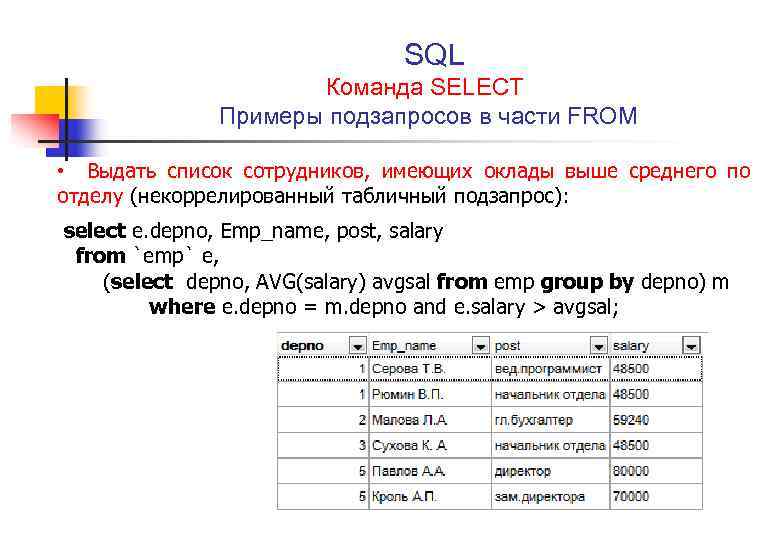
Mysql group by несколько полей: Группировка по нескольким столбцам
Содержание
Группировка по нескольким столбцам
Группировка по нескольким столбцам
Группировка
по нескольким столбцам
В предложениях GROUP BY можно
указывать столько столбцов, сколько вам необходимо, разделяя имена
элементы
списка запятыми. Таким образом, путем группировки одновременно по
нескольким
элементам можно создавать группы внутри групп. Каждый элемент из списка
GROUP
BY должен обязательно присутствовать в списке выбора —
другими словами,
группировать можно только выбираемые элементы.
Пример
SQL:
SELECT region, sex, COUNT(*) AS num_clients
FROM tbl_clients
GROUP BY
region, sex
Результат:
| region | sex | num_clients |
| California | f | 18 |
| California | m | 15 |
| Los Angeles | f | 42 |
| Los Angeles | m | 57 |
| New Jersey | f | 12 |
| New Jersey | m | 21 |
| New York | f | 15 |
| New York | m | 18 |
| Oregon | f | 15 |
| Oregon | m | 18 |
| Portland | f | 12 |
| Portland | m | 32 |
| Seattle | f | 37 |
| Seattle | m | 40 |
| Washington | f | 21 |
| Washington | m | 11 |
Сначала строки таблицы разделяются
по городам, а затем каждая полученная группа разделяется по полу
клиента. В
В
результате получается 16 групп, или наборов. После этого к каждому
такому
набору применяется агрегирующая функция, которая вычисляет для каждого
города
количество клиентов женского и мужского пола.
« Previous | Next »
SQL GROUP BY — группировка в запросах
Навигация по уроку
- Группировка по одному столбцу без агрегатных функций
- Группировка по нескольким столбцам без агрегатных функций
- Группировка с агрегатными функциями
- Особенности применения группировки в MS SQL Server
Связанные темы
- Оператор SELECT
- Агрегатные функции
| Назад | Содержание | Вперёд>>> |
Оператор SQL GROUP BY служит для распределения строк — результата запроса — по группам, в которых
значения некоторого столбца, по которому происходит группировка, являются одинаковыми. Группировку можно
Группировку можно
производить как по одному столбцу, так и по нескольким.
Часто оператор SQL GROUP BY применяется вместе с агрегатными функциями (COUNT, SUM, AVG, MAX, MIN).
В этих случаях агрегатные функции служат для вычисления соответствующего агрегатного значения ко всему
набору строк, для которых некоторый столбец — общий.
