Как посмотреть процессы базы 1с под ms sql: Чек-лист по настройке инфраструктуры для повышения скорости работы 1С с MS SQL (особенно важно в облаках) / Хабр
Содержание
Чек-лист по настройке инфраструктуры для повышения скорости работы 1С с MS SQL (особенно важно в облаках) / Хабр
При размещении 1С в облачной инфраструктуре и среде виртуализации наиболее важными и непростыми задачами являются повышение скорости работы платформы «1С» и настройка СУБД. Для достижения максимальной производительности инфраструктуры 1С рекомендуется правильно выбирать архитектуру инфраструктуры, режимы работы, проверить и выполнить ряд важных настроек.
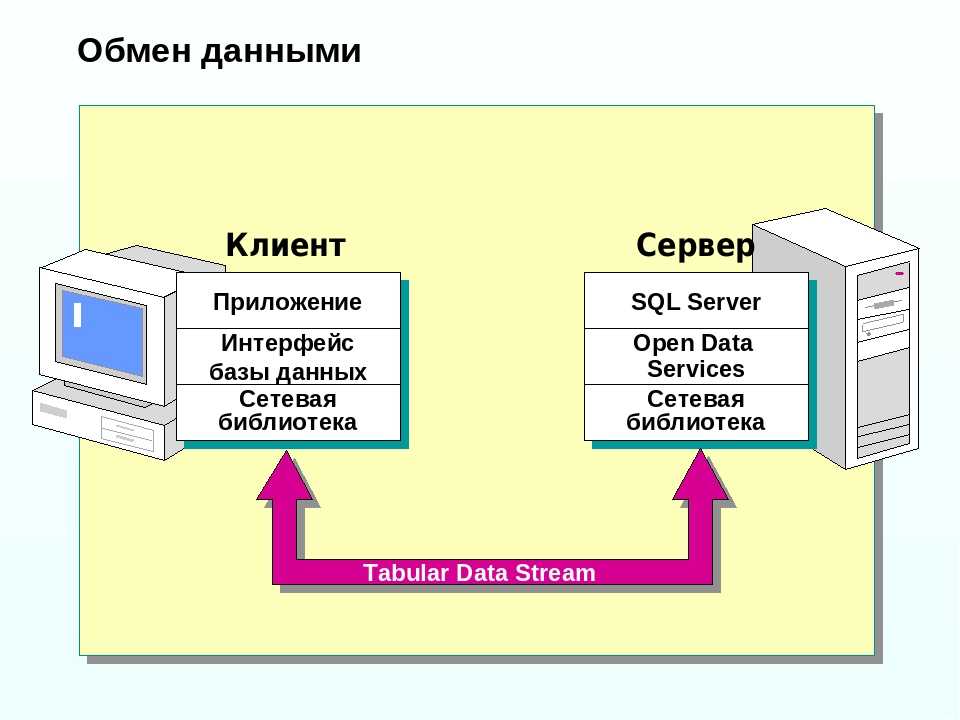
В зависимости от количества пользователей, размера баз данных и ограничений бюджета (с учетом стоимости дополнительных лицензий на сервер «1С:Предприятие 8» и лицензий на СУБД) платформа «1С» может работать в файловом и клиент-серверном вариантах (на основе трехуровневой архитектуры «клиент-сервер» (рис. 1): клиентское приложение, кластер серверов «1С:Предприятия 8», СУБД).
Рис. 1
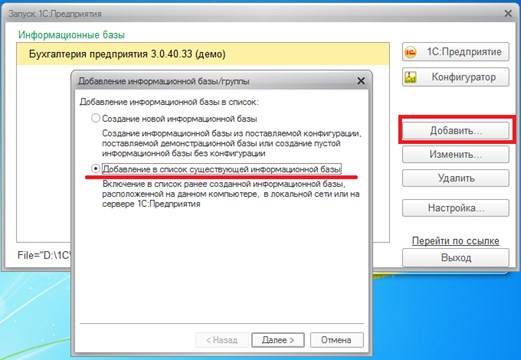
Как правильно выбрать вариант/режим работы 1С: файловый или SQL?
Обычно для 1-10 пользователей выбирается файловый режим
От 10 и более пользователей выбирается режим работы с использованием SQL
В файловом варианте все пользователи могут работать на одной виртуальной машине в облаке, например на терминальном сервере.
Для клиент-серверного варианта лучше выбрать не менее двух виртуальных машин:
Сервер с клиентским приложением, например терминальный сервер с клиентской частью «1С» (толстый клиент)
Сервер «1С» и СУБД (MS SQL или PostgreSQL)
Как рассчитать мощности сервера для 1С в файловом режиме работы?
В обоих вариантах: файловом и SQL, для работы с пользовательским приложением 1С в классическом режиме, например, «удаленного рабочего стола» (так называемый «толстый клиент»), необходимы следующие минимальные ресурсы виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + 0,25 * количество пользователей
Объем памяти RAM = 1 или 2 ГБ для ОС + 0,5 ГБ * количество пользователей
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (0,1-10) ГБ * количество пользователей. Для ОС и 1С рекомендуется использовать самые быстрые диски
Как рассчитать мощности сервера для 1С в варианте работы с SQL?
В клиент-серверном варианте работы 1С, в котором используется СУБД SQL, рекомендуется разместить 1С Сервер и сервер SQL на отдельном виртуальном сервере в общей с клиентским сервером локальной подсети. Необходимы следующие минимальные мощности для этого виртуального сервера:
Необходимы следующие минимальные мощности для этого виртуального сервера:
Количество виртуальных ядер CPU = 1 или 2 для ОС + (2-4) для Cервера 1С + (2-8-16…) для СУБД SQL в зависимости от объема и количества баз данных
Объем памяти RAM = 1 или 2 ГБ для ОС + (2-4) ГБ для Cервера 1С + (2-4-8-16-32…) ГБ для СУБД SQL в зависимости от объема и количества баз данных
Размер диска/хранилища HDD = 20-40 ГБ для ОС и приложений + (10-1000) ГБ в зависимости от объема и количества баз данных. Для ОС и СУБД рекомендуется использовать самые быстрые диски
————
ОС — операционная система, например, Windows Server
Здесь Сервер 1С — ПО «сервер «1С:Предприятия 8»
Наиболее важными и непростыми задачами являются повышение продуктивности использования платформы «1С» в облаке и настройка СУБД. Типичные проблемы при развертывании и эксплуатации облачной инфраструктуры для «1С» следующие:
Неправильный выбор мощностей
Неквалифицированная настройка сервисов виртуальной инфраструктуры
Недостаточное внимание к тестированию производительности платформы «1С»
Для достижения максимальной производительности рекомендуется проверить и выполнить ряд настроек. Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
Прежде всего необходимо исключить свопинг, для чего с помощью системы мониторинга следует обязательно удостовериться в том, что объем оперативной памяти достаточен для работы ВМ. Кроме того, файл подкачки ОС, профили пользователей, файлы баз данных, файлы логов транзакций (SQL) и tempDB (SQL) лучше разместить на дополнительных SSD-дисках, а для файла подкачки установить фиксированный размер.
На SQL-сервере необходимо выключить все ненужные службы, например FullText Search и Integration Services, установить максимально возможный объем оперативной памяти, максимальное количество потоков (Maximum Worker Threads) и повышенный приоритет сервера (Boost Priority), задать ежедневную дефрагментацию индексов и обновление статистики, настроить автоматическое увеличение файла базы данных (не менее 200 Мбайт) и файла лога (не менее 50 Мбайт), а также полную реиндексацию не реже одного раза в неделю. При размещении серверов SQL и «1С:Предприятие» на одной ВМ следует включить протокол Shared Memory.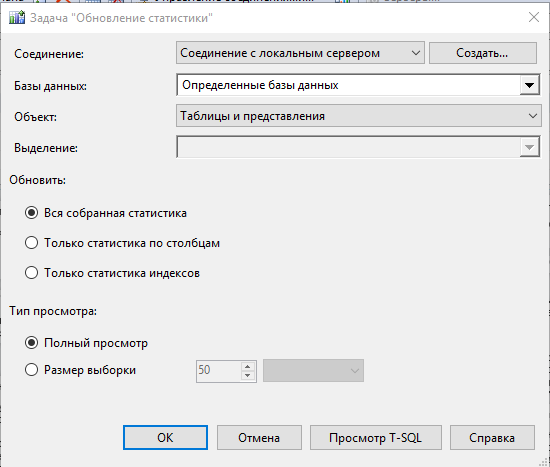
При расчете требуемых мощностей в облаке лучше выбрать минимальные первоначальные значения без запаса, поскольку биллинг почасовой, а мощности в любой момент можно увеличить или уменьшить. Такой подход позволяет существенно экономить ресурсы и средства. Вместе с тем надо обязательно протестировать и оценить быстродействие системы, для чего можно использовать, например, бесплатные нагрузочные тесты Гилева и «1С:Корпоративный инструментальный пакет» (https://its.1c.ru/db/kip или http://v8.1c.ru/expert/etp.htm).
С помощью тестов Гилева можно быстро и достаточно легко понять, насколько эффективно работает платформа «1С», как влияют на ее производительность те или иные настройки, а также найти и устранить узкие места инфраструктуры. Для более детального анализа нагрузки и поиска узких мест рекомендуется использовать утилиту Process Explorer Марка Русиновича (https://technet.microsoft.com/en-us/sysinternals/processexplorer).
