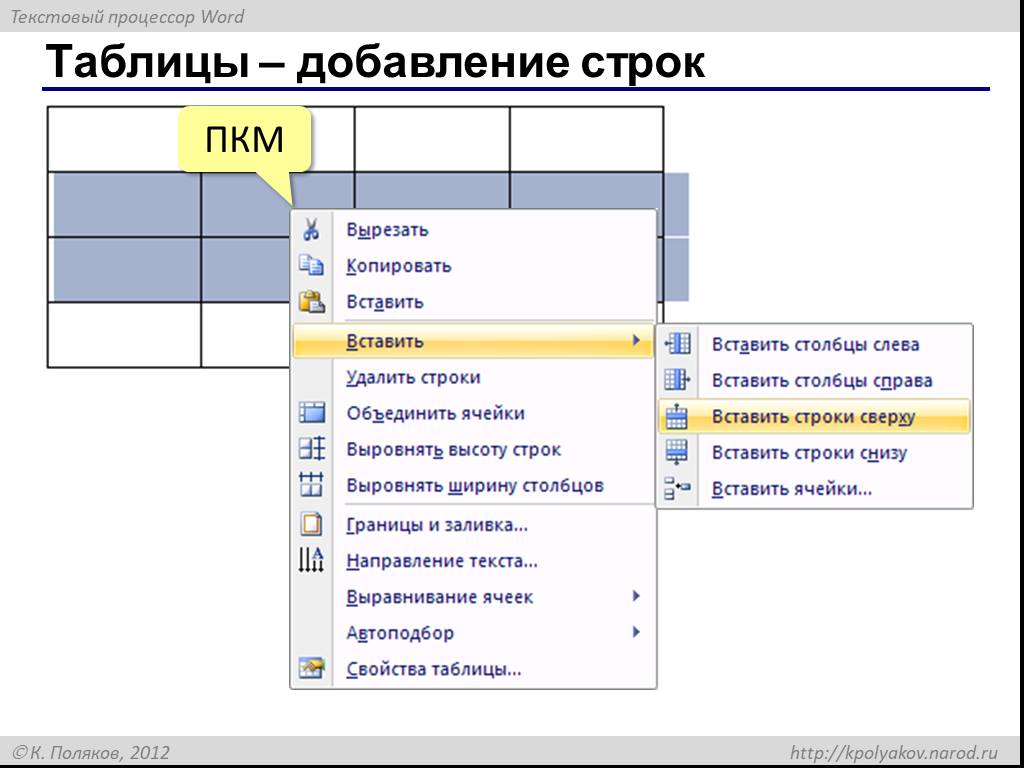
Добавить столбец в таблицу oracle: ALTER TABLE ОПЕРАТОР — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Содержание
Как добавить столбец в таблицу sql oracle
Есть таблица с данными, есть формула, по которой рассчитано значения последнего столбца. Как мне создать ещё один столбец, заполнить его значениями, вычисленными по формуле для дальнейшего сравнения двух столбцов этой таблицы ? Например, есть таблица из трёх столбцов: В первом единицы, во втором двойки, а в третьем их сумма. Я хочу создать ещё один столбец (4-й), который я заполню формулой суммирования 1-го и второго столбцов, чтобы в результате весть столбец имел значение «3», как и 3-й столбец.
Цель: В рамках тестирования проверить правильно ли реализовано заполнение таблицы (3-й столбец) по конкретной формуле. Я хочу добавить свой столбец с логикой, прописанной в спецификации по расчёту этого столбца и сравнить есть ли строки с отличающимися значениями 3 и 4 столбцов
Оператор ALTER TABLE противоречил ограничениям FOREIGN KEY
(8)
Можно создать внешний ключ, используя ALTER TABLE tablename WITH NOCHECK . который позволит данные, нарушающие внешний ключ.
который позволит данные, нарушающие внешний ключ.
«ALTER TABLE tablename WITH NOCHECK . », чтобы добавить FK. Это решение сработало для меня.
У меня возникла проблема при попытке добавить внешний ключ в таблицу tblDomare ; что я делаю неправильно здесь?
Сообщение об ошибке:
Оператор ALTER TABLE противоречил ограничению FOREIGN KEY «FK_ tblDomare _PersN__5F7E2DAC». Конфликт произошел в базе данных «almu0004», таблице «dbo.tblBana», в столбце «BanNR».
Очистите данные от своих таблиц, а затем создайте связь между ними.
Смутье верно, и Чад ХеджКок предложил пример великого непрофессионала. Id нравится строить на примере Чада, предлагая способ найти / удалить эти записи. Мы будем использовать Клиента в качестве родителя и ордера в качестве ребенка. CustomerId является общим полем.
если вы читаете эту тему . вы получите результаты. Это осиротевшие дети. выберите * from Order Child left join Родитель клиента в Child. CustomerId = Parent.CustomerId, где Parent.CustomerId равно null Обратите внимание на количество строк в правом нижнем углу.
CustomerId = Parent.CustomerId, где Parent.CustomerId равно null Обратите внимание на количество строк в правом нижнем углу.
Убедитесь, что вы / кто бы вам ни понадобился, чтобы удалить эти строки!
