Ms sql xml: XML-данные (SQL Server) — SQL Server
Содержание
Запросы к XML-столбцам—Справка | Документация
- Извлечение нескольких значений из XML-столбца
В системных таблицах базы геоданных GDB_Items и GDB_ItemRelationships есть несколько XML-столбцов, содержащих сведения о схеме и отношениях элементов. В частности, в столбце Definition в таблице GDB_Items записываются подробные сведения о базе геоданных. Тип документа XML в столбце зависит от конкретного типа элемента. Например, определение класса пространственных объектов содержит информацию о полях, доменах и подтипах таблицы, пространственной привязке геометрии, а также о том, участвует ли класс пространственных объектов в наборе данных контроллера.
Для работы со значением из столбца XML в системной таблице в IBM Db2, Microsoft SQL Server или PostgreSQL необходимо получить XML-документ из базы данных целиком и работать с ним локально в XML или текстовом средстве просмотра. Для программистов, работающих с Java, C++ или C#, будет удобнее просматривать документ в Document Object Model (DOM). Разработчики SQL могут использовать функции базы данных XML для получения определенных значений из определений элементов с помощью XPath (языка запросов для XML-документов).
Разработчики SQL могут использовать функции базы данных XML для получения определенных значений из определений элементов с помощью XPath (языка запросов для XML-документов).
В базах геоданных под управлением Oracle и Informix столбцы XML используют ArcSDE XML, который хранит информацию в виде больших двоичных объектов в нескольких отдельных таблицах. К ним можно обращаться напрямую с помощью SQL.
Для просмотра содержимого в столбцах XML системных таблиц баз геоданных под управлением Oracle предусмотрены два системных вида, в которых содержимое столбцов XML-таблиц базы геоданных хранится в виде объектов с типом данных CLOB. Вид GDB_Items_vw отображает содержимое столбцов Определение, Документация и Информация об элементе из таблицы GDB_Items в столбцах типа CLOB. Вид GDB_ItemRelationships_vw отображает содержимое столбцов Атрибуты из таблицы GDB_ItemRelationships в столбце типа CLOB. Содержимое столбца CLOB можно просмотреть в виде текста.
Примечание:
В разных СУБД подписи и поведение XML-функций могут существенно отличаться.
В следующем примере показано определение элемента определения интервального домена в XML-документе:
<? xml version = "1.0" encoding="utf-8"?>
<GPRangeDomain2
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:typens = "http://www.esri.com/schemas/ArcGIS/10.0"
xsi:type = "typens:GPRangeDomain2">
<DomainName>Angle</DomainName>
<FieldType>esriFieldTypeInteger</FieldType>
<MergePolicy>esriMPTDefaultValue</MergePolicy>
<SplitPolicy>esriSPTDuplicate</SplitPolicy>
<Description>Valid rotation angles</Description>
<Owner>harley</Owner>
<MaxValue xsi:type = "xs:int">359</MaxValue>
<MinValue xsi:type = "xs:int">0</MinValue>
</GPRangeDomain2>
Двумя наиболее важными значениями для интервального домена являются минимальное и максимальное значения. Эти элементы представлены выражениями /GPRangeDomain2/MinValue и /GPRangeDomain2/MaxValue, соответственно. Ниже приведен пример запроса SQL, извлекающего эти значения конкретного интервального домена в базе геоданных в SQL Server.
Ниже приведен пример запроса SQL, извлекающего эти значения конкретного интервального домена в базе геоданных в SQL Server.
--Queries an sde-schema geodatabase in SQL Server
SELECT
Definition.value('(/GPRangeDomain2/MinValue)[1]','nvarchar(max)') AS "MinValue",
Definition.value('(/GPRangeDomain2/MaxValue)[1]','nvarchar(max)') AS "MaxValue"
FROM
sde.GDB_ITEMS INNER JOIN sde.GDB_ITEMTYPES
ON sde.GDB_ITEMS.Type = sde.GDB_ITEMTYPES.UUID
WHERE
sde.GDB_ITEMS.Name = 'Angle' AND
sde.GDB_ITEMTYPES.Name = 'Range Domain'
MinValue MaxValue
0 359
Предыдущий пример относительно прост. Для более сложных решений см. статью XML-схема базы геоданных, особенно приложение для разработчиков, работающих с системными таблицами.
Вы можете выполнять запросы к другим XML-столбцам системных таблиц также, как они формулируются для столбца Definition таблицы GDB_Items. Учтите, что для столбца Documentation не предусмотрено XML-схемы, определяемой базой геоданных. В столбце Documentation содержатся метаданные, связанные с элементами базы геоданных. В разных организациях элементы метаданных, содержащиеся в этом столбце, отличаются, так как это зависит от стандартов метаданных и рабочих процессов, используемых для управления ими. Документ XML DTD с описанием структуры метаданных ArcGIS – ArcGISmetadatav1.dtd – поставляется вместе с ArcGIS Desktop и находится в папке \Metadata\Translator\Rules директории установки ArcGIS.
В столбце Documentation содержатся метаданные, связанные с элементами базы геоданных. В разных организациях элементы метаданных, содержащиеся в этом столбце, отличаются, так как это зависит от стандартов метаданных и рабочих процессов, используемых для управления ими. Документ XML DTD с описанием структуры метаданных ArcGIS – ArcGISmetadatav1.dtd – поставляется вместе с ArcGIS Desktop и находится в папке \Metadata\Translator\Rules директории установки ArcGIS.
