Синтаксис insert sql: INSERT | SQL | SQL-tutorial.ru
Содержание
Команда INSERT — вставка записей в базу данных
Команда INSERT вставляет записи в базу данных.
Можно вставить или одну запись, или сразу несколько.
См. также команды
SELECT,
UPDATE,
DELETE,
которые отвечают за получение, редактирование и удаление записей.
См. также команду
SELECT INTO,
которая копирует данные из одной таблицы в другую.
Синтаксис
Первый синтаксис:
INSERT INTO имя_таблицы SET поле1=значение1, поле2=значение2, поле3=значение3...
Второй синтаксис:
INSERT INTO имя_таблицы (поле1, поле2...) VALUES (значение1, значение2...)
Одновременно много записей:
INSERT INTO имя_таблицы (поле1, поле2...) VALUES (значение1, значение2...), (значение1, значение2...)..."
Примеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
Пример
Добавим с помощью первого синтаксиса
нового работника Васю с возрастом 23 и зарплатой 500:
INSERT INTO workers SET name='Вася', age=23, salary=500
Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
Пример
Добавим с помощью второго синтаксиса
нового работника Васю с возрастом 23 и зарплатой 500:
INSERT INTO workers (name, age, salary) VALUES ('Вася', 23, 500)Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
Пример
Добавим одновременно
нового работника Васю с возрастом 23 и зарплатой 500
и работника Колю с возрастом 30 и зарплатой 1000:
INSERT INTO workers (name, age, salary) VALUES ('Вася', 23, 500), ('Коля', 30, 1000)Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 500 |
| 4 | Коля | 30 | 1000 |
Пример
Давайте добавим
нового работника Васю с возрастом 23, но не указав ему зарплату.
Вместо нее вставится значение по умолчанию:
INSERT INTO workers (name, age) VALUES ('Вася', 23)Таблица workers станет выглядеть так:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 400 |
| 2 | Петя | 25 | 500 |
| 3 | Вася | 23 | 0 |
← Предыдущая страница
Следующая страница →
Синтаксис | ClickHouse Docs
В системе есть два вида парсеров: полноценный парсер SQL (recursive descent parser) и парсер форматов данных (быстрый потоковый парсер).
Во всех случаях кроме запроса INSERT, используется только полноценный парсер SQL.
В запросе INSERT используется оба парсера:
INSERT INTO t VALUES (1, 'Hello, world'), (2, 'abc'), (3, 'def')
Фрагмент INSERT INTO t VALUES парсится полноценным парсером, а данные (1, 'Hello, world'), (2, 'abc'), (3, 'def') — быстрым потоковым парсером.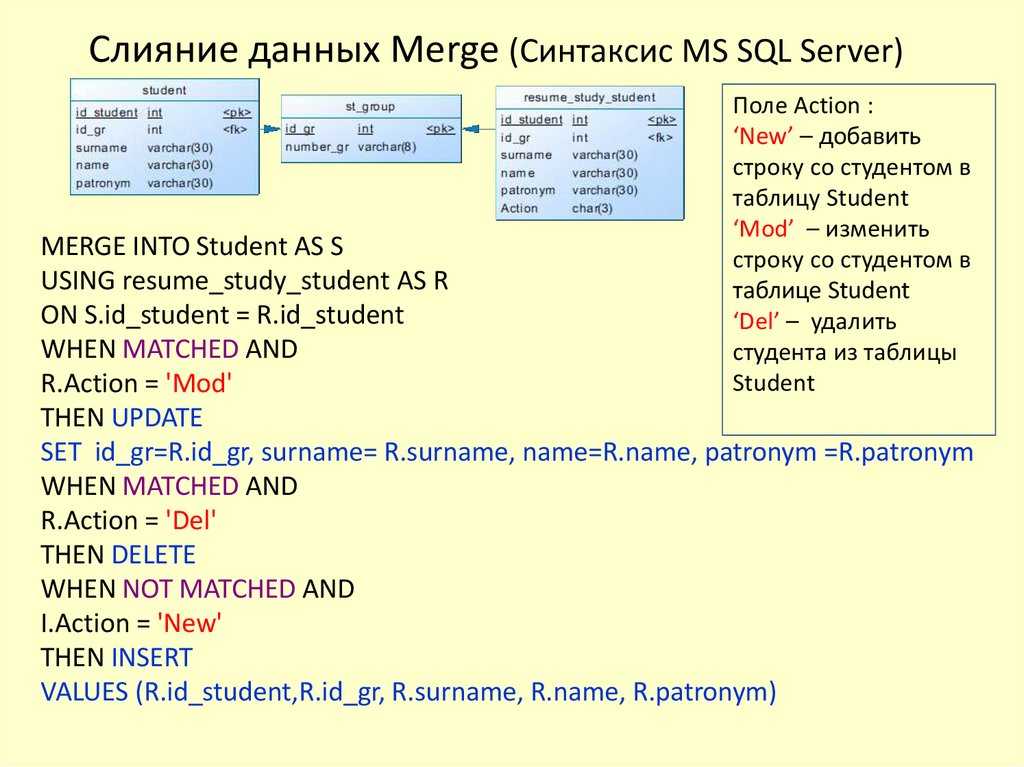
Данные могут иметь любой формат. При получении запроса, сервер заранее считывает в оперативку не более max_query_size байт запроса (по умолчанию, 1МБ), а всё остальное обрабатывается потоково.
Таким образом, в системе нет проблем с большими INSERT запросами, как в MySQL.
При использовании формата Values в INSERT запросе может сложиться иллюзия, что данные парсятся также, как выражения в запросе SELECT, но это не так. Формат Values гораздо более ограничен.
