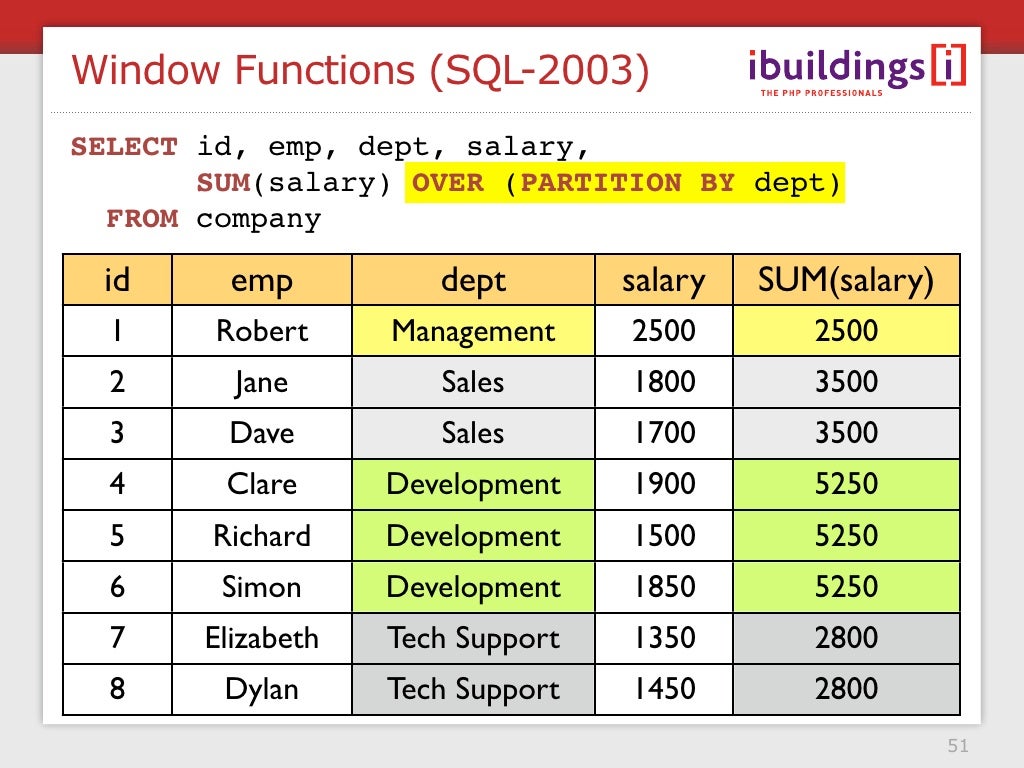
Rank over by partition: SQL Server RANK() Function By Practical Examples
Содержание
RANK (Transact-SQL) — SQL Server
-
Статья -
- Чтение занимает 3 мин
-
Область применения: SQL Server (все поддерживаемые версии) База данных SQL Azure Управляемый экземпляр SQL Azure Azure Synapse Analytics Analytics Platform System (PDW)
Возвращает ранг каждой строки в секции результирующего набора. Ранг строки вычисляется как единица плюс количество рангов, находящихся до этой строки.
Функции ROW_NUMBER и RANK похожи. ROW_NUMBER нумерует все строки по порядку (например, 1, 2, 3, 4, 5). RANK назначает одинаковое числовое значение строкам, претендующим на один ранг (например, 1, 2, 2, 4, 5).
Примечание
RANK — это временное значение, вычисляемое во время выполнения запроса. Сведения о хранении номеров в таблице см. в разделах Свойство IDENTITY и SEQUENCE.
Синтаксические обозначения в Transact-SQL
Синтаксис
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
Примечание
Ссылки на описание синтаксиса Transact-SQL для SQL Server 2014 и более ранних версий, см. в статье Документация по предыдущим версиям.
Аргументы
OVER ( [ partition_by_clause ] order_by_clause)
partition_by_clause делит результирующий набор, полученный с помощью предложения FROM, на секции, к которым применяется функция. Если этот параметр не указан, функция обрабатывает все строки результирующего набора запроса как отдельные группы. order_by_clause определяет порядок данных перед применением функции. Аргумент order_by_clause является обязательным. В функции RANK нельзя указывать <предложение ROWS или RANGE/> предложения OVER. Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).
Дополнительные сведения см. в статье Предложение OVER (Transact-SQL).