Довольно часто имеет смысл извлечь из одного XML-документа несколько значений сразу. Ниже приведено значение Definition для одного из таких примеров, домена кодированных значений:
<? xml version = "1.0" encoding="utf-8"?>
<GPCodedValueDomain2
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xmlns:xs = "http://www.w3.org/2001/XMLSchema"
xmlns:typens = "http://www.esri.com/schemas/ArcGIS/10.0"
<DomainName>Material</DomainName>
<FieldType>esriFieldTypeString</FieldType>
<MergePolicy>esriMPTDefaultValue</MergePolicy>
<SplitPolicy>esriSPTDuplicate</SplitPolicy>
<Description>Valid pipe materials</Description>
<Owner>aelflad</Owner>
<CodedValues xsi:type= "typens:ArrayOfCodedValue">
<CodedValue xsi:type= "typens:CodedValue">
<Name>Cast iron</Name>
<Code xsi:type= "xs:string">CI</Code>
</CodedValue>
<CodedValue xsi:type= "typens:CodedValue">
<Name>Ductile iron</Name>
<Code xsi:type= "xs:string">DI</Code>
</CodedValue>
<CodedValue xsi:type= "typens:CodedValue">
<Name>PVC</Name>
<Code xsi:type= "xs:string">PVC</Code>
</CodedValue>
<CodedValue xsi:type= "typens:CodedValue">
<Name>Asbestos concrete</Name>
<Code xsi:type= "xs:string">AC</Code>
</CodedValue>
<CodedValue xsi:type= "typens:CodedValue">
<Name>Copper</Name>
<Code xsi:type= "xs:string">COP</Code>
</CodedValue>
</CodedValues>
</GPCodedValueDomain2>
Как правило разработчикам и администраторам требуются пары кодов и значений с выражением XPath вида /GPCodedValueDomain2/CodedValues/CodedValue. В следующем примере показано, каким образом можно извлечь несколько значений из одного XML-определения, чтобы получить пары кода и значений для всех доменов в базе геоданных в SQL Server.
В следующем примере показано, каким образом можно извлечь несколько значений из одного XML-определения, чтобы получить пары кода и значений для всех доменов в базе геоданных в SQL Server.
-- Get the code/value pairs for each coded value domain in the geodatabase.
SELECT
codedValue.value('Code[1]', 'nvarchar(max)') AS "Code",
codedValue.value('Name[1]', 'nvarchar(max)') AS "Value"
FROM
dbo.GDB_ITEMS AS items INNER JOIN dbo.GDB_ITEMTYPES AS itemtypes
ON items.Type = itemtypes.UUID
CROSS APPLY
items.Definition.nodes
('/GPCodedValueDomain2/CodedValues/CodedValue') AS CodedValues(codedValue)
WHERE
itemtypes.Name = 'Coded Value Domain' AND
items.Name = 'Material'
Code Value
CI Cast iron
DI Ductile iron
PVC PVC
AC Asbestos concrete
COP Copper
XML в MS SQL Server 2000 и технологиях доступа к
данным
Алексей Шуленин Microsoft, Moscow
Отдел стратегических платформ .NET
системный инженер | 1 |
|
Зачем XML нужен в СУБД?
Передача запросов и результатов через Интернет
XML прозрачно проходит сквозь сетевые экраны
В отличие, скажем, от СОМ-объектов
Взаимодействие в гетерогенных средах
XML сейчас понимают все независимо от платформы и ОС
Интеграция не только с другими СУБД, но и с серверами B2B, электронной коммерции и пр.
Не требует установки дополнительного ПО на клиента
Клиент может быть сколь угодно тонким
Опять же потому, что средства его поддержки присутствуют изначально
2
Немного истории
ADO 2.1 (1999 г.)
Сохранить рез-ты запроса (ADODB.Recordset) в XML-формате
До этого в ADO 2.0 поддерживался только ADTG
Частный бинарный формат, использовавшийся при передаче recordset’a в удаленном доступе с помощью RDS
На выходе – нормальный XML со своей схемой
Можно делать все, что и с обычным XML- документом
Открыть при пом. DOM, запросить при пом. XPath, преобразовать при пом. XSL и т.д.
Посмотреть код
3
Немного истории
ADO 2.5
Промежуточное сохранение в файл – лишние затраты
Появилась возможность напрямую в программе передавать полученный поток (stream) XML любому объекту, подд. IStream
Посмотреть код
Возм. и обр.ситуация — чтение XML из потока и его запись в recordset
За счет введения нового сервисного провайдера
Microsoft OLE DB Persistence | 4 |
Provider («Provider=MSPersist») |
|
Появление XML в SQL
Server
Рассмотренные ранее подходы имеют две особенности
Преобразование в XML происходит на клиенте
XML получается по предопределенной схеме
Требуется дополнительное XSL- преобразование
В SQL Server 2000 появилась возможность получения XML на стороне сервера
SELECT . | Посмотреть код |
 .. FOR XML …
.. FOR XML …5
SELECT … FOR XML | Посмотреть код | |
|
| |
Клиент | Поэтому все XPath- и updategrams- | Сервер |
| преобразования вып-ся на стороне |
|
| клиента |
|
FOR XML
XML
sqlxmlx.dll
SQLOLEDB
XML-документ
FOR XML |
|
SQLXMLOLEDB | SQLOLEDB |
XML | XML-документ |
| |
sqlxml3.dll |
|
Документ получается на сервере, но ввиду отс-я встроенного типа XML он может только отдать его клиенту
Его нельзя использовать как результат подзапросов, |
|
хранимых функций и всего остального, что | 6 |
предполагает дальнейшую обработку на SQL Server |
|
Поддержка XML в SQL
Server
Впервые появилась в составе SQL Server
2000
Август 2000 г.
