Partition by over: Оконные функции SQL простым языком с примерами / Хабр
Содержание
Агрегатные функции с использованием предложений Group By, Over и Partition By в SQL | by Karthik Joshi S
Чтение: 4 мин.
·
17 мая 2020 г.
Агрегатная функция выполняет вычисление набора значений и возвращает одно значение. Они часто используются с предложением GROUP BY оператора SELECT.
Давайте разберем следующие запросы на примере в этой статье:
- Как использовать агрегатную функцию?
- Как работает предложение group by?
- Как применять агрегатные функции без использования предложения group by?
Для простоты понимания рассмотрим в качестве примера следующую сущность:
сущность клиента
Сущность клиента имеет четыре вышеуказанных атрибута, где id — первичный ключ, а dept_id — ссылка на внешний ключ из сущность отдела.
- Агрегатная функция
Давайте попробуем получить количество всех отделов вместе с их именами.
Получить количество отделов для клиента (P.S. Этот запрос не будет работать, причина будет объяснена ниже)
Здесь count — агрегатная функция, объединяющая все отделы для клиента. Если мы запустим приведенный выше запрос, мы получим следующую ошибку
агрегатная функция без группы по
Проблема:
- Поскольку мы пытаемся получить количество всех отделов вместе с их именами, приведенная выше ошибка имеет смысл. Здесь нам нужно агрегировать строки по другому полю, в данном случае это dept_name.
- Агрегатные функции могут использоваться сами по себе или в сочетании с предложением GROUP BY.
- При использовании без предложения group by агрегатная операция применяется ко всей таблице.
- Поскольку мы пытаемся получить количество отделов вместе с их именами, мы должны сгруппировать значения по имени отдела.
Решение:
Итак, нам нужно указать поле для агрегирования, что делается с помощью предложения Group By .
2.Group By с функцией агрегирования
Count with the group by (рабочий запрос)
При выполнении приведенного выше запроса все строки будут агрегированы по имени отдела, и выходные данные будут выглядеть так, как показано ниже, где отдел A , B имеет 4 и 3 клиентов соответственно.
группировать по результату
3. Агрегировать функции без группировки по:
Давайте рассмотрим вариант использования, когда нам нужно получить самую последнюю отчетную дату для каждого отдела. Есть атрибут под названием report_date в вышеуказанном объекте клиент , для которого нам нужно напечатать имя клиента, отдел и последнюю отчетную дату. Здесь последняя сообщаемая дата должна быть общей для каждого отдела.
Использование агрегатной функции MAX:
Для решения приведенного выше запроса мы будем использовать агрегатную функцию MAX, как показано ниже:
Функция MAX для получения последней отчетной даты любые ошибки не служат ожидаемому результату.
Максимальный запрос с использованием группы по
Как вы можете видеть, для одного и того же отдела в каждой строке/кортеже есть разные даты. Наш ожидаемый результат состоял в том, чтобы последняя отчетная дата была общей для одного и того же отдела. ( Первые 3 строки должны иметь одинаковую дату, а последние 4 строки должны иметь общую дату )
Решение:
Использовать Над и Разделение по предложению без применения предложения group by к агрегатным функциям 9 0003
Чтобы использовать предложения OVER и PARTITION BY, вам просто нужно указать столбец, по которому вы хотите разделить агрегированные результаты. Лучше всего это объясняется в приведенном ниже запросе.
