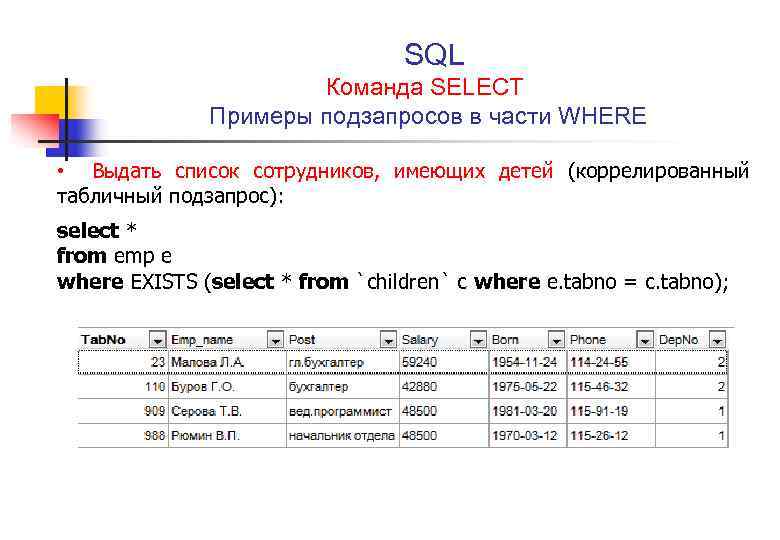
Количество символов в поле sql: Функция LENGTH — подсчет количества символов
Содержание
Выборка определенного количества символов в SQL запросе
← →
Константин_
(2006-07-26 10:30)
[0]
Как выбрать определенное количество символов в sql запросе начиная с конца поля, например «123456» > «3456»
С уважением.
← →
ЮЮ ©
(2006-07-26 10:40)
[1]
В MS SQL: RIGHT(<строка>, <количество>)
У других серверов, наверняка, что-то найдется подобное.
В стандарте, имхо, такого нет. Лишь SUBSTRING, т.е. подйдет, если количество симолов в значениях поля одинаковое и известное
← →
Константин_
(2006-07-26 11:03)
[2]
select cast(dogovor as char(3)) from pred. dbf where cast(dogovor as int)>1000
dbf where cast(dogovor as int)>1000
В таком запросе получается выборка 3 символов с начала строки, а может его можно как то изменить?
← →
Desdechado ©
(2006-07-26 11:31)
[3]
Видимо, намек указать СУБД не понят.
← →
ЮЮ ©
(2006-07-26 11:35)
[4]
БД какая?
В таком запросе получается выборка 3 символов с начала строки, а может его можно как то изменить?
С начал строки, естественно, проблем нет, коль есть Substring()
← →
Константин_
(2006-07-26 11:47)
[5]
выборка производиться из талицы DBase IV при помощи компонента Query
← →
ЮЮ ©
(2006-07-26 11:48)
[6]
SELECT dogovor from pred. dbf where cast(dogovor as int) < 10000
dbf where cast(dogovor as int) < 10000
/* 1 — 4х значные*.
UNION ALL
SELECT Substring(dogovor from 2 for 4) FROM pred.dbf
where cast(dogovor as int) BETWEEN 10000 AND 99999
/* для 5-начных*/
UNION ALL
… и так далее
З.Ы. зачем такие важные последнии символа слис со столь маловажными первыми в одом поле? Раздели, пока не поздно
← →
ЮЮ ©
(2006-07-26 11:50)
[7]
З.Ы. Как будешь различать договора 123456 и 213456 после такого запроса?
← →
Константин_
(2006-07-26 11:52)
[8]
Работа ведеться с водомерным счетчиком, а у него есть такая особенность перекручиваться… очень не хорошая.
Спасибо за помощь.
← →
Константин_
(2006-07-26 11:53)
[9]
Поля договор взял из др. базы, что бы попробовать запрос… водомеров под рукой нет
базы, что бы попробовать запрос… водомеров под рукой нет
← →
ЮЮ ©
(2006-07-26 12:01)
[10]
> а у него есть такая особенность перекручиваться… очень
> не хорошая.
