Создание индекса: CREATE INDEX (Transact-SQL) — SQL Server
Содержание
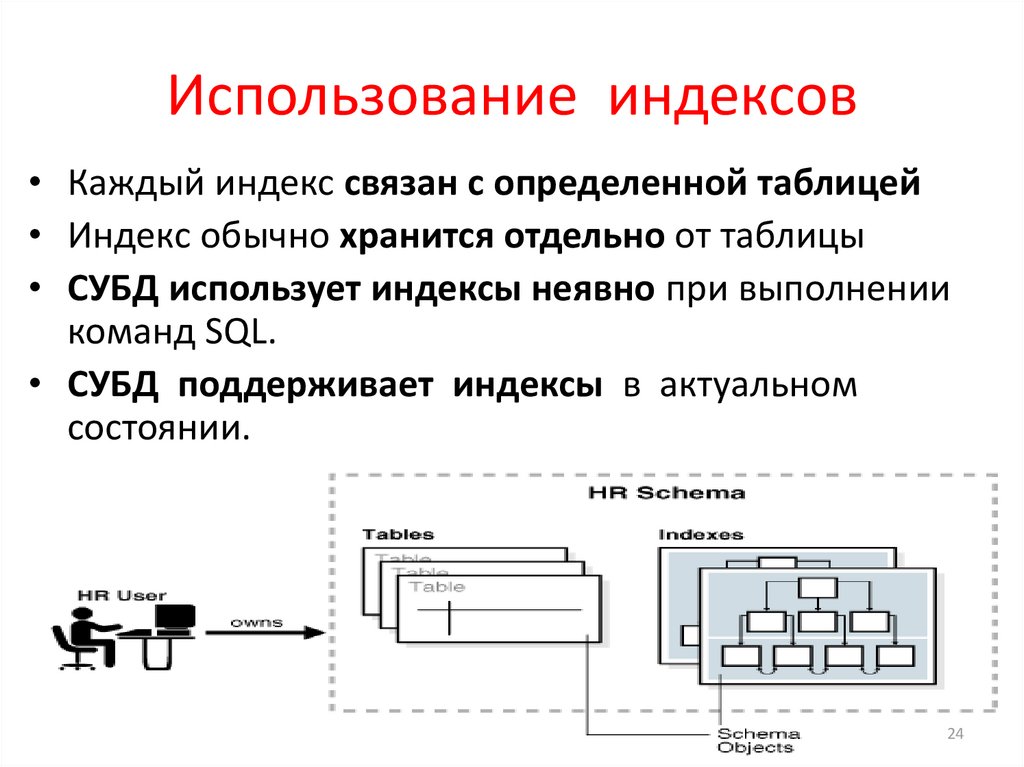
Создание и использование индекса для увеличения производительности
Если вы часто ведете поиск в таблице Access или сортировали ее записи по определенному полю, вы можете ускорить эти операции, создав для этого поля индекс. Access использует индексы в таблице при использовании индекса в книге: чтобы найти данные, Access ищет расположение данных в индексе. В некоторых случаях, например в случае первичного ключа, Access автоматически создает индекс. В других случаях индекс можно создать самостоятельно.
В этой статье дается описание индексов; рассматривается, какие поля следует индексировать; описывается создание, удаление и изменение индексов. Кроме того, в этой статье объясняется, в каких случаях приложение Access создает индексы автоматически.
В этой статье
-
Что такое индекс? -
Выбор полей для индексирования -
Создание индекса -
Удаление индекса -
Просмотр и редактирование индексов -
Автоматическое создание индексов
Примечание: Методы, описанные в данной статье, нельзя использовать для создания индекса для таблицы веб-базы данных. Производительность веб-базы данных зависит от нескольких факторов, например производительности сервера SharePoint, на котором она размещена.
Производительность веб-базы данных зависит от нескольких факторов, например производительности сервера SharePoint, на котором она размещена.
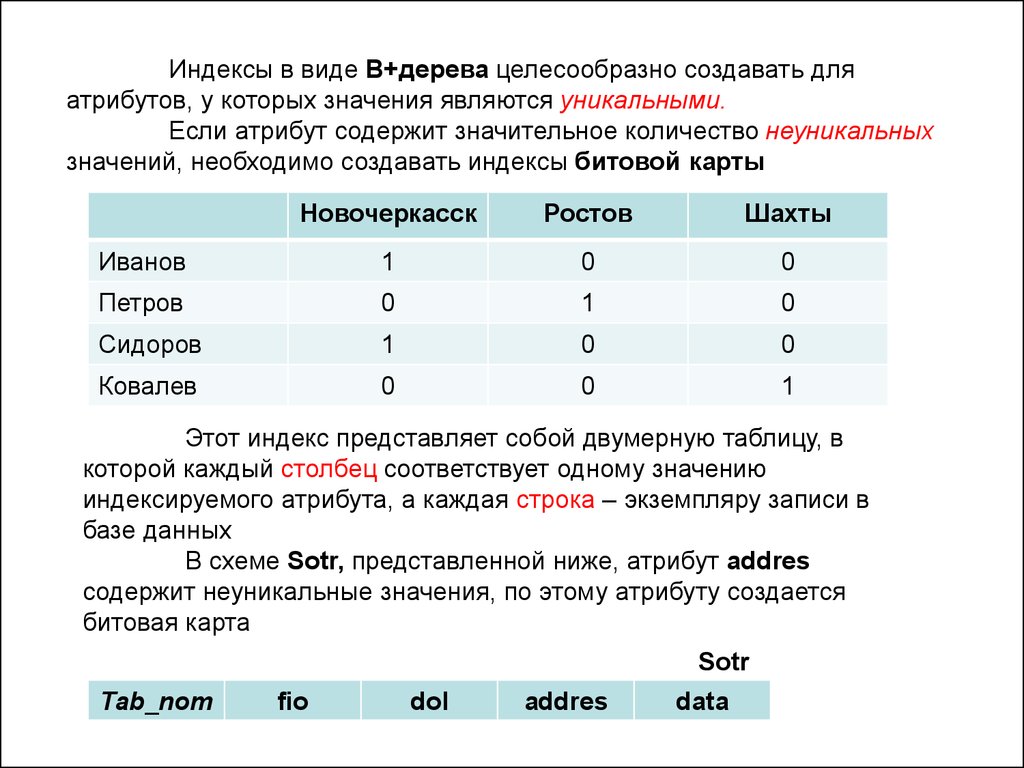
Что такое индекс?
Индексы обеспечивают поиск и сортировку записей в Access. В индексе хранится местоположение записей на основе одного или нескольких полей, которые были выбраны для индексирования. После того как Access получает сведения о позиции в индексе, он может извлечь данные путем перемещения непосредственно к нужной позиции. Благодаря этому использование индекса гораздо эффективнее просмотра всех записей для поиска необходимых данных.
Выбор полей для индексирования
Вы можете создавать индексы, основанные на одном или нескольких полях. В основном требуется индексировать поля, в которых часто осуществляется поиск, сортируемые поля и поля, объединенные с полями в других таблицах, что часто используется в запросах по нескольким таблицам. Индексы ускоряют поиск и выполнение запросов, однако они могут привести к снижению производительности при добавлении или обновлении данных. Каждый раз, когда вы добавляете или изменяете запись в таблице, содержащей один или несколько индексов, Access приходится обновлять индексы. Добавление записей с помощью запроса на добавление или с помощью импортирования записей также, скорее всего, будет происходить медленнее, если таблица-получатель содержит индексы.
Индексы ускоряют поиск и выполнение запросов, однако они могут привести к снижению производительности при добавлении или обновлении данных. Каждый раз, когда вы добавляете или изменяете запись в таблице, содержащей один или несколько индексов, Access приходится обновлять индексы. Добавление записей с помощью запроса на добавление или с помощью импортирования записей также, скорее всего, будет происходить медленнее, если таблица-получатель содержит индексы.
Примечание: Первичный ключ таблицы индексируется автоматически.
Индексировать поля с типом данных «Объект OLE», «Вычисляемый» или «Вложение» невозможно. Индексировать другие поля следует в тех случаях, когда выполняются все указанные ниже условия.
-
Тип данных поля: «Короткий текст» («Текст» в Access 2010), «Длинный текст» («Поле МЕМО» в Access 2010), «Число», «Дата/время», «Автонум», «Валюта», «Да/Нет» или «Гиперссылка».

-
Предполагается поиск значений в поле.
-
Предполагается сортировка значений в поле.
-
Предполагается сохранение большого числа различных значений в поле. Если поле содержит много одинаковых значений, то применение индекса может не дать значительного ускорения выполнения запросов.

Составные индексы
Если предполагается, что необходимо будет часто выполнять поиск или сортировку по нескольким полям, вы можете создать индекс для этого сочетания полей. Например, если в одном запросе часто задаются условия для полей «Поставщик» и «Наименование_продукта», имеет смысл создать для этих полей составной индекс.
При сортировке таблицы по составному индексу Access сначала выполняет сортировку по первому полю, заданному для индекса. Последовательность полей определяется при создании составного индекса. Если в первом поле содержатся записи с повторяющимися значениями, затем выполняется сортировка по второму полю, заданному для индекса, и т. д.
В составной индекс можно включить до 10 полей.
Создание индекса
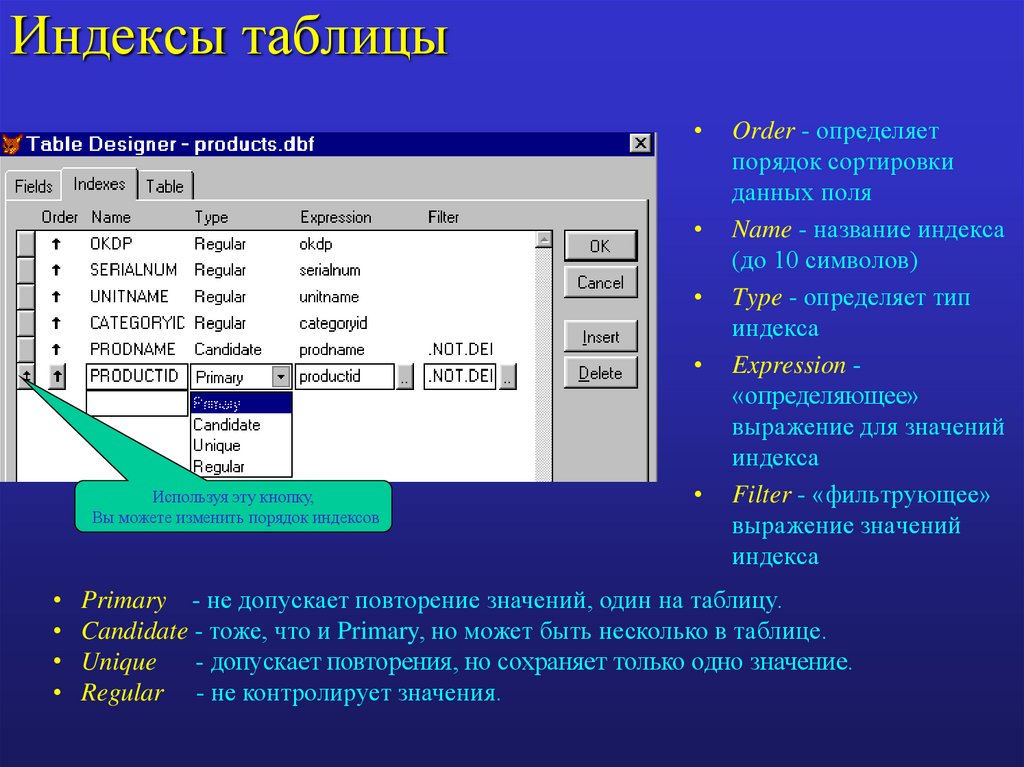
Перед созданием индекса необходимо решить, следует ли создать индекс для одного поля или составной индекс. Индекс для одного поля создается с помощью установки свойства Индексированное поле. В таблице ниже приведены возможные параметры свойства Индексированное поле.
|
|
|
|
Нет
|
Не создавать индекс для этого поля (или удалить существующий индекс)
|
|
Да (допускаются совпадения)
|
Создать индекс для этого поля
|
|
Да (совпадения не допускаются)
|
Создать уникальный индекс для этого поля
|
При создании уникального индекса невозможно ввести новое значение в определенном поле, если такое значение уже существует в том же поле другой записи. Access автоматически создает уникальный индекс для первичных ключей, однако может потребоваться запретить создание повторяющихся значений и в других полях. Например, вы можете создать уникальный индекс для поля, в котором содержатся серийные номера, чтобы двум продуктам нельзя было присвоить один и тот же серийный номер.
Access автоматически создает уникальный индекс для первичных ключей, однако может потребоваться запретить создание повторяющихся значений и в других полях. Например, вы можете создать уникальный индекс для поля, в котором содержатся серийные номера, чтобы двум продуктам нельзя было присвоить один и тот же серийный номер.
Создание индекса для одного поля
-
В области навигации щелкните правой кнопкой мыши имя таблицы, в которой необходимо создать индекс, и выберите в контекстном меню пункт Конструктор.
-
Щелкните пункт Имя поля для поля, которое следует индексировать.
 org/ListItem»>
org/ListItem»>
В разделе Свойства поля откройте вкладку Общие.
-
В свойстве Индексированное выберите значение Да (допускаются совпадения), если следует разрешить повторяющиеся значения, или значение Да (совпадения не допускаются), чтобы создать уникальный индекс.
-
Чтобы сохранить изменения, щелкните элемент Сохранить на панели быстрого доступа или нажмите клавиши CTRL+S.
Создание составного индекса
Чтобы создать составной индекс для таблицы, добавьте строку для каждого поля в индексе и укажите имя индекса только в первой строке. Все строки будут обрабатываться как часть одного индекса, пока не будет обнаружена строка с другим именем индекса. Чтобы вставить строку, щелкните правой кнопкой мыши место, куда вы хотите ее вставить, и выберите в контекстном меню команду Вставить строки.
Чтобы вставить строку, щелкните правой кнопкой мыши место, куда вы хотите ее вставить, и выберите в контекстном меню команду Вставить строки.
-
В области навигации щелкните правой кнопкой мыши имя таблицы, в которой необходимо создать индекс, и выберите в контекстном меню пункт Конструктор.
-
На вкладке Конструктор в группе Показать или скрыть щелкните пункт Индексы.
Появится окно «Индексы». Измените размеры этого окна, чтобы отображались пустые строки и свойства индекса.
-
В первой пустой строке столбца Индекс введите имя индекса.
Для индекса можно использовать либо имя одного из индексируемых полей, либо другое подходящее имя. -
В столбце Имя поля щелкните стрелку, затем щелкните первое поле, которое следует использовать в индексе.
-
Следующую строку столбца Индекс оставьте пустой, затем в столбце Имя поля укажите второе индексируемое поле. Повторите этот шаг для всех полей, которые необходимо включить в индекс.
-
Чтобы изменить порядок сортировки значений полей, в столбце Порядок сортировки окна «Индексы» щелкните пункт По возрастанию или По убыванию. По умолчанию выполняется сортировка по возрастанию.
-
В разделе Свойства индекса окна Индексы укажите свойства индекса для строки в столбце Имя индекса, содержащем имя индекса. Задайте свойства в соответствии с таблицей ниже.
Подпись
ЗначениеПервичный
Если Да, то индекс является первичным ключом.
Уникальный
Если Да, то каждое индексируемое значение должно быть уникальным.
Пропуск пустых полей
Если Да, то записи с пустыми значениями в индексируемых полях будут исключены из индекса.
-
Чтобы сохранить изменения, нажмите кнопку Сохранить на панели быстрого доступа или нажмите клавиши CTRL+S.
-
Закройте окно «Индексы».
 Для индекса можно использовать либо имя одного из индексируемых полей, либо другое подходящее имя.
