Индексы sql: Все, что необходимо знать про индексы MS SQL OTUS
Управление индексами в 1С 7.7 SQL
Задача проектирования структуры БД является ключевой с точки зрения производительности и масштабируемости ИТ систем. Под структурой можно также понимать структуру индексов sql. В зависимости от того насколько правильно расставлены индексы sql один и тот же запрос может формироваться различное время. Соотношение во времени выполнения может составлять порядки. Кроме этого, совокупная нагрузка на серверные ресурсы будет существенно отличатся. Именно поэтому технология правильной расстановки индексов является одной из приоритетных в общей технологии оптимизации.
Технология создания индексов отнюдь не тривиальна. Тем не менее, существуют некоторые относительно не сложные походы. Также фирма Microsoft предлагает специализированный мастер эффективных настроек индексов. Концепция его предполагает снятия истории запросов (трасс) и дальнейший анализ этих запросов этим мастером после чего будет предложен отчет в котором будет информация по оптимизации индексов. К данным этого отчета надо относится, тем не менее, с некоторой опаской и окончательные решения по созданию того или иного индекса принимать только после экспертного анализа.
К данным этого отчета надо относится, тем не менее, с некоторой опаской и окончательные решения по созданию того или иного индекса принимать только после экспертного анализа.
Рассмотрим среду 1С 7.7. В системе 1С невозможно стандартными средствами добавлять индексы. Это с одной стороны упрощает разработку. На начальном этапе не нужно задумываться, что такое индексы вообще. Ограничения по фильтрации и сортировке экранных форм(например в справочниках только сортировка по коду, наименованию или реквизитам с признаком отбора – т.е. по тем полям где есть по умолчанию индексы ) позволяют довольно длительный интервал времени после внедрения не беспокоится о проблеме оптимизации индексов. Но здесь есть и отрицательный момент. При увеличении объемов БД запросы с учетом стандартных sql индексов отрабатывают все хуже и хуже. Нагрузка на сервер и время отчетов увеличивается до тех пор, пока эти значения не принимают критической величины. Как правило, после этого принимается решение об коренной перестройке структуры объектов 1С либо об апгрейде серверного оборудования.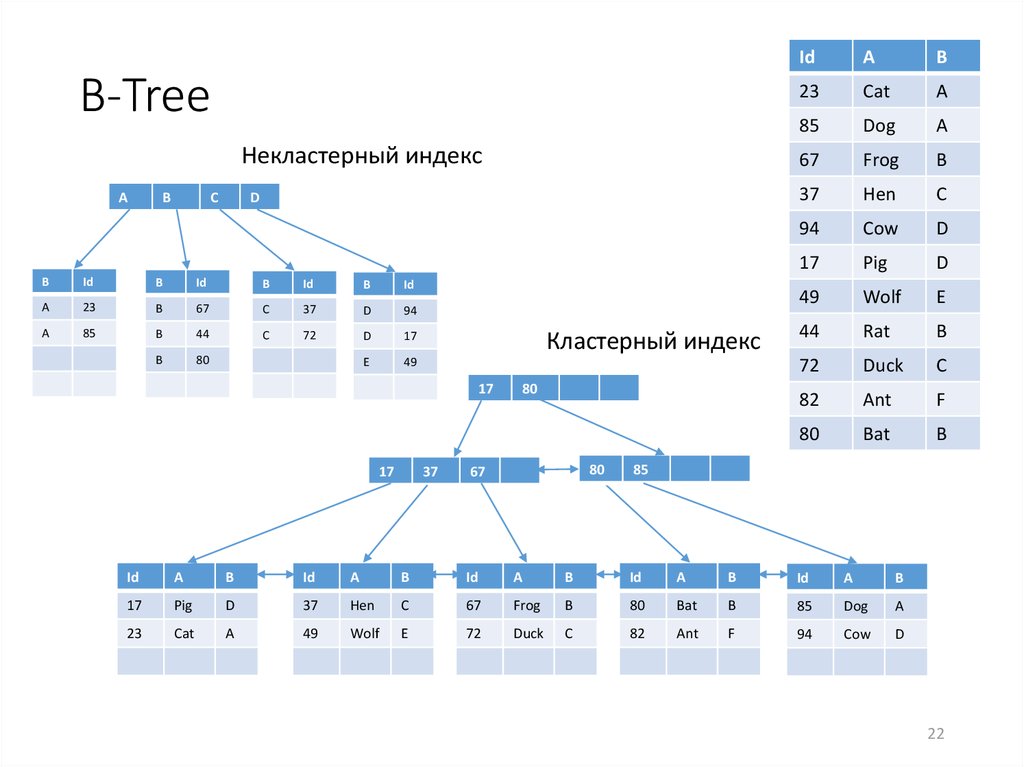 И первый, и второй вариант требуют существенных затрат. Например, иногда структура объектов в текущей реализации выглядит вполне нормальной, и вполне устраивала разработчиков, если бы была возможность, например, добавить индекс по шапке документа. Классическим примером здесь можно привести ситуацию, когда структура документов завязана иерархически и реквизит с документом родителем хранится в шапке документа. В данном случае конечно можно вынести этот реквизит в общие реквизиты но это будет неэффективное решение как с точки зрения структуры запросов так и с точки зрения общей производительности. (зачем всем документам хранить реквизит который нужен только для одного типа документов?).
И первый, и второй вариант требуют существенных затрат. Например, иногда структура объектов в текущей реализации выглядит вполне нормальной, и вполне устраивала разработчиков, если бы была возможность, например, добавить индекс по шапке документа. Классическим примером здесь можно привести ситуацию, когда структура документов завязана иерархически и реквизит с документом родителем хранится в шапке документа. В данном случае конечно можно вынести этот реквизит в общие реквизиты но это будет неэффективное решение как с точки зрения структуры запросов так и с точки зрения общей производительности. (зачем всем документам хранить реквизит который нужен только для одного типа документов?).
Не смотря на ограниченность управления индексами в 1С 7,7. решение существует. У этого метода есть все же определенные недостатки связанные с удобствами администрирования.
- Необходимо определится с префиксом наименования индекса и в дальнейшем на этом сервере все индексы в рамках баз 1С нужно называть с предопределенным префиксом.
 Пускай этот префикс будет P1С – это довольно редкий префикс.
