Postgresql восстановление базы из дампа: Резервное копирование через дамп и восстановление — база данных Azure для PostgreSQL на одиночном сервере
Содержание
Резервное копирование через дамп и восстановление — база данных Azure для PostgreSQL на одиночном сервере
Twitter
LinkedIn
Facebook
Адрес электронной почты
-
Статья -
- Чтение занимает 4 мин
-
ОБЛАСТЬ ПРИМЕНЕНИЯ: База данных Azure для PostgreSQL — отдельный сервер База данных Azure для PostgreSQL — гибкий сервер
Базу данных PostgreSQL можно извлечь в файл дампа с помощью pg_dump. Затем необходимо использовать pg_restore для восстановления базы данных PostgreSQL из файла архива, созданного
Затем необходимо использовать pg_restore для восстановления базы данных PostgreSQL из файла архива, созданного pg_dump.
Предварительные требования
Прежде чем приступить к выполнению этого руководства, необходимы следующие компоненты:
- Сервер базы данных Azure для PostgreSQL с правилами брандмауэра, разрешающими доступ к этом серверу.
- Установленные программы командной строки pg_dump и pg_restore.
Создание файла дампа, содержащего необходимые для загрузки данные
Чтобы создать резервную копию базы данных PostgreSQL локально или на виртуальной машине, выполните следующую команду:
pg_dump -Fc -v --host=<host> --username=<name> --dbname=<database name> -f <database>.dump
Например, если имеется локальный сервер с базой данных testdb, запустите на нем следующее:
pg_dump -Fc -v --host=localhost --username=masterlogin --dbname=testdb -f testdb.dump
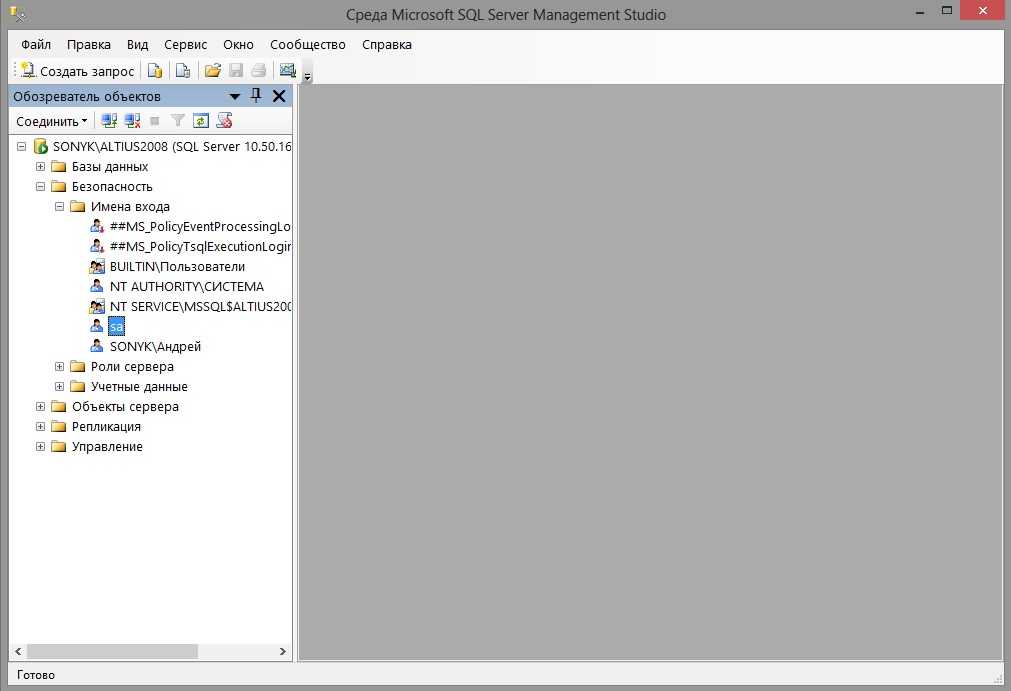
Восстановление данных в целевую базу данных
После создания целевой базы данных можно воспользоваться командой pg_restore с параметром --dbname, чтобы восстановить данные в целевую базу данных из файла дампа.
pg_restore -v --no-owner --host=<server name> --port=<port> --username=<user-name> --dbname=<target database name> <database>.dump
При включении параметра --no-owner все объекты, созданные во время восстановления, будут присвоены пользователю, отмеченному --username. Дополнительные сведения см. в документации по PostgreSQL.
Примечание
На серверах базы данных Azure для PostgreSQL соединения TLS и SSL включены по умолчанию. Если сервер PostgreSQL требует соединения TLS или SSL, но не содержит их, задайте переменную среды PGSSLMODE=require чтобы утилита pg_restore могла подключаться с помощью TLS. Без протокола TLS может появиться ошибка «FATAL: SSL connection is required. Please specify SSL options and retry.» (Критическая ошибка: необходимо соединение SSL. Настройте SSL и повторите попытку). В командной строке Windows выполните команду SET PGSSLMODE=require перед выполнением команды pg_restore. В Linux или Bash выполните команду
В Linux или Bash выполните команду export PGSSLMODE=require перед выполнением команды pg_restore.
В этом примере необходимо восстановить данные из файла дампа testdb.dump в базу данных mypgsqldb на целевом сервере mydemoserver.postgres.database.azure.com.
Ниже приведен пример использования этого pg_restore для одиночного сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin@mydemoserver --dbname=mypgsqldb testdb.dump
Ниже приведен пример использования этого pg_restore для гибкого сервера:
pg_restore -v --no-owner --host=mydemoserver.postgres.database.azure.com --port=5432 --username=mylogin --dbname=mypgsqldb testdb.dump
Оптимизация процесса миграции
Один из способов миграции существующей базы данных PostgreSQL в службу баз данных Azure для PostgreSQL — это резервное копирование базы данных в источнике и ее восстановление в Azure. Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
Чтобы свести к минимуму время, необходимое для завершения миграции, можно использовать следующие параметры с командами резервного копирования и восстановления.
Примечание
Подробные сведения о синтаксисе см. в статьях о pg_dump и pg_restore.