Для индекса можно использовать либо имя одного из индексируемых полей, либо другое подходящее имя.


Удаление индекса
Если индекс становится ненужным или приводит к значительному снижению производительности, его можно удалить. При этом удаляется только сам индекс, а не поля, на которых он основан.
При этом удаляется только сам индекс, а не поля, на которых он основан.
-
В области навигации щелкните правой кнопкой мыши имя таблицы, для которой необходимо удалить индекс, и выберите в контекстном меню пункт Конструктор.
-
На вкладке Конструктор в группе Показать или скрыть щелкните пункт Индексы.
Появится окно «Индексы». Измените размеры этого окна, чтобы отображались пустые строки и свойства индекса.
-
В окне «Индексы» выделите строки, содержащие индекс, который следует удалить, и нажмите клавишу DELETE.
-
Чтобы сохранить изменения, нажмите кнопку Сохранить на панели быстрого доступа или нажмите клавиши CTRL+S.
-
Закройте окно Индексы

Просмотр или редактирование индексов
Чтобы оценить влияние индексов на производительность или убедиться, что необходимые поля проиндексированы, просмотрите индексы в таблице.
-
В области навигации щелкните правой кнопкой мыши имя таблицы, индекс которой вы хотите изменить, и выберите в контекстном меню пункт Конструктор.
-
На вкладке Конструктор в группе Показать или скрыть щелкните пункт Индексы.
Появится окно «Индексы». Измените размеры этого окна, чтобы отображались пустые строки и свойства индекса.
-
Просмотрите или измените индексы и свойства индексов в соответствии со своими задачами.
-
Чтобы сохранить изменения, нажмите кнопку Сохранить на панели быстрого доступа или нажмите клавиши CTRL+S.
-
Закройте окно Индексы

Автоматическое создание индексов
В некоторых случаях индексы создаются автоматически. Например, индексы создаются для любых полей, которые определяются пользователем в качестве первичного ключа таблицы.
Например, индексы создаются для любых полей, которые определяются пользователем в качестве первичного ключа таблицы.
Для автоматического создания индекса также можно использовать параметр Автоиндекс при импорте и создании в диалоговом окне Параметры Access. Access автоматически проиндексирует все поля, имена которых начинаются с указанных в поле Автоиндекс при импорте и создании знаков или заканчиваются ими, например ID, ключ, код или число. Чтобы просмотреть или изменить текущие параметры, сделайте следующее:
-
Выберите Файл > Параметры.
-
Щелкните Конструкторы объектов, а затем в разделе Конструктор таблиц добавьте, измените или удалите значения в поле Автоиндекс при импорте и создании.
Для разделения значений используйте точку с запятой (;).Примечание: Если имя поля начинается со значения, указанного в списке, или заканчивается им, поле будет автоматически проиндексировано.
-
Нажмите кнопку ОК.
 Для разделения значений используйте точку с запятой (;).
Для разделения значений используйте точку с запятой (;).
Так как каждый индекс требует дополнительной обработки, производительность при добавлении или обновлении данных снижается. Поэтому рекомендуется изменить значения, указанные в поле Автоиндекс при импорте и создании или уменьшить их число, чтобы сократить количество создаваемых индексов.
К началу страницы
Создание индексов
Оператор create index создает индекс для конкретной таблицы. Общая форма этого оператора:
create [unique] [clustered |nonclustered] index index_name on table_name {columnl [asc i desc] , . ..) [ include ( column_name [,…])] [with
..) [ include ( column_name [,…])] [with
[fillfactor=n]
[[, ] pad_index = [on i off}]
[[, ] drop_existing = [on | off}]
[[, ] sort_in_tempdb = [on | off}]
[[, ] ignore_dup_key = (on | off}]
[[, ] allow_row_locks = {on i off}]
[[, ] allow_page_locks = [on | off}]
[[, ] statistics_norecompute = [on i off}]
[[, ] online = {on I off}]] [on file_group | «default»]
Здесь index_name задает имя создаваемого индекса. Индекс может быть создан для одного или более столбцов одной таблицы (tabie_name). coiumni — имя столбца, для которого создается индекс. Как вы можете видеть в форме оператора create index, вы можете создавать индекс для нескольких столбцов таблицы. Database Engine также поддерживает индексы и для представлений. Подобные представления, называемые индексированными представлениями, обсуждаются в следующей главе.
Индекс может быть простым или составным. Простой индекс имеет один столбец, в то время как составной индекс создан более чем для одного столбца.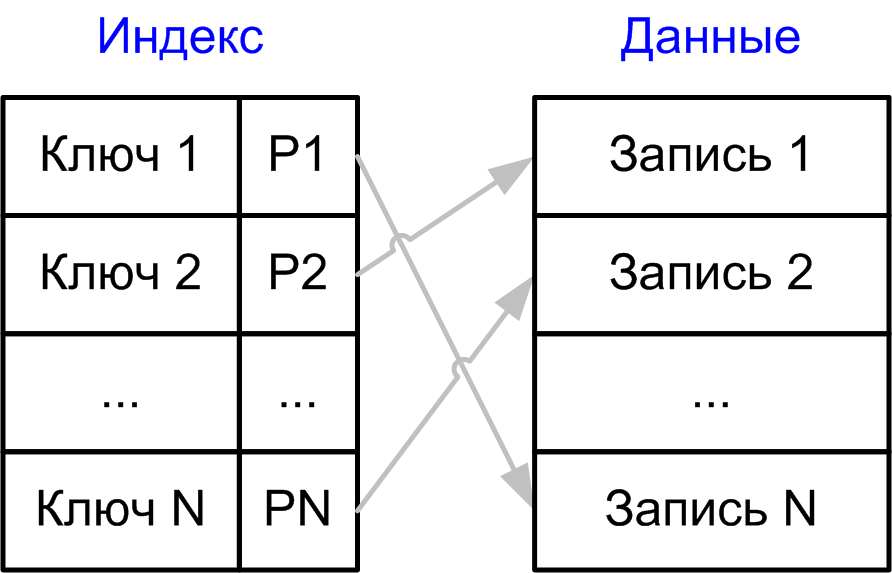 Каждый составной индекс имеет некоторые ограничения, связанные с его длиной и количеством столбцов. Максимальный размер индекса- 900 байтов, при этом индекс может содержать не более 16 столбцов.
Каждый составной индекс имеет некоторые ограничения, связанные с его длиной и количеством столбцов. Максимальный размер индекса- 900 байтов, при этом индекс может содержать не более 16 столбцов.
Опция unique указывает, что каждое значение данных может появляться только один раз в индексированном столбце. Для уникального составного индекса комбинация значений данных во всех столбцах каждой строки должна быть уникальной. Если unique не задано, допустимы дубликаты в индексируемом столбце (столбцах).
Опция clustered задает кластеризованный индекс. Опция nonclustered (значение по умолчанию) указывает, что индекс не изменяет порядок строк в таблице. Database Engine допускает максимум 249 некластеризованных индексов для одной таблицы.
Database Engine имеет улучшенную поддержку индексов, которые упорядочены по убыванию значений столбца. Опция asc после имени столбца указывает, что индекс создается с возрастающим порядком значений столбца, тогда как desc задает убывающий порядок. Это дает вам больше гибкости в плане использования индексов. Убывающие индексы должны быть созданы, когда вы создаете составной индекс для столбцов, которые имеют противоположные направления сортировки.
Это дает вам больше гибкости в плане использования индексов. Убывающие индексы должны быть созданы, когда вы создаете составной индекс для столбцов, которые имеют противоположные направления сортировки.
Опция include позволяет вам задавать неключевые столбцы, которые добавляются в страницы листьев некластеризованного индекса. Имена столбцов не могут повторяться в списке include и не могут быть одновременно использованы в качестве ключевых и неключевых столбцов. Чтобы понять преимущества опции include, вам нужно знать, что такое покрывающий индекс. Существенное повышение производительности может быть достигнуто, когда все столбцы в запросе включены в индекс, потому что оптимизатор запросов может локализовать все значения столбцов в индексных страницах без необходимости доступа к данным таблицы. Эта возможность называется покрывающим индексом или покрывающим запросом. Следовательно, если вы включаете дополнительные неключевые столбцы в страницы листьев некла-стеризованного индекса, может быть покрыто большее количество запросов, а их производительность может быть значительно более высокой. (Дальнейшее обсуждение этой темы, равно как и пример того, как оптимизатор запросов обрабатывает покрывающие индексы, см. в разд. «Покрывающий индекс» далее В этом разделе).
(Дальнейшее обсуждение этой темы, равно как и пример того, как оптимизатор запросов обрабатывает покрывающие индексы, см. в разд. «Покрывающий индекс» далее В этом разделе).
Опция FILLFACTOR=n определяет процент заполнения каждой индексной страницы во время создания индекса. Вы можете задать значение fillfactor в диапазоне от 1 до 100. Если значение л установлено в 100, то каждая индексная страница будет заполнена на 100%, т. е. существующая страница листа индекса так же, как и страница, не относящаяся к листу, не будет иметь места для добавления новых строк. По этой причине такое значение рекомендуется использовать только для статических таблиц. Значение по умолчанию 0 также указывает на то, что страница листа индекса будет заполнена полностью и каждая промежуточная страница содержит место для одной записи.
Если вы установите значение опции fillfactor в значение между 1 и 99, то новая индексная структура будет создана со страницами листьев, которые не будут заполнены полностью. Чем больше значение fillfactor, тем меньше объем памяти, который остается свободным на индексной странице. Например, установка опции fillfactor в значение 60 означает, что 40% на каждой странице листа индекса остается свободным для дальнейшего добавления строк индекса. (Индексная строка будет добавлена, когда вы выполняете либо оператор insert, либо оператор update.) По этой причине значение 60 будет разумным решением для таблиц с довольно частым изменением данных. Для всех значений опции fillfactor между 1 и 99 все промежуточные страницы, не относящиеся к листьям, будут содержать свободное место для одной записи.
Чем больше значение fillfactor, тем меньше объем памяти, который остается свободным на индексной странице. Например, установка опции fillfactor в значение 60 означает, что 40% на каждой странице листа индекса остается свободным для дальнейшего добавления строк индекса. (Индексная строка будет добавлена, когда вы выполняете либо оператор insert, либо оператор update.) По этой причине значение 60 будет разумным решением для таблиц с довольно частым изменением данных. Для всех значений опции fillfactor между 1 и 99 все промежуточные страницы, не относящиеся к листьям, будут содержать свободное место для одной записи.
Опция pad_index тесно связана с опцией fillfactor. Опция fillfactor в первую очередь задает процент свободного места, которое остается на странице листьев индекса. С другой стороны, опция pad_index указывает, что установка fillfactor должна быть применена как к индексным страницам, так и к страницам данных, имеющим отношение к этому индексу.
Опция drop_existing позволяет увеличить производительность при пересоздании кластеризованного индекса для таблицы, которая также имеет некластеризованный индекс. Подробности «Пересоздание индекса» далее В этом разделе.
Подробности «Пересоздание индекса» далее В этом разделе.
Опция sort_in_tempdb служит для помещения в системную базу данных tempdb промежуточных данных сортировки, используемой при создании индекса. Это может дать преимущество, если база данных tempdb располагается на дисковом носителе, отличном от того, где находятся сами данные. (Опция dropexisting обсуждается в разд. «Пересоздание индекса» далее В этом разделе.)
Опция ignoredupkey указывает системе, что она должна игнорировать попытки добавления дубликатов значений в индексный столбец (столбцы). Эта опция должна быть использована только для того, чтобы исключить завершение длинной транзакции в случае, когда оператор insert добавляет дубликаты данных в индексируемый столбец (столбцы). Если активирована эта опция, и оператор insert пытается добавить строки, которые нарушат уникальность индекса, то система базы данных вернет предупреждение вместо того, чтобы выдавать ошибку для всего оператора. Database Engine не добавит строки, которые пытаются создать дубликаты ключевых значений, он просто проигнорирует такие строки и добавит все оставшиеся. (Если такая опция не установлена, то все операторы будут отменены.)
(Если такая опция не установлена, то все операторы будут отменены.)
Опция allowrowlocks задает, что система использует блокировку строк, когда активирована эта опция (установлена в on). Аналогично, опция allowpagelocks задает, что система использует блокировку страниц, когда эта опция установлена в on. (Описание блокировок страниц и строк.)
Опция statistics_norecompute указывает, что статистика по указанному индексу не должна вычисляться заново автоматически. Опция on создает указанный индекс либо для файловой группы по умолчанию («default»), либо для указанной файловой группы (filegroup).
Если вы активируете опцию online, то можете создавать, пересоздавать или удалять индекс в диалоговом режиме. Эта опция допускает параллельные модификации индексируемой таблицы или данных кластеризованного индекса, а также ассоциированных индексов в процессе выполнения изменений индекса. Например, в то время как пересоздается кластеризованный индекс, вы можете продолжать выполнение изменений данных в таблице и выполнять запросы к этим данным. (Это означает, что исключительные блокировки данных соответствующей таблицы не используются в процессе пересоздания индекса).
(Это означает, что исключительные блокировки данных соответствующей таблицы не используются в процессе пересоздания индекса).
В примере 10.1 показано создание некластеризованного индекса.
В примере 10.2 показано создание уникального составного индекса.
Создание уникального индекса для столбца, который уже содержит дубликаты значений, невозможно. Создание уникального индекса возможно, если каждое существующее значение данных (в том числе значение null) появляется лишь один раз. Точно так же любая попытка добавить или изменить существующее значение данных в столбец, включенный в существующий уникальный индекс, будет отвергнуто системой в случае дублирования значения.
