Добавить в таблицу запись sql: использование инструкции INSERT INTO, синтаксис и примеры
Содержание
Запрос SQL на добавление и удаление записей
В этой статье мы разберём, пожалуй, одни из самых важных SQL-запросов. Это запросы на добавление и удаление записей из таблицы базы данных. Поскольку, ОЧЕНЬ часто приходится добавлять новые записи в таблицу, причём делать это в автоматическом режиме, то данный материал обязателен к изучению.
Для начала SQL-запрос на добавление новой записи в таблицу:
INSERT INTO users (login, pass) values('TestUser', '123456')
При добавлении записи вначале идёт команда «INSERT INTO«, затем название таблицы, в которую мы вставляем запись. Далее идёт в круглых скобках названия полей, которые мы хотим заполнить. А затем в круглых скобках после слова «values» начинаем перечислять значения тех полей, которые мы выбрали. После выполнения этого запроса в нашей таблице появится новая запись.
Иногда требуется обновить запись в таблице, для этого существует следующий SQL-запрос:
UPDATE users SET login = 'TestUser2', pass='1234560' WHERE login='TestUser'
Данный запрос является более сложным, так как он имеет конструкцию «WHERE«, но о ней чуть ниже. Вначале идёт команда «UPDATE«, затем имя таблицы, а после «SET» мы описываем значения всех полей, которые мы хотим изменить. Было бы всё просто, но встаёт вопрос: «А какую именно запись следует обновлять?«. Для этого существует «WHERE«. В данном случае мы обновляем запись, поле «login» у которой имеет значение «TestUser«. Обратите внимание, что если таких записей будет несколько, то обновятся абсолютно все! Это очень важно понимать, иначе Вы рискуете потерять свою таблицу.
Вначале идёт команда «UPDATE«, затем имя таблицы, а после «SET» мы описываем значения всех полей, которые мы хотим изменить. Было бы всё просто, но встаёт вопрос: «А какую именно запись следует обновлять?«. Для этого существует «WHERE«. В данном случае мы обновляем запись, поле «login» у которой имеет значение «TestUser«. Обратите внимание, что если таких записей будет несколько, то обновятся абсолютно все! Это очень важно понимать, иначе Вы рискуете потерять свою таблицу.
Давайте немного ещё поговорим о «WHERE«. Помимо простых проверок на равенство существуют так же и неравенства, а также логические операции: AND и OR.
UPDATE users SET login = 'TestUser2', pass='1234560' WHERE id < 15 AND login='TestUser'
Данный SQL-запрос обновит те записи, id которых меньше 15 И поле «login» имеет значение «TestUser«. Надеюсь, Вы разобрались с конструкцией «WHERE«, потому что это очень важно. Именно «WHERE» используется при выборке записей из таблиц, а это самая частоиспользуемая задача при работе с базами данных.
Именно «WHERE» используется при выборке записей из таблиц, а это самая частоиспользуемая задача при работе с базами данных.
И, напоследок, простой SQL-запрос на удаление записей из таблицы:
DELETE FROM users WHERE login='TestUser2'
После команды «DELETE FROM» идёт имя таблицы, в которой требуется удалить записи. Дальше описываем конструкцию «WHERE». Если запись будет соответствовать описанным условиям, то она будет удалена. Опять же обратите внимание, в зависимости от количества записей, удовлетворяющих условию после «WHERE«, может удалиться любое их количество.
Вот Вы и узнали, как добавлять, обновлять и удалять записи из таблицы. А в следующей статье я Вас познакомлю с тем, как делать выборку записей из таблицы, а это является, пожалуй, самым важным при работе с базами данных.
Полный курс по PHP и MySQL: http://srs.myrusakov.ru/php
Создано 16.01.2011 17:44:14
Михаил Русаков
Копирование материалов разрешается только с указанием автора (Михаил Русаков) и индексируемой прямой ссылкой на сайт (http://myrusakov. ru)!
ru)!
Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
2.16. Добавление записей — Transact-SQL В подлиннике : Персональный сайт Михаила Флёнова
С выборкой данных мы разобрались и узнали все, что необходимо знать об операторе SELECT. Я надеюсь, что смог показать вам всю мощь выборки данных и теперь вы сможете самостоятельно писать запросы для решения своих задач.
Теперь давайте познакомимся с командами добавления данных в таблицу. Когда мы вначале главы заполняли таблицу данными, то вы должны были просто выполнить сценарий. Сейчас мы познакомимся с командой INSERT, которая добавляет в таблицу запись и вы сможете понять, как работал сценарий заполнения таблицы Chapter2/fill_data.sql.
Сейчас мы познакомимся с командой INSERT, которая добавляет в таблицу запись и вы сможете понять, как работал сценарий заполнения таблицы Chapter2/fill_data.sql.
Листинг 2.4. Общий вид команды INSERT
INSERT [ INTO]
{ table_name WITH ( < table_hint_limited > [ ...n ] )
| view_name
| rowset_function_limited
}
{ [ ( column_list ) ]
{ VALUES
( { DEFAULT | NULL | expression } [ ,...n] )
| derived_table
| execute_statement
}
}
В принципе, ничего сложного в этой команде нет. Давайте рассмотрим различные варианты добавления данных в таблицу. Для начала добавим в таблицу строку, в которой все значения будут установлены сервером по умолчанию:
INSERT INTO tbPeoples DEFAULT VALUES
Посмотрите, что добавил сервер в таблицу tbPeoples. Как? Нужно посмотреть последнюю строку, а этот запрос мы рассматривали в разделе 2. 14. Напоминаю, как он выглядел:
14. Напоминаю, как он выглядел:
SELECT *
FROM tbPeoples
WHERE idPeoples=
(SELECT MAX(idPeoples) FROM tbPeoples)
В результате вы должны увидеть следующую теблицу:
idPeoples vcFamil vcName vcSurname idPosition dDateBirthDay
----------------------------------------------------------------
20 NULL NULL NULL NULL NULL
(1 row(s) affected)
В таблице tbPeoples первое поле ‘idPeoples’ является автоматически увеличиваемым, и новой строке это поле стало равным 20. Остальные поля не имеют значений по умолчанию и тут можно видеть только нулевые значения NULL.
