Postgresql функции и процедуры: PostgreSQL : Документация: 11: 38.4. Пользовательские процедуры : Компания Postgres Professional
Содержание
Вред хранимых процедур / Хабр
В чат подкаста «Цинковый прод» скинули статью о том, как некие ребята перенесли всю бизнес-логику в хранимые процедуры на языке pl/pgsql. И так как у статьи было много плюсов, то значит, есть люди, а может быть, их даже большинство, которые положительно восприняли такой рефакторинг.
Я не буду растекаться мыслью по древу, а сразу накидаю кучку минусов использования хранимых процедур.
Минусы хранимых процедур
Версионирование
Если в случае с кодом на php вы можете просто переключиться в git на другую ветку и посмотреть, что получилось, то хранимые процедуры нужно еще засунуть в базу. И традиционные миграции тут плохо помогут: если записывать все изменения хранимок как новый CREATE OR REPLACE PROCEDURE, то на кодревью будет ад: всегда новый файл, который непонятно с чем сравнивать. Поэтому придется искать какие-то дополнительные инструменты или писать свой велосипед.
Сам язык pl/pgsql
Это устаревший процедурный язык из девяностых, который вообще никак не развивается. Никакого ООП или ФП или чего бы то ни было. Синтаксис без малейшего намека на синтаксический сахар.
Никакого ООП или ФП или чего бы то ни было. Синтаксис без малейшего намека на синтаксический сахар.
Например, переменные нужно объявлять в начале процедуры, в специальном блоке DECLARE. Так делали наши деды, в этом есть некая ностальгия по языку Pascal, но спасибо, не в 2020.
Сравните две функции, которые делают одно и то же на php и pl/pgsql:
CREATE OR REPLACE FUNCTION sum(x int, y int)
RETURNS int
LANGUAGE plpgsql
AS $$
DECLARE
result int;
BEGIN
result := x + y;
return result;
END;
$$;
function sum(int $x, int $y): int
{
$result = $x + $y;
return $result;
}
Примерно в 2-3 раза больше писанины.
Кроме того, язык интерпретируемый, без JIT и т.д. (поправьте меня, если что-то изменилось в последних версиях). Т.е. все очень медленно и печально. Уж если использовать какие-то хранимки, то на чистом SQL или v8 (т.е. javascript).
Отладка
Поверьте, отлаживать код на php в 100500 раз проще. Ты просто поправил что-то и смотришь результат. Можно обложить echo или смотреть, что там через xdebug прямо в IDE.
Можно обложить echo или смотреть, что там через xdebug прямо в IDE.
Отладка хранимых процедур — это неудобно. Это надо делать в pgadmin (включив специальное расширение). PgAdmin — это далеко не PHPstorm по удобству.
Логирование и обработка ошибок
Забудьте о том, чтобы красивый json c трейсом падал с stdout, а потом в graylog и в sentry. И чтобы все это автоматически происходило, выдавая пользователю ошибку 500, в случае если контроллер не поймал exception.
В хранимках pl/pgsql вы всё будете делать вручную:
GET DIAGNOSTICS stack = PG_CONTEXT;
RAISE NOTICE E'--- Стек вызова ---\n%', stack;
Сбор метрик
Вы не можете, как в golang, просто добавить эндпоинт /metrics, который будет подсасываться Прометеусом, куда вы напихаете бизнесовые и другие метрики для мониторинга. Я просто не знаю, как тут выкрутиться с pl/pgsql.
Масштабирование
Выполнение хранимых процедур тратит ресурсы (например, CPU) сервера базы данных. В случае других языков вы можете вынести логику на другие ноды.
В случае других языков вы можете вынести логику на другие ноды.
Зависимости
В php вы, используя пакетный менеджер composer, одним движением можете подтянуть нужную библиотеку из интернета. Точно так же как в js это будет npm, в Rust это будет cargo и т.д.
В мире pl/pgsql нужно страдать. В этом языке просто нет менеджера зависимостей.
Фреймворки
В современном мире веб-приложение часто не пишут с нуля, а собирают на основе фреймворка, используя его компоненты. К примеру, на Laravel у вас из коробки есть роутинг, валидация запроса, движок шаблонов, аутентификация/авторизация, 100500 хелперов на все случаи жизни и т.д. Писать всё это вручную с нуля, на устаревшем языке — ну нет, спасибо.
Получится много велосипедов, которые потом еще и поддерживать придется.
Юнит-тесты
Сложно даже представить, как удобно организовать unit-тесты в хранимках на pl/pgsql. Я ни разу не пробовал. Поделитесь пожалуйста в комментариях.
Рефакторинг
Несмотря на то, что существует IDE для работы с базой данных (Datagrip), для обычных языков средства рефакторинга гораздо богаче. Всевозможные линтеры, подсказки по упрощению кода и т.д.
Всевозможные линтеры, подсказки по упрощению кода и т.д.
Маленький пример: в тех кусках кода, которые я привел в начале статьи, PHPStorm дал подсказку, что переменная $result необязательна, и можно просто сделать return $x + $y;
В случае с plpgsql — тишина.
Плюсы хранимых процедур
- Нет оверхеда на перегон промежуточных данных по пути бекенд-БД.
- В хранимых процедурах кешируется план запроса, что может сэкономить пару ms. т.е. как обертка над запросом иногда это имеет смысл делать (в редких случаях и не на pl/pgsql, а на голом sql), если бешеный хайлоад, а сам запрос выполняется быстро.
- Когда пишешь свой extension к посгресу — без хранимок не обойтись.
- Когда хочешь из соображений безопасности спрятать какие-то данные, дав доступ приложению только к одной-двум хранимкам (редкий кейс).
