Sql join примеры ms sql: Joins (SQL Server) — SQL Server
Содержание
Лабораторная работа №3
Содержание
Лабораторная работа №3
Использование операторов манипулирования данными в Microsoft SQL Server
Содержание работы:
Пояснения к выполнению работы
Общие положения
Сортировка
Изменение порядка следования полей
Выбор некоторых полей из двух таблиц
Внутреннее объединение (INNER JOIN)
Левое внешнее объединение (LEFT OUTER JOIN)
Правое внешнее объединение (RIGHT OUTER JOIN)
Полное объединение (FULL JOIN)
Выбор строк с указанием критериев поиска (WHERE)
Точное совпадение значений одного из полей
Использование вложенного запроса
Точное несовпадение значений одного из полей
Выбор записей по диапазону значений (Between)
Выбор записей по диапазону значений (In)
Условие неточного совпадения.
 Выбор записей с использованием Like
Выбор записей с использованием LikeВыбор записей по нескольким условиям
Многотабличные запросы (выборка из двух таблиц, выборка из трех таблиц с использованием JOIN)
Вычисления
Вычисление итоговых значений с использованием агрегатных функций
Изменение наименований полей
Использование переменных в условии
Дополнительные задания
Приложение
Создание базы данных
Контрольные вопросы.
 Выбор записей с использованием Like
Выбор записей с использованием LikeNO:user READ:@ALL EDIT:@ALL
Цель работы – научиться использовать операторы манипулирования данными Select, Insert, Update, Delete.
Содержание работы:
Создать с помощью приведенных операторов пример базы данных «Книжное дело», описанный в предыдущей лабораторной работе (если БД отсутствует на сервере).
С помощью операторов Insert создать программу в SQL Server Management Studio через «Создать запрос» для заполнения таблиц данными (по 3-5 записей).
С помощью оператора Select по заданиям выполнить запросы к БД.
Пояснения к выполнению работы
Общие положения
Создать новую базу данных с названием DB_Books с помощью оператора Create Database, создать в ней перечисленные таблицы c помощью
операторов Create table по примеру лабораторной работы №1. Сохранить файл программы с названием ФамилияСтудента_ЛАб_1_DB_Books. В
утилите SQL Server Management Studio с помощью кнопки «Создать запрос» создать отдельные программы по каждому запросу, которые сохранять на диске с названием: ФамилияСтудента_ЛАб_2_№_задания. В сами программы копировать текст задания в виде комментария. Можно сохранять все выполненные запросы в одном файле. Для проверки работы операторов SELECT предварительно создайте программу, которая с помощью операторов INSERT заполнит все таблицы БД DB_Books несколькими записями, сохраните программы с названием ФамилияСтудента_ЛАб_2_Insert.
Оператор Select используется для выбора данных из таблиц.
Для выбора данных из некоторой таблицы нет необходимости знать имена всех ее полей. Звездочка (*) после оператора SELECT означает выбор всех столбцов таблицы. Другими словами, эта команда просто выводит все данные таблицы. Синтаксис:
SELECT * FROM <имя таблицы>
Если необходимо выбрать только определенные столбцы, то нужно их непосредственно указать после слова Select.
Пример. Выбрать сведения о количестве страниц из таблицы Books (поле Pages).
SELECT Pages FROM Books
Пример. Выбрать все данные из таблицы Books.
SELECT * FROM Books
Сортировка
Для упорядочения данных по какому-то полю необходимо выполнить команду
ORDER BY <имя поля>
Записи можно упорядочивать в восходящем (параметр сортировки ASC) или в нисходящем (параметр сортировки DESC) порядке. Параметр сортировки ASC используется по умолчанию.
Пример. Выбрать все сведения о книгах из таблицы Books и отсортировать результат по коду книги (поле Code_book).
SELECT * FROM Books ORDER BY Code_book
Самостоятельно:
Выбрать из таблицы Books коды книг, названия и количество страниц (поля Code_book, Title_book и Pages), отсортировать результат по названиям книг (поле Title_book по возрастанию) и по полю Pages (по убыванию).
Выбрать из таблицы Deliveries список поставщиков (поля Name_delivery, Phone и INN), отсортировать результат по полю INN (по убыванию).
Изменение порядка следования полей
Пример. Выбрать все поля из таблицы Deliveries таким образом, чтобы в результате порядок столбцов был следующим: Name_delivery, INN, Phone, Address, Code_delivery.
SELECT Name_delivery, Phone, INN, Address_del, Code_delivery FROM Deliveries ORDER BY INN DESC
Самостоятельно:
Выбрать все поля из таблицы Publishing_house таким образом, чтобы в результате порядок столбцов был следующим: Publish, City, Code_publish.
Выбор некоторых полей из двух таблиц
Когда нужно выбрать данные, находящиеся в разных таблицах, применяют объединение таблиц. Пусть, например, необходимо выбрать данные, находящиеся в таблицах Books и Authors.
Пусть, например, необходимо выбрать данные, находящиеся в таблицах Books и Authors.