Далее пойдёт речь о полноценном парсере. О парсерах форматов, смотри раздел «Форматы».
Пробелы
Между синтаксическими конструкциями (в том числе, в начале и конце запроса) может быть расположено произвольное количество пробельных символов. К пробельным символам относятся пробел, таб, перевод строки, CR, form feed.
Поддерживаются комментарии в SQL-стиле и C-стиле.
Комментарии в SQL-стиле: от --, #! или # до конца строки. Пробел после -- и #! может не ставиться.
Комментарии в C-стиле: от /* до */. Такие комментарии могут быть многострочными. Пробелы тоже не обязательны.
Ключевые слова
Ключевые слова не зависят от регистра, если они соответствуют:
- Стандарту SQL. Например, применение любого из вариантов
SELECT,selectилиSeLeCtне вызовет ошибки. - Реализации в некоторых популярных DBMS (MySQL или Postgres). Например,
DateTimeиdatetime.
Зависимость от регистра для имён типов данных можно проверить в таблице system.data_type_families.
В отличие от стандарта SQL, все остальные ключевые слова, включая названия функций зависят от регистра.
Ключевые слова не зарезервированы (а всего лишь парсятся как ключевые слова в соответствующем контексте). Если вы используете идентификаторы, совпадающие с ключевыми словами, заключите их в кавычки. Например, запрос SELECT "FROM" FROM table_name валиден, если таблица table_name имеет столбец с именем "FROM". [a-zA-Z_][0-9a-zA-Z_]*$ и не могут совпадать с ключевыми словами. Примеры:
[a-zA-Z_][0-9a-zA-Z_]*$ и не могут совпадать с ключевыми словами. Примеры: x, _1, X_y__Z123_.
Если вы хотите использовать идентификаторы, совпадающие с ключевыми словами, или использовать в идентификаторах символы, не входящие в регулярное выражение, заключите их в двойные или обратные кавычки, например, "id", `id`.
Литералы
Существуют: числовые, строковые, составные литералы и NULL.
Числовые
Числовой литерал пытается распарситься:
- Сначала как знаковое 64-разрядное число, функцией strtoull.
- Если не получилось, то как беззнаковое 64-разрядное число, функцией strtoll.
- Если не получилось, то как число с плавающей запятой, функцией strtod.
- Иначе — ошибка.
Соответствующее значение будет иметь тип минимального размера, который вмещает значение.
Например, 1 парсится как UInt8, а 256 как UInt16. Подробнее о типах данных читайте в разделе Типы данных.
Примеры: 1, 18446744073709551615, 0xDEADBEEF, 01, 0.1, 1e100, -1e-100, inf, nan.
Строковые
Поддерживаются только строковые литералы в одинарных кавычках. Символы внутри могут быть экранированы с помощью обратного слеша. Следующие escape-последовательности имеют соответствующее специальное значение: \b, \f, \r, \n, \t, \0, \a, \v, \xHH. Во всех остальных случаях, последовательности вида \c, где c — любой символ, преобразуется в c . Таким образом, могут быть использованы последовательности \' и \\. Значение будет иметь тип String.
Минимальный набор символов, которых вам необходимо экранировать в строковых литералах: ' и \. Одинарная кавычка может быть экранирована одинарной кавычкой, литералы 'It\'s' и 'It''s' эквивалентны.
Составные
Поддерживаются конструкции для массивов: [1, 2, 3] и кортежей: (1, 'Hello, world!', 2).
На самом деле, это вовсе не литералы, а выражение с оператором создания массива и оператором создания кортежа, соответственно.
Массив должен состоять хотя бы из одного элемента, а кортеж — хотя бы из двух.
Кортежи носят служебное значение для использования в секции IN запроса SELECT. Кортежи могут быть получены как результат запроса, но они не могут быть сохранены в базе данных (за исключением таблицы Memory.)
NULL
Обозначает, что значение отсутствует.
Чтобы в поле таблицы можно было хранить NULL, оно должно быть типа Nullable.
В зависимости от формата данных (входных или выходных) NULL может иметь различное представление. Подробнее смотрите в документации для форматов данных.
При обработке NULL есть множество особенностей. Например, если хотя бы один из аргументов операции сравнения — NULL, то результатом такой операции тоже будет NULL. Этим же свойством обладают операции умножения, сложения и пр. Подробнее читайте в документации на каждую операцию.
Этим же свойством обладают операции умножения, сложения и пр. Подробнее читайте в документации на каждую операцию.
В запросах можно проверить NULL с помощью операторов IS NULL и IS NOT NULL, а также соответствующих функций isNull и isNotNull.
Heredoc
Синтаксис heredoc — это способ определения строк с сохранением исходного формата (часто с переносом строки). Heredoc задается как произвольный строковый литерал между двумя символами $, например $heredoc$. Значение между двумя heredoc обрабатывается «как есть».
Синтаксис heredoc часто используют для вставки кусков кода SQL, HTML, XML и т.п.
Пример
Запрос:
SELECT $smth$SHOW CREATE VIEW my_view$smth$;
Результат:
┌─'SHOW CREATE VIEW my_view'─┐
│ SHOW CREATE VIEW my_view │
└────────────────────────────┘
Функции
Функции записываются как идентификатор со списком аргументов (возможно, пустым) в скобках. В отличие от стандартного SQL, даже в случае пустого списка аргументов, скобки обязательны. Пример:
В отличие от стандартного SQL, даже в случае пустого списка аргументов, скобки обязательны. Пример: now().
