Перестроение индексов ms sql: Оптимальное поддержание индексов для повышения производительности и сокращения использования ресурсов — SQL Server
Задача «Перестроение индекса» (план обслуживания) — SQL Server
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
-
Применимо к:SQL Server
Диалоговое окно Задача «Перестроение индекса» используется для пересоздания индексов на таблицах в базе данных с новым коэффициентом заполнения. Коэффициент заполнения определяет количество пустого пространства на каждой странице индекса для обеспечения роста в будущем. При добавлении данных в таблицу свободное пространство заполняется, так как коэффициент заполнения не поддерживается. Восстановить свободное пространство можно путем реорганизации данных и страниц индекса.
Коэффициент заполнения определяет количество пустого пространства на каждой странице индекса для обеспечения роста в будущем. При добавлении данных в таблицу свободное пространство заполняется, так как коэффициент заполнения не поддерживается. Восстановить свободное пространство можно путем реорганизации данных и страниц индекса.
Задача «Перестроение индекса» использует инструкцию ALTER INDEX. Дополнительные сведения о параметрах, описанных на этой странице, см. в разделе ALTER INDEX (Transact-SQL).
Параметры
Соединение
Выберите соединение с сервером, которое будет использоваться для выполнения этой задачи.
Создать
Создать новое соединение с сервером для его использования при выполнении этой задачи. Диалоговое окно Создание соединения описано ниже.
Базы данных
Укажите базы данных, для которых должна выполняться эта задача.

Все базы данных
Создайте план обслуживания, который выполняет задачи обслуживания для всех баз данных SQL Server, кроме
tempdb.Все системные базы данных
Создайте план обслуживания, который выполняет задачи обслуживания для каждой из SQL Server системных баз данных, за исключением
tempdb. Для баз данных, созданных пользователями, задачи обслуживания выполняться не будут.Все пользовательские базы данных
Создается план обслуживания, по которому задачи обслуживания выполняются для всех баз данных, созданных пользователем. Для системных баз данных SQL Server задачи обслуживания выполняться не будут.
Определенные базы данных
Создается план обслуживания, по которому задачи обслуживания должны выполняться только для указанных баз данных. Если выбран этот параметр, необходимо выбрать в списке хотя бы одну базу данных.
Примечание
Планы обслуживания выполняются только для баз данных, уровень совместимости которых 80 или выше. Базы данных с уровнем совместимости 70 или ниже не отображаются.
Объект
Ограничьте сетку Выбор для отображения таблиц, представлений или обоих элементов.
Выбор
Укажите таблицы или индексы, которые должны обрабатываться этой задачей. Недоступно, если в диалоговом окне «Объект» выбран тип Таблицы и представления .
Свободное пространство по умолчанию на странице
Удалите индексы таблиц в базе данных и создайте их повторно с коэффициентом заполнения, указанным при создании индексов.
Изменить долю свободного места на странице
Удалите индексы таблиц в базе данных и создайте их повторно с новым, автоматически вычисляемым коэффициентом заполнения, резервирующим указанный объем свободного пространства на страницах индекса.
Чем выше процентное значение, тем больше свободного места резервируется на страницах индекса и тем больше будет размер индекса. Допустимые значения: от 0 до 100.Отсортировать результаты в базе данных tempdb
Параметр
SORT_IN_TEMPDBиспользуется для определения места временного сохранения промежуточных результатов сортировки, формируемых во время создания индекса. Если операция сортировки не требуется или сортировка может быть выполненаSORT_IN_TEMPDBв памяти, параметр игнорируется.разредить индекс
Укажите заполнение индекса.
Сохранять индекс в режиме «в сети»
ONLINEИспользуйте параметр , который позволяет пользователям получать доступ к базовой таблице или данным кластеризованного индекса и любым связанным некластеризованным индексам во время операций с индексами.Примечание
Операции с индексами в сети доступны не во всех выпусках Microsoft SQL Server.
Список функций, поддерживаемых выпусками SQL Server, см. в разделе Выпуски и поддерживаемые функции SQL Server 2022.Не перестраивать индексы | Перестроить индексы в режиме «вне сети»
Укажите действия для типов индексов, которые нельзя перестроить, пока они находятся в сети.
MAXDOP
Укажите значение для ограничения числа процессоров, используемых при параллельном выполнении планов.
Используется низкий приоритет
Выберите этот параметр для ожидания блокировок с низким приоритетом.
Прервать после ожидания
Укажите действие, которое должно выполняться по истечении времени, заданного параметром Максимальная длительность .
Максимальная длительность
Укажите длительность ожидания блокировок с низким приоритетом.
Просмотр T-SQL
Просмотрите инструкции Transact-SQL, выполняемые на сервере для этой задачи, на основе выбранных параметров.
Примечание
Если количество затронутых объектов велико, построение этого отображения может занять значительное время.

 Чем выше процентное значение, тем больше свободного места резервируется на страницах индекса и тем больше будет размер индекса. Допустимые значения: от 0 до 100.
Чем выше процентное значение, тем больше свободного места резервируется на страницах индекса и тем больше будет размер индекса. Допустимые значения: от 0 до 100. Список функций, поддерживаемых выпусками SQL Server, см. в разделе Выпуски и поддерживаемые функции SQL Server 2022.
Список функций, поддерживаемых выпусками SQL Server, см. в разделе Выпуски и поддерживаемые функции SQL Server 2022.
Параметры статистики индексов
В более ранних версиях Microsoft SQL Server операции реорганизации или повторного создания больших индексов могли снижать производительность системы. SQL Server 2016 (13.x) реализованы значительные улучшения производительности для этих операций с индексами.
Кроме того, в более ранних версиях было доступно меньше возможностей управления. Это заставило систему реорганизовать или перестроить некоторые индексы, даже если индексы не были сильно фрагментированы, что было расточительно. Новые элементы управления в пользовательском интерфейсе плана обслуживания позволяют исключать индексы, которые не нужно обновлять, на основе критериев статистики индекса. Для этого для внутреннего использования используются следующие динамические административные представления (DMV) Transact-SQL:
- sys.dm_db_index_usage_stats
- sys. dm_db_index_physical_stats.
 dm_db_index_physical_stats.
dm_db_index_physical_stats.Тип просмотра
Система должна использовать ресурсы для сбора статистики индексов. Вы можете выбрать объем используемых ресурсов, исходя из того, какой уровень точности, по вашему мнению, требуется для статистики индексов. В пользовательском интерфейсе доступны следующие уровни точности:
- быстрый;
- с выборкой;
- Подробно
Оптимизация индекса только в том случае, если
Пользовательский интерфейс предлагает следующие настраиваемые фильтры, которые можно использовать, чтобы избежать обновления индексов, которые еще не требуют обновления.
- Фрагментация >(%)
- число страниц >;
- использовано за последние (дни) .
Диалоговое окно «Новое соединение»
Имя соединения
Введите имя нового соединения.
Выберите или введите имя сервера
Выберите сервер для подключения при выполнении этой задачи.
