Пропускная способность pci: Все, что вы хотели знать PCI Express
Содержание
Фактическая пропускная способность: PCI Express и Thunderbolt
Все, что вам нужно знать о современных возможностях PCI Express и пропускной способности Thunderbolt и ограничениях при создании вашего следующего ПК.
Мы в будущем!
Настало время продолжить наш сцинтилляционный взгляд на интерфейсы и ограничения на пропускную способность.Мы обратили внимание на PCI Express и Thunderbolt.
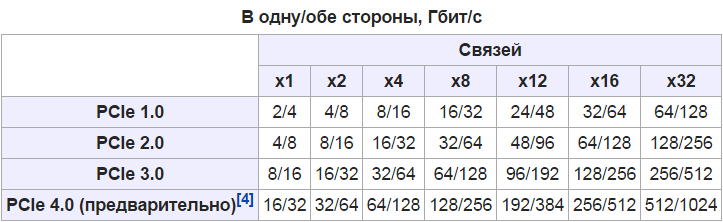
Во-первых, PCI Express: что именно это означает, когда у вас есть соединение PCIe 2.0 x8? И имеет ли значение, является ли ваше соединение x8 или x16?
PCI Express
Интерфейс PCI Express немного запутан. Соединение PCIe состоит из одной или нескольких полос передачи данных, соединенных последовательно. Каждая полоса состоит из двух пар проводников, одна для приема и одна для передачи. У вас может быть один, четыре, восемь или шестнадцать дорожек в одном слоте PCIe для потребителя — обозначены как x1, x4, x8 или x16. Каждая полоса является независимым соединением между контроллером PCI и картой расширения, а линейная ширина полосы линейно, поэтому восьмиполосное соединение будет иметь вдвое большую пропускную способность четырехполосного соединения. Это помогает избежать узких мест между, скажем, процессором и графической картой. Если вам нужна большая пропускная способность, просто используйте больше дорожек.
Это помогает избежать узких мест между, скажем, процессором и графической картой. Если вам нужна большая пропускная способность, просто используйте больше дорожек.
Существует несколько разных физических соединений, каждый из которых может функционировать электрически как слот с меньшим количеством полос движения и может также вмещать физически меньшую карту. В физическом слоте PCIe x16 можно разместить карту x1, x4, x8 или x16 и выполнить запуск x16-карты по x16, x8, x4 или x1. Слот PCIe x4 может вмещать карту x1 или x4, но не может соответствовать карте x16. И, наконец, существует несколько различных версий интерфейса PCIe, каждый из которых имеет разные ограничения пропускной способности, а многие современные материнские платы имеют слоты PCIe различного физического размера, а также разные поколения PCIe.
Начнем с максимальной теоретической пропускной способности. Одна линия PCIe 1.0 (или 1.1) может переносить до 2,5 Гбит / с в секунду (GT / s) в каждом направлении одновременно. Для PCIe 2.0, который увеличивается до 5 Гбит / с, а одна линия PCIe 3.0 может нести 8 Гбит / с.
Для PCIe 2.0, который увеличивается до 5 Гбит / с, а одна линия PCIe 3.0 может нести 8 Гбит / с.
Гигатрансферы в секунду — это то же самое (в данном случае) как гигабиты в секунду. Все версии PCI Express теряют часть своей теоретической максимальной пропускную способность для физических расходов, связанных с электронными передачами. PCIe 1. * и 2.0 используют кодирование 8b / 10b (например, SATA), результатом чего является то, что каждые 8 бит данных стоят 10 бит для передачи, поэтому они теряют 20 процентов своей теоретической пропускной способности . Это просто затраты на ведение бизнеса.
Максимальная скорость передачи данных на PCI-1.0 составляет восемьдесят процентов от 2,5 Гбит / с. Это дает нам два гигабит в секунду, или 250 Мбайт / с (помните, восемь бит в байт). Интерфейс PCIe является двунаправленным, так что это 250 Мбайт / с в каждом направлении, на дорожку. PCIe 2.0 удваивает пропускную способность на одну полосу до 5 Гбит / с, что дает нам 500 МБ / с фактической передачи данных на полосу.
Интерфейс PCIe 3.0 имеет удвоеную скорость передачи данных по сравнению PCI 2.0.
И так мы знаем, что PCIe 3.0 вдвое превышает скорость PCI 2.0, но, как мы видели выше, теоретическая пропускная способность каждой полосы составляет 8 Гбит / с, что на 60 процентов больше, чем 5GT / s PCIe 2.0. Это потому, что PCIe 3.0 и выше используют более эффективную схему кодирования под названием 128b / 130b , поэтому потребление ресурсов намного меньше — всего 1,54 процента. Это означает, что один слот PCIe 3.0 с пропускной способностью 8 Гбит / с может отправлять 985 МБ / с. Это не совсем вдвое 500 Мбайт / с, но это достаточно близко для маркетинговых целей.
Это означает, что соединение PCIe 3.0 x4 (3,94 ГБ / с) имеет почти такую же пропускную способность, как PCIe 1.1 x16 или PCIe 2.0 x8 (оба 4 ГБ / с).
Современные графические процессоры используют интерфейс x16 PCIe 2.0 или 3.0. Это не значит, что они всегда работают со скоростью x16. На многих материнских платах имеется несколько физических слотов x16, но имеется меньшее количество реальных полос PCIe.
И так ,у нас на примере на рабочем столе Z87 (Haswell) или Z77 (Ivy Bridge) процессор имеет 16 линий PCIe 3.0 . На чипсетах Intel есть еще восемь дорожек PCIe 2.0, но они обычно используются для звуковых карт, RAID-карт и т. Д. (Чипсет AMD 990FX включает в себя 32 полосы PCIe 2.0 и четыре на северном мосту). В приведенной выше плате Asus слоты PCIe 3.0 являются полосами ЦП, в то время как всем остальным приходится делиться восемью чипсетами PCIe 2.0. Использование слота PCIe 2.0 x16 в режиме x4 отключает три слота PCIe 2.0 x1.
Таким образом, одна видеокарта x16 будет использовать все 16 PCI-дорожек с процессором PCI, но добавление графического процессора во вторую полосу x16 приведет к отключению обоих подключений видеокарт до восьми полос . Добавление третьего графического процессора приведет к отключению подключеной первой карты к x8, а к подключению второй и третьей карт — к x4.
Вот почему многие люди, которые запускают установки с несколькими GPU, предпочитают архитектуры энтузиастов Intel, такие как Sandy Bridge-E и Ivy Bridge-E так как некоторые Процессоры с технологией Ivy Bridge-E имеют возможность до сорока полос в PCIe 3. 0 . Этого достаточно, чтобы запустить две карты по x16 и одну на x8, одну карту на x16 и три карты на x8 или одну на x16, две на x8 и еще две на x4.
