Кластерный индекс ms sql: Создание кластеризованных индексов — SQL Server
Содержание
Кластерные и «обычные» индексы MySQL (InnoDB) / Хабр
Все мы помним хрестоматийное объяснение «что такое индексы в БД и как они облегчают задачи поиска нужных строк». Уверен, у большинства из вас перед глазами встаёт нечто подобное:
И сразу становится очевидно, насколько меньше данных нужно перелопатить для поиска двух-трёх нужных строк. Гениально. Просто. Понятно.
И лично мне всегда казалось, что улучшать эту схему некуда… Пока я не познакомился с кластерными индексами. Оказалось, что всё не так уж радужно с «обычными» индексами.
Итак, что же такое кластерный индекс, чем он лучше некластерного, и как с ним обстоит дело у MySQL.
Некластерные индексы
Чтобы не запутаться, до поры до времени будем рассматривать простой индекс по одному полю. Упрощённо некластерный индекс можно представить как отдельную таблицу, каждая строка в которой ссылается на одну или несколько строк в таблице с данными. Строки в индексной таблице упорядочены и сгруппированы по значениям ключевых полей. Представим элементарный запрос:
Представим элементарный запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;
Совсем без индексации будет прочитана и проверена каждая строка, и неудовлетворяющие условию строки просто не попадут в результат. Но прочитаны они будут.
При использовании «обычного», некластерного индекса, задача поиска сильно ускоряется. Во-первых, индексная таблица весит много меньше таблицы с данными, а значит элементарно может быть прочитана быстрее. Во-вторых, СУБД чаще всего стараются кешировать индексы в оперативную память, которая сама по себе много шустрее жёсткого диска*. В-третьих, в индексах отсутствуют дублирующиеся строки. А значит, как только мы нашли первое значение, поиск можно прекращать — оно же и последнее. В-четвёртых, данные в индексе отсортированы. А в-третьих и в-четвёртых вместе позволяют использовать алгоритм бинарного поиска (он же метод деления пополам), эффективность которого многократно превосходит простой перебор.
* Если ресурсы позволяют, таблицу данных тоже можно (и нужно) кешировать в оперативную память. Однако индексам и месту для них в оперативной памяти, по понятным причинам, принято уделять больше внимания.
Однако индексам и месту для них в оперативной памяти, по понятным причинам, принято уделять больше внимания.
Индексация — великая сила. Но если представить все указатели индексной таблицы на строки в таблице данных ОДНОВРЕМЕННО, получится достаточно сложная «паутина»:
И эта паутина, со множеством пересекающихся стрелок, подводит нас к проблеме (просто таки наглядно её демонстрирует), которую создаёт некластерный индекс.
Фрагментация
Оптимизатор MySQL может принять решение вообще не использовать индексы для поиска по небольшим таблицам (до пары десятков записей — зависит от конкретной структуры данных и индекса). Почему? Потому что поиск простым перебором читает данные последовательно. А указатель в индексе ссылается на разрозненные участки данных. И прыжки по ссылкам из индекса в конечном итоге могут стоить дороже полного перебора.
Итак, что мы имеем на данном этапе эволюции индексирования. Представьте большую, фрагментированную с точки зрения индексации, таблицу. Как данные приходили хаотичными и неотсортированными, так они и сохранялись. Теперь представьте индексную таблицу к ней. И наш старый добрый запрос:
Как данные приходили хаотичными и неотсортированными, так они и сохранялись. Теперь представьте индексную таблицу к ней. И наш старый добрый запрос:
SELECT * FROM `t1` WHERE `fld1` = 12;
Что происходит? Находится значение в индексе — это быстро и просто — и из таблицы данных читаются строки, на которые этот индекс ссылается. Естественно, при большой фрагментированности таблицы накладные расходы на чтение из разных её частей становятся ощутимыми.
И вот тут-то нам и пригодятся…
Кластерные индексы
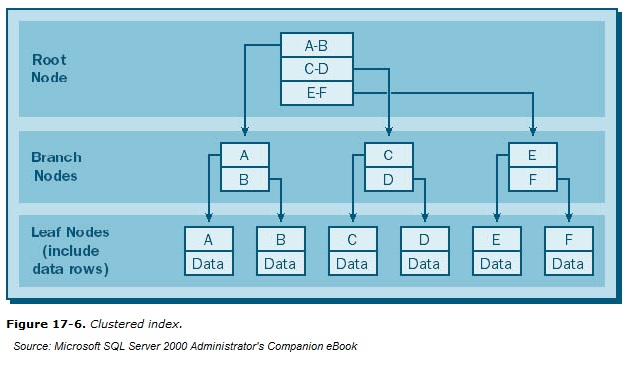
Кластерные индексы отличаются от некластерных точно так же, как оглавление книги отличается от алфавитного указателя. Алфавитный указатель (некластерный индекс) для точного слова (значения) даёт точные номера страниц (строки в БД). Оглавление же указывает диапазон страниц, соответствующих определённой главе, в которой уже найдётся искомое слово. Причём каждая глава, если она достаточно велика, может содержать собственное оглавление.
Кластерный индекс — это древовидная структура данных, при которой значения индекса хранятся вместе с данными, им соответствующими. И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла*, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
И индексы, и данные при такой организации упорядочены. При добавлении новой строки в таблицу, она дописывается не в конец файла*, не в конец плоского списка, а в нужную ветку древовидной структуры, соответствующую ей по сортировке.
* В разных движках и при разных настройках это может быть вовсе и не конец, и вовсе и не файла. Слово файл здесь означает «некую единицу измерения данных, соответствующую одной таблице», а «конец файла» употребляется как символ последовательной, линейной записи.
Один из самых мощных и производительных движков для MySQL — InnoDB. Тому много причин, и одна из них — кластерные индексы. Проще всего понять как устроены кластерные индексы, если представить их в динамике: как они разрастаются по мере добавления данных, и как начинает ветвиться таблица.
Первый этап: плоский список
Данные в InnoDB хранятся страницами по 16 Кб. Размер одной страницы — это предельный размер узла нашей древовидной структуры, от которого зависит в какой момент начнётся ветвление. Если вся таблица помещается в одну страницу, то она хранится в виде плоского списка, отсортированного по ключевому полю, без отдельной индексной таблицы.
Если вся таблица помещается в одну страницу, то она хранится в виде плоского списка, отсортированного по ключевому полю, без отдельной индексной таблицы.
Точно такими же маленькими табличками в будущем будут представлены все наши данные, а соединять их в дерево будут цепочки индексных страниц.
Второй этап: дерево
Когда данные перестают помещаться в одну страницу, список превращается в дерево. Страница с данными разделяется на две, причём в том узле (на той странице), где раньше были данные, теперь располагается индекс, охватывающий обе новые страницы. Конкретный узел такого дерева обязан включать в себя индексы всех дочерних узлов или конечные данные, если узел последний. Узлы могут ссылаться друг на друга только в одном направлении: от родителя к потомку.
По мере добавления всё новых и новых данных, дерево будет усложняться и углубляться. И чем больше оно будет и ветвистее, тем больший выйгрышь даст такая схема хранения данны.
Серые страницы идентичны странице первого этапа — это просто отсортированные данные, листья (конечные узлы) нашего дерева. Голубые страницы — это промежуточные узлы дерева, содержащие только индекс и не содержащие данных. Стрелками помечены пути поиска определённых значений ключа.
Голубые страницы — это промежуточные узлы дерева, содержащие только индекс и не содержащие данных. Стрелками помечены пути поиска определённых значений ключа.
Вспомним наш запрос (зелёная стрелка):
SELECT * FROM `t1` WHERE `fld1` = 12;
Обращаясь к таблице, запрос попадает на первую страницу и получает индекс, тут же отправляющий его на конечную страницу с данными, где находятся строки, удовлетворяющие критериям поиска. Страница уже прочитана на этапе поиска, все данные собраны, БД может вернуть ответ.
Однако индекс, указывающий на другую страницу, не обязательно ведёт сразу на страницу с данными. Индекс может указывать на страницу с промежуточным индексом. Возможно, при больших объёмах таблицы, БД придётся провести больше итераций поиска, но каждая такая итерация включает минимальный объём данных, а потому в целом всё равно поиск проходит быстрее.
