах
Заметки по JavaScript
Алгоритмический язык программирования JavaScript. Методы вывода данных в JavaScript alert (), confirm и document.write (). Вставка JavaScript в HTML страницы
Все о реляционных базах данных и системе управления базами данных MySQL. MySQL сервер
Система управления базами данных. Реляционные базы данных. Где скачать MySQL сервер, как настроить и установить
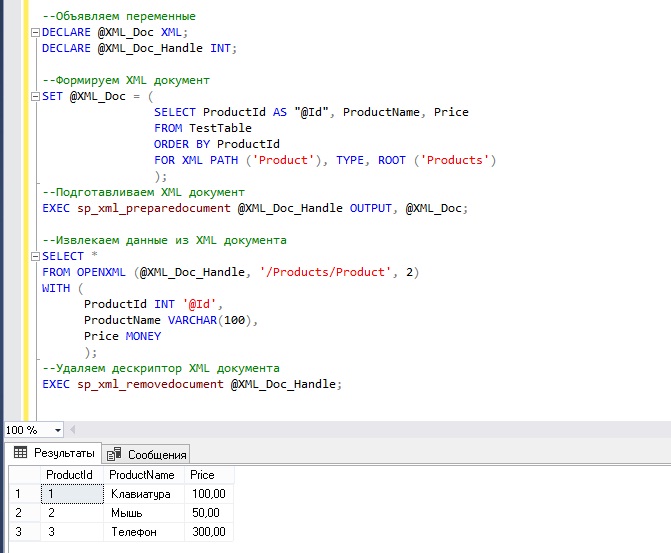
XML-синтаксис — XML-файлы
Пример документа XML:
|
 0"?>
<примечание>
0"?>
<примечание>
Первая строка в документе: Объявление XML всегда должно быть включено. Он определяет XML-версию документа. В этом случае документ соответствует спецификации 1.0 XML:
Следующая строка определяет первый элемент документа (корневой):
<примечание> |
Следующие строки определяют 4 дочерних элемента корня (до, от, заголовок и тело
):
|
Последняя строка определяет конец корневого элемента:
Все элементы XML должны иметь закрывающий тег
В HTML некоторые элементы могут не иметь закрывающего тега. Следующий код допустим в HTML:
Следующий код допустим в HTML:
|
В XML все элементы должны иметь закрывающий тег, подобный этому:
|
XML-теги чувствительны к регистру
XML-теги чувствительны к регистру. Тег
Поэтому открывающий и закрывающий теги должны быть написаны с одинаковым регистром:
|
|
Все элементы XML должны быть правильно вложены
В HTML некоторые элементы могут быть неправильно вложены друг в друга, например:
Этот текст выделен жирным шрифтом и курсивом |
В XML все элементы должны быть правильно вложены друг в друга, как это
Этот текст выделен жирным шрифтом и курсивом |
Все документы XML должны иметь корневой тег
Все документы XML должны содержать одну пару тегов для определения корневого элемента. Все остальные элементы должны быть вложены в корневой элемент. Все элементы могут иметь вложенные (дочерние) элементы. Подэлементы должны быть парами и правильно вложены в родительский элемент:
Все остальные элементы должны быть вложены в корневой элемент. Все элементы могут иметь вложенные (дочерние) элементы. Подэлементы должны быть парами и правильно вложены в родительский элемент:
<корень>
<ребенок>
<дочерний элемент>
|
Значения атрибутов всегда должны заключаться в кавычки
XML-элементы могут иметь атрибуты в парах имя/значение, как и в HTML. В XML значение атрибута всегда должно быть заключено в кавычки. Изучите два XML-документа ниже. Первое неверно, второе правильно:
<дата примечания = 11.12.99> |
|
 0"?>
<примечание дата="11.12.99">
0"?>
<примечание дата="11.12.99">
Изучение синтаксиса XML: Только для IU: Файлы: XML: Основы: Все темы обучения: UITS Библиотека материалов для обучения ИТ: Университет Индианы
Как упоминалось ранее, ключом к созданию XML-документов является соблюдение правил. Если вы выполняете несколько простых требований, вы можете создавать XML практически для любой вообразимой цели. Давайте узнаем больше об этих правилах, а затем воспользуемся ими в качестве руководства при создании XML-разметки для документа со списком вакансий.
Элементы
Основной единицей XML-документа является элемент . Элемент — это контейнер, который может содержать данные или другие элементы. Элементы обычно ограничены начальными тегами и конечными тегами , оба из которых заключены в угловые скобки. Конечные теги отличаются от открывающих тем, что перед именем элемента они включают символ косой черты (/). Ниже приведен пример элемента:
Конечные теги отличаются от открывающих тем, что перед именем элемента они включают символ косой черты (/). Ниже приведен пример элемента:
Этот текст содержится внутри элемента.
Выход из блока кода.