Для резервного копирования
Создайте резервную копию с использованием параметра -Fc, чтобы можно было выполнять восстановление параллельно. Это позволит ускорить процесс. Пример:
pg_dump -h my-source-server-name -U source-server-username -Fc -d source-databasename -f Z:\Data\Backups\my-database-backup.dump
Для восстановления
Переместите файл резервной копии на виртуальную машину Azure в том же регионе, в котором находится сервер базы данных Azure для PostgreSQL, на который выполняется миграция. Выполните
pg_restoreиз этой виртуальной машины, чтобы снизить задержку в сети. Создание виртуальной машины с ускоренной сетью.Откройте файл дампа, чтобы убедиться в том, что инструкции создания индекса находятся после вставки данных.
 Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.
Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.Для параллелизации восстановления необходимо выполнить восстановление с параметрами
-Fcи-j(с номером). Указанное вами число — это количество ядер на целевом сервере. Вы также можете попробовать установить вдвое большее количество ядер целевого сервера, чтобы оценить нагрузку.Ниже приведен пример использования этого
pg_restoreдля одиночного сервера:pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.dump
Ниже приведен пример использования этого
pg_restoreдля гибкого сервера:pg_restore -h my-target-server.postgres.database.azure.com -U azure-postgres-username@my-target-server -Fc -j 4 -d my-target-databasename Z:\Data\Backups\my-database-backup.
dump
Файл дампа также можно отредактировать, добавив в его начале команду
set synchronous_commit = off;, а в конце — командуset synchronous_commit = on;. Если не включить ее в конце, это может привести к последующей потере данных прежде, чем приложения изменят данные.Перед восстановлением рассмотрите возможность выполнения следующих действий на целевом сервере Базы данных Azure для PostgreSQL.
Отключите отслеживание производительности запросов. Эти статистические данные не требуются во время миграции. Это можно сделать, установив для параметров
pg_stat_statements.track,pg_qs.query_capture_modeиpgms_wait_sampling.query_capture_modeзначениеNONE.Используйте SKU с высоким объемом ресурсов вычисления и памяти, например модель 32 vCore Memory Optimized (32 виртуальных ядра с оптимизацией для операций в памяти), чтобы ускорить миграцию. Вы можете легко вернуться к предпочитаемому SKU после завершения восстановления.
Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра -jв командеpg_restore.Увеличьте число операций ввода-вывода в секунду на целевом сервере — это может улучшить производительность восстановления. Вы можете подготовить больше операций ввода-вывода в секунду, увеличив объем хранилища на сервере. Этот параметр необратим, но стоит принять во внимание, будет ли большее количество операций ввода-вывода в секунду полезным для вашей рабочей нагрузки в будущем.
 Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить.
Если это не так, переместите инструкции создания индекса после вставленных данных. Это должно быть сделано по умолчанию, но рекомендуется дополнительно проверить и подтвердить. dump
dump
 Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра
Чем выше номер SKU, тем большего параллелизма можно достичь, увеличив значение соответствующего параметра Не забудьте проверить и протестировать эти команды в тестовой среде, прежде чем использовать их в рабочей среде.
Дальнейшие действия
- Узнать больше о миграции базы данных PostgreSQL с помощью метода экспорта и импорта можно в статье Миграция базы данных PostgreSQL с помощью метода экспорта и импорта.
- Дополнительные сведения о переносе баз данных в службу «База данных Azure для PostgreSQL» см. в этой статье.
 в этой статье.
в этой статье.
Postgres Pro Standard : Документация: 10: 24.1. Выгрузка в SQL : Компания Postgres Professional
- 24.1.1. Восстановление дампа
- 24.1.2. Использование pg_dumpall
- 24.1.3. Управление большими базами данных
Идея, стоящая за этим методом, заключается в генерации текстового файла с командами SQL, которые при выполнении на сервере пересоздадут базу данных в том же самом состоянии, в котором она была на момент выгрузки. Postgres Pro предоставляет для этой цели вспомогательную программу pg_dump. Простейшее применение этой программы выглядит так:
pg_dumpимя_базы>файл_дампа
Как видите, pg_dump записывает результаты своей работы в устройство стандартного вывода. Далее будет рассмотрено, чем это может быть полезно. В то время как вышеупомянутая команда создаёт текстовый файл, pg_dump может создать файлы и в других форматах, которые допускают параллельную обработку и более гибкое управление восстановлением объектов.
Программа pg_dump является для Postgres Pro обычным клиентским приложением (хотя и весьма умным). Это означает, что вы можете выполнять процедуру резервного копирования с любого удалённого компьютера, если имеете доступ к нужной базе данных. Но помните, что pg_dump не использует для своей работы какие-то специальные привилегии. В частности, ей обычно требуется доступ на чтение всех таблиц, которые вы хотите выгрузить, так что для копирования всей базы данных практически всегда её нужно запускать с правами суперпользователя СУБД. (Если у вас нет достаточных прав для резервного копирования всей базы данных, вы тем не менее можете сделать резервную копию той части базы, доступ к которой у вас есть, используя такие параметры, как -n или схема-t .)таблица
Указать, к какому серверу должна подключаться программа pg_dump, можно с помощью аргументов командной строки -h и сервер-p .порт По умолчанию в качестве сервера выбирается localhost или значение, указанное в переменной окружения
По умолчанию в качестве сервера выбирается localhost или значение, указанное в переменной окружения PGHOST. Подобным образом, по умолчанию используется порт, заданный в переменной окружения PGPORT, а если она не задана, то порт, указанный по умолчанию при компиляции. (Для удобства при компиляции сервера обычно устанавливается то же значение по умолчанию.)
Как и любое другое клиентское приложение Postgres Pro, pg_dump по умолчанию будет подключаться к базе данных с именем пользователя, совпадающим с именем текущего пользователя операционной системы. Чтобы переопределить имя, либо добавьте параметр -U, либо установите переменную окружения PGUSER. Помните, что pg_dump подключается к серверу через обычные механизмы проверки подлинности клиента (которые описываются в Главе 19).
