Microsoft sql server 2018: купить лицензию по выгодной цене на официальном сайте Softline
Содержание
SPBDEV Blog — Знакомство с кластерами больших данных Microsoft SQL Server 2019
Tags:
Big Data, cluster, SQL Server 2019, Microsoft, Azure, Кластер, большие данные
Wednesday, October 31, 2018 5:07:00 PM
Недавно на конференции Microsoft Ignite было объявлено, что SQL Server 2019 теперь находится в предварительном просмотре и что SQL Server 2019 будет включать Apache Spark и распределенную файловую систему Hadoop (HDFS) для масштабируемого вычисления и хранения. Эта новая архитектура, которая объединяет механизм базы данных SQL Server, Spark и HDFS в единую платформу данных, называется кластером больших данных — «big data cluster».
В течение 25 лет Microsoft SQL Server приводил в действие организации, основанные на данных. По мере роста разнообразия типов данных и объема этих данных число типов баз данных резко возросло. На протяжении многих лет SQL Server не отставал, добавляя поддержку данных XML, JSON, in-memory и graph в базе данных. Он стал гибким механизмом базы данных, на который предприятия могут рассчитывать для получения ведущих в отрасли производительности, высокую доступности и безопасности. Тем не менее, один экземпляр SQL Server никогда не был спроектирован или создан как механизм базы данных для аналитики в масштабе петабайтов или экзабайтов. Он также не был предназначен для масштабирования вычислений для обработки данных или машинного обучения, а также для хранения и анализа данных в неструктурированных форматах, таких как медиафайлы.
Он стал гибким механизмом базы данных, на который предприятия могут рассчитывать для получения ведущих в отрасли производительности, высокую доступности и безопасности. Тем не менее, один экземпляр SQL Server никогда не был спроектирован или создан как механизм базы данных для аналитики в масштабе петабайтов или экзабайтов. Он также не был предназначен для масштабирования вычислений для обработки данных или машинного обучения, а также для хранения и анализа данных в неструктурированных форматах, таких как медиафайлы.
Предварительный просмотр SQL Server 2019 расширяет свою унифицированную платформу данных для охвата больших и неструктурированных данных путем развертывания нескольких экземпляров SQL Server вместе с Spark и HDFS в качестве кластера больших данных.
Когда Microsoft добавила поддержку Linux в SQL Server 2017, она открыла возможность глубокой интеграции SQL Server с Spark, HDFS и другими крупными компонентами данных, которые в основном базируются на Linux. Кластеры больших данных SQL Server 2019 переходят на следующую ступень, полностью охватывая современную архитектуру развертывания приложений — даже с точки зрения состояния, таких как база данных, — как контейнеры на Kubernetes. Развертывание больших кластеров данных SQL Server 2019 на Kubernetes обеспечивает предсказуемое, быстрое и эластично масштабируемое развертывание независимо от того, где оно развертывается. Кластеры больших данных могут быть развернуты в любом облаке, где есть управляемая служба Kubernetes, такая как Azure Kubernetes Service (AKS) или в локальных кластерах Kubernetes, таких как AKS на стек Azure. Встроенные службы управления в большом кластере данных обеспечивают анализ журналов, мониторинг, резервное копирование и высокую доступность через портал администратора, обеспечивая постоянный опыт управления везде, где развертывается большой кластер данных.
Кластеры больших данных SQL Server 2019 переходят на следующую ступень, полностью охватывая современную архитектуру развертывания приложений — даже с точки зрения состояния, таких как база данных, — как контейнеры на Kubernetes. Развертывание больших кластеров данных SQL Server 2019 на Kubernetes обеспечивает предсказуемое, быстрое и эластично масштабируемое развертывание независимо от того, где оно развертывается. Кластеры больших данных могут быть развернуты в любом облаке, где есть управляемая служба Kubernetes, такая как Azure Kubernetes Service (AKS) или в локальных кластерах Kubernetes, таких как AKS на стек Azure. Встроенные службы управления в большом кластере данных обеспечивают анализ журналов, мониторинг, резервное копирование и высокую доступность через портал администратора, обеспечивая постоянный опыт управления везде, где развертывается большой кластер данных.
Механизм реляционной базы данных SQL Server 2019 в кластере больших данных использует эластично масштабируемый уровень хранения, который объединяет SQL Server и HDFS для масштабирования до петабайт хранения данных. Механизм Spark, который теперь является частью SQL Server, позволяет инженерам и ученым по данным использовать возможности библиотек для подготовки данных с открытым исходным кодом и библиотек запросов для обработки и анализа данных большого объема в масштабируемом распределенном внутрипамятном уровне вычисления.
Механизм Spark, который теперь является частью SQL Server, позволяет инженерам и ученым по данным использовать возможности библиотек для подготовки данных с открытым исходным кодом и библиотек запросов для обработки и анализа данных большого объема в масштабируемом распределенном внутрипамятном уровне вычисления.
Рисунок 1: SQL Server и Spark развернуты вместе с HDFS, создавая общее озеро данных
Интеграция данных посредством виртуализации данных
Хотя извлечение, преобразование, загрузка (ETL) имеет свои варианты использования, альтернативой ETL является виртуализация данных, которая объединяет данные из разных источников, местоположений и форматов без репликации или перемещения данных для создания единого «виртуального» уровня данных , Виртуализация данных позволяет унифицировать службы данных для поддержки нескольких приложений и пользователей. Уровень виртуальных данных, иногда называемый центром данных, позволяет пользователям запрашивать данные из многих источников через единый унифицированный интерфейс. Доступ к чувствительным наборам данных можно контролировать из одного места. Задержки, присущие ETL, не должны применяться; данные всегда могут быть актуальными. Затраты на хранение и сложность управления данными сведены к минимуму.
Доступ к чувствительным наборам данных можно контролировать из одного места. Задержки, присущие ETL, не должны применяться; данные всегда могут быть актуальными. Затраты на хранение и сложность управления данными сведены к минимуму.
