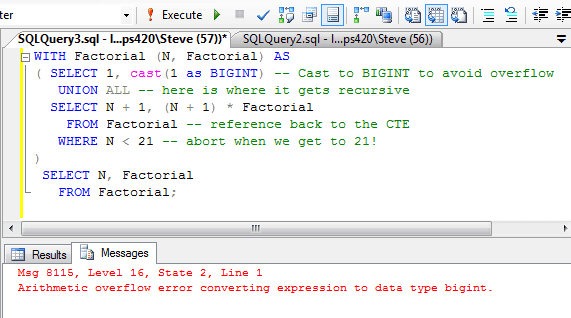
Sql cte: (CTE) | SQL | SQL-tutorial.ru
Содержание
CTE (Common Table Expressions) — что это такое в PostgreSQL
CTE, или Common Table Expressions — один из видов запросов в системах управления базами данных. На русском языке они называются обобщенными табличными выражениями. Результаты табличных выражений можно временно сохранять в памяти и обращаться к ним повторно.
Аналог CTE — временные таблицы, которые создаются только в рамках выполнения какой-либо операции и удаляются, как только становятся не нужны. Это позволяет упростить обращение к базе, сделать его быстрее и понятнее для разработчика. С помощью CTE код становится короче и яснее. Но табличные выражения отличаются от временных таблиц — мы рассмотрим различия ниже.
Чаще всего говорят об использовании CTE в СУБД PostgreSQL. Но эту возможность поддерживают и другие системы управления, например Oracle или MySQL. Названия запроса могут различаться в разных базах данных. Например, в Oracle он называется «факторинг подзапроса».
Для чего нужны CTE
- Написание сложных запросов — использование конструкции помогает уменьшить размер кода и упростить его, сделать более читаемым.

- Ускорение работы программ в случаях, когда нужно много раз подряд обращаться к одной и той же части базы, — временное хранение помогает оптимизировать выполнение. Создается структура данных, которая временно хранится в кэше, поэтому информацию не требуется искать каждый раз.
- Рекурсивный обход таблиц, в котором помогают общие табличные выражения. Существует особый их подвид — рекурсивные CTE.
- Создание представлений, или View, в SELECT-части запроса.
- Оптимизация работы, так как другие варианты временного хранения и сложного доступа часто более ресурсоемкие.
- Создание более понятного кода, который легче поддерживать.

Каким образом используются CTE
В PostgreSQL обобщенное табличное выражение начинается с ключевого слова WITH и размещается перед запросом. Оно описывает временные структуры данных, которым даны те или иные имена. Структуры описаны как комбинации запросов — так один сложный запрос разделяется на много более простых. Это выражение называется внутренним, оно вычисляется перед основным запросом и составляет суть CTE. После выполнения внутреннего выражения начинается основной запрос, и он обращается уже к полученной временной структуре.
Это выражение называется внутренним, оно вычисляется перед основным запросом и составляет суть CTE. После выполнения внутреннего выражения начинается основной запрос, и он обращается уже к полученной временной структуре.
Это может быть сложно понять по описанию, поэтому рассмотрим применение CTE на примере.
Допустим, есть база данных со множеством полей. Необходимо получить из нее подсчитанные и сгруппированные результаты отдельных полей. В этом помогут табличные выражения.
Перед началом запроса пишется ключевое слово WITH, после него — название временной структуры и ключевое слово AS. Открываются фигурные скобки, а внутри них описывается наполнение структуры.
В отличие от обычного создания таблицы, наполнение описывается не значениями, а запросами. Вместо того чтобы написать «посетитель номер 310 по имени Вася Кузнецов», мы пишем «посетитель из N-строки N-таблицы, номер получаем из N-блока N-структуры, имя — из N-блока и объединяем с фамилией, полученной из N-блока». В результате получается временный результат, с которым можно работать как с таблицей.
В результате получается временный результат, с которым можно работать как с таблицей.
Особенности CTE
CTE похожи на вложенные запросы или на временные таблицы. Но от вложенных запросов их отличает оптимизация: вложенный запрос повторяется для каждой строки, которую нашел основной запрос. Это повышает ресурсоемкость и замедляет работу кода.