Бывают обычные и агрегатные функции (смотрите раздел «Агрегатные функции»). Некоторые агрегатные функции могут содержать два списка аргументов в круглых скобках. Пример: quantile(0.9)(x). Такие агрегатные функции называются «параметрическими», а первый список аргументов называется «параметрами». Синтаксис агрегатных функций без параметров ничем не отличается от обычных функций.
Операторы
Операторы преобразуются в соответствующие им функции во время парсинга запроса, с учётом их приоритета и ассоциативности.
Например, выражение 1 + 2 * 3 + 4 преобразуется в plus(plus(1, multiply(2, 3)), 4).
Типы данных и движки таблиц
Типы данных и движки таблиц в запросе CREATE записываются также, как идентификаторы или также как функции. То есть, могут содержать или не содержать список аргументов в круглых скобках. Подробнее смотрите разделы «Типы данных», «Движки таблиц», «CREATE».
Подробнее смотрите разделы «Типы данных», «Движки таблиц», «CREATE».
Синонимы выражений
Синоним — это пользовательское имя выражения в запросе.
expr AS alias
AS— ключевое слово для определения синонимов. Можно определить синоним для имени таблицы или столбца в секцииSELECTбез использования ключевого словаAS.Например, `SELECT table_name_alias.column_name FROM table_name table_name_alias`.
В функции [CAST](/docs/ru/sql-reference/syntax#type_conversion_function-cast), ключевое слово `AS` имеет другое значение. Смотрите описание функции.
expr— любое выражение, которое поддерживает ClickHouse.Например, `SELECT column_name * 2 AS double FROM some_table`.
alias— имя длявыражения. Синонимы должны соответствовать синтаксису идентификаторов.Например, `SELECT "table t".column_name FROM table_name AS "table t"`.


Примечания по использованию
Синонимы являются глобальными для запроса или подзапроса, и вы можете определить синоним в любой части запроса для любого выражения. Например, SELECT (1 AS n) + 2, n.
Синонимы не передаются в подзапросы и между подзапросами. Например, при выполнении запроса SELECT (SELECT sum(b.a) + num FROM b) - a.a AS num FROM a ClickHouse сгенерирует исключение Unknown identifier: num.
Если синоним определен для результирующих столбцов в секции SELECT вложенного запроса, то эти столбцы отображаются во внешнем запросе. Например, SELECT n + m FROM (SELECT 1 AS n, 2 AS m).
Будьте осторожны с синонимами, совпадающими с именами столбцов или таблиц. Рассмотрим следующий пример:
CREATE TABLE t
(
a Int,
b Int
)
ENGINE = TinyLog()
SELECT
argMax(a, b),
sum(b) AS b
FROM t
Received exception from server (version 18.
Code: 184. DB::Exception: Received from localhost:9000, 127.0.0.1. DB::Exception: Aggregate function sum(b) is found inside another aggregate function in query.
 14.17):
14.17):В этом примере мы объявили таблицу t со столбцом b. Затем, при выборе данных, мы определили синоним sum(b) AS b. Поскольку синонимы глобальные, то ClickHouse заменил литерал b в выражении argMax(a, b) выражением sum(b). Эта замена вызвала исключение. Можно изменить это поведение, включив настройку prefer_column_name_to_alias, для этого нужно установить ее в значение 1.
Звёздочка
В запросе SELECT, вместо выражения может стоять звёздочка. Подробнее смотрите раздел «SELECT».
Выражения
Выражение представляет собой функцию, идентификатор, литерал, применение оператора, выражение в скобках, подзапрос, звёздочку. А также может содержать синоним.
Список выражений — одно выражение или несколько выражений через запятую.
Функции и операторы, в свою очередь, в качестве аргументов, могут иметь произвольные выражения.
Оператор SQL INSERT немного подробнее
Теперь, когда вы установили MySQL, мы более подробно рассмотрим оператор SQL INSERT .
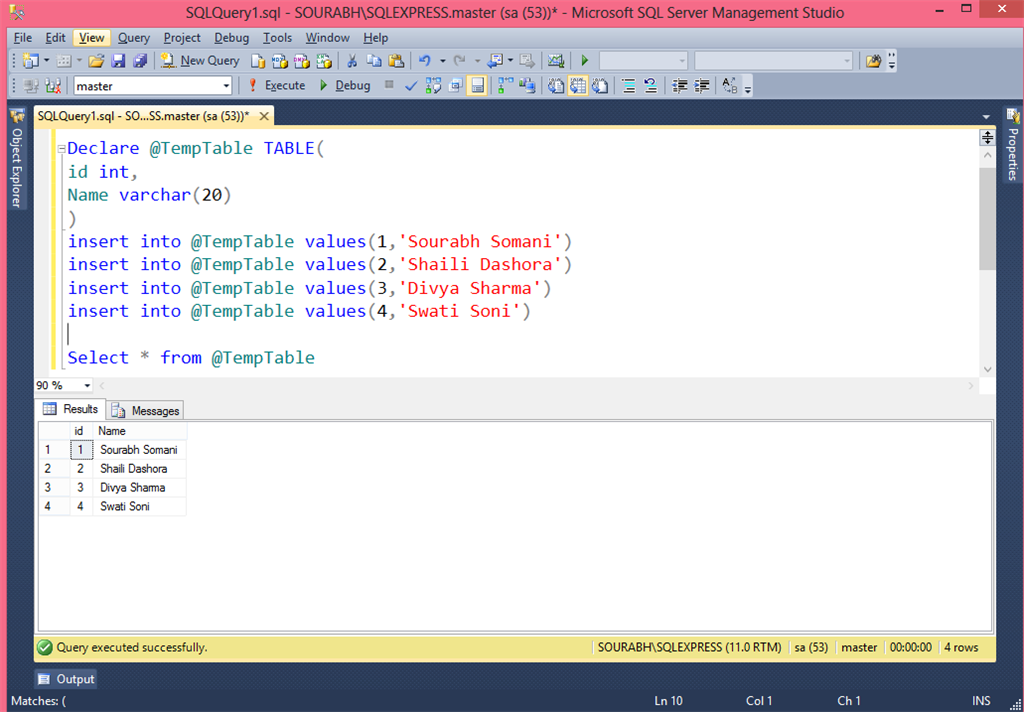
Создать запись
Давайте потренируемся вставлять несколько записей в таблицу «Сотрудники». (Если вам интересно, подробнее о записях см. в нашем руководстве Что такое повторяющиеся записи в SQL).
