Описание union sql: UNION (Transact-SQL) — SQL Server
Содержание
MySQL и Select: описание и применение OTUS
MySQL – название реляционной системы управления базами данных. Она распространяется под собственной коммерческой лицензией и GNU General Public License. Проект MySQL стремительно развивается. Его разработчики регулярно занимаются созданием новых функциональных возможностей по клиентским запросам. Соответствующая СУБД наделена механизмом репликации.
Широко применяется при создании клиент-серверных приложений и веб-серверов. MySQL – СУБД, которая часто выступает в качестве сервера. К нему будут подключаться удаленные клиенты и локальные сети. У дистрибутива системы управления данных имеется библиотека внутреннего сервера. Он отвечает за автономное функционирование СУБД.
MySQL – это система, работающая с SQL-запросами. Она позволяет извлекать строки и данные из электронных баз данных (БД). Чтобы выполнить выборку, необходимо использовать специальный оператор. Он называется the select. Далее он будет рассмотрен более подробно. Связано это с тем, что the select in the SQL используется достаточно часто. Почти каждый запрос в БД тем или иным методом связан с соответствующим оператором.
Связано это с тем, что the select in the SQL используется достаточно часто. Почти каждый запрос в БД тем или иным методом связан с соответствующим оператором.
Что такое SQL
Перед изучением команды MySQL Select, необходимо выяснить, что собой вообще представляет SQL-запрос. А еще – для чего его используют в БД.
SQL – это стандартизированный язык запросов. Его используют (use the SQL-language) для взаимодействия с базами данных. С его помощью удается выполнять различные операции:
- вносить изменения в имеющиеся данные;
- удалять записи;
- получать доступ к информации БД.
Весь SQL-язык условно делится на несколько частей:
- Синтаксис семантических языковых запросов. С его помощью происходит идентификация отдельных компонентов базы данных.
- Синтаксис, отвечающий за выдачу пользователям прав на единицы информации.
- Управляющий синтаксис. С его помощью можно искать и обновлять данные.
SQL – один из самых популярных языков запросов. Он совместим с большинством СУБД. В их число входит MySQLd (или просто MySQL). Такая концепция позволяет достаточно быстро освоить работу с БД не только маленьких, но и крупных масштабов. Далее предстоит более подробно изучить the MySQL Select. А еще – рассмотреть несколько наглядных примеров, объясняющих принципы работы команды/оператора.
Он совместим с большинством СУБД. В их число входит MySQLd (или просто MySQL). Такая концепция позволяет достаточно быстро освоить работу с БД не только маленьких, но и крупных масштабов. Далее предстоит более подробно изучить the MySQL Select. А еще – рассмотреть несколько наглядных примеров, объясняющих принципы работы команды/оператора.
Select – кратко о важном
The Select statement – это запрос, который используется чаще остальных. Он обеспечивает основную работу таблиц. Служит универсальной синтаксической конструкцией. Если добавлять в оператор различные предложения, пользователь сможет выполнять различные операции, связанные с выборкой MySQL.
The select – оператор, при помощи которого происходит выборка набора информации из таблиц. Он возвращает набор данных из имеющейся БД. Стоит запомнить следующие особенности selects запросов:
- Они могут возвращать ноль или более строк.
- Список возвращаемых столбцов указывается в части оператора, называемой предложением the select.

- A select определяет требования к возвращаемому набору данных. Это не точная инструкция по вычислению необходимых сведений.

У MySQL Select имеются различные разделы, каждый из которых отвечает за выборку с уточненными параметрами. Без них составить полноценный запрос не получится.
Спектр разделов
Оператор the Select поддерживает несколько предложений (разделов):
- Select. Работает с разными элементами in the table: как с готовыми, так и с вычисляемыми нужен для определения спектра возвращаемых столбцов. Поддерживает уточнение имен столбцов, ограничение уникальность строк в итоговом наборе и их количество.
- From. Раздел, который отвечает за формирование базового набора данных для дальнейших манипуляций. Ссылается на пространство, откуда брать информацию для расчетов. Пример – select salary from table1.
- Group by. Объединяет ряды с общими свойствами. Использует агрегатные функции в процессе своей реализации.
- Where. Предложение, используемое для создания ограничительных условий в запросах MYSQL the select from.
- Order by – предложение, которое помогает создавать критерии сортировки строк. После выполнения заданной операции отправляет готовые данные в точку первоначального вызова.
- Having – выборка между групп, определенных через параметр group by ранее.
Для более точного понимания запросов в MySQL the select from необходимо все эти разделы рассмотреть на наглядных примерах. Без них работать с tables в БД не получится – разве что осуществлять простейшую выборку. Она требуется на практике крайне редко.
Форма запроса Select
If you хотите составить the select запрос в SQL, необходимо воспользоваться специальным шаблоном. Selects-конструкция выглядит так:
Это – ее полноценное представление. Здесь:
- Поле1 и поле2 – имена имеющихся столбцов. Чтобы извлечь их все, необходимо использовать выражение «звездочка».
- Имя_таблицы – это название for the table в БД. Задает табличное имя. Оно представлено местом, где хранятся используемые пользователем данные.
