Sql insert into sql server: INSERT (Transact-SQL) — SQL Server
Содержание
Как сделать вставки в SQL Server в 100 раз быстрее с помощью Pyodbc | Анна Геллер
Опубликовано в
·
Чтение: 3 мин.
·
27 октября 2020 г.
Фото Nextvoyage из Pexels
Недавно я пытался загрузить большие наборы данных в базу данных SQL Server с питоном. Обычно для ускорения вставки с помощью pyodbc я обычно использую функцию cursor.fast_executemany = True , которая значительно ускоряет вставку. Однако сегодня я столкнулся со странной ошибкой и начал копаться глубже в том, как fast_executemany действительно работает.
Когда я пытался загрузить свои данные в SQL Server, я получил сообщение об ошибке: «Ошибка преобразования типа данных varchar в числовой».
Эта ошибка очень сбила меня с толку, поскольку типы данных моего фрейма данных Pandas идеально совпадали с типами, определенными в таблице SQL Server. В частности, данные, которые я пытался загрузить, представляли собой временной ряд с отметкой времени и столбцами измерений + некоторые столбцы метаданных.
Схема моего фрейма данных:
summertime bool
время datetime64[ns]
unique_id объект
измерение float64
введенное datetime64[ns]
обновленное datetime64[ns]
Таблица SQL Server имеет схему, подобную этой:
Schema таблицы SQL-сервера
Если вы посмотрите на типы данных, они идеально совпадают.
Чтобы быстро загрузить эти данные в базу данных SQL Server, я преобразовал кадр данных Pandas в список списков, используя df.values.tolist() . Чтобы загрузить мои данные в экземпляр базы данных, я создал:
- объект подключения к экземпляру базы данных SQL Server
- объект курсора ( из объекта подключения )
- и
INSERT INTOоператор.
Обратите внимание, что в строке 14 мы используем функцию cursor.fast_executemany = True . Выполнение скрипта дало мне следующую ошибку ( с версией: pyodbc==4. ): 0.23
0.23
Ошибка программирования: [Microsoft] [Драйвер ODBC 17 для SQL Server] [SQL Server] Ошибка преобразования типа данных varchar в числовой. (SQLExecute)
Почему pyodbc пытается преобразовать что-то из varchar в 900 13 числовое ?! Когда я закомментировал строку 14, чтобы использовать cursor.executemany() без fast_executemany , скрипт работал просто отлично! Я смог вставить свои данные без каких-либо проблем.
Единственная проблема в том, что без fast_executemany работает медленно.
Согласно Pyodbc Wiki [1]:
fast_executemanyможет повысить производительностьexecutemanyопераций за счет значительного сокращения количества обращений к серверу.
Это основная причина, по которой я хотел это исправить. Согласно выпуску Github от
Согласно выпуску Github от pyodbc репозиторий [2], pyodbc внутренне передает все десятичные значения как строки из-за некоторых несоответствий и ошибок, связанных с десятичными точками, используемыми различными драйверами баз данных . Это означает, что когда мои данные имеют значение 0.021527 или 0.02 , оба эти значения могут быть не приняты, поскольку мой тип данных SQL Server был указан как NUMERIC(18,3) . Кроме того, pyodbc нужны строки, а не числа с плавающей запятой, поэтому правильное значение будет 9.0013 ‘0.021’ т. е. строка ( not float! ) ровно с тремя числами после запятой.
Итак, мое решение сводилось к добавлению этой единственной строки:
Эта строка просто преобразует числа с плавающей запятой в строки, представляющие числа ровно с тремя десятичными точками:
«Странное» решение, которое помогло мне использовать «fast_executemany» с числами с плавающей запятой
После исправления проблема, скрипт работал в 100 раз быстрее по сравнению с его запуском без строки 14 ( cursor.). Обратите внимание, что он такой быстрый, потому что загружает все данные в память перед их загрузкой в SQL Server, поэтому примите во внимание загрузку фрагментами , если вы столкнетесь с ошибками нехватки памяти. fast_executemany = True
fast_executemany = True
Таким образом, мне удалось исправить «Ошибка преобразования типа данных varchar в числовой» путем преобразования моего столбца с плавающей запятой в строку с точно таким же числом десятичной точки, как определено в таблице SQL Server. Меня очень удивило, что pyodbc не справляется с этим под капотом ( или, может быть, это исправлено в более поздних версиях Pyodbc? ).