Запустите первый бит. Проверьте, что количество строк = что вы ожидали
Быть осторожен. Кто-то неряшливое программирование привело вас в этот беспорядок. Удостоверьтесь, что вы понимаете их, почему перед тем, как удалить сирот. Возможно, родитель должен быть восстановлен.
У меня была такая же проблема.
Она является правильным и точным решением:
в вашей таблице есть элемент данных, что его связанное значение не существует в таблице, которую вы хотите использовать в таблице первичного ключа. сделать вашу таблицу пустой или добавить связанное значение во вторую таблицу
Это произошло потому, что вы пытались создать внешний ключ из tblDomare.PersNR в tblBana.BanNR но / и значения в tblDomare.PersNR не совпадали ни с одним из значений в tblBana. BanNR . Вы не можете создать связь, которая нарушает ссылочную целостность.
BanNR . Вы не можете создать связь, которая нарушает ссылочную целостность.
Это происходит со мной, так как я разрабатываю свою базу данных, я замечаю, что я меняю свое семя на моей основной таблице, теперь реляционная таблица не имеет внешнего ключа в главной таблице.
Поэтому мне нужно обрезать обе таблицы, и теперь это работает!
Я полагаю, значение столбца в таблице внешнего ключа должно соответствовать значению столбца таблицы первичного ключа. Если мы пытаемся создать ограничение внешнего ключа между двумя таблицами, где значение внутри одного столбца (будет внешним ключом) отличается от значения столбца таблицы первичного ключа, тогда оно выдает сообщение.
Поэтому всегда рекомендуется вставлять только те значения в столбец внешнего ключа, которые присутствуют в столбце таблицы основного ключа.
Напр. Если столбец «Первичная таблица» имеет значения 1, 2, 3 и в столбце «Внешние ключи», вставленные значения различны, тогда запрос не будет выполняться, поскольку он ожидает, что значения будут находиться в пределах от 1 до 3.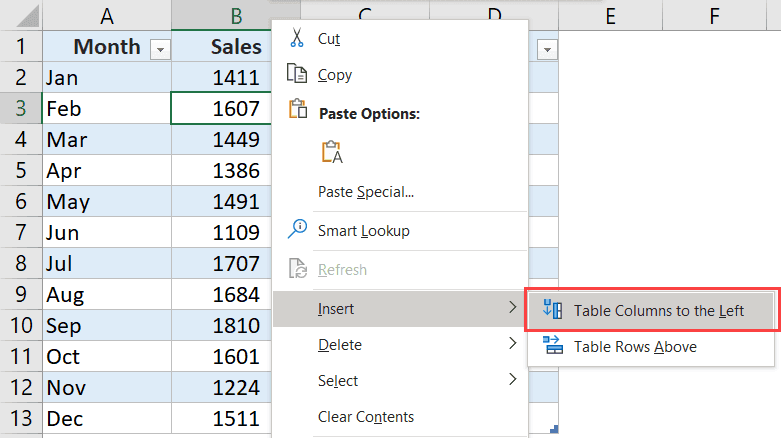
данные, которые вы ввели в таблицу (tbldomare), не соответствуют данным, которые вы назначили таблице первичных ключей. напишите между tbldomare и добавьте это слово (с помощью nocheck), затем выполните свой код.
например, вы ввели таблицу tbldomar этих данных
и вы назначили таблицу foreign key чтобы принять только 1,2,3 .
у вас есть два решения: удалить данные, которые вы ввели в таблицу, а затем выполнить код. другое записывает это слово (с помощью nocheck), помещая его между именем вашей таблицы и добавляя так:
Я пытаюсь добавить в таблицу новый столбец. В таблице MOBILE_ENTRIES есть три колонки: CLIENT_PIN, VALUE_DAY, TYPE. Я хочу добавить к ним четвёртую — CLIENT_UK. В таблице CLIENT_SDIM есть данные по клиентам и каждому CLIENT_PIN соответствует CLIENT_UK.
С ALTER TABLE я побоялся связываться, к счастью, в Oracle SQL Developer удалось добавить новую колонку с null вручную.
Но следующая проблема — как добавить данные. Пытаюсь сделать это через UPDATE:
И получаю ошибку: SQL Error: ORA-01427: подзапрос одиночной строки возвращает более одной строки.
В связи с этим, не подскажете ли мне, что я делаю не так и как мне добиться желаемого? Буду рад любому совету.
Страница «Выбор столбцов и таблиц Oracle» используется для выбора таблиц из базы данных-источника Oracle, изменения в которых будут отслеживаться. Эта страница содержит следующие элементы:
Параметры
Список «Таблица»
Список таблиц состоит из трех столбцов:
Имя таблицы Oracle: имя таблицы с указанием схемы.
Экземпляр отслеживания: имя экземпляра отслеживания, используемое для именования объектов отслеживания изменений данных по экземплярам. Значение экземпляра отслеживания не может быть равно NULL.
Если это имя не задано, то оно является производным от имени схемы источника и имени исходной таблицы в формате <schema-name>_<table-name> . Длина имени экземпляра отслеживания не может превышать 100 символов, оно должно быть уникальным в пределах базы данных.
Щелкните любую ячейку в этом столбце, чтобы изменить capture_instance вручную.
