Оператор select sql: SELECT | SQL | SQL-tutorial.ru
Содержание
Оператор SQL SELECT — CoderLessons.com
SQL – это всеобъемлющий язык баз данных. SQL, произносится как Sequel или просто SQL, является языком компьютерного программирования, используемым для запросов к реляционным базам данных с использованием непроцедурного подхода. Когда вы извлекаете информацию из базы данных с помощью SQL, это называется запросом к базе данных.
Реляционная база данных реализуется с использованием системы управления реляционными базами данных (RDBMS). СУБД выполняет все основные функции программного обеспечения СУБД, упомянутые выше, наряду с множеством других функций, которые облегчают понимание и реализацию реляционной модели. Пользователи СУБД манипулируют данными с помощью специального языка манипулирования данными. Структуры базы данных определяются с помощью языка определения данных. Команды, которые системные пользователи выполняют для хранения и извлечения данных, могут быть введены в терминале с интерфейсом СУБД путем ввода команд или введены с использованием графического интерфейса некоторого типа. Затем СУБД обрабатывает команды.
Затем СУБД обрабатывает команды.
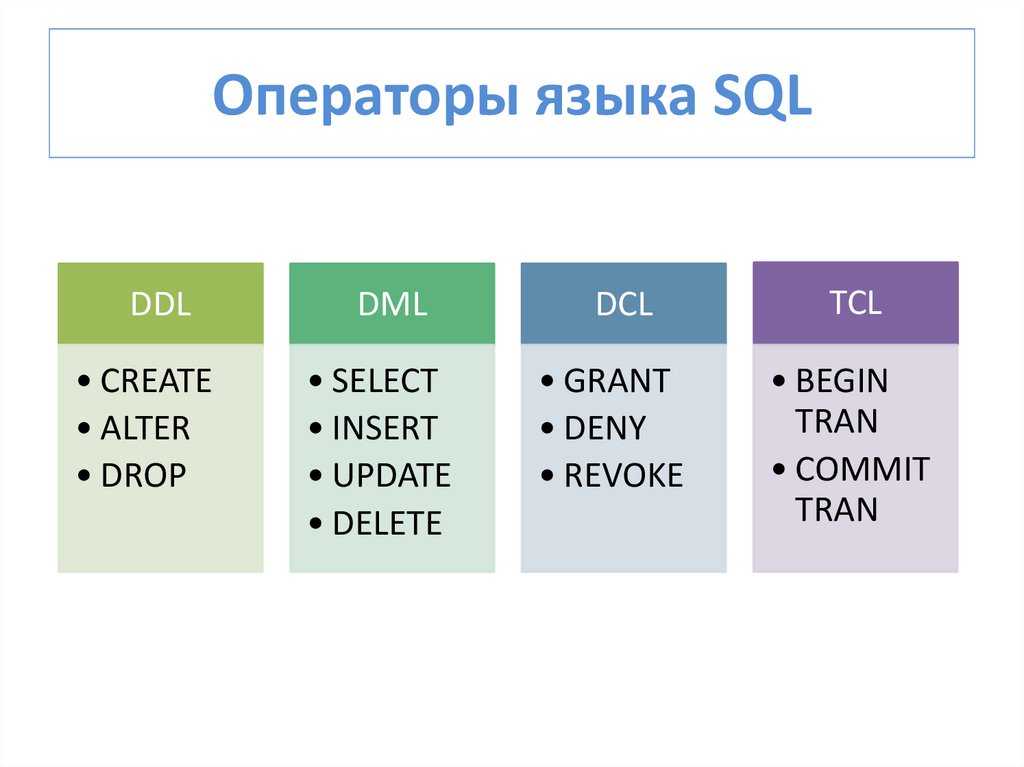
Возможности оператора SELECT
Извлечение данных из базы данных осуществляется посредством правильного и эффективного использования SQL. Три понятия из реляционной теории охватывают возможности оператора SELECT: проекция, выбор и объединение.
Проекция: операция проекта выбирает только определенные столбцы (поля) из таблицы. Таблица результатов имеет подмножество доступных столбцов и может включать в себя что угодно от одного столбца до всех доступных столбцов.
Выбор: операция выбора выбирает подмножество строк (записей) в таблице (отношение), которые удовлетворяют условию выбора. Возможность выбора строк из полного набора результатов называется «Выбор». Это включает в себя условную фильтрацию и размещение данных. Подмножество может варьироваться от ни одной строки, если ни одна из строк не удовлетворяет условию выбора, до всех строк в таблице.
Объединение. Операция объединения объединяет данные из двух или более таблиц на основе одного или нескольких общих значений столбцов.
 Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.
Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.
