Rownum в sql: Оракл для начинающих | Oracle for beginners (18+): Что такое ROWNUM
Содержание
SELECT TOP, LIMIT, ROWNUM — Учебник SQL — Schoolsw3.com
❮ Назад
Далее ❯
TOP
Инструкция SELECT TOP используется для указания количества возвращаемых записей.
Инструкция SELECT TOP полезно для больших таблиц с тысячами записей. Возврат большого количества записей может повлиять на производительность.
Примечание: Не все базы данных поддерживают SELECT TOP.
MySQL поддерживает предложение LIMIT для выбора ограниченного числа записей, в то время как Oracle использует ROWNUM.
Синтаксис SQL Server / MS Access:
SELECT TOP number|percent column_name(s)
FROM table_name
WHERE condition;
Синтаксис MySQL:
SELECT column_name(s)
FROM table_name
WHERE condition
LIMIT number;
Синтаксис Oracle:
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;
Демо база данных
Ниже приведен выбор из таблицы «Customers» в образце базы данных Northwind:
| CustomerID | CustomerName | ContactName | Address | City | PostalCode | Country |
|---|---|---|---|---|---|---|
| 1 | Alfreds Futterkiste | Maria Anders | Obere Str. 57 57 | Berlin | 12209 | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Avda. de la Constitución 2222 | México D.F. | 05021 | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mataderos 2312 | México D.F. | 05023 | Mexico |
| 4 | Around the Horn | Thomas Hardy | 120 Hanover Sq. | London | WA1 1DP | UK |
| 5 | Berglunds snabbköp | Christina Berglund | Berguvsvägen 8 | Luleå | S-958 22 | Sweden |
Примеры SQL TOP, LIMIT и ROWNUM
Следующая инструкция SQL выбирает первые три записи из таблицы «Customers»:
Пример
SELECT TOP 3 * FROM Customers;
Попробуйте сами »
Следующий оператор SQL показывает эквивалентный пример использования предложения LIMIT:
Пример
SELECT * FROM Customers
LIMIT 3;
Попробуйте сами »
Следующая инструкция SQL показывает соответствующий пример использования параметра ROWNUM:
Пример
SELECT * FROM Customers
WHERE ROWNUM <= 3;
Пример SQL TOP PERCENT
Следующая инструкция SQL выбирает первые 50% записей из таблицы «Customers»:
Пример
SELECT TOP 50 PERCENT * FROM Customers;
Попробуйте сами »
Добавить WHERE
Следующая инструкция SQL выбирает первые три записи из таблицы «Customers», где страна — «Germany»:
Пример
SELECT TOP 3 * FROM Customers
WHERE Country=’Germany’;
Попробуйте сами »
Следующий оператор SQL показывает эквивалентный пример использования LIMIT:
Пример
SELECT * FROM Customers
WHERE Country=’Germany’
LIMIT 3;
Попробуйте сами »
Следующая инструкция SQL показывает соответствующий пример использования параметра ROWNUM:
Пример
SELECT * FROM Customers
WHERE Country=’Germany’ AND ROWNUM <= 3;
❮ Назад
Далее ❯
T-SQL | Функции ранжирования
140
Работа с базами данных в . NET Framework — Оконные функции T-SQL — Функции ранжирования
NET Framework — Оконные функции T-SQL — Функции ранжирования
Исходник базы данных
Стандарт SQL поддерживает четыре оконные функции, которые служат для ранжирования. Это ROW_NUMBER, NTILE, RANK и DENSE_RANK. В стандарте первые две считаются относящимися к одной категории, а вторые две — ко второй. Это связано с различиями в отношении детерминизма. Подробнее я расскажу в процессе рассказа об отдельных функциях.
Функции ранжирования появились еще в SQL Server 2005. Тем не менее я покажу альтернативные, основанные на наборах методы для получения того же результата. Я сделаю это по двум причинам: во-первых, это может быть интересным, а во-вторых, я верю, что это помогает лучше понять нюансы работы функций. Тем не менее имейте в виду, что на практике я настоятельно рекомендую придерживаться оконных функций, потому что они и проще, и намного эффективнее, чем альтернативные решения. Подробнее об оптимизации мы поговорим позже.
Все четыре функции ранжирования поддерживают необязательное предложение секционирования и обязательное предложение упорядочения окна. Если предложение секционирования окна отсутствует, весь результирующий набор базового запроса (вспомните о входных данных этапа SELECT) считается одной секцией. Что касается предложения упорядочения окна, то оно обеспечивает упорядочение при вычислениях. Понятно, что ранжирование строк без определения упорядочения вряд ли имеет смысл. В ранжирующих оконных функциях упорядочение служит другой цели по сравнению с функциями, поддерживающими кадрирование, такими как агрегирующие оконные функции. В первом случае упорядочение имеет логический смысл для самих вычислений, а во втором — упорядочение связано с кадрированием, то есть служит целям фильтрации.
Если предложение секционирования окна отсутствует, весь результирующий набор базового запроса (вспомните о входных данных этапа SELECT) считается одной секцией. Что касается предложения упорядочения окна, то оно обеспечивает упорядочение при вычислениях. Понятно, что ранжирование строк без определения упорядочения вряд ли имеет смысл. В ранжирующих оконных функциях упорядочение служит другой цели по сравнению с функциями, поддерживающими кадрирование, такими как агрегирующие оконные функции. В первом случае упорядочение имеет логический смысл для самих вычислений, а во втором — упорядочение связано с кадрированием, то есть служит целям фильтрации.
