Реиндексация базы sql 1с: Как правильно настроить MS SQL Server для 1С: планы обслуживания
Содержание
Оптимизация 1С Предприятие регламентные операции на сервере, проактивные меры для безперебойной работы 1С
Одной из часто встречающихся причин неоптимальной работы системы является неправильное или несвоевременное выполнение регламентных операций на уровне СУБД. Особенно важно выполнять эти регламентные процедуры в крупных информационных системах, которые работают под значительной нагрузкой и обслуживают одновременно большое количество пользователей. Специфика таких систем в том, что обычных действий, выполняемых СУБД автоматически (на основании настроек) оказывает недостаточно для эффективной работы.
Если в работающей системе наблюдаются какие-либо симптомы проблем с производительностью, следует проверить, что в системе правильно настроены и регулярно выполняются все рекомендуемые регламентные операции на уровне СУБД.
Выполнение регламентных процедур должно быть автоматизировано. Для автоматизации этих операций рекомендуется использовать встроенное средства MS SQL Server: Maintenance Plan. Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2016.
Существуют так же другие способы автоматизации выполнения этих процедур. В настоящей статье для каждой регламентной процедуры дан пример ее настройки при помощи Maintenance Plan для MS SQL Server 2016.
Для MS SQL Server рекомендуется выполнять следующие регламентные операции:
- Обновление статистик
- Очистка процедурного КЭШа
- Дефрагментация индексов
- Реиндексация таблиц базы данных
Рекомендуется регулярно контролировать своевременность и правильность выполнения данных регламентных процедур.
Обновление статистик
При выполнении любого запроса, оптимизатор запросов, в рамках имеющейся у него информации, пытается построить оптимальный план выполнения — который будет отображать из себя последовательность операций, за счет выполнения, которых можно получить требуемый результат, описанный в запросе.
В процессе выбора той или иной операции, оптимизатор запросов к числу наиболее важных входных данных относит статистику, описывающую распределение значений данных для столбцов внутри таблицы или индекса.
Такая оценка количества элементов позволяет оптимизатору запросов создавать более эффективные планы выполнения. В то же время, если статистика будет содержать устаревшие данные, могут быть выбраны менее эффективные операции, которые приведут к созданию медленных планов выполнения. Например, когда для небольшой выборки на устаревшей статистике выбирается более затратный оператор Index Scan, вместо оператора Index Seek.
Чтобы быть максимально полезной для оптимизатора запросов, статистика должна быть точной и свежей. Время от времени SQL Server периодически сам обновляет статистику — данное поведение регулируется опциями AUTO_CREATE_STATISTICS и AUTO_UPDATE_STATISTICS.
Кроме того, при пересоздании индексов, статистика по ним обновляется автоматически с включенным флагом FULLSCAN, гарантирующим наиболее точное распределение данных. При реорганизации индексов же — статистика не обновляется.
Когда данные в таблицах изменяются очень часто, целесообразно выполнять избирательное обновление статистики вручную, с помощью операции UPDATE STATISTICS.
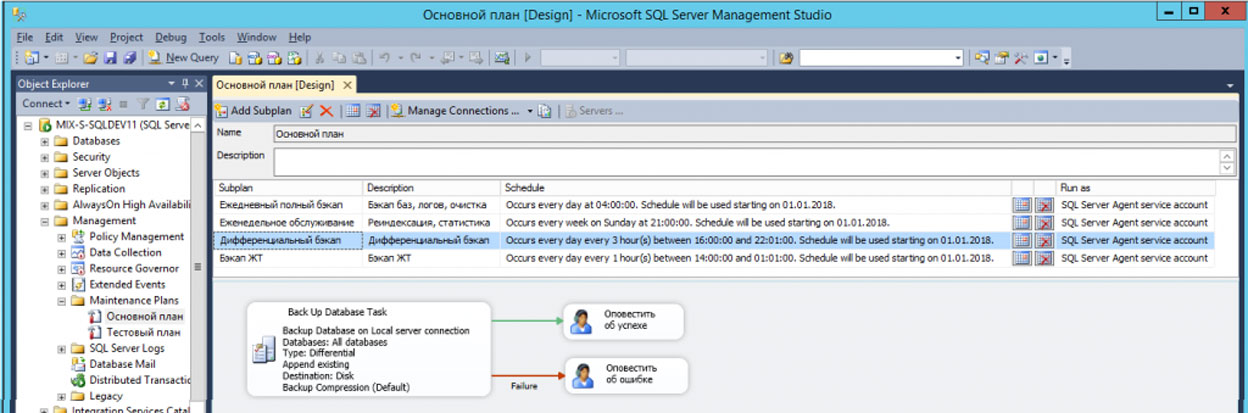
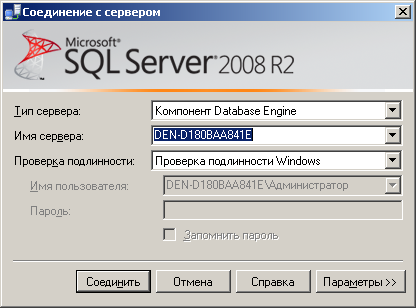
Запустите MS SQL Server Management Studio и подключитесь к серверу СУБД. Откройте папку Management и создайте новый план обслуживания:
Создайте субплан (Add Subplan) и назовите его «Обновление статистик». Добавьте в него задачу “Update Statistics Task” из панели задач:
Настройте расписание обновления статистик. Рекомендуется обновлять статистики не реже одного раза в день. При необходимости частота обновления статистик может быть увеличена.
