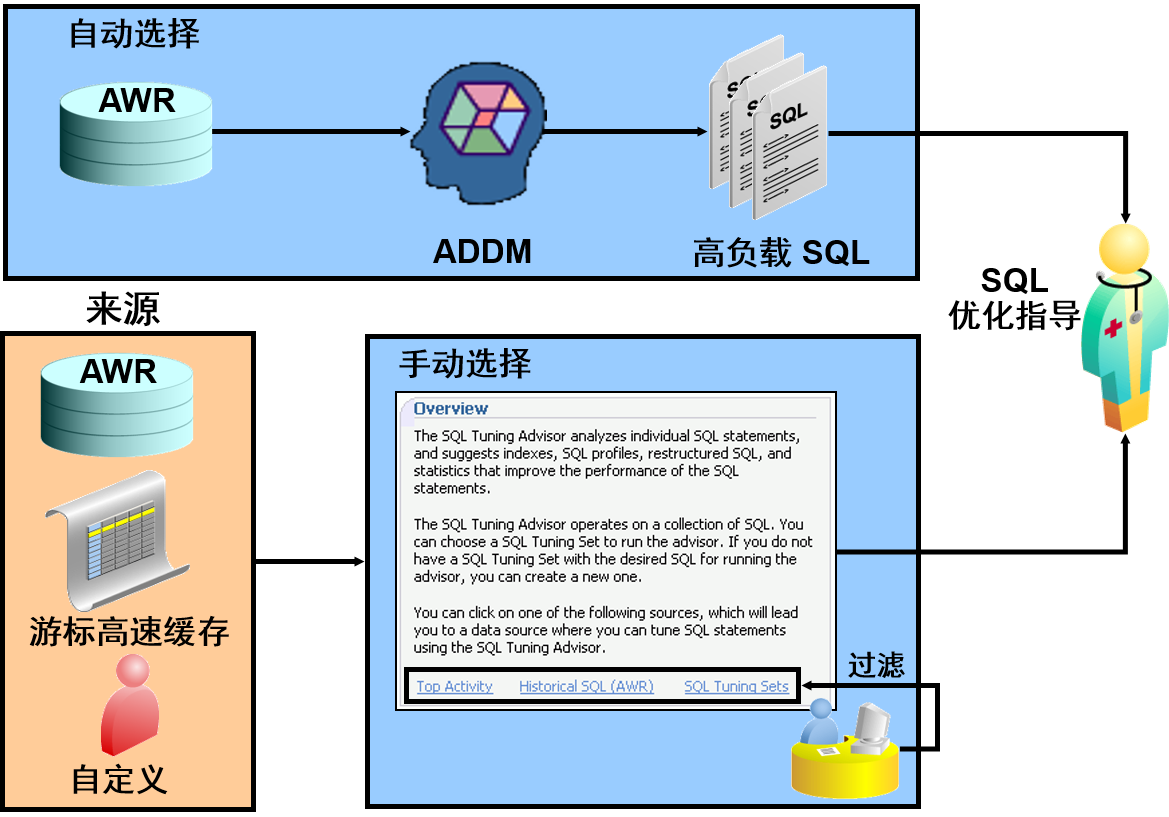
Sql group by having описание: Оператор SQL HAVING: примеры, синтаксис
Содержание
SQL: GROUP BY, HAVING и агрегатные функции
Оператор GROUP BY (инструкции SELECT) позволяет группировать данные (строки) по значению какого-либо столбца или нескольких столбцов или выражений. Результатом будет набор сводных строк.
Каждый столбец в списке выборки должен присутствовать в предложении GROUP BY, исключение составляют только константы и столбцы — операнды агрегатных функций.
Таблицу можно сгруппировать по любой комбинации ее столбцов.
Агрегатные функции используются для получения из группы строк одного единственного суммарного значения. Все агрегатные функции выполняют вычисления над одним аргументом, который может быть или столбцом, или выражением. Результатом вычислений любой агрегатной функции является константное значение, отображаемое в отдельном столбце результата.