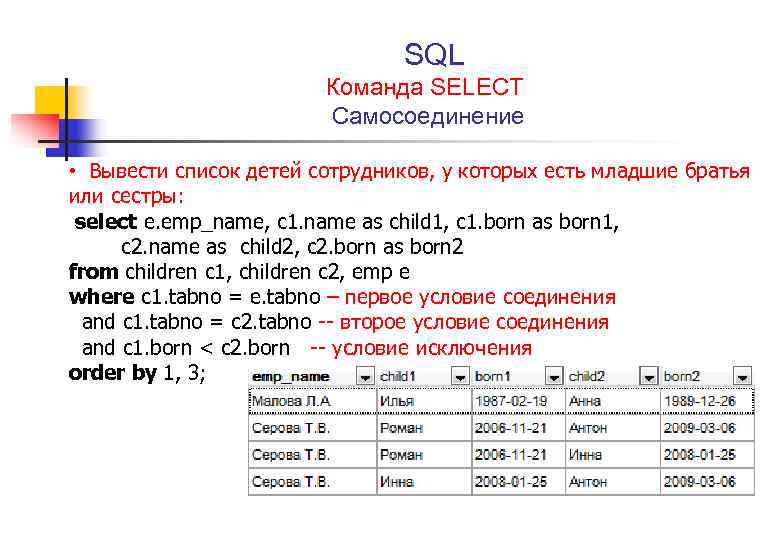 Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.
Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.Проекция: операция проекта выбирает только определенные столбцы (поля) из таблицы. Таблица результатов имеет подмножество доступных столбцов и может включать в себя что угодно от одного столбца до всех доступных столбцов.
Выбор: операция выбора выбирает подмножество строк (записей) в таблице (отношение), которые удовлетворяют условию выбора. Возможность выбора строк из полного набора результатов называется «Выбор». Это включает в себя условную фильтрацию и размещение данных. Подмножество может варьироваться от ни одной строки, если ни одна из строк не удовлетворяет условию выбора, до всех строк в таблице.
Объединение. Операция объединения объединяет данные из двух или более таблиц на основе одного или нескольких общих значений столбцов. Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.
Операция соединения позволяет пользователю информационной системы обрабатывать отношения, существующие между таблицами. Операция объединения является очень мощной, поскольку она позволяет пользователям системы исследовать отношения между элементами данных, которые могут не ожидаться во время разработки базы данных.
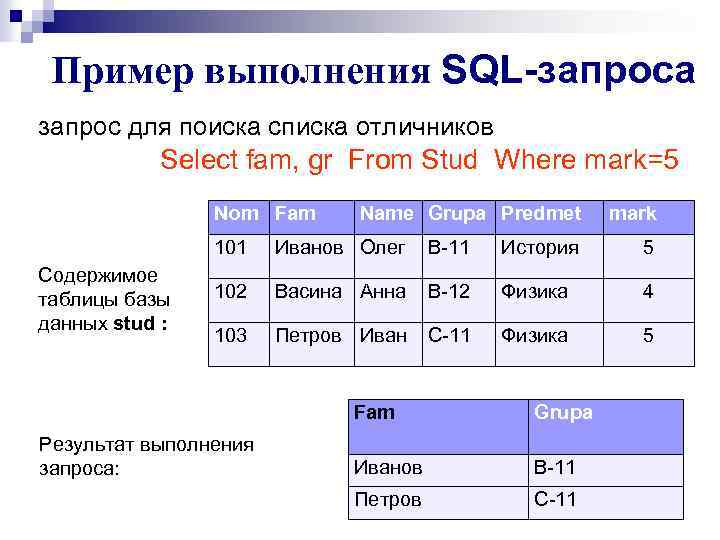
Рассмотрим приведенные выше структуры таблиц. Из таблицы EMPLOYEES выбирается имя, имя_подразделения и зарплата для одного сотрудника. Извлечение сведений о сотруднике, чья зарплата составляет менее 5000, из таблицы EMPLOYEES – Выбор. Выбор сотрудника по имени, названию отдела путем присоединения к СОТРУДНИКАМ и ОТДЕЛЕНИЯМ – Присоединение.
Базовый оператор SELECT
Основной синтаксис для оператора SELECT представлен ниже.
SELECT [DISTINCT | ALL] {* | select_list}
FROM {table_name [alias] | view_name}
[{table_name [alias] | view_name}]...
[WHERE condition]
[GROUP BY condition_list]
[HAVING condition]
[ORDER BY {column_name | column_# [ ASC | DESC ] } . .. ..
..Предложение SELECT является обязательным и выполняет операцию реляционного проекта.
Предложение FROM также является обязательным. Он идентифицирует одну или несколько таблиц и / или представлений, из которых можно извлечь данные столбца, отображаемые в таблице результатов.
Предложение WHERE является необязательным и выполняет операцию реляционного выбора. Он указывает, какие строки должны быть выбраны.
Предложение GROUP BY не является обязательным. Он организует данные в группы по одному или нескольким именам столбцов, перечисленным в предложении SELECT.
Необязательное предложение HAVING устанавливает условия относительно того, какие группы включать в таблицу результатов. Группы определяются предложением GROUP BY.
Предложение ORDER BY не является обязательным. Он сортирует результаты запроса по одному или нескольким столбцам в порядке возрастания или убывания.
