Oracle impdp пример: Экспорт и импорт дампа базы данных Oracle с помощью утилит expdp и impdp | Info-Comp.ru
Содержание
Мониторинг БД Oracle с помощью OEM / Хабр
Привет! Меня зовут Александра, я работаю в команде тестирования производительности. В этой статье расскажу базовые сведения об OEM от Oracle. Статья будет полезна для тех, кто только знакомится с платформой, но и не только для них. Основная цель статьи — помочь провести быстрый анализ производительности БД и поиск отправных точек для более глубокого анализа.
OEM (Oracle Enterprise Manager) — платформа для управления БД. OEM предоставляет графический интерфейс для выполнения большого количества операций с базами данных: резервное копирование, просмотр аварийных журналов, графиков производительности.
Performance Home
На вкладке Performance Home можно увидеть основные графики утилизации БД.
Average Runnable Process
Этот график дает общее понимание использования CPU.
| № | Показатель | Описание |
|---|---|---|
| 1 | Instance Foreground CPU | Отображает утилизацию CPU процессами текущего инстанса, напрямую запущенными клиентом, например выполнение запросов. Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете Список событий ожидания текущего инстанса можно посмотреть в AWR-отчете |
| 2 | Instance Background CPU | Отображает утилизацию CPU фоновыми процессами текущего инстанса, например LGWR. Список событий фонового процесса текущего инстанса можно посмотреть в AWR-отчете или в официальной документации Oracle |
| 3 | Non-database Host CPU | Отображает утилизацию CPU процессами, не относящимися к текущему инстансу |
| 4 | Load Average | Отображает среднюю длину очереди процессов, ожидающих выполнения |
| 5 | CPU Treads/CPU Cores | Отображает лимит максимально возможного использования CPU |
Average Active Sessions
Average Active Sessions отображает информацию в разрезе классов событий ожидания и утилизации CPU. Активные сессии представляют собой каждое подключение пользователя из какого-то процесса, находящегося в активном состоянии (то есть работают в настоящий момент) или в состоянии ожидания.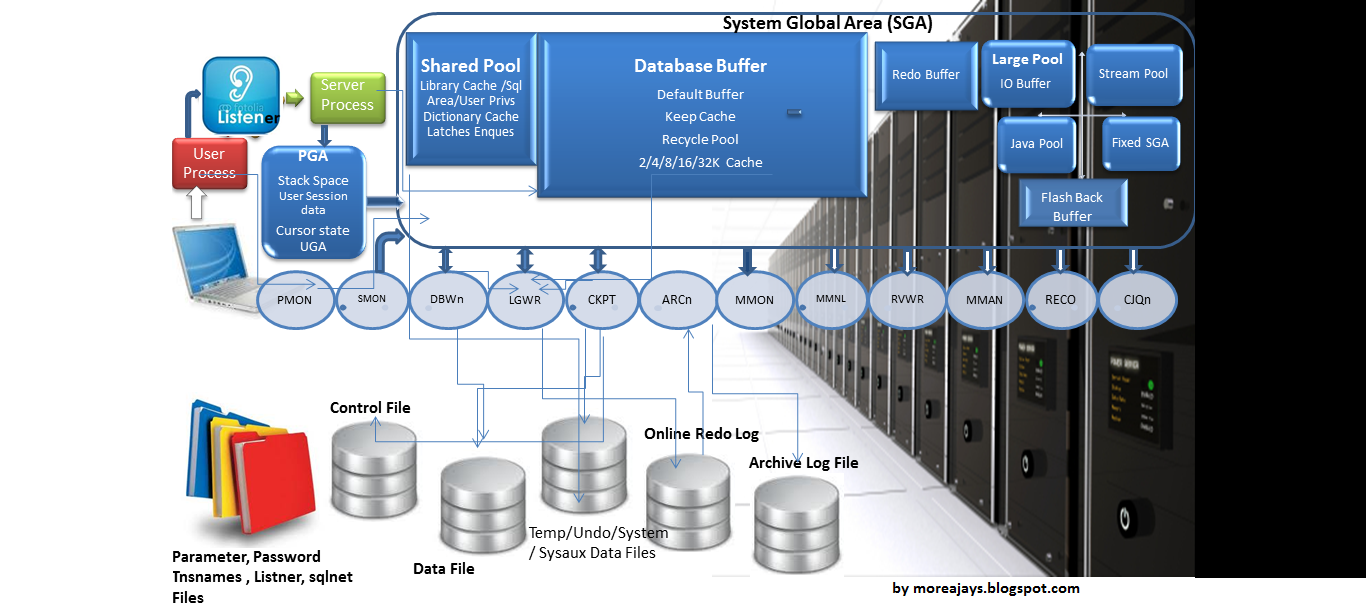 Среднее количество активных сессий рассчитывается как результат деления суммы всех событий ожидания на временной интервал.
Среднее количество активных сессий рассчитывается как результат деления суммы всех событий ожидания на временной интервал.
- Если зафиксирован рост активных сессий, то должна расти пропускная способность (график Throughput).
- Если Active Sessions превышает CPU Cores/CPU Threads, это свидетельствует о проблемах производительности.
- Если зафиксирован рост времени отклика операций, но при этом активные сессии не превышают CPU, это значит, что узкое место не в CPU и нужно более детально смотреть, по каким классам события ожидания фиксируется рост, после чего можно на графике нажать на соответствующий класс и провалиться глубже в детализацию (откроется отчет ASH — Active Session History).
