Синтаксис sql select: SELECT (Transact-SQL) — SQL Server
Содержание
Выборка. Синтаксис оператора SELECT. Язык запросов SQL
Язык запросов SQL. DML.
Все запросы выборки в языке SQL состоят из одиночной команды SELECT с достаточно простой структурой, однако путем ее умелого использования можно выполнить сложную обработку данных. В самой простой форме команда просто обращается к базе данных, чтобы извлечь информацию из таблицы.
Например, выведем информацию обо всех покупателях. Для этого достаточно написать следующий запрос:
SELECT BNum, BName, BTown FROM Buyers
Теперь поясним эту команду:
SELECT – ключевое слово, которое сообщает БД, что эта команда является запросом выборки. Этой командой начинаются все запросы такого типа.
BNum, BName, BTown – список полей из таблицы, которые необходимо выбрать. Поля, не перечисленные здесь, не будут включены в результат запроса.
FROM – ключевое слово, которое как и SELECT должно быть представлено в любом запросе такого типа. Оно указывает на источник информации (таблицу). В данном примере указана таблица Buyers.
Оно указывает на источник информации (таблицу). В данном примере указана таблица Buyers.
Не редко, когда из таблицы нужно выбрать все поля, то после ключевого слова SELECT вместо перечисления полей используют символ *. Соответственно тот же запрос можно переписать в следующем виде:
SELECT * FROM Buyers
Опишем правила написания таких запросов в общем случае:
- Запрос начинается с ключевого слова SELECT, сопровождаемого пробелом;
- Затем должен следовать список полей, которые необходимо выбрать. Имена полей разделяются между собой запятыми;
- Ключевое слово FROM сопровождается пробелом и именем таблицы, запрос к которой делается.
Эта команда способна извлечь и строго определенную информацию, такую как вывод только определенных полей таблицы.
Например, выведем номера категорий товара из списка товаров. Запрос будет выглядеть следующим образом:
SELECT GTypeNum FROM Goods
В результате получим:
| GTypeNum |
| 1 |
| 1 |
| 3 |
| 2 |
| 4 |
| 1 |
| 1 |
| 2 |
При работе с данными часто возникает потребность в удалении избыточных данных. Такая необходимость возникла в предыдущем примере. Категория с номером 1 встречается дважды в результате запроса. Удаление избыточных данных осуществляется при помощи инструкции DISTINCT. DISTINCT – это аргумент, который обеспечивает устранение повторяющихся значений из предложения SELECT. DISTINCT просматривает значения, которые были выведены ранее, и не дает им дублироваться в списке. Таким образом, чтобы избавиться от избыточности, нам необходимо переписать запрос следующим образом:
Такая необходимость возникла в предыдущем примере. Категория с номером 1 встречается дважды в результате запроса. Удаление избыточных данных осуществляется при помощи инструкции DISTINCT. DISTINCT – это аргумент, который обеспечивает устранение повторяющихся значений из предложения SELECT. DISTINCT просматривает значения, которые были выведены ранее, и не дает им дублироваться в списке. Таким образом, чтобы избавиться от избыточности, нам необходимо переписать запрос следующим образом:
SELECT DISTINCT GTypeNum FROM GOODS
В результате получим:
| GTypeNum |
| 1 |
| 3 |
| 2 |
| 4 |
Пользоваться этим аргументом следует очень внимательно, и следить за его применением. Следует знать, что DISTINCT может указываться только один раз в данном предложении SELECT. В запросах на выборку данных также допустимы условия, группировки, сортировки данных и другие предикаты и операторы языка SQL.
В запросах на выборку данных также допустимы условия, группировки, сортировки данных и другие предикаты и операторы языка SQL.
Выполнение простой команды SELECT
Практические возможности команды SELECT реализованы в исполнении команды. Ключевым моментом при выполнении любых запросов является понимание синтаксиса и правил его использования. Мы рассмотрим базовый синтаксис, затем процесс выполнения и наконец выражения и операторы, постепенно увеличивая использования данных из реляционных таблиц. Рассмотрим концпецию значения NULL и подводные камни его использования. Эти вопросы рассматриваются в следующих подпунктах
Синтаксис простой команды SELECT
Правила которые следует соблюдать
Выражения и операторы
NULL – это ничего
Синтаксис простой команды SELECT
В самой примитивной форме команда SELECT поддерживает проекцию столбцов и использование арифметических, строковых выражений, а также работу с датами. Также доступна возможность исключения дубликатов из результирующего набора. Базовый синтаксис команды SELECT
Также доступна возможность исключения дубликатов из результирующего набора. Базовый синтаксис команды SELECT
SELECT * | {[DISTINCT] column|expression [alias],…}
FROM table;
Ключевое слово (или зарезервированное) команды SELECT написано в верхнем регистре. Когда пишете команду, регистр ключевых слов не важен, но ключенвые слова нельзя использовать как название столбцов или имени другого объекта базы данных. SELECT, DISTINCT и FROM это ключевые слова. Команда SELECT обычно содержит два или более параметров. Два обязательных параметра это сама команда SELECT и слово FROM. Символ | используется как лоическое ИЛИ. То есть вы можете прочитать предыдущую команду как
SELECT * FROM table
В таком формате символ * используется для обозначения всех столбцов. SELECT * это простой способ попросить Oracle вернуть все доступные столбцы. Такой формат используется как быстрый способ вместо набора SELECT column1, column2, … columnN для выбора всех столбцов. Параметр FROM указывает какие таблицы использовать для выбора столбцов требуемых в команде SELECT. Вы можете выполнить следующий запрос для получения всех столбцов всех строк из таблицы REGIONS в схеме HR
Параметр FROM указывает какие таблицы использовать для выбора столбцов требуемых в команде SELECT. Вы можете выполнить следующий запрос для получения всех столбцов всех строк из таблицы REGIONS в схеме HR
select * from regions;
Когда выполнится это команда, результатом будет набор всех строк со всеми столбцами принадлежащие этой таблице. Использование звёздочки в команде SELECT иногда называют «слепым» запросом так как столбцы которые будут возвращены не указаны.