Сходство с временными таблицами более явное: обе структуры позволяют кэшировать данные, а потом обращаться к ним повторно. Разница в том, что CTE выполняется в рамках только одного запроса, пусть даже и сложного. В отличие от временной таблицы, данные не накапливаются и не «утяжеляют» весь код, не нагружают диск и не замедляют работу запроса.
Табличные выражения можно использовать вместе с блоками SELECT, которые показывают те или иные данные, или вместе с другими блоками — теми, которые модифицируют информацию в таблице. Это, например, INSERT, UPDATE, DELETE (вставка, обновление, удаление данных).
Существуют рекурсивные CTE, которые мы упомянули ранее. Их особенность в том, что они могут обращаться к собственным результатам. В PostgreSQL они описываются как WITH RECURSIVE — к ключевому слову WITH добавляется пометка о том, что запрос рекурсивный.
Их особенность в том, что они могут обращаться к собственным результатам. В PostgreSQL они описываются как WITH RECURSIVE — к ключевому слову WITH добавляется пометка о том, что запрос рекурсивный.
Преимущества CTE
Ускоряют код. При грамотном применении табличные выражения делают работу запросов быстрее, так как в памяти не приходится подолгу хранить лишние сущности — временные структуры работают только в рамках одного запроса.
Упрощают понимание. В рамках CTE происходит разбиение сложного запроса на несколько «блоков»: сначала описывается временная структура, а потом данные получают уже из нее. Получение данных оказывается последовательным и понятным.
Облегчают поддержку. В сложном запросе непросто разобраться стороннему программисту, который впервые увидел конкретный код. С помощью CTE запрос раскладывается на составляющие, поэтому его легче поддерживать, исправлять и модифицировать.
Улучшают функциональность. Рекурсивные CTE помогают легко обойти сложные структуры данных, такие как деревья. Без этого инструмента задача стала бы сложнее. Это не единственный пример, когда благодаря табличным выражениям решение задачи становится легче, но один из самых наглядных.
Рекурсивные CTE помогают легко обойти сложные структуры данных, такие как деревья. Без этого инструмента задача стала бы сложнее. Это не единственный пример, когда благодаря табличным выражениям решение задачи становится легче, но один из самых наглядных.
Имеют широкую поддержку. CTE используются во многих популярных системах, просто называются по-разному. Если вы освоите табличные выражения, например в PostgreSQL, то в будущем вам будет легче познакомиться с похожими структурами в Oracle или других СУБД.
Недостатки CTE
Не универсальны. Обобщенные табличные выражения — не универсальный инструмент, и в решении ряда задач они оказываются неоптимальными. CTE довольно ресурсоемки: они хранят в кэше временную структуру данных, к которой постоянно обращается как основной запрос, так, возможно, и само табличное выражение.
Имеют особенности оптимизации. Есть еще одна проблема. Она существует из-за оптимизатора — внутренней структуры PostgreSQL, которая занимается тем, что упрощает и оптимизирует введенные человеком запросы. Внутреннее выражение, то, что находится после ключевых слов WITH…AS, оптимизируется не так хорошо, как более простые функции. Поэтому есть риск, что CTE будет работать медленно, несмотря на то что по своей сути должно быть быстрым.
Внутреннее выражение, то, что находится после ключевых слов WITH…AS, оптимизируется не так хорошо, как более простые функции. Поэтому есть риск, что CTE будет работать медленно, несмотря на то что по своей сути должно быть быстрым.
Для работы потребуются созданная база данных, на которой можно тренироваться, и установленная СУБД, например PostgreSQL. Большинство СУБД, включая PostgreSQL, бесплатные, находятся в открытом доступе и хорошо задокументированы.
5 Advanced SQL концептов которые нужно знать в 2022 — bool.dev
1. Common Table Expressions (CTEs)
При работе с данными иногда вам нужно запросить результаты другого запроса. Простой способ добиться этого — использовать sub-query.