Выводы
На мой взгляд, хранимые процедуры нужны только в очень-очень редких случаях, когда вы уверены, что вы без них вообще не можете обойтись. В остальных кейсах — вы только усложните жизнь разработчикам, причем существенно.
В остальных кейсах — вы только усложните жизнь разработчикам, причем существенно.
Я бы понял, если в исходной статье часть логики переложили на SQL, это можно понять. Но зачем хранимки — это загадка.
Буду рад, если вы считаете, что я неправ или знаете, какие-то еще ситуации, связанные с хранимыми процедурами (как плюсы, так и минусы), и напишете об этом в коменты.
Морской бой на PostgreSQL — Академия Selectel
Программисты ведут ожесточенные споры о вреде и пользе хранимых процедур в базах данных. Сегодня мы отвлечемся от них и снова сделаем невероятное в невозможных условиях.
Сегодня разработчики по возможности стараются не выстраивать бизнес-логику в базах данных. Тем не менее, находятся энтузиасты, которые бросают себе вызов и создают, например, матчер биржи, а иногда целые компании переводят серверную часть на хранимые процедуры БД. Авторы таких проектов утверждают, что на базах данных можно сделать все, что угодно, если захотеть.
Тут невольно вспоминается «морской бой» по BGP.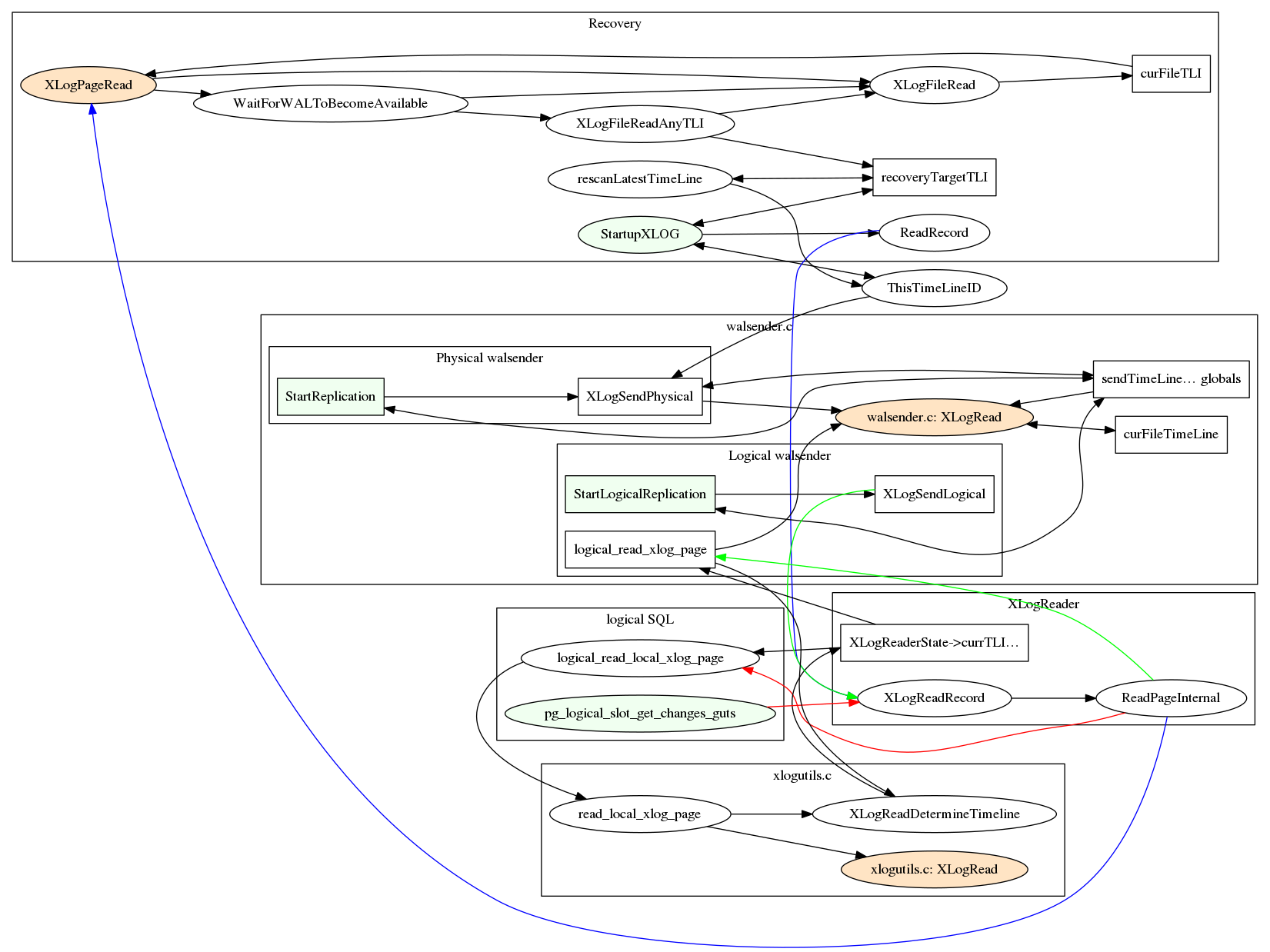 Возможно ли сделать эту игру на SQL? Для ответа на этот вопрос мы воспользуемся услугами PostgreSQL 12, а также языком PLpgSQL. Для тех, кому не терпится посмотреть «под капот», ссылка на репозиторий.
Возможно ли сделать эту игру на SQL? Для ответа на этот вопрос мы воспользуемся услугами PostgreSQL 12, а также языком PLpgSQL. Для тех, кому не терпится посмотреть «под капот», ссылка на репозиторий.
Игра «морской бой» требует постоянного ввода информации от пользователя на протяжении всей игры. Самый простой способ взаимодействия базы данных с пользователем — клиент командной строки.