0 . Этого достаточно, чтобы запустить две карты по x16 и одну на x8, одну карту на x16 и три карты на x8 или одну на x16, две на x8 и еще две на x4.
Это важно для производительности?
Два графических процессора PCIe 3.0, работающие на x8 каждый на материнской плате PCIe 3.0, имеют примерно такую же пропускную способность, что и два графических процессора PCIe 2.0, работающих на x16 — первый набор работает со скоростью 7,88 ГБ / с каждый, а второй второй работает со скоростью 8 ГБ / с. Если ваша материнская плата или видеокарта ограничена подключением PCIe 2.0, вы будете зависать из за более медленного интерфейса.
TechPowerUp продемонстрировал огромный объем производительности PCIe. В то время они тестировали две мощные карты с одним GPU — AMD Radeon HD 7970 и Nvidia GeForce GTX 680 — на x4, x8 и x16 с использованием PCIe 1.1, 2.0 и 3.0, все на одной материнской плате. Это, безусловно, лучший тест, который я когда-либо видел на масштабировании полосы пропускания PCIe.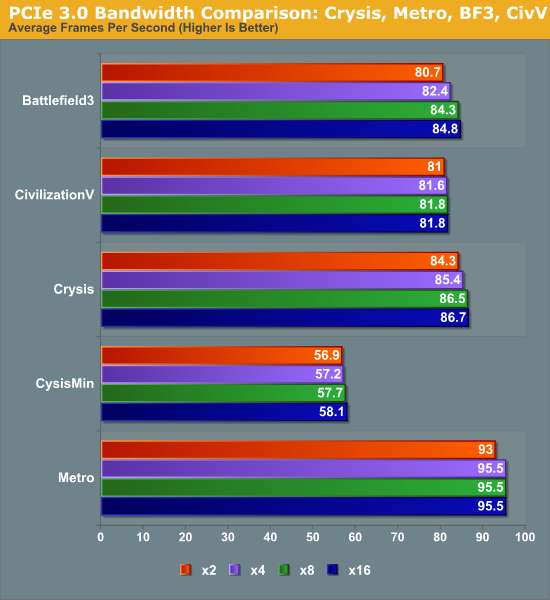 На странице сводки производительности собраны относительные результаты с первого взгляда.
На странице сводки производительности собраны относительные результаты с первого взгляда.
Как и следовало ожидать, эквивалентные конфигурации пропускной способности работают примерно одинаково. Цитируем авторов TechPowerUp : «Наше тестирование подтверждает, что современные графические карты отлично работают при меньшей скорости шины, однако производительность ухудшает скорость работы шины. Все вплоть до x16 1.1 и его эквивалентов (x8 2.0, x4 3.0) обеспечивает достаточную игровую производительность даже при использовании новейшего графического оборудования, теряя всего лишь 5% в среднем в худшем случае. [выделено мной] Только на более низких скоростях мы видим резкие потери частоты кадров, что оправдывало бы действие ».
Самая интересная часть этих результатов — это вывод о том, что самые мощные графические карты прошлого года отлично работают на PCIe 2.0 x8 или даже PCIe 3.0 x4. Это означает, что трехсторонний SLI или CrossFireX должен быть жизнеспособным, даже в x8 / x4 / x4, на Ivy Bridge или рабочих столах Haswell .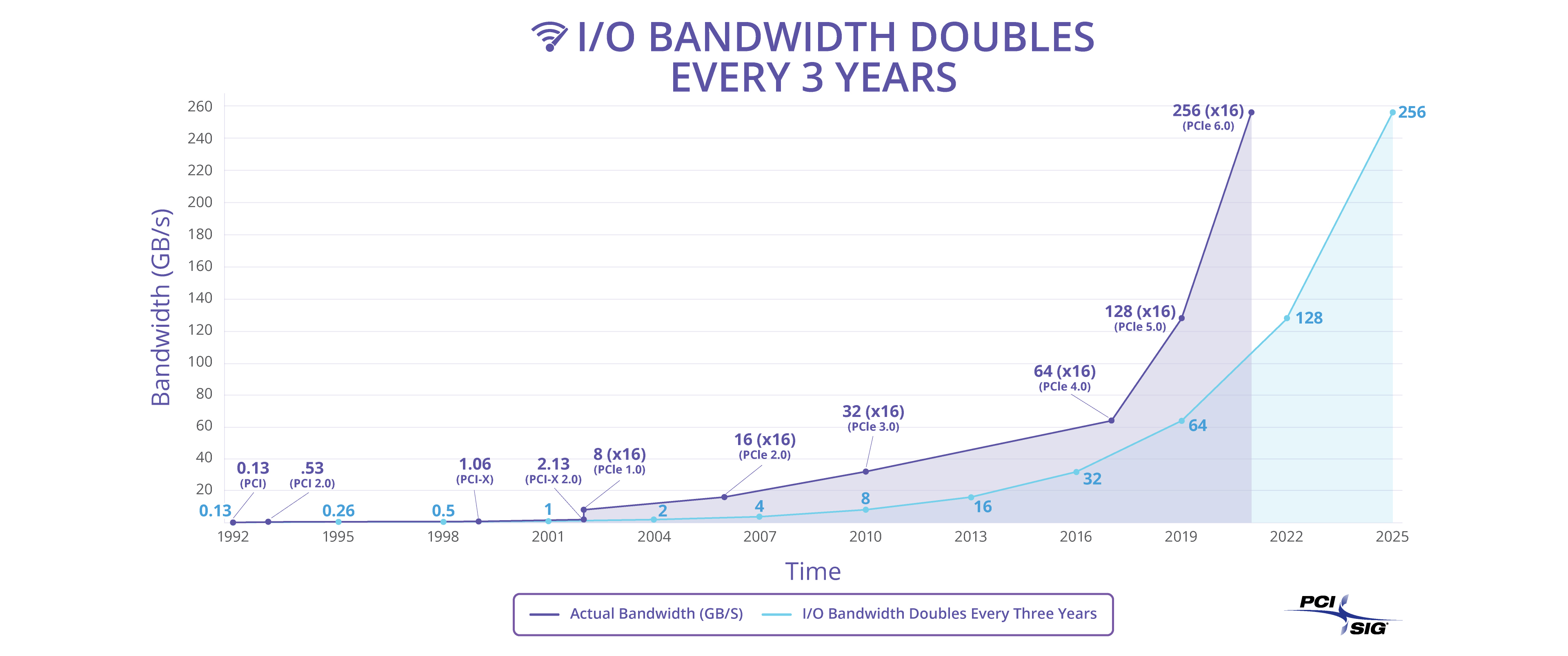 Но даже если у вас нет PCIe 3.0, вы не пропустите большую производительность на x8 на подключении PCIe 2.0.