Кластеры больших данных SQL Server 2019 с улучшениями в PolyBase действуют как центр данных для интеграции структурированных и неструктурированных данных со всей совокупности данных — SQL Server, Azure SQL Database, Azure SQL Data Warehouse, Azure Cosmos DB, MySQL, PostgreSQL, MongoDB, Oracle, Teradata, HDFS и т. Д. — используя привычные рамки программирования и инструменты анализа данных.
Рисунок 2: Источники данных, которые могут быть интегрированы с помощью PolyBase в SQL Server 2019
В кластерах больших данных SQL Server 2019 механизм SQL Server получил возможность считывать файлы HDFS, такие как CSV и паркетные файлы, с помощью экземпляров SQL Server, размещенных на каждом узле данных HDFS, для фильтрации и агрегирования данных локально и параллельно через все узлы данных HDFS.
Производительность запросов PolyBase в кластерах больших данных SQL Server 2019 может быть дополнительно повышена путем распределения агрегации перекрестных разделов и перетасовки отфильтрованных результатов запроса для «вычисления пулов», состоящих из нескольких экземпляров SQL Server, которые работают вместе.
Когда вы объединяете расширенные соединители PolyBase с пулами данных кластеров больших данных SQL Server 2019, данные из внешних источников данных можно разделить и кэшировать по всем экземплярам SQL Server в пуле данных, создав «масштабируемую витрину данных». В этом пуле данных может быть более одного масштабируемой витрины данных, а в витрине данных можно комбинировать данные из нескольких внешних источников данных и таблиц, что упрощает интеграцию и кэширование комбинированных наборов данных из нескольких внешних источников.
Рисунок 3: Использование масштабируемого пула данных для кэширования данных из внешних источников данных для повышения производительности
Полная платформа ИИ, построенная на совместном озере данных с SQL Server, Spark и HDFS
Кластеры больших данных SQL Server 2019 упрощают объединение больших наборов данных к размерным данным, обычно хранящимся в реляционной базе данных предприятия, что облегчает людям и приложениям, использующим SQL Server, запрос больших данных. Значимость больших данных значительно возрастает, когда они находятся не только в руках ученых по данным и инженеров по большим данным, но также включены в отчеты, информационные панели и приложения. В то же время ученые по данным могут продолжать использовать большие инфраструктурные инструменты данных, а также использовать простой доступ в режиме реального времени к высокоценным данным в SQL Server, потому что все это часть единой интегрированной системы.
Значимость больших данных значительно возрастает, когда они находятся не только в руках ученых по данным и инженеров по большим данным, но также включены в отчеты, информационные панели и приложения. В то же время ученые по данным могут продолжать использовать большие инфраструктурные инструменты данных, а также использовать простой доступ в режиме реального времени к высокоценным данным в SQL Server, потому что все это часть единой интегрированной системы.
Рисунок 4: Масштабируемая архитектура вычислений и хранения в кластере большмх данных SQL Server 2019
Кластеры больших данных SQL Server 2019 обеспечивают полноту AI-платформы. Данные могут легко проглатываться через Spark Streaming или традиционные вставки SQL и сохраняться в HDFS, реляционных таблицах, графиках или JSON / XML. Данные могут быть подготовлены с использованием либо Spark-заданий, либо запросов Transact-SQL (T-SQL), и загружаться в учебные процедуры модели машинного обучения в любом экземпляре Spark или SQL Server с использованием различных языков программирования, включая Java, Python, R, и Scala. Полученные модели затем могут быть введены в действие в операциях пакетного подсчета в Spark, в хранимых процедурах T-SQL для подсчета в реальном времени или инкапсулированы в контейнеры REST API, размещенные в кластере больших данных.
Полученные модели затем могут быть введены в действие в операциях пакетного подсчета в Spark, в хранимых процедурах T-SQL для подсчета в реальном времени или инкапсулированы в контейнеры REST API, размещенные в кластере больших данных.
Кластеры больших данных SQL Server предоставляют все инструменты и системы для сбора, хранения и подготовки данных для анализа, а также для обучения моделей машинного обучения, хранения моделей и их практической реализации.
Данные можно использовать с помощью Spark Streaming, вставляя данные непосредственно в HDFS через API HDFS или вставляя данные в SQL Server с помощью стандартных запросов на вставку T-SQL. Данные могут храниться в файлах в HDFS или разбиваться на разделы и храниться в пулах данных или сохраняться в главном экземпляре SQL Server в таблицах, графиках или JSON / XML. И T-SQL, и Spark можно использовать для подготовки данных путем запуска пакетных заданий для преобразования данных, их агрегации или выполнения других задач обработки данных.
Ученые по данным могут выбрать, использовать либо службы машинного обучения SQL Server в главном экземпляре для запуска сценариев обучения R, Python или Java, либо использовать Spark. В любом случае для обучения моделей можно использовать полную библиотеку библиотек обучения машин с открытым исходным кодом, таких как TensorFlow или Caffe.
Наконец, как только модели будут обучены, они могут быть задействованы в главном экземпляре SQL Server с использованием собственного скоринга в реальном времени с помощью функции PREDICT в хранимой процедуре в главном экземпляре SQL Server; или вы можете использовать пакетный подсчет по данным в HDFS с помощью Spark. В качестве альтернативы, используя инструменты, поставляемые с кластером больших данных, инженеры по данным могут легко обернуть модель в REST API и предоставить модель API + в качестве контейнера на большом кластере данных в качестве скорингового микросервиса для легкой интеграции в любое приложение.
