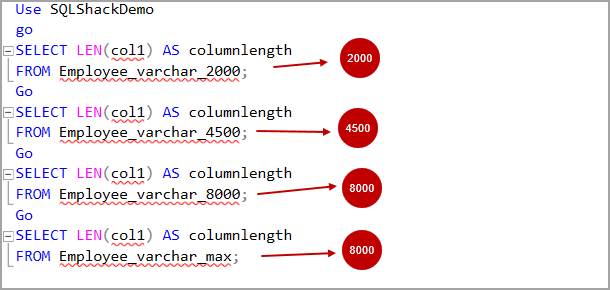
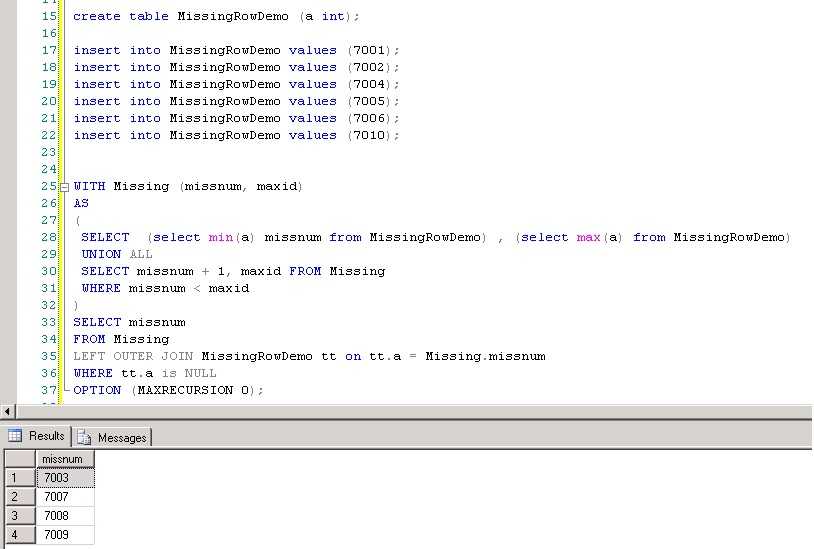
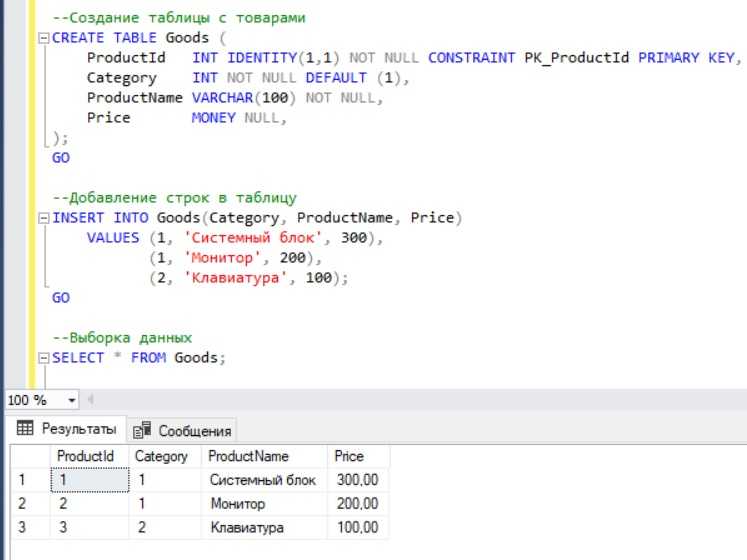
Sql длина строки: Функция LENGTH — подсчет количества символов
Содержание
2.25. Функции работы со строками
У SQL сервера достаточно много мощных функций для работы со строками и в этом разделе мы рассмотрим наиболее интересные и часто используемые из них. Из моего личного опыта (ваши задачи могут дать другой результат), наиболее часто используемой является функция SUBSTRING. Именно с нее мы и начнем.
SUBSTRING
Помниться, что мы добавили к значениям в колонке имен работников префикс ‘mr.’ (см. разд. 2.17). А как теперь от него избавится во время обращения к таблице? Достаточно просто, если воспользоваться функцией SUBSTRING, которая возвращает указанную часть строки. Этой функции необходимо передать три параметра:
- Поле, часть строки которого нужно получить;
- Первый символ;
- Количество интересующих нас символов.
Посмотрим, как вышесказанное можно реализовать в виде запроса:
SELECT idPeoples,
CASE SUBSTRING(vcFamil, 1, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END
FROM tbPeoples
В этом примере, мы выбираем только два поля: «idPeoples» и поле, результат которого зависит от проверки CASE. В данном случае CASE проверяет результат работы функции SUBSTRING, которая выбирает символы из поля «vcFamil» начиная с первого по третий. Если результат равен ‘mr.’, то необходимо обрезать этот префикс.
В данном случае CASE проверяет результат работы функции SUBSTRING, которая выбирает символы из поля «vcFamil» начиная с первого по третий. Если результат равен ‘mr.’, то необходимо обрезать этот префикс.
Для того, чтобы отбросить ненужные символы от значения поля, мы снова пользуемся функцией SUBSTRING, но теперь выбираем символы, начиная с четвертного (начиная с первого, после ‘mr.’). В качестве количества символов я указал число 255, что больше максимального значения поля, а значит, строка будет выбрана до конца, начиная 4-го.
Теперь попробуем обновить данные в таблице, чтобы в поле «vcName», чтобы в нем не было лишних символов ‘mr.’. Для этого выполняем следующий запрос:
UPDATE tbPeoples
SET vcFamil=(case SUBSTRING(vcFamil, 1, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
В этом примере полю «vcName»присваивается результат сравнения CASE, который мы уже рассмотрели выше. Таким образом, мы избавились от лишних букв в фамилиях.
LEFT
Задачу обрезание лишних символов из начала строки можно было бы решить и с использованием функции LEFT, которая возвращает указанное количество символов, начиная с 1-го. Функции нужно передать следующие два параметра:
- Поле, подстроку которого нужно получить;
- Количество символов.
Следующий пример формирует ФИО, в котором имя и отчество сокращены:
SELECT vcFamil+' '+left(vcName, 1)+'. '+left(vcSurName, 1)+'.' FROM tbPeoples
Поле «vcFamil» выводится полностью, а вот от имени и отчества выводится только один левый (первый) символ.
Теперь посмотрим, как можно было использовать LEFT для обрезания префикса ‘mr.’:
UPDATE tbPeoples
SET vcFamil=(case LEFT(vcFamil, 3)
WHEN 'mr.' THEN SUBSTRING(vcFamil, 4, 255)
ELSE vcFamil
END)
LEN
Функция LEN позволяет определить длину строки или значения поля. Функции достаточно передать строку или имя поля, длина значений которого нас интересует.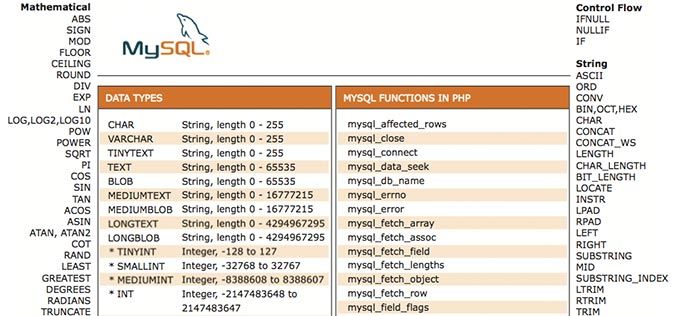 Например, следующий запрос отобразить длину всех значений в поле «vcFamil»:
Например, следующий запрос отобразить длину всех значений в поле «vcFamil»:
SELECT vcFamil, len(vcFamil) FROM tbPeoples
В следующем примере мы ищем записи, в которых фамилия состоит 7-и символов:
SELECT vcFamil FROM tbPeoples WHERE len(vcFamil)=7
LOWER
Если ваш сервер настроен так, что строки чувствительные к регистру букв, то с поиском по строковым полям могут быть серьезные проблемы. Если вы указали фамилию как Иванов, то это значение не будет равно ИВАНОВ, а значит, мы не увидим необходимую запись. Проблему решает функция LOWER, которая приводит указанную строку к нижнему регистру.
Рассмотрим пример. В следующем запросе мы выбираем все фамилии, при этом они отображаются в нижнем регистре (маленькими буквами):
SELECT LOWER(vcFamil) FROM tbPeoples
Теперь посмотрим на следующий пример:
SELECT *
FROM tbPeoples
WHERE LOWER(vcFamil)=LOWER('Сидоров')
В секции WHERE, где мы сравниваем значение поля с введенной пользователем фамилией, и то и другое приводится к нижнему регистру. Таким образом, как бы не хранилась фамилия в базе, все Ивановы будут найдены.
Таким образом, как бы не хранилась фамилия в базе, все Ивановы будут найдены.
UPPER
Функция Upper также изменяет регистр букв, только делает их все большими. Это значит, что функцию можно также использовать для сравнения двух строк разного регистра, если все буквы привести к большим:
SELECT *
FROM tbPeoples
WHERE UPPER(vcFamil)=UPPER('Сидоров')
Если вам нужно сравнить две строки не обращая внимания на используемых регистр букв внутри строк, можно использовать как UPPER, так и LOWER. Разницы никакой нет, поэтому выбирайте то, что больше нравится.
LTRIM и RTRIM
Функция LTRIM убирает все символы пробела в начале строки, а RTRIM убирает пробелы в конце строки. Допустим, что пользователь при вводе фамилии в самом начале случайно зацепил клавишу пробела. Получилось, что в базе хранится две фамилии:
Иванов Иванов
Когда смотришь на эти фамилии, то видно, что вторая строка сдвинута вправо за счет пробела вначале. Это значит, что база данных будет воспринимать эти значения по-разному. Чтобы избавится от лишних пробелов, как раз используют функции LTRIM и RTRIM. Например:
Это значит, что база данных будет воспринимать эти значения по-разному. Чтобы избавится от лишних пробелов, как раз используют функции LTRIM и RTRIM. Например:
SELECT *
FROM tbPeoples
WHERE LTRIM(vcFamil)=LTRIM(' Сидоров')
В этом примере поле «vcFamil» сравнивается с фамилией Сидоров, с пробелом в начале. Чтобы убрать пробел используется функция LTRIM. В следующем примере мы убираем и левые и правые пробелы:
-- Убрать лишние пробелы
SELECT *
FROM tbPeoples
WHERE vcFamil=LTRIM(RTRIM(' Сидоров '))
Если честно, то пробелы справа убираются сервером автоматически. Выполните следующий запрос и убедитесь сами:
SELECT * FROM tbPeoples WHERE vcFamil='Сидоров '
Если работник с фамилией Сидоров (без пробелов в конце) существует в таблице, и запрос отобразил его, то сервер автоматически убрал пробел.
PATINDEX
С помощью функции PATINDEX можно искать часть подстроки по определенному шаблону. Допустим, что нам надо найти все фамилии, в которых есть две буквы «о», между которыми может находиться любой символ. Эту задачу можно решить с помощью следующего запроса:
Допустим, что нам надо найти все фамилии, в которых есть две буквы «о», между которыми может находиться любой символ. Эту задачу можно решить с помощью следующего запроса:
SELECT vcFamil, PATINDEX('%О_О%', vcFamil)
FROM tbPeoples
Если посмотреть на функцию, то пока не понятно, чем она отличается от LIKE с шаблоном? Все очень просто – LIKE используется для создания ограничений в секции WHERE, а PATINDEX возвращает индекс символа, начиная с которого идет указанный шаблон в строке. Если бы мы использовали LIKE, то сервер вернул бы нам только те строки, где найден шаблон:
SELECT vcFamil FROM tbPeoples WHERE vcFamil LIKE '%О_О%'
Если использовать функцию PATINDEX, то в результат попадут все строки (мы не ограничиваем вывод в секции WHERE), но там где в фамилии нет шаблона, в соответствующей строке будет стоять ноль, а там где есть, будет стоять 1. Посмотрим на пример результата выполнения запроса с использованием функции PATINDEX:
vcFamil Ind ----------------------------------------------- ПОЧЕЧКИН 0 ПЕТРОВ 0 СИДОРОВ 4 КОНОНОВ 2 СЕРГЕЕВ 0
В данном примере шаблон ‘%О_О%’ присутствует в фамилии Сидоров. Начиная с четвертого символа идут буквы «оро».
Начиная с четвертого символа идут буквы «оро».
REPLACE
Функция replace позволяет найти в значении поля подстроку и заменить ее на новое значение. У этой функции три параметра:
- Строка, в которой нужно искать подстроку;
- Подстрока, которую ищем;
- Значение, которое нужно подставить.
Посмотрим пример использования этой функции:
SELECT vcFamil, REPLACE(vcFamil, 'оро', 'аро') AS Ind
FROM tbPeoples
WHERE PATINDEX('%О_О%', vcFamil)>0
Мы выбираем из таблицы два поля: фамилию и результат функции REPLACE. Функция ищет в поле «vcFamil» строку «оро» и заменяет ее на строку «аро». Чтобы лучше было понятно, посмотрим на результат работы функции:
vcFamil Ind ---------------------------------------------- СИДОРОВ СИДароВ КОНОНОВ КОНОНОВ КОРОВА КароВА МОЛОТКОВ МОЛОТКОВ САДОВОДОВ САДОВОДОВ СОДОРОЧКИН СОДароЧКИН (6 row(s) affected)
В первой колонке показана фамилия из таблицы, а во второй колонке можно увидеть модифицированный с помощью функции REPLACE вариант. Я думаю, что все понятно и без лишних комментариев.
Я думаю, что все понятно и без лишних комментариев.
REPLICATE
С помощью функции REPLICATE можно размножать строку. У функции два параметра:
- Строка или имя поля, которое нужно вывести несколько раз;
- Количество необходимых повторений
Переходим к примеру. Следующий запрос выводит в результирующий набор дважды значение поля фамилии:
SELECT REPLICATE(vcFamil, 2) FROM tbPeoples
В результате мы увидим нечто подобное:
ПОЧЕЧКИНПОЧЕЧКИН ПЕТРОВПЕТРОВ СИДОРОВСИДОРОВ КОНОНОВКОНОНОВ СЕРГЕЕВСЕРГЕЕВ ВАСИЛЬЕВВАСИЛЬЕВ ...
В данном примере мало полезного смысла, но функция не совсем бесполезна. Например, вы хотите нарисовать длинную двойную полоску. Можно нажать клавишу равенства и ждать, когда появится на экране полоска нужной длины, а можно просто клонировать знак равенства нужное количество раз. Следующий пример клонирует знак 50 раз:
SELECT REPLICATE('=', 50)
Результат:
==================================================
Красиво? А главное удобно в управлении.
REVERSE
Пару раз я встречался с необходимостью перевернуть строку задом наперед, и в этом мне помогла функция REVERSE. Ей нужно передать строку и результатом будет та же строка, только буквы будут идти в обратном порядке. Например, следующий запрос выводит все фамилии задом наперед:
SELECT REVERSE(vcFamil) FROM tbPeoples
В реальных приложениях полностью строку вы будете менять достаточно редко, а вот часть строки может меняться. Например, в следующем запросе в фамилии меняются местами первые два символа:
SELECT REPLACE(vcFamil,
LEFT(vcFamil, 2),
REVERSE(LEFT(vcFamil, 2))
)
FROM tbPeoples
Пример достаточно интересен тем, что лишний раз показывает, как использовать уже известные нам функции работы со строками. В результирующем наборе отображается результат работы функции REPLACE. Функции нужно передать:
- Название поля, где хранится фамилия;
- Первые два символа.
 Для получения первых двух символов используем уже знакомую нам функцию LEFT;
Для получения первых двух символов используем уже знакомую нам функцию LEFT; - В качестве строки, которая должна будет поставлена вместо первых двух символов фамилии, выступают те же два символа, только перевернутые.
 Для получения первых двух символов используем уже знакомую нам функцию LEFT;
Для получения первых двух символов используем уже знакомую нам функцию LEFT;
SPACE
С помощью функции SPACE можно создавать пробелы. В качестве единственного параметра нужно указать число, которое определяет количество возвращаемых пробелов. Работа функции идентична REPLICATE, если в качестве клонируемого символа указать пробел.
Допустим, что нам нужно вывести на экран поля фамилию и имя, разделенные 5-ю пробелами. Можно сделать так:
SELECT vcFamil+' '+vcName FROM tbPeoples
А можно воспользоваться функцией SPACE:
SELECT vcFamil+SPACE(5)+vcName FROM tbPeoples
Зачем нужна функция, когда можно воспользоваться без нее? Допустим, что вам нужно использовать 5 пробелов в нескольких местах большого сценария. Все легко решается без функций, но в последствии оказалось, что количество пробелов должно быть не 5, а 10. Придется пересматривать весь сценарий и корректировать пробелы. А если бы мы использовали SPACE в сочетании с переменными, то проблема решилась бы намного проще.
Придется пересматривать весь сценарий и корректировать пробелы. А если бы мы использовали SPACE в сочетании с переменными, то проблема решилась бы намного проще.
Рассмотрим пример, в котором множественные пробелы используются дважды и для задания количества используется переменная:
DECLARE @sp int SET @sp=10 SELECT vcFamil+SPACE(@sp)+vcName+SPACE(@sp)+vcSurName FROM tbPeoples
Теперь, достаточно только изменить значение переменной, и количество пробелов изменено во всем сценарии. А главное – что количество пробелов может быть определено динамически, на основе запросов к таблице.
STR
С помощью функции STR можно форматировать дробные числа в строку. Чем это отличается от преобразования типов? Тип остается тем же, а на экран мы выводим строку в нужном виде. Функции нужно передать три параметра:
- Дробное число, которое нужно форматировать;
- Общее количество символов, включая числа до и после запятой, пробелы и знак;
- Количество знаков после запятой.
Допустим, что нам нужно вывести название и цену товара. Но цена имеет тип money, который содержит слишком большое количество нулей. Чтобы избавиться от лишних чисел после запятой и получить строку, можно сначала привести тип money к типу number(10, 2), а потом результат привести к строке. Но можно решить все одной командой форматирования STR:
SELECT [Название товара], STR(Цена, 10, 2) FROM Товары
Выполните этот запрос и обратите внимание, что второе поле (отформатированная цена) выровнена вправо:
Название товара -------------------------------------------------- ---------- КАРТОФЕЛЬ 13.60 Сок 23.00 Шоколад 25.00 Хлеб 6.00 Сок 18.
 40
...
40
...
Выравнивание происходит из-за второго параметра – числа 10. Мы задали общее число символов, и выравнивание будет происходить по правой позиции указанного значения. Если второй параметр равен 10, а число состоит из 4 символов, то в начало результирующей строки будет добавлено 6 пробелов. Учитывайте это, при использовании функции STR.
STUFF
Функция STUFF позволяет вставить строку в определенную позицию другой строки. У этой функции четыре параметра:
- Строка, которую нужно изменить;
- Позиция, в которую должна произойти вставка;
- Количество удаляемых символов;
- Вставляемая строка.
Длина вставляемой строки не обязательно должна быть равна значению из 3-го параметра. Во время выполнения, функция сначала удаляет определенное количество символов, начиная с позиции из второго параметра, а затем вставляет новую строку.
Рассмотрим пример, в котором цена вставляется в поле названия товара, начиная с первой позиции, не удаляя ни одного из символов:
SELECT STUFF([Название товара], 1, 0, STR(Цена, 10, 2)+' ') FROM Товары
Результат работы функции будет следующим:
--------------------------------------------
13. 60 КАРТОФЕЛЬ
23.00 Сок
25.00 Шоколад
6.00 Хлеб
18.40 Сок
12.00 Молоко
6.00 Хлеб
...
 60 КАРТОФЕЛЬ
23.00 Сок
25.00 Шоколад
6.00 Хлеб
18.40 Сок
12.00 Молоко
6.00 Хлеб
...
60 КАРТОФЕЛЬ
23.00 Сок
25.00 Шоколад
6.00 Хлеб
18.40 Сок
12.00 Молоко
6.00 Хлеб
...
На этом примере более наглядно видно, что вставляемая цена выравнивается вправо. Так как мы указали в функции STR количество символов равное 10, то вставляется не реальный размер цены, а именно 10 символов.