- Limit – ограничитель количества строк, которые возвращаются оператором.
- Order by – сортировка результирующих значений столбца. Может быть выполнена по убыванию или по возрастанию.

Для обычной выборки with MySQL the select хватит первой строки с from. Соответствующее выражение просто выведет запрошенную информацию без дополнительных операций вроде сортировки.
Предложение Where
Selecting запросы SQL поддерживают работу с большим количеством операторов языка. Первый – это where. Он не является обязательным и может вовсе отсутствовать в MySQL Select. Используется для ввода в команду уточняющих параметров/условий. Служит альтернативой операторам OR и AND.
MySQL the select where используется с update и delete. Вот общая форма представления запроса:
Чтобы лучше понять принцип работы MySQL the select where рекомендуется рассмотреть наглядный пример. В нем создается таблица users, в которой имеются такие пункты как:
- city;
- address;
- id;
- frist_name;
- last_name;
- state;
- zip;
- email;
- username;
- password;
- contact_number;
- login_attempts.

Чтобы сформировать такую table, потребуется использовать следующий код:
При использовании where в MySQL Select иногда применяются дополнительные операторы – like, between, in/not in, больше/меньше, неравенство/равенство.
Равенства
Равенство используется для проверки двух значений полей на идентичность. Имеет форму записи в виде обычного математического знака «равно» (=). Если значения совпадают, условие получит параметр true (истина). После этого оператор будет извлекать обозначенные данные для дальнейшей обработки.
В противном случае в условии должен быть оператор неравенства. Он отвечает за действия и данные, которые будут выполняться/извлекаться, если значения не совпадают. Обозначается как (<>) без кавычек.
Выше – пример того, как использовать операторы равенства for the select from в MySQL. В нем требуется получить все записи из таблицы с городом New York.
Сравнение
Иногда to select необходимо сравнивать имеющиеся значения. Для этого используются специальные операторы:
Для этого используются специальные операторы:
- < – больше. Проверяет значение левого поля. Помогает выяснить, больше ли заданное «число», чем правое. Если да, условие выполняется.
- < – меньше. Проверяет, меньше ли значение левого поля в выражении The MySQL Select, чем правое.
Допускается одновременное применение данных условий – >/<. Тогда равенство будет проверяться одновременно.
Выше – пример, в котором необходимо вывести все записи с попытками входа более двух раз.
Like
Like в MySQL the select from table – это поиск по заданным шаблонам. Использует подстановочные символы:
- %. Подстановочный символ, которые позволяет искать ноль или несколько символов: данный. Запрос ищет пользователей с именами, начинающимися на a. Если требуется найти имена, которые дополнительно заканчиваются на s, форма записи изменится: .
- _ (символ нижнего подчеркивания). Используется для поиска по заданному шаблону. На месте подчеркивания располагается любой символ. Один такой элемент – это всего один «неизвестный» компонент.
 Один такой элемент – это всего один «неизвестный» компонент.
Один такой элемент – это всего один «неизвестный» компонент.При использовании «_» допускается одновременное написание нескольких таких элементов.
In/Not in
Команда in сравнивает несколько значений for selected после where. Ниже – пример выборки пользователей из New York и Chicago:
Not in – команда, обратная in. Если в приведенном выше примере написать ее, то на экране появятся жители не из Нью-Йорка и Чикаго.
Between
Between используется as средство извлечения информации из заданного диапазона. Область определения может быть совершенно разной – от текста до цифр.
Здесь выводятся пользователи, зарегистрированные в период с 1 по 16 июля 2017 года.
Оператор Order By
The following раздел the MySQL Select – это order by. Он помогает привести в порядок имеющиеся записи. Позволяет упорядочить данные. Отвечает за сортировку по убыванию и возрастанию.
По умолчанию в SQL-запросе используется принцип вывода информации «от меньшего к большему». Через ключевые слова desc и asc можно пенять соответствующую классификацию. В первом случае данные будут выводиться по убыванию, во втором – по возрастанию.
Через ключевые слова desc и asc можно пенять соответствующую классификацию. В первом случае данные будут выводиться по убыванию, во втором – по возрастанию.
Limit-предложения
В MySQl the select from… limit дает возможность получить некоторое количество строк из больших БД (some columns from tables). Служит ограничителем возвращаемых строк в результирующем наборе.
Передает один или два аргумента. В первом случае он послужит количеством строк, во втором – одно из значений станет смещением, задающим сдвиг первой строки, которую необходимо вернуть. Он может быть или положительным, или нулевым.
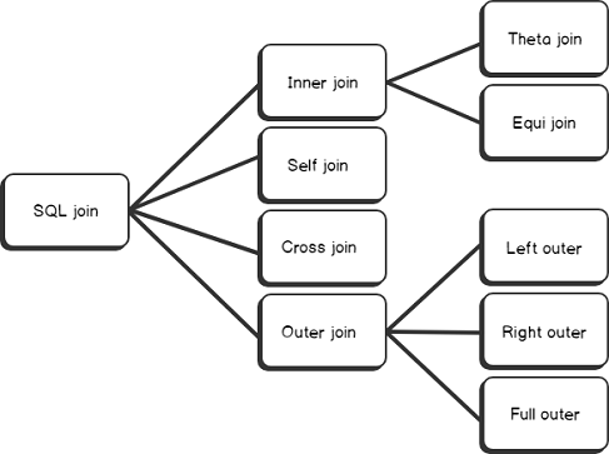
Объединение
For update и для дальнейшей работы с таблицами в БД может потребоваться их объединение. Для этого в MySQL the select from используется оператор join. Он поддерживает несколько вариантов объединения:
- inner – внутреннее;
- cross – перекрестное;
- left – левое соединение;
- right – правое.