Важно отметить, что весь этот конвейер происходит в контексте кластера больших данных SQL Server.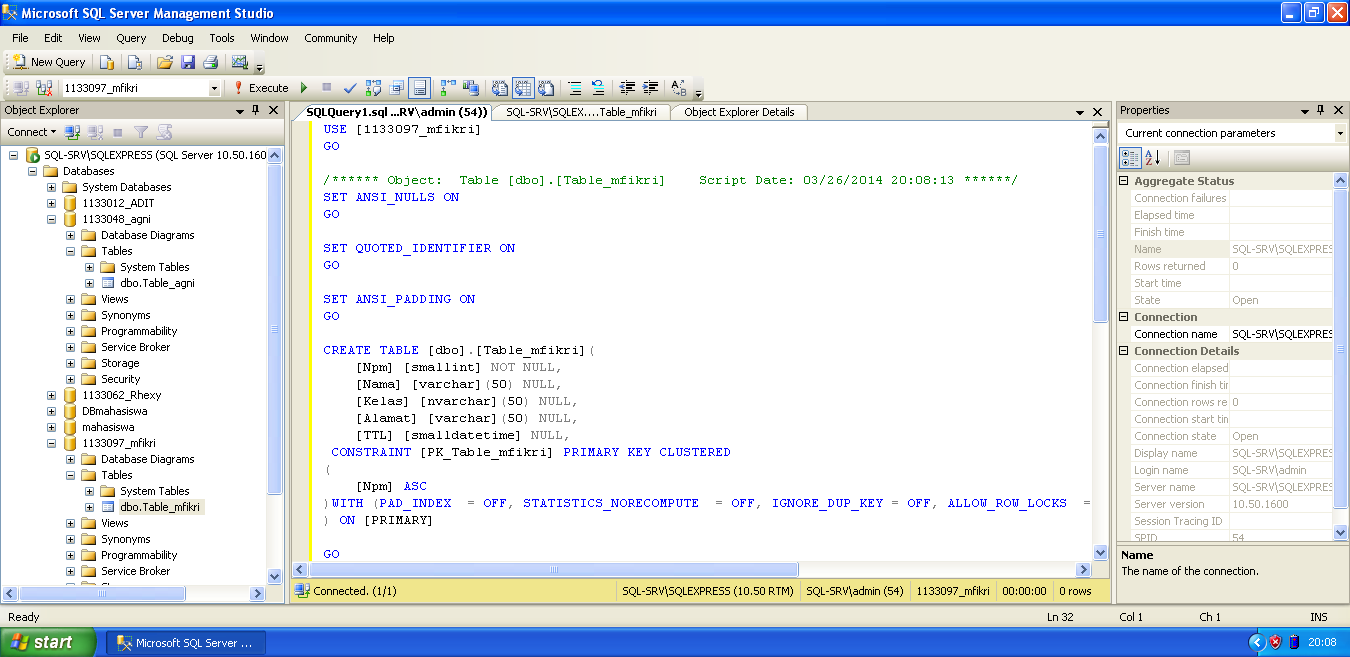 Данные никогда не покидают границы безопасности и соответствия требованиям для перехода на внешний сервер машинного обучения или компьютера ученого по данным. Для обработки данных доступна полная мощность аппаратного обеспечения, лежащего в основе кластера больших данных, и вычислительные ресурсы могут быть эластично масштабированы вверх и вниз по мере необходимости.
Данные никогда не покидают границы безопасности и соответствия требованиям для перехода на внешний сервер машинного обучения или компьютера ученого по данным. Для обработки данных доступна полная мощность аппаратного обеспечения, лежащего в основе кластера больших данных, и вычислительные ресурсы могут быть эластично масштабированы вверх и вниз по мере необходимости.
Azure Data Studio — инструмент для управления и анализа данных с открытым исходным кодом, предназначенный для администраторов баз данных, ученых и инженеров по данным. Новые расширения для Azure Data Studio интегрируют пользовательский интерфейс для работы с реляционными данными в SQL Server с большими данными. Новый браузер HDFS позволяет аналитикам, ученым и инженерам по данным легко просматривать файлы и каталоги HDFS в кластере больших данных, загружать или выгружать файлы, открывать их и удалять, если необходимо. Новые встроенные блокноты в Azure Data Studio построены на Jupyter, позволяя ученым и инженерам данных писать код Python, R или Scala с подсветкой Intellisense и синтаксисом перед отправкой кода в виде заданий Spark и просмотра результатов inline. Блокноты обеспечивают совместную работу между членами команды проекта анализа данных. Наконец, мастер внешних таблиц упрощает процесс создания внешних источников данных и таблиц, включая сопоставления столбцов.
Блокноты обеспечивают совместную работу между членами команды проекта анализа данных. Наконец, мастер внешних таблиц упрощает процесс создания внешних источников данных и таблиц, включая сопоставления столбцов.
Заключение
Кластеры больших данных SQL Server 2019 — это непревзойденный новый способ использования SQL Server для создания высокоценных реляционных данных и объемных больших данных на единой масштабируемой платформе данных. Предприятия могут использовать возможности PolyBase для виртуализации своих хранилищ данных, создания озер данных и создания масштабируемых витрин данных в единой безопасной среде без необходимости внедрения медленных дорогостоящих ETL-конвейеров. Это делает приложения и анализ данных лучше реагирующими и более продуктивными. Большие кластеры данных SQL Server 2019 предоставляют полную платформу AI для доставки интеллектуальных приложений, которые помогают сделать любую организацию более успешной.
Microsoft SQL Server 2012.