Обновить
Обновите список доступных серверов.
Введите данные для входа на сервер
Укажите способ проверки подлинности на сервере.
Использовать встроенную безопасность Windows
Подключиться к экземпляру компонента SQL Server Компонент Database Engine c проверкой подлинности Microsoft Windows.
Использовать указанные имя пользователя и пароль
Подключиться к экземпляру компонента SQL Server Компонент Database Engine с использованием проверки подлинности SQL Server. Этот параметр недоступен.
User name
Укажите имя входа, используемое при проверке подлинности SQL Server . Этот параметр недоступен.
Пароль
Укажите используемый при проверке подлинности пароль. Этот параметр недоступен.
См. также раздел
- ALTER INDEX (Transact-SQL)
- DBCC DBREINDEX (Transact-SQL)
- Инструкция CREATE INDEX (Transact-SQL)
- Параметр SORT_IN_TEMPDB для индексов
- Рекомендации по операциям с индексами в оперативном режиме
- Об операциях с индексом в сети
- Выполнение операций с индексами в оперативном режиме
5 рекомендаций для повышения производительности в DIRECTUM 5 | Статья
Иногда наши клиенты сталкиваются с ситуацией медленной работы системы DIRECTUM. В некоторых случаях низкая производительность наблюдается только у части пользователей, в других – подобное влияние испытывает на себе большинство.
В некоторых случаях низкая производительность наблюдается только у части пользователей, в других – подобное влияние испытывает на себе большинство.
Решение подобных кейсов, как правило, начинается с выполнения диагностики общего состояния системы (если вы ещё не знаете, что это, то на этот счёт есть ряд статей: Какой диагноз у вашей системы?, Диагностика системы DIRECTUM: из мухи сделали слона, Диагностика общего состояния системы DIRECTUM: 8 часто задаваемых вопросов), по результатам которой часто выдаются типовые рекомендаций, благодаря которым можно снизить нагрузку на базу данных и на клиентскую часть.
В данной статье рассмотрим эти рекомендации, и ряд рекомендаций для администратора SQL-сервера, направленных на повышение производительности системы.
1. Ссылки в предопределённых папках
Одной из самых распространённых причин, которая приводит к длительному запуску проводника DIRECTUM и долгому обновлению содержимого папок, является большое количество ссылок в предопределённых папках Входящие и Исходящие.
Дело в том, что при обновлении содержимого этих папок (а оно происходит в том числе и при запуске проводника) осуществляется серия запросов к базе данных. Чем больше ссылок находится в папках, тем дольше будет обрабатываться этот запрос базой данных и тем дольше клиентская часть на компьютере пользователя будет получать результаты этого запроса и обрабатывать их.
Таким образом, простое уменьшение количества ссылок в предопределённых папках у пользователей может увеличить скорость запуска проводника, снизить нагрузку на базу данных и сеть. Рекомендуемое значение – не более 100 ссылок на обе папки.
Полезно будет знать и о параметре FolderCacheUpdatePeriod в установках системы. Он позволяет управлять временем, через которое обновляется локальный кэш папок. При открытии папки её содержимое будет подгружаться из локального кэша и не будет нагружать базу данных. Запросы к базе данных будут выполняться только в том случае если содержимое папки изменялось или с момента предыдущего чтения содержимого папки с сервера прошло больше времени, чем задано в установке FolderCacheUpdatePeriod.
Таким образом, в системах с большим количеством пользователей полезно установить значение этого параметра побольше (например, 720), чтобы уменьшить ненужную нагрузку от обновления содержимого редко используемых папок. Интервал обновления кэша задаётся в часах. Значение 0 соответствует отключенному кэшированию, поэтому стоит его избегать.
2. Фильтр по периоду
Вторая частая причина, «благодаря» которой у пользователя долго открываются справочники и также создаётся лишняя нагрузка на базу данных – отсутствие фильтров по периоду.
Фильтр по периоду – это механизм, который позволяет выгружать с сервера и отображать пользователю только те записи, которые были созданы в заданный период. Это позволяет не только снизить нагрузку на базу данных, но и быстрее получить доступ к необходимой информации. Ведь в большинстве случаев нужен доступ к «оперативным» данным, а не записям двухлетней давности и логичнее для этого получить, скажем, 200 записей, а не 10000.
Данные об установленном для каждого пользователя фильтре по периоду хранятся в таблице XIni. Для удобства массового проставления был написан isbl-сценарий (во вложении к статье), который позволяет выбрать необходимые даты, установить только начальный или только конечный периоды сразу для всех пользователей системы:
Для удобства массового проставления был написан isbl-сценарий (во вложении к статье), который позволяет выбрать необходимые даты, установить только начальный или только конечный периоды сразу для всех пользователей системы:
Помимо описанных выше способов, есть другие, постоянные направления, которые уже полностью ложатся на плечи администратора SQL-сервера: актуализация и оптимизация состава индексов, их реорганизация, обновление планов запросов и триггеров.
3. Состав индексов
С течением времени изменяется профиль работы пользователей, работающих с системой, их количество, могут изменяться бизнес-процессы. Всё это изменяет и профиль нагрузки на SQL-сервер.
В связи с этим, для обеспечения эффективной работы необходимо регулярно осуществлять актуализацию состава индексов: создавать новые необходимые индексы, модифицировать существующие, удалять или отключать не использующиеся, т.к. они могут создавать повышенную нагрузку на дисковую систему при изменении данных в часто используемых таблицах.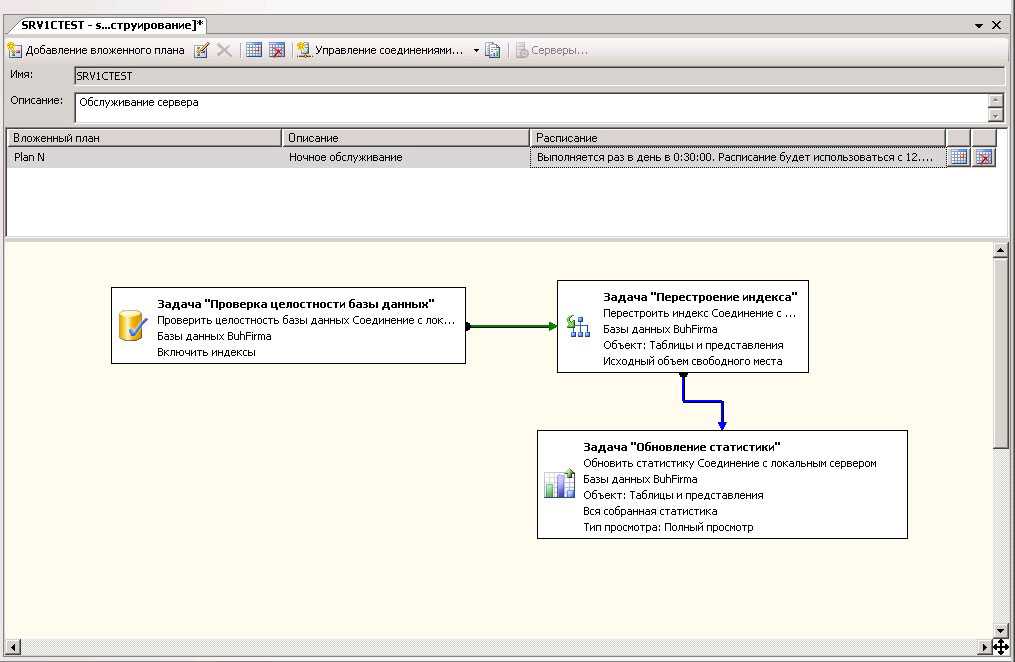 Это, в свою очередь, ведёт к снижению производительности сервера SQL.