Ввод данных
Получение данных от пользователя — наиболее сложная задача в данном проекте. Самый простой с точки зрения разработки способ — просить пользователя писать корректные SQL-запросы для вставки необходимой информации в специально подготовленную таблицу. Данный способ относительно медленный и требует от пользователя повторения запроса раз за разом. Хочется иметь возможность забирать данные без написания SQL-запроса.
PostgreSQL предлагает использовать COPY … FROM STDIN для сохранения данных из стандартного потока ввода в таблицу. Но у этого решения есть два недостатка.
Во-первых, оператор COPY нельзя ограничить по количеству загружаемой информации. Оператор COPY завершает свое выполнение только при получении признака конца файла. Таким образом, пользователю дополнительно придется вводить EOF для обозначения завершения ввода информации.
Оператор COPY завершает свое выполнение только при получении признака конца файла. Таким образом, пользователю дополнительно придется вводить EOF для обозначения завершения ввода информации.
Во-вторых, в хранимых процедурах и функциях нет файлов stdin и stdout. Стандартные потоки ввода и вывода доступы при выполнении обычных SQL-запросов через клиент, но там недоступны циклы. Таким образом, нельзя запустить игру в одну SQL-команду. Это могло бы стать концом истории, однако нашлось хитрое решение.
В PostgreSQL есть возможность логировать все запросы, в том числе некорректные. Более того, логирование может быть в формате CSV, а оператор COPY умеет работать с этим форматом. Настроим логирование в файле конфигурации postgresql.conf:
log_destination = 'csvlog' logging_collector = on log_directory = 'pg_log' log_filename = 'postgresql.log' log_min_error_statement = error log_statement = 'all'
Теперь в файле postgresql.csv будут записаны все SQL-запросы, которые выполняются в PostgreSQL. В документации, в разделе Using CSV-Format Log Output, описан способ подгрузки csv-логов при включенной ротации. Нас же интересует подгрузка логов с интервалом в одну секунду.
В документации, в разделе Using CSV-Format Log Output, описан способ подгрузки csv-логов при включенной ротации. Нас же интересует подгрузка логов с интервалом в одну секунду.
Так как проводить ротацию логов каждую секунду нецелесообразно, то будем раз за разом загружать файл логов, дополняя таблицу с логами. Решение «в лоб» из одного оператора COPY сработает только первый раз, а далее будет выводить ошибку из-за конфликтов первичных ключей. Данная проблема решается использованием промежуточной таблицы и предложения ON CONFLICT DO NOTHING.
Загрузка логов в таблицу
CREATE TEMP TABLE tmp_table ON COMMIT DROP AS SELECT * FROM postgres_log WITH NO DATA; COPY tmp_table FROM '/var/lib/postgresql/data/pg_log/postgresql.csv' WITH csv; INSERT INTO postgres_log SELECT * FROM tmp_table WHERE query is not null AND command_tag = 'idle' ON CONFLICT DO NOTHING;
Можно также добавить фильтр при переносе данных из временной таблицы в postgres_log, сократив количество ненужной информации в таблице логов. Так как мы не планируем получать от пользователя корректные SQL-запросы, то можем ограничиться запросами, где есть текст запроса и тег команды равен idle.
Так как мы не планируем получать от пользователя корректные SQL-запросы, то можем ограничиться запросами, где есть текст запроса и тег команды равен idle.
К сожалению, в PostgreSQL нет планировщика, который бы запускал процедуру по расписанию. Так как проблема находится в «серверной» части игры, то ее можно решить написанием shell-скрипта, который каждую секунду будет вызывать хранимую процедуру загрузки логов.
Теперь любая введенная пользователем строка, не являющаяся корректным SQL-запросом, появится в таблице postgres_log. Хотя этот способ требует обязательного введения разделителя — точки с запятой, это гораздо проще, чем отправка EOF.
Внимательный читатель отметит, что во время выполнения хранимой процедуры или функции клиент командной строки не будет обрабатывать команды и будет абсолютно прав. Для работы подобного решения требуются два клиента: «экран» и «клавиатура».
Клиент-экран (слева) и клиент-клавиатура (справа)
Для «сопряжения» клавиатуры экран генерирует псевдослучайную последовательность символов, которую необходимо ввести на клиенте-клавиатуре.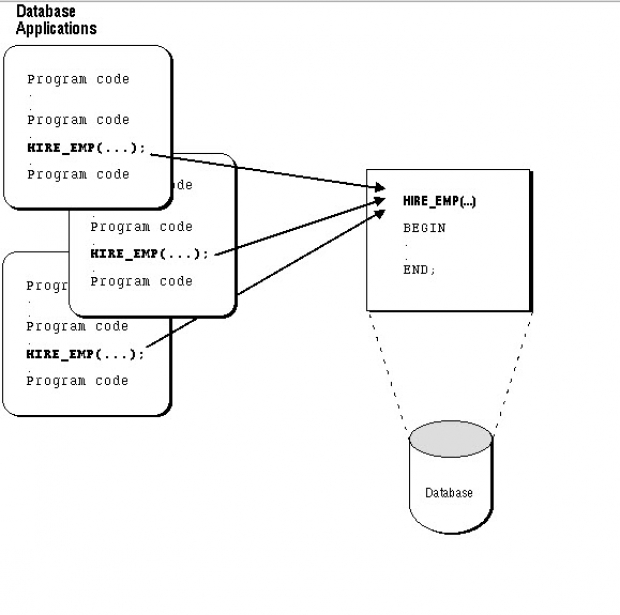 «Экран» идентифицирует клавиатуру по уникальному идентификатору сессии клиента (session_id) и далее выбирает из таблицы логов только строки с нужным идентификатором сессии.
