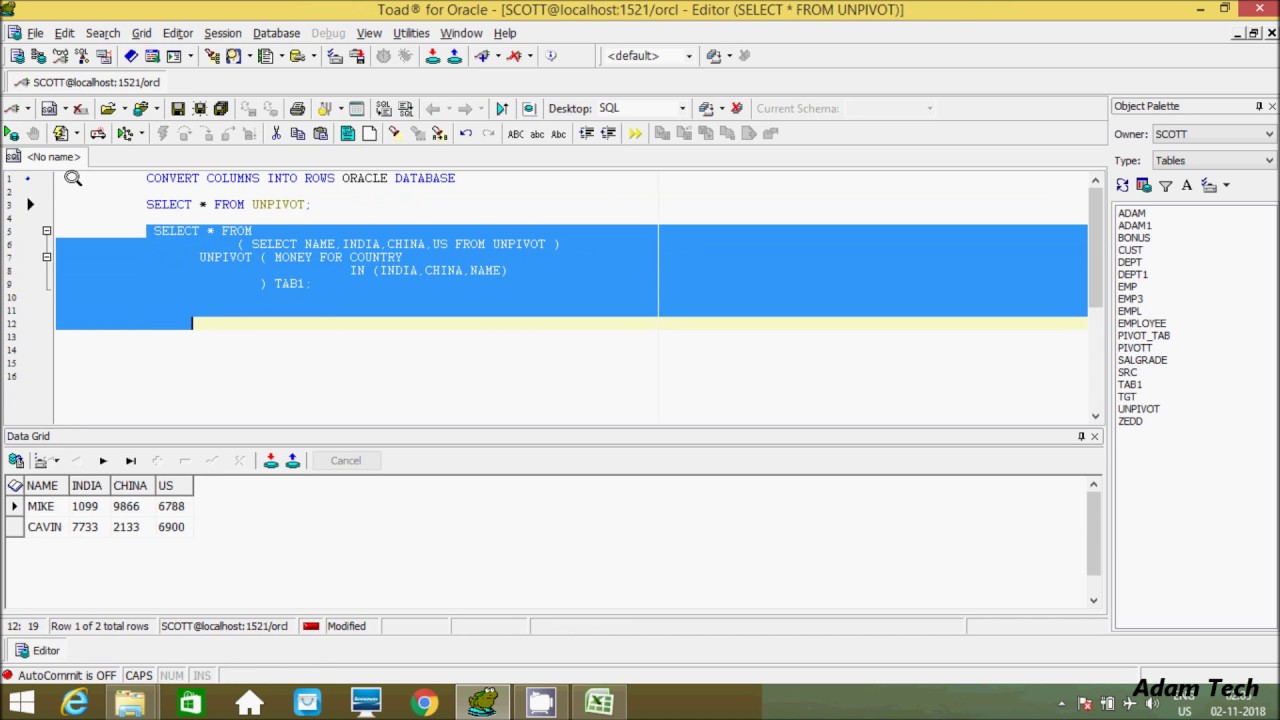
Oracle unpivot: Oracle UNPIVOT Explained By Practical Examples
Содержание
Oracle19cr1 ora-56901 non-constant expression is not allowed for pivot|unpivot values
База данных: 19c Выпуск 1
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
База данных: 19c Выпуск 1
Код ошибки: ORA-56901
Описание: non-constant expression is not allowed for pivot|unpivot values
Причина: Attempted to use non-constant expression for pivot|unpivot values.
Действие: Use constants for pivot|unpivot values.
База данных: 11g Выпуск 1
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
База данных: 11g Выпуск 2
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
База данных: 12c Выпуск 1
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
База данных: 12c Выпуск 2
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
База данных: 18c Выпуск 1
Код ошибки: ORA-56901
Описание: в качестве значений pivot|unpivot не разрешается использовать неконстантное выражение
Причина: Попытка использовать непостоянное выражение для значений pivot | unpivot.
Действие: Используйте константы для значений pivot | unpivot.
