Основы sql языка: The OpenNet Project: .
Содержание
Access SQL. Основные понятия, лексика и синтаксис
Для извлечения данных из базы данных используется язык SQL. SQL — это язык программирования, который очень напоминает английский, но предназначен для программ управления базами данных. SQL используется в каждом запросе в Access.
Понимание принципов работы SQL помогает создавать более точные запросы и упрощает исправление запросов, которые возвращают неправильные результаты.
Это статья из цикла статей о языке SQL для Access. В ней описаны основы использования SQL для выборки данных и приведены примеры синтаксиса SQL.
В этой статье
-
Что такое SQL? -
Основные предложения SQL: SELECT, FROM и WHERE -
Сортировка результатов: предложение ORDER BY -
Работа со сводными данными: предложения GROUP BY и HAVING -
Объединение результатов запроса: оператор UNION
Что такое SQL?
SQL — это язык программирования, предназначенный для работы с наборами фактов и отношениями между ними. В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
В программах управления реляционными базами данных, таких как Microsoft Office Access, язык SQL используется для работы с данными. В отличие от многих языков программирования, SQL удобочитаем и понятен даже новичкам. Как и многие языки программирования, SQL является международным стандартом, признанным такими комитетами по стандартизации, как ISO и ANSI.
На языке SQL описываются наборы данных, помогающие получать ответы на вопросы. При использовании SQL необходимо применять правильный синтаксис. Синтаксис — это набор правил, позволяющих правильно сочетать элементы языка. Синтаксис SQL основан на синтаксисе английского языка и имеет много общих элементов с синтаксисом языка Visual Basic для приложений (VBA).
Например, простая инструкция SQL, извлекающая список фамилий контактов с именем Mary, может выглядеть следующим образом:
SELECT Last_Name
FROM Contacts
WHERE First_Name = 'Mary';
Примечание: Язык SQL используется не только для выполнения операций над данными, но еще и для создания и изменения структуры объектов базы данных, например таблиц.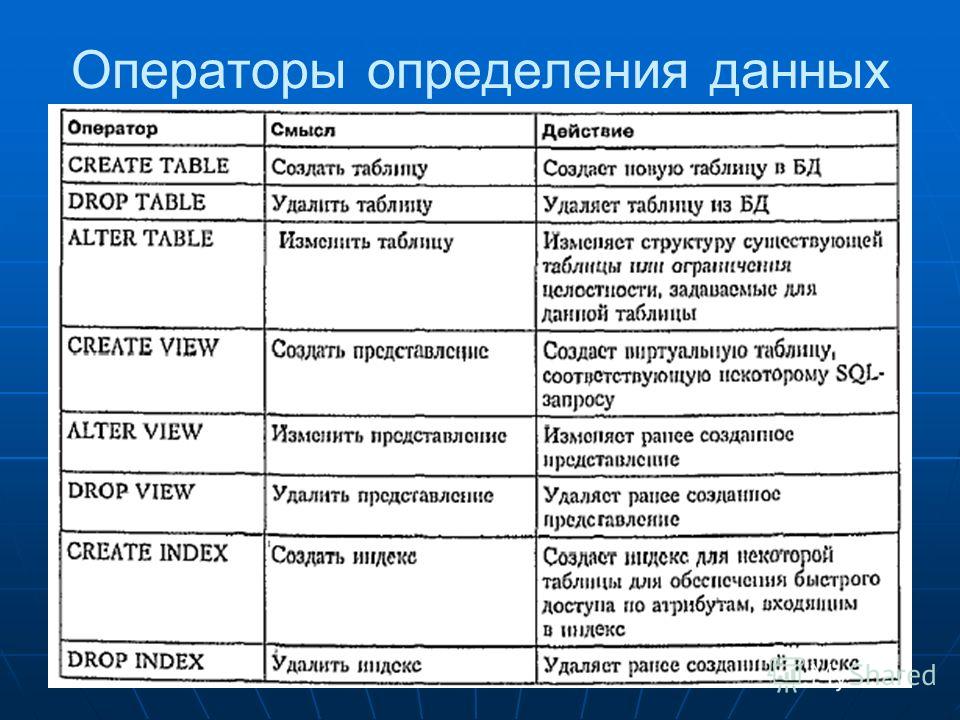 Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Та часть SQL, которая используется для создания и изменения объектов базы данных, называется языком описания данных DDL. Язык DDL не рассматривается в этой статье. Дополнительные сведения см. в статье Создание и изменение таблиц или индексов с помощью запроса определения данных.
Инструкции SELECT
Чтобы описать набор данных с помощью SQL, нужно написать заявление SELECT. Инструкция SELECT содержит полное описание набора данных, которые вы хотите получить из базы данных. К ним относятся файлы со следующими элементами:
-
таблицы, в которых содержатся данные;
-
связи между данными из разных источников;
 org/ListItem»>
org/ListItem»>
поля или вычисления, на основе которых отбираются данные;
-
условия отбора, которым должны соответствовать данные, включаемые в результат запроса;
-
необходимость и способ сортировки.
Предложения SQL
Инструкция SQL состоит из нескольких частей, называемых предложениями. Каждое предложение в инструкции SQL имеет свое назначение. Некоторые предложения являются обязательными. В приведенной ниже таблице указаны предложения SQL, используемые чаще всего.
|
|
|
|
|
SELECT
|
Определяет поля, которые содержат нужные данные.
|
Да
|
|
FROM
|
Определяет таблицы, которые содержат поля, указанные в предложении SELECT.
|
Да
|
|
WHERE
|
Определяет условия отбора полей, которым должны соответствовать все записи, включаемые в результаты.
|
Нет
|
|
ORDER BY
|
Определяет порядок сортировки результатов.
|
Нет
|
|
GROUP BY
|
В инструкции SQL, которая содержит статистические функции, определяет поля, для которых в предложении SELECT не вычисляется сводное значение.
|
Только при наличии таких полей
|
|
HAVING
|
В инструкции SQL, которая содержит статистические функции, определяет условия, применяемые к полям, для которых в предложении SELECT вычисляется сводное значение.
|
Нет
|

Термины SQL
Каждое предложение SQL состоит из терминов, которые можно сравнить с частями речи. В приведенной ниже таблице указаны типы терминов SQL.
В приведенной ниже таблице указаны типы терминов SQL.
|
|
|
|
|
|
идентификатор
|
существительное
|
Имя, используемое для идентификации объекта базы данных, например имя поля.
|
Клиенты.[НомерТелефона]
|
|
оператор
|
глагол или наречие
|
Ключевое слово, которое представляет действие или изменяет его.
|
AS
|
|
константа
|
существительное
|
Значение, которое не изменяется, например число или NULL.
|
42
|
|
выражение
|
прилагательное
|
Сочетание идентификаторов, операторов, констант и функций, предназначенное для вычисления одного значения.
|
>= Товары.[Цена]
|

К началу страницы
Основные предложения SQL: SELECT, FROM и WHERE
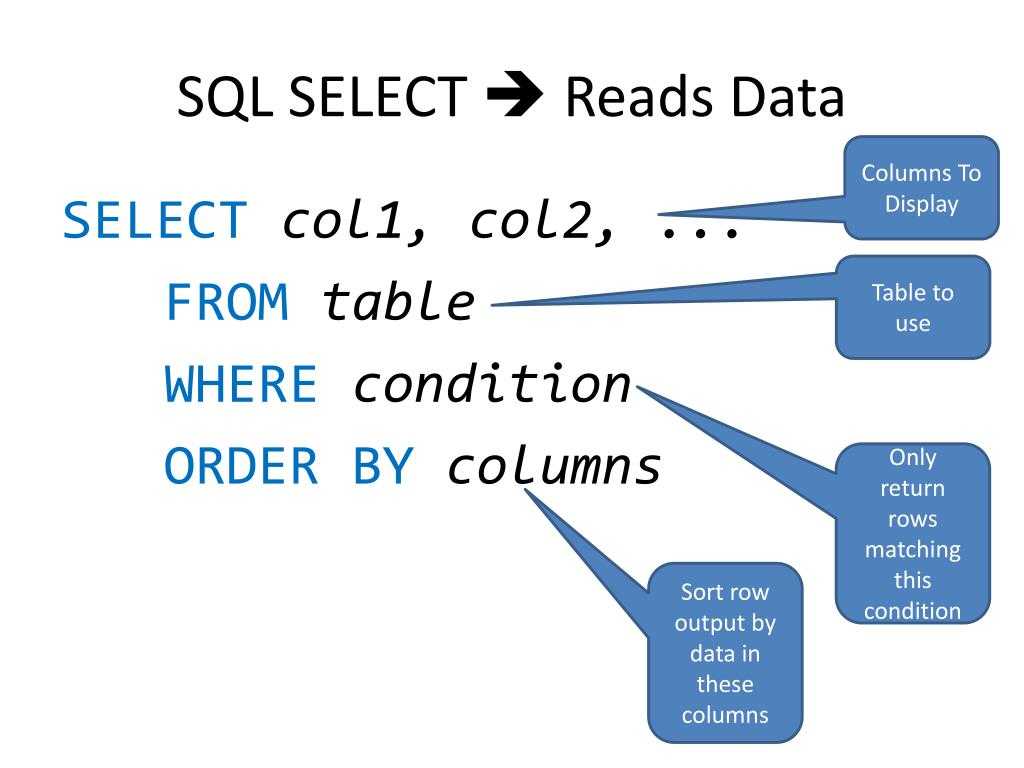
Общий формат инструкций SQL:
SELECT field_1
FROM table_1
WHERE criterion_1
;
Примечания:
-
Access не учитывает разрывы строк в инструкции SQL. Несмотря на это, каждое предложение рекомендуется начинать с новой строки, чтобы инструкцию SQL было удобно читать как тому, кто ее написал, так и всем остальным.
 org/ListItem»>
org/ListItem»>
Каждая инструкция SELECT заканчивается точкой с запятой (;). Точка с запятой может стоять как в конце последнего предложения, так и на отдельной строке в конце инструкции SQL.
Пример в Access
В приведенном ниже примере показано, как в Access может выглядеть инструкция SQL для простого запроса на выборку.
1. Предложение SELECT
2. Предложение FROM
3. Предложение WHERE
Эту инструкцию SQL следует читать так: «Выбрать данные из полей «Адрес электронной почты» и «Компания» таблицы «Контакты», а именно те записи, в которых поле «Город» имеет значение «Ростов».
Разберем пример по предложениям, чтобы понять, как работает синтаксис SQL.
Предложение SELECT
SELECT [E-mail Address], Company
Это предложение SELECT.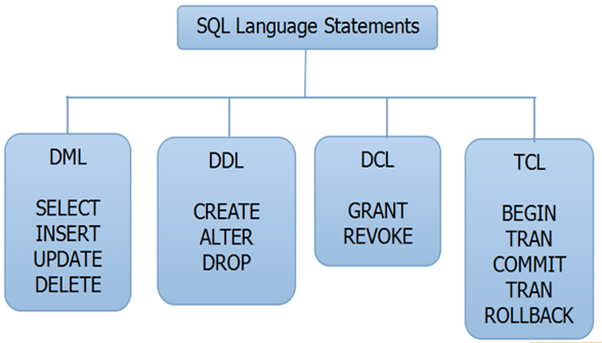 Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Оно содержит оператор (SELECT), за которым следуют два идентификатора («[Адрес электронной почты]» и «Компания»).
Если идентификатор содержит пробелы или специальные знаки (например, «Адрес электронной почты»), он должен быть заключен в прямоугольные скобки.
В предложении SELECT не нужно указывать таблицы, в которых содержатся поля, и нельзя задать условия отбора, которым должны соответствовать данные, включаемые в результаты.
В инструкции SELECT предложение SELECT всегда стоит перед предложением FROM.
Предложение FROM
FROM Contacts
Это предложение FROM. Оно содержит оператор (FROM), за которым следует идентификатор (Контакты).
В предложении FROM не указываются поля для выборки.
Предложение WHERE
WHERE City=»Seattle»
Это предложение WHERE. Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Оно содержит оператор (WHERE), за которым следует выражение (Город=»Ростов»).
Примечание: В отличие от предложений SELECT и FROM, предложение WHERE является необязательным элементом инструкции SELECT.
С помощью предложений SELECT, FROM и WHERE можно выполнять множество действий. Дополнительные сведения об использовании этих предложений см. в следующих статьях:
-
Access SQL. Предложение SELECT -
Access SQL. Предложение FROM -
Access SQL. Предложение WHERE
Предложение WHERE
 Предложение WHERE
Предложение WHERE
К началу страницы
Сортировка результатов: ORDER BY
Как и в Microsoft Excel, в Access можно сортировать результаты запроса в таблице. Используя предложение ORDER BY, вы также можете указать способ сортировки результатов при выполнении запроса. Если используется предложение ORDER BY, оно должно находиться в конце инструкции SQL.
Предложение ORDER BY содержит список полей, для которых нужно выполнить сортировку, в том же порядке, в котором будут применена сортировка.
Предположим, например, что результаты сначала нужно отсортировать по полю «Компания» в порядке убывания, а затем, если присутствуют записи с одинаковым значением поля «Компания», — отсортировать их по полю «Адрес электронной почты» в порядке возрастания. Предложение ORDER BY будет выглядеть следующим образом:
ORDER BY Company DESC, [E-mail Address]
Примечание: По умолчанию Access сортирует значения по возрастанию (от А до Я, от наименьшего к наибольшему). Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Чтобы вместо этого выполнить сортировку значений по убыванию, необходимо указать ключевое слово DESC.
Дополнительные сведения о предложении ORDER BY см. в статье Предложение ORDER BY.
К началу страницы
Работа со сводными данными: предложения GROUP BY и HAVING
Иногда возникает необходимость работы со сводными данными, такими как итоговые продажи за месяц или самые дорогие товары на складе. Для этого в предложении SELECT к полю применяется агрегатная функция. Например, если в результате выполнения запроса нужно получить количество адресов электронной почты каждой компании, предложение SELECT может выглядеть следующим образом:
SELECT COUNT([E-mail Address]), Company
Возможность использования той или иной агрегатной функции зависит от типа данных в поле и нужного выражения. Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Дополнительные сведения о доступных агрегатных функциях см. в статье Статистические функции SQL.
Задание полей, которые не используются в агрегатной функции: предложение GROUP BY
При использовании агрегатных функций обычно необходимо создать предложение GROUP BY. В предложении GROUP BY указываются все поля, к которым не применяется агрегатная функция. Если агрегатные функции применяются ко всем полям в запросе, предложение GROUP BY создавать не нужно.
Предложение GROUP BY должно следовать сразу же за предложением WHERE или FROM, если предложение WHERE отсутствует. В предложении GROUP BY поля указываются в том же порядке, что и в предложении SELECT.
Продолжим предыдущий пример. Пусть в предложении SELECT агрегатная функция применяется только к полю [Адрес электронной почты], тогда предложение GROUP BY будет выглядеть следующим образом:
GROUP BY Company
Дополнительные сведения о предложении GROUP BY см. в статье Предложение GROUP BY.
в статье Предложение GROUP BY.
Ограничение агрегированных значений с помощью условий группировки: предложение HAVING
Если необходимо указать условия для ограничения результатов, но поле, к которому их требуется применить, используется в агрегированной функции, предложение WHERE использовать нельзя. Вместо него следует использовать предложение HAVING. Предложение HAVING работает так же, как и WHERE, но используется для агрегированных данных.
Предположим, например, что к первому полю в предложении SELECT применяется функция AVG (которая вычисляет среднее значение):
SELECT COUNT([E-mail Address]), Company
Если вы хотите ограничить результаты запроса на основе значения функции COUNT, к этому полю нельзя применить условие отбора в предложении WHERE. Вместо него условие следует поместить в предложение HAVING. Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
Например, если нужно, чтобы запрос возвращал строки только в том случае, если у компании есть несколько адресов электронной почты, можно использовать следующее предложение HAVING:
HAVING COUNT([E-mail Address])>1
Примечание: Запрос может включать и предложение WHERE, и предложение HAVING, при этом условия отбора для полей, которые не используются в статистических функциях, указываются в предложении WHERE, а условия для полей, которые используются в статистических функциях, — в предложении HAVING.
Дополнительные сведения о предложении HAVING см. в статье Предложение HAVING.
К началу страницы
Объединение результатов запроса: оператор UNION
Оператор UNION используется для одновременного просмотра всех данных, возвращаемых несколькими сходными запросами на выборку, в виде объединенного набора.
Оператор UNION позволяет объединить две инструкции SELECT в одну. Объединяемые инструкции SELECT должны иметь одинаковое число и порядок выходных полей с такими же или совместимыми типами данных. При выполнении запроса данные из каждого набора соответствующих полей объединяются в одно выходное поле, поэтому выходные данные запроса имеют столько же полей, сколько и каждая инструкция SELECT по отдельности.
Примечание: В запросах на объединение числовой и текстовый типы данных являются совместимыми.
Используя оператор UNION, можно указать, должны ли в результаты запроса включаться повторяющиеся строки, если таковые имеются. Для этого следует использовать ключевое слово ALL.
Запрос на объединение двух инструкций SELECT имеет следующий базовый синтаксис:
SELECT field_1
FROM table_1
UNION [ALL]
SELECT field_a
FROM table_a
;
Предположим, например, что имеется две таблицы, которые называются «Товары» и «Услуги». Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
Обе таблицы содержат поля с названием товара или услуги, ценой и сведениями о гарантии, а также поле, в котором указывается эксклюзивность предлагаемого товара или услуги. Несмотря на то, что в таблицах «Продукты» и «Услуги» предусмотрены разные типы гарантий, основная информация одна и та же (предоставляется ли на отдельные продукты или услуги гарантия качества). Для объединения четырех полей из двух таблиц можно использовать следующий запрос на объединение:
SELECT name, price, warranty_available, exclusive_offer
FROM Products
UNION ALL
SELECT name, price, guarantee_available, exclusive_offer
FROM Services
;
Дополнительные сведения об объединении инструкций SELECT с помощью оператора UNION см. в статье Просмотр объединенных результатов нескольких запросов с помощью запроса на объединение.
К началу страницы
SQL запросы быстро.