Настройте параметры задачи. Для этого следует два раза кликнуть на задачу в правом нижнем углу окна. В появившейся форме укажите имя базу данных (или несколько баз данных) для которых будет выполняться обновление статистик. Кроме этого, вы можете указать для каких таблиц обновлять статистики (если точно неизвестно, какие таблицы требуется указать, то устанавливайте значение All).
Обновление статистик необходимо проводить с включенной опцией Full Scan.
Сохраните созданный план. При наступлении указанного в расписании срока обновление статистик будет запущено автоматически.
Очистка процедурного КЭШа
Оптимизатор MS SQL Server кэширует планы запросов для их повторного выполнения. Это делается для того, чтобы экономить время, затрачиваемое на компиляцию запроса в том случае, если такой же запрос уже выполнялся и его план известен.
Возможна ситуация, при которой MS SQL Server, ориентируясь на устаревшую статистическую информацию, построит неоптимальный план запроса. Этот план будет сохранен в процедурном КЭШе и использован при повторном вызове такого же запроса. Если Вы обновили статистику, но не очистили процедурный кэш, то SQL Server может выбрать старый (неоптимальный) план запроса из КЭШа вместо того, чтобы построить новый (более оптимальный) план.
Таким образом, рекомендуется всегда после обновления статистик очищать содержимое процедурного КЭШа.
Поскольку процедурный КЭШ необходимо очищать при каждом обновлении статистики, данную операцию рекомендуется добавить в уже созданный субплан «Обновление статистик». Для этого следует открыть субплан и добавить в его схему задачу Execute T-SQL Statement Task. Затем следует соединить задачу Update Statistics Task стрелочкой с новой задачей.
В тексте созданной задачи Execute T-SQL Statement Task следует указать запрос «DBCC FREEPROCCACHE»:
Дефрагментация индексов
Помимо фрагментации файловой системы и лог-файла, ощутимое влияние на производительность базы данных оказывает фрагментация внутри файлов данных. После операций вставки, обновления и удаления записей неизбежно возникают пустые пространства на страницах. Ничего страшного в этом нет, поскольку данная ситуация вполне нормальная.
Основная причина возникновения этого вида фрагментации — операции разбиения страницы. Например, согласно структуре первичного ключа, новую строку необходимо вставить на определенную страницу индекса, но этой на странице недостаточно места, чтобы разместить вставляемые данные. В таком случае, создается новая страница, на которую переместиться примерно половина записей со старой страницы. Новая страница, зачастую не является физически смежной со старой и, следовательно, помечается системой как фрагментированная.
Например, согласно структуре первичного ключа, новую строку необходимо вставить на определенную страницу индекса, но этой на странице недостаточно места, чтобы разместить вставляемые данные. В таком случае, создается новая страница, на которую переместиться примерно половина записей со старой страницы. Новая страница, зачастую не является физически смежной со старой и, следовательно, помечается системой как фрагментированная.
В любом случае, фрагментация ведет к росту числа страниц для хранения того же объема информации. Это автоматически приводит к увеличению размера базы данных и росту неиспользуемого места.
В ранее созданном плане обслуживания создайте новый субплан с именем «Дефрагментация индексов». Добавьте в него задачу Reorganize Index Task:
Задайте расписание выполнения для задачи дефрагментации индексов. Рекомендуется выполнять задачу не реже одного раза в неделю, а при высокой изменчивости данных в базе еще чаще – до одного раза в день.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Реиндексация таблиц базы данных
Реиндексация таблиц включает полное перестроение индексов таблиц базы данных, что приводит к существенной оптимизации их работы. Рекомендуется выполнять регулярную переиндексацию таблиц базы данных.
Реиндексация таблиц блокирует их на все время своей работы, что может существенно сказаться на работе пользователей. В связи с этим реиндексацию рекомендуется выполнять во время минимальной загрузки системы. После выполнения реиндексации нет необходимости делать дефрагментацию индексов.
В ранее созданном плане обслуживания создайте новый субплан с именем «Реиндексация». Добавьте в него задачу Rebuild Index Task:
Задайте расписание выполнения для задачи реиндексирования таблиц. Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Рекомендуется выполнять задачу во время минимальной нагрузки на систему, не реже одного раза в неделю.
Настройте задачу, указав базу данных (или несколько баз данных) и выбрав необходимые таблицы. Если точно неизвестно, какие таблицы следует указать, то устанавливайте значение All.
