Join запросы sql: SQL: оператор JOIN. Основные типы объединения
Содержание
sql — Объединение таблиц: Join(ы) или обычным способом?
Читаю про Join(ы) и вижу такие примеры:
Вот пример без Join(a)
SELECT prod_name, vend_name, prod_price, quantity FROM OrderItems, Products, Vendors WHERE Products.vend_id = Vendors.vend_id AND OrderItems.prod_id = Products.prod_id AND order_num = 20007;
А вот пример с ним:
SELECT vend_name, prod_name, prod_price FROM Vendors INNER JOIN Products ON Vendors.vend_id = Products.vend_id;
Хотел спросить в чем отличие? Что первый что второй запрос выдают один и тот же результат. Помню на лекциях говорили, что: Чем меньше кода тем лучше. В данном случае вижу что с INNER JOIN кода меньше поэтому он лучше? Есть ли различия по производительности? Почему все JOIN(ы) используют, а не первый пример допустим?
- sql
- postgresql
SQL — это декларативный язык. Вы просто говорите, что вы хотите получить, а СУБД уже сама решает, как ваши данные достать. Оба запроса описывают один и тот же результат.
Оба запроса описывают один и тот же результат.
Помню на лекциях говорили, что: Чем меньше кода тем лучше.
Это спорно. В моем окружении программисты придерживаются мнения, что код должен быть максимально понятным. Отсюда, краткость — не всегда хорошо.
В данном случае вижу что с INNER JOIN кода меньше поэтому он лучше?
Я склонен считать, что inner join лучше, т.к. с ним запрос более понятен. Это становится особенно актуально, когда в запросе таблиц 5 и больше.
Есть ли различия по производительности?
Часто движок СУБД изменяет запросы, по этому правильно сравнивать производительность запросов не по их тексту, а по плану запроса.
from table1, table2
Это полный эквивалент для
from table1 cross join table2
Из-за дополнительных условий в where может быть похож на inner join, но в первую очередь это декартово произведение множеств (Cartesian product).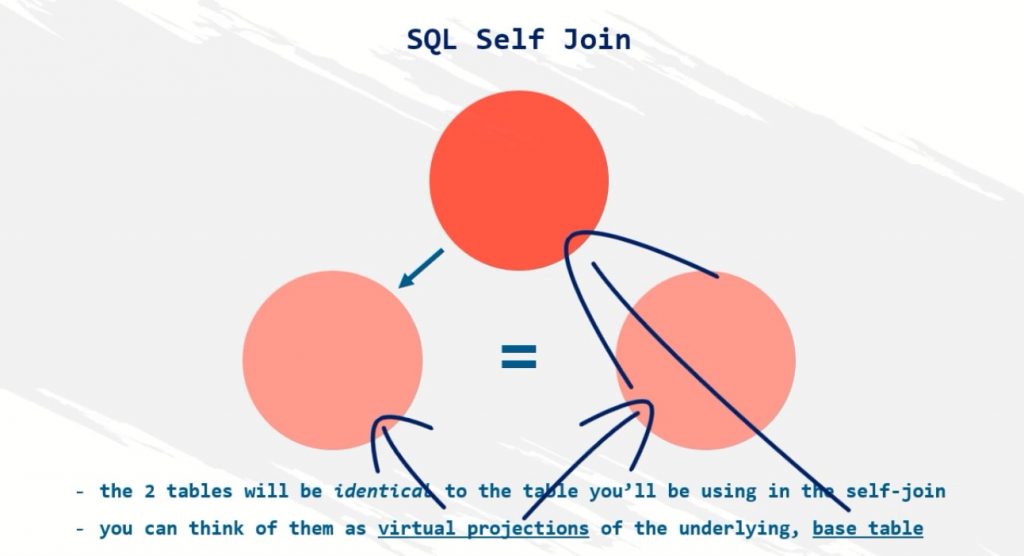
По стилю написания — это вопрос холивара и стандартов кодирования на проекте. Здесь не может быть однозначного ответа.
В то же время синтаксис from table1, table2 — это только декартово произведение, тогда как синтаксис join даёт больше возможностей. Например, left join через декартово произведение не сделать.
По производительности — планировщик СУБД в любом случае перепишет запрос так как ему больше понравится опираясь на свою статистику значений и модель cost-based оптимизатора. У postgresql вообще нет какого-то абстрактного оператора объединения таблиц. Потому что даже такую простую штуку как inner join для двух таблиц postgresql может выполнить минимум 6 разными способами: используя алгоритмы nested loops, hash или merge join и для прямого и для обратного порядка объединения таблиц. Затем помножить число возможных планов выполнения на возможности параллельного выполнения. Затем помножить на возможности выполнения по индексам (3 разных способа) или последовательным чтением всей таблицы. И на вопрос производительности запроса может ответить только конкретный
И на вопрос производительности запроса может ответить только конкретный explain (analyze,buffers)
Оператор JOIN проще и понятнее, чем WHERE с кучей условий. Плюс JOIN, как правило, выполняется быстрее. Но, для того чтобы точно сказать о производительности нужно смотреть план выполнения конкретного запроса в конкретной СУБД.
1
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как расширенные объединения и оконные функции могут вывести ваши SQL-запросы на новый уровень — Machine learning на vc.
 ru
ru
36
просмотров
Вы устали просматривать бесчисленные результаты SQL-запросов, пытаясь извлечь необходимую информацию из ваших данных?