Также стоит обратить внимание на ключевое слово Union. С его помощью несколько the selects-запросов объединяются в единую таблицу. Операция доступна, если у каждого результирующего набора одинаковое количество столбцов с одними и теми же типами данных.
С его помощью несколько the selects-запросов объединяются в единую таблицу. Операция доступна, если у каждого результирующего набора одинаковое количество столбцов с одними и теми же типами данных.
Удаление повторений
Оптимизация таблиц, полученных при помощи the MySQL Select, поддерживает использование команды distinct. Она отвечает за удаление повторяющихся значений из итогового набора информации.
Distinct обрабатывает NULL в качестве отдельных значений.
SQL и pandas — Разработка на vc.ru
Если у Вас имеется опыт работы с SQL и Вы начали изучать Python, то этот небольшой обзор покажет аналогию некоторых операций SQL, которые можно реализовать в Python с помощью библиотеки Pandas.
7164
просмотров
pandas — это библиотека на языке Python, созданная для анализа и обработки данных. Имеет открытый исходный код и поддерживается разработчиками Anaconda. Эта библиотека хорошо подходит для структурированных (табличных) данных.

Для начала импортируем библиотеки, которые пригодятся нам по ходу работы:
import pandas as pd
import numpy as np
И для наглядности возьмём csv таблицу:
Далее мы записываем информацию из csv в DataFrame, который назовем test_csv, и убедимся, что полученная таблица будет иметь тоже имя и структуру, как и оригинальный csv:
Ввод: test_csv = pd.read_csv(‘test.csv’)
test_csv.head()
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
0 45 Горбунов В.Ф. В работе 02/05/2020 NaN 1500 0.8
1 49 Нестерова В.В. В работе 02/05/2020 NaN 2300 0.9
2 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1
3 54 Нестерова В.В. В работе 03/05/2020 NaN 750 0.6
4 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95
Select
В SQL выборка необходимых нам столбцов происходит перечислением имен этих столбцов через запятую или с помощью * для выбора всех столбцов:
SELECT ID, ID_STATUS, CLOSE
FROM test_csv
LIMIT 5;
В Pandas выбор столбцов происходит с помощью перечисления необходимых названий столбцов в списке в нашем DataFrame:
Ввод: test_csv[[‘ID’, ‘ID_STATUS’, ‘CLOSE’]].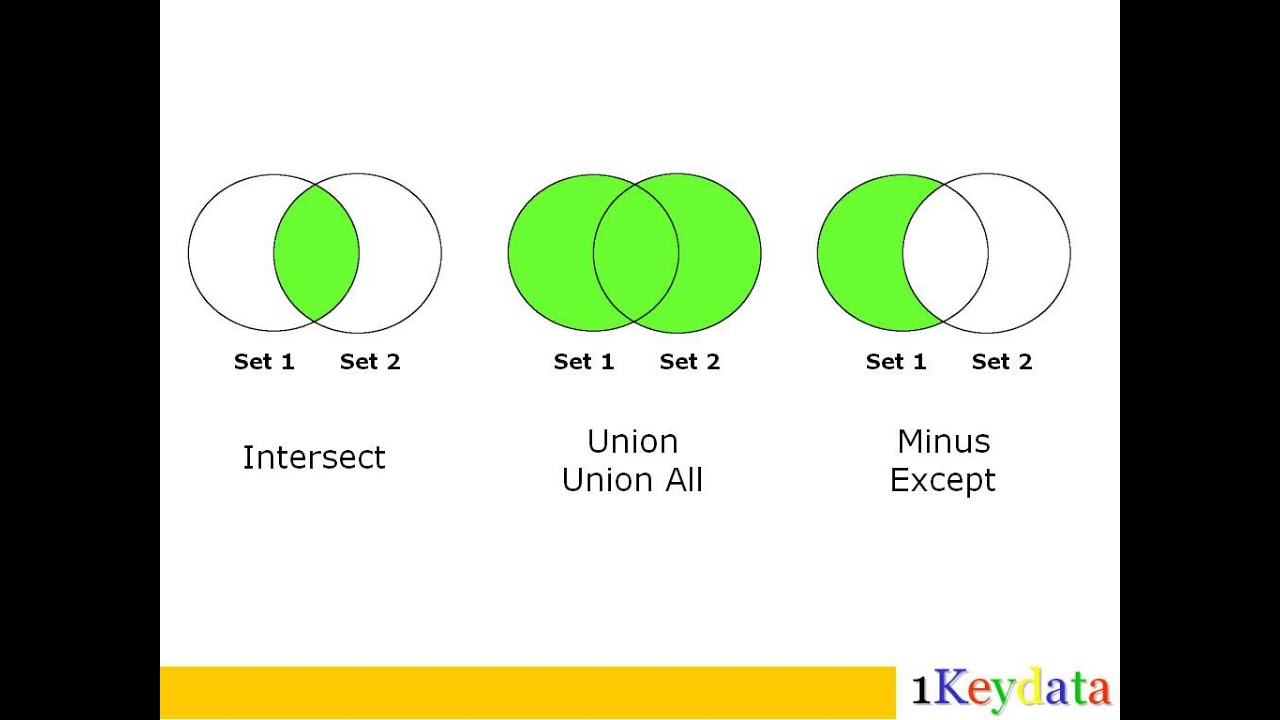 head(5)
head(5)
Вывод:
ID ID_STATUS CLOSE
0 45 В работе NaN
1 49 В работе NaN
2 52 Выполнено 04/05/2020
3 54 В работе NaN
4 55 Выполнено 06/05/2020
А если же мы вызываем DataFrame без листа с названиями столбцов, то это отобразить все столбцы словно * в SQL.
