Подзапросы в sql примеры: Подзапросы в основных командах SQL
Содержание
Подзапросы в выражении CASE / Хабр
По материалам статьи Craig Freedman: Subqueries in CASE Expressions
В этой статье будет рассмотрено, как SQL Server обрабатывает подзапросы в выражении CASE. Кроме того, будут рассмотрены несколько экзотических возможностей соединений.
Скалярные выражения
Для простых случаев использования выражений CASE (без подзапросов), возможна оценка только выражения CASE, состоящего из нескольких скалярных выражений:
create table T1 (a int, b int, c int) select case when T1.a > 0 then T1.b else T1.c end from T1
|—Compute Scalar(DEFINE:([Expr1004]=CASE WHEN [T1].[a]>(0) THEN [T1].[b] ELSE [T1].[c] END)) |—Table Scan(OBJECT:([T1])) |
Этот план запроса подразумевает просмотр таблицы T1 и оценку выражения CASE для каждой её строки. Оператор Compute Scalar вычисляет значение выражения CASE, включая оценку условия и принятие решения, будет ли выполняться оценка в предложении THEN или ELSE.
Оператор Compute Scalar вычисляет значение выражения CASE, включая оценку условия и принятие решения, будет ли выполняться оценка в предложении THEN или ELSE.
Если в выражение CASE поместить подзапросы, всё становится немного сложнее и существенно интересней.
Предложение WHEN
Давайте сначала добавим к предложению WHEN простой подзапрос:
create table T2 (a int, b int) select case when exists (select * from T2 where T2.a = T1.a) then T1.b else T1.c end from T1
|—Compute Scalar(DEFINE:([Expr1009]=CASE WHEN [Expr1010] THEN [T1].[b] ELSE [T1].[c] END)) |—Nested Loops(Left Semi Join, OUTER REFERENCES:([T1].[a]), DEFINE:([Expr1010] = [PROBE VALUE])) |—Table Scan(OBJECT:([T1])) |—Table Scan(OBJECT:([T2]), WHERE:([T2].[a]=[T1]. |
 [a]))
[a]))Как и для других EXISTS подзапросов, этот план использует левое полусоединение, позволяющее проверить, имеется ли для каждой строки в T1 соответствующая строка в T2. Однако, нормальное полусоединение (или анти-полусоединение) возвращает только парные строки (или непарные). В этом случае, должно быть возвращено хоть что-то (T1.b или T1.c) для каждой строки в T1. Мы не можем просто отказаться от строки T1 только потому, что для неё нет соответствующей строки в T2.
Решением стал специальный тип полусоединения со столбцом пробной таблицы. Это полусоединение возвращает все внешние соответствующие или не соответствующие строки, и устанавливает столбец пробной таблицы (в нашем случае это [Expr1010]) в истину или ложь, что указывает, была ли найдена соответствующая строка T1. После этого, выполняется оценка выражения CASE, для чего используется столбец пробной таблицы, с помощью которого определяется, какое значение будет возвращено.
Предложение THEN
Давайте теперь попробуем добавить к предложению THEN простой подзапрос:
create table T3 (a int unique clustered, b int) insert T1 values(0, 0, 0) insert T1 values(1, 1, 1) select case when T1.a > 0 then (select T3.b from T3 where T3.a = T1.b) else T1.c end from T1
 a > 0 then
(select T3.b from T3 where T3.a = T1.b)
else
T1.c
end
from T1
a > 0 then
(select T3.b from T3 where T3.a = T1.b)
else
T1.c
end
from T1Я добавил к T3 ограничение уникальности, позволяющее гарантировать, что скалярный подзапрос возвратит только одну строку. Без ограничения, план запроса был бы более сложен, поскольку оптимизатору нужно было бы гарантировать, что подзапрос действительно возвратит только одну строку, и ему пришлось бы выдавать ошибку, если бы вернулось больше одной строки.
Я также добавил в T1 ещё две строки, причём, условие в предложение WHEN выдаст ложь для первой строки и истину для второй строки. Таким образом, первая строка у нас будет подходить для ELSE, а вторая для THEN. Обратите внимание, что значение подзапроса в THEN будет использоваться, только если предложение WHEN будет истинно.
Ниже показан профиль статистики для плана исполнения этого запроса:
Rows Executes 0 0 |—Compute Scalar(DEFINE:([Expr1008]=CASE WHEN [T1]. THEN [T3].[b] ELSE [T1].[c] END)) 2 1 |—Nested Loops(Left Outer Join, PASSTHRU: (IsFalseOrNull [T1].[a]>(0)), OUTER REFERENCES:([T1].[b])) 2 1 |—Table Scan(OBJECT:([T1])) 0 1 |—Clustered Index Seek(OBJECT:([T3].[UQ__T3__412EB0B6]), SEEK:([T3].[a]=[T1].[b]) ORDERED FORWARD) |
 [a]>(0)
[a]>(0) Этот план запроса использует специальный тип соединения вложенных циклов, в котором задействуется предикат PASSTHRU.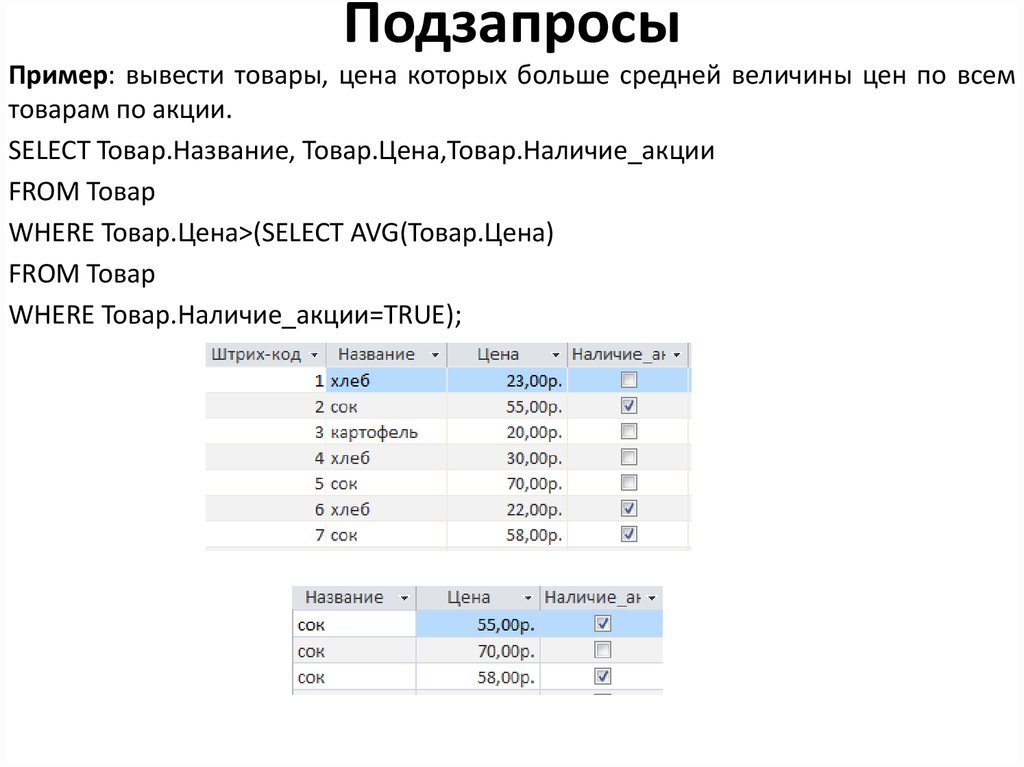 Соединение оценивает предикат PASSTHRU для каждой внешней строки. Если предикат PASSTHRU оценивается как истина, соединение немедленно возвращает строку, подобную полусоединению или внешнему соединению. Если же предикат PASSTHRU оценивается как ложь, соединение выполняется обычным образом, т.е. выполняется попытка соединения внешней строки с внутренней строкой.