Следуя перечисленным выше рекомендациям, можно добиться увеличения быстродействия платформы «1С» в облаке в 1,5–2 раза.
Квалифицированное размещение ИТ-сервисов, в том числе «1С», на облачной платформе позволяет:
Существенно сократить расходы
Повысить уровни безопасности (доступ к данным, резервное копирование, антивирусная защита и др.) и технического обслуживания
Обеспечить централизованное администрирование и мониторинг
Организовать эффективную и безопасную удаленную работу
Воспользоваться гибкими возможностями масштабирования, лицензирования и оперативного перехода на необходимые версии конфигураций «1С»
ЧЕК-ЛИСТ ПО ОПТИМИЗАЦИИ ИНФРАСТРУКТУРЫ 1С С MS SQL
1. Включить возможность мгновенной инициализации файлов (Database instant file initialization)
Это позволяет ускорить работу таких операций как:
Создание базы данных
Добавление файлов, журналов или данных в существующую базу данных
Увеличение размера существующего файла (включая операции автоувеличения)
Восстановление базы данных или файловой группы
Подробности здесь
Для включения настройки:
На компьютере, где будет создан файл резервной копии, откройте приложение Local Security Policy (secpol.
 msc)
msc)Разверните на левой панели узел Локальные политики, а затем кликните пункт Назначение прав пользователей
На правой панели дважды кликните Выполнение задач по обслуживанию томов
Нажмите кнопку «Добавить» пользователя или группу и добавьте сюда пользователя, под которым запущен сервер MS SQL Server
Нажмите кнопку Применить
 msc)
msc)2. Включить параметр «Блокировка страниц в памяти» (Lock pages in memory)
Эта настройка определяет, какие учетные записи могут сохранять данные в оперативной памяти, чтобы система не отправляла страницы данных в виртуальную память на диске, что может повысить производительность.
Подробности здесь
Для включения настройки:
В меню Пуск выберите команду Выполнить. В поле Открыть введите gpedit.msc
В консоли Редактор локальных групповых политик разверните узел Конфигурация компьютера, затем узел Конфигурация Windows
Разверните узлы Настройки безопасности и Локальные политики
Выберите папку Назначение прав пользователя
Политики будут показаны на панели подробностей
На этой панели дважды кликните параметр Блокировка страниц в памяти
В диалоговом окне Параметр локальной безопасности — блокировка страниц в памяти выберите «Добавить» пользователя или группу
В диалоговом окне Выбор: пользователи, учетные записи служб или группы добавьте ту учетную запись, под которой у вас запускается служба MS SQL Server
Чтобы изменения вступили в силу, перезагрузите сервер или зайдите под тем пользователем, под которым у вас запускается MS SQL Server
3.
 Включить каталоги с файлами базы данных в правила исключения для антивируса.
Включить каталоги с файлами базы данных в правила исключения для антивируса.
Если антивирус будет сканировать файлы базы, это может сильно замедлить работу СУБД.
Для опытных администраторов: антивирус на сервер СУБД лучше не устанавливать.
4. Включить каталоги с файлами базы данных в список исключений для системы автоматического копирования.
Если на сервере установлена система автоматического копирования файлов, то, когда она будет копировать файлы базы, это может привести к замедлению работы. Копии базы необходимо делать средствами самой СУБД.
5. Отключить механизм DFSS для дисков.
Механизм Dynamic Fair Share Scheduling отвечает за балансировку и распределение аппаратных ресурсов между пользователями. Иногда его работа может негативно сказываться на производительности 1С.
Чтобы отключить его только для дисков, нужно:
6. Отключить сжатие данных для каталогов, в которых лежат файлы базы.
При включенном сжатии ОС будет пытаться дополнительно обрабатывать файлы при модификации, что замедлит сам процесс записи, но сэкономит место.
Чтобы отключить сжатие файлов в каталоге, необходимо:
Открыть свойства каталога
На закладке Общие нажать кнопку Другие
Снять флаг «Сжимать» содержимое для экономии места на диске
7. Установить параметр «Максимальная степень параллелизма» (Max degree of parallelism) в значение 1.
Данный параметр определяет, во сколько потоков может выполняться один запрос. По умолчанию параметр равен 0, это означает, что сервер сам подбирает число потоков. Для баз с характерной для 1С нагрузкой рекомендуется поставить данный параметр в значение 1, т.к. в большинстве случаев это положительно скажется на работе запросов.
Для настройки параметра необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Дополнительно
Установить значение параметра равное единице
8. Ограничить максимальный объем памяти сервера MS SQL Server.
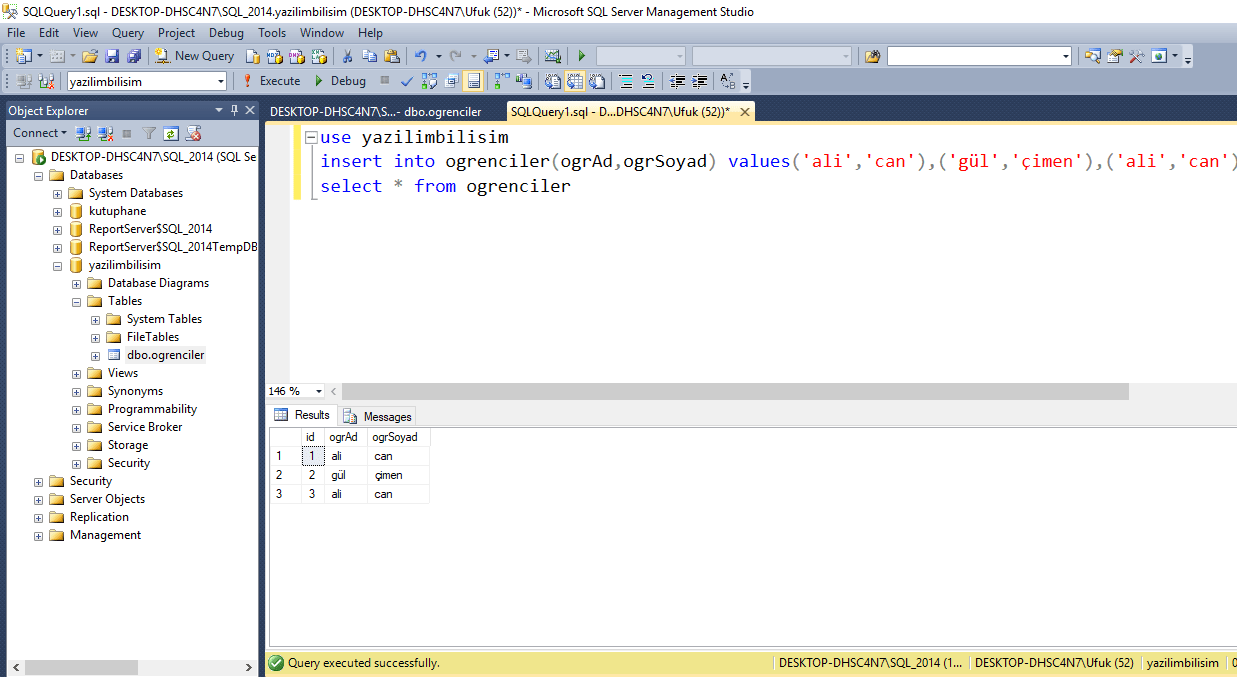
Необходимо ограничить максимальный объем памяти, потребляемый MS SQL Server, особенно это критично, если роли сервера 1С и сервера СУБД совмещены. Максимальный объем памяти, рекомендуемый для MS SQL Server, можно рассчитать по следующей формуле:
Память для MS SQL Server = Память всего – Память для ОС – Память для сервера 1С
Например, на сервере установлено 64 ГБ оперативной памяти, необходимо понять, сколько памяти выделить серверу СУБД, чтобы хватило серверу 1С.
Для нормальной работы ОС в большинстве случаев более чем достаточно 4 ГБ, обычно – 2-3 ГБ.
Чтобы определить, сколько памяти требуется серверу 1С, необходимо посмотреть, сколько памяти занимают процессы кластера серверов в разгар рабочего дня. Этими процессами являются ragent, rmngr и rphost, подробно данные процессы рассматриваются в разделе, который посвящен кластеру серверов. Снимать данные нужно именно в период пиковой рабочей активности, когда в базе работает максимальное количество пользователей. Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Получив эти данные, необходимо прибавить к ним 1 ГБ – на случай запуска в 1С «тяжелых» операций.
Чтобы установить максимальный объем памяти, используемый MS SQL Server, необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Память
Указать значение параметра Максимальный размер памяти сервера
9. Включить флаг «Поддерживать» приоритет SQL Server (Boost SQL Server priority).
Данный флаг позволяет повысить приоритет процесса MS SQL Server над другими процессами.
Имеет смысл включать флаг только в том случае, если на компьютере с сервером СУБД не установлен сервер 1С.
Для установки флага необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства сервера и выбрать закладку Процессоры
Включить флаг «Поддерживать приоритет SQL Server (Boost SQL Server priority)» и нажать Ок
10.
 Установить размер авто увеличения файлов базы данных.
Установить размер авто увеличения файлов базы данных.