У него наверное всего 4 числа то и есть и для него естественно «перекручиваться», а вот откуда в базе появляются неестественные 5-е цифры?
← →
Константин_
(2006-07-26 12:04)
[11]
начальные показания 9985 последние показания 0010 в баз 10010
← →
ЮЮ ©
(2006-07-26 12:20)
[12]
Ну и откуда эта 1 в базе?
следующее показание будет 0100, а у тебя уже предыдущее 10010. Опять перекрутка нужна? Или пририсовка?
Опять перекрутка нужна? Или пририсовка?
Может лучше оставлять как есть 0010?
А при расчетах учитывать возможность «перекрутки»
← →
Константин_
(2006-07-26 12:26)
[13]
Можно было бы оставить… но прога уже в эксплуатации… недоглядел, теперь мучаюсь
REGEXP_COUNT ФУНКЦИЯ — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать функцию REGEXP_COUNT Oracle/PLSQL с синтаксисом и примерами.
Описание
Функция Oracle/PLSQL REGEXP_COUNT подсчитывает количество вхождений шаблона в строку. Эта функция, введенная в Oracle 11g, позволит вам подсчитать количество раз, когда подстрока встречается в строке с использованием сопоставления шаблонов регулярных выражений.
Синтаксис
Синтаксис функции Oracle/PLSQL REGEXP_COUNT:
REGEXP_COUNT( string, pattern [, start_position [, atch_parameter ] ] )
Параметры или аргументы
string
Строка для поиска. ]
]
start_position
Необязательный. Это позиция в строке, откуда начнется поиск.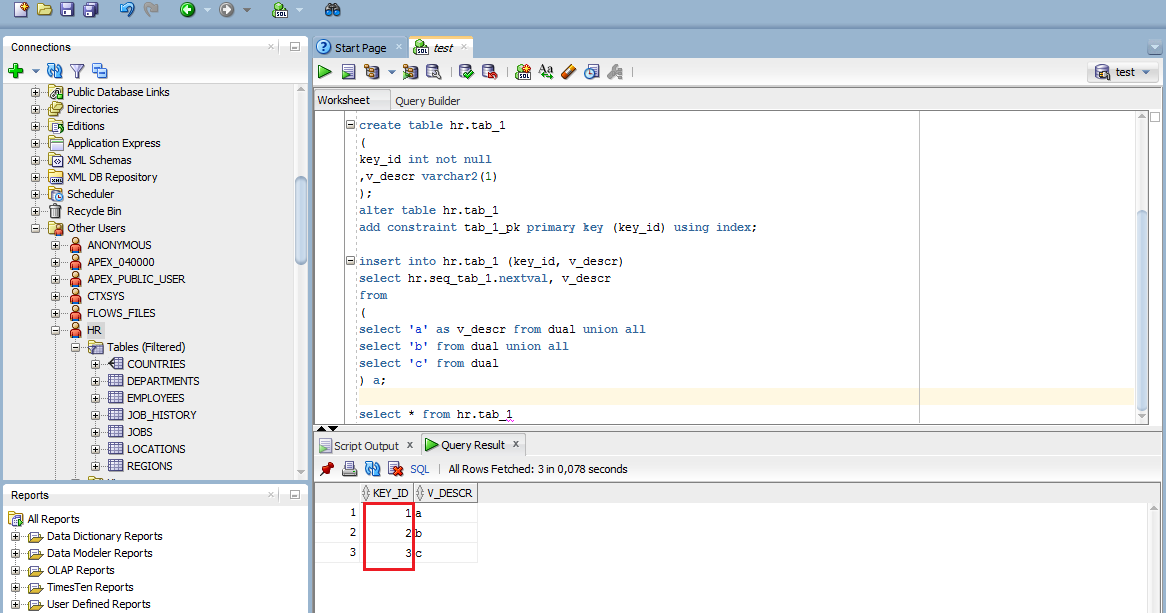 это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. По умолчанию предполагается, что выражение в одной строке.