Если вы нашли это полезным, подпишитесь на меня, чтобы не пропустить мои следующие статьи.
Ресурсы:
[1] https://github.com/mkleehammer/pyodbc/wiki/Features-beyond-the-DB-API
[2] https://github.com/mkleehammer/pyodbc /issues/388
Расширенный SQL: вставка выходных данных параметризованной функции с табличным значением в таблицу SQL
Автор Нисарг Упадхьяй• 7 февраля 2019 г. •
•
15:29•
Разработка баз данных, Таблицы
HomeDatabase development, TablesAdvanced SQL: Вставка вывода параметризованной функции, возвращающей табличное значение, в таблицу SQL
В этой статье я собираюсь продемонстрировать следующее:
- Как вставить вывод функции, возвращающей табличное значение, в таблицу SQL .
- Как вставить выходные данные функции с табличным значением, созданной на удаленном сервере базы данных.
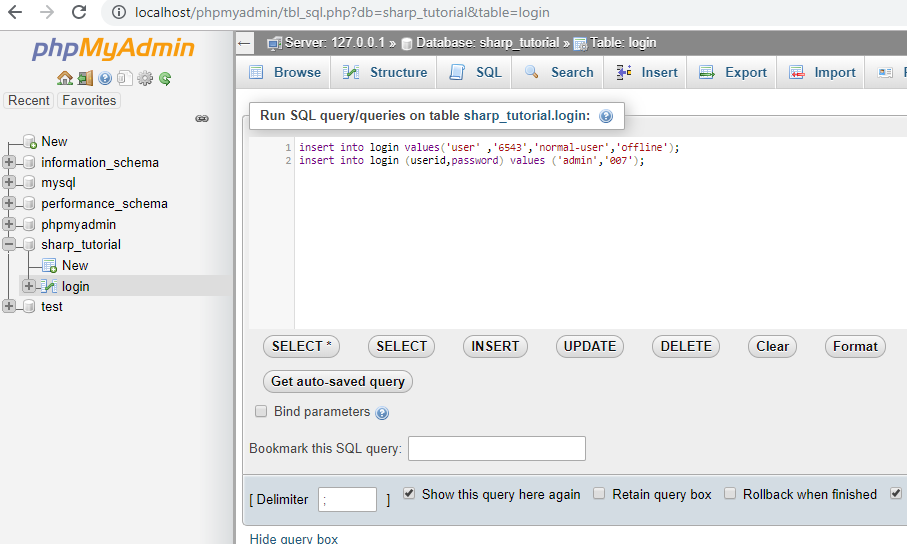
Что такое оператор «Вставить в»
В СУБД «Вставить в» является одним из основных операторов SQL. Он используется для вставки новых записей в таблицу SQL. Используя оператор, мы можем выполнять следующие задачи:
- Вставка новых записей в таблицу (базовая вставка).
- Вставить значения определенного столбца в таблицу.
- Вставьте выходные данные, созданные хранимой процедурой, в таблицу SQL.
Чтобы продемонстрировать вышеизложенное, давайте создадим таблицу с именем « Студенты » на DemoDatabase. Выполните следующий код, чтобы создать таблицу:
Выполните следующий код, чтобы создать таблицу:
CREATE TABLE STUDENTS
(
ID INT IDENTITY(1, 1) PRIMARY KEY,
ИМЯ VARCHAR(250),
ФАМИЛИЯ VARCHAR(250),
ДАТА ПРИЕМА ДАТАВРЕМЯ,
ОЦЕНКА СИМВОЛ(1)
) Выполнение базовой вставки
Чтобы выполнить базовую вставку, нам необходимо указать имя целевой таблицы и значения таблицы. Ниже приведен базовый синтаксис основного оператора вставки:
ВСТАВИТЬ В ЗНАЧЕНИЯ <ИМЯ целевой ТАБЛИЦЫ> ( <значение ДЛЯ СТОЛБЦА 1 >,.. )
Например, мы хотим вставить имя, фамилию и оценку трех учеников в таблицу «Студенты». Для этого выполните следующий код:
INSERT INTO STUDENTS
ЗНАЧЕНИЯ ('NISARG',
'УПАДХЬЯЙ',
'2018-09-11',
«А»)
(«РАГАВ»,
'ДАТТА',
'2017-10-01',
«А»)
(«КИРАН»,
'АМИН',
'2016-01-31',
«А») Выполните запрос «Выбрать» для «Студент», чтобы просмотреть результаты.