Если на графике нажать кнопку Include Background, можно увидеть дополнительно статистику по фоновым процессам.
В Oracle есть такие классы события ожидания:
| № | Класс события ожидания | Описание |
|---|---|---|
| 1 | Cluster | События ожидания, связанные с управлением кластером RAC (Real Cluster Application) |
| 2 | Queueing | Содержит события, которые показывают задержки получения дополнительных данных в канальной среде. Время, затраченное в этих ожиданиях, указывает на неэффективность или другие проблемы в канале, что влияет на такие функции Oracle, как Oracle Streams, параллельные запросы или PL/SQL пакеты DBMS_PIPE Время, затраченное в этих ожиданиях, указывает на неэффективность или другие проблемы в канале, что влияет на такие функции Oracle, как Oracle Streams, параллельные запросы или PL/SQL пакеты DBMS_PIPE |
| 3 | Network | Сетевые события ожидания, включая события, возникающие во время обмена сообщениями по сети |
| 4 | Administrative | Ожидание выполнения DBA-команд, например пересоздание индекса |
| 5 | Configuration | Ожидания, вызванные неправильной конфигурацией ресурсов базы данных или экземпляра (например, недостаточный размер лог-файла) |
| 6 | Commit | События ожидания фиксации. Включает в себя одно-единственное событие ожидания log file sync (событие ожидания синхронизации файлов журналов), которое вызывают выполняемые в базе данных операции фиксации |
| 7 | Application | События ожидания, возникающие из-за кода приложения |
| 8 | Concurency | Ожидает внутренних ресурсов базы данных |
| 9 | System I/O | События ожидания системного ввода-вывода. Включает в себя события ожидания, связанные с фоновыми процессами ввода-вывода, в том числе событие db file parallel write (событие ожидания выполнения параллельной записи в файлы базы данных), которого ожидает фоновый процесс записи в базу данных, и события, связанные с чтением и записью в архивные журналы и журналы повторного выполнения Включает в себя события ожидания, связанные с фоновыми процессами ввода-вывода, в том числе событие db file parallel write (событие ожидания выполнения параллельной записи в файлы базы данных), которого ожидает фоновый процесс записи в базу данных, и события, связанные с чтением и записью в архивные журналы и журналы повторного выполнения |
| 10 | User I/O | События ожидания пользовательского ввода-вывода. Включает в себя события ожидания, связанные с пользовательскими процессами ввода-вывода, в том числе db file sequential read (событие ожидания выполнения последовательного чтения из файлов базы данных) и db file scattered read (событие ожидания выполнения чтения из файлов базы данных «вразброс») |
| 11 | Scheduler | События ожидания планировщика, включает в себя события ожидания, связанные с работой приложения Resource Manager (диспетчер ресурсов) |
| 12 | Other | Другие события ожидания, включает в себя разнородные события ожидания |
Throughput
Раздел Throughput отображает пропускную способность. Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пропускная способность базы данных измеряет объем работы, которую база данных выполняет за единицу времени.
Пики на графике Throughput должны соответствовать пикам на графике Average Active Sessions. Если заметен рост времени ожидания, необходимо убедиться, что увеличивается пропускная способность. Если пропускная способность низкая, а время ожидания растет — необходимо изменить настройки БД.
I/O
Latency показывает задержку чтения блоков. Это разница между временем выполнения чтения и временем обработки чтения БД. Показатель должен стремиться к нулю.
Оптимальным считается значение до 10 мс. Этот график — основной показатель производительности в этом блоке. Если зафиксирован рост времени задержки, нужно посмотреть, не растет ли количество I/O операций и их вес, также на рост Latency может влиять утилизация CPU.
Статистику по I/O можно смотреть в разрезе функций, в разрезе типов и в разрезе групп потребителей ресурсов (группы пользователей).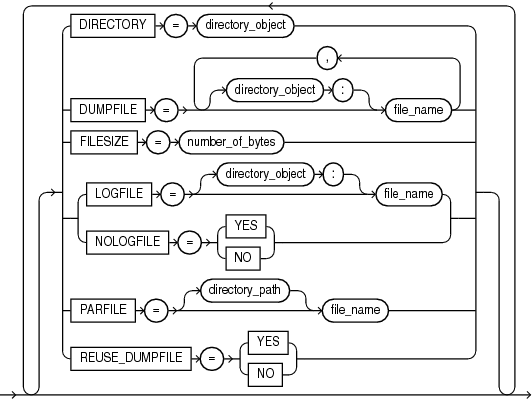 Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
Для этого на графике необходимо выбрать соответствующий Breakdown. Графики показывают количество I/O-операций в секунду и их вес в разрезе выбранного значения Breakdown. Для большей детализации можно провалиться глубже в статистику, выбрав соответствующее значение на графике или в легенде, и посмотреть статистику именно по выбранному значению.
I/O Function
График дает представление об уровне утилизации диска приложениями или джобами. То есть на графике можно увидеть, какие процессы больше всего читали и писали за определенный период.