Вернемся к запросу добавления записи и рассмотрим его подробнее. В данном запросе выполняется оператор INSERT INTO (вставить в), после которого указывается имя таблицы, в которую нужно вставить запись. Далее может идти описание имен полей, которые нужно заполнять или список значений. В нашем случае нет ни того, ни другого, зато есть DEFAULT VALUES (значения по умолчанию), который указывает на необходимость заполнить все поля значениями по умолчанию.
В таблице tbPeoples только у одного поля указывается значение по умолчанию – это автоматически увеличиваемое поле первичного ключа. Хотя мы не указывали DEFAULT значение, автоматически увеличиваемое поле обязательно получает значение, тем более что это первичный ключ, и он должен быть заполнен. Все остальные поля будут нулевыми.
Следующий запрос пытается добавить запись с явно указанными данными:
INSERT INTO tbPeoples VALUES(122, 'ИВАНОВ', 'ИВАН', 'СЕРГЕЕВИЧ', 1, '01.01.1971')
Первая строка ничем не отличается от предыдущего запроса. Мы снова указываем, что строка добавляется в таблицу tbPeoples. Во второй строке идет ключевое слово VALUES, после которого в скобках должны быть перечислены значения для всех полей таблицы. Перечисление значений должно быть в том же порядке, что и список полей в таблице, и при этом, указываемые значения должны иметь необходимый тип данных. Если хотя бы одно поле не будет указано или указано, но не верно (например, вместо числа будет указана строка), то запрос не будет выполнен.
В данном запросе указаны все поля и указаны в соответствии со всеми типами, но почему я сказал, что этот запрос «пытается добавить строку»? Ничего в голову не приходит? Первое поле имеет тип автоматического увеличиваемого числа. Это поле изменять нельзя, поэтому сервер вернет ошибку:
An explicit value for the identity column in table ‘tbPeoples’ can only be specified when a column list is used and IDENTITY_INSERT is ON.
Явное значение для авто увеличиваемой колонки в таблице ‘tbPeoples’ может быть указано только когда используется список колонок и свойство IDENTITY_INSERT установлено в ON.
Неужели нельзя добавить строку? Конечно же, есть способ решения этой проблемы, просто необходимо явным образом задать список колонок, которые должны изменяться и установить им нужные значения.
Список колонок указывается в скобках после имени таблицы:
INSERT INTO tbPeoples (idPeoples, vcFamil, vcName, vcSurname, idPosition, dDateBirthDay) VALUES (122, 'ИВАНОВ', 'ИВАН', 'СЕРГЕЕВИЧ', 1, '01.01.1971')
 01.1971')
01.1971')
В данном случае в скобках перечислены все поля в таком же порядке, в котором они описаны в таблице tbPeoples. Но это не является обязательным. Поля могут быть в любом порядке, но в этом случае значения в скобках после ключевого слова VALUES должны идти в том же порядке, в котором вы их перечислили. Но об этом мы еще поговорим.
Но этого не достаточно. Необходимо установить нужное свойство. Мы этого пока свойства не изменяли, но это делается с помощью оператора SET. Затем идет имя свойства (IDENTITY_INSERT), имя таблицы, свойство которой нужно изменить и напоследок – значение (чаще всего ON или OFF). В виде Transact-SQL команды это выглядит следующим образом:
SET IDENTITY_INSERT tbPeoples ON
Необходимо заметить, что изменение подобных свойств относится только к Transact-SQL и MS SQL Server.
Теперь посмотрим на полную SQL команду добавления записи с явным указанием значения для автоматически увеличиваемого значения:
SET IDENTITY_INSERT tbPeoples ON
INSERT INTO tbPeoples
(idPeoples, vcFamil, vcName, vcSurname,
idPosition, dDateBirthDay)
VALUES(122, 'ИВАНОВ', 'ИВАН', 'СЕРГЕЕВИЧ',
1, '01. 01.1971')
 01.1971')
01.1971')
После выполнения команды желательно вернуть значение параметра IDENTITY_INSERT в OFF:
SET IDENTITY_INSERT tbPeoples OFF
Вот теперь команда будет выполнена корректно и новая запись будет успешно добавлена в таблицу. Но я не рекомендую вам явно указывать значение для автоматически увеличиваемого поля. Так вы можете нарушить целостность, поэтому доверьте выделение значения для IDENTITY поля серверу баз данных.