Предложение Over and Partition by Результат выполнения предложения Over и Partition by
Понимание предложения Partition by and Over:
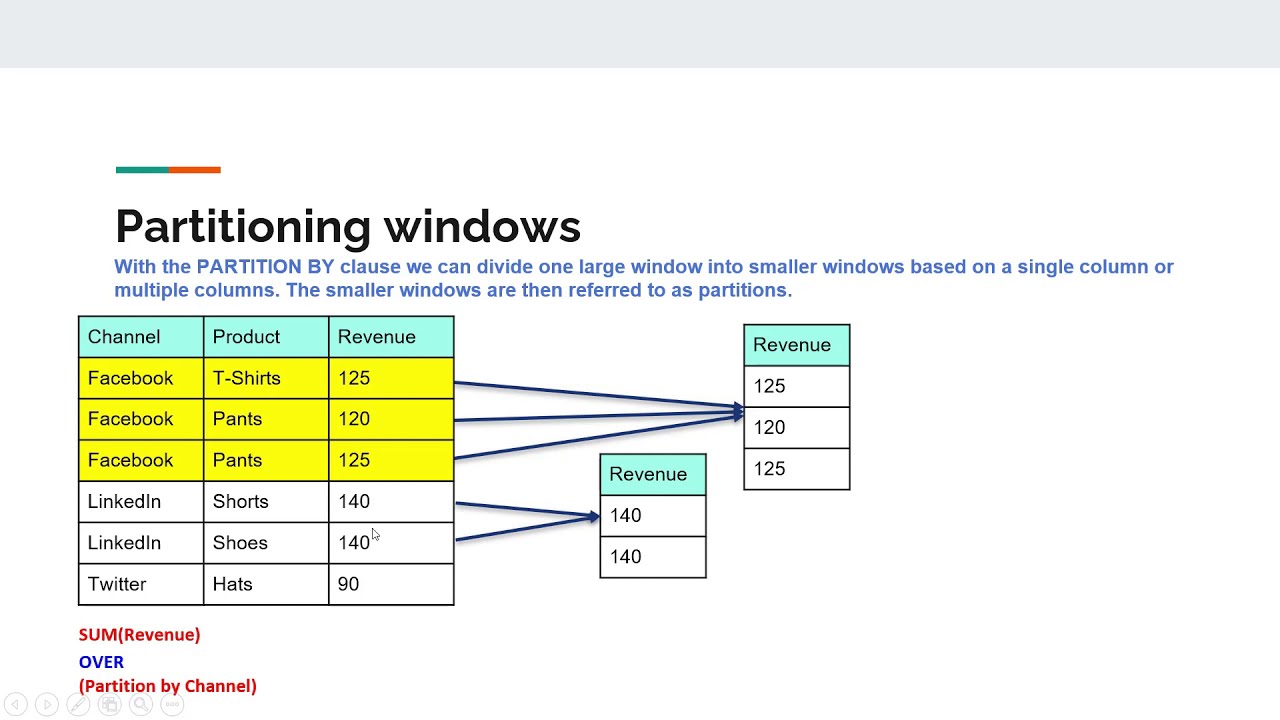
- Over позволяет получить совокупную информацию без использования GROUP BY .
 Другими словами, вы можете получить все строки и вместе с ними получить совокупные данные.
Другими словами, вы можете получить все строки и вместе с ними получить совокупные данные. - Предложение Partition By , используемое с предложением Over , делит набор результатов на разделы и возвращает имя, отдел и последнюю отчетную дату (используя здесь MAX) для всех отделов в одной строке. Это означает, что у нас будут повторяющиеся данные, но это подходит для случая использования, когда мы не хотим терять ни одну строку, в отличие от группировки по.
- Предложение Partition By не уменьшает количество возвращаемых строк, в отличие от group by.
 Другими словами, вы можете получить все строки и вместе с ними получить совокупные данные.
Другими словами, вы можете получить все строки и вместе с ними получить совокупные данные.Примечание:
Приведенные выше запросы, использованные в нашем примере, будут работать практически для всех СУБД (MySQL, Postgres, Oracle…)
Обычно используемые агрегатные функции:
AVG ( 900 37 выражение )Рассчитать среднее выражения.
COUNT ( выражение ) Подсчет вхождений ненулевых значений, возвращаемых выражением.
COUNT (*) Подсчитывает все строки в указанной таблице.
МИН ( выражение ) Находит минимальное значение выражения.
MAX ( выражение ) Находит максимальное значение выражения.
СУММ ( выражение ) Вычислить сумму выражения.
Спасибо.
Оконные функции PySpark — Spark By {Examples}
Распространение любви
Оконные функции PySpark используются для вычисления результатов, таких как ранг, номер строки и т. д., по диапазону входных строк. В этой статье я объяснил концепцию оконных функций, синтаксис и, наконец, как их использовать с PySpark SQL и PySpark DataFrame API. Это удобно, когда нам нужно выполнять агрегатные операции в определенном фрейме окна в столбцах DataFrame.
