Over sql partition by: OVER, предложение (Transact-SQL) — SQL Server
Содержание
Оконные функции в SQL — что это и зачем они нужны
Многие разработчики, даже давно знакомые с SQL, не понимают оконные функции, считая их какой-то особой магией для избранных. И, хотя реализация оконных функций поддерживается с SQL Server 2005, кто-то до сих пор «копипастит» их со StackOverflow, не вдаваясь в детали. Этой статьёй мы попытаемся развенчать миф о неприступности этой функциональности SQL и покажем несколько примеров работы оконных функций на реальном датасете.
Почему не GROUP BY и не JOIN
Сразу проясним, что оконные функции — это не то же самое, что GROUP BY. Они не уменьшают количество строк, а возвращают столько же значений, сколько получили на вход. Во-вторых, в отличие от GROUP BY, OVER может обращаться к другим строкам. И в-третьих, они могут считать скользящие средние и кумулятивные суммы.
Примечание Оконные функции не изменяют выборку, а только добавляют некоторую дополнительную информацию о ней. Для простоты понимания можно считать, что SQL сначала выполняет весь запрос (кроме сортировки и limit), а уже потом считает значения окна.
Окей, с GROUP BY разобрались. Но в SQL практически всегда можно пойти несколькими путями. К примеру, может возникнуть желание использовать подзапросы или JOIN. Конечно, JOIN по производительности предпочтительнее подзапросов, а производительность конструкций JOIN и OVER окажется одинаковой. Но OVER даёт больше свободы, чем жёсткий JOIN. Да и объём кода в итоге окажется гораздо меньше.
Для начала
Оконные функции начинаются с оператора OVER и настраиваются с помощью трёх других операторов: PARTITION BY, ORDER BY и ROWS. Про ORDER BY, PARTITION BY и его вспомогательные операторы LAG, LEAD, RANK мы расскажем подробнее.
Все примеры будут основаны на датасете олимпийских медалистов от Datacamp. Таблица называется summer_medals и содержит результаты Олимпиад с 1896 по 2010:
ROW_NUMBER и ORDER BY
Как уже говорилось выше, оператор OVER создаёт оконную функцию. Начнём с простой функции ROW_NUMBER, которая присваивает номер каждой выбранной записи:
SELECT athlete, event, ROW_NUMBER() OVER() AS row_number FROM Summer_Medals ORDER BY row_number ASC;
Каждая пара «спортсмен — вид спорта» получила номер, причём к этим номерам можно обращаться по имени row_number.
ROW_NUMBER можно объединить с ORDER BY, чтобы определить, в каком порядке строки будут нумероваться. Выберем с помощью DISTINCT все имеющиеся виды спорта и пронумеруем их в алфавитном порядке:
SELECT sport, ROW_NUMBER() OVER(ORDER BY sport ASC) AS Row_N FROM ( SELECT DISTINCT sport FROM Summer_Medals ) AS sports ORDER BY sport ASC;
PARTITION BY и LAG, LEAD и RANK
PARTITION BY позволяет сгруппировать строки по значению определённого столбца. Это полезно, если данные логически делятся на какие-то категории и нужно что-то сделать с данной строкой с учётом других строк той же группы (скажем, сравнить теннисиста с остальными теннисистами, но не с бегунами или пловцами). Этот оператор работает только с оконными функциями типа LAG, LEAD, RANK и т. д.
LAG
Функция LAG берёт строку и возвращает ту, которая шла перед ней. Например, мы хотим найти всех олимпийских чемпионов по теннису (мужчин и женщин отдельно), начиная с 2004 года, и для каждого из них выяснить, кто был предыдущим чемпионом.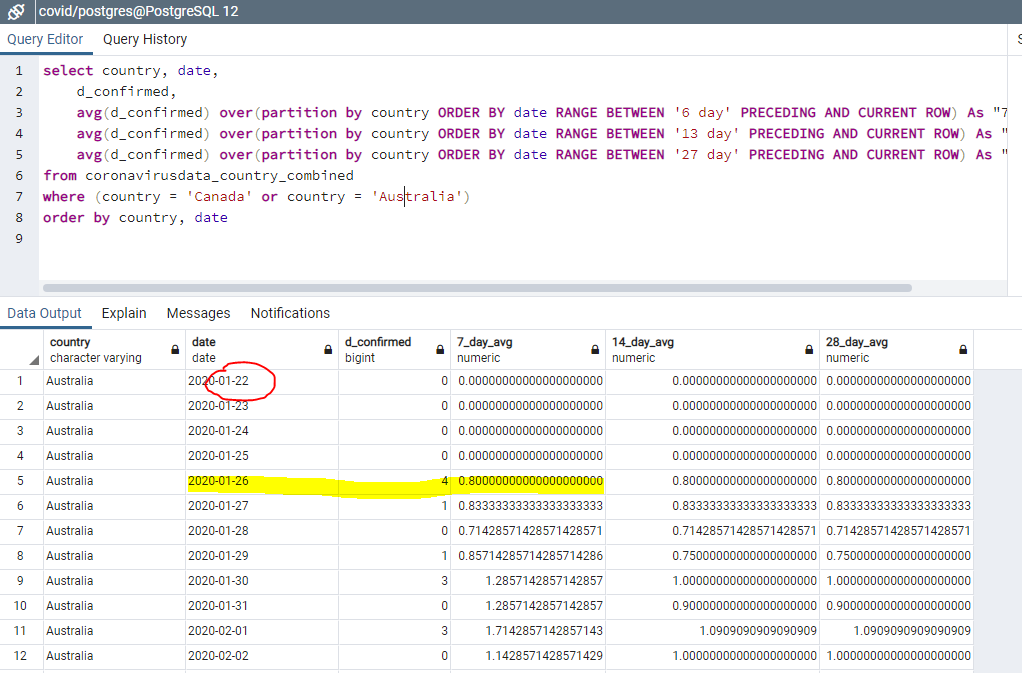
Решение этой задачи требует нескольких шагов. Сначала надо создать табличное выражение, которое сохранит результат запроса «чемпионы по теннису с 2004 года» как временную именованную структуру для дальнейшего анализа. А затем разделить их по полу и выбрать предыдущего чемпиона с помощью LAG:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из предыдущей строки SELECT Athlete as Champion, Gender, Year, LAG(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Last_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;
Функция PARTITION BY в таблице вернула сначала всех мужчин, потом всех женщин.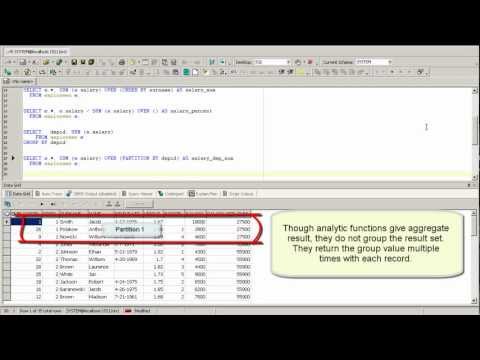 Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
Для победителей 2008 и 2012 года приведён предыдущий чемпион; так как данные есть только за 3 олимпиады, у чемпионов 2004 года нет предшественников, поэтому в соответствующих полях стоит null.