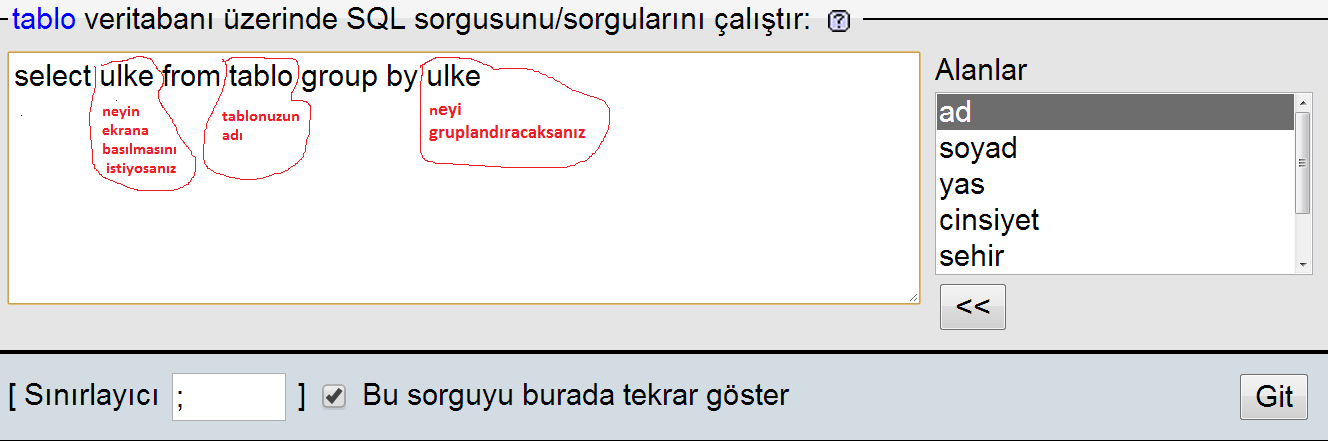
Оператор GROUP BY имеет следующий синтаксис:
SELECT ИМЕНА_СТОЛБЦОВ
FROM ИМЯ_ТАБЛИЦЫ
[WHERE УСЛОВИЕ]
GROUP BY ИМЕНА_СТОЛБЦОВ
Если в результате запроса требуется вывести один столбец и по этому же столбцу производится группировка,
то оператор GROUP BY просто выбирает уникальные значения и убирает дубликаты, то есть выполняет те же задачи, что и ключевое слово DISTINCT.
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД
не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Скрипт для создания базы данных библиотеки, её таблиц и заполения таблиц данными —
в файле по этой ссылке.
В примерах работаем с базой данных библиотеки и ее таблицей «Книга в пользовании» (Bookinuse). Отметим, что
оператор GROUP BY ведёт себя несколько по-разному в MySQL и в MS SQL Server. Эти различия будут показаны на
примерах.
| Author | Title | Pubyear | Inv_No | Customer_ID |
| Толстой | Война и мир | 2005 | 28 | 65 |
| Чехов | Вишневый сад | 2000 | 17 | 31 |
| Чехов | Избранные рассказы | 2011 | 19 | 120 |
| Чехов | Вишневый сад | 1991 | 5 | 65 |
| Ильф и Петров | Двенадцать стульев | 1985 | 3 | 31 |
| Маяковский | Поэмы | 1983 | 2 | 120 |
| Пастернак | Доктор Живаго | 2006 | 69 | 120 |
| Толстой | Воскресенье | 2006 | 77 | 47 |
| Толстой | Анна Каренина | 1989 | 7 | 205 |
| Пушкин | Капитанская дочка | 2004 | 25 | 47 |
| Гоголь | Пьесы | 2007 | 81 | 47 |
| Чехов | Избранные рассказы | 1987 | 4 | 205 |
| Пушкин | Сочинения, т. 1 1 | 1984 | 6 | 47 |
| Пастернак | Избранное | 2000 | 137 | 18 |
| Пушкин | Сочинения, т.2 | 1984 | 8 | 205 |
| NULL | Наука и жизнь 9 2018 | 2019 | 127 | 18 |
| Чехов | Ранние рассказы | 2001 | 171 | 31 |
Пример 1. Вывести авторов выданных книг, сгруппировав их. Пишем
следующий запрос:
SELECT Author
FROM BOOKINUSE
GROUP BY Author
Этот запрос вернёт следующий результат:
| Author |
| NULL |
| Гоголь |
| Ильф и Петров |
| Маяковский |
| Пастернак |
| Пушкин |
| Толстой |
| Чехов |
Как видим, в таблице стало меньше строк, так как фамилии
авторов остались каждая по одной.
