Group by mssql: MS SQL Server и T-SQL
Содержание
MS SQL Server и T-SQL
Последнее обновление: 19.07.2017
Для группировки данных в T-SQL применяются операторы GROUP BY и HAVING, для использования которых применяется следующий формальный синтаксис:
SELECT столбцы FROM таблица [WHERE условие_фильтрации_строк] [GROUP BY столбцы_для_группировки] [HAVING условие_фильтрации_групп] [ORDER BY столбцы_для_сортировки]
GROUP BY
Оператор GROUP BY определяет, как строки будут группироваться.
Например, сгруппируем товары по производителю
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer
Первый столбец в выражении SELECT — Manufacturer представляет название группы, а второй столбец — ModelsCount представляет результат функции Count,
которая вычисляет количество строк в группе.
Стоит учитывать, что любой столбец, который используется в выражении SELECT (не считая столбцов, которые хранят результат агрегатных функций),
должны быть указаны после оператора GROUP BY. Так, например, в случае выше столбец Manufacturer указан и в выражении SELECT, и в выражении
Так, например, в случае выше столбец Manufacturer указан и в выражении SELECT, и в выражении
GROUP BY.
И если в выражении SELECT производится выборка по одному или нескольким столбцам и также используются агрегатные функции, то необходимо использовать
выражение GROUP BY. Так, следующий пример работать не будет, так как он не содержит выражение группировки:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products
Другой пример, добавим группировку по количеству товаров:
SELECT Manufacturer, ProductCount, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer, ProductCount
Оператор GROUP BY может выполнять группировку по множеству столбцов.
Если столбец, по которому производится группировка, содержит значение NULL, то строки со значением NULL составят
отдельную группу.
Следует учитывать, что выражение GROUP BY должно идти после выражения WHERE, но до выражения
ORDER BY:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price > 30000 GROUP BY Manufacturer ORDER BY ModelsCount DESC
Фильтрация групп.
 HAVING
HAVING
Оператор HAVING определяет, какие группы будут включены в выходной результат, то есть выполняет фильтрацию групп.
Применение HAVING во многом аналогично применению WHERE. Только есть WHERE применяется к фильтрации строк, то HAVING используется для фильтрации групп.
Например, найдем все группы товаров по производителям, для которых определено более 1 модели:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products GROUP BY Manufacturer HAVING COUNT(*) > 1
При этом в одной команде мы можем использовать выражения WHERE и HAVING:
SELECT Manufacturer, COUNT(*) AS ModelsCount FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING COUNT(*) > 1
То есть в данном случае сначала фильтруются строки: выбираются те товары, общая стоимость которых больше 80000. Затем выбранные товары
группируются по производителям. И далее фильтруются сами группы — выбираются те группы, которые содержат больше 1 модели.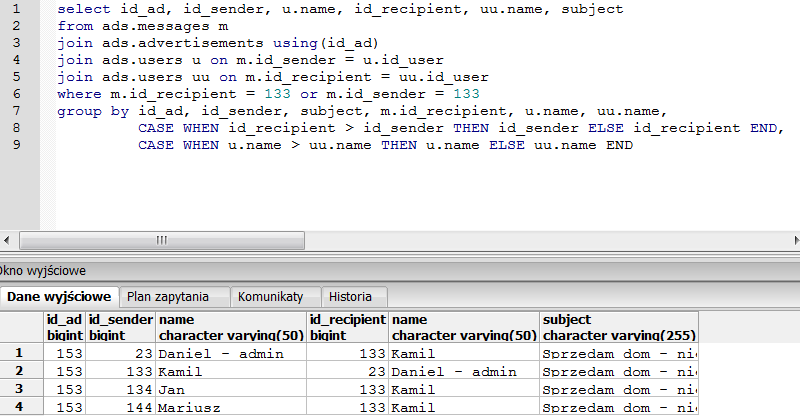
Если при этом необходимо провести сортировку, то выражение ORDER BY идет после выражения HAVING:
SELECT Manufacturer, COUNT(*) AS Models, SUM(ProductCount) AS Units FROM Products WHERE Price * ProductCount > 80000 GROUP BY Manufacturer HAVING SUM(ProductCount) > 2 ORDER BY Units DESC
В данном случае группировка идет по производителям, и также выбирается количество моделей для каждого производителя (Models)
и общее количество всех товаров по всем этим моделям (Units). В конце группы сортируются по количеству товаров по убыванию.