С помощью расширенных объединений вы можете объединять данные из нескольких таблиц в БД на основе их взаимосвязей, в то время как оконные функции позволяют выполнять вычисления по наборам связанных строк.
В этой статье мы рассмотрим четыре распространённых типа соединений, а также различные типы доступных оконных функций.
К концу этой статьи вы будете обладать знаниями, необходимыми для того, чтобы вывести ваши SQL-запросы на новый уровень и раскрыть истинную мощь ваших данных.
Базы данных
Базы данных играют решающую роль в управлении и организации данных для различных приложений. Учитывая, что каждый день генерируются огромные объёмы данных, важно иметь надёжный и эффективный способ получения необходимой нам информации. Расширенные объединения и оконные функции — это два мощных метода, которые могут помочь нам извлекать информацию из нескольких таблиц в базе данных. В этой статье мы рассмотрим, что такое расширенные объединения и оконные функции, как они работают и почему они полезны.
В этой статье мы рассмотрим, что такое расширенные объединения и оконные функции, как они работают и почему они полезны.
Расширенные объединения
Когда у нас есть данные, распределённые по нескольким таблицам, нам нужно объединить их вместе, чтобы получить необходимую нам информацию. В базе данных существует несколько типов соединений, которые мы можем использовать в зависимости от связей между таблицами. Давайте рассмотрим четыре распространённых типа соединений: INNER JOIN, OUTER JOIN, CROSS JOIN и SELF JOIN.
INNER JOIN
INNER JOIN — это наиболее часто используемое соединение в SQL. Оно возвращает только те строки, которые имеют совпадающие значения в обеих объединяемых таблицах. Другими словами, он возвращает только те данные, которые являются общими для обеих таблиц.
Давайте рассмотрим пример, в котором у нас есть две таблицы — одна содержит информацию о клиенте, а другая — информацию о заказе:
SELECT *
FROM customers
INNER JOIN orders
ON customers. customer_id = orders.customer_id;
customer_id = orders.customer_id;
В этом запросе мы объединяем таблицы customers и orders, используя столбец customer_id. Результатом будет таблица, содержащая только строки, в которых значение customer_id присутствует в обеих таблицах.
OUTER JOIN
В отличие от INNER JOIN, OUTER JOIN возвращает все строки из одной таблицы и соответствующие строки из другой таблицы. Другими словами, он возвращает все данные из одной таблицы и любые совпадающие данные из другой таблицы. Существует три типа OUTER JOIN: LEFT OUTER JOIN, RIGHT OUTER JOIN и FULL OUTER JOIN.
Давайте взглянем на пример LEFT OUTER JOIN:
SELECT *
FROM customers
LEFT OUTER JOIN orders
ON customers.customer_id = orders.customer_id;
В этом запросе мы объединяем таблицы customers и orders, используя столбец customer_id.
Результатом будет таблица, содержащая все строки из таблицы customers и любые соответствующие строки из таблицы orders.
Если в таблице заказов нет совпадающих строк, результат будет содержать нулевые значения для столбцов в этой таблице.
CROSS JOIN
CROSS JOIN возвращает декартово произведение двух таблиц, что означает, что оно возвращает все возможные комбинации строк. Другими словами, он объединяет каждую строку из одной таблицы с каждой строкой из другой таблицы.
SELECT *
FROM customers
CROSS JOIN orders;
В этом запросе мы объединяем таблицы customers и orders с помощью CROSS JOIN. Результатом будет таблица, содержащая все возможные комбинации строк из обеих таблиц.
SELF JOIN
SELF JOIN — это соединение, при котором таблица соединяется сама с собой. Это полезно, когда у нас есть таблица, содержащая иерархические данные, например организационную схему.
В этом случае мы можем использовать SELF JOIN для получения информации о связях между различными уровнями иерархии.
SELECT *
FROM employees AS e1
JOIN employees AS e2
ON e1.manager_id = e2.employee_id;
В этом запросе мы объединяем таблицу employees с самой таблицей, используя столбцы manager_id и employee_id.
Результатом будет таблица, содержащая информацию об отношениях между сотрудниками и их менеджерами.
Оконные функции
Оконная функция — это мощная функция SQL, которая позволяет нам выполнять вычисления по набору строк, связанных с текущей строкой.
Оконные функции обычно используются в аналитических запросах, таких как вычисление скользящих средних или определение тенденций в данных. Существует несколько типов оконных функций, включая ROW_NUMBER().
ROW_NUMBER()
ROW_NUMBER() — это оконная функция, которая присваивает уникальное целочисленное значение каждой строке в результирующем наборе. Значение определяется порядком, в котором обрабатываются строки.
Давайте рассмотрим пример, в котором мы хотим присвоить уникальный номер каждому клиенту в зависимости от его возраста:
SELECT customer_id, age, ROW_NUMBER() OVER (ORDER BY age) as row_num
FROM customers;
В этом запросе мы используем функцию ROW_NUMBER(), чтобы присвоить уникальный номер каждому клиенту в зависимости от его возраста.
Результатом будет таблица, содержащая customer_id, age и row_num, присвоенные каждому клиенту.
RANK()
RANK() — это оконная функция, которая присваивает рейтинг каждой строке в результирующем наборе на основе значения указанного столбца. Значения рейтинга присваиваются в порядке значений столбцов, причём связям присваивается тот же рейтинг. Давайте рассмотрим пример, в котором мы хотим ранжировать клиентов на основе их общей стоимости заказа:
SELECT customer_id, total_order_value, RANK() OVER (ORDER BY total_order_value DESC) as rank
FROM orders
GROUP BY customer_id;
В этом запросе мы используем функцию RANK(), чтобы присвоить рейтинг каждому клиенту на основе их общей стоимости заказа.