В следующем примере увидим, что оператор GROUP BY не следует путать
с оператором ORDER BY и поймём, чем эти операторы отличаются друг от друга.
Пример 2. Вывести авторов и названия выданных книг,
сгруппировав по авторам. Пишем
следующий запрос, который допустим в MySQL:
SELECT Author, Title
FROM Bookinuse
GROUP BY Author
Этот запрос вернёт следующий результат:
| Author | Title |
| NULL | Наука и жизнь 9 2018 |
| Гоголь | Пьесы |
| Ильф и Петров | Двенадцать стульев |
| Маяковский | Поэмы |
| Пастернак | Доктор Живаго |
| Пушкин | Капитанская дочка |
| Толстой | Война и мир |
| Чехов | Вишнёвый сад |
Как видим, в таблице каждому автору соответствует лишь одна книга, причём та,
которая в таблице BOOKINUSE является первой по порядку записей.
Если бы нам требовалось вывести все книги, причём авторы должны были бы следовать
не «вразброс», а по порядку: сначала Гоголь и все его книги, затем другие авторы и все их книги,
то мы применили бы не оператор GROUP BY, а оператор ORDER BY.
По-другому ведёт себя оператор GROUP BY в MS SQL Server.
И всё же вывести все записи, соответствующие значению столбца, по которому происходит
группировка, можно. Но в этом случае в результирующей таблице должен появиться ещё один столбец. Такой
случай проиллюстирован в следующем примере.
Пример 3. Вывести авторов, названия выданных книг, ID пользователя и
инвентарный номер выданной книги.
Сгруппировать по авторам, ID пользователя и инвентарному номеру. На MySQL запрос будет следующим:
SELECT Author, Title, Customer_ID, Inv_no
FROM Bookinuse
GROUP BY Author, Customer_ID, Inv_no
Этот запрос вернёт следующий результат:
| Author | Title | Customer_ID | Inv_no |
| Гоголь | Пьесы | 47 | 81 |
| Ильф и Петров | Двенадцать стульев | 31 | 3 |
| Маяковский | Поэмы | 120 | 2 |
| Пастернак | Избранное | 18 | 137 |
| Пастернак | Доктор Живаго | 120 | 69 |
| Пушкин | Капитанская дочка | 47 | 25 |
| Пушкин | Сочинения, т. 1 1 | 47 | 6 |
| Пушкин | Сочинения, т.2 | 205 | 8 |
| Толстой | Воскресенье | 47 | 77 |
| Толстой | Война и мир | 65 | 28 |
| Толстой | Анна Каренина | 205 | 7 |
| Чехов | Вишневый сад | 31 | 19 |
| Чехов | Ранние рассказы | 31 | 171 |
| Чехов | Вишневый сад | 65 | 5 |
| Чехов | Избранные рассказы | 120 | 19 |
| Чехов | Избранные рассказы | 205 | 4 |
Как видим, в результирующей таблице присутствуют все книги всех авторов, причём авторы
следуют по порядку, как если бы мы применили оператор ORDER BY. Кроме того, видно, что записи сгруппированы
и по второму указанному столбцу — Customer_ID. Так, у автора Пушкина сначала перечисляются книги, выданные
пользователю с Customer_ID 47, а затем — 205. У автора Чехова сначала перечисляются книги, выданные
У автора Чехова сначала перечисляются книги, выданные
пользователю с Customer_ID 31, а затем — с другими номерами. Третий столбец, по которому происходит группировка — Inv_no —
добавлен только для того, чтобы в результирующей таблице выводились все строки, соответствующие значениям
ранее перечисленных столбцов для группировки, а не только уникальные.
По-другому ведёт себя
оператор GROUP BY в MS SQL Server
и в случае этого запроса.