«Экран» идентифицирует клавиатуру по уникальному идентификатору сессии клиента (session_id) и далее выбирает из таблицы логов только строки с нужным идентификатором сессии.
Легко заметить, что вывод клиента-клавиатуры не несет пользы, а ввод в клиент-экран ограничивается вызовом одной процедуры. Для удобства эксплуатации можно отправить «экран» в фон, а вывод «клавиатуры» погасить:
psql <<<'select keyboard_init()' & psql >/dev/null 2>&1
Теперь у нас есть возможность вводить в базу данных информацию со стандартного потока ввода и использовать хранимые процедуры.
Игровой цикл
Активная часть игры
Игра условно разделена на следующие фазы:
- сопряжение клиента-экрана с клиентом-клавиатурой;
- создание лобби или подключение к существующему;
- расстановка кораблей;
- активная часть игры.
Игра состоит из пяти таблиц:
- визуальное отображение поля, две таблицы;
- список кораблей и их состояние, две таблицы;
- список событий в игре.

Во время создания лобби игрок A, сервер, создает все таблицы и заполняет их начальными значениями. Для возможности проведения нескольких игр параллельно все таблицы в названии имеют десятизначный идентификатор лобби, который генерируется псевдослучайным образом при старте игры.
Разработка логики игры в целом очень похожа на разработку на традиционных языках программирования и отличается по большей части синтаксисом и отсутствием библиотеки для красивого форматирования. Для вывода используется оператор RAISE, который для psql выводит сообщение с префиксом уровня логирования. Избавиться от него не получится, но это не мешает игре.
Различия в разработке тоже есть, и они заставляют мозг закипать.
Время коммитов
Вся логика игры запускается клиентом-экраном, то есть от начала до завершения выполняется одна процедура. Причем за одну транзакцию, если явно не указан оператор COMMIT.
Это означает, что новые таблицы и новые данные в существующих таблицах не изменятся для второго игрока до тех пор, пока транзакция не будет завершена.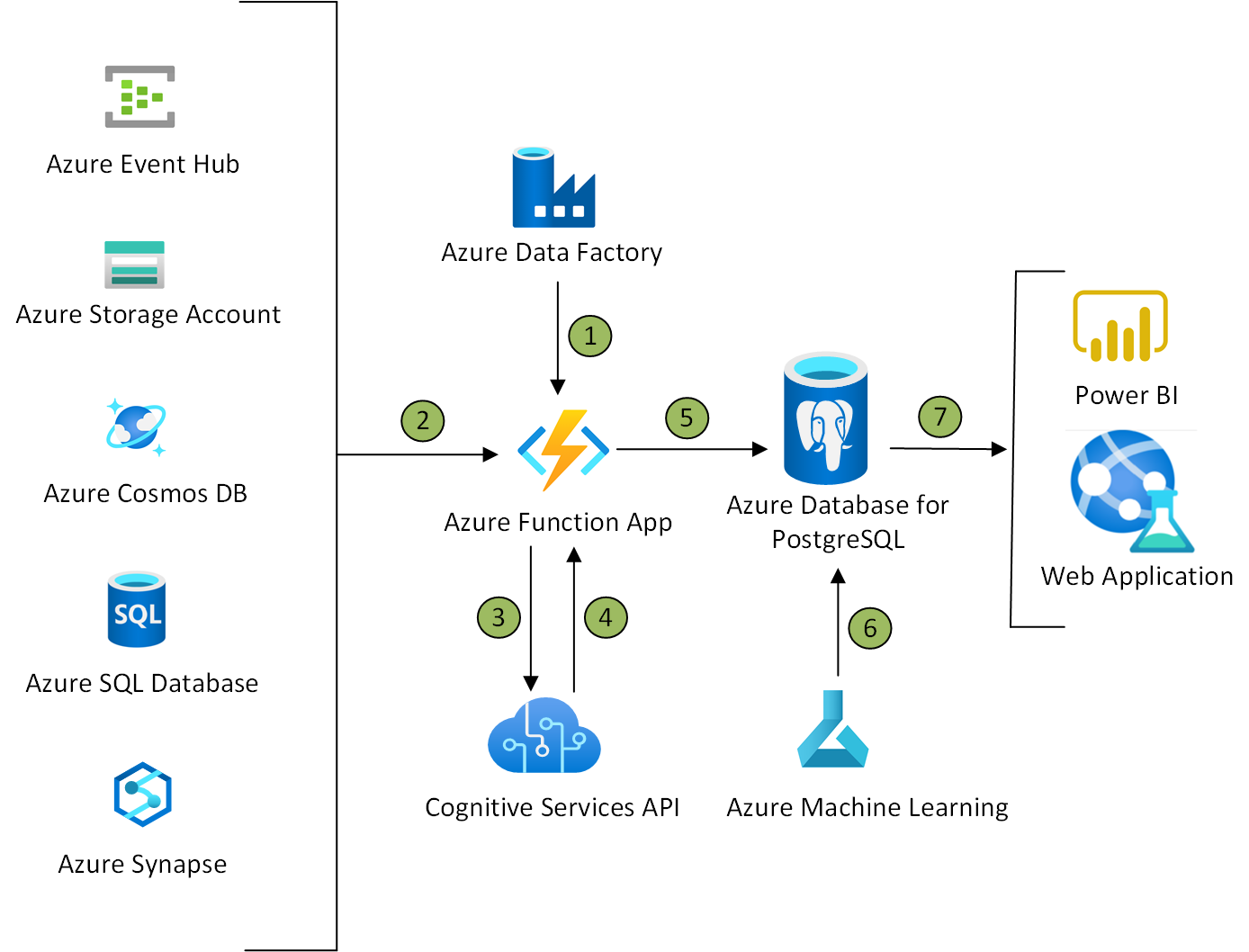 Более того, при работе со временем важно помнить, что функция now() возвращает текущее время на момент начала транзакции.