Попробуйте увеличить третий параметр до 1. В этом случае, первый символ в названии товара будет удален, а вместо него будет вставлена цена.
Строки, символы
char
Строка фиксированный длины, дополненная пробелами
char(n)
varchar
Строка с ограничем максимальной длины
varchar(n)
text, varchar
Строка без ограничения длины
Функции, выделение частей
length, char_length
Длина строки в символах
select
length('Привет, мир!')
, char_length('Привет, мир!')
/*
12
12
*/
octet_length
Длина строки в байтах, зависит от кодировки
select
octet_length('Привет, мир!')
/*
21
*/
position, strpos
Позиция подстроки
select
position('мир' in 'Привет, мир!')
, strpos('Привет, мир!', 'мир')
/*
9
*/
substring, substr
Выделение подстроки
select
substring('Привет, мир!' from 9 for 3)
, substring('Привет, мир!' from 9)
, substr('Привет, мир!', 9, 3)
, substr('Привет, мир!', 9)
/*
мир
, мир
, мир!
, мир!
*/
left, right
Подстрока слева или справа
select
left('Привет, мир!', 6)
, right('Привет, мир!', 4)
/*
Привет
, мир!
*/
Функции, изменений
overlay
Замена подстроки
select
overlay('Привет, мир!' placing 'PostgreSQL' from 9 for 3)
/*
Привет, PostgreSQL!
*/
replace
Замена всех вхождений подстроки
select
replace('Привет, мир!', 'р', 'ррр')
/*
Пррривет, миррр!
*/
translate
Замена символов по соответствию
select
translate('Привет, мир!', 'Првтмие', 'Prvtm')
/*
Prvt, mr!
*/
lower, upper, initcap
Преобразование регистра (зависит от CTYPE)
select
lower('Привет, мир!')
, upper('Привет, мир!')
, initcap('Привет, мир!')
/*
привет, мир!
ПРИВЕТ, МИР!
Привет, Мир!
*/
trim, ltrim, rtrim, btrim
Отрезание символов с концов строки (по умолчанию — пробелы)
select
trim( leading 'Пр!' from 'Привет, мир!')
, ltrim('Привет, мир!', 'Пр!')
, trim(trailing 'Пр!' from 'Привет, мир!')
, rtrim('Привет, мир!', 'Пр!')
, trim( both 'Пр!' from 'Привет, мир!')
, btrim('Привет, мир!', 'Пр!')
/*
ивет, мир!
, ивет, мир!
, Привет, ми
, Привет, ми
, ивет, ми
, ивет, ми
*/
lpad, rpad
Дополнение слева или справа (по умолчанию — пробелами)
select
lpad('Привет, мир!', 17, '. ')
, rpad('Привет, мир!', 17, '. ')
/*
. . .Привет, мир!
, Привет, мир!. . .
*/
 ')
, rpad('Привет, мир!', 17, '. ')
/*
. . .Привет, мир!
, Привет, мир!. . .
*/
')
, rpad('Привет, мир!', 17, '. ')
/*
. . .Привет, мир!
, Привет, мир!. . .
*/
reverse
переворачивает строку
select
reverse('Привет, мир!')
/*
!рим ,тевирП
*/
Функции, конструрирования
concat, concat_ws
Склейка строк (произвольное число аргументов)
select
concat('Привет,', ' ', 'мир!')
, 'Привет,' || ' ' || 'мир!'
, concat_ws(', ', 'Привет', 'о', 'мир!')
/*
Привет, мир!
, Привет, мир!
, Привет, о, мир!
*/
string_agg
+++
Агрегация строк
select
string_agg(s, ', ' order by id)
from (
values
(2,'мир!'),
(1,'Привет')
) v(id,s)
/*
Привет, мир!
*/
repeat
+++
Повторение строки
select
repeat('Привет', 2)
/*
ПриветПривет
*/
chr
Символ по коду (зависит от кодировки)
select
chr(34)
/*
"
*/
Функции, экранирования
quote_ident
Представление строки в виде идентификатора
select
quote_ident('id')
, quote_ident('foo bar')
quote_literal, quote_nullable
Ппредставление в виде строкового литерала
SELECT
quote_literal('id')
, quote_nullable('id')
, quote_literal($$What's up?$$)
, quote_nullable($$What's up?$$)
, quote_literal(null)
, quote_nullable(null)
/*
'id'
, 'id'
, 'What''s up?'
, 'What''s up?'
, null
, null
*/
format
Форматированный текст
select
format('Привет, %s!', 'мир')
, format('UPDATE %I SET s = %L', 'tbl', $$What's up?$$)
, 'UPDATE '||quote_ident('tbl')||' SET s = '||quote_nullable($$What's up?$$)
/*
Привет, мир!
, UPDATE tbl SET s = 'What''s up?'
, UPDATE tbl SET s = 'What''s up?'
*/
Функции, привидения типов
to_char
Число, дату к строке
Форматирование строк
9 цифра
0 цифра с ведущим нулем
.
— (точка) — десятичная точка, — (разделитель) разделитель разрядов
G — разделитель разрядов (из локали)
D — точка или запятая (из локали)
RN — римскими цифрами
EEEE — экспоненциальная запись
MI — минус (<0)
PL — плюс (>0)
SG — плюс или минус
FM — без ведущих нулей и пробелов
 — (точка) — десятичная точка
— (точка) — десятичная точкаФорматирование дат
YYYY — год
MM — месяц (01-12)
MON — месяц (сокр.)
MONTH — месяц полностью
DD — день (01-31)
D — номер дня недели (1-7)
DY — день недели (сокр.)
DAY — день недели
HH — час (01-12)
Hh34 — час (00-23)
MI — минуты
SS — секунды
TZ — часовой пояс
OF — смещение часового пояса
FM — без ведущих пробелов
TM — перевод для дней и месяцев
select to_char(3.
 1416, 'FM99D00')
, to_char(3.1416, 'FM99D000000')
, to_char(56789, '999G999G999')
, to_char(123456789, '999G999G999')
, to_char(123456789, '999G999G999')
/*
3,14
3,141600
56 789
123 456 789
123 456 789
*/
1416, 'FM99D00')
, to_char(3.1416, 'FM99D000000')
, to_char(56789, '999G999G999')
, to_char(123456789, '999G999G999')
, to_char(123456789, '999G999G999')
/*
3,14
3,141600
56 789
123 456 789
123 456 789
*/
select
to_char(now(), 'DD.MM.YYYY Hh34:MI:SSOF')
, to_char(now(), 'FMDD TMmonth YYYY, day')
/*
15.11.2016 11:52:08+03
, 15 ноября 2016, среда
*/
Функции, сравнения
Nvarchar max сколько символов • Вэб-шпаргалка для интернет предпринимателей!
Содержание
- 1 Аргументы Arguments
- 2 Remarks Remarks
- 3 Преобразование в символьные данные Converting Character Data
- 3.1 Рекомендуем к прочтению
ОБЛАСТЬ ПРИМЕНЕНИЯ: SQL Server База данных SQL Azure Azure Synapse Analytics (хранилище данных SQL) Parallel Data Warehouse APPLIES TO: SQL Server Azure SQL Database Azure Synapse Analytics (SQL DW) Parallel Data Warehouse
Символьные типы данных имеют фиксированный (nchar) или переменный (nvarchar) размер. Character data types that are either fixed-size, nchar, or variable-size, nvarchar. Начиная с SQL Server 2012 (11.x) SQL Server 2012 (11.x) при использовании параметров сортировки с поддержкой дополнительных символов эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-16. Starting with SQL Server 2012 (11.x) SQL Server 2012 (11.x) , when a Supplementary Character (SC) enabled collation is used, these data types store the full range of Unicode character data and use the UTF-16 character encoding. Если указаны параметры сортировки без поддержки дополнительных символов, эти типы данных хранят только подмножество символьных данных, поддерживаемых кодировкой UCS-2. If a non-SC collation is specified, then these data types store only the subset of character data supported by the UCS-2 character encoding.
Character data types that are either fixed-size, nchar, or variable-size, nvarchar. Начиная с SQL Server 2012 (11.x) SQL Server 2012 (11.x) при использовании параметров сортировки с поддержкой дополнительных символов эти типы данных хранят весь диапазон символьных данных Юникод и используют кодировку UTF-16. Starting with SQL Server 2012 (11.x) SQL Server 2012 (11.x) , when a Supplementary Character (SC) enabled collation is used, these data types store the full range of Unicode character data and use the UTF-16 character encoding. Если указаны параметры сортировки без поддержки дополнительных символов, эти типы данных хранят только подмножество символьных данных, поддерживаемых кодировкой UCS-2. If a non-SC collation is specified, then these data types store only the subset of character data supported by the UCS-2 character encoding.
Аргументы Arguments
nchar [ ( n ) ] nchar [ ( n ) ]
Строковые данные фиксированного размера. Fixed-size string data. n определяет размер строки в парах байтов и должно иметь значение от 1 до 4000. n defines the string size in byte-pairs and must be a value from 1 through 4,000. Размер хранилища — дважды n байт. The storage size is two times n bytes. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт, а количество хранимых символов равно n. For UCS-2 encoding, the storage size is two times n bytes and the number of characters that can be stored is also n. Для кодировки UTF-16 размер при хранении также равен дважды n байт, но количество хранимых символов может быть меньше n, так как дополнительные символы используют две пары байтов (также называются суррогатными парами). For UTF-16 encoding, the storage size is still two times n bytes but the number of characters that can be stored may be smaller than n because Supplementary Characters use two byte-pairs (also called surrogate-pair).
Fixed-size string data. n определяет размер строки в парах байтов и должно иметь значение от 1 до 4000. n defines the string size in byte-pairs and must be a value from 1 through 4,000. Размер хранилища — дважды n байт. The storage size is two times n bytes. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт, а количество хранимых символов равно n. For UCS-2 encoding, the storage size is two times n bytes and the number of characters that can be stored is also n. Для кодировки UTF-16 размер при хранении также равен дважды n байт, но количество хранимых символов может быть меньше n, так как дополнительные символы используют две пары байтов (также называются суррогатными парами). For UTF-16 encoding, the storage size is still two times n bytes but the number of characters that can be stored may be smaller than n because Supplementary Characters use two byte-pairs (also called surrogate-pair). 30-1 characters (2 GB). Размер при хранении определяется как дважды n байт + 2 байта. The storage size is two times n bytes + 2 bytes. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт + 2 байта, а количество хранимых символов равно n. For UCS-2 encoding, the storage size is two times n bytes + 2 bytes and the number of characters that can be stored is also n. Для кодировки UTF-16 размер при хранении также равен дважды n байт + 2 байта, но количество хранимых символов может быть меньше n, так как дополнительные символы используют две пары байтов (также называются суррогатными парами). For UTF-16 encoding, the storage size is still two times n bytes + 2 bytes but the number of characters that can be stored may be smaller than n because Supplementary Characters use two byte-pairs (also called surrogate-pair). Синонимами типа nvarchar по стандарту ISO являются типы national char varying и national character varying.
30-1 characters (2 GB). Размер при хранении определяется как дважды n байт + 2 байта. The storage size is two times n bytes + 2 bytes. В случае с кодировкой UCS-2 размер при хранении определяется как дважды n байт + 2 байта, а количество хранимых символов равно n. For UCS-2 encoding, the storage size is two times n bytes + 2 bytes and the number of characters that can be stored is also n. Для кодировки UTF-16 размер при хранении также равен дважды n байт + 2 байта, но количество хранимых символов может быть меньше n, так как дополнительные символы используют две пары байтов (также называются суррогатными парами). For UTF-16 encoding, the storage size is still two times n bytes + 2 bytes but the number of characters that can be stored may be smaller than n because Supplementary Characters use two byte-pairs (also called surrogate-pair). Синонимами типа nvarchar по стандарту ISO являются типы national char varying и national character varying. The ISO synonyms for nvarchar are national char varying and national character varying.
The ISO synonyms for nvarchar are national char varying and national character varying.
Remarks Remarks
Часто ошибочно считают, что в типах данных NCHAR(n) и NVARCHAR(n) число n указывает на количество символов. A common misconception is to think that NCHAR(n) and NVARCHAR(n), the n defines the number of characters. Однако на самом деле число n в NCHAR(n) и NVARCHAR(n) — это длина строки в парах байтов (0–4000). But in NCHAR(n) and NVARCHAR(n) the n defines the string length in byte-pairs (0-4,000). n никогда не определяет количество хранимых символов. n never defines numbers of characters that can be stored. То же самое верно и в отношении типов CHAR(n) и VARCHAR(n). This is similar to the definition of CHAR(n) and VARCHAR(n).
Заблуждение возникает из-за того, что при использовании символов, определенных в диапазоне Юникода 0–65 535, на каждую пару байтов приходится один хранимый символ.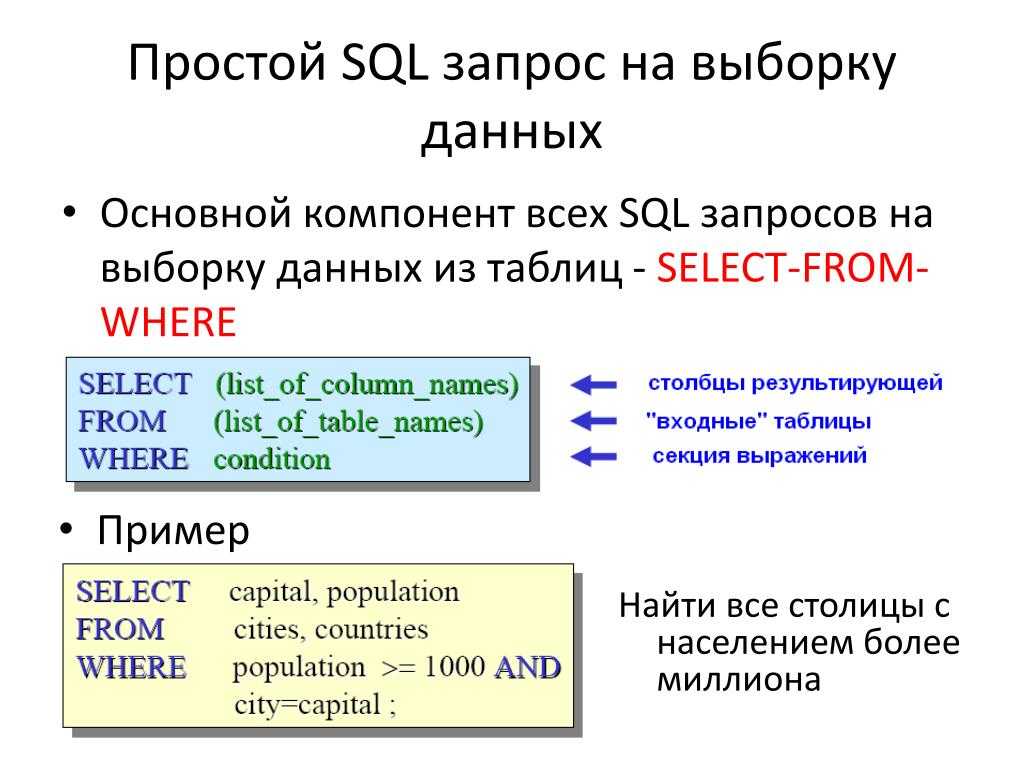 The misconception happens because when using characters defined in the Unicode range 0-65,535, one character can be stored per each byte-pair. Однако в старших диапазонах Юникода (65 536–1 114 111) один символ может занимать две пары байтов. However, in higher Unicode ranges (65,536-1,114,111) one character may use two byte-pairs. Например, в столбце, определенном как NCHAR(10), Компонент Database Engine Database Engine может хранить 10 символов, занимающих одну пару байтов (диапазон Юникода 0–65 535), но меньше 10 символов, занимающих две пары байтов (диапазон Юникода 65 536–1 114 111). For example, in a column defined as NCHAR(10), the Компонент Database Engine Database Engine can store 10 characters that use one byte-pair (Unicode range 0-65,535), but less than 10 characters when using two byte-pairs (Unicode range 65,536-1,114,111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе Различия в хранении UTF-8 и UTF-16. For more information about Unicode storage and character ranges, see Storage differences between UTF-8 and UTF-16.
The misconception happens because when using characters defined in the Unicode range 0-65,535, one character can be stored per each byte-pair. Однако в старших диапазонах Юникода (65 536–1 114 111) один символ может занимать две пары байтов. However, in higher Unicode ranges (65,536-1,114,111) one character may use two byte-pairs. Например, в столбце, определенном как NCHAR(10), Компонент Database Engine Database Engine может хранить 10 символов, занимающих одну пару байтов (диапазон Юникода 0–65 535), но меньше 10 символов, занимающих две пары байтов (диапазон Юникода 65 536–1 114 111). For example, in a column defined as NCHAR(10), the Компонент Database Engine Database Engine can store 10 characters that use one byte-pair (Unicode range 0-65,535), but less than 10 characters when using two byte-pairs (Unicode range 65,536-1,114,111). Дополнительные сведения о хранении символов Юникода и их диапазонах см. в разделе Различия в хранении UTF-8 и UTF-16. For more information about Unicode storage and character ranges, see Storage differences between UTF-8 and UTF-16.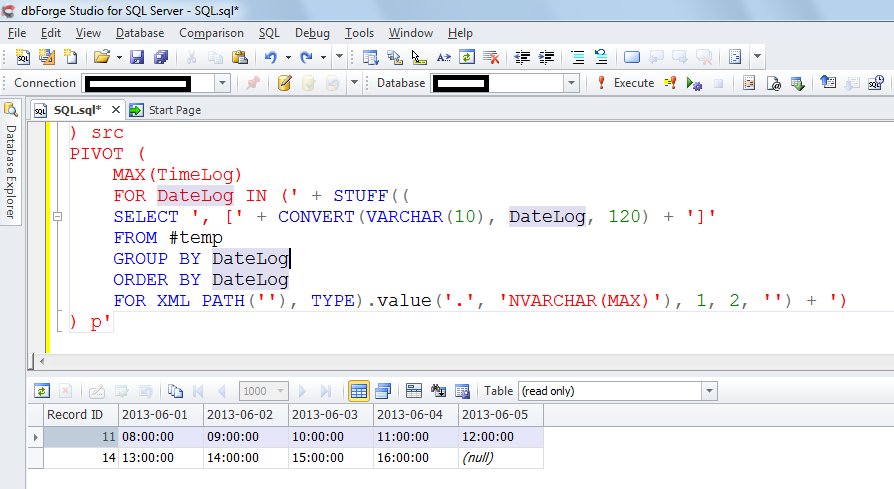
Если значение n в определении данных или в инструкции объявления переменной не указано, то длина по умолчанию равна 1. When n is not specified in a data definition or variable declaration statement, the default length is 1. Когда n не задано функцией CAST, длина по умолчанию равняется 30. When n is not specified with the CAST function, the default length is 30.
Если вы используете nchar или nvarchar, мы рекомендуем: If you use nchar or nvarchar, we recommend to:
- использовать nchar, если размеры записей данных в столбцах одинаковые; Use nchar when the sizes of the column data entries are consistent.
- использовать nvarchar, если размеры записей данных в столбцах существенно отличаются; Use nvarchar when the sizes of the column data entries vary considerably.
- использовать nvarchar(max) , если размеры записей данных в столбцах существенно отличаются и длина строки может превышать 4000 пар байтов. Use nvarchar(max) when the sizes of the column data entries vary considerably, and the string length might exceed 4,000 byte-pairs.
 Use nvarchar(max) when the sizes of the column data entries vary considerably, and the string length might exceed 4,000 byte-pairs.
Use nvarchar(max) when the sizes of the column data entries vary considerably, and the string length might exceed 4,000 byte-pairs.Тип sysname — это предоставляемый системой определяемый пользователем тип данных, который функционально эквивалентен типу nvarchar(128) за исключением того, что он не допускает значения NULL. sysname is a system-supplied user-defined data type that is functionally equivalent to nvarchar(128), except that it is not nullable. Тип sysname используется для ссылки на имена объектов баз данных. sysname is used to reference database object names.