В SQL мы сразу можем добавить столбец с нужными нам расчетами:
SELECT *, PRICE*SALE as SUM
FROM test_csv
LIMIT 5;
В Pandas для добавления столбца с расчетами мы воспользуемся DataFrame.assign():
Ввод: test_csv.assign(SUM=test_csv[‘PRICE’] / test_csv[‘SALE’]).head(5)
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE SUM
0 45 Горбунов В.Ф. В работе 02/05/2020 NaN 1500 0.8 1200
1 49 Нестерова В.В. В работе 02/05/2020 NaN 2300 0.9 2070
2 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1 3500
3 54 Нестерова В.В. В работе 03/05/2020 NaN 750 0. 6 450
6 450
4 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95 1168.5
WHERE
Фильтрация в SQL происходит при помощи WHERE:
SELECT *
FROM test_csv
WHERE ID_STATUS = ‘Выполнено’
LIMIT 3;
DataFrame же может быть отфильтрован несколькими способами, но самыми частым из них является логическое сравнение:
Ввод: test_csv[test_csv[‘ID_STATUS’] == ‘Выполнено’].head(3)
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
1 52 Горбунов В.Ф. Выполнено 02/05/2020 04/05/2020 3500 1
2 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95
3 56 Горбунов В.Ф. Выполнено 03/05/2020 07/05/2020 767 0.35
Также, как и в SQL, в DataFrame мы можем использовать операторы И/ИЛИ:
SELECT *
FROM test_csv
WHERE ID_STATUS = ‘Выполнено’ AND PRICE > 1000;
Ввод: test_csv[(test_csv[‘ID_STATUS’] == ‘Выполнено’) & (test_csv[‘PRICE’] > 1000)]
Вывод:
ID FIO ID_STATUS OPEN CLOSE PRICE SALE
0 52 Горбунов В. Ф. Выполнено 02/05/2020 04/05/2020 3500 1
Ф. Выполнено 02/05/2020 04/05/2020 3500 1
1 55 Мамонтов Б.А. Выполнено 03/05/2020 06/05/2020 1230 0.95
Для проверки наличия в значении NULL, мы используем notna() и isna(). Для примера создадим DataFrame с NULL значениями.
Ввод: test_1 = pd.DataFrame({‘C1’: [‘1’, ‘1’, np.NaN, ‘1’, ‘1’],
‘C2’: [‘2’, np.NaN, ‘2’, ‘2’, np.NaN],
‘C3’: [np.NaN, ‘3’, ‘3’, ‘3’, np.NaN]})
test_1
Вывод:
C1 C2 С3
0 1 2 NaN
1 1 NaN 3
2 NaN 2 3
3 1 2 3
4 1 NaN NaN
И теперь для примера выберем все строки, где С2 IS NULL:
SELECT *
FROM test_1
WHERE C2 IS NULL;
Ввод: test_1[test_1[‘C2’].isna()]
Вывод:
C1 C2 С3
0 1 NaN 3
1 1 NaN NaN
Для получения IS NOT NULL значений по столбцу С3 воспользуемся notna():
SELECT *
FROM test_1
WHERE C3 IS NOT NULL;
Ввод: test_1[test_1[‘C3’].notna()]
Вывод:
C1 C2 С3
0 1 NaN 3
1 NaN 2 3
2 1 2 3
Union
UNION ALL в pandas осуществляется с помощью concat():
Ввод: set_1 = pd. DataFrame({‘name’: [‘Банан’, ‘Арбуз’, ‘Яблоко’],
DataFrame({‘name’: [‘Банан’, ‘Арбуз’, ‘Яблоко’],
‘price’: [90, 30, 150]})
set_2 = pd.DataFrame({‘name’: [‘Арбуз’, ‘Ананас’, ‘Груша’],
»price’: [30, 190, 80]})
SELECT name, price
FROM set_1
UNION ALL
SELECT name, price
FROM set_2;
/*
name price
Банан 90
Арбуз 30
Яблоко 150
Арбуз 30
Ананас 190
Груша 80
*/
Ввод: pd.concat([set_1, set_2])
Вывод:
name price
0 Банан 90
1 Арбуз 30
2 Яблоко 150
3 Арбуз 30
4 Ананас 190
5 Груша 80
UNION из SQL похожа по функционалу на UNION ALL с отличием только в том, что UNION удаляет дубликаты строк.
