Oracle unpivot пример: UNPIVOT | SQL | SQL-tutorial.ru
Содержание
аналитический SQL для хранилищ данных. Аналітичний SQL для зберігання даних. Курс Analytic SQL for Data Warehousing
Закрыть
12cASDW. Oracle Database 12c: аналитический SQL для хранилищ данных. Analytic SQL for Data Warehousing
- FL FL тренер
ОТПРАВИТЬ ЗАЯВКУ
Описание Курса:
В ходе курса 12cASDW. Oracle Database 12c: аналитический SQL для хранилищ данных изучается, как использовать аналитический SQL для агрегирования, анализа, составления отчетов и моделирования данных, а также облачная служба Oracle Business Intelligence.
Курс 12cASDW. Oracle Database 12c: аналитический SQL для хранилищ данных рассматривает, как интерпретировать концепцию иерархического запроса, создавать отчет с древовидной структурой, форматировать иерархические данные и исключать ветви из древовидной структуры. А также как использовать регулярные выражения и подвыражения для поиска, сопоставления и замены строк.
Аудитория:
- Администраторы
- Аналитики
- Архитекторы
- Разработчики
Предварительная подготовка:
- Знание концепции реляционных баз данных
- Знание теории и реализация хранилища данных, концепции серверов Oracle (включая настройку приложений и серверов)
- Знание среды операционной системы, в которой работает сервер базы данных Oracle
Приобретаемые навыки:
По окончании курса Аналітичний SQL для зберігання даних участники смогут:
- Использовать SQL с операторами агрегирования, SQL для функций анализа и отчетности
- Группировать и агрегировать данные, используя операторы ROLLUP и CUBE, функцию GROUPING, составные столбцы и объединенные группировки
- Анализировать и сообщать данные, используя функции ранжирования, функции LAG / LEAD и предложения PIVOT и UNPIVOT
- Выполнять расширенное сопоставление с образцом
- Использовать регулярные выражения для поиска, сопоставления и замены строк
- Получить представление об облачной службе Oracle Business Intelligence
Содержание курса:
Вступление
- Цели курса, повестка дня курса и информация об учетной записи класса
- Опишите схемы и приложения, используемые в уроке
- Обзор среды SQL * Plus
- Обзор разработчика SQL
- Обзор аналитического SQL
- Oracle Database SQL и документация по хранилищу данных
Группировка и агрегация данных с использованием SQL
- Генерация отчетов путем группировки связанных данных
- Обзор групповых функций
- Просмотр предложения GROUP BY и HAVING
- Использование операторов ROLLUP и CUBE
- Использование функции группировки
- Работа с операторами GROUPING SET и составными столбцами
- Использование составных группировок с примером
Иерархический поиск
- Использование иерархических запросов
- Образец данных из таблицы СОТРУДНИКОВ
- Структура натурального дерева
- Иерархические запросы: синтаксис
- Ходьба по дереву: указание отправной точки
- Ходьба по дереву: указание направления запроса
- Использование предложения WITH
- Пример иерархического запроса: использование предложения CONNECT BY
Работа с регулярными выражениями
- Представляем регулярные выражения
- Использование функций и условий регулярных выражений в SQL и PL / SQL
- Представляем метасимволы
- Использование метасимволов с регулярными выражениями
- Функции и условия регулярных выражений: синтаксис
- Выполнение базового поиска с использованием условия REGEXP_LIKE
- Поиск паттернов с помощью функции REGEXP_INSTR
- Извлечение подстрок с помощью функции REGEXP_SUBSTR
Анализ и отчетность данных с использованием SQL