LEAD
Функция LEAD похожа на LAG, но вместо предыдущей строки возвращает следующую. Можно узнать, кто стал следующим чемпионом после того или иного спортсмена:
-- Табличное выражение ищет теннисных чемпионов и выбирает нужные столбцы WITH Tennis_Gold AS ( SELECT Athlete, Gender, Year, Country FROM Summer_Medals WHERE Year >= 2004 AND Sport = 'Tennis' AND event = 'Singles' AND Medal = 'Gold')
-- Оконная функция разделяет по полу и берёт чемпиона из следующей строки SELECT Athlete as Champion, Gender, Year, LEAD(Athlete) OVER (PARTITION BY gender ORDER BY Year ASC) AS Future_Champion FROM Tennis_Gold ORDER BY Gender ASC, Year ASC;
RANK
Оператор RANK похож на ROW_NUMBER, но присваивает одинаковые номера строкам с одинаковыми значениями, а «лишние» номера пропускает.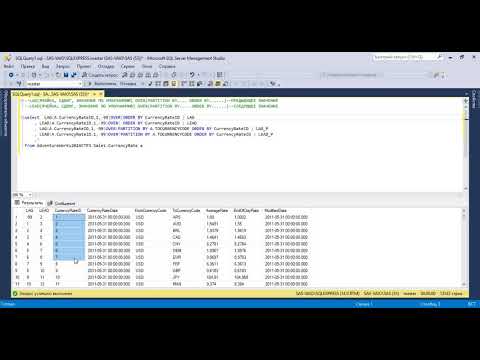 Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
Есть также DENSE_RANK, который не пропускает номеров. Звучит запутанно, так что проще показать на примере. Вот ранжирование стран по числу олимпиад, в которых они участвовали, разными операторами:
- Row_number — ничего интересного, строки просто пронумерованы по возрастанию.
- Rank_number — строки ранжированы по возрастанию, но нет номера 3. Вместо этого, 2 строки делят номер 2, а за ними сразу идёт номер 4.
- Dense_rank — то же самое, что и rank_number, но номер 3 не пропущен. Номера идут подряд, но зато никто не оказался пятым из пяти.
Вот код:
-- Табличное выражение выбирает страны и считает годы
WITH countries AS (
SELECT
Country,
COUNT(DISTINCT year) AS participated
FROM
Summer_Medals
WHERE
Country in ('GBR', 'DEN', 'FRA', 'ITA','AUT')
GROUP BY
Country)
-- Разные оконные функции ранжируют страны
SELECT
Country,
participated,
ROW_NUMBER()
OVER(ORDER BY participated DESC) AS Row_Number,
RANK()
OVER(ORDER BY participated DESC) AS Rank_Number,
DENSE_RANK()
OVER(ORDER BY participated DESC) AS Dense_Rank
FROM countries
ORDER BY participated DESC;Напоследок
Вот так мы и разложили этот датасет по полочкам при помощи оконных функций. На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
На этом наше введение в оконные функции заканчивается. Надеемся, это было интересно и не так сложно, как могло показаться.
Конечно, это далеко не все возможности оконных функций. Для них есть много других полезных вещей, например ROWS, NTILE и агрегирующие функции (SUM, MAX, MIN и другие), но об этом поговорим в другой раз.
Адаптированный перевод статьи «Intro to Window Functions in SQL»
Полезные оконные функции SQL — Разработка на vc.ru
Можно бесконечно долго «воротить нос» от использования SQL для Data Preparation, отдавая лавры змеиному языку, но нельзя не признавать факт, что чаще мы используем и еще долго будем использовать SQL для работы с данными, в том числе и очень объемными.
34 557
просмотров
Более того, считаем, что на текущий момент SQL окажется под рукой сотрудника с большей вероятностью, чем Python, и поможет быстро решить аналитическую задачку с приоритетом «-1».
Предложение OVER помогает «открыть окно», т.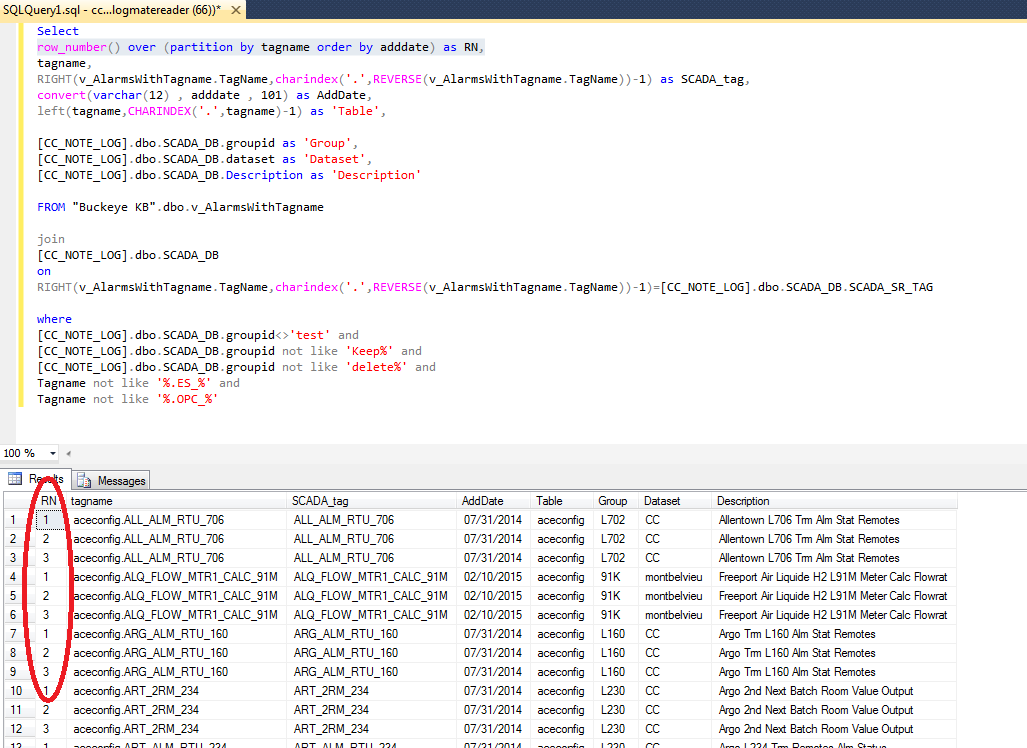 е. определить строки, с которым будет работать та или иная функция.
е. определить строки, с которым будет работать та или иная функция.
Предложение partion BY не является обязательным, но дополняет OVER и показывает, как именно мы разделяем строки, к которым будет применена функция.
ORDER BY определит порядок обработки строк.
В одном select может быть больше одного OVER, эта прекрасная особенность упростит выполнение аналитической задачи в дальнейшем.
Итак, оконные функции делятся на:
- Агрегатные функции
- Ранжирующие функции
- Функции смещения
- Аналитические функции
Собственно, те же, что и обычные, только встроенные в конструкцию с OVER
SUM/ AVG / COUNT/ MIN/ MAX
Для наглядности работы данных функций воспользуемся базовым набором данных (T)
Задача:
Найти максимальную задолженность в каждом банке.