Однако с ростом сложности sub-query вычислений становятся трудными для чтения и отладки. Именно тогда на сцену выходят CTE, которые облегчают вашу жизнь. CTE упрощают написание и обслуживание сложных запросов. ✅
Например, рассмотрим следующее извлечение данных с использованием sub-query:
SELECT Sales_Manager, Product_Category, UnitPrice
FROM Dummy_Sales_Data_v1
WHERE Sales_Manager IN (SELECT DISTINCT Sales_Manager
FROM Dummy_Sales_Data_v1
WHERE Shipping_Address = 'Germany'
AND UnitPrice > 150)
AND Product_Category IN (SELECT DISTINCT Product_Category
FROM Dummy_Sales_Data_v1
WHERE Product_Category = 'Healthcare'
AND UnitPrice > 150)
ORDER BY UnitPrice DESCЗдесь используется только два подзапроса с понятным кодом.
Если добавить больше вычислений в подзапросы или даже добавить еще несколько подзапросов — сложность возрастает , что делает код менее читабельным и трудным в обслуживании.
Теперь давайте посмотрим на упрощенную версию вышеуказанного подзапроса с CTE:
WITH SM AS ( SELECT DISTINCT Sales_Manager FROM Dummy_Sales_Data_v1 WHERE Shipping_Address = 'Germany' AND UnitPrice > 150 ), PC AS ( SELECT DISTINCT Product_Category FROM Dummy_Sales_Data_v1 WHERE Product_Category = 'Healthcare' AND UnitPrice > 150 ) SELECT Sales_Manager, Product_Category, UnitPrice FROM Dummy_Sales_Data_v1 WHERE Product_Category IN (SELECT Product_Category FROM PC) AND Sales_Manager IN (SELECT Sales_Manager FROM SM) ORDER BY UnitPrice DESC
Сложный подзапрос разбивается на более простые блоки кодов, которые необходимо использовать.
Таким образом, сложные подзапросы переписываются в два CTE SM, PCкоторые легче читать и изменять. 🎯
🎯
Оба приведенных выше запроса, требующие одинакового времени для выполнения, вернули такой результат:
CTE по существу позволяют вам создать временную таблицу из результата запроса. Это улучшает читаемость кода и его обслуживание. ✅
Реальные наборы данных могут содержать миллионы или миллиарды строк, занимающих тысячи ГБ памяти. Выполнение расчетов с использованием данных из этих таблиц и особенно непосредственное объединение их с другими таблицами будет довольно затратным.
Окончательным решением таких задач является использование CTE. 💯
Забегая вперед, давайте посмотрим, как можно присвоить целочисленный «ранг» каждой строке в наборе данных с помощью оконных функций.
2. ROW_NUMBER() vs RANK() vs DENSE_RANK()
Второй часто используемой концепцией при работе с реальными наборами данных является ранжирование записей. Компании используют его в различных сценариях, таких как:
- Рейтинг самых продаваемых брендов по количеству проданных единиц
- Ранжирование лучших продуктовых вертикалей по количеству заказов или полученному доходу
- Получение названия фильма в каждом жанре с наибольшим количеством просмотров
ROW_NUMBER, RANK()и DENSE_RANK()по существу используются для присвоения последовательных целых чисел каждой записи в указанном разделе результирующего набора.
Поведение и способ, которым целые числа присваиваются каждой записи, изменяются, когда в результирующей таблице есть повторяющиеся строки. ✅
Давайте рассмотрим пример с Dummy Sales Dataset, чтобы перечислить все категории продуктов, адрес доставки в порядке убывания стоимости доставки.
SELECT Product_Category,
Shipping_Address,
Shipping_Cost,
ROW_NUMBER() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RowNumber,
RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as RankValues,
DENSE_RANK() OVER
(PARTITION BY Product_Category,
Shipping_Address
ORDER BY Shipping_Cost DESC) as DenseRankValues
FROM Dummy_Sales_Data_v1
WHERE Product_Category IS NOT NULL
AND Shipping_Address IN ('Germany','India')
AND Status IN ('Delivered')Как вы можете видеть, синтаксис для всех трех одинаковый, однако он приводит к разным выводам, как показано ниже:
RANK()is извлекает ранжированные строки на основе условия ORDER BYпредложения. Как видите, между первыми двумя строками есть связь, т. е. первые две строки имеют одинаковое значение в столбце Shipping_Cost ( о котором говорится в
Как видите, между первыми двумя строками есть связь, т. е. первые две строки имеют одинаковое значение в столбце Shipping_Cost ( о котором говорится в ORDER BYпункте ).