ВЫБЕРИТЕ ИМЯ, ФАМИЛИЯ, ДАТА ПРИЕМА, ОЦЕНКА ОТ СТУДЕНТОВ
Результат выглядит следующим образом:
Вставка значений определенного столбца в таблицу
Чтобы вставить значения в определенные столбцы таблицы, необходимо указать имя целевой таблицы и имя столбцов в который вы хотите вставить данные. Ниже приведен синтаксис.
Ниже приведен синтаксис.
ВСТАВИТЬ В <ИМЯ ЦЕЛЕВОЙ ТАБЛИЦЫ> ( СТОЛБЦ 1 , СТОЛБЦ 2 ) ЦЕННОСТИ ( <ЗНАЧЕНИЕ ДЛЯ СТОЛБЦА 1 >, <ЗНАЧЕНИЕ ДЛЯ СТОЛБЦА 1 >.. )
Например, мы хотим вставить имя и фамилию двух студентов в таблицу « Студенты ». Для этого выполните следующий код:
INSERT INTO STUDENTS
(ИМЯ,
ФАМИЛИЯ)
ЗНАЧЕНИЯ ('НИМЕШ',
Упадхья),
(«РУПЕШ»,
'ДАТТА') Выполните запрос «Выбрать» для таблицы « Студенты ».
ВЫБЕРИТЕ ИМЯ, ФАМИЛИЯ, ДАТА ПРИЕМА, ОЦЕНКА FROM STUDENTS
Вывод выглядит следующим образом:
Вставить вывод, сгенерировать с помощью хранимой процедуры
Чтобы вставить вывод хранимой процедуры в таблицу, нам нужно указать имя целевой таблицы и исходную хранимую процедуру . Чтобы сгенерировать вывод хранимой процедуры, нам нужно использовать ключевое слово «exec» или «EXECUTE». Итак, нам нужно указать имя таблицы или имена столбцов, за которыми следует ключевое слово «exec». Ниже приведен синтаксис:
Ниже приведен синтаксис:
ВСТАВИТЬ В <ИМЯ ЦЕЛЕВОЙ ТАБЛИЦЫ> ( СТОЛБЦ 1 , СТОЛБЦ 2 ) EXEC
Например, мы хотим вставить выходные данные процедуры, которая заполняет имена студентов, чья дата поступления не равна нулю. Для этого мы создадим хранимую процедуру с именем « spGet_Student_AdmissionDate ». Чтобы создать хранимую процедуру, выполните следующий код:
USE DEMODATABASE. ИДТИ СОЗДАТЬ ПРОЦЕДУРУ SPGET_STUDENT_ADMISSIONDATE КАК НАЧИНАТЬ ВЫБЕРИТЕ ISNULL(FIRSTNAME, '') + ' ' + ISNULL(LASTNAME, '') AS ИМЯ СТУДЕНТА, ДАТА ПРИЕМА, ОЦЕНКА ОТ СТУДЕНТОВ ГДЕ ДАТА ПРИЕМА НЕ НУЛЕВАЯ КОНЕЦ
После создания процедуры запустите ее, выполнив следующий код:
EXECUTE spGet_Student_Admissiondate
Вывод выглядит следующим образом:
Как я упоминал выше, мы хотим вставить вывод хранимой процедуры с именем « spGet_Student_Admissiondate »во временной таблице. Во-первых, выполните следующий код, чтобы создать таблицу:
( ID INT IDENTITY(1, 1), ИМЯ СТУДЕНТА VARCHAR(250), ДАТА ПРИЕМА ДАТАВРЕМЯ, ОЦЕНКА СИМВОЛ(1) )
После создания таблицы выполните следующий код, чтобы вставить вывод « spGet_Student_Admissiondate » в « #TempStudents ».
ВСТАВИТЬ В #TEMPSTUDENTS EXECUTE SPGET_STUDENT_ADMISSIONDATE Вывод: (затронуты 3 строки)
Теперь давайте проверим вывод « #TEMPSTUDENTS ». Для этого выполните следующий код:
Теперь, как я упоминал выше, я собираюсь продемонстрировать, как мы можем вставить выходные данные, сгенерированные функцией с табличным значением, в таблицу SQL. Во-первых, давайте разберемся, что такое табличная функция.