Мы можем извлечь 10 записей из таблицы «Сотрудники», чтобы посмотреть, как там организована информация. Большой! Итак…
Мы получили 10 строк, каждая из которых содержит информацию в следующих столбцах: «номер сотрудника», «дата рождения», «имя» и «фамилия», «пол» и «дата приема на работу». Всего шесть столбцов. Хорошо.
Давайте посмотрим, как мы создадим запись в таблице «Сотрудники».
После ключевой фразы INSERT INTO, мы должны указать имя таблицы, в которую мы хотим добавить информацию. Затем в круглых скобках мы должны указать имена столбцов, куда будут вставлены данные.
Затем в круглых скобках мы должны указать имена столбцов, куда будут вставлены данные.
Обратите внимание — не обязательно использовать названия всех шести столбцов! Вы можете указать только те, в которые хотите вставить данные.
Дальнейшее интуитивно понятно: за ключевым словом VALUES следует такое же количество значений данных, как и количество столбцов, указанное в скобках после оператора INSERT INTO . Обратите внимание, что значения данных также должны быть указаны в круглых скобках.
Вы уже знакомы с синтаксисом, который мы только что обсуждали. Теперь давайте применим это на практике — мы создадим запись человека по имени Джон Смит.
Мы напечатаем INSERT INTO «Сотрудники», а затем в скобках укажем столбцы, в которые мы хотим добавить информацию, разделив их запятой. Это столбцы «номер сотрудника», «дата рождения», «имя», «фамилия», «пол» и «дата приема на работу». Затем после ключевого слова VALUES, и в круглых скобках введите значения данных, которые будут частью этих столбцов, снова разделив их запятой.
Чтобы увидеть типы данных вставляемых значений, необходимо проверить типы данных полей этой таблицы. Вы можете сделать это, перейдя в раздел информации и просмотрев типы данных на вкладке «Столбцы».
Номер сотрудника является целым числом; тогда у вас есть два значения даты, два значения VARCHAR и ENUM. Поэтому при вставке новых записей все значения должны быть заключены в одинарные кавычки, кроме номера сотрудника.
Присвоим номер 9-9-9-9-0-1 и дату рождения 21 st апреля 1986. Эта запись будет относиться к Джону Смиту, мужчине, который был нанят 1 st № от января 2011 г.
Чтобы зарегистрировать эту строку в таблице данных, нам нужно выполнить запрос INSERT.
Примечание: Если вы хотите научиться включать подзапросы SQL в запросы, ознакомьтесь со связанным руководством.
Итак, мы видим, что затронута одна строка.
Теперь давайте выберем 10 сотрудников с наибольшим количеством сотрудников, чтобы посмотреть, появится ли там наша запись.
Отлично! А вот и он! Джон Смит на высоте!
Позвольте мне прокомментировать это странное число, 9-9-9-9-0-1.
Очевидно, это не очередной порядковый номер в нашем сверхдлинном списке сотрудников, не так ли? Помните, что использование такого номера сотрудника — ловкий профессиональный трюк. Когда данные создаются для тестирования системы баз данных, вставляемое значение должно быть довольно высоким. Таким образом, становится очевидным, где были размещены новые данные. (Если вам нужно освежить знания, перейдите по ссылке на наш учебник Первые шаги в манипулировании данными и операторы в SQL.)
По этой причине мы увидели Джона Смита в верхней части списка «сотрудников» с самым большим числом сотрудников.
