Ms sql server 2018: Материалы для скачивания по SQL Server
Содержание
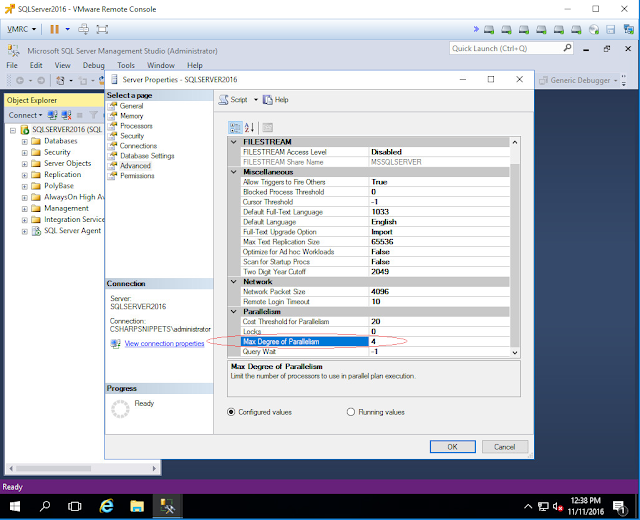
Техподдержка: Настройка регулярного резервного копирования БД MS SQL Server
Рекомендуется настроить регулярное резервное копирование базы данных (на случай аппаратных или программных сбоев), причем лучше всего с сохранением резервных копий за последние несколько дней, например семь (за последнюю неделю).
Для этого можно использовать либо встроенный в SQL Server планировщик заданий – «SQL Server Agent» (в бесплатную версию не входит), либо стандартный «Планировщик Windows» в сочетании с утилитой SQLCMD.EXE, которая позволяет выполнять запросы к SQL Server из командной строки. В планировщике необходимо создать как минимум семь заданий (по одному на каждый день недели), каждое из которых будет (раз в неделю) заменять один из семи файлов, содержащих соответствующую резервную копию базы данных.
Кроме того, файлы резервных копий рекомендуется хранить не только на жестком диске компьютера, где установлен SQL Server, но и дублировать их на ленту или жесткий диск другого компьютера в сети. Для этого можно использовать либо специальное ПО, которое позволяет делать резервные копии всего диска, либо с помощью того же планировщика копировать файлы на ленту или другой компьютер (вторым шагом).
Для этого можно использовать либо специальное ПО, которое позволяет делать резервные копии всего диска, либо с помощью того же планировщика копировать файлы на ленту или другой компьютер (вторым шагом).
- С помощью «Планировщика Windows» (для бесплатной версии)
- С помощью «SQL Server Agent» (в бесплатную версию не входит)
С помощью «Планировщика Windows» (для бесплатной версии)
Чтобы создать задание в «Планировщике Windows» надо:
Запустить программу «Блокнот» (Пуск->Все программы->Стандартные->Блокнот) и ввести следующие две строки, после чего сохранить их в виде командного файла (*.BAT):
SQLCMD -S (local) -E -Q «BACKUP DATABASE AltaSVHDb TO DISK = ‘D:\BACKUP\ AltaSVHDb_monday.bak’ WITH INIT, NOFORMAT, SKIP, NOUNLOAD»
XCOPY D:\BACKUP\ AltaSVHDb_monday.bak \\BACKUP_SERVER\Folder\*.* /Y
где «(local)» – имя сервера (в случае установки именованного экземпляра SQL Server надо указать имя полностью: «ИМЯ_КОМПА\SQLEXPRESS»), «AltaSVHDb» – имя базы данных, «D:\BACKUP\ AltaSVHDb_monday. bak» – имя файла для создания в нем резервной копии (будет различаться по дням недели), «BACKUP_SERVER» – имя компьютера, на который будет выполняться дополнительное копирование, «Folder» – папка на этом компьютере (к ней должен быть предоставлен общий доступ).
bak» – имя файла для создания в нем резервной копии (будет различаться по дням недели), «BACKUP_SERVER» – имя компьютера, на который будет выполняться дополнительное копирование, «Folder» – папка на этом компьютере (к ней должен быть предоставлен общий доступ).
Запустить мастер планирования заданий (Панель управления->Назначенные задания->Добавить задание) и нажать кнопку «Далее»:
Нажать кнопку «Обзор» и указать путь к командному файлу (*.BAT), созданному на шаге a):
Указать имя для задания, выбрать вариант запуска «еженедельно» и нажать кнопку «Далее»:
Поставить галочку возле нужного дня недели, а в поле «Время начала» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью), затем нажать кнопку «Далее»:
Ввести имя пользователя и пароль (дважды) учетной записи ОС, от имени которой будет выполняться задание, и нажать кнопку «Далее»:
Внимание! Чтобы задание успешно выполнялось необходимо предоставить указанной здесь учетной записи (домена или локального компьютера) права записи в вышеупомянутую папку «\\BACKUP_SERVER\Folder», а также настроить доступ к самому SQL Server.
Нажать кнопку «Готово»
Примечание. Чтобы проверить работоспособность созданного задания, необходимо в списке заданий (Панель управления->Назначенные задания) нажать правой кнопкой мыши на интересующем задании и в контекстном меню выбрать пункт «Выполнить», затем убедиться, что файл резервной копии БД успешно создался по тем путям, которые были указаны на шаге a).
С помощью «SQL Server Agent» (в бесплатную версию не входит)
Чтобы создать задание в «SQL Server Agent» надо:
Запустить утилиту SQL Server Management Studio и подключиться к серверу под учетной записью администратора.
В левой части окна нажать правой кнопкой мыши на разделе «Объекты сервера/Устройства резервного копирования» и в контекстном меню выбрать пункт «Создать устройство резервного копирования»:
В поле «Имя устройства» ввести имя, которое будет ассоциироваться с файлом резервной копии БД, при необходимости изменить путь в поле «Файл» и нажать «ОК»:
В левой части окна нажать правой кнопкой мыши на разделе «Агент SQL Server/Задания» и в контекстном меню выбрать пункт «Создать задание»:
В поле «Имя» ввести имя задания:
На странице «Шаги» нажать кнопку «Создать»:
В появившемся окне ввести имя в поле «Имя шага», проверить, что в поле «Тип» выбрано «Сценарий Transact-SQL (T-SQL)», а в поле «Команда» ввести строку:
BACKUP DATABASE AltaSVHDb TO AltaSVHDb_monday WITH INIT, NOFORMAT, SKIP, NOUNLOAD
где «AltaSVHDb» – имя базы данных, «AltaSVHDb_monday» – имя устройства резервного копирования, созданного на шаге c) (будет различаться по дням недели):
В предыдущем окне нажать кнопку «ОК», в результате на странице «Шаги» должна появиться строка:
Чтобы файл резервной копии БД сразу копировался на другой компьютер в сети необходимо повторить пункты f) – h), в окне «Создание шага задания» выбрав в поле «Тип» значение «Операционная система (CmdExec)», а в поле «Команда» указав строку:
XCOPY D:\MSSQL\BACKUP\AltaSVHDb_monday.