Создание индексов файлов PDF, Adobe Acrobat
- Руководство пользователя Acrobat
- Введение в Acrobat
- Доступ к Acrobat с настольных компьютеров, мобильных устройств и интернета
- Новые возможности Acrobat
- Комбинации клавиш
- Системные требования
- Рабочее пространство
- Основные сведения о рабочем пространстве
- Открытие и просмотр файлов PDF
- Открытие документов PDF
- Навигация по страницам документа PDF
- Просмотр установок PDF
- Настройка режимов просмотра PDF
- Включение предварительного просмотра эскизов файлов PDF
- Отображать PDF в браузере
- Работа с учетными записями облачного хранилища в Интернете
- Доступ к файлам из Box
- Доступ к файлам из Dropbox
- Доступ к файлам из OneDrive
- Доступ к файлам из SharePoint
- Доступ к файлам из Google Диска
- Acrobat и macOS
- Уведомления Acrobat
- Сетки, направляющие и измерения в PDF
- Использование азиатского текста, кириллицы и текста слева направо в документах PDF
- Создание документов PDF
- Обзор процедуры создания документов PDF
- Создание файлов PDF в Acrobat
- Создание документов PDF с помощью PDFMaker
- Использование принтера Adobe PDF
- Преобразование веб-страниц в PDF
- Создание файлов PDF с помощью Acrobat Distiller
- Настройки преобразования Adobe PDF
- Шрифты PDF
- Редактирование документов PDF
- Редактирование текста в документах PDF
- Редактирование изображений и объектов в документе PDF
- Поворот, перемещение, удаление и изменение нумерации страниц PDF
- Редактирование отсканированных документов PDF
- Улучшение фотографий документов, снятых на камеру мобильного устройства
- Оптимизация документов PDF
- Свойства документов PDF и метаданные
- Ссылки и вложенные файлы в PDF
- Слои документов PDF
- Миниатюры страниц и закладки в документах PDF
- Мастер операций (Acrobat Pro)
- Файлы PDF, преобразованные в веб-страницы
- Настройка документов PDF для использования в презентации
- Статьи PDF
- Геопространственные файлы PDF
- Применение операций и сценариев к файлам PDF
- Изменение шрифта по умолчанию для добавления текста
- Удаление страниц из документов PDF
- Сканирование и распознавание текста
- Сканирование документов в формат PDF
- Улучшение фотографий документов
- Устранение неполадок сканера при использовании Acrobat для сканирования
- Формы
- Основные положения для работы с формами PDF
- Создание форм с нуля в Acrobat
- Создание и рассылка форм PDF
- Заполнение форм PDF
- Свойства полей форм PDF
- Заполнение и подписание форм PDF
- Настройка кнопок для выполнения действий в формах PDF
- Публикация интерактивных веб-форм PDF
- Основные положения для работы с полями форм PDF
- Поля форм PDF для штрих-кода
- Сбор данных формы PDF и управление ими
- Инспектор форм
- Помощь с формами PDF
- Отправка форм PDF получателям с использованием эл. почты или внутреннего сервера
- Объединение файлов
- Объединение или слияние файлов в один файл PDF
- Поворот, перемещение, удаление и перенумерация страниц PDF
- Добавление верхних и нижних колонтитулов, а также нумерации Бейтса в документы PDF
- Обрезка страниц PDF
- Добавление водяных знаков в документы PDF
- Добавление фона в документы PDF
- Работа с файлами, входящими в портфолио PDF
- Публикация портфолио PDF и предоставление совместного доступа
- Обзор портфолио PDF
- Создание и настройка портфолио PDF
- Общий доступ, редактирование и комментирование
- Предоставление общего доступа к документам PDF и их отслеживание онлайн
- Пометка текста при редактировании
- Подготовка к редактированию документа PDF
- Запуск процесса редактирования файлов PDF
- Размещение совместных рецензий на сайтах SharePoint или Office 365
- Участие в редактировании документа PDF
- Добавление комментариев в документы PDF
- Добавление штампа в файл PDF
- Процессы утверждения
- Управление комментариями | просмотр, добавление ответа, печать
- Импорт и экспорт комментариев
- Отслеживание редактирования PDF и управление им
- Сохранение и экспорт документов PDF
- Сохранение PDF
- Преобразование файлов PDF в формат Word
- Преобразование документа PDF в файл JPG
- Преобразование и экспорт документов PDF в файлы других форматов
- Параметры форматирования файлов для экспорта в PDF
- Повторное использование содержимого PDF
- Защита
- Повышенный уровень защиты документов PDF
- Защита документов PDF с помощью паролей
- Управление цифровыми удостоверениями
- Защита документов PDF с помощью сертификатов
- Открытие защищенных документов PDF
- Удаление конфиденциальных данных из документов PDF
- Установка политик безопасности файлов PDF
- Выбор метода защиты для документов PDF
- Предупреждения безопасности при открытии документов PDF
- Защита файлов PDF с Adobe Experience Manager
- Функция защищенного просмотра PDF-документов
- Обзор функций защиты в программе Acrobat и файлах PDF
- Язык JavaScript в файлах PDF, представляющий угрозу безопасности
- Вложения как угроза безопасности
- Разрешить или заблокировать ссылки в PDF-файлах
- Электронные подписи
- Подписание документов PDF
- Съемка подписи на мобильное устройство и использование ее в любых приложениях
- Отправка документов на электронные подписи
- О подписях сертификатов
- Подписи на основе сертификата
- Подтверждение цифровых подписей
- Доверенный список, утвержденный Adobe
- Управление доверенными лицами
- Печать
- Основные задачи печати файлов PDF
- Печать брошюр и портфолио в формате PDF
- Дополнительные настройки печати PDF
- Печать в PDF
- Печать цветных документов PDF (Acrobat Pro)
- Печать файлов PDF с помощью заказных размеров
- Расширенный доступ, теги и перекомпоновка
- Создание и проверка средств расширенного доступа к документам PDF
- Возможности расширенного доступа в файлах PDF
- Инструмент «Порядок чтения» в PDF
- Чтение документов PDF при помощи возможностей расширенного доступа и перекомпоновки
- Редактирование структуры документа на панелях «Содержимое» и «Теги»
- Создание документов PDF с расширенным доступом
- Поиск и индексация
- Индексирование файлов PDF
- Поиск в документах PDF
- 3D-модели и мультимедиа
- Добавление аудио, видео и интерактивных объектов в файлы PDF
- Добавление 3D-моделей в файлы PDF (Acrobat Pro)
- Отображение 3D-моделей в файлах PDF
- Взаимодействие с 3D-моделями
- Измерение 3D-объектов в файлах PDF
- Настройка 3D-видов в файлах PDF
- Включение 3D-содержимого в документе PDF
- Добавление мультимедийного контента в документы PDF
- Добавление комментариев для 3D-макетов в файлах PDF
- Воспроизведение видео-, аудио- и мультимедийных форматов в файлах PDF
- Добавление комментариев в видеоролики
- Инструменты для допечатной подготовки (Acrobat Pro)
- Обзор инструментов для допечатной подготовки
- Типографские метки и тонкие линии
- Просмотр цветоделения
- Обработка прозрачности
- Преобразование цветов и управление красками
- Цветовой треппинг
- Предпечатная проверка (Acrobat Pro)
- Файлы, совместимые с PDF/X-, PDF/A- и PDF/E
- Профили предпечатной проверки
- Расширенная предпечатная проверка
- Отчеты предпечатной проверки
- Просмотр результатов предпечатной проверки, объектов и ресурсов
- Методы вывода в PDF
- Исправление проблемных областей с помощью инструмента «Предпечатная проверка»
- Автоматизация процедуры анализа документов с помощью дроплетов или операций предпечатной проверки
- Анализ документов с помощью инструмента «Предпечатная проверка»
- Дополнительная проверка с помощью инструмента «Предпечатная проверка»
- Библиотеки предпечатной проверки
- Предпечатные переменные
- Управление цветом
- Обеспечение согласованности цветов
- Настройки цветов
- Управление цветом документов
- Работа с цветовыми профилями
- Основы управления цветом
 почты или внутреннего сервера
почты или внутреннего сервераСоздание индексов и управление ими в файлах PDF
Можно уменьшить затрачиваемое на поиск большого файла PDF время путем встраивания индекса слов документа.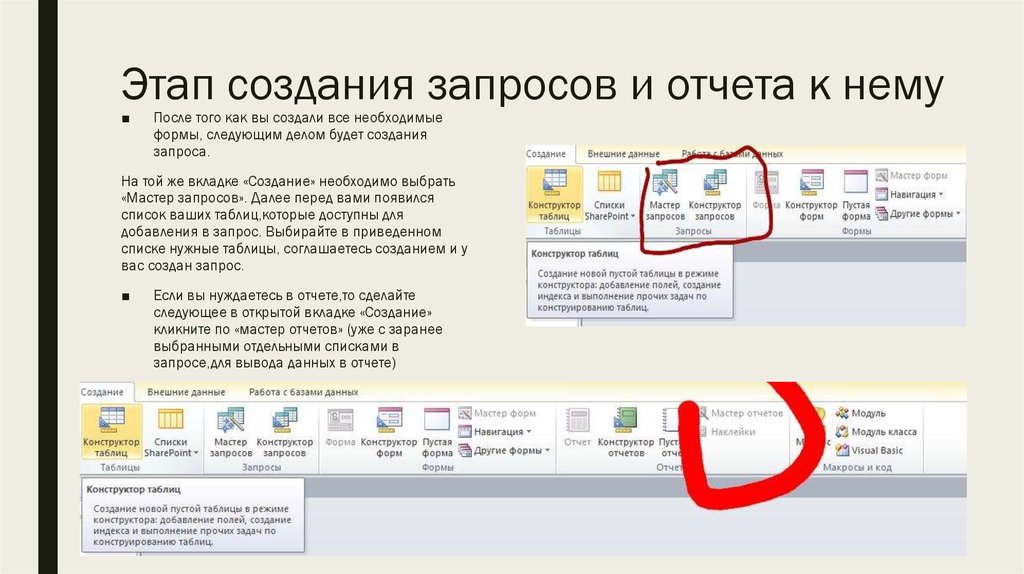 Acrobat производит поиск по индексу значительно быстрей, чем по документу. Встроенный индекс включается в распространяемые копии файлов PDF. Поиск по файлам PDF со встроенными индексами происходит точно так же, как если бы индексов не было, — никаких дополнительных шагов не требуется.
Acrobat производит поиск по индексу значительно быстрей, чем по документу. Встроенный индекс включается в распространяемые копии файлов PDF. Поиск по файлам PDF со встроенными индексами происходит точно так же, как если бы индексов не было, — никаких дополнительных шагов не требуется.
Начиная с выпуска Acrobat и Acrobat Reader за декабрь 2018 г. для поиска по PDF больше не используется встроенных индекс. Если вы все же хотите использовать индексы для поиска, смотрите статью Включение встроенных индексов в PDF для поиска.
Добавление индекса в файл PDF
В документе, открытом в Acrobat, выберите Инструменты > Индекс.
На дополнительной панели инструментов отобразится набор инструментов «Индекс».
На дополнительной панели инструментов выберите Управление встроенным индексом.
В диалоговом окне «Управление встроенным индексом» нажмите Встроить индекс.
Прочитайте появившиеся сообщения и нажмите OK.
В Outlook и Lotus Notes есть возможность встраивания индекса при преобразовании в PDF сообщений электронной почты или папок. Особенно это рекомендуется для папок, содержащих много сообщений электронной почты.
Обновление или удаление встроенного индекса в документе PDF
Выберите Инструменты > Индекс.
На дополнительной панели инструментов отобразится набор инструментов «Индекс».
На дополнительной панели инструментов выберите Управление встроенным индексом.
Нажмите Обновить индекс или Удалить индекс.
О функции «Каталог» (Acrobat Pro)
Можно сделать определенную группу документов PDF каталогом и создать общий индекс для всех входящих в него документов. Индекс позволяет гораздо быстрее осуществлять процедуру поиска определенных данных в каталогизированных документах PDF.
Индекс можно поместить вместе с документами PDF в коллекцию файлов, распространяемую на компакт-диске.
Каталогизировать можно документы, написанные латинскими, китайскими, японскими или корейскими символами. Каталогизируемыми элементами могут быть: текст документа, комментарии, закладки, поля форм, теги, метаданные объектов или документа, вложения, сведения о документе, цифровые подписи, метаданные изображений XIF (расширенный формат файлов-изображений) и пользовательские свойства документа.
Подготовка документов PDF к индексации (Acrobat Pro)
Сначала необходимо создать папку, в которой будут храниться индексируемые файлы PDF. Все файлы PDF должны содержать данные содержимого и электронных свойств, таких как ссылки, закладки и поля форм. Если индексируемые файлы содержат сканированные документы, убедитесь, что текст этих документов распознан и может быть использован при поиске. Для повышения производительности поиска разбейте длинные документы на небольшие документы размером с одну главу. Для улучшения поиска к свойствам документа можно добавить соответствующие сведения.
Для улучшения поиска к свойствам документа можно добавить соответствующие сведения.
Перед индексированием коллекции документов важно установить структуру документа на диске или томе сетевого сервера и проверить имена межплатформенных файлов. Имена файлов могут оказаться урезанными, а межплатформенный поиск вследствие этого — затруднительным. Чтобы избежать этой проблемы, следуйте дальнейшим указаниям.
Переименуйте файлы, папки и индексы в соответствии с соглашением об именовании файлов в MS-DOS (восемь или менее символов, за которыми следует файловое расширение из трех символов). Это тем более необходимо сделать, если планируется поставлять коллекцию документов вместе с индексом на компакт-диске формата ISO 9660.
Удалите из имен файлов и папок символы расширенного набора, например символы ударений или неанглийские символы. (Шрифт, используемый функцией «Каталог», не поддерживает коды символов с 133 по 159.)
Не используйте папки с глубоким уровнем вложения или с длиной пути к файлу, превышающей 256 символов, в индексах, которые будут использоваться для Mac OS.
При использовании Mac OS на сервере OS/2 LAN настройте IBM® LAN Server Macintosh (LSM) так, чтобы использовались имена файлов MS-DOS, или индексируйте только тома FAT. (Тома HPFS [High Performance File System] могут содержать длинные неизвлекаемые имена файлов).
Если структура документа включает в себя подпапки, не предназначенные для индексирования, их можно исключить из процесса индексирования.
Добавление метаданных к свойствам документа (Acrobat Pro)
Чтобы облегчить поиск документа PDF, можно добавить сведения о файле, называемые метаданными, в свойства документа (свойства открытого в настоящий момент документа PDF можно просмотреть, выбрав меню Файл > Свойства и перейдя на вкладку Описание).
При добавлении данных в свойства документа придерживайтесь следующих рекомендаций:
Используйте информативный заголовок в поле «Заголовок». Имя файла документа должно отображаться в диалоговом окне Результаты поиска.
Для информации подобного рода всегда используйте одно и то же поле. Например, не рекомендуется добавлять важный термин в поле Тема для одного документа и тот же термин в поле Ключевые слова для другого документа.
Используйте единообразные, согласованные термины для одинаковых данных. Например, не рекомендуется использовать слово биология для одних документов и термин наука о жизни для других.
Заполняйте поле Автор — это поможет определить ответственных за создание и ведение документа. Например, автором документа, посвященного стратегии найма сотрудников, может быть отдел по работе с персоналом.
Если вы используете номера для обозначения различных частей документа, добавьте их в качестве ключевых слов. Например, добавление в ключевые слова doc#=m234 может обозначать определенный документ из нескольких сотен документов на заданную тематику.
Для классификации документов по типу используйте поля Тема и Ключевые слова либо по отдельности, либо в сочетании друг с другом. Например, для одного документа в поле «Тема» можно указать отчет о состоянии, а в поле «Ключевые слова» внести слова ежемесячный или еженедельный.
Если у вас уже есть опыт работы с документами Adobe PDF, то при создании индекса можно определить пользовательские поля, например Тип документа, Номер документа и Идентификатор документа. Выполнять эти действия рекомендуется только опытным пользователям, они не описываются в справке по Acrobat.

Создание индекса для коллекции (Acrobat Pro)
При построении нового индекса Acrobat создает файл с расширением .pdx и новую вспомогательную папку, в которой содержится один или несколько файлов с расширением .idx. IDX-файлы содержат записи индекса. Все эти файлы должны быть доступны пользователям, которые хотят осуществлять поиск по индексу.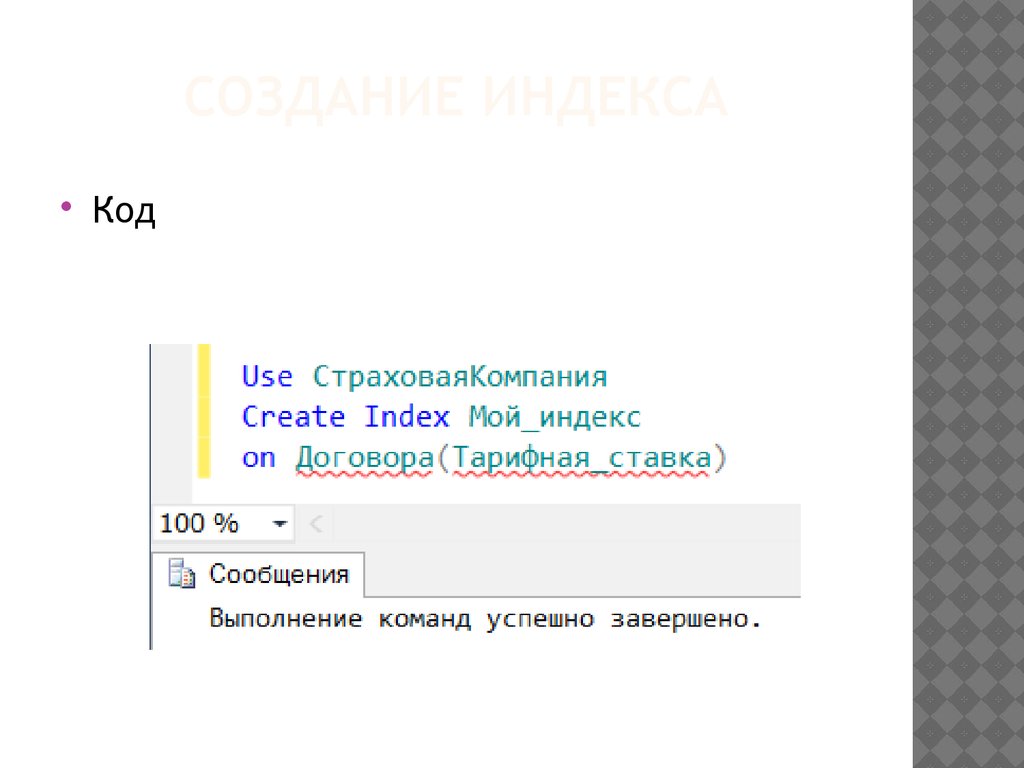
Выберите Инструменты > Индекс.