Теперь позвольте мне поделиться с вами еще одной функцией MySQL.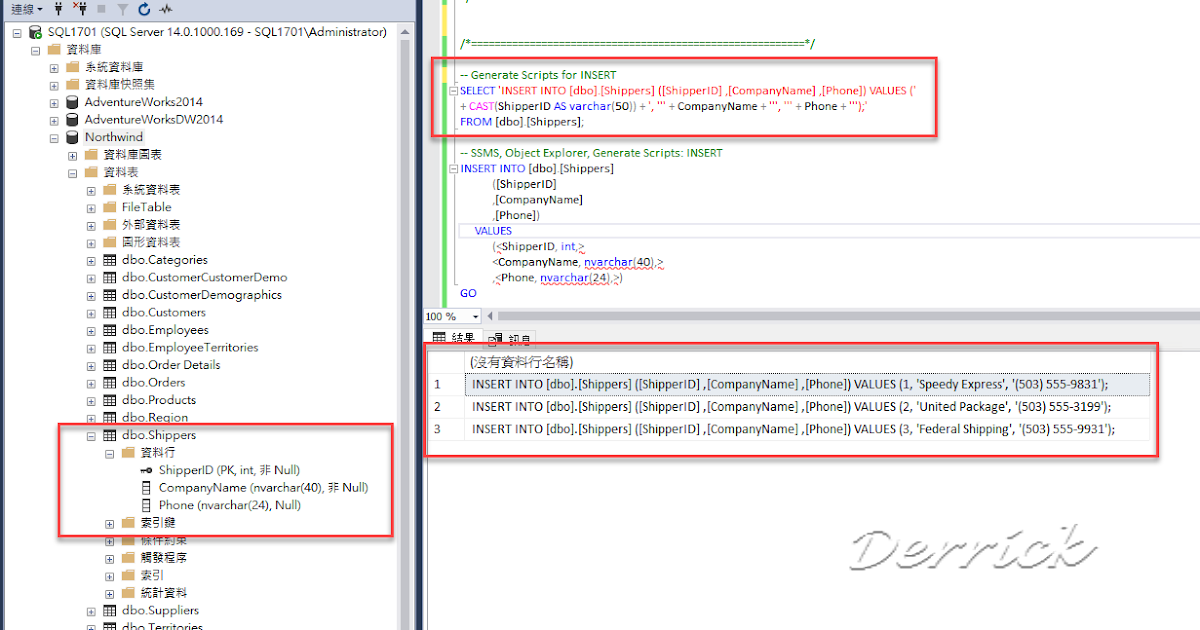 Вопреки всему, что мы говорили до сих пор, оказалось, что целые числа тоже можно записывать в кавычках. При желании можно попробовать вставить еще одну запись с номером сотрудника в кавычках; вы увидите, что данные по-прежнему зарегистрированы как целое число. Объяснение этому в том, что MySQL автоматически (или, как сказали бы некоторые профессионалы, прозрачно) преобразует строку в целое число. Лучше всего избегать записи целых чисел в кавычках, так как это преобразование требует времени и препятствует бесперебойной работе более продвинутых функций MySQL. (Тем временем, если вы хотите узнать, как ускорить работу MySQL, ознакомьтесь с нашим руководством Работа с индексами в MySQL.)
Вопреки всему, что мы говорили до сих пор, оказалось, что целые числа тоже можно записывать в кавычках. При желании можно попробовать вставить еще одну запись с номером сотрудника в кавычках; вы увидите, что данные по-прежнему зарегистрированы как целое число. Объяснение этому в том, что MySQL автоматически (или, как сказали бы некоторые профессионалы, прозрачно) преобразует строку в целое число. Лучше всего избегать записи целых чисел в кавычках, так как это преобразование требует времени и препятствует бесперебойной работе более продвинутых функций MySQL. (Тем временем, если вы хотите узнать, как ускорить работу MySQL, ознакомьтесь с нашим руководством Работа с индексами в MySQL.)
В заключение, идея в том, что да, вы можете написать целое число в кавычках, но это не считается лучшей практикой. Именно поэтому мы хотели бы дать вам следующий совет. Пожалуйста, не забывайте вводить целые числа как простые числа, без использования кавычек.
Отлично! Давайте продолжим в том же темпе для следующего раздела.
ВСТАВИТЬ пункт
Хорошо. Идеальный. Давайте продолжим с предложением INSERT .
Обычно администраторы баз данных следят за порядком столбцов в зависимости от того, как они отображаются в данной таблице данных.
Однако в некоторых случаях они предпочитают вставлять значения данных в другом порядке. MySQL допускает такие типы вставки данных. Например, если мы создадим запись данных о Патрисии Лоуренс, мы могли бы сначала вставить ее дату рождения, , затем ее номер сотрудника, а затем указать остальные значения в указанном порядке.
Посмотрим, сработает ли…
Сто процентов! Последняя созданная нами строка содержит информацию о Патрисии Лоуренс!
Итак, имейте в виду, что мы должны расположить ЗНАЧЕНИЯ точно в том порядке, в котором мы перечислили имена столбцов.
Фантастика!
Хорошо. Давайте рассмотрим интересную особенность синтаксиса INSERT .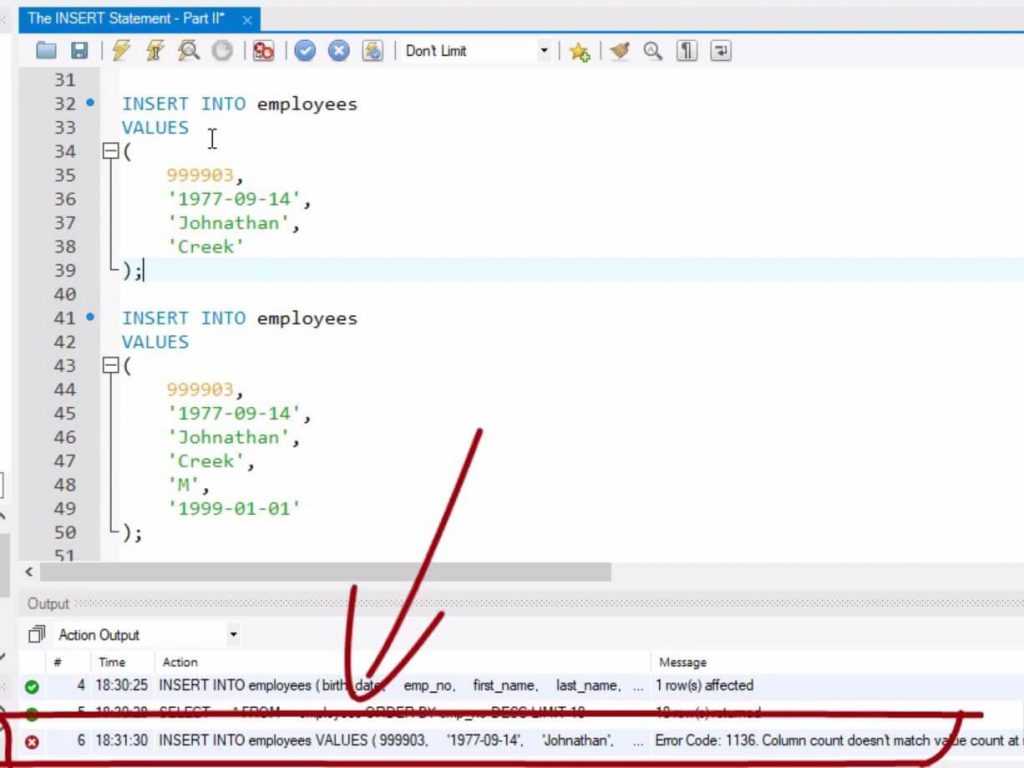 Технически первую пару скобок вместе с именами столбцов между ними можно опустить. Обязательными являются только части INSERT INTO, имя таблицы и части VALUES .