Типы возвращаемых данных
bigint
Если на один ранг претендуют две и более строки, все они получат одинаковый ранг. Например, если двум лучшим продавцам соответствует одинаковое значение SalesYTD, им обоим присваивается ранг 1. Менеджер по продажам со следующим по величине значением SalesYTD получит ранг номер три, так как перед ним находятся две строки с более высоким рангом. Поэтому функция RANK не всегда возвращает последовательные целые числа.
Порядок сортировки, используемый для всего запроса, определяет порядок, в котором строки будут появляться в результирующем наборе.
Функция RANK не детерминирована. Дополнительные сведения см. в разделе Deterministic and Nondeterministic Functions.
Примеры
A. Ранжирование строк внутри секции
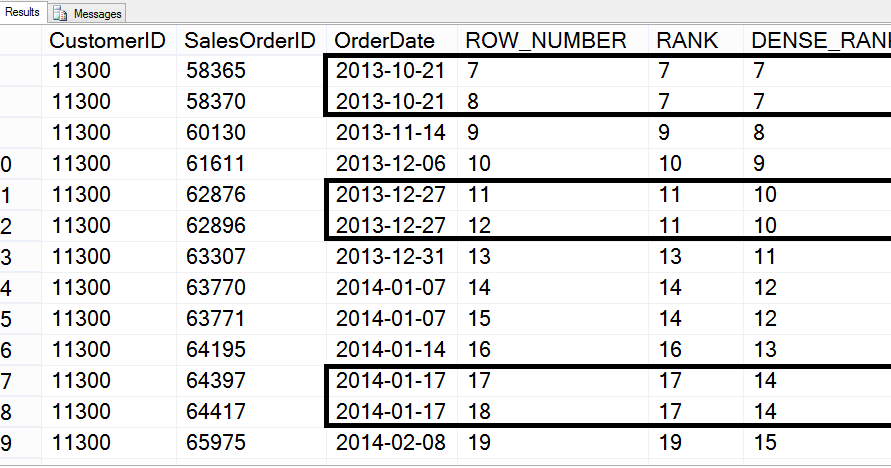
Следующий пример ранжирует продукты по количеству в указанных местоположениях в описи. Результирующий набор секционируется по LocationID и логически сортируется по Quantity.![]() Обратите внимание, что количество продуктов 494 и 495 совпадает. Так как они занимают одно и то же место, рейтинг обоих продуктов равен единице.
Обратите внимание, что количество продуктов 494 и 495 совпадает. Так как они занимают одно и то же место, рейтинг обоих продуктов равен единице.
USE AdventureWorks2012;
GO
SELECT i.ProductID, p.Name, i.LocationID, i.Quantity
,RANK() OVER
(PARTITION BY i.LocationID ORDER BY i.Quantity DESC) AS Rank
FROM Production.ProductInventory AS i
INNER JOIN Production.Product AS p
ON i.ProductID = p.ProductID
WHERE i.LocationID BETWEEN 3 AND 4
ORDER BY i.LocationID;
GO
Результирующий набор:
ProductID Name LocationID Quantity Rank ----------- ---------------------- ------------ -------- ---- 494 Paint - Silver 3 49 1 495 Paint - Blue 3 49 1 493 Paint - Red 3 41 3 496 Paint - Yellow 3 30 4 492 Paint - Black 3 17 5 495 Paint - Blue 4 35 1 496 Paint - Yellow 4 25 2 493 Paint - Red 4 24 3 492 Paint - Black 4 14 4 494 Paint - Silver 4 12 5 (10 row(s) affected)
Б.
 Ранжирование всех строк в результирующем наборе
Ранжирование всех строк в результирующем наборе
Следующий пример возвращает список первых десяти сотрудников, отранжированных по их окладу. Поскольку предложение PARTITION BY не указывалось, функция RANK применялась ко всем строкам результирующего набора.