Важное преимущество pg_dump в сравнении с другими методами резервного копирования, описанными далее, состоит в том, что вывод pg_dump обычно можно загрузить в более новые версии Postgres Pro, в то время как резервная копия на уровне файловой системы и непрерывное архивирование жёстко зависят от версии сервера. Также, только метод с применением pg_dump будет работать при переносе базы данных на другую машинную архитектуру, например, при переносе с 32-битной на 64-битную версию сервера.
Также, только метод с применением pg_dump будет работать при переносе базы данных на другую машинную архитектуру, например, при переносе с 32-битной на 64-битную версию сервера.
Дампы, создаваемые pg_dump, являются внутренне согласованными, то есть, дамп представляет собой снимок базы данных на момент начала запуска pg_dump. pg_dump не блокирует другие операции с базой данных во время своей работы. (Исключение составляют операции, которым нужна исключительная блокировка, как например, большинство форм команды ALTER TABLE.)
24.1.1. Восстановление дампа
Текстовые файлы, созданные pg_dump, предназначаются для последующего чтения программой psql. Общий вид команды для восстановления дампа:
psqlимя_базы<файл_дампа
где файл_дампа — это файл, содержащий вывод команды pg_dump. База данных, заданная параметром имя_базы, не будет создана данной командой, так что вы должны создать её сами из базы template0 перед запуском psql (например, с помощью команды createdb -T template0 ).имя_базы Программа psql принимает параметры, указывающие сервер, к которому осуществляется подключение, и имя пользователя, подобно pg_dump. За дополнительными сведениями обратитесь к справке по psql. Дампы, выгруженные не в текстовом формате, восстанавливаются утилитой pg_restore.
Программа psql принимает параметры, указывающие сервер, к которому осуществляется подключение, и имя пользователя, подобно pg_dump. За дополнительными сведениями обратитесь к справке по psql. Дампы, выгруженные не в текстовом формате, восстанавливаются утилитой pg_restore.
Перед восстановлением SQL-дампа все пользователи, которые владели объектами или имели права на объекты в выгруженной базе данных, должны уже существовать. Если их нет, при восстановлении будут ошибки пересоздания объектов с изначальными владельцами и/или правами. (Иногда это желаемый результат, но обычно нет).
По умолчанию, если происходит ошибка SQL, программа psql продолжает выполнение. Если же запустить psql с установленной переменной ON_ERROR_STOP, это поведение поменяется и psql завершится с кодом 3 в случае возникновения ошибки SQL:
psql --set ON_ERROR_STOP=onимя_базы<файл_дампа
В любом случае вы получите только частично восстановленную базу данных. В качестве альтернативы можно указать, что весь дамп должен быть восстановлен в одной транзакции, так что восстановление либо полностью выполнится, либо полностью отменится. Включить данный режим можно, передав psql аргумент
В качестве альтернативы можно указать, что весь дамп должен быть восстановлен в одной транзакции, так что восстановление либо полностью выполнится, либо полностью отменится. Включить данный режим можно, передав psql аргумент -1 или --single-transaction. Выбирая этот режим, учтите, что даже незначительная ошибка может привести к откату восстановления, которое могло продолжаться несколько часов. Однако это всё же может быть предпочтительней, чем вручную вычищать сложную базу данных после частично восстановленного дампа.
Благодаря способности pg_dump и psql писать и читать каналы ввода/вывода, можно скопировать базу данных непосредственно с одного сервера на другой, например:
pg_dump -hhost1имя_базы| psql -hhost2имя_базы
Важно
Дампы, которые выдаёт pg_dump, содержат определения относительно template0. Это означает, что любые языки, процедуры и т.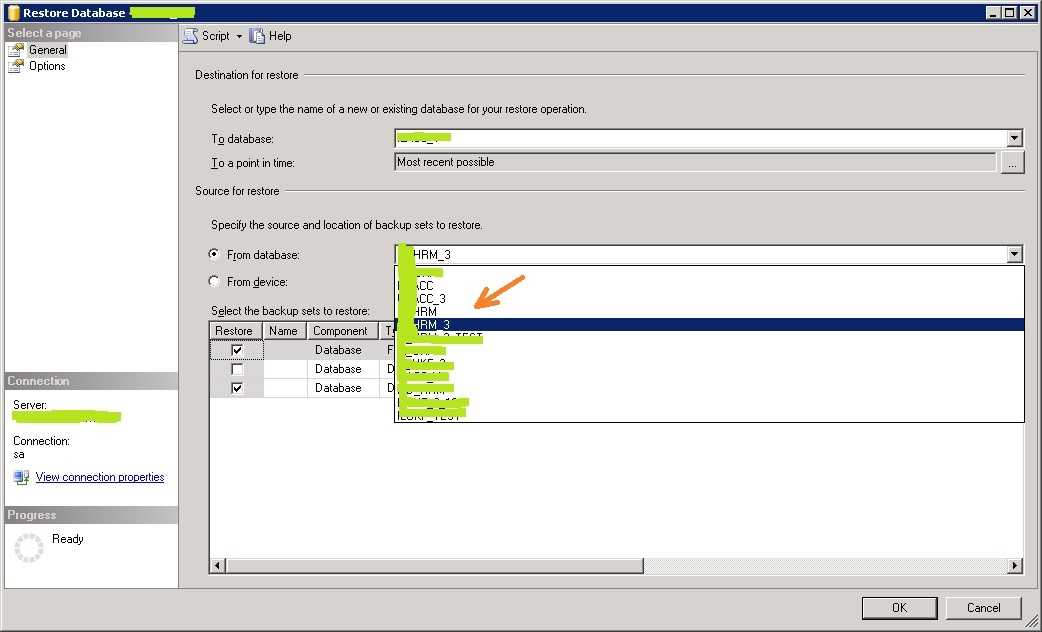 п., добавленные в базу через
п., добавленные в базу через template1, pg_dump также выгрузит в дамп. Как следствие, если при восстановлении вы используете модифицированный template1, вы должны создать пустую базу данных из template0, как показано в примере выше.
