Базы данных индексы: 14 вопросов об индексах в SQL Server, которые вы стеснялись задать / Хабр
Содержание
что это и зачем нужны — Блог Lineate
ко всем статьям
< ко всем статьям
<
Автор: Татьяна Сергиенко, Software Engineer
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Что такое индексы?
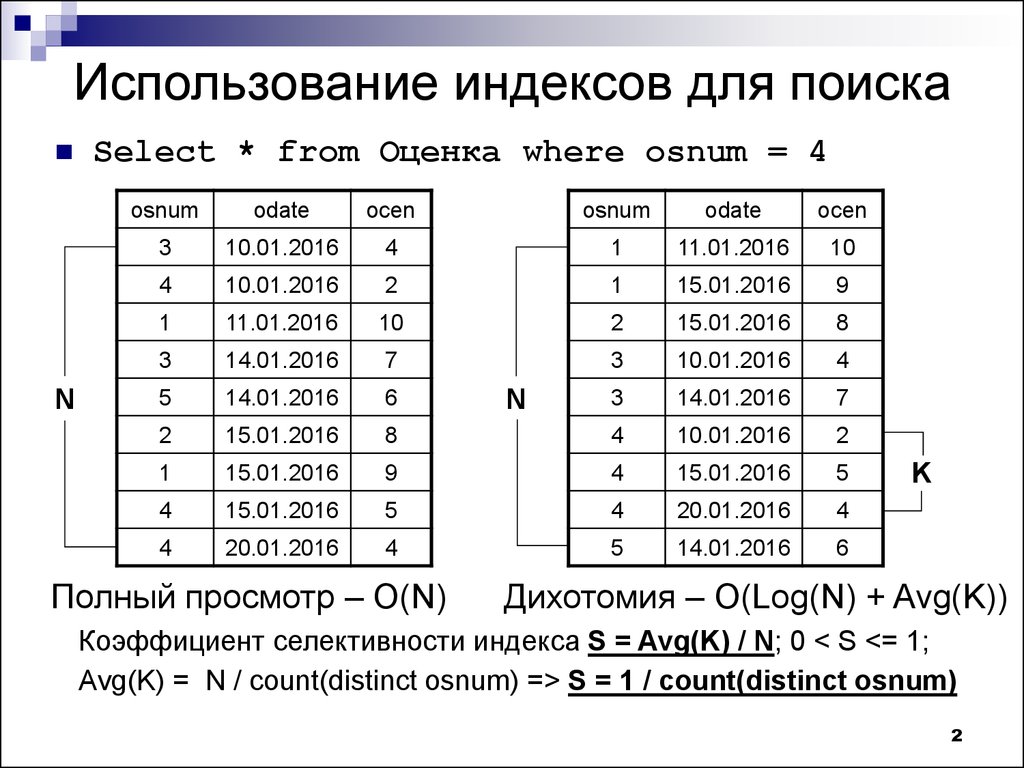
Когда мы работаем с базой данных, нам нужно выполнять запросы, которые позволяют быстро найти нужную информацию. Если этих данных очень много, то базе придется перебирать все строки нашей таблицы, чтобы найти нужный ответ.
Важность индексов увеличивается по мере роста объема данных. Если у вас какая-то небольшая база данных, она может работать без индексов, но производительность ваших запросов может сильно упасть, как только она начнет расти.
Для чего используются индексы?
Индексы помогают:
- быстро находить строки, соответствующие выражению WHERE
- извлекать строки из других таблиц при выполнении объединений
- находить величины MAX() или MIN() для заданного индексированного столбца
- производить сортировку или группирование в таблице, если эти операции делаются на крайнем левом префиксе используемого ключа (например, ORDER BY key_part_1, key_part_2).


Индекс – это специальная структура данных, обычно это B-Tree дерево, которое позволяет повышать скорость извлечения данных за счет дополнительных операций записи и хранения. Здесь стоит отметить, что индексы хранятся отдельно от данных.
Схематично B-Tree можно изобразить так: дерево состоит из корня (верхняя вершинка), дальше у нас идут ветви, ветви заканчиваются листьями, на листьях находится нужная информация.
Мощность Индекса
Мощность индекса относится к уникальности значений, хранящихся в указанном столбце индекса.
MySQL генерирует количество элементов индекса на основе статистики, хранящейся в виде целых чисел, поэтому значение не обязательно может быть точным.
При создании индексов нужно найти золотую середину, не создавая индексы на каждый столбец, в этом поможет оптимизация баз данных. Можно пересмотреть запросы, убрать неэффективные, перестроить индексы, убрать дубликаты. Мощность индекса позволяет проанализировать значения.
Действия с индексами MySQL
Создание индекса
Есть два варианта, которые можно использовать в зависимости от ситуации:
- при создании таблицы мы можем указать, какие поля мы хотим создать и тут же указать, какое из этих полей у нас будет индексом
- или мы можем создать индекс отдельно.
Если вы уже работаете с готовой базой данных, в которой нет индекса, вы можете с помощью ALTER-команды обновить таблицу, добавив в нее нужный вам индекс.
Просмотр индексов
Немаловажная возможность – посмотреть, какие индексы есть у таблицы в целом или, например, выбрать индексы с каким-то определенным параметром.
Удаление индекса
В зависимости от ситуации мы можем руководить процессом удаления индексов или указать, какой алгоритм использовать, как блокировать.
ДРУГИЕ СТАТЬИ
>
ко всем статьям
Wednesday, August 18
Индексы MySQL: что это и зачем нужны — Блог Lineate
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Wednesday, August 18
Типы индексов MySQL — Блог Lineate
Кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае). Некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Давайте работать вместе
Присоединяйтесь к нашей команде!
Смотреть вакансии
Индексы — SQL Server | Microsoft Learn
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 3 мин
-
Применимо к:База данныхSQL Server Azure SQL Управляемый экземпляр SQL Azure
Доступные типы индексов
В следующей таблице перечислены типы индексов, доступные в SQL Server, и приведены ссылки на дополнительные сведения.
