C isnull: Checking for NULL pointer in C/C++
Содержание
Изучаем pandas. Урок 4. Работа с пропусками в данных
Очень часто большие объемы данных, которые подготавливаются для последующего анализа, имеют пропуски. Для того, чтобы можно было использовать алгоритмы машинного обучения, строящие модели по этим данным, в большинстве случаев, необходимо эти пропуски чем-то и как-то заполнить. На вопрос “чем заполнять?” мы не будем отвечать в рамках данного урока, а вот на вопрос “как заполнять?” ответим.
- pandas и отсутствующие данные
- Замена отсутствующих данных
- Удаление объектов/столбцов с отсутствующими данными
Для начала, хочется сказать, что в документации по библиотеке pandas есть целый раздел, посвященный данной тематике.
Для наших экспериментов создадим структуру DataFrame, которая будет содержать пропуски. Для этого импортируем необходимые нам библиотеки.
In [1]: import pandas as pd In [2]: from io import StringIO
После этого создадим объект в формате csv. CSV – это один из наиболее простых и распространенных форматов хранения данных, в котором элементы отделяются друг от друга запятыми, более подробно о нем можете прочитать здесь.
CSV – это один из наиболее простых и распространенных форматов хранения данных, в котором элементы отделяются друг от друга запятыми, более подробно о нем можете прочитать здесь.
In [3]: data = 'price,count,percent\n1,10,\n2,20,51\n3,30,' In [4]: df = pd.read_csv(StringIO(data))
Полученный объект df – это DataFrame с пропусками.
In [5]: df Out[5]: price count percent 0 1 10 NaN 1 2 20 51.0 2 3 30 NaN
В нашем примере, у объектов с индексами 0 и 2 отсутствуют данные в поле percent. Отсутствующие данные помечаются как NaN. Добавим к существующей структуре еще один объект (запись), у которого будет отсутствовать значение в поле count.
In [6]: df.loc[3] = {'price':4, 'count':None, 'percent':26.3}
In [7]: df
Out[7]:
price count percent
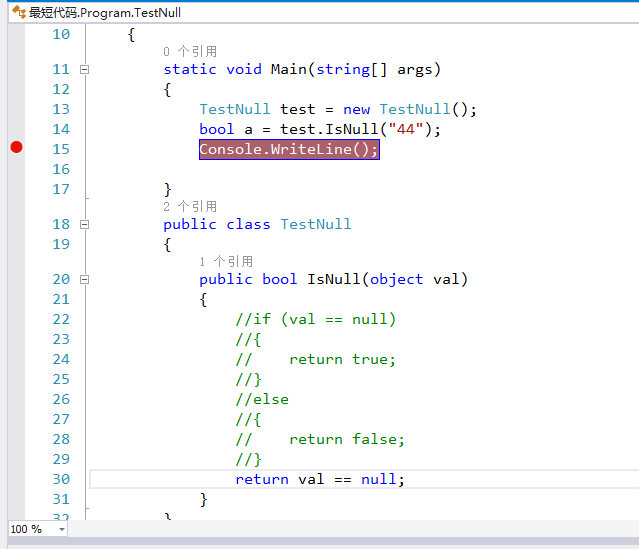
0 1.0 10.0 NaN
1 2.0 20.0 51.0
2 3.0 30.0 NaN
3 4. 0 NaN 26.3
0 NaN 26.3
 0 NaN 26.3
0 NaN 26.3
Для начала обратимся к методам из библиотеки pandas, которые позволяют быстро определить наличие элементов NaN в структурах. Если таблица небольшая, то можно использовать библиотечный метод isnull. Выглядит это так.
In [8]: pd.isnull(df) Out[8]: price count percent 0 False False True 1 False False False 2 False False True 3 False True False
Таким образом мы получаем таблицу того же размера, но на месте реальных данных в ней находятся логические переменные, которые принимают значение False, если значение поля у объекта есть, или True, если значение в данном поле – это NaN. В дополнение к этому можно посмотреть подробную информацию об объекте, для этого можно воспользоваться методом info().
In [9]: df.info() <class 'pandas.core.frame.DataFrame'> Int64Index: 4 entries, 0 to 3 Data columns (total 3 columns): price 4 non-null float64 count 3 non-null float64 percent 2 non-null float64 dtypes: float64(3) memory usage: 128.
В нашем примере видно, что объект df имеет три столбца (count, percent и price), при этом в столбце price все объекты значимы – не NaN, в столбце count – один NaN объект, в поле percent – два NaN объекта. Можно воспользоваться следующим подходом для получения количества NaN элементов в записях.
