Как сетевой сервер управляет запросами от нескольких клиентов для различных служб: Как сервер обрабатывает запросы веб-сервисов от нескольких клиентов. Как сетевой сервер управляет запросами от нескольких клиентов для различных служб
Содержание
Настройка диспетчера запросов в SharePoint Server — SharePoint Server
-
Статья -
- Чтение занимает 11 мин
-
APPLIES TO:2013 2016 2019 Subscription Edition SharePoint in Microsoft 365
Обзор
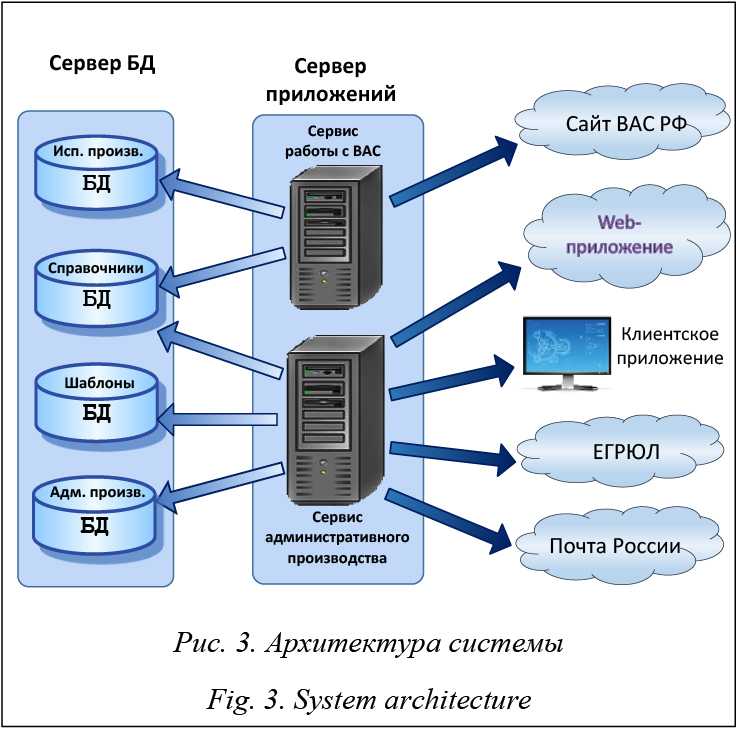
Диспетчер запросов — это функциональность SharePoint Server, которая позволяет администраторам управлять входящими запросами и определять, как SharePoint Server направляет эти запросы.
При обнаружении запросов диспетчер использует настроенные правила для выполнения следующих задач:
- отказ в доступе к ферме SharePoint для потенциально вредоносных запросов;
- передача допустимых запросов на доступный сервер;
- оптимизация производительности вручную.


Сведения, которые администраторы или автоматический процесс предоставляют диспетчеру запросов, определяют эффективность маршрутизации запросов.
В следующей таблице описаны возможные сценарии и проблемы, которые может решить диспетчер запросов.
| Область | Сценарий | Решение |
|---|---|---|
| Надежность и производительность | Направление новых запросов на интерфейсный веб-сервер с низкой производительностью может увеличить задержку и время ожидания. | Диспетчер может направлять запросы на интерфейсные веб-серверы с более высокой производительностью, сохраняя доступность интерфейсных веб-серверов с более низкой производительностью. |
| Запросы от пользователей и роботов имеют одинаковый приоритет. | Определение приоритета запросов посредством регулирования количества запросов от роботов, обслуживаемых вместо запросов от конечных пользователей. | |
| Планирование управляемости, отчетности и емкости | SharePoint Server не отвечает или отвечает медленно, но причину отказа или замедления трудно определить. | Диспетчер запросов может отправлять все запросы определенного типа, например поиск, профили пользователей или Office Online, на определенные компьютеры. Если компьютер не отвечает или отвечает медленно, диспетчер запросов может определить проблему. |
| Все интерфейсные веб-серверы должны быть способны обрабатывать запросы, так как они могут отправляться на любой интерфейсный веб-сервер. | Диспетчер запросов может отправить один или несколько запросов на интерфейсные веб-серверы, которые предназначены для их обработки. | |
| Ограничения масштабирования | Масштабирование оборудования ограничено подсистемой балансировки нагрузки | Диспетчер запросов может выполнять маршрутизацию приложений и горизонтальное масштабирование по мере необходимости, так что подсистема балансировки нагрузки может быстро распределять нагрузки на уровне сети. |
Установка и развертывание
Диспетчер запросов отвечает на два вопроса: примет ли ферма SharePoint запрос и, в случае положительного ответа, на какой интерфейсный веб-сервер система SharePoint Server отправит его.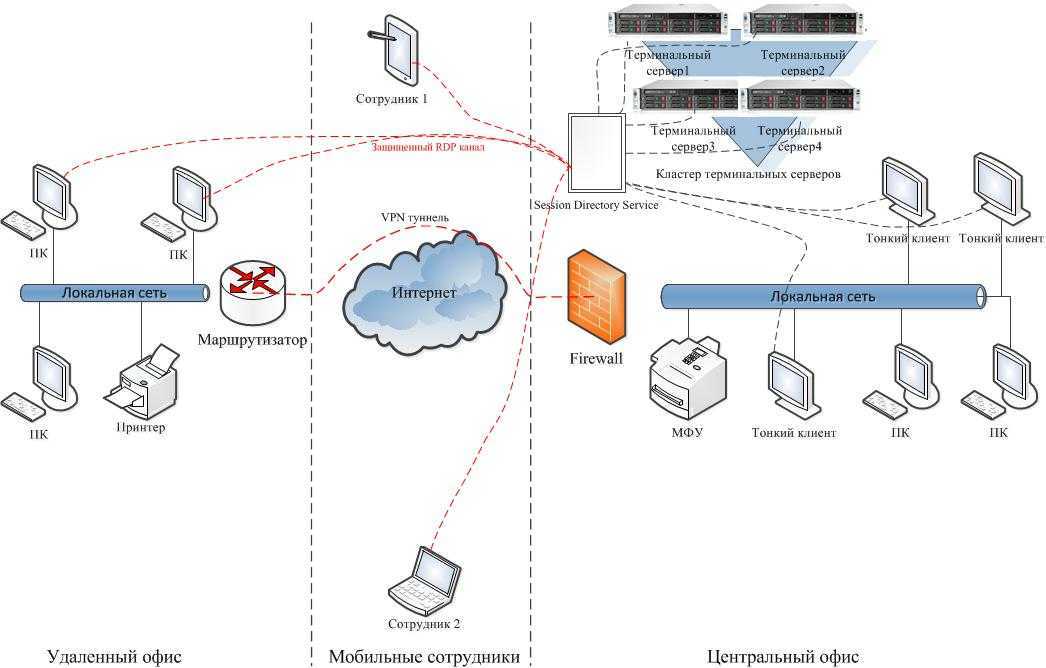 Основными функциональными компонентами диспетчера запросов являются маршрутизация, регулирование, определение приоритетов и балансировка нагрузки запросов. Эти компоненты определяют, как обрабатываются запросы. Диспетчер запросов управляет всеми запросами на уровне веб-приложения. Так как диспетчер запросов входит в модуль IiS SharePoint Server, он влияет только на запросы, которые размещаются в IIS.
Основными функциональными компонентами диспетчера запросов являются маршрутизация, регулирование, определение приоритетов и балансировка нагрузки запросов. Эти компоненты определяют, как обрабатываются запросы. Диспетчер запросов управляет всеми запросами на уровне веб-приложения. Так как диспетчер запросов входит в модуль IiS SharePoint Server, он влияет только на запросы, которые размещаются в IIS.
При получении нового запроса код диспетчера запросов выполняется первым в ферме SharePoint. Хотя диспетчер запросов устанавливается при установке SharePoint Server на интерфейсный веб-сервер, служба управления запросами не активируется. Командлеты Start-SPServiceInstance и Stop-SPServiceInstance можно использовать для запуска и остановки экземпляра службы управления запросами соответственно или страницы управления службами на сервере на веб-сайте центра администрирования SharePoint. Для изменения свойств диспетчера запросов можно использовать параметры RoutingEnabled или ThrottlingEnabled командлета Set-SPRequestManagementSettings Microsoft PowerShell.
Примечание.
Для настройки свойств диспетчера запросов пользовательский интерфейс не предусмотрен. Единственным средством для выполнения этой задачи является командлет Windows PowerShell.
Диспетчер запросов поддерживает два режима развертывания: выделенный и интегрированный.