Более того, при работе со временем важно помнить, что функция now() возвращает текущее время на момент начала транзакции.
Сделать коммит не так просто, как кажется. Они допустимы только в процедурах. Попытка зафиксировать транзакцию в функции приведет к ошибке, так как она работает в рамках внешней по отношению к функции транзакции.
Запуск игры
Начало игры
Запускать такую игру в реальном окружении мы не рекомендуем. К счастью, есть возможность быстро и без сложностей развернуть базу данных с игрой. В репозитории можно найти Dockerfile, который соберет образ с PostgreSQL 12.4 и необходимой конфигурацией. Сборка и запуск образа:
docker build -t sql-battleships . docker run -p 5432:5432 sql-battleships
Подключение к БД в образе:
psql -U postgres <<<'call screen_loop()' & psql -U postgres
Обратите внимание, что PostgreSQL в контейнере использует политику аутентификации trust, то есть разрешает все подключения без пароля. Не забывайте отключать контейнер после завершения всех партий!
Не забывайте отключать контейнер после завершения всех партий!
Заключение
Использование специальных инструментов не по назначению часто вызывает негатив со стороны профессионалов. Однако решение бессмысленных, но интересных задач тренирует нестандартное мышление и позволяет изучить инструмент с разных точек зрения в поиске подходящего решения.
Сегодня мы лишний раз подтвердили, что на SQL при желании можно написать все, что угодно. Тем не менее, мы рекомендуем в продакшене использовать инструменты по назначению, а такие забавы делать исключительно как маленькие домашние проекты.
PostgreSQLБазы данных
Как создавать и использовать процедуры и функции в PostgreSQL
Введение
PostgreSQL — самая популярная объектно-реляционная система баз данных. Это надежная, высокопроизводительная система баз данных. Кроме того, с открытым исходным кодом и бесплатно. В этой статье мы обсудим, как использовать процедуры и функции для выполнения таких операций, как вставка, удаление, обновление и выбор.
Функция
В общем, функция представляет собой набор операторов SQL, которые выполняют любую операцию, такую как выбор, вставка, удаление и обновление. В PostgreSQL есть два типа функций: «определяемые системой функции» и «определяемые пользователем функции». В этой статье мы обсудим определяемую пользователем функцию.
Синтаксис
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ФУНКЦИЮ имя_функции (список параметров)
- ВОЗВРАТЫ return_type
- ЯЗЫК plpgsql
- КАК
- $$
- ОБЪЯВЛЕНИЕ
- — переменные
- НАЧАЛО
- — операторы SQL (логика)
- КОНЕЦ
- $$
Листинг 1.
Преимущество
В функции может быть несколько операторов SQL, и вы можете возвращать результаты любого типа, такие как таблица или одно значение (целое число, varchar, дата, временная метка и т. д. ).
д. ).
Ограничение
Вы не можете использовать транзакции внутри функции.
Процедура
Чтобы преодолеть ограничения функции, в PostgreSQL есть процедура, поддерживающая транзакции. В процедуре мы можем запустить, зафиксировать, откатить транзакцию. Однако процедура не может вернуть результирующий набор, например таблицу. Он может возвращать только параметры INOUT.
Синтаксис
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ имя_процедуры (список параметров)
- ЯЗЫК plpgsql
- КАК
- $$
- ОБЪЯВИТЬ
- — Переменные
- НАЧАЛО
- — операторы SQL (логика)
- КОНЕЦ
- $$
Листинг 2.
Создать базу данных
Чтобы создать базу данных, щелкните правой кнопкой мыши базы данных и выберите Создать базу данных, как показано на рисунке 1.
Рисунок 1.
В общем случае вкладка устанавливает имя базы данных в этой демонстрации. В нашем случае мы используем «EmployeeManagementSystem».
. Листинг 1.
- СОЗДАТЬ ТАБЛИЦУ Сотрудники
- (
- Серийный идентификатор,
- Имя VARCHAR(100),
- DateOfBirth Date,
- Город VARCHAR(100),
- Обозначение VARCHAR(100),
- Дата присоединения
- )
Листинг 3.
Нажмите кнопку «Выполнить», чтобы выполнить приведенный выше сценарий, как показано на рисунке 3.