Пускай этот префикс будет P1С – это довольно редкий префикс. - В процедуре master.dbo.sp_statistics (процедура, ответственная за проверку наличия индексов таблиц) необходимо изменить небольшую часть кода. Смысл изменений в том что если эту процедуру вызывает приложение 1С то в этом случае в результат выполнения этой процедуры не будут попадать индексы с префиксом P1С.
if app_name()='1CV7' /* это проверка какое приложение вызывает процедуру*/
begin /*этот вариант срабатывает если запущена процедура из 1С */
SELECT
TABLE_QUALIFIER,
TABLE_OWNER,
TABLE_NAME,
NON_UNIQUE,
INDEX_QUALIFIER,
INDEX_NAME,
TYPE,
SEQ_IN_INDEX,
COLUMN_NAME,
COLLATION,
CARDINALITY,
PAGES,
FILTER_CONDITION = convert(varchar(128),null)
FROM #TmpIndex
WHERE
(INDEX_NAME like @index_name /* If matching name */
or INDEX_NAME is null) /* If SQL_TABLE_STAT row */
and (substring(INDEX_NAME,1,3)'P1C' or INDEX_NAME is NULL)
/*вот это проверка на префикс, если он начинается на P1C*/
/*то в результат выполнения процедуры не попадает*/
ORDER BY 4, 7, 6, 8
end
else
begin /* это старый вариант реализации, стандартный*/
SELECT
TABLE_QUALIFIER,
TABLE_OWNER,
TABLE_NAME,
NON_UNIQUE,
INDEX_QUALIFIER,
INDEX_NAME,
TYPE,
SEQ_IN_INDEX,
COLUMN_NAME,
COLLATION,
CARDINALITY,
PAGES,
FILTER_CONDITION = convert(varchar(128),null)
FROM #TmpIndex
WHERE
(INDEX_NAME like @index_name /* If matching name */
or INDEX_NAME is null) /* If SQL_TABLE_STAT row */
end - Каждый добавленный индекс фиксировать в T-SQL скрипт. Данный скрипт поставить на исполнение в SQL jobs. Смысл этих действий обуславливается тем что при структурном(как правило это редкая операция) изменении объектов 1С удаляет старый объект и создает новый. Таким образом если не будет job-а то в этом случае после структурного изменения объекта все дополнительные индексы по нему исчезнут. Реализация скрипта очень простая . Проверяется наличие дополнительных индексов и если какого то из них нет то он создается. Эту операцию можно выполнять даже в рабочем режиме. Хотя ее достаточно выполнять один раз после изменения конфигурации. Я например ставлю частоту выполнения 1 час – этого более чем достаточно.
 Пускай этот префикс будет P1С – это довольно редкий префикс.
Пускай этот префикс будет P1С – это довольно редкий префикс. Данный скрипт поставить на исполнение в SQL jobs. Смысл этих действий обуславливается тем что при структурном(как правило это редкая операция) изменении объектов 1С удаляет старый объект и создает новый. Таким образом если не будет job-а то в этом случае после структурного изменения объекта все дополнительные индексы по нему исчезнут. Реализация скрипта очень простая . Проверяется наличие дополнительных индексов и если какого то из них нет то он создается. Эту операцию можно выполнять даже в рабочем режиме. Хотя ее достаточно выполнять один раз после изменения конфигурации. Я например ставлю частоту выполнения 1 час – этого более чем достаточно.
Данный скрипт поставить на исполнение в SQL jobs. Смысл этих действий обуславливается тем что при структурном(как правило это редкая операция) изменении объектов 1С удаляет старый объект и создает новый. Таким образом если не будет job-а то в этом случае после структурного изменения объекта все дополнительные индексы по нему исчезнут. Реализация скрипта очень простая . Проверяется наличие дополнительных индексов и если какого то из них нет то он создается. Эту операцию можно выполнять даже в рабочем режиме. Хотя ее достаточно выполнять один раз после изменения конфигурации. Я например ставлю частоту выполнения 1 час – этого более чем достаточно.
Предлагаем вашему вниманию следующую технологию с целью возможного расширения индексов. Сразу хочу отметить, что в 99-и процентов случаев индексы от 1С по умолчанию работают эффективно (конечно, кроме тех случаев, когда бездумно ставят сортировку и отбор на реквизиты). Поэтому варианты с удалением индексов 1С мы не рассматриваем.
После изменения процедуры sp_statistics мы можем беспрепятственно добавлять индексы. Эффект от правильной расстановки индексов может быть очень большим. Например, один из отчетов который формировался ранее порядка 7-и часов, стал формироваться порядка 20-и минут. Это и не удивительно так по миллионной таблице осуществлялось множество запросов с фильтром по реквизиту без индекса, в результате чего осуществлялся full scan. Кроме длительно времени выполнения запроса еще большим минусом является в момент выполнения запроса большая загрузка сервера.
Теперь кратко рассмотрим, как пользоваться средством SQL-сервера для оптимизации индексов – Index Tuning wizard. Запустим профайлер и выберем пункт «Index Tuning wizard».
Откроется диалоговое окно Index Tuning wizard.
Перейдем на следующую страницу помощника. Откроется диалог авторизации.
Необходимо выбрать сервер и указать логин и пароль для входа.
После будет нужно выбрать анализируемую базу данных и режим анализа. Важно оставить пометку «keep all existing indexes» включенной, чтобы помощник не пытался удалить существующие индексы, даже если они не оптимальны. Режим «Fast» не следует использовать из-за его неточности. Режим «Thorough» может занять слишком много времени для анализа. Поэтому используем золотую середину. Переходим к следующему окну.
Важно оставить пометку «keep all existing indexes» включенной, чтобы помощник не пытался удалить существующие индексы, даже если они не оптимальны. Режим «Fast» не следует использовать из-за его неточности. Режим «Thorough» может занять слишком много времени для анализа. Поэтому используем золотую середину. Переходим к следующему окну.
Здесь мы должны указать трассу, которую мы будем анализировать в виде файла на диске или таблицы в базе данных. Вместо трассы можно указать файл, содержащий SQL-запрос, который мы хотим проанализировать. После указания трассы нужно обязательно посмотреть «Advanced Options».
Это диалоговое окно содержит 3 важных параметра. Первый из них, важнейший, количество запросов для анализа. По-умолчанию там стоит цифра 200. Это означает, что из трассы случайным образом будут выбраны 200 запросов, которые и будут проанализированы. Если снять пометку, то будет проанализирована вся трасса. Это очень важный момент. Важно, чтобы анализировалась трасса, которая содержит как можно более репрезентативную выборку запросов, но не содержит в себе множества легковесных запросов. Если трасса небольшая, то можно снять пометку, чтобы анализировались все запросы. Второй параметр – это максимальный объем места на диске для индексов, которые будут добавляться. Индексы, которые превышают этот объем, добавляться не будут. Третий параметр – ограничение на количество колонок, входящих в индекс. После выбора значений и возврата в основную форму, переходим к следующей странице помощника.
Если трасса небольшая, то можно снять пометку, чтобы анализировались все запросы. Второй параметр – это максимальный объем места на диске для индексов, которые будут добавляться. Индексы, которые превышают этот объем, добавляться не будут. Третий параметр – ограничение на количество колонок, входящих в индекс. После выбора значений и возврата в основную форму, переходим к следующей странице помощника.
На этой странице нам предстоит выбрать таблицы, индексы к которым будут анализироваться. Рекомендуется выбрать важные таблицы, остальные оставить не помеченными. Также, с учетом будущего роста базы можно установить значения в колонке «Projected Rows», указать, какое количество строк в данной таблице планируется с ростом базы. После нажатия на кнопку «Далее», будет осуществляться анализ.
Когда процесс анализа будет завершен, мы увидим таблицу результатов анализа.
В этой таблице будут представлены и существующие индексы, и новые, если помощник посчитал, что они необходимы. Новые индексы обозначены специальным значком (см. индекс с именем «RA11583»). Ниже в тексте написано, сколько процентов прироста производительности оттестированных запросов повлечет за собой создание рекомендуемых индексов. Перейдем дальше.