Выделенный режим
Набор интерфейсных веб-серверов выделяется исключительно для управления запросами. Интерфейсные веб-серверы, выделенные для диспетчера запросов, находятся в собственной ферме, которая расположена между аппаратными балансировщиками нагрузки (HLB) и фермой SharePoint. Аппаратные балансировщики нагрузки отправляют все запросы на интерфейсные веб-серверы диспетчера запросов. Диспетчер запросов, который выполняется на этих интерфейсных веб-серверах, определяет, на какие интерфейсные веб-серверы SharePoint отправлять запросы, и отправляет их. В зависимости от правил маршрутизации и регулирования, диспетчер запросов может игнорировать некоторые запросы и не отправлять их на другой сервер.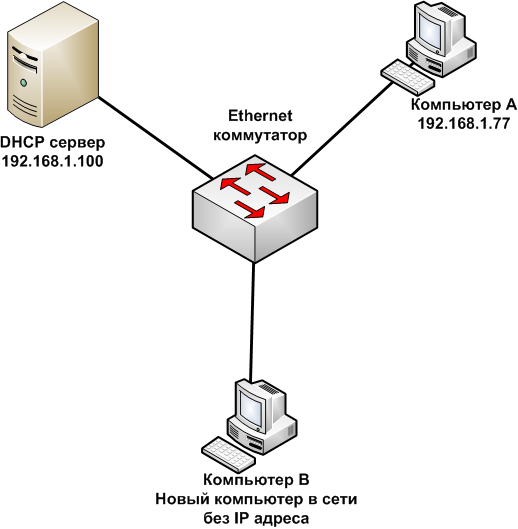 Интерфейсные веб-серверы SharePoint выполняют свои обычные задачи по обработке запросов и отправляют ответы клиентам через интерфейсные веб-серверы диспетчера запросов.
Интерфейсные веб-серверы SharePoint выполняют свои обычные задачи по обработке запросов и отправляют ответы клиентам через интерфейсные веб-серверы диспетчера запросов.
Обратите внимание, что все фермы настраиваются, как фермы SharePoint. Все интерфейсные веб-серверы являются интерфейсными веб-серверами SharePoint, каждый из которых может выполнять ту же работу, что и любой другой. Разница между фермами заключается в том, что на интерфейсных веб-серверах диспетчера запросов активирован диспетчер запросов.
Выделенный режим подходит для крупномасштабных развертываний, в которых физические компьютеры легкодоступны. Возможность создания отдельной фермы для диспетчера запросов предоставляет два преимущества: отсутствие конкуренции за ресурсы между процессами диспетчера запросов и SharePoint, а также возможность их масштабирования независимо друг от друга. Это позволяет лучше контролировать производительность каждой роли.
- Процессы диспетчера запросов и SharePoint не конкурируют за ресурсы.
- Возможность отдельного масштабирования каждой фермы, которая позволяет лучше контролировать производительность каждой фермы.
Интегрированный режим
В развертывании интегрированного режима диспетчер запросов выполняется на всех интерфейсных веб-серверах SharePoint. Аппаратные балансировщики нагрузки отправляют запросы на все интерфейсные веб-серверы. Когда интерфейсный веб-сервер получает запрос, диспетчер запросов решает, как его обрабатывать:
- разрешить его обработку локально;
- передать его на другой интерфейсный веб-сервер;
- отказать в обработке запроса.
Интегрированный режим подходит для небольших развертываний, в которых многие физические компьютеры не всегда доступны. Этот режим позволяет выполнять диспетчер запросов и остальные процессы SharePoint Server на всех компьютерах. Интегрированный режим является обычным для локальных развертываний.
Конфигурация
Диспетчер запросов имеет две настраиваемые части: общие параметры и сведения о принятии решений. Общие параметры включают и отключают маршрутизацию запросов, регулирование количества запросов и определение приоритета. Сведения о принятии решений это правила маршрутизации и регулирования, используемые соответствующими процессами.
Общие параметры включают и отключают маршрутизацию запросов, регулирование количества запросов и определение приоритета. Сведения о принятии решений это правила маршрутизации и регулирования, используемые соответствующими процессами.
Примечание.
Диспетчер запросов настраивается в ферме, а функциональные возможности выполняются на уровне веб-приложения в SharePoint Server 2013 и роли веб-приложения в SharePoint Server 2016 и 2019.
Общие параметры
Маршрутизация, регулирование и определение приоритета запросов включены по умолчанию. Командлет Set-SPRequestManagementSettings можно использовать для изменения свойств маршрутизации, регулирования и определения приоритета запросов, а также для выбора схемы веса маршрутизации.
В таблице описывается пример конфигурации и используемый синтаксис Windows PowerShell.
| Ситуация | Пример Microsoft PowerShell |
|---|---|
| Включение маршрутизации и регулирования для всех веб-приложений | Get-SPWebApplication | Set-SPRequestManagementSettings -RoutingEnabled $true -ThrottlingEnabled $true |
| Включение маршрутизации со статическим взвешиванием для всех веб-приложений | Get-SPWebApplication | Get-SPRequestManagementSettings | Set-SPRequestManagementSettings -RoutingEnabled $true -ThrottlingEnabled $false -RoutingWeightScheme Static |
В некоторых ситуациях подходящими целями для одного запроса будут несколько интерфейсных веб-серверов.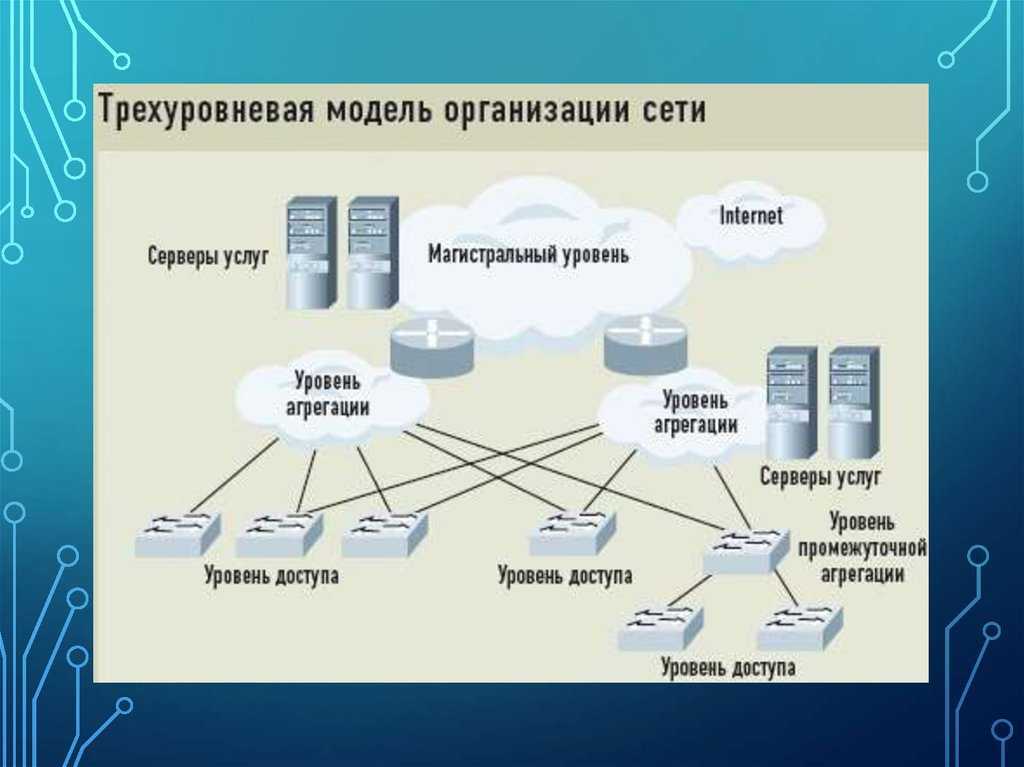 В таких случаях система SharePoint Server по умолчанию выбирает сервер случайным образом.
В таких случаях система SharePoint Server по умолчанию выбирает сервер случайным образом.
Одной из схем веса маршрутизации является статическая взвешенная маршрутизация. В этой схеме с интерфейсными веб-серверами связываются статические веса и диспетчер запросов в процессе выбора всегда отдает предпочтение серверам с более высоким весом. При использовании этой схемы можно задать дополнительный вес более мощным серверам и снизить нагрузку на менее мощные. С каждым интерфейсным веб-сервером связывается статический вес. Значением веса может быть любое целое число; значением по умолчанию является 1. Значение меньше 1 представляет более низкий вес, а значение больше 1 более высокий.