Арифметические выражения и значения NULL в инструкции SELECT
Арифметическое выражение может быть создано с использованием имен столбцов, операторов и постоянных значений для встраивания выражения в оператор SELECT. Оператор, применимый к столбцу, зависит от типа данных столбца. Например, арифметические операторы не будут соответствовать буквенным значениям символов. Например,
Оператор, применимый к столбцу, зависит от типа данных столбца. Например, арифметические операторы не будут соответствовать буквенным значениям символов. Например,
SELECT employee_id, sal * 12 ANNUAL_SAL FROM employees;
Приведенный выше запрос содержит арифметическое выражение (sal * 12) для расчета годовой зарплаты каждого сотрудника.
Арифметические операторы
Операторы действуют на столбцы (известные как операнды), чтобы привести к другому результату. В случае нескольких операторов в выражении порядок эваляции определяется приоритетом оператора. Вот элементарные правила приоритета –
Умножение и деление происходят до сложения и вычитания.
Операторы с одинаковым приоритетом оцениваются слева направо.
Используйте паретезы, чтобы переопределить поведение операторов по умолчанию.
Умножение и деление происходят до сложения и вычитания.
Операторы с одинаковым приоритетом оцениваются слева направо.
Используйте паретезы, чтобы переопределить поведение операторов по умолчанию.
Ниже в таблице приведены приоритеты операторов в таких случаях. Операция Символ оператора уровня приоритета
Description Operator Precedence Addition + Lowest Subtraction - Lowest Multiplication * Medium Division / Medium Brackets ( ) Highest
Изучите приведенные ниже запросы (а), (б) и (в)
SQL> SELECT 2*35 FROM DUAL;
SQL> SELECT salary + 1500 FROM employees;
SQL> SELECT first_name, salary, salary + (commission_pct* salary) FROM employees;
Запрос (а) умножает два числа, в то время как (б) показывает прибавку 1500 долларов к зарплате всех сотрудников. Запрос (c) показывает добавление комиссионного компонента к зарплате сотрудника. В соответствии с предыдущим, первая комиссия будет рассчитываться на зарплату, а затем добавляется к зарплате.
Колонка Псевдоним
Псевдоним используется для переименования столбца или выражения во время отображения. Псевдоним столбца или выражения отображается как заголовок в выводе запроса. Это полезно для обеспечения значимого заголовка для длинных выражений в запросе SELECT. По умолчанию псевдоним отображается в верхнем регистре в выводе запроса без пробелов. Чтобы переопределить это поведение, псевдоним должен быть заключен в двойные кавычки, чтобы сохранить регистр и пробелы в имени псевдонима.
SELECT price * 2 as DOUBLE_PRICE, price * 10 "Double Price" FROM products; DOUBLE_PRICE Double Price ------------ ------------ 39.9 39.9 60 60 51.98 51.98
Операторы конкатенации
Оператор конкатенации можно использовать для объединения двух строковых значений или выражений в запросе SELECT. Символ двойной вертикальной черты используется в качестве оператора конкатенации строк. Это применимо только для символьных и строковых значений столбцов, приводящих к новому символьному выражению. пример
пример
SQL> SELECT 'ORACLE'||' CERTIFICATION' FROM dual;
Приведенный выше запрос показывает объединение двух символьных литералов значений.
литералы
Любое жестко закодированное значение, которое не хранится в базе данных в предложении SELECT, известно как Literal. Это может быть число, символ или значение даты. Значения символов и даты должны быть заключены в кавычки. Рассмотрим приведенные ниже SQL-запросы. Примеры использования литералов разных типов данных в SQL-запросах.
В приведенном ниже запросе используются два символьных литерала для их объединения.
SQL> SELECT 'ORACLE'||' CERTIFICATION' FROM DUAL
В приведенном ниже запросе используются символьные литералы для печати зарплаты сотрудника.
SQL> SELECT first_name ||'earns'|| salary||' as of '|||sysdate FROM employees
Оператор цитаты
Оператор цитаты используется для указания собственного разделителя кавычек. Вы можете выбрать удобный разделитель, добавляющий данные.
SELECT department_name|| ' Department' ||q'['s Manager Id: ]'|| manager_id FROM departments;
НОЛЬ
Если столбец не имеет определенного значения, он считается равным NULL. Значение NULL обозначает неизвестный или недоступный. Это не ноль для числовых значений, не пробел для символьных значений.
Столбцы со значением NULL могут быть выбраны в запросе SELECT и могут быть частью арифметического выражения. Любое арифметическое выражение, использующее значения NULL, приводит к NULL. По этой причине столбцы со значением NULL должны обрабатываться по-разному, указывая их альтернативные значения с помощью функций Oracle, таких как NVL или NULLIF.
SQL> SELECT NULL + 1000 NUM FROM DUAL; NUM --------
DISTINCT Ключевое слово
Если ожидается, что данные будут иметь повторяющиеся результаты, используйте ключевое слово DISTINCT, чтобы устранить дубликаты и отобразить только уникальные результаты в выводе запроса. Только выбранные столбцы проверяются на дублирование, и строки будут логически исключены из результатов запроса. Следует отметить, что ключевое слово DISTINCT должно появляться сразу после предложения SELECT.
Следует отметить, что ключевое слово DISTINCT должно появляться сразу после предложения SELECT.