Можно выделить следующие категории:
| № | Категория | Описание |
|---|---|---|
| 1 | Фоновые процессы | Включают в себя ARCH, LGWR, DBWR (полный список фоновых процессов есть в документации) |
| 2 | Активность | XML DB, Streams AQ, Data Pump, Recovery, RMAN |
| 3 | Тип I/O | Включает прямую запись и чтение (в том числе чтение из кэша) |
| 4 | Другое | Включает операции ввода/вывода управляющих файлов |
I/O Type
Выводит статистику по тяжести операций ввода-вывода. Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Маленькими считаются операции, которые обрабатывают до 128 КБ. К большим операциям ввода-вывода относятся: сканирование таблиц и индексов, прямая загрузка данных, резервное копирование, восстановление и архивирование.
Consumer group
Дает представление об утилизации диска в разрезе групп пользователей: показывает, какая группа пользователей выполняет операции чтения и записи в определенный период. Включает в себя фоновые процессы.
Parallel Executions
Раздел дает представление о показателях, связанных с параллельным выполнением запросов. Параллельный запрос делится на несколько процессов для ускорения выполнения запроса. Параллельное выполнение полезно при выполнении тяжелых запросов. Подробнее можно прочесть в официальной документации Oracle.
Services
Службы на этом графике представляют собой группы приложений. Отображаются только сессии активных служб, находящиеся в ожидании в определенный момент времени. Например, служба SYS$USERS — это установка пользовательского сеанса.
ASH Report
ASH Report (Active Session History) дает более подробную информацию по потреблению ресурсов. Чтобы перейти к графику, в меню Performance нужно выбрать пункт Performance Hub/ASH Report. Также перейти к ASH Report можно при выборе класса события ожидания на графике Average Active Session.
На графике можно выбрать признак, по которому хочется посмотреть статистику. Основные признаки:
- События ожидания и группы событий ожидания.
- Группы пользователей, пользователи, сервисы, инстансы.
- SQL-запросы.
На графике выше можно увидеть, что с 02:00 до 02:24 наблюдается рост времени ожидания чтения с диска, превышающего количество процессоров в системе.
Помимо этого можно посмотреть статистику по SQL-запросам, перейдя на вкладку SQL Monitoring.
На этой вкладке отображается топ-100 запросов по выбранному критерию (например, продолжительность, последние запросы, распределение по DB Time, утилизация диска). Нажав на SQL ID, можно провалиться глубже в детализацию и посмотреть как сам запрос, так и план его выполнения и потребляемые ресурсы. Подробнее про план выполнения запросов можно почитать в статьях Методы доступа к данным в Oracle и Опыт и рекомендации по оптимизации SQL-запросов.
Нажав на SQL ID, можно провалиться глубже в детализацию и посмотреть как сам запрос, так и план его выполнения и потребляемые ресурсы. Подробнее про план выполнения запросов можно почитать в статьях Методы доступа к данным в Oracle и Опыт и рекомендации по оптимизации SQL-запросов.
Рассмотрим ситуацию, возникшую во время проведения нагрузочного тестирования одного из сервисов.
На графике явно прослеживается рост времени ожидания сети в моменты запуска тестов. При более детальном рассмотрении в списке SQL-запросов был найден запрос, который утилизировал сеть. Он обращался по dblink к другой БД.
AWR
AWR (Automatic Workload Repository) дает подробную информацию о процессах, происходящих с БД в определенный период. Для построения AWR-отчета нужно выбрать пункт меню Performance/AWR/AWR Report. Также есть возможность сравнивать два временных промежутка. Для этого нужно выбрать пункт меню Performance/AWR/Compare Period Report.
Ниже будут описаны наиболее показательные разделы AWR-отчета, описание остальных разделов можно поискать в официальной документации.
Load Profile
Здесь отображается общая информация по тому, как была загружена БД за выбранный период.
| № | Параметр | Описание |
|---|---|---|
| 1 | DB Time(s) | Сумма времени утилизации процессора и время ожидания (без простоя) |
| 2 | DB CPU(s) | Нагрузка на процессор |
| 3 | Background CPU(s) | Загрузка процессора фоновыми задачами |
| 4 | Redo size | Объем чтения |
| 5 | Logical reads | Среднее количество логических чтений блоков |
| 6 | Block changes | Среднее значение измененных блоков |
| 7 | Physical reads | Физическое чтение в блоках |
| 8 | Physical writes | Количество записей в блоках |
| 9 | Read I/O requests | Количество чтений |
| 10 | Write I/O requests | Количество записей |
| 11 | Read I/O (MB) | Объем чтения |
| 12 | Write I/O (MB) | Объем записей |
| 13 | IM scan rows | Количество строк в In-Memory Compression Units (IMCU), которые были доступны |
| 14 | Session Logical Read IM | Чтения в In-Memory |
| 15 | User calls | Пользовательские вызовы |
| 16 | Parses | Разборы |
| 17 | Logons | Количество входов |
| 18 | Excecutes | Количество вызовов |
| 19 | Rollback | Количество откатов данных |
| 20 | Transacions | Количество транзакций |
Instance Efficiency Percentages
| № | Показатель | Критерии |
|---|---|---|
| 1 | Buffer nowait | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size Возможно, нужно увеличить data block buffer size |
| 2 | Buffer Hit | Если показатель меньше 95%, значит, буферы data block buffer используются неправильно. Возможно, нужно увеличить data block buffer size |
| 3 | Library cache hit | Если показатель меньше 95% — нужно расширять shared pool (либо причина в bind-переменных) |
| 4 | Redo NOWAIT | Если показатель меньше 95%, это говорит о проблеме в redo log buffer или redo log |
| 5 | Parse CPU to Parse Elapsd | Показатель должен быть больше или равен 90%, тогда большинство процессов не ожидает ресурсов, что говорит о правильной работе базы данных |
| 6 | Non-Parse CPU | Показатель должен приближаться к 100%, это значит, что большинство ресурсов CP используется в различных операциях, кроме parsing, что говорит о правильной работе базы данных. Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы Если Non-Parse CPU низкий, значит, база много времени тратит на разбор запроса вместо реальной работы |
| 7 | In-memory sort | Значение меньше 100 говорит о том, что сортировка идет через диск, а также есть потенциальные проблемы с PGA_AGGREGATE_TARGET,SORT_AREA_SIZE,HASH_AREA_SIZE и bitmap setting |
| 8 | Soft Parse | Чем он выше, тем меньше у нас Hard Parse |
| 9 | Latch Hit | Чем он выше, тем меньше мы ждем Latches (если он низкий — у нас проблемы с CPU-Bound и Latches) |
Top 10 Foreground Events by Total Wait Time
В разделе находится топ-10 событий, которые ожидали ресурсов дольше остальных.