Как добавить строку, и при этом не указывать значение ключевого поля, чтобы сервер смог его установить самостоятельно? Очень просто. Дело в том, что перечислять все поля необязательно. Можно указать только те имена полей, значения которых вы хотите явно изменить. Например, в следующем запросе мы не указываем значение для ключевого поля «idPeoples»:
INSERT INTO tbPeoples
(vcFamil, vcName, vcSurname, idPosition, dDateBirthDay)
VALUES('ИВАНОВ', 'ИВАН', 'АЛЕКСЕЕВИЧ', 1, '01.01.1971')
В списке полей и в списке VALUES не указывается значение для поля «idPeoples». Да и в списке значений после ключевого слова VALUES мы указываем значения, начиная с поля «vcFamil». Вместо этого, сервер самостоятельно добавит очередное значение точно так же, как когда мы добавляли строку из всех значений по умолчанию.
Да и в списке значений после ключевого слова VALUES мы указываем значения, начиная с поля «vcFamil». Вместо этого, сервер самостоятельно добавит очередное значение точно так же, как когда мы добавляли строку из всех значений по умолчанию.
Давайте добавим строку, в которой укажем только фамилию работника. Для этого, в списке полей нужно указать только имя поля «vcName», а в списке значений должно быть только одно строковое значение, ведь фамилия имеет строковый тип:
INSERT INTO tbPeoples (vcFamil)
VALUES('ПЕТРОВ')
Если в вашей программе удобнее сделать перечисление всех полей, но при этом заполняются далеко не все значения, вместо не заполняемых значений можно указать значение NULL или DEFAULT. В следующем примере, вместо фамилии и даты рождения указано ключевое слово DEFAULT и этим полям сервер установит значение по умолчанию. Для поля фамилии указывается значение NULL:
INSERT INTO tbPeoples
(vcFamil, vcName, vcSurname, idPosition, dDateBirthDay)
VALUES('СЕРГЕЕВ', DEFAULT, NULL, 1, DEFAULT)
Ключевые слова DEFAULT и NULL можно указывать для любых типов полей, кроме автоматически увеличиваемого, потому что это поле не может содержать NULL и не имеет значения по умолчанию. Автоматическое увеличение к значению по умолчанию не относиться.
Автоматическое увеличение к значению по умолчанию не относиться.
В перечислении можно указывать поля в любом порядке, и только те, которые необходимы. При этом в списке VALUES значения должны идти в том же порядке, в котором вы их перечисляли. Например, в следующем примере поля фамилии, имени и отчества заполняются в обратном порядке. При этом между отчеством и именем идет поле «idPosition»:
INSERT INTO tbPeoples
(vcSurname, idPosition, vcName, vcFamil)
VALUES('ПЕТРОВИЧ', 12, 'СЕРГЕЙ', 'СМИРНОВ')
В разделе 2.6 мы рассматривали, как можно использовать SELECT INTO для создания новой таблицы. Теперь давайте посмотрим, как можно импортировать данные в уже существующую таблицу, ведь SELECT INTO не может выбирать данные в таблицу, если она уже существует.
Для этого создадим новую таблицу tbPeoples2, которая будет состоять из таких же полей, как и у tbPeoples. Единственная разница, ключевое поле не будет автоматически увеличиваемым, чтобы сервер не ругался, на вставку значений в первичный ключ. Посмотрите на SQL код создания новой таблицы tbPeoples2, показан в листинге 2.5.
Посмотрите на SQL код создания новой таблицы tbPeoples2, показан в листинге 2.5.
Листинг 2.5. Создание новой таблицы, копии tbPeoples
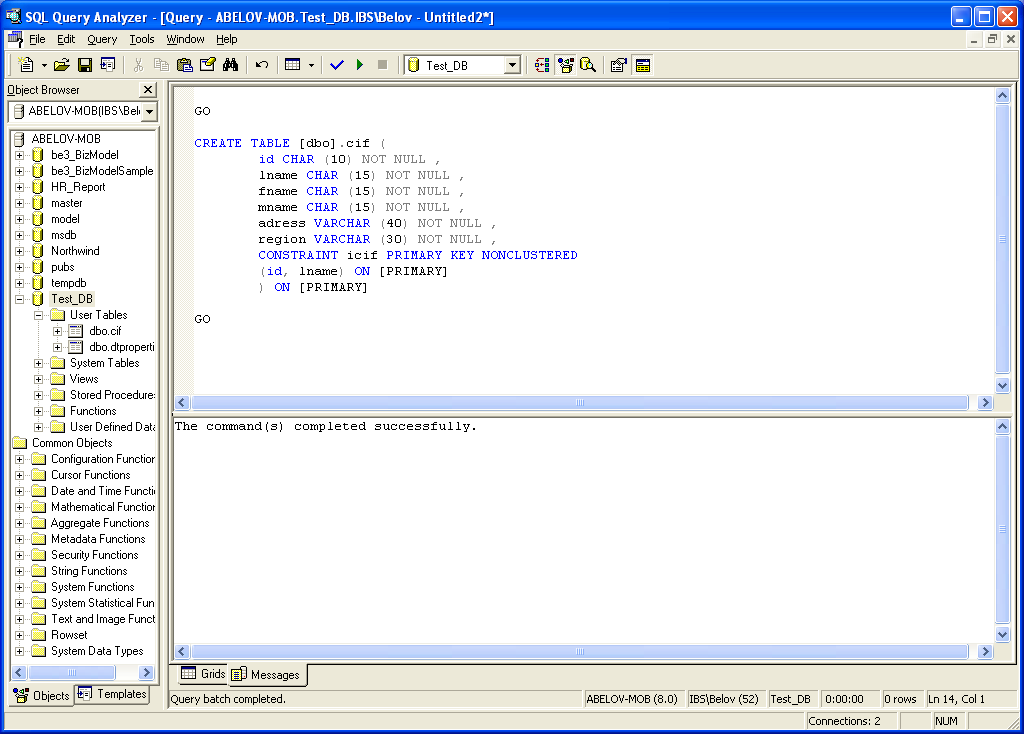
CREATE TABLE tbPeoples2
(
-- Описание полей
idPeoples2 int,
vcFamil varchar(50),
vcName varchar(50),
vcSurname varchar(50),
idPosition int,
dDateBirthDay datetime,
-- Описание ключей
CONSTRAINT PK_idPeoples2 PRIMARY KEY (idPeoples2),
CONSTRAINT FK_idPosition2 FOREIGN KEY (idPosition)
REFERENCES tbPosition (idPosition),
-- Описание ограничений
CONSTRAINT check_dDateBirthDay2 CHECK (dDateBirthDay<getdate())
)
Так как имена ограничений в таблице должны быть уникальными внутри базы данных, к каждому имени ограничения добавлена цифра 2. В принципе, имя таблицы тоже содержит цифру два (tbPeoples2), т.е. все соответствует тому, чему мы договорились.