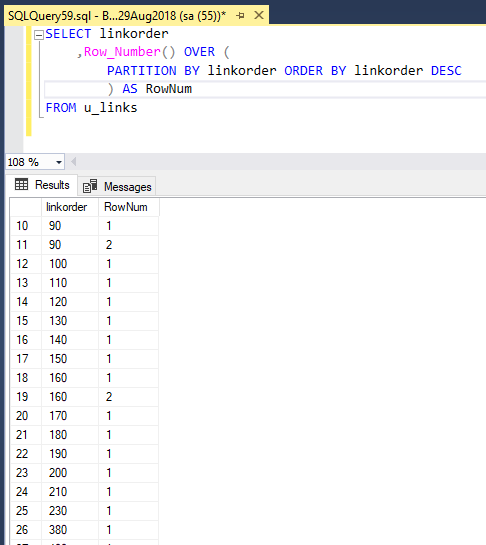
Функция ROW_NUMBER
Эта функция вычисляет последовательные номера строк, начиная с 1, в соответствующей секции окна и в соответствии с заданным упорядочением окна. Посмотрите на пример запроса:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY orderid) AS rownum FROM Sales.OrderValues;
Вот сокращенный результат выполнения этого запроса:
Этот запрос кажется тривиальным, но здесь есть несколько моментов, о которых стоит сказать.
Так как в запросе нет предложения представления ORDER BY, упорядочение представления не гарантируется. Поэтому упорядочение представления здесь нужно считать произвольным. На практике SQL Server оптимизирует запрос с учетом отсутствия предложения ORDER BY, поэтому строки могут возвращаться в любом порядке. Если нужно гарантировать упорядочение представления, нужно не забыть добавить предложение представления ORDER BY. Если нужно, чтобы упорядочение представления выполнялось на основе номера строки, можно использовать псевдоним, назначенный в процессе вычисления предложения представления ORDER BY примерно так:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY orderid) AS rownum FROM Sales.OrderValues ORDER BY rownum;
Считайте вычисление номеров строк генерацией еще одного атрибута в результирующем наборе запроса. Естественно, если хочется, можно получить упорядочение представления, которое отличается от упорядочения окна, как в следующем запросе:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY orderid) AS rownum FROM Sales.OrderValues ORDER BY val DESC;
 OrderValues
ORDER BY val DESC;
OrderValues
ORDER BY val DESC;Можно использовать оконный агрегат COUNT для создания операции которая логически эквивалентна функции ROW_NUMBER. Допустим, WPO — определение секционирования и упорядочения окна, примененное в функции ROW_NUMBER. Тогда ROW_NUMBER OVER WPO эквивалентно COUNT(*) OVER(WPO ROWS UNBOUNDED PRECEDING). Например, следующее эквивалентно запросу из листинга предыдущего примера:
SELECT orderid, val,
COUNT(*) OVER(ORDER BY orderid
ROWS UNBOUNDED PRECEDING) AS rownum
FROM Sales.OrderValues;
Как я говорил, это хорошая тренировка — попытаться и создать альтернативные варианты вместо использования оконных функций, и не важно, что эти варианты сложнее и менее эффективные. Если уж мы говорим о функции ROW_NUMBER, то вот основанная на наборах стандартная альтернатива запросу, в которой оконные функции не используются:
SELECT orderid, val, (SELECT COUNT(*) FROM Sales.OrderValues AS O2 WHERE O2.
 orderid <= O1.orderid) AS rownum
FROM Sales.OrderValues AS O1;
orderid <= O1.orderid) AS rownum
FROM Sales.OrderValues AS O1;В этом решении используется агрегат COUNT во вложенном запросе для определения, у скольких строк значение упорядочения (в нашем случае orderid) меньше или равно текущему. Это просто, если у вас уникальное упорядочение, основанное на одном атрибуте. Но все сильно усложняется, если упорядочение неуникально, что я и продемонстрирую при обсуждении детерминизма.
Детерминизм
Если упорядочение окна уникально, вычисление ROW_NUMBER является детерминистическим. Это означает, что у запроса есть только одни правильный результат, то есть если не менять входные данные, вы гарантировано будете получать повторяющиеся результаты. Но если упорядочение окна не уникально, вычисление становится недетерминистическим. Функция ROW_NUMBER генерирует уникальные номера строк в рамках секции, даже для строк с одинаковыми значениями в атрибутах упорядочения окна. В качестве примера посмотрите на следующий запрос:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS rownum FROM Sales.
 OrderValues;
OrderValues;Так как атрибут orderdate не уникальный, упорядочение строк с одинаковым значением orderdate следует считать произвольным. В принципе существует более одного корректного результата этого запроса. В качестве примера возьмем четыре строки с датой заказа 2008-05-06. Любой порядок строк с номерами от 1 до 4 считается правильным. Поэтому если вы выполните запрос снова, то в принципе можете получить другой порядок — сейчас не будем оценивать вероятность такого события, обусловленную особенностями реализации SQL Server.
Если нужно гарантировать повторяемость результатов, нужно сделать запрос детерминистическим. Это можно сделать, добавив дополнительный параметр в определение упорядочения окна, чтобы обеспечить уникальность в рамках секции. К примеру в следующем запросе уникальность упорядочения в окне достигается за счет добавления в список orderid DESC:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS rownum FROM Sales.
 OrderValues;
OrderValues;При использовании оконных функций детерминизм вычисления номеров страниц реализуется просто. Сделать то же, не прибегая к оконным функция сложнее, но вполне реально:
SELECT orderdate, orderid, val,
(SELECT COUNT(*)
FROM Sales.OrderValues AS O2
WHERE O2.orderdate >= O1.orderdate
AND (O2.orderdate > O1.orderdate
OR O2.orderid >= O1.orderid)) AS rownum
FROM Sales.OrderValues AS O1;Но вернемся к функции ROW_NUMBER: как мы выдели, ее можно использовать для создания недетерминистических вычислений при использовании неуникального упорядочения. Таким образом, недетерминизм разрешен, но странно то, что он не разрешен полностью. Я имею в виду то, что предложение ORDER BY обязательно. Но что, если вы хотите просто получить в секции уникальные номера строк не обязательно в каком-то определенном порядке? Можно создать такой запрос:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER() AS rownum FROM Sales.