Агрегатные функции указываются в списке столбцов инструкции SELECT, которая также может содержать предложение GROUP BY. Если в инструкции SELECT отсутствует предложение GROUP BY, а список столбцов выборки содержит, по крайней мере, одну агрегатную функцию, тогда он не должен содержать простых столбцов. С другой стороны, список выборки столбцов может содержать имена столбцов, которые не являются аргументами агрегатной функции, если эти столбцы служат аргументами предложения GROUP BY.
С другой стороны, список выборки столбцов может содержать имена столбцов, которые не являются аргументами агрегатной функции, если эти столбцы служат аргументами предложения GROUP BY.
Если запрос содержит предложение WHERE, то агрегатные функции вычисляют значение для результатов выборки.
Агрегатные функции MIN и MAX вычисляют наименьшее и наибольшее значение столбца соответственно. Аргументами могут быть числа, строки и даты. Все значения NULL удаляются перед вычислением (т.е. в расчет не берутся).
Агрегатная функция SUM вычисляет общую сумму значений столбца. Аргументами могут быть только числа. Использование параметра DISTINCT устраняет все повторяющиеся значения в столбце перед применением функции SUM. Аналогично удаляются все значения NULL перед применением этой агрегатной функции.
Агрегатная функция AVG возвращает среднее значение для всех значений столбца. Аргументами также могут быть только числа, а все значения NULL удаляются перед вычислением.
Агрегатная функция COUNT имеет две разные формы:
- COUNT([DISTINCT] col_name) — подсчитывает количество значений в столбце col_name, значения NULL не учитываются
- COUNT(*) — подсчитывает количество строк в таблице, значения NULL также учитываются
Если в запросе используется ключевое слово DISTINCT, перед применением функции COUNT удаляются все повторяющиеся значения столбца.
Функция COUNT_BIG аналогична функции COUNT. Единственное различие между ними заключается в типе возвращаемого ими результата: функция COUNT_BIG всегда возвращает значения типа BIGINT, тогда как функция COUNT возвращает значения данных типа INTEGER.
В предложении HAVING определяется условие, которое применяется к группе строк. Оно имеет такой же смысл для групп строк, что и предложение WHERE для содержимого соответствующей таблицы (WHERE применяется до группировки, HAVING после):
Transact-SQL
HAVING condition
HAVING condition |
Параметр condition содержит агрегатные функции или константы.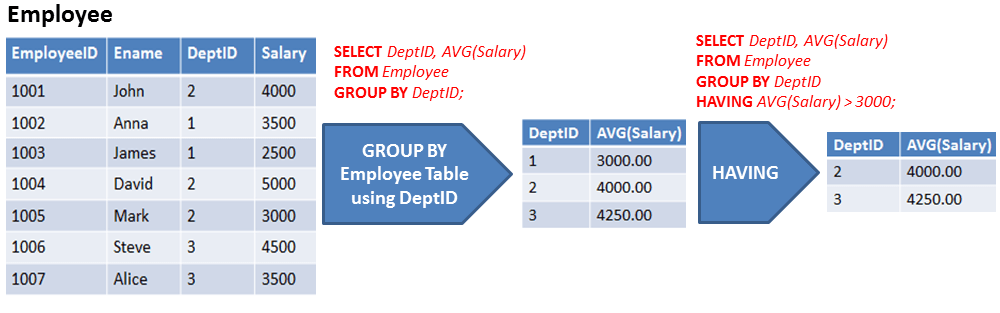
Опубликовано Автор Roman KazakovРубрики SQLМетки MySQL, SQL, Transact-SQL
SQL SELECT Раздел HAVING — Условия поиска на группу строк — HAVING COUNT и HAVING MIN
SELECT HAVING
Наконец, последним при вычислении табличного выражения используется раздел HAVING (если он присутствует).
Раздел HAVING может осмысленно появиться в табличном выражении только в том случае, когда в нем присутствует раздел GROUP BY. Условие поиска этого раздела задает условие на группу строк сгруппированной таблицы. Формально раздел HAVING может присутствовать и в табличном выражении, не содержащем GROUP BY. В этом случае полагается, что результат вычисления предыдущих разделов представляет собой сгруппированную таблицу, состоящую из одной группы без выделенных столбцов группирования.