Теперь посмотрим, как заполнить новую таблицу записями работников из таблицы tbPooples, и при этом взять только те записи, у которых поле «idPosition» содержит значение более или равное 10.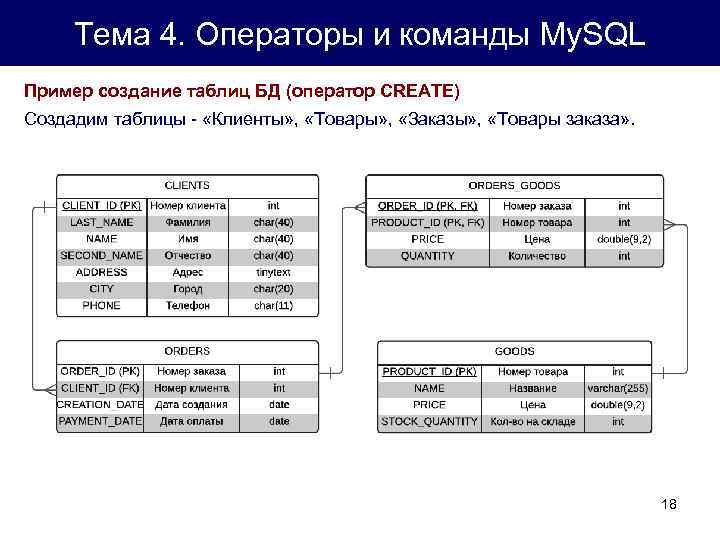 Все достаточно просто:
Все достаточно просто:
INSERT INTO tbPeoples2 SELECT * FROM tbPeoples WHERE idPosition>=10
В первой строке пишем оператор INSERT INTO и имя таблицы tbPeoples2, в которую необходимо вставить данные. Затем идет просто запрос SELECT, в котором мы получаем нужные данные из таблицы tbPeoples. Все строки, полученные с помощью этого запроса, будут добавлены в таблицу tbPeoples2.
Все так просто только потому, что обе таблицы содержат одинаковое количество полей, и типы полей совпадают. А если поля будут разными? Давайте создадим третью таблицу tbPeoples3, в которой будут только поля для хранения фамилии, имени и даты рождения.
CREATE TABLE tbPeoples3 ( -- Описание полей vcFamil varchar(50), vcName varchar(50), dDateBirthDay datetime, )
Теперь посмотрим, как можно заполнить эту таблицу значениями:
INSERT INTO tbPeoples3 SELECT vcFamil, vcName, dDateBirthDay FROM tbPeoples WHERE idPosition>=10
Обратите внимание, что мы выбираем с помощью запроса SELECT только три поля и именно в таком порядке, в котором они описаны в таблице tbPeoples3. Названия полей в таблицы, и выбираемые поля могут не совпадать, но типы данных обязаны совпадать полностью, иначе выполнение запроса завершиться ошибкой. Здесь сервер не может производить автоматического преобразования, поэтому, или типы должны совпадать, или вы должны их явно преобразовывать. О явном преобразовании мы поговорим в разделе 2.21.
Названия полей в таблицы, и выбираемые поля могут не совпадать, но типы данных обязаны совпадать полностью, иначе выполнение запроса завершиться ошибкой. Здесь сервер не может производить автоматического преобразования, поэтому, или типы должны совпадать, или вы должны их явно преобразовывать. О явном преобразовании мы поговорим в разделе 2.21.
С помощью оператора INSERT INTO вы можете копировать данные между таблицами или даже переносить их с сервера на сервер с помощью распределенных запросов, о которых мы поговорим в разделе 5.1.