Результатом будет таблица, содержащая customer_id, total_order_value и rank, присвоенный каждому клиенту.
DENSE_RANK()
Функция DENSE_RANK() похожа на функцию RANK() в том смысле, что она присваивает ранг каждой строке в результирующем наборе на основе значения указанного столбца. Однако DENSE_RANK() присваивает последовательные значения ранга связанным строкам, тогда как RANK() присваивает тот же ранг связанным строкам.
Однако DENSE_RANK() присваивает последовательные значения ранга связанным строкам, тогда как RANK() присваивает тот же ранг связанным строкам.
Давайте рассмотрим пример, в котором мы хотим присвоить каждому клиенту высокий рейтинг на основе общей стоимости их заказа:
SELECT customer_id, total_order_value, DENSE_RANK() OVER (ORDER BY total_order_value DESC) as dense_rank
FROM orders
GROUP BY customer_id;
В этом запросе мы используем функцию DENSE_RANK(), чтобы присвоить каждому клиенту высокий рейтинг на основе их общей стоимости заказа.
Результатом будет таблица, содержащая customer_id, total_order_value и rank, присвоенный каждому клиенту.
NTILE()
NTILE() — это оконная функция, которая присваивает номер группы каждой строке в результирующем наборе на основе указанного количества групп.
Строки разделены на группы равного размера, причём количество строк в каждой группе зависит от общего количества строк и указанного количества групп.
Давайте рассмотрим пример, в котором мы хотим разделить клиентов на три группы равного размера в зависимости от общей стоимости их заказа:
SELECT customer_id, total_order_value, NTILE(3) OVER (ORDER BY total_order_value DESC) as group_num
FROM orders
GROUP BY customer_id;
В этом запросе мы используем функцию NTILE(), чтобы присвоить номер группы каждому клиенту на основе их общей стоимости заказа.
Результатом будет таблица, содержащая customer_id, total_order_value и номер группы, присвоенный каждому клиенту.
Расширенные объединения и оконные функции
Расширенные объединения и оконные функции — это мощные возможности SQL, которые позволяют нам извлекать информацию из нескольких таблиц в базе данных.
С помощью расширенных объединений мы можем объединять данные из нескольких таблиц на основе их взаимосвязей, а с помощью оконных функций мы можем выполнять вычисления по набору строк, связанных с текущей строкой.
Овладев этими методами, мы сможем раскрыть весь потенциал наших данных и получить ценную информацию, которая может быть использована при принятии бизнес-решений.
Заключение
Независимо от того, работаете ли вы с небольшими или большими базами данных, знание того, как использовать расширенные объединения и оконные функции, может существенно повысить эффективность и точность ваших запросов.
Когда дело доходит до расширенных соединений, важно понимать различные доступные типы соединений и когда использовать каждый из них. INNER JOIN отлично подходит для извлечения данных, общих для обеих таблиц, в то время как OUTER JOIN полезно для извлечения всех данных из одной таблицы и любых совпадающих данных из другой таблицы. CROSS JOIN может быть полезно при создании комбинаций строк из разных таблиц, в то время как SELF JOIN может использоваться для иерархических данных.
При работе с оконными функциями важно понимать различные доступные типы и то, как их использовать для выполнения вычислений по наборам связанных строк. ROW_NUMBER(), RANK(), DENSE_RANK() и NTILE() — всё это ценные инструменты для анализа данных и получения аналитической информации.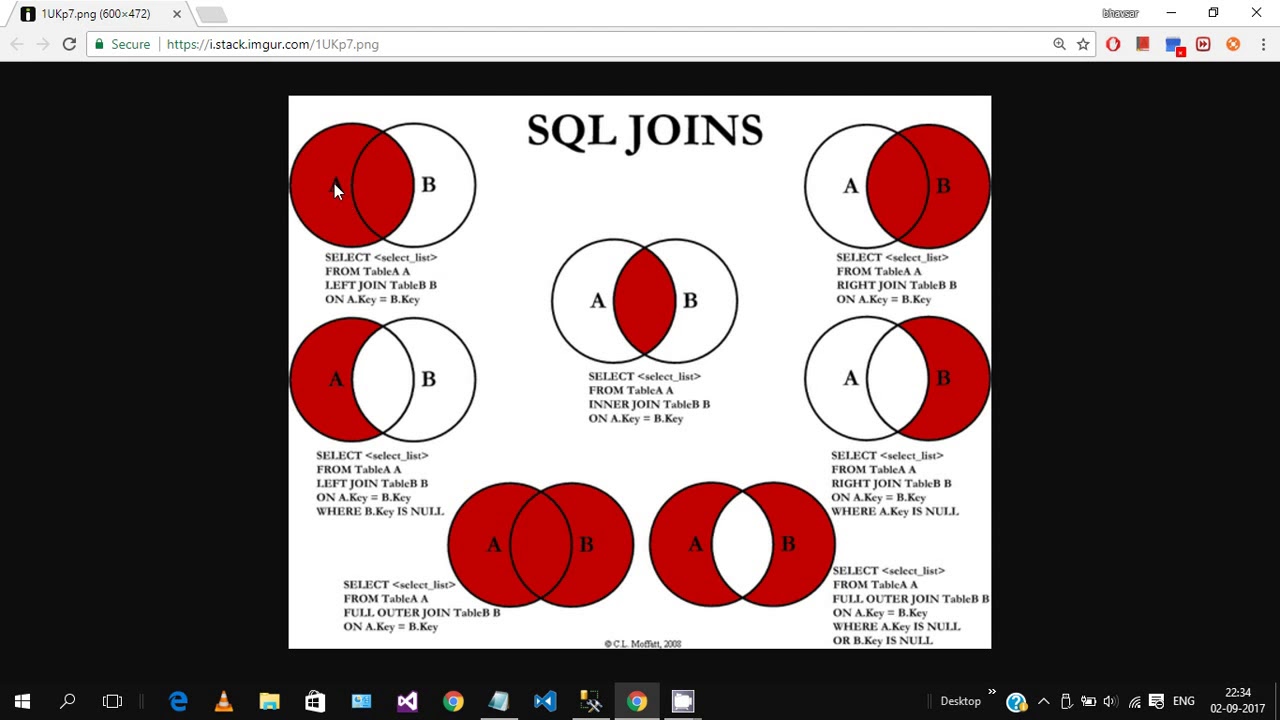
Как и в случае с любой сложной темой, важно практиковаться и экспериментировать с расширенными объединениями и оконными функциями, чтобы полностью понять, как они работают и как их можно применить к различным сценариям. К счастью, в Интернете доступно множество ресурсов для отработки SQL-запросов и оттачивания своих навыков.
