Как пользоваться файн ридером: ABBYY® FineReader PDF 15
Содержание
Обзор ABBYY Finereader 12, сканировование и распознавание текста документов
Разговор пойдет о программе ABBYY FineReader 12, то есть, о ее последней версии. Не заглядывая слишком далеко, мы выбрали самый известный продукт компании ABBYY, который, к его достоинствам, отлично русифицирован. Уже на первый взгляд Fine Reader (FR) производит впечатление программы с хорошей русскоязычной поддержкой: в этом плане, действительно, все сделано на весьма достойном уровне, включая справочную информацию.
Вначале — отступление. Всегда актуален вопрос, как перевести весь или некоторую часть архива в цифровой формат (и что, собственно, понимать под словом «цифровой»). Едва ли покупка сканера решает все проблемы. Конечно, очень часто в комплекте с документацией к сканеру поставляется диск или несколько с фирменным программным обеспечением. Однако уже на стадии санирования выясняется, что качество сканирующей программы оставляет желать лучшего либо формат, в котором происходит сохранение, к сожалению, не пригоден для хранения. Почему? Большинство графических форматов не отделяют текст от нетекстового пространства документа, и поэтому скопировать какой-либо отрывок из подобного файла не предоставляется возможным.
Почему? Большинство графических форматов не отделяют текст от нетекстового пространства документа, и поэтому скопировать какой-либо отрывок из подобного файла не предоставляется возможным.
Именно в таких случаях на выручку приходят функциональные программы-«распознавальщики» текста, в возможности которых, в частности, входит извлечение текста из изображения.
Знакомство с ABBYY FineReader
Пакет ABBYY Finereader 12 — система оптического распознавания текстов (Optical Character Recognition — OCR). Предназначена как для автоматического ввода печатных документов в компьютер, так и для конвертирования PDF–документов и фотографий в редактируемые форматы(из руководства к программе)
Аббревиатура «OCR» применима для всех приложений для распознавания данных (а не только текста). Источником для извлечения данных может служить печатный или электронный документ. Когда-то не очень давно об OCR, в той или иной форме, мало кто знал, да и процесс перевода текста в электронный вид превращался в сущую рутину, вплоть до ручной перепечатки текста оригинала. Сегодня, обладая планшетным сканером (ручным в домашних условиях пользуются единицы) и finereader 12 — будьте уверены — никаких сложностей в сканировании и распознании не возникнет.
Сегодня, обладая планшетным сканером (ручным в домашних условиях пользуются единицы) и finereader 12 — будьте уверены — никаких сложностей в сканировании и распознании не возникнет.
Начиная с шестой версии, FineReader поддерживает импорт и экспорт в формат PDF, запатентованный компанией Adobe. Многие читатели, вероятно, сталкивались с трудностями перевода из этого формата в любой иной (doc и т. п.), поскольку действительно полезных программ в этой области не так уж и много (внимания достоин разве что дочерний продукт компании ABBYY — PDF Transformer). Дело в том, что подобные программы проводят распознавание текста только единожды, вследствие чего «идентичность» результата вовсе невелика (в зависимости от сложности документа), плюс к тому изрядно теряется форматирование документа.
В случае с FineReader все обстоит по-иному. В девятую версию программы внедрена технология под названием Document OCR. В ее основе лежит принцип цельного распознавания документа: он анализируется и распознаётся как единое целое, а не постранично. При этом всевозможные колонки, колонтитулы, шрифты, стили, сноски и изображения остаются нетронутыми или заменяются близкими к оригиналу.
При этом всевозможные колонки, колонтитулы, шрифты, стили, сноски и изображения остаются нетронутыми или заменяются близкими к оригиналу.
Установка пакета
Demo-версию Finereader 12 можно скачать на сайте Abbyy.ru, в разделе Download, полная лицензионная версия распространяется на CD-диске. О способах покупки можно узнать на этом же сайте в разделе «Купить».
На сайте разработчиков ABBYY можно скачать демонстрационную версию пакета ABBYY FineReader версии 12 (или другой, актуальной на сегодня)
ABBYY FineReader распространяется в нескольких версиях: Professional Edition, Corporate Edition, Site License Edition и др. Отличие версии Professional от остальных состоит в том, что предназначена для работы в корпоративной сети с возможностью совместной работы над распознаванием документов. В остальном разница незначительна и зависит от выбора условий лицензионного соглашения.
Сложно представить, что 12 лет назад существовал FineReader 2.0, занимавший около 10 Мб дискового пространство. Со временем пакет «вырос» десятикратно и сейчас в установленном виде занимает до 300 Мб. Много это или мало — судите сами. Новый FR поддерживает 179 языков распознавания, среди которых есть малоизвестные искусственные языки (идо, интерлингва, окциденталь и эсперанто), языки программирования, формул и т. п. Не будем забывать и о поддержке различных форматов, сценариев. Так что, если по какой-то причине вы захотите ограничить занимаемое пакетом место, при установке отметьте только те компоненты, которые будут востребованы при работе.
Со временем пакет «вырос» десятикратно и сейчас в установленном виде занимает до 300 Мб. Много это или мало — судите сами. Новый FR поддерживает 179 языков распознавания, среди которых есть малоизвестные искусственные языки (идо, интерлингва, окциденталь и эсперанто), языки программирования, формул и т. п. Не будем забывать и о поддержке различных форматов, сценариев. Так что, если по какой-то причине вы захотите ограничить занимаемое пакетом место, при установке отметьте только те компоненты, которые будут востребованы при работе.