| Тип индекса | Описание | Дополнительные сведения |
|---|---|---|
| Хэш | При использовании хэш-индекса доступ к данным осуществляется через хэш-таблицу в памяти. Хэш-индексы используют фиксированный размер памяти, который зависит от числа контейнеров. | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по проектированию хэш-индексов |
| Некластеризованный индекс, оптимизированный для памяти | Для оптимизированных для памяти некластеризованных индексов потребление памяти является функцией от количества строк и размера ключевых столбцов индекса | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по проектированию некластеризованных индексов, оптимизированных для памяти |
| Кластеризованный | Кластеризованный индекс сортирует и хранит строки данных таблицы или представления в порядке, определяемом ключом кластеризованного индекса. Кластеризованный индекс реализуется в виде сбалансированного дерева, которое поддерживает быстрое получение строк по значениям ключа кластеризованного индекса. Кластеризованный индекс реализуется в виде сбалансированного дерева, которое поддерживает быстрое получение строк по значениям ключа кластеризованного индекса. | Описание кластеризованных и некластеризованных индексов Создание кластеризованных индексов Правила проектирования кластеризованного индекса |
| Некластеризованный | Некластеризованный индекс можно определить в таблице или представлении вместе с кластеризованным индексом или в куче. Каждая строка некластеризованного индекса содержит некластеризованное ключевое значение и указатель на строку. Этот указатель определяет строку данных кластеризованного индекса или кучи, содержащую ключевое значение. Строки в индексе хранятся в порядке, определяемом значениями ключа индекса, но до создания кластеризованного индекса в таблице нет никакой гарантии того, что строки данных будут расположены в каком-либо определенном порядке. | Описание кластеризованных и некластеризованных индексов Создание некластеризованных индексов Рекомендации по созданию некластеризованных индексов |
| Уникальная идентификация | Уникальный индекс обеспечивает отсутствие повторяющихся значений ключа индекса, что, в свою очередь, приводит к тому, что каждая строка в таблице или представлении является в каком-то смысле уникальной. Как кластеризованные, так и некластеризованные индексы могут быть уникальными. | Создание уникальных индексов Правила по созданию уникальных индексов |
| columnstore | Индекс columnstore в памяти хранит данные и управляет данными с использованием основанного на столбцах хранилища данных и обработки запросов. Индексы Columnstore подходят для рабочих нагрузок хранилища данных, которые выполняют в основном массовую загрузку и запросы только для чтения. Используйте индекс columnstore для повышения производительности запросов максимум в 10 раз относительно традиционного хранилища, основанного на строках, и повышения эффективности сжатия данных до 7 раз относительно несжатых данных. | Руководство по индексам columnstore Рекомендации по проектированию индексов columnstore |
| Индекс с включенными столбцами | Некластеризованный индекс, дополнительно содержащий кроме ключевых столбцов еще и неключевые. | Создание индексов с включенными столбцами |
| Индекс на вычисляемых столбцах | Индекс на столбце, являющемся производным от одного или нескольких других столбцов или нескольких детерминированных источников. | Индексы вычисляемых столбцов |
| Filtered | Оптимизированный некластеризованный индекс, в особенности подходящий для покрытия запросов из хорошо определенного подмножества данных. Он использует предикат фильтра для индексирования части строк в таблице. Хорошо спроектированный отфильтрованный индекс позволяет повысить производительность запросов, снизить затраты на обслуживание и хранение индексов по сравнению с полнотабличными индексами. | Создание отфильтрованных индексов Рекомендации по проектированию отфильтрованных индексов |
| пространственный индекс | Пространственный индекс обеспечивает возможность более эффективного использования определенных операций с пространственными объектами (пространственными данными) в столбце типа данных geometry . Пространственные индексы снижают количество объектов, к которым должны применяться пространственные операции, требующие больших затрат. Пространственные индексы снижают количество объектов, к которым должны применяться пространственные операции, требующие больших затрат. | Общие сведения о пространственных индексах |
| XML | Вырезанное материализованное представление больших двоичных XML-объектов в столбце с типом данных xml. | XML-индексы (SQL Server) |
| Полнотекстовый | Специальный тип функционального индекса на основе маркеров, который создается и обслуживается Microsoft Full-Text Engine для SQL Server. Он обеспечивает эффективную поддержку сложных операций поиска слов в символьных строковых данных. | Заполнение полнотекстовых индексов |
Примечание
В документации по SQL Server термин «сбалансированное дерево» обычно используется в отношении индексов. В индексах rowstore SQL Server реализует B+-дерево. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в руководстве по архитектуре и разработке индексов SQL Server.
См. также
Руководство по проектированию индексов SQL Server
Параметр SORT_IN_TEMPDB для индексов
Отключение индексов и ограничений
Включение индексов и ограничений
Переименование индексов
Установка параметров индекса
Требования к месту на диске для DDL-операций индекса
Реорганизация и перестроение индексов
Указание коэффициента заполнения для индекса
Руководство по архитектуре страниц и экстентов
Описание кластеризованных и некластеризованных индексов
Как работают индексы базы данных?
Engineering15 min read
Если вы запрашивали базу данных, вы, вероятно, использовали индекс, даже если вы не знали об этом в то время. Индексы базы данных помогают ускорить запросы на чтение, создавая вспомогательные структуры данных, которые ускоряют сканирование. В этом посте будет рассказано о том, как работают индексы базы данных, с особым акцентом на MySQL, любимую всеми (ну, многими людьми) органическую базу данных собственной разработки.
Индексы — это способ ускорить ваши запросы на чтение, особенно запросы с фильтрами ( ГДЕ ) на них. Это структуры данных, которые существуют в вашем механизме базы данных, за пределами любой таблицы, с которой они работают, и указывают на данные, которые вы пытаетесь запросить.
Чтобы избежать слишком распространенной библиотечной метафоры, представьте себе — возможно, далекий от реальности сценарий — что у вас есть все ваши пользователи в таблице в вашей базе данных MySQL (конечно, работающей на PlanetScale). Вы встраиваете в свое социальное приложение некоторые функции, которые позволяют пользователям искать и фильтровать других пользователей, а это означает, что в рабочей среде будет выполняться запрос.0011 1 , который проходит через всю вашу таблицу пользователей . Хуже того, ваше приложение довольно успешное, поэтому таких «пользователей» сотни тысяч. Представь это!
К сожалению, SELECT -ing из этой таблицы пользователей сейчас не очень эффективен. Фильтры, которые вы применяете на основе входных данных в пользовательском интерфейсе — местоположения пользователя, типа учетной записи, последней активности и других столбцов в вашей базе данных — требуют сканирования всей таблицы пользователей, что в среднем составляет примерно O (N/2). Ваш запрос выполняется 5-6 секунд, что было бы неплохо для аналитика данных, выполняющего внутреннюю работу, но недостаточно для плавного взаимодействия с пользователем.
Фильтры, которые вы применяете на основе входных данных в пользовательском интерфейсе — местоположения пользователя, типа учетной записи, последней активности и других столбцов в вашей базе данных — требуют сканирования всей таблицы пользователей, что в среднем составляет примерно O (N/2). Ваш запрос выполняется 5-6 секунд, что было бы неплохо для аналитика данных, выполняющего внутреннюю работу, но недостаточно для плавного взаимодействия с пользователем.