Автоувеличение позволяет указать величину, на которую будет увеличен размер файла базы данных, когда он будет заполнен. Если поставить слишком маленький размер авторасширения, тогда файл будет слишком часто расширяться, на что будет уходить время. Рекомендуется установить значение от 512 МБ до 5 ГБ.
Для установки размера авторасширения необходимо:
Запустить Management Studio и подключиться к нужному серверу
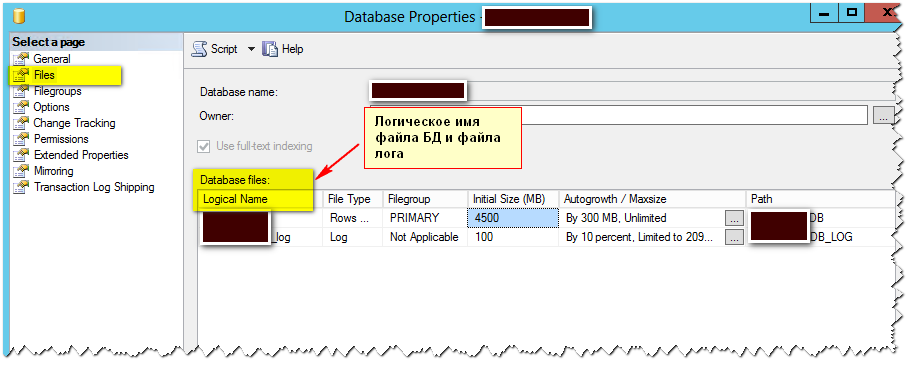
Открыть свойства нужной базы и выбрать закладку Файлы
Напротив каждого файла в колонке Автоувеличение поставить необходимое значение
Данная настройка будет действовать только для выбранной базы. Если вы хотите, чтобы такая настройка действовала для всех баз, нужно выполнить эти же действия для служебной базы model. После этого все вновь созданные базы будет иметь те же настройки, что и база model.
11. Разнести файлы данных mdf и файлы логов ldf на разные физические диски.

В этом случае работа с файлами может идти не последовательно, а практически параллельно, что повышает скорость работы дисковых операций. Лучше всего для этих целей подходят диски SSD.
Для переноса файлов необходимо:
Запустить Management Studio и подключиться к нужному серверу
Открыть свойства нужной базы и выбрать закладку Файлы
Запомнить имена и расположение файлов
Отсоединить базу, выбрав через контекстное меню Задачи – Отсоединить
Поставить флаг Удалить соединения и нажать Ок
Открыть Проводник и переместить файл данных и файл журнала на нужные носители
В Management Studio открыть контекстное меню сервера и выбрать пункт Присоединить базу
Нажать кнопку Добавить и указать файл mdf с нового диска
В нижнем окне сведения о базе данных в строке с файлом лога нужно указать новый путь к файлу журнала транзакций и нажать Ок
12. Вынести файлы базы TempDB на отдельный диск.

Служебная база данных TempDB используется всеми базами сервера для хранения, промежуточных расчетов, временных таблиц, версий строк при использовании RCSI и многих других вещей. Обычно обращений к этой базе очень много, и если она будет лежать на медленных дисках, это может замедлить работу системы.
Рекомендуется хранить базу TempDB на отдельном диске для повышения производительности работы системы.
Для переноса базы TempDB на отдельный диск необходимо:
USE master GO ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = ‘Новый_Диск:\Новый_Каталог\tempdb.mdf’) GO ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = ‘Новый_Диск:\Новый_Каталог\templog.ldf’) GO |
13. Включить Shared Memory, если сервер 1С расположен на том же компьютере, что и сервер СУБД.
Протокол Shared Memory позволит общаться приложениям через оперативную память, а не через протокол TCP/IP.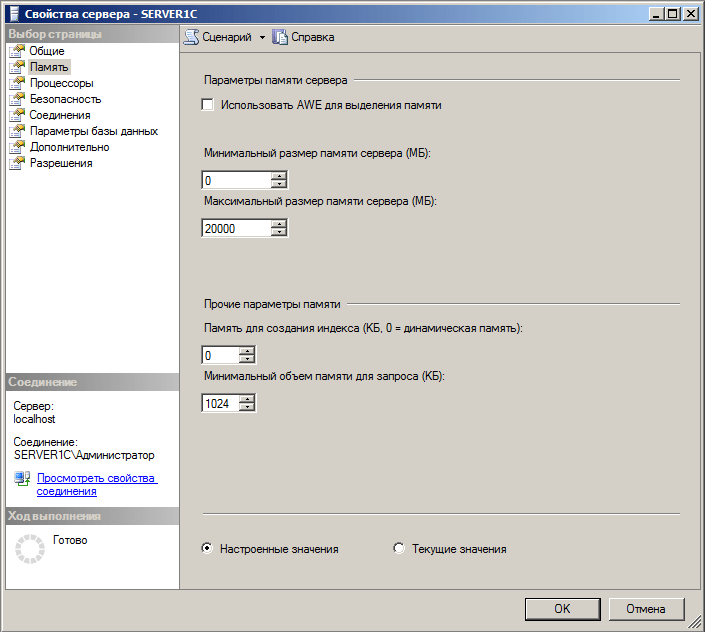
Для включения Shared Memory необходимо:
Запустить диспетчер конфигурации SQL Server
Зайти в пункт SQL Native Client – Клиентские протоколы – Общая память – Включено
Поставить значение Да и нажать Ок
Протокол Именованные каналы нужно выключить аналогичным образом
14. Перезапустить службу MS SQL Server
Внимание! Когда все настройки выполнены, необходимо перезапустить службу MS SQL Server
База 1С растёт и всё тормозит. Что делать?
Большое предприятие общественного питания ведет свою деятельность в «1С:Общепит. Модуль для 1С:ERP и 1С:КА2». Через полгода эксплуатации стали поступать жалобы от пользователей об общем замедлении работы системы. При этом замедление наблюдалось буквально во всем: открытие форм списка, формирование отчетов, проведение документов и так далее.
Компания представляет собой группу организаций общим числом более 100. Организации разнесены по базам и на разные физические серверы, чтобы сбалансировать рабочую нагрузку: количество проведенных документов, формирование отчетов в единицу времени. Приблизительно по 20 организаций на базу. Базы начали свою работу в разное время, поэтому размеры баз разные.
Приблизительно по 20 организаций на базу. Базы начали свою работу в разное время, поэтому размеры баз разные.
Заметили, что существует тенденция к снижению производительности у баз большего размера. В качестве метода решения проблемы применялось увеличение лимита использования оперативной памяти MS SQL. Это улучшало ситуацию с производительностью.
Беспокойство заключается в том, что память надо будет наращивать вместе с ростом базы.
В рамках статьи рассмотрены причины такого поведения системы, их выяснение, возможные способы воздействия, а также список выработанных рекомендаций по эксплуатации системы.
Оглавление
- Параметры и размеры баз
- Ищем проблему в MS SQL
- Собираем данные о событиях в MS SQL, технологическом журнале «1С» и счетчиках производительности Windows
- Воспроизводим проблему и анализируем
- Находим потенциальную причину замедления работы «1С»
- Ищем дополнительные возможности ускорения «1С»
- Неоптимальные бизнес-процессы могут приводить к замедлению работы баз «1С»
Параметры и размеры баз
Общие параметры
- Клиентская база «1С:Общепит. Модуль для 1С:ERP и 1С:КА2» в клиент-серверном режиме, на которой воспроизводится проблемная ситуация.
- Операционная система: Windows Server 2012 R2.
- База данных: Microsoft SQL Server 2017 64х.
 Модуль для 1С:ERP и 1С:КА2» в клиент-серверном режиме, на которой воспроизводится проблемная ситуация.
Модуль для 1С:ERP и 1С:КА2» в клиент-серверном режиме, на которой воспроизводится проблемная ситуация.
База без замедления
- Размер базы 30 Gb.
- Выделенная память для MS SQL 64 Gb.
База с замедлением
- Размер базы 200 Gb.
- Выделенная память для MS SQL 64 Gb.
Увеличение выделенной памяти для MS SQL до 96 Gb снимало проблему замедления работы.
Ищем проблему в MS SQL
Для начала посмотрим на ситуацию в реальном времени. Для этого во время возникновения проблем в системе откроем Activity Monitor. Взглянув на исполняющиеся в системе запросы, фиксируем наличие задержек вида PAGEIOLATCH:
Латчи (latches) — это группа внутренних блокировок MS SQL сервера, которая предназначена для обеспечения целостности данных объектов в памяти MS SQL Server, а также для контролируемого доступа к ним.
Блокировок типа latch в MS SQL Server большое множество, поэтому рассмотрим конкретно PAGEIOLATCH. Для этого нам понадобится познакомиться с понятием буферного кэша.
Данные в MS SQL Server хранятся постранично, по умолчанию каждая страница занимает 8 Кб. При выполнении запроса происходит считывание тех страниц, в которых находятся запрашиваемые данные. Чтобы каждый раз не обращаться к дисковой подсистеме для получения запрашиваемых страниц в MS SQL Server предусмотрена специальная область в памяти, называемая буферный кэш (buffer cache) или буферный пул (buffer pool).
Как уже понятно из названия, в ней кэшируются данные страниц, планов запросов, таблиц, индексов и так далее. Использование буферного кэша увеличивает производительность сервера за счет снижения операций ввода/вывода с файлами базы данных.