Объектам, в которых используются типы данных nchar и nvarchar, назначаются параметры сортировки базы данных по умолчанию, если только иные параметры сортировки не назначены с помощью предложения COLLATE. Objects that use nchar or nvarchar are assigned the default collation of the database unless a specific collation is assigned using the COLLATE clause.
Для типов данных nchar и nvarchar параметр SET ANSI_PADDING всегда принимает значение ON. SET ANSI_PADDING is always ON for nchar and nvarchar. Параметр SET ANSI_PADDING OFF не применяется к типам данных nchar или nvarchar. SET ANSI_PADDING OFF does not apply to the nchar or nvarchar data types.
Префикс N в строковых константах с символами Юникода указывает на входные данные в кодировке UCS-2 или UTF-16 (в зависимости от того, используются ли параметры сортировки с поддержкой дополнительных символов). Prefix a Unicode character string constants with the letter N to signal UCS-2 or UTF-16 input, depending on whether an SC collation is used or not. Без префикса N строка преобразуется в стандартную кодовую страницу базы данных, и определенные символы могут не распознаваться. Without the N prefix, the string is converted to the default code page of the database that may not recognize certain characters. Начиная с SQL Server 2019 (15.x) SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 стандартная кодовая страница может хранить символы Юникода в кодировке UTF-8. Starting with SQL Server 2019 (15.x) SQL Server 2019 (15.x) , when a UTF-8 enabled collation is used, the default code page is capable of storing UNICODE UTF-8 character set.
Начиная с SQL Server 2019 (15.x) SQL Server 2019 (15.x) при использовании параметров сортировки с поддержкой UTF-8 стандартная кодовая страница может хранить символы Юникода в кодировке UTF-8. Starting with SQL Server 2019 (15.x) SQL Server 2019 (15.x) , when a UTF-8 enabled collation is used, the default code page is capable of storing UNICODE UTF-8 character set.
Когда строковая константа имеет префикс N и ее длина не превышает максимальную длину строкового типа данных nvarchar (4000), результатом неявного преобразования будет строка в кодировке UCS-2 или UTF-16. When prefixing a string constant with the letter N, the implicit conversion will result in a UCS-2 or UTF-16 string if the constant to convert does not exceed the max length for the nvarchar string data type (4,000). В противном случае результатом неявного преобразования будет большое значение nvarchar(max). Otherwise, the implicit conversion will result in a large-value nvarchar(max).
Каждому ненулевому столбцу varchar(max) и nvarchar(max) необходимо дополнительно выделить 24 байта памяти, которые учитываются в максимальном размере строки в 8060 байт во время операции сортировки. Each non-null varchar(max) or nvarchar(max) column requires 24 bytes of additional fixed allocation, which counts against the 8,060-byte row limit during a sort operation. Эти дополнительные байты могут неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max) в таблице. These additional bytes can create an implicit limit to the number of non-null varchar(max) or nvarchar(max) columns in a table. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). No special error is provided when the table is created (beyond the usual warning that the maximum row size exceeds the allowed maximum of 8,060 bytes) or at the time of data insertion. Такой большой размер строки может приводить к ошибкам (например, ошибке 512), которые пользователи не ожидают во время обычных операций.
Each non-null varchar(max) or nvarchar(max) column requires 24 bytes of additional fixed allocation, which counts against the 8,060-byte row limit during a sort operation. Эти дополнительные байты могут неявно ограничивать число ненулевых столбцов varchar(max) или nvarchar(max) в таблице. These additional bytes can create an implicit limit to the number of non-null varchar(max) or nvarchar(max) columns in a table. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). No special error is provided when the table is created (beyond the usual warning that the maximum row size exceeds the allowed maximum of 8,060 bytes) or at the time of data insertion. Такой большой размер строки может приводить к ошибкам (например, ошибке 512), которые пользователи не ожидают во время обычных операций. This large row size can cause errors (such as error 512) that users may not anticipate during some normal operations. Примерами операций могут служить обновление ключа кластеризованного индекса или сортировка полного набора столбцов. Two examples of operations are a clustered index key update, or sorts of the full column set.
This large row size can cause errors (such as error 512) that users may not anticipate during some normal operations. Примерами операций могут служить обновление ключа кластеризованного индекса или сортировка полного набора столбцов. Two examples of operations are a clustered index key update, or sorts of the full column set.
Преобразование в символьные данные Converting Character Data
Сведения о преобразовании символьных данных см. в статье char и varchar (Transact-SQL). For information about converting character data, see char and varchar (Transact-SQL).
ПРИМЕНЯЕТСЯ К: SQL Server (начиная с 2008) База данных SQL Azure Хранилище данных SQL Azure Parallel Data Warehouse
Символьные типы данных, которые являются либо фиксированной длины, nchar, или переменную длину, nvarchar, набор символов в Юникоде и использование UNICODE UCS-2.
nchar ([n])
Строковые данные постоянной длины в Юникоде. 31-1 байт (2 ГБ). Размер хранилища в байтах вдвое больше числа введенных символов + 2 байта. Синонимами по стандарту ISO для nvarchar , national char переменной и различных символов национального алфавита.
31-1 байт (2 ГБ). Размер хранилища в байтах вдвое больше числа введенных символов + 2 байта. Синонимами по стандарту ISO для nvarchar , national char переменной и различных символов национального алфавита.
Когда n не указан в определении данных или в инструкции объявления переменной, длина по умолчанию равна 1. Когда n не указан в функции CAST, длина по умолчанию равна 30.
Используйте nchar Если размеры элементов данных в столбцах предполагаются схожи.
Используйте nvarchar Если размеры элементов данных в столбцах предполагаются различные.
sysname — предоставляемый системой определяемый пользователем тип, который функционально эквивалентен nvarchar(128), за исключением того, что не допускает значение NULL. sysname используется для ссылок на имена объектов базы данных.
Объекты, использующие nchar или nvarchar назначаются параметры сортировки по умолчанию базы данных, если назначенный конкретные параметры сортировки предложением COLLATE.
SET ANSI_PADDING всегда равен ON для nchar и nvarchar. SET ANSI_PADDING OFF не применяется к nchar или nvarchar типов данных.
Префикс строковым константам в Юникоде буква N. Без префикса N строка преобразуется в кодовую страницу по умолчанию базы данных. Кодовая страница по умолчанию может не распознавать определенные символы.
| Примечание |
|---|
После добавления префикса строковой константы с букв N, если константа для преобразования не превышает Максимальная длина для типа данных строки Юникода (4000) неявное преобразование приведет к строки в Юникоде. В противном случае — неявное преобразование приведет к Юникода большого размера (max).
| Предупреждение |
|---|
 Это может создать неявных ограничений на число непустых varchar(max) или nvarchar(max) столбцы, которые могут быть созданы в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Этот крупный размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировать полный набор столбцов, который пользователи не могут использовать до выполнения операции.
Это может создать неявных ограничений на число непустых varchar(max) или nvarchar(max) столбцы, которые могут быть созданы в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Этот крупный размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировать полный набор столбцов, который пользователи не могут использовать до выполнения операции. 31-1 байт (2 ГБ). Размер хранилища в байтах вдвое больше числа введенных символов + 2 байта. Синонимами по стандарту ISO для nvarchar , national char переменной и различных символов национального алфавита.
31-1 байт (2 ГБ). Размер хранилища в байтах вдвое больше числа введенных символов + 2 байта. Синонимами по стандарту ISO для nvarchar , national char переменной и различных символов национального алфавита.
| Примечание |
|---|
| Предупреждение |
|---|
 Это может создать неявных ограничений на число непустых varchar(max) или nvarchar(max) столбцы, которые могут быть созданы в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Этот крупный размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировать полный набор столбцов, который пользователи не могут использовать до выполнения операции.
Это может создать неявных ограничений на число непустых varchar(max) или nvarchar(max) столбцы, которые могут быть созданы в таблице. При создании таблицы или во время вставки данных не возникает особых ошибок (кроме обычного предупреждения о том, что максимальный размер строки превышает максимально допустимое значение в 8060 байт). Этот крупный размер строки может вызывать ошибки (например, ошибку 512) во время некоторых обычных операций, таких как обновление ключа кластеризованного индекса, или сортировать полный набор столбцов, который пользователи не могут использовать до выполнения операции.Лимиты
- Главная
/
- Microsoft SQL Server
/
Лимиты
 org/ListItem»>
org/ListItem»>СУБД
/
- Информация о материале
- Автор: Сергей Жилин
- Категория: Microsoft SQL Server
Просмотров: 20092
В следующих таблицах приведены максимальные размеры и количество для различных объектов, определяемых в компонентах SQL Server.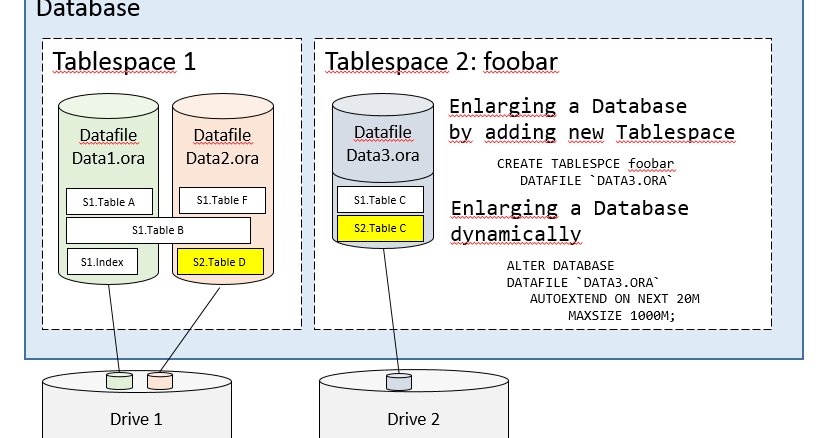
Ограничения объектов компонента Database Engine
| Пункт | Лимит | Комментарий |
|---|---|---|
| Размер пакета | 65 536 * размер сетевого пакета | Размер сетевого пакета — это размер пакетов потока табличных данных (TDS), которые используются для связи между приложениями и компонентом Database Engine. По умолчанию, он равен 4 КБ, и его управление осуществляется с помощью параметра конфигурации network packet size. |
| Байтов на столбец с короткой строкой | 8000 | |
| Байтов на GROUP BY, ORDER BY | 8060 | |
| Байтов на ключ индекса | 900 | Максимальное число байт в любом ключе индекса не может превышать 900 в SQL Server. Можно определить ключ, использующий столбцы переменной длины, максимальная длина которых может превышать 900 байт при условии, что в эти столбцы не будут вставляться строки объемом более 900 байт данных. В SQL Server в некластеризованный индекс можно включать неключевые столбцы, чтобы избежать ограничения максимального размера индексного ключа, равного 900 байт. В SQL Server в некластеризованный индекс можно включать неключевые столбцы, чтобы избежать ограничения максимального размера индексного ключа, равного 900 байт. |
| Байтов на внешний ключ | 900 | |
| Байтов на первичный ключ | 900 | |
| Байтов на строку | 8060 | SQL Server поддерживает хранение при переполнении строк, что позволяет столбцам переменной длины превышать максимальную длину строки. Для столбцов переменной длины, выходящих за границу строки, в главной записи хранится только корень длиной 24-байта. Поэтому фактический предел длины выше, чем в предыдущих версиях SQL Server. |
| Байтов в исходном тексте хранимой процедуры | Меньше размера пакета или 250 МБ | |
| Байтов на столбец varchar(max), varbinary(max), xml, text или image | 2^31-1 | |
| Символов на столбец ntext или nvarchar(max) | 2^30-1 | |
| Количество кластеризованных индексов в таблице | 1 | |
| Столбцов на GROUP BY, ORDER BY | Ограничивается только числом байтов | |
| Столбцов или выражений в инструкции GROUP BY WITH CUBE или WITH ROLLUP | 10 | |
| Столбцов на ключ индекса | 16 | Если в таблице имеется один или несколько индексов XML, ключ кластеризации пользовательской таблицы ограничивается 15 столбцами, потому что XML-столбец добавляется к ключу кластеризации первичного XML-индекса. В SQL Server в некластеризованный индекс можно включать неключевые столбцы, чтобы избежать ограничения максимального количества ключевых столбцов, равного 16. В SQL Server в некластеризованный индекс можно включать неключевые столбцы, чтобы избежать ограничения максимального количества ключевых столбцов, равного 16. |
| Столбцов на внешний ключ | 16 | |
| Столбцов на первичный ключ | 16 | |
| Столбцов на неширокую таблицу | 1024 | |
| Столбцов на широкую таблицу | 30000 | |
| Столбцов на инструкцию SELECT | 4096 | |
| Столбцов на инструкцию INSERT | 4096 | |
| Соединений на одного клиента | Максимальное значение настроенных соединений | |
| Размер базы данных | 524 272 ТБ | |
| Баз данных на один экземпляр SQL Server | 32767 | |
| Файловых групп на одну базу данных | 32767 | |
| Файлов на одну базу данных | 32767 | |
| Размер файла (данные) | 16 ТБ | |
| Размер файла (журнал) | 2 ТБ | |
| Ссылок на таблицы внешнего ключа для таблицы | 253 | Хотя таблица может содержать неограниченное число ограничений FOREIGN KEY, рекомендуемый максимум равен 253. В зависимости от конфигурации оборудования, на котором установлен SQL Server, определение дополнительных ограничений FOREIGN KEY может потребовать слишком много ресурсов для обработки с точки зрения оптимизатора запросов. В зависимости от конфигурации оборудования, на котором установлен SQL Server, определение дополнительных ограничений FOREIGN KEY может потребовать слишком много ресурсов для обработки с точки зрения оптимизатора запросов. |
| Длина идентификатора (в символах) | 128 | |
| Экземпляров на один компьютер | 50 | экземпляров на изолированном сервере для всех выпусков. 25 экземпляров в кластере отработки отказа. |
| Длина строки, содержащей инструкции SQL (размер пакета) | 65 536 * размер сетевого пакета | Размер сетевого пакета — это размер пакетов потока табличных данных (TDS), которые используются для связи между приложениями и компонентом Database Engine. По умолчанию, он равен 4 КБ, и его управление осуществляется с помощью параметра конфигурации network packet size. |
| Блокировок на соединение | Максимальное число блокировок на сервер | |
| Блокировок на экземпляр SQL Server | до 2 147 483 647 Для 64 разрядной версии ограничено только объемом памяти.  | Это значение относится только к статическим блокировкам. Количество динамических блокировок ограничивается только объемом памяти. |
| Уровней вложенных хранимых процедур | 32 | Если хранимая процедура обращается больше чем к 8 базам данных или более чем к двум базам в режиме чередования, может возникнуть ошибка. |
| Вложенных запросов | 32 | |
| Уровней вложенных триггеров | 32 | |
| Количество некластеризованных индексов у таблицы | 999 | |
| Количество уникальных выражений в предложении GROUP BY, если присутствует одна из следующих конструкций: CUBE, ROLLUP, GROUPING SETS, WITH CUBE, WITH ROLLUP | 32 | |
| Количество группирующих наборов, сформированных операторами в предложении GROUP BY | 4096 | |
| Параметров на одну хранимую процедуру | 2100 | |
| Параметров на одну пользовательскую функцию | 2100 | |
| REFERENCES на таблицу | 253 | |
| Строк на таблицу | Ограничено доступной памятью | |
| Таблиц на одну базу данных | Ограничено числом объектов в базе данных | Объекты базы данных включают такие объекты, как таблицы, представления, хранимые процедуры, пользовательские функции, триггеры, правила, значения по умолчанию и ограничения. Суммарное число всех объектов в базе данных не может превышать 2 147 483 647. Суммарное число всех объектов в базе данных не может превышать 2 147 483 647. |
| Секций на секционированную таблицу или индекс | 1,000 | |
| Статистических показателей неиндексированных столбцов | 30,000 | |
| Таблиц на инструкцию SELECT | Ограничивается только доступными ресурсами | |
| Триггеров на таблицу | Ограничено числом объектов в базе данных | Объекты базы данных включают такие объекты, как таблицы, представления, хранимые процедуры, пользовательские функции, триггеры, правила, значения по умолчанию и ограничения. Суммарное число всех объектов в базе данных не может превышать 2 147 483 647. |
| Столбцов на инструкцию UPDATE (широкие таблицы) | 4096 | |
| Соединения пользователей | 32767 | |
| XML-индексов | 249 |
Ограничения объектов программы SQL Server
| Пункт | Лимит | Комментарий |
|---|---|---|
| Компьютеры (физические или виртуальные машины) в расчете на одну программу SQL Server | 100 | |
| Экземпляров на компьютер SQL Server | 5 | |
| Общее число экземпляров SQL Server на одну программу SQL Server | 200 | SQL Server 2008 R2 Datacenter поддерживает программу SQL Server с количеством управляемых экземпляров SQL Server не более 200. SQL Server 2008 R2 Enterprise поддерживает программу SQL Server с количеством управляемых экземпляров SQL Server не более 25 SQL Server 2008 R2 Enterprise поддерживает программу SQL Server с количеством управляемых экземпляров SQL Server не более 25 |
| Пользовательских баз данных на экземпляр SQL Server, включая приложения на уровне данных | 50 | |
| Общее число пользовательских баз данных на одну программу SQL Server | 1000 | |
| Файловых групп на одну базу данных | 1 | |
| Файлов данных на одну файловую группу | 1 | |
| Файлов журналов на одну базу данных | 1 | |
| Томов на компьютер | 3 |
Назад
Вперед
You have no rights to post comments
CHAR или VARCHAR? А может быть BLOB?
Создан в 1997 году, откорректирован – 24.
 06.2002, 24.01.2003.
06.2002, 24.01.2003.
Особенности строковых типов данных
Давайте сначала повторим описание этих типов данных из документации (Data Definition Guide):
- CHAR(n) – n символов, от 1 до 32767, строковый тип фиксированной длины. Если содержимое поля меньше указанного размера, то оно «выравнивается» (добивается) дополнительными пробелами.
- VARCHAR(n) – n символов, от 1 до 32767, строковый тип переменной длины. Пробелы в конце содержимого поля игнорируются.
Максимальная длина строковых типов зависит от используемого набора символов. Наборы символов перечислены в Data Defintion Guide (Appendix A) и в Language Reference (Appendix D). Для каждого набора указано, сколько байт занимает один символ. Если один символ набора занимает больше одного байта, то максимальна длина строкового поля будет 32767/кол-во_байт_на_символ (т. е. для UNICODE_FSS – 10922 символа).
На диске запись всегда упаковывается. То есть, концевые пробелы не имеют никакого значения с точки зрения дискового пространства.
Количество концевых пробелов учитывается только для varchar. Значение char «добивается» пробелами до объявленной длины только тогда, когда с ним производятся операции присвоения или передача данных на сторону клиента.
Поэтому с точки зрения эффективности хранения различия между char и varchar практически нет. И для работы нужно выбирать то, что удобнее. Как правило это varchar.
Клиентские компоненты могут (или не могут) осуществлять обрезание концевых пробелов для столбцов CHAR. В зависимости от склонностей разработчика такого набора обрезание пробелов может быть по умолчанию, а может и потребовать установки в True какого-либо свойства или на уровне DataSet, или на уровне конкретного поля (TStringField). Поэтому, если вас замучили концевые пробелы в строках, посмотрите на свойства компонент.
Нужно отметить, что ни BDE ни dbExpress не могут выполнять обрезание концевых пробелов у строк.
Поля типа BLOB
Поля этого типа позволяют хранить безразмерную произвольную двоичную информацию (поэтому поля типа BLOB не имеют свойства «набор символов»). Запись на диск производится сегментами. Дисковый сегмент блоба это вовсе не то, что имеется в виду при объявлении столбца BLOB (SEGMENT SIZE xx). Сервер сам разбирается, как хранить конкретное значение blob на диске. Указание размера сегмента при объявлении столбца BLOB не даст никакого выигрыша или проигрыша в производительности. Оно нужно только для приложений, написанных на C (Embedded SQL) при помощи GPRE. Например, в IBX размер буфера для чтения-записи blob определен жестко в 16К, и именно такими «сегментами» оперирует IBX. Поэтому определять размер сегмента при объявлении blob не имеет смысла.
