Group by select: GROUP BY | SQL | SQL-tutorial.ru
Содержание
Select Group хороший застройщик в Дубае
Один из крупнейших застройщиков в Дубае, который за время своей деятельности зарекомендовал себя в качестве надежного и проверенного девелопера с безупречной репутацией.
Высокий уровень рентабельности
Надежные застройщики
Развитая инфраструктура
Сделки контролируются правительством
Отсутствие необходимости оплаты налогов.
Информация о застройщике Select Group
Начало деятельности компании датируется 2002 годом – именно тогда застройщик представил ряд перспективных разработок в сфере недвижимости и успешно реализовал их. Достойное качество проектов и применение высочайших стандартов во время строительства позволили компании войти в список лидеров среди застройщиков и масштабировать свою деятельность. Сегодня Select Group Dubai возводит и сдает в эксплуатацию объекты жилого, гостиничного, коммерческого типа.
Достойное качество проектов и применение высочайших стандартов во время строительства позволили компании войти в список лидеров среди застройщиков и масштабировать свою деятельность. Сегодня Select Group Dubai возводит и сдает в эксплуатацию объекты жилого, гостиничного, коммерческого типа.
В 2017 году девелопер получил ряд наград и окончательно зарекомендовал себя в качестве одного из лучших застройщиков в Дубае.
2002
Год основания компании
550+
Штат сотрудников
1,8млн. м²
Площадь застройки
Недвижимость от компании
Select Group
Многолетний опыт работы, использование новейших технологий, обеспечение высокого уровня качества в каждом объекте позволяет Select Group привлекать к своим проектам все больше инвесторов.
Six Senses The Palm от Select Group
Six Senses The Palm от Select Group
Six Senses The Palm – прибрежный жилой комплекс с новыми апартаментами премиального уровня и шикарным отельным комплексом, с которого открывается прекрасный панорамный вид на островную и главную часть города.
ПодробнееБрошюра
Peninsula III от Select Group
Peninsula III от Select Group
Peninsula Three – новый этап застройки от девелопера Select Group в виде многоэтажной башни, с которой открывается вид на красоты города и воды Персидского залива.
ПодробнееБрошюра
Jumeirah Living Business Bay
Jumeirah Living Business Bay
Жители комплекса смогут наслаждаться захватывающими видами на Dubai Canal, Burj Khalifa и панораму Дубая.
ПодробнееБрошюра
Расширения GROUP BY
Время прочтения: 3 мин.
Для начала вспомним что такое GROUP BY. Итак, GROUP BY – конструкция, которая используется в SQL для группировки данных по полю при использовании в запросе функций агрегации (например, SUM, MAX, MIN и д.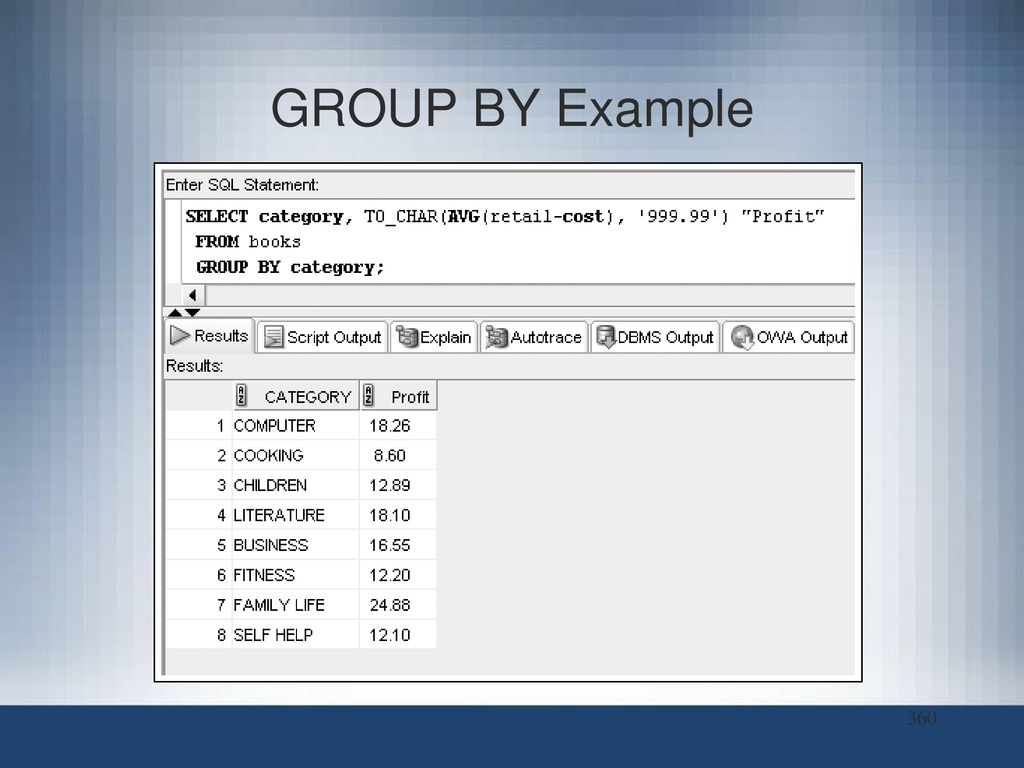 р.) либо для исключения дублирования строк (как эквивалент ключевого слова
р.) либо для исключения дублирования строк (как эквивалент ключевого слова DISTINCT).
