Заполнение таблицы sql server: MS SQL Server и T-SQL
Содержание
НОУ ИНТУИТ | Лекция | Создание и заполнение таблиц
< Дополнительный материал || Самостоятельная работа 3: 12
Аннотация: Содержит информацию о создании, настройке и заполнении таблиц в новой базе данных.
Ключевые слова: БД, ПО, меню, пункт, таблица, поле, значение, ключевое поле, префикс, Data, base, Object, microsoft sql server 2008, целочисленный тип, тип данных, DATE, real, имя таблицы, Microsoft SQL Server, management, excel
Цель: научиться создавать и заполнять таблицы
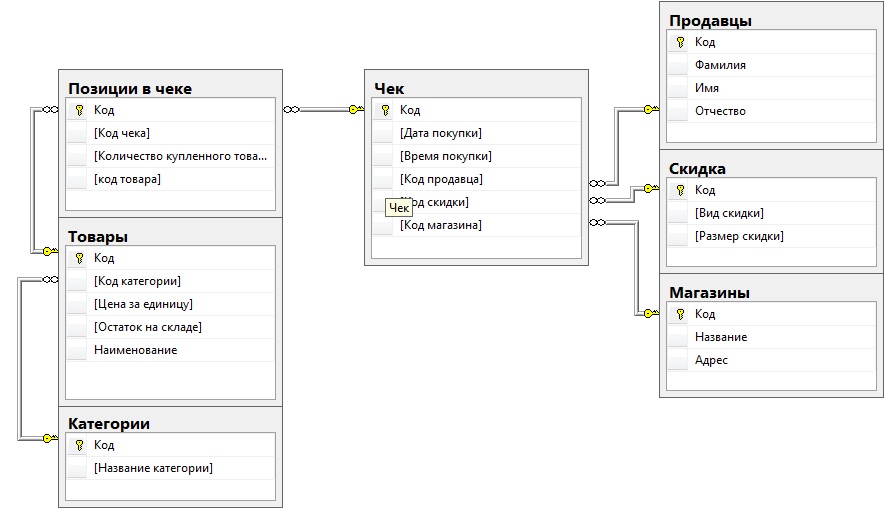
Перейдем теперь к созданию таблиц. Все таблицы нашей БД находятся в подпапке «Tables» папки «Students» в окне обозревателя объектов (
рис.
6.1).
Рис.
6.1.
Создадим таблицу «Специальности». Для этого щелкните ПКМ по папке «Tables» и в появившемся меню выберите пункт «New Table». Появится окно создания новой таблицы (
Появится окно создания новой таблицы (
рис.
6.2).
увеличить изображение
Рис.
6.2.
В правой части окна расположена таблица определения полей новой таблицы. Данная таблица имеет следующие столбцы:
- Column Name — имя поля. Имя поля должно всегда начинаться с буквы и не должно содержать различных специальных символов и знаков препинания. Если имя поля содержит пробелы, то оно автоматически заключается в квадратные скобки.
- Data Type — тип данных поля.
- Allow Nulls — допуск значения Null. Если эта опция поля включена, то в случае незаполнения поля в него будет автоматически подставлено значение Null. То есть, поле необязательно для заполнения.
 intuit.ru/2010/edi»>Замечание: Под таблицей определения полей располагается таблица свойств выделенного поля «Column Properties». В данной таблице настраиваются свойства выделенного поля. Некоторые из них будут рассмотрены ниже.
intuit.ru/2010/edi»>Замечание: Под таблицей определения полей располагается таблица свойств выделенного поля «Column Properties». В данной таблице настраиваются свойства выделенного поля. Некоторые из них будут рассмотрены ниже.Перейдем к созданию полей и настройке их свойств. В таблице определения полей задайте значения столбцов «Column Name», «Data Type» и «Allow Nulls», как показано на рисунке ниже (
рис.
6.3).
увеличить изображение
Рис.
6.3.
Из
рис.
6.3 следует, что наша таблица «Специальности» имеет три поля:
- Код специальности — числовое поле для связи с таблицей студенты,
- Наименование специальности — текстовое поле, предназначенное для хранения строк, имеющих длину не более 50 символов.