Простейший шаблон объединения двух таблиц выглядит следующим образом:
SELECT * FROM <таблица1> <тип объединения> <таблица2> ON <таблица1>.<столбец1> = <таблица2>.<столбец2>
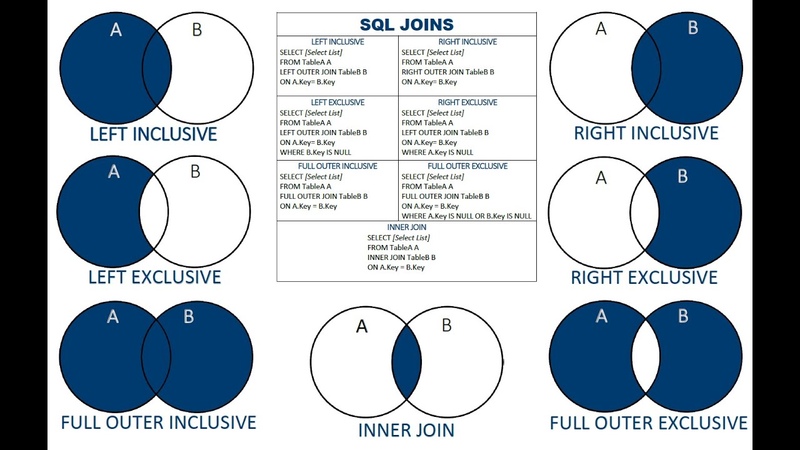
Есть 4 типа объединения.
Внутреннее объединение (INNER JOIN)
При внутреннем объединении в таблицах А и В соединяются только те строки, для которых найдено совпадение, указанное в критерии объединения (после ключевого слова ON). Это наиболее подходящий в нашем случае вариант. Следующий запрос объединяет две таблицы Books и Authors, связанные по полю Code_author.
SELECT * FROM Books INNER JOIN Authors ON Books.Code_author = Authors.Code_author
Левое внешнее объединение (LEFT OUTER JOIN)
Левое внешнее объединение таблиц А и В включает в себя все строки из левой таблицы А и те строки из правой таблицы В, для которых обнаружено совпадение, указанное в критерии объединения (после ключевого слова ON). Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL. Пример запроса:
Для строк из таблицы А, для которых не найдено соответствия в таблице В, в столбцы, извлекаемые из таблицы В, заносятся значения NULL. Пример запроса:
SELECT * FROM Books LEFT OUTER JOIN Authors ON Books.Code_author = Authors.Code_author
Правое внешнее объединение (RIGHT OUTER JOIN)
Правое внешнее объединение таблиц А и В включает в себя все строки из правой таблицы В и те строки из левой таблицы А, для которых обнаружено совпадение, указанное в критерии объединения (после ключевого слова ON). Для строк из таблицы В, для которых не найдено соответствия в таблице А, в столбцы, извлекаемые из таблицы А заносятся значения NULL. Пример запроса:
SELECT * FROM Books RIGHT OUTER JOIN Authors ON Books.Code_author = Authors.Code_author
Полное объединение (FULL JOIN)
Это комбинация левого и правого объединений. В полное объединение таблиц включаются все строки из обеих таблиц. Для совпадающих строк поля заполняются реальными значениями, для несовпадающих строк поля заполняются в соответствии с правилами левого и правого соединений. Пример запроса:
Пример запроса:
SELECT * FROM Books FULL JOIN Authors ON Books.Code_author = Authors.Code_author
Если необходимо вывести не все столбцы, например, два столбца из таблицы Books (Title_book и Authors) и один столбец из таблицы Authors. Для этого нужные столбцы надо явно указать (с учетом идентификатора таблицы, к которой они принадлежат):
SELECT Books.Title_book, Books.Pages, Authors.Name_author FROM Books INNER JOIN Authors ON Books.Code_author = Authors.Code_author
Самостоятельно:
Выбрать из таблицы Books названия книг и количество страниц (поля Title_book и Pages), а из таблицы Deliveries выбрать имя соответствующего поставщика книги (поле Name_delivery).
Выбрать из таблицы Books названия книг и количество страниц (поля Title_book и Pages), а из таблицы Publishing_house выбрать название соответствующего издательства и места издания (поля Publish и City).
Выбор строк с указанием критериев поиска (WHERE)
Предложение WHERE применяется для выбора записей, соответствующих определенным критериям. Критерий поиска состоит из одного или нескольких предикатов. Предикат задает проверку, выполняемую для каждой записи таблицы. Результат проверки может принимать одно из трех значений: «true», «false», «unknown». Команда извлекает для вывода только те строки из таблицы, для которых результат проверки равен «true». В таблице 1 приведен синтаксис различных видов сравнения.
Критерий поиска состоит из одного или нескольких предикатов. Предикат задает проверку, выполняемую для каждой записи таблицы. Результат проверки может принимать одно из трех значений: «true», «false», «unknown». Команда извлекает для вывода только те строки из таблицы, для которых результат проверки равен «true». В таблице 1 приведен синтаксис различных видов сравнения.