Теперь же рассмотрим расширения GROUP BY, которые позволяют получать промежуточные итоги и итоги в целом — ROLLUP, CUBE и GROUPING SETS. Создадим тестовую таблицу и заполним ее данными.
CREATE TABLE #tmp ( [eployee] nvarchar(10), --сотрудник [department] nvarchar(10), --подразделение [work_year] int, --год [annual_income] money –доход )
Начнем с ROLLUP, который вернет нам общую суммирующую строку. Например, мы хотим посмотреть сколько сотрудников в каждом подразделении и их доход за все время работы. Для этого напишем простой запрос:
SELECT [department] ,COUNT(DISTINCT [eployee]) as employess_count ,SUM([annual_income]) as common_income FROM #tmp GROUP BY [department]
А если нам необходимы общее количество сотрудников и их совокупный доход? Тут на помощь и придет ROLLUP.
SELECT [department] ,COUNT(DISTINCT [eployee]) as employess_count ,SUM([annual_income]) as common_income FROM #tmp GROUP BY ROLLUP([department])
Также ROLLUP нам пригодится, если мы хотим увидеть промежуточный итог с доходом каждого сотрудника за все время работы.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY ROLLUP([eployee],[work_year])
Строки, отмеченные красными стрелками, будут промежуточным итогом по сотруднику за все его время работы, а фиолетовыми – общая суммирующая строка.
Следующий на очереди — CUBE. Он похож на ROLLUP по двум столбцам из предыдущего примера за тем исключением, что CUBE добавляет суммирующие строки для каждой комбинации групп.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY CUBE([eployee],[work_year])
В нашем случае красными стрелками показаны итоги по каждому году для всех сотрудников, которые работали в этом году, синими – общие итоги по каждому сотруднику за все время работы, а фиолетовыми – общая суммирующая строка, как при использовании ROLLUP.
Но что делать, если мы хотим видеть только суммирующие строки для групп? Ответ на этот вопрос – использовать GROUPING SETS. Он, как и
Он, как и ROLLUP и CUBE, добавляет суммирующую строку для групп, но при этом не включает сами группы.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY GROUPING SETS([eployee],[work_year])
То есть на примере видим результат выполнения CUBE, из которого исключены промежуточные итоги и общий суммирующий итог.
Описанные расширения конструкции GROUP BY позволяют легко сформировать необходимые итоги, не прибегая к использованию подзапросов и облегчая код.
sql server — группа SQL по выбору
спросил
Изменено
10 лет назад
Просмотрено
11 тысяч раз
Я использую SQL Server и имею таблицу со следующими столбцами:
SessionId | Дата | имя | фамилия
Я хотел бы сделать сгруппируйте по sessionId , а затем получите строку с максимальной датой.