Здесь действует простое правило, актуальное для любого типа индекса: чем разнообразнее данные, тем эффективнее использовать индекс для поиска конкретных значений.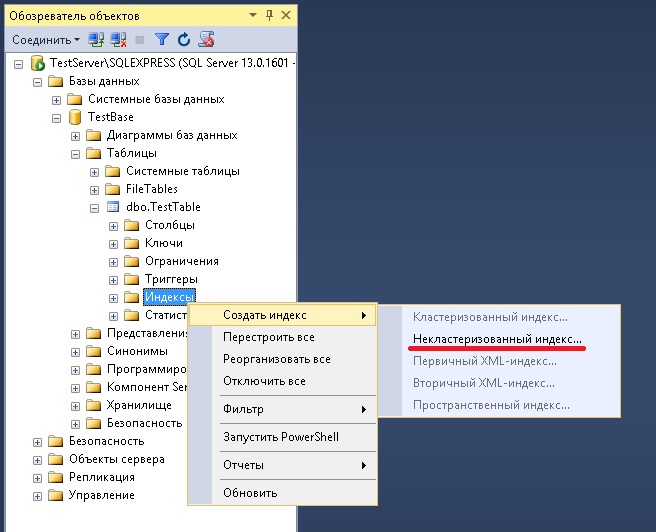
Поскольку данные являются частью индекса, отсортированы и целенаправленно фрагментированы, очевидно что для одной таблицы может использоваться только один кластерный ключ. Из такой, достаточно сложной логики хранения индексов и данных, есть ещё одно важное следствие: операции записи, а особенно изменение имеющихся данных ключевых полей — крайне ресурсоёмкий процесс. Старайтесь использовать для кластерных индексов редко изменяемые поля.
Что касается сложных (составных) кластерных ключей, для них действует абсолютно такая же схема, только сортировка данных осуществляется по двум полям. Сам же индекс мало отличается от некластерного составного ключа.
Кластерные ключи в InnoDB
Здесь всё просто. Каждая таблица InnoDB имеет кластерный ключ. Каждая. Без исключения.
Гораздо интереснее, какие поля для этого выбираются.
- Если в таблице задан PRIMARY KEY — это он
- Иначе, если в таблице есть UNIQUE (уникальные) индексы — это первый из них
- Иначе InnoDB самостоятельно создаёт скрытое поле с суррогатным ID размером в 6 байт
До третьего пункта лучше не доводить свой многострадальный сервер, и добавить таки ID самостоятельно.
И не забывайте, что InnoDB во вторичных ключах хранит полный набор значений полей кластерного ключа в качестве ссылки на конечную строку в таблице. Чем больше первичный ключ, тем больше вторичные ключи.
18) Кластерный против некластеризованного индекса
Что такое индекс?
Индекс – это ключ, построенный из одного или нескольких столбцов в базе данных, который ускоряет выборку строк из таблицы или представления. Этот ключ помогает базе данных, такой как Oracle, SQL Server, MySQL и т. Д., Быстро найти строку, связанную со значениями ключа.
Два типа индексов:
- Кластерный индекс
- Некластерный индекс
В этом уроке вы узнаете:
- Что такое индекс?
- Что такое кластерный индекс?
- Что такое некластеризованный индекс?
- Характеристика кластерного индекса
- Характеристики некластеризованных индексов
- Пример кластерного индекса
- Пример некластеризованного индекса
- Различия между кластерным индексом и некластеризованным индексом
- Преимущества кластерного индекса
- Преимущества некластеризованного индекса
- Недостатки кластерного индекса
- Недостатки некластеризованного индекса
Что такое кластерный индекс?
Индекс кластера – это тип индекса, который сортирует строки данных в таблице по их ключевым значениям. В базе данных существует только один кластеризованный индекс на таблицу.
В базе данных существует только один кластеризованный индекс на таблицу.
Кластерный индекс определяет порядок, в котором данные хранятся в таблице и могут быть отсортированы только одним способом. Таким образом, для каждой таблицы может быть только один кластеризованный индекс. В РСУБД, как правило, первичный ключ позволяет создавать кластерный индекс на основе этого конкретного столбца.
Что такое некластеризованный индекс?
Некластеризованный индекс хранит данные в одном месте и индексы в другом месте. Индекс содержит указатели на местоположение этих данных. Одна таблица может иметь много некластеризованных индексов, поскольку индекс в некластеризованном индексе хранится в разных местах.
Например, книга может иметь более одного индекса, один в начале, который отображает содержание книги, а второй индекс показывает индекс терминов в алфавитном порядке.
Некластеризованный индекс определяется в неупорядоченном поле таблицы. Этот тип метода индексации помогает повысить производительность запросов, использующих ключи, которые не назначены в качестве первичного ключа. Некластеризованный индекс позволяет добавить уникальный ключ для таблицы.
Некластеризованный индекс позволяет добавить уникальный ключ для таблицы.
Характеристика кластерного индекса
- Стандартное и отсортированное хранилище данных
- Используйте только один или несколько столбцов для индекса
- Помогает хранить данные и индексировать вместе
- фрагментация
- операции
- Сканирование кластеризованного индекса и поиск индекса
- Поиск ключей
Характеристики некластеризованных индексов
- Хранить только значения ключей
- Указатели на строки кучи / кластерного индекса
- Позволяет вторичный доступ к данным
- Мост к данным
- Операции сканирования индекса и поиска индекса
- Вы можете создать некластеризованный индекс для таблицы или представления
- Каждая строка индекса в некластеризованном индексе хранит значение некластеризованного ключа и локатор строк.
Пример кластерного индекса
В приведенном ниже примере SalesOrderDetailID является кластеризованным индексом. Пример запроса для получения данных
Пример запроса для получения данных
SELECT CarrierTrackingNumber, UnitPrice FROM SalesData WHERE SalesOrderDetailID = 6
Пример некластеризованного индекса
В следующем примере некластеризованный индекс создается для OrderQty и ProductID следующим образом
CREATE INDEX myIndex ON SalesData (ProductID, OrderQty)
Следующий запрос будет получен быстрее по сравнению с кластерным индексом.
SELECT Product ID, OrderQty FROM SalesData WHERE ProductID = 714
Различия между кластерным индексом и некластеризованным индексом
| параметры | кластерный | Некластерированных |
|---|---|---|
| Использовать для | Вы можете сортировать записи и физически хранить кластерный индекс в памяти в соответствии с порядком. | Некластеризованный индекс помогает вам создать логический порядок для строк данных и использует указатели для физических файлов данных. |
| Метод хранения | Позволяет хранить страницы данных в конечных узлах индекса. | Этот метод индексации никогда не сохраняет страницы данных в конечных узлах индекса. |
| Размер | Размер кластерного индекса довольно велик. | Размер некластеризованного индекса невелик по сравнению с кластеризованным индексом. |
| Доступ к данным | Быстрее | Медленнее по сравнению с кластерным индексом |
| Дополнительное дисковое пространство | Не требуется | Требуется хранить индекс отдельно |
| Тип ключа | По умолчанию первичные ключи таблицы являются кластерным индексом. | Его можно использовать с уникальным ограничением на таблицу, которое действует как составной ключ. |
| Главная особенность | Кластерный индекс может повысить производительность поиска данных. | Он должен быть создан на столбцах, которые используются в соединениях. |
Преимущества кластерного индекса
Плюсы / преимущества кластерного индекса:
- Кластерные индексы являются идеальным вариантом для диапазона или группы с запросами типа max, min, count
- В этом типе индекса поиск может идти прямо к определенной точке данных, чтобы вы могли продолжать последовательное чтение оттуда.
- Метод кластеризованного индекса использует механизм определения местоположения для определения позиции индекса в начале диапазона.
- Это эффективный метод для поиска диапазона, когда запрашивается диапазон значений ключа поиска.
- Помогает минимизировать передачу страниц и максимизировать попадания в кэш.
Преимущества некластеризованного индекса
Плюсы использования некластеризованного индекса:
- Некластеризованный индекс помогает быстро получать данные из таблицы базы данных.
- Помогает избежать накладных расходов, связанных с кластерным индексом
- Таблица может иметь несколько некластеризованных индексов в РСУБД.
 Таким образом, его можно использовать для создания более одного индекса.
Таким образом, его можно использовать для создания более одного индекса.
 Таким образом, его можно использовать для создания более одного индекса.
Таким образом, его можно использовать для создания более одного индекса.Недостатки кластерного индекса
Вот минусы / недостатки использования кластерного индекса:
- Много вставок в непоследовательном порядке
- Кластерный индекс создает множество постоянных разбиений страниц, включая страницы данных и страницы индекса.
- Дополнительная работа для SQL для вставки, обновления и удаления.
- Кластерный индекс занимает больше времени для обновления записей при изменении полей в кластерном индексе.
- Конечные узлы в основном содержат страницы данных в кластерном индексе.
Недостатки некластеризованного индекса
Вот минусы / недостатки использования некластеризованного индекса:
- Некластеризованный индекс помогает хранить данные в логическом порядке, но не позволяет сортировать строки данных физически.
- Процесс поиска по некластеризованному индексу становится дорогостоящим.
- Каждый раз, когда ключ кластеризации обновляется, требуется соответствующее обновление для некластеризованного индекса, поскольку он хранит ключ кластеризации.

КЛЮЧЕВАЯ РАЗНИЦА
- Кластерный индекс – это тип индекса, который сортирует строки данных в таблице по их ключевым значениям, тогда как некластеризованный индекс хранит данные в одном месте и индексы в другом месте.