Оптимизация базы данных 1С — 1С ПРОЕКТ
Эта инструкция не универсальное средство, которое можно применить к любой базе данных. Скорее это сборник пунктов, по которым нужно пройтись администраторам 1С, у которых есть трудности в работе программы. В решении задач увеличения производительности важно все: железо, сеть, нагрузка, настройка ПО, версия 1С, код 1С. То чего не будет в этой публикации — разбор оптимизации кода 1С. Мы решили, что с нашей стороны не правильно предлагать пользователям «кулибинские» решения. Тем более что речь идет о завершенном, коммерческом программном продукте «1С», а не любительской версии программы для учета. Если уж что-то где-то не так, то разработчики платформы со временем в этом разберутся лучше чем мы.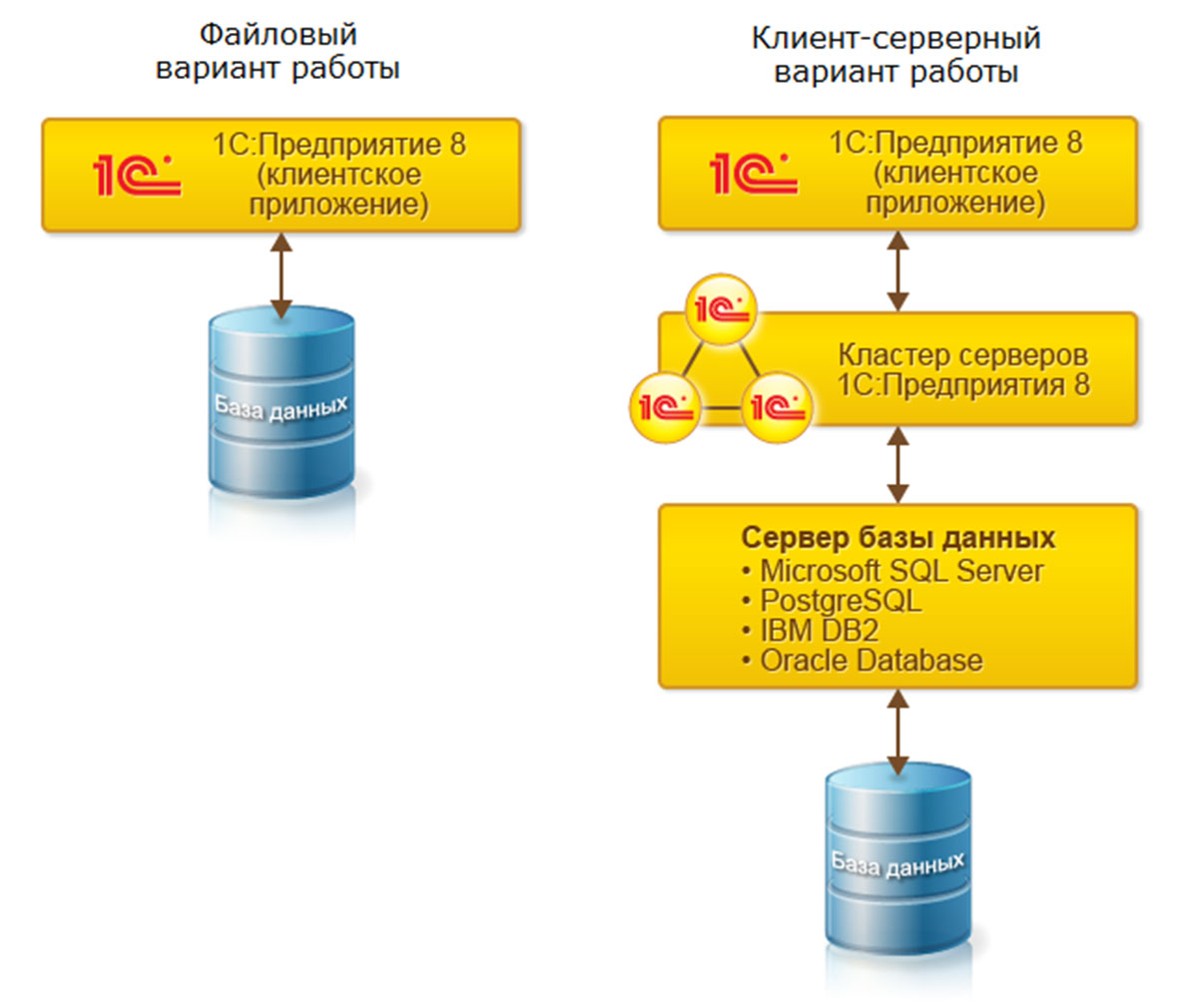 Во всем остальном, мы собрали, по нашему мнению, главные параметры, от которых зависит качество работы программы 1С. Количество метаданных подлежащих чистке (удалению) из базы данных может быть расширен по вашему усмотрению. Главное, чтобы при чистке не были удалены важные данные. НЕ РЕКОМЕНДУЕМ чистить регистры накопления. При оптимизации базы данных важно понимать что можно чистить, а что нет.
Во всем остальном, мы собрали, по нашему мнению, главные параметры, от которых зависит качество работы программы 1С. Количество метаданных подлежащих чистке (удалению) из базы данных может быть расширен по вашему усмотрению. Главное, чтобы при чистке не были удалены важные данные. НЕ РЕКОМЕНДУЕМ чистить регистры накопления. При оптимизации базы данных важно понимать что можно чистить, а что нет.