После восстановления резервной копии имеет смысл запустить ANALYZE для каждой базы данных, чтобы оптимизатор запросов получил полезную статистику; за подробностями обратитесь к Подразделу 23.1.3 и Подразделу 23.1.6. Другие советы по эффективной загрузке больших объёмов данных в Postgres Pro вы можете найти в Разделе 14.4.
24.1.2. Использование pg_dumpall
Программа pg_dump выгружает только одну базу данных в один момент времени и не включает в дамп информацию о ролях и табличных пространствах (так как это информация уровня кластера, а не самой базы данных). Для удобства создания дампа всего содержимого кластера баз данных предоставляется программа pg_dumpall, которая делает резервную копию всех баз данных кластера, а также сохраняет данные уровня кластера, такие как роли и определения табличных пространств.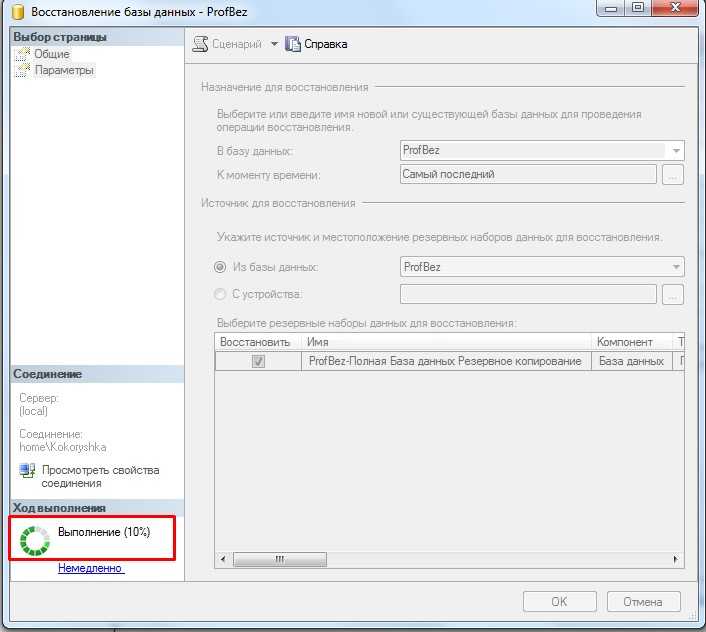 Простое использование этой команды:
Простое использование этой команды:
pg_dumpall > файл_дампа
Полученную копию можно восстановить с помощью psql:
psql -f файл_дампа postgres
(В принципе, здесь в качестве начальной базы данных можно указать имя любой существующей базы, но если вы загружаете дамп в пустой кластер, обычно нужно использовать postgres). Восстанавливать дамп, который выдала pg_dumpall, всегда необходимо с правами суперпользователя, так как они требуются для восстановления информации о ролях и табличных пространствах. Если вы используете табличные пространства, убедитесь, что пути к табличным пространствам в дампе соответствуют новой среде.
pg_dumpall выдаёт команды, которые заново создают роли, табличные пространства и пустые базы данных, а затем вызывает для каждой базы pg_dump. Таким образом, хотя каждая база данных будет внутренне согласованной, состояние разных баз не будет синхронным.
Только глобальные данные кластера можно выгрузить, передав pg_dumpall ключ --globals-only. Это необходимо, чтобы полностью скопировать кластер, когда pg_dump выполняется для отдельных баз данных.
Это необходимо, чтобы полностью скопировать кластер, когда pg_dump выполняется для отдельных баз данных.
24.1.3. Управление большими базами данных
Некоторые операционные системы накладывают ограничение на максимальный размер файла, что приводит к проблемам при создании больших файлов с помощью pg_dump. К счастью, pg_dump может писать в стандартный вывод, так что вы можете использовать стандартные инструменты Unix для того, чтобы избежать потенциальных проблем. Вот несколько возможных методов:
Используйте сжатые дампы. Вы можете использовать предпочитаемую программу сжатия, например gzip:
pg_dumpимя_базы| gzip >имя_файла.gz
Затем загрузить сжатый дамп можно командой:
gunzip -cимя_файла.gz | psqlимя_базы
или:
catимя_файла.gz | gunzip | psqlимя_базы
Используйте split. Команда
Команда split может разбивать выводимые данные на небольшие файлы, размер которых удовлетворяет ограничению нижележащей файловой системы. Например, чтобы получить части по 2 гигабайта:
pg_dumpимя_базы| split -b 2G -имя_файла
Восстановить их можно так:
catимя_файла* | psqlимя_базы
Использовать GNU split можно вместе с gzip:
pg_dump имя_базы | split -b 2G --filter='gzip > $FILE.gz' Восстановить данные после такого разбиения можно с помощью команды zcat.
Используйте специальный формат дампа pg_dump. Если при сборке Postgres Pro была подключена библиотека zlib, дамп в специальном формате будет записываться в файл в сжатом виде. В таком формате размер файла дампа будет близок к размеру, полученному с применением gzip, но он лучше тем, что позволяет восстанавливать таблицы выборочно. Следующая команда выгружает базу данных в специальном формате:
Следующая команда выгружает базу данных в специальном формате:
pg_dump -Fcимя_базы>имя_файла
Дамп в специальном формате не является скриптом для psql и должен восстанавливаться с помощью команды pg_restore, например:
pg_restore -dимя_базыимя_файла
За подробностями обратитесь к справке по командам pg_dump и pg_restore.
Для очень больших баз данных может понадобиться сочетать split с одним из двух других методов.
Используйте возможность параллельной выгрузки в pg_dump. Чтобы ускорить выгрузку большой БД, вы можете использовать режим параллельной выгрузки в pg_dump. При этом одновременно будут выгружаться несколько таблиц. Управлять числом параллельных заданий позволяет параметр -j. Параллельная выгрузка поддерживается только для формата архива в каталоге.
pg_dump -jчисло-F d -fвыходной_каталогимя_базы
Вы также можете восстановить копию в параллельном режиме с помощью pg_restore -j. Это поддерживается для любого архива в формате каталога или специальном формате, даже если архив создавался не командой
Это поддерживается для любого архива в формате каталога или специальном формате, даже если архив создавался не командой pg_dump -j.
