Select in select sql: SQL Subquery | Nested query
Содержание
пара приемов в SELECT-запросах / Хабр
Автор: Юрий Цыганенко, Senior QA
Тестирование новых функций часто проводят на данных, взятых с уже функционирующей системы. В этом случае тестировщикам порою приходится строить запросы для хитрых случаев. Например, нужно протестировать новую функциональность интернет-магазина, причём играют роль интервалы между покупками. Нам доступны данные с работающей версии — можно загрузить их на тестовый стенд и проверить работу новой версии продукта. (NB!: конечно, имея дело с «живыми» данными, нужно исключить из них приватную информацию и обеспечить возможность логина интересующим нас пользователям).
Для выбора интересных нам пользовательских аккаунтов нужно сопоставить максимальные интервалы между покупками у разных пользователей.
От тестировщика требуется построить SQL-запрос, выдающий N пользователей, у которых интервалы между датами заказов будут наибольшими.
Аналогичные задачи и их разбор — под катом.
Речь идет о поиске последовательностей записей/интервалов стандартными средствами SQL. Агрегатные функции обрабатывают все данные, попадающие в условие выборки, и поэтому только ими обойтись нельзя.
Агрегатные функции обрабатывают все данные, попадающие в условие выборки, и поэтому только ими обойтись нельзя.
В качестве примера возьмем датчик погоды, периодически выдающий состояние «ясно» или «пасмурно» и силу ветра. Рассмотрим задачи:
1. Первая часть данных выведена в таблицу ‘Weather’, включающую поля:
• time // Содержит время измерения;
• clear // Содержит оценку чистоты неба: пусть 0 — пасмурно; 1 — ясно.
Нам нужен запрос, выдающий несколько (допустим, три или менее) наиболее долгих периода (интервала) с ясной погодой. Иными словами, пары записей с ясной погодой, между которыми не будет периодов плотной облачности. Равномерность измерений при этом не подразумевается.
То есть задача сводится к поиску наборов трех или менее значений Period_1…Period_N в порядке убывания.
2. В рамках второй задачи у нас есть похожая на первую таблица ‘Wind’, включающая записи силы ветра в отдельные моменты времени. Она имеет два поля:
• Time
• Speed
Требуется найти все «локальные максимумы» скорости — т. е. моменты времени и значения скорости, по сравнению с которыми предшествующая и последующая (по времени) записи имеют меньшую скорость.
е. моменты времени и значения скорости, по сравнению с которыми предшествующая и последующая (по времени) записи имеют меньшую скорость.
На графике локальные максимумы соответствуют 3, 10, 14, 17. Для упрощения не будем считать граничную точку 19.
Полагаю, ясно, что «прямым» применением агрегатных функций не обойтись: нужно в условии каким-то образом указать, что точки следуют подряд. Для решения обеих задач воспользуемся приемами:
1. Неявный Join таблицы с ней же самой: в поле FROM через запятую перечислим записи и нашу таблицу (например, FROM Weather w1, Weather w2 ).
На всякий случай: при выборке SELECT w1.*, w2.* FROM Weather w1, Weather w2; выведутся все пары записей, включая совпадающие и повторяющиеся в обратном порядке пары. Т. е. при 10 записях в таблице выведутся 100.
2. Функция exists(), внутри которой пишем вложенный запрос.
Оба эти приема показаны в бесплатном курсе по SQL (видео): тут и тут.