Но даже если у вас нет PCIe 3.0, вы не пропустите большую производительность на x8 на подключении PCIe 2.0.
Двойная пропускная способность PCIe 3.0 x16 по сравнению с PCIe 2.0, похоже, пока не имеет большого значения. Ryan Smith от AnandTech протестировал две Nvidia GeForce GTX Titans — самые быстрые карты с одним GPU в SLI на PCIe 3.0 и 2.0 и в лучшем случае обеспечила улучшение производительности на 57 % по сравнению с 5760 x 1200.
Так что это хорошая новость для людей со старыми материнскими платами или видеокартами. Если у вас есть хотя бы PCI Express 2.0 x8, вы вряд ли оставите какую-либо надежду на производительность , даже на самых быстрых картах.
Интерфейс Thunderbolt
Thunderbolt — это интерфейс передачи данных, который может проходить через сигналы PCI Express и DisplayPort в зависимости от того, к чему он подключен. Контроллер Thunderbolt состоит из двух двунаправленных каналов данных, причем каждый канал содержит вход и выходную полосу.
Микросхемы Thunderbolt на каждом конце кабеля используются как в DisplayPort 1.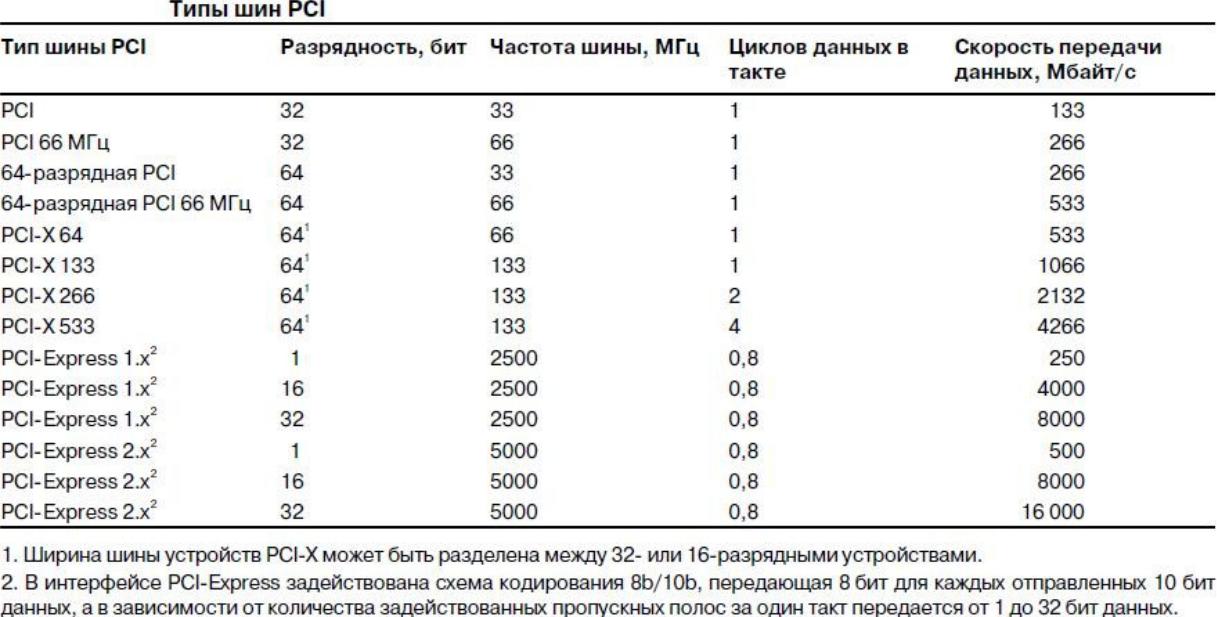 1a, как и в четырехполосной шине PCIe 2.0. Каждый канал независим и может либо переносить DisplayPort, либо PCIe, но не оба. Каждое направление в каждом канале имеет теоретическую максимальную пропускную способность 10 Гбит / с — то же, что и две полосы PCIe 2.0. Как обсуждалось выше, из-за кодирования 8b / 10b то 20 процентов теоретического предела PCI Express 2.0 посвящено служебным нагрузкам сигнала, поэтому максимальная теоретическая пропускная способность одного канала Thunderbolt составляет 1 ГБ / с в каждом направлении.
1a, как и в четырехполосной шине PCIe 2.0. Каждый канал независим и может либо переносить DisplayPort, либо PCIe, но не оба. Каждое направление в каждом канале имеет теоретическую максимальную пропускную способность 10 Гбит / с — то же, что и две полосы PCIe 2.0. Как обсуждалось выше, из-за кодирования 8b / 10b то 20 процентов теоретического предела PCI Express 2.0 посвящено служебным нагрузкам сигнала, поэтому максимальная теоретическая пропускная способность одного канала Thunderbolt составляет 1 ГБ / с в каждом направлении.
В Thunderbolt для первого поколения это так же быстро на сколько это возможно, поскольку каждое устройство может получить доступ только к одному из двух каналов, и вы не можете их комбинировать. Передача данных происходит довольно быстро, так как вы можете отправлять видео высокого разрешения на монитор DisplayPort со скоростью 10 Гбит / с по одному каналу, одновременно считывая 1 ГБ / с с SSD RAID .
Итак, сколько производительности вы можете вытащить из соединения Thunderbolt?
В пример: Gordon Ung at Maximum PC записывает максимальную скорость чтения 931 МБ / с при чтении с RAID 0 четырех SSD SandForce SF-2281 на 240 ГБ в шасси Pegasus R4.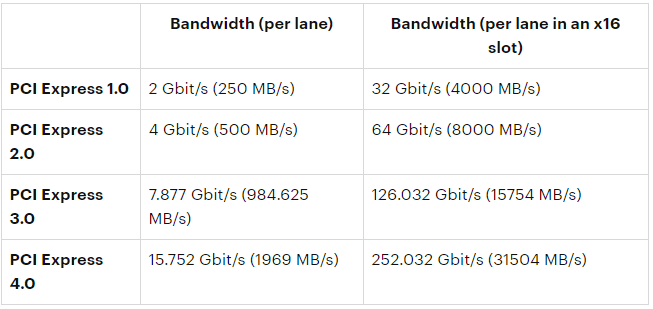
Четырехпотоковый RAID 0 SSD будет довольно быстрым для соединения Thunderbolt первого поколения. Двухдисковый RAID 0 может приближаться к скорости отдельных дисков , хороший SSD с пропускной способностью 6 Гбит / с может достигать 515 Мбайт / с. RAID 0 из двух 6 Гбит / с SSD может легко насытить соединение 10 Гбит / с, доступное в Thunderbolt первого поколения.