PostgreSQL: Документация: 8.1: Резервное копирование и восстановление
Как и все, что содержит ценные данные, базы данных PostgreSQL следует создавать резервные копии.
регулярно. Хотя процедура по существу проста, она
важно иметь базовое представление о том, что лежит в основе
техники и предположения.
Идея метода SQL-дампа заключается в создании текстового
файл с командами SQL, которые при возврате на сервер будут
воссоздать базу данных в том же состоянии, в котором она была в то время
свалки. PostgreSQL
для этой цели предусмотрена утилита pg_dump. Основное использование
этой команды:
pg_dump имя_базы > исходящий файл
Как видите, pg_dump пишет
его результаты на стандартный вывод. Ниже мы увидим, как это
может быть полезным.
pg_dump является обычным
Клиентское приложение PostgreSQL
(хотя и очень умный). Это означает, что вы можете сделать
Это означает, что вы можете сделать
эту процедуру резервного копирования с любого удаленного хоста, имеющего доступ к
базу данных. Но помните, что pg_dump не работает со специальными
разрешения. В частности, он должен иметь доступ для чтения ко всем
таблицы, для которых вы хотите создать резервную копию, поэтому на практике вы почти
всегда нужно запускать его как суперпользователя базы данных.
Чтобы указать, к какому серверу базы данных должен обращаться pg_dump, используйте команду
параметры строки -h host и -p
порт. Хост по умолчанию
локальный хост или любой другой ваш PGHOST
переменная окружения указывает. Точно так же порт по умолчанию
указывается средой PGPORT
переменная или, в противном случае, скомпилированная по умолчанию.
(Удобно, сервер обычно будет иметь один и тот же
компилируется по умолчанию.)
Как и любой другой PostgreSQL
клиентское приложение, pg_dump
по умолчанию будет подключаться с именем пользователя базы данных, которое
равно текущему имени пользователя операционной системы. Переопределить
Переопределить
это либо укажите параметр -U, либо
установите переменную среды PGUSER.
Помните, что pg_dump
соединения подлежат обычной аутентификации клиента
механизмы (которые описаны в главе 20).
Дампы, созданные pg_dump
внутренне непротиворечивы, то есть обновления в базе данных
во время работы pg_dump будет
не оказаться на свалке. pg_dump
не блокирует другие операции с базой данных, пока она
работающий. (Исключениями являются те операции, которые должны выполняться
с эксклюзивным замком, например ВАКУУМ
ПОЛНЫЙ.)
Важно: Когда ваша схема базы данных опирается на
OID (например, как внешние ключи), которые вы должны проинструктировать
pg_dump для сброса OID
также. Для этого используйте -o
вариант командной строки.
Текстовые файлы, созданные pg_dump, предназначены для чтения
программа psql.
общая форма команды для восстановления дампа
psql имя_базы_данных < infile
где infile это то что вы
используется как выходной файл для
Команда pg_dump.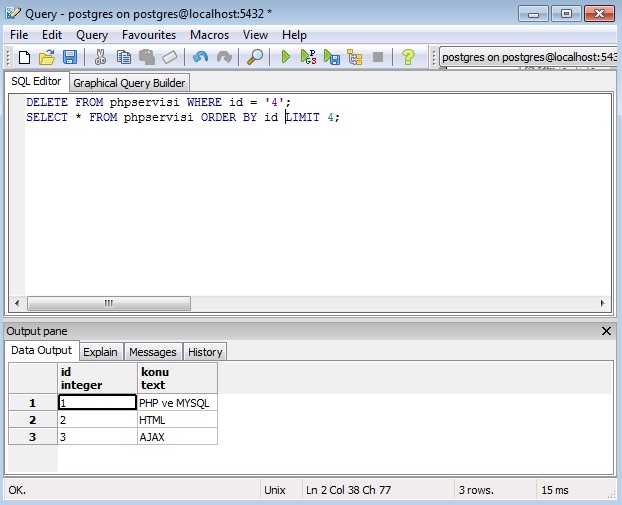
база данных dbname не будет
созданный этой командой, вы должны создать его самостоятельно из
template0 перед выполнением
psql (например, с createdb -T template0 dbname). psql поддерживает параметры, подобные
pg_dump для управления
местоположение сервера базы данных и имя пользователя. См. psql
справочная страница для получения дополнительной информации.
Мало того, что целевая база данных уже должна существовать до
начинают выполнять восстановление, но это должны делать все пользователи, которые
собственные объекты в выгруженной базе данных или были предоставлены
разрешения на объекты. Если их нет, то восстановление
не сможет воссоздать объекты с первоначальным владельцем
и/или разрешения. (Иногда это то, что вы хотите, но
обычно это не так.)
После восстановления целесообразно запустить ANALYZE для каждой базы данных, чтобы
оптимизатор имеет полезную статистику. Простой способ сделать это -
запустите Vacuumdb -a -z, чтобы ВАКУУМНО ПРОАНАЛИЗИРОВАТЬ все базы данных; Это
эквивалентно запуску VACUUM ANALYZE
вручную.
Возможность pg_dump
и psql для записи или чтения
from pipe позволяет выгружать базу данных непосредственно из
одного сервера на другой; например:
pg_dump -h хост1 имя_базы_данных | psql -h host2 имя_базы_данных
Важно: Дампы, создаваемые pg_dump, относятся к template0. Это означает, что любые языки,
процедуры и т. д., добавленные в template1, также будут сброшены
pg_dump. Как результат,
при восстановлении, если вы используете настраиваемый шаблон1, необходимо создать пустой
база данных из template0, как в
пример выше.
Для получения рекомендаций по загрузке больших объемов данных в
PostgreSQL эффективно,
см. Раздел 13.4.
Описанный выше механизм громоздкий и неуместный, когда
резервное копирование всего кластера базы данных. По этой причине
Предоставляется программа pg_dumpall.
pg_dumpall создает резервную копию каждого
базы данных в данном кластере, а также сохраняет
данные, такие как пользователи и группы. Основное использование этого
Основное использование этого
команда:
pg_dumpall > выходной файл
Полученный дамп можно восстановить с помощью psql:
psql -f входной файл postgres
(На самом деле вы можете указать любое имя существующей базы данных для
начать с, но если вы перезагружаетесь в пустой кластер, то
обычно следует использовать postgres.)