Выбор компонентов влияет на длительность установки, которая, впрочем, не должна занять много времени. В процессе инсталляции вас ознакомят с основными возможностями FR. После активации (по Интернету, через E-mail, с помощью полученного кода и др.) программа готова к полнофункциональной работе. В demo-режиме вы непременно столкнетесь с различными ограничениями, которые, к сожалению, не позволяют полноценно использовать пакет.
Интерфейс FineReader.
 Функциональные возможности
Функциональные возможности
Доступ к возможностям программы доступен как с помощью сценариев, которые появятся в главном меню сразу после процесса инсталляции, так и, собственно, через основной интерфейс.
Заставка при запуске FineReader
Внешний вид программы из версии к версии не претерпевает особых изменений: разработчики не видят смысла его кардинально менять. Значительное внимание уделяется эргономике, что заметно по всем продуктам компании ABBYY (Lingvo, PDF Transformer, FlexiCapture…). Другими словами, интерфейс Fine Reader 12 хорошо продуман и предрасположен ко всем пользователям, не исключая новичков. Принцип «Получить результат за одно нажатие» придется по вкусу тем, кто не привык что-то настраивать и изменять. С другой стороны, более опытные пользователи могут тщательно настроить FineReader через диалог настроек (Сервис -> Опции…). Единственный нюанс: для комфортной работы в приложении желательно установить разрешение экрана в 1280?800, чтобы все инструменты всегда были, что называется, под рукой.
После запуска программы Файн Ридер появится окно с кнопками быстрого доступа к функциям программы. Данное меню также доступно через меню Сервис -> ABBYY FineReader, кнопку «Основные сценарии» в крайнем правом углу программы или через сочетание клавиш Ctrl+N (по аналогии с Word, где данной комбинацией вызывается открытие нового документа).
Сканировать в Microsoft Word: в девятой версии FineReader появилась поддержка пока еще не успевшего стать популярным Microsoft Word 2007. В свою очередь, на панели инструментов в приложениях Microsoft Office, в разделе надстроек после установки FR появляется «фирменный» красный значок.
Меню для экспорта распознанного документа FineReaderВыбор языков для сканирования и распознания документов
Помимо Microsoft Office, FR поддерживает интеграцию с Microsoft Outlook, обеспечивает экспорт результатов распознавания в те же Microsoft Word, Excel, Lotus Word Pro, Corel WordPerect и Adobe Acrobat. Эти возможности в некоторой мере облегчают и ускоряют работу с программой, в особенности, если вам приходится регулярно в ней работать.
PDF или изображения в Microsoft Word: распознать данные из PDF- или графического файла другого типа, поддерживаемого Finereader 12 версии. Следует отметить, что технология извлечения текста из PDF-файла в FR — это не просто «отслаивание» текстового наполнения (текстовый слой в PDF может и отсутствовать) от графического. На самом деле, технология распознавания достаточно непроста: проанализировав содержание документа, программа решает, что и как нужно делать с текстом: просто извлечь или распознать, — и так применительно к каждому текстовому фрагменту.
Сканировать в Microsoft Excel: сканирование в XLS (формат программы Microsoft Excel) может быть оправдано в том случае, если сканируемое изображение содержит таблицы.
Сканировать в PDF: поводов для сканирования в PDF может быть множество. Один из них — безопасность: это единственный формат, знакомый FR, в настройках которого можно установить блокировку паролем. Пароль устанавливается не только на открытие документа, но и на его печать и другие операции. Имеется возможность выбрать один из трёх уровней шифрования: 40-битный, 128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте AES (Advanced Encryption Standard).
Имеется возможность выбрать один из трёх уровней шифрования: 40-битный, 128-битный на основе стандарта RC4, 128-битный уровень, основанный на стандарте AES (Advanced Encryption Standard).
Конвертировать фотографию в Microsoft Word: перевод файла из графического формата (причем это может быть PDF или многостраничное изображение) в DOC/DOCX.
Сканировать и сохранить изображение: непосредственное сканирование аналогового графического формата в графический же, но электронный.
Открыть в Файн Ридер: открыть графический файл (PDF, BMP, PCX, DCX, JPEG, JPEG 2000, TIFF, PNG) для распознавания FineReader.
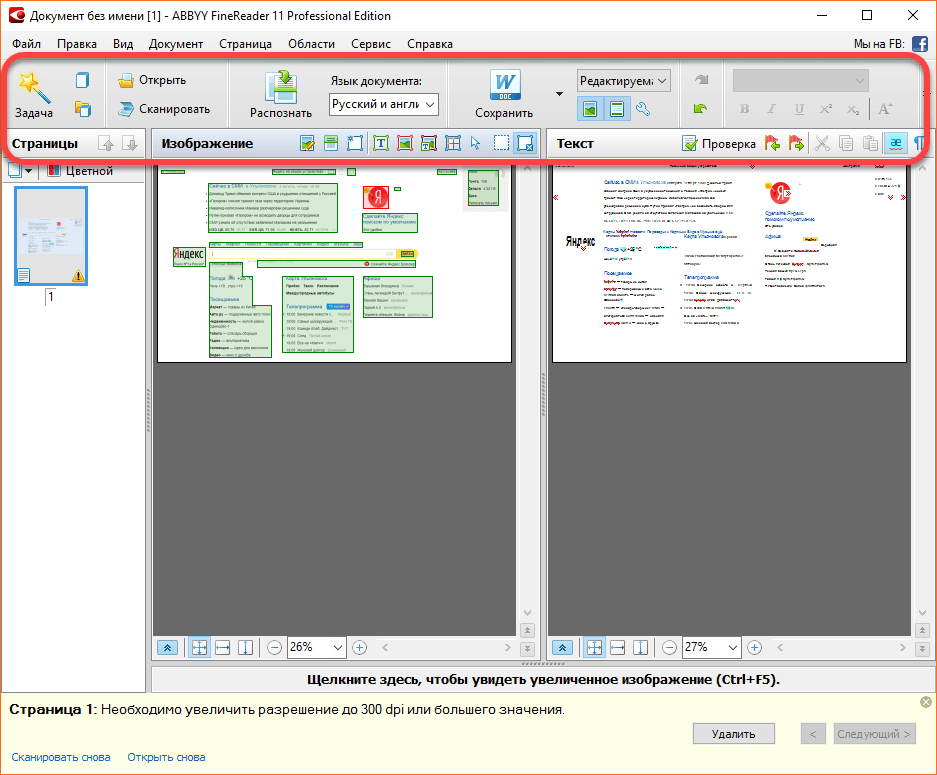
Работа в FineReader
Сейчас — вкратце об особенностях работы программы. Весь процесс делится на сканирование, распознавание и сохранение результатов. После того как вы выбрали тип действия программы, указали файл или устройство для сканирования, FineReader поэтапно выполняет свою задачу, кстати, достаточно ресурсоемкую для центрального процессора.