Дополняется и расширяется SQLXML веб-
релизами
| Выкладываются на сайт SQL Server |
| Доступны для бесплатного скачивания и |
| установки зарегистрированными пользователями |
Текущий на данный момент – SQLXML 3.0
В составе Microsoft SQL Server 2000 Web Services
Toolkit
http://msdn.microsoft.com/downloads/sample.asp?ur l=/MSDN-FILES/027/001/872/msdncompositedoc.xml&fr ame=true
7
SQLXML Managed Classes | |
Dataset | для .NET |
Fill Update
SqlXmlAdapter
SqlXmlCommand
XPath XQuery Template
XML |
XmlReader |
XML |
SqlCommand |
FOR XML |
X | Посмотреть код |
| |
M |
|
L |
|
V |
|
I |
|
E |
|
W | БД |
| 8 |
FOR XML на клиенте Посмотреть код
Клиент | Сервер |
| Команда |
Data Provider = | SQLOLEDB |
SQLOLEDB | Rowset |
Rowset
FOR XML
SQLXMLOLEDB
XML
Какой-нибудь Команда
другой провайдер Rowset
В перспективе SQLXMLOLEDB можно использовать с любыми источниками данных
Provider= SQLXMLOLEDB;DataProvider=…
Однако в настоящее время в качестве
провайдера данных поддерживается только SQL 9
Server
Другие способы получения XML на клиенте.
 ADO.Net
ADO.Net
Типовой сценарий
Получить внутри DataSet таблицы как результаты запросов к источнику данныхВозможно, к разным
Связать их между собой на основе объектов DataRelation
Создать XML-представление DataSet’a при помощи XmlDataDocument
Посмотреть код
Управление XML-данными в SQL Server
Когда среднему разработчику базы данных приходится манипулировать XML, либо превращая его в реляционный формат, либо создавая его из SQL, это часто делается «на расстоянии вытянутой руки». Позор, поскольку эффективное использование методов, выходящих за рамки основ, может сэкономить много кода и, вероятно, будет работать лучше.
Часто возникает необходимость создавать, измельчать, комбинировать или иным образом воссоздавать XML-данные, чтобы они соответствовали определенной цели. Иногда бизнес-требования диктуют, что фрагменты XML должны быть объединены, в то время как другие запросы требуют измельчения документов или полей XML и импорта их значений в таблицы. Иногда данные XML необходимо создавать непосредственно из существующих таблиц. SQL Server предоставляет множество инструментов, связанных с XML, но как узнать, какие из них использовать и когда?
Иногда данные XML необходимо создавать непосредственно из существующих таблиц. SQL Server предоставляет множество инструментов, связанных с XML, но как узнать, какие из них использовать и когда?
Давайте рассмотрим некоторые из этих задач, требующих манипулирования XML, используя образец базы данных AdventureWorks2012 (другие версии AdventureWorks должны работать нормально, но могут быть различия в схемах данных и/или таблиц).
Создание XML
Одним из распространенных требований является создание структуры XML, основанной на схеме существующей таблицы. Предположим, мы получили запрос на создание XML-данных из соответствующих полей в Person.Person 9.Таблица 0008 для лица, имеющего BusinessEntityID 10 0 01 . Нам нужно собрать значения из этой строки:
— выберите запись человека SELECT * FROM Person.Person WHERE BusinessEntityID = 10001 GO |
Нам необходимо включить поле BusinessEntityID и некоторые столбцы данных имени в новую структуру XML. Обратите внимание, что в таблице есть существующий столбец XML — Демография поле.
Обратите внимание, что в таблице есть существующий столбец XML — Демография поле.
SQL Server предоставляет параметр XML для использования с предложением FOR, что позволяет использовать простой метод преобразования данных таблицы в узлы XML . FOR XML может принимать разные аргументы — давайте выясним, какой из них нам подходит.
Аргумент AUTO является одним из самых простых в использовании. Он создает один узел для каждой записи, возвращаемой предложением SELECT:
| . 1 2 3 4 5 6 7 8 9 10 11 12 | — создать структуру XML с использованием FOR XML AUTO SELECT BusinessEntityID, PersonType, Title, FirstName, MiddleName, 90 002 Фамилия, Суффикс ОТ Person.Person ГДЕ BusinessEntityID = 10001 ДЛЯ XML АВТО GO |
По умолчанию аргумент AUTO организует каждое поле, отличное от XML, в атрибут узла .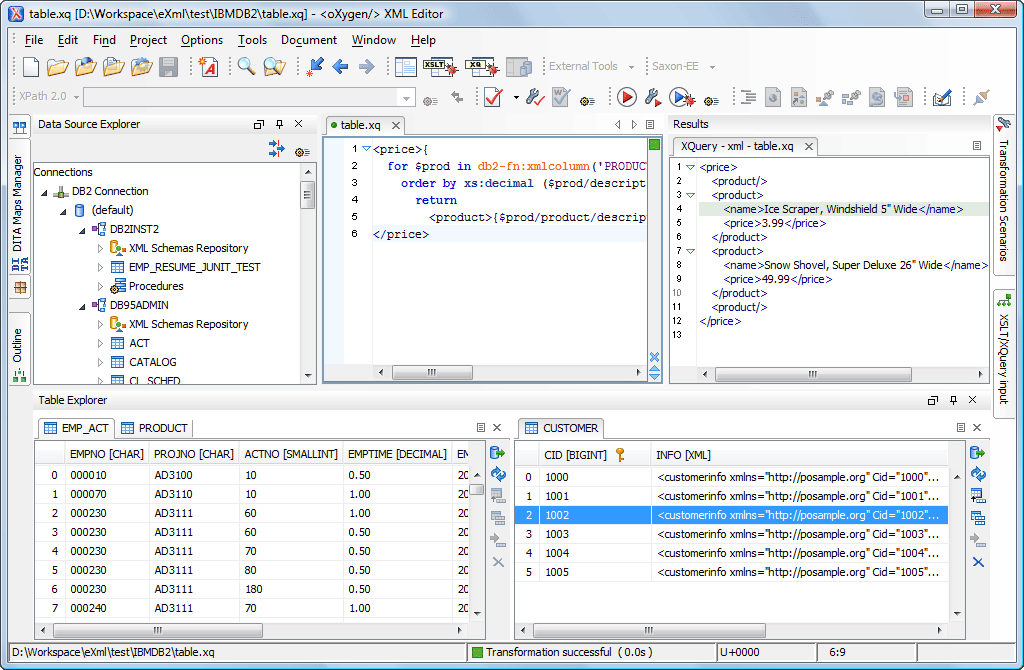 Чтобы указать, что значения должны создаваться как элементы узла , а не атрибуты, мы можем дополнительно указать аргумент ELEMENTS:
Чтобы указать, что значения должны создаваться как элементы узла , а не атрибуты, мы можем дополнительно указать аргумент ELEMENTS:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 | — создать структуру XML с использованием FOR XML AUTO SELECT BusinessEntityID, PersonType, Title, FirstName, MiddleName, 90 002 Фамилия, Суффикс ОТ Person.Person ГДЕ BusinessEntityID = 10001 ДЛЯ XML AUTO, ELEMENTS GO |
Результирующий XML:
Аргумент ELEMENTS заставляет каждое значение создаваться как элемент узла . Теперь у нас есть отдельный узел для каждого значения и корневой узел-оболочка. В первом примере результирующий XML содержал те же данные, но значения отображались как атрибуты.