Грубое решение первой задачи: выбираем все пары записей с плохой погодой, между которыми все записи с хорошей погодой, причем не менее 1 (то есть нет плохой поды в промежуточных записях):
SELECT (w2.time - w1.time) as duration FROM Weather w1, Weather w2 WHERE w2.time > w1.time # вторая точка позде первой AND w2.clear=0 # в первой точке плохая погода AND w1.clear=0 # во второй точке плохая погода AND exists ( # Существуют точки SELECT * FROM Weather wg WHERE wg.clear = 1 # с ясной погодой AND wg.time > w1.time # в промежутке от первой точки AND wg.time < w2.time # до второй ) AND not exists ( # Нет точек SELECT * FROM Weather w3 WHERE w3.clear=0 # с плохой погодой AND w3.time>w1.time # в промежутке от первой точки AND w3.time<w2.time # до второй ) Order by duration DESC LIMIT 3;
 time - w1.time) as duration
FROM Weather w1, Weather w2
WHERE w2.time > w1.time # вторая точка позде первой
AND w2.clear=0 # в первой точке плохая погода
AND w1.clear=0 # во второй точке плохая погода
AND exists ( # Существуют точки
SELECT * FROM Weather wg
WHERE wg.clear = 1 # с ясной погодой
AND wg.time > w1.time # в промежутке от первой точки
AND wg.time < w2.time # до второй
)
AND not exists ( # Нет точек
SELECT * FROM Weather w3
WHERE w3.clear=0 # с плохой погодой
AND w3.time>w1.time # в промежутке от первой точки
AND w3.time<w2.time # до второй
)
Order by duration DESC
LIMIT 3;
time - w1.time) as duration
FROM Weather w1, Weather w2
WHERE w2.time > w1.time # вторая точка позде первой
AND w2.clear=0 # в первой точке плохая погода
AND w1.clear=0 # во второй точке плохая погода
AND exists ( # Существуют точки
SELECT * FROM Weather wg
WHERE wg.clear = 1 # с ясной погодой
AND wg.time > w1.time # в промежутке от первой точки
AND wg.time < w2.time # до второй
)
AND not exists ( # Нет точек
SELECT * FROM Weather w3
WHERE w3.clear=0 # с плохой погодой
AND w3.time>w1.time # в промежутке от первой точки
AND w3.time<w2.time # до второй
)
Order by duration DESC
LIMIT 3;
Нюансы: в разных СУБД возможно, потребуются:
• конвертации для типа timestamp, чтобы можно было вычитать w1.time и w2.time;
• ограничение на количество выводимых строк — limit или top.
Проблемы при таком решении:
• Границы периода наблюдений: если все записи в таблице только с ясной погодой, ответа мы не получим. Как, впрочем, не получим и периоды ясной погоды в начале и конце наблюдений;
Как, впрочем, не получим и периоды ясной погоды в начале и конце наблюдений;
• В ответе отсутствуют точные данных о первой и финальной записи с хорошей погодой.
Строго говоря, такое решение не отвечает условию задачи («пары записей с ясной погодой, между которыми не будет иной…»).
Обе проблемы лечатся этими же приемами.
Оттачиваем решение: ищем пары записей с хорошей погодой, между которыми нет записей с плохой погодой. Причем так, чтобы у первой записи в паре не было бы предшествующей записи с хорошей погодой (т. е. это была бы запись, начинающая ясный период). Соответственно, у второй записи в паре не должно быть последующей записи с хорошей погодой (т. е. запись замыкала бы ясный период).
Полагаю, достаточно идеи запроса.
Решение второй задачи: ищем тройки последовательных записей, в которых скорость ветра в средней точке больше, чем в каждой из соседних. Соседство проверяется функцией exists аналогично первой задаче: not exists(…). Порядок точек проверяется сравнением значений времени.
На этом я статью завершаю и еще раз рекомендую Стэндфордский курс!
Enjoy!
Подзапросы SQL — Полное руководство
Подзапросы SQL позволяют вам писать запросы, которые являются более динамичными и управляемыми данными. Думайте о них как о запросе внутри другого запроса.
В этой статье я познакомлю вас с подзапросами и некоторыми их концепциями высокого уровня. Я покажу вам, как написать подзапрос SQL как часть инструкции SELECT. Подзапросы возвращают два типа результатов: либо одно значение, называемое скалярным значением, либо табличное значение, похожее на результат запроса.
Работая с примерами, помните, что они основаны на Microsoft SQL Server Management Studio и базе данных AdventureWorks2012. Начните использовать эти бесплатные инструменты с помощью моего руководства Начало работы с SQL Server .