Другой схемой взвешивания является взвешенная работоспособность. При маршрутизации со взвешенной работоспособностью предпочтение отдается интерфейсным веб-серверам, показатель работоспособности которых ближе к нулю; на серверы с более высокими значениями показателя работоспособности будет отправляться меньше запросов. Вес работоспособности может принимать значения от 0 до 10; значение 0 имеют наиболее работоспособные серверы, которые будут получать наибольшее количество запросов. По умолчанию все интерфейсные веб-серверы определяются как работоспособные и имеют одинаковые веса. Основанная на показателе работоспособности система мониторинга SharePoint назначает серверу вес и отправляет значение показателя работоспособности в качестве заголовка ответа на запрос. Диспетчер запросов использует этот показатель и сохраняет его в локальной памяти.
Вес работоспособности может принимать значения от 0 до 10; значение 0 имеют наиболее работоспособные серверы, которые будут получать наибольшее количество запросов. По умолчанию все интерфейсные веб-серверы определяются как работоспособные и имеют одинаковые веса. Основанная на показателе работоспособности система мониторинга SharePoint назначает серверу вес и отправляет значение показателя работоспособности в качестве заголовка ответа на запрос. Диспетчер запросов использует этот показатель и сохраняет его в локальной памяти.
Сведения о принятии решений
Сведения о принятии решений применяются к целям маршрутизации, правилам маршрутизации и правилам регулирования.
Цели маршрутизации
Маршрутизация запроса определяет доступные цели при выборе пула маршрутизации для запроса. Область целей маршрутизации в настоящее время ограничена интерфейсными веб-серверами, однако структура диспетчера запросов не исключает маршрутизацию на серверы приложений. Список интерфейсных веб-серверов в ферме автоматически сохраняется в базе данных конфигурации.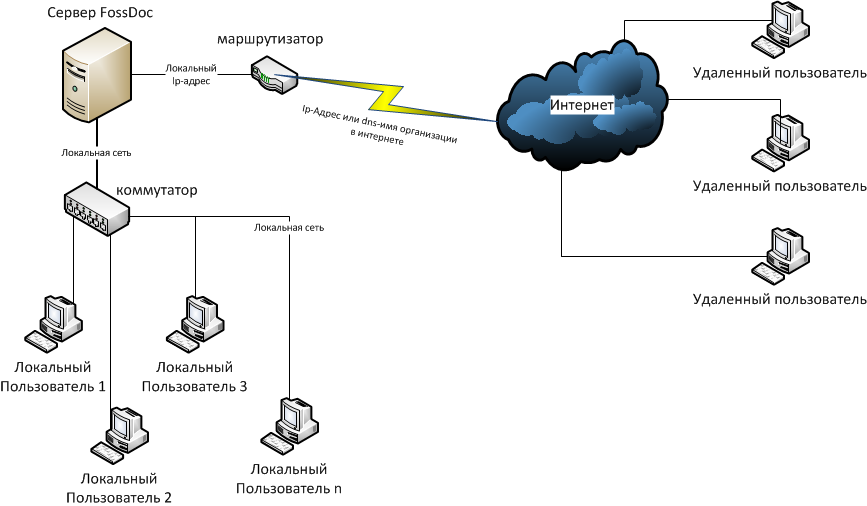 Для изменения этого списка (как правило, в выделенном режиме) администратор должен использовать командлеты маршрутизации, предназначенные для получения, добавления, задания и удаления целей маршрутизации.
Для изменения этого списка (как правило, в выделенном режиме) администратор должен использовать командлеты маршрутизации, предназначенные для получения, добавления, задания и удаления целей маршрутизации.
В следующей таблице описываются задачи, связанные с целями маршрутизации, и используемый для них синтаксис Windows PowerShell.
| Задача | Пример Microsoft PowerShell |
|---|---|
| Возврат списка целевых объектов маршрутизации для всех доступных веб-приложений | Get-SPWebApplication | Get-SPRequestManagementSettings | Get-SPRoutingMachineInfo -Availability Available |
| Добавление новой цели маршрутизации для указанного веб-приложения. | $web=Get-SPWebApplication -Identity <URL of web application> |
Изменение доступности и статического веса существующего целевого объекта маршрутизации для указанного веб-приложения.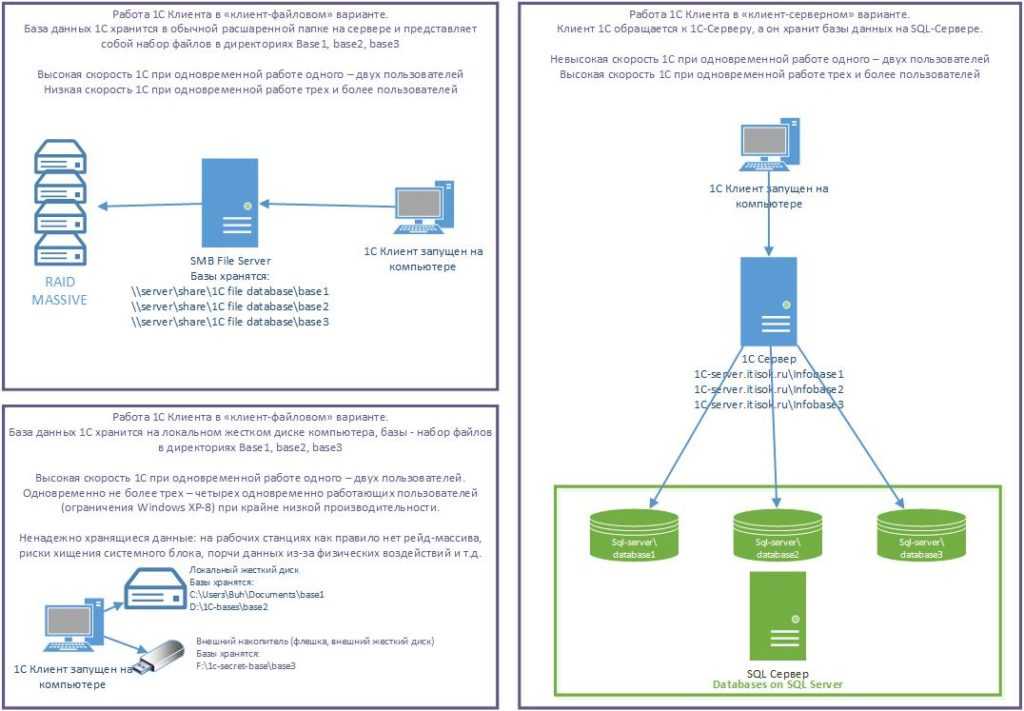 | $web=Get-SPWebApplication -Identity <URL of web application> |
| Удалите целевой объект маршрутизации из указанного веб-приложения. | $web=Get-SPWebApplication -Identity <URL of web application> |
Примечание.
Удаление интерфейсных веб-серверов, которые находятся в ферме, невозможно. Вместо этого можно использовать параметр Availability командлета Set-SPRoutingMachineInfo, чтобы сделать их недоступными.
Правила маршрутизации и регулирования
Маршрутизация, регулирование и определение приоритета запросов — это алгоритмы выбора решения, которые используют правила для назначения различных действий. Правила определяют, как диспетчер запросов обрабатывает запросы.
Правила делятся на две категории, правила маршрутизации и правила регулирования, которые используются в маршрутизации запросов и регулировании и определении приоритета запросов соответственно. Правила маршрутизации проверяют запросы на соответствие условиям и отправляют их в соответствующий пул машин. Правила регулирования проверяют запросы на соответствие условиям и регулируют их на основании известных показателей работоспособности компьютеров.
Маршрутизация запросов
Обработка запроса — это все операции, которые выполняются последовательно с момента получения запроса диспетчером до отправки ответа клиенту.
Обработка запросов делится на следующие компоненты:
- маршрутизация запросов;
- обработчик входящих запросов;
- регулирование и определение приоритета запросов;
- балансировка нагрузки запросов.

Обработчик входящих запросов
Обработчик входящих запросов определяет, должен ли диспетчер обрабатывать запрос. Если регулирование и определение приоритета запросов отключены и очередь диспетчера запросов пуста, диспетчер отправляет запрос в экземпляр SharePoint Server, выполняемый на текущем интерфейсном веб-сервере. Если включено регулирование запросов и определение приоритетов, регулирование запросов и определение приоритетов определяют, следует ли разрешить или отклонять запрос на текущем интерфейсном веб-сервере.
Обработчик входящих запросов выполняет следующие действия:
- определяет, следует ли применить к запросу регулирование или маршрутизацию;
- для маршрутизируемых запросов выполняет алгоритм балансировки нагрузки;
- направляет запрос в конечную точку подсистемы балансировки нагрузки.
Маршрутизация, регулирование и определение приоритета запроса выполняются, только если они включены и настроены для фермы. Балансировщик нагрузки выполняется, только если запрос определен как подлежащий маршрутизации. Обработчик исходящих запросов выполняется, только если запрос должен быть отправлен на другой интерфейсный веб-сервер. Обработчик исходящих запросов отправляет запрос на выбранный интерфейсный веб-сервер, ожидает ответ и возвращает его источнику.