Для чего тут оконные функции? Можно же просто написать:
SELECT TB, max(OSZ) OSZ
FROM T
group by TB
В данном контексте, действительно, применение оконных функций нецелесообразно, но, когда речь заходит о задаче:
Собрать дэшборд, в котором содержится информация о максимальной задолженности в каждом банке, а также средний размер процентной ставки в каждом банке в зависимости от сегмента, плюс еще количество договоров всего всем банкам (в голове рисуются множественные джойны из подзапросов и как-то сразу тяжело на душе). Однако, как я говорил выше, в одном select можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
Однако, как я говорил выше, в одном select можно использовать много OVER, а также еще один прекрасный факт: набор строк в окне, связывается с текущей строкой, а не с группой агрегированных. Таким образом:
SELECT TB, ID_CLIENT, ID_DOG, OSZ, PROCENT_RATE, RATING, SEGMENT
, MAX(OSZ) OVER (PARTITION BY TB) ‘Максимальная задолженность в разбивке по банкам’
, AVG(PROCENT_RATE) OVER (PARTITION BY TB, SEGMENT) ‘Средняя процентная ставка в разрезе банка и сегмента’
, COUNT(ID_DOG) OVER () ‘Всего договоров во всех банках’
FROM T
На примере AVG(procent_RATE) OVER (partition BY TB, segment) подробнее:
- Мы применяем AVG – агрегатную функцию по подсчету среднего значения к столбцу procent_RATE.
- Затем предложением OVER определяем, что будем работать с некоторым набором строк. По умолчанию, если указать OVER() с пустыми строками, то этот набор строк равен всей таблице.
- Предложением partition BY выделяем разделы в наборе строк по заданному условию, в нашем случае, в разбивке на Территориальные банки и Сегмент.

- В итоге, к каждой строке базовой таблицы применится функция по подсчету среднего из набора строк, разбитых на разделы (по Территориальным Банкам и Сегменту).
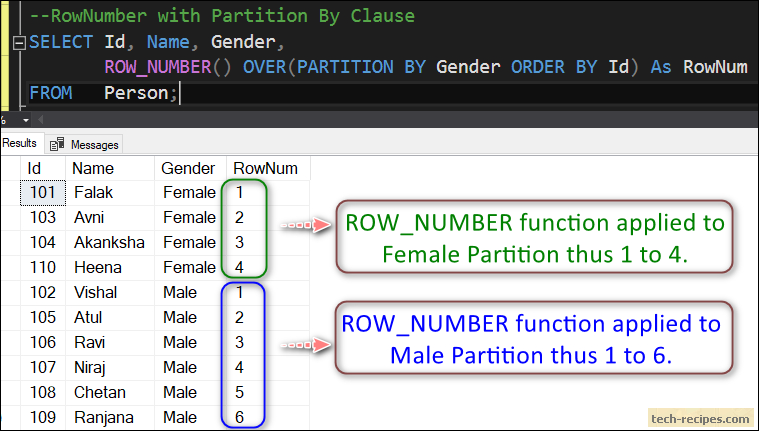
Другой тип оконных функций, надо признать, мой любимый и был использован для решения многих задач. Функции ранжирования для каждой строки в разделе возвращают значение рангов или рейтингов. Все ведь любят рейтинги, правда…?
Базовый набор данных: банки, отделы и количество ревизий.
Сами ранжирующие функции:
ROW_number – нумерует строки в результирующем наборе.
RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается с пропуском.
DENSE_RANK -присваивает ранг для каждой строки, если найдутся одинаковые значения, то следующий ранг присваивается без пропуска.
NTILE – помогает разделить результирующий набор на группы.
Для понимания написанного, проранжируем таблицу по убыванию количества ревизий:
SELECT *
, ROW_NUMBER() OVER(ORDER BY count_revisions desc)
, Rank() OVER(ORDER BY count_revisions desc)
, DENSE_RANK() OVER(ORDER BY count_revisions desc)
, NTILE(3) OVER(ORDER BY count_revisions desc)
FROM Table_Rev
ROW_number – пронумеровал столбцы в порядке убывания количества ревизий.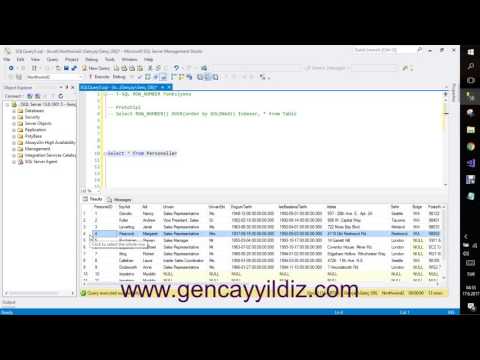
RANK – проранжировал отделы во всех банках в порядке убывания количества ревизий, но как только встретились одинаковые значения (количество ревизий 95), функция присвоила им ранг 4, а следующее значение получило ранг 6.
DENSE_RANK – аналогично RANK, но как только встретились одинаковые значения, следующее значение получило ранг 5.
NTILE – функция помогла разбить таблицу на 3 группы (указал в аргументе). Так как в таблице 18 значений, в каждую группу попало по 6.
Задача:
Найти второй отдел во всех банках по количеству ревизий.
Можно, конечно, воспользоваться чем-то вроде:
SELECT MAX(count_revisions) ms
FROM Table_Rev
WHERE count_revisions!=(SELECT MAX(count_revisions) FROM Table_Rev)
Но если речь идет не про второй отдел, а про трети? .. уже сложнее. Действительно, никто не списывает со счетов offset, но в этой статье говорится об оконных функциях, так почему бы не написать так:
With T_R as
(
SELECT *
, DENSE_RANK() OVER(ORDER BY count_revisions desc) ds
FROM Table_Rev
)
SELECT * FROM T_R
WHERE ds=3
Как и во всех других типах функций, здесь можно выделять разделы с помощью partitionby. Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по территориальным банкам, сортируем по возрастанию:
Например, найти отдел в каждом банке, с меньшим количеством проведенных ревизий, для этого разделяем на секции по территориальным банкам, сортируем по возрастанию:
With T_R as
(
SELECT *
, DENSE_RANK() OVER(PARTITION BY tb ORDER BY count_revisions) ds
FROM Table_Rev
)
SELECT tb,dep,count_revisions
FROM T_R
WHERE ds=1
Получаем:
Оконные функции смещения помогут нам, когда необходимо обратиться к строке в наборе данных из окна, относительно текущей строки с некоторым смещением. Проще говоря, узнать, какое значение (событие/ дата) идет после/до текущей строки. Похоже на отличную штуку в предобработке лога данных.
LAG — смещение назад.
LEAD — смещение вперед.
FIRST_VALUE — найти первое значение набора данных.
LAST_VALUE — найти последнее значение набора данных.
LAG и LEAD имеют следующие аргументы:
- Столбец, значение которого необходимо вернуть
- На сколько строк выполнить смешение (дефолт =1)
- Что вставить, если вернулся NULL
Как обычно, на практике проще:
Базовый набор данных, содержит id задачи, события внутри нее и их дату:
Применяя конструкцию:
SELECT *
, LEAD (Event, 1, ‘end’) OVER (PARTITION BY ID_Task ORDER BY Date_Event) as Next_Event
, LEAD (Date_Event, 1, ‘2099-01-01’) OVER(PARTITION BY ID_Task ORDER BY Date_Event) as Next_Date
FROM Table_Task
Получаем набор данных, который хоть сейчас в graphviz (нет).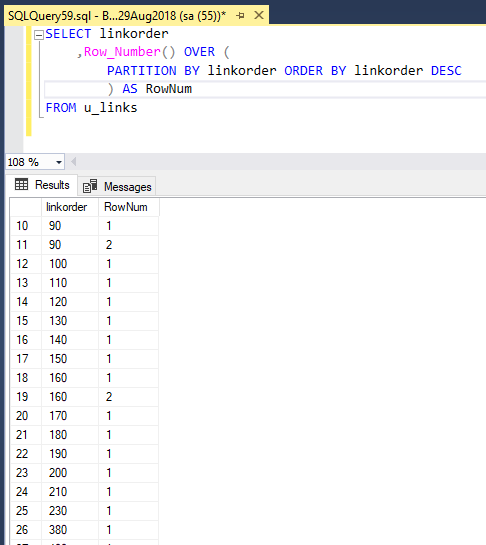
Аналитические оконные функции подходят под специфичные задачи и описывать их здесь я, пожалуй, не буду. Но, возможно, вы решите ознакомиться с ними самостоятельно, а значит будете более подготовлены к решению хитро закрученных задач.