Простой запрос ниже демонстрирует использование DISTINCT для отображения уникальных идентификаторов отделов из таблицы EMPLOYEES.
SQL> SELECT DISTINCT DEPARTMENT_ID FROM employees; DEPARTMENT_ID --------------- 10 20 30 40
Команда ОПИСАТЬ
Структурные метаданные таблицы могут быть получены путем запроса базы данных для списка столбцов, которые ее составляют, с помощью команды DESCRIBE. В нем будут перечислены имена используемых столбцов, их нулевое свойство и тип данных.
Синтаксис:
DESC[RIBE] [SCHEMA].object name
Например,
DESC EMPLOYEE
отобразит структуру таблицы EMPLOYEE, то есть столбцы, их типы данных, точность и свойство обнуляемости.
Выборка данных
Оператор
SELECT является одним из важных и часто используемых операторов языка
SQL. Он
предназначен для выборки
информации из
таблиц базы данных.
Оператор
SELECT состоит из нескольких предложений. Некоторые из
предложений являются обязательными, другие – нет.
Предложение
обычно состоит из ключевого
слова Зарезервированное слово, являющееся частью
языка SQL
и предоставляемых данных.
Упрощенный синтаксис
оператора SELECT выглядит следующим образом:
SELECT [DISTINCT]
[<table_name>.]<column_name> [,…]
FROM <table_name>
[WHERE <condition>]
[GROUP BY <column_name>[,… ]
[HAVING <condition>]
[ORDER_BY <column_name>|<column_number>
[ASC | DESC][,…]
Выборка
нескольких столбцов
Чтобы при
помощи оператора SELECT извлечь данные из таблицы, нужно указать как
минимум
две вещи — что вы хотите выбрать и откуда.
Ключевое
слово SELECT сообщает базе данных, что данное предложение является
запросом на извлечение информации. После SELECT
После SELECT
через запятую перечисляются названия полей, содержимое которых
запрашивается. Обязательным
ключевым словом в предложении-запросе SELECT является слово FROM. За
ключевым
словом FROM указывается список разделенных запятыми имен таблиц, из
которых
извлекается информация.
SQL:
SELECT name,
lastname
FROM tbl_clients;
Результатом
выполнения запроса на выборку всегда является таблица, содержащая
выбранные
записи. Приведенный выше
запрос осуществляет выборку всех значений полей name и lastname из
таблицы tbl_clients.
Порядок следования
столбцов в этой таблице соответствует порядку полей,
указанному в запросе, а не их порядку в исходной таблице.
Выборка
всех столбцов
таблицы
Помимо
возможности осуществлять выборку определенных столбцов (одного или
нескольких),
при помощи оператора SELECT можно запросить все столбцы, не перечисляя
каждый
из них.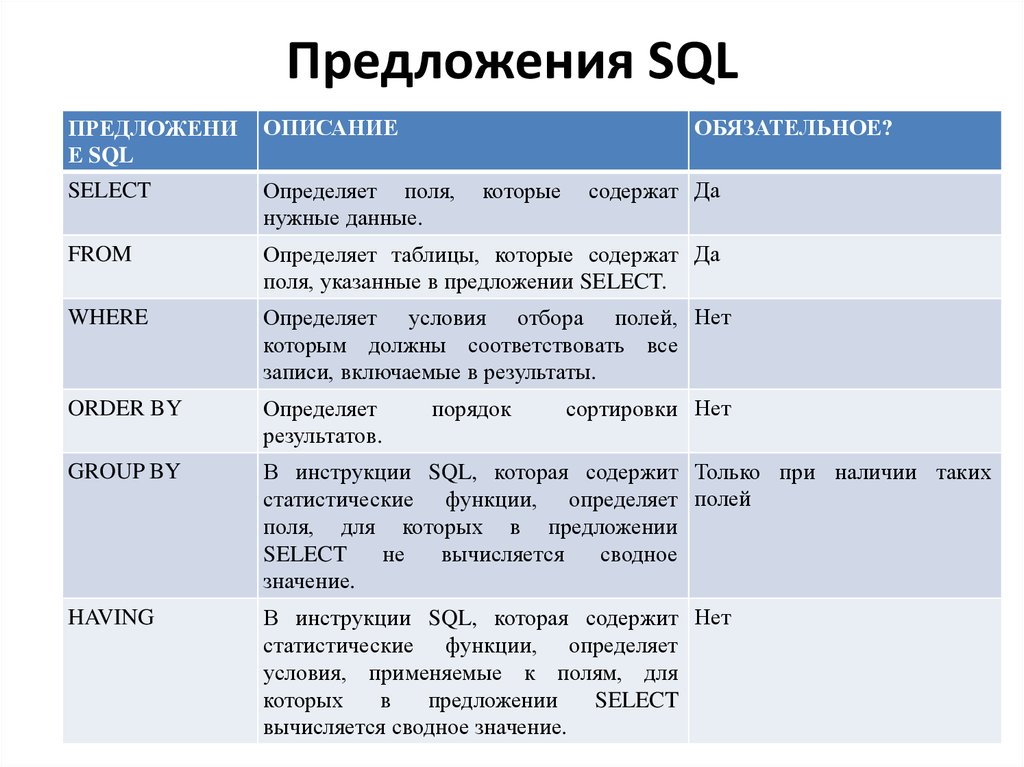 Для этого вместо имен столбцов вставляется групповой символ
Для этого вместо имен столбцов вставляется групповой символ
«звездочка» (*).