это начало строки, а $ это конец строки, независимо от позиции этих символов в выражении. По умолчанию предполагается, что выражение в одной строке.
Функция REGEXP_COUNT возвращает числовое значение.
Примечание
- Если для параметра match_parameter имеются конфликтующие значения, функция REGEXP_COUNT будет использовать последнее значение.
- Если функция REGEXP_COUNT не обнаруживает какого-либо вхождение шаблона, она вернет 0.
Применение
Функцию REGEXP_COUNT можно использовать в следующих версиях Oracle / PLSQL:
- Oracle 12c, Oracle 11g
Пример совпадения единичного символа
Рассмотрим простейший пример. Давайте посчитаем, сколько раз символ ‘a’ появляется в строке.
Например:
Oracle PL/SQL
SELECT REGEXP_COUNT (‘Aller Anfang ist schwer’, ‘a’)
FROM dual;
—Результат: 1
|
| SELECT REGEXP_COUNT (‘Aller Anfang ist schwer’, ‘a’) FROM dual;
—Результат: 1 |
Этот пример вернет 1, потому что он подсчитывает количество вхождений ‘a’ в строке. Так как мы не указали значение match_parameter, то функция REGEXP_COUNT выполнит поиск с учетом регистра, что означает, что символ ‘A’ не будет включен в счет.
Так как мы не указали значение match_parameter, то функция REGEXP_COUNT выполнит поиск с учетом регистра, что означает, что символ ‘A’ не будет включен в счет.
Если бы мы хотели включить в наш результат как ‘a’, так и ‘A’, и выполнить поиск без учета регистра, то изменим наш запрос следующим образом:
Oracle PL/SQL
SELECT REGEXP_COUNT (‘Aller Anfang ist schwer’, ‘a’, 1, ‘i’)
FROM dual;
—Результат: 3
|
| SELECT REGEXP_COUNT (‘Aller Anfang ist schwer’, ‘a’, 1, ‘i’) FROM dual;
—Результат: 3 |
Теперь, поскольку мы предоставили start_position = 1 и match_parameter = ‘i’, то запрос в качестве результата вернет 3. На этот раз значения ‘a’ и ‘A’ будут включены в счет.
Если бы мы хотели подсчитать количество ‘a’ в столбце, мы могли бы попробовать что-то вроде этого:
Oracle PL/SQL
SELECT REGEXP_COUNT (last_name, ‘a’, 1, ‘i’) AS total
FROM contacts;
|
| SELECT REGEXP_COUNT (last_name, ‘a’, 1, ‘i’) AS total FROM contacts; |
Этот запрос будет подсчитывать количество значений ‘a’ или ‘A’ в поле last_name из таблицы contacts.
Пример совпадения нескольких символов
Рассмотрим, как мы будем использовать функцию REGEXP_COUNT для соответствия многосимвольному шаблону.
Например:
Oracle PL/SQL
SELECT REGEXP_COUNT (‘Gute Saat, gute Ernte’, ‘gute’, 1, ‘i’)
FROM dual;
—Результат: 2
|
| SELECT REGEXP_COUNT (‘Gute Saat, gute Ernte’, ‘gute’, 1, ‘i’) FROM dual;
—Результат: 2 |
В этом примере будет возвращено количество раз, когда в строке появляется слово ‘gute’. Поиск выполняется без учета регистра, поэтому в результате 2 вхождения.
Oracle PL/SQL
SELECT REGEXP_COUNT (‘Gute Saat, gute Ernte’, ‘gute’, 5, ‘i’)
FROM dual;
—Результат: 1
|
| SELECT REGEXP_COUNT (‘Gute Saat, gute Ernte’, ‘gute’, 5, ‘i’) FROM dual;
—Результат: 1 |
В этом примере будет возвращено количество раз, когда слово ‘gute’ появляется в строке, начиная с позиции 5. В этом случае результат = 1, потому что перед поиском шаблона он пропустит первые 4 символа в строке.