Новые индексы обозначены специальным значком (см. индекс с именем «RA11583»). Ниже в тексте написано, сколько процентов прироста производительности оттестированных запросов повлечет за собой создание рекомендуемых индексов. Перейдем дальше.
Здесь нам предстоит выбрать, что делать с полученными данными. Предлагается два варианта: применить изменения (сразу или в назначенное время), или сохранить сгенерированный SQL-скрипт в файл. Мы выбираем второй вариант, так как автоматически сгенерированные имена индексов нам не подходят, а также, потому что потом можно будет посмотреть на рекомендации и выбрать, что из них делать, а что нет. Кроме новых индексов может быть предложено создать и соответствующую статистику. Вот как выглядит пример файла рекомендаций.
/* Created by: Index Tuning Wizard */
/* Date: 18.05.2005 */
/* Time: 10:50:10 */
/* Server Name: VLADA */
/* Database Name: TestMain */
/* Workload File Name: D:WorkSQLMSSQLTRACEТрассировка.USE [TestMain]
goSET QUOTED_IDENTIFIER ON
SET ARITHABORT ON
SET CONCAT_NULL_YIELDS_NULL ON
SET ANSI_NULLS ON
SET ANSI_PADDING ON
SET ANSI_WARNINGS ON
SET NUMERIC_ROUNDABORT OFF
goDECLARE @bErrors as bit
BEGIN TRANSACTION
SET @bErrors = 0CREATE NONCLUSTERED INDEX [RA11583] ON [dbo].[RA1158] ([SP1160] ASC )
IF( @@error 0 ) SET @bErrors = 1IF( @bErrors = 0 )
COMMIT TRANSACTION
ELSE
ROLLBACK TRANSACTIONBEGIN TRANSACTION
SET @bErrors = 0CREATE NONCLUSTERED INDEX [_1SJOURN10] ON [dbo].[_1SJOURN]
([IDDOCDEF] ASC, [DATE_TIME_IDDOC] ASC, [CLOSED] ASC )
IF( @@error 0 ) SET @bErrors = 1IF( @bErrors = 0 )
COMMIT TRANSACTION
ELSE
ROLLBACK TRANSACTION/* Statistics to support recommendations */
CREATE STATISTICS [hind_874486194_6A_1A] ON [dbo].[RA1158]
([SP1160], [IDDOC])
CREATE STATISTICS [hind_429960608_9A_4A] ON [dbo].[_1SJOURN]
([CLOSED], [IDDOCDEF])
CREATE STATISTICS [hind_429960608_9A_3A] ON [dbo].
([CLOSED], [IDDOC])
CREATE STATISTICS [hind_429960608_6A_4A] ON [dbo].[_1SJOURN]
([DATE_TIME_IDDOC], [IDDOCDEF])
CREATE STATISTICS [hind_429960608_3A_4A] ON [dbo].[_1SJOURN]
([IDDOC], [IDDOCDEF])
CREATE STATISTICS [hind_429960608_6A_3A] ON [dbo].[_1SJOURN]
([DATE_TIME_IDDOC], [IDDOC])
CREATE STATISTICS [hind_429960608_9A_6A] ON [dbo].[_1SJOURN]
([CLOSED], [DATE_TIME_IDDOC])
CREATE STATISTICS [hind_429960608_3A_6A] ON [dbo].[_1SJOURN]
([IDDOC], [DATE_TIME_IDDOC])
CREATE STATISTICS [hind_429960608_3A_9A] ON [dbo].[_1SJOURN]
([IDDOC], [CLOSED])
CREATE STATISTICS [hind_429960608_6A_9A_3A] ON [dbo].[_1SJOURN]
([DATE_TIME_IDDOC], [CLOSED], [IDDOC])
CREATE STATISTICS [hind_429960608_4A_6A_3A] ON [dbo].[_1SJOURN]
([IDDOCDEF], [DATE_TIME_IDDOC], [IDDOC])
CREATE STATISTICS [hind_429960608_6A_9A_4A] ON [dbo].[_1SJOURN]
([DATE_TIME_IDDOC], [CLOSED], [IDDOCDEF])
 trc */
trc */ [_1SJOURN]
[_1SJOURN]
Полный текст измененной процедуры sp_statistics для SQL-2000 sp3:
/* Procedure for 8.
ALTER PROCEDURE sp_statistics (
@table_name sysname,
@table_owner sysname = null,
@table_qualifier sysname = null,
@index_name sysname = '%',
@is_unique char(1) = 'N',
@accuracy char(1) = 'Q')
AS
set nocount on
DECLARE @indid int
DECLARE @lastindid int
DECLARE @table_id int
DECLARE @full_table_name nvarchar(257)create table #TmpIndex(
TABLE_QUALIFIER sysname collate database_default NULL,
TABLE_OWNER sysname collate database_default NULL,
TABLE_NAME sysname collate database_default NOT NULL,
INDEX_QUALIFIER sysname collate database_default null,
INDEX_NAME sysname collate database_default null,
NON_UNIQUE smallint null,
TYPE smallint NOT NULL,
SEQ_IN_INDEX smallint null,
COLUMN_NAME sysname collate database_default null,
COLLATION char(1) collate database_default null,
index_id int null,
CARDINALITY int null,
PAGES int null,
status int NOT NULL)if @table_qualifier is not null
begin
if db_name() @table_qualifier
begin /* If qualifier doesn't match current database */
raiserror (15250, -1,-1)
return
end
endif @accuracy not in ('Q','E')
begin
raiserror (15251,-1,-1,'accuracy','''Q'' or ''E''')
return
endif @table_owner is null
begin /* If unqualified table name */
SELECT @full_table_name = quotename(@table_name)
end
else
begin /* Qualified table name */
if @table_owner = ''
begin /* If empty owner name */
SELECT @full_table_name = quotename(@table_owner)
end
else
begin
SELECT @full_table_name = quotename(@table_owner) +
'.
end
end
/* Get Object ID */
SELECT @table_id = object_id(@full_table_name)/* Start at lowest index id */
SELECT @indid = min(indid) FROM sysindexes
WHERE not (@table_id is null)
AND id = @table_id
AND indid > 0
AND indid/* Create a temp table to correct the ordinal position of the columns */
create table #TmpColumns
(ordinal int identity(1,1),
colid smallint not null)/* Load columns into the temp table */
insert into #TmpColumns (colid)
select c.colid
from syscolumns c
where c.id = @table_id
order by c.colidWHILE @indid is not NULL
BEGIN
INSERT #TmpIndex /* Add all columns that are in index */
SELECT
DB_NAME(), /* TABLE_QUALIFIER*/
USER_NAME(o.uid), /* TABLE_OWNER*/
o.name, /* TABLE_NAME*/
o.name, /* INDEX_QUALIFIER*/
x.name, /* INDEX_NAME*/
case /* NON_UNIQUE*/
WHEN x.status&2 2 then 1 /* Nonunique index*/
else 0 /* Unique index*/
end,
case /* TYPE*/
when @indid > 1 then 3 /* Non-Clustered*/
else 1 /* Clustered index*/
end,
tc.