Соединение оценивает предикат PASSTHRU для каждой внешней строки. Если предикат PASSTHRU оценивается как истина, соединение немедленно возвращает строку, подобную полусоединению или внешнему соединению. Если же предикат PASSTHRU оценивается как ложь, соединение выполняется обычным образом, т.е. выполняется попытка соединения внешней строки с внутренней строкой.
В показанном выше примере, предикат PASSTHRU выражения CASE является инверсией (обратите внимание на функцию IsFalseOrNull) предложения WHEN. Если предложение WHEN оценивается как истина, предикат PASSTHRU оценивается как ложь, происходит соединение, и поиск по внутренней части соединения выполняет оценку подзапроса THEN. Если предложение WHEN оценивается как ложь, предикаты PASSTHRU оценивается как истина, соединение пропускается, а поиск или подзапрос THEN не выполняется.
Обратите внимание, что просмотр T1 возвращает 2 строки, хотя поиск в T3 выполняется только один раз. Так происходит потому, что в нашем примере предложение WHEN истинно только для одной из двух строк. Предиката PASSTHRU является единственным механизмом, когда число строк на внешней стороне соединения вложенных циклов не соответствует в точности числу строк на внутренней стороне.
Предиката PASSTHRU является единственным механизмом, когда число строк на внешней стороне соединения вложенных циклов не соответствует в точности числу строк на внутренней стороне.
Также обратите внимание, что после того, как будет использовано внешнее соединение, невозможно гарантировать, что подзапрос в THEN вернёт хоть что-нибудь (в действительности гарантируется только то, что благодаря ограничению уникальности будет возвращено не более одной строки). Если подзапрос не возвращает строк, внешнее соединение просто возвратит NULL для T3.b. Если бы использовалось внутреннее соединение, отказаться от строки T1 было бы неправильно. Предостережение: я прогонял эти примеры на SQL Server 2005. Если Вы будете выполнять этот пример на SQL Server 2000, предикат PASSTHRU будет виден, но в плане исполнения запроса он появится как регулярный предикат предложения WHERE. К сожалению, для SQL Server 2000 не существует простого пути различения регулярных предикатов и предиката PASSTHRU.
Предложение ELSE и несколько предложений WHEN
Подзапрос в предложении ELSE работает точно так же, как и подзапрос в предложении THEN. Для оценки условия подзапроса будет использован предикат PASSTHRU.
Для оценки условия подзапроса будет использован предикат PASSTHRU.
Точно так же выражение CASE с несколькими предложениями WHEN с подзапросами в каждом предложении THEN будет работать аналогичным образом. Отличие только в том, что предикатов PASSTHRU будет больше.
Например:
create table T4 (a int unique clustered, b int) create table T5 (a int unique clustered, b int) select case when T1.a > 0 then (select T3.b from T3 where T3.a = T1.a) when T1.b > 0 then (select T4.b from T4 where T4.a = T1.b) else (select T5.b from T5 where T5.a = T1.c) end from T1
|—Compute Scalar(DEFINE:([Expr1016]=CASE WHEN [T1].[a]>(0) THEN [T3].[b] ELSE CASE WHEN [T1].[b]>(0) THEN [T4]. ELSE [T5].[b] END END)) |—Nested Loops(Left Outer Join, PASSTHRU:([T1].[a]>(0) OR [T1].[b]>(0)), OUTER REFERENCES:([T1].[c])) |—Nested Loops(Left Outer Join, PASSTHRU:([T1].[a]>(0) OR IsFalseOrNull [T1].[b]>(0)), OUTER REFERENCES:([T1].[b])) | |—Nested Loops(Left Outer Join, PASSTHRU: (IsFalseOrNull [T1].[a]>(0)), OUTER REFERENCES:([T1]. | | |—Table Scan(OBJECT:([T1])) | | |—Clustered Index Seek(OBJECT:([T3].[UQ__T3__164452B1]), SEEK:([T3].[a]=[T1].[a]) ORDERED FORWARD) | |—Clustered Index Seek(OBJECT:([T4].[UQ__T4__182C9B23]), SEEK:([T4].[a]=[T1].[b]) ORDERED FORWARD) |—Clustered Index Seek(OBJECT:([T5].[UQ__T5__1A14E395]), SEEK:([T5].[a]=[T1].[c]) ORDERED FORWARD) |
 [b]
[b] [a]))
[a]))В этом плане запроса три соединения вложенных циклов с предикатами PASSTHRU. Для каждой строки T1, только один из трех предикатов PASSTHRU оценивается как истина, и только один из трех подзапросов будет выполнен. Обратите внимание, что пока второе предложение WHEN соответствует «T1.b > 0», это значит, что первое предложение WHEN, где «T1.a > 0» оказалось ложным. Это также относится и к предложению ELSE. Таким образом, предикаты PASSTHRU для второго и третьего подзапроса включают проверку «T1.a > 0 OR…».
Для каждой строки T1, только один из трех предикатов PASSTHRU оценивается как истина, и только один из трех подзапросов будет выполнен. Обратите внимание, что пока второе предложение WHEN соответствует «T1.b > 0», это значит, что первое предложение WHEN, где «T1.a > 0» оказалось ложным. Это также относится и к предложению ELSE. Таким образом, предикаты PASSTHRU для второго и третьего подзапроса включают проверку «T1.a > 0 OR…».
Столбец пробной таблицы в качестве предиката PASSTHRU
Наконец, давайте рассмотрим запрос с подзапросами в предложениях WHEN и в предложениях THEN. Также, для разнообразия, давайте переместим выражение CASE из списка SELECT в предложение WHERE.
select * from T1 where 0 = case when exists (select * from T2 where T2.a = T1.a) then (select T3.b from T3 where T3.a = T1.b) else T1.c end
|—Filter(WHERE:((0)=CASE WHEN [Expr1013] THEN [T3]. ELSE [T1].[c] END)) |—Nested Loops(Left Outer Join, PASSTHRU:(IsFalseOrNull [Expr1013]), OUTER REFERENCES:([T1].[b])) |—Nested Loops(Left Semi Join, OUTER REFERENCES:([T1].[a]), DEFINE:([Expr1013] = [PROBE VALUE])) | |—Table Scan(OBJECT:([T1])) | |—Table Scan(OBJECT:([T2]), WHERE:([T2].[a]=[T1].[a])) |—Clustered Index Seek(OBJECT:([T3].[UQ__T3__164452B1]), SEEK:([T3].[a]=[T1].[b]) ORDERED FORWARD) |
 [b]
[b] В этом плане исполнения запроса имеется левое полусоединение со столбцом пробной таблицы, позволяющее оценить подзапрос в предложении WHEN, и соединение вложенных циклов с предикатом PASSTHRU для столбца пробной таблицы, позволяющее решить, выполнять ли оценку подзапроса в предложении THEN. Поскольку выражение CASE было перемещено в предложение WHERE, для оценки выходных значений из списка SELECT вместо оператора Compute Scalar используется оператор Filter, с помощью которого определяется, какие строки будут возвращены. Все остальное работает точно так же.