Это, в свою очередь, ведёт к снижению производительности сервера SQL.
Как можно определить какие индексы нужны, а какие нет? Сервер SQL ведёт статистику по частоте использования существующих индексов, а также, на основе статистики запросов, формирует рекомендации по их созданию (отмечу, что статистика ведётся с момента запуска SQL-сервера и при его перезапуске сбрасывается).
Эту статистику можно получить SQL-запросами, представленными в сценариях: «Поиск редко используемых индексов.sql», «Поиск не используемых индексов.sql», «Рекомендуемые индексы.sql» (тексты этих запросов во вложении к статье).
Результат поиска редко используемых индексов будет выглядеть примерно так:
Он содержит в себе имя и тип индекса, таблицу на которой он создан, имя базы данных, содержащее эту таблицу, и статистику обращения к этому индексу.
Результат поиска неиспользуемых индексов схож с предыдущим:
Он содержит более подробную информацию по количеству и типам обращений к индексу и занимаемый индексами объём на диске.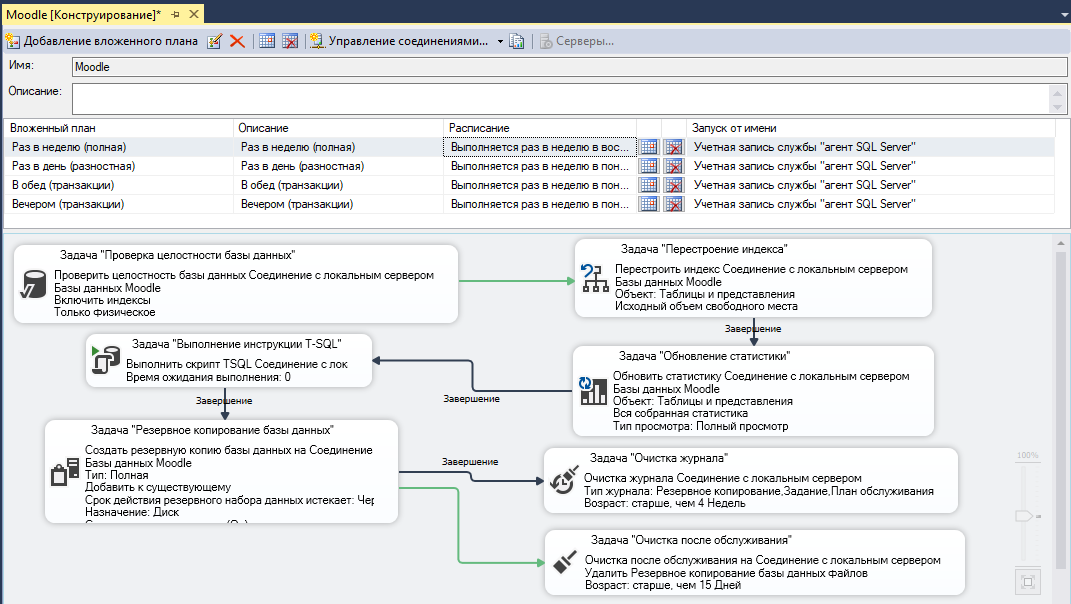
Рекомендации по необходимым индексам выглядят так:
В них указывается таблица, для которой рекомендован индекс и генерируется текст запроса, которым можно этот индекс создать. Также, фигурирует показатель среднего расчётного воздействия Avg_Estimated_Impact. Описать его можно, как среднее оценочное уменьшение «стоимости» выполнения запроса в процентах.
Эти данные следует воспринимать, как задающие направление для возможной оптимизации, а не как прямое руководство к действию, т.к., механизм сбора данной статистики может быть не совсем точен в своей оценке. При изменении состава индексов стоит внимательно анализировать возможные последствия. Не стоит создавать на таблицу больше 5-10 индексов, т.к. избыточное их количество будет только замедлять работу.
Кроме того, полезно проводить анализ SQL-трейсов базы данных. Суть состоит в том, что записав в течение одного рабочего дня трейс с помощью SQL Server Profiler, можно, накладывая различные фильтры, выделять группы ресурсоёмких запросов, которые имеют высокое потребление процессорного времени, большое количество операций чтения-записи и т. п. Выделив «тяжёлые» запросы, можно попытаться их оптимизировать – модифицировать прикладную разработку, создать новые индексы или изменить существующие.
п. Выделив «тяжёлые» запросы, можно попытаться их оптимизировать – модифицировать прикладную разработку, создать новые индексы или изменить существующие.
Полезно предварительно подвергнуть разбору действительный план выполнения запроса (Actual Execution Plan). Его можно записать и в трейсе, но «вычленять» его оттуда для конкретного запроса несколько неудобно, поэтому можно выполнить интересующий запрос в SQL Management Studio, предварительно включив на тулбаре кнопку Include Actual Execution Plan. План запроса будет выглядеть примерно так:
Если оптимизатор запросов посчитает, что для наилучшего выполнения запроса не хватает какого-то индекса, то напишет об этом в шапке плана запроса. Также, сгенерирует шаблон текста запроса для создания этого индекса.