Роль безопасности. Имя шлюзовой роли базы данных, используемой для управления доступом к информации об изменениях.
Щелкните любую ячейку в этом столбце, чтобы изменить security_role вручную.
Добавить таблицы
Нажмите кнопку Добавить таблицы , чтобы открыть диалоговое окно «Выбор таблицы», где вы можете выбрать таблицы Oracle для отслеживания изменений.
Edit (Изменение)
Выберите таблицу из списка, а затем Правка , чтобы открыть диалоговое окно Свойства этой таблицы, позволяющее вносить изменений в выбранные для отслеживания изменений таблицы.
Удалить
Выберите таблицу из списка и нажмите Удалить , чтобы удалить таблицу из экземпляра CDC.
Автоматизация загрузки данных из Oracle в MS SQL Server с помощью Python, без создания таблиц вручную и указания типа полей
Время прочтения: 7 мин.
Задачу по загрузке данных из Oracle и их записи в таблицу на MS SQL Server можно решить большим количеством способов. Как правило, даже для выполнения простого запроса приходится потратить большое количество времени, особенно, когда надо передать в Oracle перечень ID для поиска информации. Для решения задачи можно загрузить данные в файлы, затем написать код создания таблицы и в нее с помощью BCP загрузить информацию, либо использовать Мастер импорта и экспорта.
На самом деле, получить данные и создать для них таблицу на MS SQL Server можно используя Python, при этом весь процесс возможно заложить в одну функцию. В такую функцию необходимо заложить следующие алгоритмы:
- загрузка данных с Oracle;
- автоматическое определение типов столбцов для таблицы на MS SQL Server на основании типов столбцов Oracle;
- создание таблицы и вставка в нее полученной с Oracle информации.
Назовем эту функцию oracle_download и определим для нее перечень входящих переменных:
- table_name – наименование таблицы, в которой мы хотим видеть полученные из Oracle данные;
- ids_sql – запрос для получения перечня ID, которые будут переданы в запросе к Oracle;
- ids_column – наименование столбца, содержащего ID из запроса в переменной ids_sql;
- sql_mask – запрос к Oracle.


В рассматриваемом примере в Oracle будет передаваться перечень ID, содержащий числовые значения. Ниже представлен код для импорта необходимых библиотек, определения строк подключения и указания входных переменных для функции.
import pandas as pd
import pyodbc as sql_db_connect
import cx_Oracle
#Установка подключения к MS SQL Server
link_server = 'Driver={SQL Server Native Client 11.0};Server=*наименование сервера*;Network Library=DBMSSOCN;Trusted_Connection=Yes'
ms_server = sql_db_connect.connect(link_server)
#Установка подключения к Oracle
oracle = cx_Oracle.connect('', '', '*наименование сервера*', encoding = 'UTF-8', nencoding = 'UTF-8')
#Переменная table_name содержит наименование целевой таблицы
table_name = '[DATABASE].[kay].[NTA_test_created_table]'
#Переменная ids_sql содержит запрос для получения перечня ID с MS SQL Server
ids_sql = """select
ID
from [DATABASE].[kay].[NTA_ids] with (nolock)
order by ID"""
#Переменная ids_column содержит наименование столбца, который содержит перечень ID
ids_column = 'ID'
#Переменная sql_mask содержит запрос, выполняемый на стороне Oracle
sql_mask = """SELECT
t1. column_1
,t1.column_2
,t1.column_3
,t1.column_4
,t2.column_ext
FROM oracle_table_1 t1
,oracle_table_2 t2
WHERE (1 = 1)
AND t1.ID in ( %s )
and t1.EXT_ID = t2.ID"""
 column_1
,t1.column_2
,t1.column_3
,t1.column_4
,t2.column_ext
FROM oracle_table_1 t1
,oracle_table_2 t2
WHERE (1 = 1)
AND t1.ID in ( %s )
and t1.EXT_ID = t2.ID"""
column_1
,t1.column_2
,t1.column_3
,t1.column_4
,t2.column_ext
FROM oracle_table_1 t1
,oracle_table_2 t2
WHERE (1 = 1)
AND t1.ID in ( %s )
and t1.EXT_ID = t2.ID"""
Сразу определим функцию для разделения перечня ID на части по несколько штук, так как передавать более 1000 в IN нельзя.
# Функция chunks разделяет выборку на части
def chunks(lst, n):
for i in range(0, len(lst), n):
yield lst[i:i + n]
Теперь перейдем непосредственно к написанию кода функции.
# Функция oracle_download содержит код для загрузки по перечню ID информации из БД Oracle и создания таблицы на основе полученных данных def oracle_download(table_name, ids_sql, ids_column, sql_mask):
Для загрузки данных из таблиц MS SQL Server используется функция read_sql и полученный перечень ID делится на несколько частей, например, по 100 ID (как в коде ниже) для подстановки в запрос к Oracle.