По возможности старайтесь использовать стандартную библиотеку, так как она немного более безопасна во время компиляции, обрабатывает null и работает лучше по сравнению с UDF. Если производительность вашего приложения критична, старайтесь любой ценой избегать использования настраиваемых UDF, поскольку они не гарантируют производительность.
Если производительность вашего приложения критична, старайтесь любой ценой избегать использования настраиваемых UDF, поскольку они не гарантируют производительность.
Учебное пособие по PySpark для начинающих (Испания)
Пожалуйста, включите JavaScript
Учебное пособие по PySpark для начинающих (Spark с Python)
1. Функции окна
Функции окна PySpark работают с группой строк (например, кадр, раздел) и возвращать одно значение для каждой входной строки PySpark SQL поддерживает три типа оконных функций:
- функции ранжирования
- аналитические функции
- агрегатные функции
оконные функции PySpark
В приведенной ниже таблице определены ранжирующие и аналитические функции, а для агрегатных функций мы можем использовать любые существующие агрегатные функции в качестве оконной функции.
Чтобы сначала выполнить операцию над группой, нам нужно разделить данные, используя Window.partitionBy() , а для номера строки и функции ранга нам нужно дополнительно упорядочить данные раздела, используя 9Заказ 0227 По пункту .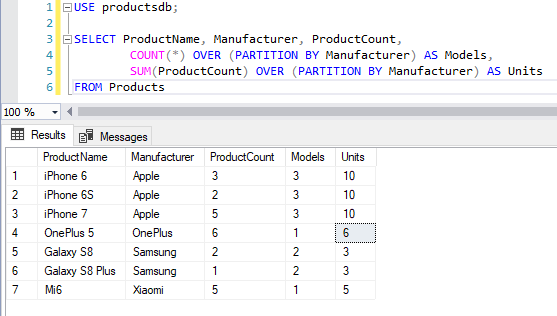
Нажмите на каждую ссылку, чтобы узнать больше об этих функциях вместе с примерами Scala.
| Использование и синтаксис оконных функций | Описание оконных функций PySpark |
|---|---|
| row_number(): Column | начиная с 1 в разделе окна |
| rank(): Столбец | Возвращает ранг строк в разделе окна с промежутками. |
| процент_ранк(): Столбец | Возвращает процентильный ранг строк в разделе окна. |
| плотности_rank(): столбец | Возвращает ранг строк в разделе окна без пробелов. Где as Rank() возвращает ранг с пробелами. |
| ntile(n: Int): столбец | Возвращает идентификатор ntile в разделе окна |
| cume_dist(): столбец | Возвращает кумулятивное распределение значений в разделе окна |
| отставание(e: Столбец, смещение: Int): Столбец отставание(columnName: String, offset: Int): Столбец отставание(columnName: String, offset: Int, defaultValue: Any): Столбец | возвращает значение значение, которое представляет собой «смещенные» строки перед текущей строкой, и «нулевое», если перед текущей строкой меньше «смещенных» строк.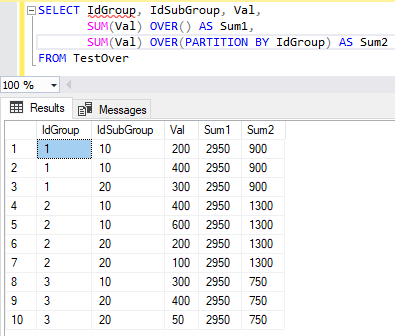 |
| отведение (имя столбца: строка, смещение: целое): столбец отведение (имя столбца: строка, смещение: целое): столбец отведение (имя столбца: строка, смещение: целое, значение по умолчанию: любое): столбец | возвращает значение, которое представляет собой «смещенные» строки после текущей строки, и «нулевое», если после текущей строки меньше «смещенных» строк. |
Прежде чем мы начнем с примера, сначала давайте создадим PySpark DataFrame для работы.