Всегда необходимо иметь доступ суперпользователя базы данных, когда
восстановление дампа pg_dumpall,
так как это требуется для восстановления пользователя и группы
Информация.
Так как PostgreSQL позволяет
таблицы больше, чем максимальный размер файла в вашей системе, это
может быть проблематично выгрузить такую таблицу в файл, так как
результирующий файл, вероятно, будет больше максимального размера
разрешено вашей системой. Так как pg_dump может писать в стандартный
вывод, вы можете просто использовать стандартные инструменты Unix для обхода
эта возможная проблема.
Использовать сжатые дампы. Вы можете использовать свой любимый
программа сжатия, например gzip.
pg_dump имя_базы | gzip > имя файла.gz
Перезагрузить с помощью
createdb имя_базы_данных gunzip -c имя_файла.gz | psql имя_базы_данных
или
кошка имя файла.gz | оружейный | psql имя_базы_данных
Использовать раздельно.
Команда split позволяет разделить
выход на куски, приемлемые по размеру для
базовая файловая система. Например, чтобы сделать куски 1
мегабайт:
pg_dump имя_базы | split -b 1m - имя файла
Перезагрузить с помощью
createdb имя_базы_данных имя файла кота* | psql имя_базы_данных
Использовать пользовательский формат дампа. Если PostgreSQL был построен на системе с
сжатие zlib
установленная библиотека, пользовательский формат дампа будет сжимать
данные по мере их записи в выходной файл. Это произведет
Это произведет
размеры файла дампа аналогичны использованию gzip, но у него есть дополнительное преимущество, заключающееся в том, что
таблицы могут быть восстановлены выборочно. Следующая команда
дамп базы данных с использованием пользовательского формата дампа:
pg_dump -Fc имя_базы_данных > имя файла
Дамп пользовательского формата не является сценарием для psql, а вместо этого должен быть восстановлен
с pg_restore. См.
Справочные страницы pg_dump и pg_restore для
Детали.
PostgreSQL: Документация: 15: 26.1. Дамп SQL
- 26.1.1. Восстановление дампа
- 26.1.2. Использование pg_dumpall
- 26.1.3. Работа с большими базами данных
Идея этого метода создания дампа заключается в создании файла с командами SQL, которые при отправке на сервер воссоздают базу данных в том же состоянии, в каком она была во время создания дампа. PostgreSQL предоставляет для этой цели служебную программу pg_dump.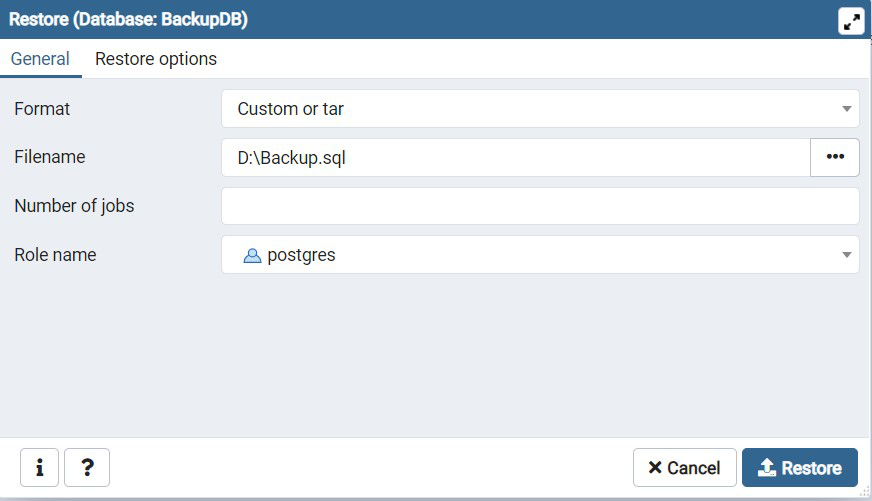 Основное использование этой команды:
Основное использование этой команды:
pg_dumpимя_базы_данных>файл дампа
Как видите, pg_dump выводит результат на стандартный вывод. Ниже мы увидим, как это может быть полезно. В то время как приведенная выше команда создает текстовый файл, pg_dump может создавать файлы в других форматах, обеспечивающих параллелизм и более точное управление восстановлением объектов.