 Руководство для начинающих
Руководство для начинающих
Нет в наличии
Петкович Душан
| Артикул | 2207 |
| ISBN | 978-5-9775-0854-4 |
| Количество страниц | 816 |
| Формат издания | 170 x 240 мм |
| Печать | Черно-белая |
| Серия | Внесерийные книги |
819 ₽
# Microsoft# MS# services# базы данных
- Описание
- Детали
- Отзывы (0)
Описание
Просто и доступно рассмотрены теоретические основы СУБД SQL Server 2012. Показана установка, конфигурирование и поддержка MS SQL Server 2012. Описан язык манипулирования данными Transact-SQL. Рассмотрены создание базы данных, изменение таблиц и их содержимого, запросы, индексы, представления, триггеры, хранимые процедуры и функции, определенные пользователем. Показана реализация безопасности с использованием аутентификации, шифрования и авторизации. Уделено внимание автоматизации задач администрирования СУБД. Рассмотрено создание резервных копий данных и выполнение восстановления системы. Описаны службы Microsoft Analysis Services, Microsoft Reporting Services и другие инструменты для бизнес-анализа. Рассмотрены технология работы с документами XML, управление пространственными данными, полнотекстовый поиск и многое другое….
Показана реализация безопасности с использованием аутентификации, шифрования и авторизации. Уделено внимание автоматизации задач администрирования СУБД. Рассмотрено создание резервных копий данных и выполнение восстановления системы. Описаны службы Microsoft Analysis Services, Microsoft Reporting Services и другие инструменты для бизнес-анализа. Рассмотрены технология работы с документами XML, управление пространственными данными, полнотекстовый поиск и многое другое….
Детали
| Артикул | 2207 |
|---|---|
| ISBN | 978-5-9775-0854-4 |
| Количество страниц | 816 |
| Серия | Внесерийные книги |
| Переплет | Мягкая обложка |
| Печать | Черно-белая |
| Год | 2014 |
| Габариты, мм | 240 × 170 × 38 |
| Вес, кг | 0.914 |
- ✓ Новинки на 2 недели раньше магазинов
- ✓ Цены от издательства ниже до 30%
- ✓ Акции и скидки только для подписчиков
- ✓ Важные новости БХВ
ПОЛЕЗНАЯ РАССЫЛКА КНИЖНЫХ НОВОСТЕЙ
Подписываясь на рассылку, вы соглашаетесь с политикой конфиденциальности и обработкой своих персональных данных.
Рекомендуем также
-
Microsoft SQL Server 2008: Data Mining – интеллектуальный анализ данных – Бумажная книга
603₽
-
Microsoft SQL Server 2005 Analysis Services. OLAP и многомерный анализ данных – Бумажная книга
861₽
- Бондарь Александр Григорьевич
Microsoft SQL Server 2012
741 ₽
630 ₽ -
Microsoft SQL Server 2008. Основы T-SQL – Бумажная книга
509₽
Шоколадное программное обеспечение | Microsoft SQL Server 2019 Developer Edition 15.0.2000.20210324
Требуется модуль Puppet Chocolatey Provider. См. документацию по адресу https://forge.puppet.com/puppetlabs/chocolatey.
## 1. ТРЕБОВАНИЯ ## ### Вот требования, необходимые для обеспечения успеха. ### а. Настройка внутреннего/частного облачного репозитория ### #### Вам понадобится внутренний/частный облачный репозиторий, который вы можете использовать.Это #### вообще очень быстро настраивается и вариантов довольно много. #### Chocolatey Software рекомендует Nexus, Artifactory Pro или ProGet, поскольку они #### являются серверами репозиториев и дают вам возможность управлять несколькими #### репозитории и типы с одной установки сервера. ### б. Загрузите пакет Chocolatey и поместите во внутренний репозиторий ### #### Вам также необходимо загрузить пакет Chocolatey. #### См. https://chocolatey.org/install#organization ### в. Другие требования ### #### я. Требуется модуль puppetlabs/chocolatey #### См. https://forge.puppet.com/puppetlabs/chocolatey ## 2. ПЕРЕМЕННЫЕ ВЕРХНЕГО УРОВНЯ ## ### а. URL вашего внутреннего репозитория (основной). ### #### Должно быть похоже на то, что вы видите при просмотре #### на https://community.chocolatey.org/api/v2/ $_repository_url = 'URL ВНУТРЕННЕГО РЕПО' ### б. URL-адрес загрузки шоколадного nupkg ### #### Этот URL-адрес должен привести к немедленной загрузке, когда вы перейдете к нему в #### веб-браузер $_choco_download_url = 'URL ВНУТРЕННЕГО РЕПО/package/chocolatey.
 Это
#### вообще очень быстро настраивается и вариантов довольно много.
#### Chocolatey Software рекомендует Nexus, Artifactory Pro или ProGet, поскольку они
#### являются серверами репозиториев и дают вам возможность управлять несколькими
#### репозитории и типы с одной установки сервера.
### б. Загрузите пакет Chocolatey и поместите во внутренний репозиторий ###
#### Вам также необходимо загрузить пакет Chocolatey.
#### См. https://chocolatey.org/install#organization
### в. Другие требования ###
#### я. Требуется модуль puppetlabs/chocolatey
#### См. https://forge.puppet.com/puppetlabs/chocolatey
## 2. ПЕРЕМЕННЫЕ ВЕРХНЕГО УРОВНЯ ##
### а. URL вашего внутреннего репозитория (основной). ###
#### Должно быть похоже на то, что вы видите при просмотре
#### на https://community.chocolatey.org/api/v2/
$_repository_url = 'URL ВНУТРЕННЕГО РЕПО'
### б. URL-адрес загрузки шоколадного nupkg ###
#### Этот URL-адрес должен привести к немедленной загрузке, когда вы перейдете к нему в
#### веб-браузер
$_choco_download_url = 'URL ВНУТРЕННЕГО РЕПО/package/chocolatey.