Вторая форма запроса SELECT использует такую же часть FROM но другой формат SELECT
SELECT {[DISTINCT] column|expression [alias],…} FROM table;
Такой запрос может быть разбит на два формата
SELECT column1 (possibly other columns or expressions) [alias optional]
или
SELECT DISTINCT column1 (possibly other columns or expressions) [alias optional]
Алиас это альтернативное имя столбца или выражения. Алиасы обычно используются для отображения результата в понятном пользователю виде. Они также используются для сокращения количество символов для набора когда ссылаешься на столбец или выражение. Перечисляя столбцы в команде SELECT вы фактически проецируете конкретную выборку результата которую вы хотите получить. Следующий запрос вернёт только столбец REGION_NAME таблицы REGIONS
Они также используются для сокращения количество символов для набора когда ссылаешься на столбец или выражение. Перечисляя столбцы в команде SELECT вы фактически проецируете конкретную выборку результата которую вы хотите получить. Следующий запрос вернёт только столбец REGION_NAME таблицы REGIONS
select region_name from regions;
Вас могут попросить предоставить все должности сотрудников организации за всё время. Для этого вы можете выполнить команду SELECT * FROM JOB_HISTORY. Но такой запрос вернёт вам также EMPLOYEE_ID, START_DATE и END_DATE столбцы. Запрос который возвращает только нужные столбцы JOB_ID и DEPARTMENT_ID можно написать так
select job_id, department_id from job_history;
Использование ключевого слова DISTINCT позволит убрать дубликаты из результата. В некоторых случаях уникальность строк необходима. Важно понимать что критерий определения уникальности для Oracle находится после слова DISTINCT. Выборка уникальных значений job_ib из таблицы job_history с помощью следующего запроса вернёт восемь уникальных должностей
select distinct job_id from job_history
Важно понимать что уникальность определяется комбинацией столбцов после слова DISTINCT.
select distinct department_id from job_history;
select distinct job_id,department_id from job_history;
Правила которые следует соблюдать
SQL достаточно строгий язык с точки зрения синтаксиса, но он остаётся достаточно простым и гибким для поддержки разных стилей программирования. В этом разделе рассмотрим несколько базовых правил управляющих SQL запросами.
Верхний или нижний регистр
Регист в запросах это дело вкуса разработчика. Многие предпочитают писать запросы в нижнем регистре. Также некоторые считают что ключевые слова нужно писать в верхнем регистре, но это не так. Однако стоит придерживаться одного и того же последовательного и стандартизированного формата в группе разработчиков.
Есть только один нюанс в использовании разного регистра. Когда вы работаете со значениями литералов – регистр имеет значение. Раасмотрим столбец JOB_ID таблицы JOB_HISTORY. Этот столбец хранит строки данных в верхнем регистре: SA_REP, ST_CLERK и т.д. Когда вы пишете запрос который будет ограничиваться значениями литералов – регистр важен. Oracle рассматривает запрос к таблице JOB_HISTORY с условием St_Clerk по другому чем запрос с условием ST_CLERK.
Этот столбец хранит строки данных в верхнем регистре: SA_REP, ST_CLERK и т.д. Когда вы пишете запрос который будет ограничиваться значениями литералов – регистр важен. Oracle рассматривает запрос к таблице JOB_HISTORY с условием St_Clerk по другому чем запрос с условием ST_CLERK.
Метаданные об объектах БД хранятся по умолчанию в верхнем регистре в словаре данных. Если вы посмотрите данные о таблицах в схеме HR – все имена будут в верхнем регистре. Это не значит что таблица не может быть создана с именем в нижнем регистре – это можно делать. Это всего лишь общее поведение по умолчанию.
Exam tip
SQL запросы могут быть написаны с использованием любого регистра. Нужно следить за регистром когда вы работаете со значениями-литералами и алиасами. Использование в запросе JOB_ID или job_id в названии столбца вернёт одинаковый результат, но запрос на поиск значения PRESIDENT или President вернёт разный результат.
Символ конца запроса
Обычно используется “;” как символ конца запроса. SQL *Plus всегда требует символа конца запроса и обычно это “;”. Запросы или группы запросов часто сохраняются как файлы скрипты для будущего использования. Запросы в скриптах обычно пишутся в нескольких строках разделяемых символом перевода строки и после завершения одной команды используется “/” или “;”. Вы можете написать команду SELECT разбить её на строки символом переноса строки, а затем после последней строки добавить новую строку в которой будет “/” и сохранить это как файл. Затем файл можно вызвать из SQL *Plus. SQL Developer не требует символа конца строки если создаётся только один запрос. Считается хорошим тоном всегда завершать ваши запросы символом конца строки. Рассмотрим два запроса в SQL *Plus:
SQL *Plus всегда требует символа конца запроса и обычно это “;”. Запросы или группы запросов часто сохраняются как файлы скрипты для будущего использования. Запросы в скриптах обычно пишутся в нескольких строках разделяемых символом перевода строки и после завершения одной команды используется “/” или “;”. Вы можете написать команду SELECT разбить её на строки символом переноса строки, а затем после последней строки добавить новую строку в которой будет “/” и сохранить это как файл. Затем файл можно вызвать из SQL *Plus. SQL Developer не требует символа конца строки если создаётся только один запрос. Считается хорошим тоном всегда завершать ваши запросы символом конца строки. Рассмотрим два запроса в SQL *Plus:
select country_name, country_id, location_id from countries;
select
city,
location_id,
state_province,
country_id
from
locations
;
Первый пример показывает два важных правила. Первое – запрос заканчивается “;”. Второе – весь запрос написан в одну строку. Допустимо использовать и первый и второй варинты запроса, главное чтобы все слова запроса были до символа конца запроса.