Чтобы исправить это, вы создаете индекс базы данных для столбца «самая последняя активность» в вашей таблице пользователей с помощью CREATE INDEX. За кулисами MySQL создает новую псевдотаблицу в базе данных с двумя столбцами: значением самой последней активности и указателем на запись в таблице пользователей . Хитрость здесь, однако, заключается в том, что таблица упорядочивается и сохраняется в виде двоичного дерева с упорядоченными значениями для этого самого последнего столбца активности. В результате ваш запрос эффективен в O Log(n) и выполняется всего за секунду или меньше.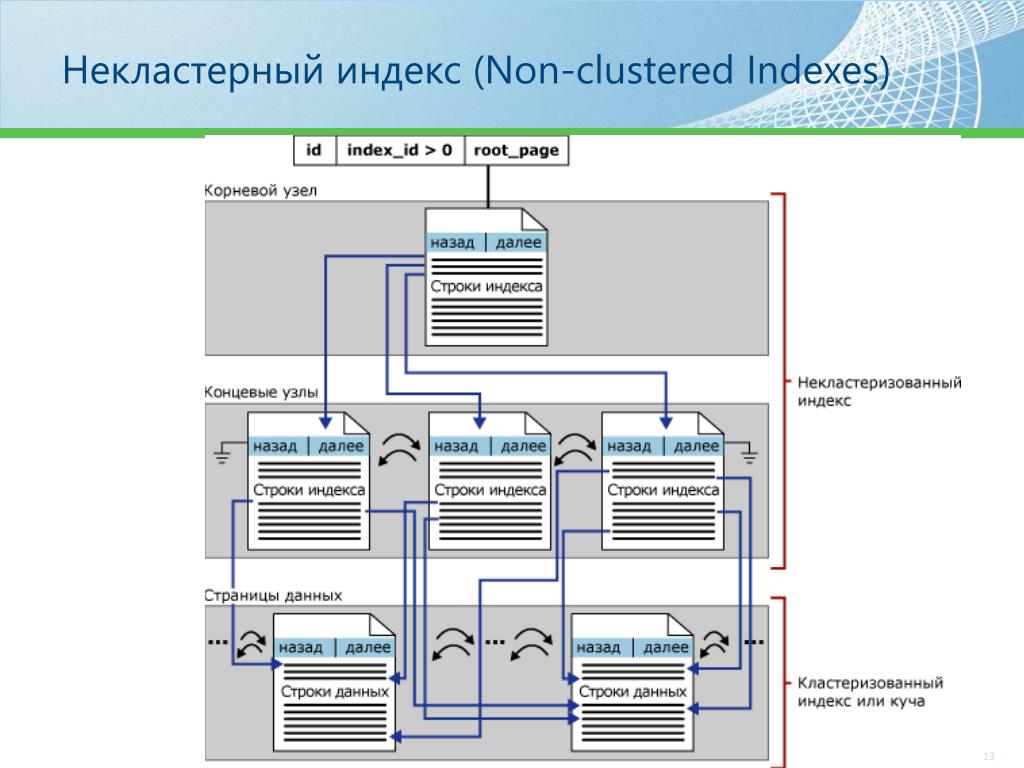
Это основная суть индексов. Если вы знаете, что вы собираетесь многократно запускать конкретный запрос и беспокоитесь о производительности чтения, создание индекса (или нескольких) может помочь ускорить этот запрос.
Это простая версия; под капотом происходит гораздо больше, и слишком много индексов могут даже ухудшить производительность, которую вы стремились улучшить.
Индекс — это , а не магия — это структура базы данных, которая содержит указатели на определенные записи базы данных. Без индекса данные в базе данных обычно хранятся в виде куча , в основном куча неупорядоченных 2 , несортированных строк. На самом деле это параметр, который вы можете переключать в Microsoft SQL Server и базе данных SQL Azure.
На практике данные редко хранятся полностью несортированными. Вместо этого вы обычно будете использовать какой-то первичный ключ, который в MySQL может быть идентичен индексу, который может быть чем-то вроде автоинкрементного целого числа. Но данные, конечно, могут быть отсортированы только по одному столбцу , что ограничивает «бинарную» эффективность сортировки (с уникальными значениями) запросом, фильтрующим этот один упорядоченный столбец. Индекс — это, по сути, способ отсортировать вашу таблицу по несколько столбцов , что позволяет получить эффективность бинарного поиска в нескольких столбцах фильтра.
Но данные, конечно, могут быть отсортированы только по одному столбцу , что ограничивает «бинарную» эффективность сортировки (с уникальными значениями) запросом, фильтрующим этот один упорядоченный столбец. Индекс — это, по сути, способ отсортировать вашу таблицу по несколько столбцов , что позволяет получить эффективность бинарного поиска в нескольких столбцах фильтра.
Когда вы создаете индекс для столбца, вы создаете новую таблицу с двумя столбцами: один для столбца, для которого вы индексировали, и другой, который содержит указатель на то, где хранится рассматриваемая запись. Хотя индекс будет иметь ту же длину , что и исходная таблица, ширина , вероятно, будет намного короче, и поэтому для хранения и перемещения потребуется меньше дисковых блоков. Указатели в MySQL довольно малы, обычно менее 5 байт. Вышеуказанный теперь «легендарный» пост о переполнении стека посвящен математике количества блоков, необходимых для хранения, для тех, кто заинтересован в более глубоком изучении.
Если вы не настроили его самостоятельно, скорее всего, уже создано несколько индексов в любой базе данных, которую вы используете прямо сейчас. Вы можете просмотреть любые индексы, существующие в конкретной таблице, с помощью:
SHOW INDEX FROM table_name FROM db_name;
Если вы запустите оператор EXPLAIN для своего запроса, вы также должны увидеть информацию о том, какие индексы планирует использовать запрос. Вот таблица возможных выходных значений EXPLAIN из документов MySQL; обратите внимание на возможных_ключей и ключевых значений, оба относятся к выбору индекса.