INDEX_COL(@full_table_name, indid, tc.ordinal),/* COLUMN_NAME*/
'A', /* COLLATION*/
@indid, /* index_id*/
case /* CARDINALITY*/
when @indid > 1 then NULL /* Non-Clustered*/
else x.rows /* Clustered index*/
end,
case /* PAGES*/
when @indid > 1 then NULL /* Non-Clustered*/
else x.dpages /* Clustered index*/
end,
x.status /* status*/
FROM sysindexes x, syscolumns c, sysobjects o, #TmpColumns tc
WHERE
not (@table_id is null)
AND x.id = @table_id
AND x.id = o.id
AND x.id = c.id
AND tc.colid = c.colid
AND tc.ordinal /* all but Unique Clust indices have an extra key */
AND INDEX_COL(@full_table_name, indid, tc.ordinal) IS NOT NULL
AND indid = @indid
AND (x.status&2 = 2
OR @is_unique 'Y')
AND (x.status&32) = 0
/*
** Now move @indid to the next index.
*/
SELECT @lastindid = @indid
SELECT @indid = NULLSELECT @indid = min(indid)
FROM sysindexes
WHERE not (@table_id is null)
AND id = @table_id
AND indid > @lastindid
AND indid END/* now add row for table statistics */
INSERT #TmpIndex
SELECT
DB_NAME(), /* TABLE_QUALIFIER*/
USER_NAME(o.
o.name, /* TABLE_NAME */
null, /* INDEX_QUALIFIER*/
null, /* INDEX_NAME */
null, /* NON_UNIQUE */
0, /* SQL_TABLE_STAT */
null, /* SEQ_IN_INDEX */
null, /* COLUMN_NAME */
null, /* COLLATION */
0, /* index_id */
x.rows, /* CARDINALITY */
x.dpages, /* PAGES */
0 /* status */
FROM sysindexes x, sysobjects o
WHERE not (@table_id is null)
AND o.id = @table_id
AND x.id = o.id
AND (x.indid = 0 or x.indid = 1)/*If there are no indexes*/
/*then table stats are in*/
/*a row with indid =0*/
if app_name()='1CV7'
begin
SELECT
TABLE_QUALIFIER,
TABLE_OWNER,
TABLE_NAME,
NON_UNIQUE,
INDEX_QUALIFIER,
INDEX_NAME,
TYPE,
SEQ_IN_INDEX,
COLUMN_NAME,
COLLATION,
CARDINALITY,
PAGES,
FILTER_CONDITION = convert(varchar(128),null)
FROM #TmpIndex
WHERE
(INDEX_NAME like @index_name /* If matching name*/
or INDEX_NAME is null) /* If SQL_TABLE_STAT row*/
and (substring(INDEX_NAME,1,3)'P1C' or INDEX_NAME is NULL)
ORDER BY 4, 7, 6, 8
end
else
begin
SELECT
TABLE_QUALIFIER,
TABLE_OWNER,
TABLE_NAME,
NON_UNIQUE,
INDEX_QUALIFIER,
INDEX_NAME,
TYPE,
SEQ_IN_INDEX,
COLUMN_NAME,
COLLATION,
CARDINALITY,
PAGES,
FILTER_CONDITION = convert(varchar(128),null)
FROM #TmpIndex
WHERE
(INDEX_NAME like @index_name /* If matching name */
or INDEX_NAME is null)/* If SQL_TABLE_STAT row */
endDROP TABLE #TmpIndex, #TmpColumns
GO
 0 server */
0 server */ ' + quotename(@table_name)
' + quotename(@table_name)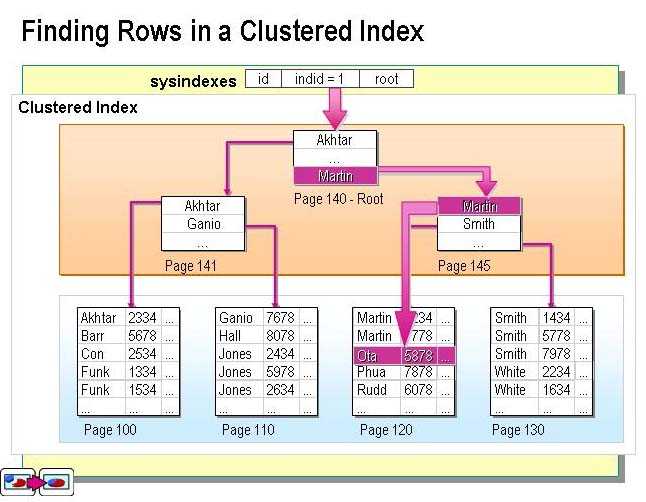 ordinal, /* SEQ_IN_INDEX*/
ordinal, /* SEQ_IN_INDEX*/ uid), /* TABLE_OWNER */
uid), /* TABLE_OWNER */
Компания «СофтПоинт» предлагает вашему вниманию продукт, который позволит облегчить выполнение задачи оптимизации индексов.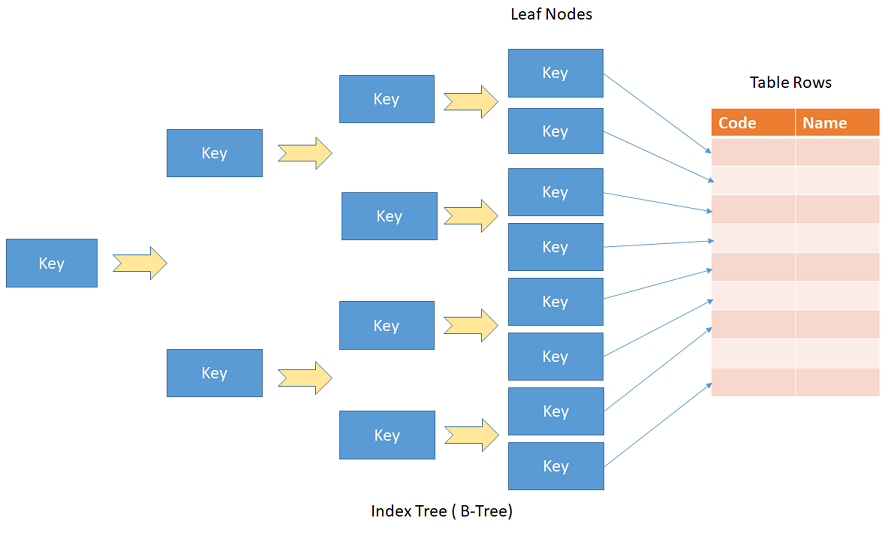 Кроме того, компания «СофтПоинт» имеет штат высококлассных специалистов, которые проводят работы, в том числе и по оптимизации индексов, которые могут качественно выполнить эту работу.
Кроме того, компания «СофтПоинт» имеет штат высококлассных специалистов, которые проводят работы, в том числе и по оптимизации индексов, которые могут качественно выполнить эту работу.
Перепечатка, воспроизведение в любой форме, распространение, в том числе в переводе, любых материалов с сайта www.softpoint.ru возможны только с письменного разрешения компании «СофтПоинт». Это правило действует для всех без исключения случаев, кроме тех, когда в материале прямо указано разрешение на копирование (основание: Закон Российской Федерации «Об авторском праве и смежных правах»).
