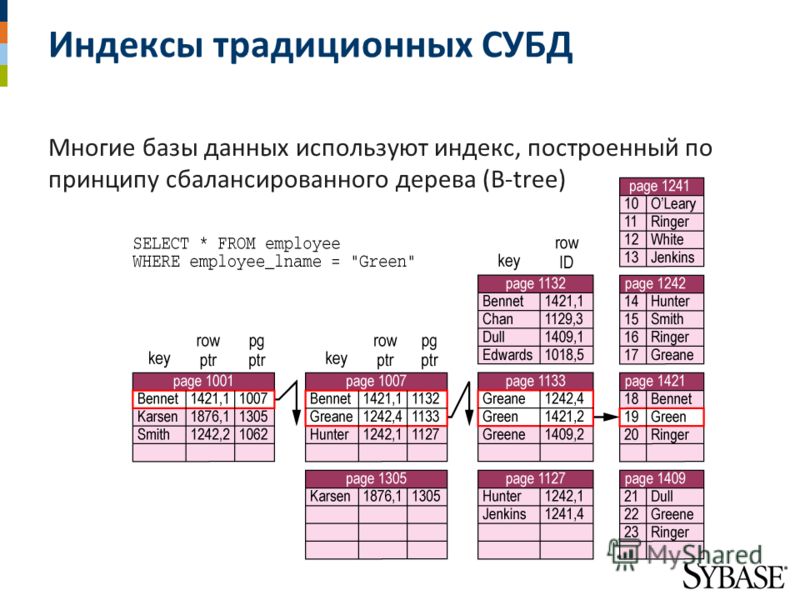
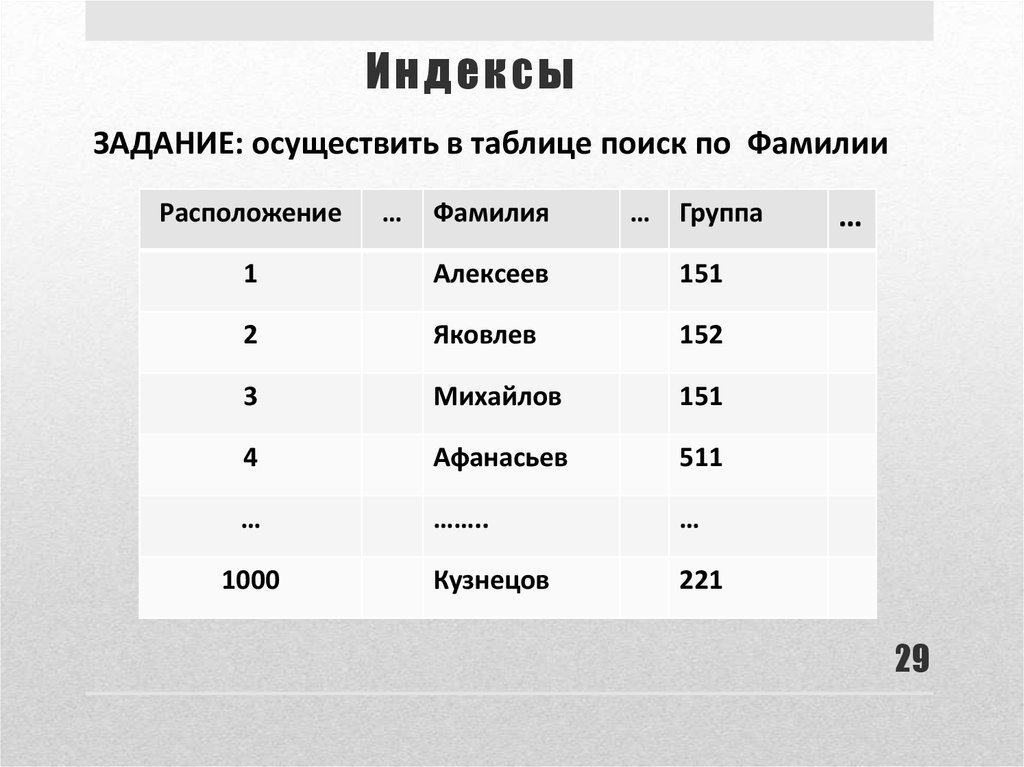
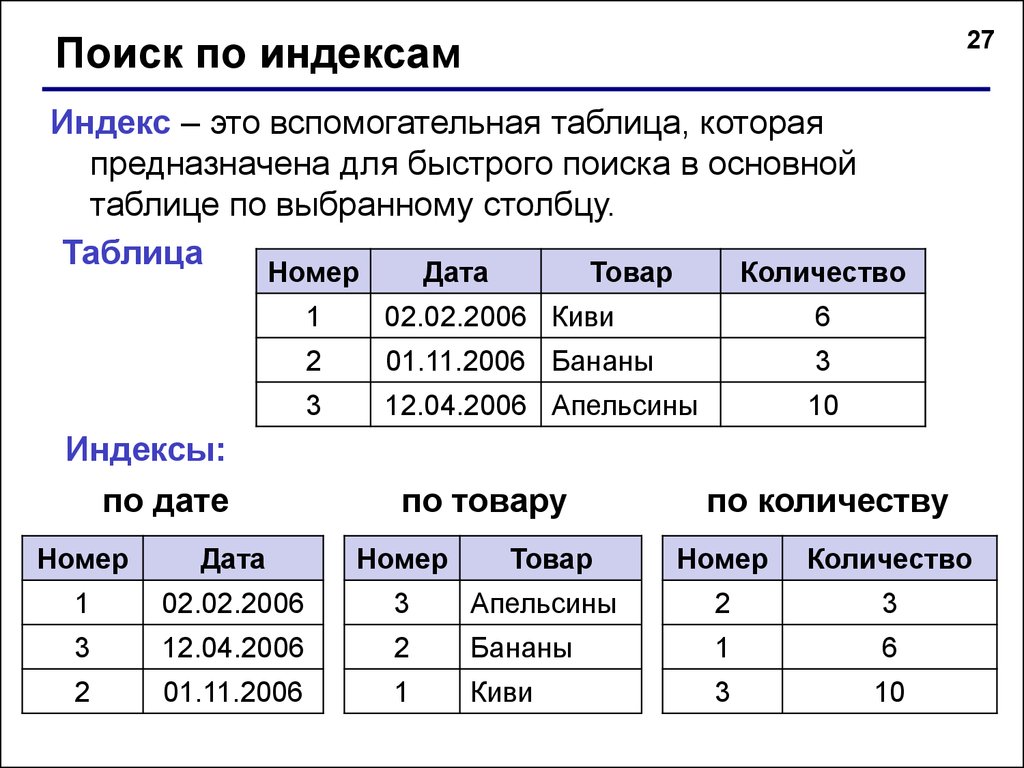
Индексы базы данных: 14 вопросов об индексах в SQL Server, которые вы стеснялись задать / Хабр
Содержание
Что такое индексы в 1С 8.3 и MS SQL
Что такое индексы в 1С?
ПОЛЕЗНЫЕ ССЫЛКИ:
Выгрузка базы данных 1С
Восстановление базы 1С
Выбор сервера для 1С 8.3
Выбор СУБД для 1С
Как избежать ошибок при обновлении 1С?
Что это — индексы «1С»?
Так называют ссылки, которые служат для роста производительности СУБД MS SQL. Обычно их распределяют в разные столбцы. Индексы позволяют быстро обнаруживать необходимые сведения в таблице. Плюс к этому, они помогают более оперативно выполнять запросы и уменьшают количество проблем от блокировок (в основном это относится к многопользовательскому режиму).
Алгоритмы создания индексов в «1С»
Способ №1
Не выраженный. В этом варианте платформа сама формирует индексы, но лишь тогда, когда для каждого объекта метаданных существуют ключи (к примеру, код или ссылка).
Способ №2
Выраженный. Он дает возможность использовать три варианта создания индексов:
1. Установить флажок «Индексировать» около значка «реквизиты»/«измерения». Используя функцию «Индексировать с дополнительным упорядочиванием» добавить индекс в строку «Код»/«Наименование» (это необходимо в начале проделать с динамичными списками).
2. В раздел «Критерии отбора» вставить дополнительное поле.
3. Использовать функцию «Индексировать по» для обозначения поля для индексации.
Виды индексов
Эти значения выглядят как страница с данными. «Вес» каждой – 8 Кбайт.