RANKприсваивает одно и то же целое число обеим строкам. Однако он добавляет количество повторяющихся строк к повторяющемуся рангу, чтобы получить ранг следующей строки. Вот почему третья строка ( отмечена красным ) RANKприсваивает ранг 3( 2 повторяющихся строки + 1 повторяющийся ранг )
DENSE_RANKпохож на RANK, но он не пропускает ни одного числа, даже если между строками есть ничья. Это вы можете увидеть в синей рамке на картинке выше.
В отличие от двух предыдущих, ROW_NUMBERпросто присваивает последовательные номера каждой записи в разделе, начиная с 1. Если он обнаруживает два одинаковых значения в одном разделе, он присваивает обоим разные ранговые номера.
Для следующего partition для product category > shipping address > Entertainment — India, rank по 3-м функциям начнется с 1-цы как показано ниже:
ROW_NUMBER, RANK, DENSE_RANK в разных Partition’ах
В конечном случае, если в столбце, который юзается для ORDER BY эти фунуции вернут один и тот же результат.
3. CASE WHEN
Оператор Case позволит вам реализовать if-else в SQL.
При работе над реальными проектами данных оператор CASE часто используется для категоризации данных на основе значений в других столбцах. Его также можно использовать вместе с агрегатными функциями.
SELECT OrderID,
OrderDate,
Sales_Manager,
Quantity,
CASE WHEN Quantity > 51 THEN 'High'
WHEN Quantity < 51 THEN 'Low'
ELSE 'Medium'
END AS OrderVolume
FROM Dummy_Sales_Data_v1В случае с конкретным примером выражение добавило доп колонку, где вставляет значение high, medium или low в зависимости от значений в столбце Quantity.
Другим часто используемым, но менее известным вариантом использования оператора CASE — Data Pivoting.
Data Pivoting — это когда мы меняем местами колонки со строками.
Например, давайте выясним, сколько заказов обработал каждый менеджер по продажам для Сингапура, Великобритании, Кении и Индии.
SELECT Sales_Manager,
COUNT(CASE WHEN Shipping_Address = 'Singapore' THEN OrderID
END) AS Singapore_Orders,
COUNT(CASE WHEN Shipping_Address = 'UK' THEN OrderID
END) AS UK_Orders,
COUNT(CASE WHEN Shipping_Address = 'Kenya' THEN OrderID
END) AS Kenya_Orders,
COUNT(CASE WHEN Shipping_Address = 'India' THEN OrderID
END) AS India_Orders
FROM Dummy_Sales_Data_v1
GROUP BY Sales_Managerиспользуя CASE..WHEN..THEN, мы создали отдельные столбцы для каждого адреса доставки, чтобы получить ожидаемый результат, как показано ниже.
В зависимости от ваших задач вы также можете использовать различные агрегации, такие как SUM, AVG, MAX, MIN с оператором CASE.
4. Extract Data From Date — Time Columns
В некоторых собесах или просто в рабочих задачах вас попросят агрегировать данные по месяцам или рассчитать определенные показатели за конкретный месяц.
И когда в наборе данных нет отдельного столбца месяца, вам нужно извлечь нужную часть даты из переменной даты и времени в данных.
Различные среды SQL имеют разные функции для извлечения частей даты. В MySQL вы должны знать —
EXTRACT(part_of_date FROM date_time_column_name) YEAR(date_time_column_name) MONTH(date_time_column_name) MONTHNAME(date_time_column_name) DATE_FORMAT(date_time_column_name)
например, давайте узнаем общее количество заказов каждый месяц
SELECT strftime('%m', OrderDate) as Month,
SUM(Quantity) as Total_Quantity
from Dummy_Sales_Data_v1
GROUP BY strftime('%m', OrderDate)Ниже приведено изображение, на котором показаны наиболее часто извлекаемые части даты и ключевые слова, которые следует использовать в EXTRACTфункции.
5. SELF JOIN
Они точно такие же, как и другие JOIN в SQL, с той лишь разницей, что SELF JOINвы соединяете таблицу с самой собой.