Второе – весь запрос написан в одну строку. Допустимо использовать и первый и второй варинты запроса, главное чтобы все слова запроса были до символа конца запроса.
Отступы, читаемость и good practices
Рассмотрим запрос
select
city,
location_id,
state_province,
country_id
from
locations
/
Этот запрос показывает преимущества разделения запроса на строки для улучшения читаемости кода. Oracle всё равно как написан запрос, в одну строку или в несколько, какие отступы использованы и так далее. Хорошим тоном считается разделение блоков запроса на разные строки. Когда выражения в блоке SELECT или WHERE достаточно сложные, то разбиение этих блоков на разные строки существенно улучшает читаемость запроса. Когда вы пишете запрос – обычно этот процесс итеративный. Интерпретатор SQL гораздо более полезен если вы разрабатываете сложные выражения разбивая их на строки, так как ошибки интерпретатора выглядят как “Error at line X:”. Процесс отладки станет гораздо проще.
Процесс отладки станет гораздо проще.
Выражения и операторы
В синтаксисе простого запроса SELECT мы видели что можно использовать столбцы или выражения. Выражения – это обычно результат какой-либо операции над значениями одного (или нескольких) столбцов или выражений. Операторы которые могут использоваться в выражениях зависят от типа данных операндов. Для численных значений доступны сложение, вычитание, умножение и деление. Для строк доступно сложения (конкатенация). Сложение и вычитание доступно для типов данных даты и времени. Как и в обычной арифметике существует предопределённый порядок выполнения операторов (operator precedence) если в выражении используется больше чем один оператор. Круглые кавычки имеют самый высокий приоритет. Деление и умножение следующие в иерархии и рассчитываются до выполнения операторов сложения и вычитания, которые имеют наименьший приоритет.
Операторы с одинаковым приоритетом вычисляются слева направо. Круглые кавычки можно использовать для изменения поведения по умолчанию. Использование кавычек нельзя недооценить при создании сложных выражений. Использование выражений открывает много возможностей в работе с данными.
Использование кавычек нельзя недооценить при создании сложных выражений. Использование выражений открывает много возможностей в работе с данными.
Арифметические операторы
Рассмотрим таблицу JOB_HISTORY где хранится дата начала и конца назначения должности сотруднику. Для расчёта налогов или пенсии может возникнуть потребность расчёта как долго сотрудник занимал определённую должность. Эту информацию можно получить используя арифметический оператор. Рассмотрим некоторые элементы запроса и результата выполнения этого запроса показанные на рисунке 9-5.
Рисунок 9-5 – Запрос с использованием арфметического оператора
В блоке SELECT перечислены пять элементов. Четыре из них это обычные столбцы таблицы JOB_HISTORY, когда пятый используя значения исходных столбцов рассчитывает сколько дней провел сотрудник в конкретной должности. Рассмотрим сотрудника с номером 176, 9 строку результата. Этот сотрудник работал как менеджер по продажам с 1 Января 2007 года по 31 Декабря 2007 года. То есть сотрудник работал в этой должности ровно один год, 2007, который состоял из 365 дней.
То есть сотрудник работал в этой должности ровно один год, 2007, который состоял из 365 дней.
Данные из пятого элемента нашего запроса показывают сколько сотрудник проработал в той или иной должности и могут быть использованы для расчёта сколько и в какой должности сотрудник работал в компании. Пятый элемент запроса и есть выражение. Это выражение показывает арифметическую операцию произведённую над информацией типа данных дата, которая возвращает численное значение представляющее собой количество дней.
Для улучшения читаемости, подвыражение (операция вычитания над датами) end_date-start_date выделено кавычками. Добавление единицы заставляет результат учитывать последний день.
Tip
Во время работы с SQL вы можете часто встречать две распространённые ошибки «ORA-00923: FROM keyword not found where expected» и «ORA-00942: table or view does not exist». Обычно они указаывают на ошибку в синтаксисе или пунктуации, такие как пропущенная круглая кавычка или забытый символ конца литерала при работе со строками.
Выражения и псевдонимы столбцов
На рисунке 9-5 показан новый принцип называющийся псевдонимом столбца. Обратите внимание что столбец с результатом выражения в результате выполнения запроса озаглавлен понятным названием “Days Employed”. Этот заголовок – это и есть псевдоним. Псевдоним это альтернативное имя для столбца или выражения. Если в этом выражении не использовать псевдоним, заголовок столбца будет (END_DATE-START_DATE)+1, что не очень понятно. Псевдонимы особенно полезны при работе с выражениями или суммированием и могут реализовываться несколькими способами. Есть несколько правил при работе с псевдонимами в команде SELECT. Псевдоним “Days Employed” на рисунке 9-5 был указан путём добавления пробела после выражения и заключен в двойные кавычки. Эти кавычки обязательны по двум причинам. Во-первых, псевдоним сотоит из нескольких слов. Во-вторых, сохранение регистра псевдонима возможно только при его заключении в двойные кавычки.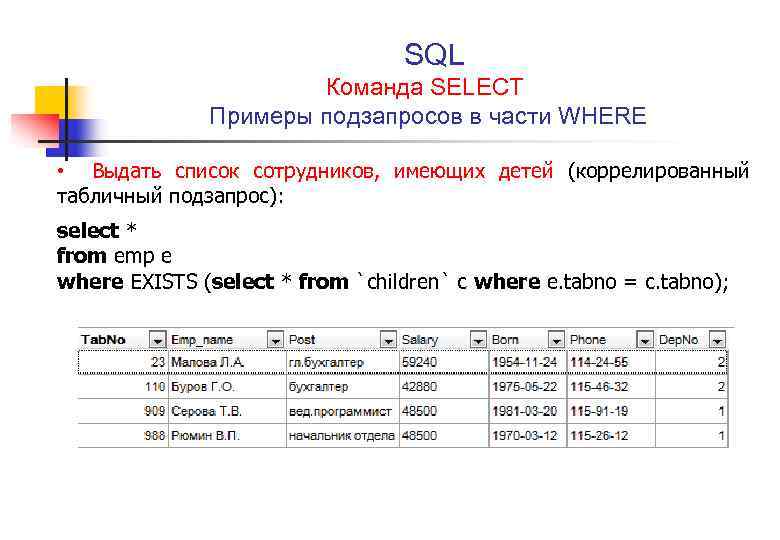 Если вы укажете псевдоним из двух слов разделённых пробелом без кавычек – вы получите ошибку «ORA-00923: FROM keyword not found where expected». SQL предлагает более формальный метод указания псевдонимов путём добавления ключевого слова AS между столбцом или выражением и его псевдонимом.