Поскольку выражение CASE было перемещено в предложение WHERE, для оценки выходных значений из списка SELECT вместо оператора Compute Scalar используется оператор Filter, с помощью которого определяется, какие строки будут возвращены. Все остальное работает точно так же.
Далее…
В следующей статье, я рассмотрю несколько других типов подзапросов.
Использование подзапросов в SQL | Info-Comp.ru
Продолжаем изучать SQL, и сегодня мы будем говорить о достаточно полезной вещи в SQL это «Подзапрос». Рассмотрим что такое подзапрос и, конечно же, как обычно напишем несколько примеров, для того чтобы лучше понять, как писать эти подзапросы и в каких случаях их лучше использовать.
Как я уже сказал, о SQL мы разговариваем достаточно часто, так как это знание и умение использовать SQL требуется практически везде, будь то база данных сайта в Интернете или баз данных в организациях. Причем, даже совсем в небольших организациях, где всего один программист или системный администратор, но при этом имеется какая-нибудь база данных и для того, что ее администрировать, выгружать какие-то данные, для отчета, необходимы начальные знания SQL.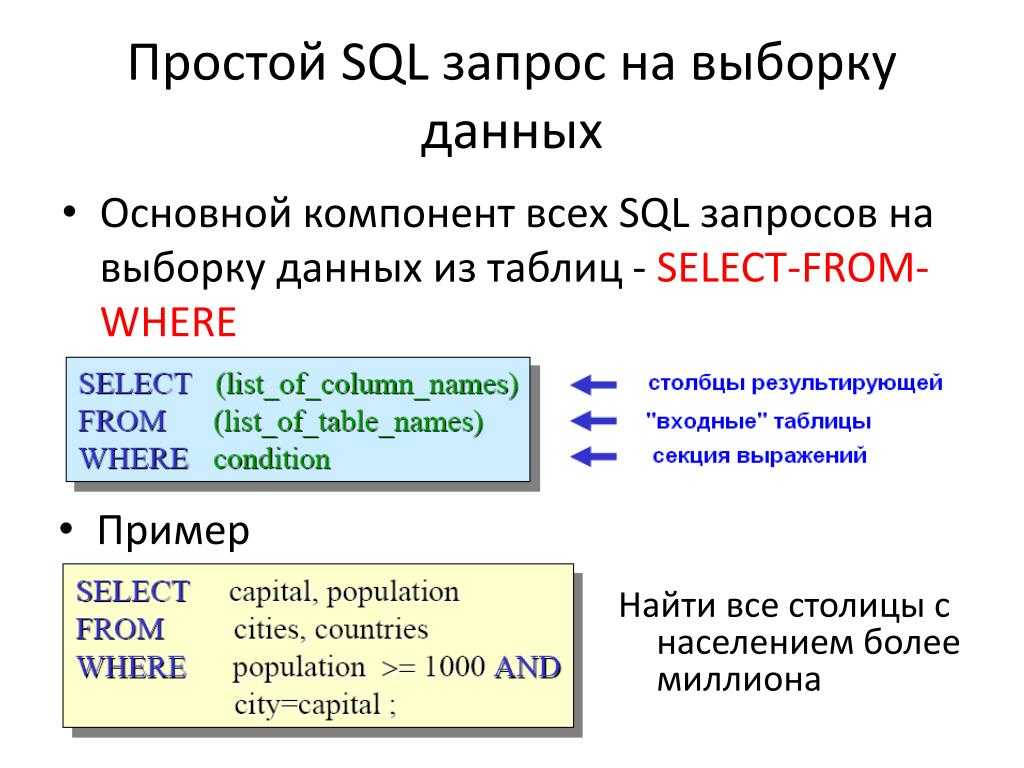 Основы SQL мы рассматривали во многих статьях таких как «Язык запросов SQL – Оператор SELECT» или как «добавить колонку в таблицу на SQL». Но, так или иначе, тему подзапросов мы не затрагивали, и пришло время поговорить об этом.
Основы SQL мы рассматривали во многих статьях таких как «Язык запросов SQL – Оператор SELECT» или как «добавить колонку в таблицу на SQL». Но, так или иначе, тему подзапросов мы не затрагивали, и пришло время поговорить об этом.
И начнем мы как всегда с теории.
Содержание
- Что такое подзапрос?
- В каких случаях использовать подзапрос?
- Где можно использовать подзапрос?
Что такое подзапрос?
Подзапрос – это отдельный запрос внутри другого запроса, который может объединяться с основным, но не обязательно.
Использовать подзапросы бывает достаточно удобно в некоторых случаях, но помните, что злоупотреблять ими не нужно. Так как это значительно усложняет план запроса и соответственно замедляет его работу.
О том, что еще влияет на скорость выполнения запросов, и чего лучше не надо делать можете посмотреть полезные советы по написанию SQL запросов.
Для наглядности я попытался изобразить подзапрос схематично:
В каких случаях использовать подзапрос?
Как я уже сказал писать вложенные запросы направо и налево не стоит, но иногда можно.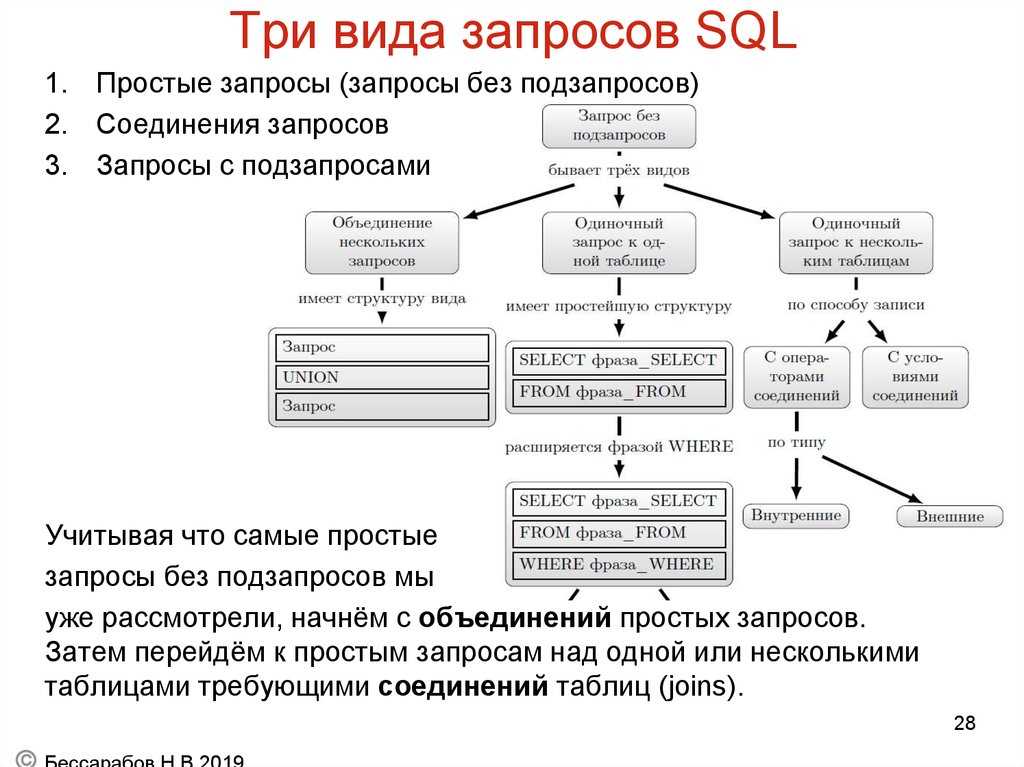
Например, когда выборка идет из одной таблице, которая имеет определенный ключ, а Вам необходимо получить одну колонку с максимальным значением из другой таблицу по этому ключу, при этом, не объединяя эти таблицы (в данном случае подзапрос пишется в конструкции select). Или, например, Вам необходимо обращаться к данным, которые расположены во многих таблицах, при том, что данные, из этих таблиц будут браться путем каких-то вычислений и уже к этим данным Вам необходимо обращаться, это можно сделать путем написания запроса в конструкции from, без написания дополнительных VIEW представлений, допустим, что Вам этот запрос потребуется только один раз, и чтобы не засорять базу, Вы не будете создавать представление.