- Группировка по одному столбцу без агрегатных функций
- Группировка по нескольким столбцам без агрегатных функций
- Группировка с агрегатными функциями
- Особенности применения группировки в MS SQL Server
Поделиться с друзьями
| Назад | Содержание | Вперёд>>> |
sql — Можно ли сгруппировать несколько столбцов с помощью MySQL?
спросил
Изменено
4 года, 7 месяцев назад
Просмотрено
509 тысяч раз
Возможно ли GROUP BY более одного столбца в запросе MySQL SELECT ? Например:
СГРУППИРОВАТЬ ПО fV.tier_id И 'f.form_template_id'
 tier_id И 'f.form_template_id'
tier_id И 'f.form_template_id'
- mysql
- sql
- группировка по
4
ГРУППИРОВАТЬ ПО col1, col2, col3
Да, вы можете группировать по нескольким столбцам. Например,
ВЫБЕРИТЕ * ИЗ таблицы СГРУППИРОВАТЬ ПО col1, col2
Результаты сначала будут сгруппированы по столбцу 1, а затем по столбцу 2. В MySQL предпочтения столбцов идут слева направо.
3
Да, но что означает группировка по двум столбцам? Ну, это то же самое, что и группировка по каждой уникальной паре в строке. Порядок, в котором вы перечисляете столбцы, меняет способ сортировки строк.
В вашем примере вы должны написать
GROUP BY fV.tier_id, f.form_template_id
Между тем, код
GROUP BY f.form_template_id, fV.tier_id
900 даст аналогичные результаты иначе.
группа по fV.
 tier_id, f.form_template_id
tier_id, f.form_template_id
Чтобы использовать простой пример, у меня был счетчик, который должен был суммировать уникальные IP-адреса на посещенную страницу на сайте. Это в основном группировка по имени страницы, а затем по IP. Я решил это с помощью комбинации DISTINCT и GROUP BY.
ВЫБЕРИТЕ имя страницы, COUNT(DISTINCT ipaddress) AS visit_count FROM log_visitors GROUP BY pagename ORDER BY visit_count DESC;
1
Если вы предпочитаете (мне нужно применить это) группировать по двум столбцам одновременно, я только что увидел этот пункт:
SELECT CONCAT (col1, '_', col2) AS Group1 ... GROUP BY Group1
1
ГРУППИРОВКА ПО СЦЕП (столбец1, '_', столбец2)
6
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
sql — выбрать несколько столбцов из таблицы, но сгруппировать по одному
спросил
Изменено
11 месяцев назад
Просмотрено
315 тысяч раз
Имя таблицы "OrderDetails" и столбцы приведены ниже:
OrderDetailID || ID товара || Название продукта || Заказанное Количество
Я пытаюсь выбрать несколько столбцов и сгруппировать по ProductID, имея SUM для OrderQuantity.
Выберите ProductID, ProductName, OrderQuantity Sum (OrderQuantity) из группы OrderDetails по ProductID
Но конечно этот код выдает ошибку. Мне нужно добавить другие имена столбцов для группировки, но это не то, что я хочу, и, поскольку мои данные содержат много элементов, поэтому результаты в этом случае неожиданны.
Образец запроса данных:
ProductID, ProductName, OrderQuantity from OrderDetails
Ниже приведены результаты:
ProductID ProductName OrderQuantity
1001 азбука 5
1002 abc 23 (названия продуктов могут совпадать)
2002 хиз 8
3004 год 15
4001 аз 19
1001 abc 7 (2-я строка того же ProductID)
Ожидаемый результат:
ProductID ProductName OrderQuantity
1001 abc 12 (группировать по productID при суммировании)
1002 абв 23
2002 хиз 8
3004 год 15
4001 аз 19Как выбрать несколько столбцов и столбец Group By ProductID, поскольку ProductName не является уникальным?