- Кластерный индекс хранит страницы данных в конечных узлах индекса, в то время как метод некластеризованного индекса никогда не сохраняет страницы данных в конечных узлах индекса.
- Кластерный индекс не требует дополнительного дискового пространства, тогда как некластеризованный индекс требует дополнительного дискового пространства.
- Кластерный индекс предлагает более быстрый доступ к данным, с другой стороны, некластеризованный индекс медленнее.
Когда использовать кластеризованные или некластеризованные индексы в SQL Server
Индексы базы данных используются для повышения скорости операций базы данных в таблице с большим количеством записей. Индексы баз данных (как кластеризованные, так и некластеризованные индексы) по своей функциональности очень похожи на книжные индексы. Указатель книги позволяет вам сразу перейти к различным темам, обсуждаемым в книге. Если вы хотите найти конкретную тему, вы просто переходите к индексу, находите номер страницы, содержащей тему, которую вы ищете, а затем можете перейти прямо на эту страницу. Без указателя вам пришлось бы искать всю книгу.
Указатель книги позволяет вам сразу перейти к различным темам, обсуждаемым в книге. Если вы хотите найти конкретную тему, вы просто переходите к индексу, находите номер страницы, содержащей тему, которую вы ищете, а затем можете перейти прямо на эту страницу. Без указателя вам пришлось бы искать всю книгу.
Индексы базы данных работают таким же образом. Без индексов вам пришлось бы искать всю таблицу, чтобы выполнить определенную операцию с базой данных. С индексами вам не нужно сканировать все записи таблицы. Индекс указывает вам непосредственно на запись, которую вы ищете, что значительно сокращает время выполнения вашего запроса.
Индексы SQL Server можно разделить на два основных типа:
- Кластеризованные индексы
- Некластеризованные индексы
В этой статье мы рассмотрим, что такое кластеризованный и некластеризованный индекс, как они создаются и каковы основные различия между ними. Мы также рассмотрим, когда следует использовать кластеризованные или некластеризованные индексы в SQL Server.
Начнем с кластеризованного индекса.
Кластерный индекс — это индекс, который определяет физический порядок, в котором записи таблицы хранятся в базе данных. Поскольку может быть только один способ физического хранения записей в таблице базы данных, для каждой таблицы может быть только один кластеризованный индекс. По умолчанию кластеризованный индекс создается для столбца первичного ключа.
Кластеризованные индексы по умолчанию
Давайте создадим фиктивную таблицу со столбцом первичного ключа, чтобы увидеть кластеризованный индекс по умолчанию. Выполните следующий скрипт:
CREATE DATABASE Больница
CREATE TABLE Пациенты
(
id INT PRIMARY KEY,
имя VARCHAR(50) НЕ NULL,
пол VARCHAR(50) НЕ NULL, 90 029 возраст INT NOT NULL
)
Приведенный выше сценарий создает фиктивную базу данных Hospital. В базе 4 столбца: id, имя, пол, возраст. Столбец id является столбцом первичного ключа. Когда приведенный выше сценарий выполняется, для столбца id автоматически создается кластеризованный индекс. Чтобы увидеть все индексы в таблице, вы можете использовать хранимую процедуру «sp_helpindex».
Чтобы увидеть все индексы в таблице, вы можете использовать хранимую процедуру «sp_helpindex».
USE Больница
EXECUTE sp_helpindex Пациенты
Вот результат:
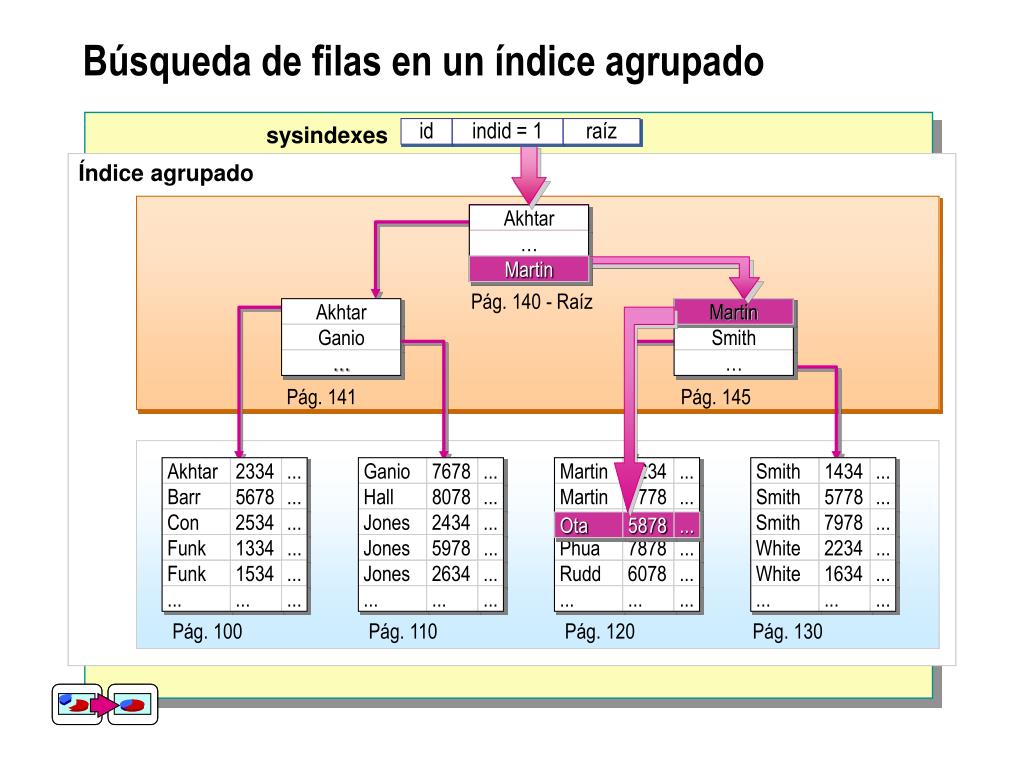
Вы можете увидеть имя индекса, описание и столбец, для которого создан индекс. Если вы добавите новую запись в таблицу «Пациенты», она будет храниться в порядке возрастания значения в столбце id. Если первая запись, которую вы вставляете в таблицу, имеет идентификатор три, запись будет сохранена в третьей строке, а не в первой строке, поскольку кластеризованный индекс поддерживает физический порядок.
Пользовательские кластерные индексы
Вы можете создавать свои собственные кластерные индексы. Однако, прежде чем вы сможете это сделать, вы должны создать существующий кластеризованный индекс. У нас есть один кластеризованный индекс из-за столбца первичного ключа. Если мы удалим ограничение первичного ключа, кластер по умолчанию будет удален. Следующий сценарий удаляет ограничение первичного ключа.
USE Больница
ALTER TABLE Пациенты
DROP CONSTRAINT PK__Patients__3213E83F3DFAFAAD
GO
Следующий сценарий создает настраиваемый индекс «IX_tblPatient_Age» в столбце age таблицы «Patients». Благодаря этому индексу все записи в таблице «Пациенты» будут храниться в порядке возрастания возраста.
use Hospital
CREATE CLUSTERED INDEX IX_tblPatient_Age
ON Пациенты (возраст ASC)
Теперь добавим несколько фиктивных записей в таблицу «Пациенты», чтобы увидеть, действительно ли они вставлены в порядке возрастания возраста:
ЕГЭ Больница
ВСТАВЬТЕ В ПАЦИЕНТЫ
ЗНАЧЕНИЯ
(1, «Сара», «Женщина», 34),
(2, «Джон», «Мужчина», 20),
(3, «Майк», «Мужчина» , 54),
(4, ‘Ана’, ‘Женщина’, 10),
(5, ‘Ник’, ‘Женщина’, 29)
В приведенном выше скрипте мы добавляем 5 фиктивных записей. Обратите внимание на значения столбца возраста. Они имеют случайные значения и не находятся в каком-либо логическом порядке.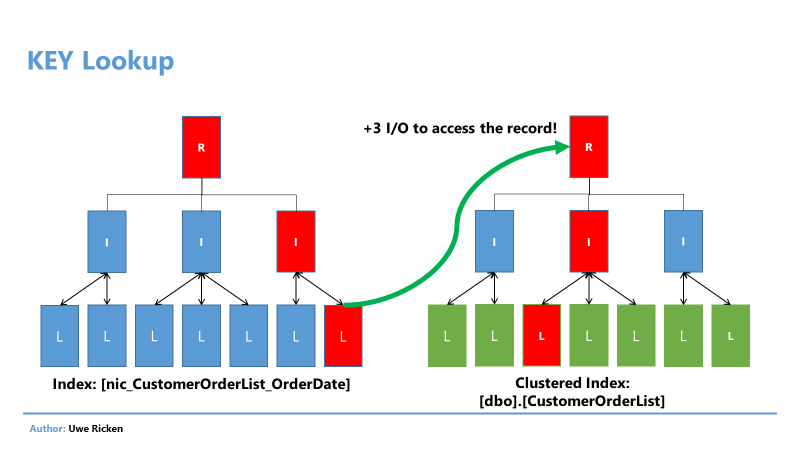 Однако, поскольку мы создали кластеризованный индекс, записи будут фактически вставлены в порядке возрастания значения в столбце возраста. Вы можете убедиться в этом, выбрав все записи из таблицы «Пациенты».