SQL:
SELECT * FROM tbl_clients;
Представленный
оператор извлекает все столбцы из таблицы tbl_clients и отображает их в
соответствии с порядком, в
котором они были определены при создании таблицы. При использовании
символа «*» столбцы возвращаются в том порядке, в котором они были
определены
при создании таблицы.
Исключение
дубликатов
строк
Получаемые в
результате SQL-запроса
таблицы могут содержать повторяющиеся строки. Например, запрос для
получения списка
названий городов, где проживают клиенты, можно записать в следующем
виде:
SQL:
SELECT region FROM tbl_clients
Его результатом
будет таблица:
| region |
| Portland |
| Seattle |
| Seattle |
| New
Jersey |
| Seattle |
| Seattle |
| Washington |
| Los
Angeles |
. ….. …..
|
Проблема состоит в
том, что в набор
результатов этого запроса включается каждое появление каждого названия
города,
обнаруженного в таблице tbl_clients. Например, если имеется 20 человек
из,
Сиэтла, 7 человек из Вашингтона и 3 из Лос-Анджелеса, то в наборе
результатов
будет 20 раз упомянут Сиэтл, 7 раз Вашингтон и 3-Вашингтон. Очевидно,
что эта
избыточная информация не нужна.
Для исключения из
результата
запроса повторяющихся записей используется ключевое слово DISTINCT.
Если запрос
SELECT извлекает множество полей, то DISTINCT исключает дубликаты
строк, в которых значения всех
выбранных полей
идентичны.
Предыдущий запрос
можно записать в
следующем виде:
SQL:
SELECT
DISTINCT region FROM tbl_clients
В результате получим
таблицу, в
которой дубликаты строк исключены:
| region |
| Portland |
| Seattle |
| New
Jersey |
| Washington |
| Los
Angeles |
| California |
| Oregon |
| New
York |
Оператор SELECT и предложение FROM
Учебники > Базы данных
Запуск базы данных SQL и просмотр данных
Это урок о том, как просто открыть базу данных и показать данные из базы данных. Если вы думаете, «Какого черта? В Excel я просто открываю файл, а там данные» …
Если вы думаете, «Какого черта? В Excel я просто открываю файл, а там данные» …
Ага!_ Верно. Оператор SQL SELECT и предложение FROM покажут, как явный SQL сравнивается с вашей стандартной электронной таблицей. Электронная таблица будет удобно отображать все свое содержимое при открытии. База данных SQL покажет вам только , что вы скажете, чтобы показать вам .
Примечание. В этом уроке SQL я буду использовать графический интерфейс Sequel Pro для ядра базы данных MySQL и буду запрашивать отчеты об инцидентах SFPD, отнесенные к категории 9.0015 НАПАДЕНИЕ
Если вы хотите увидеть те же результаты, что и я, вам нужно загрузить и импортировать базу данных MySQL с отчетами о нападениях с 2003 по 2013 год из SFPD__.
Я также создал версию этой базы данных SQLite , которая должна функционально совпадать с версией MySQL.
Для MySQL и SQLite я также создал базу данных всех отчетов SFPD с 2003 по 2013 год. Все запросы должны работать одинаково, за исключением того, что вы можете исследовать все различные категории преступлений. Компромисс заключается в том, что база данных намного больше, и поэтому ее загрузка, импорт и запросы будут происходить медленнее. Если вы совершенно новичок во всем этом, я бы просто пошел с атакует базу данных , поэтому любые ошибки, которые вы совершаете, не занимают больше времени, чтобы их понять.
- MySQL отчетов о нападениях: 130 097 строк
- MySQL все отчеты об инцидентах: 1 491 764 строки
- Отчеты о нападениях SQLite : 130 097 строк
- SQLite все отчеты об инцидентах: 1 491 764 строки

Настойчивость интерпретатора SQL в том, чтобы ему точно говорили, что делать, может раздражать, когда вы просто хотите видеть все по умолчанию, поэтому большинство графических интерфейсов баз данных позволяют вам просмотреть таблицу данных через Browse/Content функциональные возможности:
Но что, если вы хотите видеть только несколько столбцов, просто чтобы уменьшить визуальный беспорядок? В спреде вам пришлось бы вручную переставлять или скрывать столбцы — или, как делают некоторые глупые новички, о которых потом сожалеют: удалить ненужные столбцы.
С помощью SQL вы можете выбрать полей данных с помощью такого запроса:
ВЫБЕРИТЕ категорию, описание, дату, время ИЗ sfpd_incidents
Видео
Посмотрите, как я выполняю запрос SELECT с Sequel Pro:
Ввод текста может показаться утомительным, но компромисс заключается в том, что, задав явное , вы избавитесь от неуклюжих движений «щелчок-и-перетаскивание-и-нажатие-кнопки», которые неизбежно приведут к неприятным ошибкам в данных, даже для лучших из лучших. Excel-мастера; спросите об этом экономистов из Гарварда.