искра = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = (("Джеймс", "Продажи", 3000), \
("Майкл", "Продажи", 4600), \
("Роберт", "Продажи", 4100), \
("Мария", "Финанс", 3000), \
("Джеймс", "Продажи", 3000), \
("Скотт", "Финансы", 3300), \
("Джен", "Финанс", 3900), \
("Джефф", "Маркетинг", 3000), \
("Кумар", "Маркетинг", 2000 г.),\
("Саиф", "Продажи", 4100)\
)
columns= ["employee_name", "отдел", "зарплата"]
df = spark. createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
 createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
Урожайность ниже выпуска
корень |-- имя_сотрудника: строка (можно обнулить = истина) |-- отдел: строка (nullable = true) |-- зарплата: long (nullable = true) +-------------+----------+------+ |employee_name|отдел|зарплата| +-------------+----------+------+ |Джеймс |Продажи |3000 | |Майкл |Продажи |4600 | |Роберт |Продажи |4100 | |Мария |Финансы |3000 | |Джеймс |Продажи |3000 | |Скотт |Финансы |3300 | |Джен |Финансы |3900 | |Джефф |Маркетинг |3000 | |Кумар |Маркетинг |2000 | |Саиф |Продажи |4100 | +-------------+----------+------+
2. Окно PySpark
Функции ранжирования
2.1 Оконная функция row_number
row_number() Оконная функция используется для присвоения последовательного номера строки, начиная с 1 и заканчивая результатом каждого раздела окна.
из окна импорта pyspark.sql.window из pyspark.
 sql.functions импортировать row_number
windowSpec = Window.partitionBy("отдел").orderBy("зарплата")
df.withColumn("номер_строки",номер_строки().over(windowSpec)) \
.show(усечение=ложь)
sql.functions импортировать row_number
windowSpec = Window.partitionBy("отдел").orderBy("зарплата")
df.withColumn("номер_строки",номер_строки().over(windowSpec)) \
.show(усечение=ложь)
Выход ниже выходного.
+-------------+----------+------+----------+ |employee_name|отдел|зарплата|номер_строки| +-------------+----------+------+----------+ |Джеймс |Продажи |3000 |1 | |Джеймс |Продажи |3000 |2 | |Роберт |Продажи |4100 |3 | |Саиф |Продажи |4100 |4 | |Майкл |Продажи |4600 |5 | |Мария |Финансы |3000 |1 | |Скотт |Финансы |3300 |2 | |Джен |Финансы |3900 |3 | |Кумар |Маркетинг |2000 |1 | |Джефф |Маркетинг |3000 |2 | +-------------+----------+------+----------+
2.2 Оконная функция rank
rank() Оконная функция используется для присвоения ранга результату в разделе окна. Эта функция оставляет пробелы в рангах, когда есть ничья.
"""классифицировать"""
из рейтинга импорта pyspark.sql.functions
df.withColumn ("ранг", rank(). over (windowSpec)) \
. показывать()
 показывать()
показывать()
Выход ниже выходного.
+-------------+----------+------+----+ |employee_name|отдел|зарплата|ранг| +-------------+----------+------+----+ | Джеймс| Продажи| 3000| 1| | Джеймс| Продажи| 3000| 1| | Роберт| Продажи| 4100| 3| | Саиф| Продажи| 4100| 3| | Майкл| Продажи| 4600| 5| | Мария| Финансы| 3000| 1| | Скотт| Финансы| 3300| 2| | Джен| Финансы| 3900| 3| | Кумар| Маркетинг| 2000 | 1| | Джефф| Маркетинг| 3000| 2| +-------------+----------+------+----+
Это то же самое, что и функция RANK в SQL.
2.3 Оконная функция плотности_ранга
Оконная функция плотности_ранка() используется для получения результата с рангом строк в разделе окна без пробелов. Это похоже на отличие функции rank() от того, что функция ранга оставляет пробелы в ранге, когда есть связи.
"""денс_ранг"""
из pyspark.sql.functions импортирует плотное_ранг
df.withColumn("dense_rank",dense_rank().over(windowSpec)) \
. показывать()
Выход ниже выходного.
+-------------+----------+------+----------+ |employee_name|отдел|зарплата|dense_rank| +-------------+----------+------+----------+ | Джеймс| Продажи| 3000| 1| | Джеймс| Продажи| 3000| 1| | Роберт| Продажи| 4100| 2| | Саиф| Продажи| 4100| 2| | Майкл| Продажи| 4600| 3| | Мария| Финансы| 3000| 1| | Скотт| Финансы| 3300| 2| | Джен| Финансы| 3900| 3| | Кумар| Маркетинг| 2000 | 1| | Джефф| Маркетинг| 3000| 2| +-------------+----------+------+----------+
Это то же самое, что и функция DENSE_RANK в SQL.