Библиотека кодов ошибок базы данных Oracle
- _10gR1 Коды ошибок
- _10gR2 Коды ошибок
- _11gR1 Коды ошибок
- _11gR2 Коды ошибок
- _12cR1 Коды ошибок
- _12cR2 Коды ошибок
- _18cR1 Коды ошибок
- _19cR1 Коды ошибок
Параметры базы данных Oracle
- Список параметров
Пакеты баз данных Oracle
Список пакетов
- Список пакетов
- _Пакеты Oracle Database 12cR1
- _Пакеты Oracle Database 11gR2
- _Пакеты Oracle Database 11gR1
- _Пакеты Oracle Database 10gR2
Словарь данных базы данных Oracle
- _База данных Oracle 10gR2 Словарь данных
- _База данных Oracle 11gR2 Словарь данных
- _База данных Oracle 12cR1 Словарь данных
- _База данных Oracle 12cR2 Словарь данных
- _База данных Oracle 18cR1 Словарь данных
- _База данных Oracle 19cR1 Словарь данных
НОУ ИНТУИТ | Лекция | Выборка данных.
 Фраза SELECT предложения SELECT
Фраза SELECT предложения SELECT
Аннотация: Приводятся правила построения и возможности фразы SELECT, используемой для формирования столбцов окончательного ответа в предложении SELECT. Рассматривается фраза PIVOT/UNPIVOT, логически объединяющая фразы SELECT и FROM.
Ключевые слова: список, частичный результат, синтаксически корректный, оконные функции, функции ранжирования, lag, функция регрессии, Oracle, pivot, SQL
Фраза SELECT и функции в предложении SELECT
Фраза SELECT — вторая, вместе с FROM, обязательная для каждого предложения SELECT. Ее назначение состоит в формировании столбцов таблицы — окончательного результата выполнения запроса. Типично она сохраняет количество строк, поступивших ей на входе от предшествующих фраз, и занимается только переформулированием столбцов, но в некоторых случаях она способна вдобавок и сократить количество строк.
Обычно состав фразы SELECT — список через запятую выражений для столбцов окончательного ответа. В отдельных случаях у такой структуры могут существовать свои особенности.
В отдельных случаях у такой структуры могут существовать свои особенности.
Сокращенная запись для «всех столбцов таблицы»
Если делается запрос по одной таблице-источнику данных и требуется выдать все поля строк этой таблицы без изменений, вместо списка выражений во фразе SELECT можно указать символ *:
SELECT * FROM dept;
Символ * может быть предварен именем таблицы:
SELECT dept.* FROM dept;
В данном случае в этом нужды нет, но если бы источников данных было несколько, такое уточнение было бы оправдано.
Два последних примера равносильны и выдадут то же, что и следующая формулировка:
SELECT dept.deptno, dept.dname, dept.loc FROM dept;
Еще пример. Следующие два предложения равносильны:
SELECT emp.ename, dept.deptno, dept.dname, dept.loc FROM dept, emp WHERE dept.deptno = emp.deptno; SELECT emp.ename, dept.* FROM dept, emp WHERE dept.deptno = emp.deptno;
 deptno, dept.dname, dept.loc
FROM dept, emp
WHERE dept.deptno = emp.deptno;
SELECT emp.ename, dept.*
FROM dept, emp
WHERE dept.deptno = emp.deptno;
deptno, dept.dname, dept.loc
FROM dept, emp
WHERE dept.deptno = emp.deptno;
SELECT emp.ename, dept.*
FROM dept, emp
WHERE dept.deptno = emp.deptno;
Символ * не связан с единичностью источника и означает «все столбцы частичного результата обработки, пришедшие на вход фразе SELECT, без каких-либо преобразований». Пример употребления в запросе к двум таблицам:
SELECT * FROM dept, emp WHERE dept.deptno = emp.deptno;
Использование SELECT * может показаться привлекательным в силу экономности записи, однако стоит напомнить, что это нереляционная конструкция, так как она полагается на порядок столбцов в таблице, в то время как в реляционной модели атрибуты в отношении порядка не имеют и допускают обращение к ним только по названиям. В предположении порядка столбцов (тем более неявном) кроется определенный риск, так как таблицы в Oracle допускают добавление и удаление столбцов, из-за чего запросы в программе могут потерять синтаксическую корректность или, хуже того, изменить смысл.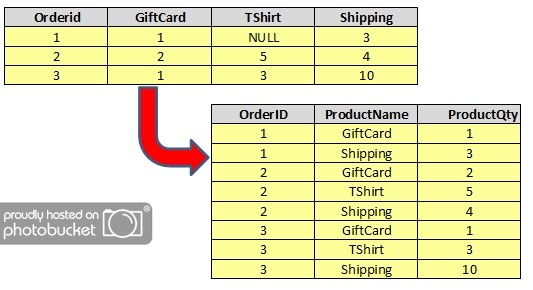
В технических запросах (не в приложении) конструкцией SELECT * можно пользоваться свободнее.