При этом также получите сумму столбца OrderQuantity.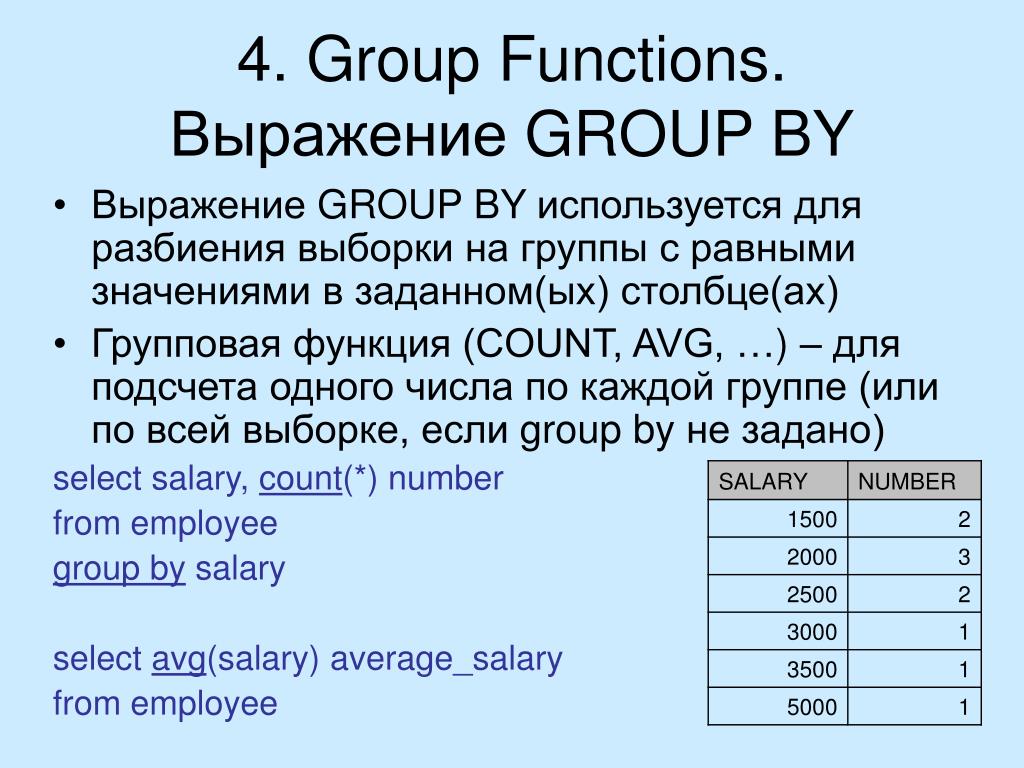
- sql
- группировка по
2
Я использую этот трюк для группировки по одному столбцу, когда у меня есть выбор из нескольких столбцов:
SELECT MAX(id) AS id,
номер,
MAX(intrare) КАК внутреннее,
MAX(iesire) КАК iesire,
МАКС.(внутренний) КАК запас,
МАКС(данные) AS данные
ИЗ ПРОДУКТА
СГРУППИРОВАТЬ ПО НОМЕРУ
ЗАКАЗАТЬ ПО НОМЕРУ
Это работает.
11
Я просто хотел добавить более эффективный и универсальный способ решения подобных проблем.
Основная идея заключается в работе с подзапросами.
сделайте свою группу и присоединитесь к той же таблице по ID таблицы.
ваш случай более конкретен, так как ваш productId не уникален , поэтому есть 2 способа решить эту проблему.
Начну с более конкретного решения:
Поскольку ваш productId равен не уникальный нам понадобится дополнительный шаг, который заключается в выборе DISCTINCT идентификаторов продуктов после группировки и выполнения подзапроса, например:
WITH CTE_TEST AS (SELECT productId, SUM(OrderQuantity) Total
ОТ Детали заказа
СГРУППИРОВАТЬ ПО productId)
SELECT DISTINCT(OrderDetails. ProductID), OrderDetails.ProductName, CTE_TEST.Total
ОТ Детали заказа
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.ProductID = OrderDetails.ProductID
 ProductID), OrderDetails.ProductName, CTE_TEST.Total
ОТ Детали заказа
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.ProductID = OrderDetails.ProductID
ProductID), OrderDetails.ProductName, CTE_TEST.Total
ОТ Детали заказа
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.ProductID = OrderDetails.ProductID
возвращает именно то, что ожидалось
ProductID ProductName Итого
1001 азбука 12
1002 абв 23
2002 хиз 8
3004 год 15
4001 аз 19
Но есть более чистый способ сделать это. Я предполагаю, что ProductId является внешним ключом к таблице продуктов, и я предполагаю, что в этой таблице должен быть и OrderId первичный ключ (уникальный).