 Часть 1 / Хабр
Часть 1 / Хабр
Введение
Язык SQL очень прочно влился в жизнь бизнес-аналитиков и требования к кандидатам благодаря простоте, удобству и распространенности. Из собственного опыта могу сказать, что наиболее часто SQL используется для формирования выгрузок, витрин (с последующим построением отчетов на основе этих витрин) и администрирования баз данных. И поскольку повседневная работа аналитика неизбежно связана с выгрузками данных и витринами, навык написания SQL запросов может стать фактором, из-за которого кандидат или получит преимущество, или будет отсеян. Печальная новость в том, что не каждый может рассчитывать получить его на студенческой скамье. Хорошая новость в том, что в изучении SQL нет ничего сложного, это быстро, а синтаксис запросов прост и понятен. Особенно это касается тех, кому уже доводилось сталкиваться с более сложными языками.
Обучение SQL запросам я разделил на три части. Эта часть посвящена базовому синтаксису, который используется в 80-90% случаев. Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Следующие две части будут посвящены подзапросам, Join’ам и специальным операторам. Цель гайдов: быстро и на практике отработать синтаксис SQL, чтобы добавить его к арсеналу навыков.
Практика
Введение в синтаксис будет рассмотрено на примере открытой базы данных, предназначенной специально для практики SQL. Чтобы твое обучение прошло максимально эффективно, открой ссылку ниже в новой вкладке и сразу запускай приведенные примеры, это позволит тебе лучше закрепить материал и самостоятельно поработать с синтаксисом.
Кликнуть здесь
После перехода по ссылке можно будет увидеть сам редактор запросов и вывод данных в центральной части экрана, список таблиц базы данных находится в правой части.
Структура sql-запросов
Общая структура запроса выглядит следующим образом:
SELECT ('столбцы или * для выбора всех столбцов; обязательно')
FROM ('таблица; обязательно')
WHERE ('условие/фильтрация, например, city = 'Moscow'; необязательно')
GROUP BY ('столбец, по которому хотим сгруппировать данные; необязательно')
HAVING ('условие/фильтрация на уровне сгруппированных данных; необязательно')
ORDER BY ('столбец, по которому хотим отсортировать вывод; необязательно')
Разберем структуру. Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
Для удобства текущий изучаемый элемент в запроса выделяется CAPS’ом.
SELECT, FROM
SELECT, FROM — обязательные элементы запроса, которые определяют выбранные столбцы, их порядок и источник данных.
Выбрать все (обозначается как *) из таблицы Customers:
SELECT * FROM Customers
Выбрать столбцы CustomerID, CustomerName из таблицы Customers:
SELECT CustomerID, CustomerName FROM Customers
WHERE
WHERE — необязательный элемент запроса, который используется, когда нужно отфильтровать данные по нужному условию. Очень часто внутри элемента where используются IN / NOT IN для фильтрации столбца по нескольким значениям, AND / OR для фильтрации таблицы по нескольким столбцам.
Фильтрация по одному условию и одному значению:
select * from Customers WHERE City = 'London'
Фильтрация по одному условию и нескольким значениям с применением IN (включение) или NOT IN (исключение):
select * from Customers
where City IN ('London', 'Berlin')select * from Customers
where City NOT IN ('Madrid', 'Berlin','Bern')
Фильтрация по нескольким условиям с применением AND (выполняются все условия) или OR (выполняется хотя бы одно условие) и нескольким значениям:
select * from Customers
where Country = 'Germany' AND City not in ('Berlin', 'Aachen') AND CustomerID > 15select * from Customers
where City in ('London', 'Berlin') OR CustomerID > 4GROUP BY
GROUP BY — необязательный элемент запроса, с помощью которого можно задать агрегацию по нужному столбцу (например, если нужно узнать какое количество клиентов живет в каждом из городов).
При использовании GROUP BY обязательно:
- перечень столбцов, по которым делается разрез, был одинаковым внутри SELECT и внутри GROUP BY,
- агрегатные функции (SUM, AVG, COUNT, MAX, MIN) должны быть также указаны внутри SELECT с указанием столбца, к которому такая функция применяется.
Группировка количества клиентов по городу:
select City, count(CustomerID) from Customers GROUP BY City
Группировка количества клиентов по стране и городу:
select Country, City, count(CustomerID) from Customers GROUP BY Country, City
Группировка продаж по ID товара с разными агрегатными функциями: количество заказов с данным товаром и количество проданных штук товара:
select ProductID, COUNT(OrderID), SUM(Quantity) from OrderDetails GROUP BY ProductID
Группировка продаж с фильтрацией исходной таблицы. В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
В данном случае на выходе будет таблица с количеством клиентов по городам Германии:
select City, count(CustomerID) from Customers WHERE Country = 'Germany' GROUP BY City
Переименование столбца с агрегацией с помощью оператора AS. По умолчанию название столбца с агрегацией равно примененной агрегатной функции, что далее может быть не очень удобно для восприятия.
select City, count(CustomerID) AS Number_of_clients from Customers group by City
HAVING
HAVING — необязательный элемент запроса, который отвечает за фильтрацию на уровне сгруппированных данных (по сути, WHERE, но только на уровень выше).
Фильтрация агрегированной таблицы с количеством клиентов по городам, в данном случае оставляем в выгрузке только те города, в которых не менее 5 клиентов:
select City, count(CustomerID) from Customers group by City HAVING count(CustomerID) >= 5
В случае с переименованным столбцом внутри HAVING можно указать как и саму агрегирующую конструкцию count(CustomerID), так и новое название столбца number_of_clients:
select City, count(CustomerID) as number_of_clients from Customers group by City HAVING number_of_clients >= 5
Пример запроса, содержащего WHERE и HAVING. В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
В данном запросе сначала фильтруется исходная таблица по пользователям, рассчитывается количество клиентов по городам и остаются только те города, где количество клиентов не менее 5:
select City, count(CustomerID) as number_of_clients from Customers
WHERE CustomerName not in ('Around the Horn','Drachenblut Delikatessend')
group by City
HAVING number_of_clients >= 5ORDER BY
ORDER BY — необязательный элемент запроса, который отвечает за сортировку таблицы.
Простой пример сортировки по одному столбцу. В данном запросе осуществляется сортировка по городу, который указал клиент:
select * from Customers ORDER BY City
Осуществлять сортировку можно и по нескольким столбцам, в этом случае сортировка происходит по порядку указанных столбцов:
select * from Customers ORDER BY Country, City
По умолчанию сортировка происходит по возрастанию для чисел и в алфавитном порядке для текстовых значений. Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
Если нужна обратная сортировка, то в конструкции ORDER BY после названия столбца надо добавить DESC:
select * from Customers order by CustomerID DESC
Обратная сортировка по одному столбцу и сортировка по умолчанию по второму:
select * from Customers order by Country DESC, City
JOIN
JOIN — необязательный элемент, используется для объединения таблиц по ключу, который присутствует в обеих таблицах. Перед ключом ставится оператор ON.
Запрос, в котором соединяем таблицы Order и Customer по ключу CustomerID, при этом перед названиям столбца ключа добавляется название таблицы через точку:
select * from Orders JOIN Customers ON Orders.CustomerID = Customers.CustomerID
Нередко может возникать ситуация, когда надо промэппить одну таблицу значениями из другой. В зависимости от задачи, могут использоваться разные типы присоединений. INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
INNER JOIN — пересечение, RIGHT/LEFT JOIN для мэппинга одной таблицы знаениями из другой,
select * from Orders join Customers on Orders.CustomerID = Customers.CustomerID where Customers.CustomerID >10
Внутри всего запроса JOIN встраивается после элемента from до элемента where, пример запроса:
Другие типы JOIN’ов можно увидеть на замечательной картинке ниже:
В следующей части подробнее поговорим о типах JOIN’ов и вложенных запросах.
При возникновении вопросов/пожеланий, всегда прошу обращаться!
Язык SQL как средство создания баз данных Текст научной статьи по специальности «Компьютерные и информационные науки»
УДК 004.655.3
Технические науки
Старушенкова Екатерина Евгеньевна, магистрант 2 года обучения Физико-математического факультета МГПИ им. М. Е. Евсевъева, преподаватель
факультета довузовской подготовки и среднего профессионального образования Мордовский Государственный Университет им. Н. П. Огарева,
Н. П. Огарева,
Республика Мордовия, г. Саранск Шиманова Елена Николаевна, студентка 2 курса специальности «Программирование в компьютерных системах» ФДП и СПО Мордовский Государственный Университет им. Н. П. Огарева, Республика Мордовия,
г. Саранск
Радаев Кирилл Дмитриевич, студент 3 курса специальности «Программирование в компьютерных системах» ФДП и СПО Мордовский Государственный Университет им. Н. П. Огарева, Республика Мордовия,
г. Саранск
ЯЗЫК SQL КАК СРЕДСТВО СОЗДАНИЯ БАЗ ДАННЫХ
Аннотация: В данной статье описаны принципы использования с современными системами управления базами данных, а так же подробно рассмотрены основные операторы языка запросов SQL, для каждого из которых приведены примеры запросов.
Ключевые слова: база данных, язык запросов SQL, система управлениями базами данных, запрос.
Annotation: This article describes the principles of use with modern database management systems, as well as describes in detail the basic operators of the SQL query language, for each of which examples of queries are given.
Keywords: database, SQL query language, database management system,
query.
В современном Мире в веке информационных технологий невозможно представить себе специалиста, который не владеет технологиями обработки информации. В независимости от ситуации и ориентации в информационных потоках специалист любого профиля должен уметь обрабатывать информацию при помощи персональных компьютеров, которые в связи с развитием информационного общества потерпели большие изменения.
Сейчас появилось достаточно большое количество программных продуктов для обработки информации, но встал вопрос в возможностях работы с ними. В том числе к таким программным продуктам и относятся системы управления базами данных, которые работают с реляционными базами данных на языке программирования SQL[3]. Язык SQL является новым универсальным языком запросов, при помощи которого специалист может быстро и легко работать с большими объёмами информации. Сегодня базы данных достаточно широко вошли в жизнь человека и стали частью большинства современных информационных систем, которые функционируют на основе их накопления и обработки. Именно поэтому, появляется необходимость познакомить учащихся с языком запросов SQL, и сформировать у них набор знаний, умений и навыков работы с ним.
Именно поэтому, появляется необходимость познакомить учащихся с языком запросов SQL, и сформировать у них набор знаний, умений и навыков работы с ним.
Язык SQL представляет собой язык запросов, используемый для управления или манипуляции данными в базах данных реляционного типа. В настоящее время язык имеет большую популярность, так как во всех IT-компаниях работают с базами данных и работающему человеку необходимо знать основы языка [1]. Язык SQL используется в современных наиболее популярных системах управления базами данных, начиная от самого простого бесплатного MS SQL Server, заканчивая такими наиболее сложными СУБД как Oracle, MySQL, DB2.
Все операторы языка SQL можно разделить на несколько типов:
— операторы определения объектов базы данных;
— операторы манипулирования данными;
— операторы защиты и управления данными;
— операторы параметров сеанса;
— операторы информации о базе данных.
Рассмотрим их подробнее. К операторам определения объектов базы данных относятся все операторы, отвечающие за создание или удаление самой базы данных, а также таблиц, находящихся в ней [3].
Для того, чтобы создать базу данных нам необходим оператор CREATE SCHEMA. А для создания или удаления таблиц операторы CREATE TABLE и DROP TABLE [2].
Приведем пример. Предположим, что у нас имеется база данных, в которой необходимо создать таблицу «Факультет», которая состоит из 2 столбцов. Первый столбец имеет название «Код специальности» и ограничен всего 6 символами, а 2 столбец «Название специальности», но ограничен 40 символами. При чем каждый из этих двух столбцов не может содержать в себе нулевое значение. Получим следующий код:
create table facultet(kod_spec char(6) not null,
name_cpec varchar(40) not null)
Затем, в таблице «Факультет» мы устанавливаем первичный ключ. Им будет являться столбец «Код специальности»:
alter table facultet add constraint PK_kod_spec primary
key(kod_spec)
Удаляем всю таблицу «Факультет»:
DROP TABLE facultet
К операторам манипулирования данных относятся ключевые слова, при помощи, которых происходит управление значениями в базе данных [1].
Наиболее распространенным оператором при работе с данными является оператор SELECT [1].
Оператор SELECT служит для выборки данных из базы данных. Приведем пример. Нам необходимо показать все данные из таблицы «Факультет» [3]. Под звездочкой в запросе имеются ввиду все данные, хранящиеся в таблице facultet:
SELECT * FROM facultet Как показывает практика, чаще всего в базах данных происходит выборка данных из определенного столбца, тогда получим следующее [4].
Например, нам необходимо произвести выборку в таблице facultet из колонки kod_spec:
SELECT kod_spec FROM facultet Очень часто в выборке необходимо отфильтровать данные по установленному условию, для этого в языке SQL существует свой оператор WHERE.
Приведем пример. Нам необходимо провести выборку из таблицы facultet, из столбца kod_spec и показать только те специальности, которые относятся к среднему профессиональному образованию, то есть начинаются с цифр 09 [2]:
SELECT kod_spec FROM facultet WHERE kod_spec = 09. * Заметим, что в языке SQL операторы сравнения идентичны всем языкам программирования.
* Заметим, что в языке SQL операторы сравнения идентичны всем языкам программирования.
Еще одной особенностью языка SQL является отсутствие чувствительности к регистрам, то есть системам управления базами данных не важно с какой буквы (заглавной или прописной) написано то или иное слово или оператор, это значительно упрощает работу пользователям [5].
Еще одним из важных операторов манипулирования данными является оператор INSERT. При помощи INSERT мы можем вставлять строки в уже заполненные таблицы базы данных. При чем, как одну, так и несколько [1].
Например, необходимо в таблицу facultet после столбца name_cpec вставить столбец col_chel, в котором будет содержаться количество обучающихся студентов:
INSERT INTO facultet (name_cpec, col_chel)
Еще один оператор UPDATE имеет свойство обновлять или заменять в таблицах уже имеющуюся информацию. Например, необходимо в таблице facultet в столбце kod_spec заменить значения «09.02.03» на «09.02.07»: UPDATE facultet SET kod_spec = «09. 02.03» WHERE facultet. kod_spec = 09.02.07
02.03» WHERE facultet. kod_spec = 09.02.07
Оператор DELETE удаляет все данные из таблицы по указанным условиям, либо все строки и столбцы[19].
Например. Нам необходимо удалить из таблицы facultet в базе данных в столбце kod_spec все значения равные «09.02.03»:
DELETE FROM facultet WHERE facultet. kod_spec = 09.02.03
Либо необходимо удалить из таблицы facultet строки, которые имеют в столбце kod_spec значение не равные 09.02.03:
DELETE FROM facultet WHERE facultet. kod_spec <> 09.02.03
Библиографический список:
1. Диго С. М. Базы данных: проектирование и использование / С. М. Диго. — М.: Финансы и статистика, 2005. — 153 с.
2. Колисниченко Д. В. PHP и MySQL. Разработка Web-приложений / Д. В. Колисниченко. — СПб: ХВ-Петербург, 2015. — 593 с. 3.
3. Конноли Т. Базы данных: проектирование, реализация, сопровождение / Т. Конноли, К. Бегг, А. Страчан. — М.: Вильямс, 2003. — 327 с.
4.Голицына, О. Л. Базы данных: Учеб. пособие для студ. Учреждений сред. проф. образов. / О. Л. Голицына, Н. В. Максимов, И. И. Попов — М.: ФОРУМ: ИНФРА-М, 2003. — 351с.
Учреждений сред. проф. образов. / О. Л. Голицына, Н. В. Максимов, И. И. Попов — М.: ФОРУМ: ИНФРА-М, 2003. — 351с.
5. Федорова, Г. Н. Разработка и администрирование баз данных: учеб. пособие для использования в учеб. процессе образоват. учреждений, реализ. прогр. СПО/ Г. Н. Федорова. — 2-е изд., стер. — М.: Академия, 2017. — 313 с.
6. Фуфаев, Э. В. Базы данных: учеб. пособие для студ. образоват. учреждений сред. проф. образования / Фуфаев, Эдуард Валентинович,Фуфаев, Дмитрий Эдуардович. — 3-е изд., стер. — М.: Академия, 2007. — 320 с.
работа с таблицами и их соединением OTUS
Базы данных – то, что помогает бизнесу, а также государственным органам и предприятиям. Это – хранилища информации. Работать с ними должен уметь каждый, особенно когда речь заходит о программировании.
В основном БД представлены таблицами. С ними совершают разнообразные действия:
- объединяют тем или иным способом;
- удаляют;
- корректируют;
- сохраняют;
- выводят на экран.
Делается это или посредством пользовательского интерфейса и специализированных утилит, или через специальные языки «программирования». С ними должен быть знаком каждый программер.
Определение SQL
Чтобы задействовать таблицы в приложениях, играх и прочем контенте, можно использовать SQL. Это – самый распространенный вариант развития событий.
Так называют язык структурированных запросов. Он дает возможность сохранять, управлять и извлекать информацию из реляционных баз данных.
Особенности – что умеет язык
При помощи SQL пользователь/разработчик сможет:
- заполучать доступ к информации в системах управления БД;
- производить описание данных, их структур;
- определять электронные материалы в «табличном хранилище», управляя оными;
- проводить взаимодействие с иными языками при помощи модулей, библиотек и компиляторов SQL;
- создавать новые таблички, удалять старые;
- заниматься созданием представлений, хранимых процедур и функций.

Также при работе с таблицами БД за счет SQL можно настраивать доступ к представлениям, таблицам и процедурам. Главное знать, каким именно образом действовать.
В SQL существуют всевозможные команды, использованием которых удается производить те или иные манипуляции. Далее будет рассказано всего об одном достаточно важном моменте. А именно – как использовать оператор Join. Он пригодится и новичкам, и тем, кто долгое время работает с таблицами и БД.
Что представляет собой JOIN
JOIN – команда/оператор, который используется, когда нужно произвести объединение нескольких таблиц в базах данных. Вследствие нее происходит преобразование двух строк в одну. И не обязательно оные окажутся в разных табличках. JOIN может работать в пределах одного «хранилища» информации.
Команда выполняется при перечислении двух и более таблиц в операторе SQL. Определение JOIN – соединение. Синтаксис здесь довольно простой. Но стоит обратить внимание на то, что вариантов объединения несколько. У каждого – своя запись.
У каждого – своя запись.
Типы
Возможные слияния зависят от того, что именно хочет получить пользователь в конечном итоге. Существуют следующие типы соединений таблиц и иных материалов в рассматриваемом языке запросов:
- простое;
- left outer join;
- right outer join;
- full outer join.