Запрос SELECT в INSERT INTO может быть любой сложности, и тут ограничений на используемые операторы нет. Другое дело, что не всегда сортировка может иметь смысл. Например, если вставлять отсортированные данные в таблицу tbPeoples, то таким образом можно повлиять только на идентификатор добавляемых строк, потому что тут автоматически увеличиваемое поле, которое генерируется последовательно. Но если бы первичный ключ был GUID полем, то сортировка потеряла бы смысл, потому что GUID поле генерируется случайным образом.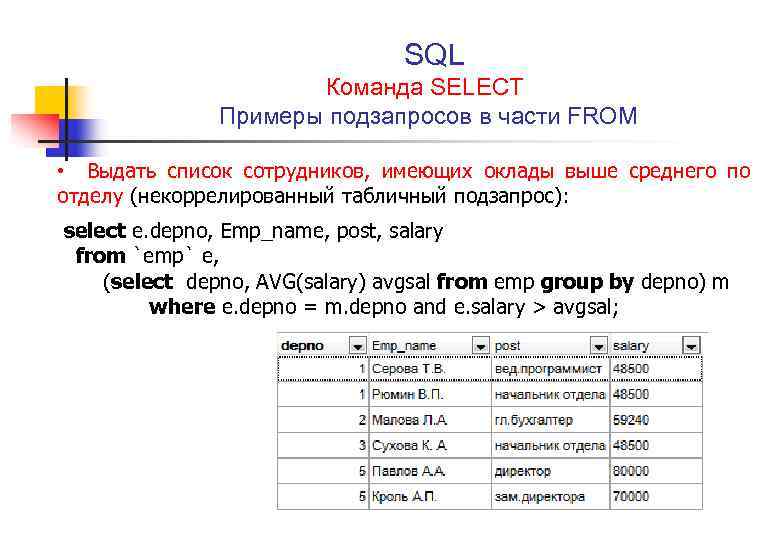
Больше индексов, медленнее INSERT
Количество индексов в таблице является наиболее важным фактором для
вставка исполнение. Чем больше индексов а
таблица, тем медленнее становится выполнение. Оператор вставки — единственная операция, которая
не может получить непосредственную выгоду от индексации, поскольку в нем нет пункта , где .
Добавление новой строки в таблицу включает несколько шагов. Во-первых,
база данных должна найти место для хранения строки. Для обычной кучи
таблица — в которой нет определенного порядка строк — база данных может принимать любую таблицу
блок, в котором достаточно свободного места. Это очень простой и быстрый процесс,
в основном выполняется в основной памяти. Все, что база данных должна сделать после этого, это
для добавления новой записи в соответствующий блок данных.
Если в таблице есть индексы, база данных должна убедиться, что
новая запись также находится через эти индексы.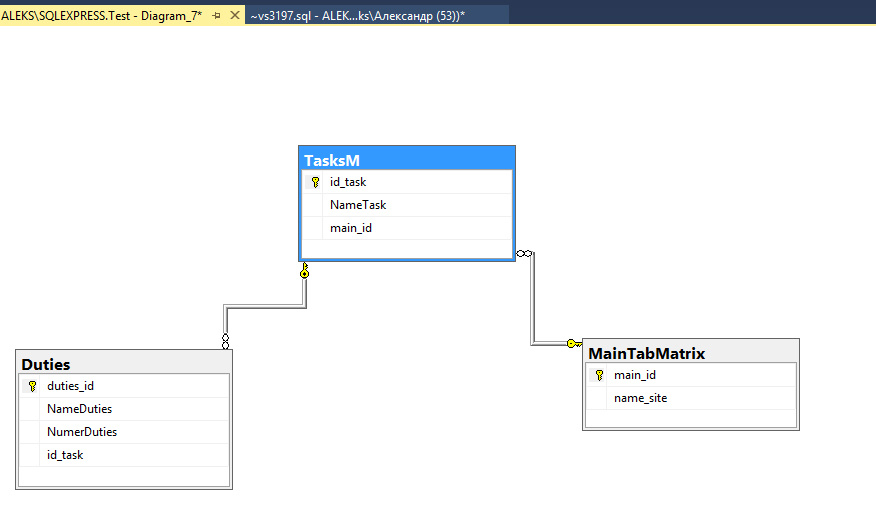 По этой причине он должен добавить
По этой причине он должен добавить
новая запись для каждого индекса в этой таблице. Количество индексов
поэтому является множителем стоимости оператора вставки .
От своего имени
Я зарабатываю на жизнь обучением SQL, настройкой и консультированием SQL, а также своей книгой «Объяснение производительности SQL». Узнайте больше на https://winand.at/.
Кроме того, добавление записи в индекс намного дороже, чем
вставка одного в структуру кучи, потому что база данных должна хранить
порядок индексов и баланс дерева. Это означает, что новая запись не может быть записана
к любому блоку — он принадлежит определенному листу
узел. Хотя база данных использует индекс
дерева, чтобы найти правильный конечный узел, ему все равно нужно прочитать
несколько индексных блоков для обхода дерева.