— настройка плана обслуживания БД
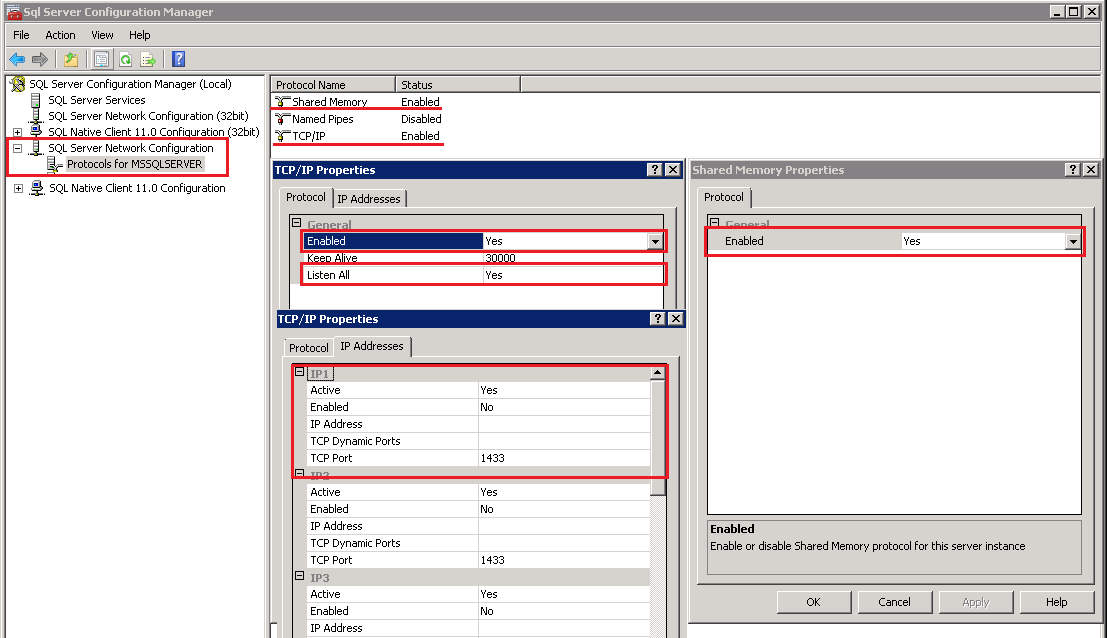
— перевод SQL в режим Shared Memory (если SQL и Сервер 1С на одной машине)
— Сжатие базы данных (Shrank)
— Разместить на разных дисках журнал транзакций и файл базы данных. Журнал более требователен к производительности жесткого диска. Идеально, если оба файла будут лежать на твердотельных быстрых дисках SSD.
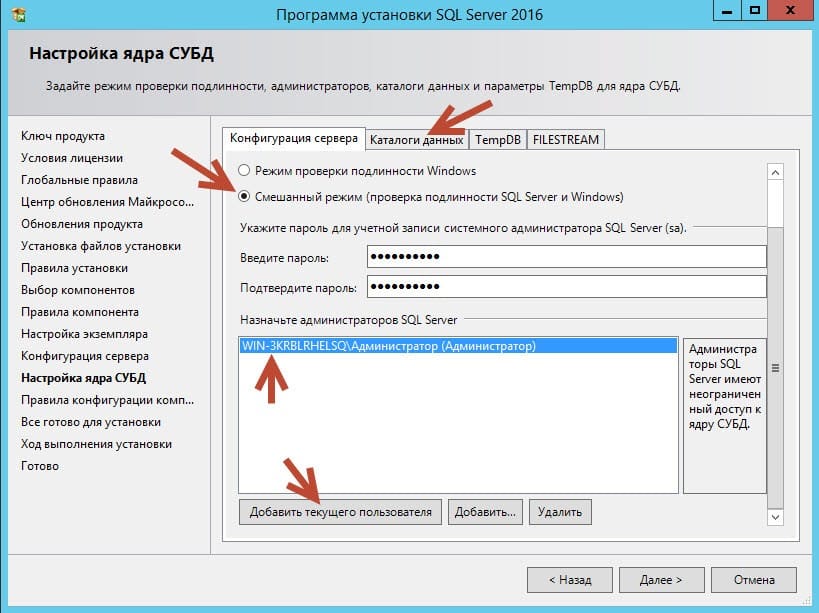
— переход на версию MS SQL Server Enterprise, в случае, если в этом есть необходимость. Версии MS SQL Server Standart и ниже имеют ограничение (64 Гб) на выделение оперативной памяти для обслуживания баз. Для нормальной работы 1С необходимо выделение SQL сервером ОЗУ в количестве 70 % от физических файлов md всех обслуживаемых баз 1С SQL сервером.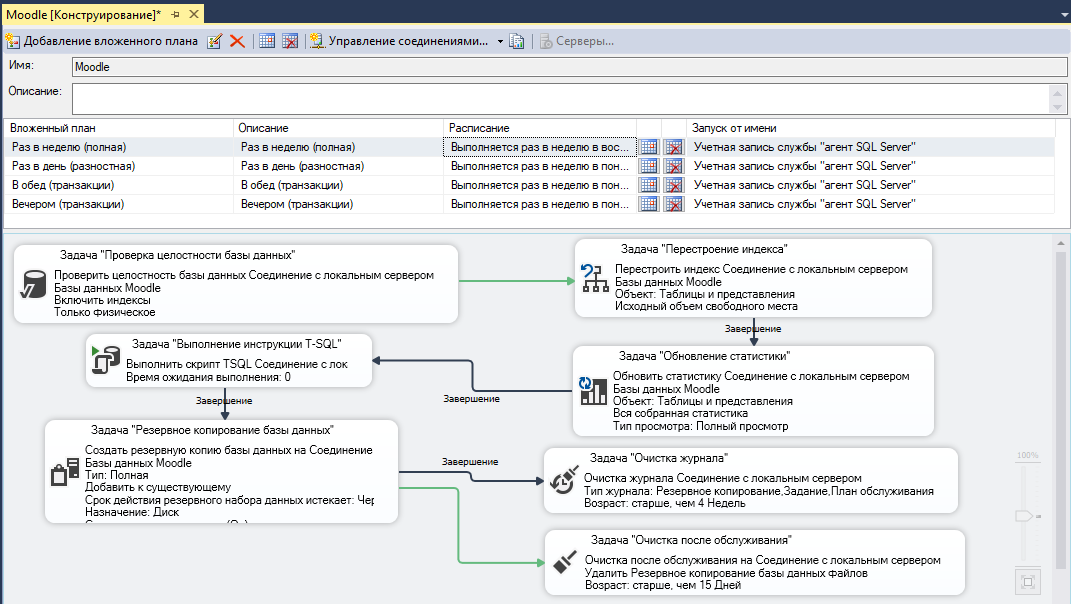
Оптимизация базы средствами 1С
— уменьшение размера БД
— выгрузка и загрузка БД в формате dt, как следствие чистка кеша, устаревших индексов и прочей ненужной информации и журнала регистрации. При этом желательно удаление с сервера БД 1С, создание по новой базы данных в кластере и в SQL сервере.