Обработчик исходящих запросов выполняется, только если запрос должен быть отправлен на другой интерфейсный веб-сервер. Обработчик исходящих запросов отправляет запрос на выбранный интерфейсный веб-сервер, ожидает ответ и возвращает его источнику.
Маршрутизация запросов
Маршрутизация запросов выбирает интерфейсный веб-сервер, на который отправляется запрос. Если правила маршрутизации не определены, доступный веб-сервер выбирается случайным образом.
Алгоритм маршрутизации запросов состоит из двух частей: сравнения запроса с правилами и выбора интерфейсного веб-сервера.
Сравнение запроса с правилами
Каждое правило имеет одно или несколько условий для сравнения, которые состоят из трех частей: свойства, типа и значения сравнения.
В следующей таблице описываются свойства и типы сравнений.
| Свойство сравнения | Тип сравнения |
|---|---|
| Hostname (Имя узла) | ReqEx |
| URL-адрес | Равняется |
| Номер порта | Начинается с |
| Тип MIME | Заканчивается на |
Например, администратор будет использовать следующие критерии соответствия http://contoso для сопоставления запросов: Match Property=URL; Match value= http://contoso; Match type=RegEx.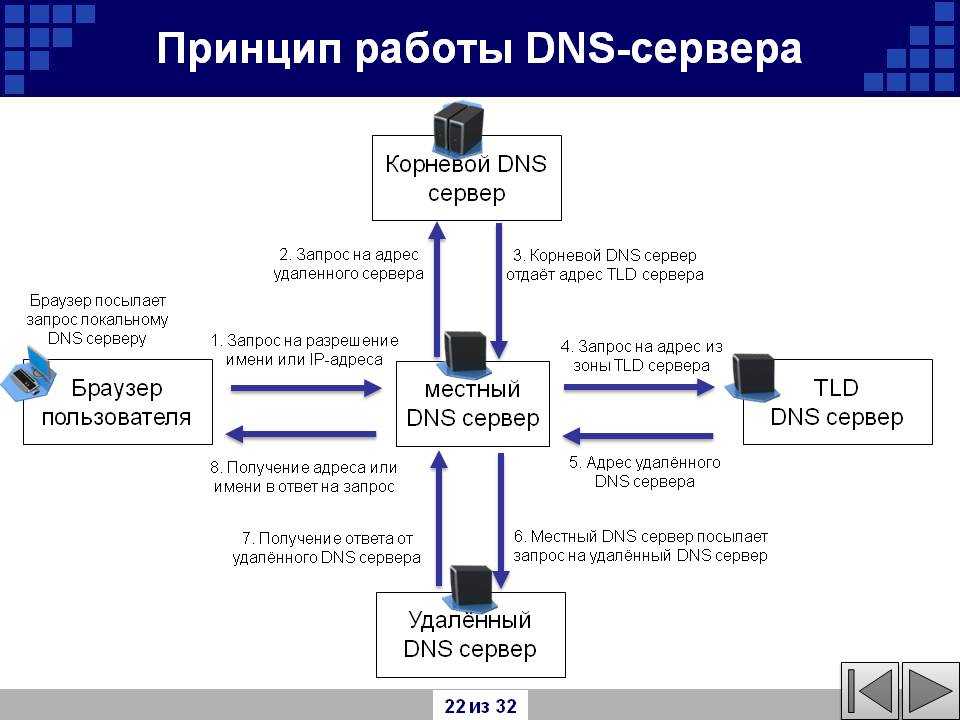
Выбор интерфейсного веб-сервера
Выбор интерфейсного веб-сервера использует все правила маршрутизации, независимо от того, соответствуют ли они данному запросу. Соответствующие правила имеют пулы машин; запрос, сбалансированный по нагрузке, отправляется на любой компьютер пула машин любого соответствующего правила. Если запрос не соответствует ни одному правилу, он отправляется (сбалансированный по нагрузке) на любую доступную цель маршрутизации.
ПРИМЕЧАНИЕ. Для SharePoint Server 2016 и 2019 используется тип роли внешнего интерфейса.
Маршрутизация и определение приоритета запросов
При использовании системы мониторинга работоспособности маршрутизация и определение приоритета запросов уменьшают пул маршрутизации, в который попадают только компьютеры с хорошим показателем работоспособности для обработки запросов. Если маршрутизация запросов включена, в пул маршрутизации может попасть любой выбранный интерфейсный веб-сервер. Если маршрутизация запросов отключена, пул маршрутизации содержит только текущий интерфейсный веб-сервер.
Маршрутизацию и определение приоритета запросов можно разделить на две части: сравнение запроса с правилами и фильтрация интерфейсных веб-серверов. Сравнение запроса с правилами выполняется точно так же, как при маршрутизации запросов. Фильтрация интерфейсных веб-серверов использует параметр порогового значения работоспособности из правил регулирования в сочетании с данными о работоспособности интерфейсных веб-серверов, чтобы определить, могут ли серверы в выбранном пуле маршрутизации обработать данный запрос.
Процесс фильтрации интерфейсных веб-серверов выполняет следующие действия:
- включает в пул маршрутизации либо текущий интерфейсный веб-сервер, либо один или несколько веб-серверов, выбранных маршрутизацией запроса;
- проверяет все подходящие правила, чтобы найти наименьшее пороговое значение работоспособности;
- удаляет из пула маршрутизации интерфейсные веб-серверы, показатель работоспособности которых больше или равен наименьшему пороговому значению работоспособности.
Например, маршрутизация запросов отключена, текущий интерфейсный веб-сервер имеет показатель работоспособности 7 и имеется правило «блокировать OneNote» без порогового значения работоспособности (то есть пороговое значение работоспособности = 0).
В пул маршрутизации попадает текущий интерфейсный веб-сервер, пороговое значение работоспособности которого равно нулю (0). Следовательно, наименьшим пороговым значением интерфейсного веб-сервера должен быть ноль. Поскольку текущий интерфейсный веб-сервер имеет показатель работоспособности 7, диспетчер запросов отклоняет запрос и удаляет его.
Балансировка нагрузки запросов
Балансировка нагрузки запросов выбирает одну цель для отправки запроса. Для выбора цели используются схемы веса маршрутизации. Исходным весом всех целей маршрутизации является 1. Если статическое взвешивание включено, балансировка нагрузки запросов использует набор статических весов каждой цели маршрутизации для изменения веса; значением может быть допустимое целое число. Если включен вес работоспособности, балансировка нагрузки запросов использует сведения о работоспособности, чтобы добавить вес к более исправным целевым объектам и удалить вес с менее работоспособных целевых объектов.
Если включен вес работоспособности, балансировка нагрузки запросов использует сведения о работоспособности, чтобы добавить вес к более исправным целевым объектам и удалить вес с менее работоспособных целевых объектов.
Мониторинг и обслуживание
Мониторинг и ведение журналов являются ключевыми средствами для управления запросами из диспетчера запросов.
- Правила, которые подошли.
- Правила, которые не подошли.
- Окончательное решение для запроса.
Решения могут содержать полезные сведения; некоторые из них перечислены ниже.
- Был ли запрос отклонен?
- Какой интерфейсный веб-сервер был выбран и из каких пулов маршрутизации.
- Запрос выполнен удачно или нет, и почему?
- Сколько времени заняла маршрутизация, регулирование и ожидание ответа от интерфейсного веб-сервера?
Администратор может использовать эти сведения для изменения наборов правил маршрутизации и регулирования, чтобы оптимизировать работу системы и устранить неполадки. Для упрощения отслеживания и оценки производительности фермы можно создать файл журнала мониторинга производительности и добавить в него следующие счетчики производительности диспетчера запросов SharePoint Foundation.