Каждый join запрос в SQL имеет собственные нюансы. О них будет рассказано далее. Разобраться, какой вариант подойдет в том или ином случае поможет простая математика. Там тоже есть объединение. Если разобрать соответствующий вопрос там, в программировании добиться успеха удастся в считанные минуты.
Важно: есть еще один вариант – cross join. Встречается на практике не слишком часто, но помнить о подобном раскладе тоже нужно.
Проще простого – Inner
Первый вариант – это использование простого объединения. Встречается на практике чаще всего. Возвращает пересечение нескольких (обычно двух) множеств. В табличной терминологии — происходит возврат записи, которая имеется в обоих таблицах. Оная должна соответствовать выставленному заранее критерию.
Оная должна соответствовать выставленному заранее критерию.
Для реализации поставленной задачи применяется INNER JOIN. Чтобы лучше понимать данный процесс, стоит составить диаграмму Венна:
- нарисовать круг – пусть это будет «таблица 1»;
- рядом, задевая область первой фигуры, изобразить второй круг – это «таблица 2»;
- закрасить область пересечения – это и есть результат операции inner join.
Рисунок выше – наглядный пример диаграммы Венна. С его помощью удастся разобраться в принципах «простого» объединения нескольких табличек.
Запись
Для того, чтобы выполнять те или иные операции в запросовом языке, стоит уточнить синтаксис желаемой команды. В случае с обычным (простым) объединением необходимо использовать следующий шаблон:
Здесь никаких проблем возникнуть не должно. Код легко читается:
- выбрать колонки;
- from table1 – из первой таблицы;
- объединить с таблицей 2.
Для наглядного примера стоит рассмотреть несколько таблиц с информацией, а также принцип joins типа inner.
Наглядный пример
Пусть будет дана таблица под названием customer. В ней такая информация:
Далее – создается таблица orders:
Теперь нужно joining поля в этих хранилищах информации простым объединением. Для реализации поставленной задачи составляется команда типа:
| SELECT customers.customer_id, orders.order_id, orders.order_date FROM customers INNER JOIN orders ON customers.customer_id = orders.customer_id ORDER BY customers.customer_id; |
В конечном итоге при обработке запроса на экран будет выведен следующий результат:
Здесь выбираются поля в таблице, которые имеют одинаковые значения customer_id в обоих хранилищах. Поэтому другие поля будут пропущены. А строчка, где order_id = 5 в orders опускается, так как customer_id идут со значениями null. То есть, их нет в customers.
Left Join
В отличие от предыдущего объединения, left join – это возврат всех строк из левой таблицы по установленным принципам. Это – левостороннее соединение, осуществляемое через условие ON. Вследствие обработки операции:
Это – левостороннее соединение, осуществляемое через условие ON. Вследствие обработки операции:
- проводится проверка на соответствие условия соединения;
- если оно выполняется – строчка из второй прибавляется к первой таблице.
Именно такое описание можно дать команде left join. Представив его в виде диаграмм, необходимо запомнить следующее представление:
Вся закрашенная область – это результат обработки команды left join в языке SQL.
Запись и пример
Указанным ранее вариантом соединения пользуются чаще всего. Но иногда, особенно при работе с большим количеством информации, может потребоваться левостороннее «слияние». Оно обладает такой формой записи:
Ключевое слово OUTER может быть пропущено. Это нормальное явление, допускаемое некоторыми языками запросов. Помогает значительно сократить исходный код при его написании.
Для примера необходимо взять таблицу с информацией:
Вторая база данных:
Названия тут будут такими же, как и в прошлом случае. Теперь составляется запрос выполнения левостороннего слияния:
Теперь составляется запрос выполнения левостороннего слияния:
После обработки оного на экране появятся всего 6 записей:
Так произошло, потому что left join произвел внутреннее объединение только строки customers и те строчки из orders, где объединенные поля обладают равными значениями. Также стоит запомнить следующие важные сведения:
- когда значение в customer_id из customers отсутствует в orders, поля «ордерс» отображаются в виде null;
- если выставленный параметр слияния не выполняется, поля/строчки «отбрасываются».
Ничего трудного. Такой тип объединения табличек в программировании и базах данных тоже встречается не слишком редко.
Right Join
Описание right join предельно простое – правостороннее соединение. Результатом будут служить строчки из второй таблицы, соответствующие выставленному условию слияния. Наглядно это выглядит так:
Результат запроса исключает поля левой таблицы, не соответствующие выставленным при составлении команды критериям.
О синтаксической записи и примерах
Синтаксис в команды будет иметь вид:
Чтобы понять, как работает right join в языке SQL, рекомендуется обратить внимание на наглядный пример. Он опять осуществляется с табличками customer и orders. Пример будет прописан в операторе SELECT.
Даны две таблицы с информацией:
Далее, чтобы joined две таблички по правостороннему принципу, требуется отправить соответствующий запрос. Он обладает такой формой записи:
Как только операция пройдет обработку, на экране устройства появится результат. Он будет состоять из пяти элементов:
Здесь:
- возвращаются строки из orders – все;
- на экран дополнительно выводятся строчки из customers, которые имеют с «ордерс» одинаковые значения;
- если customers_id в orders отсутствует в «кастомерс», соответствующие поля имеют значение null.
Но и это еще не все. Для полного осознания запросов слияния электронных материалов, требуется в первую очередь изучить все доступные расклады. Их осталось еще 2. Встречаются на практике не слишком часто, из-за чего доставляют немалые хлопоты. Особенно тем, кто занимается запросовым языком относительно недавно.
Их осталось еще 2. Встречаются на практике не слишком часто, из-за чего доставляют немалые хлопоты. Особенно тем, кто занимается запросовым языком относительно недавно.
По полной программе
Предпоследний вариант, который предусматривает join в языке SQL – это full. Можно назвать данный процесс созданием единой таблицы. Информациях из обеих БД будет выведена на экран. Здесь не важно, где именно осуществляется непосредственное пересечение полей.
При full join происходит:
- проверка на невыполнение условия;
- вывод на экран всех строчек из левой и правой таблиц со значениями null, когда условие не выполнено.
Выглядит это так:
Если говорить математическим языком, вследствие обработки запроса произойдет слияние двух множеств. На диаграмме виден результат – это закрашенная область.
Как записывать и применять
Форма записи окажется такого типа:
Full – это внутреннее соединение всех полей в табличках предоставленных баз данных. Для того, чтобы намного лучше разобраться в этом вопросе, составляются таблички:
Для того, чтобы намного лучше разобраться в этом вопросе, составляются таблички:
Они называются так же, как и предлагал последний наглядный пример. Запрос обладает следующим видом:
Итог:
Перекрестным типом
Еще один довольно интересный подход, который относится к основным – это cross. Называется перекрестным. Ин6огда – декартово. При его использовании происходит генерация того же результата, что и при вызове двух таблиц без рассматриваемой команды. Это значит, что:
- на экране появится итог слияния первой таблицы и второй;
- каждая запись одной таблицы будет дублироваться для каждого поля из другой.
Так, если в таблице1 a записей, а в таблице2 b, результирующей окажется таблица a x b полей. В виде диаграммы представить подобный процесс проблематично. Она только запутает разработчиков.
Обладает запрос следующим синтаксисом:
Внимание: cross join – это декартово произведение. Так будет проще понять, о чем идет речь.
Комбинации
Для того, чтобы объединять пары табличек, можно воспользоваться self join.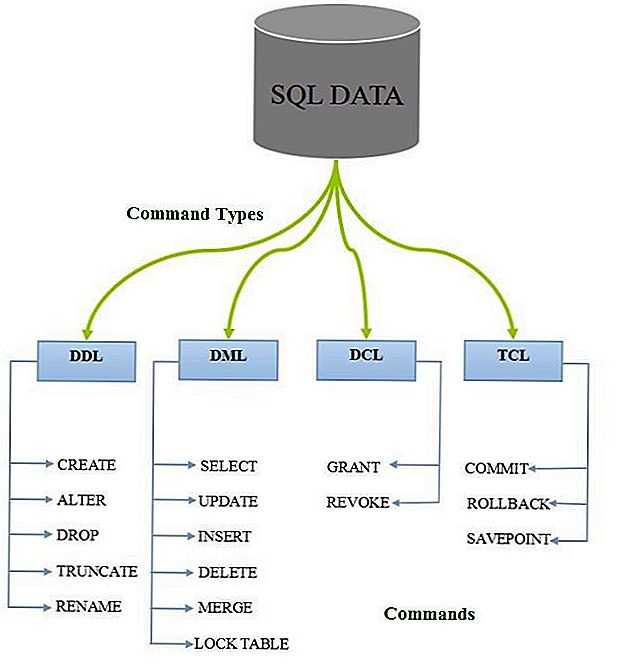 Чтобы разобраться в принципах работы запроса, необходимо рассмотреть пример. Сам запрос выглядит так:
Чтобы разобраться в принципах работы запроса, необходимо рассмотреть пример. Сам запрос выглядит так:
А итог:
Представить такое произведение множеств наглядно тоже проблематично. Зато на примере – нет. Тут показано, что у Гарри нет начальника.
Исключение
После рассмотрения внешнего соединения и другого объединения в языке SQL, важно не забывать об исключении. Результатом будут данные из первой таблицы, но исключая поля, совпадающие со второй табличкой. Наглядно это выглядит так:
Чтобы воспользоваться подобным приемом, не нужно знать ни декартово произведение, ни какие-то другие сложные понятия. В запрос добавляется оператор Where.
А вот пример записи команды:
Планы исполнения
Для того, чтобы грамотно использовать join в SQL, нужно учитывать планы исполнения запросов. То, как именно (в какой последовательности) будет происходить обработка операторов и необходимые вычисления.
Очередность такая:
- from;
- join;
- where.

Данный принцип актуален для всех СУБД. Если не принимать его во внимание, можно в конечном итоге получить таблички с неверной информацией.
Важно: для того, чтобы ускорить обработку команд, важно использовать кластерные индексы. Они применяются Server Query Optimizer для обеих таблиц. Автоматическое создание кластерных индексов производится для первичных ключей. С остальными придется производить соответствующую настройку.
Описание join в языке SQL не должно вызывать вопросов. А если хочется лучше понять, что это такое, а также разобраться в принципах работы queries, стоит посетить дистанционные специализированные курсы. По окончанию обучения выдается сертификат, подтверждающий знания и навыки в выбранном направлении.
Книги по SQL: подборка для новичков и специалистов
SQL — декларативный язык программирования, который используют для описания, изменения и извлечения информации в реляционных базах данных. Язык структурированных запросов популярен у программистов, разработчиков и администраторов баз данных.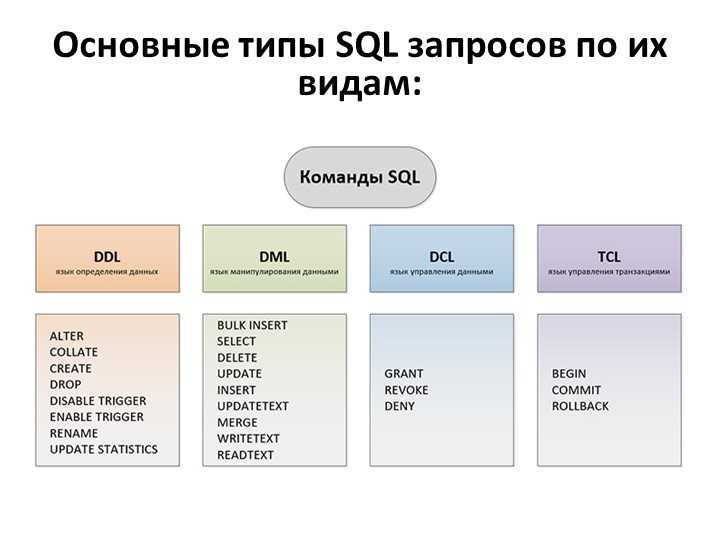 В этом обзоре собрали 6 книг, которые помогут на старте изучения SQL и при углублении в тему.
В этом обзоре собрали 6 книг, которые помогут на старте изучения SQL и при углублении в тему.
Алан Болье «Изучаем SQL»
Уровень: начинающие
«Изучаем SQL» охватывает большинство тем, необходимых для начинающего разработчика в области баз данных, — от азов SQL и возможных применений языка до аналитических функций и работы с БД.
Вы изучите, как данные взаимодействуют с запросами, и примените инструкции для создания, управления и извлечения данных. Также разберетесь, как работают SQL-выражения и блоки, типы условий и подзапросы. Автор рассматривает особенности реализации SQL на серверах баз данных MySQL, Oracle Database, SQL Server.
Книга написана легким языком и не перегружена теорией — все знания применяются на практике в ходе изучения. Для каждой задачи приведено наглядное пособие с иллюстрациями и примерами решения задач. В конце каждой главы есть упражнения для применения теории на практике.
Для закрепления полученных знаний Алан Болье создает учебную базу MySQL и приводит практические примеры запросов, охватывающие теорию.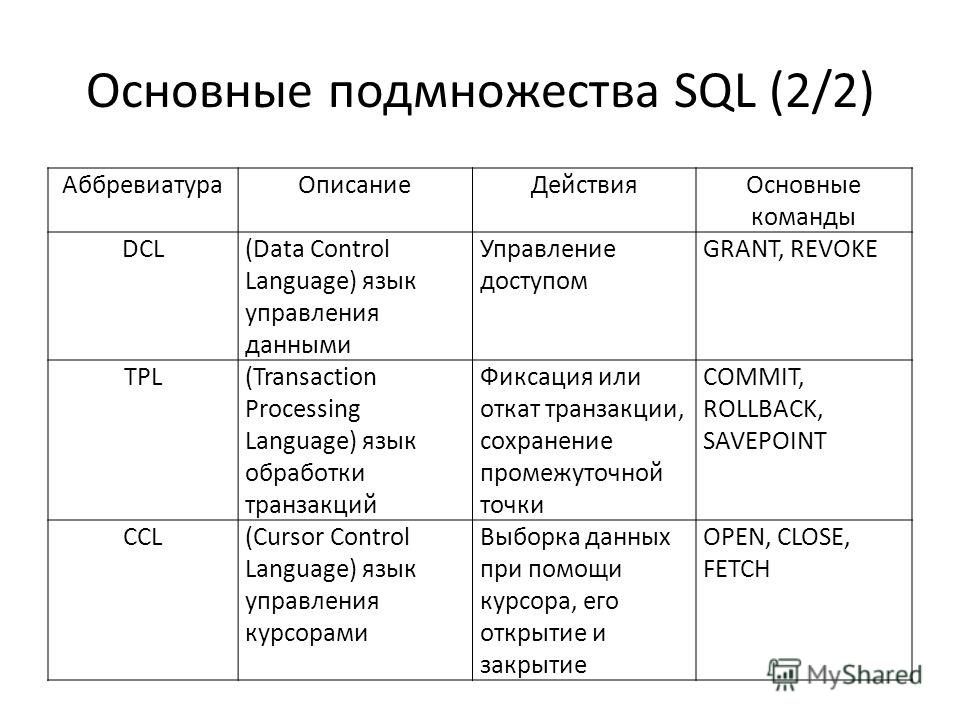
Аллен Тейлор «SQL для чайников»
Уровень: начинающие
Последняя версия «SQL для чайников» поможет разобраться в проектировании, управлении и защите базы данных. Вы изучите построение многотабличных реляционных БД, управление информацией, создание сложных запросов, работу с реляционными операторами, обработку наборов данных с помощью курсоров.
В книге подробно описываются средства защиты данных от кражи, случайного или вредоносного повреждения, а также потери из-за сбоев оборудования и рекомендации по устранению ошибок в работе. Например, функции временных данных, позволяющие устанавливать допустимое время для выполнения транзакций, которые предотвращают повреждение БД.
Также вы узнаете, как работает:
- доступ к данным с помощью ODBC и JDBC,
- XML-данные,
- SQL и JSON,
- процедурное программирование и хранимые модули,
- обработка ошибок,
- триггеры.
Аллен Тейлор — автор более 40 книг, его стаж в компьютерной индустрии — более 30 лет. Последний «SQL для чайников» — девятое издание бестселлера. Помимо написания обучающих книг, Тейлор читает лекции по компьютерным технологиям и ведет онлайн-курсы по работе с базами данных.
Последний «SQL для чайников» — девятое издание бестселлера. Помимо написания обучающих книг, Тейлор читает лекции по компьютерным технологиям и ведет онлайн-курсы по работе с базами данных.
Уолтер Шилдс «SQL: быстрое погружение»
Уровень: смешанный
В первую очередь Уолтер Шидс в своей книге рассказывает о базовых инструментах SQL, необходимых для понимания и получения полезной информации из баз данных. Для более опытных читателей, владеющих базовыми или профессиональными навыками работы с базами данных, «SQL: быстрое погружение» будет удобным справочником.
Автор разбирает создание среды обучения SQL, куда входят такие темы, как:
- базовая терминология,
- типы данных,
- главные элементы и типология реляционных СУБД,
- инструменты и стратегии SQL,
- работа с запросами,
- методы преобразования данных,
- функции языка.
После изучения необходимых основ вы разберетесь в расширенных возможностях SQL. Научитесь использовать подзапросы, представления, овладеете языком управления данными DML.
Автор работает с базами данных уже более 18 лет. Уолтер Шидс — основатель компании в сфере образования SQL Training Wheels. Параллельно обучению студентов Шидс работает над проектом Datadecided для Tableau, компании-разработчика BI-системы.
Энтони Молинаро, Роберт де Грааф «SQL. Сборник рецептов»
Уровень: смешанный
Сборник рецептов с удобной структурой: постановка задачи, решение с кодом и детальное объяснение. Книга научит использовать SQL для решения широкого круга задач: извлечение данных, операции внутри БД, передача данных по сети в приложения.
В руководстве подробно описаны методы извлечения записей из таблиц и работа с несколькими таблицами, сортировка результатов запросов. Также вы изучите расширенные методы работы с хранилищами данных:
- обработка запросов с метаданными,
- применение оконных функций и специальных операторов,
- создание гистограмм, резюмирование данных в блоки,
- выполнение агрегации скользящего диапазона значений,
- формирование текущих сумм и подсумм,
- упрощение вычисления внутри строки,
- двойное разворачивание результирующего множества,
- обход строки, позволяющий использовать SQL для синтаксического разбора строки на символы, слова или элементы строки с разделителями.