Это выражение извлекает столбцы. При использовании отдельно он будет извлекать буквальные или вычисляемые значения. Это не особенно интересно, пока мы не обратимся к таблиц , но давайте посмотрим, как выглядит синтаксис сам по себе:
ВЫБЕРИТЕ значение
Выполнение этого базового запроса:
ВЫБЕРИТЕ "привет, мир";
Возвращает один столбец с названием "hello world" и одну строку со значением "hello world" . Здесь ничего особенного:
Здесь ничего особенного:
Запрос вычислительного оператора , например сложения двух чисел:
ВЫБЕРИТЕ 10 + 32;
– получится:
| 10+32 |
|---|
| 42 |
SELECT ряд значений/столбцов
Используйте запятые для выбора нескольких полей/значений:
ВЫБЕРИТЕ «А», «В», 9 + 7, «Привет, мир»
| А | Б | 9 + 7 | Привет, мир |
|---|---|---|---|
| А | Б | 16 | Привет, мир |
ОТ пункт
Если мы думаем о SELECT как о предложении , то наши предложения до сих пор были очень простыми. Как и в английском языке, мы усложняем наши операторы SQL с помощью предложений .
Пока что программа SQL фактически не затрагивала наши таблицы базы данных. С предложением
С предложением FROM мы можем указать столбцов мы хотим SELECT . «Грамматика» выглядит так:
SELECT [имя столбца] FROM [имя таблицы]
Записано как оператор SQL:
ВЫБЕРИТЕ местоположение ИЗ sfpd_incidents
Результат:
Запрос вернет значение столбца Location для для каждой строки. Если вы используете базу данных только нападений SFPD с 2003 по 2013 год, результат будет содержать 130,097 рядов.
В качестве упражнения попробуйте запросить:
ВЫБЕРИТЕ «привет, мир» ИЗ sfpd_incidents;
Результат должен выглядеть так:
(снова одна строка)
| привет мир |
|---|
| привет мир |
| привет мир |
| привет мир |
| …(130 097 раз) |
Примечание. Скорее всего, вы никогда не будете делать что-то подобное, но стоит еще раз подчеркнуть основы
Скорее всего, вы никогда не будете делать что-то подобное, но стоит еще раз подчеркнуть основы ВЫБЕРИТЕ здесь.
Выбор нескольких столбцов из таблицы
Никаких сюрпризов:
ВЫБЕРИТЕ местоположение, X, Y ИЗ sfpd_incidents
| Местоположение | х | Д |
|---|---|---|
| 300 Блок WOODSIDE AV | -122,452194214 | 37.745666504 |
| 400 Блок НАТОМА ST | -122.406684875 | 37.781009674 |
| 300 Блок COLUMBUS AV | -122.407066345 | 37,798183441 |
| 300 Блок ELLIS ST | -122.412330627 | 37,784889221 |
| 300 Блок ELLIS ST | -122.412330627 | 37,784889221 |
| 1900 Блок JENNINGS ST | -122,387695312 | 37. 728080750 728080750 |
| 1000 Блок SUTTER ST | -122,416862488 | 37.788208008 |
| 400 Блок TURK ST | -122,416641235 | 37,782432556 |
| 400 Блок TURK ST | -122,416641235 | 37,782432556 |
| 1300 Блок НАТОМА ST | -122,418441772 | 37.767608643 |
Выбор всех столбцов
Иногда вам просто нужны все столбцы таблицы. Вы могли бы сделать это вручную, например.
ВЫБЕРИТЕ IncidntNum, Категория, Описание, DayOfWeek, Дата, Время, PdDistrict, Разрешение, Расположение, X, Y ИЗ sfpd_incidents
Однако вы можете использовать звездочку в качестве сокращения для « все столбцы »:
sql
ВЫБЕРИТЕ * ИЗ sfpd_incidents
Частые ошибки
Даже сегодня самая распространенная ошибка SQL, которую я допускаю, это:
ВЫБЕРИТЕ IncidentNum, Категория, Описание
Приведенный выше оператор вернет ошибку, потому что я пропустил, какую таблицу я хочу выбрать для этих столбцов из . В графическом интерфейсе только потому, что вы выбрали таблицу, щелкнув по ней, и запрашивали ту же таблицу в течение последнего часа, не означает, что интерпретатор SQL автоматически предположит, что вы используете ту же таблицу.
В графическом интерфейсе только потому, что вы выбрали таблицу, щелкнув по ней, и запрашивали ту же таблицу в течение последнего часа, не означает, что интерпретатор SQL автоматически предположит, что вы используете ту же таблицу.
Кроме того, приведенный выше запрос выдаст ошибку, потому что я написал ‘IncidntNum’ как ‘Incid__e__ntNum’; программное обеспечение базы данных не будет делать за вас догадки, когда дело доходит до опечаток.
Имейте в виду необходимость быть явным (и повторяющимся). Это типичное поведение для языков программирования.
