Rank over partition by: SQL Server RANK() Function By Practical Examples
Содержание
sql — Как использовать rank() вместо PARTITION BY в Mysql
спросил
Изменено
3 года, 6 месяцев назад
Просмотрено
4к раз
Предположим, что существует три типа материалов, таких как («ХЛОПОК», «КОЖА», «ШЕЛК»), и я хочу получить идентификатор dress_id, который содержит все эти три типа материалов. Я тоже хочу их ранжировать.
Кто-нибудь может пошагово объяснить, как это сделать?
Я привел несколько примеров, и ни один из них не кажется мне понятным.
Вывод должен выглядеть примерно так ПЛАТЬЕ_ID МАТЕРИАЛ LAST_UPDATED_DATE РАНГ 111 ХЛОПОК 2019-08-29 1 111 ШЕЛК 2019-08-30 2 111 КОЖА 2019-08-31 3 222 ХЛОПОК 2019-08-29 1 222 ШЕЛК 2019-08-30 2 222 КОЖА 2019-08-31 3 222 КОЖА 2019-09-02 4
Я получаю сообщение об ошибке в рабочей области MYSQL при выполнении этого запроса.
Код ошибки: 1305. Ранг FUNCTION не существует.
ВЫБРАТЬ dress_id,
rank() over(PARTITION BY dress_id, material ORDER by LAST_UPDATED_DATE asc) как ранг
ОТ dress_types;
- mysql
- sql
- оконные функции
- плотный ранг
3
В более ранних версиях MySQL можно использовать либо переменные, либо коррелированный подзапрос.
Поскольку у вас есть всего несколько материалов для каждого платья, коррелированный подзапрос является разумным, особенно с правильным индексом. Код выглядит так:
ВЫБРАТЬ d.dress_id, d.material,
(ВЫБЕРИТЕ КОЛИЧЕСТВО(*)
ОТ dress_types d2
ГДЕ d2.dress_id = d.dress_id И
d2.last_updated_date <= d.last_updated_date
) как ранг
ОТ dress_types d;
Обратите внимание, что это реализует логику, основанную на ваших данных , а не на запросе. Соответствующий запрос будет:
ВЫБРАТЬ dress_id,
rank() более (PARTITION BY dress_id ORDER by LAST_UPDATED_DATE asc) как ранг
ОТ dress_types;
Индекс, который вам нужен, находится на dress_types(dress_id, last_updated_date) .![]()
На самом деле это одно и то же, если нет дубликатов (по дате). Логика может быть другой, если есть дубликаты.
0
Для предыдущих версий MySQL 8.0 вы должны использовать переменные для имитации ранжирования:
УСТАНОВИТЬ @rownum := 0; УСТАНОВИТЬ @group_number := 0; ВЫБЕРИТЕ dress_id, материал, last_updated_date, ранг ОТ ( ВЫБЕРИТЕ @rownum := случай когда @group_number = dress_id, тогда @rownum + 1 еще 1 конец рейтинга AS, dress_id, material, last_updated_date, @group_number := dress_id ИЗ dress_types СОРТИРОВАТЬ ПО dress_id, ПОЛЕ(материал, 'ХЛОПОК', 'ШЕЛК', 'КОЖА'), last_updated_date ) т
См. демонстрацию.