Типы индексов MySQL — Блог Lineate
ко всем статьям
< ко всем статьям
<
Автор: Татьяна Сергиенко, Software Engineer
В литературе встречается следующая терминология:
- кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае)
- некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Кластеризованный индекс – это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
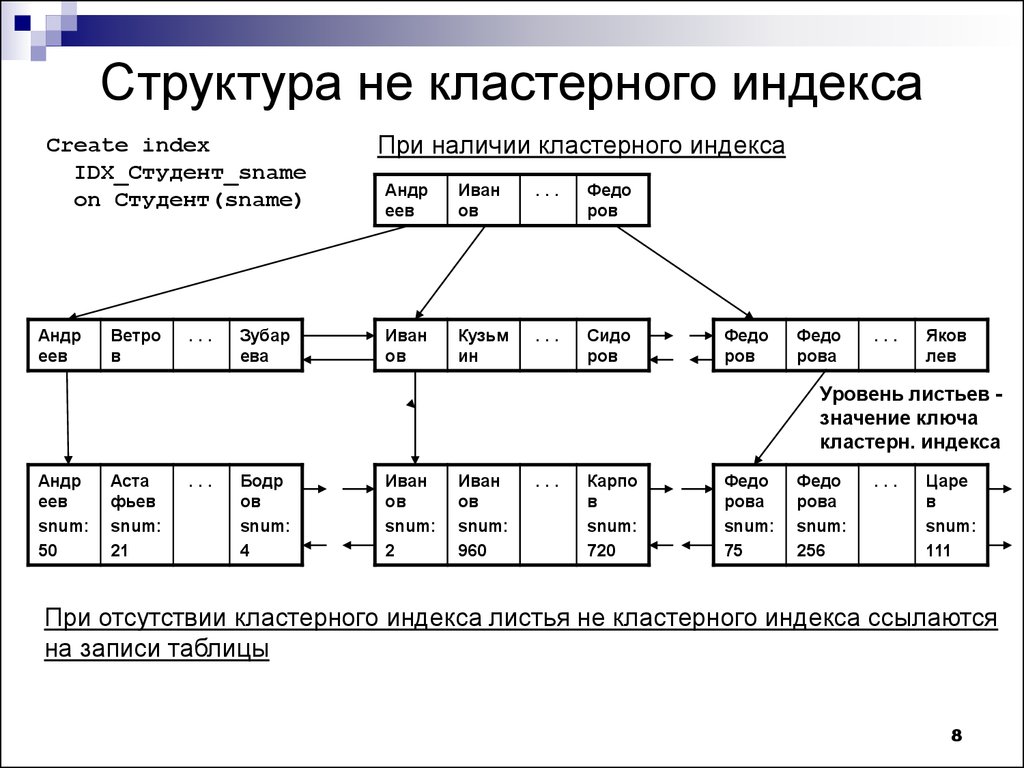
В некластеризованном индексе на листьях древовидной структуры хранятся указатели (или ссылки) на соответствующие строки с данными в таблице. Каждая запись во вторичном индексе содержит столбцы первичного ключа для строки, а также столбцы, указанные в некластеризованном индексе.
Общие правила при создании индекса:
- Каждая таблица всегда имеет только один кластеризованный индекс.
- Когда вы определяете PRIMARY KEY для таблицы, MySQL использует PRIMARY KEY в качестве кластеризованного индекса.
- Если у вас нет PRIMARY KEY для таблицы, MySQL будет искать первый UNIQUE индекс, в котором находятся все ключевые столбцы, и будет использовать этот UNIQUE индекс в качестве кластеризованного индекса.
- В случае, если таблица не имеет PRIMARY KEY или подходящего UNIQUE индекса, MySQL внутренне генерирует скрытый кластерный индекс, названный GEN_CLUST_INDEX на синтетическом столбце, который содержит значения идентификатора строки.
Ключи в системе индексов MySQL
MySQL использует значение первичного ключа для поиска строк в некластеризованном индексе.
Следовательно, предпочтительно иметь короткий первичный ключ, иначе вторичные индексы будут использовать больше места. Обычно для столбца первичного ключа используется целочисленный столбец с автоинкрементом.
Primary key (первичный ключ)
Первичный ключ — это столбец или набор столбцов, которые однозначно идентифицируют каждую строку в таблице.
Первичный ключ следует следующим правилам:
- Первичный ключ должен содержать уникальные значения. Если первичный ключ состоит из нескольких столбцов, комбинация значений в этих столбцах должна быть уникальной.
- Столбец первичного ключа не может иметь NULL значений. Любая попытка вставить или обновить NULL столбцы первичного ключа приведет к ошибке.
Обратите внимание, что MySQL неявно добавляет NOT NULL ограничение к столбцам первичного ключа.
- Таблица может иметь один и только один первичный ключ.
Unique key
Чтобы обеспечить значение уникальности одного или нескольких столбцов, часто используют PRIMARY KEY. Однако каждая таблица может иметь только один первичный ключ.
UNIQUE index позволяет обеспечить уникальность значений в одном или нескольких столбцах. В отличие от PRIMARY KEY, вы можете создать более одного UNIQUE индекса для каждой таблицы.
Также, в отличие от PRIMARY key, MySQL допускает NULL значения в UNIQUE индексе.
Индекс префиксов
Если столбцы являются строковыми, при создании индекса, он будет занимать много места на диске и потенциально замедлять INSERT операции.
Чтобы решить эту проблему, MySQL позволяет создавать индекс для ведущей части значений столбцов строковых столбцов.
Невидимый индекс (только для MySQL 8. 0)
0)
По умолчанию индексы видимые (VISIBLE). Невидимые индексы (INVISIBLE) позволяют помечать индексы как недоступные для оптимизатора запросов.
MySQL поддерживает невидимые индексы в актуальном состоянии при изменении данных в столбцах, связанных с индексами.
Чтобы сделать индекс невидимым, с помощью ключевых слов VISIBLE и INVISIBLE, вы должны явно заявить о видимости индекса во время создания или с помощью ALTER TABLE команды.
Например, вы можете сделать индекс невидимым, чтобы увидеть, влияет ли он на производительность, и снова пометить индекс как видимый, если это так.
PRIMARY key оr UNIQUE index нельзя сделать невидимыми.
Составной индекс
Составной индекс — это индекс по нескольким столбцам. MySQL позволяет создавать составной индекс, состоящий до 16 столбцов.
Оптимизатор запросов использует составные индексы для запросов, которые проверяют все столбцы в индексе, или запросов, которые проверяют первые столбцы, первые два столбца и т. д.
Если вы укажете столбцы в правильном порядке в определении индекса, единый составной индекс может ускорить выполнение таких запросов к одной и той же таблице.
ДРУГИЕ СТАТЬИ
>
ко всем статьям
Wednesday, August 18
Индексы MySQL: что это и зачем нужны — Блог Lineate
MySQL — это система управления реляционными базами данных с открытым исходным кодом с моделью клиент-сервер. Говоря совсем простым языком, база данных — набор структурированных данных. Чем их больше, тем труднее найти нужные. Для облегчения поиска информации и используются индексы MySQL.
Wednesday, August 18
Типы индексов MySQL — Блог Lineate
Кластеризованные — специальные индексы, Primary Key и Unique Index (Key и Index – это синонимы в данном случае). Некластеризованные, или вторичные, индексы — все остальные индексы, которые не попадают под Primary и Unique
Давайте работать вместе
Присоединяйтесь к нашей команде!