 OrderValues;
OrderValues;Но, как уже говорилось, предложение ORDER BY в функциях ранжирования является обязательным:
The function 'ROW_NUMBER' must have an OVER clause with ORDER BY.
Вы можете поумничать и определить константу в списке ORDER BY:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER(ORDER BY NULL) AS rownum FROM Sales.OrderValues;
Ho SQL Server вернет такую ошибку:
Windowed functions and NEXT VALUE FOR functions do not support constants as ORDER BY clause expressions.
Однако решение есть, и я вскоре его приведу.
Предложение OVER и последовательности
Вам наверное интересно, что делает функция NEXT VALUE FOR в сообщении об ошибке при попытке применить константу в предложении OVER. Это связано с расширенной поддержкой последовательностей в SQL Server 2012 по сравнению со стандартом SQL. Последовательность SQL Server — это объект базы данных, который служит для автогенерации номеров, которые часто используются как ключи. Вот пример кода создания объекта-последовательности dbo.Seq1:
Вот пример кода создания объекта-последовательности dbo.Seq1:
CREATE SEQUENCE dbo.Seq1 AS INT START WITH 1 INCREMENT BY 1;
Для получения очередного значения последовательности применяется функция NEXT VALUE FOR. Вот пример:
SELECT NEXT VALUE FOR dbo.Seq1;
Эту функцию можно вызывать в запросе, возвращающем несколько строк:
SELECT orderid, orderdate, val,
NEXT VALUE FOR dbo.Seq1 AS seqval
FROM Sales.OrderValues;Это стандартный код. В SQL Server 2012 возможности функции NEXT VALUE FOR расширены и позволяют определять упорядочение в предложении OVER подобно тому, как это делается в оконных функциях. Таким образом можно гарантировать, что значения последовательности отражают желаемое упорядочение. Вот пример использования расширенной функции NEXT VALUE FOR:
SELECT orderid, orderdate, val,
NEXT VALUE FOR dbo.Seq1 OVER(ORDER BY orderdate, orderid) AS seqval
FROM Sales.OrderValues;Аналогичный принцип детерминизма применим к предложению OVER в функции NEXT VALUE FOR, как это происходит в оконных функциях.
Итак, нет прямого способа назначить номера строкам без упорядочения, но, по-видимому, SQL Server не смущает вложенный запрос, возвращающий константу в качестве элемента упорядочения окна. Вот пример:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM Sales.OrderValues;
Функция NTILE
Эта функция позволяет разбивать строки в секции окна на примерно равные по размеру подгруппы (tiles) в соответствии с заданным числом подгрупп и упорядочением окна. Допустим, что нужно разбить строки представления OrderValues на 10 подгрупп одинакового размера на основе упорядочения по val. В представлении 830 строк, поэтому требуется 10 подгрупп, размер каждой будет составлять 83 (830 деленное на 10). Поэтому первым 83 строкам (одной десятой части), упорядоченным по val, будет назначен номер группы 1, следующим 83 строкам — номер подгруппы 2 и т. д. Вот запрос, вычисляющий номера как строк, так и подгрупп:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY val) AS rownum, NTILE(10) OVER(ORDER BY val) AS tile FROM Sales.
 OrderValues;
OrderValues;Если вы думаете, что разбиение на подгруппы похоже на разбиение на страницы, хочу вас предупредить, что не стоит их путать. При разбиении на страницы, размер страницы является константой, а число страниц меняется динамически — оно определяется делением числа строк в результате запроса на размер страницы. При разбиении на подгруппы число подгрупп является константой, а размер подгруппы меняется и определяется как число строк деленное на заданное число подгрупп. Ясно, для чего нужно разбиение на страницы, а разбиение на подгруппы обычно используется для аналитических задач — когда нужно распределить данные среди заданного числа равных по размеру сегментов с использованием упорядочения по определенному измерению.