Однако, поскольку мы создали кластеризованный индекс, записи будут фактически вставлены в порядке возрастания значения в столбце возраста. Вы можете убедиться в этом, выбрав все записи из таблицы «Пациенты».
SELECT * FROM Пациенты
Вот результат:
Вы можете видеть, что записи упорядочены в порядке возрастания значений в столбце возраста.
Некластеризованный индекс также используется для ускорения операций поиска. В отличие от кластеризованного индекса, некластеризованный индекс физически не определяет порядок, в котором записи вставляются в таблицу. Фактически некластеризованный индекс хранится отдельно от таблицы данных. Некластеризованный указатель подобен книжному указателю, который расположен отдельно от основного содержания книги. Поскольку некластеризованные индексы расположены в отдельном расположении, в каждой таблице может быть несколько некластеризованных индексов.
Чтобы создать некластеризованный индекс, вы должны использовать оператор «CREATE NONCLUSTERED».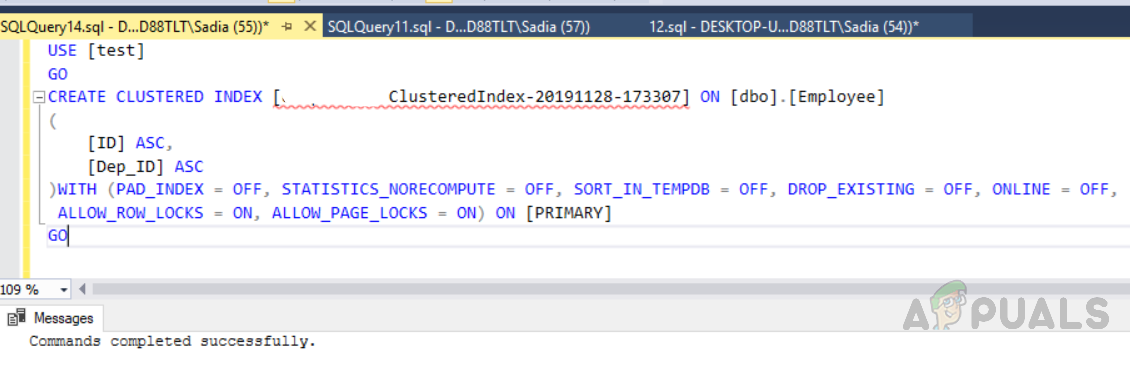 Остальной синтаксис остается таким же, как синтаксис для создания кластеризованного индекса. Следующий сценарий создает некластеризованный индекс «IX_tblPatient_Name», который сортирует записи в порядке возрастания имени.
Остальной синтаксис остается таким же, как синтаксис для создания кластеризованного индекса. Следующий сценарий создает некластеризованный индекс «IX_tblPatient_Name», который сортирует записи в порядке возрастания имени.
use Hospital
CREATE NONCLUSTERED INDEX IX_tblPatient_Name
ON Пациенты (имя ASC)
Приведенный выше сценарий создаст индекс, содержащий имена пациентов и адрес их соответствующих записей, как показано ниже:
| Имя | Адрес записи |
| Ана | Адрес записи |
| Джон | Адрес записи |
| Майк | Адрес записи |
| Ник | Адрес записи |
| Сара | Адрес записи |
Здесь «Адрес записи» в каждой строке является ссылкой на фактические записи таблицы для Пациентов с соответствующими именами.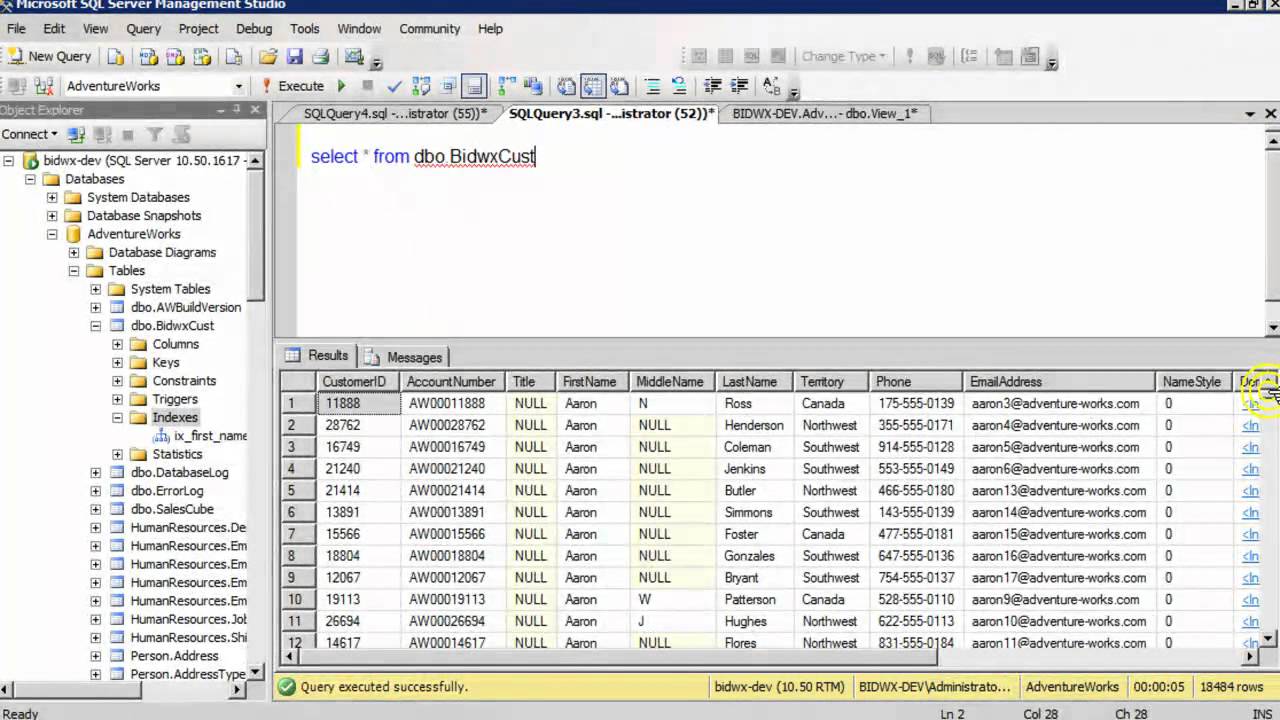
Например, если вы хотите получить возраст и пол пациента по имени «Майк», база данных сначала будет искать «Мик» в некластеризованном индексе «IX_tblPatient_Name», а из некластеризованного индекса будет извлечена фактическая ссылку на запись и будет использовать ее для возврата фактического возраста и пола пациента по имени «Майк». медленнее для операций поиска. Однако для операций INSERT и UPDATE некластеризованные индексы работают быстрее, поскольку порядок записей нужно обновлять только в индексе, а не в фактической таблице.
Когда использовать кластеризованные и некластеризованные индексы
Теперь, когда вы знаете разницу между кластеризованным и некластеризованным индексом, давайте рассмотрим различные сценарии использования каждого из них.
