Index sql: Все, что необходимо знать про индексы MS SQL OTUS
Содержание
SQL Server. Работа с индексами через запросы SQL
Иногда возникают задачи по массовой обработке индексов, например, переносу индексов на другую базу. В этой статье рассмотрим как можно получить список всех индексов, получить SQL индекса и массово перестроить индексы.
Как получить все индексы базы данных SQL Server с их определением
declare @dbTablePrefix nvarchar(256) = ''
SELECT
'if not exists( SELECT * FROM sys.indexes WHERE name='''+I.name+''' ) begin ' + CHAR(13) + CHAR(10) + --AND object_id = OBJECT_ID('Schema.YourTableName')
' CREATE ' +
CASE
WHEN I.is_unique = 1 THEN ' UNIQUE '
ELSE ''
END +
I.type_desc COLLATE DATABASE_DEFAULT + ' INDEX ' +
I.name + ' ON ' +
SCHEMA_NAME(T.schema_id) + '.' + T.name + ' ( ' +
KeyColumns + ' ) ' +
ISNULL(' INCLUDE (' + IncludedColumns + ' ) ', '') +
ISNULL(' WHERE ' + I.filter_definition, '') + ' WITH ( ' +
CASE
WHEN I. is_padded = 1 THEN ' PAD_INDEX = ON '
ELSE ' PAD_INDEX = OFF '
END + ',' +
'FILLFACTOR = ' + CONVERT(
CHAR(5),
CASE
WHEN I.fill_factor = 0 THEN 100
ELSE I.fill_factor
END
) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE
WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON '
ELSE ' IGNORE_DUP_KEY = OFF '
END + ',' +
CASE
WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF '
ELSE ' STATISTICS_NORECOMPUTE = ON '
END + ',' +
' ONLINE = OFF ' + ',' +
-- ' drop_existing = on ' + ',' +
CASE
WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON '
ELSE ' ALLOW_ROW_LOCKS = OFF '
END + ',' +
CASE
WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON '
ELSE ' ALLOW_PAGE_LOCKS = OFF '
END + ' ) ON [' +
DS. name + ' ] ' + CHAR(13) + CHAR(10) +
' print ''Create index '+ I.name +'''' + CHAR(13) + CHAR(10) +
'end -- if exists' + CHAR(13) + CHAR(10) + 'GO ' [CreateIndexScript],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
i.[name] as index_name,
KeyColumns,
IncludedColumns,
-- substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
FROM sys.indexes I
JOIN sys. tables T
ON T.object_id = I.object_id
JOIN sys.sysindexes SI
ON I.object_id = SI.id
AND I.index_id = SI.indid
JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']' + CASE
WHEN MAX(CONVERT(INT, IC1.is_descending_key))
= 1 THEN
' DESC '
ELSE
' ASC '
END
FROM sys. index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
ORDER BY
MAX(IC1.key_ordinal)
FOR XML PATH('')
),
1,
2,
''
) KeyColumns
FROM sys. index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp3
)tmp4
ON I.object_id = tmp4.object_id
AND I.Index_id = tmp4.index_id
JOIN sys.stats ST
ON ST.object_id = I.object_id
AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS
ON I.data_space_id = DS.data_space_id
JOIN sys.filegroups FG
ON I.data_space_id = FG.data_space_id
LEFT JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']'
FROM sys. index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
FOR XML PATH('')
),
1,
2,
''
) IncludedColumns
FROM sys. index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp1
WHERE IncludedColumns IS NOT NULL
) tmp2
ON tmp2.object_id = I.object_id
AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0
AND I.is_unique_constraint = 0
AND (@dbTablePrefix = '' or t.[name] like @dbTablePrefix + '%') --Comment for all tables I.Object_id = object_id(@dbTable)
--AND I.name = 'IX_Address_PostalCode' --comment for all indexes
and t.is_ms_shipped <> 1
order by table_view
is_padded = 1 THEN ' PAD_INDEX = ON '
ELSE ' PAD_INDEX = OFF '
END + ',' +
'FILLFACTOR = ' + CONVERT(
CHAR(5),
CASE
WHEN I.fill_factor = 0 THEN 100
ELSE I.fill_factor
END
) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE
WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON '
ELSE ' IGNORE_DUP_KEY = OFF '
END + ',' +
CASE
WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF '
ELSE ' STATISTICS_NORECOMPUTE = ON '
END + ',' +
' ONLINE = OFF ' + ',' +
-- ' drop_existing = on ' + ',' +
CASE
WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON '
ELSE ' ALLOW_ROW_LOCKS = OFF '
END + ',' +
CASE
WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON '
ELSE ' ALLOW_PAGE_LOCKS = OFF '
END + ' ) ON [' +
DS. name + ' ] ' + CHAR(13) + CHAR(10) +
' print ''Create index '+ I.name +'''' + CHAR(13) + CHAR(10) +
'end -- if exists' + CHAR(13) + CHAR(10) + 'GO ' [CreateIndexScript],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
i.[name] as index_name,
KeyColumns,
IncludedColumns,
-- substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
FROM sys.indexes I
JOIN sys. tables T
ON T.object_id = I.object_id
JOIN sys.sysindexes SI
ON I.object_id = SI.id
AND I.index_id = SI.indid
JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']' + CASE
WHEN MAX(CONVERT(INT, IC1.is_descending_key))
= 1 THEN
' DESC '
ELSE
' ASC '
END
FROM sys. index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
ORDER BY
MAX(IC1.key_ordinal)
FOR XML PATH('')
),
1,
2,
''
) KeyColumns
FROM sys. index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp3
)tmp4
ON I.object_id = tmp4.object_id
AND I.Index_id = tmp4.index_id
JOIN sys.stats ST
ON ST.object_id = I.object_id
AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS
ON I.data_space_id = DS.data_space_id
JOIN sys.filegroups FG
ON I.data_space_id = FG.data_space_id
LEFT JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']'
FROM sys. index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
FOR XML PATH('')
),
1,
2,
''
) IncludedColumns
FROM sys. index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp1
WHERE IncludedColumns IS NOT NULL
) tmp2
ON tmp2.object_id = I.object_id
AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0
AND I.is_unique_constraint = 0
AND (@dbTablePrefix = '' or t.[name] like @dbTablePrefix + '%') --Comment for all tables I.Object_id = object_id(@dbTable)
--AND I.name = 'IX_Address_PostalCode' --comment for all indexes
and t.is_ms_shipped <> 1
order by table_view
 is_padded = 1 THEN ' PAD_INDEX = ON '
ELSE ' PAD_INDEX = OFF '
END + ',' +
'FILLFACTOR = ' + CONVERT(
CHAR(5),
CASE
WHEN I.fill_factor = 0 THEN 100
ELSE I.fill_factor
END
) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE
WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON '
ELSE ' IGNORE_DUP_KEY = OFF '
END + ',' +
CASE
WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF '
ELSE ' STATISTICS_NORECOMPUTE = ON '
END + ',' +
' ONLINE = OFF ' + ',' +
-- ' drop_existing = on ' + ',' +
CASE
WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON '
ELSE ' ALLOW_ROW_LOCKS = OFF '
END + ',' +
CASE
WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON '
ELSE ' ALLOW_PAGE_LOCKS = OFF '
END + ' ) ON [' +
DS.
is_padded = 1 THEN ' PAD_INDEX = ON '
ELSE ' PAD_INDEX = OFF '
END + ',' +
'FILLFACTOR = ' + CONVERT(
CHAR(5),
CASE
WHEN I.fill_factor = 0 THEN 100
ELSE I.fill_factor
END
) + ',' +
-- default value
'SORT_IN_TEMPDB = OFF ' + ',' +
CASE
WHEN I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON '
ELSE ' IGNORE_DUP_KEY = OFF '
END + ',' +
CASE
WHEN ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF '
ELSE ' STATISTICS_NORECOMPUTE = ON '
END + ',' +
' ONLINE = OFF ' + ',' +
-- ' drop_existing = on ' + ',' +
CASE
WHEN I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON '
ELSE ' ALLOW_ROW_LOCKS = OFF '
END + ',' +
CASE
WHEN I.allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON '
ELSE ' ALLOW_PAGE_LOCKS = OFF '
END + ' ) ON [' +
DS. name + ' ] ' + CHAR(13) + CHAR(10) +
' print ''Create index '+ I.name +'''' + CHAR(13) + CHAR(10) +
'end -- if exists' + CHAR(13) + CHAR(10) + 'GO ' [CreateIndexScript],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
i.[name] as index_name,
KeyColumns,
IncludedColumns,
-- substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
FROM sys.indexes I
JOIN sys.
name + ' ] ' + CHAR(13) + CHAR(10) +
' print ''Create index '+ I.name +'''' + CHAR(13) + CHAR(10) +
'end -- if exists' + CHAR(13) + CHAR(10) + 'GO ' [CreateIndexScript],
schema_name(t.schema_id) + '.' + t.[name] as table_view,
i.[name] as index_name,
KeyColumns,
IncludedColumns,
-- substring(column_names, 1, len(column_names)-1) as [columns],
case when i.[type] = 1 then 'Clustered index'
when i.[type] = 2 then 'Nonclustered unique index'
when i.[type] = 3 then 'XML index'
when i.[type] = 4 then 'Spatial index'
when i.[type] = 5 then 'Clustered columnstore index'
when i.[type] = 6 then 'Nonclustered columnstore index'
when i.[type] = 7 then 'Nonclustered hash index'
end as index_type,
case when i.is_unique = 1 then 'Unique'
else 'Not unique' end as [unique],
case when t.[type] = 'U' then 'Table'
when t.[type] = 'V' then 'View'
end as [object_type]
FROM sys.indexes I
JOIN sys. tables T
ON T.object_id = I.object_id
JOIN sys.sysindexes SI
ON I.object_id = SI.id
AND I.index_id = SI.indid
JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']' + CASE
WHEN MAX(CONVERT(INT, IC1.is_descending_key))
= 1 THEN
' DESC '
ELSE
' ASC '
END
FROM sys.