- Обзор SQL для функций анализа и отчетности
- Использование аналитических функций
- Использование функций ранжирования
- Использование функций отчетности
Выполнение операций поворота и открепления
- Выполнение поворотных операций
- Использование предложений PIVOT и UNPIVOT
- Поворот на столбце QUARTER: концептуальный пример
- Выполнение операций отмены поворота
- Использование столбцов предложения UNPIVOT в операции UNPIVOT
- Создание новой сводной таблицы: пример
Сопоставление с образцом с использованием SQL
- Навигация по шаблонам строк
- Обработка пустых соответствий или несопоставленных строк
- Исключение частей шаблона из вывода
- Выражая все перестановки
- Правила и ограничения в сопоставлении с образцом
- Примеры сопоставления с образцом
Моделирование данных с использованием SQL
- Использование предложения MODEL
- Демонстрация ссылок на ячейки и диапазоны
- Использование функции CV
- Использование FOR Construct с оператором IN List, инкрементными значениями и подзапросами
- Использование аналитических функций в предложении SQL MODEL
- Различение недостающих ячеек от NULL
- Использование опций UPDATE, UPSERT и UPSERT ALL
- Эталонные модели
Обзор облачной службы Oracle Business Intelligence
- Облачная служба Oracle BI
- Представляем облачную службу Oracle Business Intelligence
- Руководство с помощью аналитического анализа и глубокого обнаружения с помощью богатого набора функций
- BICS может быстро интегрировать любой источник данных
- BICS делает любое время подходящим временем для новых идей
- Скорость, Гибкость и Экономия Облака
- Немедленный доступ к новой функциональности
- Надежность обслуживания на уровне предприятия
Другие курсы Oracle 12c
Материалы и сертификаты:
Акцент Профи
Расписание курсов на 6 месяцев
Июль | Август | Сентябрь | Октябрь | Ноябрь | Декабрь |
Возврат к списку
Data Integration — Kettle | Обработка больших XML файлов на примере базы ФИАС
⌛ 2 мин.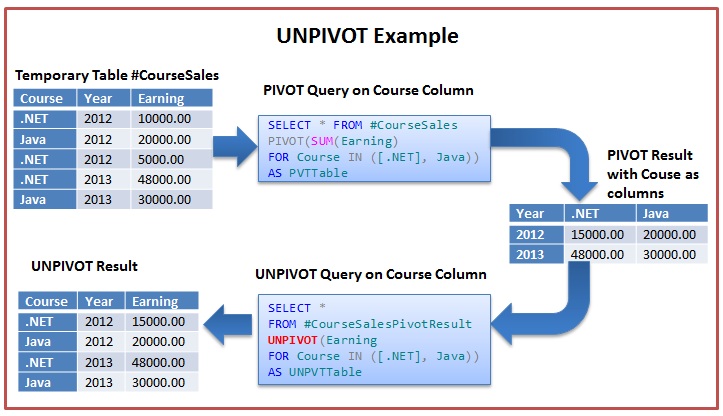
И вот очередная ночь и скрипт почти готов. Ты пытаешься прогнать его на всём объёме данных, и вдруг на твоих глазах наворачиваются слёзы, грудь сковывает отчаянье и боль за потраченное время не даёт давить по клавишам и двигать мышь. Ты увидел красными буквами надпись в логе обработке «out of memory» у шага для чтения xml файла. Ну ни чего, ты собираешься с мыслями и копаешься в документациях, примерах и прочем, что выдаст тебе «старший брат». Ну что же, я постараюсь избавить тебя от лишних телодвижений и показать путь покороче.
Разбор большого XML файла мы рассмотрим на самой большой таблице «Федеральной информационной адресной системы»
Качаем базу ФИАС и распаковываем её.
Рис.1 — Страница загрузки базы ФИАС
Создаём трансформацию.
Она будет иметь вот такой вот вид:
Рис.2 — Скрипт загрузки xml файла базы ФИАС
Ключевой шаг, который позволит нам зачитывать XML это «XML Input Stream (StAX)».
Исчерпывающую информацию по стандарту StAX вы можете найти самостоятельно, рекомендую прочитать статью для общего развития.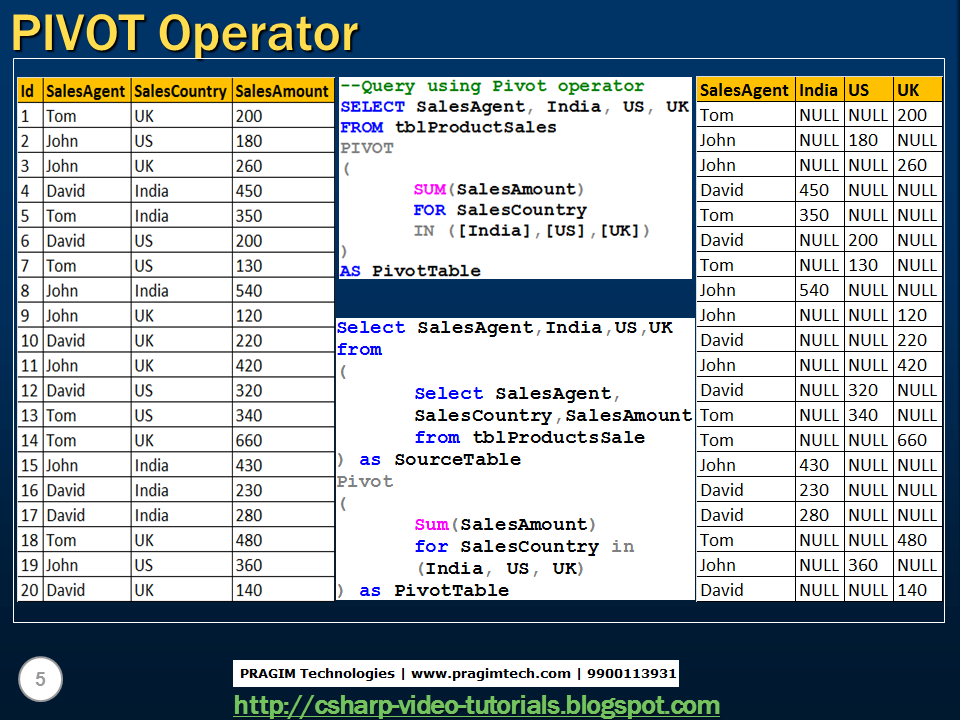 Настройки данного шага у меня выглядят вот так:
Настройки данного шага у меня выглядят вот так:
Рис.3 — Настройка шага «XML Input Stream (StAX)»
Давайте посмотрим на строки которые мы получаем на выходе из шага «XML Input Stream (StAX)»
Рис.4 — Строки на выходе «XML Input Stream (StAX)»
Исходя из структуры XML файла базы ФИАС мы видим, что нам нужны только атрибуты всех XML элементов «House».