Таблица 1
Точное совпадение значений одного из полей
Пример: вывести список названий издательств (поле Title_book) из таблицы Books, которые находятся в(поле Publish) из таблицы Publishing_house .
SELECT books.title_book, publishing_house.publish FROM books INNER JOIN publishing_house ON books.code_publish = publishing_house.code_publish WHERE publishing_house.publish='Лань'
Использование вложенного запроса
Пример: Найти название книг, автором которых является Толстой
SELECT title_book
FROM books
WHERE code_author= ( SELECT code_author
FROM authors
WHERE name_author= 'Толстой') Этот запрос работает если вложенный подзапрос выдает одно число. Если в базе данных есть несколько записей, соответствующих фамилия писателя «Толстой» то запрос завершится с ошибкой в этом случае лучше использовать конструкцию In:
Если в базе данных есть несколько записей, соответствующих фамилия писателя «Толстой» то запрос завершится с ошибкой в этом случае лучше использовать конструкцию In:
SELECT title_book
FROM books
WHERE code_author IN ( SELECT code_author
FROM authors
WHERE name_author= 'Пушкин') Точное несовпадение значений одного из полей
Пример. Вывести список названий издательств (поле Publish) из таблицы Publishing_house, которые не находятся в городе ‘Москва’ (условие по полю City).
SELECT Publish FROM Publishing_house WHERE City <> 'Москва'
Самостоятельно:
Вывести список названий книг (поле Title_book) из таблицы Books,которые выпущены любыми издательствами, кроме издательства ‘Питер-Софт’ (поле Publish из таблицы Publishing_house).
Выбор записей по диапазону значений (Between)
Пример. Вывести фамилии, имена, отчества авторов (поле Name_author) из таблицы Authors, у которых дата рождения (поле Birthday) находится в диапазоне 01. 01.1840 – 01.06.1860.
01.1840 – 01.06.1860.
SELECT name_author FROM Authors WHERE Birthday BETWEEN '01.01.1940' AND '01.01.1960'
Самостоятельно:
Вывести список названий книг (поле Title_book из таблицы Books)и количество экземпляров (поле Amount из таблицы Purchases),которые были закуплены в период с 12.03.2003 по 15.06.2003 (условие по полю Date_order из таблицы Purchases).
Вывести список названий книг (поле Title_book) и количество страниц (поле Pages) из таблицы Books, у которых объем в страницах укладывается в диапазон 200 – 300 (условие по полю Pages).
Вывести список фамилий, имен, отчеств авторов (поле Name_author) из таблицы Authors, у которых фамилия начинается на одну из букв диапазона ‘В’ – ‘Г’ (условие по полю Name_author).
Выбор записей по диапазону значений (In)
Пример. Вывести список названий книг (поле Title_book из таблицы Books)и количество (поле Amount из таблицы Purchases), которые были поставлены поставщиками с кодами 3, 7, 9, 11 (условие по полю Code_delivery из таблицы Purchases).
SELECT Books.Title_book, Purchases.Amount FROM Books INNER JOIN Purchases ON Books.Code_book = Purchases.Code_book WHERE Purchases.Code_delivery IN (3,7,9,11)
Самостоятельно:
Вывести список названий книг (поле Title_book) из таблицы Books, которые выпущены следующими издательствами: ‘Питер-Софт’, ‘Альфа’,‘Наука’ (условие по полю Publish из таблицы Publishing_house).
Вывести список названий книг (поле Title_book) из таблицы Books,которые написаны следующими авторами: ‘Толстой Л.Н.’, ‘Достоевский Ф.М.’, ‘Пушкин А.С.’ (условие по полю Name_author из таблицы Authors).
Условие неточного совпадения. Выбор записей с использованием Like
Пример. Выбрать из справочника поставщиков (таблица Deliveries) названия компаний, телефоны и ИНН (поля Name_company, Phone и INN), у которых название компании (поле Name_company) начинается с ‘ОАО’.
SELECT Name_company, Phone, INN FROM Deliveries WHERE Name_company LIKE 'ОАО%'
Самостоятельно:
Выбрать из таблицы Books названия книг и количество страниц (поля Title_book и Pages), а из таблицы Authors выбрать имя соответствующего автора книг (поле Name_ author), у которых название книги начинается со слова ‘Мемуары’.
Выбрать из таблицы Authors фамилии, имена, отчества авторов (поле Name_ author), значения которых начинаются с ‘Иванов’.
Вывести названия издательств (поле Publish) из таблицы Publishing_house, которые содержат в названии сочетание ‘софт’.
Выбрать названия компаний (поле name_company) из таблицы Deliveries, у которых значение оканчивается на ‘ский’.

Выбор записей по нескольким условиям
Пример. Выбрать коды поставщиков (поле Code_delivery), даты заказов (поле Date_order) и названия книг (поле Title_book), если количество книг (поле Amount) в заказе больше 100 или цена (поле Cost) за книгу находится в диапазоне от 200 до 500.