Для советов по оптимизации запроса можно воспользоваться инструментом Database Engine Tuning Advisor, который входит в пакет администрирования MS SQL Server. Достаточно выделить запрос в SQL Management Studio и выбрать в контекстном меню «Analyze Query in Database Tuning Advisor».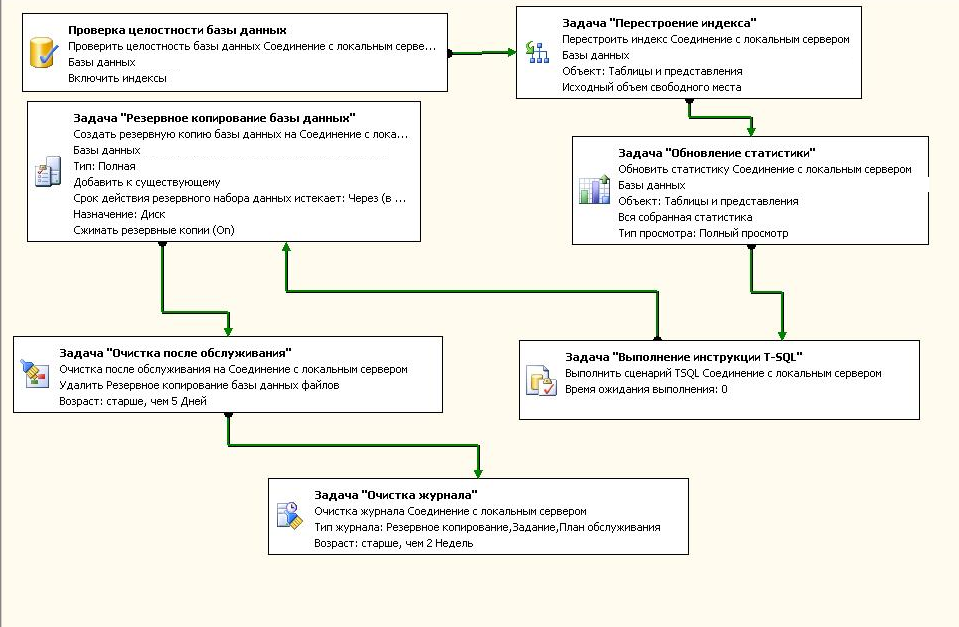 Далее запустить анализ, по окончании которого будут сформированы рекомендации по созданию индексов. Отмечу, что лучше проводить анализ запроса через этот инструмент не в рабочее время и не спешить притворять их в жизнь, а подвергнуть сначала всестороннему рассмотрению, спрогнозировать возможные последствия.
Далее запустить анализ, по окончании которого будут сформированы рекомендации по созданию индексов. Отмечу, что лучше проводить анализ запроса через этот инструмент не в рабочее время и не спешить притворять их в жизнь, а подвергнуть сначала всестороннему рассмотрению, спрогнозировать возможные последствия.
Мероприятия по актуализации состава индексов должны проводиться администратором системы регулярно.
4. Реорганизация и перестроение индексов
Зачем нужна реорганизация и перестроение индексов?
При выполнении операций добавления, изменения или удаления записей таблицы сервер SQL автоматически актуализирует её индексы и, через определённое время, данные в индексе будут «рассеяны» по базе данных – фрагментированы. Индексы будут содержать страницы, логический порядок данных в которых, основанный на ключевых значениях, будет отличается от физического порядка внутри файла данных. Таким образом, сильно фрагментированные индексы будут приводит к снижению скорости выполнения запросов за счёт увеличения времени получения данных.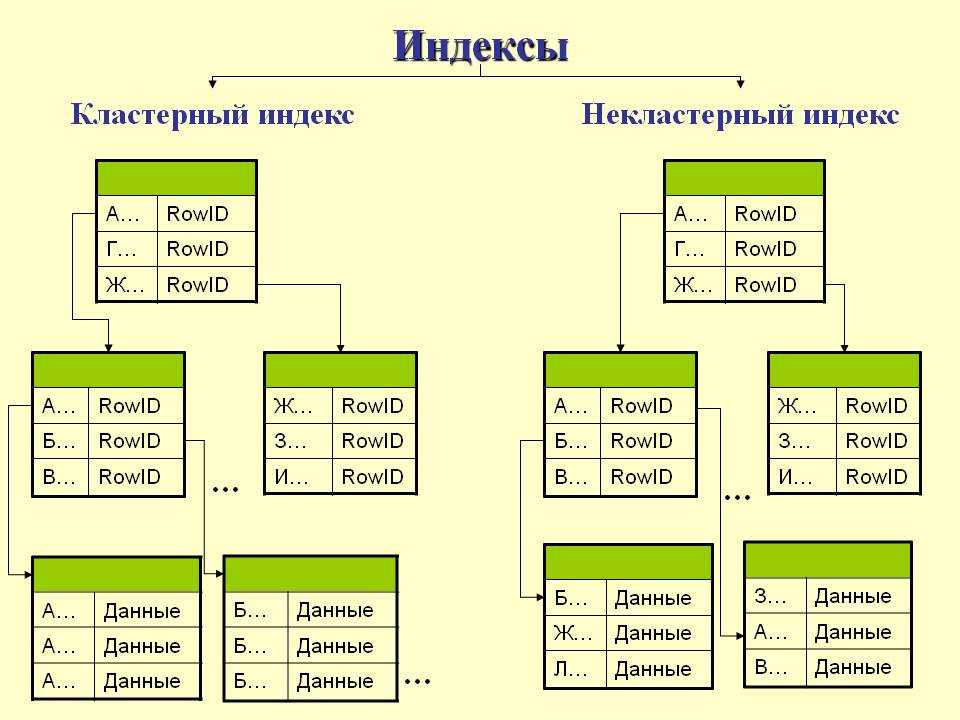
Перестроение индекса (REBUILD) удаляет и создаёт его заново, устраняя фрагментацию и уменьшая место, занимаемой им на диске. Данная операция довольно ресурсоёмка, поэтому её стоит выполнять в нерабочее время.
Процесс реорганизации (REORGANIZE) представляет из себя дефрагментацию индекса, в ходе которой происходит физическая сортировка страниц индекса в соответствии с их логическим порядком. Реорганизация индексов использует минимальное количество системных ресурсов, тем не менее тоже рекомендуется выполнять её в нерабочее время.
Полезно создать Задание (Job) по реорганизации/перестроению индексов на сервере SQL, которое будет выполняться каждые один-два дня во время наименьшей нагрузки, например, ночью. В приложении к статье есть пример sql-сценария для Job’а , который, в зависимости он степени фрагментации индекса, делает одну или другую операцию.
5. Обновление статистик
Итак, что же такое статистики и зачем их обновлять?
Статистика – это объект, который содержит статистические сведения о распределении значений в одной или более столбцах таблицы или индексированного представления. Оптимизатор запросов использует статистики для оценки количества строк в результате запроса. Эта оценка количества результирующих строк позволяет оптимизатору построить высокоэффективный план выполнения запроса, что позволяет значительно ускорить его выполнение, тем самым повышая производительность системы.
Оптимизатор запросов использует статистики для оценки количества строк в результате запроса. Эта оценка количества результирующих строк позволяет оптимизатору построить высокоэффективный план выполнения запроса, что позволяет значительно ускорить его выполнение, тем самым повышая производительность системы.
Обновление статистик обеспечивает компилирование запросов с актуальными сведениями о распределении данных, поэтому данную операцию рекомендуется проводить более-менее регулярно. Однако, не стоить этого делать и слишком часто, чтобы выигрыш в производительности за счёт эффективных планов запросов не был перевешен тратой времени на перекомпиляцию запросов.
Заключение
Следуя этим рекомендациям, регулярно проводя мероприятия по обслуживанию базы данных можно избежать ситуаций с медленной работой системы.