SELECT name, price
FROM set_1
UNION
SELECT name, price
FROM set_2;
/*
name price
Банан 90
Арбуз 30
Яблоко 150
Ананас 190
Груша 80
*/
В pandas мы можем использовать concat() в сочетании с drop_duplicates():
Ввод: pd.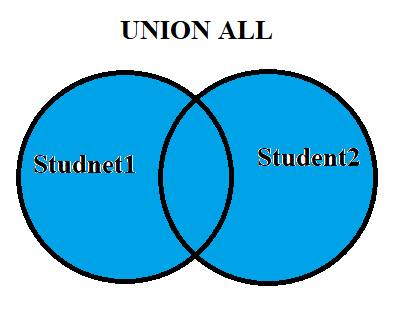 concat([set_1, set_2]).drop_duplicates()
concat([set_1, set_2]).drop_duplicates()
Вывод:
name price
0 Банан 90
1 Арбуз 30
2 Яблоко 150
3 Ананас 190
4 Груша 80
Update
С помощью update мы можем «обновить» значения:
SQL:
UPDATE test_csv
SET SALE = SALE*0.9
WHERE SALE > 0.5;
PYTHON:
test_csv.loc[test_csv[‘SALE’] > 0.5, ‘SALE’] *= 0.9
Delete
В SQL удаление с условием выглядит так:
DELETE FROM test_csv
WHERE SALE > 0.75;
В pandas же мы выбираем какие столбцы остаются, а не удаляются как это сделано в SQL:
Ввод: test_csv = test_csv.loc[test_csv[‘SALE’] <= 0.75]
Задачи
Так как мы рассмотрели основные функции SQL и pandas на примерах, то попробуем решить пару задачек, с которыми мы можем столкнуться в повседневной работе.
Пусть у нас имеется csv таблица work:
- ID – ID работника
- FIO – ФИО работника
- DEPT – Отдел
- CHIED_ID – Непосредственный руководитель
- salary – Заработная плата
Например, нам нужно вывести всех сотрудников, которые получают максимальную заработную плату в каждом из отделов.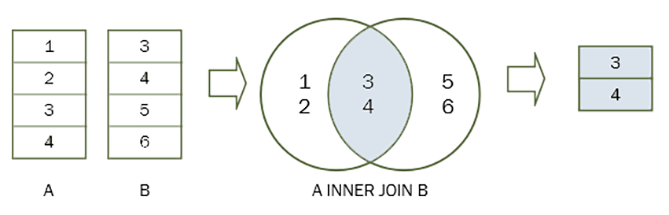
В SQL это будет выглядит так:
SELECT a.*
FROM work a
WHERE a.SALARY = ( SELECT MAX(SALARY)
FROM work b
WHERE b.DEPT = a.DEPT )
Для python одним из вариантов будет:
import pandas as pd
import numpy as np
work_csv = pd.read_csv(‘work.csv’, header=0)
unique_dept = pd.unique(df[‘DEPT’]).tolist()
for ud in unique_dept:
ud_df = work_csv[(work_csv[‘DEPT’] == ud)]
max_salary.append(ud_df.iloc[ud_df[‘SALARY’.idxmax()])
print(max_salary)
Для данной задачи мы получим вот такой ответ:
В следующей задаче нам нужно вывести список ID отделов, где количество сотрудников не превышает трех человек.
В SQL это будет выглядит так:
SELECT DEPT
FROM work
GROUP BY DEPT
HAVING COUNT(*) <= 3
Для python одним из вариантов будет:
import pandas as pd
import numpy as np
work_csv = pd.read_csv(‘work.csv’, header=0)
unique_dept = pd.unique(df[‘DEPT’]).tolist()
for ud in unique_dept:
if len(work_csv[(work_csv[‘DEPT’] == ud)] <= 3:
print(ud)
И для данной задачи мы получим ответ: 0 и 2, т. к. только они и удовлетворяют условиям нашей задачи.
к. только они и удовлетворяют условиям нашей задачи.
Мы рассмотрели основные функции SQL в рамках pandas на примерах, закрепили полученные знания на практике и теперь с уверенностью можем покорять новые горизонты!
SQL-инъекций UNION атак | Академия веб-безопасности
Когда приложение уязвимо для SQL-инъекций и результаты запроса возвращаются в ответах приложения, можно использовать ключевое слово UNION для извлечения данных из других таблиц в базе данных. Это приводит к атаке UNION с внедрением SQL.
Ключевое слово UNION позволяет выполнить один или несколько дополнительных запросов SELECT и добавить результаты к исходному запросу. Например:
SELECT a, b FROM table1 UNION SELECT c, d FROM table2
Этот запрос SQL вернет один набор результатов с двумя столбцами, содержащими значения из столбцов a и b в table1 и столбцов c и d в table2 .
Чтобы запрос UNION работал, необходимо выполнить два ключевых требования:
- Отдельные запросы должны возвращать одинаковое количество столбцов.