Подзапросы в SQL 3. Простой подзапрос для расчета среднего
- Присоединение к подзапросу
- Связи таблиц с запросом
9002 1
Подзапросы в SQL
Подзапросы предоставляют мощные средства для объединения данных из двух таблиц в один результат. Вы также можете вызывать эти вложенные запросы. Как следует из названия, подзапросы содержат один или несколько запросов, один внутри другого.
Вы также можете вызывать эти вложенные запросы. Как следует из названия, подзапросы содержат один или несколько запросов, один внутри другого.
Подзапросы очень универсальны, и это может затруднить их понимание. В большинстве случаев используйте их везде, где вы можете использовать выражение или спецификацию таблицы.
Например, вы можете использовать подзапросы в предложениях SELECT, FROM, WHERE или HAVING. Подзапрос может возвращать либо одно значение, либо несколько строк.
Одиночное значение также известно как скалярное значение.
Обзор подзапроса
Подзапросы позволяют создавать запросы, которые являются более динамичными и управляемыми данными. Например, используя подзапрос, вы можете вернуть все продукты, у которых ListPrice больше, чем средняя ListPrice для всех продуктов.
Вы можете сделать это, сначала рассчитав среднюю цену, а затем используя ее для сравнения с ценой каждого продукта.
Первое прохождение
Давайте разберем этот запрос, чтобы вы могли увидеть, как он работает.
Шаг 1: Сначала запустим подзапрос:
5 Базовые запросы инструкции SELECT в…
Пожалуйста, включите JavaScript
5 Базовые запросы инструкции SELECT в SQL
ВЫБЕРИТЕ СРЕДНЮЮ (СписочнаяЦена) ОТ Production.Product
Возвращает 438,6662 в качестве средней ListPrice
Шаг 2: Найдите товары с ценой выше средней, вставив среднее значение ListPrice в сравнение нашего запроса.
ВЫБЕРИТЕ ProductID, Имя, Список цен ИЗ производства.Продукт ГДЕ ListPrice > 438,6662
Огромное преимущество подзапросов SQL
Как видите, с помощью подзапроса мы объединили два шага. Подзапрос избавил нас от необходимости находить среднюю ListPrice, а затем подставлять ее в наш запрос.
Это огромно! Это означает, что наш запрос автоматически адаптируется к изменяющимся данным и новым средним значениям.
Надеюсь, вы увидели, как подзапросы могут сделать ваши операторы более гибкими. В этом случае, используя подзапрос, нам не нужно знать значение средней прейскурантной цены.
В этом случае, используя подзапрос, нам не нужно знать значение средней прейскурантной цены.
Мы позволяем подзапросу делать всю работу за нас! Подзапрос вычисляет среднее значение на лету; нам не нужно «обновлять» среднее значение в запросе.
Второе прохождение
Возможность динамически создавать критерий для запроса очень удобна. Здесь мы используем подзапрос для получения списка всех клиентов, на территории которых объем продаж ниже 5 000 000 долларов США.
Мы строим список «вживую» с помощью оператора IN, что избавляет нас от необходимости жестко кодировать значения.
Может быть полезно посмотреть, как выполнить этот запрос шаг за шагом:
Шаг 1: Запустите подзапрос, чтобы получить список территорий, в которых с начала года было продано менее 5 000 000:
ВЫБЕРИТЕ ID территории ОТ Sales.SalesTerritory ГДЕ Продажи с начала года < 5000000
Это возвращает 2,3,5,7,8 в виде списка значений.
Шаг 2: Теперь, когда у нас есть список значений, мы можем подставить их в оператор IN:
ВЫБЕРИТЕ ОТЛИЧНЫЙ ИД клиента ОТ Sales.SalesOrderHeader ГДЕ TerritoryID В ( 2,3,5,7,8 )
Опять же, мы могли бы просто разбить это на несколько шагов, но недостатком этого является то, что нам пришлось бы постоянно обновлять список территорий.