Рис. 5 — Структура файла HOUSE базы ФИАС.
Это означает что нам достаточно будет извлекать только атрибуты XML элементов. Все остальные извлечённые строки нам не нужны и мы их отрезаем при помощи фильтра.
Рис. 6 — Настройки шага «Filter rows»
Теперь у вас есть два варианта:
- Загрузить данные в БД и там уже преобразовать в нужную форму.
- Сразу провести преобразование и загрузить в базу данные в более удобоваримом виде. Я рекомендую именно это вариант. Связано это с тем, что даже наш боевой Oracle с трудом переваривал преобразование такого большого объема данных и приходилось обрабатывать их кусками.
 Даже написание оптимизированной процедуры для этого будет менее эффективным, чем провести преобразование на уровне kettle data-integration. Я думаю вы уже сами догадались почему. Если всё же нужно пояснить, пишите в комментариях
Даже написание оптимизированной процедуры для этого будет менее эффективным, чем провести преобразование на уровне kettle data-integration. Я думаю вы уже сами догадались почему. Если всё же нужно пояснить, пишите в комментариях
 Даже написание оптимизированной процедуры для этого будет менее эффективным, чем провести преобразование на уровне kettle data-integration. Я думаю вы уже сами догадались почему. Если всё же нужно пояснить, пишите в комментариях
Даже написание оптимизированной процедуры для этого будет менее эффективным, чем провести преобразование на уровне kettle data-integration. Я думаю вы уже сами догадались почему. Если всё же нужно пояснить, пишите в комментарияхСобственно я реализовал преобразование при помощи шага «Row denormaliser». Более подробно мы рассматривали его в статье «Data Integration — Kettle | Шаги «Row normaliser» и «Row denormaliser». ( UNPIVOT / PIVOT )» Сейчас я приведу только текущие настройки для файла с домами базы ФИАС. Настоятельно советаю определять типы на этапе преобразования. Делать так как показано в данном шаге является плохим тоном, обязательно определите типы для для каждого поля.
Рис. 7 — Настройка шага «Row denormalise»
Ну и последним нашим шагом, отправляем всё это в базу данных.
Рис. 8 — Шаг вывода результатов
Пример как обычно по ссылке:lageXML
Как использовать обратные кавычки и кавычки при запросе к базе данных MySQL
Использование обратных кавычек, двойных кавычек и одинарных кавычек при запросе к базе данных MySQL можно свести к двум основным пунктам.
- Строки заключаются в кавычки (одинарные и двойные).
- Обратные кавычки используются вокруг идентификаторов таблиц и столбцов.
Двойные кавычки
Примеры ввода и вывода с использованием двойных кавычек:
SELECT "test", "'test'", "''test'', "te""st";
Вывод выглядит следующим образом:
Заключение одинарных кавычек в двойные отменяет ожидаемое поведение одинарных кавычек в запросе MySQL и вместо этого обрабатывает его как часть строки. Это можно увидеть в столбцах 2 и 3 в приведенном выше примере.
Вставка двух двойных кавычек в середине строки отменит одну из них.
Используя одинарные кавычки, вот несколько примеров ввода и вывода:
SELECT 'test', ''test'', '""test"'', 'te''st';
Вывод выглядит следующим образом:
Как показано в демонстрации выше, одинарные кавычки в этих контекстах ведут себя так же, как двойные кавычки.