Условие поиска раздела HAVING строится по тем же синтаксическим правилам, что и условие поиска раздела WHERE, и может включать те же самые предикаты. Однако имеются специальные синтаксические ограничения по части использования в условии поиска спецификаций столбцов таблиц из раздела FROM данного табличного выражения. Эти ограничения следуют из того, что условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки.
Однако имеются специальные синтаксические ограничения по части использования в условии поиска спецификаций столбцов таблиц из раздела FROM данного табличного выражения. Эти ограничения следуют из того, что условие поиска раздела HAVING задает условие на целую группу, а не на индивидуальные строки.
Поэтому в арифметических выражениях предикатов, входящих в условие выборки раздела HAVING, прямо можно использовать только спецификации столбцов, указанных в качестве столбцов группирования в разделе GROUP BY. Остальные столбцы можно специфицировать только внутри спецификаций агрегатных функций COUNT, SUM, AVG, MIN и MAX, вычисляющих в данном случае некоторое агрегатное значение для всей группы строк. Аналогично обстоит дело с подзапросами, входящими в предикаты условия выборки раздела HAVING: если в подзапросе используется характеристика текущей группы, то она может задаваться только путем ссылки на столбцы группирования.
Результатом выполнения раздела HAVING является сгруппированная таблица, содержащая только те группы строк, для которых результат вычисления условия поиска есть TRUE. В частности, если раздел HAVING присутствует в табличном выражении, не содержащем GROUP BY, то результатом его выполнения будет либо пустая таблица, либо результат выполнения предыдущих разделов табличного выражения, рассматриваемый как одна группа без столбцов группирования.
HAVING COUNT
SELECT HAVING COUNT. Пример.
Выбрать коды товаров, покупаемых более чем одним покупателем:
SELECT stock FROM ordsale GROUP BY stock HAVING COUNT(*) > 1;
HAVING MIN
SELECT HAVING MIN. Пример.
Получить значения минимального и максимального оклада для клерков каждого отдела, где самое низкое жалованье составляет менее $1,000:
SELECT deptno, MIN(sal), MAX(sal) FROM emp WHERE job = ‘CLERK’ GROUP BY deptno HAVING MIN(sal) < 1000;
SQL GROUP BY — javatpoint
следующий → В SQL оператор Group By используется для организации похожих данных в группы.
Синтаксис: ВЫБЕРИТЕ столбец1, имя_функции (столбец2) Образец таблицы:Сотрудник
Студент
Пример: Группировать по одному столбцу: Группировать по один столбец используется для размещения всех строк с одинаковым значением. Рассмотрим следующий запрос: ВЫБЕРИТЕ ИМЯ, СУММУ (ЗАРПЛАТУ) ОТ СОТРУДНИКА Результат запроса:
В выходных данных строки, содержащие повторяющиеся ИМЯ , сгруппированы под одинаковым ИМЯ, и их соответствующая ЗАРПЛАТА представляет собой сумму ЗАРПЛАТЫ повторяющихся строк.
Рассмотрим следующий запрос: ВЫБЕРИТЕ ТЕМУ, ГОД, Количество (*) Вывод:
В приведенном выше выводе учащиеся с похожими ТЕМА и ГОД сгруппированы в одном месте. Учащиеся, которых объединяет только одно, принадлежат к разным группам. Например, если ИМЯ одинаковое, а ГОД разный. Теперь нам нужно сгруппировать таблицу по более чем одному столбцу или двум столбцам. НАЛИЧИЕ Пункт ГДЕ пункт используется для принятия решения. Наличие предложения Синтаксис: ВЫБЕРИТЕ столбец1, имя_функции (столбец2) Пример: ВЫБЕРИТЕ ИМЯ, СУММУ (ЗАРПЛАТУ) ОТ СОТРУДНИКА Вывод:
В соответствии с вышеприведенным выводом в результате было указано только одно имя в столбце NAME, потому что в базе данных есть только одни данные, сумма зарплаты которых превышает 50000. Его следует размещать в группах, а не в столбцах. Очки:
Следующая темаУчебник по SQL ← предыдущая |
 Данные дополнительно организованы с помощью эквивалентной функции. Это означает, что если разные строки в определенном столбце имеют одинаковые значения, эти строки будут объединены в группу.