SELECT Code_delivery, Date_order, Title_book FROM Purchases INNER JOIN Books ON books.code_book=Purchases.code_book WHERE Amount > '100' OR Cost BETWEEN '200' AND '500'
Самостоятельно:
Выбрать коды авторов (поле Code_author), имена авторов (поле Name_author), названия соответствующих книг (поле Title_book), если код издательства (поле Code_Publish) находится в диапазоне от 10 до 25 и количество страниц (поле Pages) в книге больше 120.
Вывести список издательств (поле Publish) из таблицы Publishing_house, в которых выпущены книги, названия которых (поле Title_book)начинаются со слова ‘Труды’ и город издания (поле City) – ‘Новосибирск’.

Многотабличные запросы (выборка из двух таблиц, выборка из трех таблиц с использованием JOIN)
Пример. Вывести список названий компаний-поставщиков (поле Name_company) и названия книг (поле Title_book), которые они поставили в период с 01.01.2002 по 31.12.2003 (условие по полю Date_order).
SELECT books.title_book, deliveries.name_company
FROM (books INNER JOIN purchases
ON books.code_book=purchases.code_book) INNER JOIN deliveries
ON purchases.code_delivery=deliveries.code_delivery
WHERE purchases.date_order BETWEEN '01.01.2010' AND '31.12.2011'Самостоятельно:
Вывести список авторов (поле Name_author), книги которых были выпущены в издательстве ‘Лань’ (условие по полю Publish).
Вывести список поставщиков (поле Name_company), которые поставляют книги издательства ‘Питер’ (условие по полю Publish).
Вывести список авторов (поле Name_author) и названия книг (поле Title_book), которые были поставлены поставщиком ‘ОАО Книготорг’ (условие по полю Name_company).

Вычисления
Рассмотрим вычисления с использованием агрегатных функций
Агрегатные функции – это функции столбца, предназначенные для того, чтобы вычислять некоторое значение для заданного множества строк. Таким множеством строк может быть группа строк, если агрегатная функция применяется к сгруппированной таблице, или вся таблица. Если запросом определено условие WHERE, то для вычисления используются только значения выбранных таким образом строк (то есть тех записей, которые удовлетворяют условию WHERE).
Рассмотрим следующие агрегатные функции:
SUM – возвращает сумму значений столбца группы записей;
COUNT – возвращает количество записей группы;
AVG – возвращает среднее значение столбца группы записей;
MIN – возвращает минимальное значение столбца группы записей;
MAX – возвращает максимальное значение столбца группы записей;
Агрегатные функции используются подобно именам полей в предложении SELECT запроса, но с одним исключением: они берут имя поля как аргумента. Только числовые поля могут использоваться с SUM и AVG. С COUNT, MAX, и MIN, могут использоваться и числовые, и символьные поля.
Только числовые поля могут использоваться с SUM и AVG. С COUNT, MAX, и MIN, могут использоваться и числовые, и символьные поля.
Пример. Определим количество поставщиков книг
SELECT COUNT(code_delivery) FROM Deliveries
Пример. Определить количество книг, имеющих 300 страниц
SELECT COUNT(code_book) FROM Books WHERE Pages >= 300
Предложение GROUP BY используется для определения группы выходных строк, к которым могут применяться агрегатные функции.
Пример. Определить количество книг, соответствующих определенным авторам
SELECT code_author, COUNT (code_book) FROM Books WHERE Pages >= 300 GROUP BY code_author
Предложение HAVING определяет критерии отбора для групп записей, является аналогом предложения WHERE, которое определяет критерии отбора для индивидуальных строк. В запросе SQL предложение HAVING следует за предложением GROUP BY.
Пример. Вывести коды авторов, написавших более одной книги
SELECT code_author, COUNT (code_book) FROM Books WHERE Pages >= 300 GROUP BY code_author HAVING COUNT (code_book) >1
Самостоятельно:
Вывести суммарную стоимость партии одноименных книг (использовать поля Amount и Cost) и название книги (поле Title_book) в каждой поставке.
Вывести стоимость одной печатной страницы каждой книги (использовать поля Cost и Pages) и названия соответствующих книг (поле Title_book).
Вывести количество лет с момента рождения авторов (использовать поле Birthday) и имена соответствующих авторов (поле Name_author).

Вычисление итоговых значений с использованием агрегатных функций
Пример. Вывести общую сумму поставок книг (использовать поле Cost),выполненных `Спектр` (условие по полю Name_company).
USE DB_book SELECT SUM(purchases.cost*purchases.amount) AS VALUE FROM deliveries INNER JOIN purchases ON deliveries.code_delivery = purchases.code_delivery WHERE deliveries.name_company = 'Спектр'
Вывести общее количество всех поставок (использовать любое поле из таблицы Purchases), выполненных в период с 01.01.2010 по 01.02.2013 (условие по полю Date_order).