Ключевого слова SELF JOINнет, вы просто юзаете join где обе таблицы, которые участвуют в нем — это одна и та же таблица
Напишите SQL-запрос, где вы находите сотрудников, которые зарабатывают больше, чем их менеджеры
. Один из наиболее часто задаваемых вопросов на собеседованиях.SELF JOIN
давайте возьмем это в качестве примера и создадим набор данных Dummy_Employees, как показано ниже.
И попробуйте узнать, какие сотрудники обрабатывают больше заказов, чем их менеджер, используя этот запрос:
SELECT t1.EmployeeName, t1.TotalOrders FROM Dummy_Employees AS t1 JOIN Dummy_Employees AS t2 ON t1.ManagerID = t2.EmployeeID WHERE t1.TotalOrders > t2.TotalOrders
Как и ожидалось, вернулись сотрудники — Абдул и Мария, — которые обработали больше заказов, чем их менеджер — Пабло.
Источник
CTE в SQL — GeeksforGeeks
Общие табличные выражения (CTE) были введены в стандартный SQL для упрощения различных классов SQL-запросов, для которых производная таблица просто не подходила. CTE был введен в SQL Server 2005, общее табличное выражение (CTE) — это временный именованный набор результатов, на который можно ссылаться в операторах SELECT, INSERT, UPDATE или DELETE. Вы также можете использовать CTE в представлении CREATE как часть запроса SELECT представления. Кроме того, начиная с SQL Server 2008, вы можете добавить CTE в новую инструкцию MERGE.
Зачем нужны CTE в SQL сервере?
Общая таблица [устарело]CTE — это мощная конструкция SQL, помогающая упростить запросы. CTE действуют как виртуальные таблицы (с записями и столбцами), которые создаются во время выполнения запроса, используются запросом и удаляются после выполнения запроса.
Использование CTE
Мы можем определить CTE, добавив предложение WITH непосредственно перед оператором SELECT, INSERT, UPDATE, DELETE или MERGE. Предложение WITH может включать одно или несколько CTE, разделенных запятыми.
Предложение WITH может включать одно или несколько CTE, разделенных запятыми.
Синтаксис:
[WITH [ …]]
::=
cte_name [(column_name [ …])]
AS (cte_query)
Аргумент
- Выражение имя: Допустимый идентификатор для общего табличного выражения. Имя_выражения должно отличаться от имен других общих табличных выражений, определенных в том же предложении WITH, но имя_выражения может совпадать с именем базовой таблицы или представления. Все ссылки на имя_выражения в запросе используют общее табличное выражение вместо базового объекта.
- Имя столбца: Задает имя столбца в обычном табличном выражении. Повторяющиеся имена в одном определении CTE не допускаются. Количество имен столбцов должно совпадать с количеством столбцов в результирующем наборе CTE_query_definition. Список имен столбцов является необязательным, только если все результирующие столбцы в определении запроса имеют разные имена.
- CTE_QueryDefinition: Указывает оператор SELECT, набор результатов которого удовлетворяет обычному табличному выражению. Оператор SELECT для CTE_query_defining должен соответствовать тем же требованиям, что и создание представления, за исключением того, что CTE не может определять другое CTE. Дополнительные сведения см. в разделе «Примечания» и CREATE VIEW (Transact-SQL). Если задано несколько CTE_query_settings, определения запроса должны быть объединены с одним из операторов набора UNION ALL, UNION, EXCEPT или INTERSECT.
Правила определения и использования рекурсивных общих табличных выражений
Следующие рекомендации применяются к определению рекурсивных общих табличных выражений:
- рекурсивный член. Вы можете определить несколько якорных и рекурсивных элементов. Однако все определения запросов элементов привязки должны быть помещены перед определением первого рекурсивного элемента. Все определения запросов CTE являются элементами привязки, если только они не ссылаются на само CTE.
- Элементы привязки должны сочетаться с одним из следующих операторов набора: ОБЪЕДИНЕНИЕ ВСЕХ, ОБЪЕДИНЕНИЕ, ПЕРЕСЕЧЕНИЕ, ИСКЛЮЧЕНИЕ. UNION ALL — единственный допустимый оператор набора между последним элементом привязки и первым рекурсивным элементом при объединении нескольких рекурсивных элементов. Якорные и рекурсивные элементы должны иметь одинаковое количество столбцов.