в этом случае нужно сделать несколько шагов, чтобы включить дополнительные столбцы при группировке только по одному. Это будет такое же решение, как следующее
. Возьмем, например, эту таблицу t_Value :
Если я хочу сгруппировать по описанию, а также отобразить все столбцы.
Все, что мне нужно сделать, это:
- создать подзапрос
WITH CTE_Nameс вашим столбцом GroupBy и условием COUNT - выберите все (или то, что вы хотите отобразить) из таблицы значений и итог из CTE
-
INNER JOINс CTE в столбце ID (первичный ключ или уникальное ограничение )
и все!
Вот запрос
WITH CTE_TEST AS (SELECT Description, MAX(Id) specID, COUNT(Description) количество
ИЗ sch_dta. t_value
СГРУППИРОВАТЬ ПО Описание)
ВЫБЕРИТЕ sch_dta.t_Value.*, CTE_TEST.quantity
ИЗ sch_dta.t_Value
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.specID = sch_dta.t_Value.Id
 t_value
СГРУППИРОВАТЬ ПО Описание)
ВЫБЕРИТЕ sch_dta.t_Value.*, CTE_TEST.quantity
ИЗ sch_dta.t_Value
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.specID = sch_dta.t_Value.Id
t_value
СГРУППИРОВАТЬ ПО Описание)
ВЫБЕРИТЕ sch_dta.t_Value.*, CTE_TEST.quantity
ИЗ sch_dta.t_Value
ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_TEST ON CTE_TEST.specID = sch_dta.t_Value.Id
И вот результат:
Ваши данные
DECLARE @OrderDetails TABLE (ProductID INT, ProductName VARCHAR(10), OrderQuantity INT) ВСТАВИТЬ В ЗНАЧЕНИЯ @OrderDetails (1001, 'abc', 5), (1002, 'abc', 23), (2002, 'xyz', 8), (3004, 'ytp', 15), (4001, 'az', 19), (1001, 'abc', 7)
Запрос
Выберите ProductID, ProductName, Sum(OrderQuantity) AS Total из @OrderDetails Сгруппировать по ProductID, ProductName ORDER BY ProductID
Результат
║ ProductID ║ ProductName ║ Итого ║ ╠═══════════╬═════════════╬═══════╣ ║ 1001 ║ азбука ║ 12 ║ ║ 1002 ║ азбука ║ 23 ║ ║ 2002 ║ хыз ║ 8 ║ ║ 3004 ║ год ║ 15 ║ ║ 4001 ║ азэ ║ 19 ║ ╚═══════════╩═════════════╩═══════╝
12
mysql GROUP_CONCAT может помочь функция https://dev. mysql.com/doc/refman/8.0/en/group-by-functions.html#function_group-concat
mysql.com/doc/refman/8.0/en/group-by-functions.html#function_group-concat
ВЫБРАТЬ ProductID, GROUP_CONCAT(DISTINCT ProductName) как имена, SUM(OrderQuantity) ИЗ OrderDetails СГРУППИРОВАТЬ ПО ProductID
Это вернет:
ProductID Имена OrderQuantity 1001 красный 5 1002 красный, черный 6 1003 оранжевый 8 1004 черный, оранжевый 15
Идея аналогична той, которую @Urs Marian опубликовал здесь https://stackoverflow.com/a/38779277/906265
1
С CTE_SUM КАК (
ВЫБЕРИТЕ ProductID, Sum(OrderQuantity) AS TotalOrderQuantity
ИЗ OrderDetails СГРУППИРОВАТЬ ПО ProductID
)
SELECT DISTINCT OrderDetails.ProductID, OrderDetails.ProductName, OrderDetails.OrderQuantity,CTE_SUM.TotalOrderQuantity
ОТ
Детали заказа ВНУТРЕННЕЕ СОЕДИНЕНИЕ CTE_SUM
ON OrderDetails.ProductID = CTE_SUM.ProductID
Пожалуйста, проверьте, работает ли это.