Данные дополнительно организованы с помощью эквивалентной функции. Это означает, что если разные строки в определенном столбце имеют одинаковые значения, эти строки будут объединены в группу. Эти значения относятся к указанному столбцу в одной группе. Это означает, что все строки будут помещать одинаковую сумму в один столбец, который относится к одному соответствующему столбцу в одной группе.
Эти значения относятся к указанному столбцу в одной группе. Это означает, что все строки будут помещать одинаковую сумму в один столбец, который относится к одному соответствующему столбцу в одной группе.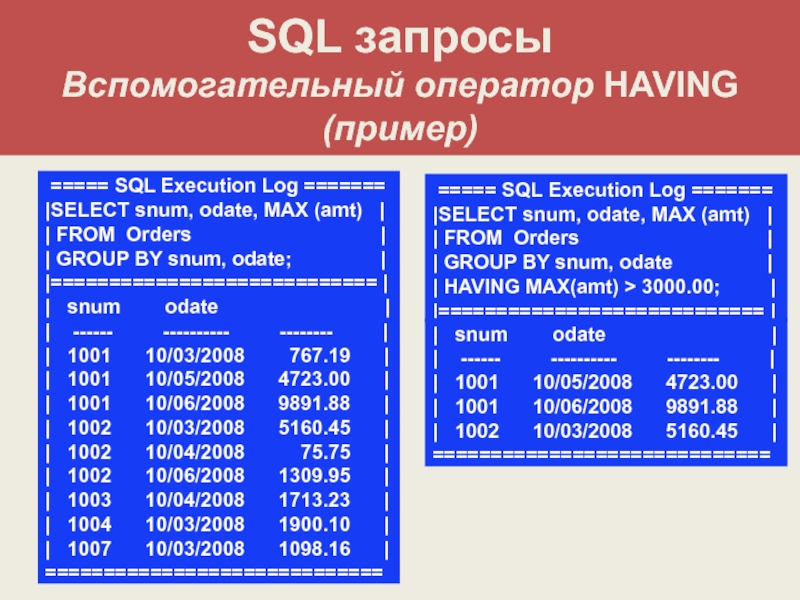 д. . Здесь мы помещаем все строки в группу с одинаковыми значениями столбца 1 и столбца 2 .
д. . Здесь мы помещаем все строки в группу с одинаковыми значениями столбца 1 и столбца 2 . Он используется для размещения условий в столбцах, чтобы определить часть последнего набора результатов группы. Здесь мы не обязаны использовать комбинированные функции, такие как COUNT(), SUM(), и т. д. с предложением WHERE . После этого нам нужно использовать предложение HAVING .
Он используется для размещения условий в столбцах, чтобы определить часть последнего набора результатов группы. Здесь мы не обязаны использовать комбинированные функции, такие как COUNT(), SUM(), и т. д. с предложением WHERE . После этого нам нужно использовать предложение HAVING .
Как использовать предложение GROUP BY в SQL
Data Science
Простые и сложные варианты использования SQL GROUP BY, менее чем за 10 минут
Опубликовано в
·
9043 5 10 минут чтения
·
авг. 4, 2022
4, 2022
Photo by Mariah Hewines on Unsplash
GROUP BY в SQL, объяснения
SQL — язык структурированных запросов — широко используемый инструмент для извлечения данных из реляционной базы данных и их преобразования.
Преобразование данных будет неполным без объединения данных, что является важной концепцией в SQL. А агрегация данных невозможна без GROUP BY! Поэтому важно освоить GROUP BY, чтобы легко выполнять все типы преобразования и агрегирования данных.