Если вы укажете псевдоним из двух слов разделённых пробелом без кавычек – вы получите ошибку «ORA-00923: FROM keyword not found where expected». SQL предлагает более формальный метод указания псевдонимов путём добавления ключевого слова AS между столбцом или выражением и его псевдонимом.
SELECT
EMPLOYEE_ID AS «Employee ID»,
JOB_ID AS «Occupation»,
START_DATE, END_DATE,
(END_DATE-START_DATE)+1 «Days Employed»
FROM JOB_HISTORY;
Оператор для работы со строками
Символ || представляет оператор конкатенации строк. Этот оператор используется для объединения строк или выражений вместе для создания более длинного выражения. Столбцы таблицы можно объединять между собой или с значением строкового-литерала для создания одного результирующего выражения.
Оператор конкатенации достаточно гибкий для использования несколько раз и в любом месте выражения. Рассмотрим пример
SELECT ‘THE ‘||REGION_NAME||’ region is on Planet Earth’ «Planetary Location» FROM REGIONS;
В этом запросе строковый-литерал “The” конкатенируется со значением столбца REGION_NAME.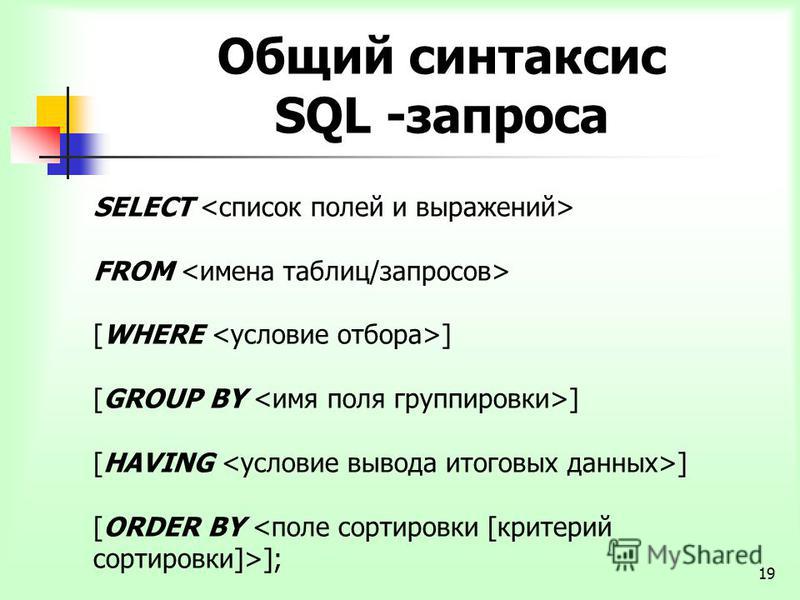 Затем полученная строка также конкатенируется со строковым литералом “region is on Planet Earth” и всему выражению назначается псевдоним “Planetary location”.
Затем полученная строка также конкатенируется со строковым литералом “region is on Planet Earth” и всему выражению назначается псевдоним “Planetary location”.
Литералы и таблица DUAL
Литералы часто используются в выражениях и ссылаются на данные которые не принадлежат объектам базы данных. Конечно конкатенация существующих столбцов тоже используется, но что делать с обработкой литералов которые не зависят от данных в столбцах таблицы. Чтобы обеспечивать согласованность, Oracle придумал решение проблемы использования базы данных для вычисления выражений которым не нужны данные объектов БД. Для того чтобы база данных рассчитала выражение, должна быть выполнена синтаксически корректная команда SELECT. Что делать если вы хотите узнать сумму двух чисел? Вы можете использовать специальную таблицу с одной строкой и одним столбцом с названием DUAL.
Вызов таблицы DUAL показан на рисунке 9-1. В таблице доступен один столбец с названием DUMMY и типом данных строка. Вы можете выполнить запрос SELECT * FROM DUAL и вам вернётся строка с одним столбцом со значением “X”. Тестирование сложных выражений в процессе разработки выполняя запросы к таблице DUAL – это эффективный метод проверки того что вычисление выражений работает как задумано. Выражения с литералами можно проверять на любой таблице, но помните что выражения будут обрабатываться для всех строк в таблице, а в таблице DUAL всего одна строка.
Вы можете выполнить запрос SELECT * FROM DUAL и вам вернётся строка с одним столбцом со значением “X”. Тестирование сложных выражений в процессе разработки выполняя запросы к таблице DUAL – это эффективный метод проверки того что вычисление выражений работает как задумано. Выражения с литералами можно проверять на любой таблице, но помните что выражения будут обрабатываться для всех строк в таблице, а в таблице DUAL всего одна строка.
select ‘literal ‘||’processing using the REGIONS table’ from regions;
select ‘literal ‘||’processing using the DUAL table’ from dual;
Первый запрос вернёт вам четыре строки, так как в таблице REGIONS четыре строки, а второй запрос вернёт одну строку.