| Column | JSON name | Definition |
|---|---|---|
id | select_id | The SELECT identifier |
select_type | None | The SELECT тип |
таблица | имя_таблицы | The table for the output row |
partitions | partitions | The matching partitions |
type | access_type | The join type |
possible_keys | возможных_ключей | Возможные индексы для выбора |
ключ | ключ | The index actually chosen |
key_len | key_length | The length of the chosen key |
ref | ref | The columns compared to the index |
строк | строк | Оценка строк для проверки |
отфильтровано | отфильтровано | Процент строк, фильтрованных в условиях таблицы |
Extra | Нет | Дополнительная информация |
Этот способ использования Объяснение может быть полезно для создания addex.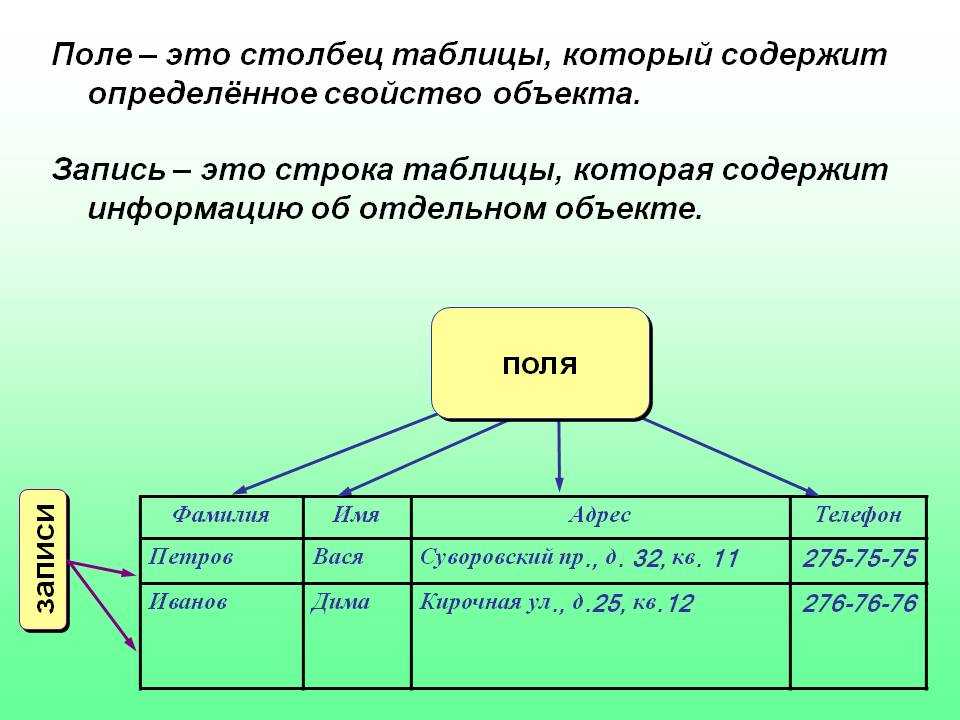 один работает по назначению.
один работает по назначению.
Хотя индексы всегда хранят указатели на запись, на которую указывает любой индекс, базе данных не всегда нужно использовать эти указатели. Сканирование только индекса (покрывающий индекс в MySQL) относится к случаю, когда значение, которое ищет ваш запрос, содержится только в индексе, и поэтому не требует поиска в таблице. В PostgreSQL не все типы индексов поддерживают сканирование только индексов.
Следует помнить об индексах: хотя они полезны для запросов на чтение (включая JOIN и агрегаты), они могут негативно повлиять на производительность вашей базы данных в целом, если вы не будете осторожны. Индексы занимают много места, даже если это место меньше, чем исходная таблица, а это место дорого; вам нужно будет следить за тем, насколько близко вы приближаетесь к пределу вашей файловой системы. Они также делают INSERT Запросы занимают больше времени и вынуждают обработчик запросов рассматривать больше вариантов, прежде чем выбирать способ выполнения запроса.
В основном мы ссылались на уникальные индексы базы данных, но оказалось, что это только один из нескольких типов. Имейте в виду, что любой из этих индексов может содержать более одного столбца (помимо указателя). MySQL фактически поддерживает до 16 столбцов в индексе. Но мы отвлеклись.
Ключи
Вы можете видеть, что «ключ» используется взаимозаменяемо с «индексом». А KEY в MySQL — это тип неуникального индекса. Поскольку индекс не уникален, сканирование по нему будет не таким эффективным, как бинарное дерево, но, вероятно, будет более эффективным, чем линейный поиск. Многие столбцы в ваших таблицах, вероятно, будут соответствовать этому счету, например. что-то вроде «имя» или «местоположение».
Между MySQL и Postgres существует довольно большая разница в том, как они обрабатывают хранилище первичных ключей. В MySQL первичные ключи хранятся с их данными , что означает, что они фактически не занимают дополнительного места для хранения. В Postgres первичные ключи обрабатываются как другие индексы и хранятся в отдельных структурах данных.
В Postgres первичные ключи обрабатываются как другие индексы и хранятся в отдельных структурах данных.
Уникальные индексы
Уникальный индекс соответствует традиционному уникальному определению — нет двух идентичных значений, отличных от NULL , — с оговоркой, что значения отсортированы. Когда данные соответствуют этим двум определениям — уникальным и отсортированным — вы можете использовать бинарный поиск и получить этот приятный, приятный O log(N). Обратите внимание, что первичный ключ — это особый тип уникального индекса, который может быть только один для каждой таблицы, а значение не может быть NULL .
Кроме того, индексы UNIQUE можно использовать как способ обеспечить уникальность определенного столбца таблицы. Поскольку индексы обновляются при каждой вставке, попытка вставить неуникальное значение в столбец с уникальным индексом вызовет ошибку. Документы Postgres прямо указывают на это.
Текстовые индексы
Использование квалификатора FULLTEXT создаст текстовый индекс в большинстве популярных реляционных баз данных.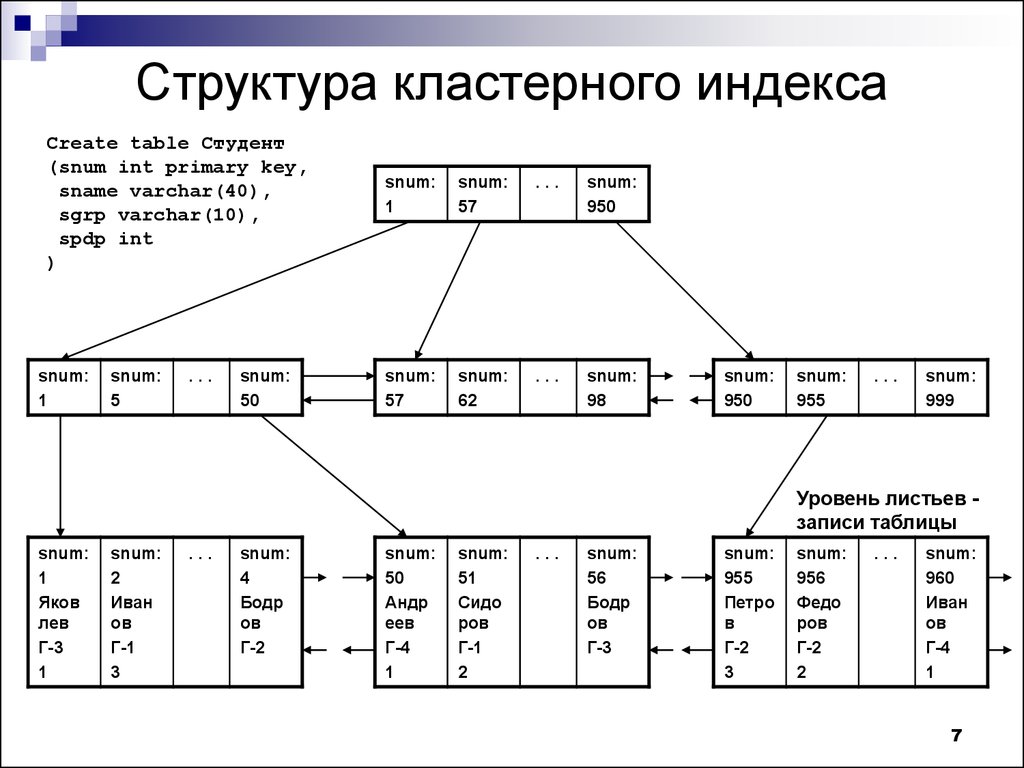 Его можно применять только к столбцам текстового типа (
Его можно применять только к столбцам текстового типа ( CHAR , VARCHAR или TEXT ) в MySQL. Что становится интересным, так это с использованием этих индексов: MySQL предоставляет множество функций из коробки, которые начинают напоминать то, что вы ожидаете от современной библиотеки синтаксического анализа текста / NLP.