Смотреть вакансии
индексов SQL | Типы индексов в SQL
Индексы SQL
Индексом называется структура на сервере SQL, поддерживаемая или хранящаяся в структуре в памяти или на диске, связанная с представлением или таблицей, которая используется в основном для идентификации какой-либо конкретной строки или таблицы. набор строк из представлений или таблицы. Индексы в SQL — это отдельные таблицы поиска, которые используются поисковой системой базы данных для ускорения поиска данных в целом.
Индекс в таблице используется для увеличения общей скорости, необходимой для поиска любых конкретных данных в базе данных. Индекс в базе данных SQL можно использовать для эффективной идентификации всех строк и некоторых совпадающих столбцов в запросе, а затем пользователь может быстро ввести подмножество таблицы, чтобы определить точные совпадения предложенного вопроса.
Индекс SQL используется для быстрого поиска данных в таблице базы данных без поиска каждой ее строки. В индексе SQL необходимо поддерживать больше места для хранения, чтобы сделать дублирующую копию базы данных. Индекс хранит полные данные в таблице, которая логически организована со столбцами и строками и физически поддерживается и хранится в данных по строкам, известных как хранилище строк, и в случае, если записи хранятся в данных по столбцам, известных как Columnstore. .
В SQL есть разные типы индексов:
- Кластерный индекс
- Некластеризованный индекс
- Уникальный индекс
- Отфильтрованный индекс
- Индекс хранилища столбцов
- Хэш-индекс
Изучение SQL от базового до продвинутого уровня с практическим обучением, размещением и т. д. с помощью онлайн-обучения
SQL
В SQL существуют различные типы индексов
Кластерный индекс
Кластерные индексы сортируют и хранят данные строк в таблице или мнение, основанное на их фундаментальных ценностях. В каждой таблице может быть только один кластеризованный индекс, так как он позволяет пользователю хранить данные в одном порядке. Собранный индекс хранит данные в отсортированном виде, и поэтому всякий раз, когда данные содержатся в таблице в отсортированном виде, это означает, что они организованы с кластеризованным индексом.
Если таблица содержит кластеризованный индекс, она называется кластеризованной таблицей. Кластерный индекс предпочтительнее использовать, когда в любой базе данных требуется изменение огромных данных. Если данные, хранящиеся в таблице или базе данных, не расположены в порядке возрастания или убывания, то таблица данных называется кучей.
Некластеризованный индекс
Некластеризованный индекс представляет собой структуру, которая отделена от строк данных. Этот тип индекса в SQL охватывает некластеризованные ключевые значения, и каждая пара значений имеет указатель на строку данных, которая имеет решающее значение. В некластеризованном индексе стрелка от строки индекса к строке данных называется локатором строки. Структура локатора строк позволяет определить, имеют ли страницы данных форму кластеризованной таблицы или кучи. В кластеризованной диаграмме указатель строки называется ключом кластеризованного индекса.
В некластеризованном индексе пользователь может легко добавлять неключевые столбцы на конечный уровень, поскольку он обходит ограничения существующих ключей индекса и выполняет полностью покрытые индексированные запросы. Некластеризованный индекс создается для повышения общей производительности часто задаваемых вопросов, которые не охвачены кластеризованными элементами.
Уникальный индекс
Уникальный индекс в SQL гарантирует и подтверждает, что ключ индекса не содержит повторяющихся значений и, следовательно, позволяет пользователям анализировать, что каждая строка в таблице уникальна тем или иным образом. Уникальный индекс специально используется, когда пользователь хочет иметь уникальную характеристику каждых данных. Уникальные индексы позволяют отдельным лицам гарантировать целостность данных каждого определенного столбца таблицы в базе данных. Этот индекс также предоставляет дополнительную информацию о таблице данных, которая полезна для оптимизатора запросов.
Отфильтрованный индекс
Отфильтрованный индекс создается, когда столбец имеет лишь небольшое количество релевантных значений для запросов к подмножеству значений. В случае, когда таблица состоит из разнородных строк данных, в SQL создается отфильтрованный индекс для одного или нескольких типов данных. Даже если оптимизатор запросов не охватывает какой-либо запрос, он все равно указывает отфильтрованный индекс для вопроса.
Отфильтрованный индекс — это новая функция SQL, которая используется для индексации части строк в таблице, что означает применение фильтра к индексу и, следовательно, повышение общей производительности запроса. Отфильтрованный индекс приводит к вычету затрат на обслуживание индекса и снижает затраты на хранение индекса по сравнению с индексами полной таблицы. Общее влияние изменения данных меньше при использовании отфильтрованного индекса, поскольку он обновляется только при вставке новой записи или при изменении данных индекса.
Индекс хранилища столбцов
Индекс хранилища столбцов — это стандартная форма индекса, когда речь идет о хранении и запросе больших таблиц фактов хранилища данных. Индекс хранилища столбцов — это индекс SQL, который был разработан для повышения производительности запросов в случае рабочих нагрузок с большими объемами данных. Этот тип индекса хранит данные в формате на основе столбцов. Индекс хранилища столбцов снижает общие затраты на хранение и обеспечивает очень высокий уровень сжатия массивных данных. Благодаря сжатию хранимых данных пользователь может эффективно выполнять функции ввода-вывода и тем самым добиться высокой производительности.
Индекс хранилища столбцов позволяет хранить данные на небольших площадях, что помогает увеличить скорость обработки. Использование этого индекса позволяет пользователю получить ввод-вывод с в 10 раз более высокой производительностью запросов по сравнению с традиционным хранилищем, ориентированным на строки. Для аналитики индекс Columnstore обеспечивает на порядок более высокую производительность, чем другие индексы в SQL. Значения индекса хранилища столбцов из одного и того же домена имеют схожие значения, что увеличивает общую скорость сжатия данных.
Хэш-индекс
Хэш-индекс в SQL — это просто массив из N сегментов или слотов, содержащий указатель и строку для каждого сегмента или слота. Хэш-индекс использует хеш-функцию F(K, N), где K является критическим, а количество сегментов равно N. Функция отображает ключ, соответствующий сегменту хеш-индекса. Каждое ведро хэш-индекса состоит из 8 байтов, которые используются для хранения адреса памяти связанного списка критических записей.
Похожие блоги
- SQL присоединяется
- Схема в SQL
- Декодировать в SQL
Учебное пособие по индексу SQL — все, что нужно знать разработчикам, Pt. 1
При правильном использовании индекс базы данных SQL может быть настолько эффективным, что может показаться магией. Но следующая серия упражнений покажет, что в глубине логика большинства SQL-индексов — и их правильное использование — довольно проста.
В этой серии Объяснение индексов SQL мы рассмотрим мотивы использования индексов для доступа к данным и разработки индексов так, как это делается во всех современных СУБД. Затем мы рассмотрим алгоритмы, используемые для возврата данных для конкретных шаблонов запросов.