Авторы рассматривают особенности конкретных СУБД: Oracle, DB2, SQL Server, MySQL и PostgreSQL. Во втором издании учтены все изменения в синтаксисе и архитектуре актуальных реализаций SQL.
Брайан Сиверсон и Джоэл Мурах «Murach’s SQL Server 2019 for Developers»
Уровень: смешанный
«Murach’s SQL Server 2019 for Developers» не имеет русскоязычного перевода. Вы можете найти электронную или печатную версию на официальном сайте.
Книга разделена на 4 части, каждая из которых постепенно углубляет знания SQL. В первом разделе вы познакомитесь с основными понятиями и терминами, необходимыми для работы с любой реляционной БД. Узнаете, как выполнять SQL-запросы с помощью Microsoft SQL Server 2019 и Management Studio.
Во втором разделе освоите навыки получения, добавления, обновления и удаления данных. Научитесь использовать внешние объединения, сводные запросы и подзапросы.
Третья часть посвящена проектированию и реализации баз данных. Вы узнаете, как спроектировать БД и реализовать проект с помощью операторов SQL или Management Studio.
Последний раздел книги даст вам продвинутые навыки работы с SQL. Вы поймете, как работают:
- представления,
- скрипты,
- хранимые процедуры,
- функции,
- триггеры,
- курсоры,
- транзакции,
- функции для работы с данными XML и BLOB.
Руководство от издательства Murach’s будет полезно разработчикам приложений и администраторам баз данных, новичкам и тем, кто хочет углубить свои знания SQL.
Джоэл Мурах «Murach’s Oracle SQL and PL/SQL for Developers»
Уровень: смешанный
Эта книга также не переведена на русский язык. Электронную или печатную версию можно найти на официальном сайте.
С помощью руководства издания Murach’s вы узнаете, как использовать Oracle Database и Oracle SQL Developer для выполнения SQL-запросов. Освоите проектирование баз данных и реализацию проекта с помощью операторов DDL (Data Definition Language).
Когда вы научитесь использовать SQL для работы с БД Oracle, сможете перенести большую часть изученного на другую СУБД: MySQL, DB2 или Microsoft SQL Server.
Джоэл Мурах в своей книге объясняет, как работать с типами данных timestamp, interval и large object. Читатели получат набор навыков работы с PL/SQL: как использовать процедурный язык Oracle, PL/SQL для создания хранимых процедур, функций и триггеров, управление транзакциями и блокировкой.
Книга включает сотни примеров: от простых до сложных. Вы сможете быстро получить представление о том, как работает та или иная функция на простых примерах, и увидеть, как функция используется в реальном мире на сложных примерах.
Для изучения «Murach’s Oracle SQL and PL/SQL for Developers» не нужно иметь знаний в области программирования. Тем не менее вы быстрее освоите материал, если у вас есть некоторый опыт разработки.
Реализуйте знания языка SQL на практике
Запустите кластер облачных баз данных за минуту и не думайте об инфраструктуре.
Создать кластер
Основы SQL — тест 1
Главная / Базы данных /
Основы SQL / Тест 1
Упражнение 1:
Номер 1
Что представляют собой базы данных?
Ответ:
 (1) аппаратные средства для хранения данных 
 (2) набор логически связанных данных 
 (3) программные средства управления данными 
 (4) компьютер с хранящимися на нем данными 
Номер 2
Каковы основные функции СУБД?
Ответ:
 (1) создание и уничтожение БД 
 (2) хранение данных 
 (3) выборка данных по требованию пользователя 
Номер 3
Назовите отличительные черты реляционных баз данных.

Ответ:
 (1) основой реляционной БД является понятие математических отношений 
 (2) основной объект реляционной БД — двумерные таблицы и связи между ними 
 (3) основной объект реляционной БД — записи и указатели на них 
 (4) основной объект реляционной БД — иерархические структуры типа бинарных деревьев 
Номер 4
Какие связи между объектами моделируются в реляционных базах данных?
Ответ:
 (1) суперкласс – класс — подкласс 
 (2) «один-ко-многим» 
 (3) отношения наследования 
Упражнение 2:
Номер 1
Назовите отличительные черты реализации от стандарта языка.

Ответ:
 (1) любая реализация языка является подмножеством стандарта 
 (2) стандарт – это подмножество любой реализации языка 
 (3) реализация является дополнением и усовершенствованием команд и опций стандарта языка 
 (4) реализация языка заключается в адаптации стандарта языка к конкретной СУБД 
Номер 2
На какое представление данных ориентирован язык SQL?
Ответ:
 (1) на логически связанные совокупности отношений 
 (2) на логические записи файлов 
 (3) на физические записи на магнитном носителе 
 (4) на физические записи с указателями связей 
Номер 3
Определите роль языка SQL в создании информационных систем.

Ответ:
 (1) разработка структуры БД 
 (2) организация пользовательского интерфейса 
 (3) обеспечение различных представлений данных 
 (4) преобразование данных 
Номер 4
Определите типы команд языка SQL.
Ответ:
 (1) управление ходом вычислений 
 (2) определение структуры данных 
 (3) манипулирование данными 
 (4) администрирование данных 
Упражнение 3:
Номер 1
Определите роль клиента в двухуровневой архитектуре «клиент-сервер».

Ответ:
 (1) управление пользовательским интерфейсом 
 (2) управление логикой приложения 
 (3) создание и выполнение запроса к БД 
Номер 2
Определите роль сервера в двухуровневой архитектуре «клиент-сервер».
Ответ:
 (1) обеспечение целостности данных 
 (2) создание пользовательского интерфейса 
 (3) управление параллельной работой пользователей 
Номер 3
Какие функции перешли к среднему уровню обработки данных в трехуровневой архитектуре «клиент-сервер»?
Ответ:
 (1) управление пользовательским интерфейсом 
 (2) управление логикой приложения 
 (3) хранение данных 
 (4) обработка запросов 
Номер 4
Назовите преимущества архитектуры «клиент-сервер»?
Ответ:
 (1) данные хранятся в единственном экземпляре на сервере 
 (2) обработка запроса выполняется на компьютере-клиенте 
 (3) результат запроса в виде файла возвращается клиенту 
Главная / Базы данных /
Основы SQL / Тест 1
Основы SQL — Практическое руководство по SQL для начинающих.
 Анализ велопроката
Анализ велопроката
1 февраля 2021 г.
В этом руководстве мы будем работать с набором данных службы велопроката Hubway, который включает данные о более чем 1,5 миллионах совершенных поездок. с обслуживанием.
Мы начнем с того, что немного рассмотрим базы данных, что они из себя представляют и почему мы их используем, а затем начнем писать собственные запросы на SQL.
Если вы хотите продолжить, вы можете загрузить файл hubway.db здесь (130 МБ).
Основы SQL: реляционные базы данных
Реляционная база данных — это база данных, которая хранит связанную информацию в нескольких таблицах и позволяет запрашивать информацию более чем в одной таблице одновременно.
Легче понять, как это работает, на примере. Представьте, что вы представляете компанию и хотите отслеживать информацию о продажах. Вы можете настроить электронную таблицу в Excel со всей информацией, которую вы хотите отслеживать, в виде отдельных столбцов: номер заказа, дата, сумма к оплате, номер отслеживания доставки, имя клиента, адрес клиента и номер телефона клиента.
Эта настройка отлично подойдет для отслеживания информации, с которой вам нужно начать, но когда вы начнете получать повторные заказы от одного и того же клиента, вы обнаружите, что их имя, адрес и номер телефона сохраняются в нескольких строках вашей электронной таблицы.
По мере роста вашего бизнеса и увеличения количества отслеживаемых заказов эти избыточные данные будут занимать ненужное место и в целом снижать эффективность вашей системы отслеживания продаж. Вы также можете столкнуться с проблемами целостности данных. Например, нет гарантии, что каждое поле будет заполнено данными правильного типа или что имя и адрес будут каждый раз вводиться одинаково.
При использовании реляционной базы данных, подобной показанной на приведенной выше диаграмме, вы избегаете всех этих проблем. Вы можете настроить две таблицы, одну для заказов и одну для клиентов. Таблица «клиенты» будет включать уникальный идентификационный номер для каждого клиента, а также имя, адрес и номер телефона, которые мы уже отслеживали. Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер для отслеживания, и вместо отдельного поля для каждого элемента данных клиента в ней будет столбец для идентификатора клиента.
Таблица «заказы» будет включать номер вашего заказа, дату, сумму к оплате, номер для отслеживания, и вместо отдельного поля для каждого элемента данных клиента в ней будет столбец для идентификатора клиента.
Это позволяет нам получать всю информацию о клиенте для любого данного заказа, но нам нужно сохранить ее только один раз в нашей базе данных, а не выводить ее снова для каждого отдельного заказа.
Наш набор данных
Начнем с нашей базы данных. В базе данных есть две таблицы: поездок и станций . Для начала мы просто посмотрим на таблицу trips . Он содержит следующие столбцы:
-
id— Уникальное целое число, которое служит ссылкой для каждой поездки -
продолжительность— Продолжительность поездки, измеряется в секундах -
start_date— Дата и время начала поездки -
start_station— Целое число, соответствующее столбцуidв таблицеstationдля станции, с которой началась поездка -
end_date— Дата и время окончания поездки -
end_station— Идентификатор станции, на которой закончилась поездка -
bike_number— Уникальный идентификатор Hubway для велосипеда, использованного в поездке -
sub_type— Тип подписки пользователя.«Зарегистрированный»для пользователей с членством,«Обычный»для пользователей без членства -
zip_code— Почтовый индекс пользователя (доступно только для зарегистрированных пользователей) -
birth_date— Год рождения пользователя (доступно только для зарегистрированных пользователей) -
пол— Пол пользователя (доступно только для зарегистрированных пользователей)
.
Наш анализ
С этой информацией и командами SQL, которые мы скоро изучим, вот несколько вопросов, на которые мы попытаемся ответить в ходе этого поста:
- Какова была продолжительность самой длинной поездки?
- Сколько поездок совершили «зарегистрированные» пользователи?
- Какова средняя продолжительность поездки?
- Зарегистрированные или случайные пользователи совершают длительные поездки?
- На каком велосипеде было совершено больше всего поездок?
- Какова средняя продолжительность поездок пользователей старше 30 лет?
Команды SQL, которые мы будем использовать для ответа на эти вопросы:
-
ВЫБОР -
ГДЕ -
ПРЕДЕЛ -
ЗАКАЗАТЬ -
ГРУППА ПО -
И -
ИЛИ -
МИН -
МАКС -
АВГ -
СУММА -
СЧЕТ
Установка и настройка
Для целей этого руководства мы будем использовать систему баз данных под названием SQLite3. SQLite входит в состав Python, начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет и SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
SQLite входит в состав Python, начиная с версии 2.5, поэтому, если у вас установлен Python, у вас почти наверняка будет и SQLite. Python и библиотеку SQLite3 можно легко установить и настроить с помощью Anaconda, если у вас их еще нет.
Использование Python для запуска нашего кода SQL позволяет нам импортировать результаты в фрейм данных Pandas, чтобы упростить отображение наших результатов в удобном для чтения формате. Это также означает, что мы можем выполнять дальнейший анализ и визуализацию данных, которые мы извлекаем из базы данных, хотя это выходит за рамки этого руководства.
В качестве альтернативы, если мы не хотим использовать или устанавливать Python, мы можем запустить SQLite3 из командной строки. Просто загрузите «предварительно скомпилированные двоичные файлы» с веб-страницы SQLite3 и используйте следующий код, чтобы открыть базу данных:
~$ sqlite hubway.db Версия SQLite 3.14.0 2016-07-26 15:17:14Введите «.help» для использования подсказок.sqlite>
Отсюда мы можем просто ввести запрос, который хотим запустить, и мы увидим данные, возвращенные в нашем окне терминала.
Альтернативой использованию терминала является подключение к базе данных SQLite через Python. Это позволило бы нам использовать блокнот Jupyter, чтобы мы могли видеть результаты наших запросов в аккуратно отформатированной таблице.
Для этого мы определим функцию, которая принимает наш запрос (сохраненный в виде строки) в качестве входных данных и отображает результат в виде форматированного фрейма данных:
импорт sqlite3
span>импортировать панд как pd
б = sqlite3.connect('hub.db')
span>def run_query (запрос):
вернуть pd.read_sql_query (запрос, БД) Конечно, нам не обязательно использовать Python с SQL. Если вы уже являетесь программистом R, наш курс «Основы SQL для пользователей R» станет отличным стартом.
ВЫБЕРИТЕ
Первая команда, с которой мы будем работать, это SELECT . SELECT будет основой почти каждого написанного нами запроса — он сообщает базе данных, какие столбцы мы хотим видеть. Мы можем указать столбцы по имени (разделенные запятыми) или использовать подстановочный знак
Мы можем указать столбцы по имени (разделенные запятыми) или использовать подстановочный знак * для возврата каждого столбца в таблице.
В дополнение к столбцам, которые мы хотим получить, мы также должны сообщить базе данных, из какой таблицы их получить. Для этого мы используем ключевое слово FROM , за которым следует имя таблицы. Например, если мы хотим увидеть start_date и bike_number для каждой поездки в таблице trips , мы можем использовать следующий запрос:
ВЫБЕРИТЕ start_date, bike_number ИЗ поездок;
В этом примере мы начали с команды SELECT , чтобы база данных знала, что мы хотим, чтобы она нашла для нас некоторые данные. Затем мы сообщили базе данных, что нас интересуют столбцы start_date и bike_number . Наконец, мы использовали FROM , чтобы сообщить базе данных, что столбцы, которые мы хотим видеть, являются частью таблицы trips .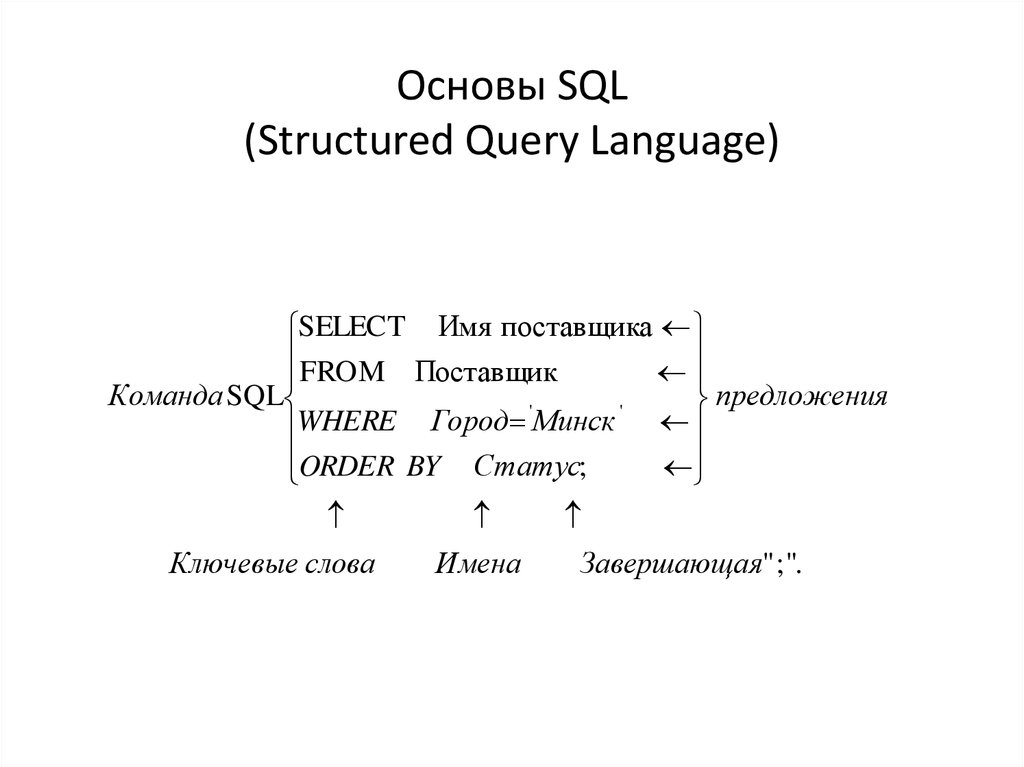
Одна важная вещь, о которой следует помнить при написании SQL-запросов, заключается в том, что мы хотим заканчивать каждый запрос точкой с запятой ( ; ). Не каждая база данных SQL на самом деле требует этого, но некоторые требуют, поэтому лучше сформировать эту привычку.
ПРЕДЕЛ
Следующая команда, которую нам нужно знать, прежде чем мы начнем выполнять запросы к нашей базе данных Hubway, — это LIMIT . LIMIT просто сообщает базе данных, сколько строк вы хотите вернуть.
Запрос SELECT , который мы рассмотрели в предыдущем разделе, возвращает запрошенную информацию для каждой строки в таблице trips , но иногда это может означать большой объем данных. Мы можем не хотеть всего этого. Если бы вместо этого мы хотели увидеть start_date и bike_number для первых пяти поездок в базе данных, мы могли бы добавить LIMIT к нашему запросу следующим образом:
ВЫБЕРИТЕ start_date, bike_number ИЗ поездок LIMIT 5;
Мы просто добавили команду LIMIT , а затем число, представляющее количество строк, которые мы хотим вернуть. В этом примере мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
В этом примере мы использовали 5, но вы можете заменить его любым числом, чтобы получить соответствующий объем данных для проекта, над которым вы работаете.
Мы будем часто использовать LIMIT в наших запросах к базе данных Hubway в этом руководстве — таблица trips содержит более 1,5 миллиона строк данных, и нам, конечно же, не нужно отображать их все!
Давайте запустим наш первый запрос к базе данных Hubway. Сначала мы сохраним наш запрос в виде строки, а затем воспользуемся функцией, которую мы определили ранее, чтобы запустить его в базе данных. Взгляните на следующий пример:
запрос = 'ВЫБЕРИТЕ * ИЗ ОГРАНИЧЕНИЯ 5 поездок;' un_query(запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 9 | 28. 07.2011 10:12:00 | 23 | 28.07.2011 10:12:00 | 23 | B00468 | Зарегистрировано | ‘97217 | 1976,0 | Мужчина |
| 1 | 2 | 220 | 2011-07-28 10:21:00 | 23 | 28-07-2011 10:25:00 | 23 | B00554 | Зарегистрировано | ‘02215 | 1966.0 | Мужчина |
| 2 | 3 | 56 | 28-07-2011 10:33:00 | 23 | 2011-07-28 10:34:00 | 23 | B00456 | Зарегистрировано | ‘02108 | 1943.0 | Мужчина |
| 3 | 4 | 64 | 28-07-2011 10:35:00 | 23 | 28-07-2011 10:36:00 | 23 | B00554 | Зарегистрировано | ‘02116 | 1981.0 | Женщина |
| 4 | 5 | 12 | 28-07-2011 10:37:00 | 23 | 28-07-2011 10:37:00 | 23 | B00554 | Зарегистрировано | ‘97214 | 1983,0 | Женщина |
Этот запрос использует * в качестве подстановочного знака вместо указания возвращаемых столбцов. Это означает, что команда SELECT предоставила нам каждый столбец в таблице trips . Мы также использовали функцию LIMIT , чтобы ограничить вывод первыми пятью строками таблицы.