Существуют предопределенные подтипы (SUB_TYPE) BLOB: 0 – двоичные данные, 1 – текстовые данные. На самом деле разницы между ними нет, и подтип имеет значение только для вашего приложения (или при написании фильтров BLOB). Пользовательские подтипы можно определить, указав SUB_TYPE с отрицательным знаком – -1, -2, -10, -200 и т. д., и опять же это имеет значение только для приложения, работающего с данными или для фильтра.
Пользовательские подтипы можно определить, указав SUB_TYPE с отрицательным знаком – -1, -2, -10, -200 и т. д., и опять же это имеет значение только для приложения, работающего с данными или для фильтра.
Сегменты BLOB всегда записываются на свободное пространство, и занимают только действительный объем данных BLOB.
Если размер BLOB превышает размер страницы, то создается массив указателей на страницы BLOB. При очень больших размерах BLOB могут появиться указатели на страницы указателей BLOB.
При изменении записи, если содержимое blob не менялось, его blobID остается тем же самым. Собственно, в новой версии записи пишутся только те поля, которые были изменены. Следовательно, при модификации записи, если не затронуто поле BLOB, данные blob не «дублируются». Если же блоб меняется, то как и версия записи, он находится на диске в двух экземплярах – старом и новом. Учитывайте это для блобов, хранящих большой объем данных.
Примечание. Индексировать по полям BLOB невозможно.
CHAR или BLOB?
Итак, мы рассмотрели все аспекты хранения данных CHAR, VARCHAR и BLOB, и теперь можем перечислить рекомендации по выбору типа:
- Если длина поля < 255 символов, то
- лучше использовать VARCHAR – по хранению varchar на 2 байта больше char, зато в приложениях не надо писать отрезание концевых пробелов у строк.
- в старых версиях IB при использовании VARCHAR могут возникнуть проблемы с производительностью при использовании протокола TCP/IP.
- не имеет смысла использовать BLOB – выборка BLOB осуществляется по его идентификатору, поэтому происходит чуть дольше и требует немного больше затрат на программирование.
- Если длина поля > 255, но < ~10000 символов
- Можно использовать как CHAR или VARCHAR, так и BLOB. Индексирование по полями такой длины невозможно, к тому же есть шанс что однажды записываемые данные превысят 10000 символов, и может быть BLOB подойдет больше. Ориентируйтесь только на удобство работы с такими данными в приложении.
- Можно использовать как CHAR или VARCHAR, так и BLOB. Индексирование по полями такой длины невозможно, к тому же есть шанс что однажды записываемые данные превысят 10000 символов, и может быть BLOB подойдет больше.
- Если длина поля > ~5000 символов, или информация может быть произвольной
- лучше использовать BLOB. Подтип может быть любой, информацию в таком поле можно хранить произвольную и не беспокоиться о размере данных. Стоимость доступа к данным такого размера полностью компенсирует разницу в способах хранения и извлечения полей типа CHAR и BLOB.
- Дополнительным фактором выбора может быть размер страницы. При размере страницы 8К можно для хранения строк выбирать CHAR или VARCHAR, если их длина также не превысит 8К (записи могут пересекать страницы, поэтому даже при размере страницы 1К можно объявлять строки длиной 32К). Неплохо в таких случаях создать тестовую таблицу, и попробовать скорость или удобство считывания разных вариантов типов полей, наполнив char, varchar и blob одними и теми же данными.
 Ориентируйтесь только на удобство работы с такими данными в приложении.
Ориентируйтесь только на удобство работы с такими данными в приложении.
Конвертация данных
В Firebird и Yaffil, в 3-м диалекте появилась возможность при insert (update?) содержимое блоба задавать обычной строкой.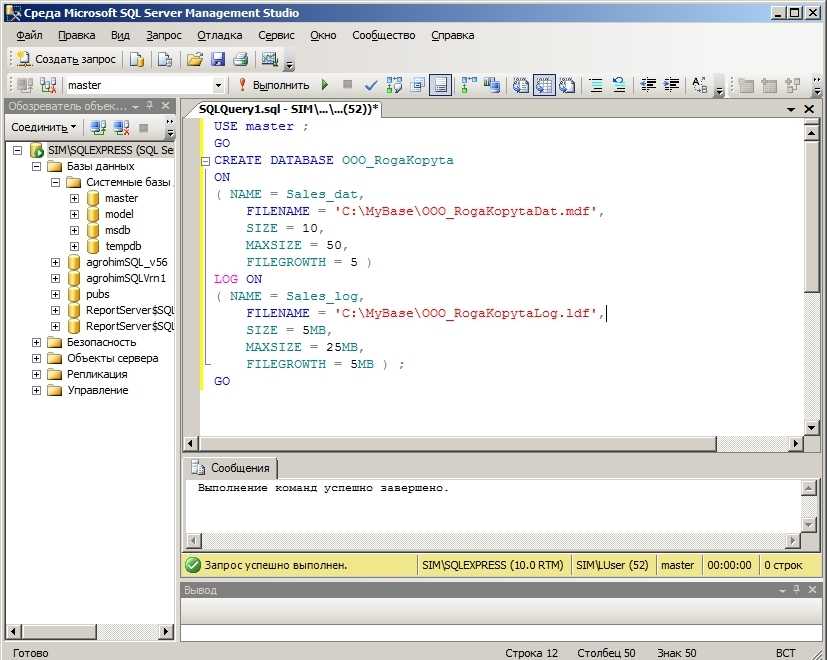 В остальных серверах при подобных действиях будет выдано стандартное сообщение о невозможности конвертации данных.
В остальных серверах при подобных действиях будет выдано стандартное сообщение о невозможности конвертации данных.
Вместе с тем уже давно существуют UDF перевода блоба в строку и обратно (FreeUDFLib и другие).
Возможные проблемы
Индексирование
- Строковые независимо от типа поля имеют ограничение на длину индекса – 84 байта при указании COLLATE и 252 байта – без COLLATE.
- BLOB-поля не могут быть проиндексированы.
Поиск
- Для поиска по полям типа CHAR, VARCHAR и BLOB можно использовать операторы STARTING WITH (начинается с), LIKE (начинается, содержит, или заканчивается на) и CONTAINING (содержит). В BLOB этими операторами можно искать произвольную информацию (необязательно текстовую), однако необходимо учитывать что поиск в BLOB может осуществляться только перебором записей.
- Если поиск производится по окончанию, например, LIKE ‘%ов’, то такой запрос по полю CHAR выдаст 0 записей, если длина значения поля хотя бы на один символ меньше объявленной длины поля. Это происходит потому, что CHAR при сравнении добивается до длины поля пробелами, и получается, что ‘Иванов ‘ не подходит под условие поиска ‘%ов’. Для решения этой проблемы нужно пользоваться VARCHAR
- Поиск или упорядочивание (ORDER BY) с использованием функции UPPER возможен только для полей типа CHAR или VARCHAR, т. к. только они имеют свойство CHARACTER SET (BLOB содержит только произвольную двоичную информацию, т. е. необязательно текстовую). Кроме того, для UPPER поля CHAR и VARCHAR должны иметь соответствующий COLLATE либо в объявлении типа поля, либо в выражении поиска или сортировки.
 Это происходит потому, что CHAR при сравнении добивается до длины поля пробелами, и получается, что ‘Иванов ‘ не подходит под условие поиска ‘%ов’. Для решения этой проблемы нужно пользоваться VARCHAR
Это происходит потому, что CHAR при сравнении добивается до длины поля пробелами, и получается, что ‘Иванов ‘ не подходит под условие поиска ‘%ов’. Для решения этой проблемы нужно пользоваться VARCHARПримечание. Вы можете написать собственную функцию, аналогичную UPPER, и избежать указанной проблемы.
Выборка данных
- При конкатенации строковых полей в запросе нужно учитывать, что CHAR-поля будут «расширены» до указанной длины пробелами, а VARCHAR – нет. Например, если в запросе производится «сборка» фамилии, имени и отчества
select last_name||first_name||middle_name from clients
то результат будет приблизительно такой: «Иванов Иван Иванович». А если это будут VARCHAR-поля, то такой же запрос выдаст результат в виде «ИвановИванИванович».
А если это будут VARCHAR-поля, то такой же запрос выдаст результат в виде «ИвановИванИванович».
Для решения этой проблемы можно для CHAR использовать UDF (типа RTrim), а для VARCHAR – вставлять дополнительные пробелы (||» «||).
- Для многоязыковых баз данных BLOB не могут быть перекодированы из одной кодировки в другую. Например, если сервер поддерживает кодировки WIN1251 и KOI8R, и база создана в WIN1251, возможно подключиться (через компоненты прямого доступа) указывая lc_ctype=KIO8R в параметрах коннекта. При этом информация будет перекодироваться из win1251 в koi8r и наоборот для всех строковых типов данных, кроме BLOB. Для конвертации данных blob хотя бы при выборке придется написать собственную UDF.
Вставка и модификация данных
- Поля BLOB невозможно передавать как параметр запроса или хранимой процедуры в BDE 2.5x и 3.x (такая возможность появилась только в BDE 4.0 и у компонент Delphi 3.0). Это приводит к необходимости использования TQuery и передачи данных в BLOB-поля через TBlobStream. Сам сервер не имеет проблем с получением или передачей blob в виде параметров запроса или параметров процедур.
 Сам сервер не имеет проблем с получением или передачей blob в виде параметров запроса или параметров процедур.
Сам сервер не имеет проблем с получением или передачей blob в виде параметров запроса или параметров процедур.Создание переносимой базы данных
- Стандарт ANSI SQL в частности определяет типы полей, но безусловно реализация этих типов, способ хранения и обработки определяет изготовитель конкретного SQL-сервера. Для обеспечения хоть какой-то возможной переносимости следует пользоваться совместимыми типами, игнорируя преимущества использовани типов данных (например CHAR в InterBase). Вам необходимо обратиться к документации или справочным файлам BDE (BDE32.HLP), для того чтобы определить совместимость различных типов между выбранными вами SQL-серверами.
Использование символьных, строковых функций и функций работы с датой в SQL
Функции, которые мы обсудим в этой части обычно используют встроенные PL/SQL код, сгруппированный в пакеты и поставляемый Oracle. Некоторые обрабатывают численные, символьные значения и значения даты, другие преобразуют данные в различные типы данных. Функции могут использовать вложенные вызовы и некоторые функции предназначены для работы со значением NULL. Функции условия CASE и DECODE позволяют отображать различный результат в зависимости от значений данных, что предоставляет возможность ветвления в контексте SQL запроса
Функции могут использовать вложенные вызовы и некоторые функции предназначены для работы со значением NULL. Функции условия CASE и DECODE позволяют отображать различный результат в зависимости от значений данных, что предоставляет возможность ветвления в контексте SQL запроса
Функции разделены на две большие группы: те, которые рассчитывают значения для каждой строки, и те, которые выполняют один рассчёт для всех строк. Мы рассмотрим функции конвертации, функции для работы с символьными данными, числовыми данными и данными типа дата.
Определение функции
Функция – это программа, которая может принимать (но необязательно) входные параметры, выполнять какие-либо операции и возвращать значение-литерал. Функция возвращает только одно значение за вызов.
Три важных компонента формируют базис определения функции. Первый – это список входных параметров. Он определяет ноль или более параметров, которые могут передаваться функции для обработки. Эти параметры, или аргументы, могут быть необязательными (иметь значение по умолчанию) и быть разными типами данных. Второй компонент – это тип данных вовзращаемого результата. После выполнения, только одно значение предопределенного типа данных возвращается функцией. Третий компонент инкапсулирует детали обработки выполняемой функцией и содержит программный код, который работает с входными параметрами, производит вычисления и возвращает значение.
Эти параметры, или аргументы, могут быть необязательными (иметь значение по умолчанию) и быть разными типами данных. Второй компонент – это тип данных вовзращаемого результата. После выполнения, только одно значение предопределенного типа данных возвращается функцией. Третий компонент инкапсулирует детали обработки выполняемой функцией и содержит программный код, который работает с входными параметрами, производит вычисления и возвращает значение.
Функция часто описывается как чёрный ящик, который берёт входные данные, делает что-то и возвращает результат. Вместо того, чтобы фокусироваться на деталях реализации функций, более полезно разобраться какой функционал предоставляют встроенные функции.
Вызовы функций могут быть вложенными, к примеру, как F1(x, y, F2(a, b), z), где функция F2 принимает два входных параметра и возвращает третий из четырёх параметров для функции F1. Функции могут работать с любыми типами данных: наиболее часто используемые это символьные и числовые данные, а также данные типа дата. Этими параметрами функции могут быть столбцами или выражениями.
Как пример можно рассмотреть функцию, которая рассчитывает возраст человека. Функция AGE принимает только один параметр, день рождения. Результат возвращаемый функцией AGE это число отображающее возраст человека. Расчёты черного ящика влючают в себя получение разницы в годах между текущей датой и днём рождения, переданным в качестве входного параметра.
Типы функций
Функции можно глобально разделить на две категории: обрабатывающие строку (строчные функции) и обрабатывающие набор строк (функции группировки). Это выделение очень важно для понимания контекста где используются различные функции.
Строчные функции
Доступны несколько видов строчных функций, включая функции работы со строками, функции работы с числами, датами, функции преобразования типа и общие функции. Эти функции обрабатывают одну строку из набора в момент времени. Если запрос выбирает десять строк, функция будет выполняться десять раз, по одному разу для каждой строки с возможным использованием значений столбцов строк как входных параметров функции.
Следующий запрос выбирает два столбца из таблицы REGIONS и выражение использующее функцию LENGTH и столбец REGION_NAME
select region_id, region_name, length(region_name) from regions;
Длина значения столбца REGION_NAME рассчитывается для каждой из четырёх строк в таблице REGIONS; функция выполняется четыре раза, возвращая каждый раз значение-литерал.
Строчные функции работают работают с данными элементами строки для выборки и форматирования их перед отображением. Входными значениями строчной функции может быть определенная пользователем константа или литерал, данные столбца, переменные или выражения, возможно использующие другифе вложенные строчные функции и т.д. Вложенные вызовы часто используемая техника. Функции могут возвращать значение типа данных, отличного от типа данных входных параметров. Прерыдущий запрос показывает, как функция LENGTH принимает входным значением строку и возвращает число.
Помимо использования функций в разделе SELECT строчные функции можно использовать в разделах WHERE и ORDER BY.
Функции, работающие с набором данных
Как можно догадаться из названия, эти функции оперируют больше чем одной строкой. Типичным использованием мультристрочной-функции является расчёт суммы или среднего значения какого-либо числового столбца или подсчёт количества строк в результате. Таким функции называются иногда функциями группировки, и мы рассмотрим их в следующей главе.
Использование функций, изменяющих регистр
Данные в таблицах могут заполняться из различных источников: программ, криптов и так далее. Не стоит полагаться что символьные данные будут вводиться в заранее определенном регистре. Строчные функции, изменяющие регистр предназначены для двух важных задач. Их можно использовать, во-первых, для изменения регистра данных при сохранении или выводе информации, либо в условиях WHERE для более гибкого поиска. Гораздо легче искать строку используя фиксированный регистр, вместро проверки всех комбинаций верхнего и нижнего регистра. Помните, что вызов функций не изменяет данные, которые хранятся в таблице. Они преобразуют данные результата запроса.
Входными параметрами могут быть символьные литералы, столбцы символьного типа данных, символьные выражения или числа и даты (которые неявно будут преобразованы в строки).
Функция LOWER
Функция LOWER заменяет все символы прописного регистра на эквивалентные символы строчного регистра. Синтакис функции LOWER(string). Рассмотрим пример запроса использующего эти функции
select lower(100+100), lower(‘SQL’), lower(sysdate) from dual
Преположим что текущая дата 17 декабря 2015 года. Результатом запроса будут строки ‘200’, ‘sql’ и ‘17-dec-2015’. Численное выражение и дата неявно преобразуются в строку перед вызовом функции LOWER.
В следующем примере функция LOWER используется для поиска строк где буквы ‘U’ и ‘R’ в любом регистре идут друг за другом
select first_name, last_name, lower(last_name) from employees
where lower(last_name) like ‘%ur%’;
Можно написать аналогичный запрос без использования функции LOWER. Например так
select first_name, last_name from employees
where last_name like ‘%ur%’ or last_name like ‘%UR%’
or last_name like ‘%uR%’ or last_name like ‘%Ur%’
Этот запрос работает, но он слишком громоздкий, и количество операторов OR возрастает экспоненциально по мере увеличения строки.
Функция UPPER
Функция UPPER логическая противоположность функции LOWER и заменяет все строчные символы на их прописные эквиваленты. Синтаксис функции – UPPER(string). Рассмотрим пример
select * from countries where upper(country_name) like ‘%U%S%A%’;
Этот запрос выбирает строки из таблцы COUNTRIES где COUNTRY_NAME содержит буквы ‘U’, ‘S’, ‘A’ в любом регистре в этом порядке.
Функция INITCAP
Функция INITCAP часто используется для отображения данных. Первые символы каждого слова в строке преобразуются к верхнему регистру, все остальные символы преобразуются в строчные эквиваленты. Под словом подразумевается набор символов не содержащих пробелов и спецсимволов. Пробел, символ подчеркивания а также спецсимволы такие как знак процента, восклицательные знак, знак доллара расцениваются как разделители. Функция INITCAP принимает один параметр и синтаксис INITCAP(string). Следующий пример показывает пример использования функции INITCAP
select initcap(‘init cap or init_cap or init%cap’) from dual
Результатом этого запроса будет строка Init Cap Or Init_Cap Or Init%Cap
Использование функций работы со строками
Функции работы со строками одна из самых мощных возможностей, предоставляемых Oracle. Они очень полезны и понятны практически без детальных объяснений и очень часто используются разными программистами при обработке данных. Часто используются вложенные вызовы этих функций. Оператор конкатенации может использоваться вместо функции CONCAT. Функции LENGTH, INSTR, SUBSTR и REPLACE могут дополнять друг друга, так же как RPAD, LPAD и TRIM.
Функция CONCAT
Функция CONCAT объединяет два литерала, столбца или выражения для составление одного большого выражения. У функции CONCAT два входных параметра. Синтаксис функции CONCAT(string1, string2) где string1 и string2 могут быть литералом, столбцом или выражением результат которого символьный литерал. Следующий пример показывает использование функции CONCAT
select concat(‘Today is:’,SYSDATE) from dual
Второй параметр функции это функция SYSDATE, которая возвращает текущее системное время. Значение преобразуется в строку и к ней присоединяется первый параметр. Если текущая системная дата 17 Декабря 2015 года, то запрос вернёт строку ‘Today is:17-DEC-2015’.
Рассмотрим как использовать функция для объединения трех элементов. Так как функция CONCAT может принимать только два входных параметра, то можно объединить только два элемента. В таком случае можно использовать вызов функции как параметр другово вызова функции. Тогда запрос будет выглядеть так
select concat(‘Outer1 ‘, concat(‘Inner1′,’ Inner2′)) from dual;
У первой функции два параметра: первый параметр это литерал ‘Outer1 ‘, а второй параметра это вложенная функция CONCAT. Вторая функция принимает два параметра: литерал ‘Inner1’ и литерал ‘ Inner2’. Результатом выполнения этого запроса будет строка ‘Outer1 Inner1 Inner 2’. Вложенные функции расмотрим чуть позже.
Функция LENGTH
Функция LENGTH возвращает число символов которые составляют строку. Пробелы, табуляция и специальные символы учитываются функцией LENGTH. У функции один параметра и синтаксис LENGTH(string). Рассмотрим запрос
select * from countries where length(country_name) > 10;
Функция LENGTH используется для выбора тех стран у которых длина названия больше чем десять символов.
Функции RPAD и LPAD
Функции RPAD и LPAD возвращают строку фиксированной длины и при необходимости дополняют исходное значение определенным набором символов слева или справа. Символами используемые для добавления могут быть литерал, значение столбца, выражение, пробел (значение по умолчанию), табуляция и спец символы. Функции LPAD и RPAD принимают три входных параметра и синтаксис LPAD(s, n, p) и RPAD(s, n, p) где s – значение строки для обработки, n – количество символов результата и p – символы для добавления. Если используется LPAD, то символы p добавляются слева до достижения длины n. Если RPAD – то справа. Обратите внимание что если длина s больше чем длина n – то результатом будет первые n символов значения s. Рассмотрим запросы на рисунке 10-1
Рисунок 10-1 – Использование функций RPAD и LPAD
Первый запрос не изменяет данные и результат не очень читабельный по сравнению с результатом второго запроса. RPAD используется для добавления пробелов там где необходимо для first_name и last_name чтобы все значения были фиксированной длины в 18 символов, и LPAD используется для добавления пробелов в начало значения salary до достижения длины 6 символов.