Статья была взята из этого источника:
Как объединять таблицы с помощью объединения в SQL
Таблицы SQL позволяют пользователю хранить более 30 типов данных с использованием различных атрибутов. А для того, чтобы получить представление и извлечь полезную информацию, данные извлекаются из более чем одной таблицы. Различные категории соединений в SQL позволяют объединять данные из нескольких таблиц в соответствии с вашими требованиями.
Что такое объединение в SQL?
В SQL существует множество категорий соединений, которые позволяют пользователям объединять строки из двух или более таблиц на основе различных типов условий в соответствии с нашими требованиями. Эти различные типы соединений в SQL подробно объясняются ниже.
Эти различные типы соединений в SQL подробно объясняются ниже.
Различные типы соединений в SQL
SQL дает возможность выбора из следующих семи типов соединений:
Натуральное соединение
Используется для объединения таблиц на основе общего столбца
Декартово соединение
Возвращает декартово произведение строк таблицы
Внутреннее соединение
Таблица результатов состоит только из общих строк
Левое внешнее соединение
Таблица результатов содержит все строки из первой таблицы
Правое внешнее соединение
Таблица результатов содержит все строки из второй таблицы
Полное внешнее соединение
Таблица результатов содержит все строки из обеих таблиц
Самостоятельное соединение
Используется для присоединения таблицы к самой себе
Давайте более подробно рассмотрим все эти объединения в SQL.
Натуральное соединение
Это объединение используется для объединения строк таблиц на основе столбцов с одинаковыми именами и типами данных в обеих таблицах. Общие столбцы появляются в результате этого соединения только один раз.
Общие столбцы появляются в результате этого соединения только один раз.
Естественное соединение может использоваться для объединения двух или более таблиц, и его синтаксис выглядит следующим образом:
ВЫБЕРИТЕ столбец_1, столбец_2,... столбец_n ИЗ таблицы_1 ЕСТЕСТВЕННОЕ СОЕДИНЕНИЕ table_2;
Если вы хотите выполнить естественное соединение всей таблицы, вы можете использовать следующий синтаксис:
ВЫБРАТЬ * ИЗ таблицы_1 ЕСТЕСТВЕННОЕ СОЕДИНЕНИЕ table_2;
Например, если есть таблица «Сотрудник»:
И вы хотите Естественный Соедините его со следующей таблицей «Отдел»:
Вы должны использовать следующий запрос, чтобы соединить эти два:
ВЫБЕРИТЕ * ОТ Сотрудника Отдел ЕСТЕСТВЕННОГО СОЕДИНЕНИЯ;
Вот как выглядит результат:
Как видите, объединение было выполнено на основе общего столбца «EmployeeID», и строки, которые имели одинаковое значение для этого столбца в обеих таблицах, были объединены.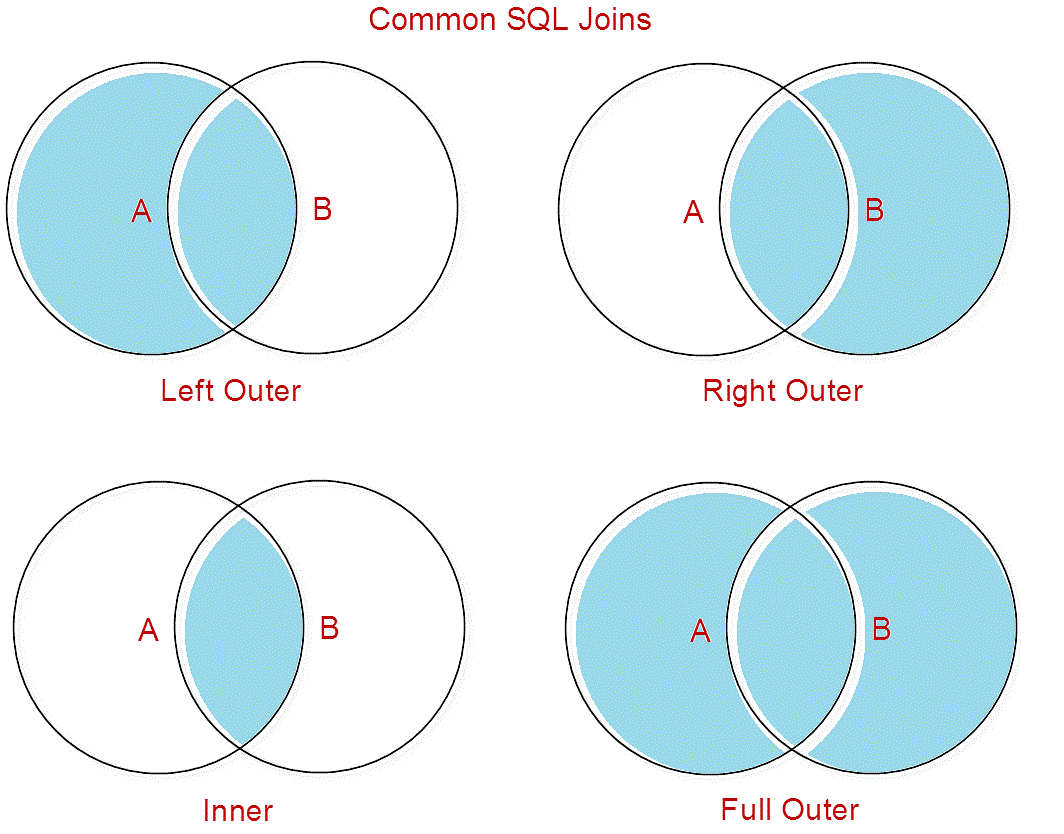