- Описание специальности — текстовое поле, предназначенное для хранения строк, имеющих неограниченную длину.

Замечание: Так как, поле «Код специальности» будет являться первичным полем связи в запросе, связывающем таблицы «Студенты» и «Специальности». То мы должны сделать его числовым счетчиком. То есть данное поле должно автоматически заполняться числовыми значениями. Более того, оно должно быть ключевым.
Сделаем поле «Код специальности» счетчиком. Для этого выделите поле, просто щелкнув по нему мышкой в таблице определения полей. В таблице свойств поля отобразятся свойства поля «Код специальности». Разверните группу свойств «Identity Specification» (Настройка особенности). Свойство «(Is Identity)» (Особенное) установите в значение «Yes» (Да). Задайте свойства «Identity Increment» (Увеличение особенности, шаг счетчика) и «Identity Seed» (Начало особенности, начальное значение счетчика) равными 1 (
рис.
6.3). Эти настройки показывают, что значение поля «Код специальности» у первой записи в таблице будет равным 1, у второй — 2, у третьей 3 и т.д.
Теперь сделаем поле «Код специальности» ключевым полем. Выделите поле, а затем на панели инструментов нажмите кнопку с изображением ключа
В таблице определения полей, рядом с полем «Код специальности» появиться изображение ключа, говорящее о том, что поле ключевое.
На этом настройку таблицы «Специальности» можно считать завершенной. Закройте окно создания новой таблицы, нажав кнопку закрытия
в верхнем правом углу окна, над таблицей определения полей. Появиться окно с запросом о сохранении таблицы (
рис.
6.4).
Рис.
6.4.
В этом окне необходимо нажать «Yes» (Да). Появиться окно «Choose Name» (Задайте имя), предназначенное для определения имени новой таблицы (
Появиться окно «Choose Name» (Задайте имя), предназначенное для определения имени новой таблицы (
рис.
6.5).
Рис.
6.5.
В этом окне задайте имя новой таблицы как «Специальности» и нажмите кнопку «Ok». Таблица «Специальности» отобразиться в обозревателе объектов в папке «Tables» БД «Students» (
рис.
6.6).
Замечание: В обозревателе объектов таблица «Специальности» отображается как «dbo.Специальности». Префикс «dbo» обозначает, что таблица является объектом БД (Data Base Object). В дальнейшем при работе с объектами БД префикс «dbo» можно опускать.
Теперь перейдем к созданию таблицы «Предметы». Как и в случае с таблицей «Специальности» щелкните ПКМ по папке «Tables» и в появившемся меню выберите пункт «New Table». Создайте поля представленные на рисунке ниже (
Создайте поля представленные на рисунке ниже (
рис.
6.6).
увеличить изображение
Рис.
6.6.
Сделайте поле «Код предмета» числовым счетчиком и ключевым полем, как это было сделано в таблице «Специальности». Закройте окно создания новой таблицы. В появившемся окне «Chose Name» задайте имя «Предметы» (
рис.
6.7).
Рис.
6.7.
Таблица «Предметы» появится в папке «Tables» в обозревателе объектов (
рис.
6.8).
Дальше >>
< Дополнительный материал || Самостоятельная работа 3: 12
SQL-Урок 13. Добавление данных (INSERT INTO)
ВВЕРХ
❮
❯
В предыдущих разделах мы рассматривали работу по получению данных с заранее созданных таблиц.
Теперь пора разобрать, каким же образом мы можем создавать/удалять таблицы, добавлять новые записи и удалять старые.
Для этих целей в SQL существуют такие операторы, как:
Начнем знакомство с данной группой операторов из оператора INSERT.
1. Добавление целых строк
Как видно из названия, оператор INSERT используется для вставки (добавления) строк в таблицу базы данных.
Добавление можно осуществить несколькими способами:
Итак, чтобы добавить новую строку в таблицу, нам необходимо указать название таблицы, перечислить названия колонок и указать значение для каждой колонки с помощью конструкции INSERT INTO название_таблицы (поле1, поле2 . .. ) VALUES (значение1, значение2 …). Рассмотрим на примере.