- Типы данных в каждом столбце должны быть совместимы между отдельными запросами.
Чтобы выполнить атаку UNION с внедрением SQL, вам необходимо убедиться, что ваша атака соответствует этим двум требованиям. Обычно это включает в себя выяснение:
- Сколько столбцов возвращается из исходного запроса?
- Какие столбцы, возвращенные исходным запросом, имеют подходящий тип данных для хранения результатов введенного запроса?
Определение количества столбцов, необходимых для SQL-инъекции UNION-атаки
При выполнении атаки UNION с внедрением SQL существует два эффективных метода определения количества столбцов, возвращаемых исходным запросом.
Первый метод включает в себя вставку серии из предложений ORDER BY и увеличение указанного индекса столбца до тех пор, пока не произойдет ошибка. Например, предположим, что точка инъекции — это строка в кавычках в пределах WHERE исходного запроса, вы должны отправить:
' ПОРЯДОК ПО 1--
ЗАКАЗАТЬ ПО 2--
ЗАКАЗАТЬ ПО 3--
и т.д.
Эта серия полезных данных изменяет исходный запрос, чтобы упорядочить результаты по разным столбцам в результирующем наборе. Столбец в предложении ORDER BY можно указать по его индексу, поэтому вам не нужно знать имена каких-либо столбцов. Когда указанный индекс столбца превышает количество фактических столбцов в результирующем наборе, база данных возвращает ошибку, например:
Позиция ORDER BY номер 3 выходит за пределы количества элементов в списке выбора.
Приложение может фактически вернуть ошибку базы данных в своем HTTP-ответе, или общую ошибку, или просто не вернуть никаких результатов.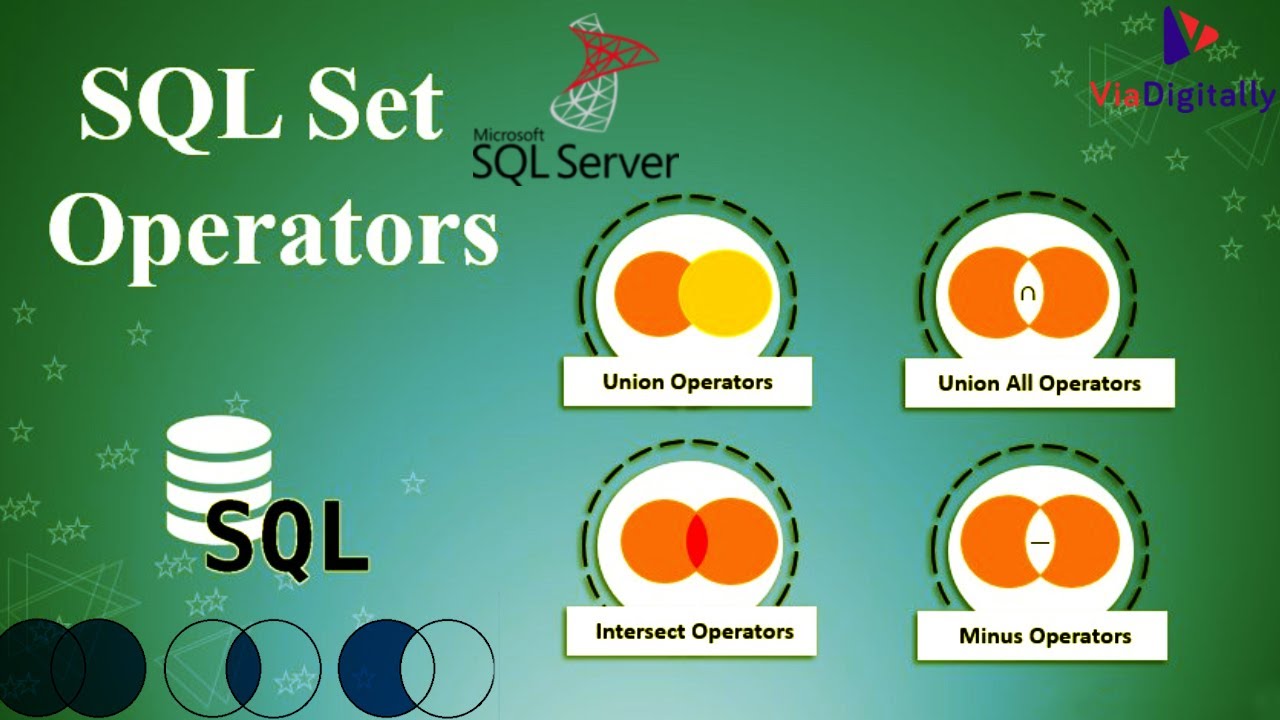 Если вы можете обнаружить некоторую разницу в ответе приложения, вы можете сделать вывод о том, сколько столбцов возвращается из запроса.
Если вы можете обнаружить некоторую разницу в ответе приложения, вы можете сделать вывод о том, сколько столбцов возвращается из запроса.