На дополнительной панели инструментов отобразится набор инструментов «Индекс».
На дополнительной панели инструментов выберите Полнотекстовый индекс с каталогом.
Отобразится диалоговое окно «Каталог».
В диалоговом окне Каталог нажмите Создать индекс.
Появится диалоговое окно «Новое определение индекса».
Диалоговое окно «Новое определение индекса».
В поле Заголовок индекса введите имя файла индекса.
В поле Описание индекса введите несколько слов, описывающих тип индекса и его назначение.
Нажмите кнопку Параметры и выберите дополнительные параметры, которые необходимо применить к индексу. Затем нажмите кнопку ОК.
В диалоговом окне «Параметры» можно указать дополнительные параметры для нового индекса.
В области Включить эти папки нажмите кнопку Добавить, выберите папку, содержащую некоторые или все файлы PDF для индексирования, и затем нажмите кнопку ОК. Чтобы добавить другие папки, повторите этот шаг.
В процесс индексирования будут включены все подпапки выбранной папки. Если не планируется перемещать индекс или любые элементы коллекции документов, к данному списку можно добавлять папки, расположенные на разных серверах или дисковых накопителях.
В области Исключить эти папки нажмите кнопку Добавить и выберите любую вложенную папку, содержащую файлы PDF, которые необходимо исключить из процесса индексирования. Нажмите кнопку OK и при необходимости повторите действия.
Просмотрите выбранные папки. Для внесения изменений в список включаемых и исключаемых из индексирования папок выберите папку, которую вы хотите удалить, и нажмите кнопку Удалить.
Нажмите кнопку Создать и укажите местоположение файла индекса. Нажмите кнопку Сохранить и затем выполните следующие действия.
При остановке процесса индексирования возобновить тот же сеанс индексирования нельзя, однако повторять все предварительные действия уже не нужно. Выбранные параметры и папки сохраняются. Можно выполнить команду «Открыть индекс», выбрать частично завершенный индекс и исправить его.
Если при использовании параметров «Включить эти папки» и «Исключить эти папки» длинные имена путей окажутся усеченными, наведите указатель на символ многоточия (…) и подождите, пока не появится подсказка, отображающая полный путь к включенной или исключенной папке.

Диалоговое окно «Параметры индексирования»
Не включать числа
При выборе этого параметра из индекса исключаются все числа, входящие в текст документа. Исключение из индекса чисел может существенно сократить размер индекса и ускорить поиск.
Добавлять идентификаторы к файлам Adobe PDF версии 1.0
Этот параметр устанавливается, если коллекция документов содержит файлы PDF, созданные в программе Acrobat версии ниже 2.0, в которых идентификаторы не добавлялись автоматически. Идентификаторы необходимы, когда длинные имена файлов в Mac OS сокращаются при их переводе в имена файлов DOS. Программа Acrobat 2.0 и более поздних версий автоматически добавляет эти идентификаторы.
Не предупреждать об измененных документах в процессе поиска
Если этот параметр не выбран, при поиске в документах, изменившихся с момента последнего построения индекса, появляется соответствующее сообщение.
Заказные свойства
Этот параметр используется для включения в индекс пользовательских свойств документа. Индексируются только пользовательские свойства документа, уже существующие в индексируемых документах PDF. Введите свойство, сделайте выбор в меню «Тип» и затем нажмите кнопку «Добавить». Эти свойства появляются в качестве параметров поиска в меню дополнительных критериев поиска окна Поиск в PDF при поиске в итоговом индексе. Например, если ввести пользовательское свойство Имя документа и определить его в меню «Тип» как строковое, то при поиске в индексе можно осуществлять поиск по этому пользовательскому свойству, выбрав в меню Использовать дополнительные критерии параметр Имя документа.
Эти свойства появляются в качестве параметров поиска в меню дополнительных критериев поиска окна Поиск в PDF при поиске в итоговом индексе. Например, если ввести пользовательское свойство Имя документа и определить его в меню «Тип» как строковое, то при поиске в индексе можно осуществлять поиск по этому пользовательскому свойству, выбрав в меню Использовать дополнительные критерии параметр Имя документа.
При создании в приложении Microsoft Office пользовательских полей, для которых в приложении PDFMaker установлен параметр «Преобразование сведений о документе», поля будут преобразовываться для любых создаваемых PDF-файлов.
Поля XMP
Этот параметр используется для включения пользовательских полей XMP. Пользовательские поля XMP индексируются и отображаются во всплывающих меню дополнительных критериев поиска для включения в поиск по выбранным индексам.
Исключения
Этот параметр используется для исключения отдельных слов (максимум 500) из результатов поиска по индексу. Введите слово, нажмите кнопку «Добавить». При необходимости повторите это действие. Исключение слов может привести к уменьшению размеров индекса на 10–15%. Стоп-слово может содержать до 128 символов и является чувствительным к регистру.
Введите слово, нажмите кнопку «Добавить». При необходимости повторите это действие. Исключение слов может привести к уменьшению размеров индекса на 10–15%. Стоп-слово может содержать до 128 символов и является чувствительным к регистру.
Чтобы пользователи напрасно не вводили поисковые запросы, содержащие эти слова, список неиндексируемых слов приведен в файле Readme каталога.
Теги структуры
Этот параметр используется для обеспечения возможности поиска по узлам тегов в документах, имеющих тегированную логическую структуру.
Параметры «Заказные свойства», «Исключения» и «Теги структуры» применяются только к текущему индексу. Чтобы применить эти параметры для всех создаваемых индексов, можно изменить настройки по умолчанию для пользовательских полей, стоп-слов и тегов в панели «Каталог» диалогового окна «Установки».
Файлы Readme каталога (Acrobat Pro)
Зачастую хорошим решением оказывается создать отдельный файл Readme и поместить его в папку с индексом. В файле Readme могут содержаться полезные сведения об индексе, например, следующие:
В файле Readme могут содержаться полезные сведения об индексе, например, следующие:
Типы индексируемых документов.
Поддерживаемые параметры поиска.
Контактные данные (имя, номер телефона) лица, которое может ответить на интересующие вопросы.
Список чисел или слов, исключаемых из индекса.
Список папок, содержащих документы, которые включены в индекс, построенный в локальной сети, или список документов, которые включены в индекс, построенный по отдельному диску. Сюда можно также включить краткое описание содержимого каждой папки или документа.
Список значений по каждому документу, если заполнены поля «Сведения о документе».
Если каталог содержит очень большое число документов, в файл Readme можно включить таблицу, описывающую значения, присвоенные каждому документу. Эта таблица может входить в состав файла Readme, либо ее можно сохранить в отдельном документе. При разработке индекса эту таблицу можно использовать для сохранения согласованности.

Изменение индекса (Acrobat Pro)
Существующий индекс можно обновить, перестроить или удалить.
Выберите Инструменты > Индекс.
На дополнительной панели инструментов отобразится набор инструментов «Индекс».
На дополнительной панели инструментов выберите Полнотекстовый индекс с каталогом.
Отобразится диалоговое окно «Каталог».
В диалоговом окне Каталог нажмите Открыть индекс.
Найдите и выберите файл определения индекса (PDX), затем нажмите кнопку Открыть.
Если индекс был создан в программе Acrobat версии 5.0 или более ранней, для создания индекса выберите команду Создать копию (не перезаписывая поверх более ранней версии) или команду Заменить старый индекс, чтобы записать новый индекс поверх старого.
В диалоговом окне Определение индекса внесите необходимые изменения, затем выберите действие, которое хотите выполнить в Acrobat:
Создать
Создает новый IDX-файл с существующими данными и обновляет его, добавляя новые элементы и отмечая измененные или устаревшие элементы как недействительные.
Если количество таких изменений велико или если часто выполнять такие изменения, вместо создания нового индекса, время поиска может увеличиться.Перестроить
Создает новый индекс, переписывая существующую индексную папку и все ее содержимое (то есть IDX-файлы).
Очистить
Удаляет содержимое индекса (IDX-файлы), не удаляя сам индексный файл (PDX).
 Если количество таких изменений велико или если часто выполнять такие изменения, вместо создания нового индекса, время поиска может увеличиться.
Если количество таких изменений велико или если часто выполнять такие изменения, вместо создания нового индекса, время поиска может увеличиться.Установки каталога (Acrobat Pro)
Можно задать установки индексирования, которые будут применяться глобально ко всем создаваемым впоследствии индексам. Некоторые из этих установок можно переопределить для конкретного индекса, выбрав для него новые параметры во время построения индекса.
В диалоговом окне Установки в разделе Категории выберите Каталог. Многие параметры совпадают с теми, которые были описаны для процесса построения индекса.
Параметр «Принудительная совместимость с ISO 9660 для папок» полезно использовать, если при подготовке документов для индексирования нет необходимости менять длинные имена документов PDF на имена файлов MS-DOS.
Тем не менее имена папок должны быть преобразованы в стандарт именования файлов MS-DOS (8 символов или меньше), даже если такое преобразование не является необходимым для имен файлов.
Обновления индекса по расписанию (Acrobat Pro)
Используйте функцию каталога и пакетный файл каталога PDX (.bpdx) для определения, когда и как часто автоматически создавать, создавать заново, обновлять и очищать индекс. Файл BPDX представляет собой текстовый файл, содержащий список флагов и путей к индексному файлу каталога в зависимости от используемой платформы. Для отображения файла BPDX в Acrobat можно использовать такие приложения, как Назначенные задания в Windows. Acrobat повторно создает индекс в соответствии с флагами в файле BPDX.
Чтобы использовать файлы BPDX, в диалоговом окне «Установки» в подразделе «Каталог» выберите «Разрешить запуск пакетных файлов каталога (.bpdx)».
Перемещение коллекций и их индексов (Acrobat Pro)
Разработанную и протестированную на локальном жестком диске индексированную коллекцию документов можно затем переместить в виде законченной коллекции на сетевой сервер или диск. Определение индекса содержит относительные пути от файла определения индекса (PDX) к папкам, содержащим индексированные документы. Если эти относительные пути не изменятся, перестраивать индекс после перемещения коллекции документов не потребуется.
Определение индекса содержит относительные пути от файла определения индекса (PDX) к папкам, содержащим индексированные документы. Если эти относительные пути не изменятся, перестраивать индекс после перемещения коллекции документов не потребуется.
Если PDX-файл и папки, содержащие индексированные документы, расположены в одной папке, сохранение относительного пути достигается простым перемещением этой папки.
Если относительный путь изменится, то после перемещения индексированной коллекции документов необходимо создать новый индекс. Однако в любом случае можно использовать исходный PDX-файл. Чтобы использовать исходный PDX-файл, вначале следует переместить индексированные документы. Затем необходимо скопировать PDX-файл в папку, в которой планируется создать новый индекс, и при необходимости изменить списки включенных или исключенных папок и подпапок.
Если индекс располагается на сетевом диске или сервере отдельно от любой части файлов коллекции, то перемещение либо коллекции, либо индекса приведет к повреждению индекса. Если коллекция документов перемещается в другое сетевое местоположение или на компакт-диск, индекс для нее необходимо создавать и строить в том же месте, куда перемещается коллекция.
Если коллекция документов перемещается в другое сетевое местоположение или на компакт-диск, индекс для нее необходимо создавать и строить в том же месте, куда перемещается коллекция.
Индексы в PostgreSQL
Виталий Сушков
Full Stack Developer в DataArt
В статье я расскажу о предназначении и основах принципов работы объектов баз данных — индексов. На примере СУБД PostgreSQL коротко рассмотрим несколько разных типов индексов и классов задач, для которых они применимы. В конце материала поделюсь ссылками на статьи с более глубоким описанием внутреннего устройства индексов в PostgreSQL.
Статья может быть полезна начинающим разработчикам и студентам, имеющим общие представления о реляционных базах данных, и опытным разработчикам, не сталкивавшимся раньше с индексами и их устройством.
Предназначение индексов
Простейший метод решения задачи поиска записей в базе данных, удовлетворяющих определенному критерию, — полный перебор. Но с ростом количества записей производительность такого подхода будет заметно падать. Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Для повышения производительности поиска создаются вспомогательные структуры — индексы. Используя индексы, можно существенно поднять скорость поиска, потому что данные в индексе хранятся в форме, позволяющей нам в процессе поиска не рассматривать области, которые заведомо не могут содержать искомые элементы.
Если провести аналогию между базой данных и книгой, индексами можно считать оглавление книги и предметный указатель. Действительно, если бы у нас не было таких «индексов», для поиска конкретной главы или для поиска определения какого-то понятия пришлось бы листать и читать всю книгу целиком, пока не найдем то, что нужно. Имея оглавление и предметный указатель, нам нужно просмотреть существенно меньший объем данных, после чего мы точно узнаем номер страницы книги, на которой находится то, что мы ищем. Индексы в базах данных по сути устроены так же, как оглавление или как предметный указатель книги.
Важно, что использование индексов не только сокращает время поиска в абсолютном выражении, но и уменьшает алгоритмическую сложность процесса поиска. Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
Это значит, что время, необходимое на поиск с помощью индексов, при росте объема базы данных будет расти существенно медленнее, чем при использовании полного перебора.
В качестве примера рассмотрим задачу поиска в списке чисел. Используя перебор элементов списка, в худшем случае, нам придется просмотреть список целиком. Алгоритмическая сложность такого метода — O(n). Но если мы будем хранить наши числа особым образом — отсортированными по возрастанию или по убыванию — сможем использовать алгоритм бинарного поиска.
2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
Допустим, необходимо определить, содержит ли этот отсортированный список число 158. Для этого:
- Смотрим на число в середине списка — 114. Наш список отсортирован по возрастанию, и мы ищем число 158 > 114. Значит, левую половину списка до числа 114 мы можем отбросить: в ней гарантированно не может быть искомого элемента.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
- Теперь делаем то же самое для правой половины списка. В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
- 2 4 5 10 23 34 38 58 112 114 115 110 123 134 138 158 180
 В середине у нее число 134, значит, мы снова можем отбросить элементы левее.
В середине у нее число 134, значит, мы снова можем отбросить элементы левее.- Делаем то же самое для элементов правее 134. В середине у них число 158 — искомый элемент. Поиск закончен.
В итоге метод бинарного поиска дал нам результат всего за три шага. При полном переборе с начала списка нам потребовалось бы 16 шагов. Бинарный поиск имеет алгоритмическую сложность O(log(n)). Используя формулы алгоритмической сложности O(n) и O(log(n)), мы можем оценить, как будет меняться приблизительное количество операций при поиске разными способами с ростом объема данных:
Результат впечатляет. Храня данные в отсортированном виде, мы не только снизили скорость поиска по ним, но и колоссально сократили скорость замедления поиска при росте объема данных.
Использование индексов в базе данных дает аналогичный результат. Принцип работы одного из важнейших индексов в базе данных (индекс на основе B-дерева) основан именно на рассмотренном нами выше принципе — возможности хранить данные в отсортированном виде.