Функция TRIM
Функция TRIM убирает символы и начала или окончания строки чтобы сделать её потенцильно короче. Функция принимает обязательный параметр и необязательный. Синтаксис функции TRIM([trailing|leading|both] trimstring from string). Параметр входная строка (s) обязательный. Следующие пункты перечисляют параметры
- TRIM(s) убираются пробелы в начале в к конце строки
- TRIM(trailing trimstring from s) убирает символы trimgstring в конце строки
- TRIM(leading trimstring from s) убирает символы trimgstring в начале строки
- TRIM(both trimstring from s) OR TRIM(trimstring from s) убирают все символы trimstring в начале и в конце строки
Запрос
select trim(both ‘*’ from ‘****Hidden****’),
trim(leading ‘*’ from ‘****Hidden****’),
trim(trailing ‘*’ from ‘****Hidden****’) from dual;
Вернёт “Hidden”, “Hidden****”, и “****Hidden”. Обратите внимание что, указав всего один символ, все символы убираются если они последовательно повторяются.
Функция INSTR
Функция INSTR ищет подстроку в строке. Возвращается число, обозначающее позицию откуда n-ное вхождение начинается, начиная с позиции поиска, относительно начала строки. Если подстрока не найдена в строке – возвращается 0.
У функции INSTR два параметра обязательных и два параметра необязательных. Синтаксис функции INSTR(source string, search string, [search start position], [n occurrence]). Значение по умолчанию для search start position=1 или другими словами начало строки source string. Значение по умолчанию для n occurrence=1 или первое вхождение. Рассмотрим несколько примеров
Query 1: select instr(‘1#3#5#7#9#’, ‘#’) from dual;
Query 2: select instr(‘1#3#5#7#9#’, ‘#’ ,5) from dual;
Query 3: select instr(‘1#3#5#7#9#’, ‘#’, 3, 4) from dual;
Первый запрос ищет первое вхождение хеш-тега в строке и возвращает значение 2. Второй запрос ищет хеш-тег в строке начиная с пятого символа и находит первое вхождение с 6 символа. Третий запрос ищет четвертое вхождение хеш-тега начиная с третьего символа и находит его в позиции 10.
Функция SUBSTR
Функция SUBSTR возвращает подстроку определённой длины из исходной строки начиная с определённой позиции. Если начальная позиция больше чем длина исходной строки – возвращается значение NULL. Если длины исходной строки недостаточно для получения значения необходимой длины начиная с определённой позиции, то возвращается часть строки с исходного символа до конца строки.
У функции SUBSTR три параметра, первые два обязательны и синтаксис SUBSTR(source string, start position, [number of characters]). Значение по умолчанию для characters to extract = разница между длиной source string и start position. Рассмотрим следующие примеры
Query 1: select substr(‘1#3#5#7#9#’, 5) from dual;
Query 2: select substr(‘1#3#5#7#9#’, 5, 3) from dual;
Query 3: select substr(‘1#3#5#7#9#’, -3, 2) from dual;
Запрос 1 возвращает подстроку начиная с позиции 5. Так как третий параметр не указан, количество символов равно длине исходной строки минус начальная позиция и будет равно шести. Первый запрос вернёт подстроку ‘5#7#9#’. Запрос два возвращает три символа начиная с пятого символа и строка результат будет ‘5#7’. Запрос три начинается с позиции минус три. Отрицательная начальная позиции говорит Oracle о том, что начальная позиция рассчитывается от конца строки. Таким образом начальная позиция будет длина строки минус три и равна 8. Третий параметр равен двум и возвращается значение ‘#9’.
Функция REPLACE
Функция REPLACE заменяет все вхождения искомого элемента на значение строки для подстановки. Если длина заменяемого элемента не равна длине элемента, на который происходит замена, длина получаемой строки будет отличной от исходной строки. Если искомая подстрока не найдена, строка возвращается без изменений. Доступно три параметра, два первых обязательные и синтаксис вызова REPLACE(source string, search element, [replace element]). Если явно не указать параметр replace element, то из исходной строки удаляются все вхождения search element. Другими словами, replace element равно пустой строке. Если все символы исходной строки заменяются пустым replace element возвращается NULL. Рассмотрим несколько запросов
Query 1: select replace(‘1#3#5#7#9#’,’#’,’->’) from dual
Query 2: select replace(‘1#3#5#7#9#’,’#’) from dual
Query 3: select replace(‘#’,’#’) from dual
Хеш в первом запрос обозначает символ для поиска и строка для замены ‘->’. Хеш появляется в строке пять раз и заменяется, получаем итоговую строку ‘1->3->5->7->9->’. Запрос 2 не указывает явно строку для замены. Значением по умолчанию является пустая строка и результатом будет ‘13579’. Запрос номер три вернёт NULL.
Использование численных функций
В Oracle доступно множество встроенных функций для работы с числами. Существенной разницой между численными функция и другими является то, что эти функции принимают параметрами только числа и возвращают только числа. Oracle предоставляет численные функции для работы с тригонометрическими, экспоненциальными и логарифмическими выражениями и со многими другими. Мы сфокусируемся на простых численных строчных функциях: ROUND, TRUNC и MOD.
Функция ROUND
Функция ROUND округляет число в зависимости от необходимой точности. Возвращаемое значение округляется либо в большую, либо в меньшую сторону, в зависимости от значения последней цифры в необходимом разряде. Если значение точности n, то цифра, которая будет округляться будет на позиции n после запятой, а значение будет зависеть от цифры на позиции (n+1). Если значение точности отрицательное, то все цифры после разряда n слева от запятой будут 0, а значение n будет зависеть от n+1. Если значение цифры от которой зависит округление больше или равно 5, то округление происходит в большую сторону, иначе в меньшую.
Функция ROUND принимает два входных параметра и синтаксис ROUND(source number, decimal precision). Source number может быть любым числом. Параметр decimal precision определяет необходимую точность и необязателен. Если этот параметр не указан, значение по умолчанию будет 0, что обозначает необходимость округления до ближайшего целого числа.
Рассмотрим таблицу 10-1 для числа 1601.916. Отрицательные значения точности находятся слева от точки (целая часть), когда положительные считаются вправо от точки (дробная часть).
Если значение точности единица, значение округляется до десятка. Если два, то значение округляется до второго порядка и т.д. Следующие запросы отображают использование этой функции
Query 1: select round(1601.916, 1) from dual;
Query 2: select round(1601.916, 2) from dual;
Query 3: select round(1601.916, -3) from dual;
Query 4: select round(1601.916) from dual;
Первый запрос использует параметр точности равные единице, что означает что число будет округлено до ближайшей десятой. Так как значение сотой части равно единице (меньше чем 5), то происходит округление в меньшую сторону и возвращается значение 1601. 9. Точность второго запроса равна двойке, таким образом значение окружается до сотой. Так как значение тысячной части равно 6 (что больше 5), то значение сотой части округляется вверх и возвращается значение 1601.92. Значение параметра точности в третьем запросе равно минус трём. Так как значение отрицательное, это значит, что округление будет происходить, основываясь на значении третьей позиции слева от точки, во втором разряде (сотни), и значение 6. Так как 6 больше пяти, то происходит округление вверх и возвращается значение 2000. Запрос 4 вызывает функцию без параметра точности. Это означает что число округляется до ближайшего целого. Так как десятая часть равна 9, то значение округляется в большую сторону и возвращется значение 1602.
Численная функция TRUNC
Функия TRUNC сокращает значение числа основываясь на значение параметра точности. Сокращение отличается от округления тем, что при сокращении лишняя часть просто отрезается и не происходит никаких изменений остальных цифр числа. Если значение точности отрицательное, то входное значение сокращается на позиции слева от запятой. Синтаксис функции TRUNC(source number, decimal precision). Параметром source number может быть любое число и этот параметр обязателен. Параметр decimal precision определяет позицию округления и не обязателен, значением по умолчанию будет ноль, что означает сокращение до целого числа.
Если значение decimal precision равно одному, то число сокращается до десятых, если два, то до сотых и так далее. Рассмотрим несколько примеров использования этой функции
Query 1: select trunc(1601.916, 1) from dual;
Query 2: select trunc(1601.916, 2) from dual;
Query 3: select trunc(1601.916, -3) from dual;
Query 4: select trunc(1601.916) from dual;
В запросе 1 используется точность равная единице, что значит сокращение значения до десятых и возвращается значение 1601.9. Точность во втором запросе равна двум, исходное значение сокращается до сотых и возвращается значение 1601. 91. Обратите внимание что получаемое значение будет отличаться от значения, возвращаемого функцией ROUND с такими же параметрами, так как при вызове ROUND произойдёт округление в большую сторону (6 больше 5). В запросе номер три используется отрицательное число как значение параметра точности. Позиция три слева от запятой означает что сокращение будет до третьего разряда (сокращаются сотни) как показано в таблице 10-1 и возвращаемое значение будет 1000. И наконец в четвертом запросе явно неуказано значение точности и сокращается дробная часть исходного числа. Результатом будет 1601.
Функция MOD
Функция MOD возвращает остаток от деления. Два числа, делимое (число которое делится) и делитель (число на которое делится) определяются как параметры и вычисляется операция деления. Если делимое делится на делитель нацело, то возвращается ноль, так как нет остатка. Если делитель ноль, то не происходит ошибки деления на ноль, а возвращается делимое. Если делитель больше чем делимое, возвращается делимое.
У функции MOD два входные параметра и синтаксис MOD(dividend, divisor). Параметры dividend и divisor могут быть численными литералами, столбцами или выражениями и могут быть положительными или отрицательными. Следующие примеры показывают использование этой функции
Query 1: select mod(6, 2) from dual
Query 2: select mod(5, 3) from dual
Query 3: select mod(7, 35) from dual
Query 4: select mod(5.2, 3) from dual
В запросе один 6 делится на два нацело без остатка и возвращается 0. В запросе два 5 делится на 3, целая часть будет 1 и возвращается остаток 2. В запросе номер три семь делится на 35. Так как делитель больше чем делимое – возвращается делимое, т.е. целая часть 0. Запрос четыре использует дробное число как делимое. Целой частью будет один и остаток будет 2.2.
Tip
Любое чётное число делится на два без остатка, любое нечётное число при делении на два вернёт остаток 1. Поэтому функцию MOD часто используют чтобы отличать чётные и нечётные числа.
Работа с датами
Функции работы с датами предлагают удобный способ решать задачи, связанные с датами без необходимости учитывать высокосные года, сколько дней в конкретном месяце. Вначале рассмотрим, как хранятся данные типа дата и форматирование даты, а также функцию SYSDATE. Затем рассмотрим функции ADD_MONTHS, MONTHS_BETWEEN, LAST_DAT, NEXT_DAY, ROUND и TRUNC.
Хранение даты в базе данных
База данных хранит данные как число, которое способно поддерживать расчёт века, года, месяца и дня, а также информации о времени, такой как час, минута и секунда. Когда происходит запрос к данным, на число накладывается определённое форматирование (маска), и по умолчанию маска отображает день, три первых буквы названия месяца и две цифры, отображающие год.
Функция SYSDATE
Функция SYSDATE не использует входные параметры и возвращает текущее время и дату установленную на сервере БД. По умолчанию функция SYSDATE возвращает дату в формате DD-MON-RR и отображает дату на сервере. Если сервер установлен в другом часовом поясе чем машина клиента, то время и дата, возвращаемые SYSDATE могут отличаться от локальных значений на клиентсой машине. Можно выполнить такой запрос для отображения системной даты на сервере
select sysdate from dual
Арифметика над датами
Следуещее уравнение отображает важный принцип при работе с датами
Date1 – Date2 = Num1
Дата может вычитаться из другой даты. Разница между двуми датами понимается как количество дней между ними. Любое число, включая дробные, может быть добавлено или вычтено из даты. В этом контексте число представляет собой количество дней. Сумма или разница между число и датой – это всегда дата. Этот принцип подразумевает что сложение, умножение или деление двух дат невозможен.
Функция MONTHS_BETWEEN
Функция MONTHS_BETWEEN возвращает количество месяцев между двумя обязательными входными параметрами. Синтаксис функции MONTHS_BETWEEN(date1, date2). Функция рассчитывает разницу между date1 и date2. Если date1 меньше чем date2, то возвращается отрицательное число. Возвращаемое значение может состоять из целой части, отражающей количество месяцев между двумя датами, и дробной части, отражающей сколько дней и часов осталось (основываясь на месяце равном 31 дню) после вычета целого количества месяцев. Целое число вовзращается если день сравниваемых месяцев одинаковый или последний день соответствующего месяца.
Следующие примеры используют функию MONTHS_BETWEEN
Query 1: select months_between(sysdate, sysdate-31) from dual;
Query 2: select months_between(’29-mar-2008′, ’28-feb-2008′) from dual;
Query 3: select months_between(’29-mar-2008′, ’28-feb-2008′) * 31 from dual;
Преположим что текущая дата 16 Апреля 2009. Запрос один вернёт один как количество месяцев между 16 апреля 2009 и 16 марта 2009. Запрос два неявно конвертирует литералы в даты используя формат DD-MON-YYYY. Так как часть о времени опущена Oracle установит значение времени 00.00.00 для обеих дат. Фукнция вернёт значение примерно равное 1.03225806. Целая часть результата обозначает что между датами один месяц. Между 28 февраля и 28 марта ровно один месяц. Тогда дробная часть должна показывать ровно один день. Результат включает в себя часы минуты и секунды, но в нашем случае временная составляющая дат одинаковая. Умножение 0.03225806 на 31 вернёт 1, так как дробная часть, возвращаемая MONTHS_BETWEEN, рассчитывается, допуская что месяц равен ровно 31 дню. Поэтому запрос номер три вернёт значение 32.
Exam tip
Популярной ошибкой является допущение что возвращаемый тип данных функции зависит от типа функции (функции работы с датой должны возвращать дату, функции обработки строк – строку). Это верное только для численных функций. Символьные функции и функции работы с датами могут возвращать значение любого типа данных. Например, INSTR явлется символьной функцией, а MONTS_BETWEEN функцией работы с датой, но обе они возвращают результатом число. Также часто ошибочно рассуждают что разница между датами – это дата, когда фактически это число.
Функция ADD_MONTHS
Функция ADD_MONTHS возвращает дату, полученную путём добавления определённого количества месяцев к исходной дате. У этой функции два обязательных параметра и синтаксис ADD_MONTHS(start date, number of months). Значение параметра number of months может быть отрицательным, тогда исходное значение будет уменьшаться на это количество месяцев и дробным, но учитываться будет только целая часть. Следующие три запроса показывают использование функции ADD_MONTHS
Query 1: select add_months(’07-APR-2009′, 1) from dual;
Query 2: select add_months(’31-DEC-2008′, 2.5) from dual;
Query 3: select add_months(’07-APR-2009′, -12) from dual;
Результатом первого запроса буде 7 мая 2009, так как день остаётся одинаковым если это возможно и месяц увеличивается на один. Во втором запросе число месяцев дробное, что игнорируется, то есть этот запроса равен ADD_MONTHS(’31-DEC-2008’,2). Добавление двух месяцев должно вернуть 31-FEB-2009, но такой даты не существует, поэтому возвращается последний день месяца. В последнем примере используется отрицательное число для параметра кол-во месяцев и возвращается дата 07-APR-2008 что на двенадцать месяцев раньше, чем исходное значение.
Функция NEXT_DAY
Функция NEXT_DATE возвращает следующий ближайший заданный день недели после исходной даты. У этой функции два обязательных параметра и синтаксис NEXT_DAY(start date, day of the week). Функция выичсляет значение, когда заданный day of the week наступит после start date. Параметр day of the week может быть задан как числом, так и строкой. Допустимые значения определяются параметром NLS_DATE_LANGUAGE и по умолчанию используются три первые буквы названия дня недели в любом регистре (SUN, mon etc) или целые числа где 1 равно воскресенью, 2 – понедельник и так далее. Также имена дней недели могут быть более чем три символа; например, воскресенье можно указать как sun, sund, Sunday. Рассмотрим несколько запросов
Query 1: select next_day(’01-JAN-2009′, ‘tue’) from dual;
Query 2: select next_day(’01-JAN-2009′, ‘WEDNE’) from dual;
Query 3: select next_day(’01-JAN-2009′, 5) from dual;
1 января 2009 года это четверг. Следущий вторник будет через 5 дней, 6 января 2009 года. Второй запрос вернёт 7 января 2009 – следующая среда после 1 января. Третий запрос использует число как параметр и если у вас установлены Американские значения, то пятый день — это четверг. Следующий четверг после 1 января ровно через неделю – 8 января 2009 года.
Функция LAST_DAY
Функция LAST_DAY возвращает дату последнего дня месяца исходной даты. Эта функция требует один обязательные параметр и синтаксис LAST_DAY(start date). Функция выбирает месяц исходной даты и затем расчитывает последний день месяца. Следующий запрос вернёт 31 января 2009 года
select last_day(’01-JAN-2009′) from dual;
Функция ROUND для работы с датами
Функция ROUND округляет значение даты до заданной точности даты. Возвращаемое значение округляется либо к большему, либо r меньшему значению в зависимости от значения округляемого элемента. Эта функция требует один обязательный параметр и допускает один необязательные и синтаксис функции ROUND(source date, [date precision forma]). Параметром source data может быть любой элемент типа данных дата. Параметр date precision format определяет уровень округления и значение по умолчанию – день. Параметром date precision format может быть век (CC) год YYYY квартал Q месяц M неделя W день DD час HH минута MI.
Округления до века эквивалентно добавление единицы к текущему веку. Округление до месяца будет в большую сторону если день больше 16 иначе будет округление до первого дня месяца. Если месяц от одного до шести округление будет до начала текущего года, иначе вернётся дата начала следующего года. Рассмотрим запрос
Предположим, что этот запрос был выполнен 17 апреля 2009 года в 00:05. Вначале происходит округление текущей даты до дня (параметр точности явно неуказан). Так как время 00:05 то день не округляется в большую сторону.Так как 1 апреля 2009 года это среда, то второй столбец вернёт среду той недели, в которую входит исходная дата. Первая среда недели, в которую входит 19 апреля – это 15 апреля 2009 года. Третий столбец оругляет месяц до следующего (так как 17 больше 16) и возвращает 01 мая 2009. Поледний столбец округляет дату до года и возвращает 1 явнваря 2009 года, так как апрель это 4ый месяц.
Функция TRUNC при работе с датами
Функция TRUNC сокращает дату основываясь на параметре точности. У этой функции один параметр обязательный и один нет и синтаксис вызова TRUNC(source date, [date precision format]). Параметром source date может быть любая валидная дата. Параметр date precision format определяет уровень сокращения даты и необязателен, значение по умолчанию – сокращение до дня. Это значит что все значения времени обнуляются – 00 часов 00 минут 00 секунд. Сокращение до месяца вернёт дату равную первому дню месяца исходной даты. Сокращение до года – вернёт первый день года исходной даты. Рассмотрим запрос, использующий функцию с разными параметрами
Этот запрос выполнятся 17 апреля в 00:05. Первый столбец сокращает системную дату до дня, время преобразуется из 00:05 в 00:00 (параметр точности явно неуказан, используется значение по умолчанию) и возвращается текущий день. Второй столбец сокращает дату до такого же дня недели, который был первого числа месяца (среда) и возвращает среду текущей недели – 15 апреля. Третий столбец сокращает дату до месяца и возвращает первый день месяца – 1 апреля. Четвертый столбец сокращает дату до года и возвращает первый день года.
Изучение функции SQL Server LEN()
Автор Раджендра Гупта• 25 марта 2022 г.•
19:43•
Разработка баз данных, SQL Server, Заявления
ГлавнаяРазработка баз данных, SQL Server, ЗаявленияИзучение функции SQL Server LEN()
SQL Server поддерживает различные типы данных для хранения соответствующих данных в таблицах SQL. Эти типы данных могут быть целочисленными, плавающими, Varchar, NVARCHAR, Float, Char, битовыми. Пока мы работаем со строковыми типами данных, часто приходится находить длину строки.