Мы заметили, что имя корневого узла — это имя схемы и таблицы ( Person.Person ). Мы хотели бы изменить это на « Person ». Чтобы указать собственный корневой элемент, мы будем использовать аргумент PATH вместо AUTO:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 | — создать XML с использованием FOR XML PATH SELECT BusinessEntityID, PersonType, Должность, Имя, Отчество, Фамилия, Суффикс FROM Person.Person WHERE BusinessEntityID = 10001 FOR XML PATH(‘Person’) GO |
Результаты:
Использование аргумента PATH позволило нам указать имя «Person» в нашей корневой оболочке.
Объединение атрибутов узла и элементов
Что делать, если мы хотим, чтобы одно или несколько значений были созданы как атрибуты узла, в результате чего получается комбинация атрибутов узла и элементов ? Мы можем создавать значения атрибутов узла, просто назначая псевдонимы столбцов, которые используют символ «@»:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 | — назначьте атрибут узла SELECT BusinessEntityID AS ‘@ID’, PersonType, Должность, Имя, Отчество, Фамилия, Суффикс FROM Person. WHERE BusinessEntityID = 10001 FOR XML PATH(‘Person’) ГО |
 Person
PersonРезультирующий XML:
Включая столбцы XML
Что произойдет, если мы добавим поле XML ( Демографические данные ) в предложение SELECT?
1 2 3 4 5 6 7 8 9 10 11 12 9 0002 13 | — включить существующий столбец XML. 0002 Фамилия, Суффикс, Демографические данные ОТ Человек. Человек ГДЕ BusinessEntityID = 10001 FOR XML PATH(‘Person’) GO |
Мы видим, что существующее поле XML создано как элемент вложенного узла . Обратите внимание, что данные пространства имен XML включены во вложенный узел.
Уничтожение XML-данных
«Уничтожение» XML-данных — еще один распространенный запрос. «Измельчить» означает отделить фактические данные от тегов разметки и организовать их в реляционном формате. Например, измельчение — это то, что происходит, когда XML-документ импортируется в таблицу, когда значение каждого узла сопоставляется с определенным полем в таблице. Популярным методом для этого является использование функции OPENXML(), но для выполнения тех же задач можно использовать и методы XQuery. OPENXML() был доступен для уничтожения до того, как были введены методы SQL Server XQuery, и несколько быстрее для больших операций с данными. Однако он значительно сложнее в использовании и требует больше памяти. Кроме того, OPENXML() не может использовать XML-индексы в отличие от методов XQuery.
«Измельчить» означает отделить фактические данные от тегов разметки и организовать их в реляционном формате. Например, измельчение — это то, что происходит, когда XML-документ импортируется в таблицу, когда значение каждого узла сопоставляется с определенным полем в таблице. Популярным методом для этого является использование функции OPENXML(), но для выполнения тех же задач можно использовать и методы XQuery. OPENXML() был доступен для уничтожения до того, как были введены методы SQL Server XQuery, и несколько быстрее для больших операций с данными. Однако он значительно сложнее в использовании и требует больше памяти. Кроме того, OPENXML() не может использовать XML-индексы в отличие от методов XQuery.
Мы получили еще один запрос: извлечь данные из некоторых узлов ( Occupation, Education, HomeOwnerFlag , NumberCarsOwned ), которые содержатся в таблице Person.Person Demographics 90 008 XML-столбец для BusinessEntityID 15291 и отобразить его вместе с другими значениями полей, отличных от XML ( FirstName , MiddleName , LastName ) из таблицы.