Основное ключевое слово для текстового поиска, установленное в MySQL, равно ПОИСКПОЗ()... ПРОТИВ() . Вы можете выбрать один из нескольких различных методов поиска, в том числе:
- Поиск на естественном языке — никаких специальных операторов, используются встроенные стоп-слова, которые вы можете настроить. Это тип поиска по умолчанию.
- Логический поиск — использует специальный язык запросов, который примерно аналогичен RegEx (но сильно отличается).
- Поиск расширения запроса — запускает обычный поиск на естественном языке, затем еще один, используя слова из возвращенных строк, отсюда и «расширение».
Каждый из этих методов имеет свои недостатки, ни один из них не является универсальным.
В MySQL есть и другие типы индексов, такие как префиксные индексы или нисходящие индексы. Для получения более полной информации ознакомьтесь с документацией MySQL по индексам.
MySQL использует довольно стандартный синтаксис для создания индексов:
CREATE [тип] INDEX имя_индекса ON имя_таблицы (имя_столбца)
Хотя команда может быть простой, объем доступных настроек впечатляет. Вот полный список доступных опций из документации MySQL:
СОЗДАТЬ [УНИКАЛЬНЫЙ | ПОЛНЫЙ ТЕКСТ | SPATIAL] INDEX index_name
[тип_индекса]
ON имя_таблицы (key_part,...)
[опция_индекса]
[опция_алгоритма | lock_option] ...
key_part: {col_name [(длина)] | (выражение)} [ASC | DESC]
index_option: {
KEY_BLOCK_SIZE [=] значение
| index_type
| С ПАРСЕРОМ parser_name
| КОММЕНТАРИЙ 'строка'
| {ВИДИМ | НЕВИДИМЫЙ}
| ENGINE_ATTRIBUTE [=] 'строка'
| SECONDARY_ENGINE_ATTRIBUTE [=] 'строка'
}
тип_индекса:
ИСПОЛЬЗОВАНИЕ {BTREE | ХЭШ}
алгоритм_опция:
АЛГОРИТМ [=] {ПО УМОЛЧАНИЮ | ВСТАВИТЬ | КОПИРОВАТЬ}
lock_option:
БЛОКИРОВКА [=] {ПО УМОЛЧАНИЮ | НЕТ | ОБЩИЙ | ЭКСКЛЮЗИВ} Например, если бы мы хотели создать индекс для столбца «самая последняя активность» в нашей таблице пользователей, мы бы использовали следующие параметры. Имейте в виду, что этот столбец содержит неуникальные значения, поэтому мы пропустим ключевое слово
Имейте в виду, что этот столбец содержит неуникальные значения, поэтому мы пропустим ключевое слово UNIQUE при создании индекса.
СОЗДАТЬ ИНДЕКС users_most_recent_activity
ВКЛ пользователей ({most_recent_activity} DESC)
КОММЕНТАРИЙ «для запроса по последней активности» Это проще. Вы можете настроить любое из следующего:
- Тип индекса – как указано выше. Вы можете выбрать неуникальные (без ключевого слова), уникальные, полнотекстовые и т. д.
- Тип индекса — хранится в виде двоичного дерева или хэша.
- Разное options – размер блока ключей, специальные парсеры, комментарии и т.д.
- Используемые алгоритмы и блокировки
Чтобы узнать больше, ознакомьтесь с документацией по MySQL.
1 — Большие запросы на чтение в рабочей среде не всегда распространены, но вы можете себе представить, что это происходит много
в аналитике.2 — Ну, технически упорядочены в том порядке, в котором вы их вставили в таблицу.

Следующее сообщение
Начало работы с интерфейсом командной строки PlanetScale
oracle — Сколько индексов базы данных слишком много?
спросил
Изменено
12 лет, 5 месяцев назад
Просмотрено
52к раз
Я работаю над проектом с довольно большой базой данных Oracle (хотя мой вопрос в равной степени относится и к другим базам данных). У нас есть веб-интерфейс, который позволяет пользователям осуществлять поиск практически по любой возможной комбинации полей.
Чтобы ускорить поиск, мы добавляем индексы к полям и комбинациям полей, в которых, по нашему мнению, пользователи обычно будут искать. Однако, поскольку мы на самом деле не знаем, как наши клиенты будут использовать это программное обеспечение, трудно сказать, какие индексы создавать.
Однако, поскольку мы на самом деле не знаем, как наши клиенты будут использовать это программное обеспечение, трудно сказать, какие индексы создавать.
Пространство не имеет значения; у нас есть 4-терабайтный RAID-накопитель, из которого мы используем лишь небольшую часть. Однако меня беспокоит возможное снижение производительности из-за слишком большого количества индексов. Поскольку эти индексы необходимо обновлять каждый раз, когда добавляется, удаляется или изменяется строка, я полагаю, что было бы плохой идеей иметь десятки индексов в одной таблице.
Так сколько же индексов считается слишком большим? 10? 25? 50? Или я должен просто охватить действительно, очень распространенные и очевидные случаи и игнорировать все остальное?
- база данных
- оракул
- дизайн базы данных
Это зависит от операций, которые происходят с таблицей.