Если вы — счастливый обладатель двухъядерного процессора, то, работая в пакете Fine Reader 12, можете оценить мощь быстродействия компьютера. Дело в том, что FR, обнаружив двухъядерный процессор, распознает не одну, а сразу две страницы документа параллельно. Мелочь — а приятно.
Вначале идет сканирование, затем — распознавание и экспорт временного документа в выбранный формат.
Процесс распознавания PDF-документа
Сканирование. Никаких предварительных настроек в приложении FineReader (кроме выбора считывающего устройства) перед сканированием делать не нужно. Именно поэтому и были придуманы сценарии: они призваны упростить выполнение однотипных действий.
Распознавание. Упрощение коснулось и других мелочей. Так, если вспомнить прошлые версии программы, раньше нам приходилось вручную менять язык (языки, если их было несколько) документа. Сейчас это происходит автоматически, правда, тоже не всегда. В последнем случае FR ненавязчиво предлагает проверить язык документа.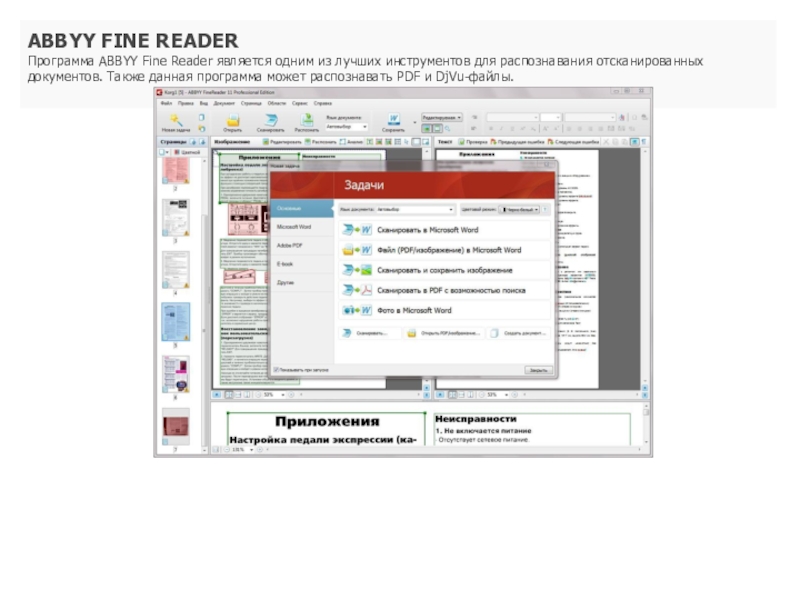
Возвращаясь к технологии распознавания FR: почему программа вначале сканирует весь документ целиком, а не постранично? Как уже было сказано, текст распознается, исходя из всего содержания: подбираются аналогичные по размеру/гарнитуре шрифты, таблицы и границы, отступы и т. п.
Не удивляйтесь, если программа FineReader 12 выдаст сообщение, мол, страница не может быть распознана, поскольку не найдено ни одной области текста. Эксперимента ради, мы сфотографировали на мобильный телефон с экрана LCD-дисплея область текстового документа (впрочем, зная, результат уже заранее). Fine Reader 12 не распознал текст изображения, поскольку оно было явно такого качества, которого для этого явно недостаточно. При втором заходе мы сфотографировали цифровым фотоаппаратом страницу с текстом при нормальном освещении.
FineReader без проблем распознал отрывок, сохранив форматирование и отметив маркерами некоторые сомнительные моменты или символы, у которых могут быть вариативное написание.
Как видно на изображении, преимущественно это точки, дефисы, запятые — в общем, мелкие символы. Кроме этого, хорошо видно, что программа учла неровности, изогнутости сфотографированной страницы и выровняла строки текста. Вывод — FR отлично справился со своей пусть и не очень сложной задачей.
Изредка могут оставаться незамеченными программой Файн Ридер кое-какие незначительные моменты, однако их легко откорректировать вручную. Благо, в пакете есть свой WYSIWYG-редактор, возможностей которого вполне достаточно для совершения окончательной правки документа. Проверка орфографии тоже имеется.