Предположим, у вас есть веб-портал, на котором пользователи создают свои профили. В разделе профиля у вас могут быть такие поля, как [Имя], [Фамилия], [Адрес]. Вы хотите проверить максимальную длину строки для данных, хранящихся в этих столбцах.
Функция SQL Server LEN() возвращает длину строки для указанного столбца в качестве входных данных. Эта функция доступна, начиная с SQL Server 2008. Эти функции также доступны в базах данных SQL Azure и управляемых экземплярах.
Синтаксис:
LEN (строковое_выражение)
- Ввод: Строковое выражение может быть константой, символом, двоичными или переменными данными.
- Вывод: тип данных выходного значения — int, за исключением varchar(max), nvarchar(max), varbinary(max), которые возвращают bigint.
Давайте рассмотрим использование функции LEN() на различных примерах.
Пример 1. Получение длины строки
В следующем примере возвращается длина строки для входной строки.
SELECT LEN('Это образец текста')
AS [StrLength] Пример 2. Получение длины строки с пробелами в конце
Клиент может вставить данные с пробелом в конце. Если мы вычисляем длину строки, учитываются ли конечные пробелы?
Нет, функция SQL LEN() избегает пробелов в конце и возвращает длину фактической строки. Строка имеет три завершающих пробела; однако LEN() возвращает длину строки, равную 8.
SELECT LEN('Rajendra ')
AS [StrLength] Пример 3: Получение длины строки с начальными пробелами
В примере 2 мы видели, что функция LEN() избегает завершающих пробелов. Однако, если у нас есть другая строка с начальными пробелами, будет ли она вести себя так же?
Да, он также учитывает начальные пробелы при вычислении длины строки. Как показано ниже, LEN() возвращает значение 11.
SELECT LEN(' Rajendra')
AS [StrLength] Пример 4. Использование функции LEN() для строковых столбцов
В предыдущих примерах мы вводили строки непосредственно в функцию LEN(). В практическом сценарии вы используете эти функции SQL для данных, хранящихся в таблицах SQL.
Например, в приведенном ниже сценарии T-SQL мы вычисляем длину строки для данных, хранящихся в столбце [Name] схемы [SalesLT] и таблице [Product].
SELECT TOP (10) [ProductID] ,[Имя] ,Len(SalesLT.Product.Name) AS StrLength ,[Номер продукта] ,[Цвет] ,[Нормативная стоимость] FROM [SalesLT].[Product]
Пример 5. Использование функции LEN() в предложении WHERE
Вы можете использовать функцию LEN(), где предикат предложения, чтобы найти записи определенной длины. Например, следующий T-SQL возвращает записи с длиной строки из столбца Name больше 21.
SELECT TOP (10) [ProductID] ,[Имя] ,[Номер продукта] ,Len(SalesLT.
Как показано ниже, в выходных данных у нас есть данные, длина которых превышает 21 символ.
Пример 6: Значение NULL в функции LEN()
Функция LEN() всегда возвращает NULL для входного значения NULL.
Таким образом, если у вас есть столбец со значениями NULL, вы также получите NULL в длине строки.
SELECT TOP (5) [CustomerID] ,[Имя] ,[Второе имя] ,[Фамилия] ,[Суффикс] ,LEN(SalesLT.Customer.Suffix) AS NULLValue ОТ [SalesLT].[Клиент]
Пример 7. Ввод строки символов Unicode в функцию LEN()
Функция LEN() работает аналогично для значений Unicode и значений, отличных от Unicode. Он возвращает количество символов независимо от однобайтовых (не Unicode) или двухбайтовых (Unicode) значений. Как показано ниже, функция LEN() возвращает 8 символов для обоих входных данных.
SELECT LEN('Rajendra') AS [Non-UnicodeStrLength]
SELECT LEN(N'Rajendra') AS [UnicodeStrLength] Пример 8.
Ввод переменной в LEN()
SQL Server поддерживает объявления переменных для определения переменной с поддерживаемыми типами данных для хранения значений. Переменная может быть ссылкой в скрипте для быстрой справки.
Следовательно, если мы объявим переменную для строковых значений, сможем ли мы вычислить длину строки с помощью LEN(). Да, мы можем сделать, как показано в следующем примере.
DECLARE @Name NVARCHAR(50)= 'Ражендра' SELECT LEN(@Name) AS StrLength
Пример 9. Использование LEN() с типами данных varchar(max), nvarchar(max) или varbinary(max)
Функция SQL Server LEN() поддерживает varchar(max), nvarchar( max) или varbinary(max). Однако возвращаемое значение будет иметь тип данных bigint.
Например, приведенный ниже T-SQL вычисляет длину данных столбца с типом данных varbinary(max).
Вы не можете использовать функцию LEN() для типов данных text, ntext и image. Это дает следующее сообщение об ошибке.
СОЗДАТЬ ТАБЛИЦУ Тест ( идентификатор целое, [пример] изображение ) SELECT LEN([Sample]) FROM test
Просмотр плана выполнения запроса с помощью функции LEN()
Если вы создаете фактический план выполнения оператора SQL с помощью функции Len(), он показывает скалярный оператор вычисления.
Примечание. Чтобы создать фактический план выполнения, нажмите CTRL + M в SQL Server Management Studio перед выполнением запроса.
Щелкните скаляр вычисления и просмотрите его свойства. Вы получаете такие сведения, как сведения о скалярном операторе, расчетный ЦП, ввод-вывод, количество выполнений, количество строк.
Сравнение функции SQL Server LEN() с DATALENGTH()
Иногда разработчики путают использование функции LEN() или DATALENGTH(). Поэтому позвольте мне добавить быстрое сравнение обеих функций.
| LEN() | DATALENGTH() |
| Функция LEN() возвращает количество символов в строке. | Возвращает количество байтов для хранения строкового выражения. |
| Не включает пробелы в конце. | Не исключает пробелы в конце при подсчете количества байтов. |
| Его результат не зависит от строки Unicode или строки, отличной от Unicode. | Для типов данных Unicode требуется хранение двух байтов, а для данных, отличных от Unicode, требуется 1 байт. Таким образом, результаты различны для обоих типов данных. |
| Возвращает NULL для входного значения NULL. | Также возвращает NULL для входного значения NULL. |
| Не поддерживает типы данных ntext, text и image для входного выражения. | Функция DATALENGTH() также работает с типами данных ntext, text и image. |
Заключение
В этой статье исследуется функция SQL LEN() для вычисления длины строки в SQL Server с использованием различных вариантов использования. Мы также сравнили функции LEN() и DATALENGTH() в соответствии со следующей сводкой.
- Используйте LEN() для вычисления количества символов в строковом выражении.
- Используйте DATALENGTH() для вычисления количества байтов, необходимых для хранения строки.
Последнее изменение: 25 марта 2022 г.
Использование строковых функций SQL для очистки данных | Расширенный SQL
Начиная здесь? Этот урок является частью полного учебника по использованию SQL для анализа данных. Проверьте начало.
В этом уроке мы рассмотрим:
- Струны для чистки
- ЛЕВЫЙ, ПРАВЫЙ И ДЛИНА
- ТРИМ
- ПОЛОЖЕНИЕ и STRPOS
- СУБСТР
- КОНКАТ
- Чемодан для смены с ВЕРХНИМ и НИЖНИМ
- Преобразование строк в даты
- Превращение дат в более полезные даты
- ОБЪЕДИНЕНИЕ
В этом уроке представлены данные о криминальных инцидентах в Сан-Франциско за 3 месяца, начиная с 1 ноября 2013 г. и заканчивая 31 января 2014 г. Они были получены с веб-сайта SF Data 16 февраля 2014 г. Для каждого инцидента есть одна строка. сообщил. Некоторые определения полей: местоположение — это GPS-местоположение места происшествия, указанное в десятичных градусах, сначала широта, потом долгота. Две координаты также разбиты на поля широты и долготы соответственно.
Начните с просмотра:
ВЫБЕРИТЕ * ИЗ tutorial.
Очистка строк
Большинство функций, представленных в этом уроке, относятся к определенным типам данных. Однако использование определенной функции во многих случаях изменит данные на соответствующий тип. LEFT , RIGHT и TRIM используются для выбора только определенных элементов строк, но их использование для выбора элементов числа или даты будет рассматривать их как строки для целей функции.
ЛЕВЫЙ, ПРАВЫЙ и ДЛИНА
Начнем с ЛЕВЫЙ . Вы можете использовать LEFT , чтобы извлечь определенное количество символов из левой части строки и представить их как отдельную строку. Синтаксис: LEFT(строка, количество символов) .
В качестве практического примера мы можем видеть, что поле даты в этом наборе данных начинается с 10-значной даты и включает отметку времени справа от нее. Следующий запрос извлекает только ogimage: «/images/og-images/sql-facebook. png»
дата:
ВЫБЕРИТЕ номер инцидента,
свидание,
СЛЕВА(дата, 10) КАК clean_date
ИЗ tutorial.sf_crime_incidents_2014_01
ПРАВО делает то же самое, но с правой стороны:
SELECT incidnt_num,
свидание,
СЛЕВА(дата, 10) КАК очищенная_дата,
ПРАВО(дата, 17) КАК очищено_время
ИЗ tutorial.sf_crime_incidents_2014_01
ПРАВО хорошо работает в этом случае, потому что мы знаем, что количество символов будет одинаковым во всем поле даты . Если бы это было непоследовательно, все же можно было бы тянуть нитку с правой стороны так, как это имеет смысл. Функция LENGTH возвращает длину строки. Таким образом, LENGTH(date) всегда будет возвращать 28 в этом наборе данных. Поскольку мы знаем, что первые 10 символов будут датой, а за ними будет следовать пробел (всего 11 символов), мы могли бы представить ПРАВО функционируйте следующим образом:
SELECT Incidnt_num,
свидание,
СЛЕВА(дата, 10) КАК очищенная_дата,
ПРАВО(дата, ДЛИНА(дата) - 11) КАК очищено_время
ИЗ tutorial. sf_crime_incidents_2014_01
При использовании функций внутри других функций важно помнить, что сначала будут оцениваться самые внутренние функции, а затем функции, которые их инкапсулируют.
TRIM
Функция TRIM используется для удаления символов из начала и конца строки. Вот пример:
ВЫБЕРИТЕ местоположение,
TRIM (оба '()' ОТ местоположения)
ИЗ tutorial.sf_crime_incidents_2014_01
Функция TRIM принимает 3 аргумента. Во-первых, вы должны указать, хотите ли вы удалить символы с начала («начальные»), с конца («завершающие») или с обоих («оба», как указано выше). Далее необходимо указать все символы, которые необходимо обрезать. Любые символы, заключенные в одинарные кавычки, будут удалены как с начала, так и с конца или с обеих сторон строки. Наконец, вы должны указать текст, который хотите обрезать, используя ИЗ .
POSITION и STRPOS
POSITION позволяет указать подстроку, а затем возвращает числовое значение, равное номеру символа (считая слева), где эта подстрока впервые появляется в целевой строке. Например, следующий запрос вернет позицию символа «A» (с учетом регистра), где он впервые появляется в поле descript :
SELECT incidnt_num,
описание,
POSITION('A' IN descript) КАК a_position
ИЗ tutorial.sf_crime_incidents_2014_01
Вы также можете использовать функцию STRPOS для достижения тех же результатов — просто замените IN запятой и поменяйте порядок строки и подстроки:
SELECT incidnt_num,
описание,
STRPOS(descript, 'A') AS a_position
ИЗ tutorial.sf_crime_incidents_2014_01
Важно отметить, что обе функции POSITION и STRPOS чувствительны к регистру. Если вы хотите искать символ независимо от его регистра, вы можете сделать всю строку одной, используя ВЕРХНЯЯ или НИЖНЯЯ функции описаны ниже.
SUBSTR
LEFT и RIGHT создают подстроки заданной длины, но они делают это только начиная со сторон существующей строки. Если вы хотите начать с середины строки, вы можете использовать SUBSTR . Синтаксис: SUBSTR(*строка*, *позиция начального символа*, *количество символов*) :
SELECT incidnt_num,
свидание,
SUBSTR(дата, 4, 2) КАК день
ИЗ tutorial.sf_crime_incidents_2014_01
Практическая задача
Напишите запрос, который разделяет поле «местоположение» на отдельные поля для широты и долготы. Вы можете сравнить свои результаты с фактическими полями «широта» и «долгота» в таблице.
Попробуйте См. ответ
CONCAT
Вы можете объединять строки из нескольких столбцов вместе (и с жестко заданными значениями), используя CONCAT . Просто закажите значения, которые вы хотите объединить, и разделите их запятыми. Если вы хотите жестко закодировать значения, заключите их в одинарные кавычки. Вот пример:
ВЫБЕРИТЕ номер инцидента,
день недели,
СЛЕВА(дата, 10) КАК очищенная_дата,
СЦЕП (день_недели, ', ', НАЛЕВО (дата, 10)) КАК день_и_дата
ИЗ tutorial. sf_crime_incidents_2014_01
Практическая задача
Объедините поля lat и lon , чтобы сформировать поле, эквивалентное полю location . (Обратите внимание, что ответ будет иметь другую десятичную точность.)
ПопробуйтеПосмотреть ответ
Кроме того, вы можете использовать две вертикальной черты ( || ) для выполнения той же конкатенации:
SELECT incidnt_num,
день недели,
СЛЕВА(дата, 10) КАК очищенная_дата,
день_недели || ', ' || СЛЕВА(дата, 10) КАК день_и_дата
ИЗ tutorial.sf_crime_incidents_2014_01
Практическая задача
Создайте такое же составное поле location , но используя || Синтаксис вместо CONCAT .
ПопробуйтеПосмотреть ответ
Практическая задача
Напишите запрос, который создает столбец даты в формате ГГГГ-ММ-ДД.
Попробуйте См. ответ
Изменение регистра с помощью UPPER и LOWER
Иногда вы просто не хотите, чтобы ваши данные выглядели так, будто они кричат на вас. Вы можете использовать LOWER , чтобы заставить каждый символ в строке стать строчным. Точно так же вы можете использовать UPPER , чтобы все буквы отображались в верхнем регистре:
SELECT incidnt_num,
адрес,
ПРОПИСНОЙ(адрес) КАК адрес_верхний,
LOWER(адрес) AS address_lower
ИЗ tutorial.sf_crime_incidents_2014_01
Практическая задача
Напишите запрос, который возвращает поле `category`, но с заглавной первой буквой и строчными буквами остальных букв.
Попробуйте См. ответ
Существует несколько вариантов этих функций, а также несколько других строковых функций, которые здесь не рассматриваются. В разных базах данных используются небольшие вариации этих функций, поэтому обязательно проверьте синтаксис соответствующей базы данных, если вы подключены к частной базе данных. Если вы используете общедоступную службу Mode, как в этом руководстве, литература Postgres содержит соответствующие функции.
Преобразование строк в даты
Даты являются одним из наиболее часто испорченных форматов в SQL. Это может быть результатом нескольких вещей:
- В какой-то момент данные были изменены в Excel, и даты были изменены на формат ММ/ДД/ГГГГ или другой формат, не соответствующий строгим стандартам SQL.
- Данные были введены вручную кем-то, кто использует наиболее знакомые ему правила форматирования.
- Дата использует текст (январь, февраль и т. д.) вместо чисел для записи месяцев.
Чтобы воспользоваться всеми замечательными функциями даты ( ИНТЕРВАЛ , а также некоторыми другими, о которых вы узнаете в следующем разделе), вам необходимо правильно отформатировать поле даты. Это часто включает в себя некоторые манипуляции с текстом, за которыми следует CAST . Давайте вернемся к ответу на одну из практических задач выше:
SELECT Incidnt_num,
свидание,
(SUBSTR(дата, 7, 4) || '-' || LEFT(дата, 2) ||
'-' || SUBSTR(дата, 4, 2))::дата КАК очищенная_дата
ИЗ tutorial. sf_crime_incidents_2014_01
Этот пример немного отличается от ответа выше тем, что мы заключили весь набор конкатенированных подстрок в круглые скобки и преобразовали результат в формат даты . Мы также можем преобразовать его в с временной меткой , что включает дополнительную точность (часы, минуты, секунды). В этом случае мы не вытаскиваем часы из исходного поля, поэтому просто будем придерживаться даты .
Практическая задача
Напишите запрос, который создает точную временную метку, используя дата и время столбцы в tutorial.sf_crime_incidents_2014_01 . Включите поле, которое ровно через 1 неделю.
Попробуйте См. ответ
Превратите даты в более полезные даты
Получив хорошо отформатированное поле даты, вы можете манипулировать им самыми разными способами. Чтобы сделать урок немного чище, мы будем использовать другую версию набора данных о преступлениях, в которой уже есть хорошо отформатированное поле даты:
ВЫБОР * ИЗ tutorial.
Вы узнали, как создать поле даты, но что, если вы хотите его разобрать? Вы можете использовать EXTRACT , чтобы отделить части одну за другой:
SELECT clean_date,
ИЗВЛЕЧЬ('год' ИЗ clean_date) КАК год,
ВЫДЕРЖКА('месяц' ИЗ clean_date) КАК месяц,
ИЗВЛЕЧЬ('день' ИЗ clean_date) КАК день,
ИЗВЛЕЧЬ('час' ИЗ clean_date) КАК час,
ИЗВЛЕЧЬ('минута' ИЗ clean_date) КАК минута,
ИЗВЛЕЧЬ('секунда' ИЗ clean_date) КАК секунда,
ИЗВЛЕЧЬ('десятилетие' ИЗ clean_date) КАК десятилетие,
ВЫДЕРЖКА ('dow' FROM clean_date) AS day_of_week
ИЗ tutorial.sf_crime_incidents_cleandate
Вы также можете округлить дату до ближайшей единицы измерения. Это особенно полезно, если вас не интересует отдельная дата, но важна неделя (или месяц, или квартал), в которой она произошла. Функция DATE_TRUNC округляет дату до любой указанной вами точности. Отображаемое значение является первым значением в этом периоде. Поэтому, когда вы DATE_TRUNC по годам, любое значение в этом году будет указано как 1 января этого года:
SELECT clean_date,
DATE_TRUNC('year' , clean_date) КАК год,
DATE_TRUNC('месяц' , clean_date) КАК месяц,
DATE_TRUNC('неделя' , clean_date) КАК неделя,
DATE_TRUNC('день' , clean_date) КАК день,
DATE_TRUNC('час' , clean_date) КАК час,
DATE_TRUNC('минута' , clean_date) КАК минута,
DATE_TRUNC('second' , clean_date) КАК секунда,
DATE_TRUNC('десятилетие' , clean_date) КАК десятилетие
ИЗ tutorial.sf_crime_incidents_cleandate
Практическая задача
Напишите запрос, который подсчитывает количество инцидентов, зарегистрированных за неделю. Превратите неделю в дату, чтобы избавиться от часов/минут/секунд.
ПопробуйтеСмотреть ответ
Что делать, если вы хотите включить сегодняшнюю дату или время? Вы можете указать своему запросу извлекать локальную дату и время во время выполнения запроса, используя любое количество функций. Интересно, что вы можете запускать их без предложения FROM :
SELECT CURRENT_DATE AS date,
CURRENT_TIME КАК время,
CURRENT_TIMESTAMP AS метка времени,
МЕСТНОЕ ВРЕМЯ КАК местное время,
LOCALTIMESTAMP AS местная временная метка,
СЕЙЧАС() КАК сейчас
Как видите, разные параметры различаются по точности. Вы могли заметить, что это время, вероятно, не является вашим местным временем. База данных Mode настроена на всемирное координированное время (UTC), что в основном совпадает с GMT. Если вы запустите функцию текущего времени для подключенной базы данных, вы можете получить результат в другом часовом поясе.
Время отображается в другом часовом поясе с помощью В ЧАСОВОМ ПОЯСЕ :
ВЫБРАТЬ ТЕКУЩЕЕ ВРЕМЯ КАК время,
CURRENT_TIME AT TIME ZONE 'PST' AS time_pst
Полный список часовых поясов см. здесь. Эта функциональность довольно сложна, потому что метки времени могут храниться с метаданными часового пояса или без них. Для лучшего понимания точного синтаксиса мы рекомендуем ознакомиться с документацией Postgres.