Если есть много SELECT и очень мало изменений, индексируйте все, что хотите.... это (потенциально) ускорит выполнение операторов SELECT.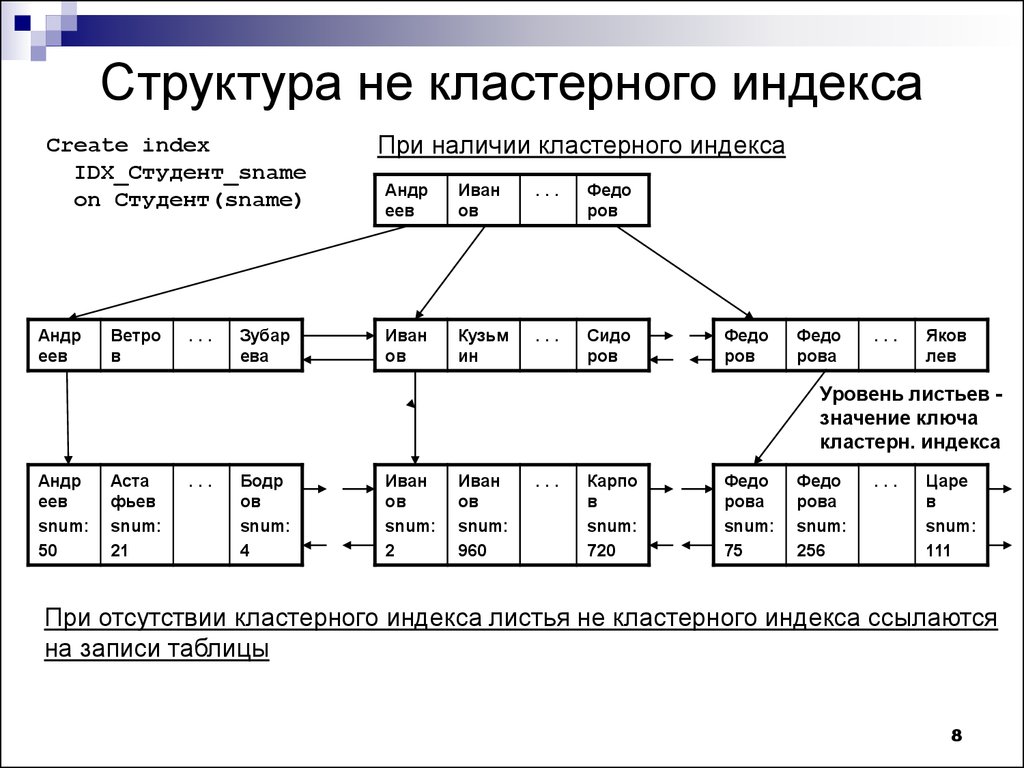
Если таблица сильно пострадала от UPDATE, INSERT + DELETE... они будут очень медленными с большим количеством индексов, так как все они должны быть изменены каждый раз, когда выполняется одна из этих операций
Сказав это, вы можете явно добавить к таблице много бессмысленных индексов, которые ничего не сделают. Добавление индексов B-Tree к столбцу с двумя различными значениями будет бессмысленным, поскольку оно ничего не добавляет с точки зрения поиска данных. Чем более уникальны значения в столбце, тем больше он выиграет от индекса.
1
Я обычно поступаю так.
- Получите журнал реальных запросов, выполненных к данным в обычный день.
- Добавьте индексы, чтобы наиболее важные запросы попадали в индексы в своем плане выполнения.
- Старайтесь не индексировать поля с большим количеством обновлений или вставок
- После нескольких индексов получите новый журнал и повторите.
Как и при любой другой оптимизации, я останавливаюсь, когда достигается запрошенная производительность (очевидно, это подразумевает, что точка 0. будет получать конкретные требования к производительности).
0
Все остальные давали тебе отличные советы. У меня есть дополнительное предложение для вас, когда вы продвигаетесь вперед. В какой-то момент вы должны принять решение относительно вашей лучшей стратегии индексации. В конце концов, даже самая лучшая ЗАПЛАНИРОВАННАЯ стратегия индексирования может привести к созданию индексов, которые в конечном итоге не будут использоваться. Одна из стратегий, позволяющая находить неиспользуемые индексы, заключается в наблюдении за использованием индексов. Вы делаете это следующим образом: -
изменить индекс my_index_name мониторинг использования;
Затем вы можете отслеживать, используется ли индекс с этого момента, запрашивая v$object_usage. Информацию об этом можно найти в Руководстве администратора базы данных Oracle®.
Информацию об этом можно найти в Руководстве администратора базы данных Oracle®.
Просто помните, что если у вас есть стратегия хранения, заключающаяся в удалении индексов перед обновлением таблицы, а затем их повторном создании, вам придется снова настроить индекс для мониторинга, и вы потеряете всю историю мониторинга для этого индекса.
В хранилищах данных очень часто используется большое количество индексов. Я работал с таблицами фактов, содержащими двести столбцов, из которых 190 проиндексированы.
Хотя это связано с накладными расходами, это следует понимать в контексте того, что в хранилище данных мы обычно вставляем строку только один раз, мы никогда не обновляем ее, но затем она может участвовать в тысячах запросов SELECT, которые могли бы выиграть от индексации на любой из столбцов.
Для максимальной гибкости хранилище данных обычно использует битовые индексы с одним столбцом, за исключением столбцов с высокой кардинальностью, где можно использовать (сжатые) индексы btree.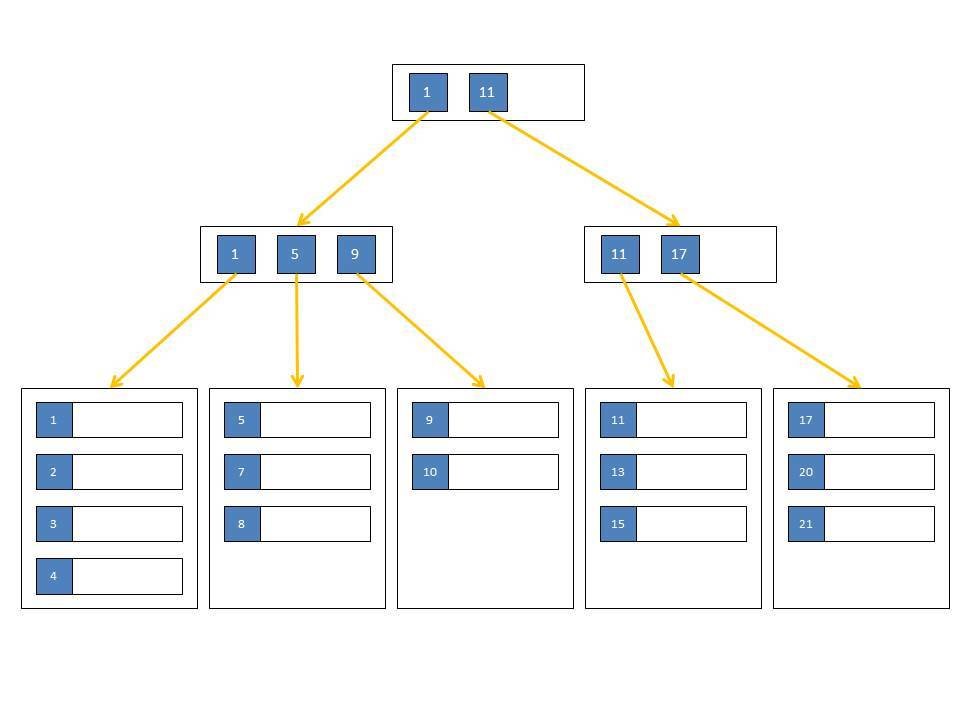
Накладные расходы на обслуживание индекса в основном связаны с затратами на запись в большое количество блоков, и блок разбивается по мере добавления новых строк со значениями, которые находятся «в середине» существующих диапазонов значений для этого столбца. Это можно смягчить путем секционирования и согласования загрузки новых данных со схемой секционирования, а также с помощью вставок прямого пути.