Чистка регистров сведений
— Объекты доступа документов (отвечает за настройку доступа к документам и прочим объектам для пользователей с отображением списка данных по организации, доступа к контрагентам и т.д.) Если механизм доступа не используется, можно чистить
— Версии объектов. Старые версии можно чистить.
— Событие календаря пользователя.
— Объекты информационных баз. Используется если есть РИБ. Если РИБ нет можно чистить.
Чистка документов
— Событие (при удалении этого документа автоматически удаляются записи регистров: события календаря пользователя
— Счет на оплату покупателю
— Удаление электронных писем
— Установка старых цен номенклатуры
Чистка справочников
— вложения электронных писем
— хранилище дополнительной информации
Свертка базы
— свертка базы 1С штатными средствами 1С
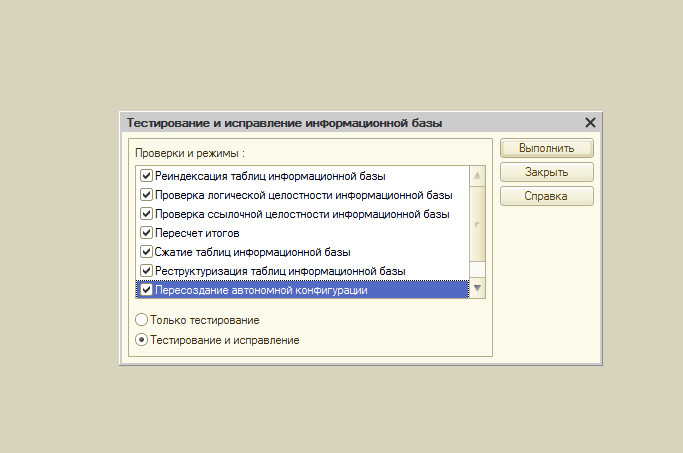
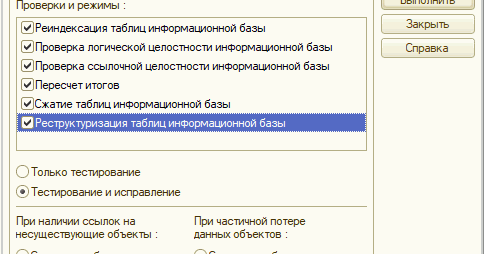
Тестирование и исправление
— в режиме Конфигуратор выполняем тестирование и исправление, сжатие, реиндексацию таблиц, пересчет итогов. Этот вариант подходит только для файловой БД. Для серверной нужно настраивать планы обслуживания.
Этот вариант подходит только для файловой БД. Для серверной нужно настраивать планы обслуживания.
Переиндексировать базу данных — Analytics4All
Бен Ларсон, доктор философии в MS SQL Server
Индексы в базах данных работают как индексы в книге. Вместо того, чтобы искать что-то на каждой странице книги, вы можете просто перейти к указателю — найти свою тему в алфавитном списке и перейти к указанному номеру страницы. Базы данных используют индексы, поэтому им не нужно просматривать каждую строку в таблице, которая может содержать от сотен тысяч до миллиардов строк.
Проблема в том, что при постоянном чтении и записи в действующую базу данных индексы быстро становятся фрагментированными, поскольку они пытаются не отставать от всех новых данных, поступающих и уходящих. Через некоторое время эта фрагментация может начать влиять на производительность вашей базы данных.
Перестроить индекс
*** Не пытайтесь сделать это с рабочей базой данных, пока она используется. Убедитесь, что база данных не используется, прежде чем что-либо делать в этом уроке.
Дефрагментация индекса в SQL Server называется перестроением. Вы можете сделать это всего несколькими щелчками мыши.
Сначала найдем наши индексы. Вы можете найти индексы, вложенные в таблицы в обозревателе объектов. Я не буду вдаваться в подробности о кластеризованных и некластеризованных, просто знаю, что каждая таблица может иметь только 1 кластеризованный индекс. Вы можете думать об этом как о главном индексе для этой таблицы, если это поможет.
Щелкните правой кнопкой мыши индекс и перейдите в «Свойства».
Выберите «Фрагментация» в окне «Выбор страницы». Обратите внимание, что мой индекс фрагментирован на 66,67%.
Щелкните за пределами этого окна и снова щелкните правой кнопкой мыши свой индекс. На этот раз нажмите Rebuild
Нажмите «ОК», и окно и ваш индекс будут перестроены. Достаточно просто.