Часто в строке может быть сокращение или прямая кавычка.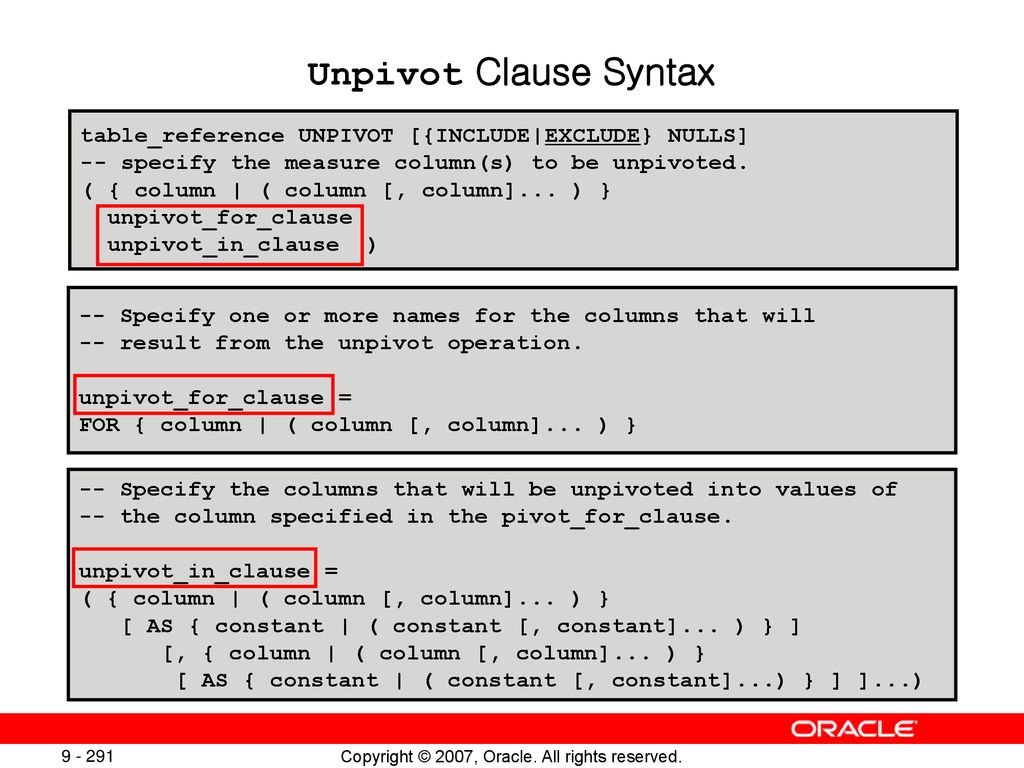 В таких ситуациях, как отчеты об опросах NPS или другие формы обратной связи с клиентами, это часто имеет место. В этих случаях использование двойных кавычек для заключения текстовой строки, содержащей сокращение, такое как . У них есть , и одинарная кавычка в строке будет сохранена как апостроф.
В таких ситуациях, как отчеты об опросах NPS или другие формы обратной связи с клиентами, это часто имеет место. В этих случаях использование двойных кавычек для заключения текстовой строки, содержащей сокращение, такое как . У них есть , и одинарная кавычка в строке будет сохранена как апостроф.
В этом случае представление строки с сокращением должно выглядеть так:
SELECT "Они сочли это руководство полезным"
Вывод выглядит следующим образом:
Или, если вам нужно использовать двойные кавычки, чтобы представить цитату из отзыва клиента в строке, вы можете использовать одинарные кавычки, чтобы заключить всю строку.
SELECT 'Они ответили: "Мы нашли это руководство полезным"'
Если вам нужно использовать одинарные и двойные кавычки в строке, которая содержит как сокращение, так и кавычку, вам нужно будет использовать обратную косую черту «», чтобы отменить следующий символ. Например: строка, содержащая это ‘, распознает обратную косую черту как инструкцию отменить синтаксическое значение одинарной кавычки и вместо этого вставить ее в строку как апостроф.
SELECT 'Они ответили: "Мы нашли это руководство полезным"'
Обратные кавычки
Обратные кавычки используются в MySQL для выбора столбцов и таблиц из источника MySQL. В приведенном ниже примере мы вызываем таблицу Album и столбец Title . Используя обратные кавычки, мы показываем, что это имена столбцов и таблиц.
ВЫБЕРИТЕ `Альбом`.`Заголовок`
ОТ `Альбом` КАК `Альбом`
СГРУППИРОВАТЬ ПО `Альбому`.`Название`
ЗАКАЗАТЬ ПО «Названию» ASC
ПРЕДЕЛ 10;
Однако обратные кавычки для имен столбцов могут не понадобиться.
ВЫБЕРИТЕ Альбом.Название
ИЗ Альбома КАК Альбома
СГРУППИРОВАТЬ ПО Альбому.Название
СОРТИРОВАТЬ ПО НАЗВАНИЮ ASC
ПРЕДЕЛ 10;
Оба этих запроса вернут один и тот же результат.
Собираем все вместе
Следующий запрос будет использовать все, что мы здесь узнали, включая двойные кавычки, одинарные кавычки и обратные кавычки.
SELECT 'Они ответили: "Мы нашли это руководство полезным"' как `Ответ`
Вернет:
Изменение данных с помощью Pivot в Spark
16 февраля 2016 г.
Примечание редактора: изначально это было опубликовано в блоге Databricks. Если вы будете на Spark Summit East на этой неделе, обязательно ознакомьтесь с докладом Эндрю о сводных данных с помощью SparkSQL.