Итак, индексы бывают:
1. Некластерные. Подобные виды создают ссылки, а таблицы остаются в прежнем формате без изменений.
2. Кластерные. Их применяют для формирования таблицы согласно индексу. К примеру, если необходимо расположить сведения по алфавиту. Этот вид не предназначен для столбцов, в которые регулярно вносят изменения. Т.к. система управления информационной базой переформатирует таблицу по этому индексу.
Т.к. система управления информационной базой переформатирует таблицу по этому индексу.
3. Уникальные. Этот индекс единственный в своем роде из-за ключевых полей, он является «надстройкой» для первых двух видов.
Как мы уже писали, индексы могут поднять эффективность работы СУБД, но вполне вероятно возникновение минусов. Они достаточно много «весят» и поэтому на компьютере займут много места, это заметно затормозит функционирование системы управления при записи строк.
Виды ключей индексов
Первичный – ряд столбцов, характеризующих строки.
Внешний – поле таблицы (в «1С» он не применяется). Во внешнем ключе есть значение первичного, благодаря чему образуется взаимодействие таблиц.
Ключевые сведения об индексах
1. Длина ключа не может быть более 900 байт и 16 разных полей (это относится ко всем СУБД, исключение составляет только «файловый» вариант).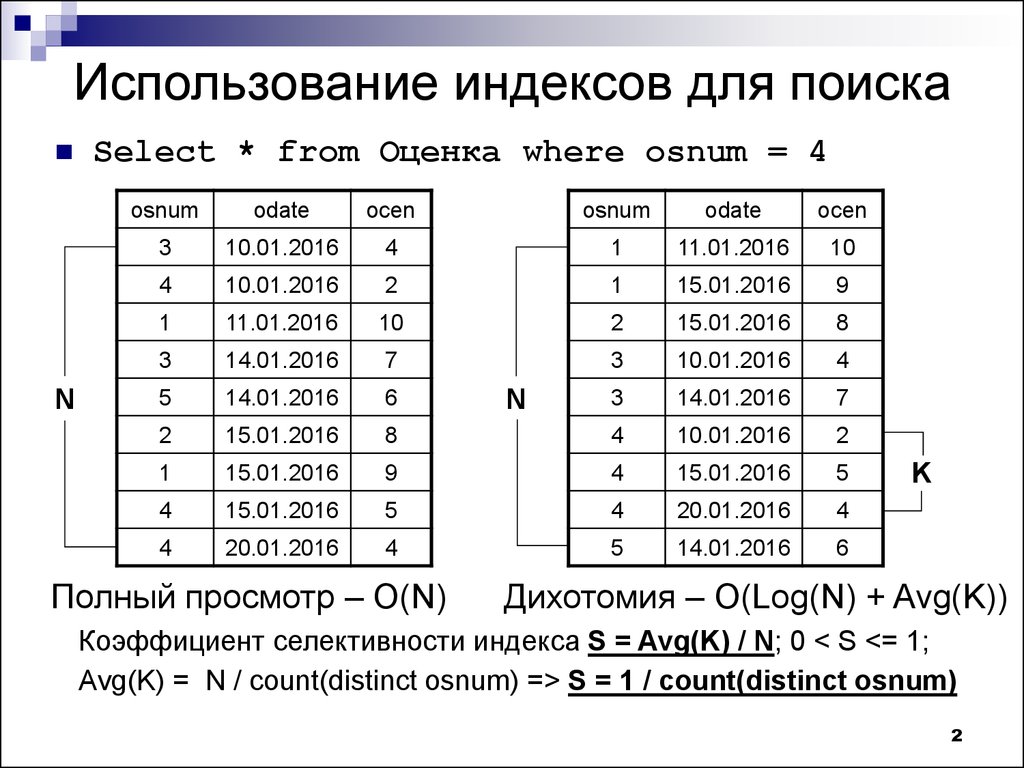
2. Уровень фрагментации не более 25%. Если индексы используются на регулярной основе, то есть вероятность возникновения эффекта фрагментации. Чтобы избежать этого необходимо периодически делать дефрагментацию индексов.