Очень короткая заметка о производительности PCIe SSD (по сравнению с Thunderbolt)
Несмотря на ограничения в Thunderbolt первого поколения, он по-прежнему намного лучше внешнего интерфейса для хранения данных, чем USB 3.0.
Жёсткий SSD диск OCZ RevoDrive 3 x2, подключенный к PCIe SSD, может достигать максимума 1,5 ГБ / с в некоторых последовательных тестах чтения на PCIe 2.0 x4-соединении. Этот диск использует контроллер SAS-PCIe, а не контроллер SATA для RAID-карты для подключения PCIe, но, безусловно, это не может объяснить всю разницу в скорости. В конце концов, Thunderbolt — это соединение PCIe 2. 0 x4, верно?
0 x4, верно?
Следующая версия Thunderbolt
Следующая версия Thunderbolt, искусно названная Thunderbolt 2, позволит вам объединить оба канала в один, с теоретическим максимумом 20 Гбит / с (2 ГБ / с, после кодирования), позволяя устройствам использовать все четыре полосы PCIe 2.0 в соединении Thunderbolt , Это также увеличивает пропускную способность на стороне дисплея; вы сможете транслировать 4K-видео на этот фантастический монитор 4K, который у вас есть. Пока Thunderbolt 2 доступен только на нескольких материнских платах от Asus
Другие материалы в этой категории:
« Как создать раздел на жёстком диске
Обзор Maingear Turbo: потрясающий игровой ПК Mini-ITX »
переход на 4-уровневую частотно-импульсную модуляцию сигнала PAM4
Разделы НОВОСТИ СТАТЬИ ВИДЕО
Отрасли
Авиация
Автотранспорт
Горная добыча
Городская инфраструктура
ЖД
Корпоративный сектор и торговля
Космос
Машиностроение
Медицина
Металлургия
Микроэлектроника
Навигация и связь
Наука и инженерия
Нефтегаз
ОПК
Робототехника
Сельское хозяйство и пищепром
Судостроение
Химическая промышленность
Энергетика
Техсредства
Бесперебойное питание
Биометрия и СКУД
Встраиваемые системы
Датчики и вторичные преобразователи
Измерительные системы
Интернет вещей
Искусственный Интеллект
Источники питания
Клеммы, кабель, монтажные конструктивы
Мобильные устройства
ПЛК
Программное обеспечение
Промышленные и коммерческие компьютеры
Серверы и ЦОД
Сети и телекоммуникации
Функциональная безопасность SIL
Человеко-машинный интерфейс
Производители
3onedata
AAEON
ACME
ADDI-DATA
ADLink
Advantech
AdvantiX
Aetina
Akiwa
AMC
AMP
Apacer
APC
APLEX
AUO
Austriamicrosystems
Avocent
Axiomtek
BD SENSORS
BDCOM
Beckhoff
Belden
Beneq
BioSmart
Bopla
Connect Tech
Control Techniques
CoreAVI
CRANE
CyberPower
Dataforth
Degson Electronics
Delta Electronics
Diamond Systems
Duagon
EA Elektro-Automatik
EKF
Emdoor
Emerson
Ensmas
etherWAN
Eurotech
Evoc
Fastwel
FLIR
GaGe
GCAN
GDS
GE DE
GeoVision
Getac
Gett
GMI
GoodView Electronics
Harting
HBT
Hilscher
HiRel
Hirschmann
HollySys
i-sft
IBASE
Iconics
IEE
iEi
IKEY
Indukey
InnoDisk
International Rectifier
Keller AG
Key Technology
Kyland
Libelium
Lippert
Litemax
Lumineq
MAIWE
Maple Systems
MasterSCADA
Men Mikro
Mitsubishi Electric
MOXA
NSI
Octagon Systems
Omron
Oring
Panasonic
Pepperl & Fuchs
Pepperl & Fuchs Elcon
Perfectron
Printec DS
Prosoft Biometrics
ProVS
QNAP
QNX
Raystar
Revisor Lab
Rittal
RST
Sandisk
Scaime
Schaefer
Schneider Electric
Schroff
Sharp
Siemens
Signatec
Sigur
Simotics
Smartek Vision
Spectrum
Swissbit
SYSGO
TDK-Lambda
Thermokon
Tiepie
Tri-M Engineering
TTTech
VIPA
Visiosens
Vivotek
WAGO
WAGO I/O
Wecon
WECON
Weidmuller
Weintek
Wind River
Wuhan Maiwe
XP Power
XP-EMCO
Yaskawa DMC
БД СЕНСОРС РУС
КОНСТЭЛ
Ленпромавтоматика
МПС Софт
ПассатИнновации
ПЛКСистемы
ПРОСОФТ
Прософт-Системы
Энергон
Технологии
В связи с высоким спросом на производительные серверные решения в центрах обработки данных (ЦОД) и в системах на базе алгоритмов искусственного интеллекта и машинного обучения большое значение приобретает увеличение скорости обмена данными по локальным шинам. Удвоение пропускной способности шины PCI Express до 64 ГТ/с увеличением частоты дискретизации цифрового сигнала ведёт к возрастанию влияния частотно-зависимых помех, при которых полезный сигнал становится неотличим от шума. В статье рассмотрен метод решения проблемы рабочей группой альянса PCI-Special Interest Group (PCI-SIG) для будущей спецификации 6.0 интерфейса PCIe.
Удвоение пропускной способности шины PCI Express до 64 ГТ/с увеличением частоты дискретизации цифрового сигнала ведёт к возрастанию влияния частотно-зависимых помех, при которых полезный сигнал становится неотличим от шума. В статье рассмотрен метод решения проблемы рабочей группой альянса PCI-Special Interest Group (PCI-SIG) для будущей спецификации 6.0 интерфейса PCIe.
Гарсия Юлия
914
В ЗАКЛАДКИ
Статья
в электронной версии
«СТА» №1 / 2022 стр. 30
Статья в PDF
581 КБ
Технология обмена данными PCI Express (PCIe) повсеместно используется в устройствах, требующих высокопроизводительных, ускоренных вычислений, подключения сетевых карт и графических ускорителей, но не исчерпывается только этим. Обладая преимуществом в высокой скорости передачи данных перед параллельными шинами PCI, PCI-X и AGP, а также низкой задержкой (временем использования шины периферийным устройством), интерфейс PCIe получил широкое распространение в построении иерархических структур хранения данных (например, подключения ОЗУ и DRAM через слоты PCIe с поддержкой протокола внутрисистемных соединений CXL (Compute Express Link) на базе PCIe 5. 0.
0.
Каждые три-семь лет скорость передачи данных PCI Express при сохранении обратной совместимости с предыдущими поколениями PCIe удваивалась (см. табл. 1).