Тем, кто слышит про данные функции впервые, надеюсь, статья окажется полезной, а, кто уже со всем этим знаком, простите, потраченное время никто не вернет.
Обзор предложения SQL PARTITION BY
В этой статье будет рассмотрено предложение SQL PARTITION BY и, в частности, разница с GROUP BY в операторе select. Мы также рассмотрим различные варианты использования SQL PARTITION BY.
Мы используем SQL PARTITION BY, чтобы разделить результирующий набор на разделы и выполнить вычисления для каждого подмножества разделенных данных.
Подготовка данных образца
Давайте создадим таблицу Orders в моей тестовой базе данных 9.0009 SQLShackDemo и вставьте записи для написания дальнейших запросов.
1 2 3 4 5 6 7 8 10 3 9 3 | Используйте SQLSHACKDEMO GO CREATE TABLE [DBO]. [Заказы] ( [ORDERID] INT, [ORDERDATE] Дата, [Customername] VARCHAR (100), [Customercity] VARCHAR(100), [Сумма заказа] MONEY ) |
Я использую ApexSQL Generate для вставки примеров данных в эту статью. Щелкните правой кнопкой мыши таблицу Orders и Generate test data .
Он запускает ApexSQL Generate. Я создал скрипт для вставки данных в таблицу Orders. Выполните этот скрипт, чтобы вставить 100 записей в таблицу Orders.
1 2 3 4 5 6 7 | USE [SQLShackDemo] GO INSERT [dbo].[Orders] VALUES (216090, CAST(N’1826-12-19′ AS Date), N’Edward’, N’Phoenix’, 4713. GO INSERT [dbo].[Orders] VALUES (508220, CAST(N’1826-12-09′ AS Date), N’Aria’, N’San Francisco’, 9832.7200) GO … |
 8900)
8900)Как только мы выполним операторы вставки, мы увидим данные в таблице Orders на следующем изображении.
Мы используем предложение SQL GROUP BY для группировки результатов по указанному столбцу и используем агрегатные функции, такие как Avg(), Min(), Max(), для вычисления необходимых значений.
Группировать по синтаксису функций
Выражение SELECT, агрегатная функция () ИЗ таблиц WHERE условия GROUP BY выражение |
Предположим, мы хотим найти следующие значения в таблице Orders
- Минимальная стоимость заказа в городе
- Максимальная стоимость заказа в городе
- Средняя стоимость заказа в городе
Выполните следующий запрос с предложением GROUP BY, чтобы вычислить эти значения.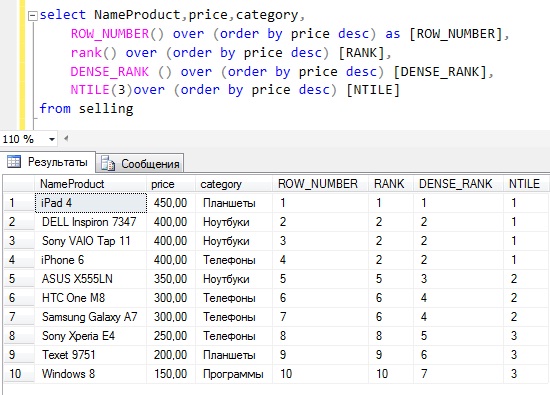
1 2 3 4 5 6 | Выберите CustomerCity, AVG (OrderAmount) в качестве Avgorderamount, мин (orderAmount) в качестве MinOrderAmount, Sum (OrderAmount) TotalOrderAnt от [DBO]. [Orders] Группа по CustomerTICTION; |
На следующем снимке экрана мы видим среднее, минимальное и максимальное значения, сгруппированные по CustomerCity.
Теперь мы хотим добавить в вывод столбцы CustomerName и OrderAmount . Давайте добавим эти столбцы в оператор select и выполним следующий код.
1 2 3 4 5 6 | SELECT Customercity, CustomerName ,OrderAmount, AVG(Orderamount) AS AvgOrderAmount, MIN(СуммаЗаказа) AS MinOrderAmount, СУММА(СуммаЗаказа) TotalOrderAmount ОТ [dbo]. ГРУППА ПО Customercity; |
 [Заказы]
[Заказы]Как только мы выполним этот запрос, мы получим сообщение об ошибке. В предложении SQL GROUP BY мы можем использовать столбец в операторе select, если он также используется в предложении Group by. В предложении select не разрешен ни один столбец, который не является частью предложения GROUP BY.
Мы можем использовать предложение SQL PARTITION BY для решения этой проблемы. Давайте рассмотрим это подробнее в следующем разделе.
РАЗДЕЛ SQL ПО
Мы можем использовать предложение SQL PARTITION BY с предложением OVER , чтобы указать столбец, для которого нам нужно выполнить агрегирование. В предыдущем примере мы использовали столбец Group By with CustomerCity и рассчитали среднее, минимальное и максимальное значения.
Давайте повторно запустим этот сценарий с предложением SQL PARTITION BY, используя следующий запрос.
Выберите CustomerCity, AVG (OrderAmount) Over (раздел CustomerCity) как Avgorderamount, мин (OrderAmount). |
 ОТ [dbo].[Заказы];
ОТ [dbo].[Заказы];На выходе мы получаем агрегированные значения, аналогичные предложению GROUP By. Вы можете заметить разницу в выводе предложений SQL PARTITION BY и GROUP BY.
Группа по | РАЗДЕЛ SQL ПО |
Мы получаем ограниченное количество записей, используя предложение Group By | Мы получаем все записи в таблице, используя предложение PARTITION BY. |
Это дает одну строку на группу в наборе результатов. Например, мы получаем результат для каждой группы CustomerCity в предложении GROUP BY. | Он дает агрегированные столбцы с каждой записью в указанной таблице. У нас есть 15 записей в таблице Orders. В выводе запроса SQL PARTITION BY мы также получаем 15 строк вместе с минимальными, максимальными и средними значениями. |
В предыдущем примере мы получаем сообщение об ошибке, если пытаемся добавить столбец, который не является частью предложения GROUP BY.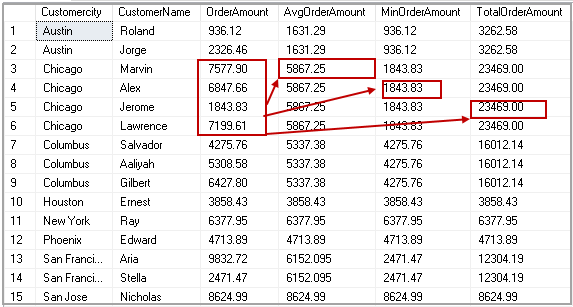
Мы можем добавить необходимые столбцы в оператор select с помощью предложения SQL PARTITION BY. Давайте добавим столбцы CustomerName и OrderAmount и выполним следующий запрос.