Вы часто будете видеть, что люди пишут ключевые слова команд в своих запросах с большой буквы (соглашение, которому мы будем следовать в этом руководстве), но это в основном вопрос предпочтений. Такое использование заглавных букв облегчает чтение кода, но фактически никак не влияет на функцию кода. Если вы предпочитаете писать свои запросы с помощью команд нижнего регистра, запросы все равно будут выполняться правильно.
Наш предыдущий пример возвратил каждый столбец в таблице trips . Если бы нас интересовали только продолжительность и столбцы start_date , мы могли бы заменить подстановочный знак именами столбцов следующим образом:
запрос = 'ВЫБЕРИТЕ продолжительность, start_date ИЗ ОГРАНИЧЕНИЯ поездок 5' un_query (запрос)
| продолжительность | start_date | |
|---|---|---|
| 0 | 9 | 28. 07.2011 10:12:00 |
| 1 | 220 | 2011-07-28 10:21:00 |
| 2 | 56 | 28-07-2011 10:33:00 |
| 3 | 64 | 28-07-2011 10:35:00 |
| 4 | 12 | 28-07-2011 10:37:00 |
ЗАКАЗАТЬ
Последняя команда, которую нам нужно знать, прежде чем мы сможем ответить на первый из наших вопросов, это ORDER BY . Эта команда позволяет нам сортировать базу данных по заданному столбцу.
Чтобы использовать его, мы просто указываем имя столбца, по которому мы хотим выполнить сортировку. По умолчанию ORDER BY сортирует по возрастанию. Если мы хотим указать порядок сортировки базы данных, мы можем добавить ключевое слово ASC для возрастания или DESC для убывания.
Например, если мы хотим отсортировать таблицу поездок от самой короткой продолжительности до самой длинной, мы можем добавить следующую строку в наш запрос:
ПОРЯДОК ПО длительности ASC
С SELECT , LIMIT и ORDER BY команд в нашем репертуаре, теперь мы можем попытаться ответить на наш первый вопрос: Какова была продолжительность самого длинного путешествия?
Чтобы ответить на этот вопрос, полезно разбить его на разделы и определить, какие команды нам потребуются для решения каждой части.
Сначала нам нужно извлечь информацию из столбца продолжительность таблицы trips . Затем, чтобы найти самую длинную поездку, мы можем отсортировать столбец продолжительности в порядке убывания. Вот как мы могли бы проработать это, чтобы придумать запрос, который получит информацию, которую мы ищем:
- Используйте
SELECT, чтобы получитьпродолжительностьстолбецИЗпоездкитаблица - Используйте
ORDER BYдля сортировки столбцапродолжительностьи используйте ключевое словоDESC, чтобы указать, что вы хотите отсортировать в порядке убывания - Используйте
LIMIT, чтобы ограничить вывод одной строкой
Использование этих команд таким образом вернет одну строку с наибольшей продолжительностью, что даст нам ответ на наш вопрос.
Еще одно замечание: по мере того, как ваши запросы добавляют больше команд и становятся более сложными, вы можете обнаружить, что их легче читать, если вы разделите их на несколько строк. Это, как и заглавные буквы, зависит от личных предпочтений. Это не влияет на то, как работает код (система просто читает код с самого начала, пока не дойдет до точки с запятой), но может сделать ваши запросы более четкими и понятными. В Python мы можем разделить строку на несколько строк, используя тройные кавычки.
Давайте запустим этот запрос и узнаем, как долго длилась самая длинная поездка.
запрос = ''' ВЫБЕРИТЕ продолжительность ИЗ поездок RDER BY продолжительность DESC ИМИТ 1; '' un_query (запрос)
| продолжительность | |
|---|---|
| 0 | 9999 |
Теперь мы знаем, что самая длинная поездка длилась 9999 секунд, или немногим более 166 минут. Однако с максимальным значением 9999 мы не знаем, действительно ли это длина самой длинной поездки или база данных была настроена только на четырехзначное число.
Если правда, что особенно длительные поездки обрезаются базой данных, то мы можем ожидать много поездок за 9999 секунд, когда они достигают предела. Давайте попробуем запустить тот же запрос, что и раньше, но скорректируем LIMIT , чтобы он возвращал 10 самых высоких значений длительности, чтобы проверить, так ли это:
запрос = ''' ВЫБЕРИТЕ продолжительность ОТ поездок RDER BY продолжительность DESC ИМИТ 10 '' un_query (запрос)
| продолжительность | |
|---|---|
| 0 | 9999 |
| 1 | 9998 |
| 2 | 9998 |
| 3 | 9997 |
| 4 | 9996 |
| 5 | 9996 |
| 6 | 9995 |
| 7 | 9995 |
| 8 | 9994 |
| 9 | 9994 |
Здесь мы видим, что на 9999 нет целой группы поездок, поэтому не похоже, что мы отрезаем верхнюю часть нашей продолжительности, но все еще трудно сказать, является ли это реальной продолжительностью. поездки или просто максимально допустимое значение.
Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут (кто-то, кто держит велосипед в течение 9999 секунд, должен будет заплатить дополнительные 25 долларов США), поэтому вполне вероятно, что они решили, что 4 цифры будут достаточными для отслеживания большинства поездок.
ГДЕ
Предыдущие команды отлично подходят для извлечения отсортированной информации для определенных столбцов, но что, если есть определенное подмножество данных, которые мы хотим просмотреть? Вот тут-то и появляется WHERE . Команда WHERE позволяет нам использовать логический оператор, чтобы указать, какие строки должны быть возвращены. Например, вы можете использовать следующую команду для возврата всех поездок, совершенных на велосипеде B00400 :
ГДЕ bike_number = "B00400"
Вы также заметите, что в этом запросе мы используем кавычки. Это потому, что bike_number хранится в виде строки. Если бы столбец содержал числовые типы данных, кавычки не были бы необходимы.
Давайте напишем запрос, который использует ГДЕ для возврата каждого столбца в таблице trips для каждой строки с длительностью более 9990 секунд:
запрос = ''' ВЫБРАТЬ * ИЗ поездок ЗДЕСЬ продолжительность > 9990; '' un_query(запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4768 | 9994 | 03.08.2011 17:16:00 | 22 | 03.08.2011 20:03:00 | 24 | B00002 | Повседневная | |||
| 1 | 8448 | 9991 | 06.08. 2011 13:02:00 | 52 | 06.08.2011 15:48:00 | 24 | B00174 | Повседневная | |||
| 2 | 11341 | 9998 | 09.08.2011 10:42:00 | 40 | 09.08.2011 13:29:00 | 42 | B00513 | Повседневная | |||
| 3 | 24455 | 9995 | 20.08.2011 12:20:00 | 52 | 20.08.2011 15:07:00 | 17 | B00552 | Повседневная | |||
| 4 | 55771 | 9994 | 14-09-2011 15:44:00 | 40 | 14-09-2011 18:30:00 | 40 | B00139 | Повседневная | |||
| 5 | 81191 | 9993 | 03.10.2011 11:30:00 | 22 | 03.10.2011 14:16:00 | 36 | B00474 | Повседневная | |||
| 6 | 89335 | 9997 | 09. 10.2011 02:30:00 | 60 | 09.10.2011, 05:17:00 | 45 | B00047 | Повседневная | |||
| 7 | 124500 | 9992 | 09.11.2011 09:08:00 | 22 | 09.11.2011 11:55:00 | 40 | B00387 | Повседневная | |||
| 8 | 133967 | 9996 | 19-11-2011 13:48:00 | 4 | 19-11-2011 16:35:00 | 58 | B00238 | Повседневная | |||
| 9 | 147451 | 9996 | 23-03-2012 14:48:00 | 35 | 23-03-2012 17:35:00 | 33 | B00550 | Повседневная | |||
| 10 | 315737 | 9995 | 03-07-2012 18:28:00 | 12 | 03.07.2012 21:15:00 | 12 | B00250 | Зарегистрировано | ‘02120 | 1964 | Мужчина |
| 11 | 319597 | 9994 | 05. 07.2012 11:49:00 | 52 | 05.07.2012 14:35:00 | 55 | B00237 | Повседневная | |||
| 12 | 416523 | 9998 | 15-08-2012 12:11:00 | 54 | 15-08-2012 14:58:00 | 80 | B00188 | Повседневная | |||
| 13 | 541247 | 9999 | 2012-09-26 18:34:00 | 54 | 2012-09-26 21:21:00 | 54 | Т01078 | Повседневная |
Как мы видим, этот запрос вернул 14 различных поездок, каждая продолжительностью 9990 секунд или более. В этом запросе выделяется то, что все результаты, кроме одного, имеют sub_type из "Casual" . Возможно, это показатель того, что "зарегистрированных" пользователей больше осведомлены о дополнительных сборах за дальние поездки. Возможно, Hubway могла бы лучше донести свою структуру ценообразования до случайных пользователей, чтобы помочь им избежать переплат.
Мы уже видим, как даже начальный уровень владения SQL может помочь нам ответить на вопросы бизнеса и найти ценную информацию в наших данных.
Возвращаясь к WHERE , мы также можем объединить несколько логических тестов в нашем предложении WHERE , используя И или ИЛИ . Если, например, в нашем предыдущем запросе мы хотели вернуть только поездки с продолжительностью в течение 9990 секунд, которые также имели подтип Зарегистрировано, мы могли бы использовать И для указания обоих условий.
Вот еще одна рекомендация по личным предпочтениям: используйте круглые скобки для разделения каждого логического теста, как показано в блоке кода ниже. Это не обязательно для функционирования кода, но круглые скобки облегчают понимание ваших запросов по мере увеличения сложности.
Давайте запустим этот запрос сейчас. Мы уже знаем, что он должен возвращать только один результат, поэтому должно быть легко проверить правильность ответа:
.
запрос = ''' ВЫБРАТЬ * ИЗ поездок ЗДЕСЬ (продолжительность >= 9990) И (sub_type = "Зарегистрировано") RDER BY продолжительность DESC; '' un_query (запрос)
| идентификатор | продолжительность | start_date | старт_станция | дата_конца | конечная_станция | велосипед_номер | подтип | почтовый индекс | дата_рождения | пол | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 315737 | 9995 | 03-07-2012 18:28:00 | 12 | 03.07.2012 21:15:00 | 12 | B00250 | Зарегистрировано | ‘02120 | 1964.0 | Мужчина |
Следующий вопрос, который мы поставили в начале поста, — «Сколько поездок было совершено «зарегистрированными» пользователями?» Чтобы ответить на него, мы могли бы запустить тот же запрос, что и выше, и изменить выражение WHERE , чтобы оно возвращало все строки, где sub_type равен 9. 0011 «Зарегистрировано» , а затем подсчитайте их.
Однако на самом деле в SQL есть встроенная команда для подсчета за нас, COUNT .
COUNT позволяет нам перенести вычисления в базу данных и избавляет нас от необходимости писать дополнительные сценарии для подсчета результатов. Чтобы использовать его, мы просто включаем COUNT(column_name) вместо (или в дополнение) столбцов, которые вы хотите SELECT , например:
ВЫБЕРИТЕ СЧЕТ(id) span>ИЗ поездок
В данном случае не имеет значения, какой столбец мы выбираем для подсчета, потому что в каждом столбце должны быть данные для каждой строки в нашем запросе. Но иногда запрос может иметь отсутствующие (или «нулевые») значения для некоторых строк. Если мы не уверены, содержит ли столбец нулевые значения, мы можем запустить наш COUNT для столбца id — столбец id никогда не бывает нулевым, поэтому мы можем быть уверены, что наш подсчет ничего не пропустит.
Мы также можем использовать COUNT(1) или COUNT(*) для подсчета каждой строки в нашем запросе. Стоит отметить, что иногда нам действительно может понадобиться запустить COUNT для столбца с нулевыми значениями. Например, мы можем захотеть узнать, сколько строк в нашей базе данных имеют пропущенные значения для столбца.
Давайте посмотрим на запрос, чтобы ответить на наш вопрос. Мы можем использовать SELECT COUNT(*) для подсчета общего количества возвращенных строк и WHERE sub_type = "Registered" , чтобы убедиться, что мы подсчитываем только поездки, совершенные зарегистрированными пользователями.
запрос = ''' ВЫБРАТЬ COUNT(*)FROM поездок ЗДЕСЬ sub_type = "Зарегистрировано"; '' un_query (запрос)
| СЧЕТ(*) | |
|---|---|
| 0 | 1105192 |
Этот запрос сработал и вернул ответ на наш вопрос. Но заголовок столбца не особенно описателен. Если бы кто-то другой посмотрел на эту таблицу, он бы не смог понять, что она означает.
Если мы хотим сделать наши результаты более читабельными, мы можем использовать AS , чтобы дать нашему выводу псевдоним (или псевдоним). Давайте повторно запустим предыдущий запрос, но дадим заголовку нашего столбца псевдоним Total Trips by Registered Users :
запрос = ''' ВЫБРАТЬ COUNT(*) AS "Общее количество поездок зарегистрированных пользователей" ROM поездки ЗДЕСЬ sub_type = "Зарегистрировано"; '' un_query (запрос)
| Всего поездок зарегистрированных пользователей | |
|---|---|
| 0 | 1105192 |
Агрегированные функции
COUNT — не единственная математическая уловка, которая есть в SQL. Мы также можем использовать SUM , AVG , MIN и MAX для возврата суммы, среднего, минимума и максимума столбца соответственно. Они, наряду с COUNT , известны как агрегатные функции.
Итак, чтобы ответить на наш третий вопрос, «Какова была средняя продолжительность поездки?» , мы можем использовать AVG в столбце продолжительность (и снова используйте AS , чтобы дать нашему выходному столбцу более описательное имя):
запрос = ''' ВЫБЕРИТЕ AVG(длительность) КАК "Средняя продолжительность" ПЗУ поездки; '' un_query (запрос)
| Средняя продолжительность | |
|---|---|
| 0 | 912.409682 |
Получается, что средняя продолжительность поездки составляет 912 секунд, что составляет около 15 минут. В этом есть смысл, поскольку мы знаем, что Hubway взимает дополнительную плату за поездки продолжительностью более 30 минут. Услуга предназначена для пассажиров, совершающих короткие поездки в один конец.
Как насчет нашего следующего вопроса, зарегистрированные или случайные пользователи совершают более длительные поездки? Мы уже знаем один способ ответить на этот вопрос — мы можем выполнить два запроса SELECT AVG(duration) FROM trips с предложениями WHERE , которые ограничивают один до "Зарегистрированных" и один до "Обычных" пользователей.
Но давайте по-другому. SQL также позволяет ответить на этот вопрос в одном запросе с помощью команды GROUP BY .
ГРУППА ПО
GROUP BY разделяет строки на группы на основе содержимого определенного столбца и позволяет нам выполнять агрегатные функции для каждой группы.
Чтобы лучше понять, как это работает, давайте взглянем на столбец пол . Каждая строка может иметь одно из трех возможных значений в столбце пол , «Мужской» , «Женский» или Нулевой (отсутствует; у нас нет данных пол для случайных пользователей).
Когда мы используем GROUP BY , база данных разделит каждую из строк на разные группы на основе значения в столбце пол , почти так же, как мы могли бы разделить колоду карт на разные масти. Мы можем представить себе две стопки, одну из всех самцов, другую из всех самок.
Когда у нас есть две отдельные стопки, база данных будет выполнять любые агрегатные функции в нашем запросе на каждой из них по очереди. Например, если бы мы использовали COUNT , запрос подсчитал бы количество строк в каждой стопке и вернул бы значение для каждой отдельно.
Давайте рассмотрим, как именно написать запрос, чтобы ответить на наш вопрос о том, совершают ли зарегистрированные или случайные пользователи более длительные поездки.
- Как и в каждом из наших запросов, мы начнем с
SELECT, чтобы сообщить базе данных, какую информацию мы хотим видеть. В этом случае нам понадобитсяsub_typeиAVG(duration). - Мы также включим
GROUP BY sub_type, чтобы разделить наши данные по типу подписки и рассчитать средние значения для зарегистрированных и случайных пользователей отдельно.
Вот как выглядит код, когда мы сложим его вместе:
запрос = ''' ВЫБЕРИТЕ подтип, AVG (продолжительность) AS «Средняя продолжительность» ROM поездки ГРУППИРОВАТЬ ПО подтипу; '' un_query (запрос)
| подтип | Средняя продолжительность | |
|---|---|---|
| 0 | Повседневная | 1519. 643897 |
| 1 | Зарегистрировано | 657.026067 |
Какая разница! В среднем зарегистрированные пользователи совершают поездки, которые длятся около 11 минут, тогда как обычные пользователи тратят почти 25 минут на поездку. Зарегистрированные пользователи, вероятно, совершают более короткие и частые поездки, возможно, в рамках поездки на работу. С другой стороны, обычные пользователи тратят примерно в два раза больше времени на поездку.
Вполне возможно, что случайные пользователи, как правило, относятся к демографическим группам (например, туристы), которые более склонны к длительным поездкам, чтобы убедиться, что они перемещаются и осматривают все достопримечательности. Как только мы обнаружим эту разницу в данных, у компании появится множество способов исследовать ее, чтобы лучше понять, что ее вызывает.