Прикреплен файл: Сценарии.zip
Как перестроить и реорганизовать индекс в SQL Server с помощью SSMS и T-SQL
Навин Шарма |
Изменено: 10 июля 2018 г. |
|
SQL Server 2016 |
Резюме : В этом документе описаны методические процедуры реорганизации и перестроения любого фрагментированного индекса в MS SQL Server. Все методы разделены на различные подразделения, чтобы сделать эту операцию несложной для пользователей. Благодаря указанным процедурам пользователи, возможно, выполнят задачу без потери данных. К последней части этой статьи также относится профессиональный метод перестроения индекса в SQL Server.
Что такое фрагментация индекса в SQL Server
Индекс SQL Server аналогичен индексу любой книги. Этот указатель помогает получить быстрое представление о содержащихся данных, но вместо навигации по какой-либо книге это каталог базы данных SQL Server.
Всякий раз, когда в SQL выполняется какая-либо операция поиска, SQL Server ищет значение в своем индексе, а затем находит всю строку данных. Поэтому SQL Server не выполняет полный процесс сканирования таблицы для поиска каких-либо данных и предоставляет нам необходимые данные через свои индексы.
SQL Server автоматически поддерживает свои индексы после выполнения в нем любой операции, такой как INSERT, UPDATE, MERGE и DELETE. Когда логический порядок страниц в индексе не совпадает с его физическим порядком данных, происходит фрагментация индекса. Глубоко фрагментированный индекс снижает производительность MS SQL Server и может быть причиной медленного отклика ОС.
Фрагментация также влияет на выполняемые запросы и процесс сканирования диапазона. Много неиспользуемого пространства может увеличить количество страниц в индексе.
Фрагментацию индекса можно отслеживать только путем перестроения или повторного создания этого индекса. Этот процесс устраняет фрагментацию и освобождает место для хранения за счет сжатия размера страниц.
В этом процессе дефрагментации мы устанавливаем конкретный или существующий коэффициент заполнения, а затем он поддерживает строки индекса на соседних страницах. Для перестроения любого индекса используются лишь незначительные системные ресурсы.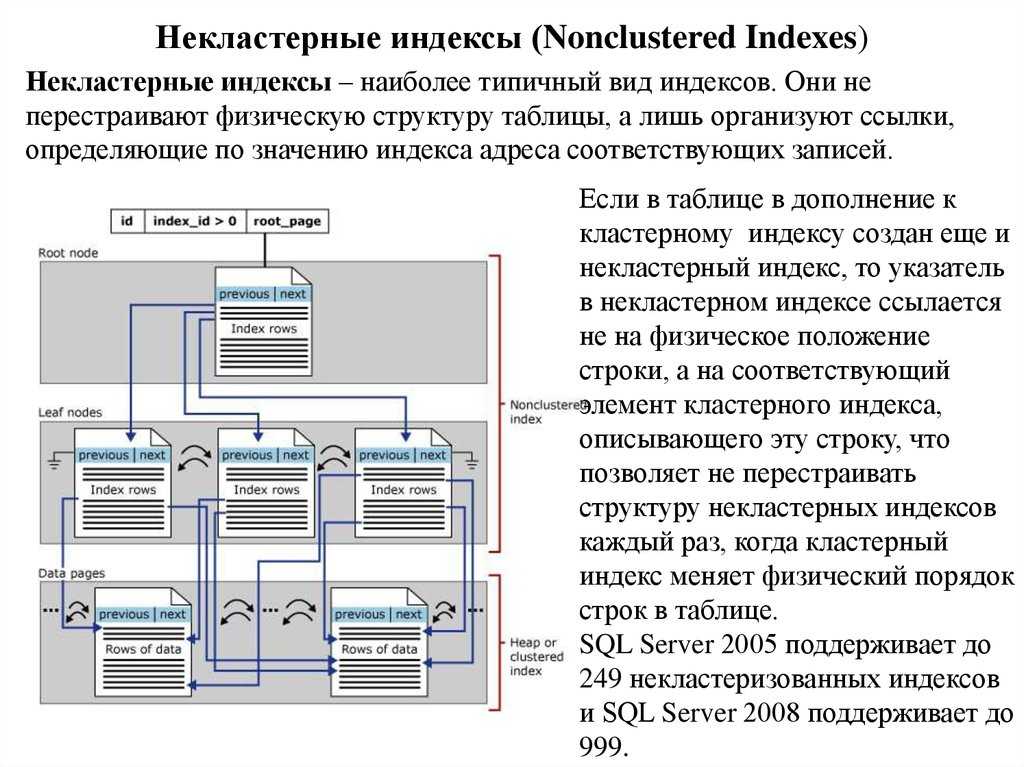 реорганизация дефрагментирует конечный уровень кластеризованного индекса и некластеризованных индексов таблиц. Перестроение индексов также сокращает количество индексных страниц. Сжатие индекса основано на представленном значении коэффициента заполнения.
реорганизация дефрагментирует конечный уровень кластеризованного индекса и некластеризованных индексов таблиц. Перестроение индексов также сокращает количество индексных страниц. Сжатие индекса основано на представленном значении коэффициента заполнения.
Как обнаружить фрагментацию индекса в SQL Server
Информацию о внутренней фрагментации индекса можно легко обнаружить с помощью представления динамического управления (DMV), которое называется sys.dm_db_index_physical_stats. DMV дефрагментирует информацию об индексе и возвращает ее точный размер. Через DMV пользователи могут получить информацию о степени фрагментации строк на конкретной странице данных. Это может определить, является ли реорганизация данных необходимой или нет.
avg_fragmentation_in_percent: средний процент логической фрагментации в индексе неточен
fragment_count: количество фрагментов в индексе
После того, как фрагментация в индексе будет воспринята, следующим шагом будет его создание. Обычно существует условное разрешение для каждого уровня фрагментации, основанное на пропорции фрагментации:
Обычно существует условное разрешение для каждого уровня фрагментации, основанное на пропорции фрагментации:
Если фрагментация < 10% – дефрагментация не требуется. Это приемлемое количество, не влияющее на работу MS SQL Server
Если фрагментация ≤ 10-30% – требуется реструктуризация индекса
Если фрагментация ≥ 30% – необходимо перестроение индекса
Реорганизация и перестроение Индекс в MS SQL Server
Реконструкция индекса необходима, когда фрагментация индекса достигает значительного процента. В этом разделе мы перестроим индекс с помощью SQL Server Management Studio и Transact-SQL.