bak \\BACKUP_SERVER\Folder\*.* /Y
 bak \\BACKUP_SERVER\Folder\*.* /Y
bak \\BACKUP_SERVER\Folder\*.* /Yгде «D:\MSSQL\BACKUP\AltaSVHDb_monday.bak» – путь, указанный на шаге c) (будет различаться по дням недели), «BACKUP_SERVER» – имя компьютера, на который будет выполняться копирование, «Folder» – папка на этом компьютере (к ней должен быть предоставлен общий доступ):
Примечание. Чтобы копирование файла успешно выполнялось необходимо запускать «SQL Server Agent» под учетной записью домена Windows, для которой предоставлены права записи в вышеупомянутую папку (см. также «SQL2005_installation.doc» или «SQL2008_installation.doc»), а также настроен доступ к самому SQL Server (см. раздел «Настройка прав доступа к БД», включить эту учетную запись надо в роль «sysadmin» на странице «Серверные роли», а на страницах «Сопоставление пользователей» и «Защищаемые объекты» ничего не делать).
На странице «Расписания» нажать кнопку «Создать»:
Ввести имя в поле «Имя», проверить, что в поле «Тип расписания» выбрано значение «Повторяющееся задание», а в поле «Выполняется» – «Еженедельно».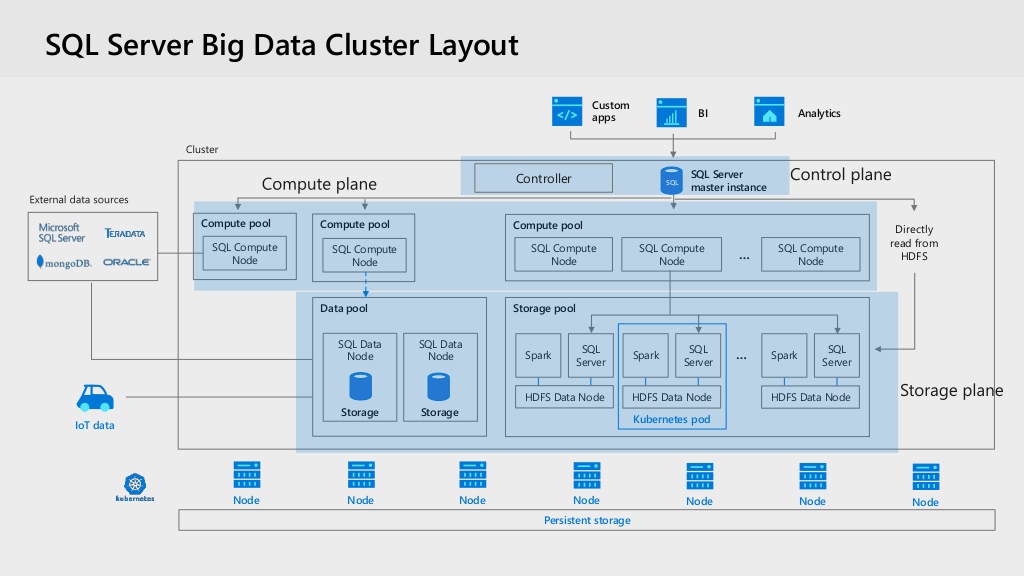 Поставить галочку возле нужного дня недели (остальные снять), а в поле «Однократное задание» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью):
Поставить галочку возле нужного дня недели (остальные снять), а в поле «Однократное задание» указать время, когда должен запускаться процесс резервного копирования (обычно это делается ночью):
В предыдущем окне нажать кнопку «ОК», в результате на странице «Расписания» должна появиться строка:
Нажать кнопку «ОК».
Примечание. Чтобы проверить работоспособность созданного задания, необходимо в разделе «Агент SQL Server/Задания» нажать правой кнопкой мыши на интересующем задании и в контекстном меню выбрать пункт «Запустить задание на шаге», в появившемся окне выбрать первый шаг данного задания и нажать «ОК». Далее появится окно отображающее ход выполнения задания. Если выполнение задания закончится с ошибкой, то подробное описание ошибки можно увидеть вызвав пункт «Просмотр журнала» того же контекстного меню.
Microsoft SQL Server
Microsoft SQL Server — система управления реляционными базами данных (СУРБД).
В моих проектах нередко необходимость использование этого продукта назревала постепенно, по мере роста бизнеса клиентов,
начинавших автоматизироваться на MS Access, который позволял автоматизировать работу малых и средних предприятий быстро.
MS Access дает удобную возможность перейти от файл-серверной технологии к клиент-серверной эволюционным путем, т.е. не меняя клиентскую часть.
Сам MS SQL рождался также постепенно. Сначала при активнейшем участии компаний Sybase, Ashton-Tate и IBM . В 1988 году появилась первая версия этого продукта
под операционной системой OS/2.
В 1993 году согласно опубликованным результатам тестирования по показателям стоимость/производительность SQL Server оказался самым эффективным сервером
из присутствовавших на том момент. Т.е., конечно, были серверы более производительные, но ПО+аппаратное обеспечение обходились заказчикам непропорционально дороже.