Блокировка типа PAGEIOLATCH возникает, когда страницы данных запрашиваются из буферного кэша и при этом отсутствуют в нем.
Сначала MS SQL Server занимается выделением места в буферном кэше для таких страниц порождая блокировку вида PAGEIOLATCH_SH. Далее происходит физическое перемещение страниц с диска в буферный кэш, что порождает дополнительную блокировку вида PAGEIOLATCH_EX.
Назначение PAGEIOLATCH в организации ожидания, пока страница данных загрузится с диска в буферный кэш сервера.
Стоит понимать — само по себе наличие таких блокировок в системе совершенно нормально и необходимо для штатной работы MS SQL Server. Однако, большое их количество приводит к существенному снижению производительности и увеличенной нагрузке на дисковую подсистему сервера, что и происходит в нашем конкретном случае.
Выдвинем гипотезу, что причины такого поведения системы заключаются в большом количестве логических чтений страниц данных в системе из-за выполнения запросов, получающих неоправданно большое количество записей.
Это приводит к тому, что буферный кэш часто не содержит нужных данных и постоянно обращается к диску. Для проверки гипотезы настроим необходимые счетчики на рабочем сервере и проведем их сбор во время возникновения проблем в системе.
Собираем данные о событиях в MS SQL, технологическом журнале «1С» и счетчиках производительности Windows
Выполним настройку механизма расширенных событий (extended events) MS SQL Server для отслеживания выполняющихся в системе запросов и параметров их выполнения.
Выберем информацию о выполняющихся в системе запросах, длительность которых более 1 секунды, которые выполняют более 100 логических чтений. Это обычная рекомендация для начала расследования, связанного с PAGEIOLATCH.
Важно понимать, что запрос может быть и не длительным, но с достаточно большим количеством чтений записей. Добавляем в отслеживание следующие события:
- rpc_completed
- batch_completed
- query_post_compilation_showplan
На закладке Global Fields для каждого события выбираем колонку sql_text, а на закладке Filter устанавливаем фильтры по:
- database_id = <id исследуемой базы>
- logical_reads > 100
- duration > 1000
Внешний вид настройки лога расширенных событий:
Для того, чтобы результаты работы extended events сохранить в файл для дальнейшего анализа на закладке Data Storage добавим тип event file.
Сохранять именно в файл критически важно, так как в режиме Watch Live Data далеко не все события попадают в анализ. Выберем место, куда система сохранит файл в формате xel, который затем можно будет прочитать в MS SQL Management Studio:
Также для того, чтобы получить контекст 1С выполняемых в MS SQL запросов настроим технологический журнал с событиями DBMSSQL и SDBL длительностью более 1 секунды:
И напоследок, настроим счетчики производительности Windows, чтобы отследить состояние буферного кэша, а также нагрузку на дисковую подсистему. Системные счетчики для отслеживания интенсивности работы с оперативной памятью и диском:
- Memory\ Available Mbytes.
- Memory\Pages/sec.
- Physical Disk\ Avg. Disk Queue Length.
- Physical Disk\ Avg. Disk sec transfer.
Счетчики MS SQL Server для отслеживания работы с буферным кэшем:
- Buffer manager\Page life expectancy.
- Buffer manager\Buffer cache hit ratio.
- Plan Cache\Plan cache hit ratio.
- Buffer Manager\Page reads/sec.
- Buffer Manager\Page writes/sec.
- Buffer Manager\Lazy writes/sec.

Внешний вид настройки счетчиков производительности Windows:
Воспроизводим проблему и анализируем
Для того, чтобы воспроизвести ситуацию, уменьшаем количество доступной оперативной памяти MS SQL Server до исходных значений (когда воспроизводились PAGEIOLATCH и наблюдалось общее замедление работы системы) и включаем настроенные счетчики.
После сбора результатов, анализируем полученные замеры. Прежде всего откроем счетчики производительности Windows и взглянем на счетчик «Ожидаемый срок хранения страницы» (Page life expectancy).
Данный счетчик показывает, какое ожидаемое время нахождения страницы данных в буферном кэше. Чем время больше, тем лучше, тем чаще мы будем выбирать такие страницы данных из буферного кэша, а не загружать с диска. В нормальной ситуации показатель должен только увеличиваться, с разной скоростью, но все-таки иметь тенденцию к увеличению.
В нормальной ситуации показатель должен только увеличиваться, с разной скоростью, но все-таки иметь тенденцию к увеличению.
Что мы видим в нашем случае:
Время жизни страницы большую часть времени находится у нулевой отметки, то есть страница почти не находится в буферном кэше.
Это очень плохо, так как в этом случае системе приходится все время обращаться к диску. Такая ситуация может наблюдаться при выполнении запросов, получающих большое количество данных, таким образом, что буферный кэш постоянно заменяется все новыми и новыми страницами и его объема явно не хватает. Именно поэтому мы и наблюдаем постоянные латчи типа PAGEIOLATCH при выполнении запросов в системе.
Перейдем к более детальному анализу, откроем лог расширенных событий и сохраним его в таблицу для более детального анализа.
Для этого в MS SQL Management Studio необходимо открыть файл лога и экспортировать его при помощи команды Extended Events -> Export to -> Table, после чего выбрать базу данных и имя таблицы, в которую будут экспортированы данные:
В итоге получим таблицу следующей структуры:
Выполним несложный запрос, чтобы выбрать запросы с самым большим количеством логических чтений:
SELECT TOP (100) * FROM [chesdm_extended_events].
 [dbo].[logical_reads_1]
ORDER BY [logical_reads] DESC
[dbo].[logical_reads_1]
ORDER BY [logical_reads] DESC
Начнем с самой верхней строки. Имеем запрос, выполнение которого произвело более 17 млн. логических чтений:
Текст запроса можно получить напрямую из поля sql_text данной таблицы или путем установки фильтра по точному времени выполнения запроса в открытом файле лога расширенных событий:
Далее по времени выполнения и тексту запроса находим соответствующее событие в логе технологического журнала по событию DBMSSQL. Контекст выполнения запроса выглядит следующим образом:
Обращаем внимание на то, что этот запрос выполняется при программном проведении документа и дальнейшем выполнении контроля остатков.
Находим потенциальную причину замедления работы «1С»
Переходим к анализу текста запроса SQL и обнаруживаем среди прочих используемых таблиц выборку данных из физической таблицы регистра накопления _AccumRg62208 с отбором по периоду, что соответствует регистру «Товары организаций».
Посмотреть значение параметров @P6 и @P7 в собранном extended events можно в поле statement, они равны 2019-06-01 23:59:59 и 3999-11-01 00:00:00 соответственно.
Получение данных из физической таблицы регистра накопления за такой большой период явно является избыточным, т.к. данные до конца января должны были быть выбраны из итоговой таблицы.
Озвучиваем клиенту гипотезу, что в базе не рассчитаны актуальные итоги и оказываемся правы. Действительно, итоги не были рассчитаны, что приводило к использованию физической таблицы при проведении документов.
После того, как в базе были пересчитаны итоги, производим повторный сбор счетчиков во время интенсивной работы пользователей и повторяем анализ. Видим небольшое улучшение на графике счетчика page life expectancy, среднее время 136 секунд является все еще довольно низкий показателем:
Ищем дополнительные возможности ускорения «1С»
Нас не устраивает полученный результат, поэтому изучаем обновленный лог расширенных событий. Видим вверху списка запросов по количеству логических чтений новых лидеров:
Видим вверху списка запросов по количеству логических чтений новых лидеров:
Обращаем внимание на то, что помимо большого количества чтений (более 25 млн.) также количество строк, возвращаемых запросом более 500 тыс. Выясняем контекст данного запроса по сопоставлению его текста с логами технологического журнала:
По контексту становится понятно, что речь идет о формировании отчета. Анализируем текст SQL запроса и делаем вывод, что происходит выборка из физической таблицы регистра накопления _AccumRg62196, что соответствует регистру «Товары на складах» за период с 23.12.2018 по 29.01.2020. Период формирования отчета узнали аналогично, по параметрам SQL запроса.
Также по логу технологического журнала можем выяснить пользователя, который сформировал отчет:
Делаем предположение о том, что отчет использует физическую таблицу регистра из-за того, что формируется с детализацией до регистратора, да еще и за очень большой период, не требующийся по бизнес-процессу предприятия. Передаем информацию клиенту и подтверждаем нашу догадку.
Передаем информацию клиенту и подтверждаем нашу догадку.
Дополнительный анализ технологического журнала указывает на то, что данный отчет с похожими параметрами формировался в системе в среднем несколько раз в час. Это послужило основной причиной большого количества логических чтений.
Клиенту рекомендовано уменьшить период формирования отчетов в системе для снижения нагрузки на буферный кэш и уменьшения количество обращений MS SQL Server к дисковой подсистеме для загрузки данных.
Неоптимальные бизнес-процессы могут приводить к замедлению работы баз «1С»
В данной статье были рассмотрены подходы к выяснения причин блокировок вида PAGEIOLATCH в MS SQL, приводящих к общей деградации производительности информационных систем «1С» на примере проблемы, с которой столкнулись пользователи решения «1С:Общепит. Модуль для 1С:ERP и 1С:КА2».
Можно сделать вывод, что в больших системах решить проблему латчей до конца техническим способом бывает не всегда возможно.