Одной из многих новых функций, добавленных в Spark 1.6, была возможность сводки данных, создания сводных таблиц с помощью DataFrame (с помощью Scala, Java или Python). Сводка — это агрегация, в которой один (или несколько в общем случае) столбцов группировки имеет свои отдельные значения, перенесенные в отдельные столбцы. Сводные таблицы являются неотъемлемой частью анализа данных и составления отчетов. Многие популярные инструменты для работы с данными (pandas, reshape2 и Excel) и базы данных (MS SQL и Oracle 11g) включают возможность поворота данных. Я кратко рассказал об этом в прошлом посте, но здесь дам вам более глубокое погружение в детали. Код для этого поста доступен здесь.
Код для этого поста доступен здесь.
Синтаксис
В ходе выполнения запроса на вытягивание для свода одной из частей исследования, которое я провел, было изучение синтаксиса многих конкурирующих инструментов. Я нашел множество вариантов синтаксиса. Двумя основными конкурентами были pandas (Python) и reshape2 (R).
Исходный кадр данных (df)
| A | Б | С | Д |
| фу | один | маленький | 1 |
| фу | один | большой | 2 |
| фу | один | большой | 2 |
| фу | два | маленький | 3 |
| фу | два | маленький | 3 |
| бар | один | большой | 4 |
| бар | один | маленький | 5 |
| бар | два | маленький | 6 |
| бар | два | большой | 7 |
Поворотный кадр данных
| A | Б | большой | маленький |
| фу | два | ноль | 6 |
| бар | два | 7 | 6 |
| фу | один | 4 | 1 |
| бар | один | 4 | 5 |
Например, предположим, что мы хотим сгруппировать по двум столбцам A и B, повернуть по столбцу C и по столбцу суммы D.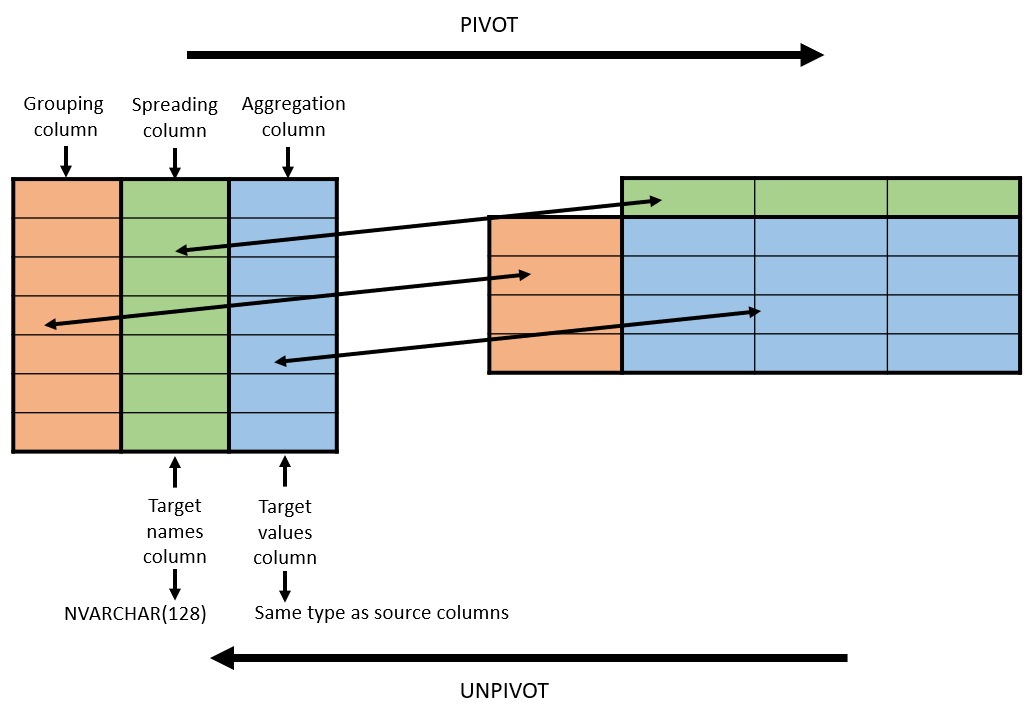 В pandas синтаксис будет таким:
В pandas синтаксис будет таким: pivot_table(df, values='D', index=['A', 'B'], columns=['C'], aggfunc=np.sum) . Это несколько многословно, но понятно. С reshape2 это dcast(df, A + B ~ C, sum) , очень компактный синтаксис благодаря использованию формулы R. Обратите внимание, что нам не нужно было указывать столбец значений для reshape2; он выводится как оставшийся столбец фрейма данных (хотя его можно указать с другим аргументом).
Мы придумали собственный синтаксис, который прекрасно сочетается с существующим способом агрегирования в DataFrame. Чтобы сделать ту же группу/поворот/сумму в Spark, используйте синтаксис df.groupBy("A", "B").pivot("C").sum("D") . Надеюсь, это довольно интуитивный синтаксис. Но есть небольшая загвоздка: чтобы повысить производительность, вам нужно указать отдельные значения сводного столбца. Если бы, например, в столбце C было два разных значения «маленький» и «большой», то более предпочтительная версия была бы 9. 0059 df.groupBy(«A», «B»).pivot(«C», Seq(«маленький», «большой»)).sum(«D») . Конечно, это версия Scala, есть аналогичные методы, которые принимают списки Java и Python.