Что такое функция с табличным значением
Функция с табличным значением — это специальный код T-SQL, который принимает параметр/параметры и на основе условий, определенных в переменной, возвращает набор результатов в табличной переменной. Ниже приведены преимущества использования функции с табличным значением:
- Его можно выполнить в запросе Select.
- Его можно использовать в нескольких частях запроса, например, в операторе Case, в предложениях where/having.
- Результатом функции, возвращающей табличное значение, является набор записей, поэтому вы можете соединить функцию с таблицами.


Вставка вывода встроенной функции, возвращающей табличное значение, в таблицу SQL
В этом разделе я собираюсь объяснить, как вставить вывод функции, возвращающей табличное значение, в таблицу SQL с помощью T-SQL.
Для демонстрации я использую базу данных AdventureWorks2014. Я создал встроенную многозначную табличную функцию с именем « GetEmployeesbyHireDate «. Эта функция заполняет информацию о сотрудниках, нанятых в течение определенной даты и времени. Функция использует @FormDate и @Toda te параметры для фильтрации данных. Вывод функции будет сохранен в таблице SQL.
Следующий код создает функцию:
CREATE FUNCTION GETEMPLOYEESBYHIREDATE (@FROMDATE AS DATETIME, @TODATE AS DATETIME) ВОЗВРАТЫ @EMPLOYEES TABLE ( EMPLOYEENAME VARCHAR (MAX), ДАТА РОЖДЕНИЯ ДАТАВРЕМЯ, ДОЛЖНОСТЬ VARCHAR(150), EMAILID VARCHAR(100), НОМЕР ТЕЛЕФОНА VARCHAR(20), HIREDATE DATETIME ) КАК НАЧИНАТЬ ВСТАВИТЬ В @EMPLOYEES SELECT ( ISNULL( B.
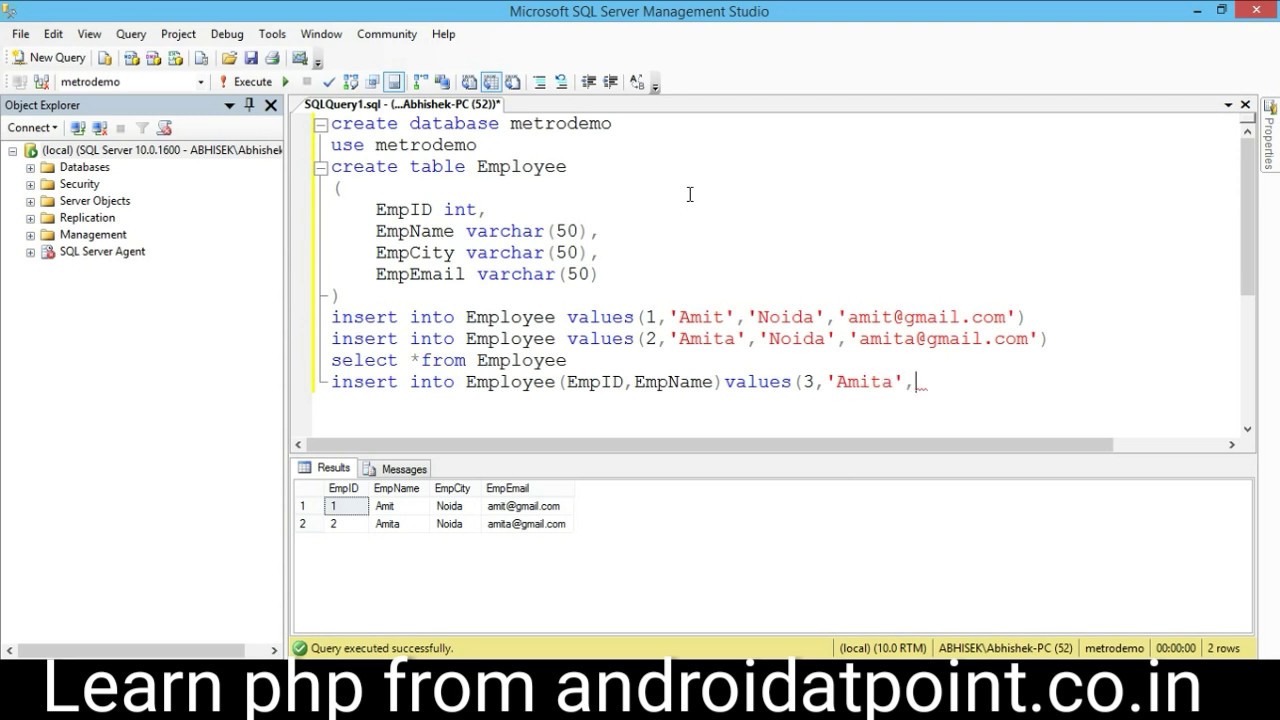 FIRSTNAME, ') + ' '
+ ISNULL( B.MIDDLENAME, ') + ' '
+ ISNULL( B.LASTNAME, '')) AS EMPLOYEENAME,
А.ДАТА РОЖДЕНИЯ,
Б.РАБОТА,
B.АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ,
B.НОМЕР ТЕЛЕФОНА,
A.HIREDATE
ОТ [ОТДЕЛ ЧЕЛОВЕКА].[СОТРУДНИК] A
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [ЧЕЛОВЕЧЕСКИЕ РЕСУРСЫ].[VEMPLOYEE] B
ON A.BUSINESSENTITYID = B.BUSINESSENTITYID
ГДЕ A.HIREDATE МЕЖДУ @FROMDATE И @TODATE
ВОЗВРАЩАТЬСЯ
КОНЕЦ