# Получение перечня ID с MS SQL Server ids_df = pd.read_sql(ids_sql, ms_server) # Все ID разделяются на несколько частей val_list = list(ids_df[ids_column].
 sort_values())
parts = list(chunks(val_list, 100)) # По 100 ID за один запрос к Oracle
sql_lists = []
for part in parts:
sql_list = ",".join(str(id_) for id_ in part)
sql_lists.append(sql_list)
sort_values())
parts = list(chunks(val_list, 100)) # По 100 ID за один запрос к Oracle
sql_lists = []
for part in parts:
sql_list = ",".join(str(id_) for id_ in part)
sql_lists.append(sql_list)
Чтобы было удобнее отслеживать процесс загрузки данных, определим значение переменной step, и для создания таблицы статус ее наличия на MS SQL Server.
# Для удобства введена переменная, позволяющая отслеживать прогресс загрузки (увеличивается с каждым успешным выполнением) step = 1 # Признак наличия таблицы в БД table_created = 0
Теперь необходимо загрузить данные с Oracle, создать для них таблицу на MS SQL Server и записать в нее данные. Ниже представлен полный код написанной функции (с кодом, представленным ранее):
# Функция oracle_download содержит код для загрузки по перечню ID информации из БД Oracle и создания таблицы на основе полученных данных и з
def oracle_download(table_name, ids_sql, ids_column, sql_mask):
# Получение перечня ID с MS SQL Server
ids_df = pd. read_sql(ids_sql, ms_server)
# Все ID разделяются на несколько частей
val_list = list(ids_df[ids_column].sort_values())
parts = list(chunks(val_list, 100)) # По 100 ID за один запрос к Oracle
sql_lists = []
for part in parts:
sql_list = ",".join(str(id_) for id_ in part)
sql_lists.append(sql_list)
# Для удобства введена переменная, позволяющая отслеживать прогресс загрузки (увеличивается с каждым успешным выполнением)
step = 1
# Признак наличия таблицы в БД
table_created = 0
for sql_list in sql_lists:
# Подстановка перечня ID в запрос
sql_query = sql_mask % sql_list
# Выполнение запроса на Oracle
part_df = pd.read_sql(sql_query, oracle)
# Необходимо проверить, существует ли таблица для вставки данных из Oracle на MS SQL Server
if table_created == 0:
# Если таблица существует, выполнится оповещение пользователя, вставка новых строк будет производиться в эту таблицу
table_exists = pd. read_sql("if OBJECT_ID ('%s') is not null select 1 else select 0" % table_name,
ms_server).values
# Если таблица для загружаемых данных не создана, тогда выполняется код для ее создания
if table_exists == 0:
print('Создание таблицы')
# Определяется перечень столбцов в запросе на получение данных из Oracle и формируется запрос для определения типов столбцов
columns_list = list(part_df.columns)
table_sql_query = """with cols_ident as (
""" + sql_query + """
)
select
""" + ','.join(['DUMP(max("' + col + '"))' for col in columns_list]) + """
from cols_ident"""
table_sql = table_sql_query
# Загрузка перечня типов входных значений
col_types = pd.read_sql(table_sql, oracle)
# Если в выборке весь столбец содержит значения NUll, данный столбец определяется как текст
types_for_tsql = {'Typ=1': 'nvarchar(255)'
, 'Typ=2': 'numeric(38, 2)'
, 'Typ=12': 'datetime'
, 'Typ=13': 'datetime'
, 'Typ=112': 'nvarchar(500)'
, 'Typ=180': 'datetime2'
, 'Typ=181': 'datetime2'
, 'Null': 'nvarchar(255)'} # Словарь типов значений
types_list = [types_for_tsql[i. split(' ')[0]] for i in col_types.values[0]]
# Так как столбцы добавились в обратном порядке, необходимо вернуть прежнюю последовательность
columns_list.reverse()
types_list.reverse()
# Далее формируется скрипт для создания таблицы на MS SQL Server
create_table = "create table %s ( \n" % table_name
while len(columns_list) > 0:
col_name = columns_list.pop()
col_type = types_list.pop()
create_table += " [%s]" % col_name + ' ' + col_type + ',\n'
create_table += ') with (data_compression = PAGE)'
# Создается таблица
cur = ms_server.cursor()
cur.execute(create_table)
cur.commit()
cur.close()
print('Таблица создана')
# Устанавливается признак наличия таблицы, чтобы данный блок кода больше не использовался
table_created = 1
else:
table_created = 1
print('Таблица существует')
# Запись результата запроса в уже созданную ранее таблицу на MS SQL Server
print('\rЧасть %s из %s - Вставка на сервер %s строк' % (str(step), str(len(sql_lists)), str(len(part_df))),
end='')