2.4 Percent_Rank Оконная функция
""" процент_ранг """
из pyspark.sql.functions импортировать процент_ранг
df.withColumn("percent_rank",percent_rank().over(windowSpec)) \
.показывать()
Выход ниже выходного.
+-------------+----------+------+------------+ |employee_name|отдел|зарплата|percent_rank| +-------------+----------+------+------------+ | Джеймс| Продажи| 3000| 0.
 0|
| Джеймс| Продажи| 3000| 0.0|
| Роберт| Продажи| 4100| 0,5|
| Саиф| Продажи| 4100| 0,5|
| Майкл| Продажи| 4600| 1,0 |
| Мария| Финансы| 3000| 0.0|
| Скотт| Финансы| 3300| 0,5|
| Джен| Финансы| 3900| 1,0 |
| Кумар| Маркетинг| 2000 | 0.0|
| Джефф| Маркетинг| 3000| 1,0 |
+-------------+----------+------+------------+
0|
| Джеймс| Продажи| 3000| 0.0|
| Роберт| Продажи| 4100| 0,5|
| Саиф| Продажи| 4100| 0,5|
| Майкл| Продажи| 4600| 1,0 |
| Мария| Финансы| 3000| 0.0|
| Скотт| Финансы| 3300| 0,5|
| Джен| Финансы| 3900| 1,0 |
| Кумар| Маркетинг| 2000 | 0.0|
| Джефф| Маркетинг| 3000| 1,0 |
+-------------+----------+------+------------+
Это то же самое, что и функция PERCENT_RANK в SQL.
2.5 Функция окна ntile
Функция окна ntile() возвращает относительный ранг результирующих строк в разделе окна. В приведенном ниже примере мы использовали 2 в качестве аргумента для ntile, поэтому он возвращает ранжирование между 2 значениями (1 и 2)
"""нетиле"""
из pyspark.sql.functions импортировать плитку
df.withColumn("ntile",ntile(2).over(windowSpec)) \
.показывать()
Выход ниже выходного.
+-------------+----------+------+-----+ |employee_name|отдел|зарплата|ntile| +-------------+----------+------+-----+ | Джеймс| Продажи| 3000| 1| | Джеймс| Продажи| 3000| 1| | Роберт| Продажи| 4100| 1| | Саиф| Продажи| 4100| 2| | Майкл| Продажи| 4600| 2| | Мария| Финансы| 3000| 1| | Скотт| Финансы| 3300| 1| | Джен| Финансы| 3900| 2| | Кумар| Маркетинг| 2000 | 1| | Джефф| Маркетинг| 3000| 2| +-------------+----------+------+-----+
Это то же самое, что и функция NTILE в SQL.
3. Аналитические функции окна PySpark
3.1 Оконная функция cume_dist
cume_dist() Оконная функция используется для получения кумулятивного распределения значений в разделе окна.
То же, что и функция DENSE_RANK в SQL.
""" cume_dist """
из pyspark.sql.functions импортировать cume_dist
df.withColumn("cume_dist",cume_dist().over(windowSpec)) \
.показывать()
+-------------+-----------+---------- -+ |employee_name|отдел|зарплата| cume_dist| +-------------+-----------+---------- -+ | Джеймс| Продажи| 3000| 0,4| | Джеймс| Продажи| 3000| 0,4| | Роберт| Продажи| 4100| 0,8| | Саиф| Продажи| 4100| 0,8| | Майкл| Продажи| 4600| 1,0 | | Мария| Финансы| 3000|0,3333333333333333| | Скотт| Финансы| 3300|0,6666666666666666| | Джен| Финансы| 3900| 1,0 | | Кумар| Маркетинг| 2000 | 0,5| | Джефф| Маркетинг| 3000| 1,0 | +-------------+-----------+---------- -+
3.2 Функция окна задержки
Это то же самое, что и функция LAG в SQL.