Технически первую пару скобок вместе с именами столбцов между ними можно опустить. Обязательными являются только части INSERT INTO, имя таблицы и части VALUES .
Если его не указать, в VALUES вам нужно будет указать столько значений данных, сколько столбцов в таблице данных. Кроме того, вам придется добавлять их в том же порядке, в котором они появляются в таблице.
Например, если мы используем эту структуру и попытаемся создать запись в таблице «Сотрудники» только с четырьмя вместо всех шести столбцов, MySQL выдаст ошибку.
Если мы попытаемся добавить в новую запись шесть значений данных, все в правильном порядке, запрос должен работать нормально.
Давайте проверим.
Хорошо. Новая порция информации есть.
В следующем разделе мы покажем вам очень мощную функцию оператора INSERT .
Вставка данных в новую таблицу
В этом разделе мы покажем вам еще один способ вставки данных в таблицу.
Соответствующий синтаксис:
INSERT INTO, имя таблицы и имена столбцов в скобках. Затем идет новая часть. Вы можете использовать классический Оператор SELECT для извлечения информации из таблицы_1 и вставки ее в таблицу_2.
Это не обязательно должны быть все данные из этой другой таблицы — с помощью ГДЕ вы сможете установить условия, которые уточнят копируемые данные.
Давайте посмотрим на пример.
Сначала проверьте столбцы таблицы «отделы». У нас есть две колонки — код отдела и название отдела.
Итак, следующее, что нужно сделать, это создать еще одну таблицу, называемую «дубликаты отделов», сократив ее до «подчеркивание отделов D.U.P.»
Это будет точная копия таблицы «отделы», которую мы только что видели. Наша задача — импортировать все данные из «отделов» в его дубликат.
Код, который нам понадобится для создания таблицы копирования, — это CREATE TABLE «Дубликаты отделов», открытые круглые скобки, «номер отдела», тип CHAR 4, добавлено ограничение NOT NULL, затем «имя отдела», VARCHAR 40, NOT NULL снова ограничение, закрыть скобки.
Выполнить… и затем обновить раздел схем в Workbench.
Вот и мы!
В список добавлена новая таблица. Кроме того, столбцы «номер отдела» и «название отдела» также видны.
Чтобы убедиться, что это все еще пустая таблица, нам придется выбрать из нее всю информацию.
Видишь? Нет информации.
Теперь пришло время реализовать структуру, которую мы представили в этом посте. Мы будем ВСТАВЛЯТЬ В столбцы «номер отдела» и «название отдела» из таблицы «Отделы дублируют» все, что мы можем выбрать из таблицы «Отделы».
Обратите внимание, что, поскольку «Отделы» содержат одинаковое количество и тип столбцов, нет необходимости добавлять определенные условия к данным, извлеченным из этой таблицы. Следовательно, подстановочный знак звездочки (*) будет работать правильно. (Вы можете изучить основные типы отношений между таблицами в SQL в связанном учебнике.)
Верно! Итак, давайте запустим этот запрос.
Хорошо! Код выполнился без ошибок.
Посмотрим, правильно ли была выполнена операция.
Было. Вероятнее всего! Мы видим, что только что созданная таблица «дубликаты отделов» была заполнена информацией из «таблицы отделов». Это потрясающе!
Другими словами, наша работа выполнена!
Я хотел бы завершить этот пост напоминанием об ограничениях MySQL. Мы едва упомянули их в этом разделе. Однако вы знаете, что если новые данные, которые вы вставляете, не удовлетворяют ограничениям, которые уже были установлены в базе данных, MySQL всегда будет показывать ошибку.
Для простоты мы тщательно разработали наш код, и таких ошибок удалось избежать. Другими словами, мы гарантировали, что не будем вставлять данные, которые не удовлетворяют существующим ограничениям. Тем не менее, имейте в виду, что соблюдение ограничений необходимо — они всегда будут играть важную роль при вставке данных.
***
Стремитесь отточить свои навыки SQL? Узнайте, как применить теорию на практике с помощью наших практических руководств !
Ознакомьтесь с нашим следующим руководством: оператор SQL UPDATE
Использование инструкции INSERT в SQL
INSERT добавляет новые записи в ваши таблицы. Вы можете добавлять статические значения, значения из хранимой процедуры или даже значения из другой таблицы. Оператор INSERT гораздо более гибкий, чем оператор UPDATE, но SQL имеет некоторые ограничения.
Вы можете добавлять статические значения, значения из хранимой процедуры или даже значения из другой таблицы. Оператор INSERT гораздо более гибкий, чем оператор UPDATE, но SQL имеет некоторые ограничения.
Как и в случае с другими операторами SQL, при попытке добавить значение, не соответствующее типу данных, установленному в структуре таблицы, SQL выдает ошибку. Вы должны знать дизайн своей таблицы, чтобы вставлять в нее новые записи. Например, если вы попытаетесь вставить «Том» в столбец с именем «CustomerId», обозначенный как целочисленный столбец, SQL выдаст ошибку, и оператор INSERT завершится ошибкой.