0059 df.groupBy(«A», «B»).pivot(«C», Seq(«маленький», «большой»)).sum(«D») . Конечно, это версия Scala, есть аналогичные методы, которые принимают списки Java и Python.
Отчетность
Давайте рассмотрим примеры реальных случаев использования. Допустим, вы крупный розничный продавец (как и мой бывший работодатель) с данными о продажах в довольно стандартном формате транзакций, и вы хотите составить сводные сводные таблицы. Конечно, вы можете агрегировать данные до управляемого размера, а затем использовать какой-либо другой инструмент для создания окончательной сводной таблицы (хотя и ограниченной степенью детализации вашего первоначального агрегирования). Но теперь вы можете делать все это в Spark (а раньше вы могли это делать, просто используя много IF). К сожалению, поскольку ни один крупный ритейлер не хочет делиться с нами необработанными данными о продажах, нам придется использовать синтетический пример. Хороший набор данных, который я использовал ранее, — это набор данных TPC-DS.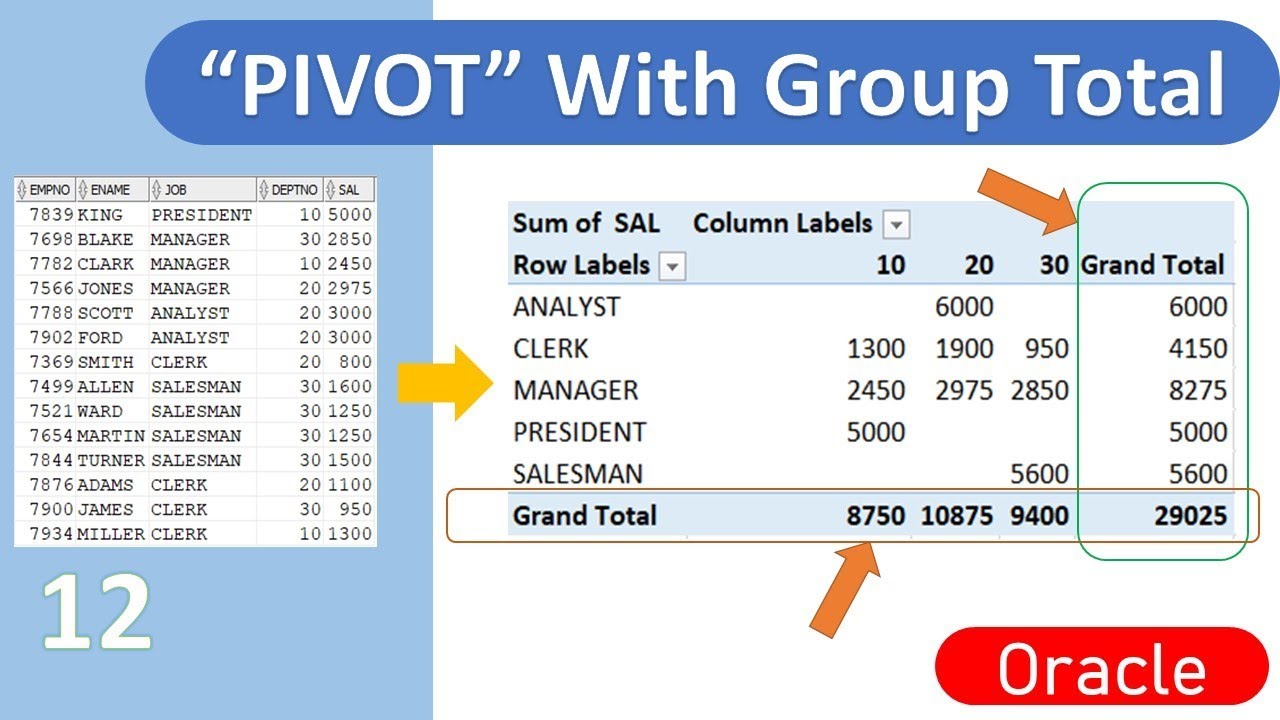 Его схема приблизительно соответствует тому, что вы найдете в реальном магазине.
Его схема приблизительно соответствует тому, что вы найдете в реальном магазине.
Поскольку TPC-DS представляет собой синтетический набор данных, который используется для сравнительного анализа баз данных «больших данных» различных размеров, мы можем генерировать его с множеством «коэффициентов масштабирования», которые определяют, насколько велик выходной набор данных. Для простоты мы будем использовать масштабный коэффициент 1, соответствующий набору данных размером около 1 ГБ. Поскольку требования немного сложны, у меня есть образ докера, которому вы можете следовать. Допустим, мы хотели подвести итоги продаж по категориям и кварталам, а последние были столбцами в нашей сводной таблице. Затем мы сделали бы следующее (более реалистичный запрос, вероятно, имел бы несколько дополнительных условий, таких как временной диапазон).