Но вернемся к результату запроса, вычисляющего номера как строк, так и подгрупп: как видите они тесно связаны друг с другом. По сути, можно считать, что номер подгруппы вычисляется на основе номера строки. В предыдущем разделе мы говорили, что если упорядочение окна не является уникальным, функция ROW_NUMBER является недетерминистической. Если разбиение на подгруппы принципиально основано на номерах строк, то это означает, что вычисление NTILE также недетерминистично, если упорядочение окна не уникально. Это означает, что у данного запроса может быть несколько правильных результатов. Можно посмотреть на это с другой стороны: двум строкам с одним значением упорядочения могут быть назначены разные номера подгрупп. Если нужен гарантированный детерминизм, можно следовать моим рекомендациям по получению детерминистических номеров строк, а именно добавить в упорядочение окна дополнительный параметр:
Если разбиение на подгруппы принципиально основано на номерах строк, то это означает, что вычисление NTILE также недетерминистично, если упорядочение окна не уникально. Это означает, что у данного запроса может быть несколько правильных результатов. Можно посмотреть на это с другой стороны: двум строкам с одним значением упорядочения могут быть назначены разные номера подгрупп. Если нужен гарантированный детерминизм, можно следовать моим рекомендациям по получению детерминистических номеров строк, а именно добавить в упорядочение окна дополнительный параметр:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY val, orderid) AS rownum, NTILE(10) OVER(ORDER BY val, orderid) AS tile FROM Sales.OrderValues;
Теперь у запроса только один правильный результат. Ранее, при описании функции NTILE я пояснил, что она позволяет разбить строки в секции окна на примерно равные подгруппы. Я использовал слово «примерно», потому что число строк, полученное в базовом запросе, может не делиться нацело на число подгрупп. Допустим, вы хотите разбить строки представления OrderValues на 100 подгрупп. При делении 830 на 100 получаем частное 8 и остаток 30. Это означает, что базовая размерность подгрупп будет 8, но часть подгрупп получать дополнительную строку. Функция NTILE не пытается распределять дополнительные строки среди подгрупп с равным расстоянием между подгруппами — она просто добавляет по одному ряду в первые подгруппы, пока не распределит остаток. При наличии остатка 30 размерность первых 30 подгрупп будет на единицу больше базовой размерности. Поэтому первые 30 будут содержать 9 рядов, а последние 70 — 8, как показано в следующем запросе:
Допустим, вы хотите разбить строки представления OrderValues на 100 подгрупп. При делении 830 на 100 получаем частное 8 и остаток 30. Это означает, что базовая размерность подгрупп будет 8, но часть подгрупп получать дополнительную строку. Функция NTILE не пытается распределять дополнительные строки среди подгрупп с равным расстоянием между подгруппами — она просто добавляет по одному ряду в первые подгруппы, пока не распределит остаток. При наличии остатка 30 размерность первых 30 подгрупп будет на единицу больше базовой размерности. Поэтому первые 30 будут содержать 9 рядов, а последние 70 — 8, как показано в следующем запросе:
SELECT orderid, val, ROW_NUMBER() OVER(ORDER BY val, orderid) AS rownum, NTILE(100) OVER(ORDER BY val, orderid) AS tile FROM Sales.OrderValues;
Следуя привычному методу, попытаемся создать альтернативные решения, заменяющие функцию NTILE и не содержащие оконных функций.
Я покажу один способ решения задачи. Для начала, вот код, который вычисляет число подгрупп по заданным размерности, числу подгрупп и числу строк:
DECLARE @cnt AS INT = 830, @numtiles AS INT = 100, @rownum AS INT = 42;
WITH C1 AS
(
SELECT
@cnt / @numtiles AS basetilesize,
@cnt / @numtiles + 1 AS extendedtilesize,
@cnt % @numtiles AS remainder
),
C2 AS
(
SELECT *, extendedtilesize * remainder AS cutoffrow
FROM C1
)
SELECT
CASE WHEN @rownum <= cutoffrow
THEN (@rownum - 1) / extendedtilesize + 1
ELSE remainder + ((@rownum - cutoffrow) - 1) / basetilesize + 1
END AS tile
FROM C2;Вычисление вполне очевидно. Для входных данных код возвращает 5 в качестве числа подгрупп.
Для входных данных код возвращает 5 в качестве числа подгрупп.
Затем применим эту процедуру к строкам представления OrderValues. Используйте агрегат COUNT, чтобы получить размерность результирующего набора, а не входные данные @cnt, а также примените описанную ранее логику для вычисления номеров строк без использования оконных функций вместо входных данных @rownum:
DECLARE @numtiles AS INT = 100;
WITH C1 AS
(
SELECT
COUNT(*) / @numtiles AS basetilesize,
COUNT(*) / @numtiles + 1 AS extendedtilesize,
COUNT(*) % @numtiles AS remainder
FROM Sales.OrderValues
),
C2 AS
(
SELECT *, extendedtilesize * remainder AS cutoffrow
FROM C1
),
C3 AS
(
SELECT O1.orderid, O1.val,
(SELECT COUNT(*)
FROM Sales.OrderValues AS O2
WHERE O2.val <= O1.val
AND (O2.val < O1.val
OR O2.orderid <= O1.orderid)) AS rownum
FROM Sales. OrderValues AS O1
)
SELECT C3.*,
CASE WHEN C3.rownum <= C2.cutoffrow
THEN (C3.rownum - 1) / C2.extendedtilesize + 1
ELSE C2.remainder + ((C3.rownum - C2.cutoffrow) - 1) / C2.basetilesize + 1
END AS tile
FROM C3 CROSS JOIN C2;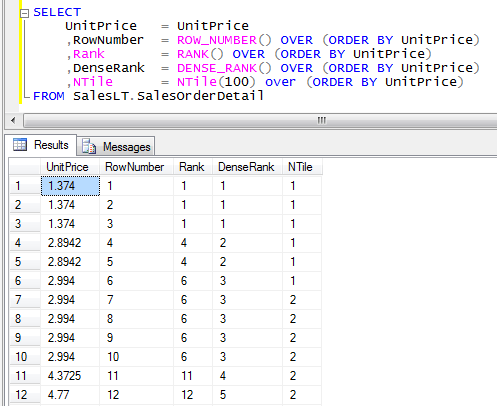 OrderValues AS O1
)
SELECT C3.*,
CASE WHEN C3.rownum <= C2.cutoffrow
THEN (C3.rownum - 1) / C2.extendedtilesize + 1
ELSE C2.remainder + ((C3.rownum - C2.cutoffrow) - 1) / C2.basetilesize + 1
END AS tile
FROM C3 CROSS JOIN C2;
OrderValues AS O1
)
SELECT C3.*,
CASE WHEN C3.rownum <= C2.cutoffrow
THEN (C3.rownum - 1) / C2.extendedtilesize + 1
ELSE C2.remainder + ((C3.rownum - C2.cutoffrow) - 1) / C2.basetilesize + 1
END AS tile
FROM C3 CROSS JOIN C2;Как обычно, не пытайтесь повторить это в производственной среде! Это пример предназначен для обучения, а его производительность в SQL Server ужасна по сравнению с функцией NTILE.