Однако для целей этого руководства давайте двигаться дальше. Наш следующий вопрос был , какой велосипед использовался для большинства поездок? . Мы можем ответить на это, используя очень похожий запрос. Взгляните на следующий пример и посмотрите, сможете ли вы понять, что делает каждая строка — после этого мы пройдемся по ним шаг за шагом, чтобы вы могли убедиться, что все правильно:
запрос = ''' ВЫБЕРИТЕ bike_number как "Номер велосипеда", COUNT(*) как "Количество поездок" ROM поездки ГРУППИРОВАТЬ ПО номеру велосипеда ЗАКАЗАТЬ ПО СЧЕТУ(*) DESC ИМИТ 1; '' un_query(запрос)
| Номер велосипеда | Количество поездок | |
|---|---|---|
| 0 | B00490 | 2120 |
Как видно из вывода, велосипед B00490 совершал больше всего поездок. Давайте пробежимся по тому, как мы туда попали:
- Первая строка — это предложение
SELECT, сообщающее базе данных, что мы хотим видеть столбецbike_numberи количество каждой строки. Он также используетAS, чтобы указать базе данных отображать каждый столбец с более удобным именем. - Во второй строке используется
FROM, чтобы указать, что данные, которые мы ищем, находятся в таблицеtrips. - В третьей строке все становится немного сложнее. Мы используем
GROUP BY, чтобы указать функцииCOUNTв строке 1 подсчитывать каждое значение дляbike_numberотдельно. - В четвертой строке у нас есть предложение
ORDER BYдля сортировки таблицы в порядке убывания и обеспечения того, чтобы наш наиболее часто используемый велосипед находился вверху. - Наконец, мы используем
LIMIT, чтобы ограничить вывод первой строкой, которая, как мы знаем, будет велосипедом, использованным в наибольшем количестве поездок, из-за того, как мы отсортировали данные в четвертой строке.
Арифметические операторы
Наш последний вопрос немного сложнее остальных. Мы хотим знать среднюю продолжительность поездок зарегистрированных пользователей старше 30 лет .
Мы могли бы просто вычислить год, в котором родились 30-летние в нашей голове, а затем подставить его, но более элегантное решение — использовать арифметические операции непосредственно в нашем запросе. SQL позволяет нам использовать +, - , * и / для выполнения арифметической операции над всем столбцом сразу.
запрос = ''' ВЫБРАТЬ AVG(длительность) из поездок ЗДЕСЬ (2017 - дата_рождения) > 30; '' un_query (запрос)
| СРЕДНЕЕ (длительность) | |
|---|---|
| 0 | 923.014685 |
ПРИСОЕДИНЯЙТЕСЬ
До сих пор мы рассматривали запросы, которые извлекают данные только из поездок табл. Однако одна из причин, по которой SQL настолько эффективен, заключается в том, что он позволяет нам извлекать данные из нескольких таблиц в одном запросе.
Наша база данных велопроката содержит вторую таблицу, станций . Таблица station содержит информацию о каждой станции в сети Hubway и включает столбец id , на который ссылается таблица trips .
Прежде чем мы начнем работать с некоторыми реальными примерами из этой базы данных, давайте вернемся к гипотетической базе данных отслеживания заказов, которую мы использовали ранее. В этой базе данных у нас было две таблицы, заказы и клиенты , и они были связаны столбцом customer_id .
Допустим, мы хотели написать запрос, который возвращал order_number и name для каждого заказа в базе данных. Если бы они оба хранились в одной таблице, мы могли бы использовать следующий запрос:
ВЫБЕРИТЕ номер_заказа, имя диапазон>ОТ заказов;
К сожалению, столбец order_number и столбец name хранятся в двух разных таблицах, поэтому нам нужно добавить несколько дополнительных шагов. Давайте уделим немного времени тому, чтобы подумать о дополнительных вещах, которые база данных должна знать, прежде чем она сможет вернуть нужную нам информацию:
- В какой таблице находится столбец
order_number? - В какой таблице находится столбец
name? - Как информация в таблице
заказовсвязана с информацией в таблицеклиентов?
Чтобы ответить на первые два из этих вопросов, мы можем включить имена таблиц для каждого столбца в нашу команду SELECT . Мы делаем это просто, записывая имя таблицы и имя столбца, разделяя их цифрой 9.0011 . . Например, вместо SELECT order_number, name мы напишем SELECT Orders.order_number, customers.name . Добавление здесь имен таблиц помогает базе данных находить искомые столбцы, сообщая ей, в какой таблице искать каждый из них.
Чтобы сообщить базе данных, как связаны таблицы заказов и клиентов , мы используем JOIN и ON . JOIN указывает, какие таблицы должны быть соединены и ON указывает, какие столбцы в каждой таблице связаны.
Мы собираемся использовать внутреннее соединение, что означает, что строки будут возвращены только в том случае, если есть совпадение в столбцах, указанных в ON . В этом примере мы хотим использовать JOIN для любой таблицы, которую мы не включили в команду FROM . Таким образом, мы можем использовать либо ОТ заказов ВНУТРЕННЕГО СОЕДИНЕНИЯ клиентов , либо ОТ клиентов ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ заказов .
Как мы обсуждали ранее, эти таблицы связаны на столбец customer_id в каждой таблице. Поэтому мы будем использовать ON , чтобы сообщить базе данных, что эти два столбца ссылаются на одно и то же, например:
.
ON orders.customer_ID = customers.customer_id
Мы снова используем . , чтобы убедиться, что база данных знает, в какой таблице находится каждый из этих столбцов. Поэтому, когда мы собираем все это вместе, мы получаем запрос, который выглядит следующим образом:
ВЫБЕРИТЕ orders.order_number, customers.name диапазон>ОТ заказов span>ВНУТРЕННЕЕ СОЕДИНЕНИЕ клиентов span>ON orders.customer_id = customers.customer_id
Этот запрос вернет номер каждого заказа в базе данных вместе с именем клиента, связанным с каждым.
Вернемся к нашей базе данных Hubway. Теперь мы можем написать несколько запросов, чтобы увидеть JOIN в действии.
Прежде чем мы начнем, мы должны взглянуть на остальные столбцы в таблице станций . Вот запрос, чтобы показать нам первые 5 строк, чтобы мы могли увидеть, как выглядит таблица станций :
запрос = ''' ВЫБРАТЬ * ОТ станций ИМИТ 5; '' un_query(запрос)
| идентификатор | станция | муниципалитет | широта | длинный | |
|---|---|---|---|---|---|
| 0 | 3 | Колледжи Фенуэя | Бостон | 42.340021 | -71.100812 |
| 1 | 4 | Тремонт-стрит на Беркли-стрит | Бостон | 42.345392 | -71.069616 |
| 2 | 5 | Северо-Восточный U / Северная парковка | Бостон | 42.341814 | -71.0 |
| 3 | 6 | Кембридж-стрит на Джой-стрит | Бостон | 42.361284999999995 | -71.06514 |
| 4 | 7 | Вентиляторный пирс | Бостон | 42. 353412 | -71.044624 |
-
id— Уникальный идентификатор для каждой станции (соответствуетстолбцы start_stationиend_stationв таблицеtrips) -
станция— Название станции -
муниципалитет— Муниципалитет, в котором находится станция (Бостон, Бруклин, Кембридж или Сомервилл) -
lat— Широта станции -
lng— Долгота станции - Какие станции чаще всего используются для поездок туда и обратно?
- Сколько поездок начинается и заканчивается в разных муниципалитетах?
Как и раньше, мы попытаемся ответить на некоторые вопросы в данных, начиная с , какая станция является наиболее частой отправной точкой? Давайте рассмотрим это шаг за шагом:
- Сначала мы хотим использовать
SELECTдля возврата столбцаstationиз таблицыstationиCOUNTколичества строк. - Затем мы указываем таблицы, к которым мы хотим
ПРИСОЕДИНИТЬСЯ, и говорим базе данных соединить ихONстолбецstart_stationв таблицеtripsи столбецidв таблицеstation. - Затем мы переходим к сути нашего запроса – мы
ГРУППИРУЕМ ПОстолбецстанцияв таблицестанций, чтобы нашCOUNTподсчитывал количество поездок для каждой станции отдельно - Наконец, мы можем
ORDER BYнашиCOUNTиLIMITвывод до управляемого количества результатов
запрос = ''' ВЫБЕРИТЕ station.station КАК "Станция", COUNT(*) КАК "Количество" ROM отключает станции INNER JOIN N trips.start_station = station.idGROUP BY station.stationORDER BY COUNT(*) DESC ИМИТ 5; '' un_query (запрос)
| Станция | Граф | |
|---|---|---|
| 0 | Южный вокзал – 700 Атлантик-авеню | 56123 |
| 1 | Бостонская публичная библиотека – 700 Boylston St. | 41994 |
| 2 | Чарльз Серкл — Чарльз-стрит на Кембридж-стрит | 35984 |
| 3 | Бикон-стрит / Масс-авеню | 35275 |
| 4 | Массачусетский технологический институт на Масс-авеню / Амхерст-стрит | 33644 |
Если вы знакомы с Бостоном, то поймете, почему это самые популярные станции. Южный вокзал — одна из главных станций пригородной железной дороги в городе, Чарльз-стрит проходит вдоль реки рядом с некоторыми красивыми живописными маршрутами, а улицы Бойлстон и Бикон проходят прямо в центре города, рядом с несколькими офисными зданиями.
Следующий вопрос, который мы рассмотрим, : какие станции чаще всего используются для поездок туда и обратно? Мы можем использовать тот же запрос, что и раньше. Мы будем SELECT те же выходные столбцы и JOIN таблицы таким же образом, но на этот раз мы добавим предложение WHERE , чтобы ограничить наш COUNT поездками, где start_station совпадает с конечная_станция .
запрос = '''ВЫБЕРИТЕ station.station AS "Станция", COUNT(*) AS "Count" ROM отключает станции INNER JOIN N trips.start_station = station.id ЗДЕСЬ trips.start_station = trips.end_station ГРУППИРОВАТЬ ПО станциям.станция ЗАКАЗАТЬ ПО СЧЕТУ(*) DESC ИМИТ 5; '' un_query(запрос)
| Станция | Граф | |
|---|---|---|
| 0 | Эспланада — Бикон-стрит на Арлингтон-стрит | 3064 |
| 1 | Чарльз Серкл — Чарльз-стрит на Кембридж-стрит | 2739 |
| 2 | Бостонская публичная библиотека – 700 Boylston St. | 2548 |
| 3 | Бойлстон-стрит на Арлингтон-стрит | 2163 |
| 4 | Бикон-стрит / Масс-авеню | 2144 |
Как мы видим, количество этих станций такое же, как и в предыдущем вопросе, но их количество намного меньше. Самые загруженные станции по-прежнему остаются самыми загруженными станциями, но в целом более низкие цифры говорят о том, что люди обычно используют велосипеды Hubway, чтобы добраться из точки А в точку Б, а не ездят на велосипеде некоторое время, прежде чем вернуться туда, где они начали.
Здесь есть одно существенное отличие — Эспланда, которая не была одной из самых загруженных станций по нашему первому запросу, оказывается самой загруженной для поездок туда и обратно. Почему? Что ж, картинка стоит тысячи слов. Это определенно похоже на хорошее место для велосипедной прогулки:
К следующему вопросу: сколько поездок начинается и заканчивается в разных муниципалитетах? Этот вопрос делает шаг вперед. Мы хотим знать, сколько поездок начинается и заканчивается в другом муниципалитете . Для этого нам нужно ПРИСОЕДИНИТЬСЯ к таблице trips к таблице станций дважды. Один раз ON столбец start_station , а затем ON столбец end_station .
Чтобы сделать это, мы должны создать псевдоним для таблицы station , чтобы мы могли различать данные, относящиеся к start_station , и данные, относящиеся к end_station . Мы можем сделать это точно так же, как мы создавали псевдонимы для отдельных столбцов, чтобы они отображались с более интуитивно понятным именем, используя AS .
Например, мы можем использовать следующий код для ПРИСОЕДИНЯЙСЯ к станциям в таблицу trips , используя псевдоним start. Затем мы можем объединить «начало» с именами наших столбцов, используя . для ссылки на данные, поступающие из этого конкретного JOIN (вместо второго JOIN мы будем делать ON в столбце end_station ):
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ станций КАК начать ВКЛ trips.start_station = start.id
Вот как будет выглядеть окончательный запрос, когда мы его запустим. Обратите внимание, что мы использовали <> для обозначения «не равно», но != тоже подойдет.
запрос = размах>''' ВЫБРАТЬ COUNT(trips.id) КАК "Count" ROM отключает станции INNER JOIN AS start N trips.
| Граф | |
|---|---|
| 0 | 309748 |
Это показывает, что около 300 000 из 1,5 миллиона поездок (или 20%) заканчивались в другом муниципалитете, чем они начинались, — еще одно свидетельство того, что люди в основном используют велосипеды Hubway для относительно коротких поездок, а не для длительных поездок между городами.
Если вы дошли до этого места, поздравляем! Вы начали осваивать основы SQL. Мы рассмотрели ряд важных команд: SELECT , LIMIT , WHERE , ORDER BY , GROUP BY и JOIN , а также агрегатные и арифметические функции. Это даст вам прочную основу для продолжения вашего пути к SQL.
Вы освоили основы SQL. Что теперь?
После изучения этого руководства по SQL для начинающих вы сможете выбрать интересующую вас базу данных и написать запросы для извлечения информации. Хорошим первым шагом может быть продолжение работы с базой данных Hubway, чтобы посмотреть, что еще вы можете узнать. Вот еще несколько вопросов, на которые вы, возможно, захотите ответить:
- За сколько поездок взимается дополнительная плата (длительностью более 30 минут)?
- Какой велосипед использовался дольше всего?
- Зарегистрированные или случайные пользователи совершили больше поездок туда и обратно?
- Какой муниципалитет имел самую большую среднюю продолжительность?
Если вы хотите пойти дальше, ознакомьтесь с нашими интерактивными курсами SQL, которые охватывают все, что вам нужно знать, от начального до продвинутого уровня SQL для работы аналитика данных и специалиста по данным.
Вы также можете прочитать наш пост об экспорте данных из ваших SQL-запросов в Pandas или ознакомиться с нашей памяткой по SQL и нашей статьей о сертификации SQL.
Изучайте SQL правильно!
- Написание реальных запросов
- Работа с реальными данными
- Прямо в браузере!
Зачем пассивно смотреть видеолекции, если можно учиться, делая ?
Зарегистрируйтесь и начните учиться!
SQLiteTutorials
Об авторе
Джеймс Коу
Профессиональный пенсионный аналитик, фотограф-любитель, спортивный фанат Бостона
Учебное пособие по SQL для начинающих.
Изучите основы SQL
Чему вы научитесь в этом учебном пособии?
Это учебное пособие по SQL для начинающих представляет собой полный набор инструментов для изучения SQL в Интернете. Из этого руководства вы получите четкое представление об основах SQL, о том, что такое язык структурированных запросов и как развертывать SQL для работы с реляционной базой данных.
Итак, язык структурированных запросов — это язык, который используется для работы с реляционными базами данных. Некоторые из основных способов использования SQL в сочетании с реляционной базой данных предназначены для хранения, извлечения и управления данными, хранящимися в реляционной базе данных.
Посетите блог Intellipaat, чтобы получить полное представление о методах оптимизации SQL !
Вот список тем, если вы хотите сразу перейти к конкретной:
- Что такое SQL?
- Зачем нужен SQL?
- Почему так широко используется программирование на SQL?
- Возможности SQL
- Приложения SQL
- Процесс SQL
- Синтаксис SQL
- Что можно делать с SQL?
- Фильтрация данных SQL
- Почему вам следует изучать SQL онлайн?
- Агрегированные функции
- Рекомендуемая аудитория
- Предпосылки
Посмотрите это видео об обучении MS SQL для начинающих
Что такое SQL?
Язык структурированных запросов, или SQL, — это язык, который помогает управлять базами данных. Он помогает создавать данные, работать с ними и извлекать их. Это также стандартный язык, используемый в системах реляционных баз данных. Различные системы реляционных баз данных, такие как MySQL, Sybase, Oracle, MS Access, Postgres, Infomix, SQL Server и т. д. используют SQL в качестве базового языка.
Чтобы узнать, что такое SQL, сначала давайте сравним SQL с NoSQL в таблице ниже:
| Критерии сравнения | SQL | NoSQL |
| Тип базы данных | Родственный | Нереляционный |
| Как хранятся данные? | Структурированные данные в таблицах | Неструктурированные данные в файлах JSON |
| Подходит для систем OLTP | Отлично | Средний |
| Соответствие базе данных | свойства КИСЛОТЫ | Теорема CAP |
Языком для связи с реляционной базой данных является SQL или язык структурированных запросов. Программирование на языке SQL помогает управлять реляционной базой данных и извлекать из нее информацию.
Некоторые из операций, которые включает SQL, — это создание базы данных, выборка, изменение, обновление и удаление строк, а также сохранение, обработка и извлечение данных в реляционной базе данных. Программирование SQL — это стандартный язык ANSI, но также используется множество версий SQL.
Зачем нужен SQL?
SQL требуется, потому что он предлагает следующие преимущества для пользователей:
- SQL помогает в создании новых баз данных, представлений и таблиц.
- Используется для вставки, обновления, удаления и извлечения записей данных в базе данных.
- Позволяет пользователям взаимодействовать с данными, хранящимися в системах управления реляционными базами данных.
- SQL требуется для создания представлений, хранимых процедур и функций в базе данных.
Изучите все тонкости MySQL с помощью нашего подробного руководства по MySQL. Начните осваивать управление базами данных сегодня и сделайте первый шаг к тому, чтобы стать профессионалом!
Почему так широко используется программирование на SQL?
Программирование на языке структурированных запросов так широко используется по следующим причинам.
- SQL позволяет получить доступ к любым данным в реляционной базе данных
- Вы можете описать данные в базе данных с помощью SQL
- С помощью SQL вы можете манипулировать данными с реляционной базой данных
- SQL может быть встроен в другие языки с помощью модулей и библиотек SQL
- SQL позволяет легко создавать и удалять базы данных и таблицы
- SQL позволяет создавать представления, функции и хранимые процедуры в базах данных
- Используя SQL, вы можете устанавливать разрешения для процедур, таблиц и представлений.
Хотите пройти собеседование по SQL? Топ-9 Intellipaat2035 Вопросы для интервью по SQL предназначены только для вас!
Возможности SQL
Здесь, в этом разделе руководства по MS SQL для начинающих, мы перечисляем некоторые основные возможности SQL, которые делают его таким вездесущим, когда речь идет об управлении реляционными базами данных.
- SQL очень простой и легкий для изучения язык.
- SQL универсален, поскольку работает с системами баз данных Oracle, IBM, Microsoft и т. д.
- SQL — это стандартный язык ANSI и ISO для создания баз данных и управления ими.