Этот факт внес напряжение в совместную разработку Microsoft & Sybase, которое логично завершилось объявлением о прекращении совместной разработки SQL Server
в 1994 году к неудовольствию клиентов этого продукта.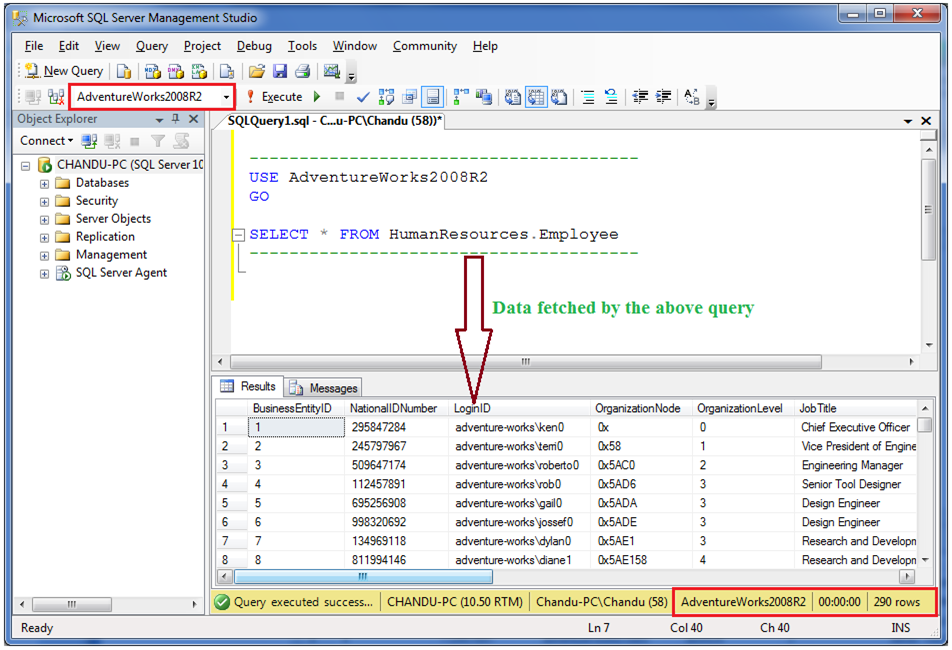
Чтобы не потерять клиентов Microsoft совершила подвиг, мотивировав работать свою группу разработчиков чуть ли не круглосуточно. MS SQL Server 6.5 был успешно
выпущен в 1995 году.
На текущий момент (конец 2018 года) наибольшее количество наработок сделано мной на – MS SQL 2012.
Напишу здесь, какие техники оптимизации запросов БД я применял для решения бизнес задач.
В большинстве случаев оптимизация начиналась и заканчивалась на 2 пункте (см. ниже), так как даже для того,
чтобы поставить индекс на таблицу, нужно пройти 10 кругов ада и архитектурных согласований.
Если давали в полное распоряжение витрину, то доходило до 6 пункта. Если давали бюджет на аппаратное обеспечение, был и 7 пункт.
-
Построение правильной структуры данных: структура должна соответствовать бизнес задачам приложения, с точки зрения реляционной парадигмы, быть близко к 3НФ,
связка таблиц по суррогатным ключам и т.д. -
Семантическая и синтаксическая оптимизация запросов. -
Правильное индексирование полей в таблицах. -
Кластеризация взаимосвязанных таблиц -
Партиционирование/секционирование/фрагментация/сегментирование таблиц и индексов -
Сегментирование таблиц -
Кластеризация серверов БД (когда запись делается на мастере, а чтение на репликах) -
А был еще такой случай. Пользователи стали жаловаться, что отчеты (причем все, в их департаменте) резко начали тормозить. Поскольку организация большая,
жалобы пользователей выстояли в очереди несколько дней. Вторая линия поддержки сделать ничего не смогла. Что интересно, и третья линия поддержки сделать
ничего не смогла. Пришлось использовать организацонно-аналитический подход. Выяснилось, что поддержка инфраструктуры, как-то не особенно афишируя,
перенесла СХД на более производительную твердотельную платформу. Казалось бы, отчеты должны работать еще быстрее. Но факты говорили об обратном.
Пришлось заставить ребят протестировать все оборудование, это было, надо сказать не просто, во первых, они этого делать не хотели, а во-вторых,
для тестирования им пришлось обратиться к вендору, который тоже как-то реагировал не быстро. И выяснилось, что коннектор к СХД – с брачком, таким брачком,
который удалось заметить только после проведения комплексного тестирования оборудования. В итоге, после месяца мучений, ругани и эскалаций, поменяли,
грубо говоря, шнурок, и все взлетело с реактивной скоростью.
 Пользователи стали жаловаться, что отчеты (причем все, в их департаменте) резко начали тормозить. Поскольку организация большая,
Пользователи стали жаловаться, что отчеты (причем все, в их департаменте) резко начали тормозить. Поскольку организация большая,
 И выяснилось, что коннектор к СХД – с брачком, таким брачком,
И выяснилось, что коннектор к СХД – с брачком, таким брачком,
Из наиболее ярких успехов в оптимизации запросов: в одной компании, только прибегая к семантической оптимизации, удавалось сократить время генерации
отчета с 14 часов до 30 минут.
Фактически я только менял текст хранимых процедур. Не могу сказать, что все было написано плохо. В процессе оптимизации наткнулся на фрагмент кода,
рассчитывавшего себестоимость по FIFO. Сначала не понял, как это работает. Разбирался с относительно небольшим скриптом не меньше часа.
Разбирался с относительно небольшим скриптом не меньше часа.
А когда понял, был чрезвычайно восхищен остроумием этого алгоритма. Притом, что в целом код формирования отчета был изначально не оптимален,
расчет FIFO был написан талантливым программистом.
8 основных функций SQL Server 2022
Введение в SQL Server 2021
Корпорация Майкрософт, в связи с новыми требованиями и другими технологическими достижениями в индустрии программного обеспечения, выпустила обновленную версию SQL Server 2021, которая называется SQL Server 2021. Это было анонсировано и представлено на мероприятии Ignite 2018 24 сентября. Однако это был всего лишь предварительный выпуск. Более технически продвинутая и подробная картина SQL Server 2021 была представлена только на саммите PASS, который состоялся позднее, в ноябре того же года.
В более новой версии SQL Server реализована более совершенная интеграция таких модулей, как база данных Azure SQL, поддержка Apache Kafka в концентраторах событий Azure, хранилище данных SQL Azure и распределенная файловая система Hadoop (HDFS).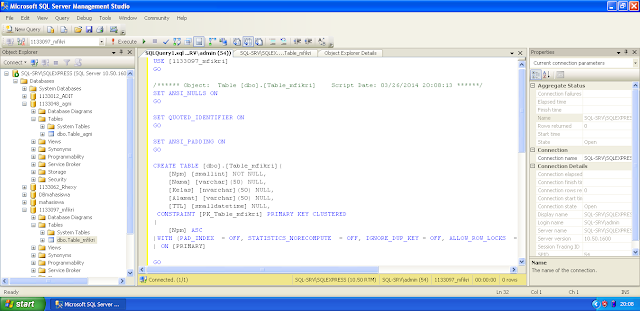 предоставить единое интегрированное решение
предоставить единое интегрированное решение
Microsoft SQL Server 2021 создан с целью сделать шаг вперед в области искусственного интеллекта (ИИ) за счет интеграции больших данных со службами баз данных.
Если вы хотите построить свою карьеру с сертифицированным специалистом по SQL Server, зарегистрируйтесь здесь Учебный курс по SQL Server. Этот курс поможет вам достичь совершенства в этой области.