Вам не нужно много знать об индексах, чтобы следовать Объяснение индексов SQL . Есть только два предварительных условия:
- Базовые знания SQL
- Базовые знания любого языка программирования
Основные темы Объяснение индексов SQL войдет в:
- Зачем нам нужны индексы базы данных SQL; визуализация планов выполнения с использованием индексов
- Дизайн индекса: какие индексы делают запрос быстрым и эффективным
- Как мы можем написать запрос для эффективного использования индексов
- Влияние использования индексов в SQL на эффективность чтения/записи
- Накрывающие индексы
- Разделение, его влияние на чтение и запись и когда его использовать
Это не просто руководство по индексам SQL — это глубокое погружение в понимание базовой механики индексов.
Мы собираемся выяснить, как СУБД использует индексы, выполняя упражнения и анализируя наши методы решения проблем. Наш учебный материал состоит из таблиц Google, доступных только для чтения. Чтобы выполнить упражнение, вы можете скопировать Google Sheet ( File → Сделайте копию ) или скопируйте его содержимое в свой собственный Google Sheet.
В каждом упражнении мы покажем SQL-запрос, использующий синтаксис Oracle. Для дат мы будем использовать формат ISO 8601, ГГГГ-ММ-ДД .
Упражнение 1: все бронирования клиента
Первая задача — пока не делайте этого — найти все строки из электронной таблицы Reservation для конкретного клиента системы бронирования отелей и скопировать их в свою собственную электронную таблицу. , имитируя выполнение следующего запроса:
ВЫБОР
*
ИЗ
Бронирование
КУДА
ID клиента = 12;
Но мы хотим следовать определенному методу.
Подход 1: Без сортировки, без фильтрации
При первой попытке не используйте функции сортировки или фильтрации. Пожалуйста, зафиксируйте потраченное время. Полученный лист должен содержать 73 строки.
Этот псевдокод иллюстрирует алгоритм выполнения задачи без сортировки:
Для каждой строки из Reservations Если Reservations.ClientID = 12, выберите Reservations.*
В этом случае нам пришлось проверить все 841 строку, чтобы вернуть и скопировать 73 строки, удовлетворяющие условию.
Подход 2: Только сортировка
При второй попытке отсортируйте таблицу в соответствии со значением столбца ClientID . Не используйте фильтры. Запишите время и сравните его со временем выполнения задачи без сортировки данных.
После сортировки подход выглядит так:
Для каждой строки из Reservations Если ClientID = 12, тогда получите Reservations.* В противном случае, если ClientID > 12, выход
На этот раз нам пришлось проверить «всего» 780 строк. Если бы мы могли каким-то образом перейти к первой строке, это заняло бы еще меньше времени.
Но если бы нам пришлось разрабатывать программу для задачи, это решение было бы еще медленнее, чем первое. Это потому, что нам пришлось бы сначала отсортировать все данные, а это значит, что к каждой строке нужно было бы получить доступ хотя бы один раз. Такой подход хорош только в том случае, если лист уже отсортирован в нужном порядке.
Упражнение 2. Количество бронирований, начиная с заданной даты
Теперь задача подсчитать количество чекинов 16 августа 2020:
ВЫБРАТЬ
СЧИТАТЬ (*)
ИЗ
Бронирование
КУДА
DateFrom = TO_DATE('2020-08-16', 'ГГГГ-ММ-ДД')
Используйте электронную таблицу из упражнения 1. Измерьте и сравните время, затраченное на выполнение задачи с сортировкой и без нее. Правильный счет — 91.
Для подхода без сортировки алгоритм в основном такой же, как и в упражнении 1.
Подход к сортировке также аналогичен подходу из предыдущего упражнения. Мы просто разделим цикл на две части:
-- Предположение: резервирование стола сортируется по дате от -- Найдите первое бронирование от 16 августа 2020 года.
Упражнение 3: Уголовное расследование
Инспектор полиции запрашивает список гостей, прибывших в отель 13 и 14 августа 2020 года.
ВЫБРАТЬ
ID клиента
ИЗ
Бронирование
КУДА
ДатаОт МЕЖДУ (
TO_DATE('2020-08-13', 'ГГГГ-ММ-ДД') И
TO_DATE('2020-08-14', 'ГГГГ-ММ-ДД')
)
И HotelID = 3;
Подход 1: Сортировка только по дате
Инспектор хочет быстро получить список. Мы уже знаем, что лучше отсортировать таблицу/таблицу по дате поступления. Если мы только что закончили упражнение 2, нам повезло, что таблица уже отсортирована. Итак, применяем подход, аналогичный подходу из упражнения 2.
Попробуйте, пожалуйста, зафиксировать время, количество строк, которые вам пришлось прочитать, и количество элементов в списке.
-- Предположение: резервирование стола сортируется по дате от -- Найдите первое бронирование от 13 августа 2020 года. Повторение Читать следующую строку До DateFrom >= '2020-08-13' -- Подготовить список В то время как DateFrom < '2020-08-15' Если HotelID = 3, то запишите ClientID Прочитайте следующую строку
При таком подходе нам пришлось прочитать 511 строк, чтобы составить список из 46 гостей. Если бы мы могли точно скользить вниз, нам фактически не нужно было бы выполнять 324 считывания из цикла повторения только для того, чтобы найти первое прибытие 13 августа. Однако нам все равно пришлось прочитать более 100 строк, чтобы проверить, прибыл ли гость в отель с HotelID из 3 .
Инспектор ждал все это время, но не был счастлив: Вместо имен гостей и других важных данных мы предоставили только список бессмысленных идентификаторов.
Мы вернемся к этому аспекту позже. Давайте сначала найдем способ подготовить список быстрее.
Подход 2: Сортировка по отелю, затем по дате
Чтобы отсортировать строки в соответствии с ID отеля , затем DateFrom , мы можем выбрать все столбцы, а затем использовать пункт меню Google Sheets Данные → Диапазон сортировки .
-- Допущение: отсортировано по HotelID и DateFrom -- Найдите первое бронирование для HotelID = 3. Повторение Читать следующую строку Пока идентификатор отеля >= 3 -- Найти первый приезд в отель 13 августа Пока HotelID = 3 и DateFrom < '2020-08-13' Прочитайте следующую строку -- Подготовить список Пока HotelID = 3 и DateFrom < '2020-08-15' Запишите идентификатор клиента Прочитайте следующую строку
Нам пришлось пропустить первые 338 прибытий, прежде чем найти первого в нашем отеле. После этого мы просмотрели 103 более ранних прибытия, чтобы найти первое 13 августа. Наконец, мы скопировали 46 последовательных значений ClientID . Нам помогло то, что на третьем шаге мы смогли скопировать блок последовательных идентификаторов. Жаль, что мы не могли каким-то образом перейти на первую строку из этого блока.
Подход 3: Сортировка только по отелю
Теперь попробуйте выполнить то же упражнение, используя электронную таблицу, упорядоченную по Только HotelID .
Алгоритм, применяемый к таблице, упорядоченной по HotelID , менее эффективен, чем при сортировке по HotelID и DateFrom (в таком порядке):
-- Предположение: Сортировка по HotelID
-- Найдите первое бронирование для HotelID = 3.
Повторение
Читать следующую строку
Пока идентификатор отеля >= 3
-- Подготовить список
Пока HotelID = 3
Если DateFrom между «2020-08-13» и «2020-08-14»
Запишите идентификатор клиента
Прочитайте следующую строку
В этом случае мы должны прочитать все 166 прибытий в отель с HotelID из 3 и для каждого проверить, принадлежит ли DateFrom запрошенному интервалу.
