Ms sql query xml: How can I query a value in SQL Server XML column
Содержание
Работа с XML данными в Microsoft SQL Server 2008. Тип данных «xml».
В прошлой статье мы узнали, каким образом из базы можно извлекать реляционные данные в виде XML структуры. Сегодня мы познакомимся с принципами хранения структуры XML данных в базе.
Основной элемент поддержки XML в MS SQL Server – тип данных “xml”. Данный тип может использоваться для объявления переменных и как тип колонки в таблице наравне со стандартными типами данных SQL (int, nvarchar и т.д.).
Для типа данных XML доступны следующие специализированные операции. Приведем их краткое описание:
query() – осуществляет запросы к XML данным;
nodes() – извлекает поддерево из структуры XML.
value() – позволяет извлекать значения атрибутов из XML элемента;
exist() – проверяет существуют ли результаты запроса;
modify() – производит обновление XML данных;
Рассмотрим данные команды подробнее:
Команда «query()».
Эта команда позволяет писать запросы к XML дереву. Команда возвращает набор результатов, соответствующих запросу. Рассмотрим пример. Допустим, у нас есть следующая XML структура:
1: DECLARE @xmlData XML =N'
2: <Shops>
3: <Shop>
4: <device name="Sensation" vendor="HTC" />
5: <device name="iPhone" vendor="Apple" />
6: </Shop>
7: <Shop>
8: <device name="Mozart" vendor="HTC" />
9: <device name="Lumia" vendor="Nokia" />
10: </Shop>
11: </Shops>';
Выполним следующий запрос:
1: SELECT @xmlData.query('/Shops/Shop/device')Как результат, мы получим все элементы <device>, путь к которым соответствует нашему запросу:
1: <device name="Sensation" vendor="HTC" />
2: <device name="iPhone" vendor="Apple" />
3: <device name="Mozart" vendor="HTC" />
4: <device name="Lumia" vendor="Nokia" />
Стоит отметить, что имена элементов и атрибутов регистрозависимые, как в XML структуре, так и в тексте запроса.
Также, в запросе, можно наложить некоторые ограничения на выбираемые данные, помимо пути. Например, давайте напишем запрос, который будет выбирать из структуры XML все устройства, производителем которых является компания «HTC»:
1: SELECT @xmlData.query('/Shops/Shop/device/.[@vendor cast as xs:string? = "HTC"]') as DataЗапрос вернет следующий результат:
Команда «nodes()».
Разбивает XML структуру на одно или несколько поддеревьев, в соответствии с указанным запросом. Для примера будем использовать ту же структуру данных @xmlData.
Выполним следующий запрос:
1: SELECT shop.query('.') as data FROM @xmlData.nodes('/Shops/Shop') col(shop)Данный запрос разобьет исходную структуру на строки, по количеству элементов <Shop> и вернет нам две строки:
Разберем текст запроса подробнее.
‘@xmlData.nodes(‘/Shops/Shop’)’ — собственно разбивает данные по указанному запросу.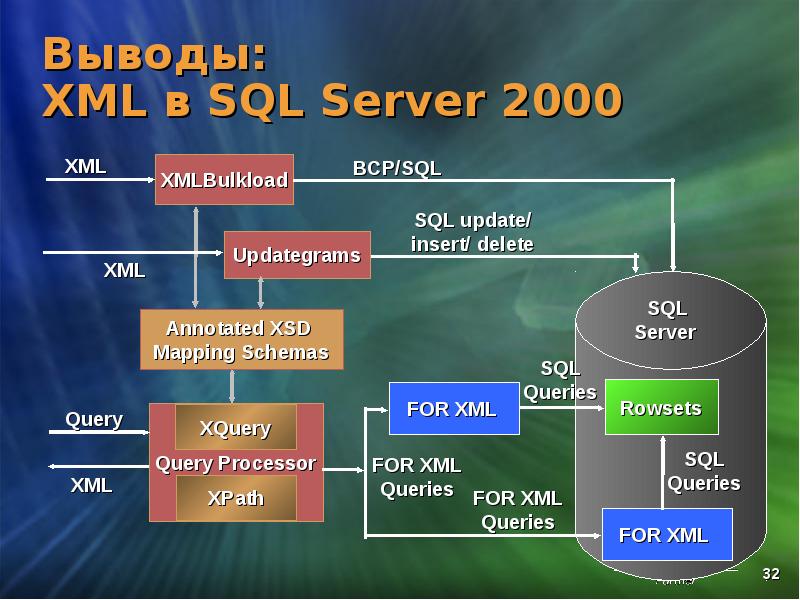
‘col(shop)’ – это псевдоним для результатов разбиения. Данный псевдоним необходим для дальнейшей работы с результатами.