Кавычки
Строковые литералы в нашим примерах были простыми выражениями иногда добавляемыми к столбцам. Такие строковые литералы заключаются в одинарные кавычки. Например
select ‘I am a character literal string’ from dual;
А что если литерал уже содержит символ кавычки? Рассмотрим пример
select ‘Plural’s have one quote too many’ from dual;
Этот запрос вернёт ошибку ORA-00923. Так как обрабатывать такие строки? Для этого доступно два способа. Первый и самый популярный это добавление дополнительной одинарной кавычки для каждого встречаемого значения кавычки в выражении. Предыдущий пример с использованием этого способа будет выглядеть так
Так как обрабатывать такие строки? Для этого доступно два способа. Первый и самый популярный это добавление дополнительной одинарной кавычки для каждого встречаемого значения кавычки в выражении. Предыдущий пример с использованием этого способа будет выглядеть так
select ‘Plural»s have one quote too many’ from dual;
Использование двух одинарных кавычек для обработки каждой кавычки в тексте может быть неудобным и приводить к ошибкам по мере увеличения количества таких кавычек. Oracle предоставляет способ переопределить символ начала и конца литерала с помощью оператора q. Oracle выбрала одинарную кавычку как символ начала и конца строки, но этим символом можно назначить другой символ.
Рассмотрим оператор q. Он позволяет установить символом начала и конца строкового литерала либо одинарный символ или один из четырёх видо скобок (), {}, [], <>. Рассмотрим примеры использования оператора q
SELECT q'<Plural’s can also be specified with alternate quote operators>’ «q<>» FROM DUAL;
SELECT q'[Even square brackets’ [] can be used for Plural’s]’ «q[]» FROM DUAL;
SELECT q’XWhat about UPPER CASE X for Plural’sX’ «qX» FROM DUAL;
Синтаксис оператора q
q‘delimiter character literal which may include single quotes delimiter’
где delimiter может быть символ или соотвествующая скобка. В примерах выше показано использование скобок (в первом и втором запросе), и использование символа “X” как символа начала и конца строкового литерала. Обратите внимание что символ X тоже может использоваться в значении литерала – конец строки обозначается символом “X” и одинарной кавычкой.
В примерах выше показано использование скобок (в первом и втором запросе), и использование символа “X” как символа начала и конца строкового литерала. Обратите внимание что символ X тоже может использоваться в значении литерала – конец строки обозначается символом “X” и одинарной кавычкой.
NULL – это ничего
NULL обозначает отсутствие данных. Строка в которой содержится NULL в столбце – рассматривается как строка у которой нет данного для этого столбца. Формально NULL обозначает значение, которое неизвестно или непреминимо. Если не обрабатывать специальным образом значения NULL то ваши запросы скорее всего не выполнятся или что ещё хуже, вернёт неправильный результат. В этом разделе мы рассматриваем как обрабатывать значение NULL в столбце и как значение NULL влияет на вычисление выражений.
Обязательные и необязательные столбцы
Таблица хранят строки данные которые разбиты на один или несколько столбцов. У этих столбцов есть названия и тип данных. Некоторые из столбцов имею ограничения на обязательность указания значения. Таким образом любая строка дожна хранить какое либо значение отличное от NULL в этих столбцах. Когда столбец таблицы не указан как обязательный то вы рискуете встретить значение NULL для этого столбца.
У этих столбцов есть названия и тип данных. Некоторые из столбцов имею ограничения на обязательность указания значения. Таким образом любая строка дожна хранить какое либо значение отличное от NULL в этих столбцах. Когда столбец таблицы не указан как обязательный то вы рискуете встретить значение NULL для этого столбца.
Tip
Любая арифметическая операция со значением NULL всегда возвращает NULL
Oracle позволяет работать со значением NULL используя специальные функции. Подробнее об этом мы поговорим в главе 10. Деление на NULL вернёт NULL, а деление на 0 приведёт к ошибке. Когда строка объединяется со значением NULL – то значение NULL игнорируется.
SELECT 1+NULL FROM DUAL;
SELECT ‘1’||NULL FROM DUAL;
Внешние ключи и необязательные столбцы
Модель данных иногда ведёт к проблемным ситуациям когда таблицы связаны через первичный и внешний ключ, но столбец внешнего ключа необязателен.
Первичный ключ таблицы DEPARTAMENTS – это столбец DEPARTMENT_ID. В таблице EMPLOYEES столбец DEPARTMENT_ID хранит ограничение внешнего ключа для связи с таблицей DEPARTAMENTS. Это значит что в таблице EMPLOYEES не может находиться запись с таким значением столбца DEPARTMENT_ID которого нет в таблице DEPARTMENTS. Такое ограничение обусловлено выполнением третьей нормальной формы и критически важно для ограничения целостности базы данных.
В таблице EMPLOYEES столбец DEPARTMENT_ID хранит ограничение внешнего ключа для связи с таблицей DEPARTAMENTS. Это значит что в таблице EMPLOYEES не может находиться запись с таким значением столбца DEPARTMENT_ID которого нет в таблице DEPARTMENTS. Такое ограничение обусловлено выполнением третьей нормальной формы и критически важно для ограничения целостности базы данных.
А что насчёт значений NULL? Может быть значение NULL в столбце DEPARTAMENT_ID таблицы DEPARTAMENTS? Ответ – нет. Значение первичного ключа всегда должно быть указано. А значение в таблице EMPLOYEES? Это спорный вопрос, так как для обеспечения гибкости и покрытия всех возможных сценаривев, Oracle не может настаивать на том чтобы столбцы используемые для обеспечения ссылочной целостности были обязательными.
Поэтому поле DEPARTMENT_ID в таблице EMPLOYEES необязательное и существует вероятность что в таблице будут существовать записи со значением NULL в столбце DEPARTMENT_ID. И такие записи существуют. Модель данных позвоняет сотруднику работать в каком-то отделе или не работать ни в одном отделе. Когда происходит операция объединения то абсолютно возможно что какие-то записи которые содержат NULL в значении ключа будут отсутствовать в результате. В главе 12 мы рассмотрим как работать с объединениями.