Второй способ предполагает подачу серии из UNION SELECT полезной нагрузки, указывающей другое количество нулевых значений:
'ОБЪЕДИНЕНИЕ ВЫБЕРИТЕ NULL--
' ОБЪЕДИНЕНИЕ SELECT NULL, NULL--
' ОБЪЕДИНЕНИЕ SELECT NULL, NULL, NULL--
и т.д.
Если количество нулей не соответствует количеству столбцов, база данных возвращает ошибку, например:
Все запросы, объединенные с помощью оператора UNION, INTERSECT или EXCEPT, должны иметь одинаковое количество выражений в своих целевых списках.
Опять же, приложение может на самом деле вернуть это сообщение об ошибке или может просто вернуть общую ошибку или никаких результатов. Когда количество пустых значений совпадает с количеством столбцов, база данных возвращает дополнительную строку в результирующем наборе, содержащую нулевые значения в каждом столбце. Влияние на результирующий HTTP-ответ зависит от кода приложения. Если вам повезет, вы увидите дополнительный контент в ответе, например дополнительную строку в таблице HTML. В противном случае нулевые значения могут вызвать другую ошибку, например
Влияние на результирующий HTTP-ответ зависит от кода приложения. Если вам повезет, вы увидите дополнительный контент в ответе, например дополнительную строку в таблице HTML. В противном случае нулевые значения могут вызвать другую ошибку, например NullPointerException . В худшем случае ответ может быть неотличим от ответа, вызванного неправильным количеством нулей, что делает этот метод определения количества столбцов неэффективным.
ЛАБОРАТОРИЯ
ПРАКТИК
SQL-инъекция UNION-атака, определяющая количество столбцов, возвращаемых запросом
Note
Дополнительные сведения о синтаксисе, специфичном для базы данных, см. в памятке по SQL-инъекциям.
Поиск столбцов с полезным типом данных в атаке UNION с внедрением SQL
Причина выполнения атаки UNION с внедрением SQL заключается в том, чтобы иметь возможность получить результаты из внедренного запроса. Как правило, интересные данные, которые вы хотите получить, будут в форме строки, поэтому вам нужно найти один или несколько столбцов в исходных результатах запроса, тип данных которых является или совместим со строковыми данными.
Уже определив количество необходимых столбцов, вы можете проверить каждый столбец, чтобы проверить, может ли он содержать строковые данные, отправив серию из UNION SELECT полезные данные, которые помещают строковое значение в каждый столбец по очереди. Например, если запрос возвращает четыре столбца, вы должны отправить:
' ОБЪЕДИНЕНИЕ ВЫБЕРИТЕ 'a', NULL, NULL, NULL--
' UNION SELECT NULL,'a',NULL,NULL--
' UNION SELECT NULL, NULL, 'a', NULL--
' UNION SELECT NULL,NULL,NULL,'a'--
Если тип данных столбца несовместим со строковыми данными, введенный запрос вызовет ошибку базы данных, например:
Ошибка преобразования при преобразовании значения varchar 'a' в тип данных int.
Если ошибка не возникает, а ответ приложения содержит некоторое дополнительное содержимое, включая введенное строковое значение, то соответствующий столбец подходит для получения строковых данных.
ЛАБОРАТОРИЯ
ПРАКТИК
Атака UNION с внедрением SQL, поиск столбца, содержащего текст
Использование атаки UNION с внедрением SQL для извлечения интересных данных
Когда вы определили количество столбцов, возвращаемых исходным запросом, и нашли, какие столбцы могут содержать строковые данные, вы можете получить интересные данные.
Предположим, что:
- Исходный запрос возвращает два столбца, оба из которых могут содержать строковые данные.
- Точка внедрения — это строка в кавычках в предложении
WHERE. - База данных содержит таблицу с именем
пользователейсо столбцамиимя пользователяипароль.
В этой ситуации вы можете получить содержимое таблицы пользователей , отправив ввод:
' ОБЪЕДИНЕНИЕ ВЫБЕРИТЕ имя пользователя, пароль ОТ пользователей--
Конечно, ключевая информация, необходимая для выполнения этой атаки, заключается в том, что существует таблица с именем 9.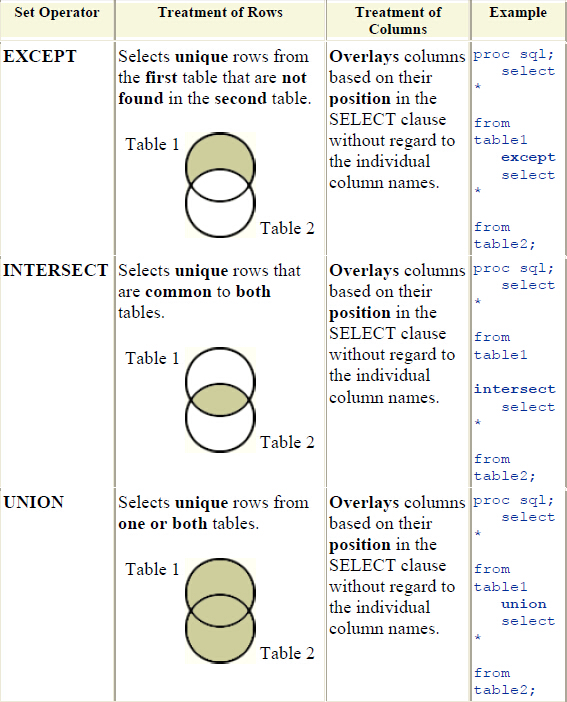 0003 пользователей с двумя столбцами, называемыми
0003 пользователей с двумя столбцами, называемыми имя пользователя и пароль . Без этой информации вам пришлось бы пытаться угадать имена таблиц и столбцов. Фактически, все современные базы данных предоставляют способы изучения структуры базы данных, чтобы определить, какие таблицы и столбцы она содержит.