Чтобы ответить на ваш вопрос более конкретно, я думаю, что было бы неплохо сначала проиндексировать очевидное, но не бойтесь добавлять больше индексов, если запросы к таблице принесут пользу.
2
Перефразируя Эйнштейна о простоте, добавьте столько индексов, сколько вам нужно, и не более того.
А если серьезно, каждый добавляемый вами индекс требует обслуживания при каждом добавлении данных в таблицу. Для таблиц, которые в основном предназначены только для чтения, большое количество индексов — это хорошо. На очень динамичных столах чем меньше, тем лучше.
На очень динамичных столах чем меньше, тем лучше.
Мой совет — охватить распространенные и очевидные случаи, а затем, когда возникнут проблемы, требующие большей скорости при получении данных из конкретных таблиц, оценить и добавить индексы в этот момент.
Кроме того, рекомендуется каждые несколько месяцев пересматривать свои схемы индексации, просто чтобы увидеть, есть ли что-то новое, что требует индексации, или созданные вами индексы, которые ни для чего не используются и должны быть получены избавиться от.
1
В дополнение к пунктам, поднятым всеми остальными, оптимизатор на основе затрат берет на себя затраты при создании плана для оператора SQL, если имеется больше индексов, потому что он должен учитывать больше комбинаций. Вы можете уменьшить это, правильно используя переменные связывания, чтобы операторы SQL оставались в кэше SQL. Затем Oracle может выполнить программный анализ и повторно использовать план, найденный в прошлый раз.
Как всегда все не просто. Если есть перекошенные столбцы и гистограммы, это может быть плохой идеей.
В наших веб-приложениях мы склонны ограничивать допустимые комбинации поиска. В противном случае вам пришлось бы тестировать буквально каждую комбинацию на предмет производительности, чтобы убедиться, что у вас нет скрытой проблемы, которую кто-то однажды обнаружит. Мы также ввели ограничения на ресурсы, чтобы это не вызывало проблем в других частях приложения, если что-то пойдет не так.
3
Я провел несколько простых тестов в своем реальном проекте и в реальной базе данных MySql. Я уже ответил в этой теме: Какова стоимость индексации нескольких столбцов БД?
Но я думаю будет лучше, если я процитирую его здесь:
Я сделал несколько простых тестов, используя свой реальный
проекта и реальной базы данных MySql.Мои результаты: добавление среднего индекса
(1-3 столбца в индексе) к таблице -
делает вставки медленнее на 2,1%.
вы добавите 20 индексов, ваши вставки будут
быть медленнее на 40-50%. Но ваш выбор
будет в 10-100 раз быстрее.Можно ли добавлять много индексов? - Это
зависит 🙂 я дал вам свои результаты - вы
решать!
 Так что если
Так что если1
В конечном счете, сколько индексов вам нужно, зависит от поведения ваших приложений, работающих поверх вашего сервера базы данных.
В целом, чем больше вы вставляете, тем более болезненными становятся ваши индексы. Каждый раз, когда вы выполняете вставку, все индексы, включающие эту таблицу, должны обновляться.
Теперь, если ваше приложение имеет приличное количество операций чтения или, тем более, если оно почти полностью читает, то индексы — это то, что вам нужно, так как вы получите значительное улучшение производительности при очень небольших затратах.
На мой взгляд, статического ответа не существует, такие вещи подпадают под «настройку производительности».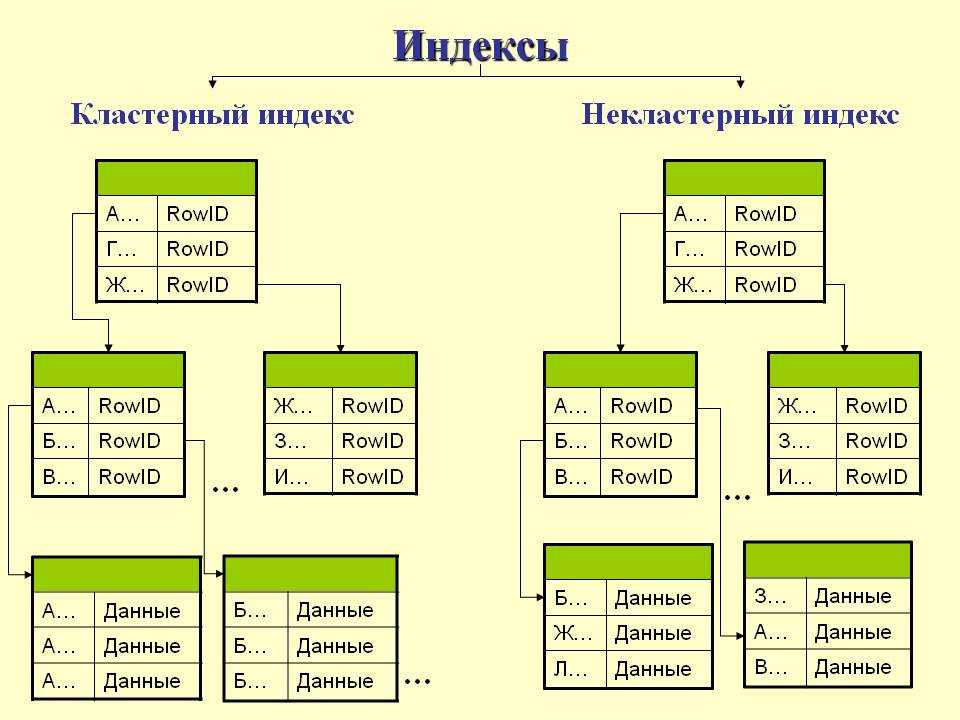
Возможно, все, что делает ваше приложение, ищется по первичному ключу, а может быть и наоборот, запросы выполняются с использованием неограниченных комбинаций полей, и любое конкретное поле может быть использовано в любой момент времени.
Помимо простого индексирования, ваша БД реорганизуется для включения вычисляемых полей поиска, разделяемых таблиц и т. д. — это действительно зависит от ваших форм загрузки и параметров запроса, сколько/каких данных «действительно» нужно вернуть по запросу.
Если вся ваша БД защищена фасадами хранимых процедур, обращение становится немного проще, так как вам не нужно беспокоиться о каждом специальном запросе. Или у вас может быть глубокое понимание того, какие запросы будут попадать в вашу БД, и вы можете ограничить настройку ими.
Для SQL Server мне показался полезным советник по настройке ядра базы данных — вы настраиваете «типичные» рабочие нагрузки, и он может давать рекомендации по добавлению/удалению индексов и статистики. Я уверен, что в других БД есть аналогичные инструменты, либо «официальные», либо сторонние.
Я уверен, что в других БД есть аналогичные инструменты, либо «официальные», либо сторонние.