В SQL GROUP BY используется для агрегирования данных с использованием агрегатных функций. например СУММ() , МИН() , МАКС() , СРЕДНИЙ() и СЧЕТ() .
Но почему функция агрегации используется в сочетании с GROUP BY?
В SQL предложение GROUP BY используется для группировки строк. Поэтому, когда вы используете агрегатную функцию для столбца, результат описывает данные для этой конкретной группы строк.
В этой статье я объясню 5 примеров использования предложения GROUP BY в запросе SQL, которые помогут вам использовать GROUP BY без каких-либо проблем.
Я сделал эту статью довольно короткой, чтобы вы могли быстро закончить ее и освоить одну из важных концепций SQL.
С помощью этого указателя вы можете быстро перейти к любимой части.
· GROUP BY с агрегатными функциями
· GROUP BY без агрегатных функций
· GROUP BY с H AVING
· ГРУППА ПО С ЗАКАЗОМ
· ГРУППА BY с WHERE, HAVING и ORDER BY
📍 Примечание. Я использую браузер SQLite DB и самостоятельно созданные данные о продажах, созданные с использованием Фейкер . Вы можете получить его в моем репозитории Github бесплатно по лицензии MIT License !
Это простой набор данных 9999 x 11, как показано ниже.
Набор фиктивных данных о продажах | Изображение автора
Итак, начнем…
Хорошо, прежде чем двигаться дальше, всегда помните одно правило GROUP BY..
должен либо присутствовать в предложении GROUP BY , либо встречаться как параметр в агрегированной функции.
Теперь давайте начнем с самого простого варианта использования.
Это наиболее часто используемый сценарий, в котором функция агрегирования применяется к одному или нескольким столбцам. Как упоминалось выше, GROUP BY просто группирует вместе строки, которые имеют схожие значения в указанных в нем столбцах.
Например, предположим, вы хотите получить статистическую сводку цены за единицу по каждой категории продуктов. В этом примере конкретно объясняется, как использовать все агрегатные функции.
Такую статистическую сводку можно получить с помощью запроса —
ВЫБЕРИТЕ Product_Category,
MIN(UnitPrice) КАК Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice 904 91 FROM Dummy_Sales_Data_v1
СГРУППИРОВАТЬ ПО Product_Category
Агрегация данных в SQL | Изображение автора
Как вы видите в приведенном выше запросе, вы использовали два столбца — Product_Category и UnitPrice — и последний всегда используется в агрегатных функциях. Следовательно,
Следовательно, Предложение GROUP BY содержит только один оставшийся столбец.
Вы можете заметить, что первая запись в Product_Category — это NULL , что означает, что GROUP BY объединяет все значения NULL в Product_Category 9051 4 в одной группе. Это соответствует стандарту SQL, как указано в Microsoft —
«Если столбец группировки содержит значения NULL, все значения NULL считаются равными и собираются в одну группу».
Кроме того, по умолчанию таблица результатов упорядочена в порядке возрастания столбцов в GROUP BY с NULL (если присутствует) вверху. Если вы не хотите, чтобы NULL был частью вашей таблицы результатов, вы можете в любое время использовать функцию COALESCE и дать осмысленное имя для NULL , как показано ниже.
ВЫБЕРИТЕ ОБЪЕДИНЕНИЕ(Категория_продукта,'Неопределенная_категория') КАК Категория_продукта ,
МИН(Цена за единицу) КАК Самая низкая_Цена за единицу,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
ГРУППИРОВАТЬ ПО Product_Category 90 510 Значения NULL в SQL GROUP BY | Image by Author🚩 Здесь важно отметить —
Хотя
COALESCEприменяется к столбцу Product_Category, на самом деле вы не агрегируете значения из этого столбца.Таким образом, это должно быть частью GROUP BY.