pg_dump — обычное клиентское приложение PostgreSQL (хотя и очень умное). Это означает, что вы можете выполнить эту процедуру резервного копирования с любого удаленного хоста, имеющего доступ к базе данных. Но помните, что pg_dump не работает со специальными разрешениями. В частности, он должен иметь доступ для чтения ко всем таблицам, для которых вы хотите создать резервную копию, поэтому для резервного копирования всей базы данных вам почти всегда придется запускать ее как суперпользователя базы данных. (Если у вас нет достаточных привилегий для резервного копирования всей базы данных, вы все равно можете создавать резервные копии частей базы данных, к которым у вас есть доступ, используя такие параметры, как -n or schema -t . table 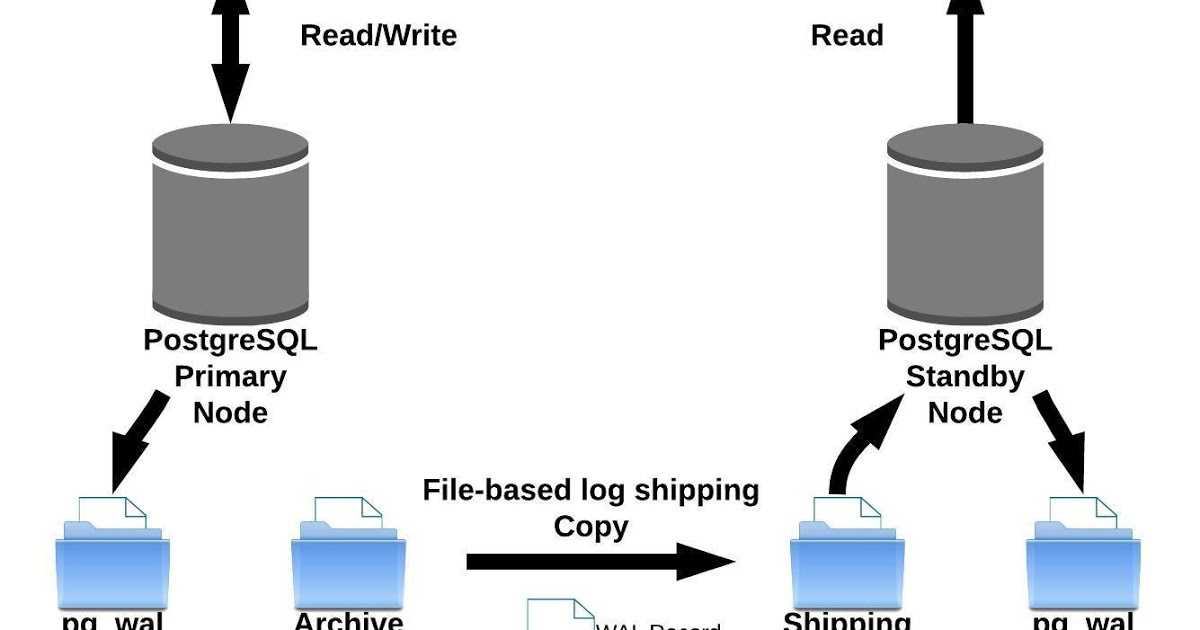 )
)
To specify which database server pg_dump should contact, use the command line options -h and host -p . Хост по умолчанию — это локальный хост или любой другой, указанный в вашей переменной среды порт PGHOST . Точно так же порт по умолчанию указывается переменной среды PGPORT или, в противном случае, скомпилированным значением по умолчанию. (Для удобства сервер обычно будет иметь такое же скомпилированное значение по умолчанию.)
Как и любое другое клиентское приложение PostgreSQL, pg_dump по умолчанию подключается к базе данных с именем пользователя, совпадающим с текущим именем пользователя операционной системы. Чтобы переопределить это, либо укажите параметр -U , либо установите переменную среды PGUSER . Помните, что на соединения pg_dump распространяются обычные механизмы аутентификации клиента (описанные в главе 21).
Важным преимуществом pg_dump по сравнению с другими методами резервного копирования, описанными ниже, является то, что выходные данные pg_dump, как правило, можно повторно загрузить в более новые версии PostgreSQL, в то время как резервное копирование на уровне файлов и непрерывное архивирование сильно зависят от версии сервера. pg_dump также является единственным методом, который будет работать при переносе базы данных на машину с другой архитектурой, например при переходе с 32-разрядного сервера на 64-разрядный.
pg_dump также является единственным методом, который будет работать при переносе базы данных на машину с другой архитектурой, например при переходе с 32-разрядного сервера на 64-разрядный.
Дампы, созданные pg_dump, внутренне непротиворечивы, т. е. дамп представляет собой моментальный снимок базы данных на момент запуска pg_dump. pg_dump не блокирует другие операции с базой данных во время работы. (Исключениями являются операции, требующие монопольной блокировки, такие как большинство форм ALTER TABLE .)
26.1.1. Восстановление дампа
Текстовые файлы, созданные pg_dump, предназначены для чтения программой psql. Общая форма команды для восстановления дампа:
psqlимя_базы_данных<файл дампа
, где файл дампа — это файл, выводимый командой pg_dump. База данных dbname не будет создана этой командой, поэтому вы должны создать ее самостоятельно из template0 перед выполнением psql (например, с помощью createdb -T template0 ). dbname  psql поддерживает параметры, аналогичные pg_dump, для указания сервера базы данных для подключения и используемого имени пользователя. См. справочную страницу psql для получения дополнительной информации. Дампы нетекстовых файлов восстанавливаются с помощью утилиты pg_restore.
psql поддерживает параметры, аналогичные pg_dump, для указания сервера базы данных для подключения и используемого имени пользователя. См. справочную страницу psql для получения дополнительной информации. Дампы нетекстовых файлов восстанавливаются с помощью утилиты pg_restore.
Перед восстановлением дампа SQL все пользователи, владеющие объектами или получившие права доступа к объектам в базе данных дампа, должны уже существовать. В противном случае при восстановлении не удастся воссоздать объекты с первоначальным владельцем и/или разрешениями. (Иногда это то, что вам нужно, но обычно это не так.)
По умолчанию сценарий psql продолжает выполняться после обнаружения ошибки SQL. Возможно, вы захотите запустить psql с переменной ON_ERROR_STOP , установленной для изменения этого поведения, и иметь выход psql со статусом выхода 3, если произойдет ошибка SQL:
psql --set ON_ERROR_STOP=onимя_базы_данных<файл дампа
В любом случае у вас будет только частично восстановленная база данных. В качестве альтернативы вы можете указать, что весь дамп должен быть восстановлен как одна транзакция, поэтому восстановление либо полностью завершается, либо полностью откатывается. Этот режим можно указать, передав параметры командной строки
В качестве альтернативы вы можете указать, что весь дамп должен быть восстановлен как одна транзакция, поэтому восстановление либо полностью завершается, либо полностью откатывается. Этот режим можно указать, передав параметры командной строки -1 или --single-transaction в psql. При использовании этого режима имейте в виду, что даже незначительная ошибка может привести к откату восстановления, которое уже выполнялось в течение многих часов. Однако это все же может быть предпочтительнее ручной очистки сложной базы данных после частично восстановленного дампа.