Вывести среднюю стоимость (использовать поле Cost) и среднее количество экземпляров книг (использовать поле Amount) в одной поставке, где автором книги является `Акунин` (условие по полю Name_author).
Вывести все сведения о поставке (все поля таблицы Purchases), а также название книги (поле Title_book) с минимальной общей стоимостью (использовать поля Cost и Amount).
Вывести все сведения о поставке (все поля таблицы Purchases), а также название книги (поле Title_book) с максимальной общей стоимостью (использовать поля Cost и Amount).
Изменение наименований полей
Пример. Вывести название книги (поле Title_book), суммарную стоимость партии одноименных книг (использовать поля Amount и Cost), поместив в результат в поле с названием Itogo, в поставках за период с 01.01.2010 по 01.06.2012 (условие по полю Date_order).
USE DB_book SELECT books.title_book, purchases.cost*purchases.amount AS Itogo FROM books INNER JOIN purchases ON books.code_book = purchases.code_book WHERE purchases.date_order BETWEEN '01.01.2010' AND '01.06.2012'
Вывести стоимость одной печатной страницы каждой книги (использовать поля Cost и Pages), поместив результат в поле с названием One_page, и названия соответствующих книг (поле Title_book).
Вывести общую сумму поставок книг (использовать поле Cost) и поместить результат в поле с названием Sum_cost, выполненных ‘ОАО Луч’ (условие по полю Name_company).

Использование переменных в условии
Пример. Вывести список книг (поле Title_book), которых закуплено меньше, чем указано в запросе пользователя (условие с использованием поля Amount).
USE DB_book
DECLARE @min_amount INT -- объявляем целочисленную переменную
SET @min_amount = 10 -- присваиваем этой переменной значение 10
SELECT books.title_book, purchases.amount
FROM books INNER JOIN purchases
ON books.code_book = purchases.code_book
WHERE amount < @min_amount -- выбираем из таблицы только те записи названий книг,
-- количество которых меньше @min_amount Вывести список сделок (все поля из таблицы Purchases) за последний месяц (условие с использованием поля Date_order).
Вывести список авторов (поле Name_author), возраст которых меньше заданного пользователем (условие с использованием поля Birthday).

Дополнительные задания
Оператор обработки данных Update
Изменить в таблице Books содержимое поля Pages на 300, если код автора (поле Code_author) =56 и название книги (поле Title_book) =’Мемуары’.
Изменить в таблице Deliveries содержимое поля Address на ‘нет сведений’, если значение поля является пустым.
Увеличить в таблице Purchases цену (поле Cost) на 20 процентов, если заказы были оформлены в течение последнего месяца (условие по полю Date_order).
Оператор обработки данных Insert
Добавить в таблицу Purchases новую запись, причем так, чтобы код покупки (поле Code_purchase) был автоматически увеличен на единицу, а в тип закупки (поле Type_purchase) внести значение ‘опт’.
Добавить в таблицу Books новую запись, причем вместо ключевого поля поставить код (поле Code_book), автоматически увеличенный на единицу от максимального кода в таблице, вместо названия книги (поле Title_book) написать ‘Наука.
Техника. Инновации’.Добавить в таблицу Publish_house новую запись, причем вместо ключевого поля поставить код (поле Code_publish), автоматически увеличенный на единицу от максимального кода в таблице, вместо названия города – ‘Москва’ (поле City), вместо издательства – ‘Наука’ (поле Publish).
 Техника. Инновации’.
Техника. Инновации’.Оператор обработки данных Delete
Удалить из таблицы Purchases все записи, у которых количество книг в заказе (поле Amount) = 0.
Удалить из таблицы Authors все записи, у которых нет имени автора в поле Name_Author.
Удалить из таблицы Deliveries все записи, у которых не указан ИНН (поле INN пусто)
CREATE DATABASE DB_BOOKS
USE DB_BOOKS
CREATE TABLE Authors(
Code_author INT PRIMARY KEY NOT NULL, -- Код автора
Name_author CHAR(30), -- Фамилия автора
Birthday DATETIME -- Дата рождения
)
CREATE TABLE Publishing_house(
Code_publish INT PRIMARY KEY NOT NULL, -- Код издательства
Publish CHAR(30), -- Название издательства
City CHAR(20) -- Город издательства
)
CREATE TABLE Books(
Code_book INT PRIMARY KEY NOT NULL, -- Код книги
Title_book CHAR(40), -- Название книги
Code_author INT FOREIGN KEY REFERENCES Authors(Code_author),
Pages INT,
Code_publish INT FOREIGN KEY REFERENCES Publishing_house(Code_publish)
)
CREATE TABLE Deliveries(
Code_delivery INT PRIMARY KEY NOT NULL, -- Код доставщика
Name_delivery CHAR(30), -- Наименование доставщика
Name_company CHAR(20), -- Наименование компании
Address_company VARCHAR(100), -- Адрес
Phone BIGINT, -- Телефон
INN CHAR(13) -- ИНН
)
CREATE TABLE Purchases(
Code_purchase INT PRIMARY KEY NOT NULL, -- Код продажи
Code_book INT FOREIGN KEY REFERENCES Books(Code_book),
Date_order SMALLDATETIME, -- Дата
Code_delivery INT FOREIGN KEY REFERENCES Deliveries(Code_delivery),
Type_purchase BIT, -- Тип продажи
Cost FLOAT, -- Цена
Amount INT -- Количество
)Для чего применяется предложение WHERE?