Функции RANK и DENSE_RANK
Функции RANK и DENSE RANK похожи на ROW_NUMBER, но в отличие от нее они не создают уникальные значения в оконной секции. При упорядочении окна по возрастанию «Обычный ранг» RANK вычисляется как единица плюс число строк со значением, по которому выполняется упорядочение, меньшим, чем текущее значение в секции. «Плотный ранг» DENSE_RANK вычисляется как единица плюс число уникальных строк со значением, по которому выполняется упорядочение, меньшим, чем текущее значение в секции. При упорядочении окна по убыванию RANK вычисляется как единица плюс число строк со значением, по которому выполняется упорядочение, большим, чем текущее значение в секции.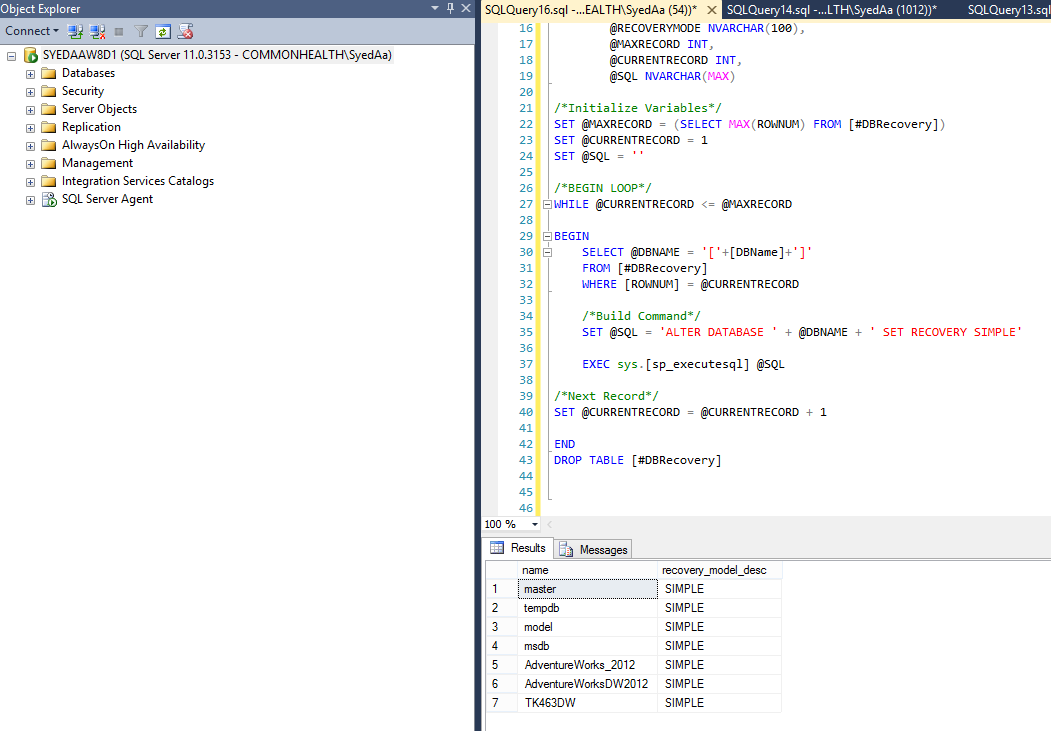 DENSE_RANK вычисляется как единица плюс число уникальных строк со значением, по которому выполняется упорядочение, большим, чем текущее значение в секции.
DENSE_RANK вычисляется как единица плюс число уникальных строк со значением, по которому выполняется упорядочение, большим, чем текущее значение в секции.
Вот пример запроса, вычисляющего номера строк, ранги и «уплотненные» ранги. При этом используется секционирование окна по умолчанию и упорядочение по orderdate DESC:
SELECT orderid, orderdate, val, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS rownum, RANK() OVER(ORDER BY orderdate DESC) AS rnk, DENSE_RANK() OVER(ORDER BY orderdate DESC) AS drnk FROM Sales.OrderValues;
Атрибут orderdate не уникален. Но заметьте, что при этом номера строк уникальны. Значения RANK и DENSE_RANK не уникальны. Все строки с одной датой заказа, например 2008-05-05, получили одинаковый «неплотный» ранг 5 и «плотный» ранг 2. Ранг 5 означает, что есть четыре строки с большими (более поздними) датами заказов (упорядочение ведется по убыванию), а «плотный» ранг 2 означает, что есть одна более поздняя уникальная дата.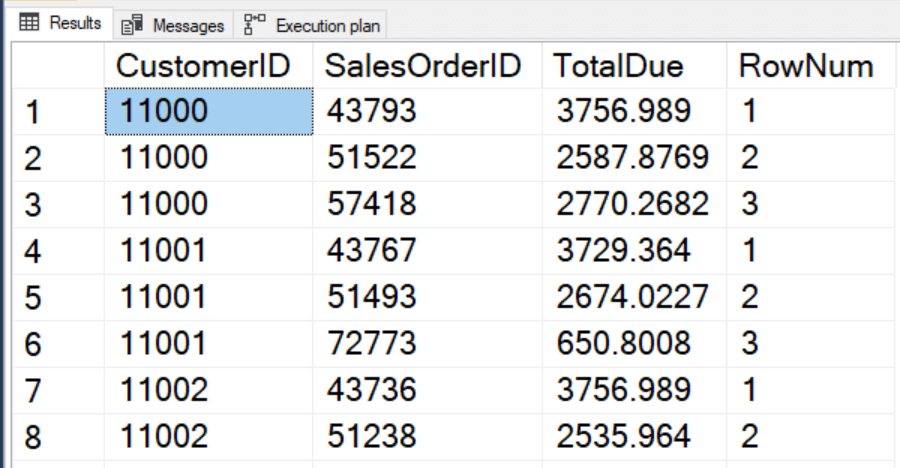
Альтернативное решение, заменяющее RANK и DENSE_RANK и не использующие оконные функции, создается просто:
SELECT orderid, orderdate, val, (SELECT COUNT(*) FROM Sales.OrderValues AS O2 WHERE O2.orderdate > O1.orderdate) + 1 AS rnk, (SELECT COUNT(DISTINCT orderdate) FROM Sales.OrderValues AS O2 WHERE O2.orderdate > O1.orderdate) + 1 AS drnk FROM Sales.OrderValues AS O1;
Для вычисления ранга определяется число строк с большим значением, по которому ведется упорядочение, (как вы помните, упорядочение ведется по убыванию) и к нему добавляется единица. Для вычисления плотного ранга нужно пересчитать уникальные большие значения, по которым ведется упорядочение, и добавить к полученному числу единицу.