3. Отсутствие индексов. По этой причине возможно стартует сканирование всей таблицы, из-за чего возникнут лишние блокировки. Мы бы не рекомендовали использовать индексацию по мелким (не значительным) наборам данных (к примеру, «справочник»). Вполне возможно, что в таком случае произойдет обратный эффект – снизится производительность.
Безусловно, создание индексов – отличный способ оптимизировать вашу информационную базу. Но перед тем, как начать оптимизацию «1С», следует привлечь к анализу системы опытного профессионала. А уже потом решить (лучше тоже со специалистом) какой способ «работы над ошибками» выбрать и как организовать процесс повышения производительности.
При возникновении потребности в ускорении работы «1С» на своем рабочем месте – обратитесь в МастерСофт. Наши специалисты проведут аудит базы данных вашей организации и предложат наиболее оптимальный метод оптимизации.
Наши специалисты проведут аудит базы данных вашей организации и предложат наиболее оптимальный метод оптимизации.
Вернуться в блог
НОВОСТИ
Перейти в Блог
17.04
Интервью со студенткой Оренбургского филиала РЭУ им. Г.В. Плеханова Анастасией Кужбаевой
17.01
Интенсив по СПС ГАРАНТ для студентов ОГУ
29.12
XVIII Всероссийский профессиональный Конкурс «Правовая Россия»
Отзывы о компании
Сивелькина С. В.
ПАО «НИКО-БАНК» выражает свою благодарность за оперативную и грамотную работу.
В условиях постоянно меняющегося законодательства Банк заинтересован иметь полную и актуальную номативную базу. Это обеспечивается использованием Банком справочно-нормативной системы «Гарант».
Безусловным плюсом в работе компании «МастерСофт» является быстрое реагирование сотрудников при предоставлении документов по запросу Банка, принятых до обновления справочно-правовой системы.
Мордвинцев С. П.
Коллектив компании «АЭРОПОРТ ОРЕНБУРГ» выражает благодарность за взаимовыгодное сотрудничество с МастерСофт-ИТ. Оперативная поставка антивирусных программ Dr. Web обеспечила надежную защиту нашей компьтерной сети.
Особая благодарность сотрудникам Департамента продаж СЦ ИТ за профессиональный подход в решении всех возникающих задач.Ряховская Н. А.
ООО «Орский Вагонный Завод» выражает искреннюю благодраность за качество обслуживания вашими специалистами. Консультации и поставка антивирусов всегда проходят оперативно и на высоком профессиональном уровне.
Уверены, что и в дальнейшем наше сотрудничество на взаимовыгодных условиях продолжится.Кетерер Т.
М.Главный бухгалтер муниципального бюджетного учреждения дополнительного образования «Дворец творчества детей и молодёжи» Кетерер Татьяна Михайловна выражает благодарность специалистам МастерСофт:
«Я хотела бы объявить благодарность вашим сотрудникам. Работает с нами по программе «1С: Бухгалтерия бюджетного учреждения 8» непосредственно Шевлягина Юлия.
Так же огромная благодарность за отзывчивость, терпение и квалифицированную, своевременную помощь Набокиной Олесе и Ерёменко Татьяне (они нас сопровождают по программе «Зарплата и Кадры»).
Им очень с нами тяжело, но они терпеливо продолжают сотрудничать. С вами очень надёжно. Конечно же наши ошибки есть и без вас мы бы вообще о них не знали и в суде, наверное, судились бы. А сейчас мы решаем вопросы…».
 М.
М.MongoDB | Индексы
Последнее обновление: 29.07.2022
При поиске документов в небольших коллекциях мы не испытаем особых проблем. Однако когда коллекции содержат миллионы документов, а нам надо
Однако когда коллекции содержат миллионы документов, а нам надо
сделать выборку по определенному полю, то поиск нужных данных может занять некоторое время, которое может оказаться критичным для нашей задачи.
В этом случае нам могут помочь индексы.
Индексы позволяют упорядочить данные по определенному полю, что впоследствии ускорит поиск. Например, если мы в своем приложении или задаче,
как правило, выполняем поиск по полю name, то мы можем индексировать коллекцию по этому полю.
Создание индекса
Для создания индекса применяется функция createIndex(), в которую передается объект с указанием полей, для которых создается индекс.