Сколько существует типов объединения? Опишите их.
Как сделать выбор записей по диапазону значений?
Что такое вложенный запрос?
Для чего используются агрегатные функции?
Для чего используется конструкция SELECT * ?
Как можно объединить в запросе три таблицы?

Назад: Лабораторная работа №3
SQL optimization. Join против In и Exists. Что использовать?
«Раньше было проще» — Подумал я, садясь за оптимизацию очередного запроса в SQL management studio. Когда я писал под MySQL, реально все было проще — или работает, или нет. Или тормозит или нет. Explain решал все мои проблемы, больше ничего не требовалось. Сейчас у меня есть мощная среда разработки, отладки и оптимизации запросов и процедур/функций, и все это нагромождение создает по-моему только больше проблем. А все почему? Потому что встроенный оптимизатор запросов — зло. Если в MySQL и PostgreSQL я напишу
select * from a, b, c where a.id = b.id, b.
 id = c.id
id = c.idи в каждой из табличек будет хотя бы по 5к строк — все зависнет. И слава богу! Потому что иначе в разработчике, в лучшем случае, вырабатывается ленность писать правильно, а в худшем он вообще не понимает что делает! Ведь этот же запрос в MSSQL пройдет аналогично
select * from a join b on a.id = b.id join c on b.id = c.id
Встроенный оптимизатор причешет быдлозапрос и все будет окей.
Он так же сам решит, что лучше делать — exist или join и еще много чего. И все будет работать максимально оптимально.
Только есть одно НО. В один прекрасный момент оптимизатор споткнется о сложный запрос и спасует, и тогда вы получите большущую проблему. И получите вы ее, возможно, не сразу, а когда вес таблиц достигнет критической массы.
Так вот к сути статьи. exists и in — очень тяжелые операции. Фактически это отдельный подзапрос для каждой строчки результата. А если еще и присутствует вложенность, то это вообще туши свет. Все будет окей, когда возвращается 1, 10, 50 строк. Вы не почувствуете разницы, а возможно join будет даже медленнее. Но когда вытаскивается 500 — начнутся проблемы. 500 подзапросов в рамках одного запроса — это серьезно.
Вы не почувствуете разницы, а возможно join будет даже медленнее. Но когда вытаскивается 500 — начнутся проблемы. 500 подзапросов в рамках одного запроса — это серьезно.
Пусть с точки зрения человеческого понимания in и exists лучше, но с точки зрения временных затрат для запросов, возвращающих 50+ строк — они не допустимы.
Нужно оговориться, что естественно, если где-то убывает — где-то должно прибывать. Да, join более ресурсоемок по памяти, ведь держать единовременно всю таблицу значений и оперировать ею — накладнее, чем дергать подзапросы для каждой строки, быстро освобождая память. Нужно смотреть конкретно по запросу и замерять — критично ли будет использование лишней памяти в угоду времени или нет.
Приведу примеры полных аналогий. Вообще говоря, я не встречал еще запросов такой степени сложности, которые не могли бы быть раскручены в каскад join’ов. Пусть на это уйдет день, но все можно раскрыть.
select * from a where a.id in (select id from b) select * from a where exists (select top 1 1 from b where b.
 id = a.id)
select * from a join b on a.id = b.id
id = a.id)
select * from a join b on a.id = b.id
select * from a where a.id not in (select id from b) select * from a where not exists (select top 1 1 from b where b.id = a.id) select * from a left join b on a.id = b.id where b.id is null
Повторюсь — данные примеры MSSQL оптимизатор оптимизирует под максимальную производительность и на таких простейших запросах тупняков не будет никогда.
Рассмотрим теперь пример реального запроса, который пришлось переписывать из-за того что на некоторых выборках он просто намертво зависал (структура очень упрощена и понятия заменены, не нужно пугаться некоей не оптимальности структуры бд).
Нужно вытащить все дубликаты «продуктов» в разных аккаунтах, ориентируясь на параметры продукта, его группы, и группы-родителя, если таковая есть.
select d.PRODUCT_ID from PRODUCT s, PRODUCT_GROUP sg left join M_PG_DEPENDENCY sd on (sg.
 PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID),
PRODUCT d, PRODUCT_GROUP dg
left join M_PG_DEPENDENCY dd on (dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID)
where s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID
and d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID
and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC
and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME
and s.PRODUCT_NAME=d.PRODUCT_NAME
and s.PRODUCT_TYPE=d.PRODUCT_TYPE
and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE
and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT
and dg.PRODUCT_GROUP_IS_TMPL=0
and (
(
sd.M_PG_DEPENDENCY_CHILD_ID is null
and
dd.M_PG_DEPENDENCY_CHILD_ID is null
)
or exists
(
select 1 from PRODUCT_GROUP sg1, PRODUCT_GROUP dg1
where sd.M_PG_DEPENDENCY_PARENT_ID = sg1.PRODUCT_GROUP_ID and
dd.M_PG_DEPENDENCY_PARENT_ID = dg1.PRODUCT_GROUP_ID and
sg1.PRODUCT_GROUP_PERSPEC=dg1.
PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID),
PRODUCT d, PRODUCT_GROUP dg
left join M_PG_DEPENDENCY dd on (dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID)
where s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID
and d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID
and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC
and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME
and s.PRODUCT_NAME=d.PRODUCT_NAME
and s.PRODUCT_TYPE=d.PRODUCT_TYPE
and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE
and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT
and dg.PRODUCT_GROUP_IS_TMPL=0
and (
(
sd.M_PG_DEPENDENCY_CHILD_ID is null
and
dd.M_PG_DEPENDENCY_CHILD_ID is null
)
or exists
(
select 1 from PRODUCT_GROUP sg1, PRODUCT_GROUP dg1
where sd.M_PG_DEPENDENCY_PARENT_ID = sg1.PRODUCT_GROUP_ID and
dd.M_PG_DEPENDENCY_PARENT_ID = dg1.PRODUCT_GROUP_ID and
sg1.PRODUCT_GROUP_PERSPEC=dg1. PRODUCT_GROUP_PERSPEC and
sg1.PRODUCT_GROUP_NAME=dg1.PRODUCT_GROUP_NAME and
)
)
PRODUCT_GROUP_PERSPEC and
sg1.PRODUCT_GROUP_NAME=dg1.PRODUCT_GROUP_NAME and
)
)
Так вот это тот случай, когда оптимизатор спасовал. И для каждой строчки выполнялся тяжеленный exists, что убивало базу.
select d.PRODUCT_ID
from PRODUCT s
join PRODUCT d on
s.PRODUCT_TYPE=d.PRODUCT_TYPE
and s.PRODUCT_NAME=d.PRODUCT_NAME
and s.PRODUCT_IS_SECURE=d.PRODUCT_IS_SECURE
and s.PRODUCT_MULTISELECT=d.PRODUCT_MULTISELECT
join PRODUCT_GROUP sg on s.PRODUCT_GROUP_ID=sg.PRODUCT_GROUP_ID
join PRODUCT_GROUP dg on d.PRODUCT_GROUP_ID=dg.PRODUCT_GROUP_ID
and sg.PRODUCT_GROUP_NAME=dg.PRODUCT_GROUP_NAME
and sg.PRODUCT_GROUP_PERSPEC=dg.PRODUCT_GROUP_PERSPEC
left join M_PG_DEPENDENCY sd on sg.PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_CHILD_ID
left join M_PG_DEPENDENCY dd on dg.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_CHILD_ID
left join PRODUCT_GROUP sgp on sgp. PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_PARENT_ID
left join PRODUCT_GROUP dgp on
dgp.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_PARENT_ID
and sgp.PRODUCT_GROUP_NAME = dgp.PRODUCT_GROUP_NAME
and isnull(sgp.PRODUCT_GROUP_IS_TMPL, 0) = isnull(dgp.PRODUCT_GROUP_IS_TMPL, 0)
where
(
sd.M_PG_DEPENDENCY_CHILD_ID is null
and
dd.M_PG_DEPENDENCY_CHILD_ID is null
)
or
(
sgp.PRODUCT_GROUP_NAME is not null
and
dgp.PRODUCT_GROUP_NAME is not null
)
go
 PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_PARENT_ID
left join PRODUCT_GROUP dgp on
dgp.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_PARENT_ID
and sgp.PRODUCT_GROUP_NAME = dgp.PRODUCT_GROUP_NAME
and isnull(sgp.PRODUCT_GROUP_IS_TMPL, 0) = isnull(dgp.PRODUCT_GROUP_IS_TMPL, 0)
where
(
sd.M_PG_DEPENDENCY_CHILD_ID is null
and
dd.M_PG_DEPENDENCY_CHILD_ID is null
)
or
(
sgp.PRODUCT_GROUP_NAME is not null
and
dgp.PRODUCT_GROUP_NAME is not null
)
go
PRODUCT_GROUP_ID = sd.M_PG_DEPENDENCY_PARENT_ID
left join PRODUCT_GROUP dgp on
dgp.PRODUCT_GROUP_ID = dd.M_PG_DEPENDENCY_PARENT_ID
and sgp.PRODUCT_GROUP_NAME = dgp.PRODUCT_GROUP_NAME
and isnull(sgp.PRODUCT_GROUP_IS_TMPL, 0) = isnull(dgp.PRODUCT_GROUP_IS_TMPL, 0)
where
(
sd.M_PG_DEPENDENCY_CHILD_ID is null
and
dd.M_PG_DEPENDENCY_CHILD_ID is null
)
or
(
sgp.PRODUCT_GROUP_NAME is not null
and
dgp.PRODUCT_GROUP_NAME is not null
)
go
После данных преобразований производительность вьюхи увеличилась экспоненциально количеству найденных продуктов. Вернее сказать, время поиска оставалось практически независимым от числа совпадений и было всегда очень маленьким. Как и должно быть.