НазадСодержаниеВперед
Transact-SQL группировка данных GROUP BY | Info-Comp.ru
Мы с Вами рассмотрели много материала по SQL, в частности Transact-SQL, но мы не затрагивали такую, на самом деле простую тему как группировка данных GROUP BY. Поэтому сегодня мы научимся использовать оператор group by для группировки данных.
Многие начинающие программисты, когда сталкиваются с SQL, не знают о такой возможности как группировка данных с помощью оператора GROUP BY, хотя эта возможность требуется достаточно часто на практике, в связи с этим наш сегодняшний урок, как обычно с примерами, посвящен именно тому, чтобы Вам было проще и легче научиться использовать данный оператор, так как Вы с этим обязательно столкнетесь. Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
Если Вам интересна тема SQL, то мы, как я уже сказал ранее, не раз затрагивали ее, например, в статьях Язык SQL – объединение JOIN или Объединение Union и union all , поэтому можете ознакомиться и с этим материалом.
И для вступления небольшая теория.
Содержание
- Что такое оператор GROUP BY
- Примеры использования оператора GROUP BY
- Группируем данные с помощью запроса group by
Что такое оператор GROUP BY
GROUP BY – это оператор (или конструкция, кому как удобней) SQL для группировки данных по полю, при использовании в запросе агрегатных функций, таких как sum, max, min, count и других.
Как Вы знаете, агрегатные функции работают с набором значений, например sum суммирует все значения. А вот допустим, Вам необходимо просуммировать по какому-то условию или сразу по нескольким условиям, именно для этого нам нужен оператор group by, чтобы сгруппировать все данные по полям с выводом результатов агрегатных функций.
Как мне кажется, наглядней будет это все разобрать на примерах, поэтому давайте перейдем к примерам.
Примечание! Все примеры будем писать в Management Studio SQL сервера 2008.
Примеры использования оператора GROUP BY
И для начала давайте создадим и заполним тестовую таблицу с данными, которой мы будет посылать наши запросы select с использованием группировки group by. Таблица и данные конечно выдуманные, чисто для примера.
Создаем таблицу
CREATE TABLE [dbo].[test_table](
[id] [int] NULL,
[name] [varchar](50) NULL,
[summa] [money] NULL,
[priz] [int] NULL
) ON [PRIMARY]
GO
Я ее заполнил следующими данными:
Где,
- Id –идентификатор записи;
- Name – фамилия сотрудника;
- Summa- денежные средства;
- Priz – признак денежных средств (допустим 1- Оклад; 2-Премия).


Группируем данные с помощью запроса group by
И в самом начале давайте разберем синтаксис group by, т.е. где писать данную конструкцию:
Синтаксис:
Select агрегатные функции
From источник
Where Условия отбора
Group by поля группировки
Having Условия по агрегатным функциям
Order by поля сортировки
Теперь если нам необходимо просуммировать все денежные средства того или иного сотрудника без использования группировки мы пошлем вот такой запрос:
SELECT SUM(summa)as summa FROM test_table WHERE name='Иванов'
А если нужно просуммировать другого сотрудника, то мы просто меняем условие. Согласитесь, если таких сотрудников много, зачем суммировать каждого, да и это как-то не наглядно, поэтому нам на помощь приходит оператор group by. Пишем запрос:
SELECT SUM(summa)as summa, name FROM test_table GROUP BY name
Как Вы заметили, мы не пишем никаких условий, и у нас отображаются сразу все сотрудники с просуммированным количеством денежных средств, что более наглядно.
Примечание! Сразу отмечу то, что, сколько полей мы пишем в запросе (т.е. поля группировки), помимо агрегатных функций, столько же полей мы пишем в конструкции group by. В нашем примере мы выводим одно поле, поэтому в group by мы указали только одно поле (name), если бы мы выводили несколько полей, то их все пришлось бы указывать в конструкции group by (в последующих примерах Вы это увидите).
Также можно использовать и другие функции, например, подсчитать сколько раз поступали денежные средства тому или иному сотруднику с общей суммой поступивших средств. Для этого мы кроме функции sum будем еще использовать функцию count.
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник]
FROM test_table
GROUP BY name
Но допустим для начальства этого недостаточно, они еще просят, просуммировать также, но еще с группировкой по признаку, т. е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
е. что это за денежные средства (оклад или премия), для этого мы просто добавляем в группировку еще одно поле, и для лучшего восприятия добавим сортировку по сотруднику, и получится следующее:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник] ,
Priz [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Теперь у нас все отображается, т.е. сколько денег поступило сотруднику, сколько раз, а также из какого источника.