Запись Person.Person для BusinessEntityID 15291 , а их расширенный экземпляр XML Demographics показан ниже:
SELECT * FROM Person.Person WHERE BusinessEntityID = 15291 GO |
Метод XQuery value() — это простой способ извлечения значений из данных XML с сохранением типов данных:
1 2 3 4 5 6 7 8 9 10 11 | — Значения экстракта (Shred) из узлов столбцов XML Select FirstName, Middlename, LastName, Демография. 2004/07/adventure-works/IndividualSurvey»; (/ns:IndividualSurvey/ns:Occupation)[1]’,’varchar(50)’) AS Occupation, Demographics.value(‘declare namespace ns=»http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey»; (/ns:IndividualSurvey/ns:Education)[1]’,’ varchar(50)’) AS Education, Demographics. Demographics.value(‘declare namespace ns=»http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey» ; (/ns:IndividualSurvey/ns:NumberCarsOwned)[1]’,’int’) AS NumberCarsOwned ОТ Person.Person ГДЕ BusinessEntityID = 15291 GO |
 value(‘declare namespace ns=»http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey»; (/ns:IndividualSurvey/ ns:HomeOwnerFlag)[1]’,’bit’) AS HomeOwnerFlag,
value(‘declare namespace ns=»http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey»; (/ns:IndividualSurvey/ ns:HomeOwnerFlag)[1]’,’bit’) AS HomeOwnerFlag,Пространства имен XML
Хотя это возвращает измельченный результат , который нам нужен, повторяющиеся объявления пространств имен увеличивают размер нашего запроса — поскольку мы возвращаем четыре значения узла XML, мы должны объявить пространство имен четыре раза. Объявление пространства имен необходимо, поскольку структура XML Demographics использует типизированный XML — его XML-данные связаны со схемой XML. Однако вместо этого мы можем использовать предложение WITH XML NAMESPACES для объявления пространства имен XML — это позволяет нам объявить пространство имен только один раз для всего блока кода:0003
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 | — извлечь (уничтожить) значения из узлов столбца XML, используя WITH XMLNAMESPACES ;WITH XMLNAMESPACES (‘http://schemas. SELECT Имя, Отчество, Фамилия, Demographics.value(‘(/ns:IndividualSurvey/ns:Occupation)[1]’,’varchar(50)’) AS Occupation, Demographics.value(‘(/ns:IndividualSurvey/ns :Education)[1]’,’varchar(50)’) AS Education, Demographics.value(‘(/ns:IndividualSurvey/ns:HomeOwnerFlag)[1]’,’bit’) AS HomeOwnerFlag, Demographics .value(‘(/ns:IndividualSurvey/ns:NumberCarsOwned)[1]’,’int’) AS NumberCarsOwned FROM Person.Person WHERE BusinessEntityID = 15291 ГО |
 microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey’ AS ns)
microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey’ AS ns)Метод XQuery nodes()
Метод XQuery nodes() — это еще одна опция, которая позволяет нам указать определенный набор узлов , в котором нужно искать нужные дочерние узлы:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 | — извлечение (уничтожение) значений из узлов столбцов XML с использованием метода XQuery nodes() SELECT Имя, Отчество, Фамилия, C. C.value(‘ns:Educ ация[1 ]’,’varchar(50)’) AS Education, C.value(‘ns:HomeOwnerFlag[1]’,’bit’) AS HomeOwnerFlag, C.value(‘ns:NumberCarsOwned[1]’,’int’) AS NumberCarsOwned ОТ Person.Person ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ Demographics.nodes(‘/ns:IndividualSurvey’) AS T(C) ГДЕ BusinessEntityID = 15291 GO |
.jpg) value(‘ns:Occupation[1]’,’varchar(50)’) AS Occupation,
value(‘ns:Occupation[1]’,’varchar(50)’) AS Occupation, Мы использовали метод nodes() для детализации (на один уровень) до местоположения узла « IndividualSurvey », а затем вернули фактические значения с помощью метода XQuery value(). Мы использовали CROSS APPLY для присоединения набора узлов обратно к таблице. В CROSS APPLY не было бы необходимости, если бы мы уничтожали переменную XML, а не из столбца XML в таблице. Метод nodes() легко удаляет данные XML из столбцов XML, а также из переменных XML. Для метода nodes() требуются псевдонимы таблиц и столбцов ( T (C ) ), чтобы другие методы XQuery (например, метод value()) могли получить доступ к набору узлов, возвращаемому методом nodes(). Псевдонимы столбцов и таблиц не имеют значения.
Псевдонимы столбцов и таблиц не имеют значения.
Обратите внимание, что мы использовали предложение WITH XML NAMESPACES для объявления пространства имен XML. Объявление пространства имен необходимо, поскольку XML-структура Demographics использует типизированный XML — его XML-данные связаны со схемой XML.
Теперь, когда наши XML-данные измельчены, результаты можно сохранить в таблице или объединить с другими запросами.
Применение и эффективность метода Nodes()
Имейте в виду, что использование метода nodes() в простых запросах может излишне снизить эффективность запроса . При запуске в том же пакете наш запрос, использующий метод nodes(), стоил 54% пакета, тогда как запрос только с методом value() стоил всего 46%:
1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 14 15 16 17 18 90 003 19 20 21 22 23 24 25 | — только с использованием метода value() , Фамилия, Demographics. Demographics.value(‘(/ns:IndividualSurvey/ns:Education)[ 1]’,’varchar(50)’) AS Education, Demographics.value(‘(/ns:IndividualSurvey/ns:HomeOwnerFlag)[1]’,’bit’) AS HomeOwnerFlag, Demographics.value(‘ (/ns:IndividualSurvey/ns:NumberCarsOwned)[1]’,’int’) AS NumberCarsOwned FROM Person.Person WHERE BusinessEntityID = 15291 GO — с использованием метода nodes() ;С XMLNAMESPACES (‘http://schemas.microsoft.com/sqlserver/2004/07/adventure-works/IndividualSurvey’ AS ns) SELECT FirstName, MiddleName, LastName, C.value(‘ns:Occupation[1]’,’varchar(50)’) AS Occupation, C.value(‘ns:Education[1]’,’varchar( 50)’) AS Education, C.value(‘ns:HomeOwnerFlag[1]’,’bit’) AS HomeOwnerFlag, C.value(‘ns:NumberCarsOwned[1]’,’int’) AS NumberCarsOwned FROM Person.Person ПЕРЕКРЕСТНОЕ ПРИМЕНЕНИЕ Demographics. WHERE BusinessEntityID = 15291 GO |
 value(‘(/ns:IndividualSurvey/ns:Occupation)[1]’,’varchar(50)’) AS Occupation,
value(‘(/ns:IndividualSurvey/ns:Occupation)[1]’,’varchar(50)’) AS Occupation, nodes(‘/ns:IndividualSurvey’) AS T(C)
nodes(‘/ns:IndividualSurvey’) AS T(C)В свете этого, зачем вообще использовать метод nodes()? Для простых запросов, вероятно, лучше не использовать его, хотя разница в стоимости пакета или времени выполнения запроса может быть незначительной. Мы показали использование nodes() на очень простом примере, но его также можно использовать в более сложных запросах, где необходимо возвращать подмножества наборов узлов — используя nodes() в результате nodes(). Его также очень удобно использовать для создания нового XML из существующих узлов. Поскольку nodes() работает путем рендеринга логических частей экземпляров XML в виде наборов узлов, он идеально подходит для случаев, когда результаты запроса должны быть возвращены в форме узла.