Практическая задача
Напишите запрос, который показывает, как давно было сообщено о каждом инциденте. Предположим, что набор данных находится в стандартном тихоокеанском времени (UTC-8).
ПопробуйтеПосмотреть ответ
COALESCE
Иногда у вас будет набор данных, в котором есть несколько пустых значений, которые вы бы предпочли, чтобы они содержали фактические значения. Это часто происходит с числовыми данными (часто предпочтительнее отображать нули как 0) и при выполнении внешних соединений, которые приводят к некоторым несовпадающим строкам. В подобных случаях можно использовать COALESCE для замены нулевых значений:
SELECT incidnt_num,
описание,
COALESCE(описание, 'Без описания')
ИЗ tutorial.sf_crime_incidents_cleandate
ЗАКАЗАТЬ ПО ОПИСАНИЮ DESC
Встроенные скалярные функции SQL
Основные функции, показанные ниже, доступны по умолчанию.
Функции даты и времени,
агрегатные функции,
оконные функции,
математические функции и
Функции JSON документированы отдельно. Ан
Приложение может определять дополнительные
функции, написанные на C и добавленные в движок базы данных с помощью
API sqlite3_create_function().
абс( X )
Функция abs(X) возвращает абсолютное значение числового
аргумент X. Abs(X) возвращает NULL, если X имеет значение NULL.
Abs(X) возвращает 0,0, если X является строкой или большим двоичным объектом.
который не может быть преобразован в числовое значение. Если Х является
целое число -9223372036854775808, тогда abs(X) выдает целочисленное переполнение
ошибка, так как не существует эквивалентного положительного 64-битного значения с двумя дополнениями.
изменения()
Функция changes() возвращает количество строк базы данных, которые были изменены.
либо вставлены, либо удалены последней выполненной командой INSERT, DELETE,
или оператор UPDATE, исключая операторы в триггерах более низкого уровня.
Функция SQL changes() представляет собой оболочку функции sqlite3_changes64().
C/C++ и, следовательно, следует тем же правилам подсчета изменений.
символ( X1 , X2 ,…, XN )
Функция char(X1,X2,…,XN) возвращает строку, состоящую из символов, имеющих
значения кодовой точки Юникода для целых чисел от X1 до XN соответственно.
сливаются( X , Y ,…)
Функция Coalesce() возвращает копию своего первого аргумента, отличного от NULL, или
NULL, если все аргументы равны NULL. Coalesce() должен иметь как минимум
2 аргумента.
формат( ФОРМАТ ,…)
Функция format(FORMAT,…) SQL работает так же, как sqlite3_mprintf() C-языка
функция и функция printf() из стандартной библиотеки C.
Первый аргумент — это строка формата, указывающая, как построить вывод.
строка, использующая значения, взятые из последующих аргументов. Если аргумент ФОРМАТ
отсутствует или NULL, тогда результат будет NULL. Формат %n молча игнорируется и
не потребляет аргумент. Формат %p является псевдонимом для %X. Формат %z
взаимозаменяем с %s. Если в списке аргументов слишком мало аргументов,
предполагается, что отсутствующие аргументы имеют значение NULL, которое преобразуется в
0 или 0.0 для числовых форматов или пустая строка для %s. См.
встроенная документация printf() для получения дополнительной информации.
шарик( X , Y )
Функция glob(X,Y) эквивалентна функции
выражение « Y GLOB X «.
Обратите внимание, что аргументы X и Y в функции glob() меняются местами.
относительно инфиксного оператора GLOB. Y — это строка, а X — это
шаблон. Так, например, следующие выражения эквивалентны:
имя GLOB '*гелий*'
шар('*гелий*',имя)
Если интерфейс sqlite3_create_function() используется для
переопределите функцию glob(X,Y) альтернативной реализацией, затем
оператор GLOB вызовет альтернативную реализацию.
шестнадцатеричный ( X )
Функция hex() интерпретирует свой аргумент как BLOB и возвращает
строка, представляющая собой шестнадцатеричное представление содержимого в верхнем регистре
эта капля.
Если аргумент X в «hex( X )» является
целое число или число с плавающей запятой, тогда «интерпретирует свой аргумент как BLOB» означает
что двоичное число сначала преобразуется в текстовое представление UTF8, а затем
этот текст интерпретируется как BLOB. Следовательно, «шестнадцатеричный (12345678)» отображает
как «3132333435363738», а не двоичное представление целочисленного значения
«0000000000BC614E».
если нуль ( X , Y )
Функция ifnull() возвращает копию своего первого аргумента, отличного от NULL, или
NULL, если оба аргумента равны NULL. Ifnull() должно иметь ровно 2 аргумента.
Функция ifnull() эквивалентна Coalesce() с двумя аргументами.
iif( X , Y , Z )
Функция iif(X,Y,Z) возвращает значение Y, если X истинно, и Z в противном случае.
Функция iif(X,Y,Z) логически эквивалентна и генерирует то же самое.
байт-код как выражение CASE «CASE WHEN X THEN Y ELSE Z END».
инстр( X , Y )
Функция instr(X,Y) находит первое вхождение строки Y в
строка X и возвращает количество предшествующих символов плюс 1 или 0, если
Y нигде не встречается в X.
Или, если X и Y оба являются BLOB, то instr(X,Y) возвращает один
больше, чем число байтов до первого вхождения Y, или 0, если
Y нигде не встречается внутри X.
Если оба аргумента X и Y для instr(X,Y) не равны NULL и не являются большими двоичными объектами.
то оба интерпретируются как строки.
Если либо X, либо Y имеют значение NULL в instr(X,Y), то результат равен NULL.
last_insert_rowid()
Функция last_insert_rowid() возвращает ROWID
вставки последней строки из соединения с базой данных, которое вызвало
функция.
SQL-функция last_insert_rowid() представляет собой оболочку для
sqlite3_last_insert_rowid() функция интерфейса C/C++.
длина( X )
Для строкового значения X функция length(X) возвращает количество
символов (не байтов) в X до первого символа NUL.
Поскольку строки SQLite обычно не содержат символов NUL, длина (X)
Функция обычно возвращает общее количество символов в строке X.
Для значения большого двоичного объекта X функция length(X) возвращает количество байтов в большом двоичном объекте.
Если X равно NULL, то длина (X) равна NULL.
Если X является числовым, то length(X) возвращает длину строки
представление Х.
Обратите внимание, что для строк функция length(X) возвращает символов .
длина строки, а не длина байта. Длина символа — это число
символов в строке. Длина символа всегда отличается от
длина в байтах для строк UTF-16 и может отличаться от длины в байтах
для строк UTF-8, если строка содержит многобайтовые символы.
Для значений BLOB length(X) всегда возвращает длину BLOB в байтах.
Для строковых значений length(X) должна прочитать всю строку в память, чтобы
для вычисления длины символа. Но для значений BLOB это не обязательно, так как
SQLite знает, сколько байтов в BLOB. Следовательно, для многомегабайтных значений
функция length(X) обычно намного быстрее для больших двоичных объектов, чем для строк, поскольку
ему не нужно загружать значение в память.
нравится( X , Y )
нравится( X , Y , З )
Функция like() используется для реализации
« Y LIKE X [ESCAPE Z] » выражение.
Если присутствует необязательное предложение ESCAPE, то
Функция like() вызывается с тремя аргументами. В противном случае это
вызывается только с двумя аргументами. Обратите внимание, что параметры X и Y
перевернуто в функции like() по отношению к инфиксному оператору LIKE.
X — это шаблон, а Y — строка, соответствующая этому шаблону.
Следовательно, следующие выражения эквивалентны:
имя НРАВИТСЯ '%neon%'
нравится('%неон%',имя)
Интерфейс sqlite3_create_function() можно использовать для переопределения
функцию like() и тем самым изменить работу
НРАВИТСЯ оператор. При переопределении функции like() может быть важно
переопределить версии с двумя и тремя аргументами функции like()
функция. В противном случае может быть вызван другой код для реализации
LIKE в зависимости от того, было ли предложено условие ESCAPE.
указано.
вероятность( X , Y )
Функция правдоподобия (X, Y) возвращает аргумент X без изменений.
Значение Y в вероятности (X, Y) должно быть константой с плавающей запятой.
от 0,0 до 1,0 включительно.
Функция правдоподобия (X) не является операцией, которую генератор кода
оптимизирует так, чтобы он не потреблял циклы ЦП во время выполнения
(то есть во время вызовов sqlite3_step()).
Назначение функции правдоподобия (X, Y) состоит в том, чтобы дать подсказку
планировщику запросов, что аргумент X является логическим значением, то есть
верно с вероятностью приблизительно Y.
Функция маловероятности (X) является сокращением для вероятности (X, 0,0625).
Функция вероятного (X) является сокращением для правдоподобия (X, 0,9375).
вероятно( X )
Функция вероятного(X) возвращает аргумент X без изменений.
Функция вероятного (X) не является операцией, которую генератор кода
оптимизирует так, чтобы он не потреблял циклы ЦП в
во время выполнения (то есть во время вызовов sqlite3_step()).
Назначение функции вероятностного(X) состоит в том, чтобы дать подсказку
планировщику запросов, что аргумент X является логическим значением
обычно это правда. Функция вероятного (X) эквивалентна
вероятности (X, 0,9375). См. также: маловероятно(X).
load_extension( X )
load_extension( X , Y )
Функция load_extension(X,Y) загружает расширения SQLite из общего
файл библиотеки с именем X, используя точку входа Y. Результат load_extension()
всегда NULL. Если Y опущен, используется имя точки входа по умолчанию.
Функция load_extension() вызывает исключение, если расширение не
загрузить или инициализировать правильно.
Функция load_extension() завершится ошибкой, если расширение попытается
изменить или удалить функцию SQL или последовательность сопоставления.
расширение может добавлять новые функции или последовательности сопоставления, но не может
изменить или удалить существующие функции или последовательности сопоставления, потому что
эти функции и/или последовательности сопоставления могут использоваться в другом месте
в текущем операторе SQL. Чтобы загрузить расширение, которое
изменяет или удаляет функции или последовательности сопоставления, используйте
sqlite3_load_extension() API языка C.
Из соображений безопасности загрузка расширений отключена по умолчанию и должна
быть включена предварительным вызовом sqlite3_enable_load_extension().
нижний( X )
Функция lower(X) возвращает копию строки X со всеми символами ASCII.
преобразованы в нижний регистр. Встроенная по умолчанию функция lower() работает
только для символов ASCII. Для преобразования регистра в не-ASCII
символов, загрузите расширение ICU.
ltrim( X )
ltrim( X , Y )
Функция ltrim(X,Y) возвращает строку, образованную удалением всех без исключения
символы, которые появляются в Y слева от X.
Если аргумент Y опущен, ltrim(X) удаляет пробелы с левой стороны
Х.
макс( X , Y ,…)
Функция max() с несколькими аргументами возвращает аргумент с
максимальное значение или вернуть NULL, если какой-либо аргумент равен NULL.
Функция max() с несколькими аргументами ищет аргументы слева направо.
для аргумента, который определяет функцию сортировки и использует эту функцию сортировки
функция для всех сравнений строк. Если ни один из аргументов max()
определить функцию сопоставления, тогда используется функция сопоставления BINARY.
Обратите внимание, что max() — простая функция, когда
имеет 2 или более аргументов, но работает как
агрегатная функция, если задан только один аргумент.
мин( X , Y ,…)
Функция min() с несколькими аргументами возвращает аргумент с
минимальное значение.
Функция min() с несколькими аргументами ищет аргументы слева направо.
для аргумента, который определяет функцию сортировки и использует эту функцию сортировки
функция для всех сравнений строк. Если ни один из аргументов min()
определить функцию сопоставления, тогда используется функция сопоставления BINARY.
Обратите внимание, что min() — это простая функция, когда
имеет 2 или более аргументов, но работает как
агрегатная функция, если задана
только один аргумент.
nullif( X , Y )
Функция nullif(X,Y) возвращает свой первый аргумент, если аргументы
разные и NULL, если аргументы совпадают. Функция nullif(X,Y)
ищет в своих аргументах слева направо аргумент, определяющий
функция сопоставления и использует эту функцию сопоставления для всех строк
сравнения. Если ни один из аргументов nullif() не определяет функцию сопоставления
затем используется функция сопоставления BINARY.
printf( ФОРМАТ ,…)
SQL-функция printf() является псевдонимом SQL-функции format().
SQL-функция format() первоначально называлась printf(). Но название было позже
изменен на format() для совместимости с другими механизмами баз данных. Оригинал
Имя printf() сохраняется как псевдоним, чтобы не нарушать устаревший код.
цитата( X )
Функция quote(X) возвращает текст литерала SQL, который
является значением его аргумента, подходящим для включения в оператор SQL.
Строки заключаются в одинарные кавычки с экранированием во внутренних кавычках.
по мере необходимости. BLOB кодируются как шестнадцатеричные литералы.
Строки со встроенными символами NUL не могут быть представлены в виде строки.
литералы в SQL и, следовательно, возвращаемый строковый литерал усекается до
до первого НУЛ.
случайный()
Функция random() возвращает псевдослучайное целое число.
между -9223372036854775808 и +9223372036854775807.
случайный блоб( N )
Функция randomblob(N) возвращает N-байтовый BLOB-объект, содержащий псевдослучайные
байт. Если N меньше 1, возвращается случайный двоичный объект размером 1 байт.
Подсказка: приложения могут генерировать глобально уникальные идентификаторы
используя эту функцию вместе с hex() и/или
ниже() вот так:
шестнадцатеричный (случайный двоичный объект (16))
ниже (шестнадцатеричный (случайный двоичный объект (16)))
заменить( X , Y , Z )
Функция replace(X,Y,Z) возвращает строку, образованную заменой
строка Z для каждого вхождения строки Y в строку X.
последовательность сопоставления используется для сравнения. Если Y пустое
строка, затем верните X без изменений. Если Z изначально не
строка, перед обработкой она преобразуется в строку UTF-8.
круглый( X )
круглый( X , Y )
Функция round(X,Y) возвращает число с плавающей запятой.
значение X округляется до Y цифр справа от запятой.
Если аргумент Y опущен или отрицателен, он принимается равным 0.
rtrim( X )
rtrim( X , Y )
Функция rtrim(X,Y) возвращает строку, образованную удалением всех без исключения
символы, которые появляются в Y с правой стороны X.
Если аргумент Y опущен, rtrim(X) удаляет пробелы справа
сторона Х.
знак( X )
Функция sign(X) возвращает -1, 0 или +1, если аргумент X является числовым.
отрицательное, нулевое или положительное значение соответственно. Если аргумент
to sign(X) имеет значение NULL или является строкой или большим двоичным объектом, который не может быть преобразован без потерь
в число, то sign(X) возвращает NULL.
саундекс( X )
Функция soundex(X) возвращает строку, которая представляет собой кодировку soundex.
строки Х.
Строка «?000» возвращается, если аргумент имеет значение NULL или содержит
нет буквенных символов ASCII.
Эта функция отсутствует в SQLite по умолчанию.
Он доступен, только если параметр времени компиляции SQLITE_SOUNDEX
используется при сборке SQLite.
sqlite_compileoption_get ( N )
SQL-функция sqlite_compileoption_get() является оболочкой для
Функция sqlite3_compileoption_get() C/C++.
Эта подпрограмма возвращает N-й параметр времени компиляции, используемый для сборки SQLite.
или NULL, если N выходит за пределы допустимого диапазона. См. также прагму compile_options.
sqlite_compileoption_used( X )
SQL-функция sqlite_compileoption_used() является оболочкой над
Функция sqlite3_compileoption_used() C/C++.
Когда аргумент X для sqlite_compileoption_used(X) является строкой,
— это имя параметра времени компиляции, эта процедура возвращает значение true (1) или
false (0) в зависимости от того, использовалась ли эта опция во время
строить.
sqlite_offset( X )
Функция sqlite_offset(X) возвращает смещение в байтах в базе данных
файл для начала записи, из которой будет считываться значение.
Если X не является столбцом в обычной таблице, тогда sqlite_offset(X) возвращает
НУЛЕВОЙ. Значение, возвращаемое sqlite_offset(X), может ссылаться либо на
исходная таблица или индекс, в зависимости от запроса. Если бы значение X
обычно извлекается из индекса, sqlite_offset(X) возвращает
смещение к соответствующей индексной записи. Если бы значение X было
извлекается из исходной таблицы, затем sqlite_offset(X) возвращает смещение
к записи таблицы.
SQL-функция sqlite_offset(X) доступна, только если SQLite собран
используя параметр времени компиляции -DSQLITE_ENABLE_OFFSET_SQL_FUNC.
sqlite_source_id()
Функция sqlite_source_id() возвращает строку, идентифицирующую
конкретная версия исходного кода, которая использовалась для сборки SQLite
библиотека. Строка, возвращаемая sqlite_source_id(),
дата и время, когда исходный код был проверен, а затем
хэш SHA3-256 для этой регистрации. Эта функция
SQL-оболочка вокруг интерфейса sqlite3_sourceid() C.
sqlite_version()
Функция sqlite_version() возвращает строку версии для SQLite.
библиотека, которая работает. Эта функция является SQL
оболочка вокруг C-интерфейса sqlite3_libversion().
substr( X , Y , Z )
substr( X , Y )
substring( X , Y , Z )
substring( X , Y )
Функция substr(X,Y,Z) возвращает подстроку входной строки X, которая начинается
с Y-м символом и длиной Z символов.
Если Z опущен, то substr(X,Y) возвращает все символы до конца
строки X, начиная с Y-го.
Крайний левый символ X — это число 1. Если Y отрицательное
то первый символ подстроки находится путем отсчета от
справа, а не слева. Если Z отрицательно, то
возвращаются символы abs(Z), предшествующие Y-му символу.
Если X является строкой, то индексы символов относятся к фактическому UTF-8.
персонажи. Если X является BLOB, то индексы относятся к байтам.
«substring()» — это псевдоним для «substr()», начиная с версии SQLite 3.34.
total_changes()
Функция total_changes() возвращает количество изменений строки
вызвано INSERT, UPDATE или DELETE
операторов с момента открытия текущего соединения с базой данных.
Эта функция является оболочкой для sqlite3_total_changes64().
Интерфейс С/С++.
отделка( X )
отделка( X , и )
Функция trim(X,Y) возвращает строку, образованную удалением всех без исключения
символы, которые появляются в Y с обоих концов X.
Если аргумент Y опущен, trim(X) удаляет пробелы с обоих концов X.
тип( X )
Функция typeof(X) возвращает строку, указывающую тип данных
выражение X: «null», «integer», «real», «text» или «blob».
Юникод ( X )
Функция unicode(X) возвращает числовую кодовую точку Unicode, соответствующую
первый символ строки X. Если аргумент unicode(X) не является строкой
то результат не определен.
маловероятно( X )
Функция маловероятно(X) возвращает аргумент X без изменений.
Функция маловероятности (X) не является операцией, которую генератор кода
оптимизирует так, чтобы он не потреблял циклы ЦП в
во время выполнения (то есть во время вызовов sqlite3_step()).
Функция маловероятности (X) предназначена для предоставления подсказки
планировщику запросов, что аргумент X является логическим значением
обычно это не так. Функция маловероятности (X) эквивалентна
вероятности (X, 0,0625).
верхний( X )
Функция upper(X) возвращает копию входной строки X, в которой все
символы ASCII нижнего регистра преобразуются в эквивалентные им символы верхнего регистра.
нулевое пятно( N )
Функция zeroblob(N) возвращает BLOB, состоящий из N байтов 0x00.
SQLite очень эффективно управляет этими нулевыми каплями. Zeroblobs можно использовать для
резервное пространство для BLOB, который позже записывается с использованием
добавочный ввод-вывод BLOB.
Эта функция SQL реализована с использованием функции sqlite3_result_zeroblob().
из интерфейса C/C++.