USE AdventureWorks2012
SELECT TOP(10) BusinessEntityID, Rate,
RANK() OVER (ORDER BY Rate DESC) AS RankBySalary
FROM HumanResources.EmployeePayHistory AS eph2
WHERE RateChangeDate = (SELECT MAX(RateChangeDate)
FROM HumanResources.EmployeePayHistory AS eph3
WHERE eph2.BusinessEntityID = eph3.BusinessEntityID)
ORDER BY BusinessEntityID;
Результирующий набор:
BusinessEntityID Rate RankBySalary ---------------- --------------------- -------------------- 1 125.50 1 2 63.4615 4 3 43.2692 8 4 29.8462 19 5 32.6923 16 6 32.6923 16 7 50.4808 6 8 40.8654 10 9 40.8654 10 10 42.4808 9
Примеры: Azure Synapse Analytics и Система платформы аналитики (PDW)
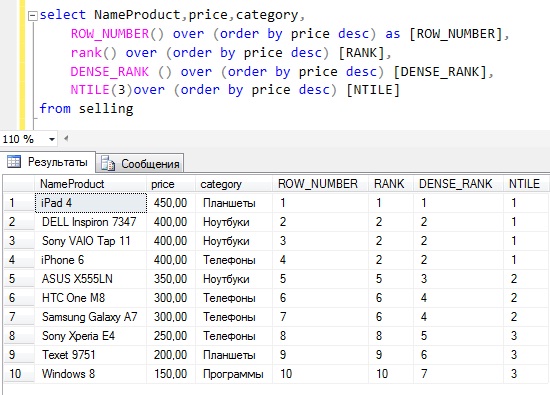
В. Ранжирование строк внутри секции
В приведенном ниже примере торговые представители на каждой территории продаж ранжируются в соответствии с общим объемом продаж. Набор строк секционируется по столбцу SalesTerritoryGroup и сортируется по столбцу SalesAmountQuota.
-- Uses AdventureWorks
SELECT LastName, SUM(SalesAmountQuota) AS TotalSales, SalesTerritoryRegion,
RANK() OVER (PARTITION BY SalesTerritoryRegion ORDER BY SUM(SalesAmountQuota) DESC ) AS RankResult
FROM dbo.DimEmployee AS e
INNER JOIN dbo.FactSalesQuota AS sq ON e.EmployeeKey = sq.EmployeeKey
INNER JOIN dbo.DimSalesTerritory AS st ON e.SalesTerritoryKey = st. SalesTerritoryKey
WHERE SalesPersonFlag = 1 AND SalesTerritoryRegion != N'NA'
GROUP BY LastName, SalesTerritoryRegion;
 SalesTerritoryKey
WHERE SalesPersonFlag = 1 AND SalesTerritoryRegion != N'NA'
GROUP BY LastName, SalesTerritoryRegion;
SalesTerritoryKey
WHERE SalesPersonFlag = 1 AND SalesTerritoryRegion != N'NA'
GROUP BY LastName, SalesTerritoryRegion;
Результирующий набор:
LastName TotalSales SalesTerritoryRegion RankResult ---------------- ------------- ------------------- -------- Tsoflias 1687000.0000 Australia 1 Saraiva 7098000.0000 Canada 1 Vargas 4365000.0000 Canada 2 Carson 12198000.0000 Central 1 Varkey Chudukatil 5557000.0000 France 1 Valdez 2287000.0000 Germany 1 Blythe 11162000.0000 Northeast 1 Campbell 4025000.0000 Northwest 1 Ansman-Wolfe 3551000.0000 Northwest 2 Mensa-Annan 2753000.0000 Northwest 3 Reiter 8541000.0000 Southeast 1 Mitchell 11786000.0000 Southwest 1 Ito 7804000.0000 Southwest 2 Pak 10514000.
 0000 United Kingdom 1
0000 United Kingdom 1
См. также:
DENSE_RANK (Transact-SQL)
ROW_NUMBER (Transact-SQL)
NTILE (Transact-SQL)
Ранжирующие функции (Transact-SQL)
Встроенные функции (Transact-SQL)
РАНГ
(Transact-SQL) — SQL Server
- Статья
- 3 минуты на чтение
Применимо к:
SQL Server (все поддерживаемые версии)
База данных SQL Azure
Управляемый экземпляр Azure SQL
Аналитика синапсов Azure
Система аналитической платформы (PDW)
Возвращает ранг каждой строки в разделе результирующего набора. Ранг строки равен единице плюс количество рангов, предшествующих рассматриваемой строке.
ROW_NUMBER и RANK похожи. ROW_NUMBER последовательно нумерует все строки (например, 1, 2, 3, 4, 5). RANK предоставляет одинаковое числовое значение для ничьих (например, 1, 2, 2, 4, 5).
RANK предоставляет одинаковое числовое значение для ничьих (например, 1, 2, 2, 4, 5).
Примечание
RANK — это временное значение, вычисляемое при выполнении запроса. Чтобы сохранить числа в таблице, см. Свойство IDENTITY и SEQUENCE.