FIRSTNAME, ') + ' '
+ ISNULL( B.MIDDLENAME, ') + ' '
+ ISNULL( B.LASTNAME, '')) AS EMPLOYEENAME,
А.ДАТА РОЖДЕНИЯ,
Б.РАБОТА,
B.АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ,
B.НОМЕР ТЕЛЕФОНА,
A.HIREDATE
ОТ [ОТДЕЛ ЧЕЛОВЕКА].[СОТРУДНИК] A
ВНУТРЕННЕЕ СОЕДИНЕНИЕ [ЧЕЛОВЕЧЕСКИЕ РЕСУРСЫ].[VEMPLOYEE] B
ON A.BUSINESSENTITYID = B.BUSINESSENTITYID
ГДЕ A.HIREDATE МЕЖДУ @FROMDATE И @TODATE
ВОЗВРАЩАТЬСЯ
КОНЕЦ Используя запрос Select, мы можем получить вывод функции SQL. Например, вы хотите заполнить список сотрудников, принятых на работу в 2009 году. Чтобы получить список, выполните следующий запрос:
DECLARE @FROMDT DATETIME. DECLARE @TODT DATETIME НАБОР @FROMDT='2009-01-01' НАБОР @TODT='2009-12-31' ВЫБИРАТЬ * FROM GETEMPLOYEESBYHIREDATE(@FROMDT, @TODT)
Вывод приведенного выше запроса выглядит следующим образом:
Теперь создайте таблицу с именем » tblEmploye e» для хранения вывода функции « GetEmployeesbyHiredate ». Следующий код создает таблицу с именем « tblEmployee ».
СОЗДАТЬ ТАБЛИЦУ TBLEMPLOYEES ( EMPLOYEENAME VARCHAR (MAX), ДАТА РОЖДЕНИЯ ДАТАВРЕМЯ, ДОЛЖНОСТЬ VARCHAR(150), EMAILID VARCHAR(100), НОМЕР ТЕЛЕФОНА VARCHAR(20), HIREDATE DATETIME )
Как я упоминал ранее, мы хотим заполнить информацию о сотрудниках, принятых на работу в 2009 году.. Для этого вставьте выходные данные функции GetEmployeesbyHireDate в таблицу tblEmployees . Для этого выполните следующий код:
DECLARE @FROMDT DATETIME. DECLARE @TODT DATETIME НАБОР @FROMDT='2009-01-01' НАБОР @TODT='2009-12-31' ВСТАВИТЬ В TBLEMPLOYEES ВЫБЕРИТЕ ИМЯ СОТРУДНИКА, ДАТА РОЖДЕНИЯ, ДОЛЖНОСТЬ, EMAIL ID, НОМЕР ТЕЛЕФОНА, ДАТА ПРИЕМА НА РАБОТУ FROM GETEMPLOYEESBYHIREDATE(@FROMDT, @TODT)
Давайте проверим, что данные были вставлены в таблицу. Для этого выполните следующий код:
ВЫБЕРИТЕ * FROM TBLEMPLOYEES
Вывод выглядит следующим образом:
Вставка данных в таблицы из удаленных баз данных
Иногда может потребоваться извлечь данные с серверов, хранящихся в другом центре обработки данных. Это можно сделать с помощью SQL Linked server.