Заключение
Чему мы здесь научились? Не так много, просто определенный синтаксис SQL, необходимый для вывода содержимого наших таблиц данных. Но замените этот синтаксис на , потому что наши «предложения» очень скоро станут намного более запутанными с различными типами предложений.
Упражнения
- Напишите запрос, который создает таблицу результатов, в которой все столбцы из
sfpd_incidents, но перечислите их в алфавитном порядке . Да, это означает набирать его вручную. - Напишите запрос, который создает таблицу результатов с одним столбцом, содержащим сумму столбцов
XиYизsfpd_incidents
 Да, это означает набирать его вручную.
Да, это означает набирать его вручную.Раствор 1
ВЫБЕРИТЕ Категория, Дата, Описание, IncidntNum, Местоположение, PdDistrict, Разрешение, Время, X, Y ИЗ sfpd_incidents
Раствор 2
ВЫБЕРИТЕ Х + Y ИЗ sfpd_incidents
Прочие ресурсы:
SQL: предыстория (Excel и базы данных)
Нежное введение в SQL с использованием SQLite, часть I
Учебник Питера Олдхауса по SQLite
Не начинайте SQL-запросы с оператора «Выбор» | Анмол Томар | Декабрь 2022 г.
Следуйте этому правильному подходу к написанию ваших SQL-запросов
Изображение предоставлено: Unsplash
Проблема
Большинство разработчиков начинают писать свои SQL-запросы с предложения «SELECT», а затем пишут «FROM», «WHERE». ‘, ‘ИМЕТЬ’… и так далее. Но это не «правильный» способ написания ваших SQL-запросов, поскольку он очень подвержен синтаксическим ошибкам, особенно если вы новичок в SQL.
‘, ‘ИМЕТЬ’… и так далее. Но это не «правильный» способ написания ваших SQL-запросов, поскольку он очень подвержен синтаксическим ошибкам, особенно если вы новичок в SQL.
Решение
«Идеальная» последовательность написания запроса должна соответствовать тому, как исполнитель SQL выполняет запросы. Это гарантирует, что вы не совершите синтаксических ошибок и будете писать эффективные SQL-запросы. Вы узнаете, как фильтровать данные перед выполнением соединения, когда использовать предложение «HAVING» или «WHERE» и многое другое.
В этом сообщении блога мы рассмотрим «идеальный» способ написания SQL-запроса, который поможет вам стать эффективным разработчиком SQL.
Мы будем использовать таблицы «Клиент» и «Заказ» (ниже), чтобы найти двух крупнейших клиентов из США/Великобритании, общая сумма расходов которых превышает 300 долларов США.
Таблица клиентов (изображение автора)Таблица заказов (изображение автора)
Давайте углубимся в правильный способ написания SQL-запросов.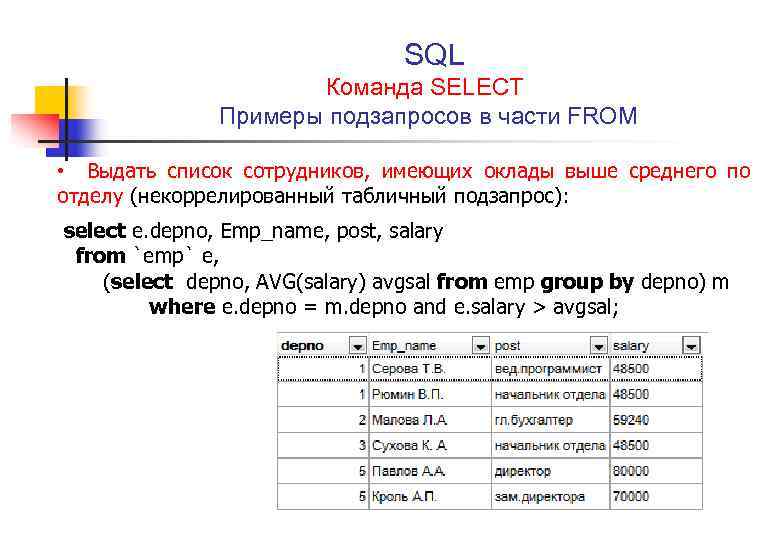
1. Всегда начинайте с FROM/JOIN
Интуитивно понятно, что первым шагом является чтение таблиц с использованием предложения FROM и выполнение JOIN (при необходимости). Таким образом, вы всегда должны начинать свой запрос с оператора «FROM» / «JOIN».
FROM Customers
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
Мы также можем фильтровать строки из входных таблиц еще до выполнения соединения. Мы можем сделать это, добавив предложение «И» после предложения «ON» соединения.
-- Фильтр выполняется перед присоединениемОТ клиентов
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Заказы
ВКЛ Customers.customer_id = Orders.customer_id
И страна в ('США', 'Великобритания')
2. Затем перейдите к WHERE
Второй предложение в порядке выполнения является предложением WHERE. Он используется для фильтрации таблиц данных после применения соединения.
Предложение WHERE очень полезно для уменьшения количества строк, особенно когда мы работаем с большими наборами данных, содержащими миллионы строк.