(sql (""" выберите *, concat ('Q', d_qoy) как qoy
из store_sales
присоединиться к date_dim на ss_sold_date_sk = d_date_sk
присоединиться к элементу на ss_item_sk = i_item_sk""")
. groupBy("я_категория")
.pivot("кой")
.agg(круглый(сумма("ss_sales_price")/1000000,2))
.show)  groupBy("я_категория")
.pivot("кой")
.agg(круглый(сумма("ss_sales_price")/1000000,2))
.show)
groupBy("я_категория")
.pivot("кой")
.agg(круглый(сумма("ss_sales_price")/1000000,2))
.show) +-----------+----+----+----+----+ | я_категория| Q1| Q2| Q3| Q4| +-----------+----+----+----+----+ | Книги|1.58|1.50|2.84|4.66| | Женщины|1,41|1,36|2,54|4,16| | Музыка|1.50|1.44|2.66|4.36| | Дети|1,54|1,46|2,74|4,51| | Спорт|1.47|1.40|2.62|4.30| | Обувь|1,51|1,48|2,68|4,46| | Ювелирные изделия|1.45|1.39|2,59|4,25| | ноль|0,04|0,04|0,07|0,13| |Электроника|1.56|1.49|2.77|4.57| | Главная|1.57|1.51|2.79|4.60| | Мужчины|1,60|1,54|2,86|4,71| +-----------+----+----+----+----+
Обратите внимание, что мы указываем число продаж в миллионах с точностью до двух знаков после запятой, чтобы это было легко увидеть. Мы замечаем пару вещей. Во-первых, четвертый квартал сумасшедший, это не должно удивлять тех, кто знаком с розничной торговлей. Во-вторых, большинство этих значений в пределах одного квартала, за исключением нулевой категории, примерно одинаковы.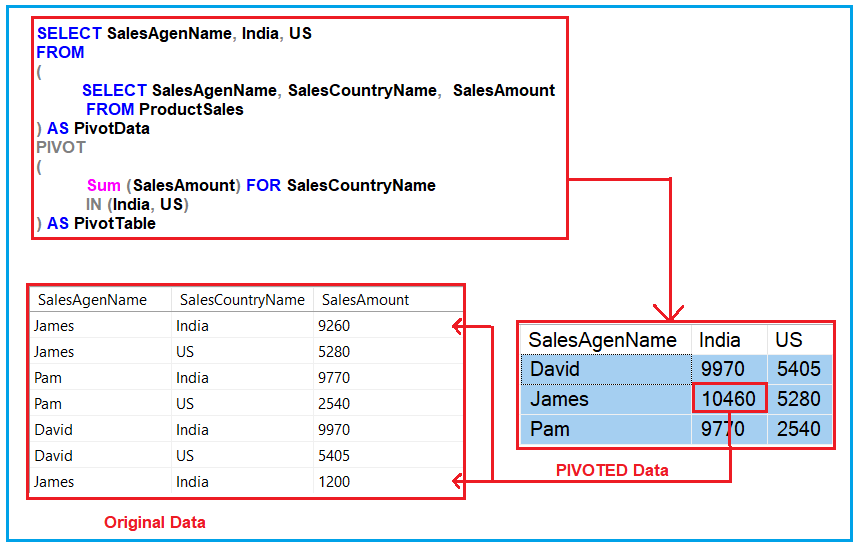 К сожалению, даже этот великолепный синтетический набор данных не совсем реалистичен. Дайте мне знать, если у вас есть что-то лучше, что находится в открытом доступе.
К сожалению, даже этот великолепный синтетический набор данных не совсем реалистичен. Дайте мне знать, если у вас есть что-то лучше, что находится в открытом доступе.
Генерация признаков
В качестве второго примера рассмотрим создание признаков для прогностических моделей. Нередко есть наборы данных со многими наблюдениями за вашей целью в формате по одному на строку (называемые длинными или узкими данными). Чтобы построить модели, нам нужно сначала преобразовать это в одну строку для каждой цели; в зависимости от контекста это может быть достигнуто несколькими способами. Один из способов — с поворотом. Это потенциально то, что вы не сможете сделать с другими инструментами (такими как pandas, reshape2 или Excel), поскольку набор результатов может состоять из миллионов или миллиардов строк.