In [10]: df.isnull().sum() Out[10]: price 0 count 1 percent 2 dtype: int64
Отсутствующие данные объектов можно заменить на конкретные числовые значения, для этого можно использовать метод fillna(). Для экспериментов будем использовать структуру df, созданную в предыдущем разделе.
In [11]: df.isnull().sum() Out[11]: price 0 count 1 percent 2 dtype: int64 In [12]: df Out[12]: price count percent 0 1.0 10.0 NaN 1 2.0 20.0 51.0 2 3.0 30.0 NaN 3 4.0 NaN 26.
 3
In [13]: df.fillna(0)
Out[13]:
price count percent
0 1.0 10.0 0.0
1 2.0 20.0 51.0
2 3.0 30.0 0.0
3 4.0 0.0 26.3
3
In [13]: df.fillna(0)
Out[13]:
price count percent
0 1.0 10.0 0.0
1 2.0 20.0 51.0
2 3.0 30.0 0.0
3 4.0 0.0 26.3
Этот метод не изменяет текущую структуру, он возвращает структуру DataFrame, созданную на базе существующей, с заменой NaN значений на те, что переданы в метод в качестве аргумента. Данные можно заполнить средним значением по столбцу.
In [14]: df.fillna(df.mean()) Out[14]: price count percent 0 1.0 10.0 38.65 1 2.0 20.0 51.00 2 3.0 30.0 38.65 3 4.0 20.0 26.30
В зависимости от задачи используется тот или иной метод заполнения отсутствующих элементов, это может быть нулевое значение, математическое ожидание, медиана и т.п. Для замены NaN элементов на конкретные значения, можно использовать интерполяцию, которая реализована в методе interpolate(), алгоритм интерполяции задается через аргументы метода.
Довольно часто используемый подход при работе с отсутствующими данными – это удаление записей (строк) или полей (столбцов), в которых встречаются пропуски. Для того, чтобы удалить все объекты, которые содержат значения NaN воспользуйтесь методом dropna() без аргументов.
In [15]: df.dropna() Out[15]: price count percent 1 2.0 20.0 51.0
Вместо записей, можно удалить поля, для этого нужно вызвать метод dropna с аргументом axis=1.
In [16]: df.dropna() Out[16]: price count percent 1 2.0 20.0 51.0 In [17]: df.dropna(axis=1) Out[17]: price 0 1.0 1 2.0 2 3.0 3 4.0
pandas позволяет задать порог на количество не-NaN элементов. В приведенном ниже примере будут удалены все столбцы, в которых количество не-NaN элементов меньше трех.
In [18]: df.dropna(axis = 1, thresh=3) Out[18]: price count 0 1.
 0 10.0
1 2.0 20.0
2 3.0 30.0
3 4.0 NaN
0 10.0
1 2.0 20.0
2 3.0 30.0
3 4.0 NaN
Все уроки по библиотеке Pandas собраны в книге “Pandas. Работа с данными”.
<<< Урок 3. Доступ к данным в структурах pandas
Проверка указателя NULL в C/C++
Я начну с этого: согласованность превыше всего, решение менее важно, чем согласованность в вашей кодовой базе.
В C++
NULL определяется как 0 или 0L в C++.
Если вы читали Язык программирования C++ Бьярн Страуструп предлагает явно использовать 0 , чтобы избежать макроса NULL при выполнении присваивания, я не уверен, что он сделал то же самое со сравнениями, это было давно Я читал книгу, я думаю, что он только что сделал if(some_ptr) без явного сравнения, но я не уверен в этом.
Причина этого в том, что макрос NULL обманчив (как почти все макросы), на самом деле это литерал 0 , а не уникальный тип, как следует из названия. Избегание макросов — одно из основных правил C++. С другой стороны,
Избегание макросов — одно из основных правил C++. С другой стороны, 0 выглядит как целое число, а не при сравнении с указателями или присвоении им значения. Лично я мог бы пойти любым путем, но обычно я пропускаю явное сравнение (хотя некоторым людям это не нравится, вероятно, поэтому у вас есть участник, предлагающий изменение в любом случае).
Независимо от личных ощущений, это в значительной степени выбор наименьшего зла, поскольку не существует единственно правильного метода.