Реорганизация и перестроение индекса с помощью MS SQL Server Management Studio
Для перестроения любого фрагментированного индекса SQL Server могут быть два возможных условия: перестроение одного индекса и перестроение всех индексов таблицы. Вот полные решения о том, как реорганизовать и перестроить любой индекс с помощью SQL Server Management Studio:
Случай 1: Реорганизация одного индекса
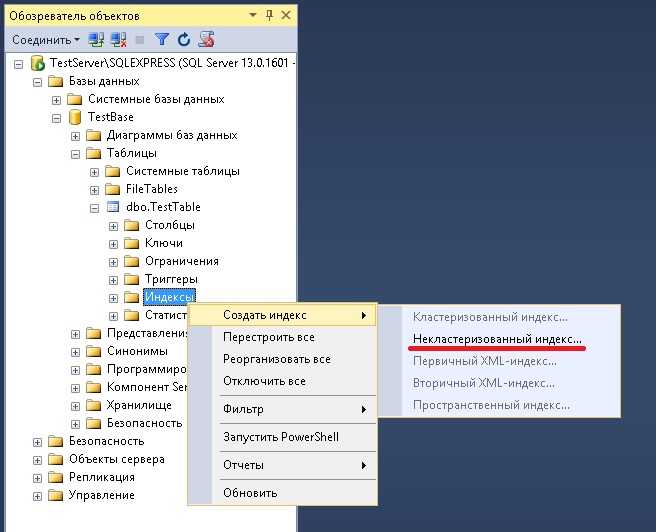
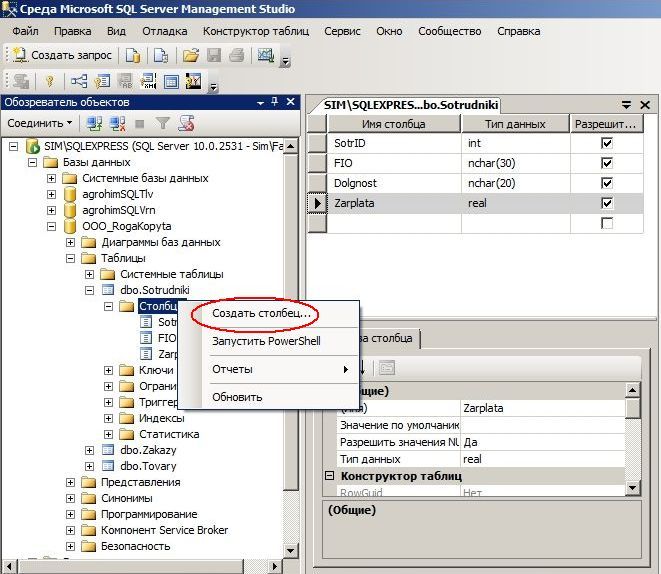
- Нажмите на стрелку обозревателя объектов ; выберите базу данных, содержащую таблицу, которую необходимо реорганизовать и перестроить
- Выберите папку Tables
- Щелкните индекс и израсходуйте папку Indexes
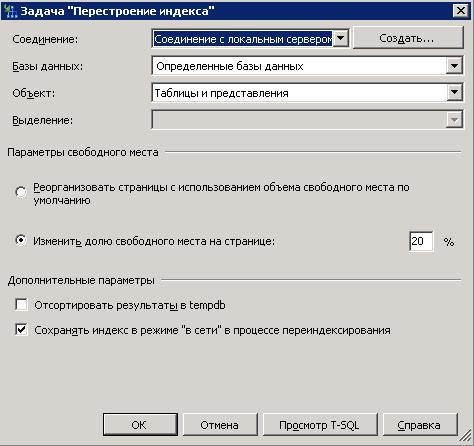
- Щелкните правой кнопкой мыши индекс , который необходимо реорганизовать, и выберите реорганизацию из расширенного списка меню.
- Проверьте индекс из Индексов для реорганизации и нажмите кнопку Ok
- Теперь нажмите Компактные данные столбца больших объектов
- Установите этот флажок, чтобы указать, что целые страницы, содержащие данные больших объектов (LOB) также должны быть сжаты
- Нажмите кнопку Ok
Случай 2: Реорганизация всех индексов таблицы
- Щелкните стрелку раскрывающегося списка базы данных, содержащей таблицу, в которой необходимо реорганизовать индексы
- Теперь нажмите на Таблицы , чтобы развернуть список меню
- Щелкните правой кнопкой мыши Индексы и выберите реорганизовать все
- В реорганизовать индексы 9Мастер 0006, проверьте индексы из Индексы для реорганизации
- Если вам нужно удалить любой индекс, выберите этот индекс и нажмите кнопку Удалить
- Выберите Сжать данные столбца больших объектов и убедитесь, что все страницы, содержащие данные больших объектов (LOB), сжаты или нет
- Затем нажмите кнопку Ok
Перестроение индекса в MS SQL Server
- Выберите базу данных и нажмите на ее стрелка проводника объекта
- Нажмите на таблицу , в которой есть индексы, необходимые для перестроения
- Выберите Таблицы папку и разверните ее
- После этого нажмите на нужный индекс нужно его реорганизовать и открыть
- Теперь щелкните правой кнопкой мыши индекс и выберите реорганизовать вариант
- Окно Rebuild Indexes теперь открыто, установите флажок input index через Indexes to rebuild option
- Нажмите кнопку «ОК»
- Для указания всех страниц данных больших объектов (LOB) нажмите Компактные данные столбца больших объектов
- Нажмите кнопку Ok
Нажмите кнопку
Реорганизация и перестроение индекса с помощью T-SQL
В этом разделе мы обсудим метод распознавания и перестроения любого одного или нескольких индексов любой таблицы с помощью Transact-SQL.
Случай 1: Реорганизация одного дефрагментированного индекса
- Нажмите Обозреватель объектов
- На стандартной панели нажмите Новый запрос вариант
- Теперь скопируйте указанную команду и вставьте ее в окно запроса
- После этого нажмите Выполнить
Случай 2. Реорганизация всех дефрагментированных индексов
- Выберите базу данных и изучите ее
- Соедините его с ядром базы данных
- Нажмите кнопку «Новый запрос», которая находится на стандартной панели
- Скопируйте указанные ниже команды и вставьте их в панель запросов
- Нажмите кнопку «Выполнить»
.
Восстановление одного дефрагментированного индекса
- Щелкните обозреватель объектов и подключите его к компоненту Database Engine
- Выберите новый запрос из стандартных опций панели
- Скопируйте указанные команды и вставьте их в окно запроса
Перестроение всех дефрагментированных индексов
- Подключение обозревателя объектов к компоненту Database Engine
- Щелкните Новый запрос
- Теперь скопируйте упомянутые ниже запросы и вставьте их в панель запросов
- Выполнение этих команд восстановит все индексы, связанные с таблицей
Автоматическая перестройка индекса и управление статистикой
Ручные методы являются рискованными и требуют времени. Пользователям необходимы технические знания для перестроения индексов в MS SQL Server. Поэтому для предотвращения пользователей через эти недостатки ручных методов мы представляем мощное решение, т.е. Средство восстановления индекса SQL Server . Он автоматически управляет дефрагментацией индекса вместе с обновлениями статистики, предназначенными для одной или дополнительных баз данных. Это метод автоматической перестройки или реорганизации любого индекса в соответствии с уровнем его фрагментации. Это способно восстановить данные, пострадавшие от атаки программы-вымогателя кошелька.