Индексы в PostgreSQL
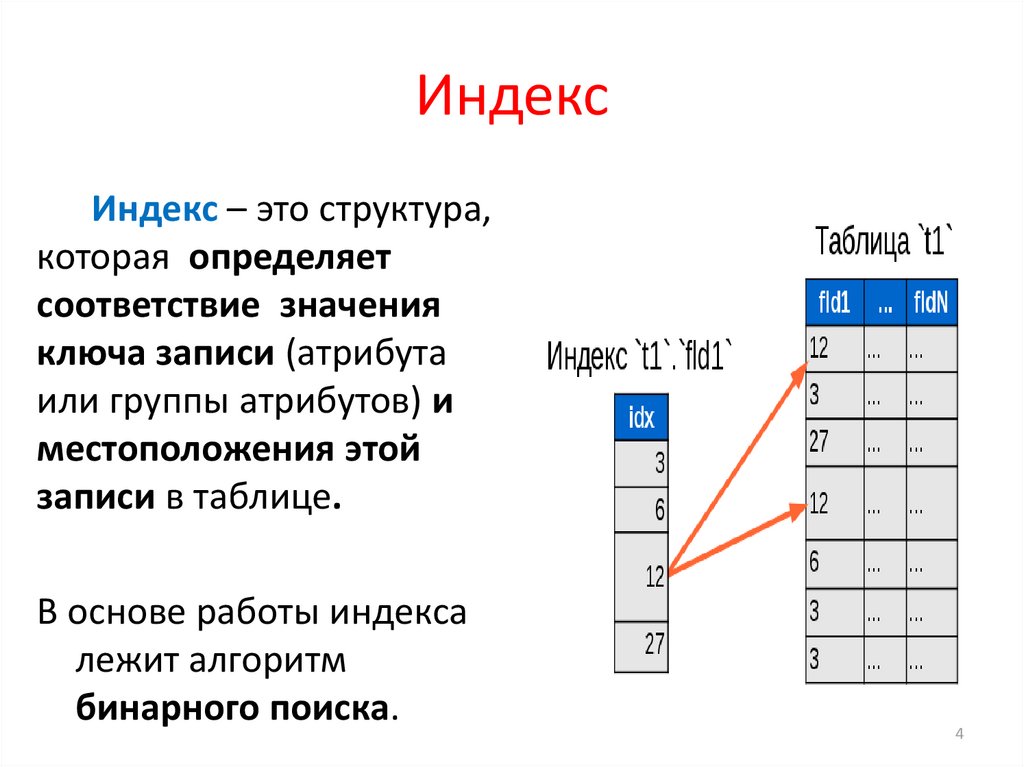
В базах данных, таких как PostgreSQL, индекс формируется из значений одного или нескольких столбцов таблицы и указателей на строки этой таблицы.
Рассмотрим запрос:
SELECT * FROM table_name WHERE P(column_name) = 1
Здесь выражение P(column_name) = 1 означает, что значение в колонке column_name удовлетворяет некоторому условию (предикату) P.
В отсутствии индекса для колонки column_name, PostgreSQL для выполнения этого запроса был бы вынужден просмотреть таблицу table_name целиком, вычисляя для каждой строки значение предиката P и, если значение истинно, добавлял бы строку к результатам запроса.
Имея индекс для колонки column_name, PostgreSQL может быстро, не просматривая таблицу целиком, получить из индекса указатели на строки таблицы, которые удовлетворяют условию P, и затем уже по этим указателям прочитать данные из таблицы и сформировать результат. Это аналогично тому, как мы, вместо того чтобы просматривать всю книгу целиком, смотрим только ее оглавление, читаем номера страниц, соответствующие интересующим нам главам, а затем переходим на эти страницы.
Предикат P может вычисляться от значения нескольких колонок. В этом случае для ускорения запроса используется индекс, построенный не для одной колонки, а для нескольких. Такие индексы называют составными.
Если мы хотим ускорить выполнение запроса, условие которого вычисляется по одной или нескольким колонкам, в PostgreSQL нам необходимо создать для этих колонок индекс с помощью команды CREATE INDEX:
CREATE INDEX index_name ON table_name (column_name_1, column_name_2,....)
Эта команда имеет большой перечень дополнительных параметров, с полным списком которых можно ознакомиться в документации.
Например, индекс может поддерживать ограничение на уникальность и не допускать появления в таблице нескольких строк, значения индексируемых столбцов у которых совпадают. Для этого при создании индекса указывают ключевое слово UNIQUE:
CREATE UNIQUE INDEX index_name ON table_name (column_name_1, column_name_2,....)
Или мы можем создать индекс не по полю таблицы, а по функции или скалярному выражению с одной или несколькими колонками таблицы (такие индексы называют функциональными или индексами по выражению). Это позволяет быстро находить данные в таблице по результатам вычислений. Например, мы хотим ускорит запрос регистронезависимого поиска по текстовому полю:
SELECT * FROM table_name WHERE lower(text_field) = 'some_string_in_lower_case'
Если мы создадим обычный индекс по полю text_field, он нам никак не поможет, т. к. PostgreSQL проиндексирует те значения, которые хранятся в этом поле в исходном виде (необязательно в нижнем регистре), а мы хотим искать по значениям этого поля, приведенные к нижнему регистру вызовом функции lower. Однако мы можем создать индекс по результатам вычисления выражения lower(text_fields):
CREATE INDEX index_name ON table_name(lower(text_field))
И такой индекс уже может успешно применяться для ускорения нашего запроса.
В зависимости от типа индексируемых данных, для индексирования применяются разные подходы. По умолчанию при создании индекса используется индекс на основе B-дерева. Но PostgreSQL поддерживает разные типы индексов для очень широкого круга задач, и при необходимости мы можем указать другой тип индекса, отличный от B-tree. Для этого перед списком индексируемых полей необходимо указать директиву USING <тип_индекса>. Например, для использования индекса типа GiST:
CREATE INDEX index_name ON table_name USING GIST (column_name)
B-tree
Этот тип индекса используется по умолчанию и покрывает очень широкий круг задач (базы данных большинства приложений успешно могут обходиться только индексами на основе B-деревьев).
С помощью B-дерева можно проиндексировать любые данные, которые могут быть отсортированы, т. е. для которых применимы операции сравнения больше/меньше/равно. Сюда можно отнести числа, строки, даты и время, логический тип и любые данные, которые можно ими закодировать.
Какой тип запросов может быть ускорен с помощью B-дерева? На самом деле, практически любой запрос, условие которого является выражением, состоящим из полей входящих в индекс, логических операторов и операций равенства/сравнения. Например:
- Найти пользователя по его email:
SELECT * FROM users WHERE email='user@mail.com'
- Найти товары одной из двух категорий:
SELECT * FROM goods WHERE category_id = 10 OR category_id = 20
- Найти количество пользователей, зарегистрировавшихся в конкретный месяц:
SELECT COUNT(id) FROM users WHERE reg_date >= 01.01.2021 AND reg_date <= 31.01.2021
Выполнение этих и многих других запросов может быть ускорено с помощью B-дерева. Кроме того, индекс на основе B-дерева ускоряет сортировку результатов, если в ORDER BY указано проиндексированное поле.
Принцип работы индекса на основе B-дерева основан на рассмотренном нами ранее алгоритме бинарного поиска: т. к. все значения упорядочены, мы можем быстро определять области, в которых гарантированно не может быть данных, удовлетворяющих запрос, существенно снижая таким образом количество перебираемых записей.
Однако хранить индекс просто в виде отсортированного массива мы не можем, т. к. данные могут модифицироваться: значения могут меняться, записи — удаляться или добавляться. Чтобы эффективно поддерживать хранение индексируемых данных в отсортированном виде, индекс хранят в виде сбалансированного сильно ветвящегося дерева, называемого B-деревом (B-tree).
Корневой узел B-дерева содержит в упорядоченном виде несколько значений из общего набора, допустим, t элементов. Тогда все остальные элементы можно распределить по t+1 дочерним поддеревьям по следующему правилу:
- Первое поддерево будет содержать элементы, которые меньше, чем 1-й элемент корневого узла (на рисунке выше первое поддерево содержит числа, меньшие 30).
- Второе поддерево будет содержать элементы, которые находятся между 1-м и 2-м элементами корневого узла (на рисунке выше второе поддерево содержит числа между 30 и 70).
- И т. д. — последнее поддерево будет содержать элементы, большие элемента корневого узла с номером t (на рисунке выше третье поддерево содержит элементы, большие 70).
Каждое поддерево, в свою очередь, тоже является B-деревом, имеет корневой элемент и строится далее рекурсивно по такому же принципу.
За счет того что элементы в каждом узле отсортированы, при поиске мы сможем быстро определить, в каком поддереве может находиться искомый элемент, и не рассматривать вообще другие поддеревья. Допустим, нам нужно найти число 67:
- Корневой узел содержит числа 30 и 70, значит, искомый элемент следует искать во втором поддереве, т.к. 67 > 30 и 67 < 70.
- Корневой узел второго поддерева содержит элементы 40 и 50. Т. к. 67 > 50, искомый элемент следует искать в третьем потомке этого узла.
- На третьем шаге мы получили узел, не имеющий потомков, среди элементов которого находим искомое число 67.
Таким образом, при поиске в B-дереве необходимо максимум h раз выполнить линейный или бинарный поиск в относительно небольших списках, где h — это высота дерева. Т.к. B-дерево — сильно-ветвящееся и сбалансированное (т. е. при его построении и модификации применяются алгоритмы, сохраняющие его высоту минимальной, см. статью), число h обычно совсем невелико, и при росте общего количества элементов оно растет логарифмически. Как мы уже видели ранее, это приносит очень хорошие результаты.
Кроме того, важное и полезное свойство B-дерева при его использовании в СУБД — возможность эффективно хранить его во внешней памяти. Каждый узел B-дерева обычно хранит такой объем данных, который может быть эффективно записан на диск или прочитан за одну операцию ввода-вывода. B-дерево даже может не помещаться целиком в оперативной памяти. В этом случае СУБД может держать в памяти только узлы верхнего уровня (которые вероятно будут часто использоваться при поиске), читая узлы нижних уровней только при необходимости.
Индекс на основе B-дерева может ускорять запросы, которые используют не целиком входящие в индекс поля, а любую часть, начиная с начала. Например, индекс может ускорить запрос LIKE для поиска строк, которые начинаются с заданной подстроки:
SELECT * FROM table_name WHERE text_field LIKE 'start_substring%'
Если индекс построен по нескольким колонкам, он может ускорять запросы, в которых фигурируют одна или несколько первых колонок. Поэтому важен порядок, в котором мы указываем колонки при создании индекса. Допустим, у нас есть индекс по колонкам col_1 и col_2. Тогда он может использоваться в том числе для ускорения запроса вида:
SELECT * FROM table_name WHERE col_1 = 123
И нам не нужно создавать отдельный индекс для колонки col_1. Будет использоваться составной индекс (col_1, col_2).
Однако для запроса только по колонке col_2 такой составной индекс уже использовать не получится.
Подробнее, как индекс на основе B-дерева реализован в PostgreSQL, см. статью.
GiST и SP-GiST
GiST — сокращение от «generalized search tree». Это сбалансированное дерево поиска, точно так же, как и рассмотренный ранее b-tree. Но b-tree применимо только к тем типам данных, для которых имеет смысл операция сравнения и есть возможность упорядочивания. Но PostgreSQL позволяет хранить и такие данные, для которых операция упорядочивания не имеет смысла, например, геоданные и геометрические объекты.
Тут на помощь приходит индексный метод GiST. Он позволяет распределить данные любого типа по сбалансированному дереву и использовать это дерево для поиска по самым разным условиям. Если при построении B-дерева мы сортируем все множество объектов и делим его на части по принципу больше-меньше, при построении GiST индексов можно реализовать любой принцип разбиения любого множества объектов.
Например, в GiST-индекс можно уложить R-дерево для пространственных данных с поддержкой операторов взаимного расположения (находится слева, справа; содержит и т. д.). Такой индекс доступен в PostgreSQL и может быть полезен при разработке геоинформационных систем, в которых возникают запросы вида «получить множество объектов на карте, находящихся от заданной точки на расстоянии не более 1 км».
SP-GiST похож GiST, но он позволяет создавать несбалансированные деревья. Такие деревья могут быть полезны при разбиении множества на непересекающиеся объекты. Буквы SP означают space partitioning. К такому типу индексов можно отнести kd-деревья, реализация которых присутствует в PostgreSQL. Его, как и R-дерево, можно использовать для ускорения запросов геометрического поиска. Свойство непересечения упрощает принятие решений при вставке и поиске. С другой стороны, получающиеся деревья, как правило, слабо ветвисты, что усложняет их эффективное хранение во внешней памяти.
Кроме того, GiST и SP-GiST могут служить своеобразным фреймворком, облегчающим расширение PostgreSQL и добавление в него совершенно новых видов деревьев для индексации новых типов данных.
Подробнее об алгоритмах, лежащих в основе R- и kd-деревьев см. раз и два, а об их реализации и использовании в PostgreSQL см. в этой и этой статье.
Заключение
Индексы — важнейший инструмент баз данных, ускоряющий поиск. Он не бесплатен, создавать много индексов без лишней необходимости не стоит — индексы занимают дополнительную память, и при любом обновлении проиндексированных данных СУБД должна выполнять дополнительную работу по поддержанию индекса в актуальном состоянии.
PostgreSQL поддерживает разные типы индексов для разных задач:
- B-дерево покрывает широчайший класс задач, т. к. применимо к любым данным, которые можно отсортировать.
- GiST и SP-GiST могут быть полезны при работе с геометрическими объектами и для создания совершенно новых типов индексов для новых типов данных.
- За рамками этой статьи оказался ещё один важный тип индексов — GIN. GIN индексы полезны для организации полнотекстового поиска и для индексации таких типов данных, как массивы или jsonb. Подробнее см. в статье. Современные версии PostgreSQL имеют вариацию такого индекса под названием RUM (см. статью).
Ссылки на полезные материалы
- Создание индекса в PostgreSQL
- Алгоритмы работы с B-деревом
- Релизация B-дерева в PostgreSQL
- R-дерево
- Kd-дерево
- Индекс типа GiST в PostgreSQL
- Индекс типа SP-GiST в PostgreSQL
- Индекс типа GIN в PostgreSQL
- Индекс типа RUM в PostgreSQL
НОУ ИНТУИТ | Лекция | Создание и использование индексов
< Лекция 16 || Лекция 17: 123456789 || Лекция 18 >
Аннотация: Чем больше становится ваша база данных, тем, вероятнее всего, возрастает количество и сложность запросов. Для повышения эффективности производительности запросов путем снижения количества операций ввода-вывода используются индексы. Некоторые аспекты из теории программирования необходимо знать для лучшего усвоения материала. Рассматриваются простые и составные индексы, их отличие и применение. Проводится обзор мастеров: Create Index Wizard и Full-Text Indexing Wizard. И, конечно же, использованию T-SQL уделено немало разделов.
Ключевые слова: базы данных, производительность, индекс, SQL, server, доступ, создание индекса, связанный список, кластеризованные индексы, некластеризованные индексы, критерии поиска, оптимизатор запросов, запрос на предложения, селективность, уникальный индекс, ключ индекса, план исполнения, topic, предупреждающее сообщение, table column, подсистема ввода-вывода, population, TIMESTAMP, создание каталогов, удаление индекса, кластерный ключ, оператор UPDATE, percent, hint, estimated
Индексы – одно из самых мощных средств, доступных разработчику базы данных. Индекс – это вспомогательная структура, позволяющая вам повышать производительность запросов за счет снижения количества операций ввода-вывода, необходимых для поиска запрошенных данных; т.е. индекс позволяет системе Microsoft SQL Server 2000 находить данные, используя меньшее число операций ввода-вывода, чем при поиске данных путем доступа только к таблице базы данных. Если для поиска строки данных вы используете индекс таблицы базы данных, SQL Server может быстро определить, где хранятся эти данные и сразу считать эти данные. Таким образом, индексы таблиц базы данных во многом похожи на индексы (алфавитные указатели) в книгах: в обоих случаях обеспечивается быстрый доступ к большим объемам информации.