Объединение XML
Другой, возможно, более необычной процедурой является объединение данных XML из разных экземпляров. Давайте сделаем это для демонстрации — объединим все данные опроса магазина из таблицы Sales. Store в одну XML-структуру для SalesPersonID 282 . Данные опроса магазина находятся в XML-столбце Demographics . Мы также хотим включить 2 не-XML поля для каждого магазина: Имя и BusinessEntityID, как атрибуты узла в родительском Сохранить ‘ узел. Чтобы завершить процесс, мы завершим окончательную XML-структуру корневым узлом « StoreSurveys ».
Store в одну XML-структуру для SalesPersonID 282 . Данные опроса магазина находятся в XML-столбце Demographics . Мы также хотим включить 2 не-XML поля для каждого магазина: Имя и BusinessEntityID, как атрибуты узла в родительском Сохранить ‘ узел. Чтобы завершить процесс, мы завершим окончательную XML-структуру корневым узлом « StoreSurveys ».
Возьмем образец из 5 записей из таблицы Sales.Store для SalesPersonID 282 :
—получить первые 5 записей для SalesPerson 282 SELECT TOP 5 * FROM Sales.Store WHERE SalesPersonID = 282 GO |
XML-данные опроса магазина (столбец Demographics ) для магазина Vinyl and Plastic Goods Corporation выглядят следующим образом:
Чтобы собрать все данные опроса магазина для одного продавца в один экземпляр XML, мы можем снова используйте предложение FOR XML. Как и при предыдущем использовании FOR XML, аргумент AUTO будет первым, который мы попробуем. Помните, что аргумент AUTO по умолчанию собирает каждое поле, отличное от XML, в структуру XML в форме атрибута узла 9.0048 . Как и аргумент PATH, он также вкладывает любые существующие данные столбца XML в виде узлов элементов :
Как и при предыдущем использовании FOR XML, аргумент AUTO будет первым, который мы попробуем. Помните, что аргумент AUTO по умолчанию собирает каждое поле, отличное от XML, в структуру XML в форме атрибута узла 9.0048 . Как и аргумент PATH, он также вкладывает любые существующие данные столбца XML в виде узлов элементов :
| . 1 2 3 4 5 6 7 8 | — XML-данные опроса магазина SELECT Name, BusinessEntityID AS ID, Demographics.query(‘/’) ИЗ Sales.Store AS Store ГДЕ SalesPersonID = 2 82 ДЛЯ XML АВТО GO |
Мы использовали метод XQuery query() для запроса, начиная с корня каждого экземпляра XML (используя «/» в выражении пути). Похоже, мы получили желаемый результат, за исключением того, что вокруг всей структуры нет корневого узла. Мы использовали аргумент PATH в нашем другом примере FOR XML, но мы не можем использовать его здесь, так как мы используем AUTO для получения значений атрибутов узла. Чтобы создать узел-оболочку при использовании аргумента AUTO, мы будем использовать аргумент ROOT:
Чтобы создать узел-оболочку при использовании аргумента AUTO, мы будем использовать аргумент ROOT:
1 2 3 4 5 6 7 8 | — объединить XML-данные опроса магазина с использованием ROOT-аргумента E SalesPersonID = 282 ДЛЯ XML AUTO, ROOT(‘StoreSurveys’) GO |
Добавление аргумента ROOT дает нам требуемый узел-оболочку верхнего уровня, объединяющий все записи опроса магазина для продавца в один экземпляр XML с корневым узлом.