Это можно сделать с помощью SQL Linked server.
В этом разделе я объясню, как вставить вывод табличной функции, созданной на удаленном сервере. Теперь, чтобы продемонстрировать сценарий, следующая установка.
[идентификатор таблицы = 57 /]
В демо-версии мы выполним следующие задачи:
- На исходном сервере ( SQL_VM_1 ) создадим табличную функцию с именем « getCustomerByCountry » на « База данных AdventureWorks2014 для заполнения данных.
- На целевом сервере создайте связанный сервер с именем « Remote_Server » для выполнения функции ( getCustomerByCountry ).
- На целевом сервере создайте таблицу с именем « Customer » для хранения данных, полученных удаленной функцией ( getCustomerByCountry ).
На следующем изображении показана установка.
Задача, выполняемая на исходном сервере:
На исходном сервере (SQL_VM_1 ) создайте функцию с именем « getCustomerByCountry ».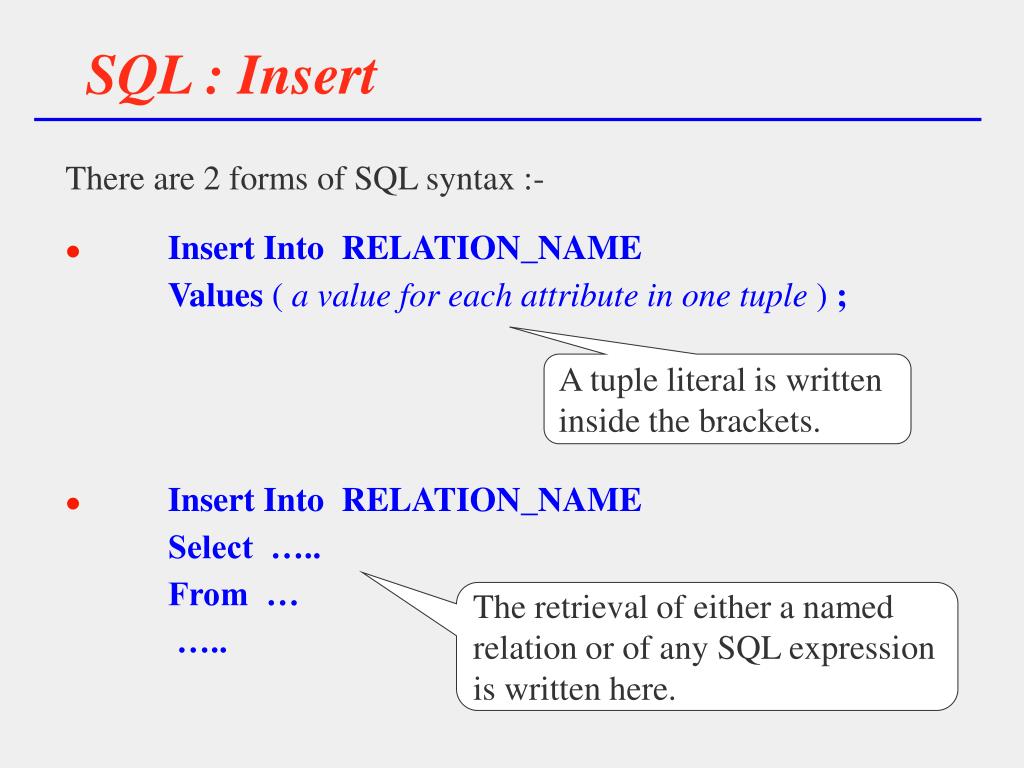 Он заполняет сведения о клиенте, находящемся в определенной стране или регионе. Функция использует параметр @CountryName для фильтрации данных. Выполните следующий код, чтобы создать функцию.
Он заполняет сведения о клиенте, находящемся в определенной стране или регионе. Функция использует параметр @CountryName для фильтрации данных. Выполните следующий код, чтобы создать функцию.