tables T
ON T.object_id = I.object_id
JOIN sys.sysindexes SI
ON I.object_id = SI.id
AND I.index_id = SI.indid
JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']' + CASE
WHEN MAX(CONVERT(INT, IC1.is_descending_key))
= 1 THEN
' DESC '
ELSE
' ASC '
END
FROM sys. index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
ORDER BY
MAX(IC1.key_ordinal)
FOR XML PATH('')
),
1,
2,
''
) KeyColumns
FROM sys.
index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
0
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
ORDER BY
MAX(IC1.key_ordinal)
FOR XML PATH('')
),
1,
2,
''
) KeyColumns
FROM sys.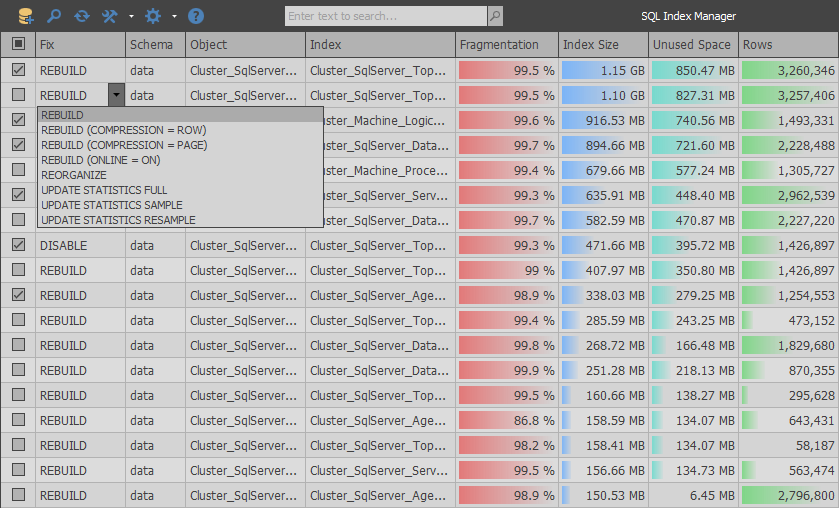 index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp3
)tmp4
ON I.object_id = tmp4.object_id
AND I.Index_id = tmp4.index_id
JOIN sys.stats ST
ON ST.object_id = I.object_id
AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS
ON I.data_space_id = DS.data_space_id
JOIN sys.filegroups FG
ON I.data_space_id = FG.data_space_id
LEFT JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']'
FROM sys.
index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp3
)tmp4
ON I.object_id = tmp4.object_id
AND I.Index_id = tmp4.index_id
JOIN sys.stats ST
ON ST.object_id = I.object_id
AND ST.stats_id = I.index_id
JOIN sys.data_spaces DS
ON I.data_space_id = DS.data_space_id
JOIN sys.filegroups FG
ON I.data_space_id = FG.data_space_id
LEFT JOIN (
SELECT *
FROM (
SELECT IC2.object_id,
IC2.index_id,
STUFF(
(
SELECT ' , [' + C.name + ']'
FROM sys.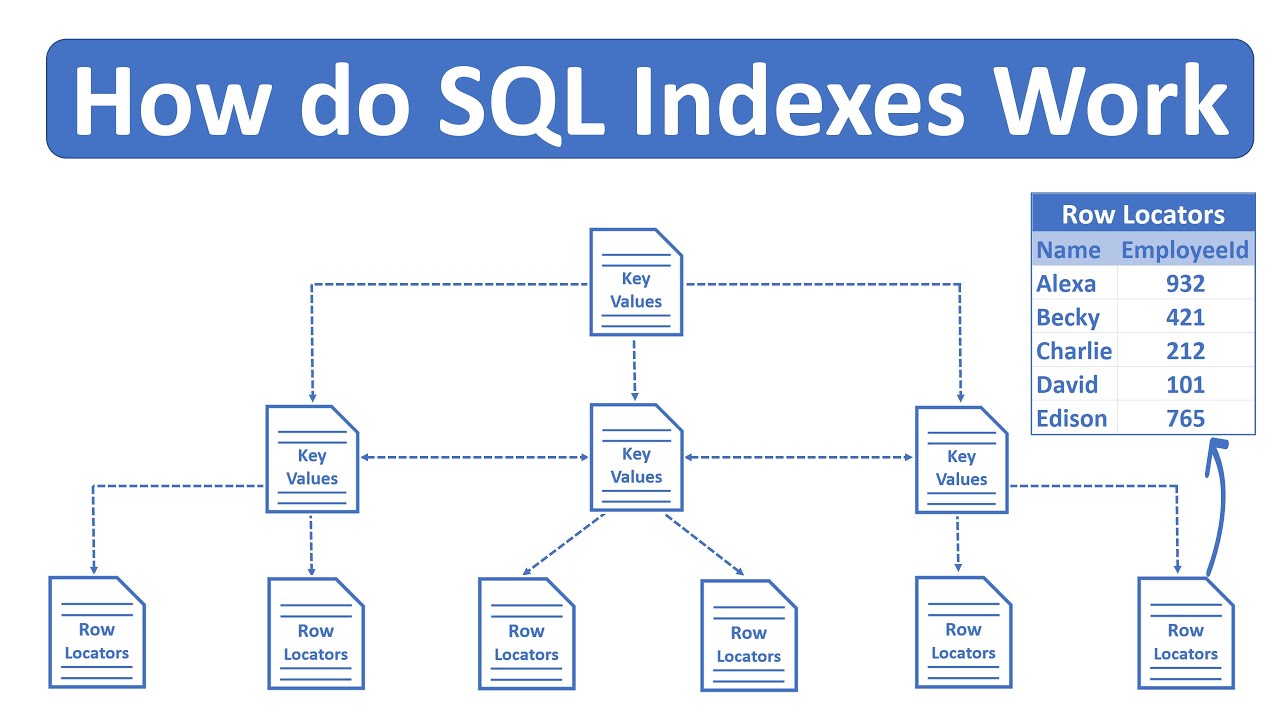 index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
FOR XML PATH('')
),
1,
2,
''
) IncludedColumns
FROM sys.