Тип параметров
Прежде чем создавать процедуру и функцию, давайте обсудим тип параметров, есть три типа параметров, мы можем использовать in функцию и процедуру:
- IN
- ВЫХОД
- ВХОД
В
IN представляет параметр типа ввода.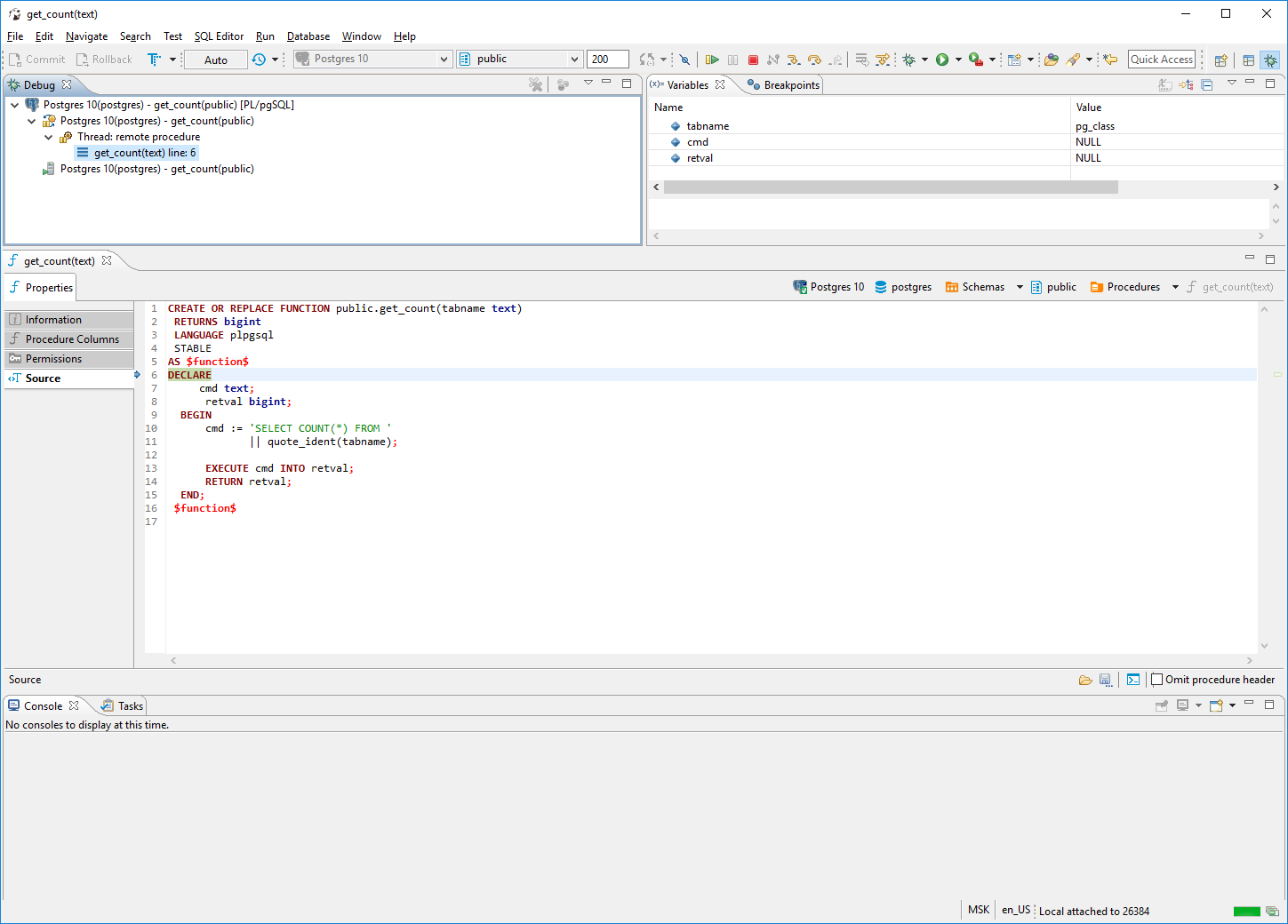 Он используется для передачи значения в функцию или процедуру, по умолчанию все параметры имеют тип ввода, если мы не используем ключевое слово IN после имени параметра.
Он используется для передачи значения в функцию или процедуру, по умолчанию все параметры имеют тип ввода, если мы не используем ключевое слово IN после имени параметра.
OUT
OUT представляет параметры типа вывода. Он возвращает значение; вы можете передать его как null или он может быть неинициализирован, потому что эти типы параметра используются только для установки и возврата значения из функции и процедуры параметров можно использовать для передачи значения, а также для возврата значения из функции или процедуры.
Создать процедуру
Используйте приведенный ниже сценарий для создания процедуры с именем «AddEmployee». Это вставит информацию о сотруднике в таблицу сотрудников.
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ AddEmployee
- (
- EmpId INOUT INT,
- EmpName VARCHAR(100),
- DATE EmpDob,
- EmpCity VARCHAR(100),
- EmpDesignation VARCHAR(100),
- EmpJoiningDate DATE
- )
- ЯЗЫК plpgsql КАК
- $$
- НАЧАЛО
- ВСТАВИТЬ В Сотрудники (Имя,ДатаРождения,Город,Должность,Дата приема на работу) ЗНАЧЕНИЯ
- (EmpName,
- EmpDob,
- EmpCity,
- ИмпНазначение,
- EmpJoiningDate
- ) ВОЗВРАЩЕНИЕ Id В EmpId;
- КОНЕЦ
- $$;
Листинг 4.
Рисунок 4.
Давайте выполним эту процедуру, используя оператор SQL, как показано в листинге 5. Он вставит записи о сотрудниках в таблицу сотрудников.
- CALL AddEmployee(null,’Питер Паркер’,’1997-10-01′,’Нью-Йорк’,’Веб-разработчик’,’2020-11-01′)
Листинг 5.
Рисунок 5.
Теперь проверьте таблицу, чтобы увидеть вставленную запись с помощью оператора help select, как показано в листинге 6.
- ВЫБЕРИТЕ * ИЗ Сотрудников
Листинг 6.
Рисунок 6.
Теперь мы создадим процедуру для обновления записи о сотруднике, как показано в листинге 7.
- CREATE OR REPLACE ПРОЦЕДУРА UpdateEmployee
- (
- EmpId INT,
- EmpName VARCHAR(100),
- DATE EmpDob,
- EmpCity VARCHAR(100),
- EmpDesignation VARCHAR(100),
- EmpJoiningDate DATE
- )
- ЯЗЫК plpgsql КАК
- $$
- НАЧАЛО
- ОБНОВЛЕНИЕ Набор сотрудников
- Имя = EmpName,
- DateOfBirth = EmpDob,
- Город = EmpCity,
- Обозначение = EmpDesignation,
- JoiningDate = EmpJoiningDate
- Где Id = EmpId;
- КОНЕЦ
- $$;
Листинг 7.
Рисунок 7.