Изменить ФУНКЦИЮ Getcustomerbycountry(@CountryName VARCHAR)
возвращает ТАБЛИЦУ @Customers (
имя_клиента VARCHAR(500),
числовое обозначение VARCHAR(50),
адрес электронной почты VARCHAR(100),
адрес VARCHAR(max),
город ВАРЧАР(150),
страна ВАРЧАР(250),
почтовый индекс VARCHAR(50))
КАК
НАЧИНАТЬ
ВСТАВЬТЕ В @Customers
ВЫБЕРИТЕ имя_клиента,
феникс,
Адрес электронной почты,
адрес,
город,
страна,
Почтовый индекс
ОТ клиентов
ГДЕ страна [электронная почта защищена]
ВОЗВРАЩАТЬСЯ
КОНЕЦ Задачи, которые необходимо выполнить на целевом сервере:
Чтобы заполнить данные с исходного сервера ( SQL_VM_1 ), сначала создайте связанный сервер между исходным ( SQL_VM_1 ) и целевым (SQL_VM_ 2). Выполните следующий код на целевом сервере ( SQL_VM_2 ), чтобы создать связанный сервер.
Выполните следующий код на целевом сервере ( SQL_VM_2 ), чтобы создать связанный сервер.
ИСПОЛЬЗОВАНИЕ [ГЛАВНЫЙ] ИДТИ EXEC MASTER.DBO.SP_ADDLINKEDSERVER @SERVER = N'SQL_VM_1', @SRVPRODUCT=N'SQL SERVER' ИДТИ EXEC MASTER.DBO.SP_ADDLINKEDSRVLOGIN @RMTSRVNAME=N' Remote_Server',@USESELF=N'FALSE',@LOCALLOGIN=NULL,@RMTUSER=N'SA',@RMTPASSWORD='########' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'COLLATION COMPATIBLE', @OPTVALUE=N'TRUE' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'DATA ACCESS', @OPTVALUE=N'TRUE' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'DIST', @OPTVALUE=N'FALSE' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'PUB', @OPTVALUE=N'FALSE' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'RPC', @OPTVALUE=N'TRUE' ИДТИ EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'RPC OUT', @OPTVALUE=N'TRUE' ИДТИ EXEC MASTER.
 DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'SUB', @OPTVALUE=N'FALSE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'CONNECT TIMEOUT', @OPTVALUE=N'0'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'COLLATION NAME', @OPTVALUE=NULL
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'LAZY SCHEMA VALIDATION', @OPTVALUE=N'FALSE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'QUERY TIMEOUT', @OPTVALUE=N'0'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'USE REMOTE COLLATION', @OPTVALUE=N'TRUE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'REMOTE PROC TRANSACTION PROMOTION', @OPTVALUE=N'FALSE'
ВПЕРЕД
DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'SUB', @OPTVALUE=N'FALSE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'CONNECT TIMEOUT', @OPTVALUE=N'0'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'COLLATION NAME', @OPTVALUE=NULL
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'LAZY SCHEMA VALIDATION', @OPTVALUE=N'FALSE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'QUERY TIMEOUT', @OPTVALUE=N'0'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'USE REMOTE COLLATION', @OPTVALUE=N'TRUE'
ИДТИ
EXEC MASTER.DBO.SP_SERVEROPTION @SERVER=N'Remote_Server', @OPTNAME=N'REMOTE PROC TRANSACTION PROMOTION', @OPTVALUE=N'FALSE'
ВПЕРЕД После создания связанного сервера создайте таблицу SQL для хранения информации о клиентах и заполните ее, выполнив функцию SQL, созданную на исходном сервере ( SQL_VM_1 ).
Выполните следующий код, чтобы создать таблицу.
ИСПОЛЬЗОВАТЬ БАЗУ ДЕМОДАННЫХ
ИДТИ
СОЗДАТЬ ТАБЛИЦУ КЛИЕНТОВ
(
ID INT IDENTITY(1, 1),
ИМЯ ЗАКАЗЧИКА VARCHAR(500),
ТЕЛЕФОННЫЙ НОМЕР VARCHAR(50),
АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ VARCHAR(100),
АДРЕС VARCHAR(MAX),
ГОРОД ВАРЧАР(150),
СТРАНА ВАРЧАР(250),
ПОЧТОВЫЙ ИНДЕКС VARCHAR(50)
) Используя связанный сервер, мы можем выполнить табличную функцию, созданную на удаленном сервере базы данных. При попытке выполнить функцию с помощью связанного сервера возникает следующая ошибка:
Сообщение 4122, уровень 16, состояние 1, строка 28. Удаленные вызовы табличных функций не допускаются.