1. Количество индексов
Это довольно очевидно. Если вам нужно создать несколько индексов в базе данных, используйте некластеризованный индекс, поскольку может быть только один кластеризованный индекс.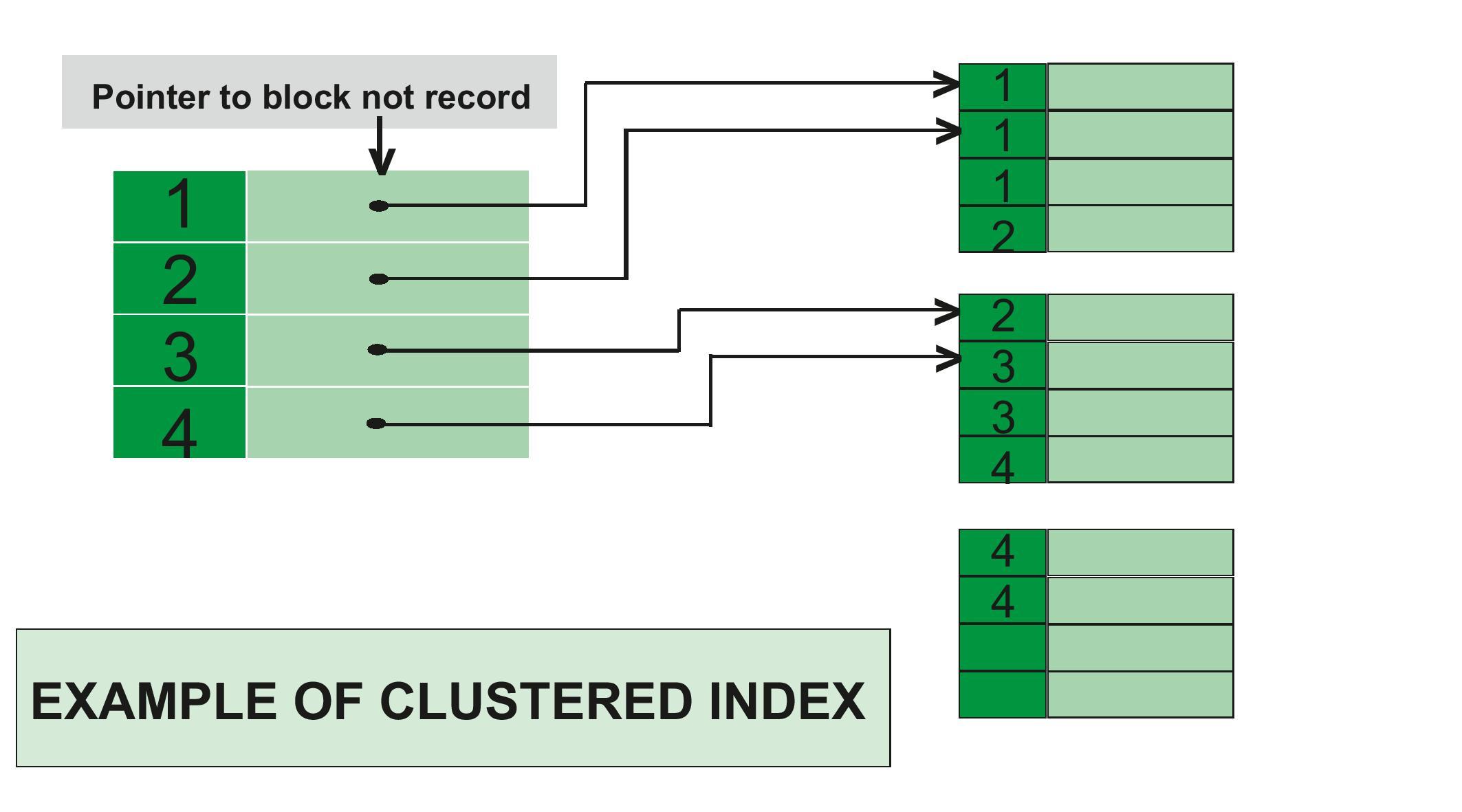
2. Операции SELECT
Если вы хотите выбрать только значение индекса, которое используется для создания и индексирования, некластеризованные индексы работают быстрее. Например, если вы создали индекс для столбца «имя» и хотите выбрать только имя, некластеризованные индексы быстро вернут это имя.
Однако, если вы хотите выбрать другие значения столбца, такие как возраст, пол, используя индекс имени, операция SELECT будет выполняться медленнее, поскольку сначала имя будет искаться в индексе, а затем будет использоваться ссылка на фактическую запись таблицы. для поиска возраста и пола.
С другой стороны, при использовании кластеризованных индексов, поскольку все записи уже отсортированы, операция SELECT выполняется быстрее, если данные выбираются из столбцов, отличных от столбца с кластеризованным индексом.
3. Операции INSERT/UPDATE
Операции INSERT и UPDATE выполняются быстрее с некластеризованными индексами, поскольку фактические записи не требуется сортировать при выполнении операций INSERT или UPDATE.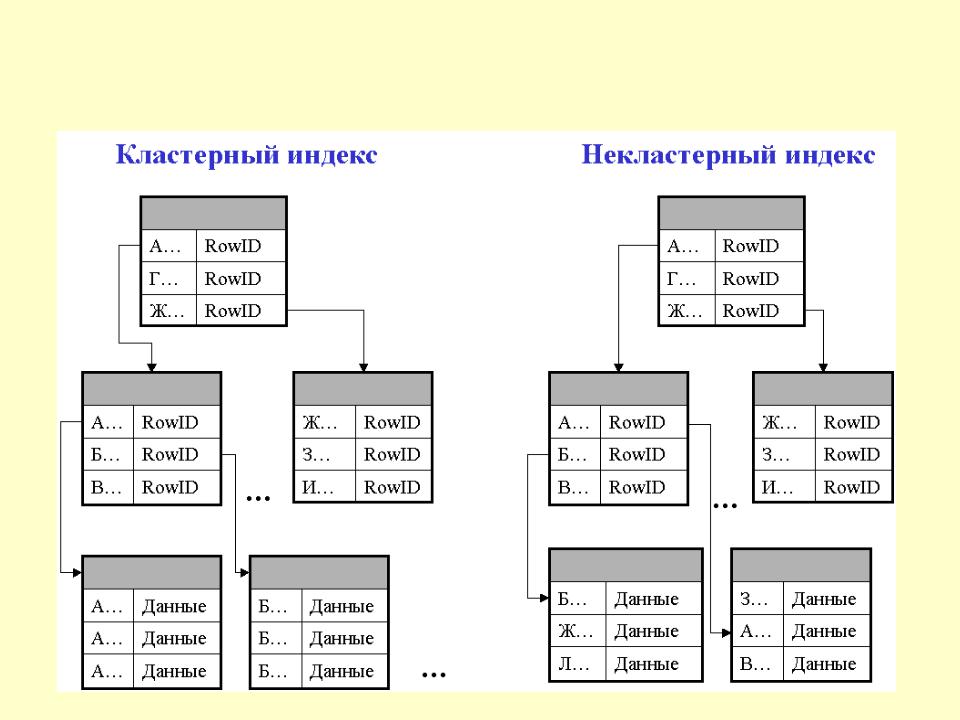 Скорее, в обновлении нуждается только некластеризованный индекс.
Скорее, в обновлении нуждается только некластеризованный индекс.
4. Место на диске
Поскольку некластеризованные индексы хранятся отдельно от исходной таблицы, некластеризованные индексы занимают дополнительное место на диске. Если дисковое пространство является проблемой, используйте кластеризованный индекс.
5. Окончательный вердикт
Как правило, каждая таблица должна иметь хотя бы один кластеризованный индекс, предпочтительно для столбца, который используется для ВЫБОРА записей и содержит уникальные значения. Столбец первичного ключа — идеальный кандидат для кластеризованного индекса.
С другой стороны, столбцы, которые часто используются в запросах INSERT и UPDATE, должны иметь некластеризованный индекс, предполагая, что место на диске не имеет значения.
Включите JavaScript для просмотра комментариев с помощью Disqus.
Разработка эффективных кластерных индексов SQL Server
В предыдущих статьях этой серии (полный указатель см. внизу) мы подробно описали структуру таблиц и индексов SQL Server, основы и рекомендации, которые помогут нам в разработке правильного индекса, и, наконец, список операций, которые необходимо выполнить. могут быть выполнены с индексами SQL Server. В этой статье мы увидим, как можно спроектировать эффективный кластерный индекс, от которого всегда будет выигрывать оптимизатор запросов SQL Server, ускоряя процесс извлечения данных, что является основной целью построения индекса.
внизу) мы подробно описали структуру таблиц и индексов SQL Server, основы и рекомендации, которые помогут нам в разработке правильного индекса, и, наконец, список операций, которые необходимо выполнить. могут быть выполнены с индексами SQL Server. В этой статье мы увидим, как можно спроектировать эффективный кластерный индекс, от которого всегда будет выигрывать оптимизатор запросов SQL Server, ускоряя процесс извлечения данных, что является основной целью построения индекса.
Обзор структуры кластерного индекса
В кластеризованной таблице кластеризованный индекс SQL Server используется для хранения строк данных, отсортированных на основе значений ключа кластеризованного индекса. SQL Server позволяет нам создавать только один кластеризованный индекс для каждой таблицы, так как данные могут быть отсортированы в таблице с использованием одного критерия порядка. В таблицах кучи отсутствие кластеризованного индекса означает, что данные не отсортированы в базовой таблице.
Кластерный индекс организован как 8 КБ страниц с использованием структуры B-дерева , чтобы ядро SQL Server Engine могло быстро находить запрошенные строки, связанные со значениями ключа индекса. Каждая страница в структуре B-дерева индекса рассматривается как узел индекса. Узел верхнего уровня называется корневым узлом , а узлы нижнего уровня называются конечными узлами , где страницы данных таблицы хранятся и сортируются на основе значений ключа индекса. Все узлы, расположенные между корневым и конечным узлами, называются 9.0121 Узлы промежуточного уровня . Все страницы, расположенные на корневом и промежуточном уровнях, содержат отсортированные значения ключа индекса с указателем на следующий узел промежуточного уровня или страницу данных на конечном уровне индекса. Помимо сортировки данных на страницах индекса на основе значений ключей индекса, сами страницы будут отсортированы и связаны в двусвязном списке внутри индекса. Любое новое значение, вставленное в этот индекс, будет следовать последовательности упорядочения ключей индекса среди существующих строк.