После определения правильного конечного узла база данных
подтверждает, что в этом узле осталось достаточно свободного места. Если нет, то
база данных разбивает конечный узел и распределяет записи между старым и новым узлом.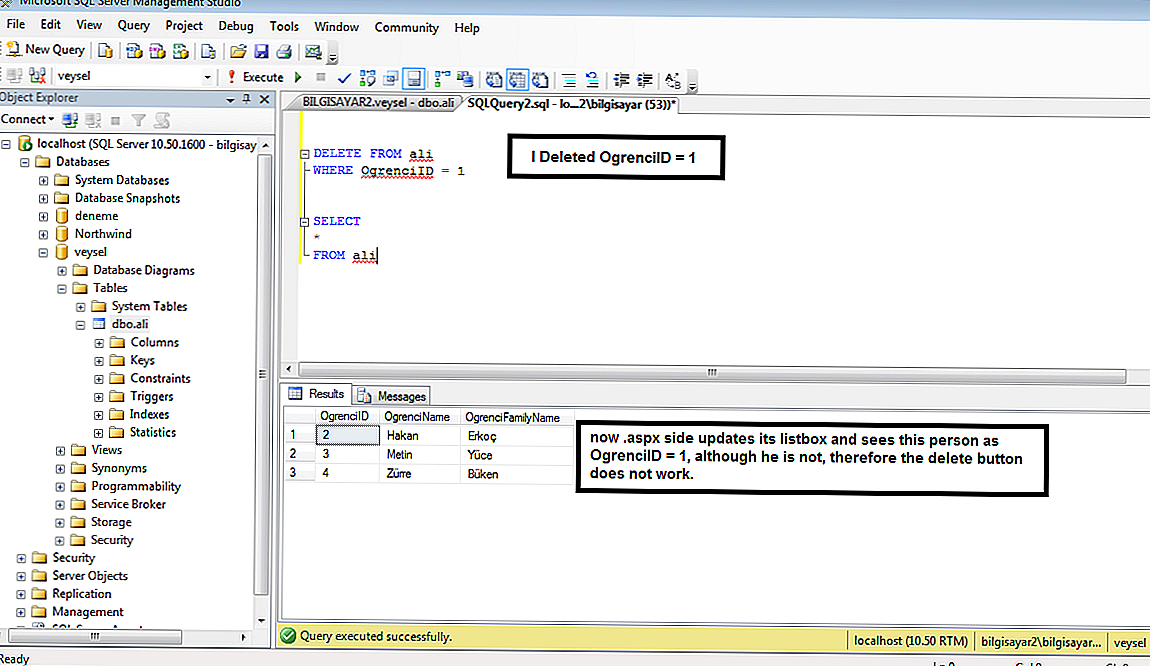
Этот процесс также влияет на ссылку в соответствующем узле ответвления.
так как это также должно быть продублировано. Излишне говорить, что узел ответвления может
также не хватает места, поэтому, возможно, его тоже придется разделить. В худшем
случае база данных должна разделить все узлы до корневого узла. Это единственный случай, когда дерево получает
дополнительный слой и растет в глубину.
Ведение индекса, в конце концов, самая дорогая часть
вставка операция. Это тоже видно
на рисунке 8.1, «Производительность вставки по количеству индексов »: время выполнения едва видно, если
у таблицы нет индексов. Тем не менее, добавление одного индекса
достаточно, чтобы увеличить время выполнения в сто раз. Каждый
дополнительный индекс еще больше замедляет выполнение.
Примечание
Первый индекс имеет наибольшее значение.
Чтобы оптимизировать производительность вставки ,
очень важно, чтобы число индексов было небольшим.
Совет
Используйте индексы преднамеренно и
экономно и по возможности избегайте избыточных индексов.
Это также полезно для удалить
и обновляют операторы .
Принимая во внимание вставить заявления
только было бы лучше вообще избегать индексов — это дает
лучшая вставка производительность. Однако таблицы
без индексов довольно нереалистичны в реальных приложениях. Ты
обычно хотят снова получить сохраненные данные, поэтому вам нужны индексы для
улучшить скорость запросов. Даже таблицы журналов только для записи часто имеют первичный ключ.
и соответствующий индекс.
Тем не менее, производительность без индексов настолько хороша, что может
имеет смысл временно удалить все индексы при загрузке большого количества
данные — при условии, что индексы не нужны никаким другим операторам SQL в
тем временем. Это может привести к резкому ускорению, которое видно на
диаграммы и, по сути, является обычной практикой в хранилищах данных.
Подумайте об этом
Как бы Рис 8.1
измениться при использовании индекса
организованная таблица или кластеризованный индекс?
Есть ли какой-либо косвенный способ, которым оператор вставки мог бы извлечь выгоду из
индексация? То есть может ли дополнительный индекс сделать оператор вставки ?
Быстрее?
Научитесь писать SQL-запрос для создания таблицы и вставки данных
Если вы знаете что-то об использовании компьютера, вы наверняка слышали о термине SQL. Но, может быть, вы не знаете, что это такое, и никогда не удосужились понять это. Ну, это не ракетостроение, специально для вас, а человек, донельзя зеленый в технологиях, наверное. Итак, прежде всего, в чем смысл SQL? Чтобы начать с инициалов SQL, расшифровывайте язык структурированных запросов.
Не столь подробное определение SQL заключается в том, что это то, что используется при общении с базой данных. Опять же, что такое база данных? База данных — это электронная система, в которой можно легко получить доступ к данным. Он не только получает данные, но и пользователь может манипулировать ими, а также обновлять их. Предприятия используют базы данных для хранения, управления и извлечения информации.
Он не только получает данные, но и пользователь может манипулировать ими, а также обновлять их. Предприятия используют базы данных для хранения, управления и извлечения информации.
База данных нового поколения поддерживается тем, что мы знаем как СУБД, что означает систему управления базами данных. Примеры баз данных включают Microsoft Access, FileMaker, FoxPro, Oracle, Clipper, dBASE, RDBMS, PostgreSQL, MySQL и SQL Server. Простейшее определение того, что такое база данных, — это сбор информации, профессионально называемой данными, которая хранится на сервере.
Поэтому SQL, согласно Американскому национальному институту стандартов, ANSI и SQL, является стандартным языком для системы управления базами данных. Оператор SQL используется для выполнения таких задач, как обновление данных в существующей базе данных, извлечение этих данных из базы данных и, в равной степени, управление ими.
Применение SQL
Как было сказано ранее, SQL имеет множество применений, включая сценарии интеграции данных, аналитические запросы, извлечение информации и многие другие приложения.
Сценарий интеграции данных
SQL используется для написания сценариев интеграции данных администратором базы данных или разработчиком
Аналитические запросы
Аналитики данных постоянно используют язык структурированных вопросов для постановки, а также выполнения аналитических вопросов.