‘shop.query(‘.’)’ – здесь осуществляется запрос к каждой строке результатов, при помощи псевдонима. Данный подзапрос не осуществляет фильтрации, выбирая все данные из поддерева.
Команда «value()».
С помощью данной команды можно извлекать значения из XML дерева. Команда умеет конвертировать строковые литералы из XML текста в любые типы данных среды MS SQL Server.
В качестве примера давайте преобразуем XML структуру @xmlData в табличное представление, выполнив следующий запрос:
1: SELECT
2: device.value('@id', 'int') as Id, 3: device.value('@vendor', 'nvarchar(50)') as Company, 4: device.value('@name', 'nvarchar(50)') as Name 5: FROM @xmlData.nodes('/Shops/Shop/device') col(device)Данный запрос вернет следующий табличный результат:
Команда value() принимает два параметра: название атрибута с префиксом @ и название типа данных, к которому необходимо привести переменную.
Аналогичным способом можно получить доступ к значению, расположенным внутри элемента хмл, например:
1: DECLARE @data XML = N'
2: <Shops>
3: <Shop>Winodws Marketplace</Shop>
4: </Shops>';
5:
6: SELECT
7: shop.value('@id', 'int') as Id, 8: shop.value('.[1]', 'nvarchar(50)') as CompanyName 9: FROM @data.nodes('/Shops/Shop') col(shop)Результат будет следующим:
Также можно получить доступ к родительскому элементу любого уровня. Давайте модернизируем наш первый запрос к @xmlData, добавив в выборку Id магазина, в котором находится устройство:
1: SELECT
2: device.value('@id', 'int') as Id, 3: device.value('@vendor', 'nvarchar(50)') as Company, 4: device.value('@name', 'nvarchar(50)') as Name,5: device.value('../@id', 'int') as ShopId
 value('../@id', 'int') as ShopId
value('../@id', 'int') as ShopId 6: FROM @xmlData.nodes('/Shops/Shop/device') col(device)Результат похож на то, что мы хотели:
Результат отобразился как надо, однако при больших объемах данных такой запрос будет крайне медленным и неэффективным. Проблема в том, что для каждого устройства среда выполнения запроса ищет родительский элемент и считывает его атрибут. Перепишем запрос следующим образом:
1: SELECT
2: device.value('@id', 'int') as Id, 3: device.value('@vendor', 'nvarchar(50)') as Company, 4: device.value('@name', 'nvarchar(50)') as Name, 5: shop.value('@id', 'int') as ShopId6: FROM
7: @xmlData.nodes('/Shops/Shop') col(shop)8: CROSS APPLY
9: shop.nodes('device') tab(device)Результат будет аналогичным, однако теперь мы поменяли логику запроса таким образом, что вначале будут выбираться все магазины, а потом, для каждого магазина, будут присоединяться устройства. Поскольку устройств всегда будет намного больше, чем магазинов, данный запрос даст нам существенный прирост производительности.
Поскольку устройств всегда будет намного больше, чем магазинов, данный запрос даст нам существенный прирост производительности.