Например, создание индекса по полю «name»:
db.users.createIndex({"name" : 1})
При создании индекса консоль вернет нам название индекса:
test> db.users.createIndex({"name" : 1})
name_1
test>
То есть в примере выше был создани индекс с именем «name_1» по полю name. MongoDB позволяет установить до 64 индексов на одну коллекцию.
MongoDB позволяет установить до 64 индексов на одну коллекцию.
Для создания нескольких индексов применяется функция createIndexes() — в нее передается массив объектов, которые устанавливают поля для индексов:
db.users.createIndexes([{"name" : 1}, {"age": 1}])
В данном случае создаются два индекса — один для поля name, другой для поля age.
Удаление индексов
Для удаления индексов применяется функция dropIndex(), в которую передается имя индекса. Например, удалим выше определенный индекс «name_1»:
db.users.dropIndex("name_1")
Настройка индексов
Если мы просто определим индекс для коллекции, например, db.users.createIndex({"name" : 1}), то мы все еще сможем
добавлять в коллекцию документы с одинаковым значением ключа name. Однако, если нам потребуется, чтобы в коллекцию можно было добавлять
документ с одним и тем же значением ключа только один раз, мы можем установить флаг unique:
db.
 users.createIndex({"name" : 1}, {"unique" : true})
users.createIndex({"name" : 1}, {"unique" : true})
При этом при добавлении уникального индекса в коллекции не должно быть документов, у которых для определенного поля имеются одинаковые значения.
Теперь, если мы попытаемся добавить в коллекцию два документа с одним и тем же значением name, то мы получим ошибку.
В тоже время тут есть свои тонкости. Так, документ может не иметь ключа name. В этом случае для добавляемого документа автоматически
создается ключ name со значением null. Поэтому при добавлении второго документа, в котором не определен ключ name, будет выброшено исключение, так как
ключ name со значением null уже присутствует в коллекции.
Также можно задать один индекс сразу для двух полей:
db.users.createIndex({"name" : 1, "age" : 1})
Однако в этом случае все добавляемые документы должны иметь уникальные значения для обоих полей.
Кроме того, тут есть свои ограничения. Например, значение поля, по которому идет индексация, не должно быть больше 1024 байт.
Управление индексами
Все индексы базы данных хранятся в системной коллекции indexes. Для обращения к ней мы можем использовать функцию
getIndexes, например, чтобы вывести всю информацию об индексах для конкретной коллекции:
db.users.getIndexes()
Данная команда вернет вывод наподобие следующего:
test> db.users.getIndexes()
[
{ v: 2, key: { _id: 1 }, name: '_id_' },
{ v: 2, key: { name: 1 }, name: 'name_1' }
]
test>
Как мы видим, здесь для коллекции users (из бд test) определено 2 индекса: id и name. Поле key используется для поиска максимального и минимального значений,
для различных операций, где надо применять данный индекс. Поле name применяется в качестве идентификатора для операций администрирования,
например, для удаления индекса:
НазадСодержаниеВперед
sql — Каковы недостатки индексов в таблицах базы данных?
спросил
Изменено
2 года назад
Просмотрено
38 тысяч раз
Есть ли причина, по которой мне не следует создавать индекс для каждой из таблиц моей базы данных, чтобы повысить производительность? Казалось бы, должны быть какие-то причины, иначе все таблицы автоматически будут иметь один по умолчанию.
Я использую MS SQL Server 2016.
- sql
- sql-server
- база данных
- индексация
3
Один индекс в таблице не имеет большого значения. У вас автоматически создается индекс для столбцов (или комбинаций столбцов), которые являются первичными ключами или объявлены уникальными.
Есть некоторые накладные расходы на индекс. Сам индекс занимает место на диске и в памяти (при использовании). Таким образом, если возникают проблемы с пространством или памятью, проблема может заключаться в слишком большом количестве индексов. Когда данные вставляются/обновляются/удаляются, индекс необходимо поддерживать так же, как и исходные данные. Это замедляет обновления и блокирует таблицы (или их части), что может повлиять на обработку запросов.
Разумно небольшое количество индексов в каждой таблице. Они должны быть разработаны с учетом типичной нагрузки запроса. Если вы проиндексируете каждый столбец в каждой таблице, то изменение данных замедлится. Если ваши данные статичны, то это не проблема. Однако использование всей памяти индексами может быть проблемой.