Перестроить все индексы в таблице
Если вы хотите перестроить все индексы в таблице, вы можете щелкнуть папку «Индекс» и нажать «Перестроить все»
можно использовать следующий код SQL
Reindex Code
DBCC означает команды консоли базы данных. Это список полезных инструментов, которые вы можете использовать для администрирования SQL Server. Приведенный ниже синтаксис выглядит следующим образом: DBCC DBREINDEX(ИМЯ ТАБЛИЦЫ, индекс, который вы хотите перестроить (‘ ‘ = все индексы), коэффициент заполнения)
DBCC DBREINDEX([HumanResources].[Employee],' ',90)
Краткое примечание о коэффициенте заполнения. Фактор заполнения, равный 0 или 100, указывает SQL полностью заполнять каждую страницу индекса, не оставляя лишнего места. Если бы данные были застойными, это могло бы сработать, но когда данные постоянно записываются и удаляются, индексам нужно место для исправления. Вот почему вы часто будете видеть, что 80 или 90 используются в качестве коэффициента заполнения. Это дает небольшое пространство для маневра для реальной функциональности базы данных.
Фактор заполнения, равный 0 или 100, указывает SQL полностью заполнять каждую страницу индекса, не оставляя лишнего места. Если бы данные были застойными, это могло бы сработать, но когда данные постоянно записываются и удаляются, индексам нужно место для исправления. Вот почему вы часто будете видеть, что 80 или 90 используются в качестве коэффициента заполнения. Это дает небольшое пространство для маневра для реальной функциональности базы данных.
Переиндексировать все таблицы
Если вы хотите переиндексировать все таблицы в базе данных, вы можете сделать это с помощью цикла Cursor и While. Если вы не знаете курсоры в SQL, ознакомьтесь с моим предыдущим уроком о курсорах: SQL: научитесь использовать курсоры — список имен таблиц
Единственным новым элементом, который вы заметите здесь, является то, что я комбинирую TABLE_SCHEMA+’.’+TABLE_NAME. Ниже я привожу пример, чтобы показать вам, как это работает.
Обратите внимание, что выполнение этого запроса занимает несколько секунд (или минут в зависимости от скорости машины и размера базы данных). Вы ничего не увидите, пока запрос не будет выполнен.
Вы ничего не увидите, пока запрос не будет выполнен.
использовать AdventureWorks2012 идти объявить @tableName nvarchar(255) объявить myCursor КУРСОР ДЛЯ выберите TABLE_SCHEMA+'.'+TABLE_NAME из INFORMATION_SCHEMA.TABLES где TABLE_TYPE = 'базовая таблица' открыть мой курсор Получить следующее из myCursor в @tableName Пока @@FETCH_STATUS = 0 Начинать print 'Работаем над: '+@tableName DBCC DBREINDEX(@TableName,' ',90) Получить следующее из myCursor в @tableName конец закрыть мойКурсор Освободить myCursor
TABLE_SCHEMA+’.’+TABLE_NAME
Первый результирующий набор, схема и имя таблицы — разные столбцы. Во втором наборе результатов они объединены с файлом . между.
Примерно так:
Нравится Загрузка…
перестроить индекспереиндексировать базу данныхпереиндексировать все таблицы в базе данныхsql dbccsql dbreindexsql server indexes
Как реорганизовать и перестроить индексы в базе данных SQL Server?
В базе данных MS-SQL Server данные хранятся на страницах , где каждая страница имеет ширину 8 КБ, а 8 смежных страниц образуют экстент .
На следующем изображении показано, как страницы связаны друг с другом через структуру индекса B-дерева .
Индексная структура B-дерева (где буква «B» означает «сбалансированный») — это многоуровневая структура, имеющая корневой, промежуточный и конечный уровни. Страницы, связанные между собой, позволяют выполнять поиск по индексу. На уровне листьев «двухсвязный список» связывает страницы. Эта ссылка используется для сканирования индекса.
Мы видим, что это кластеризованный индекс, потому что на уровне листа есть страницы данных. Это означает, что:
- Физические данные хранятся в кластеризованном индексе
- Кластеризованные индексы определяют логический порядок таблицы
Некластеризованный индекс, с другой стороны, имеет ту же структуру B-дерева, но указывает на кластеризованный индекс для своих данных.
Что такое фрагментация индекса?
Фрагментация является естественным явлением и определяется как условие отсутствия смежных данных. Это связано с непрерывными операциями вставки, обновления и удаления данных в базе данных.
Это связано с непрерывными операциями вставки, обновления и удаления данных в базе данных.
Мы можем сказать, что индекс B-дерева фрагментирован, когда есть страницы, где логический порядок (внутри индекса, основанный на ключевых значениях индекса) не соответствует физическому порядку страниц индекса.
Например, когда мы добавляем строки в таблицу, индекс становится фрагментированным (также называемым разбросанным). Механизм базы данных также автоматически изменяет задействованные индексы. Это может привести к разделению существующих страниц, чтобы освободить место для новых строк.
Если мы вставляем новую строку на страницу, но места недостаточно, выделяется новая страница данных или даже новый экстент, а часть данных из существующей страницы данных перемещается на вновь выделенную страницу данных. Для сохранения логического порядка сортировки в индексе указатель на обеих страницах обновляется.
Существует два типа фрагментации индекса:
- Логическая фрагментация — , когда логический порядок страниц не соответствует физическому порядку.

- Внутренняя фрагментация — когда страницы данных в индексе содержат свободное место.
С точки зрения производительности логическая фрагментация приводит к увеличению числа физических операций чтения. Внутренняя фрагментация приводит к увеличению логических операций чтения.
Обновление полей в таблице также может привести к фрагментации. Может случиться так, что когда мы записываем больше данных, одна страница данных заполняется и требуется другая.