А сейчас для закрепления давайте напишем еще более сложный запрос с группировкой, но еще добавим названия этого источника, так как согласитесь по идентификаторам признака не понятно из какого источника поступили средства. Для этого мы используем конструкцию case.
SELECT SUM(summa) AS [Всего денежных средств],
COUNT(*) AS [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz
ORDER BY name
Вот теперь все достаточно наглядно и не так уж сложно, даже для начинающих.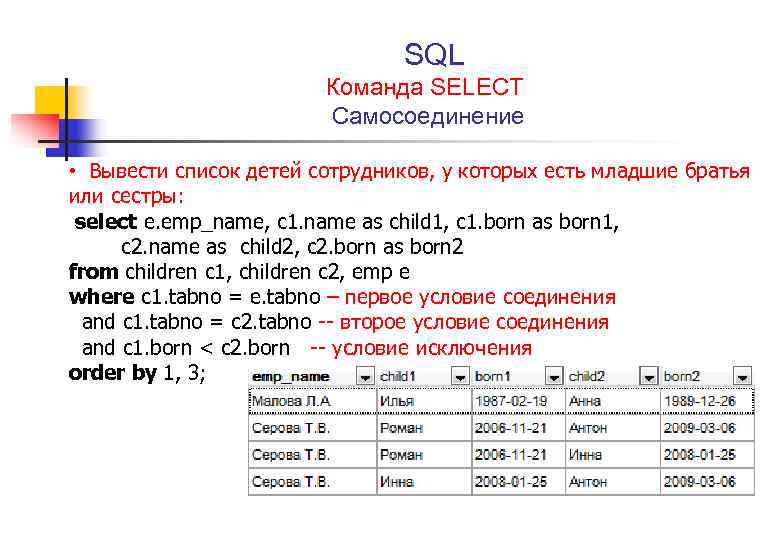
Также давайте затронем условия по итоговым результатам агрегатных функций (having). Другими словами, мы добавляем условие не по отбору самих строк, а уже на итоговое значение функций, в нашем случае это sum или count. Например, нам нужно вывести все то же самое, но только тех, у которых «всего денежных средств» больше 200. Для этого добавим условие having:
SELECT SUM(summa)as [Всего денежных средств],
COUNT(*) as [Количество поступлений],
Name [Сотрудник],
CASE WHEN priz = 1 then 'Оклад'
WHEN priz = 2 then 'Премия'
ELSE 'Без источника'
END AS [Источник]
FROM test_table
GROUP BY name, priz --группируем
HAVING SUM(summa) > 200 --отбираем
ORDER BY name -- сортируем
Теперь у нас вывелись все значения sum(summa), которые больше 200, все просто.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Надеюсь, после сегодняшнего урока Вам стало понятно, как и зачем использовать конструкцию group by. Удачи! А SQL мы продолжим изучать в следующих статьях.
SQL Server GROUP BY
Резюме : в этом руководстве вы узнаете, как использовать предложение SQL Server GROUP BY для упорядочения строк в группах по одному или нескольким столбцам.
Введение в SQL Server
Предложение GROUP BY
Предложение GROUP BY позволяет группировать строки запроса. Группы определяются столбцами, указанными в предложении GROUP BY .
Ниже показано GROUP BY синтаксис предложения:
SELECT
select_list
ОТ
имя_таблицы
ГРУППА ПО
имя_столбца1,
имя_столбца2,...;
Язык кода: SQL (язык структурированных запросов) (sql) В этом запросе предложение GROUP BY создало группу для каждой комбинации значений в столбцах, перечисленных в предложении GROUP BY .
Рассмотрим следующий пример:
ВЫБОР
Пользовательский ИД,
ГОД (дата_заказа) год_заказа
ОТ
заказы на продажу
ГДЕ
customer_id IN (1, 2)
СОРТИРОВАТЬ ПО
Пользовательский ИД;
Язык кода: SQL (язык структурированных запросов) (sql) В этом примере мы получили идентификатор клиента и год заказа клиентов с идентификаторами клиента один и два.
Как видно из вывода, клиент с идентификатором one разместил один заказ в 2016 году и два заказа в 2018 году. Клиент с идентификатором two разместил два заказа в 2017 году и один заказ в 2018 году.