Когда происходит операция объединения то абсолютно возможно что какие-то записи которые содержат NULL в значении ключа будут отсутствовать в результате. В главе 12 мы рассмотрим как работать с объединениями.
SQL ВЫБРАТЬ | Базовый SQL
Начиная отсюда? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Базовый синтаксис: SELECT и FROM
- Что на самом деле происходит при выполнении запроса?
- Соглашение о форматировании
- Имена столбцов
- Практическая задача
Базовый синтаксис: SELECT и FROM
В любом запросе SQL есть два обязательных компонента: ВЫБЕРИТЕ и ИЗ — и они должны быть в таком порядке. SELECT указывает, какие столбцы вы хотите просмотреть, а FROM определяет таблицу, в которой они живут.
месяц,
запад
ОТ tutorial. us_housing_units
us_housing_units
Чтобы увидеть результаты самостоятельно, скопируйте и вставьте этот запрос в редактор запросов Mode и запустите код. Если у вас уже есть код SQL в редакторе запросов, вам нужно будет вставить или удалить запрос, который был там ранее. Если вы просто скопируете и вставите этот запрос под предыдущим, вы получите сообщение об ошибке — вы можете запустить только один SELECT операторов за раз.
Попробуйте.
Так что же происходит в приведенном выше запросе? В этом случае запрос указывает базе данных вернуть столбцы year , month и west из таблицы tutorial.us_housing_units . (Помните, что при ссылке на таблицы именам таблиц должно предшествовать имя пользователя, который их загрузил.) Когда вы запустите этот запрос, вы получите набор результатов, которые показывают значения в каждом из этих столбцов.
Обратите внимание, что имена трех столбцов в запросе разделены запятой. Всякий раз, когда вы выбираете несколько столбцов, они должны быть разделены запятыми, но вы должны , а не включать запятую после имени последнего столбца.
Всякий раз, когда вы выбираете несколько столбцов, они должны быть разделены запятыми, но вы должны , а не включать запятую после имени последнего столбца.
Если вы хотите выбрать каждый столбец в таблице, вы можете использовать * вместо имен столбцов:
SELECT * ОТ tutorial.us_housing_units
Теперь попробуйте сами решить эту практическую задачу:
Практическая задача
Напишите запрос для выбора всех столбцов в таблице tutorial.us_housing_units без использования * .
Попробуйте См. ответ
Примечание. Практические задания будут отображаться в полях, подобных приведенному выше, на протяжении всего этого руководства.
Когда вы решите указанную выше практическую задачу, проверьте свой ответ, нажав «Посмотреть ответ». Перейдя по ссылке, вы увидите наше решение SQL-запроса. Чтобы просмотреть результаты этого запроса решения, нажмите «Результаты» на левой боковой панели:
Это покажет вам таблицу результатов запроса, которые должны совпадать с результатами вашего запроса (если ваш ответ правильный):
Чтобы сравнить ваш запрос или результаты с нашим решением, вернитесь к окну, в котором вы редактируете практические решения. В редакторе можно многое изучить (дополнительные сведения см. в разделе «Как использовать редактор запросов»), но для начала вы можете поэкспериментировать с созданием диаграммы с помощью нашего построителя диаграмм с помощью перетаскивания — просто щелкните зеленую кнопку кнопка «плюс» рядом с вкладкой «Показать таблицу»:
В редакторе можно многое изучить (дополнительные сведения см. в разделе «Как использовать редактор запросов»), но для начала вы можете поэкспериментировать с созданием диаграммы с помощью нашего построителя диаграмм с помощью перетаскивания — просто щелкните зеленую кнопку кнопка «плюс» рядом с вкладкой «Показать таблицу»:
Это приведет вас к построителю диаграмм Mode с помощью перетаскивания. Чтобы узнать больше о построении диаграмм в режиме, ознакомьтесь с разделом «Как строить диаграммы».
Если вы особенно гордитесь своей работой, возможно, вы захотите изучить, как она выглядит в представлении отчетов Mode — очищенном представлении, предназначенном для обмена запросами и результатами. Просто нажмите «Просмотр» в шапке:
Теперь вы увидите очищенную версию вашего отчета, которую можно опубликовать. Вы можете узнать больше о просмотре и построении отчетов на справочном сайте Mode. На данный момент самое важное, что нужно знать, это то, что вы можете поделиться этим отчетом с кем угодно, щелкнув меню «Поделиться» в редакторе запросов и выбрав канал, который вы хотите использовать для обмена:
Отправьте всем своим друзьям по электронной почте или в Slack!
Вы также можете поделиться своей незавершенной работой в режиме редактирования, где вы писали свои запросы. Чтобы вернуться к редактированию запроса, нажмите «Изменить» в строке заголовка:
Чтобы вернуться к редактированию запроса, нажмите «Изменить» в строке заголовка:
Вы вернетесь в редактор запросов, где сможете редактировать свой SQL, диаграммы или отчеты.
Что на самом деле происходит при выполнении запроса?
Вернемся к этому! Когда вы запускаете запрос, что вы получаете в ответ? Как видно из выполнения запросов выше, вы получаете таблицу. Но эта таблица не хранится в базе данных постоянно. Он также не изменяет никакие таблицы в базе данных — tutorial.us_housing_units будет содержать одни и те же данные каждый раз, когда вы его запрашиваете, и данные никогда не изменятся, независимо от того, сколько раз вы их запрашиваете. Режим сохраняет все ваши результаты для будущего доступа, но операторы SELECT ничего не меняют в базовых таблицах.