Для упрощения отслеживания и оценки производительности фермы можно создать файл журнала мониторинга производительности и добавить в него следующие счетчики производительности диспетчера запросов SharePoint Foundation.
| Имя счетчика | Описание |
|---|---|
| Текущие подключения | Общее число подключений, открытых диспетчером запросов в данный момент. |
| Число повторно используемых подключений в секунду | Число подключений в секунду, которые используются повторно, когда одно и то же подключение к клиенту делает другой запрос без закрытия подключения. |
| Число маршрутизированных запросов в секунду | Число маршрутизированных запросов в секунду. Экземпляр определяет пул приложений и сервер, для которого отслеживается этот счетчик. |
| Число регулируемых запросов в секунду | Число регулируемых запросов в секунду. |
| Число неудачных запросов в секунду | Заканчивается на |
| Тип MIME | Число неудачных запросов в секунду.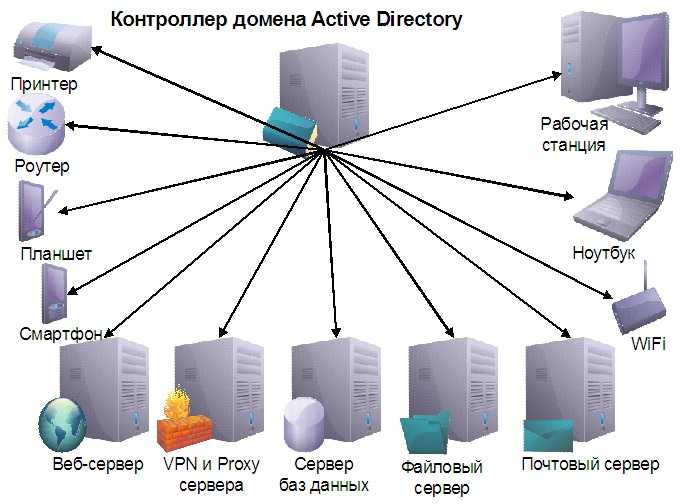 |
| Среднее время обработки | Заканчивается на |
| Тип MIME | Время обработки запроса, то есть время, которое было затрачено на оценку всех правил и определение цели маршрутизации. |
| Задержка при последней проверке связи | Задержка при последней проверке связи (то есть при выполнении функции диспетчера запросов PING). Экземпляр определяет пул приложений и целевой компьютер. |
| Текущие конечные точки подключений | Общее число подключенных конечных точек для всех активных подключений. |
| Текущие маршрутизируемые запросы | Число незавершенных маршрутизированных запросов. Экземпляр определяет пул приложений и целевой компьютер. |
Наряду с созданием файла журнала монитора производительности уровень подробного ведения журнала можно включить с помощью следующего синтаксиса Microsoft PowerShell:
Set-SPLogLevel "Request Management" -TraceSeverity Verbose
Лекция 7
Лекция 7
Лекция 7
- Серверы и сетевые сервисы
- Организация управления в компьютерных сетях
- Сети с централизованным управлением
- Одноранговые сети
- Ведение баз данных в компьютерных сетях
- Архитектура «файл-сервер»
- Архитектура «клиент-сервер»
- Распределенные базы данных
Серверы и сетевые сервисы
Как уже говорилось ранее (см.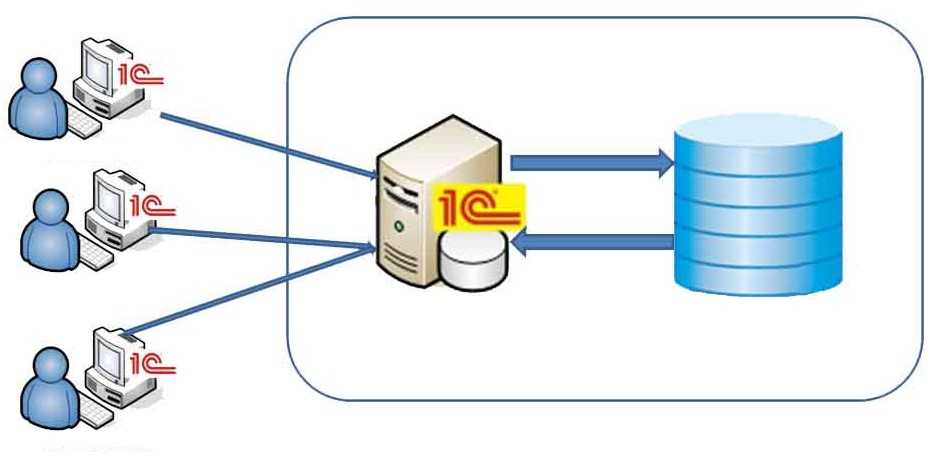 Лекция 2, п.2), основными компонентами сети
Лекция 2, п.2), основными компонентами сети
являются коммуникационное оборудование, рабочие станции и серверы сети. На
рабочих станциях пользователями сети реализуются прикладные задачи, для решения
которых приходится обращаться к общим сетевым ресурсам. Управление тем или иным
ресурсом осуществляется серверами.
Каждый конкретный сервер определяется видом того ресурса, которым он владеет.
Например, назначением сервера баз данных является обслуживание запросов
клиентов, связанных с обработкой данных; файловый сервер управляет доступом к
файлам и т.д. Этот принцип распространяется и на взаимодействие программ.
Программа, выполняющая предоставление соответствующего набора услуг,
рассматривается в качестве сервера, а программы, пользующиеся этими услугами,
называют клиентами.
Таким образом, серверы сети — это аппаратно-программные системы, выполняющие
функции управления распределение сетевых ресурсов общего доступа, которые могут
работать и как обычная абонентская система. В качестве аппаратной части сервера
В качестве аппаратной части сервера
используются достаточно мощный ПК или компьютер, спроектированный специально как
сервер. В локальной компьютерной сети может быть несколько различных серверов
для управления сетевыми ресурсами. С другой стороны, на одном компьютере может
быть запущено несколько серверов (сетевых служб), решающих различные сетевые
задачи.
Рассмотрим некоторые виды сервисов, которые могут функционировать как на
одном выделенном для этих целей компьютере, так и по отдельности.
- Файловый сервер (file server) —
- обеспечивает одновременный доступ пользователей к общим данным.
- хранение данных;
- архивирование данных;
- согласование изменений данных, выполняемых разными пользователями;
- передача данных.
Функции файл-сервера:
Как правило,
под файл-сервер выделяют специальный компьютер с большим объемом дискового
пространства. - Сервер баз данных (database server) —
- обеспечивает хранение, обработку и управление файлами баз данных.
- хранение баз данных, поддержка их целостности, полноты, актуальности;
- прием и обработка запросов к базам данных, а также пересылка результатов обработки на рабочую станцию;
- обеспечение авторизированного доступа к базам данных, поддержка системы ведения и учета пользователей, разграничение доступа пользователей;
- согласование изменений данных, выполняемых разными пользователями;
- поддержка распределенных баз данных, взаимодействие с другими серверами баз данных, расположенными в другом месте.
Функции сервера баз данных: - Сервер прикладных программ (application server) —
- обеспечивает выполнение прикладных программ для пользователей,
работающих на своих рабочих станциях. - Коммуникационный сервер (communications server) —
- предоставляет пользователям локальной сети прозрачный доступ к своим
последовательным портам ввода/вывода. С помощью коммуникационного сервера
можно создать разделяемый модем, подключив его к одному из портов сервера.
Пользователь, подключившись к коммуникационному серверу, может работать с
таким модемом так же, как если бы модем был подключен непосредственно к
рабочей станции. - Сервер доступа (access server) —
- позволяет выполнять удаленную обработку заданий. Программы, инициируемые
с удаленной рабочей станции, выполняются на этом сервере. От удаленной
рабочей станции принимаются команды, введенные пользователем с клавиатуры, а
возвращаются результаты выполнения задания. - Факс-сервер (fax server) —
- выполняет рассылку и прием факсимильных сообщений для пользователей
локальной сети. - Сервер резервного копирования данных (backup server)
— - обеспечивает создание, хранение и восстановление копий данных,
расположенных на файловых серверах и рабочих станциях.
 С помощью коммуникационного сервера
С помощью коммуникационного сервера
Еще раз отметим, что все перечисленные типы серверов могут функционировать на
одном выделенном для этих целей компьютере.
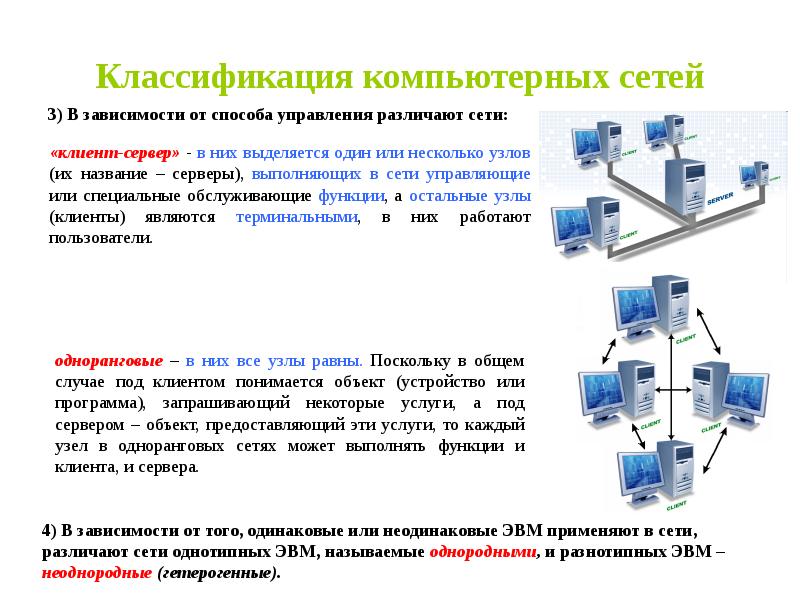
Организация управления в компьютерных
сетях
По организации управления локальные вычислительные сети различаются на сети с
централизованным и децентрализованным управлением.