В этой лекции вы узнаете об основах индексирования, включая создание индекса и типы индексов, доступные в SQL Server. Вы также узнаете, когда использовать индексы и когда не нужно их использовать, поскольку использование индекса не всегда эффективно – в некоторых ситуациях это приводит к снижению производительности.
Что такое индекс?
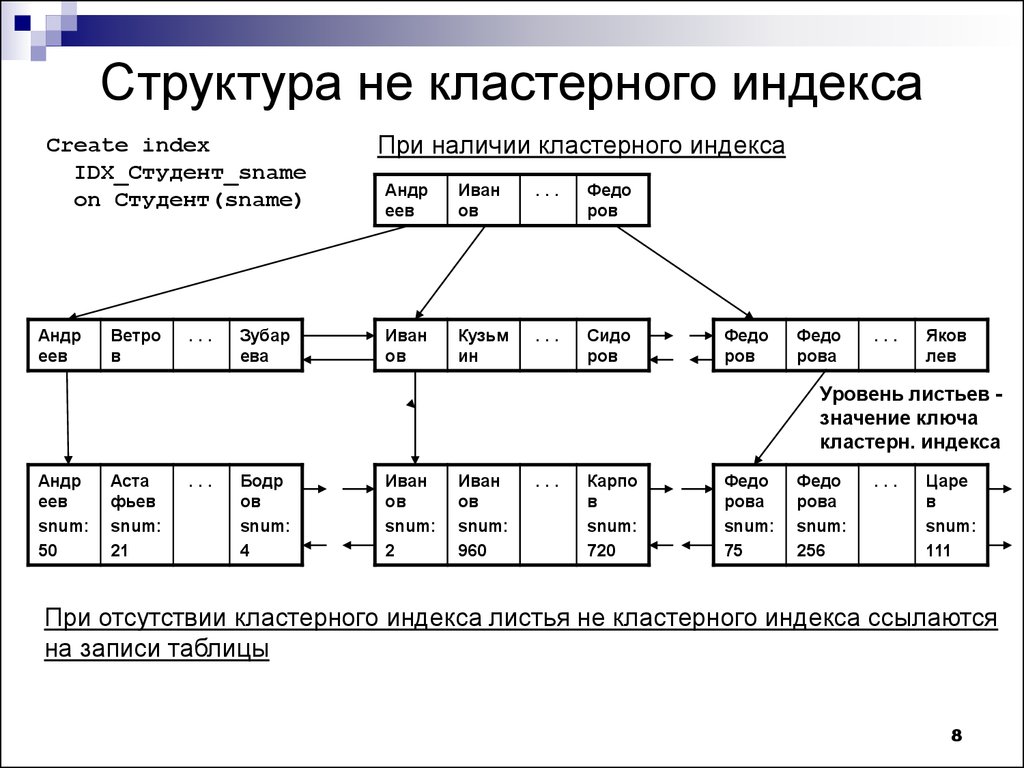
Как уже говорилось, индекс – это вспомогательная структура данных, используемая системой SQL Server для доступа к данным. В зависимости от типа индекса он хранится вместе с данными или отдельно от данных. Независимо от типа все индексы действуют одинаковым в своей основе способом, о котором вы узнаете в этом разделе.
В системах без индексов весь поиск данных должен выполняться путем сканирования таблиц. При сканировании таблиц приходится читать все данные и сравнивать их с запрашиваемыми данными. Обычно стараются обойтись без сканирования таблиц – из-за количества операций ввода-вывода, которое для этого требуется: сканирование больших таблиц может занимать длительный период времени и требовать использования большого количества системных ресурсов. Используя индекс, вы можете кардинально снизить количество операций ввода-вывода, ускорив доступ к данным и освободив системные ресурсы для других операций.
Индекс базы данных организован в виде структуры B-дерева. Каждая страница индекса называется индексной страницей, или узлом индекса. Структура индекса начинается на верхнем уровне с корневого узла. Корневой узел соответствует началу индекса: это первые данные, к которым осуществляется доступ при поиске данных. Корневой узел содержит ряд строк индекса. Эти строки содержат значение ключа и указатель на определенную индексную страницу (которая называется узлом-ветвью) (рис. 17.1). Эта конфигурация необходима, поскольку в случае таблицы данных среднего масштаба индекс состоит из тысяч или миллионов индексных страниц. Начав поиск с корневого узла и перемещаясь по узлам индекса, SQL Server может постепенно «приближаться» к нужным вам данным.
Если использовать в качестве аналога книгу, то индекс действует следующим образом: предположим, что началом индекса (алфавитного указателя) является страница, где указаны номера страниц для статей индекса на букву «a», «b», «c» и т. д. Затем предположим, что эти страницы содержат номера страниц для статей в диапазонах aa-ab, Ас-ad, ae-af и т.д., а соответствующие страницы – номера страниц для записей в диапазонах aaa-aab, aАс-aad, aae-aaf и т.д. При подобной организации вы можете быстро найти то, что вам нужно, с использованием относительно небольшого количества операций поиска. Такая структура аналогична индексу таблицы базы данных, когда первой страницей является корневой узел.
Рис.
17.1.
Корневой узел и узлы-ветви
Как и корневой узел, каждый узел-ветвь содержит ряд индексных строк в структуре индексной страницы. Каждая индексная строка указывает на другой узел-ветвь или на узел-лист (конечный узел) (рис. 17.2). Узел-лист является последним уровнем индекса. В отличие от корневого узла каждый узел-ветвь содержит также связанный список узлов-ветвей того же уровня. Иными словами, узел «знает» о смежных узлах и об узлах более низкого уровня.
Рис.
17.2.
Дерево поиска с узлами-ветвями и узлами-листьями
Как следует из названия «B-дерево», узлы-ветви разветвляются от корневого узла в древовидной форме. Каждая группа узлов-ветвей одного уровня в древовидной структуре называется уровнем индекса (рис. 17.3). Количество операций ввода-вывода, которое требуется для достижения узлов-листьев (узлов самого нижнего уровня дерева), зависит от количества уровней индекса. Если таблица базы данных содержит лишь небольшое количество данных, то корневой узел может указывать непосредственно узлы-листья, и тогда для индекса вообще не требуется никаких узлов-ветвей (маловероятная ситуация).
Рис.
17.3.
Уровни индекса
В некластеризованном индексе узел-лист содержит значение ключа, а также идентификатор строки (Row ID), указывающий нужную строку в таблице, или ключ кластеризованного индекса, если имеется также кластеризованный индекс по этой таблице. А в кластеризованном индексе в узле-листе находятся сами данные. (О кластеризованных и некластеризованных индексах см. раздел «Типы индексов» далее.) Количество строк в узле-листе зависит от размера индексных записей, а в случае кластеризованного индекса – от размера данных.
Примечание. Row ID – это указатель, который автоматически формируется системой SQL Server из идентификатора файла (File ID), номера страницы и номера строки данных. Используя Row ID, вы можете считывать данные с помощью всего лишь одной дополнительной операции ввода-вывода. Поскольку вы знаете, какую страницу нужно считывать, а SQL Server «знает», где эта страница находится, то она считывается в память с помощью единственного запроса ввода-вывода. Именно простота этого процесса определяет эффективность использования индексов для считывания данных и обеспечивает столь значительное повышение производительности.
Имейте в виду, что, поскольку индекс создается в отсортированном порядке, любые изменения в данных могут приводить к дополнительной нагрузке на систему. Например, если вставка приводит к созданию новой строки индекса, которую нужно поместить в узел-лист, который уже заполнен до конца, то SQL Server должен создать место для новой строки индекса. Он выполняет эту задачу, перемещая приблизительно половину строк узла-листа на другую страницу. Это перемещение данных называется расщеплением страницы. Расщепление страницы на одном уровне дерева может приводить к каскадным расщеплениям на более высоких уровнях. Расщепления страниц можно избежать путем соответствующей настройки коэффициента заполнения. (См. раздел «Использование коэффициента заполнения для предупреждения расщеплений страниц» далее.)
Дальше >>
< Лекция 16 || Лекция 17: 123456789 || Лекция 18 >
НОУ ИНТУИТ | Лекция | Создание и использование индексов
< Дополнительный материал 4 || Лекция 17: 123456789
Аннотация: Чем больше становится ваша база данных, тем, вероятнее всего, возрастает количество и сложность запросов. Для повышения эффективности производительности запросов путем снижения количества операций ввода-вывода используются индексы. Некоторые аспекты из теории программирования необходимо знать для лучшего усвоения материала. Рассматриваются простые и составные индексы, их отличие и применение. Проводится обзор мастеров: Create Index Wizard и Full-Text Indexing Wizard. И, конечно же, использованию T-SQL уделено немало разделов.
Ключевые слова: базы данных, производительность, индекс, SQL, server, доступ, создание индекса, связанный список, кластеризованные индексы, некластеризованные индексы, критерии поиска, оптимизатор запросов, запрос на предложения, селективность, уникальный индекс, ключ индекса, план исполнения, topic, предупреждающее сообщение, table column, подсистема ввода-вывода, population, TIMESTAMP, создание каталогов, удаление индекса, кластерный ключ, оператор UPDATE, percent, hint, estimated
Индексы – одно из самых мощных средств, доступных разработчику базы данных. Индекс – это вспомогательная структура, позволяющая вам повышать производительность запросов за счет снижения количества операций ввода-вывода, необходимых для поиска запрошенных данных; т.е. индекс позволяет системе Microsoft SQL Server 2000 находить данные, используя меньшее число операций ввода-вывода, чем при поиске данных путем доступа только к таблице базы данных. Если для поиска строки данных вы используете индекс таблицы базы данных, SQL Server может быстро определить, где хранятся эти данные и сразу считать эти данные. Таким образом, индексы таблиц базы данных во многом похожи на индексы (алфавитные указатели) в книгах: в обоих случаях обеспечивается быстрый доступ к большим объемам информации.
В этой лекции вы узнаете об основах индексирования, включая создание индекса и типы индексов, доступные в SQL Server. Вы также узнаете, когда использовать индексы и когда не нужно их использовать, поскольку использование индекса не всегда эффективно – в некоторых ситуациях это приводит к снижению производительности.
Что такое индекс?
Как уже говорилось, индекс – это вспомогательная структура данных, используемая системой SQL Server для доступа к данным. В зависимости от типа индекса он хранится вместе с данными или отдельно от данных. Независимо от типа все индексы действуют одинаковым в своей основе способом, о котором вы узнаете в этом разделе.
В системах без индексов весь поиск данных должен выполняться путем сканирования таблиц. При сканировании таблиц приходится читать все данные и сравнивать их с запрашиваемыми данными. Обычно стараются обойтись без сканирования таблиц – из-за количества операций ввода-вывода, которое для этого требуется: сканирование больших таблиц может занимать длительный период времени и требовать использования большого количества системных ресурсов. Используя индекс, вы можете кардинально снизить количество операций ввода-вывода, ускорив доступ к данным и освободив системные ресурсы для других операций.
Индекс базы данных организован в виде структуры B-дерева. Каждая страница индекса называется индексной страницей, или узлом индекса. Структура индекса начинается на верхнем уровне с корневого узла. Корневой узел соответствует началу индекса: это первые данные, к которым осуществляется доступ при поиске данных. Корневой узел содержит ряд строк индекса. Эти строки содержат значение ключа и указатель на определенную индексную страницу (которая называется узлом-ветвью) (рис. 17.1). Эта конфигурация необходима, поскольку в случае таблицы данных среднего масштаба индекс состоит из тысяч или миллионов индексных страниц. Начав поиск с корневого узла и перемещаясь по узлам индекса, SQL Server может постепенно «приближаться» к нужным вам данным.
Если использовать в качестве аналога книгу, то индекс действует следующим образом: предположим, что началом индекса (алфавитного указателя) является страница, где указаны номера страниц для статей индекса на букву «a», «b», «c» и т. д. Затем предположим, что эти страницы содержат номера страниц для статей в диапазонах aa-ab, Ас-ad, ae-af и т.д., а соответствующие страницы – номера страниц для записей в диапазонах aaa-aab, aАс-aad, aae-aaf и т.д. При подобной организации вы можете быстро найти то, что вам нужно, с использованием относительно небольшого количества операций поиска. Такая структура аналогична индексу таблицы базы данных, когда первой страницей является корневой узел.
Рис.
17.1.
Корневой узел и узлы-ветви
Как и корневой узел, каждый узел-ветвь содержит ряд индексных строк в структуре индексной страницы. Каждая индексная строка указывает на другой узел-ветвь или на узел-лист (конечный узел) (рис. 17.2). Узел-лист является последним уровнем индекса. В отличие от корневого узла каждый узел-ветвь содержит также связанный список узлов-ветвей того же уровня. Иными словами, узел «знает» о смежных узлах и об узлах более низкого уровня.
Рис.
17.2.
Дерево поиска с узлами-ветвями и узлами-листьями
Как следует из названия «B-дерево», узлы-ветви разветвляются от корневого узла в древовидной форме. Каждая группа узлов-ветвей одного уровня в древовидной структуре называется уровнем индекса (рис. 17.3). Количество операций ввода-вывода, которое требуется для достижения узлов-листьев (узлов самого нижнего уровня дерева), зависит от количества уровней индекса. Если таблица базы данных содержит лишь небольшое количество данных, то корневой узел может указывать непосредственно узлы-листья, и тогда для индекса вообще не требуется никаких узлов-ветвей (маловероятная ситуация).
Рис.
17.3.
Уровни индекса
В некластеризованном индексе узел-лист содержит значение ключа, а также идентификатор строки (Row ID), указывающий нужную строку в таблице, или ключ кластеризованного индекса, если имеется также кластеризованный индекс по этой таблице. А в кластеризованном индексе в узле-листе находятся сами данные. (О кластеризованных и некластеризованных индексах см. раздел «Типы индексов» далее.) Количество строк в узле-листе зависит от размера индексных записей, а в случае кластеризованного индекса – от размера данных.
Примечание. Row ID – это указатель, который автоматически формируется системой SQL Server из идентификатора файла (File ID), номера страницы и номера строки данных. Используя Row ID, вы можете считывать данные с помощью всего лишь одной дополнительной операции ввода-вывода. Поскольку вы знаете, какую страницу нужно считывать, а SQL Server «знает», где эта страница находится, то она считывается в память с помощью единственного запроса ввода-вывода. Именно простота этого процесса определяет эффективность использования индексов для считывания данных и обеспечивает столь значительное повышение производительности.
Имейте в виду, что, поскольку индекс создается в отсортированном порядке, любые изменения в данных могут приводить к дополнительной нагрузке на систему. Например, если вставка приводит к созданию новой строки индекса, которую нужно поместить в узел-лист, который уже заполнен до конца, то SQL Server должен создать место для новой строки индекса. Он выполняет эту задачу, перемещая приблизительно половину строк узла-листа на другую страницу. Это перемещение данных называется расщеплением страницы. Расщепление страницы на одном уровне дерева может приводить к каскадным расщеплениям на более высоких уровнях. Расщепления страниц можно избежать путем соответствующей настройки коэффициента заполнения. (См. раздел «Использование коэффициента заполнения для предупреждения расщеплений страниц» далее.)
Дальше >>
< Дополнительный материал 4 || Лекция 17: 123456789
Создать и обновить указатель
В указателе перечислены термины и темы, обсуждаемые в документе, а также страницы, на которых они появляются. Чтобы создать указатель, вы помечаете записи указателя, указывая имя основной записи и перекрестную ссылку в своем документе, а затем строите указатель.