Это понятная и распространенная идиома, и я предпочитаю ее, нет возможности случайно присвоить значение во время сравнения, и она ясно читается:
if (some_ptr) {}
Это понятно, если вы знаете, что some_ptr — это тип указателя, но это также может выглядеть как целочисленное сравнение:
if (some_ptr != 0) {}
Это понятно, в общих случаях имеет смысл… Но это дырявая абстракция, NULL на самом деле является литералом 0 и может быть легко использовано неправильно:
if (some_ptr != NULL) {}
C++11 имеет nullptr , который теперь является предпочтительным методом, поскольку он явный и точный, просто будьте осторожны со случайным присвоением:
if (some_ptr != nullptr) {}
Пока вы не сможете перейти на C++0x, я бы сказал, что это пустая трата времени, беспокоясь о том, какой из этих методов вы используете, все они недостаточны, поэтому был изобретен nullptr (наряду с общими проблемами программирования, которые возникли идеальная переадресация. ) Самое главное — поддерживать согласованность.
) Самое главное — поддерживать согласованность.
В C
C — другой зверь.
В C NULL может быть определен как 0 или как ((void *)0) , C99 позволяет реализовать определенные константы нулевого указателя. Таким образом, на самом деле все сводится к определению реализации NULL , и вам придется проверить его в своей стандартной библиотеке.
Макросы очень распространены, и в целом они часто используются для восполнения недостатков универсальной поддержки программирования в языке и других вещей. Язык намного проще, а использование препроцессора более распространено.
С этой точки зрения я бы, вероятно, рекомендовал использовать определение макроса NULL в C.
c — В чем разница между NULL, ‘\0’ и 0?
Примечание: Этот ответ относится к языку C, а не к C++.
Нулевые указатели
Литерал целочисленной константы 0 имеет разные значения в зависимости от контекста, в котором он используется. Во всех случаях это по-прежнему целочисленная константа со значением
Во всех случаях это по-прежнему целочисленная константа со значением 0 , просто она описывается по-разному.
Если указатель сравнивается с константным литералом 0 , то это проверка, чтобы увидеть, является ли указатель нулевым указателем. Это 0 затем называется константой нулевого указателя. Стандарт C определяет, что 0 , приведенное к типу void * , является как нулевым указателем, так и константой нулевого указателя.
Кроме того, для удобства чтения макрос NULL предоставляется в файле заголовка stddef.h . В зависимости от вашего компилятора может быть возможно #undef NULL и переопределить его на что-нибудь дурацкое.
Вот несколько допустимых способов проверки нулевого указателя:
if (pointer == NULL)
NULL определяется для сравнения с нулевым указателем. Реализация определяет фактическое определение NULL , если это допустимая константа нулевого указателя.
если (указатель == 0)
0 — еще одно представление константы нулевого указателя.
если (!указатель)
Этот оператор if неявно проверяет, что «не равно 0», поэтому мы обращаем это значение, чтобы оно означало «равно 0».
Ниже перечислены НЕВЕРНЫЕ способы проверки нулевого указателя:
int mynull = 0; <какой-то код> если (указатель == mynull)
Для компилятора это не проверка нулевого указателя, а проверка на равенство двух переменных. Этот может работать, если mynull никогда не изменяется в коде, а константа оптимизации компилятора сворачивает 0 в оператор if, но это не гарантируется, и компилятор должен выдать по крайней мере одно диагностическое сообщение (предупреждение или ошибку) в соответствии с C Стандарт.
Обратите внимание, что значение нулевого указателя в языке C не имеет значения для базовой архитектуры. Если в базовой архитектуре значение нулевого указателя определено как адрес 0xDEADBEEF, компилятор должен разобраться в этом беспорядке.
Таким образом, даже в этой забавной архитектуре следующие способы проверки нулевого указателя остаются допустимыми:
if (!pointer) если (указатель == NULL) если (указатель == 0)
Ниже перечислены НЕДОПУСТИМЫЕ способы проверки нулевого указателя:
#define MYNULL (пусто *) 0xDEADBEEF если (указатель == MYNULL) если (указатель == 0xDEADBEEF)
, так как они воспринимаются компилятором как обычные сравнения.
Нулевые символы
'\0' определяется как нулевой символ, то есть символ, в котором все биты установлены на ноль. '\0' (как и все символьные литералы) является целочисленной константой, в данном случае с нулевым значением. Таким образом, '\0' полностью эквивалентно целочисленной константе 0 без прикрас — единственная разница в намерение , которое он передает читателю («Я использую это как нулевой символ»).
'\0' не имеет ничего общего с указателями.