Теперь, когда вы увидели, как мы используем подзапрос в операторе SQL, давайте рассмотрим их использование в предложении WHERE.
Подзапросы в предложении SELECT
Запросы, используемые в списке столбцов, должны возвращать одно значение. В этом случае вы можете думать о подзапросе как о выражении с одним значением. Возвращаемый результат ничем не отличается от выражения «2 + 2». Конечно, подзапросы также могут возвращать текст, но суть вы поняли!
Основная инструкция SQL называется внешним запросом; он вызывает подзапрос. Заключите подзапросы в круглые скобки, это обязательно, но также облегчает их обнаружение.
Будьте осторожны при использовании подзапросов. Их может быть интересно использовать, но по мере того, как вы добавляете больше к своему запросу, они могут начать замедлять ваш запрос.
Простой подзапрос для вычисления среднего значения
Давайте начнем с простого запроса, чтобы показать SalesOrderDetail и сравнить его с общим средним значением SalesOrderDetail LineTotal. Мы будем использовать оператор SELECT:
.
ВЫБЕРИТЕ SalesOrderID, LineTotal, (ВЫБЕРИТЕ СРЕДНЕЕ(СуммаЛинии) FROM Sales.SalesOrderDetail) AS AverageLineTotal ОТ Sales.SalesOrderDetail;
Этот запрос возвращает результаты как:
Средняя сумма строки вычисляется с помощью подзапроса, показанного красным цветом.
ВЫБЕРИТЕ СРЕДНЕЕ (Сумма строк) ОТ Sales.SalesOrderDetail
Затем этот результат снова вставляется в список столбцов, и запрос продолжается.
Наблюдения
Хочу отметить несколько вещей:
- SQL требует, чтобы подзапросы заключались в круглые скобки.
- Подзапросы, используемые в SELECT, могут возвращать только одно значение. Это должно иметь смысл, простой выбор столбца возвращает одно значение для строки, и нам нужно следовать тому же шаблону.
- Как правило, подзапрос выполняется только один раз для всего запроса, а его результат используется повторно. Это связано с тем, что результат запроса не меняется для каждой возвращаемой строки.
- Важно использовать псевдонимы для имен столбцов, чтобы улучшить читаемость.
Простой подзапрос в выражении
Результат подзапроса можно использовать в других выражениях. Опираясь на предыдущий пример, давайте воспользуемся подзапросом, чтобы определить, насколько наш LineTotal отличается от среднего.
Дисперсия - это просто общая сумма строк минус средняя сумма строк. В следующем подзапросе я выделил его синим цветом. Вот формула дисперсии:
LineTotal - (ВЫБРАТЬ AVG(LineTotal)
ОТ Sales.SalesOrderDetail) Оператор SELECT, заключенный в круглые скобки, является подзапросом. Как и в предыдущем примере, этот запрос выполняется один раз, возвращает числовое значение, которое затем вычитается из каждого значения LineTotal.
Как и в предыдущем примере, этот запрос выполняется один раз, возвращает числовое значение, которое затем вычитается из каждого значения LineTotal.
Вот запрос в окончательной форме:
ВЫБЕРИТЕ SalesOrderID,
LineTotal,
(ВЫБЕРИТЕ СРЕДНЕЕ(СуммаЛинии)
ОТ Sales.SalesOrderDetail) AS AverageLineTotal,
LineTotal - (SELECT AVG(LineTotal)
ОТ Sales.SalesOrderDetail) AS Отклонение
ОТ Sales.SalesOrderDetail Вот результат:
При работе с подзапросами в операторах select я обычно сначала создаю и тестирую подзапрос SQL. Сделайте это, чтобы устранить неполадки, прежде чем собирать сложный запрос! Лучше наращивать их постепенно. Создавая и тестируя различные части по отдельности, это действительно помогает при отладке.
Подробнее: Коррелированные подзапросы>>
Подзапросы в предложении WHERE
Давайте посмотрим, как написать подзапрос в предложении where. Для этого мы будем использовать оператор IN, чтобы проверить, является ли значение частью результата, возвращаемого подзапросом.