Сети с централизованным управлением
В сетях с централизованным управлением выделяются одна или несколько машин,
управляющих работой сети. Диски выделенных машин (файл-серверов или серверов баз
данных) доступны всем другим компьютерам (рабочим станциям) сети. На серверах
работает сетевая операционная система. Рабочие станции имеют доступ к дискам
серверов и совместно используемым принтерам, но, как правило, не могут работать
непосредственно с дисками других ПК. Серверы могут быть выделенными, и тогда они
выполняют только задачи управления сетью и не используются как ПК, или
невыделенными, когда параллельно с задачей управления сетью выполняют
пользовательские программы (при этом снижается производительность сервера и
надежность работы всей сети из-за возможной ошибки в пользовательской программе,
которая может привести к остановке работы сети). В сетях с централизованным
В сетях с централизованным
управлением большая часть информационно-вычислительных ресурсов сосредоточена в
центральной системе. Они отличаются также более надежной системой защиты
информации.
В сетях с централизованным управлением сетевая операционная система (ОС
сервера), обеспечивает выполнение базовых функций, таких, как поддержка файловой
системы, планирование задач, управление памятью. Сетевая операционная система и
ОС рабочей станции решают разные задачи, поэтому для обеспечения взаимодействия
сервера и ПК в рабочую станцию вводится специальная программа, называемая
сетевой оболочкой. Она воспринимает прикладные запросы пользователей сети и
определяет место их обработки — в локальной ОС станции или в сетевой ОС на
сервере. Если запрос должен обрабатываться в сети, оболочка преобразует его в
соответствии с принятым протоколом, обеспечивая тем самым передачу запроса по
нужному адресу.
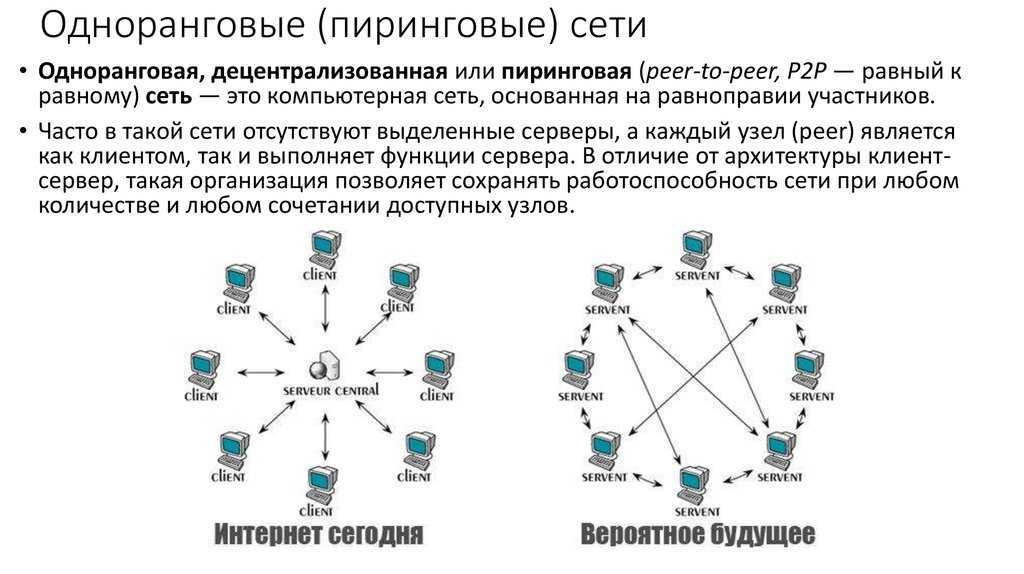
Одноранговые сети
Если информационно-вычислительные ресурсы локальной компьютерной сети
равномерно распределены по большому числу абонентских станций сети,
централизованное управление малоэффективно из-за резкого увеличения служебной
(управляющей) информации.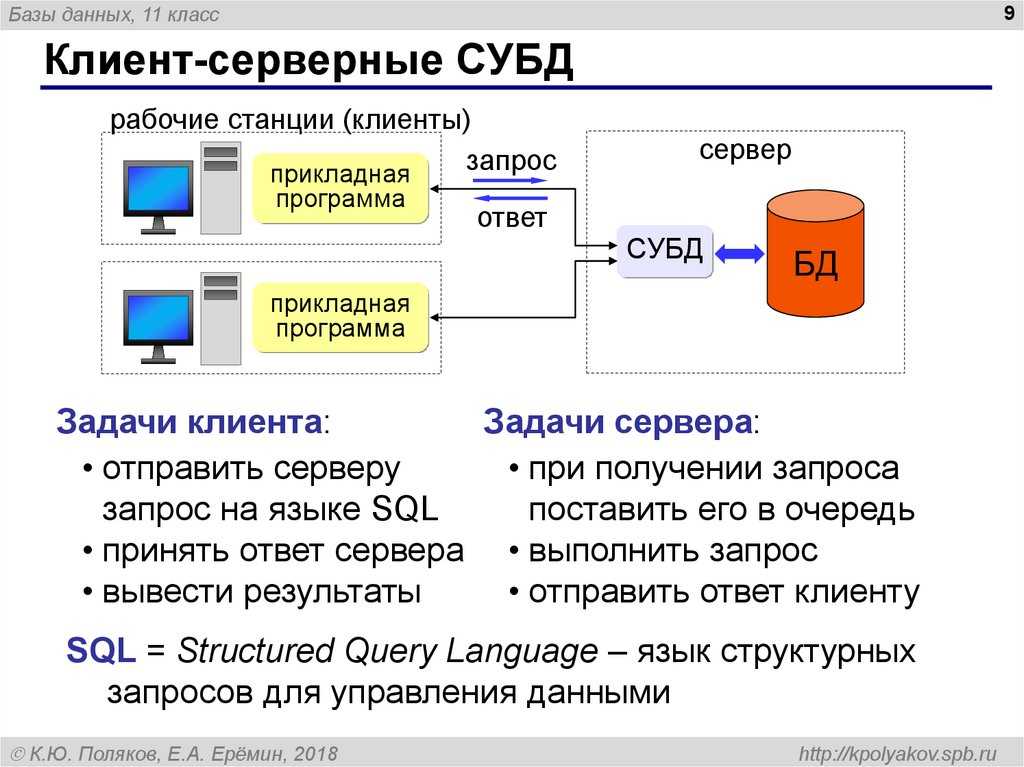 В этом случае эффективными оказываются сети с
В этом случае эффективными оказываются сети с
децентрализованным (распределенным) управлением, или одноранговые сети.
В таких сетях нет выделенных серверов, функции управления сетью передаются по
очереди от одного ПК к другому. Рабочие станции имеют доступ к дискам и
принтерам других ПК. Это облегчает совместную работу групп пользователей, но
производительность сети несколько понижается. Такие сети отличаются простотой
обеспечения функций взаимодействия между абонентскими станциями ЛКС, но их
применение целесообразно при сравнительно небольшом числе абонентских станций в
сети. Недостатки одноранговых сетей: зависимость эффективности функционирования
сети от количества абонентских станций, сложность обеспечения защиты информации
от несанкционированного доступа.
В одноранговых сетях объединяются компьютеры, каждый из которых может быть и
сервером, и клиентом. В такой сети любой компьютер работает под управлением
обычной дисковой ОС, а для выполнения сетевых функций в его оперативную память
загружаются программы одноранговой сетевой ОС.
Ведение баз данных в компьютерных сетях
Эффективность функционирования локальных компьютерных сетей в значительной
степени определяется способами создания и ведения баз данных. В локальных сетях
для создания БД реализованы две архитектуры: файл-сервер и
клиент-сервер. Кроме того, могут использоваться распределенные базы данных.
Архитектура «файл-сервер»
В случае использования архитектуры «файл-сервер» файлы базы данных
располагаются на дисках файл-сервера (в качестве файл-сервера применяется мощный
ПК), и все рабочие станции получают к нему доступ, т.е. на рабочую станцию
устанавливаются сетевые версии широко распространенных СУБД персональных
компьютеров. Основной недостаток такой архитектуры заключается в необходимости
пересылки по линиям связи сети фрагментов файлов базы данных значительных
объемов, что приводит к быстрому насыщению сетевого трафика и возрастанию
времени реакции информационной системы. Следователь, не обеспечивается
Следователь, не обеспечивается
достаточная производительность сети (особенно при большом количестве рабочих
станций).