Если ваши данные статичны, то это не проблема. Однако использование всей памяти индексами может быть проблемой.
3
Преимущество наличия индекса
- Скорость чтения: Быстрее SELECT, когда этот столбец находится в предложении WHERE
Недостатки наличия индекса
- Пространство : Требуется дополнительное место на диске/памяти
- Скорость записи : Медленнее INSERT/UPDATE/DELETE
Как минимум, я обычно рекомендую иметь по крайней мере 1 индекс на таблицу, он будет автоматически создан для первичного ключа вашей таблицы, например столбца IDENTITY. Тогда внешние ключи обычно выигрывают от индекса, его нужно будет создать вручную. Другие столбцы, которые часто включаются в предложения WHERE, должны быть проиндексированы, особенно если они содержат много уникальных значений. Преимущество индексации столбцов, таких как пол (низкая кардинальность), когда оно имеет только 2 значения, является спорным.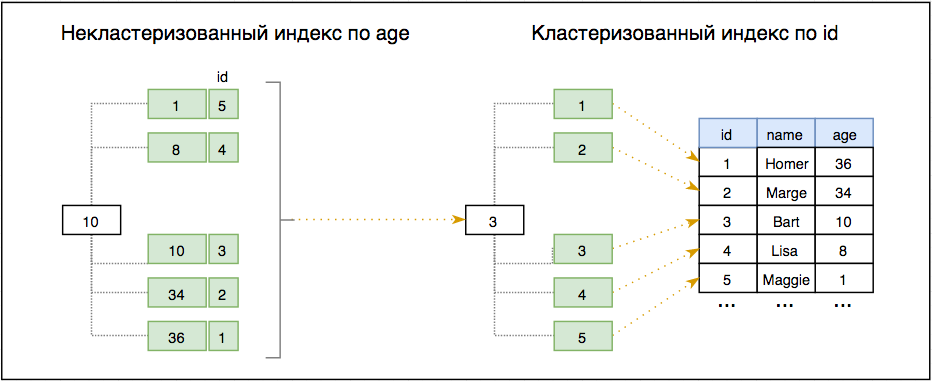
Большинство таблиц в моих базах данных имеют от 1 до 4 индексов, в зависимости от данных в таблице и способа извлечения этих данных.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
sql — Индексы базы данных: хорошо, плохо или пустая трата времени?
Задавать вопрос
спросил
Изменено
2 года, 2 месяца назад
Просмотрено
10 тысяч раз
Добавление индексов часто предлагается здесь как средство от проблем с производительностью.
(я говорю ТОЛЬКО о чтении и запросах, мы все знаем, что индексы могут замедлить запись).
Я пробовал это средство много раз, в течение многих лет, как на DB2, так и на MSSQL, и результат неизменно разочаровывал.
Я пришел к выводу, что каким бы «очевидным» ни было то, что индекс может улучшить ситуацию, оказалось, что оптимизатор запросов оказался умнее, а мой разумно выбранный индекс почти всегда ухудшал ситуацию.
Должен отметить, что мой опыт связан в основном с небольшими таблицами (менее 100 000 строк).
Может ли кто-нибудь предоставить некоторые практические рекомендации по выбору индексации?
Правильным ответом будет список рекомендаций, например:
- Никогда/всегда не индексировать таблицу, в которой меньше/больше записей NNNN
- Никогда/всегда не учитывайте индексы для ключей с несколькими полями
- Никогда/всегда не используйте кластеризованные индексы
- Никогда/всегда не используйте больше индексов NNN в одной таблице
- Никогда/всегда не добавляйте индекс, когда [какое-то волшебное состояние, о котором мне не терпится узнать]
В идеале ответ будет содержать несколько поучительных примеров.
- sql
- дизайн базы данных
- кроссплатформенный
4
Индексы подобны химиотерапии… слишком много — и это убьет тебя… слишком мало — и ты умрешь… сделаешь это неправильно, и ты умрешь. Вы должны знать, сколько, как часто и какого рода, чтобы это не убило вас.
Ваше оборудование, платформа, среда, нагрузка — все это играет роль. Итак, чтобы ответить на ваши вопросы…
Да, возможно, иногда.