"""отставание"""
от задержки импорта pyspark.sql.functions
df.withColumn ("отставание", отставание ("зарплата", 2). над (windowSpec)) \
.показывать()
+-------------+----------+------+----+ |employee_name|отдел|зарплата| отставание| +-------------+----------+------+----+ | Джеймс| Продажи| 3000|нуль| | Джеймс| Продажи| 3000|нуль| | Роберт| Продажи| 4100|3000| | Саиф| Продажи| 4100|3000| | Майкл| Продажи| 4600|4100| | Мария| Финансы| 3000|нуль| | Скотт| Финансы| 3300|нуль| | Джен| Финансы| 3900|3000| | Кумар| Маркетинг| 2000|нуль| | Джефф| Маркетинг| 3000|нуль| +-------------+----------+------+----+
3.3 Функция окна руководства
Это то же самое, что и функция LEAD в SQL.
"""вести"""
из руководства по импорту pyspark.sql.functions
df.withColumn («лидер», лид («зарплата», 2). над (windowSpec)) \
.показывать()
+-------------+----------+------+----+ |employee_name|отдел|зарплата|руководство| +-------------+----------+------+----+ | Джеймс| Продажи| 3000|4100| | Джеймс| Продажи| 3000|4100| | Роберт| Продажи| 4100|4600| | Саиф| Продажи| 4100|нуль| | Майкл| Продажи| 4600|нуль| | Мария| Финансы| 3000|3900| | Скотт| Финансы| 3300|нуль| | Джен| Финансы| 3900|нуль| | Кумар| Маркетинг| 2000|нуль| | Джефф| Маркетинг| 3000|нуль| +-------------+----------+------+----+
4.
 Агрегатные функции окна PySpark
Агрегатные функции окна PySpark
В этом разделе я объясню, как рассчитать сумму, минимум, максимум для каждого отдела с использованием функций окна PySpark SQL Aggregate и WindowSpec . При работе с агрегатными функциями нам не нужно использовать предложение order by.
903:00
windowSpecAgg = Window.partitionBy(«отдел»)
из pyspark.sql.functions импортировать col, avg, sum, min, max, row_number
df.withColumn («строка», row_number(). over (windowSpec)) \
.withColumn («среднее», среднее (столбец («зарплата»)). над (windowSpecAgg)) \
.withColumn («сумма», сумма (столбец («зарплата»)). над (windowSpecAgg)) \
.withColumn («мин», мин (столбец («зарплата»)). над (windowSpecAgg)) \
.withColumn(«max», max(col(«зарплата»)).over(windowSpecAgg)) \
.where(col(«row»)==1).select(«отдел»,»средний»,»сумма»,»минимум»,»максимум») \
.показывать()
Выход ниже
+----------+------+-----+----+----+ |отдел| среднее | сумма| мин| макс | +----------+------+-----+----+----+ | Продажи|3760,0|18800|3000|4600| | Финансы|3400.
 0|10200|3000|3900|
| Маркетинг|2500.0| 5000|2000|3000|
+----------+------+-----+----+----+
0|10200|3000|3900|
| Маркетинг|2500.0| 5000|2000|3000|
+----------+------+-----+----+----+
Дополнительные агрегатные функции см.
Пример исходного кода оконных функций
импортировать pyspark
из pyspark.sql импортировать SparkSession
искра = SparkSession.builder.appName('SparkByExamples.com').getOrCreate()
simpleData = (("Джеймс", "Продажи", 3000), \
("Майкл", "Продажи", 4600), \
("Роберт", "Продажи", 4100), \
("Мария", "Финанс", 3000), \
("Джеймс", "Продажи", 3000), \
("Скотт", "Финансы", 3300), \
("Джен", "Финанс", 3900), \
("Джефф", "Маркетинг", 3000), \
("Кумар", "Маркетинг", 2000 г.),\
("Саиф", "Продажи", 4100)\
)
columns= ["employee_name", "отдел", "зарплата"]
df = spark.createDataFrame (данные = simpleData, схема = столбцы)
df.printSchema()
df.show (усечение = Ложь)
из окна импорта pyspark.sql.window
из pyspark.sql.functions импортировать row_number
windowSpec = Window.partitionBy("отдел").orderBy("зарплата")
df. withColumn("номер_строки",номер_строки().over(windowSpec)) \
.show(усечение=ложь)
из рейтинга импорта pyspark.sql.functions
df.withColumn ("ранг", rank(). over (windowSpec)) \
.показывать()
из pyspark.sql.functions импортирует плотное_ранг
df.withColumn("dense_rank",dense_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать процент_ранг
df.withColumn("percent_rank",percent_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать плитку
df.withColumn("ntile",ntile(2).over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать cume_dist
df.withColumn("cume_dist",cume_dist().over(windowSpec)) \
.показывать()
от задержки импорта pyspark.sql.functions
df.withColumn ("отставание", отставание ("зарплата", 2). над (windowSpec)) \