Таким образом, вы можете добавить столько столбцов, сколько вам нужно в
SELECT, примените агрегатную функцию к некоторым или всем столбцам и укажите оставшиеся имена столбцов в предложенииGROUP BY, чтобы получить желаемые результаты.Ну, речь шла об использовании
GROUP BYвместе с функцией агрегации. Но вы также можете использовать это предложение без агрегатных функций, как объяснено далее.Хотя в большинстве случаев
GROUP BYиспользуется вместе с агрегатными функциями, его все же можно использовать без агрегатных функций — для поиска уникальных записей .Предположим, вы хотите получить все уникальные комбинации Sales_Manager и Product_Category . Используя GROUP BY, это очень просто. Все, что вам нужно сделать, это указать все имена столбцов в
GROUP BY, которые вы упомянули вSELECT, как показано ниже.ВЫБЕРИТЕ Product_Category,
Sales_Manager
FROM Dummy_Sales_Data_v1
СГРУППИРОВАТЬ ПО Product_Category,
Sales_ManagerSQL GROUP BY без агрегатных функций | Изображение автора
На данный момент некоторые могут возразить, что те же результаты можно получить, используя ключевое слово
DISTINCTперед именами столбцов.Однако есть две основные причины, по которым вам следует выбрать
GROUP BYвместоDISTINCT, чтобы получить уникальные записи.
- Результаты, полученные с помощью предложения GROUP BY, по умолчанию упорядочены в порядке возрастания. Таким образом, вам не нужно сортировать записи отдельно.
- DISTINCT может быть дорогостоящим, если вы работаете с набором данных с миллионами строк, а ваш SQL-запрос содержит JOIN
Таким образом, использование GROUP BY позволяет эффективно получать уникальные записи из базы данных, даже если вы используете несколько JOIN.
Вы можете прочитать о другом интересном примере использования предложения
GROUP BYв одной из моих предыдущих статей —3 лучших способа найти уникальные записи в SQL
Прекратите использовать DISTINCT! Начните использовать эти быстрые альтернативы, чтобы избежать путаницы!
в направлении datascience.com
Двигаясь дальше, давайте узнаем больше о том, как можно эффективно ограничить выходные данные, полученные с помощью предложения GROUP BY.
В SQL
HAVINGработает по той же логике, что и предложениеWHERE, с той лишь разницей, что оно фильтрует группу записей, а не каждую другую запись.Например, предположим, что вы хотите получить уникальные записи с Категория продукта, менеджер по продажам и стоимость доставки , если стоимость доставки превышает 34 .
Этого можно добиться с помощью
WHERE, а также предложенияHAVING, как указано ниже.-- WHERE пункт SELECT Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
WHERE Shipping_Cost >= 34
ГРУППА ПО Product_Category,
Sales_Manager,
Shipping_Cost -- ИМЕЕТ пункт ВЫБЕРИТЕ Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost
HAV ING Shipping_Cost >= 34Тот же вывод WHERE и HAVING in GROUP BY | Изображение автора
Хотя вышеприведенные оба запроса генерируют один и тот же результат, логика полностью отличается. Предложение
WHEREвыполняется передGROUP BY, поэтому, по сути, оно сканирует весь набор данных на наличие заданного условия.Однако
HAVINGвыполняется послеGROUP BY, поэтому сканируется сравнительно небольшое количество записей, поскольку строки уже сгруппированы.ИМЕЕТ, что экономит время.Ну, допустим, вас мало волнует эффективность. Но теперь вам нужны все категории продуктов и менеджер по продажам , где общая стоимость доставки превышает 6000. И это когда
ИМЕЕТ.Здесь для фильтрации записей здесь нужно использовать условие
SUM(Shipping_Cost) > 6000, и вы не можете использовать какую-либо агрегатную функцию в предложенииWHERE.В этой ситуации вы можете использовать
HAVING, как показано ниже —SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
HAVING SUM(Shipping_Cost) > 6000SQL ГРУППА ПО НАЛИЧИИ | Изображение автора
Как вы использовали агрегацию на Shipping_Cost , в
указывать не нужно ГРУППИРОВАТЬ ПО.ИМЕЮТсканирование на наличие заданного состояния во всех этих группах.Таким образом,
HAVING, используемый в сочетании сGROUP BY, представляет собой оптимизированный способ фильтрации строк на основе условия.🚩 Примечание. Поскольку HAVING выполняется до SELECT, вы не можете использовать псевдонимы столбцов в условиях в предложении HAVING.