Любое новое значение, вставленное в этот индекс, будет следовать последовательности упорядочения ключей индекса среди существующих строк.
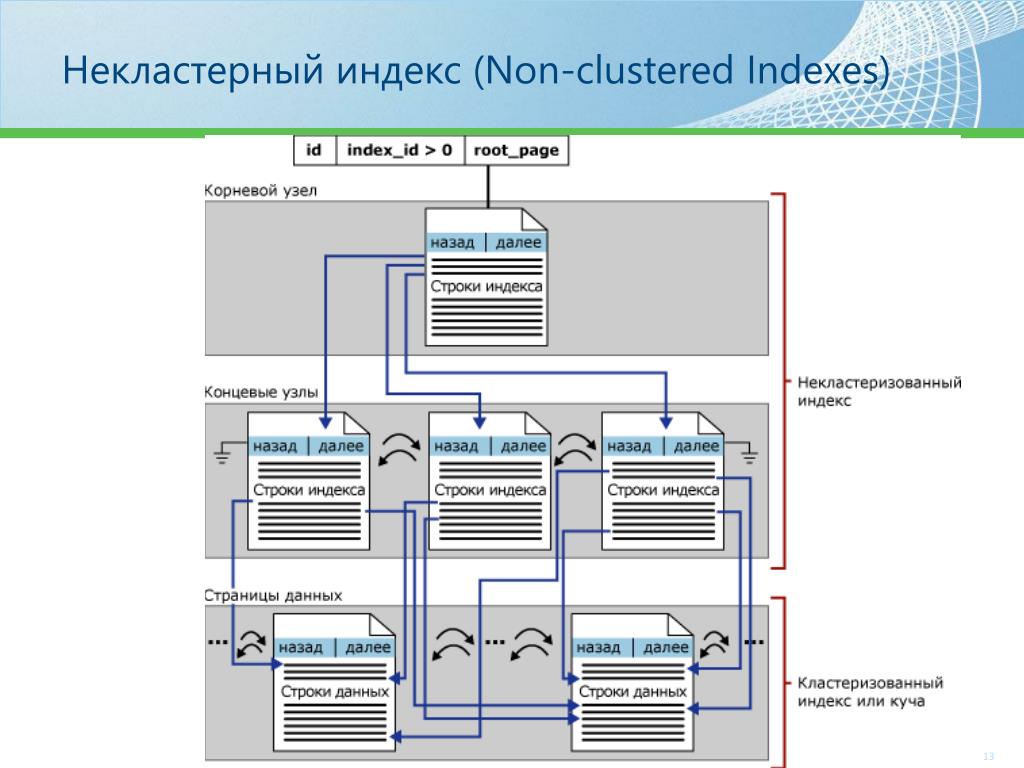
Кластерный индекс SQL Server содержит одну или несколько единиц распределения, которые используются для хранения сохраненных данных и управления ими в зависимости от типов данных ключевых столбцов в этом индексе, при этом единица распределения IN_ROW_DATA доступна во всех кластеризованных индексах. Единица распределения LOB_DATA будет использоваться в кластеризованном индексе, содержащем данные больших объектов (LOB), и единица распределения ROW_OVERFLOW_DATA для столбцов переменной длины, которые превышают ограничение размера строки в 8060 байт. На приведенном ниже рисунке из Microsoft Books Online показана описанная структура кластеризованного индекса в одном разделе, который всегда будет иметь значение index_id, равное 1, в таблице sys.partitions:
Рекомендации по проектированию кластеризованного индекса
Кластерный индекс может быть полезен для запросов, которые считывают 90 121 больших 90 122 наборов результатов, состоящих из 90 121 упорядоченных последовательных данных. В этом случае ядро SQL Server найдет строку с первым запрошенным значением, используя кластеризованный индекс, и продолжит последовательное извлечение остальных строк, которые физически соседствуют на страницах индекса, в правильном порядке, не используя ядро SQL Server. время и ресурсы на сортировку данных, которые уже отсортированы в кластеризованном индексе, что положительно влияет на общую производительность запросов. Например, если запрос возвращает все строки со значением идентификатора больше 950, SQL Server Engine будет использовать кластеризованный индекс, чтобы найти строку со значением идентификатора, равным 950, и продолжить последовательное извлечение остальных строк.
В этом случае ядро SQL Server найдет строку с первым запрошенным значением, используя кластеризованный индекс, и продолжит последовательное извлечение остальных строк, которые физически соседствуют на страницах индекса, в правильном порядке, не используя ядро SQL Server. время и ресурсы на сортировку данных, которые уже отсортированы в кластеризованном индексе, что положительно влияет на общую производительность запросов. Например, если запрос возвращает все строки со значением идентификатора больше 950, SQL Server Engine будет использовать кластеризованный индекс, чтобы найти строку со значением идентификатора, равным 950, и продолжить последовательное извлечение остальных строк.
Характеристики лучших ключей кластеризации можно свести к нескольким пунктам, которым следует большинство дизайнеров:
- Короткий : Хотя SQL Server позволяет нам добавлять до 16 столбцов к ключу кластеризованного индекса с максимальным размером ключа 900 байт, типичный ключ кластеризованного индекса намного меньше, чем разрешено, с таким количеством столбцов, как возможный. Ключ широкого кластеризованного индекса также повлияет на все некластеризованные индексы, созданные на основе этого кластеризованного индекса, поскольку ключ кластеризованного индекса будет использоваться в качестве ключа поиска для всех некластеризованных индексов, указывающих на него.
- Статический : рекомендуется выбирать столбцы, которые не изменяются часто в ключе кластеризованного индекса. Изменение значений ключа кластеризованного индекса означает, что вся строка будет перемещена на новую правильную страницу, чтобы сохранить значения данных в правильном порядке.
- Увеличение : Использование возрастающего столбца, такого как столбец IDENTITY, в качестве ключа кластеризованного индекса поможет улучшить процесс INSERT, который будет непосредственно вставлять новые значения в логический конец таблицы. Этот настоятельно рекомендуемый выбор поможет уменьшить объем памяти, необходимый для буферов страниц, свести к минимуму необходимость разбивать страницу на две страницы, чтобы соответствовать вновь вставленным значениям, и возможность возникновения фрагментации, которая требует повторной перестройки или реорганизации индекса.
- Уникальный : рекомендуется объявить ключевой столбец кластерного индекса или комбинацию столбцов уникальными для повышения производительности запросов. В противном случае SQL Server автоматически добавит столбец уникальности, чтобы обеспечить уникальность ключа кластеризованного индекса.
- Частый доступ : Это связано с тем, что строки будут храниться в кластеризованном индексе в отсортированном порядке на основе того ключа индекса, который используется для доступа к данным.
- Используется в предложении ORDER BY : В этом случае компоненту SQL Server Engine не нужно сортировать данные для их отображения, поскольку строки уже отсортированы на основе ключа индекса, используемого в предложении ORDER BY.
 Ключ широкого кластеризованного индекса также повлияет на все некластеризованные индексы, созданные на основе этого кластеризованного индекса, поскольку ключ кластеризованного индекса будет использоваться в качестве ключа поиска для всех некластеризованных индексов, указывающих на него.
Ключ широкого кластеризованного индекса также повлияет на все некластеризованные индексы, созданные на основе этого кластеризованного индекса, поскольку ключ кластеризованного индекса будет использоваться в качестве ключа поиска для всех некластеризованных индексов, указывающих на него.