Вы можете попробовать следующий запрос. Я предполагаю, что у вас есть одна таблица для всех ваших данных.
Я предполагаю, что у вас есть одна таблица для всех ваших данных.
ВЫБЕРИТЕ OD.ProductID, OD.ProductName, CalQ.OrderQuantity
ОТ (ВЫБЕРИТЕ РАЗЛИЧНЫЕ ProductID, ProductName
ОТ ЗаказДетали) ОД
ВНУТРЕННЕЕ СОЕДИНЕНИЕ (ВЫБЕРИТЕ ProductID, СУММА OrderQuantity (OrderQuantity)
ОТ Детали заказа
СГРУППИРОВАТЬ ПО ProductID) CalQ
ON CalQ.ProductID = OD.ProductID
На мой взгляд, это серьезный недостаток языка, из-за которого SQL отстает от других языков на световые годы. Это мой невероятно хакерский обходной путь. Это полный кладж, но он всегда работает.
Прежде чем я это сделаю, я хочу обратить внимание на ответ @Peter Mortensen, который, на мой взгляд, является правильным ответом. Единственная причина, по которой я делаю это ниже, заключается в том, что большинство реализаций SQL имеют невероятно медленные операции соединения и заставляют вас ломать «не повторяйтесь». Мне нужно, чтобы мои запросы заполнялись быстро.
Также это старый способ ведения дел. STRING_AGG и STRING_SPLIT намного чище. Опять же, я делаю это так, потому что это всегда работает.
STRING_AGG и STRING_SPLIT намного чище. Опять же, я делаю это так, потому что это всегда работает.
-- помните, что подстрока индексируется 1, а не 0
ВЫБЕРИТЕ идентификатор продукта
, ПОДСТРОКА (
MAX(enc.pnameANDoq), 1, CHARINDEX(';', MAX(enc.pnameANDoq)) - 1
) КАК Название продукта
, СУММА ( ПРИВЕДЕНО ( ПОДСТРОКА (
MAX(enc.pnameAndoq), CHARINDEX(';', MAX(enc.pnameANDoq)) + 1, 9999
) КАК INT )) КАК Количество Заказа
ОТ (
SELECT CONCAT (ProductName, ';', CAST (OrderQuantity AS VARCHAR (10)))
AS pnameANDoq, ProductID
ОТ Детали заказа
) enc
СГРУППИРОВАТЬ ПО ProductID
Или на простом языке:
- Склеить все поля, кроме одного, в строку с разделителем, который, как вы знаете, не будет использоваться
- Использовать подстроку для извлечения данных после их группировки
С точки зрения производительности У меня всегда была более высокая производительность при использовании строк по сравнению с такими вещами, как, скажем, bigints. По крайней мере, с microsoft и oracle substring - это быстрая операция.
По крайней мере, с microsoft и oracle substring - это быстрая операция.
Это позволяет избежать проблем, с которыми вы сталкиваетесь при использовании MAX(), когда при использовании MAX() для нескольких полей они больше не согласуются и поступают из разных строк. В этом случае ваши данные гарантированно будут склеены именно так, как вы просили.
Для доступа к 3-му или 4-му полю вам понадобятся вложенные подстроки, "после первой точки с запятой ищите 2-ю". Вот почему STRING_SPLIT лучше, если он доступен.
Примечание. Хотя это выходит за рамки вашего вопроса, это особенно полезно, когда вы находитесь в противоположной ситуации и группируете по комбинированному ключу, но не хотите, чтобы отображались все возможные перестановки, то есть вы хотите выставить «foo ' и 'bar' в качестве комбинированного ключа, но хотите сгруппировать по 'foo'
==EDIT==
Я еще раз проверил ваш вопрос и пришел к выводу, что это невозможно.