- Тип данных столбцов рекурсивного элемента должен совпадать с типом данных соответствующего столбца элемента привязки.
- Следующие элементы не разрешены в ее CTE_query_definition для рекурсивных членов:
Пожалуйста, выберите другой группировка PIVOT (для уровня совместимости базы данных 110 и выше. См. раздел Критические изменения функций ядра СУБД в SQL Server 2016. Субпродукты Скалярная агрегация Вверх ВЛЕВО, ВПРАВО, ВНЕШНЕЕ СОЕДИНЕНИЕ (ВНУТРЕННЕЕ СОЕДИНЕНИЕ разрешено) подзапрос Подсказка, применяемая к рекурсивным ссылкам на CTE в CTE_query_definition.
Создание рекурсивного общего табличного выражения
Рекурсивное CTE — это выражение, которое ссылается на себя в этом CTE. Рекурсивное CTE полезно при работе с иерархическими данными, поскольку CTE продолжает выполняться до тех пор, пока запрос не вернет всю иерархию.
Рекурсивное CTE полезно при работе с иерархическими данными, поскольку CTE продолжает выполняться до тех пор, пока запрос не вернет всю иерархию.
Типичным примером иерархических данных является таблица, содержащая список сотрудников. Для каждого сотрудника в таблице указана ссылка на его руководителя. Эта ссылка сама по себе является идентификатором сотрудника в той же таблице. Вы можете использовать рекурсивное CTE для отображения иерархии данных о сотрудниках.
Если CTE создан неправильно, он может войти в бесконечный цикл. Чтобы предотвратить это, можно добавить подсказку MAXRECURSION в предложение OPTION основного оператора SELECT, INSERT, UPDATE, DELETE или MERGE.
Таблица создана:
CREATE TABLE Сотрудники ( EmployeeID int NOT NULL PRIMARY KEY, Имя varchar(50) НЕ NULL, Фамилия varchar(50) НЕ NULL, ID менеджера целое NULL ) ВСТАВЬТЕ В ЗНАЧЕНИЯ сотрудников (1, «Кен», «Томпсон», NULL) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (2, «Терри», «Райан», 1) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (3, «Роберт», «Дурелло», 1) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (4, «Роб», «Бейли», 2) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (5, «Кент», «Эриксон», 2) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (6, «Билл», «Голдберг», 3) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (7, «Райан», «Миллер», 3) ВСТАВЬТЕ В ЗНАЧЕНИЯ сотрудников (8, «Датчанин», «Отметка», 5) ВСТАВЬТЕ В ЦЕННОСТИ сотрудников (9, 'Чарльз', 'Мэттью', 6) INSERT INTO Employees VALUES (10, 'Michael', 'Jhonson', 6)
После создания таблицы Employees создается следующая инструкция SELECT, которой предшествует предложение WITH, включающее CTE с именем cteReports:
WITH
cteReports (EmpID, Имя, Фамилия, MgrID, EmpLevel)
КАК
(
ВЫБЕРИТЕ EmployeeID, Имя, Фамилия, ManagerID, 1
ОТ сотрудников
ГДЕ ManagerID имеет значение NULL
СОЮЗ ВСЕХ
ВЫБЕРИТЕ e. EmployeeID, e.FirstName, e.LastName, e.ManagerID,
r.EmpLevel + 1
ОТ сотрудников e
ВНУТРЕННЕЕ СОЕДИНЕНИЕ cteReports r
ON e.ManagerID = r.EmpID
)
ВЫБИРАТЬ
Имя + ' ' + Фамилия КАК ФИО,
ЭмпУровень,
(ВЫБЕРИТЕ Имя + '' + Фамилия ОТ Сотрудников
ГДЕ EmployeeID = cteReports.MgrID) AS Manager
ИЗ cteReports
ЗАКАЗАТЬ ПО EmpLevel, MgrID  EmployeeID, e.FirstName, e.LastName, e.ManagerID,
r.EmpLevel + 1
ОТ сотрудников e
ВНУТРЕННЕЕ СОЕДИНЕНИЕ cteReports r
ON e.ManagerID = r.EmpID
)
ВЫБИРАТЬ
Имя + ' ' + Фамилия КАК ФИО,
ЭмпУровень,
(ВЫБЕРИТЕ Имя + '' + Фамилия ОТ Сотрудников
ГДЕ EmployeeID = cteReports.MgrID) AS Manager
ИЗ cteReports
ЗАКАЗАТЬ ПО EmpLevel, MgrID
EmployeeID, e.FirstName, e.LastName, e.ManagerID,
r.EmpLevel + 1
ОТ сотрудников e
ВНУТРЕННЕЕ СОЕДИНЕНИЕ cteReports r
ON e.ManagerID = r.EmpID
)
ВЫБИРАТЬ
Имя + ' ' + Фамилия КАК ФИО,
ЭмпУровень,
(ВЫБЕРИТЕ Имя + '' + Фамилия ОТ Сотрудников
ГДЕ EmployeeID = cteReports.MgrID) AS Manager
ИЗ cteReports
ЗАКАЗАТЬ ПО EmpLevel, MgrID Таким образом, CTE могут быть полезны, когда вам нужно сгенерировать временные наборы результатов, к которым можно получить доступ в операторах SELECT, INSERT, UPDATE, DELETE или MERGE.