Содержание
- Новые возможности SQL Server 2019
- Кластеры больших данных
- Поддержка UTF-8 (CTP 2.2)
- Создание возобновляемого онлайн-индекса (CTP 2.0)
- Интеллектуальная обработка запросов (CTP 2.0)
- Группы доступности AlwaysOn
- Машинное обучение в Linux
- Новые функции для SQL Server в Linux
- Безопасность
- Microsoft SQL Server 2017 и 2019
- Стандартный SQL Server 2019 по сравнению с. Корпоративные версии
- Почему следует выполнить обновление с SQL Server 2017 до версии 2019?
 Корпоративные версии
Корпоративные версии
В SQL Server 2021 было внесено множество улучшений для выпуска новой версии SQL Server 2021 , что делает его более эффективным и стабильным. Эти новые функции подробно обсуждаются ниже.
1. Кластеры больших данных
Кластеры больших данных — это новые дополнения к выпуску SQL Server 2019. Эта функция позволяет одновременно развертывать несколько масштабируемых кластеров контейнеров SQL Server, Spark и HDFS, работающих в Kubernetes. Кластер больших данных как инфраструктура позволяет этим кластерам работать параллельно, где вы можете читать, записывать и обрабатывать большие данные из Transact-SQL в Spark. Это позволяет нам легко комбинировать и анализировать ценные реляционные данные с большими объемами данных.
Функции:
- Виртуализация данных: SQL Server PolyBase упростил задачу запроса внешних источников данных для кластеров больших данных SQL Server, уменьшив усилия по перемещению или копированию данных для создания запроса. В предварительной версии SQL Server 2019 представлены новые соединители для источников данных.
 В предварительной версии SQL Server 2019 представлены новые соединители для источников данных.
В предварительной версии SQL Server 2019 представлены новые соединители для источников данных.- Озеро данных: Кластер больших данных позволяет создать масштабируемый пул хранения HDFS. Это потенциально повышает эффективность хранения больших данных из внешних источников.
- Масштабируемая витрина данных: Кластер больших данных обеспечивает масштабируемые вычисления и хранилище для улучшения анализа данных. Данные могут быть загружены и сохранены на нескольких узлах пула данных в виде кэша для дальнейшего анализа.
- Интегрированный ИИ и машинное обучение: Кластер больших данных позволяет применять ИИ и машинное обучение к данным, хранящимся в нескольких пулах хранения и пулах данных HDFS. SQL-сервер предоставляет множество встроенных инструментов искусственного интеллекта, таких как R, Python, Scala или Java.
- Управление и мониторинг: Портал администратора кластера — это веб-сайт, предоставляющий сведения о состоянии и работоспособности модулей в кластере. Он также предоставляет ссылки на другие информационные панели для анализа журналов и мониторинга.
- Управление и мониторинг будут осуществляться с использованием комбинации инструментов командной строки, API-интерфейсов, портала администратора и динамических представлений управления.
 Он также предоставляет ссылки на другие информационные панели для анализа журналов и мониторинга.
Он также предоставляет ссылки на другие информационные панели для анализа журналов и мониторинга.[Связанная страница: Новый кластер SQL Server ]
Преимущества кластера больших данных:
- Имеет встроенные фрагменты для регулярных задач управления.
- Позволяет просматривать HDFS, создавать каталоги, просматривать файлы и загружать файлы.
- Позволяет создавать, открывать и запускать блокноты, совместимые с Jupyter.
- Мастер виртуализации данных упростил создание внешних источников данных.
- Кластер больших данных с инфраструктурой K8 увеличивает скорость настройки всей групповой инфраструктуры.
- Вопросы безопасности, возникающие при интеграции реляционной среды с большими данными, полностью решаются кластерами больших данных.
- Виртуализация данных позволяет легко интегрировать данные без необходимости выполнять ETL (извлечение, преобразование и загрузка).

Учебное пособие по SQL Server
2. Поддержка UTF-8
Новый SQL Server 2019 поддерживает очень популярную систему кодирования данных UTF-8. Кодировка символов UTF-8 используется при экспорте и импорте данных, сопоставлении данных на уровне базы данных и на уровне столбцов. Он включается при создании или изменении типа сопоставления объектов на сопоставление объектов с UTF-8. Он поддерживается для типов данных char и varchar.
Причина, по которой данные должны быть закодированы при сохранении и извлечении, в основном связана с двумя причинами.
- Для уменьшения занимаемой памяти или места для хранения.
- Для обеспечения безопасности конфиденциальных данных.

Примечание. Начиная с Microsoft SQL Server 2016, UTF-8 поддерживается BCP, BULK_INSERT и OPENROWSET.
В более ранних версиях SQL Server кодирование выполнялось в различных форматах, таких как UCS-2, и они не поддерживали формат UTF-8. Однако введение кодировки Unicode было сделано только в SQL Server 7.0.
[Связанная страница: Обработка исключений в SQL Server ]
Преимущества кодировки UTF:
Эта функция помогает в сохранении памяти благодаря использованию правильного набора символов. Например, изменение существующего типа данных столбца с латинскими строками с NCHAR(10) на CHAR(10) с использованием сопоставления с поддержкой UTF-8 приводит к сокращению требований к хранилищу на 50 %. Эта экономия происходит потому, что NCHAR(10) требует 20 байтов для хранения, тогда как CHAR(10) требует 10 байтов для одной и той же строки Unicode.
CTP 2. 1 позволяет выбирать параметры сортировки UTF-8 по умолчанию во время предварительной установки SQL Server 2019.
1 позволяет выбирать параметры сортировки UTF-8 по умолчанию во время предварительной установки SQL Server 2019.
CTP 2.2 позволяет выбрать использование кодировки символов UTF-8 с репликацией SQL Server.
3. Возобновляемое создание онлайн-индекса (CTP 2.0)
Это функция, позволяющая приостановить и возобновить операцию создания индекса прямо с того места, где операция завершилась неудачно или была приостановлена, вместо того, чтобы запускать весь процесс. снова.
Индекс является одним из мощных инструментов управления базами данных. Чем больше операций над базами данных, таких как вставка, обновление и удаление, индекс становится более фрагментированным и, следовательно, менее эффективным. Чтобы бороться с этим, администраторы баз данных все чаще применяют операции перестроения индексов.
Возобновляемое оперативное перестроение индекса (ROIR) было перенято из SQL Server 2017 как важная функция для повышения производительности базы данных.
Однако в версии SQL Server 2019 включена более новая версия функции, которая называется « Resumable Online Index Create »
Возможности Resumable Online Index Create
- Вы можете возобновить создание индекса операция после индекса приводит к сбою в случае чрезмерного использования дискового пространства или при потере базы данных.