Соглашения о синтаксисе Transact-SQL
Синтаксис
RANK ( ) OVER ( [ partition_by_clause ] order_by_clause )
Примечание
Чтобы просмотреть синтаксис Transact-SQL для SQL Server 2014 и более ранних версий, см. документацию по предыдущим версиям.
Аргументы
OVER ( [ partition_by_clause ] order_by_clause )
partition_by_clause делит результирующий набор на разделы, которые применяются к разделам F. Если не указано, функция обрабатывает все строки набора результатов запроса как одну группу. order_by_clause определяет порядок данных перед применением функции. Требуется order_by_clause .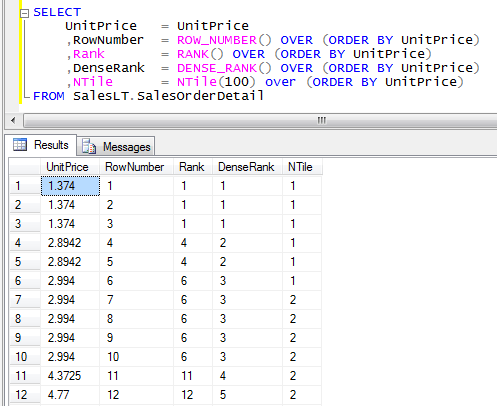 Предложение <строки или диапазон/> предложения OVER не может быть указано для функции RANK. Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Предложение <строки или диапазон/> предложения OVER не может быть указано для функции RANK. Дополнительные сведения см. в разделе Предложение OVER (Transact-SQL).
Типы возвращаемых значений
bigint
Если две или более строк имеют одинаковый ранг, каждая связанная строка получает одинаковый ранг. Например, если у двух лучших продавцов одинаковое значение SalesYTD, они оба получают один рейтинг. Продавец со следующим самым высоким значением SalesYTD занимает третье место, потому что есть две строки с более высоким рейтингом. Поэтому функция RANK не всегда возвращает последовательные целые числа.
Порядок сортировки, используемый для всего запроса, определяет порядок, в котором строки появляются в результирующем наборе.
РАНГ недетерминирован. Дополнительные сведения см. в разделе Детерминированные и недетерминированные функции.
Примеры
A. Ранжирование строк в разделе
В следующем примере продукты ранжируются в указанных местах хранения в соответствии с их количеством.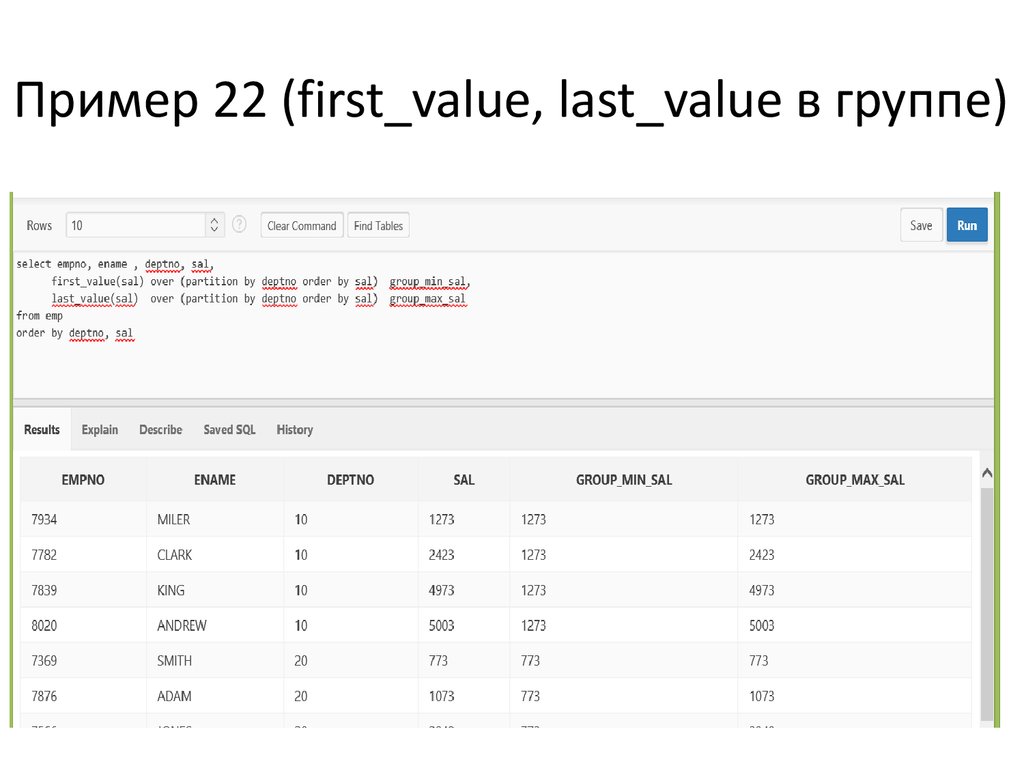 Набор результатов разделен на
Набор результатов разделен на LocationID и логически упорядочен по Количество . Обратите внимание, что продукты 494 и 495 имеют одинаковое количество. Поскольку они равны, они оба занимают первое место.