Вы можете создать запись указателя для отдельного слова, фразы или символа для темы, которая охватывает диапазон страниц или которая ссылается на другую запись, например, «Транспорт». См. Велосипеды». Когда вы выбираете текст и помечаете его как элемент указателя, Word добавляет специальное поле XE (элемент указателя), которое включает отмеченную основную запись и любую информацию о перекрестных ссылках, которую вы решите включить.
После того, как вы пометите все записи указателя, вы выбираете схему указателя и создаете готовый указатель. Word собирает элементы указателя, сортирует их в алфавитном порядке, ссылается на номера страниц, находит и удаляет повторяющиеся элементы с одной и той же страницы и отображает указатель в документе.
Отметить записи
В этих шагах показано, как помечать слова или фразы для указателя, но вы также можете пометить элементы указателя для текста, охватывающего диапазон страниц.
Выберите текст, который вы хотите использовать в качестве элемента указателя, или просто щелкните в том месте, где вы хотите вставить элемент.
На Ссылки , в группе Index нажмите Mark Entry .
Вы можете редактировать текст в диалоговом окне Mark Entry .
Вы можете добавить второй уровень в поле Subentry . Если вам нужен третий уровень, поставьте после текста подзаписи двоеточие.
Чтобы создать перекрестную ссылку на другую запись, щелкните Перекрестная ссылка в разделе Параметры , а затем введите в поле текст для другой записи.
Чтобы отформатировать номера страниц, которые будут отображаться в указателе, установите флажок Жирный или Курсив под Формат номера страницы .
Нажмите Отметить , чтобы отметить элемент указателя. Чтобы пометить этот текст везде, где он появляется в документе, нажмите Отметить все .
org/ListItem»>
Чтобы пометить дополнительные элементы указателя, выделите текст, щелкните в диалоговом окне Пометить элемент указателя и повторите шаги 3 и 4.
Создать индекс
После того, как вы отметите записи, вы готовы вставить индекс в свой документ.
Щелкните место, где вы хотите добавить указатель.
На вкладке References в группе Index щелкните Insert Index .
В диалоговом окне Index можно выбрать формат для текстовых записей, номеров страниц, знаков табуляции и надстрочных знаков.
Вы можете изменить общий вид указателя, выбрав в раскрывающемся меню Форматы . Предварительный просмотр отображается в окне слева вверху.
Нажмите OK .
Отредактируйте или отформатируйте запись указателя и обновите указатель
Если вы отметите больше записей после создания указателя, вам потребуется обновить указатель, чтобы увидеть их.
Если поля XE не отображаются, нажмите Показать/скрыть в группе Параграф на вкладке Главная .
Найдите поле XE для записи, которую вы хотите изменить, например, { XE «Callisto» \t » See Moons» } .
Чтобы отредактировать или отформатировать элемент указателя, измените текст в кавычках.
Чтобы обновить индекс, щелкните его и нажмите F9. Или щелкните Обновить индекс в группе Индекс на вкладке Ссылки .
Если вы обнаружите ошибку в указателе, найдите запись указателя, которую вы хотите изменить, внесите изменение, а затем обновите указатель.
Удалить запись индекса и обновить индекс
Выберите все поле ввода указателя, включая фигурные скобки ( {} ), а затем нажмите клавишу DELETE.
Если поля XE не отображаются, нажмите Показать/скрыть в группе Параграф на вкладке Главная .
Чтобы обновить индекс, щелкните индекс и нажмите клавишу F9.. Или щелкните Обновить индекс в группе Индекс на вкладке Ссылки .
Создание индекса — Руководство по MongoDB
Навигация
Эта версия документации заархивирована и больше не поддерживается.
- Индексы >
- Концепции индекса >
- Создание индекса
На этой странице
- Фоновая конструкция
- Имена индексов
MongoDB предоставляет несколько параметров, которые только влияют на создание
индекс. Укажите эти параметры в документе в качестве второго аргумента
к методу db.collection.createIndex() . Эта секция
описывает использование этих параметров создания и их поведение.
Фоновая конструкция
По умолчанию создание индекса блокирует все другие операции над
база данных. При построении индекса коллекции база данных, которая
удерживает коллекцию недоступной для операций чтения или записи до тех пор, пока
построение индекса завершено. Любая операция, требующая чтения или записи
заблокировать все базы данных (например, listDatabases ) будет ждать
построение индекса переднего плана для завершения.
Для потенциально длительных операций построения индекса рассмотрите
фоновая операция , чтобы база данных MongoDB оставалась доступной
во время операции построения индекса. Например, чтобы создать индекс в
фон поля почтовый индекс коллекции человек ,
выдать следующее:
скопировать
db.
По умолчанию background равно false для построения индексов MongoDB.
Вы можете комбинировать фоновый вариант с другими вариантами, как в
далее:
копировать
db.people.createIndex({zipcode: 1}, {фон: true, sparse: true})
Поведение
Начиная с MongoDB версии 2.4, экземпляр mongod может создавать больше
более одного индекса в фоновом режиме одновременно.
Изменено в версии 2.4: До версии 2.4 а Экземпляр mongod может построить только один
фоновый индекс для каждой базы данных за раз.
Операции фонового индексирования выполняются в фоновом режиме, поэтому другие базы данных
операции могут выполняться при создании индекса. Однако монго
сеанс оболочки или соединение, где вы создаете
индекс будет заблокирован до завершения построения индекса. Продолжать
отдавая команды базе данных, открыть другую
соединение или экземпляр mongo .
Запросы не будут использовать частично построенные индексы: индекс будет только
можно использовать после завершения построения индекса.
Примечание
Если MongoDB строит индекс в фоновом режиме, вы не можете
выполнять другие административные операции, связанные с этой коллекцией,
включая запуск repairDatabase , удаление
коллекция (например, db.collection.drop() ) и запуск
компактный . Эти операции вернут ошибку во время
построение фонового индекса.
Производительность
Фоновая операция индексирования использует добавочный подход, т.е.
медленнее, чем обычное построение индекса «переднего плана». Если индекс
больше, чем доступная оперативная память, то инкрементный процесс может занять
намного длиннее, чем сборка переднего плана.
Если ваше приложение
включает createIndex()
операций, а индекса не существует для других операционных
опасения, построение индекса может оказать серьезное влияние на
производительность базы данных.
Во избежание проблем с производительностью убедитесь, что ваше приложение проверяет
для индексов при запуске с использованием
Метод getIndexes() или аналогичный
метод для вашего драйвера и завершается, если правильные индексы не
существовать. Всегда создавайте индексы в производственных экземплярах, используя отдельные
код приложения во время назначенных периодов обслуживания.
Прерванные построения индекса
Если выполняется фоновое построение индекса, когда mongod
процесс завершается, когда экземпляр перезапускается, построение индекса будет
перезапустите как сборку индекса переднего плана. Если при построении индекса
ошибки, такие как ошибка дублирования ключа, mongod выйдет
с ошибкой.
Чтобы запустить mongod после неудачного построения индекса, используйте
storage.indexBuildRetry или --noIndexBuildRetry , чтобы пропустить построение индекса при запуске.
.. _index-creation-building-indexes-on-secondary:
Построение индексов на вторичных серверах
Изменено в версии 2. 6: Вторичные члены теперь могут создавать индексы в
фон. Ранее все построения индекса на вторичных серверах находились в
передний план.
Фоновые операции с индексами в наборе реплик
второстепенные начинаются после основных
завершает построение индекса. Если MongoDB строит индекс в
фон на первичном, вторичные затем построят этот индекс
на заднем фоне.
Для создания больших индексов на вторичных серверах лучше всего использовать
перезапускать по одному вторичному серверу в автономном режиме и строить
индекс. После построения индекса перезапустите как член
набор реплик, позволить ему догнать других членов набора,
а затем построить индекс на следующем вторичном сервере. Когда все
вторичные серверы имеют новый индекс, отключите первичный, перезапустите его как
автономный и построить индекс на бывшем первичном.
Количество времени, необходимое для построения индекса на вторичном сервере, должно быть
в окне оплога, чтобы вторичный мог
догнать первичку.
Индексы на вторичных элементах в режиме «восстановления» всегда встроены
на переднем плане, чтобы позволить им наверстать упущенное как можно скорее.
Подробную информацию о процедуре для
построение индексов на вторичных серверах.
Имена индексов
Имя индекса по умолчанию — это объединение индексированных ключей.
и направление каждой клавиши в индексе, 1 или -1.
Пример
Введите следующую команду, чтобы создать индекс для элемента 9 .0220
и количество :
копировать
db.products.createIndex({элемент: 1, количество: -1})
Результирующий индекс называется: item_1_quantity_-1 .
Дополнительно можно указать имя для индекса вместо использования
имя по умолчанию.
Пример
Введите следующую команду, чтобы создать индекс для элемента .
и количество и укажите инвентаризация в качестве имени индекса:
копия
db.products.createIndex({элемент: 1, количество: -1}, {имя: "инвентарь"})
Полученный индекс имеет имя инвентаризация .
Чтобы просмотреть имя индекса, используйте метод getIndexes() .
←
Разреженные индексы
Индекс пересечения
→
Индексы | Документация Meilisearch v1.0
Маршрут /indexes позволяет создавать индексы, управлять ими и удалять их.
Подробнее об индексах.
Index object
| Name | Type | Default value | Description |
|---|---|---|---|
uid | String | N/A | Unique identifier of the index. После создания его нельзя изменить |
createdAt | Строка | Н/Д | Дата создания индекса, представленная в формате RFC 3339 (opens new window). Создается автоматически при создании индекса |
updatedAt | Строка | Н/Д | Последняя дата обновления индекса, представленная в формате RFC 3339 (opens new window). Создается автоматически при создании или обновлении индекса |
primaryKey | Строка / null | null | Первичный ключ индекса. Если не указано, Meilisearch угадывает ваш первичный ключ из первого документа, который вы добавляете в индекс |
Список всех индексов
GET
/indexes Список всех индексов. Результаты могут быть разбиты на страницы с помощью параметров запроса offset и limit .
Query parameters
| Query parameter | Description | Default value |
|---|---|---|
offset | Number of indexes to skip | 0 |
limit | Number of indexes to return | 20 |
Response
| Name | Type | Description |
|---|---|---|
results | Массив | Массив индексов |
смещение | Целое число | Количество пропущенных индексов |
limit | Integer | Number of indexes returned |
total | Integer | Total number of indexes |
Example
Response:
200 Ok
Получить один индекс
GET
/indexes/{index_uid} Получить информацию об индексе.
Параметры пути
| Name | Type | Description |
|---|---|---|
index_uid * | String | uid of the requested index |
Example
Response:
200 Ok
Создать индекс
POST
/indexes Создать индекс.
Тело
| Имя | Тип | Значение по умолчанию | Description |
|---|---|---|---|
uid * | String | N/A | uid of the requested index |
primaryKey | String / null | null | Первичный ключ запрошенного индекса |
Пример
Ответ:
202 Accepted
Вы можете использовать 9 ответов0219 taskUid для отслеживания статуса вашего запроса.
Обновить индекс
ИСПРАВЛЕНИЕ
/indexes/{index_uid} Обновить первичный ключ индекса. Вы можете свободно обновлять первичный ключ индекса, если он не содержит документов.
Чтобы изменить первичный ключ индекса, который уже содержит документы, необходимо сначала удалить все документы в этом индексе. Затем вы можете изменить первичный ключ и снова проиндексировать свой набор данных.
ПРИМЕЧАНИЕ
Невозможно изменить индекс идентификатор .
Path parameters
| Name | Type | Description |
|---|---|---|
index_uid * | String | uid of the requested index |
Body
| Имя | Тип | Значение по умолчанию | Описание |
|---|---|---|---|
primaryKey * | String / null | N/A | Primary key of the requested index |
Example
Response:
202 Accepted
You can use the response’s taskUid to отслеживать статус вашего запроса.
Удалить индекс
УДАЛИТЬ
/indexes/{index_uid} Удалить индекс.
Параметры пути
| Name | Type | Description |
|---|---|---|
index_uid * | String | uid of the requested index |
Example
Response:
202 Accepted
You can используйте ответ taskUid , чтобы отслеживать статус вашего запроса.
Поменять местами индексы
POST
/swap-indexes
Поменять местами документы, настройки и историю задач двух или более индексов. : Вы можете обмениваться индексами только парами. Однако один запрос может поменять местами любое количество пар индексов.
Замена индексов является атомарной транзакцией: либо все индексы успешно заменены, либо ни один.
Замена indexA и indexB также заменит каждое упоминание indexA на indexB и наоборот в истории задач. поставленных в очередь задач остаются без изменений.
Чтобы узнать больше о замене индексов, обратитесь к этому краткому руководству.
Тело
Массив объектов. Каждый объект имеет только один ключ: индексов .
| Name | Type | Default value | Description |
|---|---|---|---|
indexes * | Array of strings | N/A | Array of the two indexUid s to be swapped |
Каждый массив индексов должен содержать только два элемента: indexUid с двух индексов, подлежащих обмену. Отправка пустого массива ( [] ) действительна, но операция подкачки выполняться не будет.
ПРИМЕЧАНИЕ
Вы можете поменять местами несколько пар индексов одним запросом. Для этого должен быть один объект для каждой пары индексов, подлежащих обмену.
Пример
Ответ
ПРИМЕЧАНИЕ
Поскольку indexSwap является глобальной задачей, indexUid всегда равен null .
Вы можете использовать taskUid ответа для отслеживания статуса вашего запроса.
Получить процент создания динамического индекса в SQL Server
В нашей повседневной работе в качестве администратора баз данных мы должны создавать индексы для повышения производительности запросов, запускаемых к производственным таблицам. Необходимым инструментом было бы знать, какой процент создания имеет наш индекс.
Во многих случаях у нас нет версии SQL Server Enterprise, и мы не можем создавать эти индексы «в сети». В чем проблема? Блокировка таблицы, для которой выполняется создание индекса.
Сколько раз вы создаете индекс в SQL Server, блокируете важную таблицу и сомневаетесь, сколько времени это займет ? Или … Стоит ли отменить создание индекса? А если почти готово?
SQL Server напрямую не предоставляет нам информацию о проценте создания индекса, но у нас есть решение .
Первым действием будет открытие нового запроса , где мы активируем профиль , используя следующий код: сеанс нашего запроса, чтобы использовать его позже.
ВЫБРАТЬ @@SPID как Session_id
После того, как предыдущие шаги были выполнены, мы можем перейти к созданию индекса , код должен выглядеть следующим образом:
ВКЛЮЧИТЬ СТАТИСТИЧЕСКИЙ ПРОФИЛЬ
ИДТИ
ВЫБЕРИТЕ @@SPID как Session_id
ИДТИ
ИСПОЛЬЗОВАТЬ [база данных]
ИДТИ
СОЗДАТЬ НЕКЛАСТЕРНЫЙ ИНДЕКС [имя_индекса] НА [имя_таблицы]
(
[поле1] АСЦ,
[поле2] АСЦ,
[полеN] ASC
)
Go GO
Давайте перейдем к важной части поста, узнаем процент создания и предполагаемое время , оставшееся для завершения этого , нам нужно только выполнить его в новом запросе (окне), пока индекс создается.
ВАЖНО: Измените переменную @session_id на значение, полученное ранее.