Как решить проблему?
Чтобы уменьшить фрагментацию, мы можем выполнить одну из двух задач, разработанных Microsoft.
1. Реорганизовать задачу
Задача реорганизации перемещает страницы индекса в более эффективный порядок поиска. Для этого:
- Объединяет строки индекса, чтобы попытаться освободить некоторые страницы индекса.
- Меняйте местами оставшиеся страницы небольшими транзакциями, пока все страницы не будут в логическом порядке. В конце процесса физический порядок страниц совпадает с логическим порядком.
 В конце процесса физический порядок страниц совпадает с логическим порядком.
В конце процесса физический порядок страниц совпадает с логическим порядком.В результате будут созданы логически упорядоченные страницы, а не физически смежные страницы. Этот подход очень экономичен, поскольку требует только страницы размером 8 КБ в качестве области временного хранения для страниц, которые будут перемещены.
Во время выполнения задачи реорганизации базовая таблица или индекс не заблокированы. Однако эта задача займет больше времени, чем переиндексация, если индексы логически сильно фрагментированы. Важным аспектом задачи реорганизации является то, что она выполняется в виде небольшой атомарной транзакции.
При работе с огромным индексом мы можем остановить откат только небольшой части задачи, а затем возобновить задачу позже.
2. Задача восстановления
Задача перестроения работает иначе, чем задача реорганизации. Этот процесс создает новый индекс и удаляет старый. Это происходит независимо от фрагментации, присутствующей в старом индексе.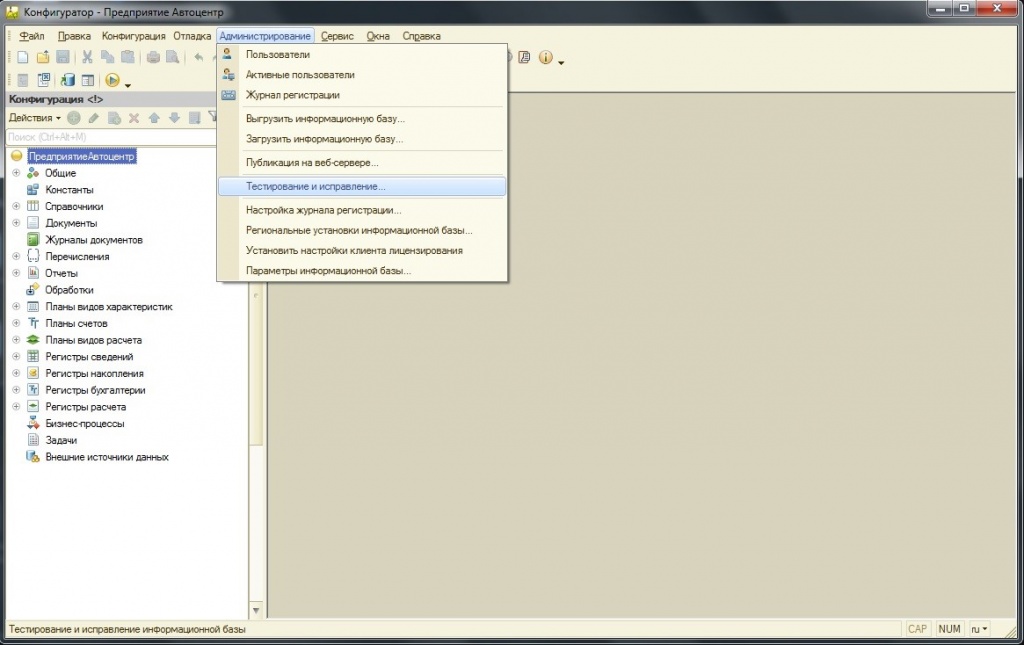 Такой способ действий означает, что нам нужно иметь достаточно места для нового индекса.
Такой способ действий означает, что нам нужно иметь достаточно места для нового индекса.
MS SQL Server имеет два разных типа задач перестроения индекса: в сети и в автономном режиме. Стандартная версия MS SQL Server поддерживает только тип Offline, а версии Enterprise и Developer также поддерживают тип Online.
Термины Online и Offline указывают, можно ли сохранить индекс доступным во время операции перестроения.
Восстановление в автономном режиме
- Эта операция перемещает страницы, чтобы сделать их физически смежными.
- Эта операция является атомарной на уровне одного индекса. Это означает, что если мы прервем процесс, вся работа над индексом будет отменена и потеряна.
- На время выполнения процедуры индекс или таблица будут заблокированы и недоступны для обновления.
Восстановить онлайн
- Онлайновое перестроение индекса работает точно так же, как и автономная процедура.
- Основное отличие заключается в том, что оперативное перестроение блокирует базовый индекс или таблицу.
Стратегия дефрагментации
Давайте обсудим, как получить степень фрагментации и как реорганизовать или перестроить фрагментированный индекс с помощью SQL Server Management Studio (SSMS) или Transact-SQL.
Степень фрагментации
Мы не можем начать дефрагментацию, не зная степень фрагментации . Мы можем получить эту информацию, используя DMF sys.dm_db_index_physical_stats.
С помощью следующего оператора мы можем получить процент фрагментации для каждого индекса каждой таблицы:
Получив процент фрагментации, мы можем выбрать лучший метод дефрагментации индекса.
Microsoft Books Online предоставляет следующие значения:
- Если фрагментация менее 5%, дефрагментация не требуется.