Давайте добавим Предложение GROUP BY к запросу, чтобы увидеть эффект:
SELECT
Пользовательский ИД,
ГОД (дата_заказа) год_заказа
ОТ
заказы на продажу
ГДЕ
customer_id IN (1, 2)
ГРУППА ПО
Пользовательский ИД,
ГОД (дата_заказа)
СОРТИРОВАТЬ ПО
Пользовательский ИД;
Язык кода: SQL (язык структурированных запросов) (sql) Предложение GROUP BY упорядочивает первые три строки в две группы, а следующие три строки в две другие группы с уникальными комбинациями идентификатора клиента и заказа. год.
год.
С функциональной точки зрения предложение GROUP BY в приведенном выше запросе дало тот же результат, что и следующий запрос, использующий предложение DISTINCT :
SELECT DISTINCT
Пользовательский ИД,
ГОД (дата_заказа) год_заказа
ОТ
заказы на продажу
ГДЕ
customer_id IN (1, 2)
СОРТИРОВАТЬ ПО
Пользовательский ИД;
Язык кода: SQL (язык структурированных запросов) (sql) SQL Server
Предложение GROUP BY и агрегатные функции
На практике предложение GROUP BY часто используется с агрегатными функциями для создания сводных отчетов.
Агрегатная функция выполняет вычисление для группы и возвращает уникальное значение для каждой группы. Например, COUNT() возвращает количество строк в каждой группе. Другими часто используемыми агрегатными функциями являются SUM() , AVG() (среднее), MIN() (минимум), MAX() (максимум).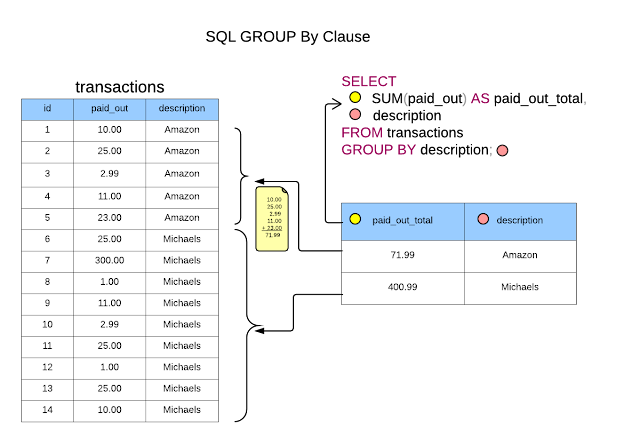
Предложение GROUP BY упорядочивает строки в группы, и агрегатная функция возвращает сводку (количество, минимум, максимум, среднее, сумма и т. д.) для каждой группы.
Например, следующий запрос возвращает количество заказов, размещенных клиентом по годам:
ВЫБЕРИТЕ
Пользовательский ИД,
ГОД (дата_заказа) год_заказа,
COUNT (идентификатор_заказа) order_placed
ОТ
заказы на продажу
ГДЕ
customer_id IN (1, 2)
ГРУППА ПО
Пользовательский ИД,
ГОД (дата_заказа)
СОРТИРОВАТЬ ПО
Пользовательский ИД;
Язык кода: SQL (язык структурированных запросов) (sql) Если вы хотите сослаться на столбец или выражение, не указанное в предложении GROUP BY , вы должны использовать этот столбец в качестве входных данных агрегатной функции. В противном случае вы получите сообщение об ошибке, поскольку нет гарантии, что столбец или выражение вернет одно значение для каждой группы. Например, следующий запрос завершится ошибкой:
SELECT
Пользовательский ИД,
ГОД (дата_заказа) год_заказа,
статус заказа
ОТ
заказы на продажу
ГДЕ
customer_id IN (1, 2)
ГРУППА ПО
Пользовательский ИД,
ГОД (дата_заказа)
СОРТИРОВАТЬ ПО
Пользовательский ИД;
Язык кода: SQL (язык структурированных запросов) (sql) Дополнительные примеры
GROUP BY
Давайте рассмотрим еще несколько примеров, чтобы понять, как работает предложение GROUP BY .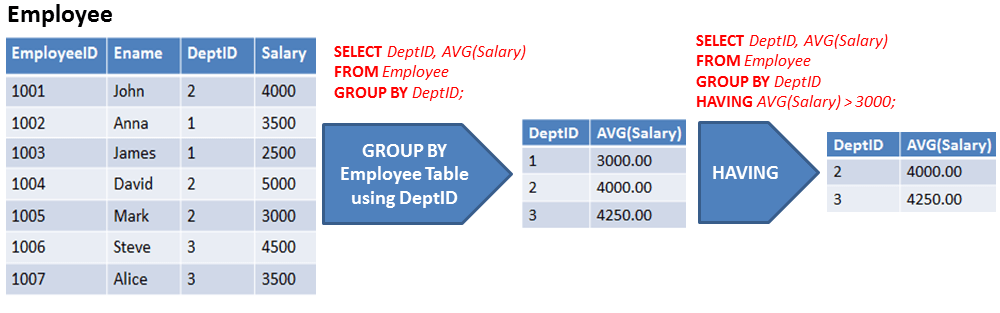
Использование предложения
GROUP BY с примером функции COUNT()
Следующий запрос возвращает количество клиентов в каждом городе:
SELECT
город,
COUNT (идентификатор_клиента) количество_клиентов
ОТ
продажи.клиенты
ГРУППА ПО
город
СОРТИРОВАТЬ ПО
город;
Язык кода: SQL (язык структурированных запросов) (sql) В этом примере предложение GROUP BY группирует клиентов по городам, а функция COUNT() возвращает количество клиентов в каждом городе.