.. ) VALUES (значение1, значение2 …). Рассмотрим на примере.
INSERT INTO Sellers (ID, Address, City, Seller_name, Country)
VALUES ('6', '1st Street', 'Los Angeles', 'Harry Monroe', 'USA')
Также можно изменять порядок указания названий колонок, однако одновременно нужно менять и порядок значений в параметре VALUES.
2. Добавление части строк
В предыдущем примере при использовании оператора INSERT мы явно отмечали имена столбцов таблицы. Используя данный синтаксис, мы можем пропустить некоторые столбцы. Это значит, что вы вводите значение для одних столбцов но не предлагаете их для других. Например:
INSERT INTO Sellers (ID, City, Seller_name)
VALUES ('6', 'Los Angeles', 'Harry Monroe')
В данном примере мы не указали значение для двух столбцов Address и Country . Вы можете исключать некоторые столбцы из оператора INSERT INTO, если это позволяет производить определение таблицы. В этом случае должно соблюдаться одно из условий: этот столбец определен как допускающий значение NULL (отсутствие какого-либо значения) или в определение таблицы указанное значение по умолчанию. Это означает, что, если не указано никакое значение, будет использовано значение по умолчанию. Если вы пропускаете столбец таблицы, которая не допускает появления в своих строках значений NULL и не имеет значения, определенного для использования по умолчанию, СУБД выдаст сообщение об ошибке, и это строка не будет добавлена.
В этом случае должно соблюдаться одно из условий: этот столбец определен как допускающий значение NULL (отсутствие какого-либо значения) или в определение таблицы указанное значение по умолчанию. Это означает, что, если не указано никакое значение, будет использовано значение по умолчанию. Если вы пропускаете столбец таблицы, которая не допускает появления в своих строках значений NULL и не имеет значения, определенного для использования по умолчанию, СУБД выдаст сообщение об ошибке, и это строка не будет добавлена.
3. Добавление отобранных данных
В предыдущей примерах мы вставляли данные в таблицы, прописывая их вручную в запросе. Однако оператор INSERT INTO позволяет автоматизировать этот процесс, если мы хотим вставлять данные из другой таблицы. Для этого в SQL существует такая кострукция как INSERT INTO … SELECT … . Данная конструкция позволяет одновременно выбирать данные из одной таблицы, и вставить их в другую.
Предположим мы имеем еще одну таблицу Sellers_EU с перечнем продавцов нашего товара в Европе и нам нужно их добавить в общую таблицу Sellers.
Структура этих таблиц одинакова (то же количество колонок и те же их названия), однако другие данные.
Для этого мы можем прописать следующий запрос:
INSERT INTO Sellers (ID, Address, City, Seller_name, Country)
SELECT ID, Address, City, Seller_name, Country
FROM Sellers_EU
Нужно обратить внимание, чтобы значение внутренних ключей не повторялись (поле ID), в противном случае произойдет ошибка.
Оператор SELECT также может включать предложения WHERE для фильтрации данных.
Также следует отметить, что СУБД не обращает внимания на названия колонок, которые содержатся в операторе SELECT, для нее важно только порядок их расположения.
Поэтому данные в первом указанном столбце, что были выбраны из-за SELECT, будут в любом случае заполнены в первый столбец таблицы Sellers, указанной после оператора INSERT INTO, независимо от названия поля.
4. Копирование данных из одной таблицы в другую
Часто при работе с базами данных возникает необходимость в создании копий любых таблиц, с целью резервирования или модификации. Чтобы сделать полную копию таблицы в SQL предусмотрен отдельный оператор SELECT INTO.
Например, нам нужно создать копию таблицы Sellers, нужно будет прописать запрос следующим образом:
SELECT * INTO Sellers_new FROM Sellers
В отличие от предыдущей конструкции INSERT INTO … SELECT … , когда данные добавляются в существующую таблицу, конструкция SELECT … INTO … FROM … копирует данные в новую таблицу. Также можно сказать, что первая конструкция импортирует данные, а вторая — экспортирует.