Например:
ххх | 21.12.2012 | f1 | л1 ХХХ | 20.12.2012 | f2 | л2 ггг | 21.12.2012 | f3 | л3 ггг | 20.12.2012 | f4 | л4
Я хочу получить следующие строки:
xxx | 21.12.2012 | f1 | л1 ггг | 21.12.2012 | f3 | л3
Спасибо
- sql
- sql-сервер
- tsql
3
Попробуйте это:
С MAXSessions
КАК
(
ВЫБИРАТЬ
*,
ROW_NUMBER() OVER(PARTITION BY SessionID ORDER BY Date DESC) rownum
ОТ Сессии
)
ВЫБИРАТЬ
Идентификатор сессии,
Дата,
имя,
фамилия
ОТ MAXSessions
ГДЕ ряд = 1;
Или:
ВЫБЕРИТЕ
s.SessionId,
с.Дата,
с.имя,
с.фамилия
ОТ Сессии с
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(
ВЫБЕРИТЕ SessionID, MAX(Date) LatestDate
ОТ сессий
СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса
) MAXs ON maxs.SessionID = s.SessionID
И maxs.LatestDate = s.Date;
Обновление: Чтобы получить количество сеансов, вы можете сделать это:
ВЫБРАТЬ s.SessionId, с.Дата, с.имя, с.фамилия, maxs.SessionsCount ОТ Сессии с ВНУТРЕННЕЕ СОЕДИНЕНИЕ ( SELECT SessionID, COUNT(SessionID), SessionsCount, MAX(Date) LatestDate ОТ сессий СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса ) MAXs ON maxs.SessionID = s.SessionID И maxs.LatestDate = s.Date;
 SessionId,
с.Дата,
с.имя,
с.фамилия,
maxs.SessionsCount
ОТ Сессии с
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(
SELECT SessionID, COUNT(SessionID), SessionsCount, MAX(Date) LatestDate
ОТ сессий
СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса
) MAXs ON maxs.SessionID = s.SessionID
И maxs.LatestDate = s.Date;
SessionId,
с.Дата,
с.имя,
с.фамилия,
maxs.SessionsCount
ОТ Сессии с
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(
SELECT SessionID, COUNT(SessionID), SessionsCount, MAX(Date) LatestDate
ОТ сессий
СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса
) MAXs ON maxs.SessionID = s.SessionID
И maxs.LatestDate = s.Date;
7
Вот живой пример ответа Махмуда — SQL Fiddle
Вот то же самое, только с использованием подзапроса:
SELECT a.*
ОТ
#Таблица а
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
(
ВЫБИРАТЬ
Идентификатор сессии,
[mx] = МАКС([Дата])
ИЗ #Таблица
СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса
) б
НА
a.[SessionId] = b.SessionID И
а.[Дата] = b.mx;
ЗДЕСЬ SQL FIDDLE ДЛЯ ВЫШЕУКАЗАННОЙ ВЕРСИИ ПОДЗАПРОСА
Вы также можете использовать EXISTS — это мой любимый:
ВЫБЕРИТЕ
а.*,
с.CNT
ОТ
#Таблица а
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
( --чтобы вернуть количество идентификаторов сеансов
ВЫБИРАТЬ
Идентификатор сессии,
[CNT] = СЧЁТ(*)
ИЗ #Таблица
СГРУППИРОВАТЬ ПО ИДЕНТИФИКАТОРу сеанса
) в
ON a. SessionID = c.SessionID
ГДЕ
СУЩЕСТВУЕТ
(
ВЫБЕРИТЕ 1
ИЗ #Таблица б
ГДЕ
a.[SessionId] = b.SessionID И
а.[Дата] > б.[Дата]
)
 SessionID = c.SessionID
ГДЕ
СУЩЕСТВУЕТ
(
ВЫБЕРИТЕ 1
ИЗ #Таблица б
ГДЕ
a.[SessionId] = b.SessionID И
а.[Дата] > б.[Дата]
)
SessionID = c.SessionID
ГДЕ
СУЩЕСТВУЕТ
(
ВЫБЕРИТЕ 1
ИЗ #Таблица б
ГДЕ
a.[SessionId] = b.SessionID И
а.[Дата] > б.[Дата]
)
ЗДЕСЬ SQL FIDDLE С ДОПОЛНИТЕЛЬНЫМ СЧЕТЧИКОМ
1
Вот так, просто это будет делать
выберите a.date1,a.first_name,a.last_name из (выберите row_number () over(раздел по SessionId порядок по SessionId) rnk,date1,first_name,last_name из таблицы1) a где a.rnk=1
SQL_FIDDLE_DEMO
Несколько вариантов, один из них — использовать CTE, ранжирующий строки по дате:
Отредактировано для включения счетчика сеансов
WITH Sessions AS (
ВЫБЕРИТЕ SessionId, [Дата], Имя, Фамилия,
ROW_NUMBER() OVER (PARTITION BY SessionId ORDER BY [Date] DESC) AS Ord
ИЗ вашего стола
)
ВЫБЕРИТЕ S.SessionId, S.Date, S.FirstName, S.LastName, X.SessionCount
ОТ Сессии S
ВНУТРЕННЕЕ СОЕДИНЕНИЕ (
ВЫБЕРИТЕ SessionId, COUNT (*) AS SessionCount
ОТ Сессии
СГРУППИРОВАТЬ ПО SessionId
) X ON X. SessionId = S.SessionId
ГДЕ S.Ord = 1
 SessionId = S.SessionId
ГДЕ S.Ord = 1
SessionId = S.SessionId
ГДЕ S.Ord = 1
Функции ранжирования — ваш друг в подобных ситуациях, когда вы хотите получить целые строки, которые соответствуют определенным критериям «упорядочения», например максимальной дате.