1 2 3 4 5 6 7 | Выберите CustomerCity, Customername, OrderAmount, AVG (OrderAmount) Over (раздел по CustomerCity) как AvgorderAmount, мин (orderAmount). (РАЗДЕЛ ПО Customercity) TotalOrderAmount ОТ [dbo].[Заказы]; |
Мы получаем столбцы CustomerName и OrderAmount вместе с выходными данными агрегированной функции. Мы также получаем все строки, доступные в таблице Orders.
На следующем снимке экрана вы можете увидеть CustomerCity Chicago , он выполняет агрегирование (Avg, Min и Max) и дает значения в соответствующих столбцах.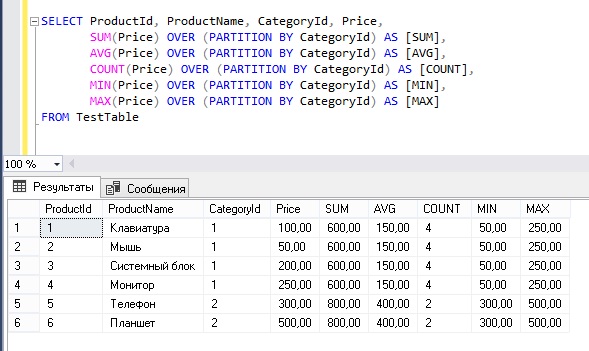
Точно так же мы можем использовать другие агрегатные функции, такие как count, чтобы узнать общее количество заказов в конкретном городе с предложением SQL PARTITION BY .
1 2 3 4 5 6 7 8 | SELECT Customercity, CustomerName, OrderAmount, COUNT(OrderID) OVER(PARTITION BY Customercity) AS CountOfOrders, AVG (OrderAmount) Over (раздел по Customercity) как Avgorderamount, мин (OrderAmount). [Заказы]; |
Мы можем видеть количество заказов для определенного города. Например, у нас есть два заказа из города Остин, поэтому; он показывает значение 2 в столбце CountofOrders .
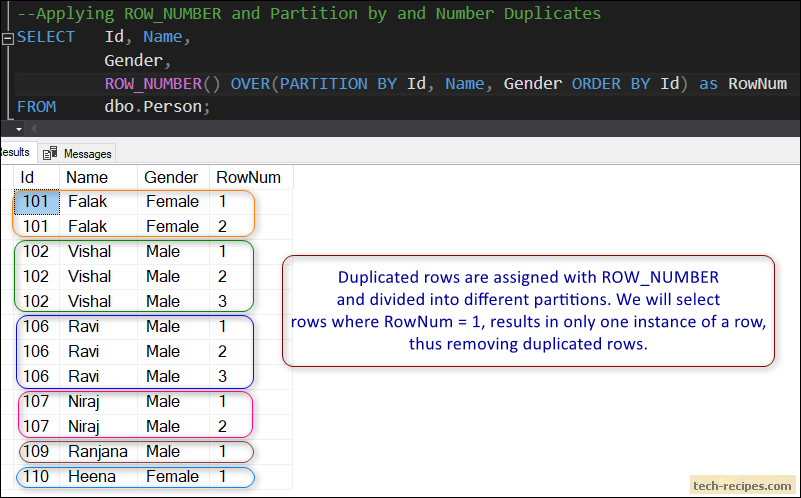
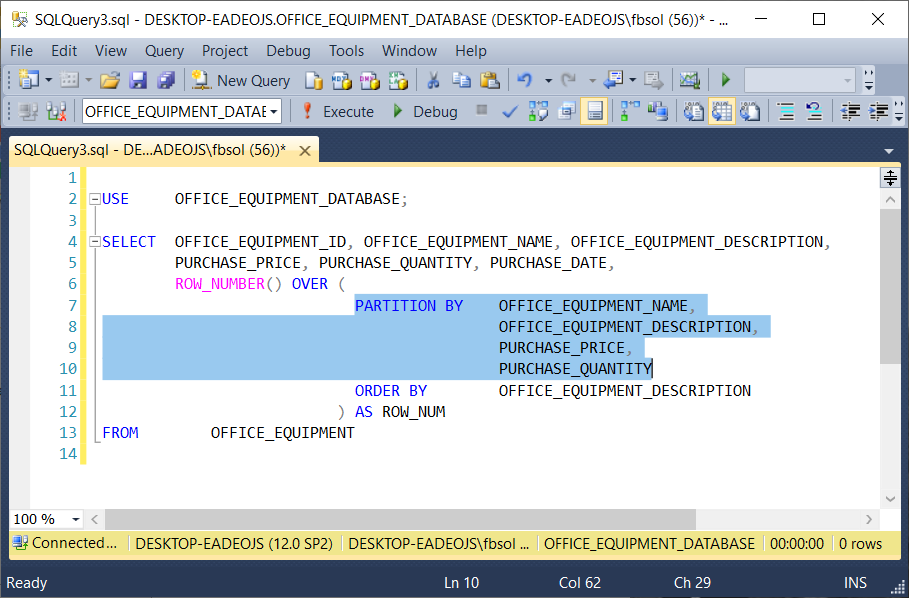
Предложение PARTITION BY с ROW_NUMBER()
Мы можем использовать предложение SQL PARTITION BY с функцией ROW_NUMBER(), чтобы иметь номер строки для каждой строки. Мы определяем следующие параметры для использования ROW_NUMBER с предложением SQL PARTITION BY.
Мы определяем следующие параметры для использования ROW_NUMBER с предложением SQL PARTITION BY.
- РАЗДЕЛЕНИЕ ПО столбцу — в этом примере мы хотим разделить данные по столбцу CustomerCity
- Порядок: В столбце ORDER BY мы определяем столбец или условие, которое определяет номер строки. В этом примере мы хотим отсортировать данные по OrderAmount столбец
1 2 3 4 5 6 7 8 10 3 9 3 | Выберите CustomerCity, CustomerName, ROW_NUMBER () OUR (разделение по CustomerCity Заказ по OrderAmount Disc) как «номер строки», OrderAmount, Count (OrderId). , AVG (OrderAmount) Over (раздел по Customercity) как Avgorderamount, мин (OrderAmount). [Заказы]; |
На следующем снимке экрана мы видим для CustomerCity Chicago , у нас есть строка номер 1 для заказа с наибольшей суммой 7577,90. он предоставляет номер строки с убывающим значением OrderAmount.
он предоставляет номер строки с убывающим значением OrderAmount.