При анализе необходимо обратить внимание на класс события ожидания. Если wait class System I/O, User I/O или Other, это нормально для БД. Если класс события ожидания Concurrency, это может свидетельствовать о проблемах.
Классы события ожидания можно посмотреть в разделе Wait Classes by Total Wait Time. В разделе находится статистика по классам события ожидания с сортировкой по времени ожидания.
Описание некоторых событий ожидания:
| № | Событие ожидания | Описание |
|---|---|---|
| 1 | DB CPU | Отображает процессорное время, затраченное на пользовательские операции над БД. Это событие должно находиться на первом месте списка |
| 2 | db file sequential read | Метрика сигнализирует, что пользовательский процесс не находит нужный блок в buffer cache, загружает его с диска в SGA и ждет физического ввода/вывода |
| 3 | db file scattered read | Указывает на проблему с фулл-сканами, возможно, нужны индексы |
| 4 | read by other session | Может говорить о том, что размер блока слишком большой или задержка (latency) слишком большая |
| 5 | enq TX – row lock contention | Событие возникает при ожидании блокировки строки для дальнейшей ее модификации DML-запросом. Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами Если показатель больше 10%, необходимо разбираться в причинах. Более детальную информацию можно посмотреть в разделе Segments by Row Lock Waits, в котором есть сведения о том, какие таблицы были заблокированы и какими запросами |
| 6 | DB FILE SEQUENTIAL READ | Если среднее значение параметра больше 100 мс, это может свидетельствовать о том, что диск работает медленно |
| 7 | LOG FILE SYNC | Значение AVG WAIT более 20 мс может свидетельствовать о проблемах |
| 8 | DB FILE SCATTERED READ | Если это событие выполняется — возможно, имеет смысл создать дополнительные индексы. Для более подробной информации нужно перейти к разделу Segments By Physical Read, в котором находится информация по таблицам и индексам, в которых происходит физическое чтение |
| 9 | direct path read temp ИЛИ direct path write temp | Эти события дают информацию по использованию временных файлов |
| 10 | Buffer Busy Wait | Событие указывает на то, что несколько процессов пытаются обратиться к одному блоку памяти, то есть пока первый процесс работает с конкретным блоком памяти, остальные процессы находятся в статусе ожидания |
Host CPU и Instance CPU
Здесь стоит обратить внимание на %Idle и %Total CPU. Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
Если показатель %Idle низкий, а %Total CPU высокий, это может свидетельствовать о том, что процессор является узким местом.
Foreground Wait Class, Foreground Wait events и Background Wait Events
Показывают классы и события, которые провели в ожидании большего всего. Foreground Wait events дополняет информацию раздела Top 10 Foreground Events By Total Wait Time. Background Wait Events показывает детализацию по событиям ожидания фоновых процессов.
SQL statistics
Раздел содержит несколько таблиц со статистикой по SQL-запросам, отсортированным по определенному критерию.
Подробнее про оптимизацию запросов и примеры типичных проблем в запросах можно почитать в статье Проактивная оптимизация производительности БД Oracle.
| № | Параметр | Описание |
|---|---|---|
| 1 | SQL ordered by Elapsed Time | Топ SQL-запросов по затраченному времени на их выполнение |
| 2 | SQL ordered by CPU Time | Топ SQL-запросов по процессорному времени |
| 3 | SQL ordered by User I/O Wait Time | Топ SQL-запросов по времени ожидания ввода/вывода для пользователя |
| 4 | SQL ordered by Gets | Запросы к БД, упорядоченные по убыванию логических операций ввода/вывода. При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры При анализе стоит учитывать, что для PL/SQL-процедур их количество прочитанных Buffer Gets будет состоять из суммы всех запросов в рамках этой процедуры |
| 5 | SQL ordered by Reads | Этот раздел схож с предыдущим: в нем указываются все операции ввода/вывода, наиболее активно физически считывающие данные с жесткого диска. Именно на эти запросы и процессы надо обратить внимание, если система не справляется с объемом ввода/вывода |
| 6 | SQL ordered by Physical Reads (UnOptimized) | В этом разделе выводятся неоптимизированные запросы. В Oracle неоптимизированными считаются все запросы, которые не обслуживаются DSFC или Exadata Cell Smart Flash Cache (ECSFC) |
| 7 | SQL ordered by Executions | Наиболее часто выполняемые запросы |
| 8 | SQL ordered by Parse Calls | Отображает количество попыток разбора SQL-запросов до его выполнения |
| 9 | SQL ordered by Sharable Memory | Запросы, занимающие больший объем памяти общего пула SGA |
| 10 | SQL ordered by Version Count | Здесь показано количество SQL-операторов экземпляров одного и того же оператора в разделяемом пуле |
| 11 | Complete List of SQL Text | Показывает полный SQL-запрос, не только его хэш. В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from…», запросы с большим количеством «like» и т. п.) В этой таблице можно найти неоптимальные запросы (например, запросы по всем столбцам таблицы «select * from…», запросы с большим количеством «like» и т. п.) |
Active Session History (ASH) Report
В данной таблице находятся самые тяжелые SQL запросы, на которые приходится наибольший процент активности и наибольшее время ожидания.