Пользователям необходимы технические знания для перестроения индексов в MS SQL Server. Поэтому для предотвращения пользователей через эти недостатки ручных методов мы представляем мощное решение, т.е. Средство восстановления индекса SQL Server . Он автоматически управляет дефрагментацией индекса вместе с обновлениями статистики, предназначенными для одной или дополнительных баз данных. Это метод автоматической перестройки или реорганизации любого индекса в соответствии с уровнем его фрагментации. Это способно восстановить данные, пострадавшие от атаки программы-вымогателя кошелька.
Заключение
После понимания значения фрагментации индексов MS SQL Server становится необходимым распознать и перестроить индексы. Для перестроения фрагментированных индексов мы обсудили различные методы перестроения индекса в SQL Server. Пользователи могут выполнять эту задачу двумя разными способами: вручную и автоматически, как указано выше. Инструмент восстановления SQL Server — одно из лучших решений для беспроблемного выполнения упомянутой задачи.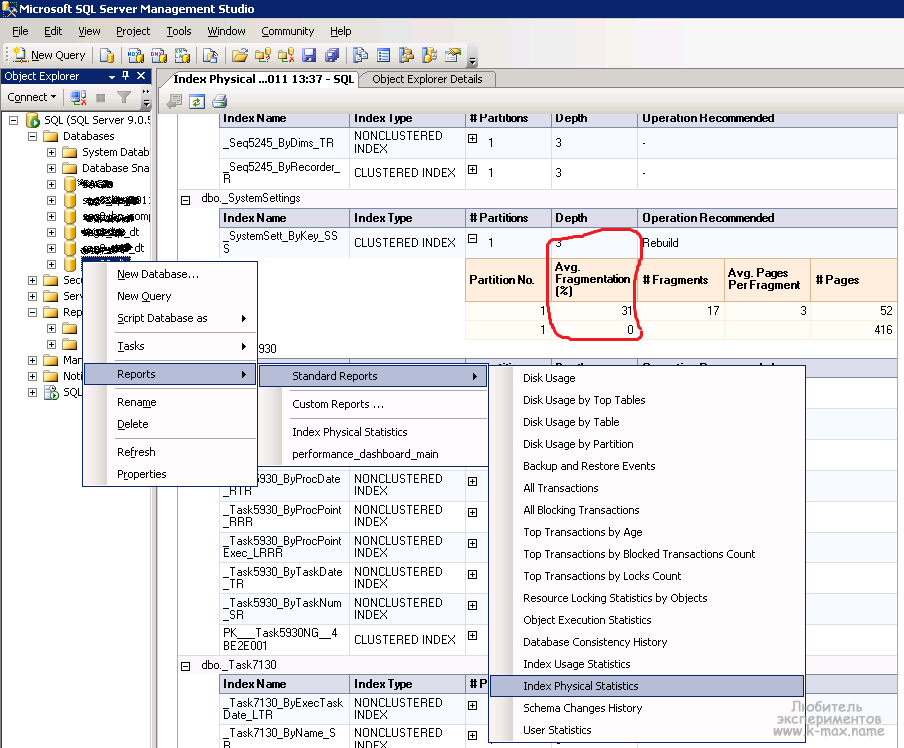 Теперь пользователи могут выбрать любую подходящую технику, чтобы сделать это.
Теперь пользователи могут выбрать любую подходящую технику, чтобы сделать это.
Реорганизация индекса по сравнению с перестроением индекса в плане обслуживания сервера Sql
Я исследовал Интернет и нашел несколько хороших статей. В конце я написал функцию и сценарий ниже, которые реорганизуют, воссоздают или перестраивают все индексы в базе данных.
Сначала вам может понадобиться прочитать эту статью, чтобы понять, почему мы не просто воссоздаем все индексы.
Во-вторых, нам нужна функция для построения сценария создания файла index. Так что эта статья может помочь. Также я делюсь рабочей функцией ниже.
Последний шаг — создание цикла while для поиска и организации всех индексов в базе данных. Это видео является отличным примером, чтобы сделать это.
Функция:
создать функцию GetIndexCreateScript(
@index_name nvarchar(100)
)
возвращает nvarchar (макс.)
как
начинать
объявить @Return varchar (макс.)
ВЫБЕРИТЕ @Return = 'СОЗДАТЬ' +
CASE WHEN I. is_unique = 1 THEN 'UNIQUE 'ELSE '' END +
I.type_desc COLLATE DATABASE_DEFAULT + 'ИНДЕКС' +
I.name + 'ВКЛ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
Ключевые столбцы + ' ) ' +
ISNULL(' ВКЛЮЧИТЬ ('+IncludedColumns+' ) ','') +
ISNULL(' ГДЕ '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- значение по умолчанию
'SORT_IN_TEMPDB = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
СЛУЧАЙ, КОГДА ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- значение по умолчанию
'DROP_EXISTING = ВКЛ ' + ',' +
-- значение по умолчанию
' ОНЛАЙН = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
СЛУЧАЙ, КОГДА I. allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS.имя + ' ] '
ИЗ sys.indexes I
ПРИСОЕДИНЯЙТЕСЬ к sys.tables T ON T.Object_id = I.Object_id
ПРИСОЕДИНЯЙТЕСЬ к sys.sysindexes SI ON I.Object_id = SI.id И I.index_id = SI.indid
ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 0
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
ЗАКАЗАТЬ ПО МАКСИМАЛЬНОМУ (IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2. object_id, IC2.index_id) tmp3) tmp4
ON I.object_id = tmp4.object_id И I.Index_id = tmp4.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.stats ST ON ST.object_id = I.object_id И ST.stats_id = I.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.data_spaces DS ON I.data_space_id=DS.data_space_id
ПРИСОЕДИНЯЙТЕСЬ к sys.filegroups FG ON I.data_space_id=FG.data_space_id
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 1
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2.object_id, IC2.index_id) tmp1
ГДЕ IncludedColumns НЕ NULL) tmp2
ON tmp2. object_id = I.object_id И tmp2.index_id = I.index_id
ГДЕ I.is_primary_key = 0 И I.is_unique_constraint = 0
И я. [имя] = @index_name
вернуть @Return
конец
 is_unique = 1 THEN 'UNIQUE 'ELSE '' END +
I.type_desc COLLATE DATABASE_DEFAULT + 'ИНДЕКС' +
I.name + 'ВКЛ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
Ключевые столбцы + ' ) ' +
ISNULL(' ВКЛЮЧИТЬ ('+IncludedColumns+' ) ','') +
ISNULL(' ГДЕ '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- значение по умолчанию
'SORT_IN_TEMPDB = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
СЛУЧАЙ, КОГДА ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- значение по умолчанию
'DROP_EXISTING = ВКЛ ' + ',' +
-- значение по умолчанию
' ОНЛАЙН = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
СЛУЧАЙ, КОГДА I.