При использовании конструкции SELECT … INTO … FROM … следует учитывать следующее:
Статьи по теме:
 Комбинированные запросы (UNION)
Комбинированные запросы (UNION)sql server — Создание и заполнение таблицы в T-SQL
спросил
Изменено
7 лет, 7 месяцев назад
Просмотрено
2к раз
Я новичок в T-SQL и пытаюсь научиться создавать скрипт в T-SQL для создания и заполнения таблицы (StaffData). StaffData определяется следующим образом:
staffid — целочисленный первичный ключ, идентификатор начинается с 1, увеличивается на 1 managerid — целое число, допускает нули, указатель на другую запись в таблице менеджеров имя – строка из 50 символов зарплата - деньги
Что я могу сделать, чтобы создать таблицу и заполнить ее набором данных..?
- sql
- sql-сервер
- tsql
Вот правильный SQL. Я проверил это (только что заметил, что вы хотите, чтобы managerId обнулялся — я добавил это):
Я проверил это (только что заметил, что вы хотите, чтобы managerId обнулялся — я добавил это):
- он использует лучшие соглашения для имен таблиц и столбцов (вы не должны использовать «данные» в именах таблиц — мы знаем, что они содержат данные)
- он называет ваши ограничения первичного ключа, что является лучшей практикой — вы можете сделать что-то подобное для ограничения FK, если хотите, я только что сделал это встроенным
- он использует операторы «USE» и «GO», чтобы гарантировать, что вы создаете вещи в правильной базе данных (критично, когда вы работаете на больших производственных системах).
- использует столбцы nvarchar — они нужны для надежного хранения данных из международных наборов символов (например, у менеджера русское имя)
- Я использую nvarchar(max), так как нельзя быть уверенным, что имя будет состоять только из 50 символов. Используйте nvarchar(50), если нужно, но размер базы данных обычно не имеет большого значения.
Сначала вам нужно создать таблицу Manager, так как от нее зависит таблица Staff:
USE [yourDatabaseName] -- вам не нужны квадратные скобки, но они не мешают
-- Создать таблицу менеджеров
СОЗДАТЬ ТАБЛИЦУ Менеджер
(
идентификатор int ИДЕНТИФИКАЦИЯ (1,1),
имя nvarchar (макс. ),
ОГРАНИЧЕНИЕ pk_manager ПЕРВИЧНЫЙ КЛЮЧ (id)
)
СОЗДАТЬ СТОЛ Персонал
(
идентификатор int ИДЕНТИФИКАЦИЯ (1,1),
имя nvarchar (макс.),
зарплата деньги,
managerId int FOREIGN KEY REFERENCES Manager(id) NULL,
ОГРАНИЧЕНИЕ pk_staff ПЕРВИЧНЫЙ КЛЮЧ (id)
)
--Чтобы заполнить таблицу менеджера:
ВСТАВЬТЕ В [Менеджер]
(
-- значение столбца id генерируется автоматически
имя
)
ЦЕННОСТИ
(
'Джон Доу'
)
--Чтобы заполнить таблицу персонала:
ВСТАВИТЬ В [Посох]
(
-- значение столбца id генерируется автоматически
имя, зарплата, идентификатор менеджера
)
ЦЕННОСТИ
(
«Джейн Доу», 60000, 1
)
ИДТИ
 ),
ОГРАНИЧЕНИЕ pk_manager ПЕРВИЧНЫЙ КЛЮЧ (id)
)
СОЗДАТЬ СТОЛ Персонал
(
идентификатор int ИДЕНТИФИКАЦИЯ (1,1),
имя nvarchar (макс.),
зарплата деньги,
managerId int FOREIGN KEY REFERENCES Manager(id) NULL,
ОГРАНИЧЕНИЕ pk_staff ПЕРВИЧНЫЙ КЛЮЧ (id)
)
--Чтобы заполнить таблицу менеджера:
ВСТАВЬТЕ В [Менеджер]
(
-- значение столбца id генерируется автоматически
имя
)
ЦЕННОСТИ
(
'Джон Доу'
)
--Чтобы заполнить таблицу персонала:
ВСТАВИТЬ В [Посох]
(
-- значение столбца id генерируется автоматически
имя, зарплата, идентификатор менеджера
)
ЦЕННОСТИ
(
«Джейн Доу», 60000, 1
)
ИДТИ
),
ОГРАНИЧЕНИЕ pk_manager ПЕРВИЧНЫЙ КЛЮЧ (id)