Это
#### вообще очень быстро настраивается и вариантов довольно много.
#### Chocolatey Software рекомендует Nexus, Artifactory Pro или ProGet, поскольку они
#### являются серверами репозиториев и дают вам возможность управлять несколькими
#### репозитории и типы с одной установки сервера.
### б. Загрузите пакет Chocolatey и поместите во внутренний репозиторий ###
#### Вам также необходимо загрузить пакет Chocolatey.
#### См. https://chocolatey.org/install#organization
### в. Другие требования ###
#### я. Требуется модуль puppetlabs/chocolatey
#### См. https://forge.puppet.com/puppetlabs/chocolatey
## 2. ПЕРЕМЕННЫЕ ВЕРХНЕГО УРОВНЯ ##
### а. URL вашего внутреннего репозитория (основной). ###
#### Должно быть похоже на то, что вы видите при просмотре
#### на https://community.chocolatey.org/api/v2/
$_repository_url = 'URL ВНУТРЕННЕГО РЕПО'
### б. URL-адрес загрузки шоколадного nupkg ###
#### Этот URL-адрес должен привести к немедленной загрузке, когда вы перейдете к нему в
#### веб-браузер
$_choco_download_url = 'URL ВНУТРЕННЕГО РЕПО/package/chocolatey. 2.1.0.nupkg'
### в. Центральное управление Chocolatey (CCM) ###
#### Если вы используете CCM для управления Chocolatey, добавьте следующее:
#### я. URL-адрес конечной точки для CCM
# $_chocolatey_central_management_url = 'https://chocolatey-central-management:24020/ChocolateyManagementService'
#### II. Если вы используете клиентскую соль, добавьте ее сюда.
# $_chocolatey_central_management_client_salt = "clientsalt"
#### III. Если вы используете служебную соль, добавьте ее здесь
# $_chocolatey_central_management_service_salt = 'сервисная соль'
## 3. УБЕДИТЕСЬ, ЧТО ШОКОЛАД УСТАНОВЛЕН ##
### Убедитесь, что Chocolatey установлен из вашего внутреннего репозитория
### Примечание: `chocolatey_download_url полностью отличается от обычного
### исходные местоположения. Это прямо к голому URL-адресу загрузки для
### Chocolatey.nupkg, похожий на то, что вы видите при просмотре
### https://community.chocolatey.org/api/v2/package/chocolatey
класс {'шоколад':
шоколадный_download_url => $_choco_download_url,
use_7zip => ложь,
}
## 4.
2.1.0.nupkg'
### в. Центральное управление Chocolatey (CCM) ###
#### Если вы используете CCM для управления Chocolatey, добавьте следующее:
#### я. URL-адрес конечной точки для CCM
# $_chocolatey_central_management_url = 'https://chocolatey-central-management:24020/ChocolateyManagementService'
#### II. Если вы используете клиентскую соль, добавьте ее сюда.
# $_chocolatey_central_management_client_salt = "clientsalt"
#### III. Если вы используете служебную соль, добавьте ее здесь
# $_chocolatey_central_management_service_salt = 'сервисная соль'
## 3. УБЕДИТЕСЬ, ЧТО ШОКОЛАД УСТАНОВЛЕН ##
### Убедитесь, что Chocolatey установлен из вашего внутреннего репозитория
### Примечание: `chocolatey_download_url полностью отличается от обычного
### исходные местоположения. Это прямо к голому URL-адресу загрузки для
### Chocolatey.nupkg, похожий на то, что вы видите при просмотре
### https://community.chocolatey.org/api/v2/package/chocolatey
класс {'шоколад':
шоколадный_download_url => $_choco_download_url,
use_7zip => ложь,
}
## 4. НАСТРОЙКА ШОКОЛАДНОЙ БАЗЫ ##
### а. Функция FIPS ###
#### Если вам нужно соответствие FIPS — сделайте это первым, что вы настроите
#### перед выполнением какой-либо дополнительной настройки или установки пакетов
#chocolateyfeature {'useFipsCompliantChecksums':
# убедиться => включено,
#}
### б. Применить рекомендуемую конфигурацию ###
#### Переместите расположение кеша, чтобы Chocolatey был очень детерминирован в отношении
#### очистка временных данных и доступ к локации для администраторов
шоколадный конфиг {'расположение кеша':
значение => 'C:\ProgramData\chocolatey\cache',
}
#### Увеличьте таймаут как минимум до 4 часов
шоколадный конфиг {'commandExecutionTimeoutSeconds':
значение => '14400',
}
#### Отключить прогресс загрузки при запуске choco через интеграции
Chocolateyfeature {'showDownloadProgress':
гарантировать => отключено,
}
### в. Источники ###
#### Удалить источник репозитория пакетов сообщества по умолчанию
Chocolateysource {'chocolatey':
гарантировать => отсутствует,
местоположение => 'https://community.
НАСТРОЙКА ШОКОЛАДНОЙ БАЗЫ ##
### а. Функция FIPS ###
#### Если вам нужно соответствие FIPS — сделайте это первым, что вы настроите
#### перед выполнением какой-либо дополнительной настройки или установки пакетов
#chocolateyfeature {'useFipsCompliantChecksums':
# убедиться => включено,
#}
### б. Применить рекомендуемую конфигурацию ###
#### Переместите расположение кеша, чтобы Chocolatey был очень детерминирован в отношении
#### очистка временных данных и доступ к локации для администраторов
шоколадный конфиг {'расположение кеша':
значение => 'C:\ProgramData\chocolatey\cache',
}
#### Увеличьте таймаут как минимум до 4 часов
шоколадный конфиг {'commandExecutionTimeoutSeconds':
значение => '14400',
}
#### Отключить прогресс загрузки при запуске choco через интеграции
Chocolateyfeature {'showDownloadProgress':
гарантировать => отключено,
}
### в. Источники ###
#### Удалить источник репозитория пакетов сообщества по умолчанию
Chocolateysource {'chocolatey':
гарантировать => отсутствует,
местоположение => 'https://community. Если у тебя когда-нибудь возникнут проблемы здесь,
## пароль - это GUID вашей лицензии.
Chocolateysource {'chocolatey.licensed':
гарантировать => отключено,
приоритет => '10',
пользователь => «клиент»,
пароль => '1234',
require => Package['chocolatey-license'],
}
### в. Убедитесь, что лицензионное расширение Chocolatey ###
#### Вы загрузили лицензионное расширение во внутренний репозиторий
####, так как вы отключили лицензированный репозиторий на шаге 5b.