Архитектура «клиент-сервер»
В архитектуре «клиент-сервер» этот недостаток устранен, в связи с чем
обеспечивается совместная работа многих пользователей с большими БД в реальном
масштабе времени. Помимо файл-сервера к сети подключается еще один мощный
компьютер (сервер баз данных, на котором размещается серверная СУБД)
исключительно для работы с БД. Сама база данных может располагаться на дисках
сервера баз данных или файл-сервера. Принимая запросы от рабочей станции на
поиск данных в БД, сервер баз данных сам осуществляет поиск и его результаты
отсылает через сеть в запросившую их рабочую станцию. Следовательно, по сети
передаются только запрос и найденные данные. Серверная СУБД обычно работает в
среде многозадачной ОС, которая сама занимается распределением ресурсов при
поступлении одновременно нескольких запросов от рабочих станций.
Распределенные базы данных
Важным фактором в обеспечении высокой эффективности функционирования
локальной компьютерной сети является организация распределенной базы данных,
представляющей собой логически единую базу данных, отдельные физические части
которой размещены на нескольких ЭВМ сети. Основная особенность распределенной БД
— ее «прозрачность», означающая независимость пользователей и прикладных
программ от способа размещения информации на ЭВМ сети. Локализация данных,
декомпозиция запросов и композиция результатов должны выполняться системой без
участия пользователей. В процессе работы пользователи не должны учитывать, что
их запросы будут обрабатываться в сети, возможно, на нескольких ЭВМ.
Сайт управляется системой uCoz
Сеть
. Как веб-сервер может обрабатывать входящие запросы нескольких пользователей одновременно на одном порту (80)?
спросил
Изменено
1 год, 5 месяцев назад
Просмотрено
72к раз
Как веб-сервер обрабатывает несколько входящих запросов одновременно на одном порту (80)?
Пример:
В то же время 300 тыс. пользователей хотят видеть изображение с сайта www.abcdef.com, которому назначен IP 10.10.100.100 и порт 80. Так как же www.abcdef.com может справиться с такой входящей нагрузкой пользователей?
пользователей хотят видеть изображение с сайта www.abcdef.com, которому назначен IP 10.10.100.100 и порт 80. Так как же www.abcdef.com может справиться с такой входящей нагрузкой пользователей?
Может ли один сервер (которому присвоен IP-адрес 10.10.100.100) обрабатывать такое огромное количество входящих пользователей? Если нет, то как можно назначить один IP-адрес более чем одному серверу для обработки этой нагрузки?
- сеть
- веб-приложения
- сеть
- TCP
- сетевое программирование
2
Порт — это просто магическое число. Это не соответствует аппаратному обеспечению. Сервер открывает сокет, который «слушает» порт 80 и «принимает» новые подключения из этого сокета. Каждое новое соединение представлено новым сокетом, чей локальный порт также является портом 80, но чей удаленный IP: порт соответствует клиенту, который подключился. Так они не перепутаются.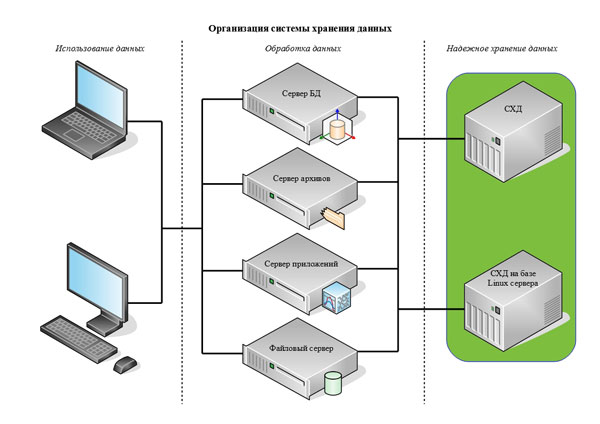 Поэтому вам не нужно несколько IP-адресов или даже несколько портов на стороне сервера.
Поэтому вам не нужно несколько IP-адресов или даже несколько портов на стороне сервера.
2
Из tcpipguide
Эта идентификация соединений с использованием как клиентских, так и серверных сокетов обеспечивает гибкость в разрешении множественных соединений между устройствами, которые мы считаем само собой разумеющимися в Интернете. Например, загруженные серверные процессы приложений (такие как веб-серверы) должны иметь возможность обрабатывать соединения от более чем одного клиента, иначе Всемирная паутина будет практически непригодна для использования. Поскольку соединение идентифицируется с помощью сокета клиента, а также сокета сервера, это не проблема. В то время как веб-сервер поддерживает соединение, упомянутое выше, он может легко иметь другое соединение, например, порт 2,19.9 по IP-адресу 219.31.0.44. Это представлено идентификатором соединения:
(41.199.222.3:80, 219.
 31.0.44:2199).
31.0.44:2199).
На самом деле у нас может быть несколько подключений от одного клиента к одному и тому же серверу. Каждому клиентскому процессу будет назначен различный временный номер порта, поэтому, даже если все они попытаются получить доступ к одному и тому же процессу сервера (например, процессу веб-сервера по адресу 41.199.222.3:80), все они будут иметь разные клиентские сокеты и представлять уникальные связи. Это то, что позволяет вам делать несколько одновременных запросов к одному и тому же веб-сайту с вашего компьютера.
Опять же, TCP отслеживает каждое из этих соединений независимо, поэтому каждое соединение не знает о других. TCP может обрабатывать сотни или даже тысячи одновременных подключений. Единственным ограничением является мощность компьютера, на котором работает протокол TCP, и пропускная способность физических подключений к нему: чем больше подключений выполняется одновременно, тем больше ресурсов приходится на каждое из них.
2
TCP Обеспечивает идентификацию клиента
Как я уже сказал, TCP заботится об идентификации клиента, а сервер видит только «сокет» для каждого клиента.
Допустим, сервер с адресом 10.10.100.100 прослушивает порт 80 для входящих TCP-соединений (HTTP создан поверх TCP). Браузер клиента (по адресу 10.9.8.7) подключается к серверу, используя клиентский порт 27143. Сервер видит: «клиент 10.9.8.7:27143 хочет подключиться, вы согласны?». Серверное приложение принимает и получает «дескриптор» (сокет) для управления всей связью с этим клиентом, и этот дескриптор всегда будет отправлять пакеты на 10.9..8.7:27143 с соответствующими заголовками TCP.
Пакеты никогда не бывают одновременными
Теперь физически существует только одно (или два) соединения, связывающее сервер с Интернетом, поэтому пакеты могут приходить только в последовательном порядке. Возникает вопрос: какова максимальная пропускная способность оптоволокна и сколько ответов сервер может вычислить и отправить в ответ. Помимо затраченного времени ЦП или узких мест в памяти при ответе на запросы, сервер также должен поддерживать некоторые ресурсы (по крайней мере, 1 активный сокет на каждого клиента) до тех пор, пока связь не будет завершена, и, следовательно, потреблять ОЗУ. Пропускная способность достигается за счет некоторых оптимизаций (не исключающих друг друга): неблокирующие сокеты (чтобы избежать конвейерной обработки/задержек сокетов), многопоточность (чтобы использовать больше ядер/потоков ЦП).
Помимо затраченного времени ЦП или узких мест в памяти при ответе на запросы, сервер также должен поддерживать некоторые ресурсы (по крайней мере, 1 активный сокет на каждого клиента) до тех пор, пока связь не будет завершена, и, следовательно, потреблять ОЗУ. Пропускная способность достигается за счет некоторых оптимизаций (не исключающих друг друга): неблокирующие сокеты (чтобы избежать конвейерной обработки/задержек сокетов), многопоточность (чтобы использовать больше ядер/потоков ЦП).
Дальнейшее повышение пропускной способности запросов: балансировка нагрузки
И, наконец, сервер на «лицевой стороне» веб-сайтов обычно не выполняет всю работу самостоятельно (особенно более сложные вещи, такие как запросы к базе данных, вычисления и т. д.) , и откладывать задачи или даже пересылать HTTP-запросы на распределенные серверы, в то время как они продолжают тривиально обрабатывать (например, пересылать) столько запросов в секунду, сколько могут. Распределение работы по нескольким серверам называется load-balancing .
1
1) Как веб-сервер обрабатывает несколько входящих запросов одновременно на одном порту (80)
==> а) один экземпляр веб-службы (пример: микросервис весенней загрузки) запускается/прослушивается на сервере машина на порту 80.
b) Этому веб-сервису (приложение Spring boot) нужен контейнер сервлетов, как в основном tomcat.