index_columns IC1
JOIN sys.columns C
ON C.object_id = IC1.object_id
AND C.column_id = IC1.column_id
AND IC1.is_included_column =
1
WHERE IC1.object_id = IC2.object_id
AND IC1.index_id = IC2.index_id
GROUP BY
IC1.object_id,
C.name,
index_id
FOR XML PATH('')
),
1,
2,
''
) IncludedColumns
FROM sys. index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp1
WHERE IncludedColumns IS NOT NULL
) tmp2
ON tmp2.object_id = I.object_id
AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0
AND I.is_unique_constraint = 0
AND (@dbTablePrefix = '' or t.[name] like @dbTablePrefix + '%') --Comment for all tables I.Object_id = object_id(@dbTable)
--AND I.name = 'IX_Address_PostalCode' --comment for all indexes
and t.is_ms_shipped <> 1
order by table_view
index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Comment for all tables
GROUP BY
IC2.object_id,
IC2.index_id
) tmp1
WHERE IncludedColumns IS NOT NULL
) tmp2
ON tmp2.object_id = I.object_id
AND tmp2.index_id = I.index_id
WHERE I.is_primary_key = 0
AND I.is_unique_constraint = 0
AND (@dbTablePrefix = '' or t.[name] like @dbTablePrefix + '%') --Comment for all tables I.Object_id = object_id(@dbTable)
--AND I.name = 'IX_Address_PostalCode' --comment for all indexes
and t.is_ms_shipped <> 1
order by table_view
Если указать @dbTablePrefix, то мы получим только индексы на таблицы, начинающиеся с заданного префикса.
В результате выполнения скрипта мы получим скрипты вида:
if not exists( SELECT * FROM sys.
 indexes WHERE name='ind_apiActions_code' ) begin
CREATE NONCLUSTERED INDEX ind_apiActions_code ON dbo.as_api_actions ( [code] ASC )
WITH ( PAD_INDEX = OFF ,FILLFACTOR = 100 ,SORT_IN_TEMPDB = OFF ,
IGNORE_DUP_KEY = OFF , STATISTICS_NORECOMPUTE = OFF , ONLINE = OFF ,
ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY ]
print 'Create index ind_apiActions_code'
end
GO
indexes WHERE name='ind_apiActions_code' ) begin
CREATE NONCLUSTERED INDEX ind_apiActions_code ON dbo.as_api_actions ( [code] ASC )
WITH ( PAD_INDEX = OFF ,FILLFACTOR = 100 ,SORT_IN_TEMPDB = OFF ,
IGNORE_DUP_KEY = OFF , STATISTICS_NORECOMPUTE = OFF , ONLINE = OFF ,
ALLOW_ROW_LOCKS = ON , ALLOW_PAGE_LOCKS = ON ) ON [PRIMARY ]
print 'Create index ind_apiActions_code'
end
GO Копируем определения индексов и выполняем массово на другой базе. Если такой индекс был, то он пропускается. Если нет какого-то столбца или таблицы, то будет просто ошибка, но другие индексы создадутся.
Поиск дубликатов индексов SQL Server
При массовом добавлении индексов может возникнуть такая ситуация, что какие-то индексы будут дублироваться — называются они по разному, но имеют одинаковые настройки. Выявить их можно через такой скрипт:
-- Ищем дубликаты индексов (создает нагрузку на процессор) select t1.tablename,t1.indexname,t1.columnlist,t2.indexname,t2.columnlist from (select distinct object_name(i.
 object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i.index_id=ic.index_id inner join
sys.objects o on i.object_id=o.
object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i.index_id=ic.index_id inner join
sys.objects o on i.object_id=o. object_id
where o.is_ms_shipped=0) t1 inner join
(select distinct object_name(i.object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i.