Где можно использовать подзапрос?
Подзапрос можно использовать практически во всех конструкциях, давайте разберем самые часто используемые.
1. В конструкции Select. Пример:
select t1.
 col1, t1.col2,
(select max(t2.col3) from table2 as t2 where t2.col1=t1.col1) as col3
from table1 as t1
col1, t1.col2,
(select max(t2.col3) from table2 as t2 where t2.col1=t1.col1) as col3
from table1 as t1
2. В конструкции From. Пример:
SELECT col1, col2, col3
FROM (SELECT t1.col1 AS col1, t2.col2 AS col2, t1.col1+t2.col2 AS col3
FROM table1 as t1
LEFT JOIN table2 as t2 ON t1.col3=t2.col3
WHERE t1.col1 >1000) AS Q1
3.В конструкции WHERE. Пример:
select col1, col2, col3 from table1 where col1 = (select avg(col1) from table2)
4. При объединении. Другими словами можно осуществить объединение таблицы с подзапросом. Пример:
select t1.col1, t1.col2, t1.col3, q1.col1, q1.col2, q1.col3
from table1 as t1
left join (select col1, col2, col3 from table2) as q1 on t1.col1=q1.col1
Вот такие простенькие примеры, но это не все где можно использовать подзапрос, просто это наиболее распространенные варианты использования таких запросов. Надеюсь, стало немного понятно, и на последок давайте приведем пример многоуровневого запроса, просто так, он не из жизни, но так тоже можно писать. Пример:
Надеюсь, стало немного понятно, и на последок давайте приведем пример многоуровневого запроса, просто так, он не из жизни, но так тоже можно писать. Пример:
select col1, col2, col3, col4, col5, col6
from (select t1.col1 as col1, t1.col2 as col2, t1.col3 as col3,
q1.col1 as col4, q1.col2 as col5, q1.col3 as col6
from table1 as t1
left join (select col1, col2,
(select avg(col1) from table3) as col3 from table2) as q1
on t1.col1=q1.col1
where t1.col1 >1000)
В данном запросе, мы обращаемся к подзапросу, в котором в свою очередь идет объединение с вложенным запросом, а в котором используется подзапрос в конструкции select.
Вот такие примеры, они не являются примером выхода из каких-то ситуаций, на практике они могут, и не понадобится, но для общего синтаксиса я их привел. На сегодня все, в дальнейшем будем осваивать новые тонкости SQL. Пока. Удачи!
Заметка! Для комплексного изучения языка SQL и T-SQL рекомендую посмотреть мои видеокурсы по T-SQL, которые помогут Вам «с нуля» научиться работать с SQL и программировать на T-SQL в Microsoft SQL Server.

Руководство для начинающих (с примерами кода)
Каждому специалисту по данным необходимо разбираться в базе данных SQL, включая подзапросы. Вот введение.
В этой статье мы рассмотрим основы подзапросов SQL, их синтаксис, их полезность, а также когда и как их использовать при выполнении запросов к базе данных.
В этой статье предполагается, что у вас есть базовые знания о выборе данных с помощью SQL, таких как группировка данных, агрегатные функции, фильтрация и базовые соединения.
Что такое подзапрос
Подзапрос — это не что иное, как запрос внутри другого запроса. В основном мы используем их для добавления нового столбца к основному результату запроса, для создания фильтра или для создания консолидированного источника, из которого можно выбирать данные.
Подзапрос всегда будет заключен в круглые скобки и может появляться в разных местах в основном запросе, в зависимости от цели — обычно в оговорках SELECT , FROM или WHERE .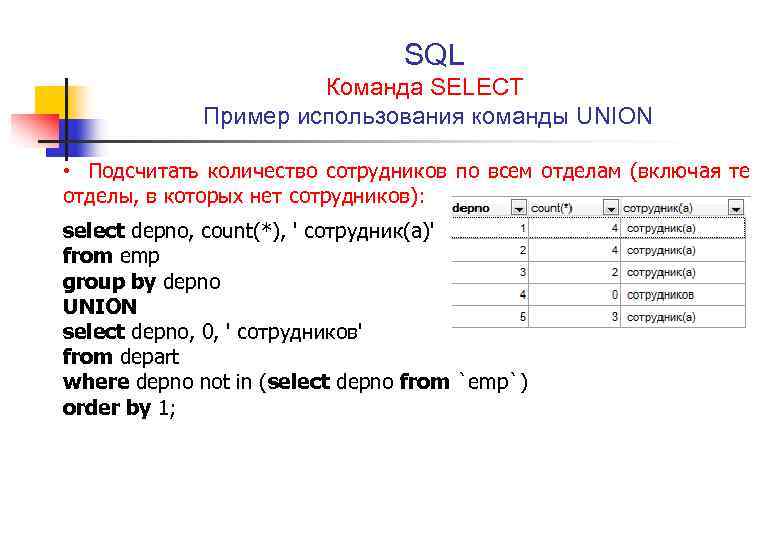 Кроме того, количество подзапросов не ограничено, что означает, что вы можете иметь столько вложенных запросов, сколько вам нужно.
Кроме того, количество подзапросов не ограничено, что означает, что вы можете иметь столько вложенных запросов, сколько вам нужно.
База данных
Чтобы написать реальный код SQL, мы будем использовать базу данных Chinook в качестве примера. Это образец базы данных, доступный для нескольких типов баз данных.
База данных содержит информацию о вымышленном цифровом музыкальном магазине, такую как данные об исполнителях, песнях, плейлистах, музыкальных жанрах и альбомах из музыкального магазина, а также информацию о сотрудниках магазина, покупателях и покупках.
Это схема базы данных, чтобы вы могли лучше понять, как работают запросы, которые мы напишем:
Подзапрос для создания нового столбца
Первый вариант использования подзапроса состоит в том, чтобы использовать его для добавления нового столбца к выходным данным основного запроса. Вот как будет выглядеть синтаксис:
ВЫБЕРИТЕ столбец_1,
столбцы_2,
(ВЫБИРАТЬ
. ..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1  ..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1
..
ИЗ таблицы_2
СГРУППИРОВАТЬ ПО 1)
ИЗ таблицы_1
GROUP BY 1 Давайте рассмотрим практический пример.