Кроме того, несмотря на то, что
GROUP BYупорядочивает записи в возрастающем или алфавитном порядке, иногда может потребоваться расположить записи в соответствии с агрегированными столбцами. И тут в дело вступаетORDER BY.В SQL
ORDER BYиспользуется для сортировки результатов и по умолчанию сортирует их в порядке возрастания. Однако, чтобы получить результат в порядке убывания, вам нужно просто добавить ключевое словоDESCпосле имен столбцов в предложенииORDER BY.Продолжим рассмотренный выше пример. Вы можете видеть, что последний результат упорядочен в возрастающем (алфавитном) порядке, сначала по столбцу Product_Category , а затем по Sales_Manager . Однако значения в последнем столбце — Total_Cost — не упорядочены.
Этого можно добиться с помощью пункта
ORDER BY, как указано ниже.ВЫБЕРИТЕ Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
ГРУППИРОВАТЬ ПО Product_Category,
Sales_Manager
ORDER BY Total_Cost DESCORDER BY По убыванию в SQL | Изображение автора
Понятно, что последний столбец теперь расположен в порядке убывания. Кроме того, вы можете видеть, что теперь нет определенного порядка значений в первых двух столбцах. И это потому, что вы включили их только в
GROUP BY, но не в предложениеORDER BY.Эту проблему можно решить, упомянув их в
Предложение ORDER BY, как показано ниже —SELECT Product_Category,
Sales_Manager,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager 904 91 ЗАКАЗАТЬ ПО Product_Category,
Sales_Manager,
Total_Cost DESCЗАКАЗАТЬ ПО несколько столбцов в SQL | Image by Author
Теперь первые два столбца расположены в порядке возрастания, и только последний столбец — Total_Cost — в порядке убывания. И это потому, что ключевое слово
DESCиспользуется только после имени этого столбца.🚩 Это дает вам важный урок —
Вы можете упорядочить набор данных результатов SQL по нескольким столбцам в разном порядке, т.е. расположить некоторые столбцы в порядке возрастания, а остальные в порядке убывания. Но обратите внимание на порядок, в котором имена столбцов упоминаются в
ORDER BY, так как это меняет результирующий набор.В этом случае важно понять, как работает GROUP BY. Вы задали себе вопрос —
Почему вы не можете видеть все значения в столбце
Total_Costв порядке убывания❓Это потому, что в
упоминаются только первые два столбцаGROUP BY. Все записи организованы в группы на основе значений только в этих двух столбцах, а общая стоимость рассчитывается путем агрегирования значений в столбце Shipping_Cost .Таким образом, итоговые значения затрат в результате располагаются по этим группам, а не по всей таблице.
Вперед, давайте рассмотрим пример, который поможет вам понять разницу между фильтрацией записей и когда использовать
WHEREиHAVINGв сочетании сGROUP BY.Поскольку вы уже ознакомились со всеми концепциями в статье, давайте начнем непосредственно с примера.
Предположим, вы хотите получить список менеджеров по продажам и категорий продуктов для всех заказов, которые не доставлены клиенту.
Теперь вы можете решить эту проблему, выполнив следующие 3 шага —
- Отфильтровать все записи, используя условие
Статус = «Не доставлено». Поскольку это не агрегированный столбец, вы можете использовать для этого WHERE.- Фильтрация записей на основе общей стоимости доставки с использованием условия
SUM(Shipping_Cost) > 1600. Поскольку это агрегированный столбец, для этого следует использовать HAVING.- Чтобы рассчитать общую стоимость доставки, вам необходимо сгруппировать записи по менеджерам по продажам и категориям продуктов, используя
GROUP BYЕсли вы следуете далее, ваш запрос должен выглядеть так —
SELECT Sales_Manager,
Product_Category,
SUM(Shipping_Cost) AS Total_Cost
FROM Dummy_Sales_Data_v1
ГДЕ Статус = «Не доставлено»
СГРУППИРОВАТЬ ПО Sales_Manager,
Product_Category
HAVING SUM(Shipping_Cost) > 1600SQL GROUP BY с WHERE и HAVING | Image by Author
Выдает все уникальные комбинации менеджера по продажам и категорий товаров, удовлетворяющие условиям, указанным в примере.