Как повысить точность распознавания, чтобы затем в меньшей степени заниматься правкой текста? Во-первых, вы можете подключить пользовательский словарь Microsoft Word. Правда, сложно судить о повышении точности, разве что о повышении словарного запаса спеллчекера (модуля, проверяющего орфографию и грамматику). Кроме всего прочего, для улучшения распознавания есть смысл ознакомиться с настройками программы (Сервис -> Опции) и выбрать один из двух режимов:
тщательное распознавание — его можно выбрать при распознавании документов любой «сложности»: с таблицами без линий сетки, текста, графиков, таблиц на цветном фоне и др.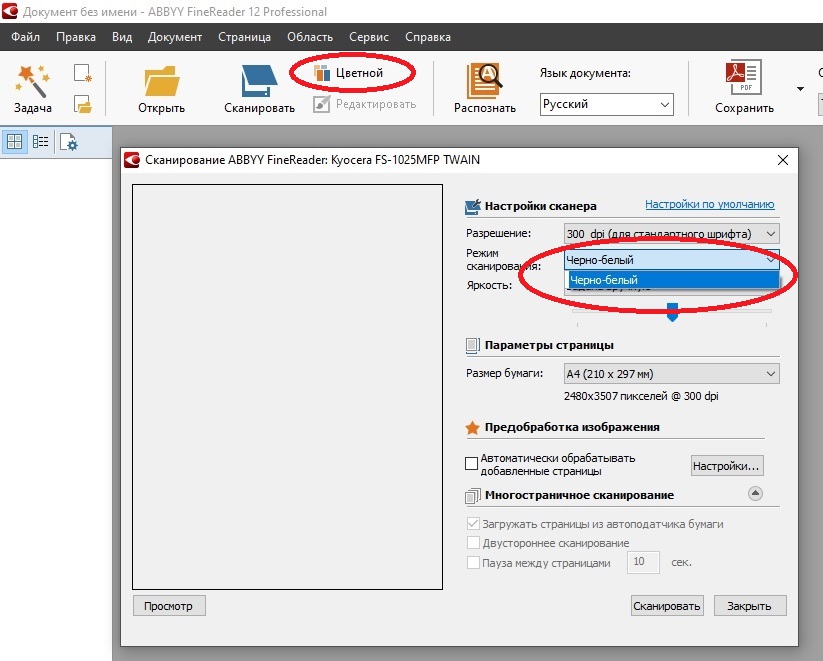 Также может помочь при некачественном источнике для распознавания
Также может помочь при некачественном источнике для распознавания
быстрое распознавание — данный режим рекомендуется для обработки больших объемов документов с простым оформлением или же в том случае, если время не позволяет проводить тщательное распознавание. В большинстве случаев, когда вы имеете с черным печатным текстом на белом фоне, можно остановиться на быстром распознавании.
Вообще, улучшение качества работы FineReader — это отдельная тема для разговора, о деталях которой вы можете узнать из официальной справки, а именно в разделе «Как улучшить полученные результаты».
Сохранение документа. Последний этап работы в программе Fine Reader 12 — сохранение итогового результата в определенный графический/текстовый формат. Предварительно настройки сохранения можно указать в опциях FR: Сервис ->Опции, вкладка «Сохранить». Для каждого формата предусмотрены свои настройки. При сохранении в DOCX-формате следует побеспокоится о совместимости форматов (Файлы DOCX-формата не распознаются в Word 2003 <). В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
В txt-файлах не забудьте проверить правильность кодировки (особенно в случае с текстом в кириллице).
ABBYY Screenshot Reader
Во многие объемные пакеты очень часто разработчики любят добавлять мелкие сервисные утилиты. Скажем, в состав известного приложения для записи дисков Nero входит набор из 3 — 5 утилит, позволяющих то, чего не может даже сам Nero. Обзор Nero Express доступен здесь (здесь же можно скачать в составе Файн Ридер 12).
Что касается FineReader, то в его составе обнаруживается одно небольшое приложение Screenshot Reader. С его помощью вы можете сделать снимок экрана и быстро перевести его в желаемый формат посредством FR. Программа доступна через меню «Пуск» (Пуск -> Все программы -> ABBYY FineReader 12.0 -> ABBYY Screenshot Reader.).
Возможности Screenshot Reader несколько шире, чем может показаться на первый взгляд. (а иначе можно было бы обойтись простым нажатием клавиши «PrintScreen» на клавиатуре). В дополнение к тому, что Screenshot Reader делает снимок экрана (или, точнее, выбранной области экрана), программа тесно интегрирована с FR.
При нажатии на кнопку «Снимок» на панели Screenshot Reader курсор меняет форму и включается инструмент выделения области экрана. Выделенная область изображения заключается в рамку для дальнейшего распознавания текста (оно запускается автоматически).
В выпадающем списке вы можете выбрать желаемое действие: по сути, Screenshot Reader дублирует быстрые сценарии FR c той разницей, что вместо снимка со сканера «на вход» поступает снимок экрана.
Следует отметить, программа, наравне со всем пакетом, требует активации. При регистрации продукта ABBYY FineReader 12 Professional Edition Screenshot Reader предоставляется бесплатно, в качестве «бонуса».
Заключение
FineReader — незаменимая программа для сканирования и распознавания графических данных. Русскоязычный интерфейс и доступность настроек не отпугнут неопытного пользователя. Поддержка новейших форматов, инновационные технологии и, как следствие, качественное распознавание делают программу оптимальным выбором, тем более что конкурентов в этой области у ABBYY FineReader все еще не предвидится.