FROM Customers
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE страна в ('USA','UK')
3. Затем используйте GROUP BY
Предложение Group By должно быть написано после предложения Where . Он используется для группировки строк на основе выбранного столбца/столбцов.
В следующем запросе мы группируем строки на основе идентификатора клиента. После группировки каждый идентификатор клиента будет иметь одну строку в выходных данных. Обычно мы используем агрегацию (сумма, минимум, максимум и т. д.), когда группируем данные. В этом примере мы найдем сумму столбца суммы в таблице «Заказы».
FROM Customers
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE страна в (США, Великобритания)
GROUP BY Customers.customer_id
выполняемый после GROUP BY, он используется для фильтрации агрегированных строк, которые были сгенерированы в группе по операции.
В нашем примере мы отфильтруем сумму, потраченную каждым клиентом, чтобы она превышала 300.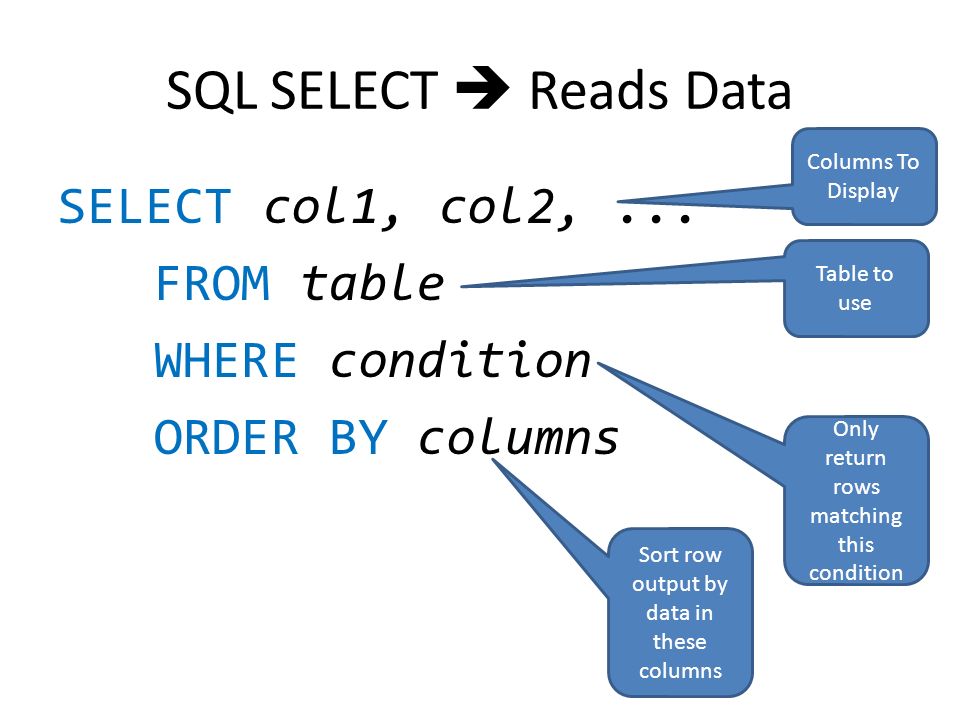
ОТ клиентов
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
WHERE страна в ('USA','UK')
GROUP BY Customers.customer_id
HAVING sum(amount) >300
Предложение WHERE выполняется перед GROUP BY, в то время как HAVING выполняется после него. Таким образом, предложение WHERE не может фильтровать агрегированные данные.
5. Затем напишите предложение SELECT
Столбцы, которые мы хотим показать в выводе, выбираются с помощью предложения SELECT.
Если мы группируем наши данные с помощью предложения GROUP BY, нам нужно выбрать сгруппированный столбец с помощью оператора SELECT.
В нашем примере мы выберем идентификатор клиента и сумму (сумму), чтобы показать расходы, соответствующие каждому клиенту.
выберите Customers.customer_id, sum(amount) как total_amount
FROM Customers
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
ГДЕ страна в ('USA','UK')
GROUP BY Customers.
HAVING сумма(количество) >300
 customer_id
customer_id Вывод (изображение автора)
6. Используйте ORDER BY после предложения SELECT
После выбора столбцов следующим шагом является указание порядка, в котором мы хотим вывести строки.
В нашем примере мы можем использовать предложение ORDER BY, чтобы упорядочить строки в порядке убывания общих расходов.
ВЫБЕРИТЕ Customers.customer_id, sum(amount) as total_amount
FROM Customers
INNER JOIN Orders
ON Customers.customer_id = Orders.customer_id
ГДЕ страна в ('USA','UK')
GROUP BY Customers.customer_id
HAVING sum(amount) >=300
ORDER BY total_amount desc
Вывод (изображение автора)
7. Напишите, наконец, предложение LIMIT!
Последним шагом в последовательности записи является ограничение количества строк, которые мы хотим видеть в выводе.
В нашем примере мы можем ограничить общее количество выходных строк до 2.
SELECT Customers.customer_id, sum(amount) as total_amount
FROM Customers
INNER JOIN Orders
ON Customers.