Чтобы пример было легко воспроизвести, я буду использовать относительно небольшой набор данных MovieLens 1M. Это около 1 миллиона оценок фильмов от 6040 пользователей на 3952 фильмах.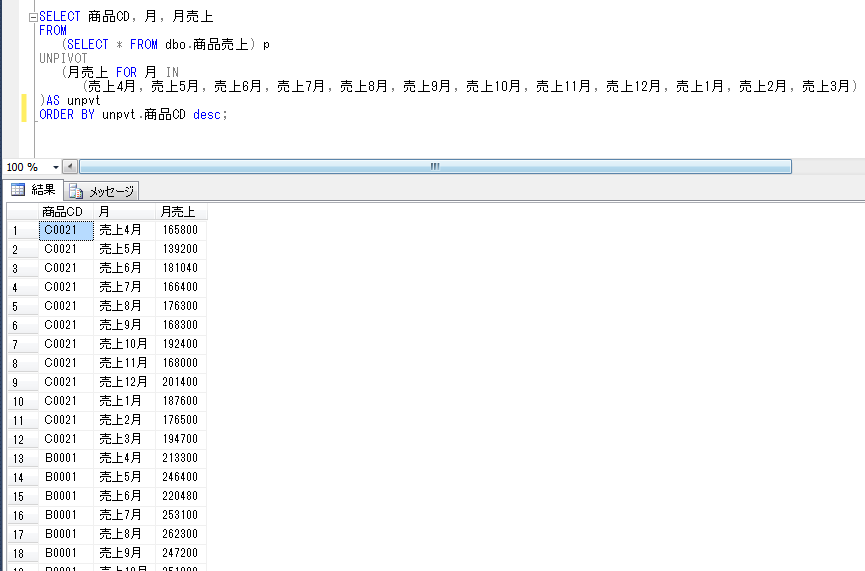 Давайте попробуем предсказать пол пользователя на основе его оценок 100 самых популярных фильмов. В приведенном ниже примере таблица рейтингов состоит из трех столбцов: пользователь, фильм и рейтинг.
Давайте попробуем предсказать пол пользователя на основе его оценок 100 самых популярных фильмов. В приведенном ниже примере таблица рейтингов состоит из трех столбцов: пользователь, фильм и рейтинг.
+----+-----+------+ |пользователь|фильм|рейтинг| +----+-----+------+ | 11| 1753| 4| | 11| 1682| 1| | 11| 216| 4| | 11| 2997| 4| | 11| 1259| 3| ...
Чтобы получить по одной строке для каждого пользователя, мы делаем поворот следующим образом:
val ratings_pivot = ratings.groupBy("user").pivot("movie",
Popular.toSeq).agg(expr("coalesce(first(rating),3)").cast("double")) Здесь Popular — это список самых популярных фильмов (по количеству оценок), и мы используем рейтинг по умолчанию, равный 3. Для пользователя 11 это дает что-то вроде:
+----+----+- --+----+----+---+----+---+----+----+---+... |пользователь|2858|260|1196|1210|480|2028|589|2571|1270|593|... +----+----+---+----+----+---+----+---+----+----+---+.
 ..
| 11| 5,0|3,0| 3.0| 3.0|4.0| 3.0|3.0| 3.0| 3.0|5.0|...
+----+----+---+----+----+---+----+---+----+----+---+...
..
| 11| 5,0|3,0| 3.0| 3.0|4.0| 3.0|3.0| 3.0| 3.0|5.0|...
+----+----+---+----+----+---+----+---+----+----+---+... Данные широкой формы, необходимые для моделирования. См. полный пример здесь. Некоторые примечания: я использовал только 100 самых популярных фильмов, потому что в настоящее время поворот на тысячи различных значений не особенно быстр в текущей реализации. Подробнее об этом позже.
Советы и рекомендации
Для лучшей производительности укажите отдельные значения сводного столбца (если они вам известны). В противном случае будет немедленно запущено задание для их определения (это ограничение других SQL-движков, а также Spark SQL, поскольку выходные столбцы нужны для планирования). Кроме того, они будут размещены в отсортированном порядке. Для многих вещей это имеет смысл, но для некоторых, например для дня недели, это не так (пятница, понедельник, суббота и т. д.).
Pivot, как и обычные агрегаты, поддерживает несколько агрегатных выражений, просто передайте несколько аргументов в метод agg. Например:
Например: df.groupBy("A", "B").pivot("C").agg(sum("D"), avg("D")) .
Хотя синтаксис позволяет выполнять поворот только по одному столбцу, вы можете комбинировать столбцы, чтобы получить тот же результат, что и при повороте нескольких столбцов. Например:
df.withColumn("p", concat($"p1", $"p2"))
.groupBy («а», «б»)
.пивот ("р")
.agg(…) Наконец, вам может быть интересно узнать, что существует максимальное количество значений для сводного столбца, если ни одно из них не указано. В основном это делается для того, чтобы ловить ошибки и избегать ситуаций OOM. Ключ конфигурации spark.sql.pivotMaxValues , значение по умолчанию — 10 000. Вы, вероятно, не должны изменить его.
Реализация
Реализация добавляет новый логический оператор (o.a.s.sql.catalyst.plans.logical.Pivot) . Этот логический оператор преобразуется новым правилом анализатора (o.a.s.sql.catalyst.analysis.Analyzer.ResolvePivot) , которое в настоящее время переводит его в агрегацию с большим количеством операторов if, по одному выражению на значение сводки.