- SQL имеет четко определенную структуру, поскольку использует давно установленные стандарты
- SQL очень быстро и эффективно извлекает большие объемы данных.
- SQL позволяет вам управлять базами данных, не зная большого количества кода.
Ознакомьтесь с нашими сертификационными курсами по базам данных, чтобы получить профессиональную подготовку.
Приложения SQL
В этом разделе учебника Advanced SQL мы узнаем о приложениях SQL, которые делают его столь важным в мире, управляемом данными, где управление огромными базами данных является нормой дня.
- SQL используется в качестве языка определения данных (DDL), что означает, что вы можете самостоятельно создать базу данных, определить ее структуру, использовать ее, а затем отказаться от нее, когда вы закончите с ней
- Он также используется в качестве языка манипулирования данными (DML), что означает, что вы можете использовать его для обслуживания уже существующей базы данных. SQL — это мощный язык для ввода данных, изменения данных и извлечения данных из базы данных 9.0046
- Он также развернут как язык управления данными (DCL), который указывает, как вы можете защитить свою базу данных от повреждения и неправильного использования.
- Он широко используется в качестве языка клиент/сервер для соединения внешнего интерфейса с внутренним, таким образом поддерживая архитектуру клиент/сервер
- Его также можно использовать в трехуровневой архитектуре клиента, сервера приложений и базы данных, которая определяет архитектуру Интернета.
Хотите узнать больше о SQL? Вот онлайн-обучение Microsoft SQL, предоставленное Intellipaat.
Процесс SQL
Когда вы запускаете команду SQL для любой РСУБД, система определяет лучший способ выполнить ваш запрос, а механизм SQL определяет, как его интерпретировать.
Эта процедура состоит из нескольких компонентов. Диспетчер запросов, механизмы оптимизации, классический механизм запросов и механизм запросов SQL — вот некоторые из этих элементов. Запросы, отличные от SQL, обрабатываются классическим механизмом запросов, но логические файлы не обрабатываются механизмом запросов SQL.
Синтаксис SQL
Синтаксис представляет собой набор правил и указаний, которых придерживается SQL. Поскольку SQL нечувствителен к регистру, термины SELECT и select в операторах SQL имеют тот же смысл. MySQL, с другой стороны, различает имена таблиц. Если вы используете MySQL, вам нужно указать имена таблиц точно так, как они появляются в базе данных.
Различные ключевые слова SQL:
- INSERT
- ОБНОВЛЕНИЕ
- УДАЛИТЬ
- ИЗМЕНИТЬ
- СБРОС
- СОЗДАТЬ
- ЕГЭ и т. д.
Что можно делать с SQL?
С помощью SQL мы можем создавать, обновлять, реорганизовывать и изменять данные. Мы можем решать проблемы с электронными таблицами, например, в Microsoft Excel мы можем компилировать много данных, потому что SQL предназначен для компиляции и обработки данных в гораздо больших количествах. С помощью SQL Server мы можем преобразовывать необработанные данные в осмысленные идеи, а также выполнять операции бизнес-аналитики. Интеграция данных и операции ETL легко выполняются с помощью SQL.
Фильтрация данных SQL
SQL имеет возможность фильтровать данные в базе данных, то есть мы можем выбирать только необходимые записи из набора данных. Фильтр представляет собой предложение SQL WHERE, которое указывает набор сравнений, которые должны быть истинными, чтобы элемент данных возвращался для базы данных SQL и внутренних типов данных. Обычно эти различия делаются между именами полей и их значениями.
Остались вопросы? Приходите в Intellipaat’s SQL Community развейте все свои сомнения и преуспейте в своей карьере!
Получите 100% повышение!
Овладейте самыми востребованными навыками прямо сейчас!
Почему вам следует изучать SQL онлайн?
Сегодня, вне зависимости от систем реляционных баз данных крупных корпораций, таких как Oracle, IBM, Microsoft и других, их объединяет только язык структурированных запросов или SQL.
Итак, если вы освоите SQL в Интернете, вы сможете сделать очень широкую карьеру, охватывающую множество ролей и обязанностей. Кроме того, если вы изучаете SQL, то это также важно для карьеры в области науки о данных, поскольку специалисту по данным также придется иметь дело с реляционными базами данных и запрашивать их, используя стандартный язык SQL.
Агрегирующие функции
Агрегирующая функция в управлении базами данных — это функция, которая группирует значения нескольких строк в качестве входных данных для определенных параметров для создания единого значения, имеющего более важное значение.
Различные агрегатные функции
COUNT – подсчитывается количество элементов в данной группе
SUM – вычисляется общее количество данного атрибута/выражения в указанной категории
AVG – вычисляется среднее значение данного атрибута/выражения в фиксированной категории
MIN — находит наименьшее значение в наборе чисел.
MAX — возвращает наибольшее значение в определенной группе. Разработчики программного обеспечения, администраторы баз данных, архитекторы и менеджеры могут воспользоваться этим бесплатным учебным пособием в качестве первого шага к изучению SQL и преуспеть в своей карьере.
Предварительные условия
Нет предварительных условий для изучения SQL с помощью этого SQL для начинающих. Если у вас есть базовые знания компьютерных языков и баз данных, это будет полезно.
Часто задаваемые вопросы
Как быстро выучить SQL?
Ответ на этот вопрос полностью зависит от знаний учащегося в области программирования. Если учащийся знаком с базовыми навыками программирования, он может освоить основы SQL за несколько дней. Однако, чтобы овладеть продвинутыми навыками SQL, учащиеся должны пройти онлайн-обучение SQL под руководством инструктора. Это обучение длится до 4 недель.
Как я могу попрактиковаться в SQL бесплатно?
Этот учебник по базе данных SQL поможет вам всесторонне понять концепции SQL. Вы также можете обратиться к нашему бесплатному видеоруководству по SQL на YouTube.
Легко ли выучить SQL для начинающих?
Да, с помощью этого руководства легко выучить SQL, поскольку сам по себе он не является языком программирования; скорее это язык запросов. Большинство синтаксисов SQL похожи на английский язык, и поэтому почти каждый, кто понимает английский, может с легкостью писать запросы SQL.
Как я могу изучать SQL дома?
Вы можете изучить основы SQL, обратившись к этому учебному пособию по основам SQL или бесплатным видеоруководствам по SQL на YouTube или записавшись к нам на онлайн-обучение SQL.
Почему SQL такой мощный?
SQL является мощным, поскольку это основной язык, который используется для управления большими базами данных в организациях. Соединения в SQL позволяют пользователям получать данные из нескольких источников и сравнивать их для внесения необходимых изменений. SQL позволяет персоналу баз данных управлять базами данных с минимальными усилиями.
Для чего используется SQL?
Основные области применения SQL включают написание сценариев интеграции данных, установку и выполнение аналитических запросов, извлечение подмножеств информации из базы данных для аналитических приложений и обработки транзакций, а также добавление, обновление и удаление строк и столбцов данных в базе данных.
Стоит ли изучать SQL?
SQL — самый популярный язык баз данных в мире информационных технологий, поэтому его стоит изучить. С обширными приложениями в различных вертикалях SQL может помочь вам построить прибыльную карьеру в области управления базами данных.
Сколько существует типов SQL?
Существует несколько типов операторов SQL. Это:
- Язык определения данных (DDL)
- Язык обработки данных (DML)
- Язык управления данными (DCL)
- Заявления об управлении транзакциями (TCS)
- Операторы управления сеансом (SCS)
Расписание курсов
Изучение SQL за 7 дней
Ричард Петерсон
часов
Обновлено
Краткий обзор учебника по SQL
Базы данных можно найти почти во всех программных приложениях. SQL — это стандартный язык для запросов к базе данных. Этот учебник по SQL для начинающих научит вас проектировать базы данных. Кроме того, он учит вас базовому и продвинутому SQL.
Что я должен знать?
Курс предназначен для начинающих пользователей SQL. Опыт работы с БД не требуется.
Программа SQL
Основы баз данных
| 👉 Урок 1 | Что такое база данных? — определение, значение, типы, пример |
| 👉 Урок 2 | Что такое SQL? — Изучите основы SQL, полную форму SQL и как использовать |
| 👉 Урок 3 | Учебное пособие по MySQL Workbench для начинающих — Как установить и использовать MySQL Workbench |
Проектирование баз данных
| 👉 Урок 1 | Учебное пособие по проектированию баз данных — Изучение моделирования данных |
| 👉 Урок 2 | Что такое нормализация? — Пример базы данных 1NF, 2NF, 3NF, BCNF |
| 👉 Урок 3 | Что такое ER-моделирование? — Учитесь на примере |
Основы SQL
| 👉 Урок 1 | Создание таблицы MySQL — Как создать базу данных в MySQL |
| 👉 Урок 2 | Инструкция MySQL SELECT — изучите пример |
| 👉 Урок 3 | MySQL WHERE Пункт — AND, OR, IN, NOT IN Пример запроса |
| 👉 Урок 4 | MySQL INSERT INTO Query — Как добавить строку в таблицу (пример) |
| 👉 Урок 5 | MySQL DELETE Query — Как удалить строку из таблицы |
| 👉 Урок 6 | MySQL UPDATE Query — Изучите пример |
Сортировка данных
| 👉 Урок 1 | ORDER BY в MySQL — Запрос DESC и ASC с ПРИМЕРОМ |
| 👉 Урок 2 | SQL GROUP BY и HAVING Пункт — изучите пример |
| 👉 Урок 3 | Учебное пособие по подстановочным знакам MySQL — Нравится, НЕ нравится, Escape, (%), (_) |
| 👉 Урок 4 | Регулярные выражения MYSQL (REGEXP) — Что такое, синтаксис и примеры |
Функции
| 👉 Урок 1 | Функции MySQL — строковые, числовые, пользовательские, сохраненные |
| 👉 Урок 2 | Учебное пособие по агрегатным функциям MySQL, часть — СУММА, СРЕДНЯЯ, МАКСИМАЛЬНАЯ, МИНИМАЛЬНАЯ, СЧЕТЧИКА, РАЗЛИЧНЫЕ |
Должен знать!
| 👉 Урок 1 | MySQL IS NULL & IS NOT NULL Tutorial — Изучите пример |
| 👉 Урок 2 | MySQL AUTO_INCREMENT — Изучите пример |
| 👉 Урок 3 | MYSQL — ALTER, DROP, RENAME, MODIFY — что такое, синтаксис с примерами |
| 👉 Урок 4 | MySQL LIMIT & OFFSET — изучите пример |
Самые страшные темы!
| 👉 Урок 1 | Учебное пособие по подзапросам MySQL — обучение на примере |
| 👉 Урок 2 | MySQL JOINS Tutorial — ВНУТРЕННЯЯ, ВНЕШНЯЯ, ЛЕВАЯ, ПРАВАЯ, ПЕРЕКРЕСТНАЯ |
| 👉 Урок 3 | MySQL UNION — Полное руководство |
| 👉 Урок 4 | Представления MySQL — Как создать представление из таблиц с примерами |
| 👉 Урок 5 | Учебное пособие по индексу MySQL — создание, добавление и удаление |
Что дальше!
| 👉 Урок 1 | Ваше первое приложение с использованием MySQL и PHP — Приступаем к работе! |
| 👉 Урок 2 | Сертификация Oracle MySQL 5. 6 — Учебное пособие по Oracle MySQL 5.6 |
| 👉 Урок 3 | SQL против MySQL — в чем разница между SQL и MySQL? |
| 👉 Урок 4 | Лучшие инструменты SQL — 25 лучших инструментов SQL, ПО для баз данных и IDE |
| 👉 Урок 5 | Построители и редакторы SQL-запросов — 10 лучших конструкторов и редакторов SQL-запросов |
| 👉 Урок 6 | Онлайн-компилятор и редакторы SQL — 10 ЛУЧШИХ онлайн-компиляторов и редакторов SQL |
| 👉 Урок 7 | Бесплатные курсы SQL — 11 лучших бесплатных курсов SQL и сертификация |
| 👉 Урок 8 | Книги по SQL — 14 лучших книг по SQL для начинающих и экспертов |
| 👉 Урок 9 | Памятка по SQL — Памятка по командам SQL |
| 👉 Урок 10 | Вопросы для собеседования по SQL — Топ 50 вопросов и ответов для собеседования по SQL |
| 👉 Урок 11 | Учебное пособие по SQL в формате PDF — Загрузить учебное пособие по SQL в формате PDF для начинающих |
MariaDB
| 👉 Урок 1 | Учебное пособие по MariaDB — Изучение синтаксиса, команды с примерами |
| 👉 Урок 2 | MariaDB против MySQL — в чем разница между MariaDB и MySQL |
Что такое СУБД?
Система управления базами данных (СУБД) — это программное обеспечение, используемое для хранения и управления данными. Это гарантирует качество, долговечность и конфиденциальность информации. Наиболее популярным типом СУБД являются системы управления реляционными базами данных или РСУБД. Здесь база данных состоит из структурированного набора таблиц, и каждая строка таблицы является записью.
Что такое SQL?
Язык структурированных запросов (SQL) — это стандартный язык для обработки данных в СУБД. Проще говоря, он используется для общения с данными в СУБД. Ниже приведены типы операторов SQL
- Язык определения данных (DDL) позволяет создавать такие объекты, как схемы, таблицы в базе данных
- Язык управления данными (DCL) позволяет управлять правами доступа к объектам базы данных
- Язык манипулирования данными (DML) используется для поиска, вставки, обновления и удаления данных, которые будут частично рассмотрены в этом руководстве по SQL.
Что такое запрос?
Запрос — это набор инструкций, отдаваемых системе управления базой данных. Он сообщает любой базе данных, какую информацию вы хотели бы получить из базы данных. Например, чтобы получить имя студента из таблицы базы данных STUDENT, вы можете написать SQL-запрос следующим образом:
SELECT Student_name from STUDENT;
Процесс SQL
Если вы хотите выполнить команду SQL для какой-либо системы СУБД, вам необходимо найти наилучший метод для выполнения вашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важные компоненты, включенные в этот процесс SQL:
- SQL Query Engine
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет управлять всеми запросами, отличными от SQL.
Процесс SQL
Оптимизация SQL
Знать, как делать запросы, не так уж сложно, но вам нужно действительно изучить и понять, как работает хранилище данных и как читаются запросы, чтобы оптимизировать производительность SQL. Оптимизация основана на двух ключевых факторах:
- Правильный выбор при определении структуры базы данных
- Применение наиболее подходящих методов для чтения данных.
Чему вы научитесь на этом курсе SQL?
Этот учебник по основам SQL предназначен для всех, кто планирует работать с базами данных, особенно в роли системных администраторов и разработчиков приложений. Учебники помогают новичкам изучить основные команды SQL, включая SELECT, INSERT INTO, UPDATE, DELETE FROM и другие. Каждая команда SQL поставляется с четкими и краткими примерами.
В дополнение к списку команд SQL в учебнике представлены карточки с функциями SQL, такими как AVG(), COUNT() и MAX(). Наряду с этим тесты помогают проверить ваши базовые знания языка.
Этот курс SQL поможет вам разобраться с различными аспектами языка программирования SQL.
Зачем вам изучать SQL?
SQL — это простой в освоении язык, специально разработанный для работы с базами данных. Растет спрос на специалистов, умеющих работать с базами данных. Почти каждая крупная компания использует SQL. Он широко используется в различных секторах, таких как бронирование билетов, банковское дело, платформы социальных сетей, обмен данными, электронная коммерция и т. д., поэтому для разработчика SQL доступны огромные возможности.
Что такое SQL? Изучите основы SQL, полную форму SQL и как использовать
Ричард Петерсон
Часы
Обновлено
Что такое SQL?
SQL — это стандартный язык для работы с реляционными базами данных. SQL можно использовать для вставки, поиска, обновления и удаления записей базы данных. SQL может выполнять множество других операций, включая оптимизацию и обслуживание баз данных.
Полная форма SQL
SQL означает язык структурированных запросов, произносится как «S-Q-L» или иногда как «See-Quel»… Реляционные базы данных, такие как MySQL Database, Oracle, MS SQL Server, Sybase и т. д., используют ANSI SQL.
Что такое SQL?
Как использовать SQL
Пример кода SQL:
SELECT * FROM Members WHERE Возраст > 30
Синтаксисы SQL, используемые в разных базах данных, почти одинаковы, хотя немногие СУБД используют несколько разных команд и даже проприетарные синтаксисы SQL.
Нажмите здесь, если видео недоступно
Для чего используется SQL?
Вот важные причины для использования SQL
- Это помогает пользователям получать доступ к данным в системе СУБД.
- Это поможет вам описать данные.
- Это позволяет вам определять данные в базе данных и управлять этими конкретными данными.
- С помощью SQL вы можете создавать и удалять базы данных и таблицы.
- SQL предлагает вам использовать функцию в базе данных, создать представление и хранимую процедуру.
- Вы можете установить разрешения для таблиц, процедур и представлений.
Краткая история SQL
Вот важные вехи из истории SQL:
- 1970 — доктор Эдгар Ф. «Тед» Кодд описал реляционную модель для баз данных.
- 1974 — Появился язык структурированных запросов.
- 1978 — IBM выпустила продукт под названием System/R.
- 1986 — IBM разработала прототип реляционной базы данных, которая стандартизирована ANSI.
- 1989 г. — выпущена первая версия SQL
- 1999 г. — запущен SQL 3 с такими функциями, как триггеры, объектная ориентация и т. д.
- SQL 2003 — оконные функции, функции, связанные с XML, и т. д.
- SQL 2006 — поддержка языка запросов XML
- SQL 2011 — улучшенная поддержка временных баз данных
.
Типы операторов SQL
Вот пять типов широко используемых запросов SQL.
- Язык определения данных (DDL)
- Язык обработки данных (DML)
- Язык управления данными (DCL)
- Язык управления транзакциями (TCL)
- Язык запросов данных (DQL)
Список команд SQL
Вот список некоторых наиболее часто используемых команд SQL :
- CREATE — определяет схему структуры базы данных
- INSERT — вставляет данные в строку таблицы
- ОБНОВЛЕНИЕ — обновляет данные в базе данных
- DELETE — удаляет одну или несколько строк из таблицы
- SELECT — выбирает атрибут на основе условия, описанного в предложении WHERE
- DROP — удаляет таблицы и базы данных
.
Процесс SQL
Если вы хотите выполнить команду SQL для какой-либо системы СУБД, вам нужно найти наилучший метод для выполнения вашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную задачу.