# В первую строку для вставки подставляется наименование таблицы
first_row = "insert into %s values " % table_name
# Записываются все полученные строки в виде конструкции insert into . .. values (...),(...),(...)
all_inserted_rows = []
for row in part_df.values:
# Обратите внимание! Для апострофа в TSQL необходимо добавить еще один такой-же символ, чтобы вставка прошла успешно и не поменялся исходный текст
row = '( ' + ','.join(["'" + str(val).replace("'", "''") + "'" for val in row]) + ' )'
all_inserted_rows.append(row)
# Для ускорения вставки значение можно увеличить до 1000
inserted_parts = list(chunks(all_inserted_rows, 20))
# Вставка в таблицу на сервере выполняется частями
inserted_part = 1
for inserted_rows in inserted_parts:
sql_insert = first_row + '\n,'.join(inserted_rows)
sql_insert = sql_insert.replace('nan', 'Null').replace('NaT', 'Null').replace('None', 'Null').replace(
"'Null'", 'Null')
cur = ms_server.cursor()
cur.execute(sql_insert)
cur.commit()
cur.close()
inserted_part += 1
step += 1
print('\nЗагрузка выполнена')
 read_sql(ids_sql, ms_server)
# Все ID разделяются на несколько частей
val_list = list(ids_df[ids_column].sort_values())
parts = list(chunks(val_list, 100)) # По 100 ID за один запрос к Oracle
sql_lists = []
for part in parts:
sql_list = ",".join(str(id_) for id_ in part)
sql_lists.append(sql_list)
# Для удобства введена переменная, позволяющая отслеживать прогресс загрузки (увеличивается с каждым успешным выполнением)
step = 1
# Признак наличия таблицы в БД
table_created = 0
for sql_list in sql_lists:
# Подстановка перечня ID в запрос
sql_query = sql_mask % sql_list
# Выполнение запроса на Oracle
part_df = pd.read_sql(sql_query, oracle)
# Необходимо проверить, существует ли таблица для вставки данных из Oracle на MS SQL Server
if table_created == 0:
# Если таблица существует, выполнится оповещение пользователя, вставка новых строк будет производиться в эту таблицу
table_exists = pd.
read_sql(ids_sql, ms_server)
# Все ID разделяются на несколько частей
val_list = list(ids_df[ids_column].sort_values())
parts = list(chunks(val_list, 100)) # По 100 ID за один запрос к Oracle
sql_lists = []
for part in parts:
sql_list = ",".join(str(id_) for id_ in part)
sql_lists.append(sql_list)
# Для удобства введена переменная, позволяющая отслеживать прогресс загрузки (увеличивается с каждым успешным выполнением)
step = 1
# Признак наличия таблицы в БД
table_created = 0
for sql_list in sql_lists:
# Подстановка перечня ID в запрос
sql_query = sql_mask % sql_list
# Выполнение запроса на Oracle
part_df = pd.read_sql(sql_query, oracle)
# Необходимо проверить, существует ли таблица для вставки данных из Oracle на MS SQL Server
if table_created == 0:
# Если таблица существует, выполнится оповещение пользователя, вставка новых строк будет производиться в эту таблицу
table_exists = pd. read_sql("if OBJECT_ID ('%s') is not null select 1 else select 0" % table_name,
ms_server).values
# Если таблица для загружаемых данных не создана, тогда выполняется код для ее создания
if table_exists == 0:
print('Создание таблицы')
# Определяется перечень столбцов в запросе на получение данных из Oracle и формируется запрос для определения типов столбцов
columns_list = list(part_df.columns)
table_sql_query = """with cols_ident as (
""" + sql_query + """
)
select
""" + ','.join(['DUMP(max("' + col + '"))' for col in columns_list]) + """
from cols_ident"""
table_sql = table_sql_query
# Загрузка перечня типов входных значений
col_types = pd.read_sql(table_sql, oracle)
# Если в выборке весь столбец содержит значения NUll, данный столбец определяется как текст
types_for_tsql = {'Typ=1': 'nvarchar(255)'
, 'Typ=2': 'numeric(38, 2)'
, 'Typ=12': 'datetime'
, 'Typ=13': 'datetime'
, 'Typ=112': 'nvarchar(500)'
, 'Typ=180': 'datetime2'
, 'Typ=181': 'datetime2'
, 'Null': 'nvarchar(255)'} # Словарь типов значений
types_list = [types_for_tsql[i.
read_sql("if OBJECT_ID ('%s') is not null select 1 else select 0" % table_name,
ms_server).values
# Если таблица для загружаемых данных не создана, тогда выполняется код для ее создания
if table_exists == 0:
print('Создание таблицы')
# Определяется перечень столбцов в запросе на получение данных из Oracle и формируется запрос для определения типов столбцов
columns_list = list(part_df.columns)
table_sql_query = """with cols_ident as (
""" + sql_query + """
)
select
""" + ','.join(['DUMP(max("' + col + '"))' for col in columns_list]) + """
from cols_ident"""
table_sql = table_sql_query
# Загрузка перечня типов входных значений
col_types = pd.read_sql(table_sql, oracle)
# Если в выборке весь столбец содержит значения NUll, данный столбец определяется как текст
types_for_tsql = {'Typ=1': 'nvarchar(255)'
, 'Typ=2': 'numeric(38, 2)'
, 'Typ=12': 'datetime'
, 'Typ=13': 'datetime'
, 'Typ=112': 'nvarchar(500)'
, 'Typ=180': 'datetime2'
, 'Typ=181': 'datetime2'
, 'Null': 'nvarchar(255)'} # Словарь типов значений
types_list = [types_for_tsql[i. split(' ')[0]] for i in col_types.values[0]]
# Так как столбцы добавились в обратном порядке, необходимо вернуть прежнюю последовательность
columns_list.reverse()
types_list.reverse()
# Далее формируется скрипт для создания таблицы на MS SQL Server
create_table = "create table %s ( \n" % table_name
while len(columns_list) > 0:
col_name = columns_list.pop()
col_type = types_list.pop()
create_table += " [%s]" % col_name + ' ' + col_type + ',\n'
create_table += ') with (data_compression = PAGE)'
# Создается таблица
cur = ms_server.cursor()
cur.execute(create_table)
cur.commit()
cur.close()
print('Таблица создана')
# Устанавливается признак наличия таблицы, чтобы данный блок кода больше не использовался
table_created = 1
else:
table_created = 1
print('Таблица существует')
# Запись результата запроса в уже созданную ранее таблицу на MS SQL Server
print('\rЧасть %s из %s - Вставка на сервер %s строк' % (str(step), str(len(sql_lists)), str(len(part_df))),
end='')
