Group by count: sql — How to use count and group by at the same select statement
Содержание
SQL COUNT* GROUP BY больше, чем,
спросил
Изменено
5 лет, 8 месяцев назад
Просмотрено
106 тысяч раз
Я хочу выбрать отдельные ключи с номером вхождения, этот запрос работает:
SELECT ItemMetaData.KEY, ItemMetaData.VALUE, count(*) ИЗ ItemMetaData СГРУППИРОВАТЬ ПО ItemMetaData.KEY ORDER BY count(*) desc;
Но я также хочу отфильтровать этот результат, то есть я хочу только там, где count(*) больше 2500, поэтому будут показаны только случаи больше 2500, но:
SELECT *
ОТ
(
ВЫБЕРИТЕ ItemMetaData.KEY, ItemMetaData.VALUE, количество (*)
ИЗ ItemMetaData
СГРУППИРОВАТЬ ПО ItemMetaData.KEY
ORDER BY count(*) desc
) как результат WHERE count(*)>2500;
К сожалению, этот запрос приводит к синтаксической ошибке. Можете ли вы помочь мне выполнить мое требование?
Можете ли вы помочь мне выполнить мое требование?
- sql
- количество
- группировка по
1
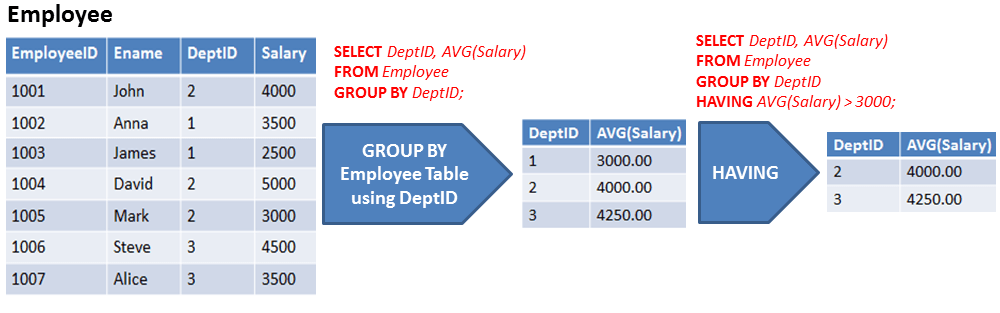
Предложение HAVING для агрегатов
SELECT ItemMetaData.KEY, ItemMetaData.VALUE, count(*) ИЗ ItemMetaData Сгруппировать по ItemMetaData.KEY, ItemMetaData.VALUE Имея количество (*)> 2500 ORDER BY count(*) desc;
Вы должны использовать с с групповыми функциями вместо , где . Например:
выберите..., count(*) from... group by... имея count(*) > 2500;
Вам не нужно использовать подзапрос — просто используйте с предложением вместо предложения where для фильтрации по агрегированному столбцу.
ВЫБОР ItemMetaData.KEY, ItemMetaData.VALUE, количество (*) ИЗ ItemMetaData СГРУППИРОВАТЬ ПО ItemMetaData.KEY Имея количество (*)> 2500 ORDER BY count(*) desc
Вот объяснение: В предложении WHERE вводится условие для отдельных строк; Предложение HAVING вводит условие для агрегаций.
Использовать ГДЕ до ГРУППИРОВАТЬ ПО и ИМЕТЬ после ГРУППИРОВАТЬ ПО . Это не обязательно, но полезно в большинстве случаев.
ВЫБОР
ItemMetaData.KEY, ItemMetaData.VALUE, СЧЕТ(*)
ИЗ ItemMetaData
ГРУППА ПО
ItemMetaData.KEY, ItemMetaData.VALUE
СЧЕТ(*) > 2500
ЗАКАЗАТЬ ПО СЧЕТУ(*) DESC;
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Pandas groupby() и count() с примерами
Распространяйте любовь
Вы можете использовать pandas DataFrame.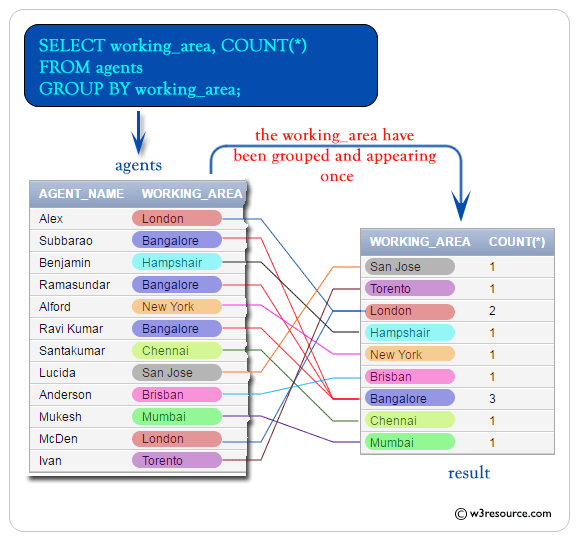 groupby().count() для группировки столбцов и вычисления количества или совокупного размера, это вычисляет количество строк для каждой группы комбинация.