Вот общий формат:
ВЫБЕРИТЕ столбец 1, столбец 2,..
ИЗ таблицы 1
ГДЕ столбец 2 В (подзапрос 1)
Пример поясняет это. Предположим, мы хотим найти все заказы на продажу, сделанные продавцом с бонусом более 5000 долларов.
Для этого напишем два запроса. Внешний для поиска заказов на продажу и внутренний (подзапрос SQL) для возврата SalesPersonID для получателей бонусов на сумму 5000 долларов США и выше.
Я выделил подзапрос цветом, чтобы вы могли его легко увидеть:
ВЫБЕРИТЕ SalesOrderID
,Дата заказа
,Номер счета
,Пользовательский ИД
,SalesPersonID
,TotalDue
ИЗ Sales.SalesOrderHeader
ГДЕ SalesPersonID IN (ВЫБЕРИТЕ BusinessEntityID
ОТ Sales.SalesPerson
ГДЕ Бонус > 5000
) При выполнении в качестве подзапроса возвращает список идентификаторов. Строка включается в результат, если SalesPersonID внешнего запроса находится в этом списке. Вот пример, который вы можете попробовать:
Вот пример, который вы можете попробовать:
Подробнее: Использование операторов Where EXISTS в SQL >>, SQL ЛЮБЫЕ и ВСЕ операторы >>
Подзапросы в пункте FROM
Как и все подзапросы, заключайте подзапросы в предложение FROM в круглые скобки. Однако, в отличие от других подзапросов, вам необходимо использовать псевдоним для производной таблицы, чтобы ваш SQL мог ссылаться на ее результаты.
В этом примере мы собираемся выбрать территории и их средние бонусы.
ВЫБЕРИТЕ ID территории,
Средний бонус
ОТ (ВЫБЕРИТЕ TerritoryID,
Avg(Bonus) AS Средний бонус
ОТ Sales.SalesPerson
СГРУППИРОВАТЬ ПО TerritoryID) AS TerritorySummary
ЗАКАЗАТЬ ПО MediumBonus Псевдоним подзапроса — TerritorySummary, он выделен красным цветом.
Присоединение к подзапросу
При выполнении этого запроса первым запускается подзапрос и создаются результаты. Затем результаты используются в предложении FROM, как если бы это была таблица. Когда эти типы запросов используются сами по себе, они не очень интересны; однако при использовании в сочетании с другими таблицами они таковы.
Когда эти типы запросов используются сами по себе, они не очень интересны; однако при использовании в сочетании с другими таблицами они таковы.
Давайте добавим соединение к нашему примеру выше.
ВЫБЕРИТЕ SP.TerritoryID, SP.BusinessEntityID, СП.Бонус, TerritorySummary.AverageBonus ОТ (ВЫБЕРИТЕ TerritoryID, AVG(Bonus) AS Средний бонус ОТ Sales.SalesPerson СГРУППИРОВАТЬ ПО TerritoryID) AS TerritorySummary ВНУТРЕННЕЕ СОЕДИНЕНИЕ Sales.SalesPerson AS SP ON SP.TerritoryID = TerritorySummary.TerritoryID
Подробнее: В чем разница между соединением и подзапросом?
Связи таблиц с запросом
С точки зрения моделирования данных этот запрос выглядит следующим образом:
Существует связь между TerritorySummary и объединенной таблицей SalesPerson. Конечно, TerritorySummary существует только как часть этой инструкции SQL, поскольку она является производной.
Используя производные таблицы, мы можем подводить итоги, используя один набор полей, и сообщать о другом. В этом случае мы суммируем по TerritoryID, но сообщаем по каждому продавцу (BusinessEntityID).
В этом случае мы суммируем по TerritoryID, но сообщаем по каждому продавцу (BusinessEntityID).