Горячие клавиши FineReader 12
- Создать новый документ ABBYY FineReader — CTRL+N
- Открыть документ ABBYY FineReader 12 — CTRL+SHIFT+N
- Сохранить страницы — CTRL+S
- Сохранить изображение в файл — CTRL+ALT+S
- Распознать все страницы документа — CTRL+SHIFT+R
- Закрыть текущую страницу — CTRL+F4
- Распознать выделенные страницы документа ABBYY FineReader — CTRL+R
- Открыть Менеджер сценариев — CTRL+T
- Открыть диалог Опции «Файн Ридер»— CTRL+SHIFT+O
- Открыть справку — F1
- Перейти в окно Документ — ALT+1
- Перейти в окно Изображение — ALT+2
- Перейти в окно Текст — ALT+3
- Перейти в окно Крупный план — ALT+4
FineReader Professional 15.0.114.4683 и код активации
| Актуальная версия | 15. 0.114.4683 0.114.4683 |
| Разработчик | ABBYY |
| Поддерживаемые ОС | Windows XP, Vista, 7, 8, 10 |
| Языки интерфейса | мульти (+ русский) |
| Архитектура | x86/x64 |
Каждый из нас сталкивался с необходимостью получить текст в редактируемом виде на электронном носителе с бумаги, изображения или PDF-файла. Однако большинство приложений лишь отчасти выполняют возложенную задачу. Всемирно известное детище компании ABBYY – Finereader Pro призвано избавить человечество от утомительного перепечатывания. Благодаря продвинутой системе OCR всего за несколько секунд можно получить документ в ключевых офисных форматах с сохранением структуры, изображений, таблиц и даже математических формул.Работа с приложением включает несколько логически выстроенных этапов: выбор подходящего сценария обработки, сканирование и анализ, проверку результата и редактирование. Качество работы зависит от выбранного алгоритма с приоритетом скорости или качества. Для внесения изменений предназначен редактор текста и изображений. В качестве новых функций предлагается контроль изменений, заполнение интерактивных форм, внесение правок непосредственно в PDF, а также поиск по готовому документу. Разработчик также реализовал поддержку 190 языков с возможностью комбинированного использования в одной сессии.
Качество работы зависит от выбранного алгоритма с приоритетом скорости или качества. Для внесения изменений предназначен редактор текста и изображений. В качестве новых функций предлагается контроль изменений, заполнение интерактивных форм, внесение правок непосредственно в PDF, а также поиск по готовому документу. Разработчик также реализовал поддержку 190 языков с возможностью комбинированного использования в одной сессии.
Сразу после первого запуска Finerader Professional попросит ввести код активации. Искать подобный вариант лицензии в паблике практически бесперспективно, зато можно использовать файлы замены. В результате получается обычная полнофункциональная версия пакета.
- Новые
- Portable
- Активация
- Старые
FineReader PDF 15.0.114.4683.exe
ru
515 Mb
FineReader PDF 15. 0.114.4683 Portable
0.114.4683 Portable
Conservator
ru
591 Mb
finereader-pdf-15.0.114.4683-key.zip
539 Kb
FineReader Pro 12.0.101.496.exe
ru
352 Mb
finereader-pro-12.0.101.496-key.zip
1 Mb
Внимание! Пароль ко всем нашим архивам: kilo
Поставили минус? Оставьте, пожалуйста, краткий комментарий, чтобы мы могли разобраться в проблеме.
119 комментариев
Пошаговое руководство по использованию ABBYY OCR
Элиза Уильямс
2023-02-10 15:06:14 • Подано по адресу:
Сравнение программного обеспечения PDF
• Проверенные решения
Независимо от того, хотите ли вы использовать программное обеспечение ABBYY OCR для классных или профессиональных задач, этот инструмент предлагает простые средства, с помощью которых пользователи могут собирать данные и готовить статистику путем преобразования отсканированных документов в формат PDF или Word. Используемые шаги обычно просты для выполнения и выполнения. Это руководство расскажет вам, как использовать ABBYY OCR в Интернете и на рабочем столе. Вы также узнаете, как исправить проблемы, которые обычно возникают при использовании инструмента.
Используемые шаги обычно просты для выполнения и выполнения. Это руководство расскажет вам, как использовать ABBYY OCR в Интернете и на рабочем столе. Вы также узнаете, как исправить проблемы, которые обычно возникают при использовании инструмента.
Как использовать лучшую альтернативу ABBYY OCR
Wondershare PDFelement — редактор PDF удовлетворит все ваши потребности в PDF. Помимо поддержки преобразования текстов распознавания OCR в MS Word, Excel, HTML и PowerPoint, среди прочего, пользователи могут эффективно редактировать отсканированные документы. Инструмент также был интегрирован с личными инструментами рисования, текстовыми полями, штампами и комментариями. Это упрощает командную работу по созданию контента и обмену им.
Попробуйте бесплатно
Попробуйте бесплатно
КУПИТЬ СЕЙЧАС
КУПИТЬ СЕЙЧАС
Шаг 1. Откройте файл PDF
Запустите PDFelement и нажмите кнопку «Открыть файл. ..» в главном интерфейсе. Затем выберите отсканированный файл, который хотите открыть, и нажмите «Открыть». Или вы можете просто перетащить его в программу.
..» в главном интерфейсе. Затем выберите отсканированный файл, который хотите открыть, и нажмите «Открыть». Или вы можете просто перетащить его в программу.
Шаг 2. Выполните OCR
Программа обнаружит, что это отсканированный файл PDF, и появится синяя лента. Нажмите на кнопку «Выполнить распознавание». Во всплывающем окне выберите кнопку «Текстовое изображение с возможностью поиска» или «Редактируемый текст». Нажмите кнопку «Выбрать язык», чтобы убедиться, что вы выбрали правильный язык для отсканированного документа. Наконец, нажмите «ОК».
Шаг 3. Редактировать текст после OCR
Теперь вы можете перейти в меню «Правка» и затем выбрать «Режим строки» или «Режим абзаца», чтобы изменить документы.
Попробуйте бесплатно
Попробуйте бесплатно
КУПИТЬ СЕЙЧАС
КУПИТЬ СЕЙЧАС
- Мощное оптическое распознавание символов (OCR): этот инструмент упрощает распознавание текстов на изображениях и отсканированных документах. Когда тексты легко идентифицируются, становится проще редактировать тексты в соответствии со своими приоритетами.