- Приостановка текущей операции создания индекса в случае блокировки приведет к временному освобождению ресурсов для возобновления заблокированных задач.
- Создание тяжелого журнала из-за громоздкой операции создания индекса может быть решено путем приостановки операции создания индекса, усечения или создания резервной копии журнала, а затем ее возобновления.
В старых версиях, когда эта функция не была введена, при сбое работы нового индекса весь процесс приходилось начинать сначала.
SQL Server 2019 также позволяет установить эту функцию по умолчанию для конкретной базы данных.
[Связанная страница: Ограничения SQL Server с примером ]
4. Интеллектуальная обработка запросов (CTP 2.0)
план выполнения запроса с меньшим временем компиляции. Эта функция расширена за счет включения многих других подфункций в SQL Server 2019., ОСАГО 2.2.
При выполнении IQP учитывается множество факторов, главным образом для создания достаточно хорошего плана выполнения. Этими факторами являются используемые структуры, соединения, которые необходимо выполнить в запросе (хэш-соединение, вложенный цикл, адаптивное слияние и т. д.), внешний ввод, режим выполнения (режим пакетного или строкового выполнения) и т. д.
SQL Server 2017 имел функцию интеллектуальной обработки запросов со следующими дополнительными функциями:
- Адаптивные соединения в пакетном режиме для динамического выбора типа соединения во время выполнения или во время выполнения на основе входных строк.
- Interleaved Execution с уровнем совместимости 140, который использует мощность таблицы с несколькими операторами в соответствии со значениями, полученными при первой компиляции, а не фиксированным предположением.
- Обратная связь о выделении памяти (пакетный режим) для управления выделением памяти. Если запрос в пакетном режиме содержит операции, требующие дополнительного дискового пространства, для него будет выделено больше памяти при последовательном выполнении. В то время как, если запрос использует менее 50% выделенной памяти, выделение памяти будет уменьшено при последовательных выполнениях.

Однако в IQP для предварительной версии SQL Server 2019 CTP 2.0 внесено множество улучшений. Вот эти функции:
- Начиная с SQL Server 2019 CTP 2.0, сервер предоставляет приблизительное значение Count Distinct для сценариев с большими данными. Count Distinct возвращает приблизительное количество уникальных ненулевых значений в группе. Эта функция уменьшает объем памяти, тем самым повышая эффективность работы.
- Пакетный режим в хранилище строк разрешено в версии 2019 года на уровне совместимости 150, что обеспечивает пакетный режим для рабочих нагрузок реляционного хранилища данных с привязкой к ЦП. Эта функция не требует наличия индексов хранилища столбцов.
- Обратная связь о выделении памяти (режим строки) для управления распределением памяти в режиме строки. Если запрос в строковом режиме содержит операции, требующие дополнительного дискового пространства, для него будет выделено больше памяти при последовательном выполнении. В то время как, если запрос использует менее 50% выделенной памяти, выделение памяти будет уменьшено при следующих выполнениях.
- Scalar UDF Inlining используется для увеличения производительности. В основном это касается преобразования скалярных UDF в эквивалентные реляционные выражения, которые «встраиваются» в вызов запроса.
- Табличная переменная Отложенная компиляция , которая немного отличается от выполнения с чередованием. Эта функция использует фактическую кардинальность табличной переменной, обнаруженной при первой компиляции, вместо фиксированного предположения.
 Эта функция уменьшает объем памяти, тем самым повышая эффективность работы.
Эта функция уменьшает объем памяти, тем самым повышая эффективность работы.
[Связанная страница: Учебное пособие по таблицам данных R с примерами ]
решение, направленное на предоставление альтернативы зеркальному отображению базы данных на уровне предприятия. Эта функция была первоначально представлена в SQL Server 2012, чтобы повысить доступность набора пользовательских баз данных для предприятия.
Группа доступности предназначена для поддержки среды репликации для набора пользовательских баз данных, называемых базами данных доступности. Группу доступности можно создать для высокой доступности (HA) или для масштабирования чтения.
Сбой группы доступности происходит на уровне реплики доступности. Доступность базы данных берет на себя, отработка отказа все вместе.
Доступность базы данных берет на себя, отработка отказа все вместе.
Возможности групп доступности Always On в SQL Server 2017
В SQL Server 2017 представлены два набора групп доступности, различающихся по своей архитектуре.
Группы доступности Always On
Это обеспечивает высокую доступность, аварийное восстановление и баланс чтения и масштабирования. Группы доступности здесь используют диспетчер кластера в случае аварийного переключения кластера. В Linux для того же используется Pacemaker, а в Windows — менеджер кластера.
Группа доступности с масштабированием для чтения
Эта архитектура предоставляет реплики только для рабочих нагрузок только для чтения. Они не обеспечивают высокую доступность. В доступности для чтения не используется диспетчер кластеров.
Каждый набор базы данных доступности размещается репликой доступности. Версия SQL Server 2017 предоставляет только 2 типа реплик. Это первичная реплика и вторичная реплика. Реплика доступности поддерживает избыточность только на уровне базы данных.
Это первичная реплика и вторичная реплика. Реплика доступности поддерживает избыточность только на уровне базы данных.
[Связанная страница: Различные типы соединений в SQL Server]
Новые добавленные функции SQL Server 2019
Помимо существующих функций SQL Server 2017, внесены новые улучшения и дополнения. SQL Server 2019.
- В отличие от предыдущей версии, в SQL Server 2019 максимальное количество реплик увеличено с 2 до 5. Из 5 реплик 1 является первичной, а остальные 4 — вторичными. Вы можете настроить эти 5 реплик для обработки отказа группы.
- Перенаправление соединения со вторичной реплики на первичную:
- Это позволяет перенаправлять клиентские подключения на первичную реплику независимо от целевых спецификаций в строке подключения. Это соединение обеспечивает перенаправление соединения без прослушивателя.
- Используйте перенаправление соединения со вторичной реплики на первичную в следующих случаях:
- В кластерной технологии отсутствует функция прослушивания.
- Когда перенаправление становится сложным в конфигурации с несколькими подсетями.
- Сценарии чтения-масштабирования или аварийного восстановления, где тип кластера НЕТ.
- В кластерной технологии отсутствует функция прослушивания.
- SQL Server 2019 предоставляет возможность настраивать группы доступности Always on с использованием Kubernetes в качестве уровня оркестровки вместо сбоя кластера Windows.
Преимущества новых функций групп доступности Always On в SQL Server 2019
- Увеличенное количество реплик доступности повышает доступность на этапе аварийного восстановления. Для каждой базы данных доступности для восстановления доступен набор из 4 вторичных реплик и одной первичной реплики.