Существует еще один тип элемента, называемый пустым элементом . Эти элементы не имеют содержимого между открывающим и закрывающим тегами. Вместо записи обоих тегов пустой элемент можно сократить, используя один тег и поставив косую черту в конце имени тега. Теги можно записать просто как . Пустые элементы часто используются в качестве маркера, например элемент HTML , обозначающий расположение изображения на веб-странице. В XML пустые элементы иногда используются для передачи команд определенным процессорам XML или в качестве контейнеров для хранения информации только в атрибутах.
Взаимосвязи элементов
Как уже упоминалось, элементы XML могут содержать другие элементы. Это означает, что XML идеально подходит для хранения информации, которая может быть структурирована как схема или древовидная иерархия. Если представить схему семейного древа, можно легко увидеть отношения между родителями, детьми, братьями и сестрами. Точно так же диаграмма XML-документа показывает те же отношения. XML-файл рецепта, показанный выше, можно визуализировать с помощью следующей схемы:
Это означает, что XML идеально подходит для хранения информации, которая может быть структурирована как схема или древовидная иерархия. Если представить схему семейного древа, можно легко увидеть отношения между родителями, детьми, братьями и сестрами. Точно так же диаграмма XML-документа показывает те же отношения. XML-файл рецепта, показанный выше, можно визуализировать с помощью следующей схемы:
Мы часто ссылаемся на элементы по их взаимосвязи или функции в XML Document:
- документ или корневой элемент — элемент, который включает все другие элементы в документ. В приведенном выше примере
<Рецепт>является элементом документа. Это единственный элемент, у которого нет родителя. Каждый документ XML должен иметь один и только один элемент документа. - Детские элементы и родительские элементы — Дочерние элементы содержатся внутри родительского элемента. У каждого ребенка может быть только один родитель, но у родителя может быть более одного ребенка. В приведенном выше примере
<ингредиент>является потомком<ингредиенты>. - Родственные элементы — Элементы, находящиеся на одном уровне и имеющие одного родителя. Элементы
<ингредиенты>являются одноуровневыми элементами в приведенном выше примере.
- документ или корневой элемент — элемент, который включает все другие элементы в документ. В приведенном выше примере
 У каждого ребенка может быть только один родитель, но у родителя может быть более одного ребенка. В приведенном выше примере
У каждого ребенка может быть только один родитель, но у родителя может быть более одного ребенка. В приведенном выше примере Правильное вложение элементов
Когда мы пишем XML-документ, нам нужно убедиться, что каждый элемент имеет один и только один родительский элемент и что он не пересекается со своими родственными элементами. Например, следующий код вызовет ошибку:
.Jones1017 S West St.
Выход из кодового блока.
Обратите внимание, что <фамилия> и <адрес> перекрывает друг друга. Чтобы исправить это, вы должны закрыть элемент до начала <адрес> , как показано в следующем коде:
Jones 1017 S West St.

Выйти из кода Блок.
Это превращает их в надлежащие элементы братьев и сестер и не вызовет никаких ошибок при обработке процессором XML.
Действительные имена элементов
Существуют некоторые ограничения на имена, которые можно выбрать для элементов. В общем, вы можете использовать буквы, цифры и следующую пунктуацию в верхнем и нижнем случае:
| Character | Example |
| underscore | |
| hyphen | |
| period | |
Следует избегать других знаков препинания, поскольку многие знаки препинания служат особым целям в XML.
ПРИМЕЧАНИЕ. Можно использовать неанглийские символы в именах элементов, если они поддерживаются Unicode, однако имейте в виду, что другим пользователям вашего XML-документа может быть сложно понять теги на неанглийском языке. английские символы, и они могут не иметь правильных шрифтов, необходимых для отображения неанглийских символов. Чтобы узнать больше об использовании неанглийских символов в XML-документах, прочитайте эту статью часто задаваемых вопросов W3C об использовании неанглийских тегов в XML.
английские символы, и они могут не иметь правильных шрифтов, необходимых для отображения неанглийских символов. Чтобы узнать больше об использовании неанглийских символов в XML-документах, прочитайте эту статью часто задаваемых вопросов W3C об использовании неанглийских тегов в XML.
Чувствительность случая
Как упоминалось ранее, вы можете использовать буквы верхнего и нижнего часа в именах элементов XML-однако, одна важная вещь, которую нужно помнить, заключается в том, что XML чувствителен к случаям. Если вы используете заглавные буквы в начале, вы должны использовать одну и ту же капитализацию в конечном итоге. Например, следующий пример кода приведет к ошибке, потому что для анализатора XML <первый шаг> -совершенно другой элемент, чем :
Первый шаг
ВЫХОДИТЕЛЬНЫЙ БЛОК.
Теперь, когда мы знаем правила синтаксиса XML, давайте начнем маркировать job_postings.