- Вмещает файлы с возможностью поиска: это позволяет пользователям выполнять важные задачи в отсканированных PDF-файлах и изображениях. С помощью этого инструмента можно копировать или искать тексты в содержимом изображения или отсканированного PDF-документа.
- Поддерживает несколько языков: приложение совместимо с несколькими языками. К ним относятся английский, испанский, китайский, португальский, немецкий, французский и т. д.
- Более продвинутые функции: высокая скорость обработки и мощные функции редактирования, добавления аннотаций, преобразования функций, защиты функций и т. д.

Как использовать ABBYY Finereader OCR (Desktop)
Шаг 1: Если вы будете использовать сканер, убедитесь, что он включен. Большинство сканеров требуют включения перед открытием компьютера.
Шаг 2: Второй шаг — запустить приложение ABBYY Finereader OCR. Но если у вас его нет, не волнуйтесь. Приложение можно легко загрузить на нескольких платформах в Интернете.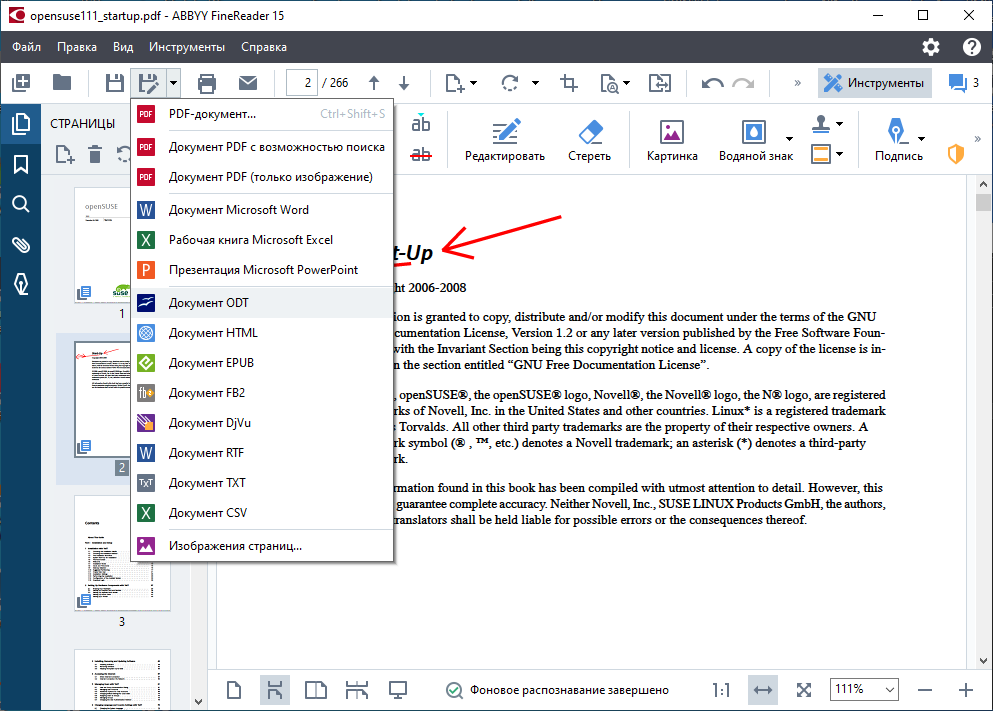
Шаг 3: Поместите документ, который нужно преобразовать, в принтер.
Шаг 4: На кнопке «Экран и чтение» щелкните стрелку вниз.
Шаг 5: Вам будут доступны следующие варианты
- Вариант 1: «Мастер сканирования и чтения» покажет вам каждую процедуру OCR.
- Вариант 2: «Сканировать и читать» может распознавать изображения, а также сканировать документы.
- Вариант 3: «Сканировать в PDF» идентифицирует изображения, сканирует документы и затем преобразует идентифицированные тексты в Adobe Acrobat/Reader.
- Опция 4: «Сканировать в Word» просматривает отсканированные документы, распознает тексты и позже отправляет их в MS Word.
Как использовать ABBYY Cloud OCR
Finereader OCR позволяет пользователям выполнять задачи онлайн. Вам не нужно будет загружать и устанавливать программу, что экономит время и место на вашем устройстве. Этот сайт позволяет пользователям конвертировать до пяти страниц бесплатно.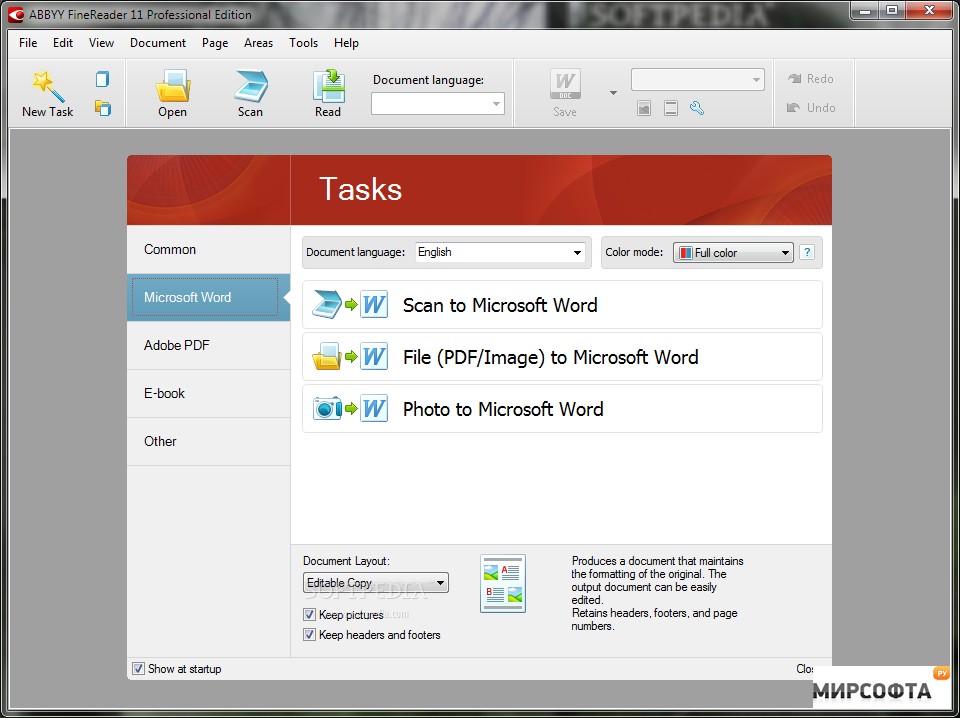 И если кому-то все еще потребуется конвертировать больше страниц, он / она будет обязан подписаться на подходящий план оплаты.