)
СОЗДАТЬ СТОЛ Персонал
(
идентификатор int ИДЕНТИФИКАЦИЯ (1,1),
имя nvarchar (макс.),
зарплата деньги,
managerId int FOREIGN KEY REFERENCES Manager(id) NULL,
ОГРАНИЧЕНИЕ pk_staff ПЕРВИЧНЫЙ КЛЮЧ (id)
)
--Чтобы заполнить таблицу менеджера:
ВСТАВЬТЕ В [Менеджер]
(
-- значение столбца id генерируется автоматически
имя
)
ЦЕННОСТИ
(
'Джон Доу'
)
--Чтобы заполнить таблицу персонала:
ВСТАВИТЬ В [Посох]
(
-- значение столбца id генерируется автоматически
имя, зарплата, идентификатор менеджера
)
ЦЕННОСТИ
(
«Джейн Доу», 60000, 1
)
ИДТИ
Чтобы создать две таблицы базы данных:
-- Создать StaffData
СОЗДАТЬ ТАБЛИЦУ StaffData
(
staffid int ПЕРВИЧНЫЙ КЛЮЧ ИДЕНТИЧНОСТИ,
идентификатор менеджера
)
-- Создать таблицу менеджеров
СОЗДАТЬ ТАБЛИЦУ
(
менеджерид инт,
имя varchar(50),
зарплата деньги
)
Для заполнения таблицы StaffData:
INSERT INTO [StaffData]
(
--staffid — значение этого столбца генерируется автоматически
[managerid]
)
ЦЕННОСТИ
(
-- StaffID - инт
12345 -- ID-менеджера - интервал
)
Чтобы заполнить таблицу ManagerTable:
INSERT INTO [ManagerTable]
(
[менеджер],
[имя],
[зарплата]
)
ЦЕННОСТИ
(
12345, --managerid - интервал
'Хуан Дела Круз', -- имя - varchar
15000 -- зарплата -- деньги
)
Чтобы выбрать данные, если я понимаю вас в вашем слове Указатель вот запрос с использованием INNER JOIN объединение двух таблиц с использованием их managerid
ВЫБЕРИТЕ *
ОТ [Данные персонала]
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [ManagerTable]
ON [StaffData]. managerid = [ManagerTable].managerid
 managerid = [ManagerTable].managerid
managerid = [ManagerTable].managerid
3
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Заполнение больших таблиц случайными данными для тестирования производительности SQL Server
Автор: Ben Richardson |
Комментарии (1) | Связанный: Еще > Тестирование
Проблема
Тестирование производительности является одним из наиболее важных критериев для оценки SQL Server.
эффективность базы данных. Плохо написанные запросы влияют на производительность базы данных. Однако
если у вас есть только небольшой объем данных в базе данных, становится трудно
оценить, насколько хорошо выполняется запрос. Для небольших наборов данных разница между
производительность различных сценариев запросов не различима. Чтобы оценить запрос
производительность, нам нужны большие наборы данных. В этом совете мы увидим, как создавать большие
таблицы случайных данных, которые можно использовать для тестирования производительности.
Решение
Решение этой проблемы заключается в написании скрипта, который может добавить большое количество
случайных данных в базу данных SQL Server, чтобы можно было оценить производительность запросов
и исполнение.
Мы объясним процесс создания больших таблиц со случайными данными с
помощь примера. Мы создадим фиктивную базу данных библиотеки с двумя таблицами: tblAuthors
и таблбуки. В первой таблице будет храниться информация о воображаемых авторах и
вторая таблица будет хранить информацию о воображаемых книгах. На столах будет
отношение «один ко многим», при котором у автора может быть несколько книг. Сначала мы будем
вставить большое количество случайных данных в таблицу tblAuthors, так как это не
иметь какие-либо внешние ключи. Далее мы объясним процесс добавления случайных данных в
таблица с внешним ключом.