#### Убедитесь, что у вас установлен пакет Chocolatey.extension (также известный как Лицензионное расширение Chocolatey)
пакет {'chocolatey.extension':
гарантировать => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
#### Лицензионное расширение Chocolatey открывает все перечисленные ниже возможности, для которых также доступны элементы конфигурации/функции. Вы можете посетить страницы функций, чтобы увидеть, что вы также можете включить:
#### - Конструктор пакетов - https://docs.
Если у тебя когда-нибудь возникнут проблемы здесь,
## пароль - это GUID вашей лицензии.
Chocolateysource {'chocolatey.licensed':
гарантировать => отключено,
приоритет => '10',
пользователь => «клиент»,
пароль => '1234',
require => Package['chocolatey-license'],
}
### в. Убедитесь, что лицензионное расширение Chocolatey ###
#### Вы загрузили лицензионное расширение во внутренний репозиторий
####, так как вы отключили лицензированный репозиторий на шаге 5b.
#### Убедитесь, что у вас установлен пакет Chocolatey.extension (также известный как Лицензионное расширение Chocolatey)
пакет {'chocolatey.extension':
гарантировать => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
#### Лицензионное расширение Chocolatey открывает все перечисленные ниже возможности, для которых также доступны элементы конфигурации/функции. Вы можете посетить страницы функций, чтобы увидеть, что вы также можете включить:
#### - Конструктор пакетов - https://docs. chocolatey.org/en-us/features/paid/package-builder
#### - Package Internalizer - https://docs.chocolatey.org/en-us/features/paid/package-internalizer
#### - Синхронизация пакетов (3 компонента) - https://docs.chocolatey.org/en-us/features/paid/package-synchronization
#### - Редуктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-reducer
#### - Аудит упаковки - https://docs.chocolatey.org/en-us/features/paid/package-audit
#### – пакетный дроссель – https://docs.chocolatey.org/en-us/features/paid/package-throttle
#### — Доступ к кэшу CDN — https://docs.chocolatey.org/en-us/features/paid/private-cdn
#### – Брендинг – https://docs.chocolatey.org/en-us/features/paid/branding
#### - Self-Service Anywhere (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.chocolatey.org/en-us/features/paid/self-service-anywhere
#### - Chocolatey Central Management (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.
chocolatey.org/en-us/features/paid/package-builder
#### - Package Internalizer - https://docs.chocolatey.org/en-us/features/paid/package-internalizer
#### - Синхронизация пакетов (3 компонента) - https://docs.chocolatey.org/en-us/features/paid/package-synchronization
#### - Редуктор пакетов - https://docs.chocolatey.org/en-us/features/paid/package-reducer
#### - Аудит упаковки - https://docs.chocolatey.org/en-us/features/paid/package-audit
#### – пакетный дроссель – https://docs.chocolatey.org/en-us/features/paid/package-throttle
#### — Доступ к кэшу CDN — https://docs.chocolatey.org/en-us/features/paid/private-cdn
#### – Брендинг – https://docs.chocolatey.org/en-us/features/paid/branding
#### - Self-Service Anywhere (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs.chocolatey.org/en-us/features/paid/self-service-anywhere
#### - Chocolatey Central Management (необходимо установить дополнительные компоненты и настроить дополнительную конфигурацию) - https://docs. chocolatey.org/en-us/features/paid/chocolatey-central-management
#### - Другое - https://docs.chocolatey.org/en-us/features/paid/
### д. Обеспечение самообслуживания в любом месте ###
#### Если у вас есть настольные клиенты, в которых пользователи не являются администраторами, вы можете
#### чтобы воспользоваться преимуществами развертывания и настройки самообслуживания в любом месте
Chocolateyfeature {'showNonElevatedWarnings':
гарантировать => отключено,
}
шоколадная функция {'useBackgroundService':
убедиться => включено,
}
Chocolateyfeature {'useBackgroundServiceWithNonAdministratorsOnly':
убедиться => включено,
}
Chocolateyfeature {'allowBackgroundServiceUninstallsFromUserInstallsOnly':
убедиться => включено,
}
шоколадный конфиг {'backgroundServiceAllowedCommands':
значение => 'установить,обновить,удалить',
}
### е. Убедитесь, что центральное управление Chocolatey ###
#### Если вы хотите управлять конечными точками и составлять отчеты, вы можете установить и настроить
### Центральное управление.
chocolatey.org/en-us/features/paid/chocolatey-central-management
#### - Другое - https://docs.chocolatey.org/en-us/features/paid/
### д. Обеспечение самообслуживания в любом месте ###
#### Если у вас есть настольные клиенты, в которых пользователи не являются администраторами, вы можете
#### чтобы воспользоваться преимуществами развертывания и настройки самообслуживания в любом месте
Chocolateyfeature {'showNonElevatedWarnings':
гарантировать => отключено,
}
шоколадная функция {'useBackgroundService':
убедиться => включено,
}
Chocolateyfeature {'useBackgroundServiceWithNonAdministratorsOnly':
убедиться => включено,
}
Chocolateyfeature {'allowBackgroundServiceUninstallsFromUserInstallsOnly':
убедиться => включено,
}
шоколадный конфиг {'backgroundServiceAllowedCommands':