В этом случае результат = 1, потому что перед поиском шаблона он пропустит первые 4 символа в строке.
Теперь давайте посмотрим, как мы будем использовать функцию REGEXP_COUNT со столбцом таблицы и искать несколько символов.
Например:
Oracle PL/SQL
SELECT REGEXP_COUNT (other_comments, ‘the’, 1, ‘i’)
FROM contacts;
—Результат: 3
|
| SELECT REGEXP_COUNT (other_comments, ‘the’, 1, ‘i’) FROM contacts;
—Результат: 3 |
В этом примере мы будем подсчитывать количество появления «the» в поле other_comments в таблице contacts.
Пример сопоставления нескольких альтернатив.
Следующий пример, который мы рассмотрим, включает использование | pattern. | pattern используется как «ИЛИ», чтобы указать несколько альтернатив.
Например:
Oracle PL/SQL
SELECT REGEXP_COUNT (‘AeroSmith’, ‘a|e|i|o|u’)
FROM dual;
—Результат: 3
|
| SELECT REGEXP_COUNT (‘AeroSmith’, ‘a|e|i|o|u’) FROM dual;
—Результат: 3 |
Этот пример вернет 3, потому что он подсчитывает количество гласных (a, e, i, o или u) в строке ‘AeroSmith’. Поскольку мы не указали значение match_parameter, функция REGEXP_COUNT будет выполнять поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ не будет считаться.
Поскольку мы не указали значение match_parameter, функция REGEXP_COUNT будет выполнять поиск с учетом регистра, что означает, что ‘A’ в ‘AeroSmith’ не будет считаться.
Мы могли бы изменить наш запрос следующим образом, чтобы выполнить поиск без учета регистра следующим образом:
Oracle PL/SQL
SELECT REGEXP_COUNT (‘AeroSmith’, ‘a|e|i|o|u’, 1, ‘i’)
FROM dual;
—Результат: 4
|
| SELECT REGEXP_COUNT (‘AeroSmith’, ‘a|e|i|o|u’, 1, ‘i’) FROM dual;
—Результат: 4 |
Теперь, поскольку мы указали start_position = 1 и match_parameter = ‘i’, запрос вернет в качестве результата 4. На этот раз ‘A’ в ‘AeroSmith’ будет включена в счет.
Теперь давайте посмотрим, как мы будем использовать эту функцию со столбцом.
Итак, допустим, у нас есть таблица контактов со следующими данными:
| contact_id | last_name |
|---|---|
| 1000 | AeroSmith |
| 2000 | Joy |
| 3000 | Scorpions |
Теперь давайте запустим следующий запрос:
Oracle PL/SQL
SELECT contact_id, last_name, REGEXP_COUNT (last_name, ‘a|e|i|o|u’, 1, ‘i’) AS total
FROM contacts;
|
| SELECT contact_id, last_name, REGEXP_COUNT (last_name, ‘a|e|i|o|u’, 1, ‘i’) AS total FROM contacts; |
Результаты, которые будут возвращены запросом:
| contact_id | last_name | total |
|---|---|---|
| 1000 | AeroSmith | 4 |
| 2000 | Joy | 1 |
| 3000 | Scorpions | 3 |
sql — подсчитать количество символов в столбце nvarchar
спросил
Изменено
2 года, 1 месяц назад
Просмотрено
276 тысяч раз
Кто-нибудь знает хороший способ подсчета символов в текстовом столбце (nvarchar) на сервере Sql?
Значения могут быть текстом, символами и/или числами.
До сих пор я использовал sum(datalength(column))/2 , но это работает только для текста. (это метод, основанный на длине данных, и он может варьироваться от типа к другому).
- sql
- sql-server-2008
- длина данных
2
Количество символов можно узнать с помощью системной функции LEN .
т. е.
ВЫБРАТЬ ДЛИН(Столбец) ИЗ ТАБЛИЦЫ
8
Использовать
SELECT length(yourfield) FROM table;
1
Используйте функцию LEN :
Возвращает количество символов указанного строкового выражения, исключая конечные пробелы.