В таблице содержится статистика по запросам, на которые приходится наибольший процент выборочной активности и подробная информация о их плане выполнения. Вы можете использовать эту информацию, чтобы определить, какая часть выполнения SQL операторов значительно повлияла на затраченное время SQL оператора.
Пример создание внешней таблицы с помощью драйвера доступа ORACLE_DATAPUMP
Без рубрики
sql oracle
·
18.03.2022
·
Используя драйвер доступа ORACLE_DATAPUMP, можно выполнять с внешними таблицами операции выгрузки и повторной загрузки.
Примечание. В контексте внешних таблиц загрузка данных обозначает операцию чтения данных из внешней таблицы и их загрузку в таблицу базы данных. Под выгрузкой данных понимается чтение данных из таблицы и их вставка во внешнюю таблицу.
Пример на рисунке служит иллюстрацией спецификации, предназначенной для создания внешней таблицы с помощью драйвера доступа ORACLE_DATAPUMP. Затем данными заполняют два файла: emp1.exp и emp2.exp.
Чтобы заполнить внешнюю таблицу данными, считываемыми из таблицы EMPLOYEES, необходимо выполнить следующие действия:
- Создайте объект каталога emp_dir следующим образом:
CREATE DIRECTORY emp_dir AS '/emp_dir' ; - Выполните команду
CREATE TABLE, показанную на рисунке.
Примечание. Каталог emp_dir совпадает с каталогом, созданным в предыдущем примере использования драйвера загрузчика ORACLE_LOADER.
Запрос внешней таблицы можно реализовать, выполнив следующий программный код:
Post Views: 489
Похожие записи
Без рубрики
sql oracle
·
25. 04.2023
04.2023
·
Используя предложение WITH, можно определить блок запроса до его применения в запросе. Предложение WITH (формально называется subquery_factoring_clause) позволяет многократно использовать один и тот же блок запроса в инструкции SELECT, когда она встречается более одного раза в сложном запросе. Это особенно… Читать далее
Без рубрики
mikl
·
22.04.2023
·
Оператор WITH в SQL — это чрезвычайно полезный инструмент для создания временных таблиц и использования их внутри других запросов. Это позволяет упростить код и улучшить производительность запросов. Оператор WITH (также известный как Common Table Expression) используется для создания временных таблиц,… Читать далее
Без рубрики
sql oracle
·
15.04.2022
·
Внешняя таблица не описывает никаких данных, которые хранятся в базе данных. Внешняя таблица не описывает порядок хранения данных во внешнем источнике. Вместо этого она описывает, как уровень внешней таблицы должен представлять данные для сервера. За преобразования, которые требуется выполнять над… Читать далее
Внешняя таблица не описывает порядок хранения данных во внешнем источнике. Вместо этого она описывает, как уровень внешней таблицы должен представлять данные для сервера. За преобразования, которые требуется выполнять над… Читать далее
Без рубрики
sql oracle
·
15.04.2022
·
Позволяет восстанавливать таблицы до состояния на заданный момент времени с помощью одной инструкции. Восстанавливает табличные данные вместе со связанными индексами и ограничениями. Позволяет возвращать таблицу и ее содержимое в состояние, существовавшее на определенный момент времени, или к изменению системы, определенному… Читать далее
Без рубрики
sql oracle
·
04.04.2022
·
Внешние таблицы создаются с помощью предложения ORGANIZATION EXTERNAL инструкции CREATE TABLE. В действительности таблица не создается. Точнее, создаются метаданные в словаре данных, который можно использовать для доступа к внешним данным. Предложение ORGANIZATION применяется для указания порядка, в котором сохраняются строки… Читать далее
Предложение ORGANIZATION применяется для указания порядка, в котором сохраняются строки… Читать далее
Без рубрики
sql oracle
·
04.04.2022
·
В базе данных Oracle имеется функция для удаления таблиц. При удалении таблицы база данных не сразу освобождает пространство, занимаемое таблицей. Точнее, база данных переименовывает таблицу и помещает ее в корзину, где таблица позже может быть восстановлена с помощью инструкции FLASHBACK… Читать далее
Без рубрики
sql oracle
·
18.03.2022
·
Рассмотрим, как создаются внешние таблицы посредством драйвера доступа ORACLE_LOADER. Предположим, что существует текстовый файл, в котором имеются записи в следующем формате: 10,jones,11-Dec-1934 20,smith,12-Jun-1972 Записи разделяются символом новой строки, и все поля заканчиваются запятой ( , ). Имя файла: /emp_dir/emp.dat. … Читать далее
… Читать далее
Без рубрики
sql oracle
·
12.02.2022
·
Можно настроить много аспектов интерфейса и среды SQL Developer, изменяя предпочтения SQL Developer согласно Вашим потребностям. Чтобы изменить предпочтения SQL Developer, выберите Tools, а затем Preferences. Настройте интерфейс SQL Developer и среду. В меню Tools выберите Preferences. Предпочтения группируется в… Читать далее
Без рубрики
sql oracle
·
12.02.2022
·
В этой рубрике было рассмотрено использование SQL Developer, чтобы выполнять следующие задачи: Просматривать, создавать и редактировать объекты базы данных Выполнять SQL-операторы и сценарии на Рабочем листе SQL Создавать и сохранять пользовательские отчеты SQL Developer является бесплатным графическим инструментом, позволяющим упростить… Читать далее
Без рубрики
sql oracle
·
21. 01.2022
01.2022
·
Внешняя таблица – это таблица, доступная только для чтения, метаданные которой хранятся в базе данных, а данные – вне базы данных. Определение этой внешней таблицы может рассматриваться как представление, которое используется для запуска любых SQL-запросов внешних данных без необходимости предварительной… Читать далее
советы по команде impdp
Вопрос:
Я хочу знать, как использовать все параметры impdp. Я
знаком со всеми старыми директивами бесов, но мне нужно
понять, как использовать команды impdp.