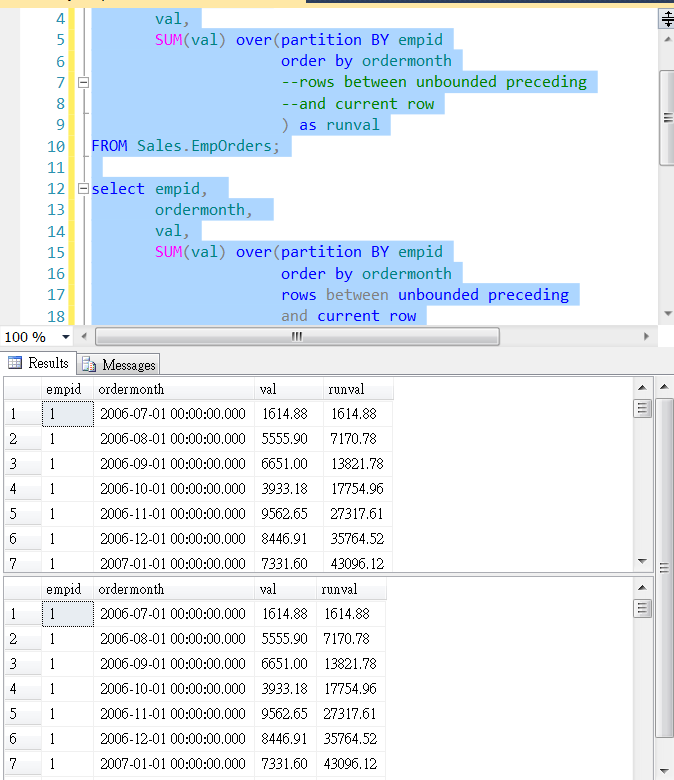
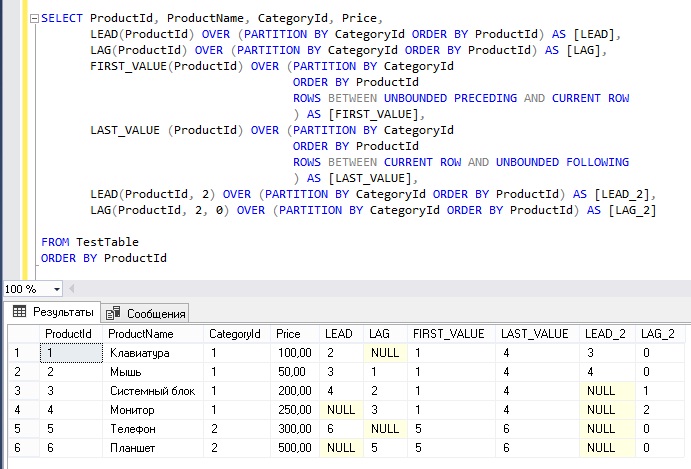
Предложение PARTITION BY с совокупным общим значением
Предположим, мы хотим получить совокупный итог по заказам в разделе. Совокупный итог должен относиться к текущей строке и следующей строке раздела.
Например, в городе Чикаго у нас четыре заказа.
CustomerCity | Имя Клиента | Классифицировать | Сумма заказа | Совокупное общее количество строк | Нарастающий итог |
Чикаго | Марвин | 1 | 7577,9 | Ранг 1 +2 | 14777,51 |
Чикаго | Лоуренс | 2 | 7199,61 | Ранг 2+3 | 14047. |
Чикаго | Алекс | 3 | 6847,66 | Ранг 3+4 | 8691,49 |
Чикаго | Джером | 4 | 1843,83 | Ранг 4 | 1843,83 |
 21
21В следующем запросе мы указали предложение ROWS для выбора текущей строки (используя CURRENT ROW) и следующую строку (используя 1 FOLLOWING). Далее он вычисляет сумму по этим строкам, используя sum(Orderamount) с разделением на CustomerCity (используя OVER(PARTITION BY Customercity ORDER BY OrderAmount DESC).
1 2 3 4 5 6 7 | Выберите CustomerCity, CustomerName, OrderAmount, ROW_NUMBER () OUT (раздел CustomerCity Заказ по порядку DESC) в качестве «номера строки», Конвертируйте (VARCHAR (20), сумма (OrderAmount). ORDER BY OrderAmount DESC ROWS МЕЖДУ ТЕКУЩЕЙ СТРОКОЙ И 1 СЛЕДУЮЩЕЙ), 1) AS CumulativeTotal, |
 (РАЗДЕЛЕНИЕ ПО Customercity
(РАЗДЕЛЕНИЕ ПО CustomercityТочно так же мы можем вычислить кумулятивное среднее, используя следующий запрос с предложением SQL PARTITION BY .
1 2 3 4 5 6 7 | SELECT Customercity, CustomerName, OrderAmount, ROW_NUMBER() OVER(РАЗДЕЛ ПО Customercity ORDER BY OrderAmount DESC) AS «Номер строки», CONVERT(VARCHAR(20), AVG(orderamount) OVER(PARTITION BY Customercity ORDER BY OrderAmount) ASMULTIVE ROWS IN 1 DESC ROWS IN 1 CURRENT |
ROWS UNBOUNDED PRECEDING с пунктом PARTITION BY
Мы можем использовать ROWS UNBOUNDED PRECEDING с предложением SQL PARTITION BY, чтобы выбрать строку в разделе перед текущей строкой и строку с наибольшим значением после текущей строки.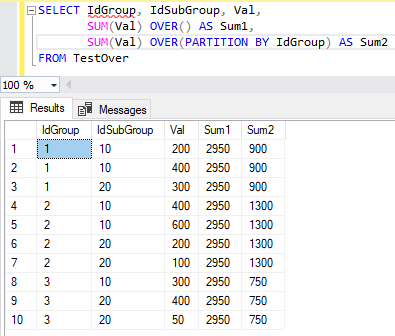
В следующей таблице мы видим для строки 1; в этом разделе нет ни одной строки с высоким значением. Таким образом, кумулятивное среднее значение такое же, как и в строке 1 OrderAmount.
Для Row2 выполняется поиск текущего значения строки (7199,61) и строки с наибольшим значением 1 (7577,9). Он вычисляет среднее значение для этих двух сумм.
Для строки 3 выполняется поиск текущего значения (6847,66) и более высокого значения суммы, чем это значение, то есть 7199,61 и 7577,9.0. Он вычисляет среднее из них и возвращает результат.
CustomerCity | Имя Клиента | Классифицировать | Сумма заказа | Совокупное среднее количество строк | Совокупное среднее |
Чикаго | Марвин | 1 | 7577,9 | Ранг 1 | 7577,90 |
Чикаго | Лоуренс | 2 | 7199,61 | Ранг 1+2 | 7388,76 |
Чикаго | Алекс | 3 | 6847,66 | Ранг 1+2+3 | 7208,39 |
Чикаго | Джером | 4 | 1843,83 | Ранг 1+2+3+4 | 5867,25 |
Выполните следующий запрос, чтобы получить этот результат с нашими примерами данных.
1 2 3 4 5 6 7 8 | SELECT Customercity, CustomerName, OrderAmount, ROW_NUMBER() OVER(РАЗДЕЛ ПО Customercity Заказ по OrderAmount desc) как «номер строки», преобразовать (varchar (20), avg (orderamount) над (раздел от Customercity Порядок по orderAmount descept nucouded), 1) как cumulativeavg dbo].[Заказы]; |
Заключение
В этой статье мы рассмотрели предложение SQL PARTIION BY и его сравнение с предложением GROUP BY. Мы также изучили его использование на нескольких примерах. Я надеюсь, что вы найдете эту статью полезной и не стесняйтесь задавать любые вопросы в комментариях ниже.
- Автор
- Последние сообщения
Раджендра Гупта
Привет! Я Раджендра Гупта, специалист по базам данных и архитектор, помогаю организациям быстро и эффективно внедрять решения Microsoft SQL Server, Azure, Couchbase, AWS, устранять связанные проблемы и настраивать производительность с более чем 14-летним опытом.
Я автор книги «DP-300 Administering Relational Database on Microsoft Azure». Я опубликовал более 650 технических статей о MSSQLTips, SQLShack, Quest, CodingSight и MultipleNines.
Я создатель одной из крупнейших бесплатных онлайн-коллекций статей по одной теме, включая серию из 50 статей о группах доступности SQL Server Always On.
Основываясь на моем вкладе в сообщество SQL Server, я неоднократно признавался престижным Лучшим автором года в 2019, 2020 и 2021 годах (2-е место) в SQLShack и наградой чемпионов MSSQLTIPS в 2020 году.