Разработка приложений искусственного интеллекта (AI – Artificial intelli-gence) и машинного обучения (ML – Machine Learning), построение высокопроизводительных серверных систем и организация облачных вычислений продолжают способствовать генерации трафика гигантских объёмов феноменальными темпами. Стараясь соответствовать непрерывно растущим запросам на увеличение скорости обмена данными между процессором и компонентами, установленными на плате (GPU, FPGA, память), консорциум PCI-SIG (PCI Special Interest Group) представил предварительную версию спецификации PCIe 6.0 со скоростью передачи данных до 64 ГТ/с, окончательное утверждение которой ожидается к концу 2021 года (рис. 1).
Рассмотрим подробнее новую версию интерфейса и его реализацию.
Главная проблема PCIe 6.0
Чтобы избежать дорогостоящей модернизации инфраструктуры, новый интерфейс должен соответствовать требованиям обратной совместимости с предыдущими спецификациями, например, электрические параметры устройств нового поколения PCIe 6.0 должны соответствовать более старым версиям на объединительной плате (например, поддерживать скорость передачи данных до 28 Гбит/с). Требование механической совместимости разъёмов PCIe не позволяет увеличивать количество линков для увеличения пропускной способности.
В спецификации PCIe 5.0 используется моделирование цифровых сигналов кодированием без возврата к нулю (NRZ, no-return-to-zero). При этом искажение сигнала для каналов может достигать 36 дБ (частота Найквиста, равная половине частоты дискретизации, при частоте тактирования 32 ГГц составляет 16 ГГц). При удвоении скорости передачи данных с 32 ГТ/с (гига-транзакций в секунду) до 64 ГТ/с кодированием без возврата к нулю частота Найквиста равна 32 ГГц, при этом частотно-зависимые потери канала увеличиваются до 70 дБ [1].
Таким образом, если пропускная способность будет увеличиваться за счёт увеличения частоты, например, до 56 ГГц, вносимые потери IL (Insertion loss) на частоте Найквиста (28 ГГц) составляли бы ~60 дБ, а отношение вносимых потерь сигнала IL к перекрёстным помехам (ICR – incertion-loss-to-crosstalk ratio) при этом стремилось бы к нулю. Это обстоятельство делает невозможным увеличение скорости передачи данных до 56 Гбит/с традиционным методом повышения частоты квантования (дискретизации). Удвоение скорости передачи данных вносит в сигнал существенные искажения, даже если речь идет о небольшом расстоянии, на которое передаётся сигнал.
Частота передачи сигнала свыше 32 ГГц делает его более нестабильным, практически неотличимым от шума.
Переход на PAM4-кодирование
Новая ревизия интерфейса PCIe использует вместо NRZ-кодирования 4-уровневую амплитудно-импульсную модуляцию (PAM4), основанную на использовании не 2, а 4 значений напряжения, и передаёт 2 бита за минимальный интервал времени между изменениями состояния сигнала (Unit Interval), в отличие от кодирования без возврата к нулю, которое передаёт только 1 бит за тот же интервал (рис. 2).
2).
Этот метод передачи сигнала позволяет увеличить пропускную способность PCIe 6.0 в 2 раза, поддерживая искажение сигнала на том же приемлемом уровне, что и в предыдущей версии стандарта PCIe 5.0.
На рис. 3 хорошо заметно, что для канала PAM4 вносимые потери IL составляют ~31 дБ, перекрёстные ICR – ~30 дБ на частоте 14 ГГц. Также можно заметить, что значения вносимых IL и перекрёстных ICR помех при моделировании сигналов NRZ (канал на объединительной плате предыдущих версий стандарта) на частоте 28 ГГц составляют 60 дБ.
Однако преимущество новой сигнальной структуры PAM4 обходится дорого: запас помехоустойчивости для PAM4-кодирования снижается на 9,5 дБ (33%). Это усугубляет неблагоприятное воздействие отражённого сигнала и шумов от источника питания.
FEC и код Грея
Несмотря на то что в интерфейсе PCIe 6.0 удвоена скорость передачи данных за счёт использования PAM4-кодирования, пониженное соотношение сигнал/шум (SNR – signal-to-noise-ratio) делает его более восприимчивым к помехам по сравнению с кодированием NRZ, способствует высокой частоте битовых ошибок и может привести к сбоям в работе системы или снижению производительности. Метод восстановления целостности сигнала в стандарте PCIe 6.0 – упреждающая коррекция ошибок FEC (forward-error-correction) – предусматривает отправление избыточных данных вместе с полезными при условии, что частота ошибок ниже определённого порогового значения. Циклическая проверка избыточности (CRC – cyclic redundancy check) выполняется для обнаружения и исправления битовых ошибок, если CRC обнаруживает ошибки после FEC, запускается механизм повторной проверки.
Метод восстановления целостности сигнала в стандарте PCIe 6.0 – упреждающая коррекция ошибок FEC (forward-error-correction) – предусматривает отправление избыточных данных вместе с полезными при условии, что частота ошибок ниже определённого порогового значения. Циклическая проверка избыточности (CRC – cyclic redundancy check) выполняется для обнаружения и исправления битовых ошибок, если CRC обнаруживает ошибки после FEC, запускается механизм повторной проверки.
Также в качестве повышения помехоустойчивости сигнала в PCIe 6.0 применяется двоичный циклический код (код Грея). Код Грея оперирует самым старшим битом (MSB – most significant bit) и самым младшим битом (LSB – least significant bit) таким образом, чтобы ошибка, вызванная электрическими помехами, приводила максимум к ошибке в одном разряде (рис. 4).
Предыдущие поколения PCIe поддерживали режим экономичного энергопотребления за счёт динамического изменения ширины канала. PCIe 6.0 вводит режим экономии энергопотребления L0p (Low Power State), который позволяет изменять потребляемую мощность пропорционально пропускной способности без прерывания трафика.
PCIe 6.0 вводит режим экономии энергопотребления L0p (Low Power State), который позволяет изменять потребляемую мощность пропорционально пропускной способности без прерывания трафика.
В спецификации PCIe 6.0 предусмотрено кодирование на основе блока управления потоком FLIT (Flow Control Unit) для обеспечения меньшей величины задержки, связанной с применением алгоритмов FEC и CRC. Таким образом, добавление вышеуказанных механизмов самокоррекции в PCIe 6.0 не должно существенно увеличивать задержку (латентность) по сравнению с версией PCIe 5.0.
Рабочая группа PCI-SIG доказала, что для PCIe 6.0 её уровень не превышает 10 нс (рис. 5).