is_unique = 1 THEN 'UNIQUE 'ELSE '' END +
I.type_desc COLLATE DATABASE_DEFAULT + 'ИНДЕКС' +
I.name + 'ВКЛ' +
Schema_name(T.Schema_id)+'.'+T.name + ' ( ' +
Ключевые столбцы + ' ) ' +
ISNULL(' ВКЛЮЧИТЬ ('+IncludedColumns+' ) ','') +
ISNULL(' ГДЕ '+I.Filter_definition,'') + ' WITH ( ' +
CASE WHEN I.is_padded = 1 THEN ' PAD_INDEX = ON ' ELSE ' PAD_INDEX = OFF ' END + ',' +
'FILLFACTOR = '+CONVERT(CHAR(5),CASE WHEN I.Fill_factor = 0 THEN 100 ELSE I.Fill_factor END) + ',' +
-- значение по умолчанию
'SORT_IN_TEMPDB = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.ignore_dup_key = 1 THEN ' IGNORE_DUP_KEY = ON ' ELSE ' IGNORE_DUP_KEY = OFF ' END + ',' +
СЛУЧАЙ, КОГДА ST.no_recompute = 0 THEN ' STATISTICS_NORECOMPUTE = OFF ' ELSE ' STATISTICS_NORECOMPUTE = ON ' END + ',' +
-- значение по умолчанию
'DROP_EXISTING = ВКЛ ' + ',' +
-- значение по умолчанию
' ОНЛАЙН = ВЫКЛ ' + ',' +
СЛУЧАЙ, КОГДА I.allow_row_locks = 1 THEN ' ALLOW_ROW_LOCKS = ON ' ELSE ' ALLOW_ROW_LOCKS = OFF ' END + ',' +
СЛУЧАЙ, КОГДА I. allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS.имя + ' ] '
ИЗ sys.indexes I
ПРИСОЕДИНЯЙТЕСЬ к sys.tables T ON T.Object_id = I.Object_id
ПРИСОЕДИНЯЙТЕСЬ к sys.sysindexes SI ON I.Object_id = SI.id И I.index_id = SI.indid
ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 0
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
ЗАКАЗАТЬ ПО МАКСИМАЛЬНОМУ (IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2.
allow_page_locks = 1 THEN ' ALLOW_PAGE_LOCKS = ON ' ELSE ' ALLOW_PAGE_LOCKS = OFF ' END + ' ) ON [' +
DS.имя + ' ] '
ИЗ sys.indexes I
ПРИСОЕДИНЯЙТЕСЬ к sys.tables T ON T.Object_id = I.Object_id
ПРИСОЕДИНЯЙТЕСЬ к sys.sysindexes SI ON I.Object_id = SI.id И I.index_id = SI.indid
ПРИСОЕДИНЯЙТЕСЬ (ВЫБЕРИТЕ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name + CASE WHEN MAX(CONVERT(INT,IC1.is_descending_key)) = 1 THEN ' DESC ' ELSE ' ASC ' END
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 0
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
ЗАКАЗАТЬ ПО МАКСИМАЛЬНОМУ (IC1.key_ordinal)
FOR XML PATH('')), 1, 2, '') KeyColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2. object_id, IC2.index_id) tmp3) tmp4
ON I.object_id = tmp4.object_id И I.Index_id = tmp4.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.stats ST ON ST.object_id = I.object_id И ST.stats_id = I.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.data_spaces DS ON I.data_space_id=DS.data_space_id
ПРИСОЕДИНЯЙТЕСЬ к sys.filegroups FG ON I.data_space_id=FG.data_space_id
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 1
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2.object_id, IC2.index_id) tmp1
ГДЕ IncludedColumns НЕ NULL) tmp2
ON tmp2.
object_id, IC2.index_id) tmp3) tmp4
ON I.object_id = tmp4.object_id И I.Index_id = tmp4.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.stats ST ON ST.object_id = I.object_id И ST.stats_id = I.index_id
ПРИСОЕДИНЯЙТЕСЬ к sys.data_spaces DS ON I.data_space_id=DS.data_space_id
ПРИСОЕДИНЯЙТЕСЬ к sys.filegroups FG ON I.data_space_id=FG.data_space_id
ЛЕВОЕ СОЕДИНЕНИЕ (ВЫБРАТЬ * ОТ (
ВЫБЕРИТЕ IC2.object_id, IC2.index_id,
STUFF((SELECT ' , ' + C.name
ИЗ sys.index_columns IC1
ПРИСОЕДИНЯЙТЕСЬ к системным столбцам C
ON C.object_id = IC1.object_id
И C.column_id = IC1.column_id
И IC1.is_included_column = 1
ГДЕ IC1.object_id = IC2.object_id
И IC1.index_id = IC2.index_id
СГРУППИРОВАТЬ ПО IC1.object_id,C.name,index_id
FOR XML PATH('')), 1, 2, '') IncludedColumns
ИЗ sys.index_columns IC2
--WHERE IC2.Object_id = object_id('Person.Address') --Комментарий для всех таблиц
СГРУППИРОВАТЬ ПО IC2.object_id, IC2.index_id) tmp1
ГДЕ IncludedColumns НЕ NULL) tmp2
ON tmp2. object_id = I.object_id И tmp2.index_id = I.index_id
ГДЕ I.is_primary_key = 0 И I.is_unique_constraint = 0
И я. [имя] = @index_name
вернуть @Return
конец
object_id = I.object_id И tmp2.index_id = I.index_id
ГДЕ I.is_primary_key = 0 И I.is_unique_constraint = 0
И я. [имя] = @index_name
вернуть @Return
конец
Sql на время:
объявить таблицу @RebuildIndex (
IndexId целое число (1,1),
Имя_индекса varchar(100),
Схема таблицы varchar (50),
имя_таблицы varchar(100),
Десятичная фрагментация (18,2)
)
вставить в @RebuildIndex (IndexName, TableSchema, TableName, Fragmentation)
ВЫБИРАТЬ
B. [имя] как «Имя_индекса»,
Schema_Name(O.[schema_id]) как 'TableSchema',
OBJECT_NAME(A.[object_id]) как 'TableName',
A.[avg_fragmentation_in_percent] Фрагментация
ОТ sys.dm_db_index_physical_stats(db_id(),NULL,NULL,NULL,'LIMITED') A
INNER JOIN sys.indexes B ON A.[object_id] = B.[object_id] и A.index_id = B.index_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sys.objects O ON O.[object_id] = B.[object_id]
где B.[name] не равно null и B.is_primary_key = 0 AND B.is_unique_constraint = 0 и A.[avg_fragmentation_in_percent] >= 5
--select * из @RebuildIndex
объявить @begin int = 1
объявить @max int
выберите @max = Max(IndexId) из @RebuildIndex
объявить @IndexName varchar(100), @TableSchema varchar(50), @TableName varchar(100), @Fragmentation decimal(18,2)
в то время как @begin <= @max начинать Выберите @IndexName = IndexName из @RebuildIndex, где IndexId = @begin выберите @TableSchema = TableSchema из @RebuildIndex, где IndexId = @begin выберите @TableName = TableName из @RebuildIndex, где IndexId = @begin выберите @Fragmentation = Фрагментация из @RebuildIndex, где IndexId = @begin объявить @sql nvarchar (макс.