Декартово соединение
Декартово соединение, также известное как перекрестное соединение, возвращает декартово произведение соединяемых таблиц, которое является комбинацией каждой строки одной таблицы с каждой строкой другой таблицы. Например, если таблица A содержит 20 строк, а таблица B состоит из 30 строк, перекрестное соединение этих таблиц приведет к тому, что таблица будет содержать 20*30 (600) строк.
Синтаксис этого соединения следующий:
ВЫБЕРИТЕ table1.column_1, table1.column_2,... table2.column_1, table2.column_2… ИЗ таблица1, таблица2;
Если вы хотите объединить все столбцы из обеих таблиц, вы можете использовать следующий синтаксис:
ВЫБЕРИТЕ * ИЗ таблицы1, таблицы2;
Например, если вы хотите перекрестно объединить столбцы «EmployeeID», «Имя», «Название_отдела» и «Должность» из наших таблиц «Сотрудник» и «Отдел», используйте следующий запрос:
В результате получится следующая таблица:
Как видите, результирующая таблица состоит из 30 строк, так как в наших таблицах «Сотрудник» и «Отдел» 6 и 5 строк соответственно.
Внутреннее соединение
Используя внутреннее соединение, таблицы объединяются на основе условия, также известного как предикат соединения. Это условие применяется к столбцам обеих таблиц по обе стороны от предложения соединения. Запрос проверяет все строки таблиц table1 и table2. В результирующую таблицу включаются только те строки, которые удовлетворяют предикату соединения.
Это объединение возвращает все строки с совпадающими значениями в обеих таблицах.
Наиболее существенное различие между внутренним соединением и «естественным соединением» заключается в том, что общие столбцы появляются более одного раза, тогда как в результате естественного соединения они появляются только один раз. Основной синтаксис этого соединения:
ВЫБЕРИТЕ table1.column_1, table2.column_2… ИЗ таблицы1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица2 ON table1.column_1 = table2.column_2;
Как видите, условие указано после оператора ON. Если условие не указано, это соединение ведет себя как «перекрестное соединение».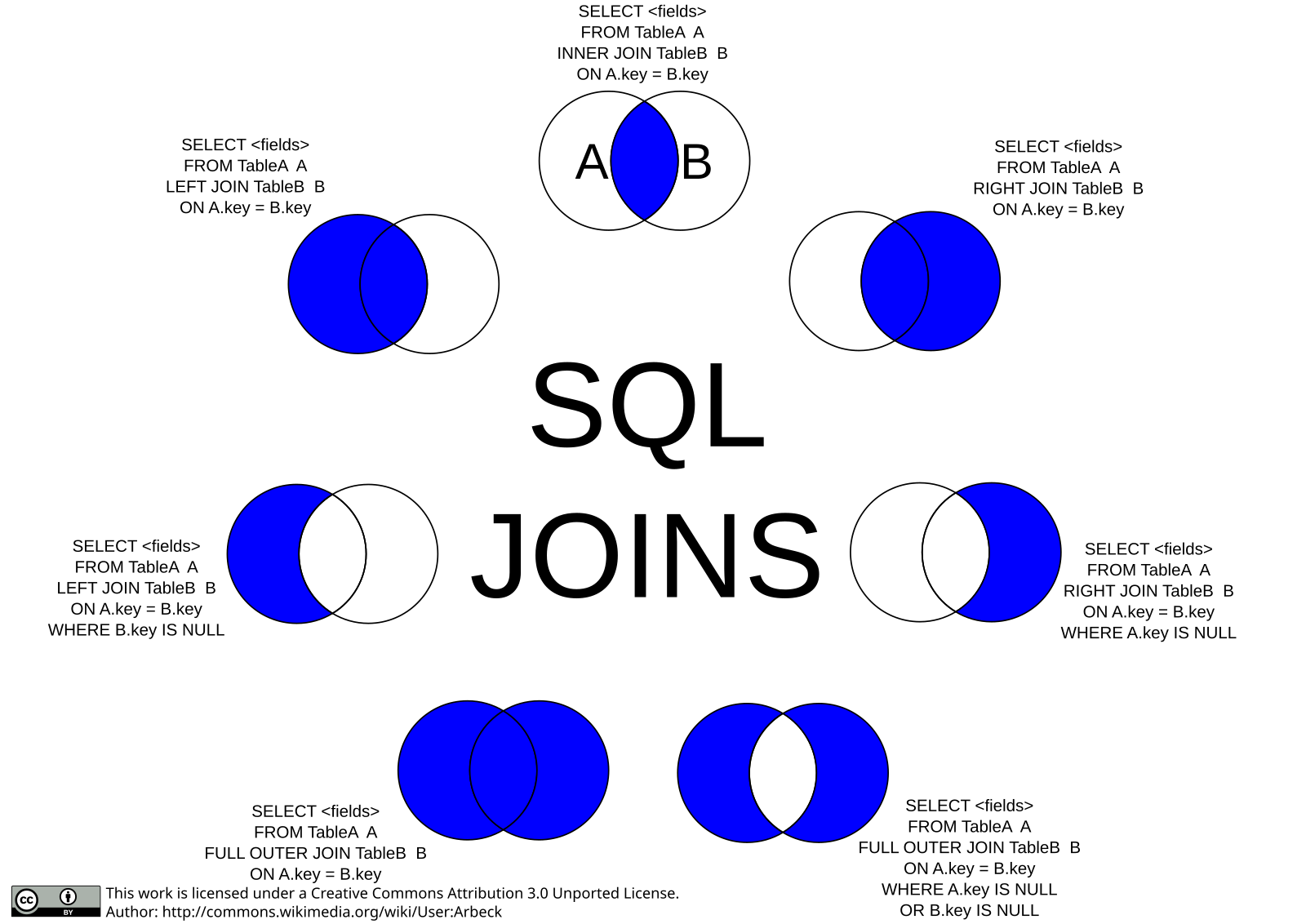
Например, если вы хотите объединить таблицы «Сотрудник» и «Отдел» на основе столбца «EmployeeID», вы должны использовать следующий запрос:
Вот как будет выглядеть финальная таблица:
Результирующая таблица содержит только три строки с одинаковым значением для столбца «EmployeeID» в обеих таблицах.
Левое внешнее соединение