И если кому-то все еще потребуется конвертировать больше страниц, он / она будет обязан подписаться на подходящий план оплаты.
При использовании ABBYY Cloud OCR требуется пять шагов. Он включает в себя:
- Шаг 1: Первый шаг — зайти на онлайн-сайт FineReader. Затем нажмите кнопку «Загрузить», чтобы загрузить отсканированный документ, изображение или файл PDF в программу.
- Шаг 2. Установите язык, который будет использоваться в вашем документе.
- Шаг 3: Выберите формат, в который будут преобразованы распознанные цифровые тексты. Это может быть документ в формате PDF или MS Word.
- Шаг 4: Нажмите кнопку «Распознать».
- Шаг 5: Наконец, загрузите преобразованный файл в память вашего устройства.
Общие проблемы и исправления для ABBYY OCR
i. Сообщение «Фатальная ошибка» при сканировании документов
Чтобы решить эту проблему, перейдите к значку «Инструменты» и щелкните по нему. Затем выберите «Параметры» > «Сканировать/Открыть вкладку». Появится интерфейс, из которого вам нужно будет выбрать «Пользовательский собственный параметр» под заголовком сканирования и, наконец, нажать «ОК».
Появится интерфейс, из которого вам нужно будет выбрать «Пользовательский собственный параметр» под заголовком сканирования и, наконец, нажать «ОК».
ii. «Сервер RPC недоступен», который отображается при запуске программы
Эту проблему, которая обычно возникает при запуске программы, можно решить, перейдя в диалоговое окно «Сервис». Щелкните правой кнопкой мыши службу лицензирования Abby FineReader, а затем выберите кнопки «Пуск и перезапуск», присутствующие в контекстном меню.
III. Когда появляется сообщение «Запрашиваемый член коллекции не существует»
Перейдите в «Поиск программ и файлов», введите Regedit и нажмите клавишу ввода. Если ваша версия Windows XP, перейдите в меню «Пуск» и выберите «Выполнить элемент». Перейдите в «Выполнить диалоговое поле», найдите Regedit и нажмите Enter.
iv. Ограничения текста
Убедитесь, что язык программы совместим с документом. Кроме того, увеличьте контрастность документов и убедитесь, что они не написаны от руки.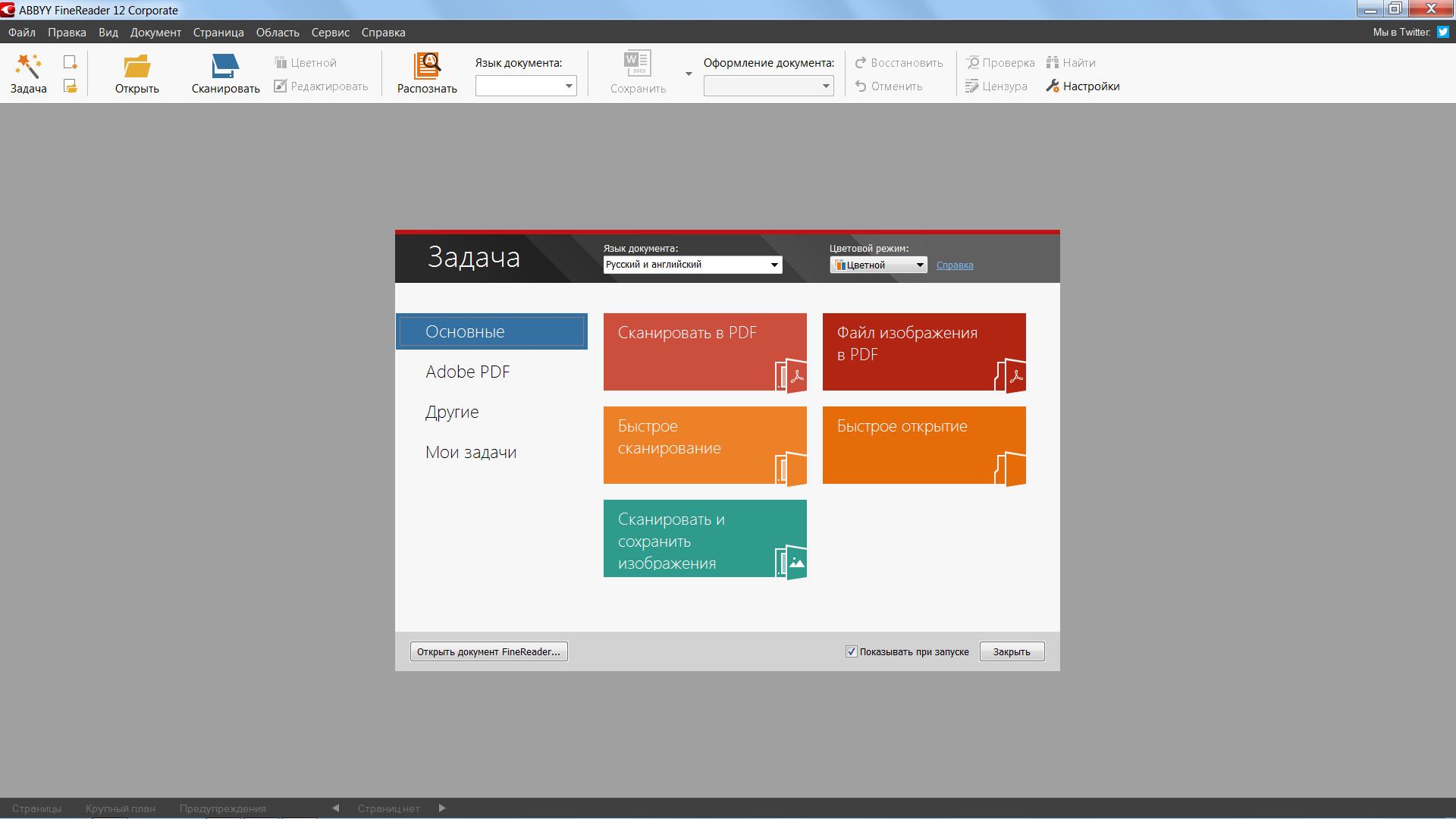
v. Общие проблемы со сканированием
Есть несколько способов решить эту проблему. Вы можете либо убедиться, что сканирование максимально прямое, уровень яркости установлен на 50%, а документ сканируется с разрешением 300 точек на дюйм.