- Перенаправление вторичной реплики на первичную повышает эффективность управления базой данных.
- Группы доступности Always On обеспечивают эффективное управление ресурсами и повышение доступности базы данных.
6. Машинное обучение в Linux
Microsoft всегда стремилась смешивать данные и код. Microsoft SQL Server стал свидетелем перехода этой тенденции от T-SQL к ориентированному на Azure U-SQL, который затем расширил T-SQL элементами C#. Затем в 2016 году SQL Server добавил встроенную поддержку R. В 2017 году этот фокус был расширен за счет добавления Python в SQL Server. Это безумно привлекло энтузиастов машинного обучения, которые даже не знакомы с SQL Server!
Microsoft SQL Server стал свидетелем перехода этой тенденции от T-SQL к ориентированному на Azure U-SQL, который затем расширил T-SQL элементами C#. Затем в 2016 году SQL Server добавил встроенную поддержку R. В 2017 году этот фокус был расширен за счет добавления Python в SQL Server. Это безумно привлекло энтузиастов машинного обучения, которые даже не знакомы с SQL Server!
Корпорация Майкрософт всегда стремилась представить новые функции, которые позволили бы SQL Servers в Linux достичь паритета с SQL Server в Windows. Некоторые улучшения в машинном обучении, внесенные в SQL Server 2019 для Linux, обсуждаются ниже.
Возможности машинного обучения для Linux в SQL Server 2017
Наличие Python и R, встроенных в SQL Server, дает множество преимуществ. Некоторые из них перечислены ниже:
- Наличие Python, встроенного в SQL Server, позволяет вам воспользоваться преимуществами функций масштабирования и повышения производительности Microsoft, получая прямой доступ к функциям базы данных в памяти и ускоряя запросы OLAP.
- Выполняемый код будет в виде хранимых процедур. Это позволяет разработчикам SQL просто получить процедуру и выполнить ее, не беспокоясь о коде, в то время как специалисты по обработке и анализу данных могут позаботиться о письменных сценариях. Это обеспечивает безопасность данных.
- Двойная поддержка R и Python в SQL-сервере была логичным переходом к Microsoft. Поскольку SQL-серверы работают как на платформе, так и в облаке, они могут работать с традиционными источниками больших данных со всеми данными.

Новые добавленные функции машинного обучения в SQL Server 2019
- Помимо R и Python, в SQL Server добавлено новое расширение языка Java.
- Контейнеры приложений заменили локальные учетные записи пользователей в группе пользователей с ограниченным доступом SQL (SQLRUUserGroup).
- Доступность членства в SQLRUUserGroup изменилась. Вместо нескольких локальных учетных записей пользователей, как в предыдущей версии, SQL Server имеет только учетную запись службы Launchpad. Все процессы R, Python и Java теперь выполняются под идентификатором службы Launchpad, изолированным от AppContainers. [
 Все процессы R, Python и Java теперь выполняются под идентификатором службы Launchpad, изолированным от AppContainers. [
Все процессы R, Python и Java теперь выполняются под идентификатором службы Launchpad, изолированным от AppContainers. [[Связанная страница: R Учебное пособие по таблицам данных с примерами ]
7. SQL Server на Linux
- Один из крупнейших улучшений Squ Server 2019 2019 2019 года. кластеры больших данных. Расширенная интеграция больших данных — одно из основных направлений деятельности Microsoft SQL Server 2019.
- Кластеры больших данных поддерживаются рядом технологий, включая SQL Server на Linux в контейнерах Docker, Apache Spark, Hadoop и Kubernetes. Разработанные кластеры больших данных позволяют пользователю развертывать масштабируемые кластерные контейнеры в Kubernetes, которые могут читать, записывать и обрабатывать большие данные с помощью T-SQL.
- Кластер больших данных состоит из контейнеров SQL Server и Spark Linux. Контейнеры Linux используют Kubernetes для управления и оркестровки контейнеров. Несколько контейнеров Docker в масштабируемой группе узлов составляют уровень вычислений, на котором запросы выполняются параллельно. Расширенная аналитика и машинное обучение хорошо поддерживаются Spark. Здесь кластеры больших данных управляются главным экземпляром SQL Server.
- Среди других непосредственных улучшений SQL Server для Linux в 2019 году — расширенная поддержка репликации транзакций и распределенных транзакций.
- Экземпляры SQL Server 2019 в Linux могут участвовать в топологиях моментальных снимков, слияния и репликации транзакций в качестве подписчика, издателя или распространителя.
- Поддержка координатора распределенных транзакций Microsoft (MSDTC) позволяет выполнять распределенные транзакции в экземплярах SQL Server Linux. Это стало возможным благодаря новой версии MSDTC для Linux, которая запускается в процессе SQL Server.
- SQL Server 2019 для Linux имеет лучшую интеграцию с Active Directory, которая предоставляет такие функции, как аутентификация пользователей, репликация, распределенные запросы и группы доступности. Кроме того, он также поддерживает OpenLDAP для сторонних поставщиков AD. Он также обеспечивает машинное обучение в базе данных.
- SQL Server 2019 для Linux предлагает новый образ контейнера Docker, сертифицированный Red Hat Enterprise Linux (RHEL): docker pull mcr.microsoft.com/mssql/rhel/server:2019-CTP2.1
- Microsoft также разработала новый главный реестр контейнеров. Этот реестр предназначен для поддержки существующих каталогов, таких как Docker Hub, Red Hat Container Catalog и Azure Marketplace.


8. Повышенная безопасность
Поскольку SQL Server непосредственно занимается управлением базой данных и закупками, безопасность транзакций и задействованных данных является одним из наиболее важных требований.
Безопасность доступа к серверам SQL обеспечивается сертификатами. Новая функция безопасности SQL Server 2019включает управление сертификатами в диспетчере конфигурации SQL Server (CTP 2.0). Этот сертификат удостоверяет безопасный доступ к экземплярам SQL Server. Управление сертификатами теперь предназначено для диспетчера конфигурации SQL Server, что упрощает выполнение других задач, таких как:
- Просмотр и проверка сертификатов, установленных в экземпляре SQL Server.
- Управление сертификатами, срок действия которых приближается.
- Управление развертыванием сертификации на компьютерах, которые участвуют в группах доступности Always On.
- Управление развертыванием сертификатов на машинах, участвующих в экземпляре отказоустойчивого кластера.
Always Encrypted использовалось как решение Microsoft для защиты данных. Однако у этого метода есть определенные ограничения, когда простые функции, такие как математические операции, не могут быть выполнены с зашифрованными данными.