Создайте пример базы данных SQL Server
Сначала нам нужно создать базу данных примера библиотеки и добавить в нее таблицы.
Взгляните на следующий скрипт:
CREATE Таблица tblAuthors ( Id первичный ключ идентификации, Автор_имя nvarchar(50), страна nvarchar(50) ) СОЗДАТЬ Таблицу tblBooks ( Id первичный ключ идентификации, Auhthor_id int ссылки на внешние ключи tblAuthors(Id), Цена инт, Издание внутр.
 )
)
Таблица tblAuthors содержит три столбца: Id, Author_name и Country.
Таблица tblBooks содержит четыре столбца: Id, Author_id, Price и Edition. Автор_id
столбец таблицы tblBooks является столбцом внешнего ключа и ссылается на столбец идентификатора
таблица tblAuthors. Это должно реализовать отношение один ко многим между
два стола.
Добавление большого количества случайных данных в таблицу tblAuthors в SQL Server
Теперь добавим данные в таблицу tblAuthors. Мы решили добавить записи
к этой таблице в первую очередь, так как это независимая таблица и не имеет внешних ключей.
С другой стороны, таблица tblBooks имеет внешний ключ, который ссылается на таблицу tblAuthors.
Следовательно, у нас должна быть запись в таблице tblAuthors, прежде чем мы сможем вставить
записи в таблице tblBooks.
Следующий сценарий вставляет 12 тысяч фиктивных записей в таблицу tblAuthors.
Вы можете добавить больше, если хотите.
Объявить @Id int
Установите @Id = 1
Пока @Id <= 12000
Начинать
Вставьте в значения tblAuthors ("Автор -" + CAST(@Id as nvarchar(10)),
'Страна -' + CAST(@Id as nvarchar(10)) + 'имя')
Распечатать @Id
Установить @Id = @Id + 1
Конец
Взгляните на приведенный выше сценарий. Здесь мы объявляем целочисленную переменную @Id и
Здесь мы объявляем целочисленную переменную @Id и
инициализируйте его с 1. Внутри цикла while мы используем оператор INSERT для вставки
записи в таблицу tblAuthors.
Посмотрите на вставляемые значения. Нам не нужно вставлять какое-либо значение для
Id, так как мы установили свойство identity, поэтому значение для этого столбца
будет автоматически вставляться с каждой записью. Мы должны вставить значения для
Столбцы Author_name и country. Для Author_name мы используем строку Author
- и соедините его со значением переменной @Id. Чтобы преобразовать @Id из
целое число в строку мы используем функцию CAST. Значения, вставленные для столбца Author_name
будет Автор - 1, Автор - 2 до Автора - 12000. Мы используем ту же технику для
добавьте значения для столбца Country.
Теперь, если вы выберете все записи из столбца tblAuthor, вы получите 12000
записи. Таблица будет выглядеть так:
| Идентификационный номер | Имя_автора | страна |
|---|---|---|
| 1 | Автор - 1 | Страна - 1 имя |
| 2 | Автор - 2 | Страна - 2 названия |
| 3 | Автор - 3 | Страна - 3 имени |
| 4 | Автор - 4 | Страна - 4 названия |
| 5 | Автор - 5 | Страна - 5 наименований |
| 6 | Автор - 6 | Страна - 6 наименований |
| 7 | Автор - 7 | Страна - 7 имя |
| 8 | Автор - 8 | Страна - 8 наименований |
| 9 | Автор - 9 | Страна - 9имя |
- | - | - |
- | - | - |
| 12000 | Автор - 12000 | Страна - 12000 имя |
Добавление большого количества случайных данных в таблицу tblBooks в SQL Server
Теперь давайте добавим некоторые данные в таблицу tblBooks. Это немного сложнее, чем
Это немного сложнее, чем
вставка данных в таблицу tblAuthors. Это связано с тем, что столбец Author_Id
таблица tblBooks ссылается на столбец Id таблицы tblAuthors. Это значит, что
столбец Author_Id может иметь значения только от 1 до 12000, т. е. значения
столбец Id автора. Также мы должны добавить случайные значения для цены и
Колонки издания.