ProductName не уникально.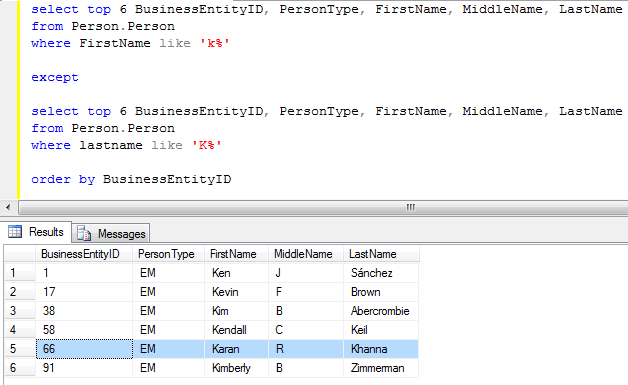 Оно должно либо входить в группу
Оно должно либо входить в группу по , либо быть исключено из ваших результатов.
Например, как SQL представит вам эти результаты, если вы Group By только ProductID?
ProductID | Название продукта | Заказанное Количество --------------------------------------- 1234 | азбука | 1 1234 | деф | 1 1234 | гхи | 1 1234 | jkl | 1
7
Вы можете попробовать это:
Выберите ProductID, ProductName, Sum (OrderQuantity) из группы OrderDetails по ProductID, ProductName
Требуется только столбцы Group By , которые не имеют агрегатной функции в предложении Select . Таким образом, вы можете просто использовать Group By ProductID и ProductName в этом случае.
3
У меня была похожая проблема с ОП. Затем я увидел ответ от @Urs Marian, который очень помог.
Но, кроме того, я искал, когда в столбце есть несколько значений, и они будут сгруппированы, как я могу получить последнее отправленное значение (например, упорядоченное по столбцу даты/идентификатора).
Пример:
У нас есть следующая структура таблицы:
CREATE TABLE имя_таблицы(
[msgstr] [число] НЕ NULL,
[идентификатор пользователя] [число] НЕ NULL,
[имя пользователя] [varchar](70) NOT NULL,
[сообщение] [varchar](5000) НЕ NULL
)
Теперь в таблице минимум два набора данных:
+-------+--------+----------+------ ---+ | msgid | идентификатор пользователя | имя пользователя | сообщение | +-------+--------+----------+---------+ | 1 | 1 | пользовательА | привет | | 2 | 1 | пользователь Б | мир | +-------+--------+----------+---------+
Следовательно, следующий сценарий SQL работает (проверено на MSSQL) для его группировки, даже если один и тот же идентификатор пользователя имеет разные значения имени пользователя. В приведенном ниже примере будет показано имя пользователя с наивысшим значением msgid:
ВЫБЕРИТЕ m.
 userid,
(выберите первое имя пользователя из таблицы, где userid = m.userid в порядке msgid desc) в качестве имени пользователя,
count(*) как сообщения
FROM имя_таблицы m
СГРУППИРОВАТЬ ПО m.userid
ORDER BY count(*) DESC
userid,
(выберите первое имя пользователя из таблицы, где userid = m.userid в порядке msgid desc) в качестве имени пользователя,
count(*) как сообщения
FROM имя_таблицы m
СГРУППИРОВАТЬ ПО m.userid
ORDER BY count(*) DESC
Элегантный способ получить желаемые результаты — использовать предложение sql «over (partion by)» следующим образом:
SELECT ProductID, ProductName, OrderQuantity
,SUM(OrderQuantity) OVER(PARTITION BY ProductID) AS 'Всего'
--,AVG(OrderQuantity) OVER(PARTITION BY ProductID) AS 'Avg'
--,COUNT(OrderQuantity) OVER(PARTITION BY ProductID) AS 'Count'
--,MIN(OrderQuantity) OVER(PARTITION BY ProductID) AS 'Min'
--,MAX(OrderQuantity) OVER(PARTITION BY ProductID) AS 'Max'
ОТ Детали заказа
ВЫБЕРИТЕ ProductID, ProductName, OrderQuantity, SUM(OrderQuantity) FROM OrderDetails WHERE(OrderQuantity) IN(SELECT SUM(OrderQuantity) FROM OrderDetails GROUP BY OrderDetails) GROUP BY ProductID, ProductName, OrderQuantity;
Я использовал приведенное выше решение для решения аналогичной проблемы в Oracle12c.