Аналогично, следующий запрос возвращает количество клиентов по штатам и городам.
ВЫБОР
город,
состояние,
COUNT (идентификатор_клиента) количество_клиентов
ОТ
продажи.клиенты
ГРУППА ПО
состояние,
город
СОРТИРОВАТЬ ПО
город,
состояние; Язык кода: SQL (язык структурированных запросов) (sql) Использование предложения
GROUP BY с функциями MIN и MAX Пример
Следующая инструкция возвращает минимальную и максимальную прейскурантные цены всех продуктов с модель 2018 г.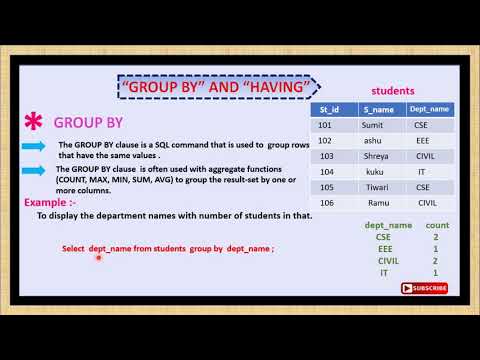 по марке:
по марке:
ВЫБЕРИТЕ
имя бренда,
МИН (списочная_цена) минимальная_цена,
МАКС. (списочная_цена) макс._цена
ОТ
производство.продукция р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ production.brands b ON b.brand_id = p.brand_id
ГДЕ
модель_год = 2018
ГРУППА ПО
имя бренда
СОРТИРОВАТЬ ПО
имя бренда;
Язык кода: SQL (язык структурированных запросов) (sql) В этом примере предложение WHERE обрабатывается перед предложением GROUP BY , как всегда.
Использование предложения
GROUP BY с примером функции AVG()
имя бренда,
СРЕДНЯЯ (списочная_цена) средняя_цена
ОТ
производство.продукция р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ production.brands b ON b.brand_id = p.brand_id
ГДЕ
модель_год = 2018
ГРУППА ПО
имя бренда
СОРТИРОВАТЬ ПО
имя бренда;
Язык кода: SQL (язык структурированных запросов) (sql)
Использование предложения
GROUP BY с примером функции SUM
См.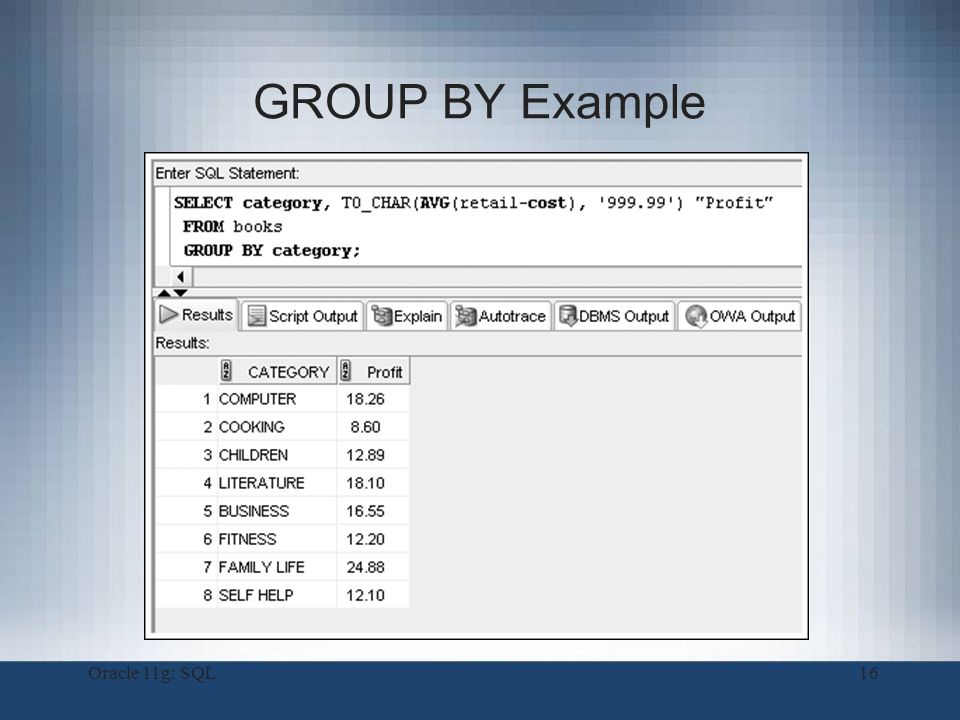 следующую таблицу
следующую таблицу order_items :
функция для получения чистой стоимости каждого заказа:
SELECT
номер заказа,
СУММА (
количество * list_price * (1 - скидка)
) чистая стоимость
ОТ
продажи.order_items
ГРУППА ПО
номер заказа;
Язык кода: SQL (язык структурированных запросов) (sql) Из этого руководства вы узнали, как использовать предложение SQL Server GROUP BY для группировки строк по указанному списку столбцов.
ГРУППА ПО в SQL Server
В SQL Server предложение GROUP BY используется для получения сводных данных на основе одной или нескольких групп.
Группы могут быть сформированы на одной или нескольких колонках.