Следуйте листингу 8, чтобы вызвать процедуру UpdateEmployee, которая позволит обновить записи о сотрудниках.
- CALL UpdateEmployee(1,’Peter S Parker’,’1999-10-01′,’Нью-Йорк’,’Web Developer’,’2020-11-01′)
Листинг 8.
Рисунок 8.
Мы создали процедуры для вставки и обновления, теперь мы создадим процедуру, которая позволит нам удалять записи о сотрудниках. См. листинг 8.9.0005
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ПРОЦЕДУРУ DeleteEmployee
- (
- EmpId INT
- )
- ЯЗЫК plpgsql КАК
- $$
- НАЧАЛО
- УДАЛИТЬ ИЗ Сотрудников, ГДЕ Id = EmpId;
- КОНЕЦ
- $$;
Листинг 8.
0005
- ЗВОНОК DeleteEmployee(2)
Листинг 9.
Рисунок 10.
Теперь пришло время создать функции. Создайте функцию GetAllEmployee(), которая будет возвращать всех сотрудников, см. листинг 10.
9002 2
Листинг 10.
Рисунок 11.
Оператор Select будет использоваться для запуска и получения данных из функции GetAllEmployee(), как показано в листинге 11.
- SELECT * FROM GetAllEmployees()
Листинг 11.
Рис. 12.
Приведенная ниже функция GetemployeeById(), показанная в листинге 12, возвращает одну строку для определенного идентификатора сотрудника.
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ФУНКЦИЮ GetEmployeeById(EmpId INT)
- ВОЗВРАТЫ Сотрудники
- ЯЗЫК SQL
- КАК
- $$
- SELECT * FROM Employees WHERE Id = EmpId;
- $$;
Листинг 12.
Рис.13.
Давайте передадим идентификатор сотрудника «3», чтобы получить запись о сотруднике с оператором выбора.
- ВЫБЕРИТЕ * ИЗ GetEmployeeById(3)
Листинг 13.
Рис. 14.
Как мы знаем, мы храним «дату рождения» сотрудника. Итак, давайте создадим функцию, которая будет возвращать возраст сотрудника. В листинге 14 мы используем определенную системой функцию «Возраст», которая будет принимать два параметра: текущую дату и дату рождения сотрудника. Он вернет разницу в качестве возраста сотрудника.
- СОЗДАТЬ ИЛИ ЗАМЕНИТЬ ФУНКЦИЮ GetEmployeeAge(EmpId INT, Age OUT VARCHAR(100))
- ЯЗЫК plpgsql
- КАК
- $$
- НАЧАЛО
- SELECT AGE(NOW()::Date,DateOfBirth) в Age FROM Employees WHEREId = EmpId;
- КОНЕЦ;
- $$
Листинг 14.
Рисунок 15.
Вызовите функцию GetEmployeeAge() для идентификатора сотрудника 1, и она вернет 21 год, 3 месяца, 21 день.
- ВЫБЕРИТЕ * ИЗ GetEmployeeAge(1)
Листинг 15.
Рис. 16.
Заключение является хорошим выбором для выполнения инструкции SQL, которая возвращает результат с одним значением или результат в формате таблицы. Однако, если вы хотите начать транзакцию, зафиксировать или откатить с помощью нескольких операторов SQL, то эта процедура является лучшим выбором.
- функция
- PostgreSQL
- процедура
- процедура сохранения
Рекомендуемая бесплатная электронная книга
Похожие статьи
Функции и процедуры в базах данных: руководство по сравнению
Учитесь на знаниях сообщества. Эксперты добавляют свои идеи в эту совместную статью на основе ИИ, и вы тоже можете.
Эксперты добавляют свои идеи в эту совместную статью на основе ИИ, и вы тоже можете.
Это новый тип статьи, которую мы начали с помощью ИИ, и эксперты продвигают ее вперед, делясь своими мыслями непосредственно в каждом разделе.
Если вы хотите внести свой вклад, запросите приглашение, поставив лайк или ответив на эту статью.
Узнать больше
— Команда LinkedIn
Последнее обновление:
27 апреля 2023 г.
Функции и процедуры — это два типа объектов базы данных, которые могут выполнять задачи и возвращать значения. Они часто используются для инкапсуляции логики, повышения производительности и упрощения кода. Но как вы решаете, когда использовать функцию или процедуру в базе данных? В этой статье мы сравним основные различия между ними и дадим некоторые рекомендации о том, когда лучше выбрать один из них.
Что такое функции и процедуры?
Функции и процедуры являются подпрограммами, которые могут храниться в базе данных и выполняться другими программами или пользователями.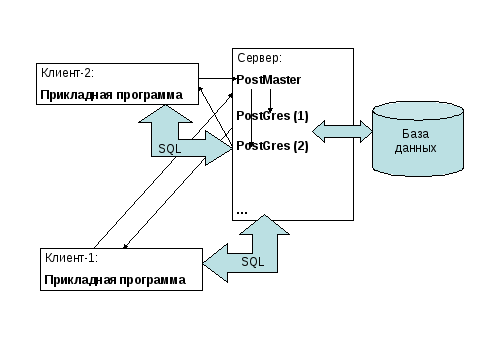 Они могут принимать параметры, выполнять вычисления, манипулировать данными и возвращать результаты. Однако у них есть некоторые ключевые отличия в синтаксисе, использовании и поведении. Функции должны возвращать одно значение определенного типа данных, в то время как процедуры могут возвращать ноль, одно или несколько значений, используя выходные параметры или курсоры. Кроме того, функции можно вызывать из операторов SQL, таких как SELECT, WHERE или ORDER BY, тогда как процедуры можно вызывать только из других процедур, функций или триггеров. Кроме того, на функции распространяются определенные ограничения, такие как запрет на изменение состояния базы данных, использование динамического SQL и исключение исключений, в то время как процедуры обладают большей гибкостью и контролем над операциями с базой данных.