Здесь мы хотим увидеть количество плейлистов в приложении, в которые пользователи добавили каждую песню.
Основной запрос возвращает два столбца: название песни и количество плейлистов, в которые ее добавили пользователи. Это второй столбец, который требует подзапроса. Подзапрос здесь необходим, потому что мы должны сопоставить track_id , назначенный списку воспроизведения, с track_id в таблице дорожек, а затем подсчитать их для каждой дорожки.
ВЫБЕРИТЕ т.имя,
(ВЫБИРАТЬ
количество (playlist_id)
ИЗ playlist_track pt
ГДЕ pt.track_id = t.track_id
) как количество_плейлистов
С дорожки т
СГРУППИРОВАТЬ ПО 1
ORDER BY number_of_playlists DESC
ПРЕДЕЛ 50 Затем мы получаем этот вывод:
| имя | количество_плейлистов |
|---|---|
Сон в летнюю ночь, Op. 61 Музыкальное сопровождение: No.7 Notturno 61 Музыкальное сопровождение: No.7 Notturno | 5 |
| Aria Mit 30 Veränderungen, BWV 988 «Вариации Гольдберга»: Ария | 5 |
| Аве Мария | 5 |
| Кармен: Увертюра | 5 |
| Кармина Бурана: О Фортуна | 5 |
| Cavalleria Rusticana \ Act \ Intermezzo Sinfonico | 5 |
| Концерт для фортепиано № 2 фа минор, соч. 21: II. Ларгетто | 5 |
| Концерт для скрипки, струнных и континуо соль мажор, соч. 3, № 9: И. Аллегро | 5 |
| Das Lied Von Der Erde, Von Der Jugend | 5 |
| Валькирия: Полет валькирий | 5 |
| Die Zauberflöte, K.620: «Der Hölle Rache Kocht in Meinem Herze» | 5 |
| Фантазия на зеленых рукавах | 5 |
| Интоитус: обожаю Деум | 5 |
| Юпитер, несущий веселье | 5 |
Карелия-сюита, Op.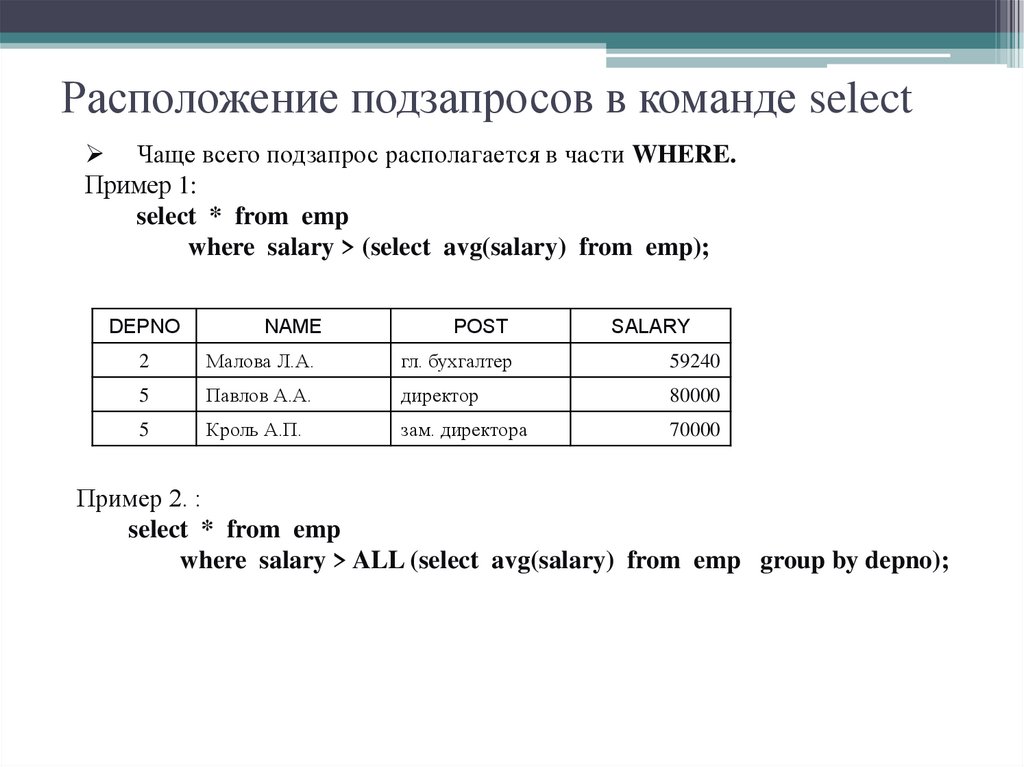 11: 2. Баллада (Tempo Di Menuetto) 11: 2. Баллада (Tempo Di Menuetto) | 5 |
| Кояанискаци | 5 |
| Плач Иеремии, первый набор \ Incipit Lamentatio | 5 |
| Метопы, соч. 29: Калипсо | 5 |
| Мизерере Мей, Деус | 5 |
Выполнение математических операций
При создании нового столбца подзапрос также может быть полезен для выполнения некоторых вычислений. Конечно, в этом случае выводом подзапроса должно быть одно число.
В следующем запросе мы хотим узнать процент треков каждого жанра в нашей базе данных. Синтаксис в основном такой же, как и в последнем примере, только подзапрос будет частью создания нового столбца, а не всего нового столбца.
Для этой задачи нам нужно разделить количество песен в каждом жанре на общее количество песен в этой таблице дорожек. Мы можем легко получить доступ к общему количеству треков с помощью этого запроса:
ВЫБИРАТЬ
count(*) как total_tracks
С трека
| общее количество треков |
|---------------|
| 3503 | Мы можем найти общее количество треков в каждом жанре с помощью следующего запроса:
ВЫБИРАТЬ
g. name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC  name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC
name как жанр,
count(t.track_id) как number_of_tracks
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC | жанр | количество дорожек |
|---|---|
| Камень | 1297 |
| Латинский | 579 |
| Металл | 374 |
| Альтернатива и панк | 332 |
| Джаз | 130 |
| Телешоу | 93 |
| Синий | 81 |
| Классический | 74 |
| Драма | 64 |
| R&B/соул | 61 |
| Регги | 58 |
| Поп | 48 |
| Саундтрек | 43 |
| Альтернатива | 40 |
| Хип-хоп/рэп | 35 |
| Электроника/Танец | 30 |
| Тяжелый металл | 28 |
| Мир | 28 |
| Научная фантастика и фэнтези | 26 |
| Легкая музыка | 24 |
| Комедия | 17 |
| Босса-Нова | 15 |
| Научная фантастика | 13 |
| Рок-н-ролл | 12 |
| Опера | 1 |
Если мы объединим эти два запроса так, что первый будет подзапросом, результатом будет процентное соотношение песен по жанру:
ВЫБИРАТЬ
g. name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC  name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC
name как жанр,
round(cast(count(t.track_id) as float) / (SELECT count(*) FROM track), 2) as perc
ИЗ жанра г
Трек INNER JOIN t на g.genre_id = t.genre_id
СГРУППИРОВАТЬ ПО 1
ЗАКАЗАТЬ ПО 2 DESC | Жанр | проц |
|---|---|
| Камень | 0,37 |
| Латинский | 0,17 |
| Металл | 0,11 |
| Альтернатива и панк | 0,09 |
| Джаз | 0,04 |
| Телешоу | 0,03 |
| Синий | 0,02 |
| Классический | 0,02 |
| Драма | 0,02 |
| R&B/соул | 0,02 |
| Регги | 0,02 |
| Альтернатива | 0,01 |
| Легкая музыка | 0,01 |
| Электроника/Танец | 0,01 |
| Тяжелый металл | 0,01 |
| Хип-хоп/рэп | 0,01 |
| Поп | 0,01 |
| Научная фантастика и фэнтези | 0,01 |
| Саундтрек | 0,01 |
| Мир | 0,01 |
| Босса-Нова | 0 |
| Комедия | 0 |
| Опера | 0 |
| Рок-н-ролл | 0 |
| Научная фантастика | 0 |
Подзапрос как фильтр
Использование подзапроса SQL в качестве фильтра основного запроса — один из моих любимых вариантов использования. В этом сценарии подзапрос будет находиться в предложении
В этом сценарии подзапрос будет находиться в предложении WHERE , и мы можем использовать такие операторы, как IN , = , <> , > и < для фильтрации в зависимости от вывода подзапроса.