Ответ:
Impdp (импорт насоса данных) заменил
более старая утилита imp, но базовая функциональность остается намного
то же самое, но с другим синтаксисом и улучшениями impdp.
Вот некоторые из наиболее распространенных функций impdp:
Как читать и записывать файлы при импорте?
Вам необходимо создать каталог для expdp и impdp
чтобы иметь возможность писать в ОС:
создать каталог
dmp_dir как ‘c:\Users\Don\Wm’;
разрешить чтение, запись в каталоге dmp_dir
к вм;
Как создать файл параметров в impdp?
импдп . ..
..
PARFILE=my_imp.par
Как отобразить таблицу
и определения индексов из базы данных?
расширение …
CONTENT=metadata_only DUMPFILE=my_metadata
Как отобразить таблицу
и определения индексов из файла expdp .dmp?
импдп …
SQLFILE=myddl.sql DUMPFILE=мои_метаданные
Что эквивалентно утилите imp «ignore-y»
команда. Я хочу предварительно создать таблицы и индексы.
импдп . . . контент = только данные
Как просмотреть все команды impdp?
impdp help=y
Импорт: выпуск
10.1.0.2.0 — Производство, суббота, 11 сентября 2004 г.
17:22
Copyright (c) 2003, Oracle. Все
права защищены.
Утилита Data Pump Import предоставляет механизм для
передача объектов данных
между базами данных Oracle. Утилита
вызывается следующей командой:
Пример: impdp scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
Вы можете управлять тем, как
Импорт запускается путем ввода команды ‘impdp’, за которой следует
.
по различным параметрам. Указать
параметры, вы используете ключевые слова:
Формат: impdp KEYWORD=value или KEYWORD=(value1,value2,…,valueN)
Пример: импдп
scott/tiger DIRECTORY=dmpdir DUMPFILE=scott.dmp
USERID должен быть
первый параметр в командной строке.
Ключевое слово
Описание (по умолчанию)
————————————————— —————————-
ПРИКРЕПЛЯТЬ
Прикрепить к существующей работе, например. ПРИСОЕДИНИТЬ [=название задания].
СОДЕРЖАНИЕ
Указывает данные для загрузки, где допустимы ключевые слова:
(ВСЕ), ТОЛЬКО ДАННЫЕ и ТОЛЬКО МЕТАДАННЫЕ.
СПРАВОЧНИК
Объект каталога, который будет использоваться для файлов дампа, журнала и sql.
ДАМФАЙЛ
Список файлов дампа для импорта (expdat.dmp),
например DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp.
ОЦЕНКА
Вычислите оценки работы, где действительные ключевые слова:
(БЛОКИ) и СТАТИСТИКА.
ИСКЛЮЧИТЬ
Исключить определенные типы объектов, например. ИСКЛЮЧИТЬ=ТАБЛИЦА:EMP.
ИСКЛЮЧИТЬ=ТАБЛИЦА:EMP.
FLASHBACK_SCN
SCN, используемый для установки моментального снимка сеанса.
FLASHBACK_TIME
Время, используемое для получения SCN, наиболее близкого к указанному времени.
ПОЛНЫЙ
Импортируйте все из источника (Y).
ПОМОЩЬ
Отобразите справочные сообщения (N).
ВКЛЮЧАЕТ
Включите определенные типы объектов, например. ВКЛЮЧИТЬ=ТАБЛИЦА_ДАННЫЕ.
ИМЯ РАБОТЫ
Имя создаваемого задания импорта.
ФАЙЛ ЖУРНАЛА
Имя файла журнала (import.log).
СЕТЬ_LINK
Имя ссылки удаленной базы данных на исходную систему.
НОЛОГФАЙЛ
Не писать лог-файл.
ПАРАЛЛЕЛЬНЫЙ
Изменить количество активных работников для текущей работы.
ПАРФАЙЛ
Укажите файл параметров.
ЗАПРОС
Предикат-предикат, используемый для импорта подмножества таблицы.
REMAP_DATAFILE
Переопределить ссылки на файлы данных во всех операторах DDL.