значение => 'установить,обновить,удалить',
}
### е. Убедитесь, что центральное управление Chocolatey ###
#### Если вы хотите управлять конечными точками и составлять отчеты, вы можете установить и настроить
### Центральное управление. Есть несколько частей для управления, так что вы увидите
### здесь раздел об агентах вместе с примечаниями по настройке сервера
### боковые компоненты.
если $_chocolatey_central_management_url {
package {'шоколадный агент':
гарантировать => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
шоколадный конфиг {'CentralManagementServiceUrl':
значение => $_chocolatey_central_management_url,
}
если $_chocolatey_central_management_client_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
если $_chocolatey_central_management_service_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
Chocolateyfeature {'useChocolateyCentralManagement':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
Chocolateyfeature {'useChocolateyCentralManagementDeployments':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
}
Есть несколько частей для управления, так что вы увидите
### здесь раздел об агентах вместе с примечаниями по настройке сервера
### боковые компоненты.
если $_chocolatey_central_management_url {
package {'шоколадный агент':
гарантировать => последний,
провайдер => шоколадный,
источник => $_repository_url,
require => Package['chocolatey-license'],
}
шоколадный конфиг {'CentralManagementServiceUrl':
значение => $_chocolatey_central_management_url,
}
если $_chocolatey_central_management_client_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
если $_chocolatey_central_management_service_salt {
Chocolateyconfig {'centralManagementClientCommunicationSaltAdditivePassword':
значение => $_chocolatey_central_management_client_salt,
}
}
Chocolateyfeature {'useChocolateyCentralManagement':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
Chocolateyfeature {'useChocolateyCentralManagementDeployments':
убедиться => включено,
требуют => Пакет['шоколадный агент'],
}
}
Создание демонстрационной среды SQL Server 2019 в контейнере Docker
Опубликовано:
Последнее обновление:
Время чтения:
5 мин
Около месяца назад я узнал кое-что новое. Я узнал, как запустить SQL Server 2019 в Docker и как настроить демонстрационную среду в контейнере. Классная вещь! Мне нравятся киты. Киты крутые.
Пока я учился, я начал писать этот пост в блог. Потом я отвлекся и так и не закончил. На этих выходных мне пришлось снова настроить демо-среду. Это была прекрасная возможность обновить содержание и, наконец, опубликовать этот пост.
( Почему мне пришлось заново все настраивать? О, это длинная история, которая включает в себя очистку диска и Кэтрин, которая любит удалять что-то, чтобы содержать свой компьютер в чистоте. Ладно, это не очень длинная история. «Ой, я случайно удалил свой контейнер» )
«Ой, я случайно удалил свой контейнер» )
В любом случае! Вернемся к фактическому содержанию.
В этом посте я делюсь своим подходом и фрагментами кода для:
- Установка Docker
- Получение SQL Server 2019
- Запуск SQL Server 2019 в контейнере Docker
- Восстановление демонстрационных баз данных (AdventureWorks и WideWorldImporters)
Установка Docker
Месяц назад я ничего не знал о Docker или контейнерах. Но! Мне повезло, что у меня есть умные друзья 🤩 Эндрю Пруски (@dbafromthecold) написал Running SQL Server 2019CTP в контейнере Docker в рамках его блестящей серии сообщений в блоге о контейнерах.
Я решил начать с его прохождения и сделать именно то, что сделал он. Это сработало очень хорошо для меня! Смотрите ниже 👇🏻
Получение SQL Server 2019
После установки Docker извлеките образ SQL Server 2019, выполнив следующий код в PowerShell:
docker pull mcr.
Загрузка образа в основном означает загрузку всех файлов, необходимых для запуска контейнера. Вы можете думать об этом как о загрузке установочных файлов SQL Server.
Когда вы закончите извлекать образ, вы можете найти его в Docker:
Если вы хотите запустить другую версию SQL Server, вы можете найти список всех доступных образов на странице Microsoft SQL Server в Docker Hub. Вы также можете получить список изображений программно.
Запуск SQL Server 2019 в контейнере Docker
Когда я начал писать этот пост месяц назад, я подписался на пост в блоге Microsoft и скопировал файлы в свой контейнер. С тех пор я узнал несколько новых вещей. Теперь я запускаю свои контейнеры с привязкой монтирования ( общий диск ). Это означает, что у меня есть доступ к локальной папке на моем компьютере из контейнера докеров.
Сначала убедитесь, что общие диски включены в Docker:
Затем запустите контейнер, выполнив следующий код в PowerShell:
запуск докера ` --имя SQL19 ` -p 1433:1433 ` -e "ПРИНЯТЬ_EULA=Y" ` -e "SA_PASSWORD=" ` -v C:\Docker\SQL:/sql ` -d mcr.
 microsoft.com/mssql/server:2019-последняя
microsoft.com/mssql/server:2019-последняя
Я даю имя своему контейнеру SQL19 и указать, что я хочу сопоставить свою локальную папку C:\Docker\SQL с путем контейнера /sql . Дополнительные сведения о других параметрах см. в статье Microsoft «Начало работы».
Запуск контейнера аналогичен установке локального экземпляра SQL Server. Просто намного быстрее и проще 🥳
Наконец, убедитесь, что контейнер работает в Docker:
Или выполнив следующий код в PowerShell:
докер пс-а
ps обозначает Состояние процесса , а -a покажет все процессы независимо от статуса. Если контейнер не запущен, его необходимо (пере)запустить:
запуск докера SQL19
Теперь вы можете подключиться из SQL Server Management Studio (SSMS) к вашему контейнеру как SA , используя свой
Если вы указали другой порт при запуске контейнера, вам придется подключиться, используя номер порта, например локальный хост, 1401
Восстановление демонстрационных баз данных
Я уже загрузил BAK-файлы AdventureWorks и WideWorldImporters в свою папку C:\Docker\SQL\Backup .![]()
Если вы откроете «Восстановить базу данных» из SQL Server Management Studio (SSMS) и перейдете к «Найти файл резервной копии», вы увидите путь /var/opt/mssql/data :
.