groupby().count() для группировки столбцов и вычисления количества или совокупного размера, это вычисляет количество строк для каждой группы комбинация.
В этой статье я объясню, как использовать агрегаты groupby() и count() вместе с примерами. группаПо() 9Функция 0036 используется для сбора идентичных данных в группы и выполнения агрегатных функций, таких как размер/счет для сгруппированных данных.
1. Краткие примеры groupby() и count() в DataFrame
Если вы спешите, ниже приведены несколько кратких примеров того, как сгруппировать по столбцам и получить количество для каждой группы из DataFrame.
# Ниже приведены краткие примеры # Использование groupby() и count() df2 = df.groupby(['Курсы'])['Курсы'].count() # Использование GroupBy и count() для нескольких столбцов df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].count() # Использование GroupBy и size() для нескольких столбцов df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].size() # используя DataFrame.size() и max() df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max() # Использовать метод size().reset_index() df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts') # Использование pandas DataFrame.reset_index() df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index() # Использование DataFrame.transform() df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик') # Используйте DataFrame.groupby() и Size() print(df.groupby(['Скидка','Продолжительность']).size() .sort_values (по возрастанию = ложь) .reset_index (имя = 'количество') .drop_duplicates (подмножество = 'Продолжительность'))
 size() и max()
df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max()
# Использовать метод size().reset_index()
df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts')
# Использование pandas DataFrame.reset_index()
df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index()
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
# Используйте DataFrame.groupby() и Size()
print(df.groupby(['Скидка','Продолжительность']).size()
.sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
size() и max()
df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max()
# Использовать метод size().reset_index()
df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts')
# Использование pandas DataFrame.reset_index()
df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index()
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
# Используйте DataFrame.groupby() и Size()
print(df.groupby(['Скидка','Продолжительность']).size()
.sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
Теперь давайте создадим DataFrame с несколькими строками и столбцами, выполним эти примеры и проверим результаты. Наш DataFrame содержит имена столбцов Courses , Fee , Duration и Discount .
# Создаем кадр данных pandas.
 импортировать панд как pd
технологии = ({
«Курсы»: ["Spark","PySpark","Hadoop","Python","Pandas","Hadoop","Spark","Python"],
«Плата»: [22000,25000,23000,24000,26000,25000,25000,22000],
«Продолжительность»: ['30дней','50дней','35дней','40дней','60дней','35дней','55дней','50дней'],
«Скидка»: [1000,2300,1000,1200,2500,1300,1400,1600]
})
df = pd.DataFrame(технологии, столбцы=['Курсы','Плата','Продолжительность','Скидка'])
печать (дф)
импортировать панд как pd
технологии = ({
«Курсы»: ["Spark","PySpark","Hadoop","Python","Pandas","Hadoop","Spark","Python"],
«Плата»: [22000,25000,23000,24000,26000,25000,25000,22000],
«Продолжительность»: ['30дней','50дней','35дней','40дней','60дней','35дней','55дней','50дней'],
«Скидка»: [1000,2300,1000,1200,2500,1300,1400,1600]
})
df = pd.DataFrame(технологии, столбцы=['Курсы','Плата','Продолжительность','Скидка'])
печать (дф)
Выход ниже выходного.