Линейность
Для метода PAM4 характерен так называемый эффект нелинейности, хорошо видимый на глаз-диаграмме (рис. 6). В левой части приведена идеальная линейность, для которой высоты разделения уровней одинаковы. Интервал между V1 и Vmin составляет одну треть интервала между V0 и Vmin. Аналогичным образом расстояние между V2 и Vmin составляет одну треть от расстояния между V3 и Vmin. В идеальном случае коэффициент рассогласования расстояния между уровнями RLM равен 1. Чем ближе реальный показатель RLM к 1, тем лучше линейность.
Аналогичным образом расстояние между V2 и Vmin составляет одну треть от расстояния между V3 и Vmin. В идеальном случае коэффициент рассогласования расстояния между уровнями RLM равен 1. Чем ближе реальный показатель RLM к 1, тем лучше линейность.
Для примера на правой части рис. 6 показан «глаз» с плохой линейностью – уровень сигнала V1 и V2 настолько низок, что интервал между V1 и Vmin составляет две трети от V0 до Vmin, а интервал от V2 до Vmin равен всего одной четверти интервала между V3 и Vmin. В этом случае расчётный показатель RLM равен 0.
Выравнивание амплитудно-частотной характеристики и усиление сигнала могут внести такие искажения, что два уровня напряжения из четырёх будут зафиксированы приёмником сигнала как один. В целом недостаточная линейность, описанная правой частью глаз-диаграммы (рис. 6), приводит к неустранимым битовым ошибкам [2].
6), приводит к неустранимым битовым ошибкам [2].
Заключение
Переход на 4-уровневую импульсно-амплитудную модуляцию (PAM4) сигнала в настоящий момент является оптимальным средством увеличения пропускной способности при условии сохранения совместимости линков и приемлемого соотношения сигнал/шум.
Несмотря на то что целый ряд задач ещё ждёт своих решений от разработчиков PCI-SIG, параметры помехоустойчивости новой спецификации интерфейса соответствуют возможностям современных приёмопередающих уст-ройств PCIe 6.0, что обеспечит центрам обработки данных, телекоммуникационным и другим системам с повышенными требованиями к пропускной способности скорость передачи данных до 64 Гбит/с на линию. ●
Литература
1. Whitepaper: Pushing the Envelope with PCIe 6.0: Bringing PAM4 to PCIe, Tony Chen, Candence. [Электронный ресурс] // URL: https://www.cadence.com/content/dam/cadence-www/global/en_US/documents/tools/ip/design-ip/pushing-the-envelope-with-pcie-6-wp. pdf.
pdf.
2. AN 835: PAM4 Signaling Fundamentals Intel. [Электронный ресурс] // URL: https://www.intel.com/content/dam/www/programmable/us/en/pdfs/literature/an/an835.pdf.
скорость — максимальная пропускная способность PCI
спросил
Изменено
5 лет, 10 месяцев назад
Просмотрено
28 тысяч раз
Здесь гипотетически, но я хочу понять.
Скажем, у меня есть подержанная машина, 4 слота PCI, 64-разрядная шина PCI 33 МГц.
Какой объем данных может обрабатывать эта шина PCI? Системная шина 133 МГц.
Я хочу использовать один слот для карты SATA II, а остальные — для карт Gig-E, чтобы максимально быстро построить NAS. Я думаю, что один слот может быть AGP2x, так что у меня остается 2 для Gig-E и один для SATAT II.
Будет ли насыщение, какова максимальная пропускная способность шины PCI?
- скорость
- пропускная способность
- pci
- архитектура компьютера
1
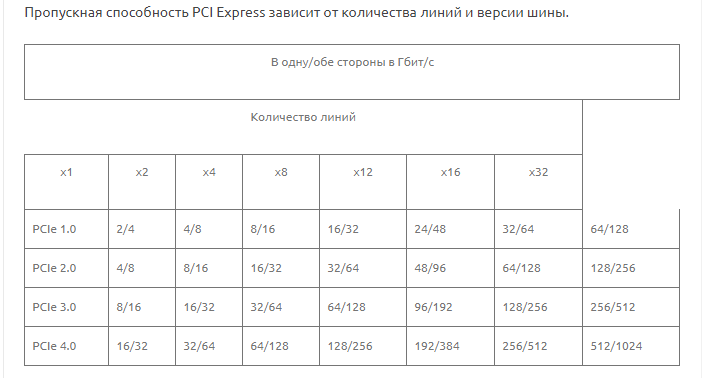
Согласно статье PCI в Википедии и списку пропускной способности устройств пропускная способность шины PCI может быть рассчитана по следующей формуле:
частота * битовая ширина = пропускная способность 33,33 МГц * 32 бита = 1067 Мбит/с = 133,32 МБ/с
Обычные шины PCI работают со следующей пропускной способностью:
- PCI 32-разрядная, 33 МГц: 1067 Мбит/с или 133,33 Мбит/с
- PCI 32-бит, 66 МГц: 266 МБ/с
- PCI 64-бит, 33 МГц: 266 МБ/с
- PCI 64-бит, 66 МГц: 533 МБ/с
По тем же ссылкам:
- SATA (SATA-150): 150 МБ/с
- SATA (SATA-300): 300 МБ/с
- Fast Ethernet (100base-X): 11,6 МБ/с
- Gig-E (1000base-X): 125 МБ/с
Теоретически у вас есть место на шине PCI для двух карт Gig-E или для карты SATA-II, но не для обеих одновременно. По крайней мере, не работает на теоретических максимумах. Если вы подключите все три, работа их всех при полной нагрузке станет узким местом на шине PCI.
По крайней мере, не работает на теоретических максимумах. Если вы подключите все три, работа их всех при полной нагрузке станет узким местом на шине PCI.
К счастью, вы не приблизитесь к теоретической скорости на интерфейсе SATA (если только вы не используете дорогие SSD-накопители). Ваши карты Gig-E, вероятно, будут ближе, но во всех случаях реальная скорость будет значительно меньше теоретической.
Я ожидаю, что такая установка будет хорошо работать для многих приложений.
Я согласен с шарлатанским донкихотом, но для вашего случая это будет быстро и просто:
Ваша общая максимальная теоретическая пропускная способность составляет 533 МБ/с.
Говоря простым языком, это действительно зависит от вашего максимального использования и нагрузки.