Результаты:
| dress_id | материал | последняя_обновленная_дата | ранг | | -------- | -------- | ------------------- | ---- | | 111 | ХЛОПОК | 2019-08-29 00:00:00 | 1 | | 111 | ШЕЛК | 2019-08-30 00:00:00 | 2 | | 111 | КОЖА | 2019-08-31 00:00:00 | 3 | | 222 | ХЛОПОК | 2019-08-29 00:00:00 | 1 | | 222 | ШЕЛК | 2019-08-30 00:00:00 | 2 | | 222 | КОЖА | 2019-08-31 00:00:00 | 3 | | 222 | КОЖА | 2019-09-02 00:00:00 | 4 |
ВЫБЕРИТЕ Т.*, СЛУЧАЙ, КОГДА @prev_dress_id != T.dress_id THEN @rank:=1 ИНАЧЕ @ранг:=@ранг+1 END как ранг, @prev_dress_id := T.dress_id как set_prev_dress_id ОТ (ВЫБЕРИТЕ dress_id, материал, last_updated_date ОТ dress_types T1 ГДЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E1, ГДЕ E1.dress_id = T1.dress_ID И E1.material = 'COTTON') И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E2, ГДЕ E2.dress_id = T1.dress_ID И E2.material = 'ШЕЛК') И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E3, ГДЕ E3.dress_id = T1.dress_ID И E3.material = 'КОЖА') ЗАКАЗАТЬ ПО dress_id по возрастанию, last_updated_date по возрастанию )T,(ВЫБЕРИТЕ @prev_dress_id:=-1)V
 *,
СЛУЧАЙ, КОГДА @prev_dress_id != T.dress_id THEN @rank:=1
ИНАЧЕ @ранг:=@ранг+1
END как ранг,
@prev_dress_id := T.dress_id как set_prev_dress_id
ОТ
(ВЫБЕРИТЕ dress_id, материал, last_updated_date
ОТ dress_types T1
ГДЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E1, ГДЕ E1.dress_id = T1.dress_ID И E1.material = 'COTTON')
И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E2, ГДЕ E2.dress_id = T1.dress_ID И E2.material = 'ШЕЛК')
И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E3, ГДЕ E3.dress_id = T1.dress_ID И E3.material = 'КОЖА')
ЗАКАЗАТЬ ПО dress_id по возрастанию, last_updated_date по возрастанию
)T,(ВЫБЕРИТЕ @prev_dress_id:=-1)V
*,
СЛУЧАЙ, КОГДА @prev_dress_id != T.dress_id THEN @rank:=1
ИНАЧЕ @ранг:=@ранг+1
END как ранг,
@prev_dress_id := T.dress_id как set_prev_dress_id
ОТ
(ВЫБЕРИТЕ dress_id, материал, last_updated_date
ОТ dress_types T1
ГДЕ СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E1, ГДЕ E1.dress_id = T1.dress_ID И E1.material = 'COTTON')
И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E2, ГДЕ E2.dress_id = T1.dress_ID И E2.material = 'ШЕЛК')
И СУЩЕСТВУЕТ (ВЫБЕРИТЕ 1 ИЗ dress_types E3, ГДЕ E3.dress_id = T1.dress_ID И E3.material = 'КОЖА')
ЗАКАЗАТЬ ПО dress_id по возрастанию, last_updated_date по возрастанию
)T,(ВЫБЕРИТЕ @prev_dress_id:=-1)V
Внутренний выбор выбирает платья, которые содержат все 3 материала и упорядочены по dress_id, last_updated_date.
Внешний присоединяется к нему с помощью переменной prev_dress_id, которую можно установить в конце каждой строки. Логика оператора case для расчета ранга на основе @prev_dress_id != или = T.dress_id.
sqlfiddle
ВЫБРАТЬ dress_id
, материал
, LAST_UPDATED_DATE
rank() over(PARTITION BY dress_id ORDER by LAST_UPDATED_DATE asc) как ранг
ИЗ dress_types
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google
Зарегистрироваться через Facebook
Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но никогда не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.![]()
Руководство по функциям окна ранжирования SQL
| Нима Бехешти
Опубликовано в
·
Чтение через 6 мин.
·
20 января 2022 г.
ROW_NUMBER(), RANK(), DENSE_RANK(), NTILE(), PERCENT_RANK(), CUME_DIST()
В мире SQL-запросов нам часто приходится создавать какое-то ранжирование, чтобы лучше понять наши данные. . К счастью для нас, функции ранжирования являются одной из основных областей под эгидой оконных функций и могут быть легко реализованы!
Шесть типов ранжирующих функций:
- ROW_NUMBER()
- RANK()
- DENSE_RANK()
- PERCENT_RANK()
- NTILE()
- CUME_DIST()
Прежде чем мы углубимся в детали каждой функции ранжирования, мы должны посмотреть, как эти функции обычно записываются:
[Функция ранжирования]() OVER([конкретная операция] имя_столбца)
Например, на практике команда SQL будет выглядеть так:
SELECT *, ROW_NUMBER() OVER(PARTITION BY column1 ORDER BY column2 DESC)
FROM table
В этом примере мы выбираем все строки в нашей таблице и ранжирование выходных данных в порядке убывания столбца 2, разделенного каждым значением столбца 1. Это станет более понятным, когда мы перейдем к описанию и примерам каждой функции ранжирования.