Это синтаксис:
ВЫБИРАТЬ
столбец_1,
столбцы_2
ИЗ таблицы_1
ГДЕ столбец_1 в
(ВЫБИРАТЬ
...
FROM table_2) Допустим, в нашем примере мы хотим узнать, сколько клиентов, потративших не менее 100 долларов США в магазине, назначено каждому сотруднику. Давайте сделаем это в два шага.
Во-первых, давайте просто получим количество клиентов для каждого сотрудника. Это простой запрос.
ВЫБЕРИТЕ идентификатор_сотрудника,
е.фамилия,
count(различный customer_id) как number_of_customers
ОТ работника е
ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ клиент c on e.employee_id = c.support_rep_id
СГРУППИРОВАТЬ НА 1,2
ORDER BY 3 DESC Это вывод:
| employee_id | фамилия | количество_клиентов |
|---|---|---|
| 3 | Павлин | 21 |
| 4 | Парк | 20 |
| 5 | Джонсон | 18 |
Теперь давайте посмотрим, какие клиенты потратили в магазине не менее 100 долларов США. Это запрос:
Это запрос:
ВЫБИРАТЬ
c.customer_id,
раунд (сумма (i.total), 2) как итог
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100
ORDER BY 2 DESC Это вывод:
| customer_id | всего |
|---|---|
| 5 | 144,54 |
| 6 | 128,7 |
| 46 | 114,84 |
| 58 | 111,87 |
| 1 | 108,9 |
| 13 | 106,92 |
| 34 | 102,96 |
Теперь, чтобы объединить эти два запроса, первый будет основным запросом, а второй будет в WHERE для фильтрации основного запроса.
Вот как это работает:
ВЫБЕРИТЕ идентификатор_сотрудника,
е.фамилия,
count(различный customer_id) как number_of_customers
ОТ работника е
ВНУТРЕННЕЕ ПРИСОЕДИНЕНИЕ клиент c on e. employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC  employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC
employee_id = c.support_rep_id
ГДЕ customer_id в (
ВЫБИРАТЬ
c.customer_id
ОТ клиента c
Счет INNER JOIN i на c.customer_id = i.customer_id
СГРУППИРОВАТЬ ПО c.customer_id
ИМЕЮЩАЯ сумма (i.total)> 100)
СГРУППИРОВАТЬ ПО 1, 2
ЗАКАЗАТЬ ПО 3 DESC Это окончательный вывод:
| employee_id | фамилия | количество_клиентов |
|---|---|---|
| 3 | Павлин | 3 |
| 4 | Парк | 3 |
| 5 | Джонсон | 1 |
Обратите внимание на два важных момента:
- Мы удалили столбец
total_purchasedпри размещении запроса 2 вWHEREпункт основного запроса. Это потому, что мы хотим, чтобы этот запрос возвращал только один столбец, который основной запрос использует в качестве фильтра. Если бы мы этого не сделали, то увидели бы такое сообщение об ошибке (в зависимости от версии SQL):
подвыборка возвращает 2 столбца - ожидается 1
- Мы использовали оператор
IN. Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США. 907:00
 Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США. 907:00
Как следует из названия, мы хотели проверить, какие клиенты были В списке столбцов с покупками на сумму более 100 долларов США. 907:00 Чтобы использовать математический оператор, такой как = или <> , подзапрос должен возвращать число, а не столбец. В этом примере это не так, но мы можем легко адаптировать код для такой работы, когда это необходимо.
Подзапрос как новая таблица
Последний подход к использованию подзапроса SQL, который мы рассмотрим в этой статье, заключается в его использовании для создания нового консолидированного источника, из которого можно извлекать данные.
Мы используем этот подход, когда основной запрос становится слишком сложным и мы хотим, чтобы наш код был удобочитаемым и организованным, а также когда мы будем использовать этот новый источник данных повторно для различных целей и мы не хотим переписывать его заново и над.
Обычно это выглядит так:
ВЫБИРАТЬ
столбец_1,
столбец_2
ОТ
(ВЫБИРАТЬ
. ..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100  ..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100