Ключ кластерного индекса соответствующие типы данных
При разработке кластеризованного индекса следует учитывать, что некоторые типы данных обычно лучше других типов данных для использования в качестве ключей кластеризации.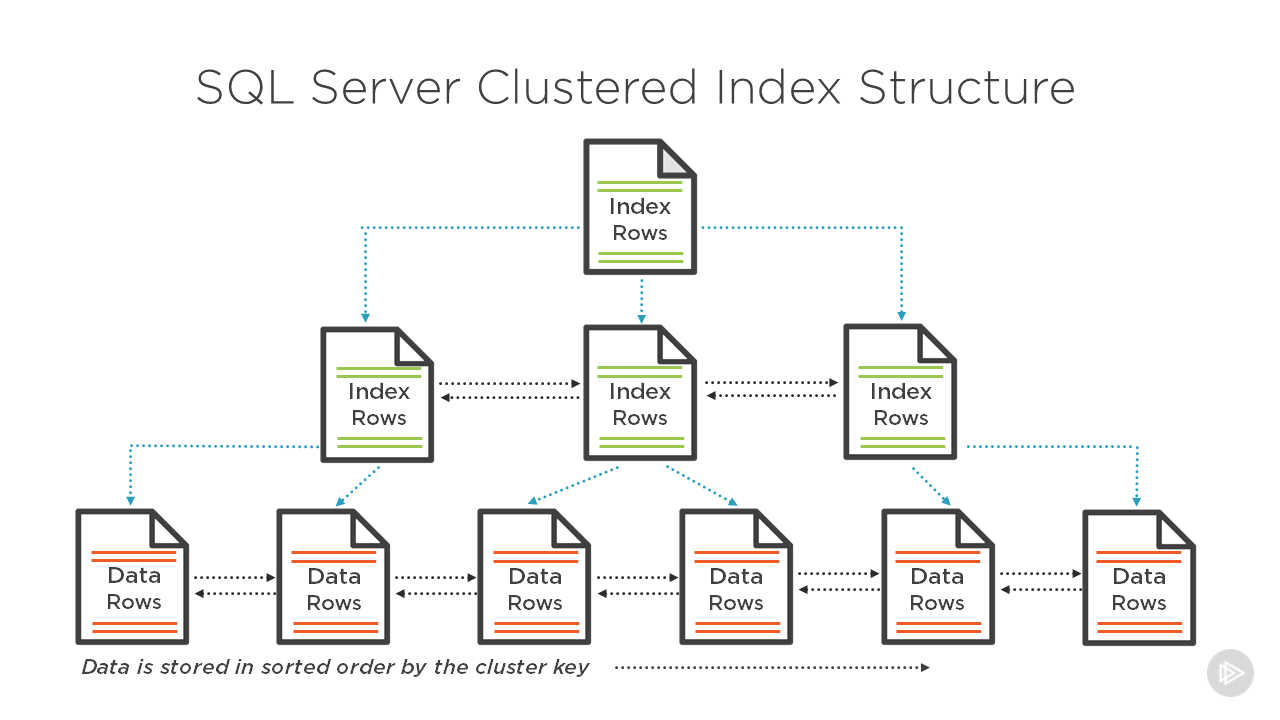 Например, столбцы с 9Типы данных 0121 SMALLINT , INT и BIGINT являются лучшим выбором в качестве ключей кластерного индекса, особенно при использовании в сочетании с ограничением IDENTITY, которое обеспечивает последовательное увеличение их значений. Кроме того, целочисленные значения IDENTITY являются узкими из-за своего небольшого размера, уникальными, если вы применяете уникальность столбца с ограничением, и статическими, поскольку они автоматически генерируются системой и невидимы для пользователей.
Например, столбцы с 9Типы данных 0121 SMALLINT , INT и BIGINT являются лучшим выбором в качестве ключей кластерного индекса, особенно при использовании в сочетании с ограничением IDENTITY, которое обеспечивает последовательное увеличение их значений. Кроме того, целочисленные значения IDENTITY являются узкими из-за своего небольшого размера, уникальными, если вы применяете уникальность столбца с ограничением, и статическими, поскольку они автоматически генерируются системой и невидимы для пользователей.
Хотя Значения GUID , которые хранятся в столбцах uniqueidentifier , обычно используются в качестве ключа кластеризованного индекса. Основная проблема, влияющая на производительность сортировки ключей кластеризованного индекса, заключается в природе значения GUID, которое больше, чем целочисленные типы данных, с размером 16 байт, и что оно генерируется случайным образом, отличным от целочисленных значений IDENTITY, которые увеличиваются.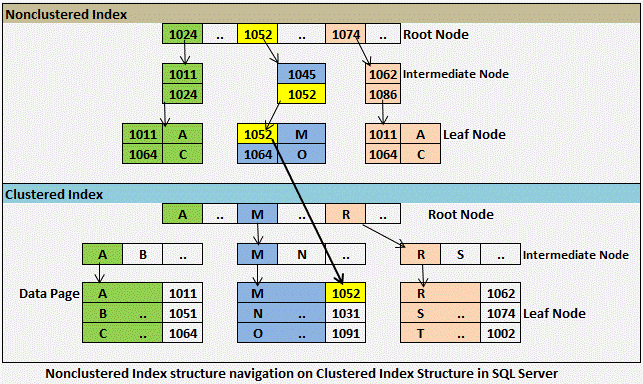 непрерывно. Большой размер и случайная генерация значений GUID всегда будут приводить к проблемам разделения страниц и фрагментации индекса, что негативно влияет на производительность использования кластеризованного индекса.
непрерывно. Большой размер и случайная генерация значений GUID всегда будут приводить к проблемам разделения страниц и фрагментации индекса, что негативно влияет на производительность использования кластеризованного индекса.
Типы данных Character также можно использовать, но не рекомендуется, в качестве ключей кластеризованного индекса. Это связано с ограниченной производительностью сортировки символьных типов данных, большим размером, невозрастающими значениями, нестатическими значениями, которые часто имеют тенденцию изменяться в бизнес-приложениях и не сравниваются как двоичные значения в процессе сортировки, поскольку символы механизм сравнения зависит от используемой сортировки. Несмотря на то, что типы данных Date не уникальны, они имеют небольшой размер и обеспечивают хорошую производительность сортировки, особенно для запросов, которые ищут диапазоны данных.
Реализация кластерного индекса
Когда вы создаете ограничение PRIMARY KEY для таблицы, уникальный кластеризованный индекс будет автоматически создан для столбца или столбцов, которые участвуют в этом ограничении, чтобы применить ограничение PRIMARY KEY с тем же именем, что и имя ограничения, если вы еще этого не сделали.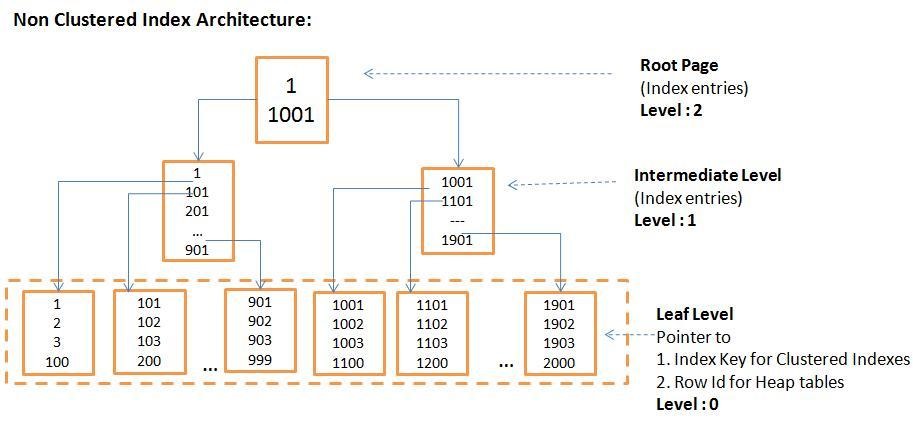 определил кластеризованный индекс для той же таблицы. SQL Server позволяет указать тип индекса, который будет создан автоматически при создании UNIQUE Ограничение на кластеризованный индекс, если для этой таблицы не создан кластеризованный индекс из-за того, что для каждой таблицы может быть создан только один кластеризованный индекс. Вы также можете создать кластеризованный индекс независимо от ограничений, если некластеризованный индекс используется для принудительного применения ограничения PRIMARY KEY.
определил кластеризованный индекс для той же таблицы. SQL Server позволяет указать тип индекса, который будет создан автоматически при создании UNIQUE Ограничение на кластеризованный индекс, если для этой таблицы не создан кластеризованный индекс из-за того, что для каждой таблицы может быть создан только один кластеризованный индекс. Вы также можете создать кластеризованный индекс независимо от ограничений, если некластеризованный индекс используется для принудительного применения ограничения PRIMARY KEY.
Кластерный индекс можно создать с помощью SQL Server Management Studio или с помощью команды CREATE CLUSTERED INDEX T-SQL. Чтобы иметь возможность создать кластеризованный индекс, пользователь должен быть членом db_owner и db_ddladmin фиксированные роли базы данных или член sysadmin фиксированная роль сервера.