Особенности и ограничения общих табличных выражений в Azure
Текущая реализация CTE в Azure Synapse Analytics and Analytics Platform System (PDW) имеет следующие функции и ограничения:
- CTE можно указать только в SELECT заявление.
- CTE можно указать только в инструкции CREATE VIEW.
- CTE можно указать только в операторе CREATE TABLE AS SELECT (CTAS).
- CTE можно указать только в операторе CREATE REMOTE TABLE AS SELECT (CRTAS).
- CTE можно указать только в операторе CREATE EXTERNAL TABLE AS SELECT (CETAS).
Освоение общего табличного выражения или CTE в SQL Server
Сводка : в этом руководстве вы узнаете об общем табличном выражении или CTE в SQL Server с помощью WITH 9пункт 0112.
Введение в CTE в SQL Server
CTE означает общее табличное выражение. CTE позволяет определить временный именованный набор результатов, временно доступный в области выполнения инструкции, такой как SELECT , INSERT , UPDATE , DELETE или MERGE .
Ниже показан общий синтаксис CTE в SQL Server:
WITH имя_выражения[(имя_столбца [...])]
КАК
(CTE_определение)
SQL_оператор;
Язык кода: SQL (язык структурированных запросов) (sql) В этом синтаксисе:
- Сначала укажите имя выражения (
имя_выражения), к которому вы сможете обращаться позже в запросе. - Затем укажите список столбцов, разделенных запятыми, после expression_name. Количество столбцов должно совпадать с количеством столбцов, определенным в
CTE_definition. - Затем используйте ключевое слово AS после имени выражения или списка столбцов, если указан список столбцов.
- После этого определите оператор
SELECT, набор результатов которого заполняет общее табличное выражение. - Наконец, обратитесь к общему табличному выражению в запросе (
SQL_statement), напримерSELECT,INSERT,UPDATE,DELETEилиMERGE.

Мы предпочитаем использовать общие табличные выражения, а не подзапросы, потому что общие табличные выражения более удобочитаемы. Мы также используем CTE в запросах, содержащих аналитические функции (или оконные функции)
Примеры SQL Server CTE
Давайте рассмотрим несколько примеров использования общих табличных выражений.
A) Простой пример CTE для SQL Server
В этом запросе используется CTE для возврата сумм продаж по отделам продаж в 2018 г.:
WITH cte_sales_amounts (персонал, продажи, год) AS (
ВЫБИРАТЬ
имя_имя + ' ' + фамилия,
СУММ(количество * список_цена * (1 - скидка)),
ГОД(дата_заказа)
ОТ
продажи.заказы o
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sales.order_items i ON i.order_id = o.order_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sales.staffs s ON s.staff_id = o.staff_id
ГРУППА ПО
имя_имя + ' ' + фамилия,
год(дата_заказа)
)
ВЫБИРАТЬ
персонал,
продажи
ОТ
cte_sales_amounts
ГДЕ
год = 2018;
Язык кода: SQL (язык структурированных запросов) (sql) На следующем рисунке показан набор результатов:
В этом примере:
- Сначала мы определили
cte_sales_amountsкак имя общего табличного выражения. CTE возвращает результат, который состоит из трех столбцовперсонал,годипродажи, полученные из определяющего запроса. - Во-вторых, мы создали запрос, который возвращает общую сумму продаж по торговому персоналу и за год, запрашивая данные из
заказы,order_itemsиштатыстолы. - В-третьих, мы ссылались на CTE во внешнем запросе и выбирали только строки, год которых равен 2018.