Личный блог: https://www.dbblogger.com
Меня всегда интересуют новые задачи, поэтому, если вам нужна консультационная помощь, свяжитесь со мной по адресу [email protected]
Просмотреть все сообщения Раджендры Гупты
Последние сообщения Раджендры Гупты (посмотреть все)
SQL PARTITION BY Пункт: Когда и как использовать — Управление базами данных — Блоги
В этой статье мы рассмотрим, когда и как использовать предложение SQL PARTITION BY и сравнить его с использованием предложения GROUP BY.
Понимание функции окна
Пользователи баз данных используют агрегатные функции, такие как MAX(), MIN(), AVERAGE() и COUNT(), для выполнения анализа данных. Эти функции работают со всей таблицей и возвращают отдельные агрегированные данные с помощью предложения GROUP BY. Иногда нам требуются агрегированные значения по небольшому набору строк. В этом случае оконная функция в сочетании с агрегатной функцией помогает достичь желаемого результата. Функция Window использует предложение OVER() и может включать следующие функции:
- Разделить по: Разделяет строки или набор результатов запроса на небольшие разделы.
- Упорядочить по: Упорядочивает строки в возрастающем или убывающем порядке для окна раздела. Порядок по умолчанию — возрастающий.
- Строка или диапазон: Вы можете дополнительно ограничить количество строк в разделе, указав начальную и конечную точки.
В этой статье мы сосредоточимся на изучении предложения SQL PARTITION BY.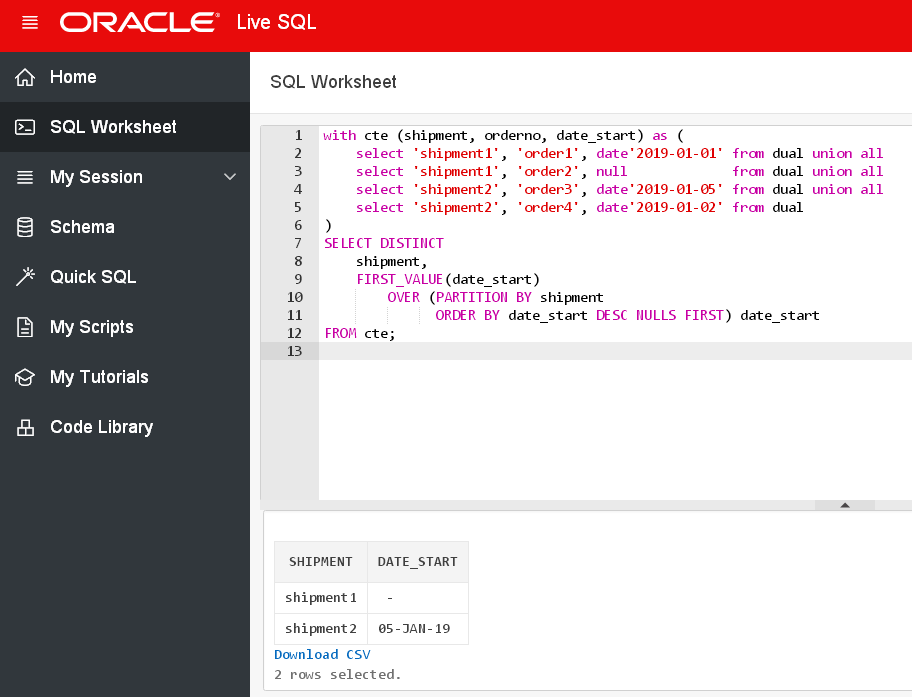
Подготовка данных образца
Предположим, у нас есть таблица [SalesLT].[Orders], в которой хранится информация о заказах клиентов. В нем есть столбец [Город], в котором указан город клиента, в котором был размещен заказ.
СОЗДАТЬ ТАБЛИЦУ [SalesLT].[Заказы] ( порядковый номер INT, дата заказа ДАТА, имя_клиента VARCHAR(100), Город ВАРЧАР(50), сумма ДЕНЬГИ ) ВСТАВЬТЕ В [SalesLT].[Заказы] ВЫБЕРИТЕ 1, '01.01.2021', 'Мохан Гупта', 'Алвар', 10000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 2, '04.02.2021', 'Счастливчик Али', 'Кота', 20000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 3, '02.03.2021', 'Радж Кумар', 'Джайпур', 5000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 4, 02.04.2021, Джйоти Кумари, Джайпур, 15000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 5, '03.05.2021', 'Рахул Гупта', 'Джайпур', 7000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 6, '04.06.2021', 'Мохан Кумар', 'Алвар', 25000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 7, '02.07.2021', 'Кашиш Агарвал', 'Алвар', 15000 СОЮЗ ВСЕХ ВЫБЕРИТЕ 8, «03.08.2021», «Нагар Сингх», «Кота», 2000 г. СОЮЗ ВСЕХ ВЫБЕРИТЕ 9,'04.09.2021','Анил КГ','Алвар',1000 Go
Допустим, мы хотим узнать общую стоимость заказов по местоположению (Город).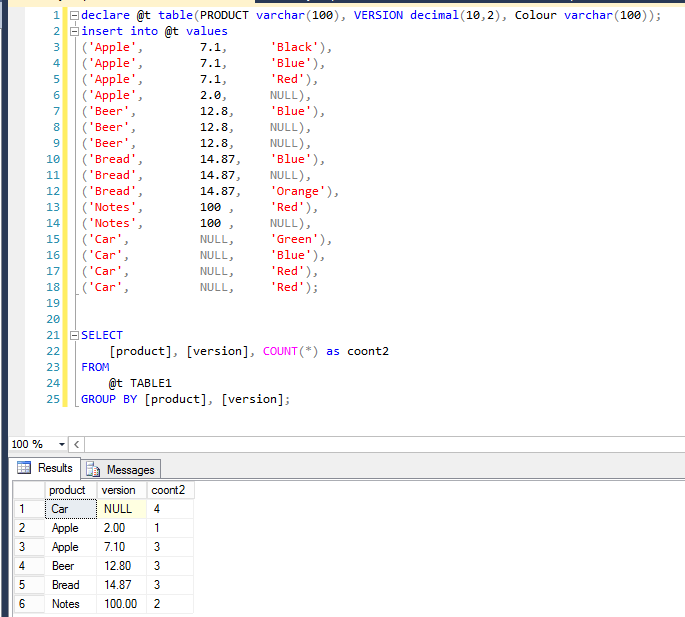 Для этого мы используем функции SUM() и GROUP BY, как показано ниже.
Для этого мы используем функции SUM() и GROUP BY, как показано ниже.
ВЫБЕРИТЕ город КАК CustomerCity ,sum(amount) AS totalamount FROM [SalesLT].[Orders] СГРУППИРОВАТЬ ПО ГОРОДУ ORDER BY city
В результирующем наборе мы не можем использовать неагрегированные столбцы в инструкции SELECT. Например, мы не можем отобразить [CustomerName] в выходных данных, поскольку оно не включено в предложение GROUP BY.
SQL Server выдает следующее сообщение об ошибке при попытке использовать неагрегированный столбец в списке столбцов.
ВЫБЕРИТЕ город КАК CustomerCity, CustomerName, сумма, SUM(сумма) OVER(РАЗБИВКА ПО городам) TotalOrderAmount FROM [SalesLT].[Orders]
Как показано ниже, предложение PARTITION BY создает меньшее окно (набор строк данных), выполняет агрегирование и отображает его. Вы также можете просмотреть неагрегированные столбцы в этом выводе.