Разделение XML
Если бы мы выполнили преобразование из предыдущего примера, нам нужно было бы извлечь отдельный блок узла StoreSurvey из объединенного экземпляра XML опросов магазинов (показанного выше) для каждого магазина. имя или идентификатор. Разделение фрагментов XML-данных на логические записи по существу включает те же процедуры, которые мы используем при измельчении XML, но в этом случае мы сохраним часть структуры XML. Чтобы продемонстрировать, давайте объединим опросы магазинов для SalesPersonID 9.0007 282 еще раз; однако на этот раз мы будем использовать переменную XML для хранения комбинированных опросов магазинов:
Чтобы продемонстрировать, давайте объединим опросы магазинов для SalesPersonID 9.0007 282 еще раз; однако на этот раз мы будем использовать переменную XML для хранения комбинированных опросов магазинов:
| . 1 2 3 4 5 6 7 8 9 9 0003 10 11 12 13 | — создать XML-экземпляр данных опроса магазина, используя переменную XML DECLARE @xml XML
SET @xml = ( SELECT Имя, BusinessEntityID AS ID, Demographics.query(‘/’) ИЗ Sales.Store AS Store WHERE SalesPersonID = 282 FOR XML AUTO, ROOT(‘StoreSurveys’) )
ВЫБЕРИТЕ @xml |
На данный момент у нас та же структура XML, что и раньше:
Теперь мы разобьем XML на логические записи, снова используя метод XQuery nodes():
1 2 3 4 5 6 7 | — отдельные XML-записи обзора магазина ;С XMLNAMESPACES (‘http://schemas. SELECT C.value(‘. ./@ID’,’int’) AS BusinessEntityID, C.value(‘../@Name’,’varchar(50)’) AS StoreName, C.query(‘.’) AS Demographics ОТ @xml.nodes(‘/StoreSurveys/Store/ns:StoreSurvey’) AS T(C) GO |
 microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey’ AS ns)
microsoft.com/sqlserver/2004/07/adventure-works/StoreSurvey’ AS ns)Новая XML-структура Demographics для BusinessEntityID 312 :
Обратите внимание, что в этот раз мы использовали , а не , используя CROSS APPLY, поскольку XML-данные были в переменной, а не в XML-столбец в таблице. Кроме того, мы использовали ‘ . ‘, аббревиатура self::node(), в выражении пути метода query() — для извлечения данных опроса магазина. Это указывает на то, что часть XML должна быть извлечена из набора узлов метода nodes() ( ‘ Store ‘ узел), тогда как выражение корневого пути ‘ / ’ привело бы к извлечению XML из корневого узла (таким образом, возвращая всю структуру XML). Также обратите внимание, что мы использовали аббревиатуру parent::node() ‘ .. ‘ для ссылки на значения атрибутов ‘ Name ‘ и ‘ ID ‘, которые находятся в узле над ‘ StoreSurvey узел (родительский узел « Store »). Вариант сценария, который не требует объявления пространства имен, может быть записано следующим образом:
Также обратите внимание, что мы использовали аббревиатуру parent::node() ‘ .. ‘ для ссылки на значения атрибутов ‘ Name ‘ и ‘ ID ‘, которые находятся в узле над ‘ StoreSurvey узел (родительский узел « Store »). Вариант сценария, который не требует объявления пространства имен, может быть записано следующим образом:
1 2 3 4 5 6 | — XML-записи опроса в отдельном магазине без объявления пространства имен StoreName, C.query(‘./child::node()’) AS Demographics ОТ @xml.nodes(‘/StoreSurveys/Store’) AS T(C) GO |
Приведенный выше скрипт использует дочернюю ось для детализации на один уровень дальше, чем набор узлов метода nodes(), тем самым устраняя необходимость напрямую ссылаться на узел « StoreSurvey ».
Резюме
Мы рассмотрели некоторые способы приведения данных XML в соответствие с конкретными потребностями. Мы обработали один распространенный запрос, создав экземпляры XML из существующих таблиц с помощью предложения FOR XML, применяя соответствующие аргументы для разработки структуры XML в соответствии с конкретными эстетическими требованиями. Мы продемонстрировали еще одну очень распространенную процедуру — измельчение XML-данных с помощью метода XQuery nodes(). Мы видели, что несколько фрагментов и экземпляров XML также можно объединить в один экземпляр с помощью инструментов FOR XML. Затем мы отменили эту операцию, разбив экземпляр XML на логические записи данных XML.
Манипулирование XML-данными в соответствии с вашими потребностями может потребовать творческого подхода и некоторых экспериментов с новыми инструментами. Мы разработали решения для нескольких основных проблем, но есть еще чему поучиться. Методы, которые мы представили здесь, должны помочь вам начать работу.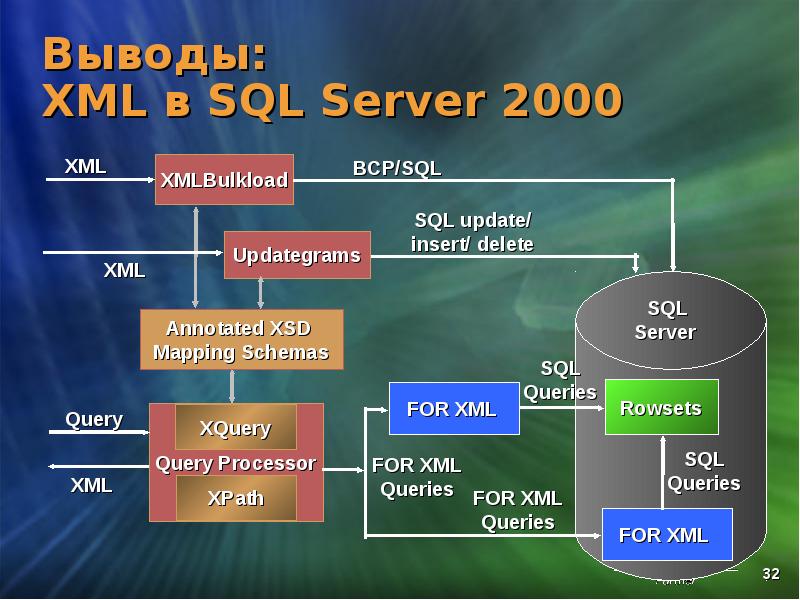
Когда следует использовать тип данных XML в SQL Server?
спросил
Изменено
4 года, 1 месяц назад
Просмотрено
22к раз
Когда следует использовать тип данных XML в Microsoft SQL Server?
- sql-сервер
- xml
0
Я проделал нечто подобное, сериализовав объектные данные в XML для хранения. Это снимает бремя наличия таблиц, столбцов и связей для хранения данных для сложных объектов. Этому процессу можно помочь, используя схему, которой соответствует результирующий XML, а таблицы базы данных можно использовать для метаинформации о рассматриваемых объектах. В моем случае расширение схемы базы данных для размещения объектов было бы большой задачей!