ЛАБОРАТОРИЯ
ПРАКТИК
Атака UNION внедрения SQL, получение данных из других таблиц
Подробнее
Изучение базы данных при атаках с внедрением SQL
В предыдущем примере предположим, что запрос возвращает только один столбец.
Вы можете легко получить несколько значений вместе в этом одном столбце, объединив значения вместе, в идеале включив подходящий разделитель, чтобы вы могли различать объединенные значения. Например, в Oracle вы можете отправить ввод:
' UNION SELECT имя пользователя || '~' || пароль ОТ пользователей--
Это использует последовательность двойной трубы || , который является оператором конкатенации строк в Oracle. Введенный запрос объединяет значения полей
Введенный запрос объединяет значения полей имя пользователя и пароль , разделенные символом ~ .
Результаты запроса позволят вам прочитать все имена пользователей и пароли, например:
...
администратор~s3cure
Винер~Питер
Карлос ~ Монтойя
...
Обратите внимание, что разные базы данных используют разный синтаксис для выполнения конкатенации строк. Дополнительные сведения см. в памятке по SQL-инъекциям.
ЛАБОРАТОРИЯ
ПРАКТИК
Внедрение SQL Атака UNION, получение нескольких значений в одном столбце
Оператор SQL UNION
« Предыдущая
Следующая глава »
Оператор SQL UNION объединяет результат двух или более
операторы SELECT.
Оператор SQL UNION
Оператор UNION используется для объединения набора результатов двух или более SELECT.
заявления.
Обратите внимание, что каждая инструкция SELECT в UNION должна иметь один и тот же номер
столбцов.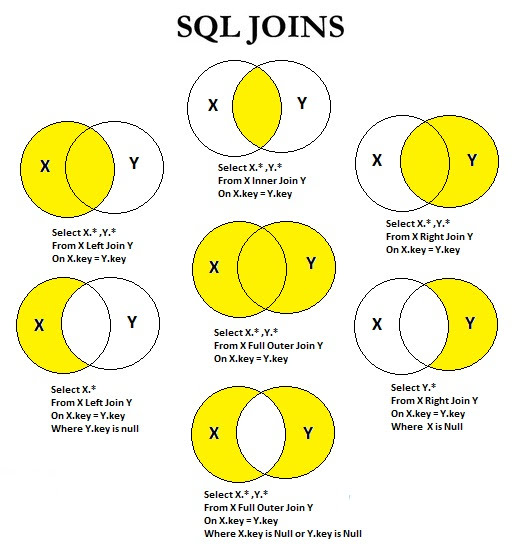 Столбцы также должны иметь схожие типы данных. Кроме того, столбцы в
Столбцы также должны иметь схожие типы данных. Кроме того, столбцы в
каждый оператор SELECT должен быть в одном и том же порядке.
Синтаксис SQL UNION
ВЫБЕРИТЕ имя_столбца(ов) ИЗ таблица1
СОЮЗ
ВЫБЕРИТЕ имя_столбца(ов) ИЗ таблица2 ;
Примечание: Оператор UNION по умолчанию выбирает только различные значения. К
разрешить повторяющиеся значения, используйте ключевое слово ALL с UNION.
SQL UNION ВСЕ Синтаксис
ВЫБЕРИТЕ имя_столбца(ов) ИЗ таблица1
СОЮЗ ВСЕХ
ВЫБЕРИТЕ имя_столбца(ов) ИЗ таблица2 ;
PS: Имена столбцов в наборе результатов UNION обычно равны
имена столбцов в первом операторе SELECT в UNION.
Демонстрационная база данных
В этом руководстве мы будем использовать известную учебную базу данных Northwind.
Ниже представлена выборка из таблицы «Клиенты»:
| CustomerID | ИмяКлиента | Имя контакта | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфред Футтеркисте | Мария Андерс | ул. Обере 57 Обере 57 | Берлин | 12209 | Германия |
| 2 | Ана Трухильо Emparedados y helados | Ана Трухильо | Авда. Конститусьон 2222 | Мексика Д.Ф. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д.Ф. | 05023 | Мексика |
И выбор из таблицы «Поставщики»:
| идентификатор поставщика | Название поставщика | Контактное имя | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Экзотическая жидкость | Шарлотта Купер | ул. Гилберта, 49 | Лондон | ЭК1 4SD | Великобритания |
| 2 | Новый Орлеан Cajun Delights | Шелли Берк | Почтовый индекс Коробка 78934 | Новый Орлеан | 70117 | США |
| 3 | Усадьба бабушки Келли | Регина Мерфи | 707 Оксфорд Роуд.
|