Извлечение данных
Администратор базы данных использует SQL для извлечения подмножества данных в базе данных для приложения аналитики, а также для обработки транзакций. Обычно используемые элементы SQL включают вставку, выбор, удаление, добавление, создание, изменение и усечение.
Важные приложения SQL
SQL изменяет структуры индексов, а также таблицы базы данных. Кроме того, администратор может добавлять, удалять и обновлять строки информации с помощью SQL.
Преимущества SQL
Существует множество преимуществ использования SQL, вот лишь несколько причин и преимуществ.
SQL Standard
Первый стандарт для этого языка был разработан в 1986 году; Международные национальные стандарты последовали за набором в 1987.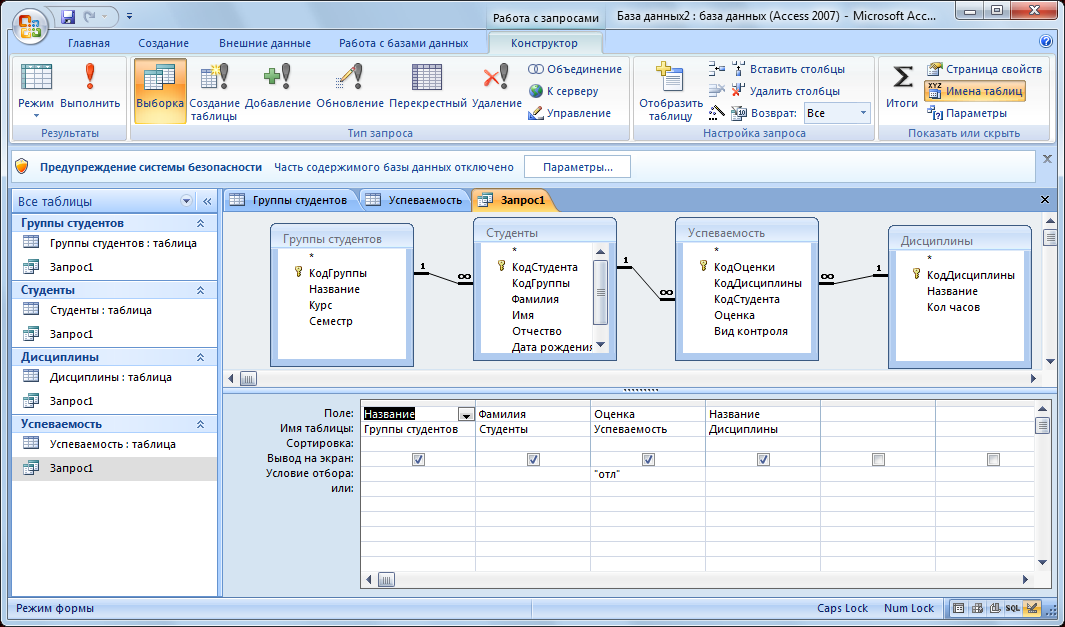 Сегодня мы используем последний стандарт, разработанный в 2011 году.
Сегодня мы используем последний стандарт, разработанный в 2011 году.
Portable
Он работает на ПК, мэйнфреймах, серверах и мобильных устройствах. Этот язык также работает в локальных системах, Интернете и интрасети. Базы данных SQL можно удобно перемещать из одной системы в другую без какой-либо компиляции.
Открытый исходный код
SQL является открытым исходным кодом, что означает, что вы можете использовать его по низкой цене в больших сообществах.
Простота в освоении и использовании
Этот язык состоит из утверждений на английском языке, что означает, что вы можете быстро выучить и использовать его. Написание SQL-запроса никогда не было проще.
Очень ценно иметь навык
Для многих должностей, таких как ИТ-поддержка, анализ бизнес-данных и веб-разработка, требуется кандидат, хорошо владеющий SQL. Именно поэтому мы хотим научить вас создавать таблицы и вставлять данные в язык структурированных запросов.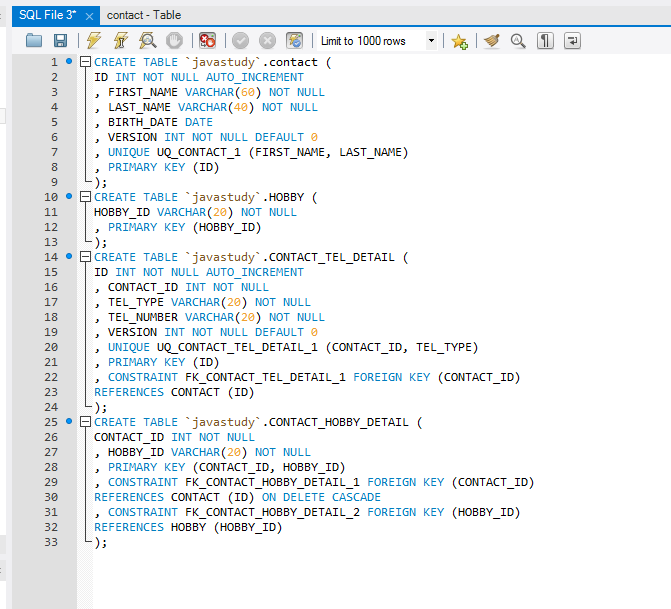
Создание таблицы в SQL и вставка данных
Во-первых, существуют различные способы создания таблиц и вставки данных в SQL. Для начала,
Можно создать таблицу с помощью оператора create; например, вы хотите создать таблицу под названием «ученики». Используйте приведенный ниже синтаксис.