REMAP_SCHEMA
Объекты из одной схемы загружаются в другую схему.
REMAP_TABLESPACE
Объект табличного пространства переназначается на другое табличное пространство.
ПОВТОРНОЕ ИСПОЛЬЗОВАНИЕ ФАЙЛОВ_ДАННЫХ
Табличное пространство будет инициализировано, если оно уже существует (N).
СХЕМЫ
Список схем для импорта.
SKIP_UNUSABLE_INDEXES Пропустить индексы
которые были установлены в состояние Index Unusable.
SQLФАЙЛ
Запишите все SQL DDL в указанный файл.
СТАТУС
Частота (сек) Состояние задания должно контролироваться, где
по умолчанию (0) будет показывать новый статус, когда он доступен.
STREAMS_CONFIGURATION Включить
загрузка метаданных потоков
TABLE_EXISTS_ACTION
Действие, которое следует предпринять, если импортированный объект уже существует.
Допустимые ключевые слова: (ПРОПУСТИТЬ), APPEND, REPLACE и TRUNCATE.
ТАБЛИЦЫ
Определяет список таблиц для импорта.
ТАБЛИЧНЫЕ ПРОСТРАНСТВА
Определяет список табличных пространств для импорта.
ПРЕОБРАЗОВАНИЕ
Преобразование метаданных для применения (Да/Нет) к определенным объектам.
Допустимые ключевые слова преобразования: SEGMENT_ATTRIBUTES и STORAGE.
бывший. TRANSFORM=SEGMENT_ATTRIBUTES:N:TABLE.
ТРАНСПОРТНЫЕ ФАЙЛЫ ДАННЫХ
Список файлов данных, которые будут импортированы переносимым режимом.
TRANSPORT_FULL_CHECK Подтвердить
сегменты хранения всех таблиц (N).
TRANSPORT_TABLESPACES Список
табличные пространства, из которых будут загружены метаданные.
Допустимо только в операциях импорта в режиме NETWORK_LINK.
ВЕРСИЯ
Версия объектов для экспорта, где допустимы ключевые слова:
(СОВМЕСТИМАЯ), ПОСЛЕДНЯЯ или любая допустимая версия базы данных.
Допустимо только для NETWORK_LINK и SQLFILE.
Следующие
команды действительны в интерактивном режиме.
Примечание: допускаются сокращения
Команда
Описание (по умолчанию) 11g
————————————————— —————————-
CONTINUE_CLIENT
Вернитесь в режим ведения журнала. Задание будет перезапущено, если оно бездействует.
ВЫХОД_КЛИЕНТ
Завершите сеанс клиента и оставьте задание работающим.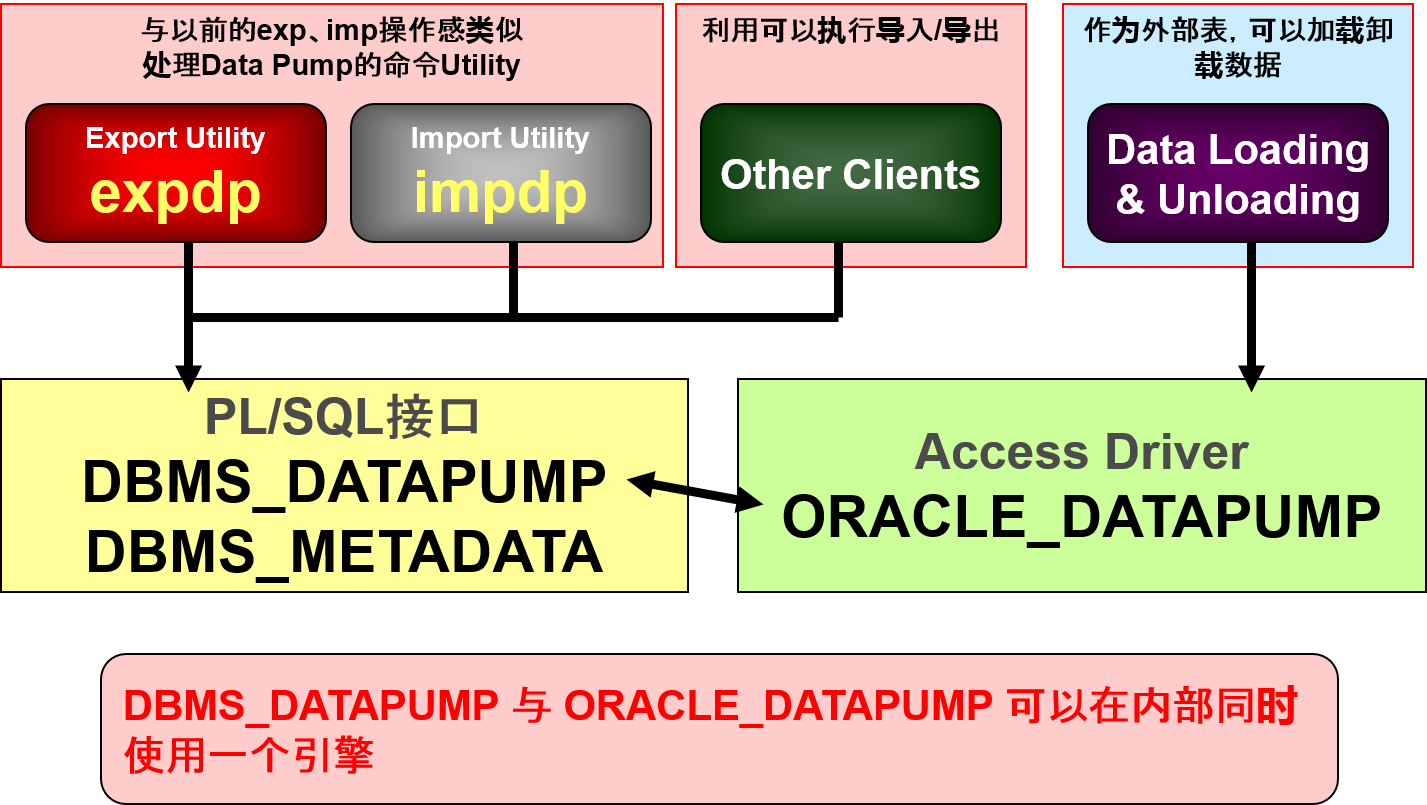
ПОМОЩЬ
Обобщить интерактивные команды.