Подход 4: Сортировка по дате, затем по гостинице
Имеет ли значение, сортируем ли мы сначала по HotelID , а затем DateFrom или наоборот? Давайте выясним: попробуйте отсортировать сначала по DateFrom , затем по HotelID .
-- Допущение: отсортировано по DateFrom и HotelID
-- Найти первое прибытие 13 августа
В то время как DateFrom < '2020-08-13'
Прочитайте следующую строку
-- Найдите первое прибытие в отель
В то время как HotelID < 3 и DateFrom < '2020-08-15'
Прочитайте следующую строку
Повторение
Если HotelID = 3
Запишите идентификатор клиента
Прочитайте следующую строку
До DateFrom > '2020-08-14' или (DateFrom = '2020-08-14' и HotelID > 3)
Мы нашли первую строку с соответствующей датой, затем читаем дальше, пока не найдем первое прибытие в отель. После этого для ряда строк выполнялись оба условия, правильная дата и правильный отель. Однако после заездов в гостиницу 3 у нас были заезды в гостиницы 4, 5 и так далее на ту же дату. После них нам пришлось снова читать строки на следующий день для отелей 1 и 2, пока мы не смогли прочитать последовательные прибытия в интересующий нас отель.
Как мы видим, все подходы имеют один последовательный блок данных в середине полного набора строк, представляющих частично совпадающие данные. Подходы 2 и 4 — единственные, в которых логика позволяет нам полностью остановить алгоритм до того, как мы достигнем конца частичных совпадений.
Подход 4 полностью совпал с данными в двух блоках, но подход 2 — единственный, в котором все целевые данные находятся в одном последовательном блоке.
| Подход 1 | Подход 2 | Подход 3 | Подход 4 | |
|---|---|---|---|---|
| Начальные пропускаемые строки | 324 | 338 + 103 = 441 | 342 | 324 |
| Строки-кандидаты для проверки | 188 | 46 | 166 | 159 |
| Пропускаемые строки после остановки алгоритма | 328 | 353 | 332 | 357 |
| Всего пропускаемых строк | 652 | 794 | 674 | 681 |
Судя по цифрам, подход 2 в данном случае имеет больше преимуществ.
Объяснение индексов SQL: выводы и дальнейшие действия
Выполнение этих упражнений должно прояснить следующие моменты:
- Чтение из правильно отсортированной таблицы выполняется быстрее.
- Если таблица еще не отсортирована, сортировка занимает больше времени, чем чтение из несортированной таблицы.
- Если найти способ перейти к первой строке, соответствующей условию поиска, в отсортированной таблице, можно сэкономить много операций чтения.
- Было бы полезно заранее отсортировать таблицу.
- Было бы полезно поддерживать отсортированные копии таблицы для наиболее частых запросов.
Отсортированная копия таблицы звучит почти как индекс базы данных. Следующая статья в Объяснение индексов SQL посвящена элементарной реализации индекса. Спасибо за чтение!
Дополнительные материалы в блоге Toptal Engineering:
- Объяснение индексов SQL, Pt. 2
- Устранение узких мест с помощью индексов и разделов SQL
- Настройка производительности базы данных SQL для разработчиков
- Руководство по синхронизации данных в Microsoft SQL Server
- Как настроить Microsoft SQL Server для повышения производительности
Понимание основ
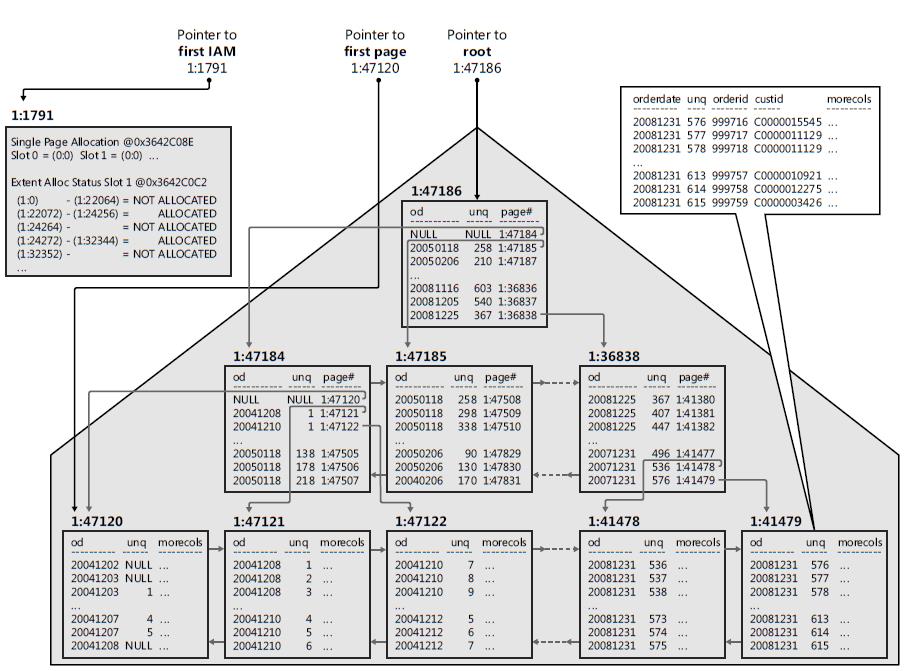
Индекс базы данных — важная вспомогательная структура данных, помогающая ускорить поиск данных. Объем данных, к которым осуществляется доступ для выполнения SQL-запроса, является основным фактором, влияющим на время выполнения. Использование хорошо спроектированных индексов сводит к минимуму объем запрашиваемых данных.
Основной вариант использования — запрос, возвращающий данные на основе условия типа «значение столбца между X и Y». Индекс столбца позволяет РСУБД быстро найти первую строку, удовлетворяющую условию, прочитать последовательные строки из заданного диапазона и остановиться без необходимости чтения каких-либо других данных.
Индексы можно классифицировать по типам несколькими способами: по их структуре (B-дерево, хеш-таблица, двоичный файл, хранилище столбцов, полнотекстовый и т. глобально или никак). Некоторые хранят целые строки, некоторые хранят производные значения, третьи хранят прямые копии столбцов.
Типичный индекс реализован с использованием сбалансированной древовидной структуры. Конечные уровни индекса сортируются на основе значений столбцов. Итак, когда мы хотим найти все строки с определенным значением индексированного столбца, мы можем быстро найти первую и прочитать последовательные строки, если они соответствуют значению.
Соответствующий индекс может значительно сократить объем данных, к которым обращается оператор SELECT, что является основным фактором, влияющим на время выполнения запроса.
Современные базы данных часто хранят и публикуют огромные объемы данных. Когда пользователь пытается получить только небольшой фрагмент данных без соответствующего индекса, поиск (иголки в стоге сена) может занять несколько часов.
Мирко Марович
Эксперт по настройке производительности баз данных
Об авторе
Мирко имеет более чем двадцатилетний опыт проектирования, разработки и оптимизации баз данных. У него была возможность работать с наиболее часто используемыми платформами баз данных: MS SQL Server, Oracle, MySQL и PostgreSQL.