Помимо обслуживания базы и пересчета итогов необходимо прорабатывать бизнес-процессы на предприятии. В частности, не допускать запросов, которые будут выбирать слишком большой пул данных за одно обращение к СУБД. Большой пул данных — это не абсолютное понятие, оно зависит от размеров базы и конфигурации сервера и требует предварительного анализа.
В итоге данная ситуация на проекте была решена организационными методами. После анализа реальных потребностей выяснилось, что по факту такой отчет и так часто строить не было необходимости и нужны данные из системы можно было получить иным способом.
Если вам интересна тема блокировок в MS SQL Server при работе «1С:Предприятия», то рекомендуем нашу предыдущую статью «Страничные блокировки в MS SQL Server при проведении документа в документе в «1С»».
Авторы статьи
Чесноков Дмитрий
Черанев Андрей
Запланированные операции на уровне СУБД для MS SQL Server
Указание на выполнение запланированных операций на уровне СУБД.
Информация может применяться для клиент-серверного варианта 1С:Предприятия 8 при использовании СУБД MS SQL Server.
Общая информация
Одной из наиболее частых причин неоптимальной работы системы является некорректное и несвоевременное выполнение запланированных операций на уровне СУБД. Особенно важно выполнять эти запланированные операции в больших информационных системах, которые работают со значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика этих систем заключается в том, что обычных действий, выполняемых СУБД автоматически (на основе настроек), недостаточно для эффективной работы.
Если в операционной системе есть некоторые симптомы проблем с производительностью, следует проверить, что все рекомендуемые запланированные операции правильно настроены в системе и регулярно выполняются на уровне СУБД.
Выполнение запланированных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенные средства MS SQL Server: План обслуживания.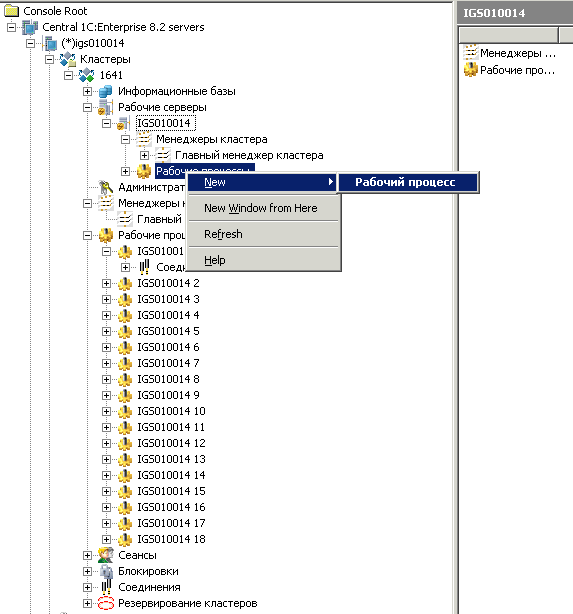 Существуют и другие способы выполнения этих процедур. В данной статье для каждой запланированной процедуры приведен пример ее настройки с помощью плана обслуживания MS SQL Server 2012.
Существуют и другие способы выполнения этих процедур. В данной статье для каждой запланированной процедуры приведен пример ее настройки с помощью плана обслуживания MS SQL Server 2012.
Для MS SQL Server рекомендуется выполнить следующие запланированные операции:
- Обновление статистики
- Очистка процедурного кеша
- Дефрагментация индексов
- Переиндексация таблиц базы данных
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных плановых процедур.
Обновление статистики
MS SQL Server строит план запроса на основе статистической информации о распределении значений в индексах и таблицах. статистическая информация собирается на основе части (выборки) данных и автоматически обновляется при изменении этих данных. иногда этого недостаточно для того, чтобы MS SQL Server устойчиво выстраивал оптимальный план выполнения всех запросов.
В этом случае возможно возникновение проблем с производительностью запросов.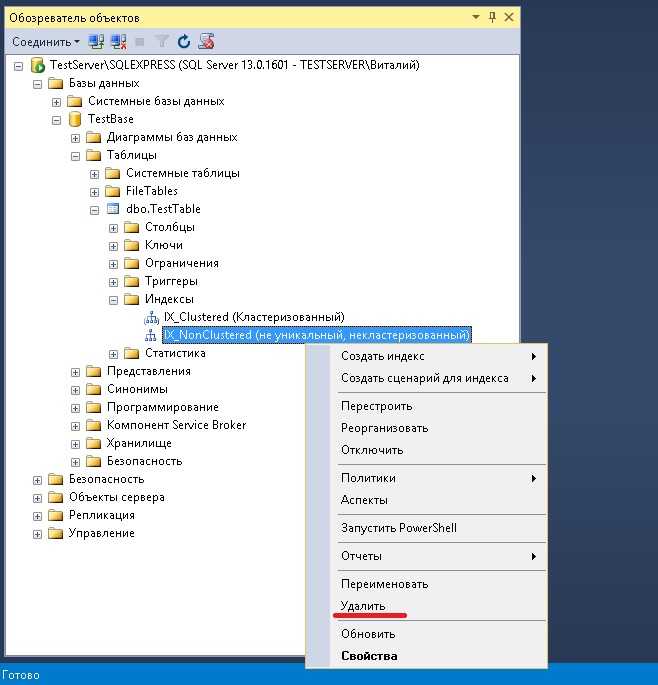 При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальной работы).
При этом в планах запросов наблюдаются характерные признаки неоптимальной работы (неоптимальной работы).
Для обеспечения наиболее корректной работы оптимизатора MS SQL Server рекомендуется регулярно обновлять статистику базы данных MS SQL.
Для обновления статистики всех таблиц базы данных необходимо выполнить следующий запрос SQL:
exec sp_msforeachtable N'UPDATE STATISTICS ? С ПОЛНЫМ СКАНИРОВАНИЕМ
Обновление статистики не блокирует таблицы и не мешает работе других пользователей. Статистика может обновляться так часто, как это необходимо. Следует отметить, что нагрузка на сервер СУБД при обновлении статистики возрастет, что может неблагоприятно сказаться на общей производительности.
Оптимальная частота обновления статистики зависит от размера и характера нагрузки на систему и определяется экспериментально. Рекомендуется обновлять статистику не реже одного раза в день.
Приведенный выше запрос обновляет статистику для всех таблиц базы данных. В реальной операционной системе разные таблицы требуют разной скорости обновления статистики. Анализируя планы запросов, можно определить, какие таблицы больше всего нуждаются в частом обновлении статистики, и настроить две (или более) разные запланированные процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит значительно сократить время обновления статистики и влияние процесса обновления статистики на работу системы в целом.
В реальной операционной системе разные таблицы требуют разной скорости обновления статистики. Анализируя планы запросов, можно определить, какие таблицы больше всего нуждаются в частом обновлении статистики, и настроить две (или более) разные запланированные процедуры: для часто обновляемых таблиц и для всех остальных таблиц. Такой подход позволит значительно сократить время обновления статистики и влияние процесса обновления статистики на работу системы в целом.
Настройка автоматического обновления статистики (MS SQL 2012)
Запустить MS SQL Server Management Studio и подключиться к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:
Создайте подплан (Add Subplan) и назовите его «Обновление статистики». Добавьте к нему задачу Обновить статистику Задача из панели задач:
Настройте расписание обновления статистики. рекомендуется обновлять статистику не реже одного раза в сутки. При необходимости частоту обновления статистики можно увеличить.
Настройте параметры задачи. Для этого необходимо два раза кликнуть по задаче в правом нижнем углу окна. В открывшейся форме укажите имя базы данных (или нескольких баз данных), для которой будет выполняться обновление статистики. Кроме того, вы можете указать, для каких таблиц вы хотите обновить статистику (если точно известно, какие именно таблицы необходимо указать, установите значение Все).
Обновление статистики необходимо производить при включенной опции Полная проверка.
Сохранить созданный план. При наступлении указанного в расписании времени обновление статистики будет запущено автоматически.
Очистка процедурного кэша
Оптимизатор MS SQL Server кэширует планы запросов для их повторного использования. Это сделано для того, чтобы сэкономить время на составление запроса в случае, когда такой запрос уже выполнялся и известен его план.
Возможна ситуация, когда MS SQL Server, ориентируясь на устаревшую статистическую информацию, будет строить неоптимальный план запроса.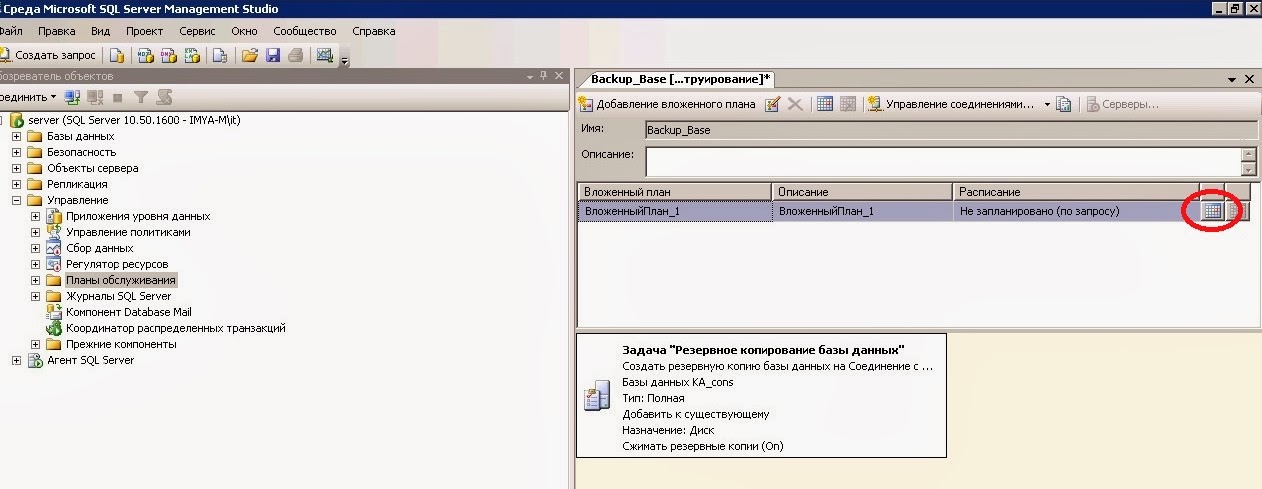 Этот план будет сохранен в процедурном кеше и использован при повторном вызове того же запроса. Если вы обновили статистику, но не очистили процедурный кеш, то SQL Server может выбрать из кеша старый (неоптимальный) план запроса вместо построения нового (более оптимального) плана.