УБИЙСТВО_РАБОТЫ
Отключить и удалить задание.
ПАРАЛЛЕЛЬНЫЙ
Изменить количество активных работников для текущей работы.
ПАРАЛЛЕЛЬ=.
START_JOB
Начать/возобновить текущую работу.
START_JOB=SKIP_CURRENT запустит задание после пропуска
любое действие, которое выполнялось, когда задание было остановлено.
СТАТУС
Статус задания частоты (сек) должен контролироваться, где
по умолчанию (0) будет показывать новый статус, когда он доступен.
СТАТУС=[интервал]
STOP_JOB
Упорядоченное завершение выполнения задания и выход из клиента.
STOP_JOB=IMMEDIATE выполняет немедленное отключение
Работа Data Pump.
Как импортировать схемы в базу данных Oracle с помощью Impdp Data Pump Import
Выполнение импорта схем вашей базы данных так же просто, как и их экспорт. Подобно экспорту схемы expdp, мы используем параметр SCHEMAS для выполнения импорта схемы. Параметр SCHEMAS указывает, что пользователь хочет выполнить импорт в режиме схемы. Также использование параметра схемы помогает вам выбрать конкретную схему из нескольких экспортируемых схем для импорта.
Подобно экспорту схемы expdp, мы используем параметр SCHEMAS для выполнения импорта схемы. Параметр SCHEMAS указывает, что пользователь хочет выполнить импорт в режиме схемы. Также использование параметра схемы помогает вам выбрать конкретную схему из нескольких экспортируемых схем для импорта.
Как и все импорты, для импорта в режиме схемы также требуется файл дампа, содержащий требуемую схему в качестве источника, а также объект каталога, указывающий на каталог, содержащий файлы дампа. Убедитесь, что эти файлы дампа созданы только экспортом expdp data pump, потому что импорт impdp Data pump может импортировать данные только из файлов дампа, созданных expdp data pump export, а не из каких-либо других файлов.
И для выполнения импорта в режиме схемы либо вы должны быть привилегированным пользователем, например sys/system, либо иметь роль Datapump_imp_full_database.
Я настоятельно рекомендую вам пройти мой учебник № 54 о том, как экспортировать схему, так как значения различных параметров, таких как каталог и файлы дампа, используются из этого руководства.
Возможны две ситуации, связанные с импортом схемы:
- В целевой базе нет схемы с именем той, которую вы собираетесь импортировать.
- В целевой базе данных уже есть схема с именем той, которую вы собираетесь импортировать.
Первый сценарий самый простой и не требует от вас никакой тяжелой работы. В такой ситуации вы можете напрямую выполнить импорт схемы.
А вот вторая ситуация довольно каверзная. Поскольку у вас уже есть схема с тем же именем, что и та, которую вы собираетесь импортировать, поэтому сначала вам нужно решить, есть ли еще требования к уже существующей схеме или нет. Если нет, то вы можете отказаться от этой схемы. Но в реальных сценариях удаление всей схемы может привести к более серьезным проблемам, поэтому, когда вы не можете удалить схему, остается только один выбор: создать дубликат уже существующей схемы. Для создания дубликата схемы вы можете указать утилите импорта impdp data pump сначала переименовать схему, а затем импортировать ее в базу данных.
Давайте посмотрим на команды impdp для обеих ситуаций.
Команда импорта насоса данных impdp для ситуации 1, когда в базе данных нет схемы с тем же именем, что и та, которую вы собираетесь импортировать, —
C:\>impdp system/oracle@ORCL DIRECTORY = exp_schema DUMPFILE = exp_schm.dmp SCHEMAS = scott
Выполнение этой команды импорта насоса данных impdp импортирует схему Скотта в вашу базу данных.
Но в ситуации 2, когда целевая база данных уже имеет схему с таким же именем, эта команда impdp вернет ошибку ORA-31684, указывающую, что «Тип объекта ПОЛЬЗОВАТЕЛЬ: «СКОТТ» уже существует» .
В этом случае, как я уже говорил выше, вы можете либо удалить схему с тем же именем из вашей базы данных, либо сделать дубликат схемы. Чтобы сделать дубликат копии, вы можете использовать параметр REMAP_SCHEMA команды импорта насоса данных impdp. Давайте посмотрим, как
C:\>impdp system/oracle@ORCL DIRECTORY = exp_schema DUMPFILE = exp_schm.![]()