Левое внешнее соединение, также известное как левое соединение, приводит к созданию таблицы, содержащей все строки из таблицы с левой стороны соединения (первая таблица) и только строки, удовлетворяющие условию соединения, из таблицы на правая часть соединения (вторая таблица). Отсутствующие значения для строк из правой таблицы в результате соединения представлены значениями NULL.
Синтаксис этого соединения следующий:
ВЫБЕРИТЕ table1.column_1, table2.column_2,... ИЗ таблицы1 ЛЕВОЕ СОЕДИНЕНИЕ таблица2 ON table1.column_1 = table2.column_2;
Чтобы выполнить объединение всех столбцов таблиц, мы можем использовать * (звездочку) вместо имен столбцов.
Например, если вы хотите левое объединение таблиц «Сотрудник» и «Отдел» на основе столбца «EmployeeID», вы должны использовать следующий запрос:
В результате получится следующая таблица:
Как видите, в результате присутствуют все строки из нашей левой таблицы «Сотрудник», а из таблицы «Отдел» присутствуют только совпадающие строки, а значения NULL представляют остальные строки из этой правой таблицы.
Правое внешнее соединение
Правое внешнее соединение, также известное как правое соединение, работает противоположно левому внешнему соединению. Он следует тем же правилам, что и левое соединение, с той лишь разницей, что в таблице результатов присутствуют все строки из правой таблицы и только строки из левой таблицы, удовлетворяющие условию.
Синтаксис этого объединения:
ВЫБЕРИТЕ table1.column_1, table2.column_2,... ИЗ таблицы1 ПРАВОЕ СОЕДИНЕНИЕ таблица2 ON table1.column_1 = table2.column_2;
Например, если вы хотите соединить столбцы «EmployeeID», «Город», «Должность» и «Название отдела» из наших таблиц «Сотрудник» и «Отдел» на основе столбца «EmployeeID», вы следует использовать следующий запрос:
В результате получится следующая таблица:
Как видите, этот результат противоположен результату левого соединения.
Полное внешнее соединение
Полное внешнее соединение, также известное как полное соединение, используется для предотвращения потери данных при объединении двух таблиц. В этом случае возвращаются все строки из обеих таблиц.
Если для какой-либо строки в любой из таблиц отсутствуют значения, они будут представлены как значения NULL в результате этого объединения в SQL.
Синтаксис этого объединения:
ВЫБЕРИТЕ table1.column_1, table2.column_2,... ИЗ таблицы1 ПОЛНОЕ СОЕДИНЕНИЕ таблица2 ON table1.column_1 = table2.column2;
Подобно «левому» и «правому» объединению, в этом случае мы также можем использовать * (звездочку) вместо столбцов, если мы хотим объединить все столбцы из обеих таблиц.
Некоторые системы баз данных, такие как MySQL, не поддерживают синтаксис полного соединения, поскольку это соединение может быть достигнуто путем выполнения операции UNION для левого и правого внешних соединений.