..
ИЗ таблицы_1
ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица_2)
ГДЕ column_1 > 100 Например, это будет наш подзапрос:
ВЫБЕРИТЕ c.customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ЗАКАЗАТЬ ПО 6 DESC Результатом является новая таблица:
| customer_id | фамилия | страна | состояние | количество_покупок | total_purchased | кол_треков |
|---|---|---|---|---|---|---|
| 5 | Вихтерлова | Чехия | Нет | 18 | 144,54 | 146 |
| 6 | Холи | Чехия | Нет | 12 | 128,7 | 130 |
| 46 | О'Рейли | Ирландия | Дублин | 13 | 114,84 | 116 |
| 58 | Парик | Индия | Нет | 13 | 111,87 | 113 |
| 1 | Гонсалвес | Бразилия | СП | 13 | 108,9 | 110 |
| 13 | Рамос | Бразилия | ДФ | 15 | 106,92 | 108 |
| 34 | Фернандес | Португалия | Нет | 13 | 102,96 | 104 |
| 3 | Трембле | Канада | КК | 9 | 99,99 | 101 |
| 42 | Жирар | Франция | Нет | 11 | 99,99 | 101 |
| 17 | Смит | США | WA | 12 | 98.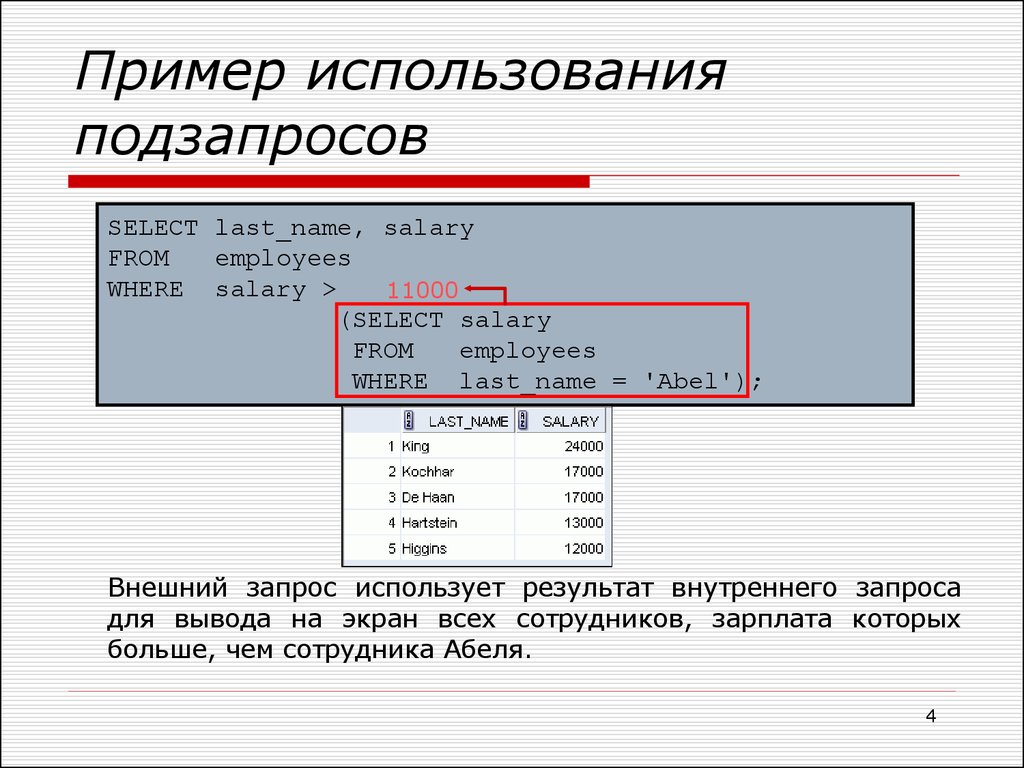 01 01 | 99 |
| 50 | Муньос | Испания | Нет | 11 | 98.01 | 99 |
| 53 | Хьюз | Соединенное Королевство | Нет | 11 | 98.01 | 99 |
| 57 | Рохас | Чили | Нет | 13 | 97.02 | 98 |
| 20 | Миллер | США | КА | 12 | 95.04 | 96 |
| 37 | Циммерманн | Германия | Нет | 10 | 94.05 | 95 |
| 22 | Ликок | США | FL | 12 | 92.07 | 93 |
| 21 | Чейз | США | НВ | 11 | 91.08 | 92 |
| 30 | Фрэнсис | Канада | НА | 13 | 91. 08 08 | 92 |
| 26 | Каннингем | США | ТХ | 12 | 86.13 | 87 |
| 36 | Шнайдер | Германия | Нет | 11 | 85,14 | 86 |
| 27 | серый | США | АЗ | 9 | 84,15 | 85 |
| 2 | Келер | Германия | Нет | 11 | 82,17 | 83 |
| 12 | Алмейда | Бразилия | РДЖ | 11 | 82,17 | 83 |
| 35 | Сампайо | Португалия | Нет | 16 | 82,17 | 83 |
| 55 | Тейлор | Австралия | Новый Южный Уэльс | 10 | 81,18 | 82 |
В этой новой таблице мы объединили идентификатор, фамилию, страну, штат, количество покупок, общую сумму потраченных долларов и количество треков, купленных для каждого клиента в базе данных.
Теперь мы можем увидеть, какие пользователи в США приобрели не менее 50 песен:
ВЫБИРАТЬ
новая_таблица.*
ОТ
(ВЫБЕРИТЕ c.customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США' Обратите внимание, что нам просто нужно выбрать столбцы и применить нужные фильтры в подзапросе SQL.
Это вывод:
| customer_id | фамилия | страна | состояние | количество_покупок | total_purchased | кол_треков |
|---|---|---|---|---|---|---|
| 17 | Смит | США | WA | 12 | 98.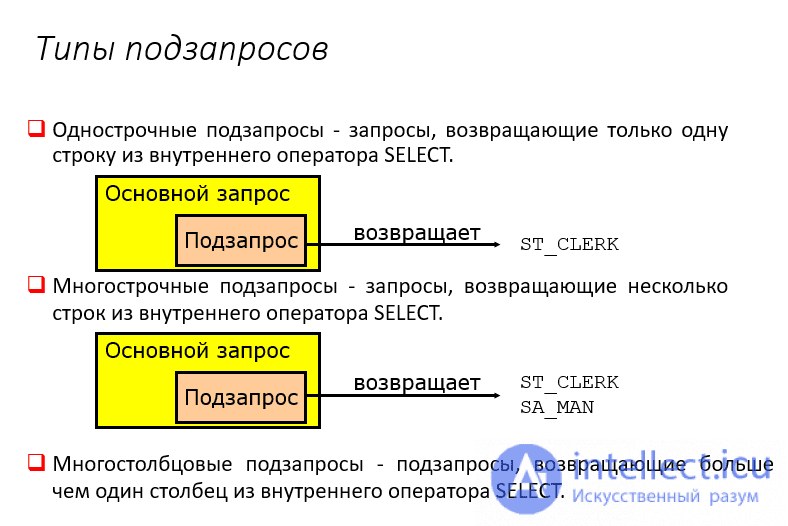 01 01 | 99 |
| 20 | Миллер | США | КА | 12 | 95.04 | 96 |
| 22 | Ликок | США | FL | 12 | 92.07 | 93 |
| 21 | Чейз | США | НВ | 11 | 91.08 | 92 |
| 26 | Каннингем | США | ТХ | 12 | 86,13 | 87 |
| 27 | серый | США | АЗ | 9 | 84,15 | 85 |
| 18 | Брукс | США | Нью-Йорк | 8 | 79,2 | 80 |
| 25 | Стивенс | США | Висконсин | 10 | 76,23 | 77 |
| 16 | Харрис | США | КА | 8 | 74,25 | 75 |
| 28 | Барнетт | США | UT | 10 | 72,27 | 73 |
| 24 | Ральстон | США | Ил | 8 | 71,28 | 72 |
| 23 | Гордон | США | МА | 10 | 66,33 | 67 |
| 19 | Гойер | США | КА | 9 | 54,45 | 55 |
Мы также можем увидеть количество пользователей, купивших не менее 50 песен в каждом штате:
ВЫБИРАТЬ
состояние,
считать(*)
ОТ
(ВЫБЕРИТЕ c. customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес  customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес
customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ГДЕ
new_table.count_tracks >= 50
И new_table.country = 'США'
СГРУППИРОВАТЬ ПО new_table.state
ЗАКАЗАТЬ ПО 2 дес Теперь нам нужно только добавить функцию агрегации count и предложение GROUP BY . Мы продолжаем работать с подзапросом, как если бы это был новый источник данных.