В этом контейнере будет настроен пул потоков .
c) когда когда-либо запросы поступают от разных пользователей одновременно, этот контейнер будет
назначить каждый поток из пула для каждого из входящих запросов.
d) Поскольку код веб-службы на стороне сервера будет иметь beans (в случае java) в основном
singleton, каждый поток, относящийся к каждому запросу, будет вызывать singleton API
, и если есть необходимость в доступе к базе данных, то синхронизация этих
потоки необходимы, что делается с помощью аннотации @transactional. Эта аннотация
синхронизирует работу базы данных.
2) Может ли один сервер (которому присвоен IP-адрес 10.10.100.100) обрабатывать такое огромное количество входящих пользователей?
Если нет, то как можно назначить один IP-адрес более чем одному серверу для обработки этой нагрузки?
==> Об этом позаботится балансировщик нагрузки вместе с таблицей маршрутизации
2
ответ: виртуальные хосты, в заголовке HTTP это имя домена, поэтому веб-сервер знает, какие файлы запускаются или отправляются клиенту
1
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя адрес электронной почты и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
http — Как несколько клиентов одновременно подключаются к одному порту, скажем, 80, на сервере?
Итак, что происходит, когда сервер прослушивает входящие соединения через TCP-порт? Например, предположим, что у вас есть веб-сервер на порту 80. Предположим, что ваш компьютер имеет общедоступный IP-адрес 24.14.181.229, а человек, который пытается подключиться к вам, имеет IP-адрес 10.1.2.3. Этот человек может подключиться к вам, открыв сокет TCP на 24.14.181.229:80. Достаточно просто.
Предположим, что ваш компьютер имеет общедоступный IP-адрес 24.14.181.229, а человек, который пытается подключиться к вам, имеет IP-адрес 10.1.2.3. Этот человек может подключиться к вам, открыв сокет TCP на 24.14.181.229:80. Достаточно просто.
Интуитивно (и ошибочно) большинство людей предполагают, что это выглядит примерно так: 9на самом деле это не то, что происходит, но это концептуальная модель, которую имеют в виду многие люди.
Это интуитивно понятно, потому что с точки зрения клиента он имеет IP-адрес и подключается к серверу по адресу IP:PORT. Раз клиент подключается к 80 порту, то и его порт тоже должен быть 80? Это разумная вещь, чтобы думать, но на самом деле не то, что происходит. Если бы это было так, мы могли бы обслуживать только одного пользователя на иностранный IP-адрес. Как только удаленный компьютер подключается, он перехватывает соединение с порта 80 на порт 80, и никто другой не может подключиться.
Необходимо понимать три вещи:
1. ) На сервере процесс прослушивает порт . Как только он получает соединение, он передает его другому потоку. Связь никогда не перегружает прослушивающий порт.
) На сервере процесс прослушивает порт . Как только он получает соединение, он передает его другому потоку. Связь никогда не перегружает прослушивающий порт.
2.) Соединения однозначно идентифицируются ОС по следующим пяти кортежам: (локальный IP-адрес, локальный порт, удаленный IP-адрес, удаленный порт, протокол). Если какой-либо элемент в кортеже отличается, то это полностью независимое соединение.
3.) Когда клиент подключается к серверу, он выбирает случайный, неиспользуемый старший исходный порт . Таким образом, один клиент может иметь до ~64 тыс. подключений к серверу для одного и того же порта назначения.
Итак, вот что на самом деле создается, когда клиент подключается к серверу:
Локальный компьютер | Удаленный компьютер | Роль
-------------------------------------------------- ---------
0.0.0.0:80 | <нет> | ПРОСЛУШИВАНИЕ
127.0.0.1:80 | 10.1.2.3:<случайный_порт> | УЧРЕДИЛ
Во-первых, воспользуемся netstat, чтобы посмотреть, что происходит на этом компьютере.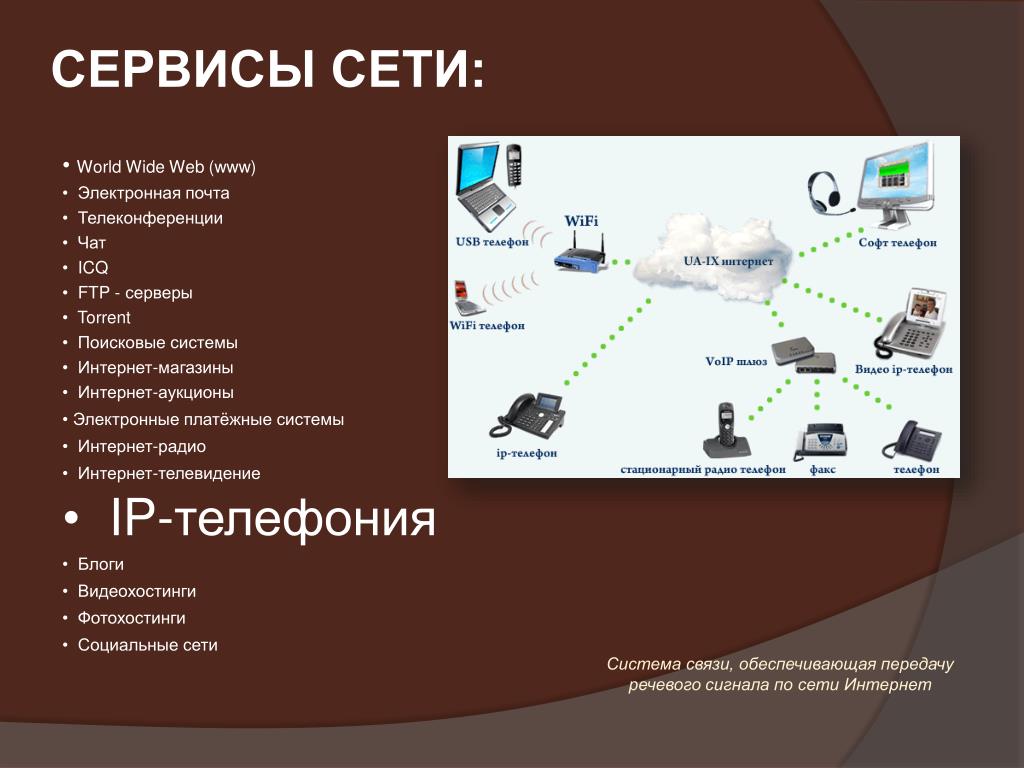 Мы будем использовать порт 500 вместо 80 (потому что на 80-м порту происходит куча всего, так как это общий порт, но функционально это не имеет значения).
Мы будем использовать порт 500 вместо 80 (потому что на 80-м порту происходит куча всего, так как это общий порт, но функционально это не имеет значения).
netstat-atnp | grep -i ":500"
Как и ожидалось, вывод пустой. Теперь запустим веб-сервер:
sudo python3 -m http.server 500
Теперь снова результат запуска netstat:
Proto Recv-Q Send-Q Local Address Foreign Address State
TCP 0 0 0.0.0.0:500 0.0.0.0:* ПРОСЛУШАТЬ -
Итак, теперь есть один процесс, который активно прослушивает (состояние: LISTEN) порт 500. Локальный адрес — 0.0.0.0, что соответствует коду «прослушивания для всех». Легко совершить ошибку — прослушивать адрес 127.0.0.1, который будет принимать соединения только с текущего компьютера. Так что это не соединение, это просто означает, что процесс запросил bind() для IP-порта, и этот процесс отвечает за обработку всех соединений с этим портом. Это намекает на ограничение, согласно которому на каждом компьютере может быть только один процесс, прослушивающий порт (есть способы обойти это с помощью мультиплексирования, но это гораздо более сложная тема). Если веб-сервер прослушивает порт 80, он не может использовать этот порт совместно с другими веб-серверами.
Если веб-сервер прослушивает порт 80, он не может использовать этот порт совместно с другими веб-серверами.
Теперь давайте подключим пользователя к нашей машине:
quicknet -m tcp -t localhost:500 -p Проверка полезной нагрузки.
Это простой скрипт (https://github.com/grokit/dcore/tree/master/apps/quicknet), который открывает TCP-сокет, отправляет полезную нагрузку (в данном случае «Проверка полезной нагрузки»), ждет несколько секунд и отключается. При повторном выполнении netstat во время этого отображается следующее:
Proto Recv-Q Send-Q Local Address Foreign Address State
TCP 0 0 0.0.0.0:500 0.0.0.0:* ПРОСЛУШАТЬ -
TCP 0 0 192.168.1.10:500 192.168.1.13:54240 УСТАНОВЛЕН -
Если вы подключитесь к другому клиенту и снова выполните netstat, вы увидите следующее:
Proto Recv-Q Send-Q Local Address Foreign Address State
TCP 0 0 0.0.0.0:500 0.0.0.0:* ПРОСЛУШАТЬ -
TCP 0 0 192.168.1.10:500 192.168.1.13:26813 УСТАНОВЛЕНО -
.