ИСПОЛЬЗОВАТЬ AdventureWorks2012;
ИДТИ
ВЫБЕРИТЕ i.ProductID, p.Name, i.LocationID, i.Quantity
,РАНГ() БОЛЕЕ
(РАЗДЕЛЕНИЕ ПО i.LocationID ORDER BY i.Quantity DESC) AS Ранг
ИЗ Production.ProductInventory AS i
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Производство. Продукт AS p
ON i.ProductID = p.ProductID
ГДЕ i.LocationID МЕЖДУ 3 И 4
ЗАКАЗАТЬ ПО i.LocationID;
ИДТИ
Вот набор результатов.
ProductID Название LocationID Количество Ранг ----------- ------- ------------ ----- --- ---- 494 Краска - Серебро 3 49 1 495 Краска - Синяя 3 49 1 493 Краска - красная 3 41 3 496 Краска — желтая 3 30 4 492 Краска — черная 3 17 5 495 Краска - Синяя 4 35 1 496 Краска – желтая 4 25 2 493 Краска - красная 4 24 3 492 Краска — черная 4 14 4 494 Краска — серебро 4 12 5 (затронуты 10 строк)
B.
 Ранжирование всех строк в результирующем наборе
Ранжирование всех строк в результирующем наборе
В следующем примере возвращаются десять лучших сотрудников, ранжированных по их зарплате. Поскольку предложение PARTITION BY не было указано, функция RANK применялась ко всем строкам результирующего набора.
ИСПОЛЬЗОВАТЬ AdventureWorks2012
ВЫБЕРИТЕ ТОП(10) BusinessEntityID, Оценить,
RANK() OVER (ORDER BY Rate DESC) AS RankBySalary
ОТ HumanResources.EmployeePayHistory AS eph2
ГДЕ RateChangeDate = (ВЫБЕРИТЕ МАКС(RateChangeDate)
ОТ HumanResources.EmployeePayHistory AS eph3
ГДЕ eph2.BusinessEntityID = eph3.BusinessEntityID)
ЗАКАЗАТЬ ПО BusinessEntityID;
Вот набор результатов.
BusinessEntityID Ставка RankBySalary ---------------- -------------------- ------------- ------- 1 125,50 1 2 63,4615 4 3 43,2692 8 4 29,8462 19 5 32,6923 16 6 32,6923 16 7 50.4808 6 8 40,8654 10 9 40,8654 10 10 42.4808 9
Примеры: Azure Synapse Analytics and Analytics Platform System (PDW)
C: ранжирование строк в разделе
В следующем примере торговые представители ранжируются в каждой территории продаж в соответствии с их общим объемом продаж. Набор строк разделен на
Набор строк разделен на SalesTerritoryGroup и отсортировано по SalesAmountQuota .
-- Использует AdventureWorks
ВЫБЕРИТЕ Фамилию, СУММУ (SalesAmountQuota) AS TotalSales, SalesTerritoryRegion,
RANK() OVER (PARTITION BY SalesTerritoryRegion ORDER BY SUM(SalesAmountQuota) DESC ) AS RankResult
ОТ dbo.DimEmployee AS e
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.FactSalesQuota AS sq ON e.EmployeeKey = sq.EmployeeKey
ВНУТРЕННЕЕ СОЕДИНЕНИЕ dbo.DimSalesTerritory AS st ON e.SalesTerritoryKey = st.SalesTerritoryKey
ГДЕ SalesPersonFlag = 1 AND SalesTerritoryRegion != N'NA'
ГРУППИРОВАТЬ ПО Фамилии, Региону Территории Продаж;
Вот набор результатов.