- Если фрагментация составляет от 5% до 30%, мы должны реорганизовать индекс.
- Если фрагментация больше 30%, мы должны перестроить индекс.
Дефрагментация с помощью команды T-SQL
Предположим, у нас есть таблица OrdTes с индексом IDX_OrdTes_DateDoc.
Мы можем реорганизовать индекс, используя первый синтаксис T-SQL, и перестроить индекс, используя второй синтаксис (см. рисунок ниже).
Мы можем реорганизовать или перестроить все индексы таблицы, используя следующий синтаксис.
Дефрагментация с помощью SQL Server Management Studio (SSMS)
Вот шаги по реорганизации индексов с помощью SSMS:
- В обозревателе объектов разверните базу данных, содержащую таблицу, для которой мы хотим реорганизовать индекс.
- Разверните папку «Таблицы».
- Разверните таблицу, в которой мы хотим реорганизовать индексы.
- Щелкните правой кнопкой мыши папку «Индексы» и выберите «Реорганизовать все».
- В диалоговом окне «Реорганизация индексов» убедитесь, что в индексах для реорганизации указаны правильные индексы. Чтобы удалить индекс из таблицы «Индексы для реорганизации», выберите индекс и нажмите клавишу «Удалить».
- Установите флажок Сжимать данные столбца больших объектов , чтобы указать, что все страницы, содержащие данные больших объектов (LOB), также должны быть сжаты.
- Нажмите «ОК».
Вот шаги по перестроению индексов:
- В обозревателе объектов разверните базу данных, содержащую таблицу, для которой мы хотим перестроить индекс.
- Разверните папку «Таблицы».
- Разверните таблицу, для которой мы хотим перестроить индекс.
- Разверните папку Indexes.
- Щелкните индекс правой кнопкой мыши и выберите «Перестроить».
- В диалоговом окне «Перестроить индексы» убедитесь, что в сетке «Индексы для перестроения» указан правильный индекс, и нажмите «ОК».
- Установите флажок Сжимать данные столбца больших объектов , чтобы указать, что все страницы, содержащие данные больших объектов (LOB), также должны быть сжаты.
- Нажмите «ОК».
Индекс дефрагментации в плане обслуживания
Как упоминалось ранее, всегда должна применяться стратегия дефрагментации. Необходимо запланировать план технического обслуживания, который периодически выполняет эту деятельность. План обслуживания не только дефрагментирует индекс, но и выполняет другие важные операции, такие как статистическое обслуживание и резервное копирование базы данных.
Чтобы создать новый план обслуживания, в меню «Управление» щелкните правой кнопкой мыши элемент обслуживания. Затем выберите пункт «Новый план обслуживания».
В план обслуживания мы можем добавлять различные задачи.
Чтобы выполнить задачу «Реорганизация индекса», перетащите задачу «Реорганизация индекса» в центр экрана. Чтобы выполнить задачу «Перестроить индекс», перетащите задачу «Перестроить индекс» в центр экрана.
После того, как мы добавили одну или обе задачи, мы должны их настроить.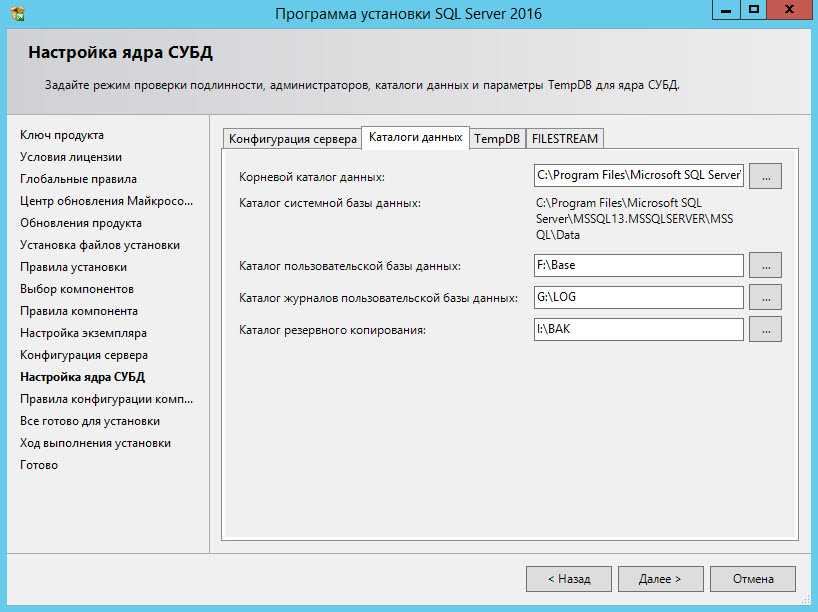
Чтобы настроить задачу реорганизации:
- Укажите, над какими базами данных должна выполняться эта операция.
- Выберите реорганизацию только необходимых баз данных, либо только пользовательских баз данных, либо только системных баз данных.
- Выберите Реорганизовать индексы только при определенных условиях, например, при превышении определенного процента фрагментации или при превышении определенного количества страниц.
Для настройки задачи Rebuild:
- Укажите, над какими базами данных должна выполняться эта операция.
- Выберите реорганизацию только необходимых баз данных, либо только пользовательских баз данных, либо только системных баз данных.
- Выберите перестроение индексов только при определенных условиях, например при превышении определенного процента фрагментации или при превышении определенного количества страниц.
По завершении настройки сохраните план обслуживания и запланируйте его запуск с определенной частотой.