1
Лично я никогда раньше не использовал тип поля XML в SQL Server, и с тех пор, как они добавили эту функцию, я много программировал для баз данных.![]() Мне всегда казалось, что изначальное использование XML-контента в базе данных сопряжено с программными издержками и накладными расходами. Честно говоря, я думал, что это уловка, потому что в начале 2000-х все были на поезде XML. «О, XML — это круто, так что давайте добавим его в SQL Server, чтобы не выглядеть устаревшим».
Мне всегда казалось, что изначальное использование XML-контента в базе данных сопряжено с программными издержками и накладными расходами. Честно говоря, я думал, что это уловка, потому что в начале 2000-х все были на поезде XML. «О, XML — это круто, так что давайте добавим его в SQL Server, чтобы не выглядеть устаревшим».
Наилучшее экономическое обоснование, которое я вижу, может заключаться в записи полученных вами сообщений данных на основе XML, когда вы можете заглянуть в их структуру и данные, но хотите сохранить целостность исходного сообщения по деловым или юридическим причинам. Накладные расходы могут быть слишком велики для преобразования XML в структуру таблицы, но использование возможностей XML в SQL Server может просто снизить стоимость проверки данных настолько, чтобы гарантировать их использование.
Вероятно, есть десятки других причин, по которым вы хотели бы использовать его, но, честно говоря, я думаю, что вам следует рассмотреть другие пути к счастью, прежде чем сходить с ума с XML в SQL Server, если у вас нет для этого особых бизнес-причин. Используйте varchar(max) или текстовое поле, если это имеет смысл.
Используйте varchar(max) или текстовое поле, если это имеет смысл.
Только мое мнение, конечно 🙂
2
Я столкнулся лишь с несколькими сценариями, в которых активно использовал бы тип данных XML в SQL Server. Это не пришло мне в голову, в порядке от менее интересного к наиболее интересному:
- Хранение/архивирование XML-ответов, сгенерированных другими приложениями.
- Например, мы используем Application Integration Framework (AIF) для связи между пользовательским приложением Silverlight и Dynamics AX. Мы храним как входящие, так и исходящие сообщения в базе данных, чтобы помочь в устранении неполадок связи между этими приложениями
- Поскольку типом поля является XML, а не общий строковый тип (т. е. VARCHAR), мы можем использовать XQuery для специального запроса сообщений, соответствующих определенным критериям. Это было бы намного сложнее с простой строкой LIKE, соответствующей
.
- Кэширование/сохранение составного ответного сообщения
- Обновите поле XML с помощью триггера или кода приложения, который будет имитировать вычисляемый столбец
- Вместо того, чтобы постоянно регенерировать XML-ответ вызывающему приложению, вы будете нести накладные расходы только при обновлении строки, а не при каждом вызове
- Это работает лучше всего, когда SELECT намного чаще, чем UPDATE/INSERT, что, как правило, верно для большинства приложений
- Сохранение нескольких значений в одном поле
- Одна из известных мне практик — использование типа данных XML для хранения набора значений в одном поле
- Одним из преимуществ является то, что вам не нужно разрабатывать дополнительный набор таблиц для простого хранилища ключей и значений
- Недостатком этого является то, что данные не полностью нормализованы, что делает запросы менее очевидными
- Однако, как упоминалось выше, вы можете использовать XQuery для этого поля XML, чтобы выбрать строки, которые соответствуют критериям идентификации, тем самым частично нейтрализуя влияние неполной нормализации.


Все это говорит о том, что в 99% случаев мне абсолютно не нужно поле XML при разработке схемы.
Несколько раз, когда я видел тип данных XML на сервере SQL, он в основном использовался как поле, которое запрашивалось так же, как и любое другое в базе данных, что может иметь очень плохие последствия для производительности, если у вас есть большое количество данных. Есть причина, по которой он называется SQL-сервером, а не XML-сервером. 🙂 Запросы, которые идут против XML, просто не так быстры, как выполнение обычного запроса на выборку.
Я мог видеть, что он используется для хранения XML, который не так часто запрашивается, скажем, для хранения полного XML-документа в типе данных XML, но с доступными для поиска полями (ключами), хранящимися отдельно с XML-документом. Таким образом, вы сможете быстрее запрашивать информацию и получать XML-документ, когда дойдете до точки, где вы хотите увидеть полный документ. На самом деле мне пришлось вернуться и сделать это с рядом приложений, в которых люди пытались использовать тип данных XML в качестве сильно запрашиваемого поля, и данные выросли до такой степени, что запрос стал слишком медленным.
Я использовал поля типа XML в основном для ведения журналов, связанных с веб-службами ASMX или службами WCF. Вы можете сохранить запрос или ответные сообщения.
В большинстве случаев вы сохраняете XML в БД для справочных целей, а не для своей обычной деловой активности (не запрашивать его каждые 5 секунд из кода). Если вы обнаружите, что делаете это, определите поля, которые вы обычно запрашиваете или используете большую часть времени, и создайте для них отдельные столбцы. Таким образом, когда вы сохраняете XML в БД, вы можете извлечь эти поля и сохранить их в соответствующих столбцах. Позже при их извлечении вам не нужно будет запрашивать XML-документ, вы можете просто использовать столбцы, созданные для этой цели.
Вот сценарии, которые сразу же приходят на ум при рассмотрении того, какие условия должны существовать для разрешения полей Xml в Sql Server:
- двоичные данные, закодированные для обмена
где вы хотите кислоту, как контроль над
ресурс - фрагментов документа, которые будут полностью воссозданы с помощью динамического
информация - отправленных пользователем документов или фрагментов, которые вы хотите изолировать
и хотя бы на временной основе сохранить
непосредственно из файловой системы.