Способность pg_dump и psql записывать или читать из каналов позволяет создавать дамп базы данных напрямую с одного сервера на другой, например:
pg_dump -hhost1dbname| psql -hхост2имя_базы_данных
Важно
Дампы, созданные pg_dump, относятся к template0 .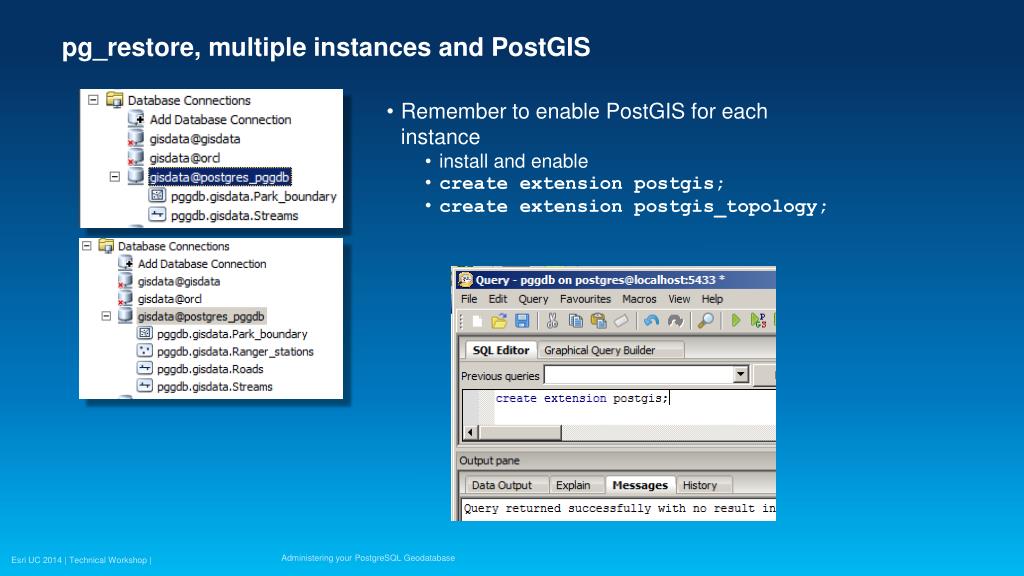 Это означает, что любые языки, процедуры и т. д., добавленные через
Это означает, что любые языки, процедуры и т. д., добавленные через template1 также будет сброшен pg_dump. В результате при восстановлении, если вы используете настроенный шаблон template1 , вы должны создать пустую базу данных из шаблона template0 , как в примере выше.
После восстановления резервной копии целесообразно запустить АНАЛИЗ для каждой базы данных, чтобы оптимизатор запросов имел полезную статистику; см. раздел 25.1.3 и раздел 25.1.6 для получения дополнительной информации. Дополнительные советы о том, как эффективно загружать большие объемы данных в PostgreSQL, см. в разделе 14.4.
26.1.2. Использование pg_dumpall
pg_dump создает дамп только одной базы данных за раз и не выводит информацию о ролях или табличных пространствах (поскольку они относятся к кластеру, а не к базе данных). Для поддержки удобного дампа всего содержимого кластера базы данных предусмотрена программа pg_dumpall. pg_dumpall создает резервную копию каждой базы данных в данном кластере, а также сохраняет данные всего кластера, такие как определения ролей и табличных пространств. Основное использование этой команды:
pg_dumpall создает резервную копию каждой базы данных в данном кластере, а также сохраняет данные всего кластера, такие как определения ролей и табличных пространств. Основное использование этой команды:
pg_dumpall > файл дампа
Полученный дамп можно восстановить с помощью psql:
psql -f файл дампа postgres
(На самом деле вы можете указать любое имя существующей базы данных для начала, но если вы загружаетесь в пустой кластер, обычно следует использовать postgres .) Всегда необходимо иметь доступ суперпользователя базы данных при восстановлении дампа pg_dumpall, так как это необходимо для восстановления информации о роли и табличном пространстве. Если вы используете табличные пространства, убедитесь, что пути табличных пространств в дампе подходят для новой установки.
pg_dumpall выдает команды для повторного создания ролей, табличных пространств и пустых баз данных, а затем вызывает pg_dump для каждой базы данных. Это означает, что хотя каждая база данных будет внутренне непротиворечива, моментальные снимки разных баз данных не синхронизируются.
Это означает, что хотя каждая база данных будет внутренне непротиворечива, моментальные снимки разных баз данных не синхронизируются.
Данные всего кластера могут быть выгружены отдельно с помощью параметра pg_dumpall --globals-only . Это необходимо для полного резервного копирования кластера при выполнении команды pg_dump для отдельных баз данных.
26.1.3. Работа с большими базами данных
В некоторых операционных системах установлены ограничения на максимальный размер файла, что вызывает проблемы при создании больших выходных файлов pg_dump. К счастью, pg_dump может записывать данные в стандартный вывод, так что вы можете использовать стандартные инструменты Unix для решения этой потенциальной проблемы. Существует несколько возможных методов:
Использовать сжатые дампы. Вы можете использовать свою любимую программу сжатия, например gzip:
pg_dumpимя_базы_данных| сжатие >имя файла.
 gz
gz
Перезагрузить с помощью:
gunzip -cимя файла.gz | psqlимя_базы_данных
или:
catимя файла.gz | оружейный | psqlимя_базы_данных
Использовать разделить . Команда split позволяет разделить вывод на файлы меньшего размера, размер которых приемлем для базовой файловой системы. Например, чтобы сделать чанки по 2 гигабайта:
pg_dumpимя_базы_данных| split -b 2G -имя файла
Перезагрузить с помощью:
кошкаимя файла* | psqlимя_базы_данных
При использовании разделения GNU можно использовать его и gzip вместе:
pg_dump имя_базы_данных | split -b 2G --filter='gzip > $FILE.gz'
Можно восстановить с помощью zcat .
Использовать собственный формат дампа pg_dump. Если PostgreSQL был собран в системе с установленной библиотекой сжатия zlib, пользовательский формат дампа будет сжимать данные при их записи в выходной файл. Это создаст размер файла дампа, аналогичный использованию gzip , но имеет дополнительное преимущество, заключающееся в том, что таблицы можно восстанавливать выборочно. Следующая команда создает дамп базы данных, используя пользовательский формат дампа:
. pg_dump -Fcимя базы данных>имя файла
Дамп пользовательского формата не является сценарием для psql, а вместо этого должен быть восстановлен с помощью pg_restore, например:
pg_restore -dимя базы данныхимя файла
Подробности смотрите на справочных страницах pg_dump и pg_restore.
Для очень больших баз данных может потребоваться сочетание split с одним из двух других подходов.