Бесплатная загрузка
или
Купить PDFelement
прямо сейчас!
Бесплатная загрузка
или
Купить PDFelement
прямо сейчас!
Купить PDFelement
прямо сейчас!
Купить PDFelement
прямо сейчас!
Другие популярные статьи от Wondershare
Функция оптического распознавания символов ABBYY FineReader для ScanSnap
ABBYY FineReader для ScanSnap — это приложение, используемое исключительно со ScanSnap. Его можно использовать для распознавания текста текстовой информации в изображении в формате PDF документа, отсканированного с помощью ScanSnap, и преобразования изображения в файл Word, Excel или PowerPoint.
В этом разделе описаны возможности и примечания к функции преобразования текстовой информации в изображение с помощью ABBYY FineReader for ScanSnap.
Особенности функции OCR программы ABBYY FineReader для ScanSnap
Параметры, которые невозможно воспроизвести в том виде, в каком они представлены в исходном документе
Документы и символы, которые могут быть неправильно распознаны
Прочие примечания
Особенности функции OCR программы ABBYY FineReader для ScanSnap
Функция OCR программы ABBYY FineReader для ScanSnap имеет следующие функции. Перед преобразованием изображения проверьте содержимое изображения, которое необходимо преобразовать.
Приложение, используемое для преобразования | Документы, пригодные для преобразования | Документы, не подходящие для преобразования |
|---|---|---|
Сканировать в Word | Документы, созданные с использованием простого макета страницы с одним или двумя столбцами. | Документы, такие как брошюры, журналы и газеты, созданные с использованием сложной компоновки страниц, состоящей из следующего:
|
Сканировать в Excel | Документы с простыми таблицами, в которых каждая граница соединяется с внешней рамкой. | Документы, содержащие следующее:
|
Сканировать в PowerPoint(R) | Документы, состоящие только из символов и простых графиков или таблиц на белом или светлом одноцветном фоне. |
|

Параметры, которые нельзя воспроизвести в том виде, в каком они представлены в исходном документе
Следующие параметры не могут быть воспроизведены в том виде, в каком они указаны в исходном документе. Проверьте преобразованные файлы с помощью Word, Excel или PowerPoint и при необходимости отредактируйте их.
Шрифт и размер символов
Междустрочный и межстрочный интервал
Подчеркнутые, полужирные и курсивные символы
Символы верхнего/нижнего индекса
Документы и символы, которые могут распознаваться неправильно
Следующие типы документов и символов могут распознаваться неправильно.
Их можно распознать, если отсканировать их, изменив цветовой режим или улучшив качество изображения в настройках профиля.
Документы, содержащие рукописные символы
Документы с мелкими символами размером менее 10 пт.
Перекошенные документы
Документы, написанные на языках, отличных от указанного
Документы с символами на неравномерно окрашенном фоне, например, с заштрихованными символами.
Документы с большим количеством декоративных символов, таких как рельефные или контурные символы
Документы с символами на узорчатом фоне, такими как символы, перекрывающие иллюстрации или диаграммы
Документы, в которых много символов касается подчеркивания или границ
Документы со сложной компоновкой и документы с шумом изображения (Распознавание текста для этих документов может занять дополнительное время.
)
 )
)Другие примечания
Когда документ большого размера на бумаге преобразуется в файл Word, он может быть преобразован в файл с максимальным размером бумаги, допустимым для Word.
При преобразовании документа в файл Excel, если результаты распознавания превышают 65536 строк, строки после 65536-й строки не сохраняются.
При преобразовании документа в файл Excel макет всего документа, диаграммы, графики, а также высота и ширина таблиц не воспроизводятся. Воспроизводятся только таблицы и символы.
При преобразовании документа в файл PowerPoint фоновые цвета и узоры не воспроизводятся.
При сканировании документа в перевернутом или боковом положении изображение не может быть правильно преобразовано. Установите [Поворот] в [Сканирование] в окне [Подробные настройки] или правильно загрузите документ, а затем отсканируйте документ.
Если включена функция уменьшения проступания, скорость распознавания текста может снизиться.