Выход:
| состояние | количество(*) |
|---|---|
| СА | 3 |
| АЗ | 1 |
| Флорида | 1 |
| Ил | 1 |
| МА | 1 |
| НВ | 1 |
| Нью-Йорк | 1 |
| ТХ | 1 |
| UT | 1 |
| Вашингтон | 1 |
| Висконсин | 1 |
Также можно использовать эту новую таблицу SQL для выполнения некоторых математических действий и выбора 10 лучших пользователей с наибольшей средней суммой денег, потраченных на заказ:
ВЫБИРАТЬ
Пользовательский ИД,
фамилия,
round(total_purchased / number_of_purchases, 2) как avg_purchase
ОТ
(ВЫБЕРИТЕ c. customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10  customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10
customer_id,
c.last_name,
c.страна,
с.состояние,
count(i.customer_id) как number_of_purchases,
round(sum(i.total), 2) как total_purchased,
(ВЫБИРАТЬ
количество (il.track_id) n_tracks
FROM invoice_line il
INNER JOIN счет i на i.invoice_id = il.invoice_id
ГДЕ i.customer_id = c.customer_id
) как count_tracks
ОТ клиента c
Счет INNER JOIN i на i.customer_id = c.customer_id
СГРУППИРОВАТЬ ПО 1, 2, 3, 4
ORDER BY 6 DESC) как new_table
ЗАКАЗАТЬ ПО 3 DESC
ПРЕДЕЛ 10 Мы используем два столбца в подзапросе для выполнения вычисления и получаем следующий результат:
| customer_id | фамилия | avg_purchase |
|---|---|---|
| 3 | Трембле | 11.11 |
| 6 | Холи | 10,72 |
| 29 | Коричневый | 10,15 |
| 18 | Брукс | 9,9 |
| 37 | Циммерманн | 9,4 |
| 27 | серый | 9,35 |
| 16 | Харрис | 9,28 |
| 42 | Жирар | 9,09 |
| 50 | Муньос | 8,91 |
| 53 | Хьюз | 8,91 |
Существует множество других способов использования данных в этом подзапросе, в зависимости от потребностей пользователя, или даже для создания более крупного подзапроса, если это необходимо.
Если подзапрос для этой цели используется слишком часто, может быть интересно создать представление в базе данных, в зависимости от ее архитектуры, и использовать это новое представление в качестве нового консолидированного источника. Проконсультируйтесь с вашей командой инженеров данных!
Заключение
Подзапросы SQL — это очень важный инструмент не только для специалистов по обработке и анализу данных, но и для всех, кто регулярно работает с SQL — определенно стоит потратить время на их понимание.
В этой статье мы рассмотрели следующее:
- Как и когда использовать подзапрос
- Использование подзапроса для создания нового столбца в основном запросе
- Использование подзапроса в качестве фильтра
- Использование подзапроса в качестве нового источника данных
Коррелированные и скалярные подзапросы в SQL
Коррелированные и скалярные подзапросы в SQL
В этом руководстве мы разберемся, что такое подзапросы и каковы различные типы подзапросов на четких примерах.
Как правило, подзапросы — это не что иное, как запрос внутри запроса. Есть много способов, которыми мы можем написать подзапросы в запросе. Подзапросы иногда могут называться внутренними запросами, а основные запросы называются внешними запросами. Подзапросы могут быть вставлены в различные места, такие как предложение SELECT, FROM или WHERE основного запроса.
Существует три основных типа подзапросов
- Скалярный подзапрос : Подзапрос, который возвращает только одну строку и один столбец. Или, вообще говоря, подзапрос, который возвращает только одно значение
- Подзапросы из нескольких строк/столбцов : Подзапрос, который возвращает несколько строк или несколько столбцов или и то, и другое.
- Коррелированный подзапрос : подзапрос, зависящий от результатов внешнего запроса.
.
Давайте подробно разберемся со скалярными и коррелированными подзапросами на примере в этом руководстве.
В этом уроке мы используем простую таблицу сотрудников, которая имеет 7 столбцов и 49 строк. Пример данных показан ниже.
Скалярные подзапросы
Скалярные подзапросы достаточно просты для понимания. Давайте рассмотрим пример, где мы хотим найти всех сотрудников из таблицы сотрудников, чья зарплата больше средней зарплаты. Лучший способ выяснить это — использовать концепцию скалярного подзапроса. Взгляните на следующий запрос.
В предложении WHERE запроса мы видим еще один простой запрос, который просто возвращает среднее значение всех зарплат. Если этот запрос выполняется отдельно, полученный результат равен 5818, что является средним значением всех зарплат. Теперь это значение можно использовать в качестве условия для предложения WHERE во внешнем запросе.
Результат вышеуказанного запроса:
| EMPLOYEE_ID | ИМЯ ИМЯ | ФАМИЛИЯ | ТИП_РАБОТЫ | ЗАРПЛАТА | ИДЕНТИФИКАТОР_МЕНЕДЖЕРА | ID ОТДЕЛА |
|---|---|---|---|---|---|---|
| 4 | Майкл | Хартштейн | МК_МАН | 13000 | 100 | 20 |
| 5 | Пат | Фэй | МК_РЕП | 6000 | 201 | 20 |
| 6 | Сьюзан | Маврис | HR_REP | 6500 | 101 | 40 |
| 7 | Герман | Бэр | PR_REP | 10000 | 101 | 70 |
| 8 | Шелли | Хиггинс | AC_MGR | 12008 | 101 | 110 |
| 9 | Уильям | Гитц | AC_ACCOUNT | 8300 | 205 | 110 |
| 10 | Нина | Кочхар | AD_VP | 17000 | 100 | 90 |
| 11 | Лекс | Де Хаан | AD_VP | 17000 | 100 | 90 |
| 12 | Александр | Хунольд | ИТ_ПРОГ | 9000 | 102 | 60 |
| 13 | Брюс | Эрнст | ИТ_ПРОГ | 6000 | 103 | 60 |
| 17 | Нэнси | Гринберг | FI_MGR | 12008 | 101 | 100 |
| 18 | Дэниел | Фавиет | FI_ACCOUNT | 9000 | 108 | 100 |
| 19 | Джон | Чен | FI_ACCOUNT | 8200 | 108 | 100 |
| 20 | Исмаил | Скиарра | FI_ACCOUNT | 7700 | 108 | 100 |
| 21 | Хосе Мануэль | Урман | FI_ACCOUNT | 7800 | 108 | 100 |
| 22 | Луис | Попп | FI_ACCOUNT | 6900 | 108 | 100 |
| 23 | День | Рафаэли | ПУ_МАН | 11000 | 100 | 30 |
| 29 | Мэтью | Вайс | ST_MAN | 8000 | 100 | 50 |
| 30 | Адам | Фрипп | ST_MAN | 8200 | 100 | 50 |
| 31 | Паям | Кауфлинг | ST_MAN | 7900 | 100 | 50 |
| 32 | Шанта | Фоллман | ST_MAN | 6500 | 100 | 50 |
Скалярные подзапросы можно использовать в различных предложениях, таких как SELECT, FROM, WHERE, JOIN, UPDATE, DELETE INSERT и т. д. Давайте попробуем переформулировать тот же пример, заменив подзапрос в другом предложении.
д. Давайте попробуем переформулировать тот же пример, заменив подзапрос в другом предложении.
Приведенный выше запрос также возвращает те же результаты, что и предыдущий запрос.
Коррелированные подзапросы
Коррелированные подзапросы можно использовать в сценариях, где необходимо выполнить подзапрос для каждой строки-кандидата во внешнем запросе. В коррелированных подзапросах подзапрос возвращает разные наборы результатов для каждой строки-кандидата, рассматриваемой основным запросом. Таким образом, внешний запрос также зависит от внутреннего запроса.
Лучший способ понять это — рассмотреть пример. В предыдущем примере мы увидели, как получить данные о сотрудниках, чья зарплата больше, чем общая средняя зарплата. В этом примере попробуем найти сотрудников, чья зарплата больше, чем средняя зарплата их отдела.
В приведенном выше запросе мы видим, что DEPARTMENT_ID внешней таблицы используется внутри предложения WHERE внутреннего запроса.