object_id
where o.is_ms_shipped=0) t1 inner join
(select distinct object_name(i.object_id) tablename,i.name indexname,
(select distinct stuff((select ', ' + c.name
from sys.index_columns ic1 inner join
sys.columns c on ic1.object_id=c.object_id and
ic1.column_id=c.column_id
where ic1.index_id = ic.index_id and
ic1.object_id=i.object_id and
ic1.index_id=i.index_id
order by index_column_id FOR XML PATH('')),1,2,'')
from sys.index_columns ic
where object_id=i.object_id and index_id=i.index_id) as columnlist
from sys.indexes i inner join
sys.index_columns ic on i.object_id=ic.object_id and
i. index_id=ic.index_id inner join
sys.objects o on i.object_id=o.object_id
where o.is_ms_shipped=0) t2 on t1.tablename=t2.tablename and
substring(t2.columnlist,1,len(t1.columnlist))=t1.columnlist and
(t1.columnlist<>t2.columnlist or
(t1.columnlist=t2.columnlist and t1.indexname<>t2.indexname))
index_id=ic.index_id inner join
sys.objects o on i.object_id=o.object_id
where o.is_ms_shipped=0) t2 on t1.tablename=t2.tablename and
substring(t2.columnlist,1,len(t1.columnlist))=t1.columnlist and
(t1.columnlist<>t2.columnlist or
(t1.columnlist=t2.columnlist and t1.indexname<>t2.indexname))Далее можно ручками удалить ненужные индексы в базе.
Реорганизация или перестройка индексов в базе SQL Server
Вы можете сделать либо reorganize либо rebuild для всех индексов в базе.
Для этого можно использовать следующий скрипт:
-- Скрипт реорганизует индексы по всем таблицам IF OBJECT_ID(N'tempdb..#RowCounts') IS NOT NULL BEGIN DROP TABLE #RowCounts END GO declare @minRows int =400 -- перестройка индекса выполняется только для таблиц где больше N строк CREATE TABLE #RowCounts(NumberOfRows BIGINT,TableName VARCHAR(128)) EXEC sp_MSForEachTable 'INSERT INTO #RowCounts SELECT COUNT_BIG(*) AS NumberOfRows, ''?'' as TableName FROM ?' select TableName, NumberOfRows from #RowCounts where NumberOfRows>@minRows ---SELECT TableName,NumberOfRows FROM #RowCounts ORDER BY NumberOfRows DESC,TableName declare @TableName nvarchar(256) declare @NumberOfRows int declare cur CURSOR LOCAL for select TableName, NumberOfRows from #RowCounts where NumberOfRows>@minRows open cur fetch next from cur into @TableName, @NumberOfRows while @@FETCH_STATUS = 0 BEGIN print @TableName -- Rebuild (блочит таблицу, но быстрее идет) или REORGANIZE (дольше.
 но не блочит таблицу)
EXEC ('ALTER INDEX ALL ON ' +@TableName + ' Rebuild ;')
fetch next from cur into @TableName, @NumberOfRows
END
close cur
deallocate cur
DROP TABLE #RowCounts
но не блочит таблицу)
EXEC ('ALTER INDEX ALL ON ' +@TableName + ' Rebuild ;')
fetch next from cur into @TableName, @NumberOfRows
END
close cur
deallocate cur
DROP TABLE #RowCountsrebuild выполняется быстрее, но блокирует таблицу. Есть режим with ONLINE,но он работает только для Enterprise версии SQL Server. Фактически это пересоздание индекса.
reorganize выполняется дольше, но не блокирует таблицу базы данных.
В скрипте есть настройка @minRows — минимальное количество строк в таблицах, для которых будет перестроен индекс.
Где нужно ставить индексы в SQL Server, какие индексы можно удалить из базы данных SQL Server