Фамилия TotalSales SalesTerritoryRegion RankResult ---------------- --------------------------- ------------------ -- -- ------ Цофлиас 1687000.0000 Австралия 1 Сарайва 7098000.0000 Канада 1 Варгас 4365000.0000 Канада 2 Карсон 12198000.0000 Центральный 1 Варки Чудукатил 5557000.0000 Франция 1 Вальдес 2287000.
 0000 Германия 1
Блайт 11162000.0000 Северо-Восток 1
Кэмпбелл 4025000.0000 Северо-Запад 1
Ансман-Вулф 3551000.0000 Северо-Запад 2
Менса-Аннан 2753000.0000 Северо-Запад 3
Рейтер 8541000.0000 Юго-Восток 1
Митчелл 11786000.0000 Юго-Запад 1
Ито 7804000.0000 Юго-Запад 2
Пак 10514000.0000 Великобритания 1
0000 Германия 1
Блайт 11162000.0000 Северо-Восток 1
Кэмпбелл 4025000.0000 Северо-Запад 1
Ансман-Вулф 3551000.0000 Северо-Запад 2
Менса-Аннан 2753000.0000 Северо-Запад 3
Рейтер 8541000.0000 Юго-Восток 1
Митчелл 11786000.0000 Юго-Запад 1
Ито 7804000.0000 Юго-Запад 2
Пак 10514000.0000 Великобритания 1
См. также
DENSE_RANK (Transact-SQL)
ROW_NUMBER (Transact-SQL)
NTILE (Transact-SQL)
Функции ранжирования (Transact-SQL)
Встроенные функции (Transact-SQL)
mysql — Rank over раздел и группировка по столбцу, как я могу это сделать?
Задавать вопрос
Спросил
Изменено
1 год, 7 месяцев назад
Просмотрено
746 раз
1
Новинка! Сохраняйте вопросы или ответы и организуйте свой любимый контент.
Узнать больше.
У меня есть таблица базы данных, содержащая результаты/счета игроков.
Данные выглядят так:
| player_id | дата_результата | оценка | тип_игры |
|---|---|---|---|
| 1 | 2020-03-01 | 154 | 1 |
| 2 | 2020-03-15 | 171 | 2 |
| 3 | 2020-03-15 | 122 | 1 |
| 2 | 17.03.2020 | 210 | 2 |
| 1 | 2020-04-01 | 190 | 2 |
| 2 | 15.05.2020 | 125 | 1 |
| 1 | 2020-06-01 | 167 | 1 |
| 2 | 10.06.2020 | 173 | 1 |
Я хотел бы получить трех лучших игроков для каждого типа игры, а также иметь возможность фильтровать по дате, но я не уверен, как это сделать.
На данный момент мой запрос выглядит так:
SELECT rr.
 * FROM
(ВЫБЕРИТЕ game_type, player_id, result_date, счет,
RANK() OVER (раздел по типу игры ORDER BY score DESC) как game_rank
ИЗ результатов
ГДЕ result_date >= '2020-01-01') rr
ИМЕЕТ game_rank <= 3;
* FROM
(ВЫБЕРИТЕ game_type, player_id, result_date, счет,
RANK() OVER (раздел по типу игры ORDER BY score DESC) как game_rank
ИЗ результатов
ГДЕ result_date >= '2020-01-01') rr
ИМЕЕТ game_rank <= 3;
Но тогда один и тот же игрок может быть оценен несколько раз.
Мне нужен только лучший результат от каждого игрока в каждом типе игры. Как я могу это сделать?
База данных Mysql 8.0.
- mysql
- sql
- база данных
- mysql-8.0
4
Вам нужно сделать два шага:
- Получить строку с лучшим результатом для каждого типа игры и игрока.
- Получите строки с лучшим результатом для каждого типа игры.
Запрос:
выбрать
game_type, player_id, result_date, счет
из
(
Выбрать
game_type, player_id, result_date, счет,
плотно_rank() над (раздел по порядку game_type по описанию счета) как game_rank
из
(
Выбрать
game_type, player_id, result_date, счет,
row_number() over (раздел по типу игры, порядок player_id по описанию счета) как rn
по результатам
где дата_результата >= дата '2020-01-01'
) топ_игры
где рн = 1
) лучшие_игроки
где game_rank <= 3
порядок по типу игры, описанию счета;
В случае, если игрок набрал наибольшее количество очков в одном типе игры более чем за одну дату, он произвольно выбирается с помощью ROW_NUMBER .