Чтобы преодолеть это, используется новая технология под названием « Secure Enclaves », которая позволяет выполнять простые функции, такие как агрегатные функции и запросы LIKE, на Данные всегда зашифрованы .
Сравнение Microsoft SQL Server 2017 и 2019
Ниже приведены несколько отличительных черт, отличающих версию SQL Server 2017 от SQL Server 2019.
| SQL Server 2017 | SQL Server 2019 | |
| Кластеры больших данных | Не включено | Добавлена новая функция кластера больших данных для решения проблем с большими данными |
| Безопасность | Always Encrypted кодирует данные. Закодированные данные не могут обрабатывать какие-либо математические или реляционные операции над ними. | «Безопасные анклавы» импровизируют с ранее закодированными данными, позволяя выполнять основные математические или реляционные операции с закодированными данными. |
| Интеллектуальная обработка запросов | Поддерживаются адаптивные соединения в пакетном режиме и обратная связь с памятью в пакетном режиме. | Наряду с функциями предыдущей версии включает обратную связь с памятью в режиме хранения строк и встраивание скалярных определяемых пользователем функций. |
| Индексы | Возобновляемое перестроение онлайн-индекса | Возобновляемый онлайн-индекс Создать |
| Группы доступности Always On | 2 копии | 5 копий Перенаправление реплики вторичного индекса на первичную |
| Linux | Не поддерживает OpenLDAP | Поддерживает OpenLDAP |
[Связанная страница: Гибридное облако с SQL Server ]
Стандартный SQL Server 2019: Standard Edition Vs.
 Корпоративные версии
Корпоративные версии
В этом разделе рассказывается о стандартных и корпоративных выпусках SQL Server 2019.и различия между ними.
Standard: Standard обеспечивает базовые функции баз данных, такие как отчеты, анализ, базовые функции доступности, аварийное восстановление и т. д.
Enterprise: Версия Enterprise включает все функции версии Standard, а также некоторые дополнительные расширенные функции. Эта версия подходит для компаний, которым нужна высокая масштабируемость и производительность.
Ниже приведены некоторые различия между стандартной и корпоративной редакцией 9.0003
| Отличия | Стандартная версия | Корпоративная версия |
| Производительность и масштабируемость | Базовая поддержка масштабируемости и ограниченная производительность по сравнению с Enterprise Edition. | Обеспечивает лучшую масштабируемость и производительность |
| Опора | Подставки для 128 ГБ | Поддерживает до 524 петабайт |
| Безопасность | Обеспечивает базовый аудит, автономные базы данных, шифрование и резервное копирование, а также определяемые пользователем роли | Обеспечивает детальный аудит, прозрачное шифрование базы данных и расширяемое управление ключами помимо основных функций стандартной безопасности |
| Репликация | Обеспечивает базовое отслеживание изменений SQL Server, репликацию слиянием и репликацию моментальных снимков. | Обеспечивает высококачественную публикацию Oracle и одноранговую репликацию транзакций, помимо базовых возможностей репликации версии Standard |
Только 3 из 11 функций версии Enterprise присутствуют в версии Standard, когда речь идет о масштабируемости и производительности. Следовательно, пользователи должны быть достаточно мудры, чтобы выбрать корпоративную версию в случае любой предполагаемой масштабируемости.
Часто задаваемые вопросы по SQL Server
Почему вам следует выполнить обновление с SQL Server 2017 до версии 2019?
Корпорация Майкрософт очень стратегична, внедряя усовершенствования и функции в каждую версию SQL Server. Приносится новая версия, всегда с учетом ограничений предыдущей версии и с новой целью. Ниже приведены некоторые причины, по которым следует перейти на SQL Server 2019..
1. Возможности работы с большими данными
В SQL Server 2019 особое внимание уделяется расширению возможностей работы с большими данными, импровизированному машинному обучению и производительности Linux SQL Server.
Поскольку большинство компаний приспосабливаются к большим данным, важно включить в SQL Server функции, поддерживающие большие данные. В SQL Server 2019 разработаны кластеры больших данных, которые справляются со всеми задачами, связанными с большими данными. Однако эта функция не была реализована в SQL Server 2017.
2. Производительность SQL Server в Linux
Корпорация Майкрософт всегда стремилась улучшить SQL Server, чтобы он адаптировался к различным платформам, таким как Windows, Linux и Mac OS. Прилагаются постоянные усилия, чтобы привести производительность двух других платформ в соответствие с производительностью Windows SQL Server. В SQL Server 2019 лучше интегрирована поддержка Linux с Kubernetes. Производительность SQL Server 2019 на экземплярах Linux стала лучше благодаря параллельной обработке задач в контейнерах.
3. Доступность
В группе доступности Always On сделано несколько улучшений. Обеспечены новые функции перенаправления соединений и расширенные проверки работоспособности базы данных.
Возобновляемое создание онлайн-индексов упростило весь процесс создания тяжелого индекса и сделало его управляемым. В противном случае в более старых выпусках при любой паузе в процессе создания индекса из-за нехватки памяти или по другой причине процесс приходилось перезапускать, что делало его громоздким.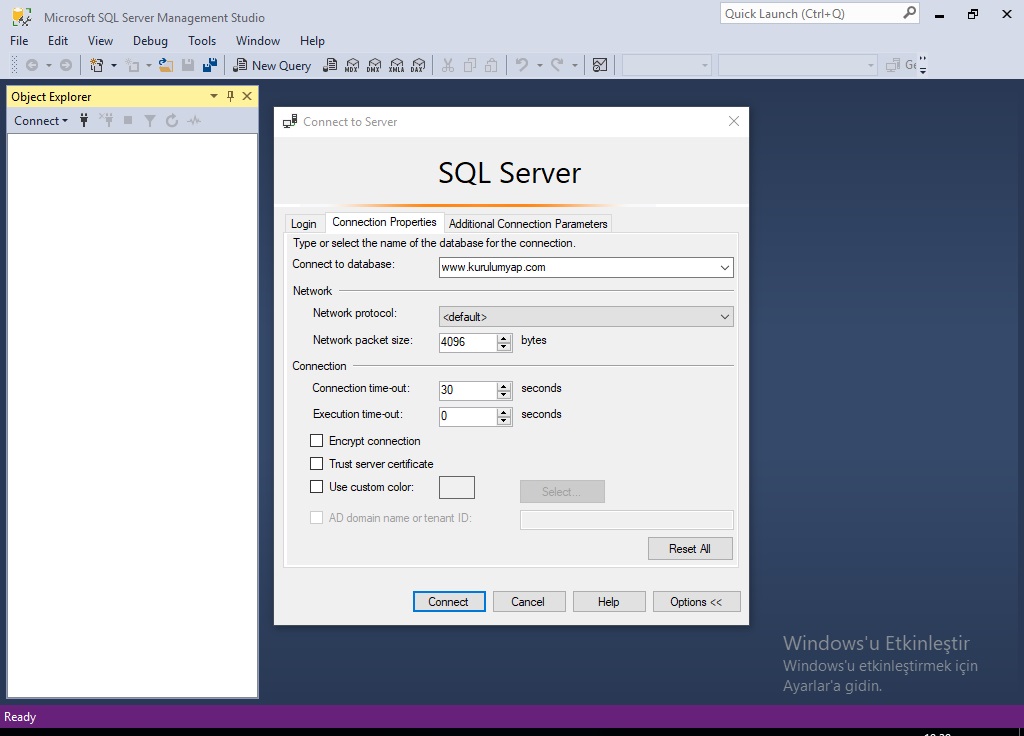
Вывод
SQL Server 2019 определенно представляет собой импровизированную версию предыдущих выпусков SQL Server. Есть много веских причин, по которым компаниям необходимо адаптироваться к новой версии. Поскольку большинство функций являются расширением существующих функций более старых версий SQL Server, не требуется никакой новой установки или настройки среды. Многие отзывы о новой установке и обновлении включают простоту установки и простоту использования инструмента. В целом, это надежный и стабильный продукт.