Соглашение о форматировании
Вы могли заметить, что SELECT и команды `FROM’ пишутся с заглавной буквы. На самом деле в этом нет необходимости — SQL поймет эти команды, если вы наберете их строчными буквами. Использование заглавных букв в командах — это просто соглашение, упрощающее чтение запросов. Точно так же SQL рассматривает один пробел, несколько пробелов или разрыв строки как одно и то же. Например, SQL обрабатывает это так же, как и предыдущий запрос:
Использование заглавных букв в командах — это просто соглашение, упрощающее чтение запросов. Точно так же SQL рассматривает один пробел, несколько пробелов или разрыв строки как одно и то же. Например, SQL обрабатывает это так же, как и предыдущий запрос:
ВЫБЕРИТЕ * ИЗ tutorial.us_housing_units
Аналогично обрабатывается и это:
SELECT * ОТ tutorial.us_housing_units
Хотя большинство правил использования заглавных букв одинаковы, существует несколько правил форматирования разрывов строк. Вы познакомитесь с некоторыми из них в этом руководстве и в работе других людей над режимом. Вам решать, какой метод форматирования вам проще всего читать и понимать.
Имена столбцов
Пока мы говорим о форматировании, стоит отметить формат имен столбцов. Все столбцы в таблице tutorial.us_housing_units названы строчными буквами и используют символы подчеркивания вместо пробелов. В самом имени таблицы также используются символы подчеркивания вместо пробелов. Большинство людей избегают использования пробелов в именах столбцов, потому что в SQL неудобно иметь дело с пробелами — если вы хотите использовать пробелы в именах столбцов, вам нужно всегда ссылаться на эти столбцы в двойных кавычках.
Большинство людей избегают использования пробелов в именах столбцов, потому что в SQL неудобно иметь дело с пробелами — если вы хотите использовать пробелы в именах столбцов, вам нужно всегда ссылаться на эти столбцы в двойных кавычках.
Если вы хотите, чтобы ваши результаты выглядели более презентабельно, вы можете переименовать столбцы, включив в них пробелы. Например, если вы хотите west , чтобы в результатах отображался West Region , вам нужно будет ввести:
SELECT west AS "West Region" ОТ tutorial.us_housing_units
Без двойных кавычек этот запрос читал бы «Запад» и «Регион» как отдельные объекты и возвращал бы ошибку. Обратите внимание, что результаты будут возвращать только заглавные буквы, если вы поместите имена столбцов в двойные кавычки. Например, следующий запрос вернет результаты с именами столбцов в нижнем регистре.
ВЫБЕРИТЕ запад КАК West_Region,
юг AS South_Region
ОТ tutorial.us_housing_units
Оттачивайте свои навыки SQL
Практические задачи
Напишите запрос для выбора всех столбцов в tutorial. и переименуйте их так, чтобы их первые буквы были заглавными. us_housing_units
us_housing_units
ПопробуйтеПосмотреть ответ
Найти отчет, но не SQL?
После того, как вы откроете отчет, просмотрите его SQL, щелкнув «Просмотреть подробности» вверху, а затем щелкнув «SQL» на боковой панели слева.
PostgreSQL ВЫБРАТЬ
Резюме : в этом руководстве вы узнаете, как использовать базовую инструкцию PostgreSQL SELECT для запроса данных из таблицы.
Обратите внимание: если вы не знаете, как выполнить запрос к базе данных PostgreSQL с помощью инструмента командной строки psql или инструмента pgAdmin с графическим интерфейсом, вы можете проверить это в руководстве по подключению к базе данных PostgreSQL.
Одной из наиболее распространенных задач при работе с базой данных является запрос данных из таблиц с помощью Оператор SELECT .
Оператор SELECT — один из самых сложных операторов в PostgreSQL. Он имеет множество предложений, которые можно использовать для формирования гибкого запроса.
Из-за его сложности мы разобьем его на множество более коротких и простых для понимания учебных пособий, чтобы вы могли быстрее изучить каждый пункт.
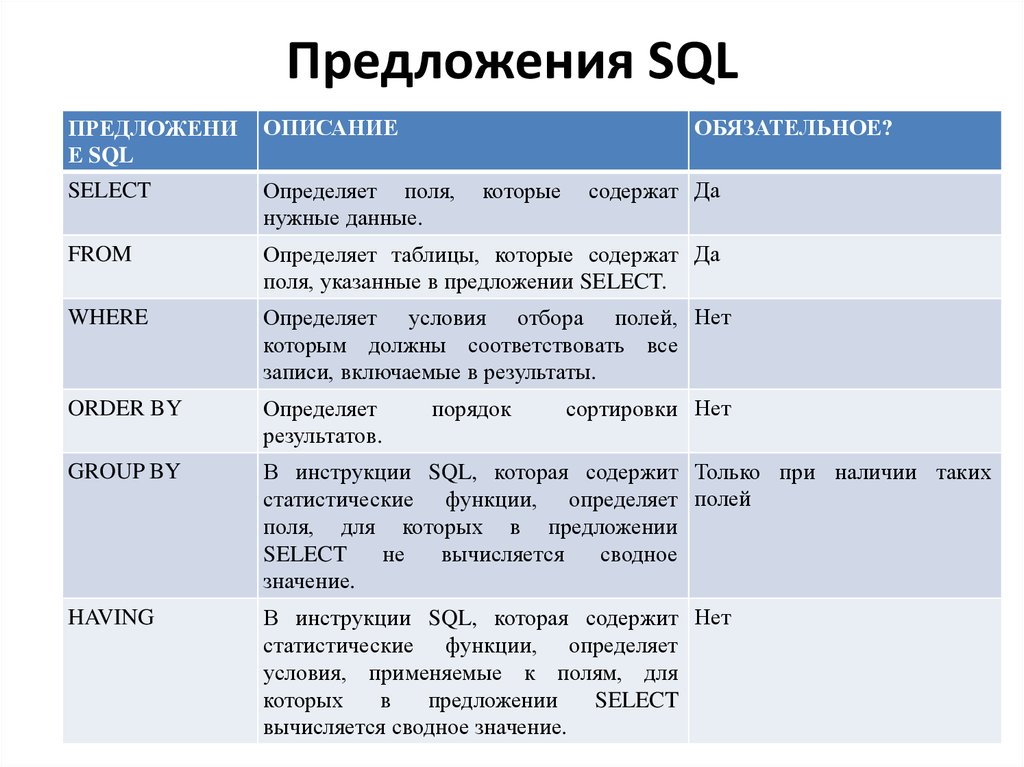
Оператор SELECT содержит следующие пункты:
- Выберите отдельные строки с помощью оператора
DISTINCT. - Сортировка строк с помощью предложения
ORDER BY. - Фильтрация строк с помощью предложения
WHERE. - Выберите подмножество строк из таблицы, используя предложение
LIMITилиFETCH. - Группировать строки в группы с помощью предложения
GROUP BY. - Фильтрация групп с помощью предложения
HAVING. - Соединение с другими таблицами с помощью таких соединений, как
INNER JOIN,LEFT JOIN,FULL OUTER JOIN,CROSS JOIN 9статьи 0026.