Во-первых, когда вы создаете операторы INSERT, вам нужен шаблон. Следующий код представляет собой шаблон INSERT:
INSERT INTO
(столбец1, столбец2) VALUES (значение1, значение2)
INSERT INTO – фраза, используемая для добавления записи в таблицу. «

Второй раздел инструкции INSERT — основная часть запроса. Первый набор скобок определяет столбцы, которые вы будете заполнять при выполнении запроса. Второй набор скобок определяет значения. У вас должно быть столько же значений, сколько у вас столбцов. Например, если у вас есть 3 столбца в первом наборе скобок и 4 значения во втором наборе скобок, SQL выдает ошибку.
Также применяются правила типов данных. Например, предположим, что столбец 1 в первом наборе скобок определен как целое число в вашей таблице, но значение 1 установлено на «Том», SQL выдает ошибку. В этой главе мы перенесем таблицу из главы 3. Таблица Customer имеет следующую структуру:
| . идентификатор клиента | Имя | Фамилия | Город | Состояние |
123 | Тим | Смарт | Майами | FL |
321 | Фрэнк | Доу | Даллас | ТХ |
Для оператора INSERT важна структура структуры таблицы. CustomerId — целое число. First_name, Last_name, City и State устанавливаются в виде varchar или строковых значений. Следующая инструкция INSERT добавляет в таблицу одну запись:
CustomerId — целое число. First_name, Last_name, City и State устанавливаются в виде varchar или строковых значений. Следующая инструкция INSERT добавляет в таблицу одну запись:
INSERT INTO Customer
(CustomerId, First_name, Last_name, City, State) VALUES (455, ‘Ed’, ‘Thompson’, ‘Atlanta’, ‘GA’)
Обратите внимание на количество столбцов, определенных в первом наборе круглые скобки — это то же количество значений, которое определено во втором наборе круглых скобок. Результатом является новая запись в вашей таблице, поэтому теперь ваша таблица выглядит как следующий набор данных:
| . идентификатор клиента | Имя_имя | Фамилия | Город | Состояние |
123 | Тим | Смарт | Майами | FL |
321 | Фрэнк | Доу | Даллас | ТХ |
455 | Эд | Томпсон | Атланта | Г. |
 А.
А.Проблема в том, что наша таблица использует первичный ключ для CustomerId. При использовании столбца первичного ключа значение поля для каждой записи должно отличаться от остальных. Что если вы случайно вставите дубликат первичного ключа? SQL выдает ошибку, когда вы пытаетесь вставить повторяющиеся значения первичного ключа. Когда оператор INSERT терпит неудачу, в таблицу ничего не вставляется, поэтому вы добавляете ошибки в свое приложение. Пользователь получает сообщение об ошибке и не может зарегистрироваться на вашем сайте.
Способ решения этой проблемы заключается в автоматическом назначении значений столбцов. В случае столбца первичного ключа администратор базы данных назначает столбцу функцию автоинкремента. Столбец автоинкремента добавляет 1 к последнему значению первичного ключа. Например, если последним значением, вставленным в вашу таблицу, было «200», функция автоинкремента автоматически присваивает следующей записи «201». Вы не устанавливаете значение для столбца первичного ключа и пропускаете его в инструкции INSERT.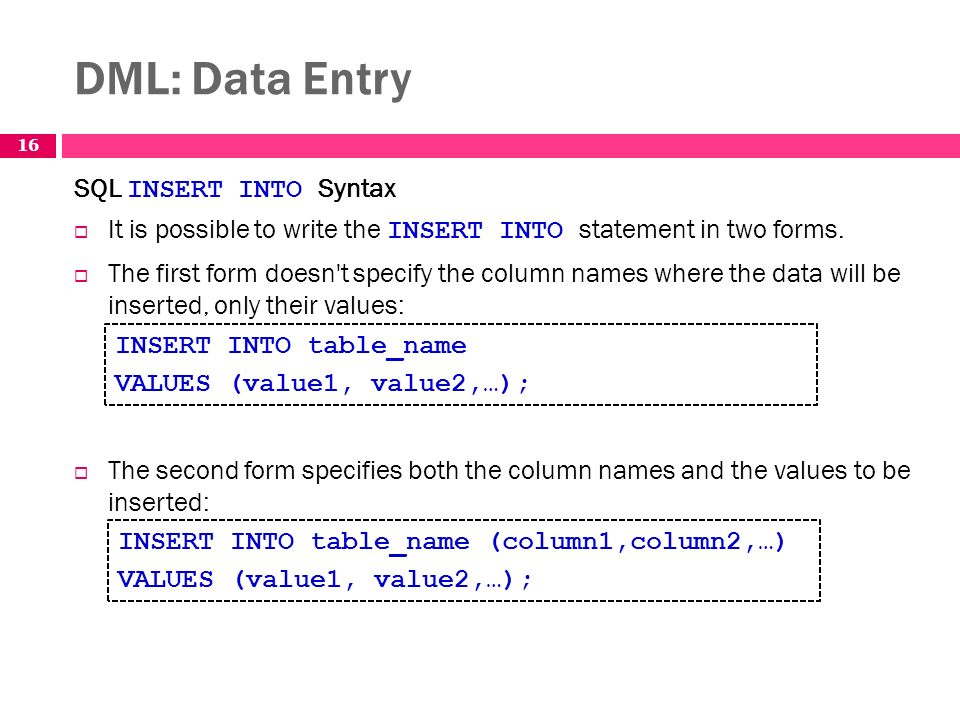
Предполагая, что для столбца первичного ключа CustomerId назначена функция автоинкремента, вы можете использовать следующую инструкцию SQL для вставки записей в таблицу Customer:
INSERT INTO Customer
(First_name, Last_name, City, State) VALUES («Ed», «Thompson», «Atlanta», «GA»)
Обратите внимание, что столбец CustomerId удален из оператора SQL, и он также удален из списка значений. Этот оператор INSERT предполагает, что столбец CustomerId предварительно заполнен значением. Администратор может предварительно заполнить любое значение в таблице, поэтому важно знать структуру вашей таблицы, прежде чем вы приступите к созданию операторов SQL. Используя автоинкремент, вы избегаете случайной вставки повторяющегося значения, и вам не нужно отслеживать последнее значение, вставленное в таблицу. База данных сделает все за вас.