Вы можете периодически запускать эти скрипты для поиска мест оптимизации индексов. Первый запрос покажет, какие индексы можно добавить. Второй запрос показывает какие индексы не используются эффективно (происходит больше записей, нежели чтения).
Данные запросы работают на основе внутренней статистики SQL Server, т.е. данные в них будут менять по мере использования базы.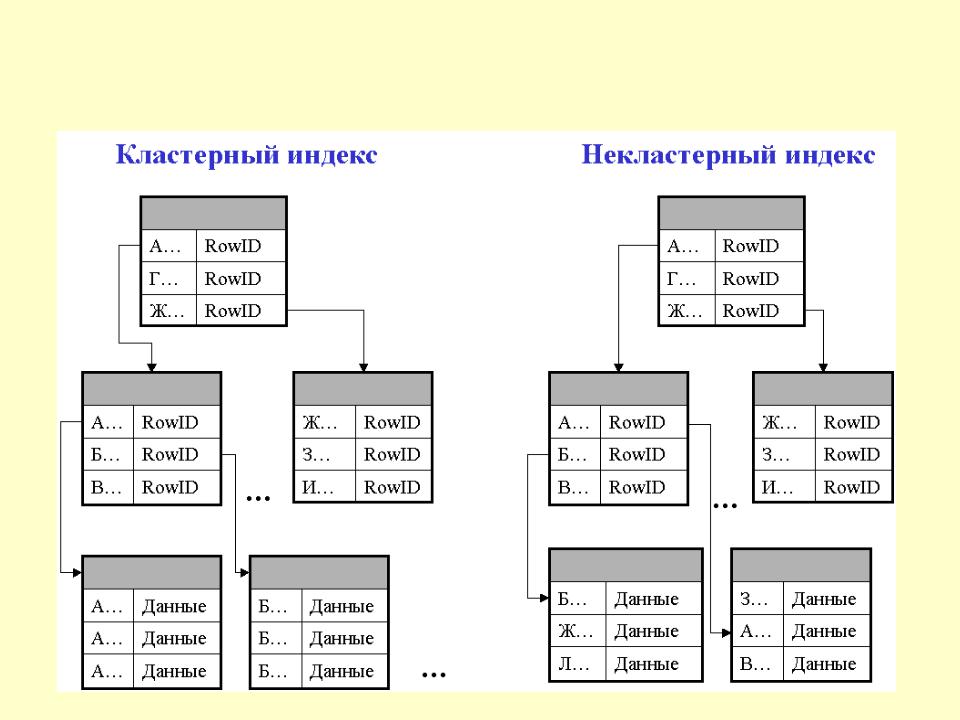
--Поиск, где можно установить индексы: select d.name AS DatabaseName, mid.* from sys.dm_db_missing_index_details mid join sys.databases d ON mid.database_id=d.database_id --Убрать лишние индексы: --там где user_updates больше чем user_lookup - можно удалить индексы SELECT d.name, t.name, i.name, ius.* FROM sys.dm_db_index_usage_stats ius JOIN sys.databases d ON d.database_id = ius.database_id JOIN sys.tables t ON t.object_id = ius.object_id JOIN sys.indexes i ON i.object_id = ius.object_id AND i.index_id = ius.index_id ORDER BY user_updates DESC
индексов — SQL Server | Microsoft Узнайте
Редактировать
Твиттер
Фейсбук
Электронная почта
- Статья
Применяется к: SQL Server База данных SQL Azure Azure SQL Управляемый экземпляр
Доступные типы индексов
В следующей таблице перечислены типы индексов, доступных в SQL Server, и приведены ссылки на дополнительную информацию.
| Тип индекса | Описание | Дополнительная информация |
|---|---|---|
| Хэш | При использовании хеш-индекса доступ к данным осуществляется через хеш-таблицу в памяти. Хэш-индексы потребляют фиксированный объем памяти, который зависит от количества сегментов. | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по проектированию хеш-индексов |
| оптимизированный для памяти Некластеризованный | Для оптимизированных для памяти некластеризованных индексов потребление памяти зависит от количества строк и размера ключевых столбцов индекса | Рекомендации по использованию индексов в таблицах, оптимизированных для памяти Рекомендации по разработке некластеризованных индексов, оптимизированных для памяти |
| Кластерный | Кластеризованный индекс сортирует и сохраняет строки данных таблицы или представления в порядке, основанном на ключе кластеризованного индекса. Кластеризованный индекс реализован в виде структуры индекса B-дерева, которая поддерживает быстрое извлечение строк на основе их значений ключа кластеризованного индекса. Кластеризованный индекс реализован в виде структуры индекса B-дерева, которая поддерживает быстрое извлечение строк на основе их значений ключа кластеризованного индекса. | Описание кластеризованных и некластеризованных индексов Создание кластеризованных индексов Руководство по проектированию кластеризованного индекса |
| Некластерный | Некластеризованный индекс можно определить для таблицы или представления с кластеризованным индексом или для кучи. Каждая строка индекса в некластеризованном индексе содержит значение некластеризованного ключа и указатель строки. Этот локатор указывает на строку данных в кластеризованном индексе или куче, имеющую значение ключа. Строки в индексе хранятся в порядке значений ключа индекса, но не гарантируется, что строки данных будут располагаться в каком-либо определенном порядке, если для таблицы не создан кластеризованный индекс. | Описание кластеризованных и некластеризованных индексов Создание некластеризованных индексов Рекомендации по проектированию некластеризованных индексов |