СОЗДАТЬ ТАБЛИЦУ УЧЕНИКОВ (
Ученик int IDENTITY (1.1) NOT NULL,
Имя varchar (200),
Фамилия varchar (200),
Электронная почта varchar (100)
) Таким образом, этот синтаксис даст вам таблицу Ученик, где идентификатор ученика не равен нулю. Если вы хотите вставить данные в эту таблицу под названием «Ученик», вот что вы делаете, используя первый метод.
Вставка в зрачки,
(
Ученик, Имя, Фамилия, электронная почта
)
Ценности
(
1, «Ватсон», «Кетер», «[email protected]»
) You can verify this query to get the following result
| Student ID | First Name | Last Name | |
|---|---|---|---|
| 1 | Watson | Keter | watsonketer@gmail .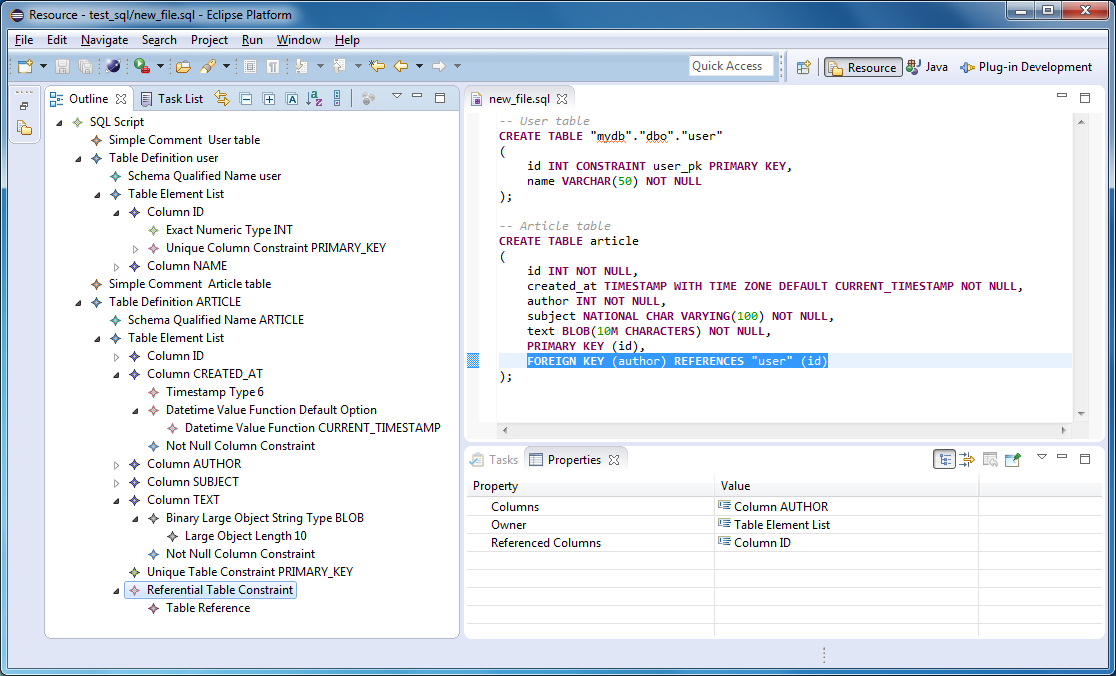 com com |
Второй метод заключается в том, как вы можете вставлять значения в таблицу, используя другую таблицу. См. ниже.
Например, у нас уже есть таблица с именем Pupils, и здесь мы хотим вставить значения этой таблицы в другую таблицу с именем Pupildemo.
Создать таблицу «Pupildemo»
CREATE TABLE Pupildemo (
Ученик int IDENTITY (1.1) NOT NULL,
Имя varchar (200),
Фамилия varchar (200),
Электронная почта varchar (100)
) На этом этапе, чтобы вставить данные таблицы «Ученики» в таблицу «Ученик», вы можете использовать следующую инструкцию.
Вставить в демо-урок (
Ученик, Имя, Фамилия, электронная почта
) Затем,
ВЫБИРАТЬ
Ученик,
Имя,
Фамилия,
электронная почта
от
Зрачки
Вы можете проверить результаты этой инструкции, чтобы получить результаты с помощью этого метода.
SELECT, FROM Pupildemo, и вы получите этот результат.
| Student ID | First Name | Last Name | |
|---|---|---|---|
| 1 | Watson | Keter | watsonketer@gmail. com com |
Note : Чтобы вы могли вставить данные из одной таблицы в другую, тип данных столбца должен быть одинаковым.
Переименовать текущую таблицу
Изменить имя таблицы «Pupildemo» на Pupilscopy
ALTER TABLE
Pupildemo ПЕРЕИМЕНОВАТЬ В Pupilscopy
Рассмотрим приведенную здесь таблицу «Ученики» и ДОБАВЬТЕ столбец «Телефон» в этой таблице.
| Student ID | First Name | Last Name | |
|---|---|---|---|
| 1 | Watson | Keter | [email protected] |
| 2 | Кимберли | Джонс | [email protected] |
Здесь вам необходимо использовать команду ALTER TABLE, чтобы добавить столбец в существующую таблицу.
Вот что происходит
ALTER TABLE
Зрачки,
затем,
ДОБАВЛЯТЬ
Телефон INT Null
Это то, что вы получите
| Студенческий билет | Имя | Фамилия | Электронная почта | Телефон |
|---|---|---|---|---|
| 1 | Watson | Keter | watsonketer@gmail.
|