Детерминизм
Как вы уже сами, наверное, поняли, что как RANK, так и DENSE_RANK детерминистичны по определению. При одном значении упорядочения — независимо от его уникальности — возвращается одно и то же значение ранга. Вообще говоря, эти две функции обычно интересны, если упорядочение неуникально. Если упорядочение уникально, они дают те же результаты, что и Функция ROW_NUMBER.
Вообще говоря, эти две функции обычно интересны, если упорядочение неуникально. Если упорядочение уникально, они дают те же результаты, что и Функция ROW_NUMBER.
SQL SELECT TOP, LIMIT, FETCH FIRST ROWS ONLY, ROWNUM
❮ Предыдущий
Далее ❯
Предложение SQL SELECT TOP
Предложение SELECT TOP используется для указания количества возвращаемых записей.
Предложение SELECT TOP полезно для больших таблиц с тысячами
записи. Возврат большого количества записей может повлиять на производительность.
Примечание: Не все системы баз данных поддерживают
Предложение SELECT TOP
поддерживает Предложение LIMIT для выбора ограниченного числа записей, в то время как Oracle использует
FETCH FIRST n ТОЛЬКО СТРОКИ ROWNUM .
Синтаксис SQL Server/MS Access:
SELECT TOP число | процентов имя_столбца(ов)
ОТ имя_таблицы
ГДЕ условие ;
Синтаксис MySQL:
SELECT имя_столбца (ов)
FROM имя_таблицы
ГДЕ условие
ПРЕДЕЛ число ;
Синтаксис Oracle 12:
SELECT имя_столбца(ов)
FROM имя_таблицы
ORDER BY
имя_столбца(ов)
FETCH FIRST номер ТОЛЬКО СТРОКИ;
Старый синтаксис Oracle:
SELECT имя_столбца(ов)
FROM имя_таблицы
WHERE ROWNUM <= число ;
Старый синтаксис Oracle (с ORDER BY):
SELECT *
FROM (SELECT имя_столбца ИЗ имя_таблицы
ORDER BY имя_столбца (ов) )
WHERE ROWNUM <= номер ;
Демонстрационная база данных
Ниже приведен выбор из таблицы «Клиенты» в образце базы данных «Борей»:
| CustomerID | ИмяКлиента | Контактное имя | Адрес | Город | Почтовый индекс | Страна |
|---|---|---|---|---|---|---|
| 1 | Альфред Футтеркисте | Мария Андерс | ул.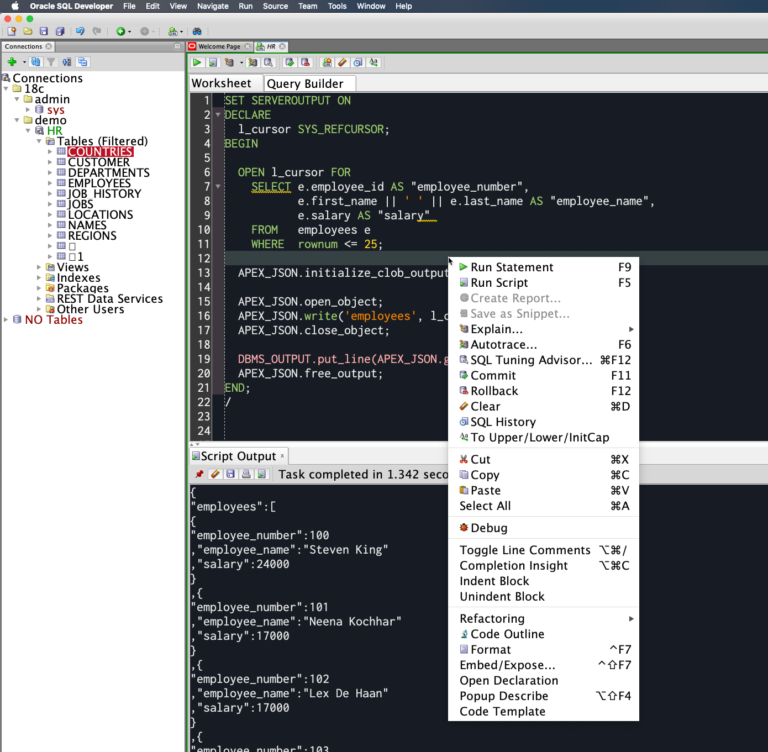 Обере 57 Обере 57 | Берлин | 12209 | Германия |
| 2 | Ана Трухильо Emparedados y helados | Ана Трухильо | Авда. Конститусьон 2222 | Мексика Д.Ф. | 05021 | Мексика |
| 3 | Антонио Морено Такерия | Антонио Морено | Матадерос 2312 | Мексика Д.Ф. | 05023 | Мексика |
| 4 | Вокруг рога | Томас Харди | Ганноверская площадь, 120 | Лондон | ВА1 1ДП | Великобритания |
| 5 | Berglunds snabköp | Кристина Берглунд | Бергувсвеген 8 | Лулео | С-958 22 | Швеция |
SQL TOP, LIMIT и FETCH FIRST Примеры
Следующая инструкция SQL выбирает первые три записи из таблицы «Клиенты».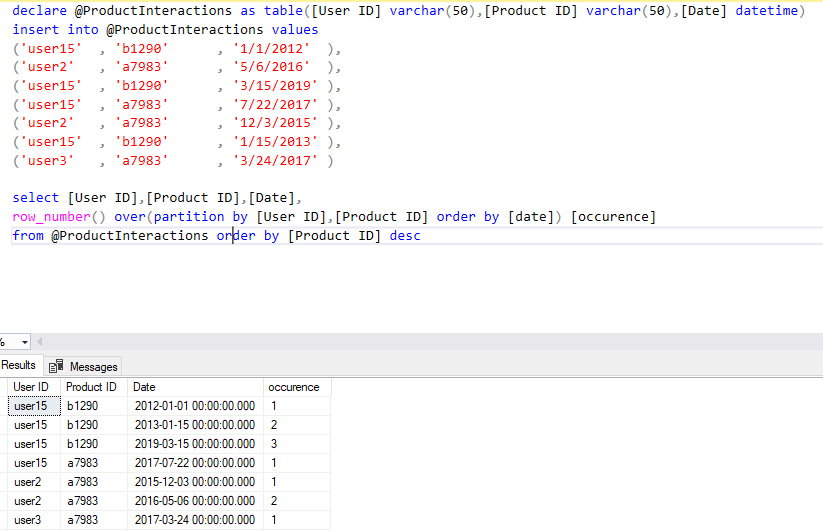
(для SQL Server/MS Access):
Пример
SELECT TOP 3 * FROM Customers;
Попробуйте сами »
Следующая инструкция SQL показывает эквивалентный пример для MySQL:
Пример
SELECT * FROM Customers
LIMIT 3;
Попробуйте сами »
Следующая инструкция SQL показывает эквивалентный пример для
Oracle:
Пример
SELECT * FROM Customers
FETCH FIRST 3 ROWS ONLY;
SQL TOP PERCENT Пример
Следующая инструкция SQL выбирает первые 50% записей из
Таблица «Клиенты» (для SQL Server/MS Access):
Пример
ВЫБЕРИТЕ ВЕРХНИЕ 50 ПРОЦЕНТОВ * ОТ Клиентов;
Попробуйте сами »
Следующая инструкция SQL показывает эквивалентный пример для
Oracle:
Пример
SELECT * FROM Customers
ВЫБЕРИТЕ ТОЛЬКО ПЕРВЫЕ 50 ПРОЦЕНТОВ СТРОК;
ДОБАВИТЬ ПРЕДЛОЖЕНИЕ WHERE
Следующая инструкция SQL выбирает первые три записи из таблицы «Клиенты»,
где страна «Германия» (для SQL Server/MS Access):
Пример
ВЫБЕРИТЕ 3 * ОТ клиентов
ГДЕ Country=’Германия’;
Попробуйте сами »
Следующая инструкция SQL показывает эквивалентный пример для MySQL:
Пример
SELECT * FROM Customers
WHERE Country=’Germany’
LIMIT 3;
Попробуйте сами »
Следующая инструкция SQL показывает эквивалентный пример для
Oracle:
Пример
SELECT * FROM Customers
WHERE Country=’Germany’
FETCH FIRST 3 ROWS ONLY;
❮ Предыдущий
Следующая ❯
НОВИНКА
Мы только что запустили
Видео W3Schools
Узнать
COLOR PICKER
КОД ИГРЫ
Играть в игру
Top Tutorials
Учебник по HTML
Учебник по CSS
Учебник по JavaScript
Учебник How To
Учебник по SQL
Учебник по Python
Учебник по W3. CSS
CSS
Учебник по Bootstrap
Учебник по PHP
Учебник по Java
Учебник по C++
Учебник по jQuery
900 Справочник
01
Справочник по HTML
Справочник по CSS
Справочник по JavaScript
Справочник по SQL
Справочник по Python
Справочник по W3.CSS
Справочник по Bootstrap
Справочник по PHP
Цвета HTML
Справочник по Java
Справочник по Angular
Справочник по jQuery
Top1 Examples
Примеры HTML
Примеры CSS
Примеры JavaScript
Примеры инструкций
Примеры SQL
Примеры Python
Примеры W3.CSS
Примеры Bootstrap
Примеры PHP
Примеры Java
Примеры XML
Примеры jQuery
FORUM |
О
W3Schools оптимизирован для обучения и обучения. Примеры могут быть упрощены для улучшения чтения и обучения.
Учебники, ссылки и примеры постоянно пересматриваются, чтобы избежать ошибок, но мы не можем гарантировать полную правильность всего содержания.
Используя W3Schools, вы соглашаетесь прочитать и принять наши условия использования,
куки-файлы и политика конфиденциальности.
Copyright 1999-2022 Refsnes Data. Все права защищены.
W3Schools использует W3.CSS.
Функция SQL ROW_NUMBER()
Резюме : в этом руководстве вы узнаете, как использовать ROW_NUMBER() для присвоения порядкового номера каждой строке в наборе результатов запроса.
SQL
ROW_NUMBER() Обзор функций
ROW_NUMBER() — это оконная функция, которая присваивает последовательное целое число каждой строке в наборе результатов запроса.