-- Создание процентного индекса M.Angel Motos @aleson-itc m.motos@aleson-itc.com
-- Объявить @session_id для установки session_id создания индекса
DECLARE @session_id AS int
УСТАНОВИТЕ @session_id = 72
-- cte для упрощения кода
;С tempdb_cte (node_id, Time_Taken)
КАК
(
ВЫБИРАТЬ
node_id,
(DATEDIFF(SECOND, DATEADD(SECOND, - 3610, DATEADD(MILLISECOD, eqp.last_active_time % 1000, DATEADD(SECOND, eqp.last_active_time / 1000, (
ВЫБЕРИТЕ create_date
ИЗ sys.databases
ГДЕ ИМЯ = 'tempdb'
)))), ДАТАДОБАВИТЬ(СЕКУНД, - 3610, ДАТАДОБАВИТЬ(МИЛЛИСЕКУНД, eqp.first_active_time % 1000, ДАТАДОБАВИТЬ(СЕКУНД, первое_активное_время / 1000, (
ВЫБЕРИТЕ create_date
ИЗ sys.databases
ГДЕ ИМЯ = 'tempdb'
))))) * - 1
) AS Time_Taken
ИЗ sys.dm_exec_query_profiles AS eqp
)
-- Начать запрос
ВЫБИРАТЬ
eqp.Node_Id,
eqp.Physical_Operator_Name,
SUM(eqp.row_count) Row_Count,
SUM(eqp. estimate_row_count) КАК Estimate_Row_Count,
CAST(SUM(eqp.row_count)*100 AS float)/SUM(eqp.estimate_row_count) AS Estimate_Percent_Complete,
СЛУЧАЙ
КОГДА eqp.node_id = 2, ТОГДА (ВЫБЕРИТЕ CAST(SUM(eqp.row_count)*50 AS float)/SUM(eqp.estimate_row_count))
ЕЩЕ
СЛУЧАЙ
КОГДА eqp.row_count = 0, ТОГДА 0
ELSE (SELECT 50+CAST(SUM(eqp.row_count)*50 AS float)/SUM(eqp.estimate_row_count))
КОНЕЦ
КОНЕЦ КАК 'Total_Percent_Complete',
СЛУЧАЙ
КОГДА eqp.row_count != 0 и node_id = 2 ТОГДА (
ВЫБИРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 2)
КОГДА eqp.row_count != 0 И node_id = 1 ТОГДА (
ВЫБИРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 1) - (
ВЫБИРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 2)
ИНАЧЕ НОЛЬ
КОНЕЦ как Time_Taken,
СЛУЧАЙ
КОГДА eqp.row_count != 0 И node_id = 1 ТОГДА
КРУГЛЫЙ((((
ВЫБИРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 1)
-
(
ВЫБИРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 2)
)* 100)
/ ((SELECT CAST(SUM(eqp.row_count)*100 AS float)/SUM(eqp.estimate_row_count)
ОТ sys. dm_exec_query_profiles AS eqp ГДЕ node_id = 1)),2,1)
КОГДА eqp.row_count != 0 И node_id = 2 ТОГДА
КРУГЛЫЙ(((ВЫБРАТЬ
Затраченное время
ОТ tempdb_cte
ГДЕ node_id = 2)
*100)/(CAST(SUM(eqp.row_count)*100 AS float)
/СУММ(eqp.estimate_row_count)),2,1)
ИНАЧЕ НОЛЬ
КОНЕЦ КАК Estimate_Time_Taken
ОТ
sys.dm_exec_query_profiles Оборудование AS
ГДЕ
session_id = @session_id
ГРУППА ПО
node_id, Physical_operator_name, row_count, оценка_row_count, last_active_time, first_active_time
СОРТИРОВАТЬ ПО
node_id DESC; Выполнение этого кода покажет нам что-то вроде этого:
Где мы можем увидеть выполняемую операцию в порядке появления: проанализированные строки, общее количество строк таблицы, процент создания шага в реальной жизни, общий процент создания, время, которое мы потратили, и предполагаемое недостающее время.
Когда мы снова выполним запрос, время будет обновлено.
После завершения первого шага истекшее время снова начнется с нуля на следующем шаге и 9Процент создания 0225 также будет обновлен с предполагаемым временем его окончания. Мы можем видеть это в следующем примере создания того же индекса, выполнив первый шаг за 57 секунд и заняв 13 секунд на второй шаг:
Когда процент создания второго шага достигает 100% , индекс будет создан успешно .
Если вы планируете перенести свою платформу в облако, у нас есть необходимый опыт, чтобы помочь вам, свяжитесь с нами по адресу info@aleson-itc.com или позвоните нам по телефону +34 962 681 242
Miguel Ángel Motos
Инженер по обработке и обработке данных Azure, многолетний опыт работы в мире.
Usamos cookies propias y de terceros necesarias para que nuestro site web funcione adecuadamente pero también utilizamos otras que nos allowen personalizar el site y sus opciones, realizar Labores analíticas de trafico y uso, of recer funciones de redes sociales, mejorar la navegación Prerencias Y Poder Mostrarte contenido уместно Y Personalizado. Dispones де Más información sobre лас mismas en Nuestra Política де Cookies. Puedes aceptar todas las cookies pulsando en el botón «Aceptar» или configurarlas tu gusto o rechazar las no necesarias, a través de las opciones que ponemos tu disposición. Информация о Aceptar
Даты создания и последнего изменения индекса в SQL Server
Во многих средах полезно точно знать, когда был создан или изменен индекс.
Последняя версия кода помогла производительности или повредила ей? Очень полезно знать, когда именно был развернут код, чтобы доказать, что ваше изменение сделало что-то лучше. Или что вам, возможно, придется откатить его назад.
Для отслеживания изменений в ваших индексах требуется небольшая подготовка, но это легко реализовать.
SQL Server по умолчанию не отслеживает дату создания или изменения индекса
Я говорю «действительно», потому что трассировка SQL Server по умолчанию фиксирует такие вещи, как команды создания и изменения индекса. Однако трассировка по умолчанию довольно быстро обновляется на большинстве активных серверов, и вы редко ищете дату создания индекса, созданного пять минут назад.
Я думаю, это нормально, что SQL Server не хранит постоянно дату создания и дату изменения для большинства индексов, потому что не все хочет эту информацию, так почему бы не сделать значение по умолчанию как можно более легким?
Вы можете получить дату создания и дату последнего изменения таблицы, но обычно этого недостаточно
SQL Server хранит сведения о создании и изменении таблиц в DMV sys.objects. Но большинство из нас создает и удаляет индексы намного позже времени создания таблицы. И многие вещи считаются модификацией в этом контексте, включая добавление столбцов или просто перестроение индекса.
Если индекс является первичным ключом или уникальным индексом/уникальным ограничением, вы можете получить дату создания
Для некоторых индексов вы можете найти дату создания с помощью простого запроса, потому что эти индексы получают свою собственную строку в sys. objects. Вы можете использовать такой запрос, чтобы узнать, когда они были созданы:
Но если вы не ищете дату создания первичного ключа, уникальный индекс или ограничение уникальности, вам не повезло.
Отслеживание создания и изменения индексов с помощью триггера DDL
Триггеры DDL — это самый простой способ отслеживать создание и удаление индексов. Это очень простой способ записи точного времени создания и изменения индексов.
Однако есть несколько вещей, которые нужно знать о триггерах DDL.
Триггеры DDL тесно связаны с исполняемым кодом
В основном, люди, которые плохо справляются с триггерами DDL, являются администраторами баз данных, которые внедряют их в производство, не тестируя их подробно и не разговаривая с их разработчиками. Они создают триггер, который отлично работает для них самих в простом тесте, но может не работать для кого-то другого — обычно из-за проблем с безопасностью.
Плохая новость заключается в том, что при сбое триггера DDL он также отменяет вызывающую команду. Не все так счастливы, когда их таблица или индекс внезапно терпят неудачу в производстве со странным сообщением об ошибке.
Чтобы хорошо провести время с триггерами DDL для отслеживания изменений индекса:
- Поместите их в каждую среду, включая разработку / текст
- Относитесь к ним как к любому изменению кода, связанному с индексом — зарегистрируйте его в исходном коде
- Использовать управление изменениями
- Поговорите со своими коллегами и, возможно, упомяните, что регистрация точного времени, когда происходит DDL, полезна для устранения неполадок и демонстрации положительных улучшений, а не для контроля
Пример кода триггера DDL
Вот простой код уровня базы данных. Обязательно ознакомьтесь со ссылками в конце этой статьи, чтобы найти больше примеров и в других местах!
Этот пример работает только для одной базы данных. (Прокрутите сообщение до конца, чтобы увидеть больше примеров в других блогах!)
Этот пример кода…
- Создает схему и таблицу для отслеживания создания и изменения таблиц и индексов. Я сделал это, потому что удаление таблицы приведет к удалению всех индексов.
- По умолчанию использует сжатие строк в таблице. Возможно, вы не хотите, чтобы процессор загружался при сжатии строк, или это не работает в вашей версии/выпуске SQL Server — не стесняйтесь менять это.
- Stores target_object_name — если вы создаете или изменяете индекс, это имя объекта. Если вы создаете или изменяете таблицу, это значение равно null.
- Сохраняет имя_объекта — если вы создаете или изменяете индекс, это имя индекса
- Stores new_object_name — заполняется, если вы используете sp_rename для таблицы или индекса
- Триггер DDL выполняется как dbo и использует ORIGINAL_LOGIN() для получения логина вызывающей стороны. Это сделано для снижения риска того, что триггер DDL приведет к сбою изменения схемы, поскольку оно выполняется учетной записью, у которой нет разрешения на запись в таблицу, которую вы используете для ведения журнала.
Вот пример кода:
Хотите увидеть сбой триггера DDL?
Просто запустите этот код после создания таблицы, затем триггер:
Вы не сможете обойти эту ошибку, поместив try/catch в триггер DDL. Вам придется отказаться от триггера DDL, чтобы удалить эту таблицу.
Альтернатива: Уведомления о событиях
Если вам не нравится «сильная связь» триггера DDL, вы можете использовать уведомления о событиях для записи точно таких же событий.
Недостатком является то, что уведомления о событиях немного сложнее в настройке и управлении. Уведомления о событиях используют Service Broker, поэтому вам необходимо освоиться с различными частями Service Broker и управлять им. Это неплохо, просто нужно еще немного научиться, и это еще одна используемая функция, за которой вам нужно следить, когда дело доходит до установки исправлений и управления.
Если вы идете по пути уведомлений о событиях, я настоятельно рекомендую вам настроить уведомления о событиях в их собственной базе данных и записывать туда все изменения индекса. Таким образом, если вы устраняете неполадки и хотите временно отключить ведение журнала, вы можете отключить Service Broker только в той базе данных, в которой вы отправляете уведомления о событиях. (Для включения Service Broker требуется эксклюзивная блокировка базы данных.)
Дополнительные примеры кода
Аарон Бертранд написал аналогичный пост о захвате операций с индексами в этой замечательной статье. Его пример триггера DDL предназначен для всех пользовательских баз данных и только для событий создания и изменения, потому что он искал любые операции перестроения индекса в соответствии с вопросом.
Аарон написал здесь еще один пост об использовании триггеров DDL для захвата еще большего количества типов изменений.
Как автоматизировать создание индекса Elasticsearch
Стремясь повысить производительность разработчиков и наблюдаемость в Otter, мы заметили, что при использовании одного индекса Elasticsearch для каждого приложения поиск становится быстрее, запросы становятся проще, а журналы можно анализировать с помощью настраиваемых регулярных выражений. шаблоны, и у нас есть полный контроль над политикой очистки при использовании Elasticsearch Curator.
Всякий раз, когда мы развертывали новое приложение, нам приходилось вручную изменять файл конфигурации. Это быстро стало очень трудоемким и подверженным ошибкам. Поскольку вся наша инфраструктура работает на Kubernetes, и мы используем Elasticsearch для нашей базы данных журналов, мы решили заменить нашу настройку Fluentbit на Filebeat и Logstash. Сделав это, мы смогли полностью автоматизировать процесс создания индекса Elasticsearch, поскольку они тесно интегрированы с другими технологиями.
Начало работы с созданием индекса Elasticsearch
Как всегда, начнем с Helm. Мы рекомендуем использовать шаблоны Helm из репозитория Elastic на GitHub, так как они все еще активно поддерживаются. Установка Elasticsearch и Kibana не входит в задачу этой статьи, поэтому мы сосредоточимся только на установке и настройке Filebeat и Logstash.
Чтобы установить официальный репозиторий Elastic, мы должны выполнить следующую команду:
helm repo add elastic https://helm.
Кроме того, в этом руководстве предполагается, что вы развертываете свои ресурсы в лось пространств имен. Чтобы создать это пространство имен, запустите:
kubectl create namespace elk
Конфигурация Filebeat
Здесь нам нужно только изменить файл значений, а затем установить диаграмму, используя его. Единственное, что нам нужно изменить из основных значений файла, ключ filebeatConfig.
файлбитконфиг:
файлbeat.yml: |
logging.level: ошибка
filebeat.autodiscover:
провайдеры:
- тип: кубернет
узел: ${NODE_NAME}
hints.enabled: правда
подсказки.default_config:
тип: контейнер
пути:
- /var/log/containers/*${data.kubernetes.container.id}.log
вывод.logstash:
хосты: ["logstash-logstash:5044"]
setup.template:
имя: "k8s"
узор: "k8s-*"
включено: ложь
setup.ilm.enabled: ложь Основные отличия заключаются в том, что мы используем функцию автообнаружения filebeat и поставщика kubernetes . Мы также включили обнаружение на основе подсказок, создали шаблон и отключили ILM (это доступно только при наличии лицензии Elastic).
Вам также следует изменить свои допуски, чтобы filebeat мог работать на других экземплярах, например, на главных узлах (ваши имена ключей могут отличаться):
допуски:
- ключ: node-role.kubernetes.io/master
оператор: существует
эффект: NoSchedule После изменения файла значений запустите:
helm install --name filebeat --namespace elk elastic/filebeat -f fb-values.yaml
или, если вы используете Helm v3:
helm install filebeat -- namespace elk elastic/filebeat -f fb-values.yaml
Настройка и запуск Logstash для Elasticsearch
Именно здесь выполняется большая часть работы. Далее мы собираемся показать вам более сложный пример, чтобы вы могли упростить его, если вам нужно. Как и в случае с файлом значений filebeat, мы изменяем только конфигурацию logstash.
logstashPipeline: logstash.
Файл конфигурации Logstash основан на условных операторах, что делает его очень мощным. Внутри условных операторов вы можете использовать различные фильтры. Мы пройдемся по краткому описанию тех, которые мы используем. Для остальных вы можете проверить документацию на веб-сайте Elastic, которая очень хорошо написана.
Еще несколько шагов
Во-первых, мы используем mutate plugin для динамического создания индексов на основе метаданных Kubernetes. Они создаются путем объединения двух меток модулей и одного поля метаданных Kubernetes. Мы используем метки приложения и среды , чтобы различать наши журналы. Более того, мы разделяем их дальше, используя имя контейнера, поэтому у нас могут быть журналы Nginx в одном индексе, а журналы PHP в другом. Мы не применяем эти метки к каждому развертыванию, так как это приведет к созданию ненужных сегментов в кластере Elasticsearch. Например, мы запускаем много заданий cron, и наличие индекса для каждого из них является излишним, поэтому, если эти метки отсутствуют, журналы отправляются в общий индекс на основе имени пространства имен. Мы также используем изменить фильтр , чтобы удалить временную метку Nginx и оставить ту, о которой сообщает filebeat.
Затем фильтр grok помогает нам анализировать наши журналы Nginx, поскольку мы используем другой формат журнала. Обратите внимание на условие if [event][module] == "nginx" . Метка event.module присутствует, потому что мы размещаем модуль Nginx в наших развертываниях. Чтобы сделать это самостоятельно, примените аннотацию к своим развертываниям следующим образом:
аннотации:
co.elastic.logs.nginx/модуль: 'nginx' В этой аннотации указано, что журналы, поступающие из контейнера nginx , следует анализировать с помощью модуля filebeat nginx , но он работает только с форматами журналов по умолчанию.
А остальные?
Остальные фильтры понятны. Мы только немного поговорим о фильтре geoip , потому что мы думаем, что он замечательный. Теперь он берет и IP-адрес, который мы берем из заголовка X-Forwarded-For , ищет его в своей базе данных GeoIP и создает другое поле с географической информацией.