14. Изучите строковые функции SQL — MySQL CONCAT, LENGTH, SUBSTR
В этом руководстве мы узнаем о функциях, которые можно использовать для простого управления строковыми данными. Для строк существует множество функций, и иногда разные базы данных, такие как Oracle, SQL Server и MySQL, используют разные методы. Мы рассмотрим строковые данные на основе MySQL.
Запрос 1. Объедините столбцы имени и фамилии клиента, чтобы создать новый столбец имени (CONCAT)
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name FROM customer;
Запрос 2. Подсчитаем длину полного имени клиента (LENGTH)
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name, LENGTH(CONCAT(first_name, last_name)) AS length_name FROM customer;
Запрос 3. Выведем только три символа имени клиента (SUBSTR)
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name, SUBSTR(CONCAT(first_name, “ “, last_name), 1 , 3) КАК short_name ОТ заказчика;
Q1. Объедините столбцы имени и фамилии клиента, чтобы создать новый столбец имени (CONCAT)
Сначала давайте посмотрим на таблицу клиентов.
ВЫБЕРИТЕ * ОТ заказчика;
В таблице показаны имена и фамилии клиентов, хранящиеся в разных столбцах. Вам может понадобиться полное имя вместе в более сложных запросах, поэтому полезно знать, как соединить два имени в одну строку. И чтобы объединить их в MySQL, вам нужно CONCAT .
#CONCAT
Начните с указания столбца, который вы хотите просмотреть: идентификатор клиента
SELECT customer_id
Мы также хотим увидеть полное имя, поэтому давайте используем СЦЕП, чтобы соединить имя и фамилию. Чтобы добавить пробел между ними, нам нужно явно указать его и выделить двойными кавычками (« »). Убедитесь, что вы разделили все три запятыми:
CONCAT(first_name, « », last_name)
Переименуйте этот новый столбец как Полное имя:
AS full_name
И, наконец, закройте его именем таблицы и точкой с запятой. Ваш полный и окончательный запрос будет выглядеть следующим образом:
SELECT customer_id, CONCAT(first_name, “ ”, last_name) AS full_name FROM customer;
😄 Интересный совет! Вы также можете добавить дополнительный текст с помощью CONCAT , например:
SELECT customer_id, CONCAT("Здравствуйте. Я ", first_name, “ “, last_name) AS full_name FROM customer; Q2. Посчитаем длину ФИО клиента (символы в имени и фамилии).
Иногда необходимо вычислить длину строки. Для этого мы будем использовать LENGTH. Эта функция принимает строковые данные в качестве входного значения и вычисляет, сколько в них символов, и выводит числа (вычисляет на основе байтов).
#LENGTH
Вы можете использовать строки или строковые столбцы непосредственно в функции LENGTH , но в этом примере мы будем использовать CONCAT . В предыдущем примере результатом функции CONCAT была строка, соответствующая имени клиента ( full_name ), поэтому мы можем использовать его без проблем. Но если для числовых расчетов используется CONCAT , вы не сможете воспроизвести этот запрос.
Вот визуальное представление того, что делает этот запрос:
Итак, сначала установите столбцы, которые вы хотите просмотреть, с помощью SELECT :
SELECT customer_id, CONCAT(first_name, “ “, фамилия) КАК полное_имя
А затем добавить ДЛИНА . Мы хотим подсчитать каждый символ в имени и фамилии, не считая пробела, который мы добавили ранее, поэтому мы собираемся переписать нашу функцию CONCAT для LENGTH . Вот как это должно выглядеть:
LENGTH(CONCAT(first_name, last_name))
Переименуйте новый столбец как Name Length и закройте запрос:
AS name_length FROM customer;
Вот как выглядит окончательный запрос:
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name, LENGTH(CONCAT(first_name, last_name)) AS name_length FROM customer;
Q3. Выведем только три символа имени клиента (первые три и последние три).
SUBSTR используется для извлечения только части полной строки. Это также позволяет вам установить начальную позицию и указать, сколько символов вы хотите извлечь.
#SUBSTR
Давайте продолжим наш предыдущий запрос. Начните с SELECT :
SELECT customer_id, CONCAT(first_name, “ “, last_name)
Не забудьте переименовать новый столбец: AS full_name
Затем подключите SUBSTR и внутри него продублируйте функцию CONCAT . Здесь у нас есть два новых фактора для размышления. Во-первых, нам нужно указать начальную позицию. Поскольку мы хотим, чтобы он начинался с самого начала, мы будем использовать число 1 . Далее нам нужно указать, сколько символов имени мы хотим напечатать. Допустим, только 3 символов:
SUBSTR(CONCAT(first_name, " ", last_name), 1, 3)
Вот наглядная демонстрация того, что делает SUBTR :
Переименуйте и этот столбец: AS short_name
Закройте его с помощью функции FROM : FROM customer;
Ваш окончательный запрос должен выглядеть следующим образом:
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name, SUBSTR(CONCAT(first_name, “ “, last_name), 1, 3) AS short_name FROM customer;
Итак, теперь мы видим только первые три символа каждого имени! МЭРИ СМИТ стало просто МАРТ . 😃 Красиво!
#Practice Time
Печать списка имен клиентов и их «цензурированных» электронных писем (используя CONCAT, SUBSTR, REPEAT, LENGTH)
При работе с личной информацией клиента, такой как имя, адрес и телефон число, нам нужно обработать его, не раскрывая. Используя функции, которые мы изучили до сих пор, давайте воспользуемся таблицей клиентов, чтобы заменить адрес электронной почты клиента строкой, которую нельзя идентифицировать.
Мы собираемся использовать CONCAT и SUBSTR для цензуры электронной почты. Вот краткое описание шагов, которые нам нужны:
- Используйте
CONCAT, чтобы получить полное имя клиента. - Используйте
CONCATиSUBSTRвместе, чтобы получить электронное письмо. - Используйте
REPEATиINSTRдля цензуры. - Используйте
AS, чтобы переименовать столбец.
📌 ПОВТОР : повторить строку столько раз, сколько нужно
📌 INSTR : возвращает позицию первого вхождения строки в другую строку
Чувствуете себя немного запутанным? Давайте разберем это:
Начните с вашей функции SELECT и следуйте за ней с первым столбцом, который вы хотите просмотреть, столбцом идентификатора клиента: SELECT customer_id
Используйте CONCAT для объединения имени и фамилии клиентов и переименуйте новый столбец как полное имя: CONCAT(first_name, “ “, last_name) AS full_name
Снова используйте CONCAT , чтобы создать столбец электронной почты secret , выполнив следующие действия: С помощью INSTR мы идентифицируем строку ( email ) и указываем определенный символ ( @ ) в качестве начальной позиции, которую мы хотим в str в g .
INSTR(email, '@ ')
* ), чтобы заполнить оставшуюся длину (символов) после исходных 3, которые мы напечатали. Поскольку эта длина разная для каждого электронного письма, нам нужно повторять ее столько раз, сколько необходимо, поэтому давайте использовать REPEAT . Мы также собираемся вычесть 1 ( -1 ) для символа @ и вычесть 3 ( -3 ) для 3 напечатанного текста электронной почты, чтобы информация не подвергалась цензуре. REPEAT('*', INSTR(email)-1-3) CONCAT : '@sakilacustomer.org') AS secret_email ОТ заказчика; Когда вы запустите запрос, вы получите первые 3 символа их электронной почты, за которыми следуют звездочки, которые подвергают цензуре остальную личную информацию! Вот полный запрос:
SELECT customer_id, CONCAT(first_name, “ “, last_name) AS full_name, CONCAT(SUBSTR(email, 1, 3), REPEAT('*', INSTR(email, '@')-1–3), '@ sakilacustomer. org') AS secret_email ОТ клиента; Это может показаться несколько сложным, но нетрудно определить каждую строку, которую вы хотите просмотреть, а затем объединить ее с функцией CONCAT . Хотя мы только продемонстрировали обычное применение этих функций, существует много других способов их использования.
Найти длину строки в Sql без начала нуля
- Главная
- Sql-сервер
- Найти длину строки в Sql, не начиная с нуля
Найти длину строки в sql без начала с нуля
Метки:
sql-сервер
, sql-сервер-2008
, CSV
Ответы:
1
|
просмотрено 1182 раза
Здесь уже есть ответы на этот вопрос :
Удаление ведущих нулей из поля в операторе SQL
(15 ответов)
Закрыт 6 лет назад.
У меня проблема. Я загружаю код сотрудника и номер счета из файла Excel (.csv), я проверю код сотрудника и обновлю или вставлю номер счета для соответствующего кода сотрудника. Но если код сотрудника начинается с «0», файл csv не будет учитывать 0 и просто отправит оставшийся символ, поэтому, когда я проверю его в sql, он не будет соответствовать данным таблицы (код сотрудника).
У меня есть план сопоставить их, но я не знаю, как это сделать.
Я пробовал выполнить запрос ниже
объявлять @EmployeeCodeNET varchar(max)='MJ300';
объявить @EmployeeCodeDB varchar(max)='00MJ300';
выберите LTRIM(REPLACE(@EmployeeCodeDB, '0', '')) -- должно быть возвращено 'MJ300'
Дэмиен_Неверующий
ответь в
15 мая 2015 г.
7″/>
Если пробелы не ожидаются, то что-то близкое к тому, что вы пробовали, это то, что вам нужно:
declare @EmployeeCodeDB varchar(max)='00MJ300';
select REPLACE(LTRIM(REPLACE(@EmployeeCodeDB, '0', ' ')),' ','0')
То есть заменить все 0 пробелами, затем ( LTRIM ) удалить все ведущих пробелов, а затем замените все пробелы на 0 s (таким образом, все исходные 0 s, которые не были в начальном положении, возвращаются обратно)
Результат:
MJ300
пробелы могут существовать в вашей строке, и они не требуются, но они не должны волшебным образом превращаться в 0 s, то вы можете заменить внутренний @EmployeeCodeDB еще одной заменой: REPLACE(@EmployeeCodeDB,' ','')
* Ответы/решения собираются из
stackoverflow, под лицензией
CC BY-SA 3. 0
Некоторые ответы по коду
declare @EmployeeCodeNET varchar(max)='MJ300';
объявить @EmployeeCodeDB varchar(max)='00MJ300';
выберите LTRIM(REPLACE(@EmployeeCodeDB, '0', '')) -- должно быть возвращено 'MJ300'
90 ]%’, @str), LEN(@str))
объявлять @EmployeeCodeNET varchar(max)='MJ300';
объявить @EmployeeCodeDB varchar(max)='00MJ300';
DECLARE @offset int SELECT @offset = LEN(@EmployeeCodeDB) - LEN(@EmployeeCodeNET) SELECT SUBSTRING(@EmployeeCodeDB, @offset+1, LEN(@EmployeeCodeNET))
Дополнительные ответы, связанные Найти длину строки в Sql без Начало нуля
Как проверить длину строки в SQL | LearnSQL.com
1 день назад
LENGTH() возвращает количество символов в заданной строке . У него всего один параметр — сама строка . Если входная строка пуста, функция возвращает 0; если строка равна NULL, то …
Показать детали
› См. также:
Нить
Функция
Функция SQL LENGTH — получение количества символов в…
4 дня назад
Во-первых, используйте функцию CONCAT, чтобы создать полное имя сотрудника, соединив имя, пробел и фамилию. Во-вторых, примените функцию LENGTH, чтобы вернуть количество …
Показать детали
› См. также:
Функция
Когда я использую подстроку, начальная точка равна 1, а не нулю (0)
3 дня назад
26 сентября 2018 г. · Первая позиция в строке – 1. MySql Official выглядит следующим образом: позиция первого символа в строке , из которой должна быть извлечена подстрока , считается равной 1. Вот …
› Отзывы: 2
Показать детали
› См. также:
Нить
Функция SQL Server LEN() — W3Schools
4 дня назад
Определение и использование. Функция LEN() возвращает длину строки . Примечание. Конечные пробелы в конце строки не учитываются при вычислении длины . Однако ведущие места в…
Показать детали
› См. также:
Нить
Функция
Строковые функции SUBSTRING, PATINDEX и CHARINDEX…
9]
строка оператор. Он находит позицию символа без алфавита, числа или пробела. 1. 2. SELECT position = PATINDEX(‘% …
Показать детали
› См. также:
Нить
Функция
Как найти строку в строке в SQL Server: объясняется с помощью…
1 неделю назад
27 июня 2022 г. · 1. Системная функция CHARINDEX. Системная функция CHARINDEX возвращает местоположение подпункта строка внутри большей строки . Обычно он используется в операторе SELECT. …
Показать детали
› См. также:
Нить
Функция
Поиск текстов, начинающихся, заканчивающихся или содержащих заданную строку — биты SQL
1 неделю назад
28 июля 2021 г. · Как выбрать строки, в которых текстовый столбец начинается, заканчивается или содержит строку . Включая чуть менее тривиальные случаи. КАК. Чтобы найти строка , которые соответствуют шаблону, LIKE …
Показать детали
› См. также:
Нить
Подстрока SQL: лучший способ извлечь набор символов
6 дней назад
27 сентября 2021 г. · Извлечение строки Sub s без указания длины. Чтобы извлечь всю строку из второго символа указанной строки , введите следующий код : Это показывает…
Показать детали
› См. также:
Нить
Как сделать строку нулевой длины по умолчанию равной NULL — SQLServerCentral
1 неделю назад
21 мая 2010 г. · 20 мая 2010 г., 17:44. №1170528. С точки зрения T-SQL вы можете сделать что-то вроде этого: обновить myTable. установить Column1 = case Column1, когда », то конец null, …
Показать детали
› См. также:
Нить
Свидание
преобразовать строку нулевой длины («») в null
1 неделю назад
07 октября 2021 г. · Пользователь 546194788 опубликовал Одно текстовое поле позволит пользователю ввести дату заказа. Если пользователь ничего не ввел, SQL-сервер сохранит дату 01.01.1900. Могу ли я код преобразовать ноль длина строка …
Показать детали
› См. также:
Нить
Как добавить 0 перед строкой на сервере MS SQL?
3 дня назад
03 мая 2014 · Вы можете использовать ведущее решение для заполнения ноль с функциями Right() и Replicate(). Вот функция, построенная поверх этих функций SQL, с именем udfLeftSQLPadding, где вы…
Показать детали
› См. также:
Нить
Функция
Как вставить строку нулевой длины в ненулевое поле — oracle-tech
4 дня назад
23 октября 2003 г. · Строка из нулей длины (») не эквивалентна значению NULL. В соответствии с переходным стандартом ANSI SQL 1992, нуль — длина или пустая строка не то же самое, что …
Показать детали
› См. также:
Нить
Оракул
Пожалуйста, оставьте свой ответ здесь:
Строковые функции — База знаний MariaDB
Функции, работающие со строками, такие как CHAR, CONVERT, CONCAT, PAD, REGEXP, TRIM и т. д.
Функции регулярных выражений
Функции для работы с регулярными выражениями
Функции динамических столбцов
Функции для хранения пар данных ключ/значение в столбце.
ASCII-код
Числовое значение ASCII крайнего левого символа.
БИН
Возвращает двоичное значение.
ДВОИЧНЫЙ Оператор
Преобразует в двоичную строку.
- г.
БИТ_ДЛИНА
Возвращает длину строки в битах.
литье
Приводит значение одного типа к другому типу.
- г.
СИМВОЛ Функция
Возвращает строку на основе целочисленных значений для отдельных символов.
CHARACTER_LENGTH
Синоним для CHAR_LENGTH().
- г.
CHAR_LENGTH
Длина строки в символах.
ЧР
Возвращает строку на основе целочисленных значений отдельных символов.
КОНКАТ
Возвращает объединенную строку.
CONCAT_WS
Объединить с разделителем.
- г.
ПРЕОБРАЗОВАТЬ
Преобразование значения из одного типа в другой тип.
ЭЛТ
Возвращает N-й элемент из набора строк.
- г.
EXPORT_SET
Возвращает строку включения для каждого установленного бита и строку отключения для каждого неустановленного бита.
ЭКСТРАКТЗНАЧ
Возвращает текст первого текстового узла, совпадающего с выражением XPath.
ПОЛЕ
Возвращает позицию индекса строки в списке.
НАЙТИ_IN_SET
Возвращает позицию строки в наборе строк.
ФОРМАТ
Форматирует число.
FROM_BASE64
Для заданной строки в кодировке base-64 возвращает декодированный результат в виде двоичной строки.
Шестнадцатеричный
Возвращает шестнадцатеричное значение.
ВСТАВИТЬ Функция
Заменяет часть строки другой строкой.
ИНСТРО
Возвращает позицию строки в строке.
LCASE
Синоним слова НИЖЕ().
ЛЕВЫЙ
Возвращает крайние левые символы из строки.
ДЛИНА
Длина строки в байтах.
ДЛИНАB
Длина данной строки в байтах.
НРАВИТСЯ
Соответствует ли выражение шаблону.
LOAD_FILE
Возвращает содержимое файла в виде строки.
НАЙТИ
Возвращает позицию подстроки в строке.
НИЖНИЙ
Возвращает строку, в которой все символы заменены на нижний регистр.
ЛПАД
Возвращает строку, дополненную слева другой строкой заданной длины.
ЛТРИМ
Возвращает строку с удаленными начальными пробелами.
MAKE_SET
Создайте набор строк, соответствующих битовой маске.
МАТЧ ПРОТИВ
Выполнение полнотекстового поиска по полнотекстовому индексу.
Стоп-слова полнотекстового индекса
Список полнотекстовых стоп-слов по умолчанию, используемых функцией ПОИСКПОЗ…ПРОТИВ.
Середина
Синоним для SUBSTRING(str,pos,len).
НАТУРАЛЬНЫЙ_СОРТ_КЛЮЧ
Сортировка, более близкая к естественной сортировке человека.
НЕ КАК
То же, что НЕ (выражение LIKE pat [ESCAPE ‘escape_char’]).
НЕ РЕГЭКСП
То же, что и NOT (выражение REGEXP pat).
ОКТЕТ_ДЛИНА
Возвращает длину заданной строки в байтах.
ОРД
Возвращает ASCII или код символа.
ПОЛОЖЕНИЕ
Возвращает позицию подстроки в строке.
ЦИТАТА
Возвращает заключенную в кавычки правильно экранированную строку.
ПОВТОР Функция
Возвращает строку, повторенную несколько раз.
ЗАМЕНИТЬ Функция
Замена вхождений строки.
ЗАДНИЙ
Меняет порядок строки на обратный.
ПРАВО
Возвращает крайние правые N символов из строки.
РПАД
Возвращает строку, дополненную справа другой строкой до заданной длины.
РТРИМ
Возвращает строку с удаленными пробелами в конце.
СФОРМАТ
Учитывая строку и спецификацию форматирования, возвращает форматированную строку.
САУНДЭКС
Возвращает строку на основе ее звучания.
Звучит как
SOUNDEX(выражение1) = SOUNDEX(выражение2).
КОСМОС
Возвращает строку пробелов.
СТРКМП
Сравнивает две строки в порядке сортировки.
СУБСТР
Возвращает подстроку из строки, начинающейся с заданной позиции.
ПОДСТРОКА
Возвращает подстроку из строки, начинающейся с заданной позиции.
SUBSTRING_INDEX
Возвращает подстроку из строки до количества вхождений разделителя.
TO_BASE64
Преобразует строку в форму, закодированную в base-64.
TO_CHAR
Преобразует выражение типа даты/времени/отметки времени в строку.
ТРИМ
Возвращает строку со всеми удаленными префиксами или суффиксами.
TRIM_ORACLE
Синоним для версии TRIM() в режиме Oracle.
UCASE
Синоним ВЕРХНЯЯ().
РАЗСЖАТИЕ
Распаковывает строку, сжатую с помощью COMPRESS().
UNCOMPRESSED_LENGTH
Возвращает длину строки до сжатия с помощью COMPRESS().
UNHEX
Интерпретирует пары шестнадцатеричных цифр как числа и преобразует в символ, представленный числом.
ОБНОВЛЕНИЕXML
Заменить XML.
ВЕРХНИЙ
Преобразует строку в верхний регистр.
WEIGHT_STRING
Вес входной строки.
Преобразование типа
Когда происходит неявное преобразование типов.
Контент, воспроизведенный на этом сайте, является собственностью его соответствующих владельцев,
и этот контент не проверяется заранее MariaDB.