Этот план будет сохранен в процедурном кеше и использован при повторном вызове того же запроса. Если вы обновили статистику, но не очистили процедурный кеш, то SQL Server может выбрать из кеша старый (неоптимальный) план запроса вместо построения нового (более оптимального) плана.
Таким образом, рекомендуется всегда после обновления статистики очищать содержимое процедурного кеша.
Для очистки процедурного кеша MS SQL Server необходимо выполнить следующий SQL-запрос:
DBCC FREEPROCCACHE
Этот запрос необходимо выполнить сразу после обновления статистики. после этого частота его выполнения должна совпадать с частотой обновления статистики.
Настройка очистки процедурного кеша (MS SQL 2012)
Поскольку процедурный кеш необходимо очищать при каждом обновлении статистики, рекомендуется добавить эту операцию в созданный подплан «Обновление статистики». для этого необходимо открыть подплан и добавить в его схему задачу Execute T-SQL Statement Task.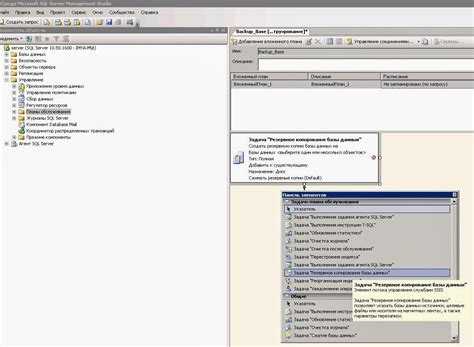 Затем необходимо связать задачу Обновление статистики с помощью стрелки с новой задачей.
Затем необходимо связать задачу Обновление статистики с помощью стрелки с новой задачей.
В тексте созданной задачи Execute T-SQL Statement Task необходимо указать запрос «DBCC FREEPROCCACHE»:
Дефрагментация индексов
При интенсивной работе с таблицами БД возникает эффект фрагментации индексов, что может привести к снижению эффективности запросов.
рекомендуется регулярно дефрагментировать индексы. Для дефрагментации всех индексов всех таблиц базы данных необходимо использовать следующий SQL-запрос (подставив предварительно имя базы):
sp_msforeachtable N'DBCC INDEXDEFRAG (, ''?'')'
Дефрагментация индексов не блокирует таблицы и не мешает работе других пользователей, но создает дополнительную нагрузку на SQL Server. оптимальная частота выполнения этой запланированной процедуры должна быть выбрана в соответствии с нагрузкой на систему в целом и эффектом, полученным от дефрагментации. Рекомендуется выполнять дефрагментацию индексов не реже одного раза в неделю.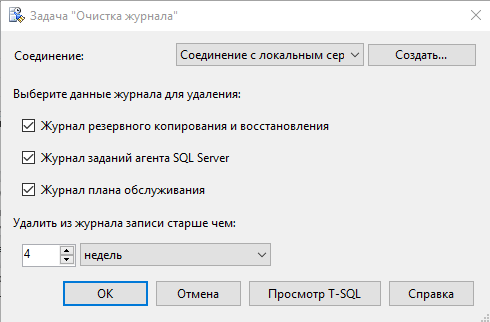
Выполнение дефрагментации возможно для одной и нескольких таблиц, но не для всех таблиц базы данных.
Настройка дефрагментации индексов (MS SQL 2012)
в созданном ранее плане обслуживания создать новый подплан с названием «Дефрагментация индексов». Добавьте к нему задачу Reorganize Index Task:
Установите расписание выполнения задачи дефрагментации индексов. рекомендуется выполнять задание не реже одного раза в неделю, а при высокой изменчивости данных в базе даже часто – до одного раза в сутки.
Настроить задачу, указав базу данных (или несколько баз) и выбрав необходимые таблицы. Если точно неизвестно, какие именно таблицы следует указать, установите значение Все.
Реиндексация таблиц базы данных
Реиндексация таблиц включает полную реконструкцию индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных. Для переиндексации всех таблиц БД необходимо выполнить следующий SQL-запрос:
sp_msforeachtable N'DBCC DBREINDEX (''?'')'
Переиндексация таблиц блокирует их на все время его работы, которые могут существенно повлиять на работу пользователя. В связи с этим рекомендуется выполнять переиндексацию при минимальной загрузке системы.
В связи с этим рекомендуется выполнять переиндексацию при минимальной загрузке системы.
После переиндексации не нужно делать дефрагментацию индексов.
Настройка переиндексации таблиц (MS SQL 2012)
В созданном ранее плане обслуживания создать новый подплан с названием «Переиндексация». Добавьте к нему задачу Rebuild Index Task:
Укажите расписание выполнения для этой задачи переиндексации таблиц. рекомендуется выполнять задачу при минимальной загрузке системы, не реже одного раза в неделю.
Настроить задачу, указав базу данных (или несколько баз) и выбрав необходимые таблицы. Если точно неизвестно, какие именно таблицы следует указать, установите значение Все.
Контроль выполнения регламентных процедур на уровне СУБД
требуется регулярный контроль выполнения регламентных процедур на уровне СУБД. Ниже приведен пример контроля выполнения плана обслуживания для MS SQL Server 2012.
Открыть созданный план обслуживания и выбрать из контекстного меню пункт «Просмотр истории»:
Откроется окно с протоколом выполнения всех определенные регламентные процедуры.
Успешно выполненная задача и задачи, выполненные с ошибками, будут отмечены соответствующими значками. Для задач, выполненных с ошибками, доступна подробная информация об ошибке.
[Всего: 0 Среднее: 0/5]
Отладка производительности SQL Server — Jama Software
Надпись SQL на фоне ноутбука и кода. Изучение языка программирования sql, компьютерные курсы, обучение.
Недавно мы работали над устранением проблем с производительностью SQL-сервера для некоторых наших крупных клиентов, использующих SQL-сервер в качестве своей базы данных. В этой статье я подведу итоги того, что узнал из этого процесса, описав некоторые шаги, которые мы можем предпринять для устранения проблем с производительностью.
Проверьте конфигурацию SQL Server
Убедитесь, что сервер базы данных настроен с достаточным количеством ресурсов, таких как количество ядер ЦП и объем памяти.
Чтобы проверить конфигурацию сервера, вы можете открыть представление «Информация о системе»:
Чтобы проверить настройки памяти SQL Server,
- Запустите SQL Server Management Studio.
- Щелкните правой кнопкой мыши экземпляр базы данных и выберите «Свойства».
- Нажмите на таблицу «Память» во всплывающем окне «Свойства сервера».
- Проверьте настройки памяти.
Убедитесь, что режим моментальных снимков включен
Убедитесь, что для базы данных включен режим моментальных снимков. Чтобы предотвратить блокировку SQL Server, необходимо включить флаг режима моментальных снимков. Выполните следующий запрос, чтобы проверить, включен ли флаг:
SELECT is_read_committed_snapshot_on FROM sys.databases WHERE name= ''
Если запрос возвращает «1», режим моментального снимка уже включен. В противном случае выполните следующий запрос, чтобы включить его.