Например, если вы хотите соединить столбцы «Код сотрудника» и «Должность» из таблиц «Сотрудник» и «Отдел», на основе столбца «Код сотрудника» следует использовать следующий запрос.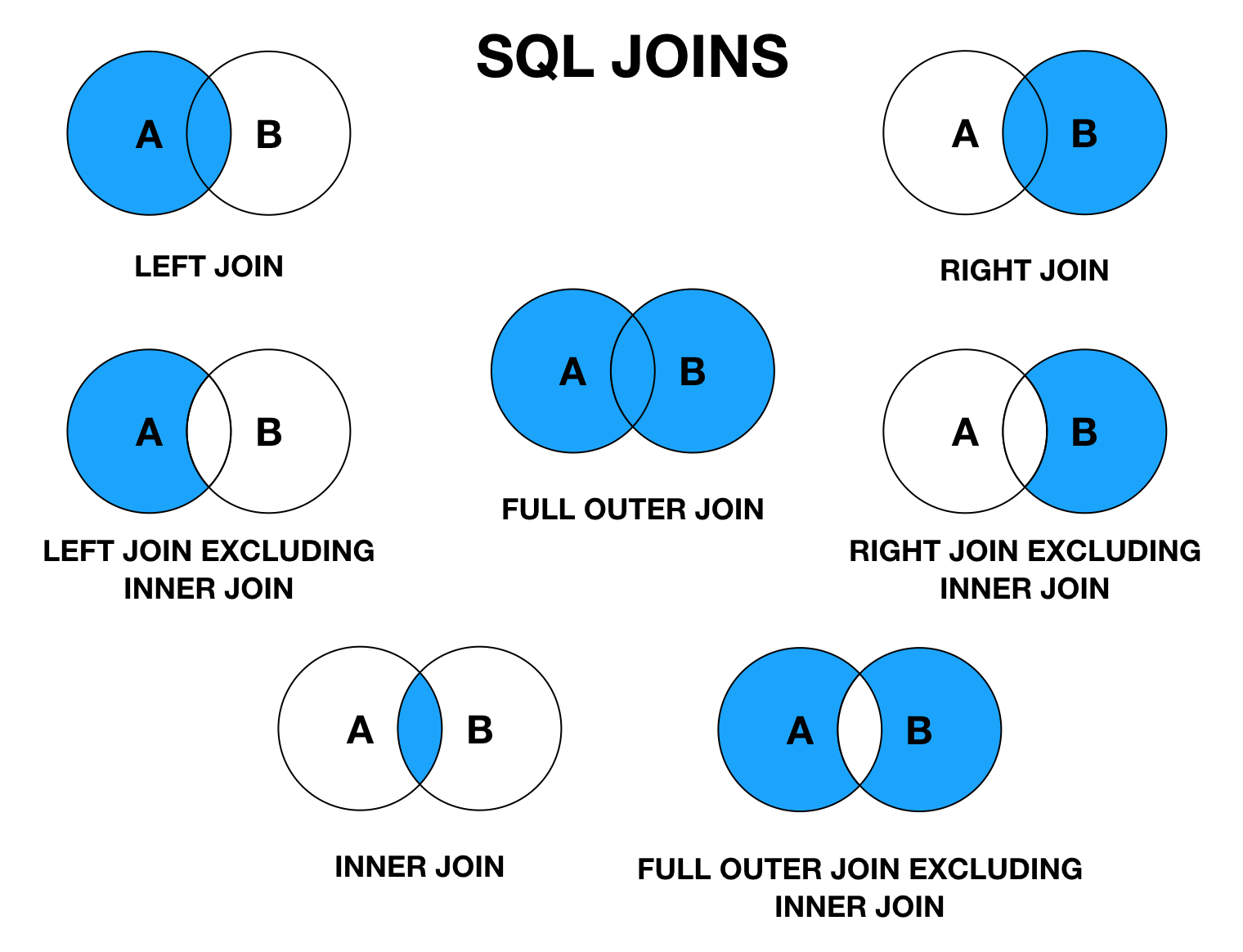
В результате получится следующая таблица:
Как видите, все строки из обеих таблиц присутствуют в этой таблице результатов, а строки, содержащие пропущенные значения, в любой из таблиц представлены как значения NULL.
Самостоятельное соединение
С помощью этого соединения можно соединить таблицу с самой собой. Это используется, когда мы хотим сравнить значения разных столбцов одной и той же таблицы.
Таблица может быть самообъединена с помощью любого из рассмотренных выше соединений, таких как «внутреннее», «левое», «правое», «полное» или «декартово».
Синтаксис этого объединения:
ВЫБЕРИТЕ A.column_1, B.column_2,... ИЗ таблицы1 А JOIN_NAME таблица2 B ВКЛ [состояние]
«A» и «B» — псевдонимы для таблицы 1.
Например, в таблице «Сотрудник», если вы хотите узнать, какие сотрудники принадлежат к одному городу, вы можете использовать следующий запрос:
Здесь мы использовали другое условие, используя предложение «И», чтобы имена не появлялись дважды в таблице результатов.
Результатом запроса будет следующая таблица:
Как видим, только два сотрудника из одного города.
Получите опыт работы с новейшими инструментами и методами бизнес-аналитики с помощью программы «Бизнес-аналитика для принятия стратегических решений». Зарегистрируйтесь сейчас!
Ваш следующий шаг
Почти все реальные запросы данных выполняются с использованием соединения в SQL. Это очень простой, но мощный инструмент, доступный специалистам по данным и всем, кто хочет понимать данные и управлять ими.
И теперь, когда вы знаете о различных типах соединений в SQL, следующим шагом будет изучение того, как выполнять различные запросы к вашему набору данных с помощью всех различных типов команд и предложений, доступных для использования. нашу магистерскую программу для бизнес-аналитиков, изучите SQL от А до Я и глубоко погрузитесь в мир данных!