Вы можете подумать, что можете просто реплицировать этот запрос с помощью ВНУТРЕННЕГО СОЕДИНЕНИЯ, но вы не можете этого сделать, так как окончательный GROUP BY для запроса должен включать BusinessEntityID, что затем отбрасывает вычисление среднего.
Подробнее: Производные таблицы >>
Подзапросы в предложении HAVING
Вы можете использовать подзапросы в предложении SQL HAVING для фильтрации групп записей. Точно так же, как предложение WHERE используется для фильтрации строк записей, предложение HAVING используется для фильтрации групп. Из-за этого он становится очень полезным при фильтрации совокупных значений, таких как средние значения, суммирование и количество.
Преимущество использования подзапроса в предложении HAVING заключается в том, что теперь вам не нужно жестко кодировать значения в сравнениях. Вы можете положиться на результаты подзапроса, чтобы сделать это за вас.
Например, теперь можно сравнивать среднее значение группы с общим средним значением. Мы всегда могли использовать среднее значение группы в предложении HAVING, но не могли вычислить общее среднее значение. Теперь, используя подзапросы, это возможно.
В этом примере мы выбираем должности сотрудников, у которых количество оставшихся часов отпуска больше, чем общее среднее значение для всех сотрудников.
Здесь я написал запрос без использования подзапроса
ВЫБЕРИТЕ JobTitle,
AVG(Часы отпуска) AS AverageЧасы отпуска
ОТ HumanResources.Employee
СГРУППИРОВАТЬ ПО Должности
HAVING AVG(часы отпуска) > 50 Подзапрос заменяет текст, выделенный красным. Теперь вот полный оператор, включая подзапрос:
ВЫБЕРИТЕ JobTitle,
AVG(Часы отпуска) AS AverageЧасы отпуска
ОТ HumanResources.Employee
СГРУППИРОВАТЬ ПО Должности
ИМЕЕТ AVG(часы отпуска) > (ВЫБРАТЬ AVG(часы отпуска)
ОТ HumanResources. Employee) 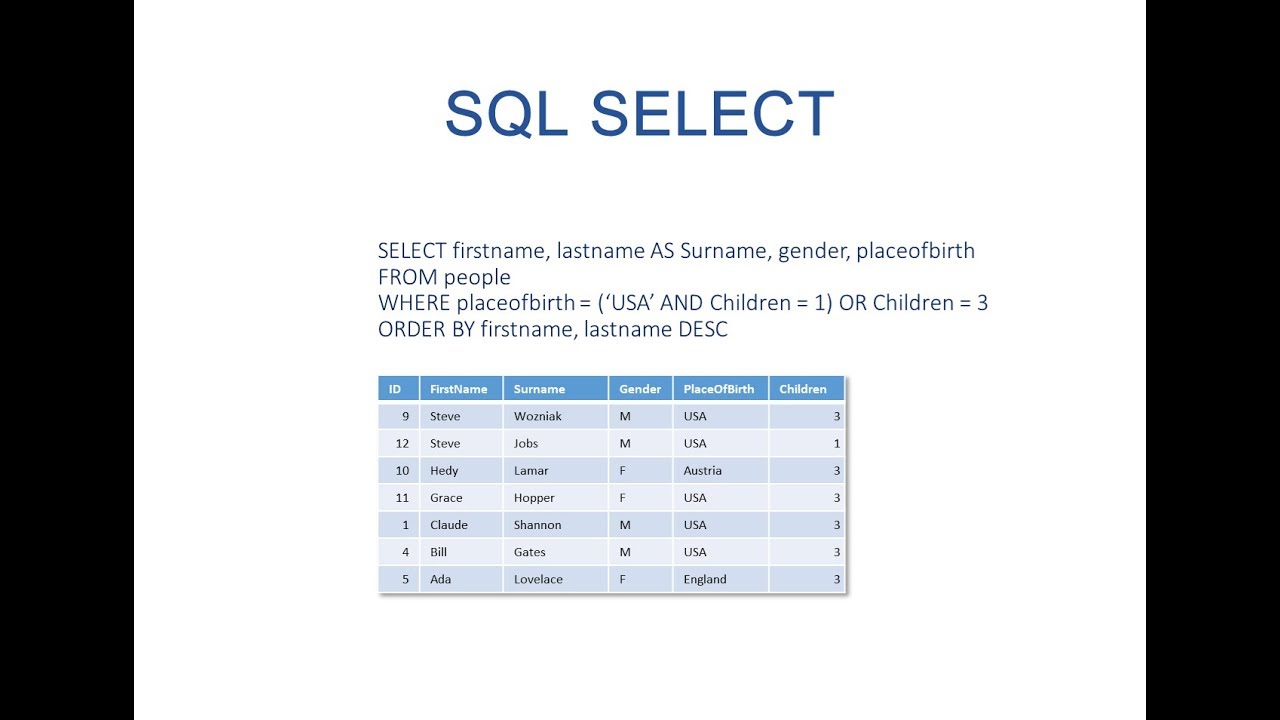 Employee)
Employee) Этот запрос выполняется как:
- Рассчитайте оставшееся среднее количество часов отпуска для всех сотрудников. (подзапрос)
- Групповые записи по JobTitle и компьютеру о среднем количестве часов отпуска.