ALTER DATABASESET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE;
СВЯЗАННЫЕ: Определение и реализация базовых показателей требований
Проверка индексов базы данных
Проверьте индексы базы данных, чтобы убедиться, что нет пропущенных индексов.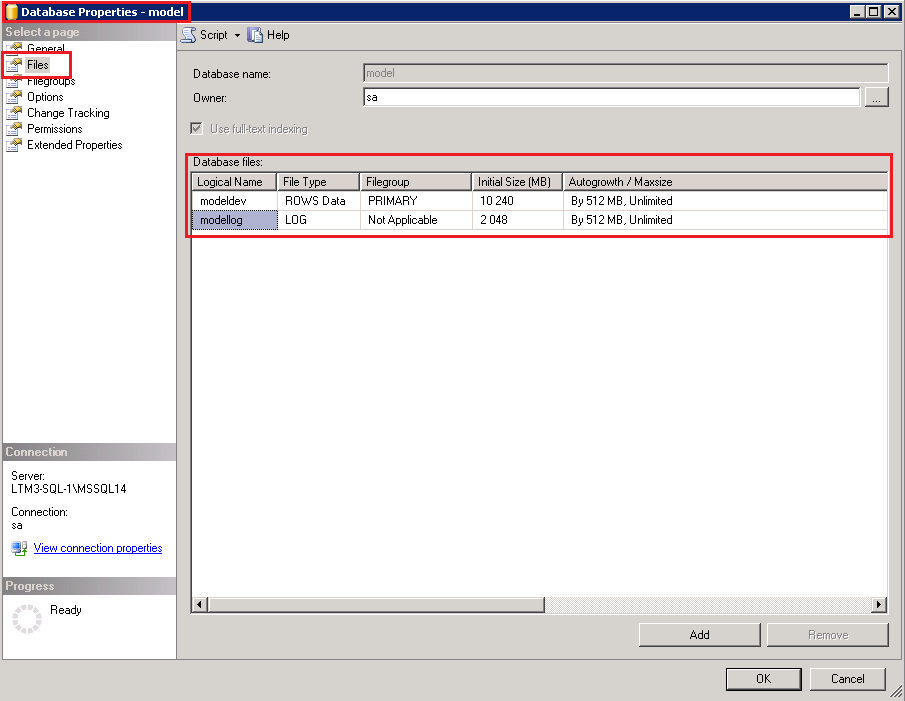 Выполните следующий запрос, чтобы получить список всех индексов в базе данных (кредит: tsql — Список всех индексов и столбцов индексов в базе данных SQL Server — Stack Overflow):
Выполните следующий запрос, чтобы получить список всех индексов в базе данных (кредит: tsql — Список всех индексов и столбцов индексов в базе данных SQL Server — Stack Overflow):
SELECT
t.name имя_таблицы,
col.name Имя_столбца,
ind.name IndexName
ИЗ
sys.indexes индекс
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.index_columns ic ON ind.object_id = ic.object_id и ind.index_id = ic.index_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.columns col ON ic.object_id = col.object_id и ic.column_id = col.column_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.tables t ON ind.object_id = t.object_id
КУДА
(ind.is_primary_key = 0
И t.is_ms_shipped = 0)
СОРТИРОВАТЬ ПО
t.name, col.name, ind.name Сохраните результаты запроса в текстовом файле со столбцами, разделенными табуляцией, чтобы их можно было позже импортировать в приложение для работы с электронными таблицами.
Избегайте фрагментации
Убедитесь, что индексы базы данных не фрагментированы. Индексы в базе данных помогают ускорить запросы к базе данных. Но когда они фрагментируются, запросы могут выполняться очень медленно. В рамках обслуживания базы данных индексы следует регулярно реорганизовывать или перестраивать.
Но когда они фрагментируются, запросы могут выполняться очень медленно. В рамках обслуживания базы данных индексы следует регулярно реорганизовывать или перестраивать.
Выполните следующий запрос, чтобы проверить процент фрагментации для всех индексов в базе данных (кредит: Как проверить фрагментацию индекса для индексов в базе данных):
ВЫБОР
dbschemas.Jama Software AS «Схема»,
dbtables.Jama Software AS «Таблица»,
dbindexes.Jama Software AS 'Индекс',
indexstats.avg_fragmentation_in_percent,
indexstats.page_count,
dbindexes.fill_factor
ИЗ
sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, NULL) КАК indexstats
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.tables dbtables ON dbtables.[object_id] = indexstats.[object_id]
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.schemas dbschemas ON dbtables.[schema_id] = dbschemas.[schema_id]
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.indexes AS dbindexes ON dbindexes.[object_id] = indexstats.[object_id] AND indexstats. index_id = dbindexes.index_id
КУДА
indexstats.database_id = DB_ID()
СОРТИРОВАТЬ ПО
indexstats.avg_fragmentation_in_percent DESC  index_id = dbindexes.index_id
КУДА
indexstats.database_id = DB_ID()
СОРТИРОВАТЬ ПО
indexstats.avg_fragmentation_in_percent DESC
index_id = dbindexes.index_id
КУДА
indexstats.database_id = DB_ID()
СОРТИРОВАТЬ ПО
indexstats.avg_fragmentation_in_percent DESC Вот пример результата запроса для базы данных с сильно фрагментированными индексами:
Для индексов с числом страниц больше 1000 значение «avg_framentation_in_percent» не должно превышать 10 %. Для небольших индексов это не имеет большого значения. Как правило, индексы с процентом фрагментации от 5% до 30% могут быть реорганизованы, а индексы с процентом фрагментации выше 30% должны быть перестроены.
Для реорганизации одного индекса:
ALTER INDEX REORGANIZE
Чтобы перестроить один индекс:
ALTER INDEX REBUILD WITH (ONLINE = ON)
Вы также можете реорганизовать или перестроить индекс с помощью SQL Server Management Studio, щелкнув правой кнопкой мыши индекс, который вы хотите перестроить или реорганизовать.
Если в базе данных много дефрагментированных индексов, вы можете выполнить следующий запрос, чтобы перестроить их все (кредит: SQL SERVER — 2008 -2005 — Перестроить каждый индекс всех таблиц базы данных — Перестроить индекс с FillFactor).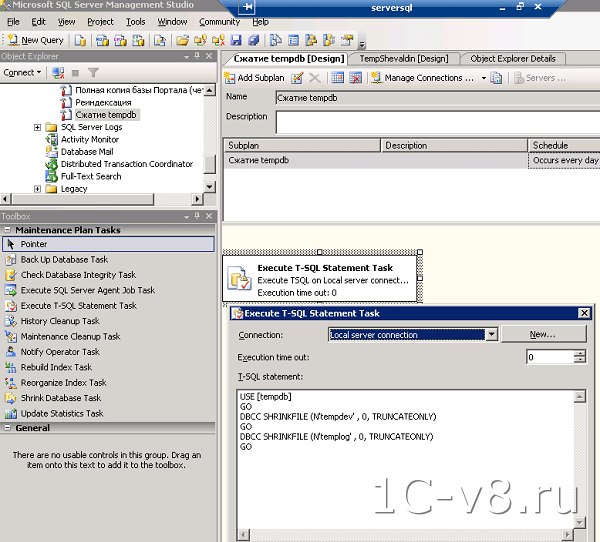 Обратите внимание, что запрос может выполняться некоторое время для большой базы данных. Рекомендуется выполнять запрос, когда база данных находится в режиме ожидания или в автономном режиме.
Обратите внимание, что запрос может выполняться некоторое время для большой базы данных. Рекомендуется выполнять запрос, когда база данных находится в режиме ожидания или в автономном режиме.
DECLARE @TableName VARCHAR(255) ОБЪЯВИТЬ @sql NVARCHAR(500) ОБЪЯВИТЬ TableCursor CURSOR FOR ВЫБЕРИТЕ OBJECT_SCHEMA_NAME([object_id])+'.'+name AS TableName ИЗ sys.tables ОТКРЫТЬ таблицуКурсор FETCH NEXT FROM TableCursor INTO @TableName ПОКА @@FETCH_STATUS = 0 НАЧИНАТЬ SET @sql = 'ИЗМЕНИТЬ ИНДЕКС ВСЕ НА' + @TableName + 'ВОССТАНОВИТЬ' ПЕЧАТЬ @sql EXEC (@sql) FETCH NEXT FROM TableCursor INTO @TableName КОНЕЦ ЗАКРЫТЬ таблицуКурсор DEALLOCATE Курсор таблицы ВПЕРЕД
Рассмотрите возможность настройки задания обслуживания в студии SQL Server, чтобы регулярно выполнять реорганизацию индекса базы данных. Хотя перестроение индексов в SQL Server, вероятно, следует выполнять в автономном режиме или во время простоя системы, реорганизацию индексов можно выполнять в интерактивном режиме. Вот хорошая статья на эту тему: Rebuild or Reorganize: SQL Server Index Maintenance.
Вот хорошая статья на эту тему: Rebuild or Reorganize: SQL Server Index Maintenance.
Чтобы настроить план реорганизации индекса в SQL Server, щелкните правой кнопкой мыши «Управление», затем «Планы обслуживания» и выберите «Новый план обслуживания» или «Мастер плана обслуживания». Следуйте инструкциям, чтобы создать план.
СВЯЗАННЫЕ: Параметры управления выпуском в Jama Connect
Запустить отчет об отсутствующих индексах
SQL Server предоставляет инструмент, который анализирует действия базы данных и рекомендует дополнительные индексы, которые могут помочь с производительностью запросов. Отчет может дать нам некоторые идеи о том, почему некоторые запросы выполняются медленно.