| Уникальный | Уникальный индекс гарантирует, что ключ индекса не содержит повторяющихся значений, поэтому каждая строка в таблице или представлении в некотором роде уникальна.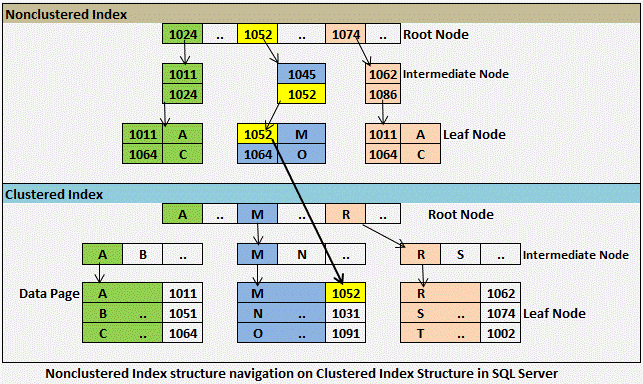 Уникальность может быть свойством как кластеризованных, так и некластеризованных индексов. | Создание уникальных индексов Рекомендации по проектированию уникальных индексов |
| Колонный магазин | Индекс columnstore в памяти хранит данные и управляет ими, используя хранилище данных на основе столбцов и обработку запросов на основе столбцов. Индексы Columnstore хорошо подходят для рабочих нагрузок хранилища данных, которые в основном выполняют массовые загрузки и запросы только для чтения. Используйте индекс columnstore, чтобы получить до 10-кратного увеличения производительности запросов, прироста по сравнению с традиционным хранилищем, ориентированным на строки, и до 7-кратного сжатия данных, по сравнению с размером несжатых данных. | Руководство по индексам Columnstore Руководство по проектированию индексов Columnstore |
| Указатель с включенными столбцами | Некластеризованный индекс, расширенный за счет включения неключевых столбцов в дополнение к ключевым столбцам. | Создание индексов с включенными столбцами |
| Индекс вычисляемых столбцов | Индекс столбца, полученный из значения одного или нескольких других столбцов или определенных детерминированных входных данных. | Индексы в вычисляемых столбцах |
| Отфильтровано | Оптимизированный некластеризованный индекс, особенно подходящий для покрытия запросов, которые выбирают из четко определенного подмножества данных. Он использует предикат фильтра для индексации части строк в таблице. Хорошо спроектированный отфильтрованный индекс может повысить производительность запросов, снизить затраты на обслуживание индекса и уменьшить затраты на хранение индекса по сравнению с полнотабличными индексами. | Создание отфильтрованных индексов Рекомендации по проектированию отфильтрованных индексов |
| Пространственный | Пространственный индекс позволяет более эффективно выполнять определенные операции над пространственными объектами ( пространственные данные ) в столбце типа данных геометрия .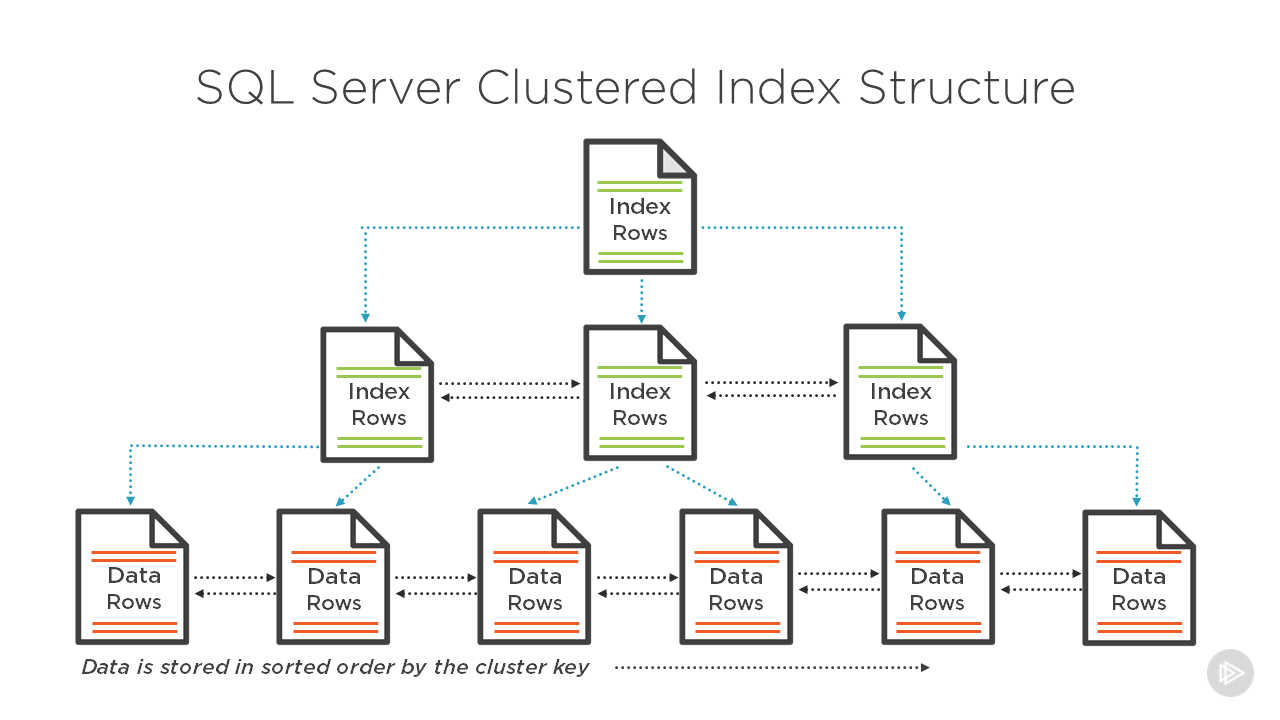 Пространственный индекс уменьшает количество объектов, к которым необходимо применять относительно дорогостоящие пространственные операции. Пространственный индекс уменьшает количество объектов, к которым необходимо применять относительно дорогостоящие пространственные операции. | Обзор пространственных индексов |
| XML | Измельченное и сохраненное представление больших двоичных объектов XML (BLOB) в xml столбец типа данных. | XML-индексы (SQL Server) |
| Полный текст | Специальный тип функционального индекса на основе токенов, который создается и поддерживается полнотекстовым механизмом Microsoft для SQL Server. Он обеспечивает эффективную поддержку сложного поиска слов в данных символьных строк. | Заполнение полнотекстовых индексов |
Примечание
В документации SQL Server термин B-дерево обычно используется в отношении индексов. В индексах rowstore SQL Server реализует дерево B+. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в Руководстве по архитектуре и дизайну индекса SQL Server.