Если у вас есть какие-либо вопросы к нам, напишите их в разделе комментариев к нашей статье «Как объединить таблицы с помощью соединения в SQL», и наши эксперты в этой области ответят на них для вас.
Что такое соединение SQL? | Integrate.io
Соединение SQL — это логическая комбинация двух таблиц SQL. Существует несколько способов объединения таблиц, большинство из которых связано с поиском общих значений между ними. Соединения SQL — это то, что делает возможной нормализацию, поскольку они позволяют запросам возвращать результаты, охватывающие несколько таблиц.
Как работает соединение SQL?
Если запрос SQL содержит соединение, СУРБД будет искать данные во всех таблицах, включенных в объединение. Затем он объединит результаты запроса в единый формат, благодаря чему они будут выглядеть так, как если бы они были получены из одной таблицы с несколькими столбцами.
Чтобы понять, как это работает, мы должны рассмотреть, как работает реляционная база данных, чтобы максимально уменьшить избыточность. Например, компания может хранить записи о сотрудниках в электронной таблице, которая выглядит следующим образом:
Этот метод хранения не очень эффективен. Если есть изменения в любом из отделов, владелец базы данных должен будет обновить каждую запись. В больших масштабах это может замедлить процессы и привести к риску потери данных.
Если есть изменения в любом из отделов, владелец базы данных должен будет обновить каждую запись. В больших масштабах это может замедлить процессы и привести к риску потери данных.
В реляционной базе данных администратор использует нормализацию, чтобы разбить ее на более мелкие таблицы с неповторяющимися значениями, например:
Это две отдельные таблицы, содержащие неповторяющиеся значения. Логические отношения между данными по-прежнему существуют через отношение первичного ключа, которым в этом примере является новое поле DEPT_ID. Владелец базы данных может управлять ими независимо, пока они сохраняют эту связь.
Однако иногда пользователю требуется полная запись сотрудника, включая полную информацию об отделе сотрудника. Мы достигаем этого с помощью соединения SQL.
Какие существуют типы соединения SQL?
Разработчики SQL могут добавлять соединения к своим запросам для создания чрезвычайно сложных представлений. В этом примере мы сосредоточимся на самых основных тестовых данных, приведенных выше, чтобы проиллюстрировать, как работают различные типы соединений.
Соединения имеют левую и правую таблицы, которые просто ссылаются на сторону команды соединения, на которой они появляются. Итак, если разработчик пишет «SELECT * FROM tableA JOIN tableB», то таблица A — это левая таблица, а таблица B — правая.
Существует пять основных типов соединений, определенных в стандарте ANSI SQL: внутреннее соединение, которое является наиболее распространенным; левое наружное соединение; правое внешнее соединение; полное внешнее соединение; и перекрестное соединение, также известное как декартово соединение.
Внутреннее соединение
Запрос JOIN на стандартном SQL создает так называемое внутреннее соединение. Это дает результаты только в том случае, если в запросе на соединение есть совпадение в обеих таблицах. Например, если мы используем этот запрос для примера данных:
ВЫБЕРИТЕ * ОТ сотрудника ВНУТРЕННЕЕ СОЕДИНЕНИЕ отдел ON сотрудника.DeptID == Department.DeptID;
Результаты запроса будут выглядеть как исходная таблица в примере:
В таблице сотрудников есть некоторые записи, которые не связаны с таблицей отдела, и наоборот. Эти записи не отображаются в результатах запроса.
Эти записи не отображаются в результатах запроса.
Внутреннее соединение является наиболее распространенным типом соединения. Это тип соединения по умолчанию, поэтому, если вы должны написать следующий запрос:
SELECT * FROM сотрудника ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ Department ON employee.DeptID == Department.DeptID;
Вы получите тот же результат.
Левое внешнее соединение
Левое внешнее соединение будет объединять строки из таблиц так же, как описано выше. Разница здесь в том, что он также будет включать все данные из левой таблицы, даже если нет соответствующих отношений с правой таблицей.
Синтаксис запроса очень похож:
ВЫБЕРИТЕ * ОТ сотрудника ЛЕВОЕ СОЕДИНЕНИЕ отдел ON сотрудник.DeptID == Department.DeptID;
Однако теперь возвращаются некоторые дополнительные строки, не содержащие данных об отделах:
Левые соединения полезны, когда фокус запроса находится в левой таблице, а данные в правой таблице могут существовать или не существовать.
Правое внешнее соединение
Правое внешнее соединение работает так же, как левое соединение, за исключением того, что оно включает все результаты из правой таблицы. Обычно принято размещать основную таблицу слева, но разработчики могут свободно использовать правые соединения там, где это удобно.
Как и выше, синтаксис требует только указания типа соединения:
ВЫБЕРИТЕ * ОТ сотрудника ПРАВО ПРИСОЕДИНИТЬСЯ к отделу ON employee.DeptID == Department.DeptID;
Результаты включают все из правой таблицы, даже если в левой нет соответствующих записей.
Обратите внимание, что, несмотря на то, что это правое соединение сосредоточено на таблице отделов, оно возвращает несколько результатов для каждого отдела. Запрос внешнего соединения возвращает все логические строки, полученные в результате запроса, а также любые оставшиеся строки, не имеющие связи с другой таблицей.
Полное внешнее соединение
Полное внешнее соединение возвращает все строки из обеих таблиц.