Чтобы сгенерировать отчет, запустите следующий запрос после того, как экземпляр базы данных поработает какое-то время (кредит: не создавайте вслепую эти «недостающие» индексы!):
ВЫБОР
д. [идентификатор_объекта],
s = OBJECT_SCHEMA_NAME(d. [object_id]),
о = ИМЯ_ОБЪЕКТА(d.[id_объекта]),
d.equality_columns,
d.inequality_columns,
д.included_columns,
s.unique_compiles,
s.user_seek, s.last_user_seek,
s.user_scans, s.last_user_scan,
s.avg_total_user_cost,
s.avg_user_impact
ИЗ
sys.dm_db_missing_index_details AS d
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_groups AS g
НА
d.index_handle = g.index_handle
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_group_stats AS s
НА
g.index_group_handle = s.group_handle
КУДА
d.database_id = DB_ID() И OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0  [object_id]),
о = ИМЯ_ОБЪЕКТА(d.[id_объекта]),
d.equality_columns,
d.inequality_columns,
д.included_columns,
s.unique_compiles,
s.user_seek, s.last_user_seek,
s.user_scans, s.last_user_scan,
s.avg_total_user_cost,
s.avg_user_impact
ИЗ
sys.dm_db_missing_index_details AS d
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_groups AS g
НА
d.index_handle = g.index_handle
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_group_stats AS s
НА
g.index_group_handle = s.group_handle
КУДА
d.database_id = DB_ID() И OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0
[object_id]),
о = ИМЯ_ОБЪЕКТА(d.[id_объекта]),
d.equality_columns,
d.inequality_columns,
д.included_columns,
s.unique_compiles,
s.user_seek, s.last_user_seek,
s.user_scans, s.last_user_scan,
s.avg_total_user_cost,
s.avg_user_impact
ИЗ
sys.dm_db_missing_index_details AS d
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_groups AS g
НА
d.index_handle = g.index_handle
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
sys.dm_db_missing_index_group_stats AS s
НА
g.index_group_handle = s.group_handle
КУДА
d.database_id = DB_ID() И OBJECTPROPERTY(d.[object_id], 'IsMsShipped') = 0 Прочтите статью Поиск отсутствующих индексов, чтобы понять вывод этого запроса.
Мониторинг сеансов базы данных
Используйте Activity Monitor для мониторинга сеансов базы данных. Microsoft SQL Server Management Studio поставляется с монитором активности, который можно использовать для мониторинга сеансов базы данных.
Поиск сеансов, заблокированных другими сеансами в течение длительного времени. Щелкните сеанс правой кнопкой мыши и выберите «Подробности», чтобы отобразить сведения о запросе, связанном с процессом.
Щелкните сеанс правой кнопкой мыши и выберите «Подробности», чтобы отобразить сведения о запросе, связанном с процессом.
Использовать монитор ресурсов Windows
Монитор ресурсов Windows можно использовать для мониторинга использования памяти и ЦП процессом SQL Server, чтобы убедиться, что в системе достаточно памяти и ЦП не загружен. Обратите внимание, что существует известная проблема для SQL Server 2008, из-за которой количество памяти, отображаемое для процесса SQL Server в мониторе ресурсов, неверно.
Идентификация медленных запросов
Если мы определили, что производительность не зависит от ресурсов, следующим шагом будет выявление медленных запросов, которые приводят к снижению производительности.
Следующий запрос возвращает 100 самых медленных запросов, которые выполняются более 300 мс (кредит: длительные запросы):
SELECT
ст.текст,
qp.query_plan,
qs.*
ИЗ (
ВЫБЕРИТЕ ТОП 50 *
ИЗ sys. dm_exec_query_stats
ЗАКАЗАТЬ ПО total_worker_time DESC
) КАК qs
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_sql_text(qs.sql_handle) КАК st
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_query_plan(qs.plan_handle) КАК qp
КУДА
qs.max_worker_time > 300
ИЛИ qs.max_elapsed_time > 300  dm_exec_query_stats
ЗАКАЗАТЬ ПО total_worker_time DESC
) КАК qs
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_sql_text(qs.sql_handle) КАК st
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_query_plan(qs.plan_handle) КАК qp
КУДА
qs.max_worker_time > 300
ИЛИ qs.max_elapsed_time > 300
dm_exec_query_stats
ЗАКАЗАТЬ ПО total_worker_time DESC
) КАК qs
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_sql_text(qs.sql_handle) КАК st
ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ sys.dm_exec_query_plan(qs.plan_handle) КАК qp
КУДА
qs.max_worker_time > 300
ИЛИ qs.max_elapsed_time > 300 Вот снимок экрана с некоторыми примерами результатов:
После того, как мы собрали список медленных запросов, мы могли запустить их непосредственно в базе данных и посмотреть на планы выполнения, чтобы понять эти запросы.
Другие инструменты
Вот список других инструментов, которые можно использовать для устранения неполадок приложений SQL Server и Java:
- Профилировщик SQL Server: может использоваться для выявления медленных запросов. Вы можете запустить его из SQL Server Management Studio 9.0019
- VisualVM: можно использовать для мониторинга использования ресурсов Java и создания дампов потоков
- Java Mission Control/Запись полета: отслеживание и запись системных событий
- JProfiler: определение медленных вызовов службы или базы данных (разработка, не поддерживается развертыванием версии 8. x)
- New Relic: может отслеживать производительность базы данных и записывать медленные запросы
 x)
x)Контрольные списки
Вот список информации, которую можно собрать для устранения неполадок SQL Server:
- Конфигурация сервера базы данных (количество ядер ЦП, физическая память, дисковое пространство, версия Windows Server, версия SQL Server, параметры памяти SQL Server)
- Конфигурация сервера приложений (количество ядер ЦП, физическая память, дисковое пространство, настройки памяти ядра Java)
- Статистика индекса базы данных
- Статистика фрагментации базы данных
- SQL Server отсутствует индексный отчет
- Память сервера базы данных и статистика ЦП, когда сервер работает медленно
- Операции, которые замедляют работу системы
- Отчет о медленных запросах сервера SQL
- Статистика таблицы базы данных
- Пара дампов потоков из Java-приложений, сделанных во время медленных операций, если применимо
Заключение
Отладка проблем с производительностью SQL-сервера не всегда проста.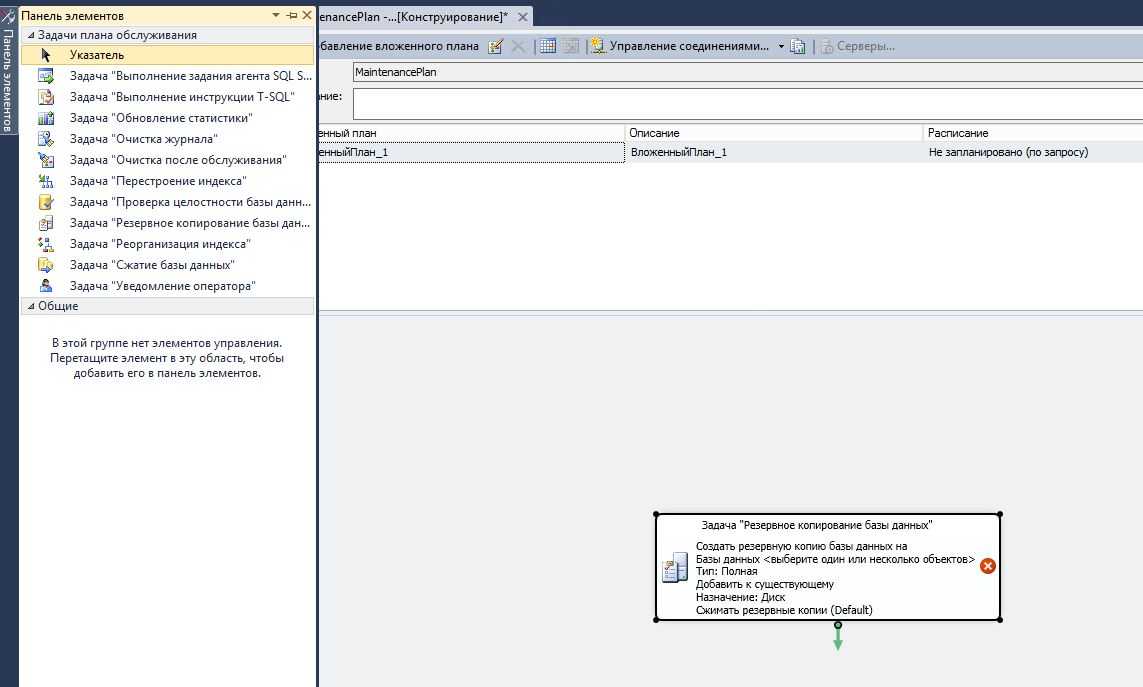 Но с правильными инструментами и терпением мы должны понять причину этих проблем. Надеюсь, что информация из этой статьи поможет вам в этом.
Но с правильными инструментами и терпением мы должны понять причину этих проблем. Надеюсь, что информация из этой статьи поможет вам в этом.
Загрузка контента…
Пожалуйста, включите JavaScript!
Проблемы разработки продукта
Помогите нам персонализировать ваш контент!
Нажмите, чтобы загрузить этот информативный технический документ и узнать, как включить тестирование на ранних этапах процесса для снижения риска:
Проверка, проверка, отслеживание и тестирование
Нажмите, чтобы посмотреть этот информативный веб-семинар и узнать, как организовать эффективную проверку циклов среди распределенных заинтересованных сторон:
Как оптимизировать проверки и сотрудничать с удаленными командами, клиентами и поставщиками
Загрузите эту электронную книгу, чтобы узнать о важности отслеживания требований без головной боли и рисков, связанных с матрицей отслеживания в Excel, и настроить свою организацию на будущий успех :
Руководство Jama Software по прослеживаемости требований
Загрузите этот технический документ, чтобы узнать, как более эффективно и результативно управлять проектами с помощью совместной работы, прослеживаемости, покрытия тестами и управления изменениями:
Успешная поставка продукта
Загрузите эту электронную книгу, чтобы получить информацию, которая поможет вам вдумчиво рассмотреть потенциальные требования и решения для управления тестированием.