Ниже показан синтаксис ROW_NUMBER() функция:
Язык кода: SQL (язык структурированных запросов) (sql)
ROW_NUMBER() OVER ( [РАЗДЕЛ ПО expr1, expr2,...] ЗАКАЗАТЬ ПО expr1 [ASC | DESC], expr2,.
 ..
)
..
)
В этом синтаксисе
- Во-первых, предложение
PARTITION BYделит набор результатов, возвращенный из предложенияFROM, на разделы. ПредложениеPARTITION BYявляется необязательным. Если его опустить, весь результирующий набор рассматривается как один раздел. - Затем предложение
ORDER BYсортирует строки в каждом разделе. ПосколькуROW_NUMBER()является функцией, чувствительной к порядку, требуется условиеORDER BY. - Наконец, каждой строке в каждом разделе назначается последовательное целое число, называемое номером строки. Номер строки сбрасывается всякий раз, когда пересекается граница раздела.
SQL
ROW_NUMBER() примеры
Мы будем использовать сотрудников и отделы таблицы из примера базы данных для демонстрации:
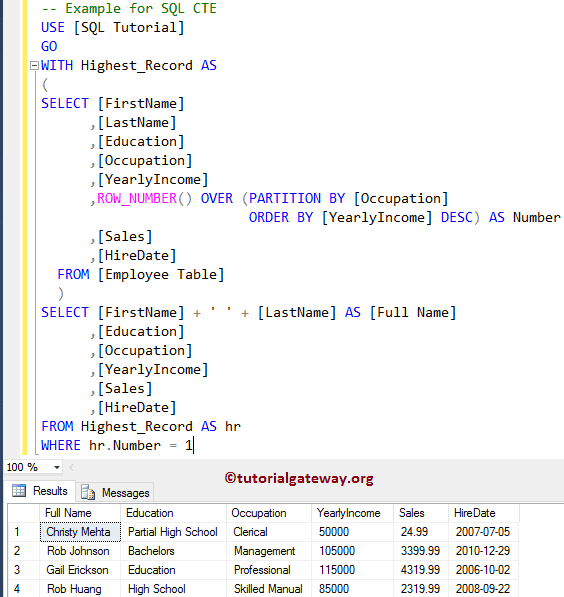
A) Простой SQL
ROW_NUMBER() пример
Следующий оператор находит имя, фамилию и зарплату всех сотрудников.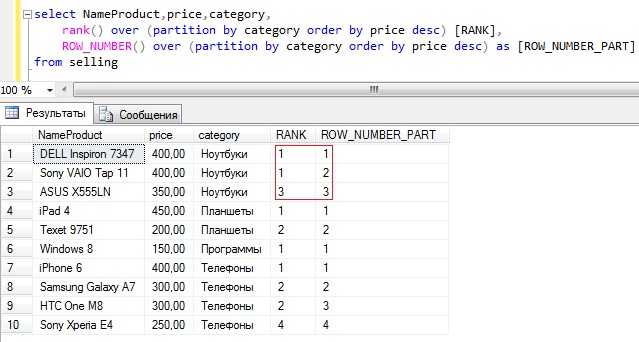 Кроме того, он использует функцию
Кроме того, он использует функцию ROW_NUMBER() для добавления последовательного целого числа к каждой строке.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ ROW_NUMBER() БОЛЕЕ ( ЗАКАЗАТЬ ПО ЗП ) номер_строки, Имя, фамилия, зарплата ИЗ сотрудники;
На следующем рисунке показан частичный набор результатов:
B) Использование SQL
ROW_NUMBER() для разбивки на страницы
Функция ROW_NUMBER() может 9 использоваться для разбиения на страницы. Например, если вы хотите отобразить всех сотрудников в таблице в приложении по страницам, каждая из которых имеет десять записей.
- Сначала используйте функцию
ROW_NUMBER(), чтобы присвоить каждой строке последовательное целое число. - Во-вторых, отфильтруйте строки по запрошенной странице. Например, на первой странице есть строки, начинающиеся с 1 до 9, а на второй странице — строки, начинающиеся с 11 по 20, и так далее.

Следующий оператор возвращает записи второй страницы, каждая страница содержит десять записей.
Язык кода: SQL (язык структурированных запросов) (sql)
-- разбиение на страницы получить страницу #2 ВЫБРАТЬ ИЗ ( ВЫБРАТЬ ROW_NUMBER() OVER (ЗАКАЗ ПО зарплате) row_num, Имя, фамилия, зарплата ИЗ сотрудники ) т КУДА row_num > 10 AND row_num <=20;
Ниже показан вывод:
Если вы хотите использовать общее табличное выражение (CTE) вместо подзапроса, вот запрос:
Язык кода: SQL (язык структурированных запросов) (sql)
С т КАК( ВЫБРАТЬ ROW_NUMBER() БОЛЕЕ ( ЗАКАЗАТЬ ПО ЗП ) номер_строки, Имя, фамилия, зарплата ИЗ сотрудники ) ВЫБРАТЬ * ИЗ т КУДА row_num > 10 И номер_строки <=20;
C) Использование SQL
ROW_NUMBER() для поиска n-го наивысшего значения в группе
В следующем примере показано, как найти сотрудников, у которых самое высокое значение зарплата в своих отделах:
-- найдите самую высокую зарплату в каждом отделе
ВЫБРАТЬ
название отдела,
Имя,
фамилия,
зарплата
ИЗ
(
ВЫБРАТЬ
название отдела,
`ROW_NUMBER()` БОЛЕЕ (
РАЗДЕЛ ПО имя_отдела
ORDER BY зарплата DESC) row_num,
Имя,
фамилия,
зарплата
ИЗ
сотрудники е
Отделы ВНУТРЕННЕГО СОЕДИНЕНИЯ d
ON d.