Курсы Стоимость Продолжительность Скидка 0 Искра 22000 30 дней 1000 1 PySpark 25000 50 дней 2300 2 Hadoop 23000 35дней 1000 3 Python 24000 40дней 1200 4 Панды 26000 60дней 2500 5 Hadoop 25000 35дней 1300 6 Искра 25000 55 дней 1400 7 Python 22000 50дней 1600
2. Используйте count() по имени столбца
Используйте pandas DataFrame.groupby() для группировки строк по столбцу и используйте count() метод для получения количества для каждой группы, игнорируя значения None и Nan. Он также работает с данными неплавающего типа. В приведенном ниже примере группируется столбец
Он также работает с данными неплавающего типа. В приведенном ниже примере группируется столбец «Курсы» и подсчитывается, сколько раз присутствует каждое значение.
# Использование groupby() и count() df2 = df.groupby(['Курсы'])['Курсы'].count() печать (df2)
Выход ниже выходного.
Курсы Хадуп 2 Панды 1 ПиСпарк 1 Питон 2 Искра 2 Название: Курсы, dtype: int64
3. pandas groupby() и count() в списке столбцов
Вы также можете отправить список столбцов, которые вы хотите сгруппировать, в метод groupby(), используя это, вы можете применить группировку к нескольким столбцам и рассчитать количество. каждой комбинированной группы. Например, df.groupby(['Courses','Duration'])['Fee'].count() выполняет группировку по столбцам Courses и Duration и, наконец, подсчитывает количество.
# Использование groupby() и count() для нескольких столбцов df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].
 count()
печать (df2)
count()
печать (df2)
Выход ниже выходного.
Продолжительность курсов
Хадуп 35дней 2
Панды 60дней 1
PySpark 50дней 1
Питон 40дней 1
50 дней 1
Искра 30дней 1
55 дней 1
Имя: Плата, dtype: int64
4. Сортировка после группировки и подсчета
Иногда требуется выполнить сортировку (по возрастанию или убыванию) после группировки и подсчета. Вы можете добиться этого, используя приведенный ниже пример.
Обратите внимание, что по умолчанию группа сортирует результаты по групповому ключу, поэтому это займет дополнительное время. Если у вас есть проблемы с производительностью и вы не хотите сортировать группу по результату, вы можете отключить эту функцию с помощью кнопки 9.0035 sort=False параметр.
# Сортировка после groupby() и count()
# Сортировка групповых ключей по убыванию
groupedDF = df.groupby('Курсы', sort=False).count()
sortedDF=groupedDF.sort_values('Курсы', по возрастанию=False)['Плата']
печать (отсортированоDF)
Выход ниже выходного.
Курсы Искра 2 Питон 2 ПиСпарк 1 Панды 1 Хадуп 2 Имя: Плата, dtype: int64
5. Использование groupby() с size()
Кроме того, вы также можете использовать size() для получения количества строк для каждой группы. Вы можете использовать df.groupby(['Courses','Duration']).size() для получения общего количества элементов для каждой группы Курсы и Продолжительность . колонны
# Использование GroupBy и size() для нескольких столбцов df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].size() печать (df2)
Выдает тот же результат, что и выше.
Используйте df.groupby(['Courses','Duration']).size().groupby(level=1).max() , чтобы указать, какой уровень вы хотите использовать в качестве вывода. Обратите внимание, что уровень начинается с нуля.
# используя DataFrame.size() и max() df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max() печать (df2)
Выход ниже выходного.
Курсы Хадуп 2 Панды 1 ПиСпарк 1 Питон 1 Искра 1 тип: int64
Затем используйте size().reset_index(name='counts') , чтобы присвоить имя столбцу счетчика.
# Использовать метод size().reset_index() df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts') печать (df2)
Выход ниже выходного.
Учитывается продолжительность курсов 0 Хадуп 35дней 2 1 Панды 60 дней 1 2 PySpark 50дней 1 3 Питон 40дней 1 4 Питон 50дней 1 5 Искра 30дней 1 6 Искра 55дней 1
6. Pandas groupby() и использование agg(‘count’)
Кроме того, вы также можете получить количество групп, используя функцию agg() илиaggregate() и передав функцию совокупного подсчета в качестве параметра. Функция reset_index() используется для установки индекса в DataFrame. Используя этот подход, вы можете вычислить несколько агрегаций.
# Использование pandas DataFrame.reset_index() df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].
 agg('count').reset_index()
печать (df2)
agg('count').reset_index()
печать (df2)
Выход ниже выходного.