 Таким образом, это должно быть частью GROUP BY.
Таким образом, это должно быть частью GROUP BY. 
 в запросе.
в запросе.
 Таким образом,
Таким образом,  Логически все строки сгруппированы вместе на основе категории продукта и менеджера по продажам, а затем
Логически все строки сгруппированы вместе на основе категории продукта и менеджера по продажам, а затем 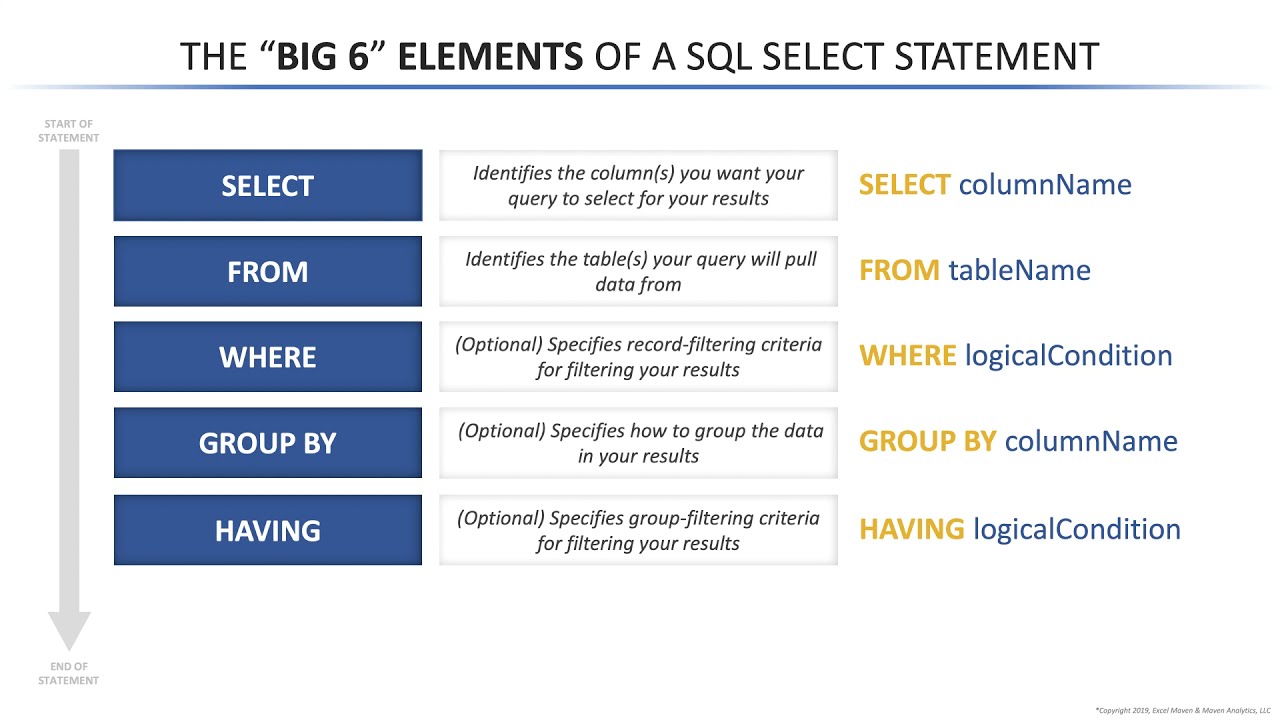


 При этом вы хотите отобразить только тех менеджеров по продажам, которые потратили более 1600 долларов США на доставку товаров в определенной товарной категории.
При этом вы хотите отобразить только тех менеджеров по продажам, которые потратили более 1600 долларов США на доставку товаров в определенной товарной категории.