в Руководстве по архитектуре и дизайну индекса SQL Server.
Следующие шаги
- Руководство по проектированию индекса SQL Server
- Опция SORT_IN_TEMPDB для индексов
- Отключить индексы и ограничения
- Включить индексы и ограничения
- Переименовать индексы
- Установить параметры индекса
- Требования к дисковому пространству для индексных операций DDL
- Реорганизация и перестроение индексов
- Укажите коэффициент заполнения для индекса
- Руководство по архитектуре страниц и экстентов
- Описание кластеризованных и некластеризованных индексов
Обратная связь
Просмотреть все отзывы о странице
Описаны кластеризованные и некластеризованные индексы — SQL Server
Редактировать
Твиттер
Фейсбук
Электронная почта
- Статья
Применяется к: SQL Server База данных SQL Azure Управляемый экземпляр Azure SQL
Индекс — это структура на диске, связанная с таблицей или представлением, которая ускоряет извлечение строк из таблицы или представления. Индекс содержит ключи, построенные из одного или нескольких столбцов в таблице или представлении. Эти ключи хранятся в структуре (B-дереве), которая позволяет SQL Server быстро и эффективно находить строку или строки, связанные со значениями ключа.
Примечание
В документации SQL Server термин B-дерево обычно используется в отношении индексов. В индексах rowstore SQL Server реализует дерево B+. Это не относится к индексам columnstore или хранилищам данных в памяти. Дополнительные сведения см. в Руководстве по архитектуре и дизайну индекса SQL Server.
Таблица или представление могут содержать следующие типы индексов:
И кластеризованные, и некластеризованные индексы могут быть уникальными. Это означает, что никакие две строки не могут иметь одинаковое значение ключа индекса. В противном случае индекс не уникален, и несколько строк могут иметь одно и то же значение ключа. Дополнительные сведения см. в разделе Создание уникальных индексов.
Это означает, что никакие две строки не могут иметь одинаковое значение ключа индекса. В противном случае индекс не уникален, и несколько строк могут иметь одно и то же значение ключа. Дополнительные сведения см. в разделе Создание уникальных индексов.
Индексы автоматически поддерживаются для таблицы или представления при каждом изменении данных таблицы.
Дополнительные типы индексов специального назначения см. в разделе Индексы.
Индексы и ограничения
Индексы создаются автоматически, когда для столбцов таблицы определены ограничения PRIMARY KEY и UNIQUE. Например, когда вы создаете таблицу с ограничением UNIQUE, компонент Database Engine автоматически создает некластеризованный индекс. Если вы настроите PRIMARY KEY, компонент Database Engine автоматически создаст кластеризованный индекс, если кластеризованный индекс еще не существует. Когда вы пытаетесь применить ограничение PRIMARY KEY к существующей таблице, а для этой таблицы уже существует кластеризованный индекс, SQL Server применяет первичный ключ, используя некластеризованный индекс.
Дополнительные сведения см. в разделах Создание первичных ключей и Создание уникальных ограничений.
Как оптимизатор запросов использует индексы
Хорошо спроектированные индексы могут сократить количество дисковых операций ввода-вывода и потреблять меньше системных ресурсов, тем самым повышая производительность запросов. Индексы могут быть полезны для различных запросов, содержащих операторы SELECT, UPDATE, DELETE или MERGE. Рассмотрим запрос SELECT Title, HireDate FROM HumanResources.Employee WHERE EmployeeID = 250 в 9База данных 0243 AdventureWorks2019 . При выполнении этого запроса оптимизатор запросов оценивает каждый доступный метод извлечения данных и выбирает наиболее эффективный метод. Метод может представлять собой сканирование таблицы или сканирование одного или нескольких индексов, если они существуют.
При сканировании таблицы оптимизатор запросов считывает все строки в таблице и извлекает строки, соответствующие критериям запроса. Сканирование таблицы создает множество операций дискового ввода-вывода и может требовать значительных ресурсов. Однако сканирование таблицы может быть наиболее эффективным методом, если, например, результирующий набор запроса представляет собой высокий процент строк из таблицы.
Сканирование таблицы создает множество операций дискового ввода-вывода и может требовать значительных ресурсов. Однако сканирование таблицы может быть наиболее эффективным методом, если, например, результирующий набор запроса представляет собой высокий процент строк из таблицы.
Когда оптимизатор запросов использует индекс, он ищет ключевые столбцы индекса, находит место хранения строк, необходимых для запроса, и извлекает соответствующие строки из этого местоположения. Как правило, поиск в индексе выполняется намного быстрее, чем поиск в таблице, потому что, в отличие от таблицы, индекс часто содержит очень мало столбцов в строке, а строки отсортированы.
Оптимизатор запросов обычно выбирает наиболее эффективный метод при выполнении запросов. Однако если индексы недоступны, оптимизатор запросов должен использовать сканирование таблицы. Ваша задача — спроектировать и создать индексы, которые лучше всего подходят для вашей среды, чтобы у оптимизатора запросов был набор эффективных индексов, из которых можно было бы выбирать.