# В первую строку для вставки подставляется наименование таблицы
first_row = "insert into %s values " % table_name
# Записываются все полученные строки в виде конструкции insert into .
split(' ')[0]] for i in col_types.values[0]]
# Так как столбцы добавились в обратном порядке, необходимо вернуть прежнюю последовательность
columns_list.reverse()
types_list.reverse()
# Далее формируется скрипт для создания таблицы на MS SQL Server
create_table = "create table %s ( \n" % table_name
while len(columns_list) > 0:
col_name = columns_list.pop()
col_type = types_list.pop()
create_table += " [%s]" % col_name + ' ' + col_type + ',\n'
create_table += ') with (data_compression = PAGE)'
# Создается таблица
cur = ms_server.cursor()
cur.execute(create_table)
cur.commit()
cur.close()
print('Таблица создана')
# Устанавливается признак наличия таблицы, чтобы данный блок кода больше не использовался
table_created = 1
else:
table_created = 1
print('Таблица существует')
# Запись результата запроса в уже созданную ранее таблицу на MS SQL Server
print('\rЧасть %s из %s - Вставка на сервер %s строк' % (str(step), str(len(sql_lists)), str(len(part_df))),
end='')
# В первую строку для вставки подставляется наименование таблицы
first_row = "insert into %s values " % table_name
# Записываются все полученные строки в виде конструкции insert into . .. values (...),(...),(...)
all_inserted_rows = []
for row in part_df.values:
# Обратите внимание! Для апострофа в TSQL необходимо добавить еще один такой-же символ, чтобы вставка прошла успешно и не поменялся исходный текст
row = '( ' + ','.join(["'" + str(val).replace("'", "''") + "'" for val in row]) + ' )'
all_inserted_rows.append(row)
# Для ускорения вставки значение можно увеличить до 1000
inserted_parts = list(chunks(all_inserted_rows, 20))
# Вставка в таблицу на сервере выполняется частями
inserted_part = 1
for inserted_rows in inserted_parts:
sql_insert = first_row + '\n,'.join(inserted_rows)
sql_insert = sql_insert.replace('nan', 'Null').replace('NaT', 'Null').replace('None', 'Null').replace(
"'Null'", 'Null')
cur = ms_server.cursor()
cur.execute(sql_insert)
cur.commit()
cur.close()
inserted_part += 1
step += 1
print('\nЗагрузка выполнена')
.. values (...),(...),(...)
all_inserted_rows = []
for row in part_df.values:
# Обратите внимание! Для апострофа в TSQL необходимо добавить еще один такой-же символ, чтобы вставка прошла успешно и не поменялся исходный текст
row = '( ' + ','.join(["'" + str(val).replace("'", "''") + "'" for val in row]) + ' )'
all_inserted_rows.append(row)
# Для ускорения вставки значение можно увеличить до 1000
inserted_parts = list(chunks(all_inserted_rows, 20))
# Вставка в таблицу на сервере выполняется частями
inserted_part = 1
for inserted_rows in inserted_parts:
sql_insert = first_row + '\n,'.join(inserted_rows)
sql_insert = sql_insert.replace('nan', 'Null').replace('NaT', 'Null').replace('None', 'Null').replace(
"'Null'", 'Null')
cur = ms_server.cursor()
cur.execute(sql_insert)
cur.commit()
cur.close()
inserted_part += 1
step += 1
print('\nЗагрузка выполнена')
Разберемся, что же происходит, после получения перечня ID с MS SQL Server. После загрузки первого результата с Oracle проверяется наличие таблицы в MS SQL Server с помощью команды OBJECT_ID. Результат проверки записывается в переменную table_exists. Если таблицы нет, она создается с помощью кода далее.
После загрузки первого результата с Oracle проверяется наличие таблицы в MS SQL Server с помощью команды OBJECT_ID. Результат проверки записывается в переменную table_exists. Если таблицы нет, она создается с помощью кода далее.