Стоимость курсов 0 Хадуп 35дней 2 1 Панды 60 дней 1 2 PySpark 50дней 1 3 Питон 40дней 1 4 Питон 50дней 1 5 Искра 30дней 1 6 Искра 55дней 1
7. Использование DataFrame.transform()
Вы можете использовать df.groupby(['Courses','Fee']).Courses.transform('count') , чтобы добавить новый столбец, содержащий группы отсчетов в DataFrame.
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
печать (df2)
Выход ниже выходного.
0 1 1 1 2 2 3 1 4 1 5 2 6 1 7 1 Название: Курсы, dtype: int64
8. Другие примеры
Теперь давайте посмотрим, как отсортировать строки из результата группировки pandas и удалить повторяющиеся строки из pandas DataFrame.
# Используйте DataFrame.groupby() и Size() print(df.groupby(['Скидка','Продолжительность']).size() .
 sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
Выход ниже выходного.
Название: Курсы, dtype: int64 Счетчик продолжительности скидки 0 1000 30 дней 1 1 1000 35 дней 1 2 1200 40 дней 1 4 1400 55 дней 1 5 1600 50 дней 1 7 2500 60 дней 1
9. Полный пример groupby и count
# Создаем кадр данных pandas.
импортировать панд как pd
технологии = ({
«Курсы»: ["Spark","PySpark","Hadoop","Python","Pandas","Hadoop","Spark","Python"],
«Плата»: [22000,25000,23000,24000,26000,25000,25000,22000],
«Продолжительность»: ['30дней','50дней','35дней','40дней','60дней','35дней','55дней','50дней'],
«Скидка»: [1000,2300,1000,1200,2500,1300,1400,1600]
})
df = pd.DataFrame(технологии, столбцы=['Курсы','Плата','Продолжительность','Скидка'])
печать (дф)
# Использование groupby() и count()
df2 = df.groupby(['Курсы'])['Курсы'].count()
печать (df2)
# Использование GroupBy и count() для нескольких столбцов
df2 = df. groupby(['Курсы','Продолжительность'])['Плата'].count()
печать (df2)
# Использование GroupBy и size() для нескольких столбцов
df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].size()
печать (df2)
# используя DataFrame.size() и max()
df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max()
печать (df2)
# Использовать метод size().reset_index()
df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts')
печать (df2)
# Использование pandas DataFrame.reset_index()
df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index()
печать (df2)
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
печать (df2)
# Используйте DataFrame.groupby() и Size()
print(df.groupby(['Скидка','Продолжительность']).size()
.sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
 groupby(['Курсы','Продолжительность'])['Плата'].count()
печать (df2)
# Использование GroupBy и size() для нескольких столбцов
df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].size()
печать (df2)
# используя DataFrame.size() и max()
df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max()
печать (df2)
# Использовать метод size().reset_index()
df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts')
печать (df2)
# Использование pandas DataFrame.reset_index()
df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index()
печать (df2)
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
печать (df2)
# Используйте DataFrame.groupby() и Size()
print(df.groupby(['Скидка','Продолжительность']).size()
.sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
groupby(['Курсы','Продолжительность'])['Плата'].count()
печать (df2)
# Использование GroupBy и size() для нескольких столбцов
df2 = df.groupby(['Курсы','Продолжительность'])['Плата'].size()
печать (df2)
# используя DataFrame.size() и max()
df2 = df.groupby(['Курсы','Продолжительность']).size().groupby(уровень=0).max()
печать (df2)
# Использовать метод size().reset_index()
df2 = df.groupby(['Курсы','Продолжительность']).size().reset_index(name='counts')
печать (df2)
# Использование pandas DataFrame.reset_index()
df2 = df.groupby(['Курсы','Продолжительность'])['Стоимость'].agg('count').reset_index()
печать (df2)
# Использование DataFrame.transform()
df2 = df.groupby(['Курсы','Продолжительность']).Courses.transform('счетчик')
печать (df2)
# Используйте DataFrame.groupby() и Size()
print(df.groupby(['Скидка','Продолжительность']).size()
.sort_values (по возрастанию = ложь)
.reset_index (имя = 'количество')
.drop_duplicates (подмножество = 'Продолжительность'))
Заключение
В этой статье вы узнали, как группировать по одному и нескольким столбцам и получать количество строк из pandas DataFrame с помощью DataFrame.