Обратите внимание, что этот пример предназначен исключительно для демонстрационных целей, чтобы помочь вам постепенно понять, как работают общие табличные выражения. Есть более оптимальный способ добиться результата без использования CTE.
B) Использование общего табличного выражения для получения средних значений отчета на основе подсчетов
В этом примере CTE используется для возврата среднего количества заказов на продажу в 2018 году для всех сотрудников отдела продаж.
С cte_sales КАК (
ВЫБИРАТЬ
staff_id,
COUNT(*) количество_заказов
ОТ
заказы на продажу
ГДЕ
ГОД(дата_заказа) = 2018
ГРУППА ПО
staff_id
)
ВЫБИРАТЬ
AVG(счетчик_заказов) среднее_заказов_по_персоналу
ОТ
cte_продажи;
Язык кода: SQL (язык структурированных запросов) (sql) Вот результат:
Average_orders_by_staff ----------------------- 48 (затронут 1 ряд) Язык кода: SQL (язык структурированных запросов) (sql)
В этом примере:
Сначала мы использовали cte_sales в качестве имени общего табличного выражения. Мы пропустили список столбцов CTE, поэтому он получен из оператора определения CTE. В этом примере он включает
Мы пропустили список столбцов CTE, поэтому он получен из оператора определения CTE. В этом примере он включает столбцов staff_id и order_count .
Во-вторых, мы используем следующий запрос для определения набора результатов, который заполняет общее табличное выражение cte_sales . Запрос возвращает количество заказов торгового персонала в 2018 году.
ВЫБОР
staff_id,
COUNT(*) количество_заказов
ОТ
заказы на продажу
ГДЕ
ГОД(дата_заказа) = 2018
ГРУППА ПО
штат_идентификатор;
Язык кода: SQL (язык структурированных запросов) (sql) В-третьих, мы ссылаемся на cte_sales во внешнем операторе и используем функцию AVG() для получения среднего заказа на продажу по всем сотрудникам.
ВЫБОР
AVG(счетчик_заказов) среднее_заказов_по_персоналу
ОТ
cte_продажи;
Язык кода: SQL (язык структурированных запросов) (sql) C) Использование нескольких CTE SQL Server в одном примере запроса
В следующем примере используются два CTE cte_category_counts и cte_category_sales для возврата количества продуктов и продаж для каждой категории продуктов. Внешний запрос объединяет два CTE, используя столбец
Внешний запрос объединяет два CTE, используя столбец category_id .
С cte_category_counts (
id_категории,
категория_имя,
product_count
)
КАК (
ВЫБИРАТЬ
c.category_id,
c.category_name,
COUNT(p.product_id)
ОТ
производство.продукция р
ВНУТРЕННЕЕ СОЕДИНЕНИЕ производство.категории c
ВКЛ c.category_id = p.category_id
ГРУППА ПО
c.category_id,
c.category_name
),
cte_category_sales(category_id, продажи) КАК (
ВЫБИРАТЬ
p.category_id,
SUM(i.quantity * i.list_price * (1 - i.discount))
ОТ
sales.order_items я
ВНУТРЕННЕЕ СОЕДИНЕНИЕ
ВКЛ p.product_id = i.product_id
ВНУТРЕННЕЕ СОЕДИНЕНИЕ sales.orders o
ON o.order_id = i.order_id
ГДЕ order_status = 4 -- выполнено
ГРУППА ПО
p.category_id
)
ВЫБИРАТЬ
c.category_id,
c.category_name,
c.product_count,
с.продажи
ОТ
cte_category_counts c
ВНУТРЕННЕЕ СОЕДИНЕНИЕ cte_category_sales s
ВКЛ s.