*Карты 2xGigE обеспечивают общую пропускную способность 4 Гбит/с (или 500 МБ/с), если вы используете максимальную пропускную способность в обоих направлениях одновременно (маловероятно, если только вы не используете VPN/конференции на таких скоростях).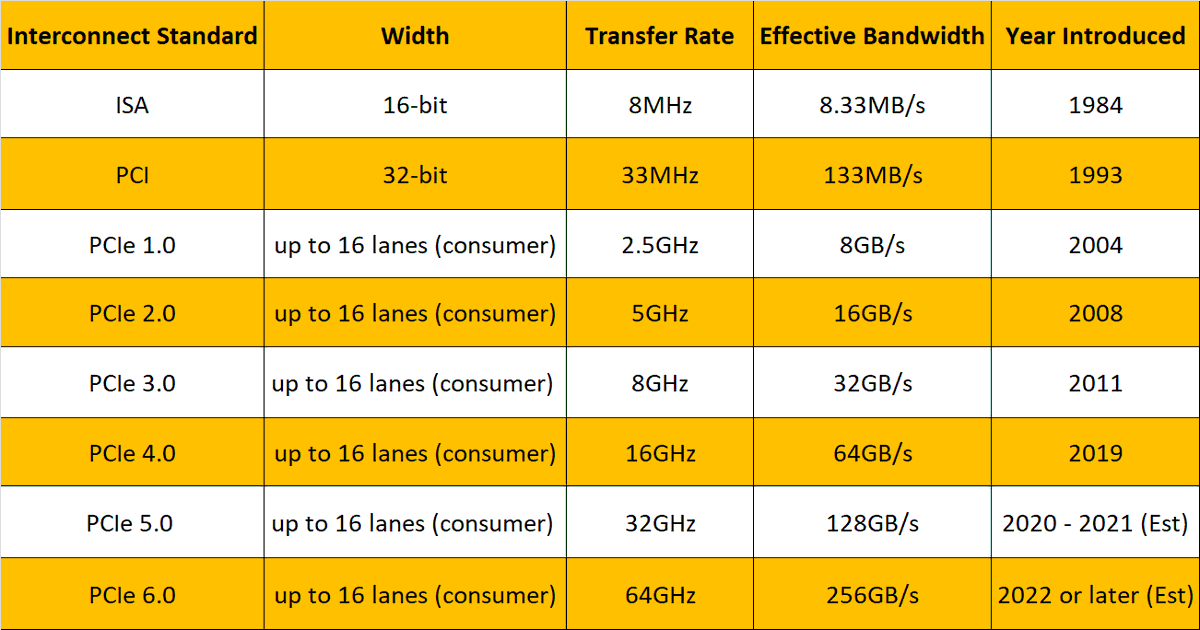
* Карта SATA 1×3 Гбит. Сколько дисков вы добавите? Новые диски SATA потребляют в среднем 170 МБ/с.
Так что это действительно зависит от средней и максимальной пропускной способности, которую вы используете для своих сетевых карт и карты SATA. Он может нормально работать без каких-либо сбоев для многих распространенных рабочих нагрузок, но если вы используете максимальную пропускную способность на 2-гигабитных сетевых адаптерах и карте SATA, у вас будет замедление из-за максимальной скорости шины PCI.
1
Я тестировал с картой Intel 2x1Gbit PCI Lan (первоначально PCI-X64-133MHz, но в обычном слоте PCI2.2 33MHz)
Отчеты BSD в статистике трафика интерфейса:
Результат ~ 550-600 Мбит при работе в режиме загрузки (или в одну сторону).
в дуплексном режиме работает ~200Mbit-Rx ~200Mbit Tx
Windows говорит 62 МБ/с.
Так я и не набрал 1000Мбит, думаю если поставить больше карт результат будет хуже.
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания, политикой конфиденциальности и политикой использования файлов cookie
.
Что такое PCIe 4.0? Объяснение PCI Express 4
Назад в блог
by Rambus Press Оставить комментарий
PCIe 4.0 — это следующая эволюция вездесущей и универсальной спецификации ввода-вывода PCI Express. Он также известен как PCIe Gen 4 и является спецификацией шины расширения Peripheral Component Interconnect Express (PCI Express) четвертого поколения, которая разрабатывается, публикуется и поддерживается PCI Special Interest Group (PCI-SIG).
В этом блоге вы узнаете все о производительности PCI Express 4 по сравнению с PCIe 3.0. Более конкретно:
1. Полоса пропускания PCIe 4.0
2. Рыночные приложения: кому нужен PCIe 4.0?
3. PCIe 3.0 и 4.0: сравнительная таблица
4. Полные решения подсистем PCI Express 4 от Rambus
5. Заключение
Читать наш учебник? Перейти к: PCI Express 5 против 4: что нового?
Полоса пропускания PCIe 4.
 0
0
Производительность межсоединения пропускная способность удваивается по сравнению со спецификацией PCIe 3.0 с достижением скорости 16 ГТ/с и сохранением совместимости с программным обеспечением и механическими интерфейсами. Архитектура PCIe 4.0 совместима с предыдущими поколениями технологии PCIe.
Диаграмма скоростей PCIe 4
Чтобы обеспечить эту эволюцию, PCI SIG усердно работает, чтобы следовать регулярному циклу, направленному на удвоение пропускной способности PCIe каждые 4 года. PCIe — это открытый стандарт, управляемый PCI SIG, 22-летней группой, которая позволяет компаниям сотрудничать в разработке стандарта.
Приложения Market: Кому нужен PCIe 4.0?
Большие данные нуждаются в пропускной способности
По словам Гэри Кинга, профессора Университета Уэзерхед, «данные текут так быстро, что общее накопление за последние два года — зеттабайт — затмевает предыдущий рекорд человеческой цивилизации». Интернет, повсеместное использование смартфонов и усиление маркетинга ускорили революцию в области больших данных, а Интернет вещей (IoT) увеличит потребность в быстрых и эффективных средах управления данными. Повышение пропускной способности и снижение энергопотребления необходимы для предотвращения появления узких мест при появлении больших данных.
Интернет, повсеместное использование смартфонов и усиление маркетинга ускорили революцию в области больших данных, а Интернет вещей (IoT) увеличит потребность в быстрых и эффективных средах управления данными. Повышение пропускной способности и снижение энергопотребления необходимы для предотвращения появления узких мест при появлении больших данных.
Сетевые приложения
Пропускная способность 4-канальной шины PCI Express (ГБ/с)
8-канальная и 16-канальная шина PCI Express 3.0 имеют пропускную способность, необходимую для работы с подключением Ethernet 40 Гбит/с. Однако использование такого количества дорожек вызывает проблемы со стоимостью, компоновкой и питанием. Более высокоскоростная связь, требующая меньшего количества полос, была бы гораздо лучшей реализацией.
Технологии хранения нуждаются в большей пропускной способности
Поток данных, обеспечиваемый PCIe 3.0 (8 ГТ/с), уже рассматривается как ограничение скорости для пропускной способности SSD. (Его можно сравнить с портом SAS 12G, обеспечивающим поток данных 12 ГТ/с). PCIe в сочетании с NVMe значительно повысит производительность до 16 ГТ/с на дорожку.