Выражения во фразе SELECT
Пример, когда во фразе SELECT приводятся выражения, а не имена столбцов:
SELECT
ename
, ' earns'
, ( sal + NVL ( comm, 0 ) ) / 1000000
, ' million dollars per month'
FROM emp
;
Первый по порядку столбец будет содержать разные имена сотрудников, второй и четвертый — постоянные значения, а третий — разные результаты оценки числового выражения.
Именование столбцов в результате запроса
Если не предпринять специальных мер, столбцы в таблице-результате именуются автоматически (чаще всего на основе имен столбцов запрошенных таблиц). При желании программист может потребовать СУБД назвать столбец по-своему, указав имя через пробел после формулировки выражения. (Имеется в виду «обобщенный пробел», который может
(Имеется в виду «обобщенный пробел», который может
состоять фактически из нескольких знаков пробела, табуляции или переходов на новую строку).
Примеры:
SELECT ename, sal salary FROM emp; SELECT ename "Сотрудники", sal "Зарплата" FROM emp; SELECT SUM ( comm ) / COUNT ( * ) "Усреднение по всем сотрудникам" FROM emp ;
Правила выбора и записи имен столбцов те же, что и для таблиц в БД.
Вместо обобщенного пробела можно с равным успехом использовать связку AS:
SELECT ename AS "Сотрудники", sal AS "Зарплата" FROM emp;
Использовать пробел или ключевое слово AS — дело вкуса и здравого смысла программиста. Ключевое слово AS добавляет тексту запроса переносимости.
Оператор UNPIVOT Oracle 11g — преобразование столбцов в строки — AMIS, блог, управляемый данными
0 0
Время чтения: 5 минут 22 секунды
Операция PIVOT часто обсуждается, когда речь идет о более сложных SQL-запросах. Сводка — это процесс переключения строк и столбцов, который, например, является расширенной функцией в Excel. До Oracle 11g существовало несколько подходов к повороту, которые не были обходными путями из-за отсутствия оператора PIVOT в языке Oracle SQL.
Сводка — это процесс переключения строк и столбцов, который, например, является расширенной функцией в Excel. До Oracle 11g существовало несколько подходов к повороту, которые не были обходными путями из-за отсутствия оператора PIVOT в языке Oracle SQL.
В Oracle 11g это изменилось. Теперь в нашем распоряжении есть оператор PIVOT и UNPIVOT. Давайте сначала посмотрим на UNPIVOT. В Oracle операция UNPIVOT — это процесс превращения столбцов в строки. Проще говоря, применяя оператор UNPIVOT к ряду столбцов, каждая строка разбивается на такое же количество строк. В каждой из этих строк есть два новых столбца: один для столбца, из которого происходит эта строка — один из столбцов, в котором набор данных был UNPIVOT — и один со значением из столбца. Исходные столбцы UNPIVOT больше не являются частью вновь созданных записей.
Давайте рассмотрим простой пример, используя известную таблицу EMP. Мы решили рассматривать столбцы SAL и COMM как два разных типа INCOME_COMPONENT. Мы хотели бы предоставить нашим сотрудникам столбец INCOME_COMPONENT — и две строки для каждого сотрудника с двумя компонентами дохода.