Теперь… Вот тут я запутался. Текущий путь использует прямую косую черту. Когда я запускал контейнер, я также сопоставлял свою локальную папку C:\Docker\SQL на путь контейнера /sql . Мне было логично попробовать /sql :
Нет! Нет не могу. Вы должны использовать \sql :
Понятия не имею почему, и я так и не понял, ошибка это или так задумано. ( Знаете ли вы? Пожалуйста, прокомментируйте! ) Я могу только предположить, что, поскольку SSMS является приложением Windows, оно использует пути Windows (с обратной косой чертой), хотя показывает пути Linux (с прямой косой чертой).
В любом случае! Выберите файл .bak…
…ааааа и УСПЕХА! 😀
Ура! Демонстрационная база данных WideWorldImporters теперь восстановлена в SQL Server 2019, работающем в контейнере Docker:
.
Насколько это круто? Просто повторите процесс для всех оставшихся баз данных. Миссия выполнена 🤓
Сценарий восстановления демонстрационных баз данных
Если вы делаете это чаще, чем несколько раз в год, обязательно автоматизируйте процесс восстановления с помощью T-SQL или PowerShell! Я использую следующий стандартный скрипт:
ИСПОЛЬЗОВАНИЕ [мастер];
ИДТИ
ВОССТАНОВИТЬ БАЗУ ДАННЫХ [AdventureWorks]
С ДИСКА = N'/sql/Backups/AdventureWorks2017.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'AdventureWorks2017' В N'/var/opt/mssql/data/AdventureWorks.mdf',
ПЕРЕМЕСТИТЕ N'AdventureWorks2017_log' В N'/var/opt/mssql/data/AdventureWorks_log.ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВИТЬ БАЗУ ДАННЫХ [AdventureWorksDW]
FROM DISK = N'/sql/Backups/AdventureWorksDW2017.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'AdventureWorksDW2017' В N'/var/opt/mssql/data/AdventureWorksDW.mdf',
ПЕРЕМЕСТИТЕ N'AdventureWorksDW2017_log' В N'/var/opt/mssql/data/AdventureWorksDW_log. ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВИТЬ БАЗУ ДАННЫХ [AdventureWorksLT]
С ДИСКА = N'/sql/Backups/AdventureWorksLT2017.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Data' В N'/var/opt/mssql/data/AdventureWorksLT.mdf',
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Log' В N'/var/opt/mssql/data/AdventureWorksLT_log.ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImportersDW]
FROM DISK = N'/sql/Backups/WideWorldImportersDW-Full.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImportersDW.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImportersDW_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImportersDW.ldf',
ПЕРЕМЕСТИТЕ N'WWIDW_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImportersDW_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImporters]
FROM DISK = N'/sql/Backups/WideWorldImporters-Full. bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImporters.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImporters_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImporters.ldf',
ПЕРЕМЕСТИТЬ N'WWI_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
 ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВИТЬ БАЗУ ДАННЫХ [AdventureWorksLT]
С ДИСКА = N'/sql/Backups/AdventureWorksLT2017.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Data' В N'/var/opt/mssql/data/AdventureWorksLT.mdf',
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Log' В N'/var/opt/mssql/data/AdventureWorksLT_log.ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImportersDW]
FROM DISK = N'/sql/Backups/WideWorldImportersDW-Full.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImportersDW.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImportersDW_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImportersDW.ldf',
ПЕРЕМЕСТИТЕ N'WWIDW_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImportersDW_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImporters]
FROM DISK = N'/sql/Backups/WideWorldImporters-Full.
ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВИТЬ БАЗУ ДАННЫХ [AdventureWorksLT]
С ДИСКА = N'/sql/Backups/AdventureWorksLT2017.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Data' В N'/var/opt/mssql/data/AdventureWorksLT.mdf',
ПЕРЕМЕСТИТЕ N'AdventureWorksLT2012_Log' В N'/var/opt/mssql/data/AdventureWorksLT_log.ldf',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImportersDW]
FROM DISK = N'/sql/Backups/WideWorldImportersDW-Full.bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImportersDW.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImportersDW_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImportersDW.ldf',
ПЕРЕМЕСТИТЕ N'WWIDW_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImportersDW_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
ВОССТАНОВЛЕНИЕ БАЗЫ ДАННЫХ [WideWorldImporters]
FROM DISK = N'/sql/Backups/WideWorldImporters-Full. bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImporters.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImporters_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImporters.ldf',
ПЕРЕМЕСТИТЬ N'WWI_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
bak'
С ФАЙЛОМ = 1,
ПЕРЕМЕСТИТЕ N'WWI_Primary' В N'/var/opt/mssql/data/WideWorldImporters.mdf',
ПЕРЕМЕСТИТЕ N'WWI_UserData' В N'/var/opt/mssql/data/WideWorldImporters_UserData.ndf',
ПЕРЕМЕСТИТЕ N'WWI_Log' В N'/var/opt/mssql/data/WideWorldImporters.ldf',
ПЕРЕМЕСТИТЬ N'WWI_InMemory_Data_1' В N'/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1',
НЕЗАГРУЗКА, СТАТИСТИКА = 5
ИДТИ
Сводка по SQL Server 2019 в Docker
Короче говоря, чтение этого поста, вероятно, займет больше времени, чем фактическое создание демонстрационной среды в контейнере Docker. Если у вас уже установлен Docker и копия ваших файлов .bak, это так же просто, как:
- Тяга
- Выполнить
- Восстановить!
Ресурсы
- Запуск SQL Server 2019 CTP в контейнере Docker (автор Эндрю Пруски)
- Краткое руководство: запуск образов контейнеров SQL Server с помощью Docker (Microsoft Docs)
- Восстановление базы данных SQL Server в контейнере Linux Docker (Microsoft Docs)
- Использование SQL Server Management Studio в Windows для управления SQL Server в Linux (Microsoft Docs)
- Страница Microsoft SQL Server в Docker Hub
Об авторе
Катрин Вильгельмсен — Microsoft Data Platform MVP, сертифицированный эксперт BimlHero, международный спикер, автор, блогер, организатор и постоянный волонтер.