Это действительно больше теоретические вопросы, чем практические. Влияние индексов на вашу производительность зависит от вашего оборудования, версии Oracle, типов индексов и т. д. Вчера я узнал, что Oracle анонсировала выделенное хранилище, сделанное HP, которое должно работать в 10 раз быстрее с базой данных 11g.
Что касается вашего случая, то тут может быть несколько решений:
1. Иметь большое количество индексов (> 20) и перестраивать их ежедневно (ночью). Это было бы особенно полезно, если таблица ежедневно получает тысячи обновлений/удалений.
2. Разделите таблицу (если это применимо к вашей модели данных).
3. Используйте отдельную таблицу для новых/обновленных данных и запускайте ночной процесс, который объединяет данные вместе. Это потребует изменения логики вашего приложения.
4. Переключитесь на IOT (индексно-организованная таблица), если ваши данные поддерживают это.
Конечно, для такого случая может быть много других решений.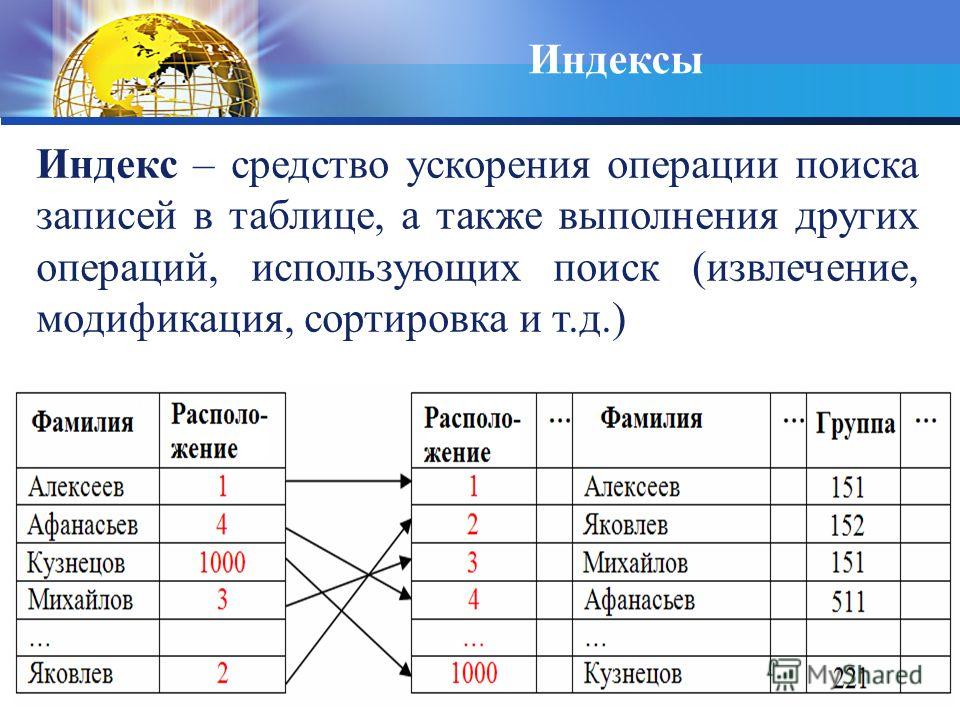 Мое первое предложение для вас было бы клонировать БД в среду разработки и провести на ней стресс-тестирование.
Мое первое предложение для вас было бы клонировать БД в среду разработки и провести на ней стресс-тестирование.
4
Индекс требует затрат при обновлении базовой таблицы. Индекс обеспечивает преимущество, когда он используется для ускорения запроса. Для каждого индекса вам необходимо сбалансировать затраты и выгоды. Насколько медленнее выполняется запрос без индекса? Какая польза от того, что вы работаете быстрее? Можете ли вы или ваши пользователи терпеть медленную скорость при отсутствии индекса?
Можете ли вы мириться с дополнительным временем, которое требуется для завершения обновления?
Вам необходимо сравнить затраты и выгоды. Это конкретно для вашей ситуации. Не существует волшебного числа индексов, которые превышают порог «слишком много».
Существует также стоимость места, необходимого для хранения индекса, но вы сказали, что в вашей ситуации это не проблема. То же самое верно в большинстве ситуаций, учитывая, насколько дешевым стало дисковое пространство.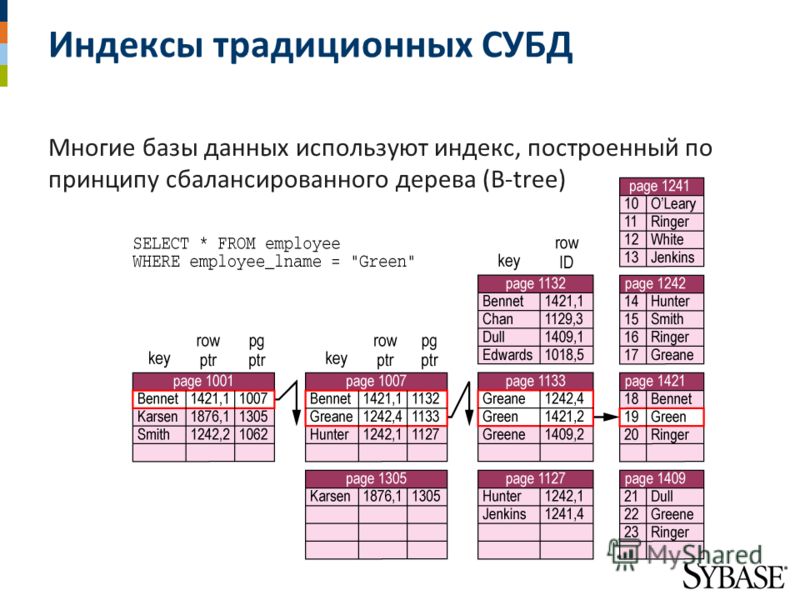
Если вы в основном читаете (и мало обновляете), то действительно нет причин не индексировать все, что вам нужно индексировать. Если вы часто обновляете, вам, возможно, придется быть осторожным с тем, сколько у вас индексов. Там нет жесткого числа, но вы заметите, когда все начнет замедляться. Убедитесь, что ваш кластеризованный индекс является наиболее целесообразным на основе данных.
Одна вещь, которую вы можете рассмотреть, это создание индексов для стандартной комбинации поиска. Если обычно выполняется поиск по столбцу1, и столбец2 часто используется вместе с ним, а столбец3 иногда используется с столбцом2 и столбцом1, то индекс по столбцу1, столбцу2 и столбцу3 в таком порядке можно использовать для любого из этих трех обстоятельств, хотя это только один индекс, который должен поддерживаться.
Сколько столбцов?
Мне всегда говорили делать индексы с одним столбцом, а не с несколькими столбцами. Так что не больше индексов, чем количество столбцов, ИМХО.
На самом деле это сводится к тому, что не добавляйте индекс, если вы не знаете (и это часто означает сбор статистики использования), что он будет использоваться гораздо чаще, чем обновляться.