Этот запрос UNPIVOT будет выглядеть так:
select *
от ( выберите имя, работа, сал, комм
из эмп
)
развернуть
(доход_компонент_значение
для типа дохода_компонента в (сал, комм)
)
/
Здесь мы указали, что строки, выбранные из emp, со столбцами ename, job, sal и comm, должны быть UNPIVOTed столбцами SAL и COMM. Это означает, что для каждой строки со значением в столбце SAL мы получаем новую строку со столбцами ENAME и JOB, новый столбец INCOME_COMPONENT_TYPE со значением «SAL» и новый столбец INCOME_COMPONENT_VALUE со значением из столбца SAL. Если эта строка также имеет значение для COMM, она порождает другую новую строку с теми же значениями ENAME и JOB, значением «COMM» для столбца INCOME_COMPONENT_TYPE и значением COMM в новом столбце INCOME_COMPONENT_VALUE:
ENAME JOB INCO INCOME_COMPONENT_VALUE ---------- --------- ---- ------- SMITH CLERK SAL 800 АЛЛЕН ПРОДАВЕЦ САЛ 1600 АЛЛЕН ПРОДАВЕЦ COMM 300 ПРОДАВЕЦ САЛОН 1250 СВЯЗЬ С ПРОДАВЦОМ 500 ДЖОНС МЕНЕДЖЕР САЛ 2975 МАРТИН ПРОДАВЕЦ САЛ 1250 МАРТИН ПРОДАВЕЦ COMM 1400 БЛЕЙК МЕНЕДЖЕР САЛ 2850 КЛАРК МЕНЕДЖЕР САЛ 2450 КОРОЛЬ ПРЕЗИДЕНТ SAL 5000 ТЕРНЕР ПРОДАВЕЦ САЛ 1500 ТЕРНЕР ПРОДАВЕЦ COMM 0 АДАМС Клерк САЛ 1100 Джеймс Клерк Сэл 950 МИЛЛЕР Клерк САЛ 1300 СКОТТ АНАЛИТИК САЛ 3000 FORD АНАЛИТИКА САЛ 3000 Выбрано 18 рядов.

С этим результатом становится легко рассчитать общий доход для наших сотрудников, хотя с помощью простой «sal+nvl(comm,0) as Income», которую можно было бы сделать, конечно, без UNPIVOT:
select ename
, работа
, сумма(income_component_value) доход
от ( выберите имя, работа, сал, комм
из эмп
)
развернуть
(доход_компонент_значение
для типа дохода_компонента в (сал, комм)
)
группа
по имени
, работа
/
ENAME ДОХОД ЗА РАБОТУ ———- ——— ———- ПРОДАВЕЦ В УОРД 1750 ПРОДАВЕЦ СМИТ 800 УПРАВЛЯЮЩИЙ КЛАРК 2450 ПРОДАВЕЦ ТЕРНЕР 1500 ДЖЕЙМС Клерк 950 ДЖОНС УПРАВЛЯЮЩИЙ 2975 МАРТИН ПРОДАВЕЦ 2650 АДАМС Клерк 1100 СКОТТ АНАЛИТИК 3000 КОРОЛЬ ПРЕЗИДЕНТ 5000 ФОРД АНАЛИТИК 3000 АЛЛЕН ПРОДАВЕЦ 1900 BLAKE MANAGER 2850 MILLER CLERK 1300 Выбрано 14 рядов.
Боюсь, этот пример мало что может проиллюстрировать полезность операции UNPIVOT. Я считаю, что это действительно сияет, когда дизайн данных не был настолько денормализован, как нам хотелось бы, и вместо транзакционного формата, который мы предпочли бы для агрегирования, мы застряли с несколькими столбцами в каждой строке. Типичными примерами являются записи со столбцами для каждого дня недели или даже дня месяца или для нескольких фиксированных — или мы так думали — моментов времени в течение каждого дня. Когда экран для ввода значений выглядит как матрица, слишком часто таблица имеет такое расположение столбцов. А операции с данными сложнее, чем должны быть. Войдите в UNPIVOT.
Типичными примерами являются записи со столбцами для каждого дня недели или даже дня месяца или для нескольких фиксированных — или мы так думали — моментов времени в течение каждого дня. Когда экран для ввода значений выглядит как матрица, слишком часто таблица имеет такое расположение столбцов. А операции с данными сложнее, чем должны быть. Войдите в UNPIVOT.
Посмотрите на этот пример.