4
Как правило, первичные и внешние ключи необходимо индексировать. Обычно первичный ключ индексируется, просто определяя его как таковой, но FK есть не в каждой базе данных (их определенно нет в SQL Server, я не могу говорить за другие базы данных). Вы будете использовать их в соединениях, поэтому их определение обычно имеет решающее значение для производительности.
Теперь, если у вас есть поля, которые вы часто используете в предложениях where, они также могут извлечь выгоду из индексов, предоставляя несколько вещей:
Сначала поле должно иметь диапазон
ценности. Битовое поле или поле с
только 2 или 3 значения почти никогда не будут
использовать индекс.Во-вторых, запросы, которые вы пишете, должны быть доступны для анализа. То есть они должны быть разработаны для использования индексов. Я подозреваю, что если вы никогда не получаете улучшения производительности от того, что выглядит вероятным кандидатом на индексацию, то у вас, вероятно, есть запросы, которые не поддаются анализу. Например, возьмите «WHERE Name like %Smith» в качестве предложения where. Не зная первых символов, оптимизатор не может использовать индекс.
 Битовое поле или поле с
Битовое поле или поле сМаленькие таблицы редко выигрывают от индексов. Если оптимизатор может хранить все это в памяти, то часто это происходит быстрее. Если бы вы работали с многомиллионными таблицами записей, вы бы увидели, что индексы имеют решающее значение.
Индексирование может быть очень сложным, и если вы интересуетесь этой темой, я предлагаю вам получить хорошую книгу по настройке производительности вашей конкретной базы данных и подробно прочитать об этом.
0
Индекс, который никогда не используется, является пустой тратой места на диске, а также увеличивает время вставки/обновления/удаления. Вероятно, лучше сначала определить индекс кластеризации, а затем определить
дополнительные индексы, когда вы обнаружите, что пишете предложения WHERE .
Одна из распространенных ошибок в индексах, которую я вижу, это люди, задающиеся вопросом, почему выборка по col2 (или col3) занимает так много времени, когда индекс определен как col1 ASC, col2 ASC, col3 ASC . Когда у вас есть индекс с несколькими столбцами, ваш WHERE 9Предложение 0158 должно использовать первый столбец индекса или первый и второй столбцы индекса и т. д.
Если вам нужно получить доступ к данным по col2, вам нужен дополнительный индекс, который определяется как col2 ASC .
С небольшими доменными таблицами иногда быстрее выполнить сканирование таблицы, чем читать строки из таблицы с помощью индекса. Это зависит от скорости вашей машины базы данных и скорости сети.
Это зависит от скорости вашей машины базы данных и скорости сети.
0
Вам нужны индексы. Только с индексами вы можете получить доступ к данным достаточно быстро.
Чтобы сделать его как можно короче:
- добавьте индексы для столбцов, которые вы часто фильтруете (или группируете). (например, штат или имя)
-
, как и, и функции sql могут заставить СУБД не использовать индексы. - добавлять индексы только для столбцов, которые имеют много разных значений (например, без логических полей)
- Обычно к внешним ключам добавляются индексы, но это не всегда необходимо.
- не добавлять индексы в очень короткие таблицы
- никогда не добавляйте индексы, если вы не знаете, как они должны повысить производительность.
Наконец: изучите планы выполнения, чтобы решить, как оптимизировать запросы.