Давайте создадим новую таблицу, которая будет использоваться в нашей демонстрации, в которой ограничение PRIMARY KEY будет использовать некластеризованный индекс для его применения, используя инструкцию CREATE TABLE T-SQL ниже:
1 2 3 4 5 6 7 8 9 10 11 | USE SQLShackDemo GO CREATE TABLE ClusteredIndexDemo ( ID INT IDENTITY (1,1) NOT NULL, GUID uniqueidentifier NOT N ULL, EmployeeName NVARCHAR(200) NOT NULL, BirthDate DATETIME NOT NULL, EmployeeAddress NVARCHAR(MAX), CONSTRAINT PK_ClusteredIndexDemo_GUID PRIMARY KEY NONCLUSTERED (GUID) ) |
Не имея кластерного индекса, определенного в предыдущей таблице, мы можем создать кластерный индекс с помощью SQL Server Management Studio, просмотрев таблицу, для которой нам нужно создать кластерный индекс, затем щелкните правой кнопкой мыши узел Indexes под этой таблицей. и из параметра New Index выберите тип кластеризованного индекса , как показано ниже:
и из параметра New Index выберите тип кластеризованного индекса , как показано ниже:
В появившемся диалоговом окне «Новый индекс» имя таблицы, для которой будет создан индекс, и тип индекса будут заполнены автоматически. Вам необходимо указать имя индекса в соответствии с соглашением об именовании вашей компании, уникальность ключевых значений этого индекса и из Добавить кнопку, вы можете выбрать столбец или список столбцов, которые будут участвовать в этом ключе индекса, как показано ниже:
Вы также можете выполнить ту же задачу из конструктора таблиц, щелкнув правой кнопкой мыши таблицу, для которой будет создан индекс, и выберите параметр «Дизайн», как показано ниже:
В отображаемом окне конструктора таблиц щелкните правой кнопкой мыши на пустом месте и выберите параметр «Индексы/ключи», показанный ниже:
В появившемся диалоговом окне нажмите кнопку «Добавить» внизу, чтобы добавить новый кластеризованный индекс, установив «Создать как кластеризованный» на «Да», укажите имя индекса, кластеризованный уникальность ключа индекса и список столбцов с правильным порядком сортировки, которые будут включены в ключ кластеризованного индекса, как показано ниже:
Кластерный индекс также можно создать с помощью команды T-SQL CREATE CLUSTERED INDEX, указав имя индекса, имя таблицы, для которой будет создан индекс, уникальность значений ключа кластерного индекса и список столбцы, которые будут включены в ключ кластеризованного индекса, как показано ниже:
СОЗДАТЬ УНИКАЛЬНЫЙ КЛАСТЕРНЫЙ ИНДЕКС IX_ClusteredIndexDemo_ID ON dbo. ( ID ASC ) WITH( SORT_IN_TEMPDB = ON, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
 ClusteredIndexDemo
ClusteredIndexDemoПодумайте о том, чтобы воспользоваться преимуществами списка параметров создания индекса, указанного в предыдущем операторе CREATE INDEX, особенно при создании кластеризованного индекса для больших таблиц, чтобы повысить производительность процесса создания индекса.
Сравнение производительности
Чтобы продолжить демонстрацию, давайте заполним созданную таблицу 100 000 записей, используя ApexSQL Generate, как показано ниже:
До этого момента таблица заполняется и сортируется на основе столбца ID. Если мы выполним приведенный ниже запрос SELECT, который выполняет поиск на основе столбца ID, и проверим статистику TIME и IO, сгенерированную при выполнении запроса:
УСТАНОВИТЬ ВРЕМЯ СТАТИСТИКИ УСТАНОВИТЬ СТАТИСТИКУ ВВОДА ВКЛ
ВЫБРАТЬ * ИЗ [dbo]. ГДЕ ID>1000 и [EmployeeAddress] LI КЕ ‘%Хиллкрест%’ |
 [ClusteredIndexDemo]
[ClusteredIndexDemo]Сгенерированная статистика покажет, что для извлечения запрошенных данных было выполнено 1075 операций логического чтения, 203 мс затрачено процессорным временем и 255 мс затрачено на выполнение запроса, как показано ниже:
создайте новый, используя столбец GUID:
1 2 3 4 5 6 7 | DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE UNIQUE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( 90 003 GUID ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON ) НА [ПЕРВИЧНОМ] GO |
И выполните приведенный ниже оператор SELECT, который выполняет поиск на основе значений столбца GUID:
SELECT * FROM [dbo]. WHERE GUID <> ‘CB2F45A0-185F-9884-88EB-B7C497AB61EA’ и [EmployeeAddress] LIKE ‘%Hillcrest%’ |
 [ClusteredIndexDemo]
[ClusteredIndexDemo]Сгенерированная статистика времени и операций ввода-вывода покажет, что для извлечения запрошенных данных на основе значений столбца GUID выполнено 1196 операций логического чтения, 2018 мс израсходовано процессорным временем и 276 мс затрачено на выполнение запроса. Все счетчики показывают, что использование столбца GUID в качестве ключа кластеризованного индекса хуже, чем использование столбца ID, как показано ниже:
Снова удаляем кластеризованный индекс и создаем новый, используя символьный столбец EmployeeName:
1 2 3 4 5 6 7 | DROP INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo. ( Имя_сотрудника ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
 ClusteredIndexDemo
ClusteredIndexDemoЗатем выполните приведенный ниже оператор SELECT, который выполняет поиск на основе значений столбца EmployeeName:
SELECT * FROM [dbo].[ClusteredIndexDemo] WHERE [EmployeeName] <> ‘Джанна’ и [EmployeeAddress] LIKE ‘%Hillcrest%’ |
Из сгенерированной статистики времени и операций ввода-вывода видно, что для извлечения запрошенных данных на основе значений EmployeeName выполняется 1287 операций логического чтения, 2018 мс потребляется процессорным временем и 289 мс затрачивается на выполнение запроса. Все счетчики снова показывают, что использование символьного столбца EmployeeName в качестве ключа кластеризованного индекса хуже, чем использование столбцов ID и GUID, как показано ниже:
1 2 3 4 5 6 7 | DROP INDEX IX_ClusteredIndexDemo_ID ON dbo. GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( BirthDate ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) НА [ПЕРВИЧНЫЙ] GO |
 ClusteredIndexDemo
ClusteredIndexDemoИ выполните приведенный ниже оператор SELECT, который выполняет поиск на основе значений столбца BirthDate:
SELECT * FROM [dbo].[ClusteredIndexDemo] ГДЕ Дата рождения МЕЖДУ ‘1950-01-01’ И ‘1950-12-31’ И [EmployeeAddress], например ‘%Hillcrest%’ |
Статистика времени и операций ввода-вывода, сгенерированная после выполнения запроса, покажет, что для извлечения запрошенных данных на основе значений диапазона BirthDate выполняется только 7 операций логического чтения, 0 мс потребляется процессорным временем и 47 мс требуется для выполнения запроса. Из результата видно, что использование столбца BirthDate Datetime в качестве ключа кластеризованного индекса является лучшим выбором при поиске на основе диапазона дат, как показано ниже:
Наконец, если вы попытаетесь удалить кластеризованный индекс и создать новый, используя столбец символов EmployeeAddress:
1 2 3 4 5 6 7 | DROP INDEX IX_ClusteredIndexDemo_ID ON dbo. GO CREATE CLUSTERED INDEX IX_ClusteredIndexDemo_ID ON dbo.ClusteredIndexDemo ( Адрес Сотрудника ASC ) WITH( SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, FILLFACTOR = 90, ONLINE = ON) ON [PRIMARY] GO |
 ClusteredIndexDemo
ClusteredIndexDemoОператор CREATE INDEX завершится ошибкой, показывая, что тип данных NVARCHAR(MAX) не разрешен в качестве ключа кластеризованного индекса, как показано в сообщении об ошибке ниже:
Как видно из предыдущих результатов, Индекс, который спроектирован правильно, может уменьшить количество потребляемых ресурсов ввода-вывода и ЦП, тем самым улучшая запросы и общую производительность системы. Оптимизатор запросов SQL Server решает использовать кластеризованный индекс для извлечения запрошенных данных, поскольку он более эффективен, намного быстрее и потребляет меньше ресурсов, чем сканирование всей таблицы, в дополнение к сортировке данных на страницах индекса.
Учтите, что при создании кластеризованного индекса для таблицы все некластеризованные индексы, созданные для этой таблицы кучи, будут перестроены для замены идентификатора строки (RID) ключом кластеризованного индекса. Таким образом, всегда лучше начинать с создания кластеризованного индекса, а затем переходить к созданию некластеризованного индекса поверх него.
Таким образом, всегда лучше начинать с создания кластеризованного индекса, а затем переходить к созданию некластеризованного индекса поверх него.
В этой статье мы попытались охватить все аспекты темы проектирования кластеризованного индекса. В следующей статье этой серии мы обсудим, как разработать эффективный и оптимальный некластеризованный индекс. Следите за обновлениями!
Содержание
| Индексы SQL Server — введение в серию |
| Обзор структуры таблицы SQL Server |
| Структура и концепции индекса SQL Server |
| Основы и рекомендации по проектированию индексов SQL Server |
| Операции с индексами SQL Server |
| Разработка эффективных кластерных индексов SQL Server |
| Разработка эффективных некластеризованных индексов SQL Server |
| Работа с разными типами индексов SQL Server |
| Отслеживание и настройка запросов с использованием индексов SQL Server |
| Сбор статистики индекса SQL Server и информации об использовании |
| Поддержка индексов SQL Server |
| 25 самых популярных вопросов и ответов на собеседованиях об индексах SQL Server |
- Автор
- Последние сообщения
Ахмад Ясин
Ахмад Ясин — инженер Microsoft по работе с большими данными, обладающий глубокими знаниями и опытом в области SQL BI, администрирования и разработки баз данных SQL Server.