SQL> описание daily_measurements Имя Нуль? Тип ----------------------------------------- -------- - -------------- ДЕНЬ ДАТА НОМЕР УТРО_ИЗМЕРЕНИЯ(5,2) НОМЕР ИЗМЕРЕНИЯ ПОСЛЕ ПОЛУДНЯ (5,2) ВЕЧЕРНЕЕ_ИЗМЕРЕНИЕ (5,2)
В какой-то момент такой дизайн стола показался хорошей идеей. К настоящему времени мы знаем лучше. Получить среднее значение за день намного сложнее, чем можно было бы подумать, зная, что наш переутомленный персонал может легко пропустить одно из ежедневных измерений, и мы, конечно, не знаем, какое именно.
ДЕНЬ УТРО_ИЗМЕРЕНИЕ ДЕНЬ_ИЗМЕРЕНИЕ ВЕЧЕР_ИЗМЕРЕНИЕ ---------------------------------- ------------------ 27.
 09.07 10,2 45,91 35,6
28-СЕН-07 16.12 25.13 38.21
29 сентября 2007 г. 21,65 81,2
09.07 10,2 45,91 35,6
28-СЕН-07 16.12 25.13 38.21
29 сентября 2007 г. 21,65 81,2
select (morning_measurement+afternoon_measurement+evening_measurement)/3 day_average не поможет. Прежде всего, нам нужно NVL(measurement,0), чтобы NULL не искажал суммирование. Затем мы должны разделить на количество измерений, которые на самом деле есть: случай, когда утреннее_измерение равно нулю, затем 0, иначе 1 конец + случай, когда послеполуденное_измерение равно нулю, тогда 0, иначе 1 конец +… — это один из способов получить коэффициент для деления. Не элегантно!
Используя UNPIVOT, жизнь становится намного проще в этих обстоятельствах:
выберите день
, среднее (измерение)
из daily_measurements
развернуть
( измерение
для измерения_время в (morning_measurement
, послеобеденное_измерение
, вечер_измерение
)
)
группа
Днем
/
СРЕДНИЙ ДЕНЬ (ИЗМЕРЕНИЕ)
--------- ----------------
27. 09.07 30.57
28-СЭП-07 26.4866667
29-SEP-07 51.425
 09.07 30.57
28-СЭП-07 26.4866667
29-SEP-07 51.425
09.07 30.57
28-СЭП-07 26.4866667
29-SEP-07 51.425
Это все, что нам нужно сделать. Мы берем три столбца измерений в таблице daily_measurements и используем их для UNPIVOTing. Каждый из этих столбцов измерений порождает — если он содержит значение — новую запись за день. Вместо одной строки на каждый день с тремя измерениями мы получаем строку на каждое измерение.
В старые времена, с Oracle 10g или более ранней версией, мы, вероятно, решили бы это с помощью чего-то вроде:
select day , измерение утреннего измерения , 'утреннее_измерение' измерение_время из daily_measurements где утреннее_измерение не равно нулю союз всех выберите день , измерение измерения после полудня , 'измерение_после полудня' измерение_время из daily_measurements где after_measurement не равен нулю союз всех выберите день , вечернее_измерение , 'вечернее_измерение' измерение_время из daily_measurements где вечернее_измерение не равно нулю /
Это работает, но с растущим количеством столбцов это некрасиво. Я не исследовал, но я ожидаю, что UNPIVOT также будет быстрее.
Я не исследовал, но я ожидаю, что UNPIVOT также будет быстрее.
Лукас Йеллема
Лукас Йеллема работает в сфере ИТ (и в Oracle) с 1994 года. Директор Oracle ACE и чемпион Oracle Developer. Архитектор и разработчик решений в различных областях, включая SQL, JavaScript, Kubernetes и Docker, машинное обучение, Java, SOA и микросервисы, события в различных формах и формах и многое другое. Автор книги Oracle Press. Oracle SOA Suite 12c Handbook. Частый докладчик в группах пользователей и общественных мероприятиях и конференциях, таких как JavaOne, Oracle Code, CodeOne, NLJUG JFall и Oracle OpenWorld.