Это станет более понятным, когда мы перейдем к описанию и примерам каждой функции ранжирования.
Данные:
Данные, использованные в этой статье, были созданы только для демонстрационных целей и не отражают точного представления изображаемых чисел. Данные состоят из трех столбцов: c_name — название города, c_state — штат города и coffee_shop_num — количество кофеен в этом городе. *Ниже показана только часть данных*
Изображение автора
ROW_NUMBER:
Функции ранжирования ROW_NUMBER() обеспечивают последовательное ранжирование данного раздела по количеству строк в этом разделе. Если две строки имеют одинаковую информацию, функция определяет, какая из них занимает первое место на основе информации, предоставленной в операторе OVER(). Используя ранжирование Row_Number, каждая строка в данном разделе получает собственный ранг без дубликатов или пропущенных номеров. Пример этой функции ниже:
SELECT *,
ROW_NUMBER() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM city
Image by Author
Здесь мы видим, что столбец рангов ранжирует каждый город в разделе штата последовательно и города, которые соответствуют ничьим, выбираются случайным образом для определенного места в рейтинге.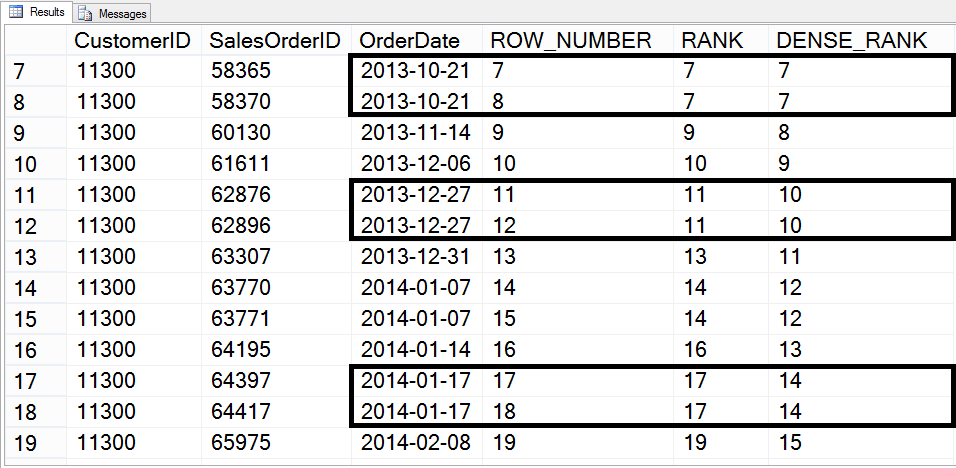
RANK :
Функция ранжирования RANK() дает такой же результат, что и функция ROW_NUMBER(), однако в функции RANK() связям присваивается одно и то же значение, а последующие значения пропускаются. Используя функцию RANK(), можно получить повторяющиеся рейтинги в разделе и иметь непоследовательные рейтинги, поскольку числа пропускаются после совпадений. Ниже приведен пример функции RANK().
SELECT *,
RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM city
Image by Author
Как видно из приведенных выше результатов, Сан-Диего и Малибу имеют одинаковое количество кофеен и оба получили ранг 3 за этот раздел, следующий ранг подскочил до 5, что также оказалось равным. Точно так же Лисбург и Ричмонд сравнялись по количеству кофеен и оба получили рейтинг 4, а следующий город, Блэксбург, получил рейтинг 6.
DENSE_RANK:
Функция ранжирования DENSE_RANK() действует как гибрид между RANK() и ROW_NUMBER(), поскольку эта функция допускает наличие связей внутри раздела, но также обеспечивает последовательное ранжирование после совпадений. Например, порядок ранжирования в разделе может выглядеть так: 1, 2, 3, 3, 4, 4, 5. Это можно увидеть в примере кода и выводе ниже, где снова Сан-Диего и Малибу занимают третье место, а следующие город получает ранг 4.