Команда «exist()».
Данная команда возвращает значения типа bit. 1 – если результаты, соответствующие запросу существуют, и 0 – если не существуют.
Запрос формируется таким же образом, как и в команде query(). Команда используется, как правило, для наложения ограничений в запросе выборки, применяя фильтрующий запрос exist() к поддереву. Приведем пример:
1: SELECT
2: shop.value('@id', 'int') as ShopId3: FROM
4: @xmlData.nodes('/Shops/Shop') col(shop) 5: WHERE shop.exist('device[@vendor cast as xs:string? = "Nokia"]') = 1Данный запрос выберет Id всех магазинов, в которых присутствуют устройства от компании «Nokia»:
На этом данная статья подходит к концу. В следующей статье мы рассмотрим последнюю команду типа «xml» — modify(), а также обсудим различные способы оптимизации взаимодействия с XML структурами в среде Microsoft SQL Server.
Использовать оператор LIKE для типа данных XML SQL Server
спросил
Изменено
1 год, 9 месяцев назад
Просмотрено
158 тысяч раз
Если у вас есть поле varchar, вы можете легко выполнить SELECT * FROM TABLE WHERE ColumnA LIKE '%Test%' , чтобы узнать, содержит ли этот столбец определенную строку.
Как это сделать для типа XML?
У меня есть следующее, которое возвращает только строки с узлом «Текст», но мне нужно выполнить поиск в этом узле
select * from WebPageContent, где data.exist('/PageContent/Text') = 1
- sql
- sql-сервер
- xml
- sql-сервер-2005
0
Еще один вариант — привести XML к типу nvarchar, а затем выполнить поиск заданной строки, как если бы XML был полем nvarchar.
ВЫБОР * ИЗ таблицы WHERE CAST (столбец как nvarchar (max)) LIKE '% TEST%'
Мне нравится это решение, так как оно чистое, легко запоминающееся, его трудно испортить, и его можно использовать как часть предложения where.
Это может быть не самое эффективное решение, поэтому дважды подумайте, прежде чем запускать его в производство. Однако он очень полезен для быстрой отладки, где я его в основном и использую.
РЕДАКТИРОВАТЬ: Как упоминает Клифф, вы можете использовать:
…nvarchar, если есть символы, которые не преобразуются в varchar
7
Вы должны легко это сделать:
SELECT *
ОТ WebPageContent
ГДЕ data.value('(/PageContent/Text)[1]', 'varchar(100)') LIKE 'XYZ%'
Метод .value дает вам фактическое значение, и вы можете определить, что оно будет возвращено как VARCHAR(), которое вы затем можете проверить с помощью оператора LIKE.
Имейте в виду, это будет не очень быстро. Итак, если у вас есть определенные поля в XML, которые вам нужно часто проверять, вы можете:
- создать хранимую функцию, которая получает XML и возвращает искомое значение в виде VARCHAR()
- определите новое вычисляемое поле в вашей таблице, которое вызывает эту функцию, и сделайте его столбцом PERSISTED
Таким образом, вы фактически «извлекаете» определенную часть XML в вычисляемое поле, сохраняете его, а затем можете очень эффективно искать по нему (черт возьми, вы даже можете ИНДЕКСировать это поле!).
Марк
4
Другим вариантом является поиск XML в виде строки путем преобразования ее в строку и последующего использования LIKE. Однако, поскольку вычисляемый столбец не может быть частью предложения WHERE, вам необходимо обернуть его в другой SELECT, например:
SELECT * FROM
(SELECT *, CONVERT (varchar (MAX), [COLUMNA]) as [XMLDataString] FROM TABLE) x
ГДЕ [XMLDataString] как '%Test%'
1
Это то, что я собираюсь использовать на основе ответа marc_s:
ВЫБОР SUBSTRING(DATA.