Чтобы увидеть решение этой проблемы, проверьте следующий сценарий. Объяснение
для этого кода следует.
Объявить @RandomAuthorId int Объявить @RandomPrice int Объявить @RandomEdition int Объявить @LowerLimitForAuthorId int Объявить @UpperLimitForAuthorId int Установите @LowerLimitForAuthorId = 1 Установите @UpperLimitForAuthorId = 12000 Объявить @LowerLimitForPrice int Объявить @UpperLimitForPrice int Установите @LowerLimitForPrice = 50 Установите @UpperLimitForPrice = 100 Объявить @LowerLimitForEdition int Объявить @UpperLimitForEdition int Установите @LowerLimitForEdition = 1 Установите @UpperLimitForEdition = 10 Объявить @count int Установите @количество = 1 Пока @count <= 20000 Начинать Выберите @RandomAuthorId = Round(((@UpperLimitForAuthorId - @LowerLimitForAuthorId) * Rand()) + @LowerLimitForAuthorId, 0) Выберите @RandomPrice = Round(((@UpperLimitForPrice - @LowerLimitForPrice) * Rand()) + @LowerLimitForPrice, 0) Выберите @RandomEdition = Round(((@UpperLimitForEdition - @LowerLimitForEdition) * Rand()) + @LowerLimitForEdition, 0) Вставить в tblBooks значения (@RandomAuthorId, @RandomPrice, @RandomEdition) Распечатать @count Установите @count = @count + 1 Конец
Взгляните на приведенный выше код. Здесь на старте мы создаем три переменные @RandomAuthorId,
Здесь на старте мы создаем три переменные @RandomAuthorId,
@RandomPrice и @RandomEdition. Эти три переменные будут хранить значения для
быть вставлены в столбцы Author_Id, Price и Edition таблицы tblBooks.
Затем мы создали переменные для хранения значений верхнего и нижнего пределов для
все столбцы Author_Id, Price и Edition. Мы хотим, чтобы столбцы Author_Id
имеют только значения от 1 до 12000, поэтому переменная @UpperLimitForAuthorId
установлено значение 12000, а для переменной @LowerLimitForAuthorId установлено значение 1. Аналогично,
Для переменной @UpperLimitForPrice установлено значение 50, а для переменной @LowerLimitForAuthorId
установлено значение 100, потому что мы хотим, чтобы цена находилась в диапазоне от 50 до 100. Наконец, @UpperLimitForEdition
установлена на 10, а переменная @LowerLimitForEdition установлена на 1, потому что
мы хотим, чтобы издание имело значения от 1 до 10.
Затем мы используем функцию Rand() , которая возвращает значения от 0 до 1 и
умножил его на результат верхних пределов нижних пределов. Это возвращает
Это возвращает
значения между указанными пределами. Однако эти значения представлены в десятичном формате. Для преобразования
его в целое число, мы используем функцию раунда. Мы указываем второй атрибут как 0.
Это округляет число до нуля знаков после запятой. Наконец, мы вставляем полученные значения
в таблицу tblBooks.
Теперь, если вы выберите все записи из таблицы tblBooks, вы увидите, что 20000
записи были вставлены. Вы увидите значение Author_Id от 1 до 12000,
значение для цены от 50 до 100 и значение для выпуска от 1 до 10
как указано в запросе. Результирующий набор будет выглядеть так:
| Идентификационный номер | Автор_id | Цена | Издание |
|---|---|---|---|
| 1 | 8878 | 56 | 2 |
| 2 | 9605 | 71 | 5 |
| 3 | 3860 | 61 | 8 |
| 4 | 7425 | 81 | 7 |
| 5 | 4775 | 77 | 5 |
| 6 | 66 | 60 | 3 |
| 7 | 241 | 78 | 9 |
| 8 | 10583 | 93 | 2 |
| 9 | 7920 | 96 | 8 |
| - | - | - | - |
| - | - | - | - |
| 20000 | 2096 | 92 | 6 |
Ваши значения будут отличаться, поскольку эти числа генерирует функция Rand.