- Сохраняйте только те группы, среднее количество часов отпуска которых превышает общее среднее значение.
Повторное рассмотрение важных моментов
- Подзапрос — это просто оператор SELECT внутри другого.
- Заключите подзапросы в круглые скобки () .
- Псевдоним подзапросов в списке столбцов, чтобы упростить чтение и ссылки на результаты.
- Подзапрос возвращает одно значение или таблицу. Помните о том, какой тип возвращает ваш запрос, чтобы убедиться, что он работает правильно в данной ситуации.
- Подзапрос, который возвращает более одного значения, обычно используется там, где список значений, например, используется в операторе и IN.
- Внимание! Подзапросы могут быть очень неэффективными. Если есть более прямые средства для достижения того же результата, например, использование внутреннего соединения, вам лучше.
- Вы можете вкладывать подзапросы до тридцати двух уровней в глубину на сервере SQL. Честно говоря, я не могу представить, почему! Я вижу максимум на четыре глубины. На самом деле я думаю, что вы углубитесь только в один или два раза.
 Если есть более прямые средства для достижения того же результата, например, использование внутреннего соединения, вам лучше.
Если есть более прямые средства для достижения того же результата, например, использование внутреннего соединения, вам лучше.Не беспокойтесь, если сейчас многое кажется запутанным. Вам все еще нужно узнать, где использовать подзапросы в операторе SELECT. Как только вы увидите их в действии, вышеперечисленные моменты станут яснее.
Заключение
Как видите, подзапросы не так уж пугают. Ключом к их пониманию является понимание их роли в операторе SQL. К настоящему моменту вы знаете, что список столбцов в операторе SELECT может содержать только одно значение.
Из этого следует, что подзапрос, используемый в списке столбцов, может возвращать только одно значение.
В других случаях, например, при использовании с оператором IN, который работает с несколькими значениями, имеет смысл, что подзапрос может возвращать более одной строки в SQL.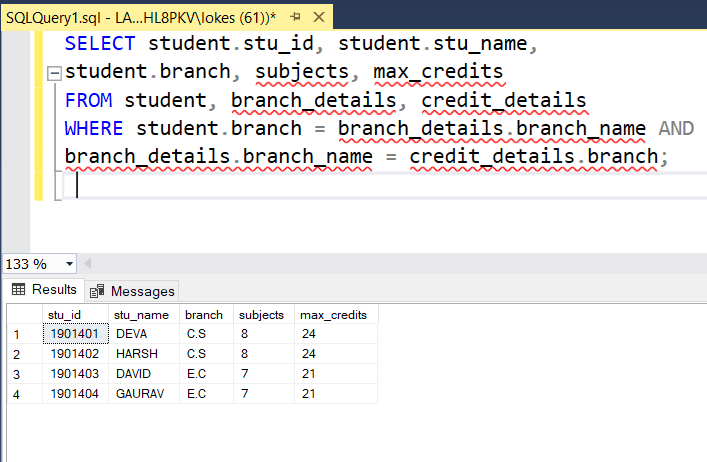
Хотите узнать больше? Ознакомьтесь с этими соответствующими статьями.