Список соответствующих сертификационных курсов Microsoft:
| SSIS | Power BI |
| SSRS | SQL Server |
| ССОО | БД SQL Server |
| SCCM | BizTalk Сервер |
| Team Foundation Server | Администратор сервера BizTalk |
Изучите образцы резюме SQL Server! Загружайте и редактируйте, чтобы вас заметили лучшие работодатели! Загрузите сейчас!
Course Schedule
| Name | Dates | |
|---|---|---|
| SQL Server Training | Nov 08 to Nov 23 | |
| SQL Server Training | Nov 12 to Nov 27 | |
| Обучение SQL Server | 15 ноября — 30 ноября | |
| Обучение SQL Server | 19 ноября — 04 декабря |
Ноябрь Обновлено 2:02209
2:00020003
Настройка Microsoft SQL Server | PaperCut
РУКОВОДСТВА ПО ПРОДУКЦИИ
Руководство по PaperCut NG и PaperCut MF
ПРЕДЛАГАЕМЫЕ ПРОДУКТЫ
Microsoft SQL Server обеспечивает производительность базы данных корпоративного класса. Для этого типа базы данных вы должны проводить переиндексацию базы данных каждый месяц. Эта оптимизация базы данных помогает повысить общую производительность и, в частности, большие запросы, выполняемые в базе данных SQL. Эти запросы включают в себя отчеты, а также массовые действия, выполняемые с несколькими точками данных.
Для этого типа базы данных вы должны проводить переиндексацию базы данных каждый месяц. Эта оптимизация базы данных помогает повысить общую производительность и, в частности, большие запросы, выполняемые в базе данных SQL. Эти запросы включают в себя отчеты, а также массовые действия, выполняемые с несколькими точками данных.
ВАЖНО
Убедитесь, что SQL Server использует протокол TCP, а для параметра проверки подлинности сервера установлено значение Проверка подлинности SQL Server и Windows .
Пользователь базы данных, созданный для PaperCut NG/MF, должен иметь только минимальный набор разрешений, необходимых для приложения PaperCut. Пользователь должен иметь полные права на создание/удаление таблиц и полный доступ ко всем созданным таблицам. Однако у пользователя не должно быть разрешения на доступ к другим базам данных, установленным на сервере баз данных.
Чтобы настроить Microsoft SQL Server, выполните следующие задачи на компьютере с установленным SQL Server:
Шаг 1: Получите драйвер для SQL Server
ПРИМЕЧАНИЕ
Если у вас установлена программа PaperCut NG/MF версии 19. 0 или более поздней, вам не нужно выполнять этот шаг — перейдите к шагу 2. Включите проверку подлинности SQL Server.
0 или более поздней, вам не нужно выполнять этот шаг — перейдите к шагу 2. Включите проверку подлинности SQL Server.
Для версий PaperCut NG/MF 18.3.9 и более ранних загрузите последнюю версию драйвера Microsoft JDBC (sqljdbc_7.0.0.0_enu.exe) для SQL Server по этой ссылке: https://docs.microsoft.com/en-us /sql/connect/jdbc/download-microsoft-jdbc-driver-for-sql-server?view=sql-server-2017
Запустите загруженный файл, чтобы извлечь файлы.
Скопируйте файл
mssql-jdbc-7.0.0.jre8.jarиз папки, в которую были извлечены файлы, в<каталог установки PaperCut MF или NG>\server\lib-ext\Запустите загруженный файл, чтобы извлечь файлы.
Скопируйте следующие записи в файл конфигурации server.properties (где полужирный текст зависит от сайта). (Закомментируйте старые записи — это будет ваш план резервного копирования!) :// serverName : portNumber ;databaseName= имя базы данных ;socketTimeout=600000
database. username= имя пользователя
database.password= парольЕсли для соединения требуются дополнительные свойства (на основании того, что мы знаем, не ожидается), вы можете найти их здесь: https://docs.microsoft.com/en-us/sql/connect/jdbc/setting-the-connection- свойства? представление = sql-сервер-2017
 username= имя пользователя
username= имя пользователя Шаг 2. Включите проверку подлинности SQL Server
PaperCut NG/MF требует, чтобы проверка подлинности SQL Server была включена на экземпляре SQL Server. Для этого:
В SQL Server Management Studio щелкните правой кнопкой мыши экземпляр SQL Server для настройки; затем выберите Свойства .
Выберите раздел Security слева.
Изменить аутентификацию сервера 9от 0016 до Режим проверки подлинности SQL Server и Windows .
Перезапустите службу Microsoft SQL Server, используя либо стандартную панель управления службой, либо инструменты SQL Server.

Шаг 3. Создайте пользователя базы данных
PaperCut NG/MF требует подключения пользователя к базе данных. Чтобы создать этого пользователя:
В SQL Server Management Studio щелкните правой кнопкой мыши Безопасность > Логины ; затем выберите Новый логин .
Введите имя пользователя (например,
papercut).Измените режим аутентификации сервера на SQL Server и режим аутентификации Windows .
Введите пароль пользователя.
Отключить истечение срока действия пароля.
Нажмите OK .
После создания базы данных PaperCut NG/MF назначьте этому пользователю
db_ownerправа доступа к базе данных, чтобы он мог создавать необходимые таблицы базы данных.Инициализировать базу данных.