Точно так же вы можете использовать функции AVG(), MIN(), MAX() для вычисления среднего, минимального и максимального количества строк в окне.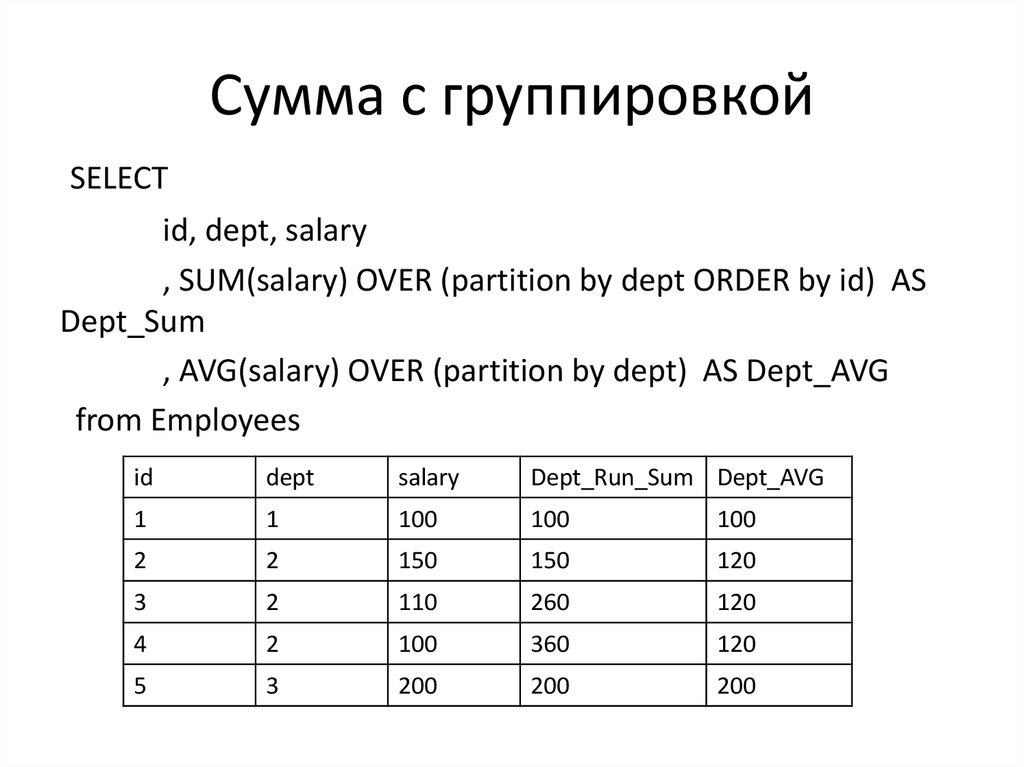
ВЫБЕРИТЕ город КАК CustomerCity, CustomerName, сумма, СУММА(сумма) ПРЕВЫШЕНИЕ(РАЗДЕЛ ПО ГОРОДУ) TotalOrderAmount, Avg(сумма) OVER(PARTITION BY city) AvgOrderAmount, Мин.(сумма) БОЛЕЕ(РАЗДЕЛ ПО ГОРОДУ) MinOrderAmount, MAX(сумма) OVER(РАЗБИВКА ПО городам) MaxOrderAmount FROM [SalesLT].[Orders]
Использование предложения SQL PARTITION BY с функцией ROW_NUMBER()
Раньше мы получали агрегированные значения в окне с помощью предложения PARTITION BY. Предположим, что вместо итога нам требуется совокупный итог в разделе.
Нарастающий итог работает следующим образом.
| Ряд | Итого |
| 1 | Ранг 1+ 2 |
| 2 | Ранг 2+3 |
| 3 | Ранг 3+4 |
Ранг строки вычисляется с помощью функции ROW_NUMBER(). Давайте сначала воспользуемся этой функцией и просмотрим ранги строк.
- Функция ROW_NUMBER() использует предложения OVER и PARTITION BY и сортирует результаты в порядке возрастания или убывания. Он начинает ранжировать строки с 1 в соответствии с порядком сортировки.
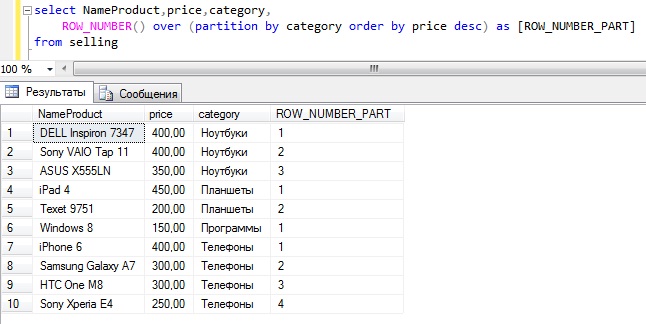 Он начинает ранжировать строки с 1 в соответствии с порядком сортировки.
Он начинает ранжировать строки с 1 в соответствии с порядком сортировки.ВЫБЕРИТЕ город КАК CustomerCity, CustomerName, сумма, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Номер строки] ОТ [SalesLT].[Заказы]
Например, в городе [Алвар] строка с наибольшей суммой (25000,00) находится в строке 1. Как показано ниже, она ранжирует строки в окне, заданном предложением PARTITION BY. Например, у нас есть три разных города [Алвар], [Джайпур] и [Кота], и каждое окно (город) получает свои ряды рангов.
Для расчета нарастающего итога мы используем следующие аргументы.
- ТЕКУЩАЯ СТРОКА: Указывает начальную и конечную точки в указанном диапазоне.
- 1 следующий: Указывает количество строк (1), следующих за текущей строкой.
ВЫБЕРИТЕ город КАК CustomerCity, CustomerName, сумма, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Номер строки], СУММА(сумма) БОЛЕЕ(РАЗДЕЛЕНИЕ ПО ГОРОДАМ ПО УСЛОВИЯМ ПО УИСШЕНИЮ СТРОК МЕЖДУ ТЕКУЩАЯ СТРОКА И 1 СЛЕДУЮЩАЯ) AS CumulativeSUM FROM [SalesLT].
 [Orders]
[Orders] На следующем изображении показано, что вы получаете совокупный итог вместо общего итога в окне, заданном предложением PARTITION BY.
Если мы используем ROWS UNBOUNDED PRECEDING в предложении SQL PARTITION BY, он вычисляет совокупный итог следующим образом. Он использует текущие строки вместе со строками, имеющими самые высокие значения в указанном окне.
| Ряд | Итого |
| 1 | Ранг 1 |
| 2 | Ранг 1+2 |
| 3 | Ранг 1+2+3 |
ВЫБЕРИТЕ город КАК CustomerCity, CustomerName, сумма, ROW_NUMBER() OVER(PARTITION BY city ORDER BY amount DESC) AS [Номер строки], СУММА(сумма) БОЛЕЕ(РАЗБИВКА ПО ГОРОДАМ ПО УСЛОВИЯМ ПО УИСЛАМ ROWS UNBOUNDED PRECEDING) AS CumulativeSUM ОТ [SalesLT].[Заказы]
Сравнение предложения GROUP BY и SQL PARTITION BY
| GROUP BY | РАЗДЕЛ ПО |
Возвращает одну строку на группу после вычисления совокупных значений.
|