(Его можно сравнить с портом SAS 12G, обеспечивающим поток данных 12 ГТ/с). PCIe в сочетании с NVMe значительно повысит производительность до 16 ГТ/с на дорожку.
PCIe 3.0 и 4.0: сравнительная таблица
Спецификации PCI Express 4
Нет изменений кодировки с 3.0 на 4.0. Были только незначительные обновления с точки зрения протокола . Действительно, эволюция до версии 4.0 в основном нацелена на работу с PHY-интерфейсом. Ожидается, что это будет самой сложной проблемой для дизайнеров.
Также имеются небольшие изменения в отношении управления на уровне каналов . PCIe 4.0 обеспечивает более надежное выравнивание.
С точки зрения производительности, с PCIe 4.0 пропускная способность на линию составляет 16 ГТ/с. Канал является полнодуплексным, что означает, что данные могут отправляться и приниматься одновременно. Общая пропускная способность: 32 ГТ/с. Никакой другой отраслевой протокол не может обеспечить пропускную способность технологии PCIe 4. 0 (общая пропускная способность до 64 Гбайт/с для PCIe 4.0 x16). Новые появляющиеся интерфейсы, такие как Ethernet 40G/100G, InfiniBand, твердотельные накопители (SSD) и флэш-память, требуют больших каналов. Эти цифры делают архитектуру PCIe единственным технологическим решением, которое достигает такого уровня производительности с минимальными новыми обновлениями программного обеспечения.
0 (общая пропускная способность до 64 Гбайт/с для PCIe 4.0 x16). Новые появляющиеся интерфейсы, такие как Ethernet 40G/100G, InfiniBand, твердотельные накопители (SSD) и флэш-память, требуют больших каналов. Эти цифры делают архитектуру PCIe единственным технологическим решением, которое достигает такого уровня производительности с минимальными новыми обновлениями программного обеспечения.
Комплексные решения для подсистем PCI Express 4 от Rambus
Rambus PCI Express (PCIe) 4.0 SerDes PHY разработан для обеспечения максимальной скорости интерфейса в сложных системных средах, характерных для высокопроизводительных вычислений. Это маломощный, оптимизированный по площади, проверенный на кремнии IP-адрес, разработанный с использованием системно-ориентированного подхода, чтобы максимизировать гибкость и упростить интеграцию для наших клиентов.
В августе 2021 года Rambus завершила сделку по приобретению PLDA. Благодаря этому приобретению Rambus расширил свои предложения цифровых контроллеров за счет дополнительных контроллеров CXL 2.:strip_icc()/i.s3.glbimg.com/v1/AUTH_08fbf48bc0524877943fe86e43087e7a/internal_photos/bs/2021/l/m/8ByeRASZuD7pXJqg2sBA/2014-06-05-tabela-mostra-evolucao-do-pcie-1.png) 0, PCIe 5.0 и PCIe 6.0 и IP-коммутаторов, а также получил важные строительные блоки для своей инициативы CXL Memory Interconnect Initiative.
0, PCIe 5.0 и PCIe 6.0 и IP-коммутаторов, а также получил важные строительные блоки для своей инициативы CXL Memory Interconnect Initiative.
Кроме того, с ядром контроллера PLDA PCIe 4.0 мы предлагаем полную подсистему PCIe 4.0 SerDes.
Почему стоит выбрать Rambus PCIe 4.0 IP?
Для надежности:
- Помимо собственного многолетнего опыта, команда PLDA дополнительно имеет более чем 20-летний опыт разработки IP-ядер для ASIC со специализацией на высокоскоростных интерфейсных протоколах и технологиях, уделяя особое внимание на PCIe. Более 5700 клиентов с несколькими сотнями ASIC.
- PCIe 3.0 уже проверена в нескольких проектах. Проверенная архитектура PCIe 3.0 сохранена, что позволяет легко перейти на PCIe 4.0. Нет необходимости в изменении интерфейса; существующее поведение сохраняется для бесшовной интеграции.
- IP-адреса контроллера PCIe 4 PLDA в настоящее время используют спецификацию PIE-8, что обеспечивает простую интеграцию с уровнями PCS от нескольких поставщиков PHY.
 PLDA активно участвует в обновлении спецификации PIE-8 2.0.
PLDA активно участвует в обновлении спецификации PIE-8 2.0.
Архитектура
 PLDA активно участвует в обновлении спецификации PIE-8 2.0.
PLDA активно участвует в обновлении спецификации PIE-8 2.0.Для гибкости:
Гибкость поддерживаемых конфигураций PIPE для PCIe 4.0:
• PIPE 16-bit поддерживается в x1, x2, x4, x8 и x16 с тактовой частотой 500MHz PIPE на скорости 8Gbps (ASIC)
• PIPE 32-bit поддерживается в x1, x2, x4, x8 с тактовой частотой PIPE 500 МГц при 16 Гбит/с (ASIC)
• 64-разрядная версия PIPE будет поддерживаться в x1, x2 и x4 с тактовой частотой 250 МГц PIPE при 16 Гбит/с (ASIC/FPGA)
Гибкость ядра конфигурация для соответствия спецификациям
- Для поддерживаемых функций:
Функции, уже проверенные в версии 3.0, оптимизированные для целевых рынков PCIe 4.0
- Конечная точка, корневой порт, коммутатор, двухрежимный общий кремний
- Готов к виртуализации с SRIOV и ATS/ARI (сеть, центр обработки данных)
- Многофункциональный
- AER и механизм обеспечения целостности данных
- Полная поддержка управления питанием: устаревшее, ASPM L0s/L1, OBFF, подсостояние L1 PM с CLKREQ
- Конечные префиксы TLP
- Поскольку он оптимизирован для задач PCIe 4. 0
 0
0Устройства расширения:
- Ожидается, что устройства повторного таймера получат широкое распространение в материнских платах и объединительных линиях PCIe 4.0.
PLDA IP Core поддерживает устройство расширения ECN
Несколько пакетов за такт:
Пропускная способность PCIe 4.0 требует больших путей передачи данных, чем в предыдущих поколениях.
Заключение
PCIe 4.0 — это последняя итерация PCIe, получившая коммерческую версию. Эти два стандарта структурно очень похожи, главное отличие заключается в более высокой скорости передачи. Он предлагает вдвое большую пропускную способность, чем его предшественник, PCIe 3.0, и вдвое большую пропускную способность, чем PCIe 3.0. Rambus предоставляет нашим клиентам полностью интегрированные подсистемные решения «Контроллер + PHY» для PCIe 4.0, предназначенные для различных комбинаций литейного производства и технологических процессов. Если у вас есть проблемы с дизайном, которые нужно решить в вашем текущем проекте, мы будем более чем рады помочь.