Они могут принимать параметры, выполнять вычисления, манипулировать данными и возвращать результаты. Однако у них есть некоторые ключевые отличия в синтаксисе, использовании и поведении. Функции должны возвращать одно значение определенного типа данных, в то время как процедуры могут возвращать ноль, одно или несколько значений, используя выходные параметры или курсоры. Кроме того, функции можно вызывать из операторов SQL, таких как SELECT, WHERE или ORDER BY, тогда как процедуры можно вызывать только из других процедур, функций или триггеров. Кроме того, на функции распространяются определенные ограничения, такие как запрет на изменение состояния базы данных, использование динамического SQL и исключение исключений, в то время как процедуры обладают большей гибкостью и контролем над операциями с базой данных.
Зачем использовать функции и процедуры?
Функции и процедуры могут предложить ряд преимуществ при разработке и обслуживании баз данных, таких как возможность повторного использования, модульность, безопасность и производительность. Повторное использование позволяет вам написать функцию или процедуру один раз и использовать их в нескольких местах, избегая дублирования и несогласованности. Модульность позволяет разбивать сложные задачи на более мелкие и простые подпрограммы, облегчая чтение, понимание и отладку кода. Безопасность позволяет вам предоставлять или отзывать разрешения на выполнение определенных функций или процедур, ограничивая доступ и действия различных пользователей или ролей. Производительность можно повысить, используя функции или процедуры, которые выполняют вычисления или операции на стороне сервера, уменьшая сетевой трафик и передачу данных.
Повторное использование позволяет вам написать функцию или процедуру один раз и использовать их в нескольких местах, избегая дублирования и несогласованности. Модульность позволяет разбивать сложные задачи на более мелкие и простые подпрограммы, облегчая чтение, понимание и отладку кода. Безопасность позволяет вам предоставлять или отзывать разрешения на выполнение определенных функций или процедур, ограничивая доступ и действия различных пользователей или ролей. Производительность можно повысить, используя функции или процедуры, которые выполняют вычисления или операции на стороне сервера, уменьшая сетевой трафик и передачу данных.
Как выбрать между функциями и процедурами?
При принятии решения об использовании функции или процедуры в базе данных не существует определенного правила, поскольку все зависит от ваших конкретных потребностей и предпочтений. Как правило, используйте функцию, когда вам нужно вернуть одно значение известного типа данных и когда задача не включает изменение состояния базы данных или выполнение сложных операций. С другой стороны, используйте процедуру, когда вам нужно вернуть несколько значений или когда задача включает изменение состояния базы данных, использование динамического SQL, создание исключений или выполнение других действий, которые не разрешены в функциях. Кроме того, используйте функцию, когда вам нужно вызвать ее из инструкции SQL, например, для фильтрации, сортировки или агрегирования данных или для создания вычисляемого столбца или виртуальной таблицы. Наконец, используйте процедуру, когда вам нужно вызвать ее из другой процедуры, функции или триггера или когда вам нужно управлять потоком выполнения, например, используя условные операторы, циклы или транзакции.
С другой стороны, используйте процедуру, когда вам нужно вернуть несколько значений или когда задача включает изменение состояния базы данных, использование динамического SQL, создание исключений или выполнение других действий, которые не разрешены в функциях. Кроме того, используйте функцию, когда вам нужно вызвать ее из инструкции SQL, например, для фильтрации, сортировки или агрегирования данных или для создания вычисляемого столбца или виртуальной таблицы. Наконец, используйте процедуру, когда вам нужно вызвать ее из другой процедуры, функции или триггера или когда вам нужно управлять потоком выполнения, например, используя условные операторы, циклы или транзакции.
Как создавать и выполнять функции и процедуры?
Синтаксис и шаги для создания и выполнения функций и процедур могут различаться в зависимости от используемой системы баз данных, например Oracle, SQL Server, MySQL или PostgreSQL. Однако общий процесс аналогичен. Чтобы создать функцию или процедуру, вам нужно использовать оператор CREATE FUNCTION или CREATE PROCEDURE, за которым следует имя, параметры и тело подпрограммы. Вы также можете использовать оператор ALTER или DROP для изменения или удаления существующей функции или процедуры. Чтобы выполнить функцию, вам нужно использовать имя функции и передать необходимые аргументы либо как часть оператора SQL, либо как отдельное выражение. Кроме того, вы можете присвоить возвращаемое значение функции переменной или столбцу. Чтобы выполнить процедуру, вам нужно использовать оператор CALL или EXECUTE, за которым следует имя процедуры и требуемые аргументы. Вы также можете использовать ключевое слово RETURN или OUT для получения выходных значений процедуры.
Вы также можете использовать оператор ALTER или DROP для изменения или удаления существующей функции или процедуры. Чтобы выполнить функцию, вам нужно использовать имя функции и передать необходимые аргументы либо как часть оператора SQL, либо как отдельное выражение. Кроме того, вы можете присвоить возвращаемое значение функции переменной или столбцу. Чтобы выполнить процедуру, вам нужно использовать оператор CALL или EXECUTE, за которым следует имя процедуры и требуемые аргументы. Вы также можете использовать ключевое слово RETURN или OUT для получения выходных значений процедуры.
Как тестировать и отлаживать функции и процедуры?
Функции и процедуры тестирования и отладки являются важными шагами для обеспечения качества и надежности кода вашей базы данных. Для выполнения этих задач можно использовать различные инструменты и методы, такие как среда разработки или IDE с функциями отладки, такими как точки останова, пошаговое выполнение, проверка переменных и обработка ошибок.