Вы добавите индексы только для одного критического запроса.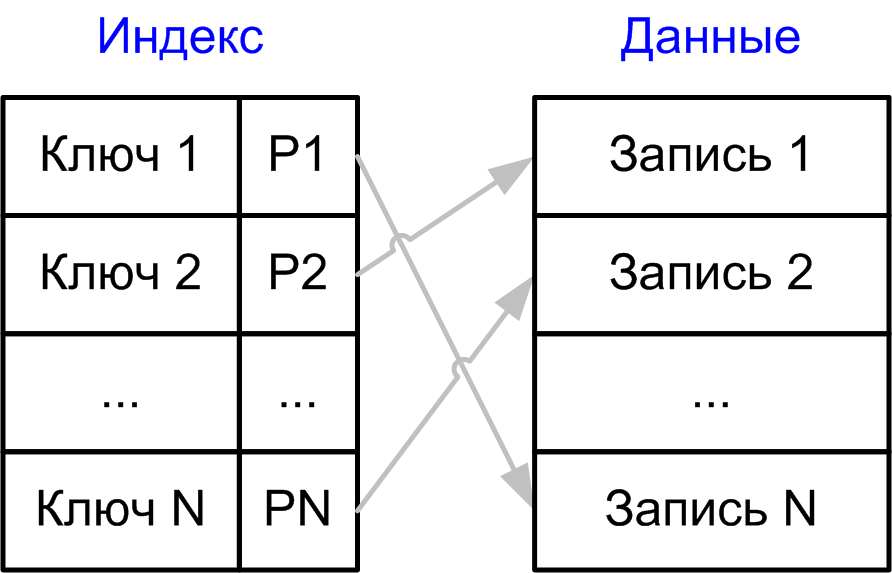 В этом случае вы добавите именно те индексы, которые необходимы в рассматриваемом запросе (многостолбцовые индексы).
В этом случае вы добавите именно те индексы, которые необходимы в рассматриваемом запросе (многостолбцовые индексы).
В основном, когда БД собирает данные и ее индексы работают, они должны идти и развиваться вместе с этим потоком. Может быть действительно хороший индекс в таблице, но после увеличения количества записей XXX тот же индекс в той же таблице бесполезен, и в этом случае его следует реорганизовать.
Чтобы иметь оптимизированную и быструю БД, единственный способ - это постоянно отслеживать ее и реорганизовывать ее по мере поступления записей. между A и B) и очень медленный запрос, где временной диапазон был другим. Тот же запрос, та же база данных, то же приложение и только одна разница во временном диапазоне.
1
Всегда используйте кластеризованные индексы.
На самом деле вы не можете не использовать их. Данные в таблице в любом случае будут располагаться на диске в определенном порядке, их нельзя сохранить в виде стопки или чего-то подобного. У вас есть возможность указать, как именно эти данные будут размещены. Зачем жечь?
У вас есть возможность указать, как именно эти данные будут размещены. Зачем жечь?
Если у вас есть таблица, к которой добавляются новые записи, и вы наблюдаете, что какое-то значение в этих записях всегда растет (например, номер вопроса StackOverflow), сделайте из нее кластеризованный индекс. Тогда новые данные не будут вставлены в середину, а будут в основном добавлены к файлу на диске, что является относительно дешевой операцией.
Если предполагается, что целью соединения будет таблица, то лучше всего иметь для этой таблицы кластеризованный индекс, чтобы соединения можно было выполнять последовательно через страницы данных. Столбцы в кластеризованном индексе (в некоторых системах БД) будут включены во все другие индексы этой таблицы, поскольку это значения, которые индексы будут использовать для ссылки на данные таблицы. Чтобы другие индексы не стали слишком большими, столбцы в кластеризованном индексе должны быть как можно более узкими, поэтому лучше использовать только числовые, а не символьные типы данных в кластеризованном индексе. В общем, чем меньше столбцов, тем лучше, чем больше, но обратите внимание, что три 9Столбцы 0157 int (12 байт на строку) намного лучше, чем один столбец
В общем, чем меньше столбцов, тем лучше, чем больше, но обратите внимание, что три 9Столбцы 0157 int (12 байт на строку) намного лучше, чем один столбец nvarchar(32) (потенциально 64 байта на строку).
Если кластеризованный индекс узкий, то несколько дополнительных индексов не должны сильно влиять на производительность даже в очень больших таблицах.
Кажется, здесь вы путаете два понятия.
Добавление индексов * вообще может только сделать запрос на чтение быстрее, очень очень редко (почти никогда) медленнее. Добавление индекса никогда не заставляет оптимизатор запросов использовать его. Он будет использовать его только в том случае, если он думает, что может извлечь из этого пользу, и, как правило, он очень разумен в таких решениях.
Для вставок/обновлений, конечно, каждый индекс снижает производительность немного больше… Но на другом конце спектра, скажем, для базы данных только для чтения (например, база данных адресов USPS, которая распространяется ежемесячно), в при рабочем использовании не было бы никаких вставок/обновлений, поэтому единственное негативное влияние дополнительных индексов — это занимаемое ими место на диске.