SELECT LEN(имя_столбца) не работает?
0
текст не работает с функцией len.
Типы данных ntext, text и image будут удалены в будущей версии.
Microsoft SQL Server. Избегайте использования этих типов данных в новых
разработка и план изменения приложений, которые в настоящее время используют
их. Вместо этого используйте nvarchar(max), varchar(max) и varbinary(max). Для
дополнительные сведения см. в разделе Использование типов данных с большими значениями.
Источник
Недавно у меня была аналогичная проблема, и вот что я сделал:
SELECT
имя столбца как «Исходное_значение»,
LEN(LTRIM(имя столбца)) как 'Orig_Val_Char_Count',
N'['+имя столбца+']' как 'UnicodeStr_Value',
LEN(N'['+имя_столбца+']')-2 как 'True_Char_Count'
ОТ моей таблицы
В первых двух столбцах рассматривается исходное значение и подсчитываются символы (минус начальные/конечные пробелы).
Мне нужно было сравнить это с истинным количеством символов, поэтому я использовал вторую функцию ДЛСТР. Он устанавливает значение столбца в строку, переводит эту строку в Юникод, а затем подсчитывает символы.
Он устанавливает значение столбца в строку, переводит эту строку в Юникод, а затем подсчитывает символы.
Используя квадратные скобки, вы гарантируете, что любые начальные или конечные пробелы также считаются символами; конечно, вы не хотите считать сами скобки, поэтому вы вычитаете 2 в конце.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Обязательно, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Подсчет вхождений строк в SQL
Подсчет вхождений строк в SQL
5 июня 2020 г. by Robert Gravelle работа со строковыми данными. Их можно использовать для удаления лишних пробелов или символов, определения длины строки и объединения нескольких значений полей. Со строковыми функциями стоит познакомиться, поскольку они могут помочь сделать ваш код более эффективным и читабельным. В сегодняшнем блоге мы узнаем, как подсчитать количество вхождений строки в char, varchar или текстовом поле, используя пару собственных строковых функций SQL.
by Robert Gravelle работа со строковыми данными. Их можно использовать для удаления лишних пробелов или символов, определения длины строки и объединения нескольких значений полей. Со строковыми функциями стоит познакомиться, поскольку они могут помочь сделать ваш код более эффективным и читабельным. В сегодняшнем блоге мы узнаем, как подсчитать количество вхождений строки в char, varchar или текстовом поле, используя пару собственных строковых функций SQL.
Сегодня мы будем использовать две функции: LENGTH(str) и REPLACE(str, from_str, to_str). LENGTH() возвращает длину строки в байтах; REPLACE() возвращает строку str, в которой все вхождения строки from_str заменены строкой to_str, выполняя сопоставление с учетом регистра.
Функция ДЛИНА() возвращает длину строки в байтах. Это имеет некоторые важные последствия, поскольку это означает, что для строки, содержащей пять 2-байтовых символов, LENGTH() возвращает 10. Чтобы подсчитать прямые символы, используйте вместо этого функцию CHAR_LENGTH().
Вот пример:
Вот пример функции REPLACE(), которая изменяет протокол URL-адреса с «http» на «https»:
Комбинируя LENGTH() и REPLACE() с функцией ROUND() , мы можем получить количество определенной подстроки в поле, содержащем текстовое содержимое. Вот пример использования базы данных Sakila Sample, которая возвращает количество слов «Документальный» в поле описания таблицы фильмов:
По сути, наш запрос заменяет вхождения целевой подстроки пустой («») строкой. и сравнивает полученные длины строк. Разница между ними заключается в количестве вхождений подстроки в поле источника.
Если вы планируете выполнять подсчет слов во многих разных таблицах или использовать различные значения подстрок, вам следует подумать о включении основного вычисления в пользовательскую функцию пользователя. Вот функция с именем count_string_instances, которую я создал в Navicat:
Тестирование функции
Мы можем протестировать нашу функцию на месте, нажав кнопку Выполнить .