2
ВЫБЕРИТЕ b.sessionid,
дата рождения,
б.фамилия, б.фамилия
ОТ (ВЫБЕРИТЕ t2.sessionid,
Макс(t2.date) AS Дата
ОТ темп1 t2
СГРУППИРОВАТЬ ПО t2.sessionid) а,
темп1 б
ГДЕ a.sessionid = b.sessionid
И а.дата = б.дата
Лучший способ найти результат
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
База данных
— GROUP BY работает со столбцами Select, не входящими в GROUP BY
спросил
Изменено
1 год, 5 месяцев назад
Просмотрено
795 раз
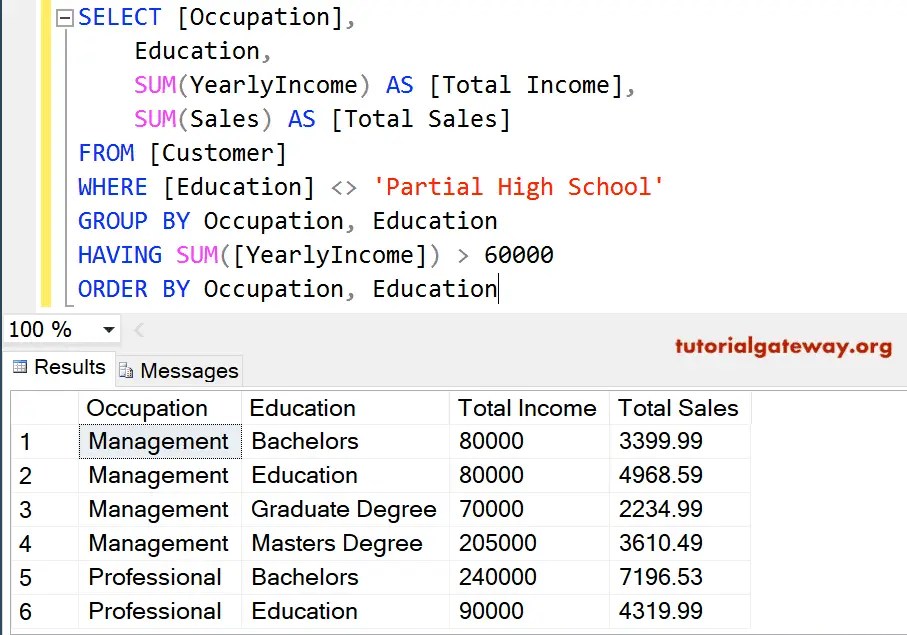
почему этот GROUP BY все еще работает, когда столбцы SELECTed не находятся ни в предложении GROUP BY, ни в агрегатной функции.
СХЕМА БАЗЫ ДАННЫХ ЗДЕСЬ
ВЫБЕРИТЕ Имя, Фамилия, Город, Электронная почта, COUNT(I.CustomerId) КАК СЧЕТА ОТ клиентов C INNER JOIN Invoices I ON C.CustomerId = I.CustomerId ГРУППА ПО C.CustomerId
- база данных
- sqlite
- выбрать
- группировать по
- агрегаты
5
Этот синтаксис разрешен и задокументирован в SQLite: пустые столбцы в агрегированном запросе.
Столбцы Имя , Фамилия , Город , Электронная почта называются голыми столбцами.
Такие столбцы получают произвольное , за исключением случая, когда используется одно (и только это) из MIN() или MAX() . В этом случае значения пустых столбцов берутся из строки, содержащей минимальное или максимальное агрегированное значение.
В любом случае будьте осторожны при использовании этого синтаксиса, потому что вы можете получить неожиданные результаты.
1
Я хочу поговорить о двух вещах:
Группировать по будет работать, если имя столбца существует в таблице, над которой вы работаете. В вашем запросе у вас есть внутренняя таблица Customer соединения с таблицей Invoice. По вашей схеме я вижу в Таблица счетов-фактур Столбец CustomerId существует.

В SQL serve необходимо указать все имена столбцов, которые вы выбрали, плюс желаемое имя столбца. Я имею в виду, что ваш запрос должен быть таким.
ВЫБЕРИТЕ Имя,
Фамилия,
Город,
Электронная почта,
COUNT(I.CustomerId) КАК СЧЕТА
ОТ клиентов C INNER JOIN Invoices I
ON C.CustomerId = I.CustomerId
ГРУППА ПО C.CustomerId,
Фамилия,
Город,
Электронная почта
Итак, я думаю, вы используете MySQL, поэтому он работает.
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.