Следовательно, для выполнения любой функции на удаленном сервере нам нужно использовать ключевое слово OPENQUERY. Он используется для инициализации специального распределенного запроса с использованием связанного сервера. Обратитесь к этой статье, чтобы понять концепцию OPENQUERY.
Чтобы использовать OPENQUERY, нам нужно включить расширенный параметр конфигурации с именем « Ad Hoc Distributed Queries » на исходном и целевом серверах. Выполните следующий код, чтобы включить его.
Выполните следующий код, чтобы включить его.
ИСПОЛЬЗОВАНИЕ МАСТЕРА ИДТИ EXEC SP_CONFIGURE 'ПОКАЗАТЬ РАСШИРЕННЫЕ ВАРИАНТЫ', 1 РЕКОНФИГУРАЦИЯ С ПЕРЕОПРЕДЕЛЕНИЕМ EXEC SP_CONFIGURE «СПЕЦИАЛЬНЫЕ РАСПРЕДЕЛЕННЫЕ ЗАПРОСЫ», 1 RECONFIGURE WITH OVERRIDE
Теперь я хочу заполнить список клиентов, находящихся в Соединенном Королевстве, и вставить их в « Customers 9».0038» таблица. Как я уже упоминал, функция принимает название страны для фильтрации записей. Теперь нам нужно выполнить следующий скрипт на целевом сервере ( SQL_VM_2 ), чтобы заполнить список клиентов, находящихся в «Соединенном Королевстве».
ВЫБЕРИТЕ ИМЯ ЗАКАЗЧИКА,
ФЕНЧИСЛО,
АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ,
АДРЕС,
ГОРОД,
СТРАНА,
ПОЧТОВЫЙ ИНДЕКС
ОТ ОТКРЫТОГО ЗАПРОСА([TTI609-VM2],
'ОБЪЯВИТЬ @COUNTRY VARCHAR(150)
НАБОР @COUNTRY=''СОЕДИНЕННОЕ КОРОЛЕВСТВО''
ВЫБЕРИТЕ * ИЗ [ADVENTUREWORKS2014].DBO.GETCUSTOMERBYCOUNTRY(''''+ @COUNTRY +'''')'
) Вывод выглядит следующим образом:
Теперь, чтобы вставить данные, заполненные в таблицу «Клиенты», выполните следующий скрипт на целевом сервере ( SQL_VM_2 ).
ВСТАВИТЬ В КЛИЕНТЫ (ИМЯ ЗАКАЗЧИКА, НОМЕР ТЕЛЕФОНА, АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ, АДРЕС, ГОРОД, СТРАНА, ПОЧТОВЫЙ КОД)
ВЫБЕРИТЕ ИМЯ ЗАКАЗЧИКА,
ФЕНЧИСЛО,
АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ,
АДРЕС,
ГОРОД,
СТРАНА,
ПОЧТОВЫЙ ИНДЕКС
ОТ ОТКРЫТОГО ЗАПРОСА([TTI609-VM2],
'ОБЪЯВИТЬ @COUNTRY VARCHAR(150)
НАБОР @COUNTRY=''СОЕДИНЕННОЕ КОРОЛЕВСТВО''
ВЫБЕРИТЕ * ИЗ [ADVENTUREWORKS2014].DBO.GETCUSTOMERBYCOUNTRY(''''+ @COUNTRY +'''')'
)
/*Выход*/
(19Затронуто 13 строк) Теперь давайте проверим, правильно ли вставлены данные. Для проверки выполните следующий запрос на целевом сервере (SQL_VM_2).
ИСПОЛЬЗОВАТЬ БАЗУ ДЕМОДАННЫХ
ИДТИ
ВЫБЕРИТЕ 20 ТОП-20 CUSTOMER_NAME,
НОМЕР ТЕЛЕФОНА,
АДРЕС ЭЛЕКТРОННОЙ ПОЧТЫ,
АДРЕС,
ГОРОД,
СТРАНА,
ПОЧТОВЫЙ ИНДЕКС
ОТ КЛИЕНТОВ Вывод выглядит следующим образом:
Резюме
В этой статье я рассмотрел:
- Оператор «Вставить в» и его использование.