- Выполнение операций над множествами с использованием
UNION,INTERSECTи, КРОМЕ.
В этом руководстве вы сосредоточитесь на предложениях SELECT и FROM .
PostgreSQL
SELECT синтаксис инструкции
Начнем с базовой формы инструкции SELECT , которая извлекает данные из одной таблицы.
Ниже показан синтаксис команды SELECT 9.Оператор 0026:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ select_list ОТ имя_таблицы;
Рассмотрим оператор SELECT более подробно:
- Сначала укажите список выбора, который может быть столбцом или списком столбцов в таблицы, из которой вы хотите получить данные. Если вы указываете список столбцов, вам нужно поставить запятую (
,) между двумя столбцами, чтобы разделить их. Если вы хотите выбрать данные из всех столбцов таблицы, вы можете использовать звездочку (*) вместо указания всех имен столбцов. Список выбора может также содержать выражения или литеральные значения. - Во-вторых, укажите имя таблицы, из которой вы хотите запросить данные после ключевого слова
FROM.
 Если вы указываете список столбцов, вам нужно поставить запятую (
Если вы указываете список столбцов, вам нужно поставить запятую ( Предложение FROM является необязательным. Если вы не запрашиваете данные из какой-либо таблицы, вы можете опустить предложение FROM в операторе SELECT .
PostgreSQL оценивает предложение FROM перед Предложение SELECT в операторе SELECT :
Обратите внимание, что ключевые слова SQL нечувствительны к регистру. Это означает, что SELECT эквивалентно select или Select . По соглашению мы будем использовать все ключевые слова SQL в верхнем регистре, чтобы упростить чтение запросов.
По соглашению мы будем использовать все ключевые слова SQL в верхнем регистре, чтобы упростить чтение запросов.
PostgreSQL
SELECT примеров
Давайте рассмотрим несколько примеров использования оператора PostgreSQL SELECT .
Мы будем использовать следующие клиентская таблица в образце базы данных для демонстрации.
1) Использование оператора PostgreSQL
SELECT для запроса данных из одного столбца пример
В этом примере используется оператор SELECT для поиска имен всех клиентов из таблицы customer :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT first_name FROM ;
Вот частичный вывод:
Обратите внимание, что мы добавили точку с запятой ( ; ) в конце инструкции SELECT . Точка с запятой не является частью оператора SQL. Он используется, чтобы сигнализировать PostgreSQL об окончании оператора SQL. Точка с запятой также используется для разделения двух операторов SQL.
Точка с запятой не является частью оператора SQL. Он используется, чтобы сигнализировать PostgreSQL об окончании оператора SQL. Точка с запятой также используется для разделения двух операторов SQL.
2) Использование оператора PostgreSQL
SELECT для запроса данных из нескольких столбцов пример
Предположим, вы просто хотите узнать имя, фамилию и адрес электронной почты клиентов, вы можете указать эти имена столбцов в 9Предложение 0025 SELECT , как показано в следующем запросе:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT имя, фамилия, электронная почта ОТ клиент;
3) Использование оператора PostgreSQL
SELECT для запроса данных из всех столбцов таблицы пример
Следующий запрос использует оператор SELECT для выбора данных из всех столбцов таблицы клиента :
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ * ОТ клиента;
В этом примере мы использовали звездочку ( * ) в предложении SELECT , которое является сокращением для всех столбцов. Вместо того, чтобы перечислять все столбцы в предложении
Вместо того, чтобы перечислять все столбцы в предложении SELECT , мы просто использовали звездочку ( * ), чтобы не печатать.
Однако не рекомендуется использовать звездочку ( * ) в операторе SELECT при встраивании операторов SQL в код приложения, например Python, Java, Node.js или PHP, по следующим причинам. :
- Производительность базы данных. Предположим, у вас есть таблица с большим количеством столбцов и большим количеством данных. Оператор
SELECTсо звездочкой (*) выберет данные из всех столбцов таблицы, которые могут не понадобиться приложению. - Производительность приложения. Извлечение ненужных данных из базы данных увеличивает трафик между сервером базы данных и сервером приложений. Как следствие, ваши приложения могут работать медленнее и менее масштабируемы.
По этим причинам рекомендуется явно указывать имена столбцов в предложении SELECT , когда это возможно, чтобы получать из базы данных только необходимые данные.
И вы должны использовать звездочку (*) только для специальных запросов, которые проверяют данные из базы данных.
4) Использование инструкции PostgreSQL
SELECT с выражениями example
В следующем примере инструкция SELECT используется для возврата полных имен и адресов электронной почты всех клиентов:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ имя_имя || ' ' || фамилия, электронная почта ОТ клиент;
Вывод:
В этом примере мы использовали оператор конкатенации || , чтобы объединить имя, пробел и фамилию каждого клиента.
В следующем уроке вы узнаете, как использовать псевдонимы столбцов для присвоения выражениям более понятных имен.
5) Использование PostgreSQL
Оператор SELECT с выражениями пример
В следующем примере используется оператор SELECT с выражением.