Например, порядок ранжирования в разделе может выглядеть так: 1, 2, 3, 3, 4, 4, 5. Это можно увидеть в примере кода и выводе ниже, где снова Сан-Диего и Малибу занимают третье место, а следующие город получает ранг 4.
SELECT *,
DENSE_RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) как ранг
FROM city
Изображение автора
NTILE:
Функция ранжирования NTILE() работает иначе, чем три функции, которые мы уже видели. Эта функция делит строки внутри раздела на указанное количество делений. Затем строки назначаются одной из этих групп в соответствии с их рангом, начиная с 1 и продолжая до указанного количества групп. Используя пример кода и выходные данные ниже, мы видим, что мы передали число 5 в функцию NTILE(), что означает, что мы разбиваем каждый раздел на 5 групп. Мы видим, что каждой строке присвоен ранг от 1 до 5, а некоторые группы содержат более одной строки, как и ожидалось, учитывая, что в каждом разделе более 5 городов.![]() В этом случае связи могут быть внутри одной группы или разделены, как в случае с Calexico и La Jolla.
В этом случае связи могут быть внутри одной группы или разделены, как в случае с Calexico и La Jolla.
SELECT *,
NTILE(5) OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) as rank
FROM city
Image by Author
PERCENT_RANK:
Функция PERCENT_RANK() предоставляет процентиль ранг каждой строки с разделом . Самый низкий ранг начинается с 0 и продолжается до единицы, при этом каждое значение интервала равно 1/(n-1), где n — число или строки в данном разделе. В приведенном ниже примере кода мы видим, что Лос-Анджелес является самым низким процентилем (самым высоким рейтингом) со значением 0, после Лос-Анджелеса каждая строка будет соответствовать значению 1/(7–1) = 0,1666, при этом работают связи. так же, как функция RANK(). Как видно ниже, Калексико и Ла-Холья имеют один и тот же ранговый процентиль, но, поскольку в совокупности они представляют 0,166 + 0,166, после Ла-Хойи следующий назначенный процентиль равен 1 для Ирвина.
SELECT *,
PERCENT_RANK() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) как процентиль
FROM city
Изображение автора
CUME_DIST:
Наша последняя функция ранжирования — CUME_DIST(), действует аналогично PERCENT_RANK( ), но вместо того, чтобы начинать с 0 и продолжать с 1/(n-1), CUME_DIST() начинается со значения 1/n и продолжается с 1/n до конечного значения 1 в данном разделе. Совпадения в CUME_DIST() обрабатываются так же, как и в PERCENT_RANK(). Как видно из примера кода и выходных данных ниже, Лос-Анджелес начинается со значения 0,143, а процентиль каждой строки соответствует прибавлению примерно 0,143, а связи соответствуют сумме количества связанных строк. В конечном итоге раздел заканчивается процентилем 1,9.0005
Совпадения в CUME_DIST() обрабатываются так же, как и в PERCENT_RANK(). Как видно из примера кода и выходных данных ниже, Лос-Анджелес начинается со значения 0,143, а процентиль каждой строки соответствует прибавлению примерно 0,143, а связи соответствуют сумме количества связанных строк. В конечном итоге раздел заканчивается процентилем 1,9.0005
SELECT *,
CUME_DIST() OVER(PARTITION BY c_state ORDER BY coffee_shop_num DESC) как процентиль
FROM city
Изображение автора
Заключение :
Эти шесть оконных функций ранжирования имеют множество вариантов использования и являются важным навыком для освоения . Многие функции похожи только в нескольких различных аспектах, что поначалу может сбивать с толку, но после некоторой практики вы будете точно знать, какую функцию использовать в любом конкретном сценарии. Я надеюсь, что это руководство было полезным, и, как всегда, благодарю вас за то, что вы нашли время, чтобы прочитать эту статью. Если вы хотите прочитать больше моих статей, подпишитесь на мою учетную запись, чтобы получать уведомления о выпуске других статей по науке о данных.