.показывать()
из руководства по импорту pyspark.sql.functions
df.withColumn («лидер», лид («зарплата», 2). над (windowSpec)) \
.показывать()
windowSpecAgg = Window. partitionBy("отдел")
из pyspark.sql.functions импортировать col, avg, sum, min, max, row_number
df.withColumn ("строка", row_number(). over (windowSpec)) \
.withColumn ("среднее", среднее (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("сумма", сумма (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("мин", мин (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn("max", max(col("зарплата")).over(windowSpecAgg)) \
.where(col("row")==1).select("отдел","средний","сумма","минимум","максимум") \
.показывать()
 withColumn("номер_строки",номер_строки().over(windowSpec)) \
.show(усечение=ложь)
из рейтинга импорта pyspark.sql.functions
df.withColumn ("ранг", rank(). over (windowSpec)) \
.показывать()
из pyspark.sql.functions импортирует плотное_ранг
df.withColumn("dense_rank",dense_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать процент_ранг
df.withColumn("percent_rank",percent_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать плитку
df.withColumn("ntile",ntile(2).over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать cume_dist
df.withColumn("cume_dist",cume_dist().over(windowSpec)) \
.показывать()
от задержки импорта pyspark.sql.functions
df.withColumn ("отставание", отставание ("зарплата", 2). над (windowSpec)) \
.показывать()
из руководства по импорту pyspark.sql.functions
df.withColumn («лидер», лид («зарплата», 2). над (windowSpec)) \
.показывать()
windowSpecAgg = Window.
withColumn("номер_строки",номер_строки().over(windowSpec)) \
.show(усечение=ложь)
из рейтинга импорта pyspark.sql.functions
df.withColumn ("ранг", rank(). over (windowSpec)) \
.показывать()
из pyspark.sql.functions импортирует плотное_ранг
df.withColumn("dense_rank",dense_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать процент_ранг
df.withColumn("percent_rank",percent_rank().over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать плитку
df.withColumn("ntile",ntile(2).over(windowSpec)) \
.показывать()
из pyspark.sql.functions импортировать cume_dist
df.withColumn("cume_dist",cume_dist().over(windowSpec)) \
.показывать()
от задержки импорта pyspark.sql.functions
df.withColumn ("отставание", отставание ("зарплата", 2). над (windowSpec)) \
.показывать()
из руководства по импорту pyspark.sql.functions
df.withColumn («лидер», лид («зарплата», 2). над (windowSpec)) \
.показывать()
windowSpecAgg = Window. partitionBy("отдел")
из pyspark.sql.functions импортировать col, avg, sum, min, max, row_number
df.withColumn ("строка", row_number(). over (windowSpec)) \
.withColumn ("среднее", среднее (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("сумма", сумма (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("мин", мин (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn("max", max(col("зарплата")).over(windowSpecAgg)) \
.where(col("row")==1).select("отдел","средний","сумма","минимум","максимум") \
.показывать()
partitionBy("отдел")
из pyspark.sql.functions импортировать col, avg, sum, min, max, row_number
df.withColumn ("строка", row_number(). over (windowSpec)) \
.withColumn ("среднее", среднее (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("сумма", сумма (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn ("мин", мин (столбец ("зарплата")). над (windowSpecAgg)) \
.withColumn("max", max(col("зарплата")).over(windowSpecAgg)) \
.where(col("row")==1).select("отдел","средний","сумма","минимум","максимум") \
.показывать()
Полный исходный код доступен в PySpark Examples GitHub для справки.
Заключение
В этом руководстве вы узнали, что такое функции PySpark SQL Window, их синтаксис и как использовать их с агрегатной функцией, а также несколько примеров в Scala.
Ссылки
Я бы рекомендовал прочитать блоги Window Functions Introduction и SQL Window Functions API для лучшего понимания функций Windows. Кроме того, обратитесь к функциям окна SQL, чтобы узнать функции окна из собственного SQL.