Важные компоненты, включенные в этот процесс SQL:
- SQL Query Engine
- Механизмы оптимизации
- Диспетчер запросов
- Классический механизм запросов
Классический механизм запросов позволяет вам управлять всеми запросами, отличными от SQL.
SQL Process
Стандарты SQL
SQL — это язык для работы с базами данных. Он включает в себя создание базы данных, удаление, выборку строк, изменение строк и т. д. SQL — это стандартный язык ANSI (Американский национальный институт стандартов). Стандарты SQL разделены на несколько частей.
Вот некоторые важные части стандартов SQL:
| Часть | Описание |
|---|---|
| Часть 1 — SQL/Framework | Предлагает логические концепции. |
| Часть 2 — SQL/Основа | Он включает в себя основные элементы SQL. |
| Часть 3 — SQL/CLI | Этот стандарт включает основные элементы SQL. |
| Часть 4. Постоянно сохраняемые модули | Сохраненные подпрограммы, внешние подпрограммы и расширения процедурного языка для SQL. |
| Часть 9. Управление внешними данными | Добавляет синтаксис и определения в SQL/Foundation, которые разрешают доступ SQL к источникам данных, отличным от SQL (файлам). |
| Часть 10. Привязки объектного языка | Связи объектного языка: Эта часть определяет синтаксис и семантику внедрения SQL в Java™. |
| Часть 11 — SQL/схема | Схемы информации и определений |
| Часть 12 — SQL/Репликация | Этот проект начался в 2000 году. Эта часть помогает определить синтаксис и семантику, позволяющие определить схемы и правила репликации. |
| Часть 13 – Подпрограммы Java и тип | Подпрограммы и типы Java: эта часть подпрограмм, использующая язык программирования Java. |
| Часть 14 — SQL/XML | SQL и XML |
| Часть 15 — SQL/MDA | Обеспечение поддержки SQL для многомерных массивов |
Элементы языка SQL
Вот важные элементы языка SQL:
- Ключевые слова: Каждое выражение SQL содержит одно или несколько ключевых слов.
- Идентификаторы: Идентификаторы — это имена объектов в базе данных, таких как идентификаторы пользователей, таблицы и столбцы.
- Строки: Строки могут быть литеральными строками или выражениями с типами данных VARCHAR или CHAR.
- Выражения: Выражения формируются из нескольких элементов, таких как константы, операторы SQL, имена столбцов и подзапросы.
- Условия поиска: Условия используются для выбора подмножества строк из таблицы или используются для управляющих операторов, таких как оператор IF, для определения управления потоком.
- Специальные значения: Специальные значения следует использовать в выражениях и в качестве значений по умолчанию для столбцов при построении таблиц.
- Переменные: Sybase IQ поддерживает локальные переменные, глобальные переменные и переменные уровня соединения.
- Комментарии: Комментарий — это еще один элемент SQL, который используется для присоединения пояснительного текста к операторам SQL или блокам операторов. Сервер базы данных не выполняет никаких комментариев.
- Значение NULL: Используйте значение NULL, которое помогает указать неизвестное, отсутствующее или неприменимо значение.
Что такое база данных в SQL?
База данных состоит из набора таблиц, в которых хранится подробный набор структурированных данных. Это таблица, содержащая набор строк, называемых записями или кортежами, и столбцы, также называемые атрибутами.
Каждый столбец в таблице предназначен для хранения определенного типа информации, например, имен, дат, сумм в долларах и чисел.
Что такое NoSQL?
NoSQL — новая категория систем управления базами данных. Его основной характеристикой является несоблюдение концепций реляционных баз данных. NoSQL означает «Не только SQL». Концепция баз данных NoSQL выросла вместе с интернет-гигантами, такими как Google, Facebook, Amazon и т. д., которые имеют дело с гигантскими объемами данных.
Когда вы используете реляционную базу данных для больших объемов данных, система начинает замедляться с точки зрения времени отклика. Чтобы преодолеть это, мы могли бы «расширить» наши системы, обновив существующее оборудование. Альтернативой вышеуказанной проблеме было бы распределение нагрузки нашей базы данных на несколько хостов по мере увеличения нагрузки. Это известно как «масштабирование».
База данных NoSQL — это нереляционные базы данных , которые масштабируются лучше, чем реляционные базы данных, и разработаны с учетом веб-приложений. Они не используют SQL для запроса данных и не следуют строгим схемам, таким как реляционные модели. При использовании NoSQL функции ACID (атомарность, согласованность, изоляция, долговечность) не всегда гарантируются.
Почему имеет смысл изучать SQL после NoSQL?
Описывая преимущества баз данных NoSQL, которые масштабируются лучше, чем реляционные модели, вы можете подумать , зачем кому-то все еще хотеть узнать о базе данных SQL? Что ж, базы данных NoSQL являются узкоспециализированными системами и имеют свои особенности использования и ограничения. NoSQL больше подходит для тех, кто работает с огромными объемами данных. Подавляющее большинство используют реляционные базы данных и связанные с ними инструменты.
Реляционные базы данных имеют следующие преимущества перед базами данных NoSQL.
- Базы данных SQL (реляционные) имеют зрелую модель хранения данных и управления. Это очень важно для корпоративных пользователей.
- База данных SQL поддерживает понятие представлений, которые позволяют пользователям видеть только те данные, на просмотр которых у них есть права. Данные, которые им не разрешено просматривать, скрыты от них.
- SQL поддерживают хранимую процедуру SQL, которая позволяет разработчикам баз данных реализовывать часть бизнес-логики в базе данных.
- Базы данных SQL имеют лучшие модели безопасности по сравнению с базами данных NoSQL.
Базы данных
Мир не отказался от использования реляционных баз данных. Существует растущий спрос на специалистов, умеющих работать с реляционными базами данных. Таким образом, изучение баз данных и основ SQL по-прежнему заслуживает внимания.
Лучшая книга для изучения SQL
Вот пять лучших книг по SQL:
- Учебное пособие по SQL для начинающих
такие темы, как объединение SQL, создание, добавление и удаление таблицы и т. д. КУПИТЬ - SQL за 10 минут:
Эта книга по SQL предлагает полноцветные примеры кода, которые помогут вам понять, как устроены операторы SQL. Вы также получите знания о ярлыках и решениях. КУПИТЬ - SQL Cookbook: В этой книге по SQL вы сможете изучить технику обхода строки, позволяющую использовать SQL для разбора символов, слов или элементов строки с разделителями. КУПИТЬ
- SQL: полный справочник Эта книга включает важные темы Microsoft SQL, такие как функции окна, преобразование строк в столбцы, обратное преобразование столбцов в строки. КУПИТЬ
- Карманное руководство по SQL: руководство по использованию SQL В книге рассказывается, как системы используют функции SQL, синтаксис регулярных выражений и функции преобразования типов. КУПИТЬ
Дополнительные книги по SQL — Щелкните здесь
Резюме/Ключевые выводы
- Язык SQL используется для запросов к базе данных
- Что означает SQL или SQL означает: язык структурированных запросов
- SQL Используется для:
- Система СУБД
- Описывать, определять и управлять данными
- Создание и удаление баз данных и таблицы
- Типы операторов SQL: DDL, DML, DCL, TCL, DQL
- Список команд SQL: CREATE, INSERT, UPDATE, DELETE, SELECT, DROP
- Элементы языка SQL: ключевые слова, идентификаторы, строки, выражения, переменные и т. д.
- NoSQL: означает, что «Не только SQL» относится к будущей категории систем управления базами данных
- Подход к базе данных имеет много преимуществ, когда речь идет о хранении данных по сравнению с традиционными системами на основе плоских файлов
.
Учебное пособие по SQL — javatpoint
следующий → Учебное пособие по SQL содержит базовые и расширенные концепции SQL. Наш учебник по SQL предназначен как для начинающих, так и для профессионалов. SQL (язык структурированных запросов) используется для выполнения операций с записями, хранящимися в базе данных, таких как обновление записей, вставка записей, удаление записей, создание и изменение таблиц базы данных, представлений и т. д. SQL — это не система баз данных, а язык запросов. Предположим, вы хотите выполнять запросы языка SQL к сохраненным данным в базе данных. В ваших системах требуется установить любую систему управления базами данных, например, Oracle, MySQL, MongoDB, PostgreSQL, SQL Server, DB2 и т. Что такое SQL?SQL — это краткая форма языка структурированных запросов, произносимая как S-Q-L или иногда как See-Quell. Этот язык базы данных в основном предназначен для обслуживания данных в системах управления реляционными базами данных. Это специальный инструмент, используемый специалистами по данным для обработки структурированных данных (данных, которые хранятся в виде таблиц). Он также предназначен для потоковой обработки в RDSMS. Вы можете легко создавать базу данных и управлять ею, получать доступ и изменять строки и столбцы таблицы и т. д. Этот язык запросов стал стандартом ANSI в 1986 году и ISO в 1987 году. Если вы хотите получить работу в области науки о данных, то это самый важный язык запросов для изучения. Крупные предприятия, такие как Facebook, Instagram и LinkedIn, используют SQL для хранения данных в серверной части. Почему SQL? В настоящее время SQL широко используется в науке о данных и аналитике.
История SQL «Реляционная модель данных для больших общих банков данных» — статья, опубликованная великим ученым-компьютерщиком Э. Исследователи IBM Рэймонд Бойс и Дональд Чемберлин первоначально разработали SEQUEL (язык структурированных английских запросов) после изучения статьи, предоставленной Э. Ф. Коддом. Они оба разработали SQL в исследовательской лаборатории корпорации IBM в Сан-Хосе в 1919 году.70. В конце 1970-х компания Relational Software Inc. разработала свой первый SQL, используя концепции Э. Ф. Кодда, Рэймонда Бойса и Дональда Чемберлина. Этот SQL был полностью основан на СУБД. Relational Software Inc., известная сейчас как Oracle Corporation, представила Oracle V2 в июне 1979 года, которая является первой реализацией языка SQL. Эта версия Oracle V2 работает на компьютерах VAX. Процесс SQLКогда мы выполняем команду SQL в любой системе управления реляционной базой данных, система автоматически находит наилучшую процедуру для выполнения нашего запроса, а механизм SQL определяет, как интерпретировать эту конкретную команду. Язык структурированных запросов содержит в своем процессе следующие четыре компонента:
Классический механизм запросов позволяет специалистам по данным и пользователям выполнять запросы, отличные от SQL. Архитектура SQL показана на следующей диаграмме: Некоторые команды SQLКоманды SQL помогают в создании базы данных и управлении ею. Наиболее часто используемые команды SQL перечислены ниже:
Команда СОЗДАТЬЭта команда помогает создать новую базу данных, новую таблицу, табличное представление и другие объекты базы данных. Команда ОБНОВЛЕНИЯЭта команда помогает обновить или изменить сохраненные данные в базе данных. Команда УДАЛИТЬЭта команда помогает удалить или стереть сохраненные записи из таблиц базы данных. Он стирает один или несколько кортежей из таблиц базы данных. Команда ВЫБОР Эта команда помогает получить доступ к одной или нескольким строкам из одной или нескольких таблиц базы данных. Команда DROPЭта команда помогает удалить всю таблицу, табличное представление и другие объекты из базы данных. Команда ВСТАВИТЬЭта команда помогает вставлять данные или записи в таблицы базы данных. Мы можем легко вставлять записи как в одну, так и в несколько строк таблицы. SQL противбез SQL В следующей таблице описаны различия между SQL и NoSQL, которые необходимо понимать:
Преимущества SQLSQL предоставляет различные преимущества, которые делают его более популярным в области науки о данных. Это идеальный язык запросов, который позволяет специалистам по данным и пользователям общаться с базой данных. Ниже приведены лучшие преимущества языка структурированных запросов: . 1. Программирование не требуется SQL не требует большого количества строк кода для управления системами баз данных. 2. Высокоскоростная обработка запросов Быстрый и эффективный доступ к большому объему данных из базы данных с помощью запросов SQL. Операции вставки, удаления и обновления данных также выполняются за меньшее время. 3. Стандартизированный язык SQL соответствует давно установленным стандартам ISO и ANSI, которые предлагают единую платформу по всему миру для всех своих пользователей. 4. Мобильность Язык структурированных запросов можно легко использовать на настольных компьютерах, ноутбуках, планшетах и даже смартфонах. Его также можно использовать с другими приложениями в соответствии с требованиями пользователя. 5. Интерактивный язык Мы можем легко выучить и понять язык SQL. 6. Более одного просмотра данных Язык SQL также помогает создавать несколько представлений структуры базы данных для разных пользователей базы данных. Недостатки SQLПомимо преимуществ SQL, он также имеет некоторые недостатки, а именно: 1. Стоимость Стоимость эксплуатации некоторых версий SQL высока. Вот почему некоторые программисты не могут использовать язык структурированных запросов. 2. Сложный интерфейс Другим большим недостатком является сложность интерфейса языка структурированных запросов, что затрудняет использование и управление пользователями SQL. 3. Частичное управление базой данных Бизнес-правила скрыты. Таким образом, специалисты по данным и пользователи, использующие этот язык запросов, не могут иметь полный контроль над базой данных. Следующая темаСинтаксис SQL следующий → |
Определение SQL
Введение
В этой статье мы дадим определение SQL и объясним, что это такое, а также поговорим о
Расширения SQL. Мы также приведем несколько примеров синтаксиса SQL.
Определение SQL
По сути, SQL означает язык структурированных запросов , который в основном является языком, используемым базами данных. Этот язык позволяет обрабатывать информацию с помощью таблиц и показывает язык для запросов к этим таблицам и другим связанным объектам (представлениям, функциям, процедурам и т. д.). Большинство баз данных, таких как SQL Server, Oracle, PostgreSQL, MySQL, MariaDB, используют этот язык (с некоторыми расширениями и вариациями) для обработки данных.
С помощью SQL вы можете вставлять, удалять и обновлять данные. Вы также можете создавать, удалять или изменять объекты базы данных.
Кто изобрел SQL?
Эдгар Фрэнк Кодд, работавший в IBM, изобрел реляционную базу данных в 70-х годах. На основе этой работы Дональд
Чемберлин и Рэймонд Бойс разработали SQL для управления данными. Первоначально он назывался SEQUEL, но из-за торговой марки
проблема, он был изменен на SQL. Тем не менее, многие люди все еще говорят SEQUEL.
Определение ANSI SQL и определение ISO SQL
Американский национальный институт стандартов (ANSI) сделал SQL стандартом в 1986 году, а Международный
Организация по стандартизации (ISO) делает SQL стандартом базы данных. Теперь все самые популярные базы данных следуют этим стандартам с некоторыми расширениями. Определение SQL — это язык для определения объектов базы данных и управления данными.
Было несколько изменений для определения того, каким будет SQL, включая типы данных, уровни изоляции, логические операторы,
синтаксис, синтаксис языка определения данных, определения языка обработки данных, процедуры, функции и т. д.
Названия ревизий содержат год, когда она была сделана. Вот вам ревизии:
- SQL 86
- SQL 89
- SQL 92
- SQL 99
- SQL 2003
- SQL 2006
- SQL 2008
- SQL 2011
- SQL 2016
Синтаксис определения SQL
Допустим, у нас есть небольшая таблица с именем студентов и некоторыми данными:
ИДЕНТИФИКАТОР | Имя | Фамилия |
1 | Джон | Рэмбо |
2 | Люк | Ходящий по небу |
3 | Питер | Чубакка |
4 | Джон | Матрица |
Если мы хотим увидеть все данные, SQL-запрос будет таким:
Выберите * среди студентов |
По сути, мы говорим, покажите мне все столбцы (*) из таблицы студентов. Если мы хотим получить только столбец ID
и имя, запрос будет выглядеть следующим образом:
Выберите ID, имя от студентов
В этом примере SQL-запрос получает идентификатор столбца Name из таблицы ученика. Важно отметить, что мы можем указывать имена столбцов в любом порядке. Я не буду говорить о производительности и индексах при использовании запросов, но порядок столбцов может повлиять на производительность в таблицах с несколькими миллионами строк или с соединениями с другими столбцами.
Для получения дополнительной информации о выбранных предложениях в T-SQL перейдите по ссылке Microsoft.
Отличительной чертой SQL является то, что вы можете запрашивать несколько таблиц. Например, если у меня есть оценки
студенты, я мог запросить информацию из обеих таблиц. Допустим, у нас есть оценка студента в таблице:
ИДЕНТИФИКАТОР | Счет |
1 | 52 |
2 | 63 |
1 | 57 |
3 | 69 |
ID — это студенческий билет. Это общий столбец между учеником и таблицей баллов. Нам нужен общий столбец
чтобы создать отношения. Если нам нужны имя, фамилия и оценка студента, запрос будет таким:
Выберите имя, фамилию, балл От студента Внутреннее соединение Оценка ON student.ID=score.ID |
Первая строка проста. Мы вызываем столбцы с требуемыми данными. Вторая строка — это просто первая таблица, а внутреннее соединение должно использовать вторую таблицу с именем score. Наконец, нам нужно указать в запросе, какие общие столбцы соответствуют данным. В этом примере идентификаторы. Чтобы отличить столбец ID от других таблиц, нам нужно указать имена таблиц, за которыми следует точка, а затем имя столбца.
Полное руководство по объединениям см. по следующей ссылке:
- Обзор типов соединений SQL и руководство
Определение SQL для UNION, INTERSECT, ЗА ИСКЛЮЧЕНИЕМ
SQL определил стандартный синтаксис для создания объединения между двумя таблицами или для получения общих строк (пересечения) или строк
которые не являются общими (кроме). В следующей статье объясняется, как их использовать:
- Обзор SQL Union, использование и примеры
Расширения определения SQL
Каждая система баз данных имеет собственное расширение SQL. Например, SQL Server использует T-SQL, который является расширением SQL. Оракул
использует PL-SQL, MySQL и MariaDB используют SQL/PSM (SQL и постоянный хранимый модуль). PSM — это стандарт ISO для хранимых
процедуры. Teradata и Informix используют SPL, и существует несколько разных расширений, используемых разными системами.
Базы данных.
Заключение
В этой статье мы объяснили определение SQL. По сути, это язык для обработки данных. Это было изначально
созданы для обработки структурированных данных, но даже базы данных NoSQL (нереляционные базы данных) обычно используют
Расширение SQL для получения данных. Платформы больших данных также используют расширения SQL для обработки своих данных, поэтому SQL
определение будет полезно в течение длительного времени.