https://www.amis.nl/
Счастливый
0 0 %
Грустный
0 0 %
Возбужденный
0 0 %
Сонный 900 03
0 0 %
Злость
0 0 %
Сюрприз
0 0 %
Нравится:
Нравится Загрузка…
Тег: UNPIVOT — SQLORA
После предыдущего сообщения о построении запроса UNPIVOT с помощью макроса SQL для вывода строк таблицы, таких как пары ключ-значение, я подумал о другом варианте использования оператора UNPIVOT, в котором имеет смысл разработать повторно используемый макрос SQL.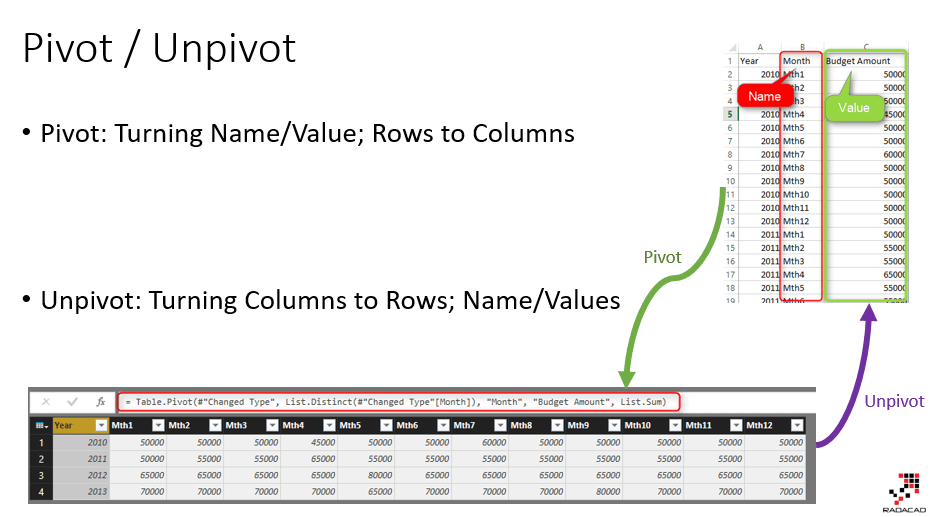 Время от времени вам нужно находить разницу между почти одинаковыми рядами. Вы знаете, что они разные, и вы можете легко проверить это, используя MINUS или GROUP BY, но если вы хотите знать, в каких именно столбцах разница, вам нужен другой подход.
Время от времени вам нужно находить разницу между почти одинаковыми рядами. Вы знаете, что они разные, и вы можете легко проверить это, используя MINUS или GROUP BY, но если вы хотите знать, в каких именно столбцах разница, вам нужен другой подход.
Читать далее →
Эта запись была опубликована в 20c, 21c, Общие, Oracle, SQL, Макросы SQL и помечена как 20c, 21c, макрос sql, макросы sql, UNPIVOT на пользователем admin.
Несколько недель назад Джонатан Льюис опубликовал заметку о print_table Тома Кайта — небольшой процедуре PL/SQL для вывода каждой строки таблицы в виде списка (имя_столбца, значение) . И поскольку эта заметка получила некоторые комментарии с другими реализациями, вот мой вклад. Угадайте как? Конечно, с макросом SQL.
Читать далее →
Эта запись была опубликована в Oracle, SQL, Макросы SQL и помечена как значение ключа, макрос sql, макросы sql, UNPIVOT пользователем admin.
У меня не было возможности написать дополнение к моему последнему сообщению о переносе столбцов в строки с помощью PTF, показывающего противоположную задачу переноса строк в столбцы прямо на следующих выходных, как я думал. Отчасти из-за нашего крутого Trivadis TechEvent, который проходил тогда, а отчасти потому, что такое упражнение оказалось намного сложнее, чем предполагалось. На самом деле это хороший пример, чтобы увидеть ограничения новой функции. Читать далее →
Эта запись была опубликована в 18c, Oracle, PL/SQL, PTF, SQL и помечена как «полиморфная табличная функция», 18c, PIVOT, PTF, табличная функция, UNPIVOT на пользователем admin.
Эй, Oracle 18c теперь доступен в облаке и для инженерных систем! Уже больше недели. Это также означает, что вы можете играть с ним на LiveSQL. И, конечно же, вы можете попробовать полиморфные табличные функции (PTF)! По крайней мере, я сделал это на этих выходных 😉 А вот и мой первый рабочий пример.