 value('(/PAGECONTENT/TEXT)[1]', 'VARCHAR(100)'),PATINDEX('%NORTH%',DATA.value('(/PAGECONTENT/TEXT)[1]', 'ВАРЧАР(100)')) - 20 999)
ИЗ ВЕБ-СТРАНИЦЫ
WHERE COALESCE(PATINDEX('%NORTH%',DATA.value('(/PAGECONTENT/TEXT)[1]', 'VARCHAR(100)')),0) > 0
value('(/PAGECONTENT/TEXT)[1]', 'VARCHAR(100)'),PATINDEX('%NORTH%',DATA.value('(/PAGECONTENT/TEXT)[1]', 'ВАРЧАР(100)')) - 20 999)
ИЗ ВЕБ-СТРАНИЦЫ
WHERE COALESCE(PATINDEX('%NORTH%',DATA.value('(/PAGECONTENT/TEXT)[1]', 'VARCHAR(100)')),0) > 0
Возвращает подстроку при поиске, где существуют критерии поиска
2
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
sql server 2005 — выберите данные из файла XML в виде таблицы в TSQL
спросил
Изменено
5 лет, 11 месяцев назад
Просмотрено
42к раз
Может ли кто-нибудь показать мне TSQL, который можно использовать для запроса XML-файла, как если бы это была таблица?
Файл находится на сервере «C:\xmlfile. xml»
xml»
И содержит
<СпангемансФильтр> 1219 Фред <Код>510 <Отдел>N <номер>305327 <СпангемансФильтр>3578 Гэри <Код>001 <Отдел>B <Число>0692690 <СпангемансФильтр>3579 Джордж <Код>001 <Отдел>X <число>35933
Пример вывода Я после
FilterID |Имя |Код |Отдел |Номер -------------------------------------------------- ------------------ 1219|Фред |510 |Н |305327 3578 |Гэри |001 |B |0692690 3579 |Джордж |001 |X |35933
- sql-server-2005
- tsql
set @xmlData='0"?>
<СпангемансФильтр> ' ВЫБИРАТЬ ref.value('FilterID[1]', 'int') КАК FilterID, ref.value('Имя[1]', 'NVARCHAR (10)') Имя КАК, ref.value('Код[1]', 'NVARCHAR (10)') КАК-код, ref.value('Отдел[1]', 'NVARCHAR (3)') AS Отдел, ref.value('Число[1]', 'целое') Номер AS ОТ @xmlData.nodes('/ArrayOfSpangemansFilter/SpangemansFilter') xmlData (ссылка)1219 Фред <Код>510 <Отдел>N <номер>305327 <СпангемансФильтр>3578 Гэри <Код>001 <Отдел>B <Число>0692690 <СпангемансФильтр>3579 Джордж <Код>001 <Отдел>X <число>35933
Производит:
FilterID Название Код Номер отдела ----------- ---------- ---------- ---------- --------- -- 1219 Фред 510 N 305327 3578 Гэри 001 B 692690 3579 Джордж 001 X 35933
Примечание.
[1] требуется, чтобы указать, что вы хотите выбрать первое значение последовательности, поскольку запрос может возвращать более одного совпадающего значения в строке (представьте, что ваш XML содержит несколько идентификаторов FilterID для каждого SpangemansFilter).
Я подумал, что это полезно знать, поэтому я погуглил и прочитал много постов, пока не нашел этот.
ОБНОВЛЕНИЕ
Для загрузки из файла:
DECLARE @xmlData XML
УСТАНОВИТЬ @xmlData = (
ВЫБЕРИТЕ * ИЗ OPENROWSET (
BULK 'C:\yourfile.xml', SINGLE_CLOB
) КАК xmlData
)
ВЫБЕРИТЕ @xmlData
1
В моем случае интересующие меня данные содержались в атрибутах узла, а не в значениях. Ниже приведен пример доступа к атрибутам.
ОБЪЯВЛЕНИЕ @xmlData XML
установить @xmlData='