Например, запрос GROUP BY будет использоваться для подсчета количества сотрудников в каждом отделе или для получения общей заработной платы по отделам.
Вы должны использовать агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() и т.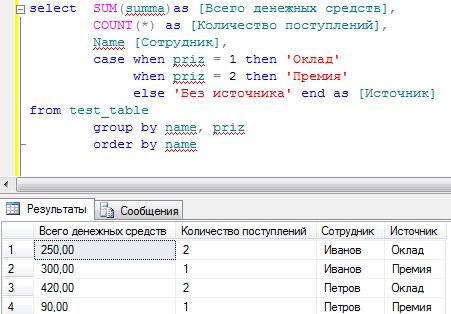 д., в запросе SELECT.
д., в запросе SELECT.
Результат предложения GROUP BY возвращает одну строку для каждого значения столбца GROUP BY.
Синтаксис:
ВЫБЕРИТЕ столбец1, столбец2,... столбецN ИЗ имя_таблицы [ГДЕ] [ГРУППИРОВАТЬ ПО столбцу1, столбцу2...столбцуN] [ИМЕЮЩИЙ] [СОРТИРОВАТЬ ПО]
Предложение SELECT может включать столбцы, которые используются с предложением GROUP BY. Таким образом, чтобы включить другие столбцы в предложение SELECT, используйте агрегатные функции, такие как COUNT() , MAX() , MIN() , SUM() , AVG() с этими столбцами.
- Предложение GROUP BY используется для формирования групп записей.
- Предложение GROUP BY должно стоять после предложения WHERE, если оно присутствует, и перед предложением HAVING.
- Предложение GROUP BY может включать один или несколько столбцов для формирования одной или нескольких групп на основе этих столбцов.
- В предложение SELECT можно включать только столбцы GROUP BY. Чтобы использовать другие столбцы в предложении SELECT, используйте с ними агрегатные функции.

Для демонстрационных целей мы будем использовать следующие таблицы Employee и Department во всех примерах.
Рассмотрим следующий запрос GROUP BY.
ВЫБРАТЬ DeptId, COUNT(EmpId) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId; --следующий запрос вернет те же данные, что и выше ВЫБЕРИТЕ DeptId, COUNT (*) как «Количество сотрудников» ОТ Сотрудника СГРУППИРОВАТЬ ПО DeptId;
Приведенный выше запрос включает предложение GROUP BY DeptId , поэтому в предложение SELECT можно включить только DeptId . Вам нужно использовать агрегатные функции для включения других столбцов в предложение SELECT, поэтому COUNT(EmpId) включен, потому что мы хотим подсчитать количество сотрудников в одном и том же DeptId .