На основе первой полученной выборки по перечню ID, для определения типов столбцов используется встроенная функция DUMP, указывающая числовое значение типа столбца в Oracle. Для основных типов в словаре types_for_tsql определены подходящие типы столбцов в MS SQL Server. Например, если команда DUMP(max(t1.column_1)) показала результат Typ=2 Len=6: 197,7,100,72,33,81 по типу можно сделать вывод, что в столбце хранятся числа, а для столбца DUMP(max(t1.column_2)) результат Typ=1 Len=6: 4,47,4,61,4,48 указывает, что значение строка. Если столбец не содержит никаких значений (т.е. все Null), можно в словаре указать значение по умолчанию, например nvarchar(255) или nvarchar(max). Подробно о функции DUMP написано в документации: https://docs.oracle.com/cd/E11882_01/server.112/e41085/sqlqr06002.htm#SQLQR959
Подробно о функции DUMP написано в документации: https://docs.oracle.com/cd/E11882_01/server.112/e41085/sqlqr06002.htm#SQLQR959
Получив типы всех столбцов создается таблица для загруженных данных командой create table. Для вставки используется конструкция insert into [table] values (…), (…), (…), при этом вставка данных выполняется частями автоматически, как и загрузка с Oracle.
В результате, с помощью одной небольшой функции можно загрузить данные с Oracle, создать для них таблицу на MS SQL Server и записать их в нее:
oracle_download(table_name, ids_sql, ids_column, sql_mask)
Добавить столбцы в таблицу вручную
Добавить столбцы в таблицу вручную
Предыдущий
Следующий
Для корректного отображения этого контента должен быть включен JavaScript
- Руководство по настройке исследования
- Настройка моделей клинических данных
- Добавить столбцы в таблицу вручную
Вы можете добавлять столбцы в таблицу как часть создания самой таблицы при загрузке
файл; см. Создание таблиц из файла.
Создание таблиц из файла.
Щелкните значок «Конфигурация исследования» на панели навигации. Затем нажмите «Клинические модели данных».
вкладкаВыберите модель и нажмите Check Out.
Внимание! Не вносите структурные изменения в таблицы в моделях InForm; см. Изменение входной модели InForm для получения информации об изменениях, которые являются и не являются
допустимый.Выберите таблицу.
На вкладке Столбец щелкните значок Добавить. Откроется окно «Создать столбец модели клинических данных». Система проверяет таблицу, если она еще не извлечена.
Заполните следующие поля:
Введите имя и описание столбца; см.
Ограничения на имена для ограничений.Тип данных Oracle: выберите соответствующий тип данных: Varchar2, число или дата. Применяются все стандартные правила для типов данных Oracle.
ДАТА: Для каждого значения даты Oracle хранит следующую информацию: век, год, месяц, дату, час, минуту и секунду. Хотя информация о дате и времени может быть представлена как в символьном, так и в числовом типе данных, тип данных Date имеет специальные связанные свойства.
ЧИСЛО: Сохраняет нулевые, положительные и отрицательные фиксированные числа и числа с плавающей запятой. Столбец «Число» может содержать число с десятичным знаком и/или знаком (-) или без него.
VARCHAR2: задает строку символов переменной длины. Для каждой строки система сохраняет каждое значение в столбце как поле переменной длины, если только значение не превышает максимальную длину столбца, и в этом случае система возвращает ошибку.
Длина: требования различаются в зависимости от типа данных:
ДАТА: Длина не требуется.
VARCHAR2: (обязательно) значение по умолчанию — 50. Значение должно быть в диапазоне от 1 до 4000.
ЧИСЛО: (обязательно) Значение по умолчанию — 10. Максимальное значение — 38.
Если тип данных — Число, вы также можете ввести значение Точности, которое представляет собой общее количество цифр, разрешенных справа от десятичной точки. Например, если для параметра Точность установлено значение 2 и в этом столбце введено значение данных 34,333, система сохранит значение данных как 34,33. Oracle гарантирует переносимость чисел с точностью от 1 до 38.
Сопоставление с фильтром: если столбец имеет ту же функцию и тип данных, что и один из
идентификаторы столбцов SDTM, рекомендуется выбирать его из
список, потому что система использует эту информацию несколькими способами; см. Использование идентификаторов SDTM для поддержки важных функций.Имя Oracle: по умолчанию система заполняет его значением, которое вы ввели для имени, усеченным до 30 символов.
Имя SAS: по умолчанию система заполняет его значением, которое вы ввели для имени, усеченным до 32 символов.
Метка SAS: (необязательно) По умолчанию система заполняет ее значением, которое вы ввели для имени. Может содержать до 256 символов.
Формат SAS: по умолчанию система вводит знак доллара ($), за которым следует значение, введенное в поле «Длина».
Значение по умолчанию: (необязательно). Введите значение данных по умолчанию.
Псевдонимы для автоматического сопоставления: введите один или несколько псевдонимов или альтернативных имен для столбца. Если вам нужно более одного псевдонима, введите список через запятую без пробелов; например:
дм,демо,демог,демографияNullable: если выбрано, наличие значения в этом столбце не требуется. Если не выбрано, все строки должны иметь значение в этом столбце.
Список кодов (необязательно): Если столбец должен быть заполнен ограниченным набором значений, определенных в списке кодов, выберите соответствующую терапевтическую область (или другую категорию), а затем список кодов.
Вы можете применить список кодов только к столбцам с типом данных varchar2.
Введите атрибуты маскирования; доступен, только если таблица имеет ослепляющий тип
Столбец; см. Указание атрибутов маскирования для столбца.Нажмите OK.
 Ограничения на имена для ограничений.
Ограничения на имена для ограничений.