Выберите поля (понятия)
По умолчанию, когда запрос возвращает записи (в отличие от количества), результат включает набор выбора по умолчанию :
- Все скалярных полей, определенных в схеме Prisma (включая перечисления)
- Нет отношений
Чтобы настроить результат:
90 012
select для возврата конкретных полей — вы также можете использовать вложенный select для включения полей отношений include для явного включения отношений ✔ уменьшить размер ответа и ✔ повысить скорость запроса.Пример схемы
Все примеры основаны на следующей схеме:
Развернуть пример схемы
Реляционные базы данных
MongoDB
клиент генератора {
провайдер = "prisma-client-js"
}
источник данных БД {
провайдер = "postgresql"
url = env("DATABASE_URL")
}
модель ExtendedProfile {
id Int @id @default(autoincrement())
биография Строка
user User @relation(поля: [userId], ссылки: [id])
userId Int @unique
}
model User {
id Int @id @default(autoincrement() )
имя Строка?
email String @unique
profileViews Int @default(0)
role Role @default(USER)
coinflips Boolean[]
posts Post[]
профиль Расширенный профиль?
}
model Post {
id Int @id @default(autoincrement())
title String
опубликовано Boolean @default(true)
автор Пользователь @relation(поля: [authorId], ссылки: [ id])
authorId Int
комментариев Json?
просмотра Int @default(0)
лайков Int @default(0)
категории Категория[]
}
model Category {
id Int @id @default(autoincrement())
name String @unique
posts Post[]
}
enum Role {
900 02 USERADMIN
}
Для реляционных баз данных используйте команду
db push, чтобы отправить пример схемы в вашу собственную базу данных$npx prisma db push
Для MongoDB убедитесь, что ваши данные имеют единую форму и соответствуют модели, определенной в схеме Prisma.
Возвращает набор выбора по умолчанию
Следующий запрос возвращает набор выбора по умолчанию (все скалярные поля, без отношений):
// Запрос возвращает пользователя или null
const getUser: User | null = await prisma.user.findUnique({
где: {
id: 22,
},
})
Скрыть результаты запроса
90 078{
id: 22,
имя: «Алиса»,
электронная почта: «[email protected]»,
profileViews: 0,
role: "ADMIN",
coinflips: [true, false],
}
Выберите определенные поля
Используйте
select, чтобы вернуть ограниченное подмножество полей вместо всех полей. В следующем примере возвращаются только поляname:// Возвращает объект или null
const getUser: object | null = ожидание prisma.user.findUnique({
, где: {
id: 22,
},
выберите: {
электронная почта: правда,
имя: правда,
},
})
Скрыть результат запроса и выберите поля отношения
Чтобы вернуть определенные поля отношения , вы можете:
- Использовать вложенный
select - Используйте
selectвinclude
Чтобы вернуть все полей отношений, используйте
includeonly — например,{ include: { posts: true } }.

В следующем запросе используется вложенный select для выбора имени каждого пользователя и заголовка каждого связанного сообщения:
const users = await prisma.user.findMany({ 900 03
выберите: {
имя: правда,
сообщения: {
выберите: {
title: true,
},
},
},
})
9007 9
Скрыть результаты запроса
{
"имя": "Сабель",
"сообщения": [
{
"название": "Начало работы с функциями Azure"
},
{
"title":"Все о базах данных"
}
]
}
Следующий запрос использует
selectвincludeи возвращает все пользовательских полей изаголовок каждого поста все пользовательские полявключают: {
сообщения: {
выберите: {
title: true,
},
},
},
} )
Скрыть результаты запроса
{
"id": 9
"имя": "Sabelle",
"email": "sabelle@prisma.