Если вы использовали приведенный выше запрос, ваша таблица будет выглядеть так:
идентификатор клиента | Имя | Фамилия | Город | Состояние |
123 | Тим | Смарт | Майами | FL |
321 | Фрэнк | Доу | Даллас | ТХ |
455 | Эд | Томпсон | Атланта | Г. |
456 | Эд | Томпсон | Атланта | Г.А. |
 А.
А.Обратите внимание, что последняя запись имеет идентификатор 456. Автоинкрементируемый столбец взял последний вставленный идентификатор и добавил 1. Затем он использовал это значение для вашего первичного ключа. Код от вас не требуется.
Иногда вам нужно импортировать значения из одной таблицы в другую. Вы можете комбинировать оператор INSERT с оператором SELECT, чтобы добавлять в свои таблицы записи из других таблиц. Предположим, у вас есть таблица, которую вы импортировали из файла. Файл содержит список клиентов, которых вы хотите добавить в свою таблицу клиентов. У вас есть нужная информация, включая имя, фамилию, город и штат. Следующая инструкция SQL импортирует данные из таблицы NewCustomers в текущую таблицу Customer:
INSERT INTO Customer
Выберите First_name, Last_name, City, State FROM NewCustomer
Обратите внимание, что столбец CustomerId исключен. Точно так же, как при ручной вставке значения первичного ключа, вы не хотите использовать идентификаторы из таблицы NewCustomer. Во второй таблице могут быть повторяющиеся идентификаторы клиентов, и в результате ваш оператор INSERT завершится ошибкой. Приведенный выше оператор SQL предполагает, что CustomerId является автоматически увеличивающимся полем, поэтому SQL-сервер заботится о значениях идентификатора.
Точно так же, как при ручной вставке значения первичного ключа, вы не хотите использовать идентификаторы из таблицы NewCustomer. Во второй таблице могут быть повторяющиеся идентификаторы клиентов, и в результате ваш оператор INSERT завершится ошибкой. Приведенный выше оператор SQL предполагает, что CustomerId является автоматически увеличивающимся полем, поэтому SQL-сервер заботится о значениях идентификатора.
Например, следующая таблица является примером таблицы с данными о клиентах.
Имя | Фамилия | Город | Состояние | Телефон |
Джо | Смит | Майами | FL | 999-999-9999 |
Фрэнк | Доу | Даллас | ТХ | 874-584-5555 |
Обратите внимание, что в приведенной выше таблице есть столбец с номером телефона. В исходной таблице Customer нет столбца Phone, поэтому вы не можете вставить его в таблицу. SQL будет вставлять только те столбцы, которые вы указали в инструкции SELECT, поэтому значения столбца Phone полностью игнорируются. Вторичная таблица остается нетронутой, поэтому у вас есть данные, но вы не перемещаете столбец в исходную таблицу Customer.
В исходной таблице Customer нет столбца Phone, поэтому вы не можете вставить его в таблицу. SQL будет вставлять только те столбцы, которые вы указали в инструкции SELECT, поэтому значения столбца Phone полностью игнорируются. Вторичная таблица остается нетронутой, поэтому у вас есть данные, но вы не перемещаете столбец в исходную таблицу Customer.
И тогда ваша таблица Customer будет выглядеть следующим образом.
идентификатор клиента | Имя | Фамилия | Город | Состояние |
123 | Тим | Смарт | Майами | FL |
321 | Фрэнк | Доу | Даллас | ТХ |
455 | Эд | Томпсон | Атланта | Г. |
456 | Эд | Томпсон | Атланта | Г.А. |
457 | Джо | Смит | Майами | FL |
458 | Фрэнк | Доу | Даллас | ТХ |
 А.
А.Наконец, ваши операторы INSERT могут использовать NULL, если вы не знаете значения для определенных столбцов. Например, предположим, что у вас есть только имя и фамилия клиента, но нет города и штата. Вы можете использовать значение NULL, чтобы добавить что-то в столбец в качестве заполнителя, пока не получите реальную информацию от клиента. В следующем операторе используются значения NULL для города и штата.
INSERT INTO Customer
(Имя, Фамилия, Город, Штат) ЗНАЧЕНИЯ («Эд», «Томпсон», NULL, NULL)
Оператор INSERT — это стандартный способ добавления данных в таблицы. Оператор INSERT обычно легче всего изучить, потому что он не имеет столько опций, как другие операторы SQL.
Оператор INSERT обычно легче всего изучить, потому что он не имеет столько опций, как другие операторы SQL.
Ваша таблица будет выглядеть как следующий набор данных.
идентификатор клиента | Имя_имя | Фамилия | Город | Состояние |
123 | Тим | Смарт | Майами | эт. |
321 | Фрэнк | Доу | Даллас | ТХ |
455 | Эд | Томпсон | Атланта | Г.А. |
456 | Эд | Томпсон | Атланта | Г. |