 Использование идентификаторов SDTM для поддержки важных функций.
Использование идентификаторов SDTM для поддержки важных функций.
 Вы можете применить список кодов только к столбцам с типом данных varchar2.
Вы можете применить список кодов только к столбцам с типом данных varchar2.Назад к настройке моделей клинических данных
Как переименовать имя столбца в SQL?
Методы переименования столбца в SQL
Мы можем использовать следующие методы для переименования столбца в SQL.
- Мы можем изменить имя столбца, используя команду ALTER вместе с командой RENAME COLUMN.
Синтаксис:
Приведенный выше синтаксис применим к MySQL, Oracle и Postgres SQL.
- Другой способ переименовать имя столбца — использовать команду CHANGE вместе с командой ALTER.
Синтаксис:
Приведенная выше команда применима к MySQL и MariaDB.
- Команду ALTER нельзя использовать для изменения имени столбца при использовании SQL Server. Для SQL Server используется команда sp_rename.
Синтаксис:
Примеры переименования имен столбцов в SQL
Теперь рассмотрим несколько примеров:
- Использование ALTER вместе с командой RENAME.
Рассмотрим следующую таблицу 9.0141 Сотрудники_деталь :
10 1 Амар Ратор Мужчина 27 102 Димпл Кханна Женщина 28 9019 3 103 Маюри Чаттерджи Женщина 27 104 Картик Падман Мужской 30 105 Айша Хан Женский 29 9019 2 106 Диана Женщина 27 107 Джасприт Мужчина 30 901 93
Мы должны переименовать имя столбца Emp_age в age_of_emp .
SQL-запрос:
Вывод:
9019 2 Дианна
9 0262
Следовательно, мы видим, что имя столбца Emp_age теперь изменено на age_of_Emp.
- Переименуйте столбец с помощью ALTER с командой CHANGE.
Рассмотрим стол факультета.
| Emp_ID | Emp_name | Emp_gender | age_of_Emp |
|---|---|---|---|
| 101 | Амар Ратор | Мужчина | 27 |
| 102 | Димпл Кханна | Женщина | 28 90 193 |
| 103 | Маюри Чаттерджи | Женщина | 27 |
| 104 | Картик Падман | Мужчина | 30 |
| 105 | Аиша Хан | Женщина | 29 |
| 106 | Женщина | 27 | |
| 107 | Джасприт | Мужчина | 30 |
9019 2 48
| f_ID | f_name | f_yoe | f_age |
|---|---|---|---|
| 201 90 193 | Д-р Аджея Кришна | 10 | 47 |
| 202 | Д-р Судханшу Джа | 15 | |
| 203 | Доктор Гарги Сен | 13 | 47 |
| 204 | Доктор Кар тик Рао | 16 | 50 |
| 205 | Д-р Айман Шадаб | 8 | 49 |
| 206 | Д-р М. Дсуза 9019 3 | 10 | 57 |
| 207 | Доктор Райшекар | 12 | 50 |
Мы переименуем столбец с именем f_name в phdf_name .
SQL-запрос
Вывод:
9017 9
| F_ID | PHDF_NAME | F_YOE | F_AGE | |||||
|---|---|---|---|---|---|---|---|---|
| Доктор Ajeya Krishna | . 0193 0193 | |||||||
| 202 | Доктор Судханшу Джа | 15 | 48 | |||||
| 203 | Д-р Гарги Сен | 13 | 47 | |||||
| 204 | Д-р Картик Рао | 16 9 0193 | 50 | |||||
| 205 | Доктор Айман Шадаб | 8 | 49 | |||||
| 206 | Доктор М. Дсуза | 10 | 57 | |||||
| 207 | Dr.Rajshekhar | 12 | 50 |
Имя столбца изменено от f_name до phdf_name .
- Пример отображения имени столбца переименования в SQL Server
Рассмотрим таблицу product_details:
9019 2 Батончик молочный
9019 2 0579 0192 300000
| Prod_ID | бренд | шоколад | продаж/день |
|---|---|---|---|
| 055 | Nestle | 10000000 | |
| 056 | Амуль | Темный шоколад | 500000 |
| Гандур | Сафари | 200000 | |
| 058 | Кэдбери | Молочное молоко | 1000000 |
| 059 | Nestle | Kitkat | 500000 |
| 060 | Cadbury | Шелк | |
| 061 | Парле | Мелодия | 5000000 |
Сейчас мы переименуем имя столбца шоколад до prod_name .
SQL-запрос:
Вывод:
| Prod_ID | бренд | prod_name | продаж/день |
|---|---|---|---|
| 055 | Nestle | Milky Батончик | 10000000 |
| 056 | Амуль | Темный шоколад | 500000 |
| 0 57 | Гандур | Сафари | 200000 |
| 058 | Кэдбери | Молоко | 1000 000 |
| 059 | Nestle | Kitkat | 500000 |
| 060 | Cadbury | Шелк | 3000 00 |
| 061 | Parle | Мелодия | 5000000 |
Следовательно, имя столбца 901 41 шоколад теперь изменено на prod_name .
Подробнее
Чтобы изучить основы SQL для написания запросов и постепенной работы с несколькими базами данных, обратитесь к этой статье по SQL.