Это наглядный пример того, как доверие MSSQL оптимизатору может сыграть злую шутку. Не доверяйте ему, не ленитесь, join’те ручками, каждый раз думайте что лучше в данной ситуации — exists, in или join.
Синтаксис соединения SQL Server
— он изменился!
Майк Уолш
Хорошо, возможно, название немного вводит в заблуждение… Синтаксис соединения SQL Server изменился некоторое время назад, когда соединения ANSI-92 стали нормой. И Microsoft угрожала удалить его на некоторое время. Старый синтаксис внешнего соединения просто не работает в SQL Server 2012.
Мы все знали, что соединения SQL Server меняются…
Я знаю… Я не сообщаю здесь многим людям ничего нового, не так ли? Большинство из нас уже давно пишет INNER JOIN и LEFT OUTER JOIN. Однако не все получили записку, и небольшая забавная история, которую я пережил со своим клиентом, является хорошим напоминанием об этом. Но сначала…
Обзор эволюции синтаксиса соединения SQL
Раньше вы просто перечисляли свои таблицы в предложении from, разделенные запятой, и соединяли таблицы через предложение where:
SELECT A.
 Column1, B.Column1
Column1, B.Column1 FROM TableName1 AS A, TableName2 AS B
WHERE A.IDColumn = B.IDColumn
Это объединяет TableName1 и TableName2 в любых строках, которые имеют совпадение в столбце ID. Если мы вернемся к нашему соединению SQL Server 101, это означает, что мы делаем внутреннее соединение. Возвращаются строки, удовлетворяющие условию — они должны быть в каждой таблице. Чтобы получить все строки из одной таблицы независимо от того, совпадают ли они, а затем вернуть информацию из других таблиц, если они совпадают, мы выполняем внешнее соединение. Левое внешнее соединение дает нам строки в левой таблице независимо от того, есть совпадение или нет со строками в правой таблице. Если есть совпадение, получите и вторую таблицу, запрошенную строками. Если нет, мы получаем NULL. «Старый» способ сделать это:
SELECT A.Column1, B.Column1
FROM TableName1 AS A, TableName2 AS B
WHERE A.IDColumn *= B.IDColumn
Когда вышел стандарт ANSI-92, слово «JOIN» было добавлен в лексикон, и в конечном итоге он начал распространяться через продукты баз данных.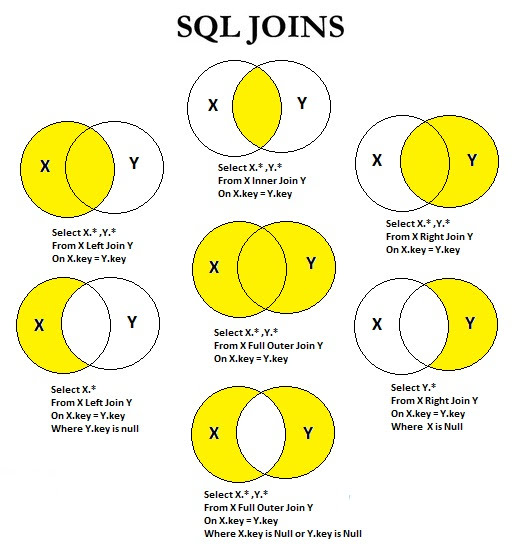 Вместо *= или += в предложении WHERE вы используете правильное слово и просто сообщаете своей СУБД, к чему вы присоединяетесь, через предложение ON. Два приведенных выше примера соответственно становятся:
Вместо *= или += в предложении WHERE вы используете правильное слово и просто сообщаете своей СУБД, к чему вы присоединяетесь, через предложение ON. Два приведенных выше примера соответственно становятся:
SELECT A.Column1, B.Column1
FROM TableName1 AS A
INNER JOIN TableName2 AS B
ON A.IDColumn *= B.IDColumn
AND
SELECT A.Column1, B.Column1
ИЗ имя_таблицы1 AS A
LEFT OUTER JOIN TableName2 AS B
ON A.IDColumn *= B.IDColumn
Хорошо… Так что я, вероятно, просто утомил 95% из вас, читающих это, потому что вы либо уже знали об этом изменении, либо никогда не знали о «старом способе» выполнения соединений. Вы по-прежнему можете выполнять внутренние соединения таким образом (я не рекомендую его по причинам, указанным ниже), но вы не можете выполнять таким образом внешние соединения в SQL Server 2012.
История о присоединениях…
Я делюсь этим не для того, чтобы подшутить над кем-то.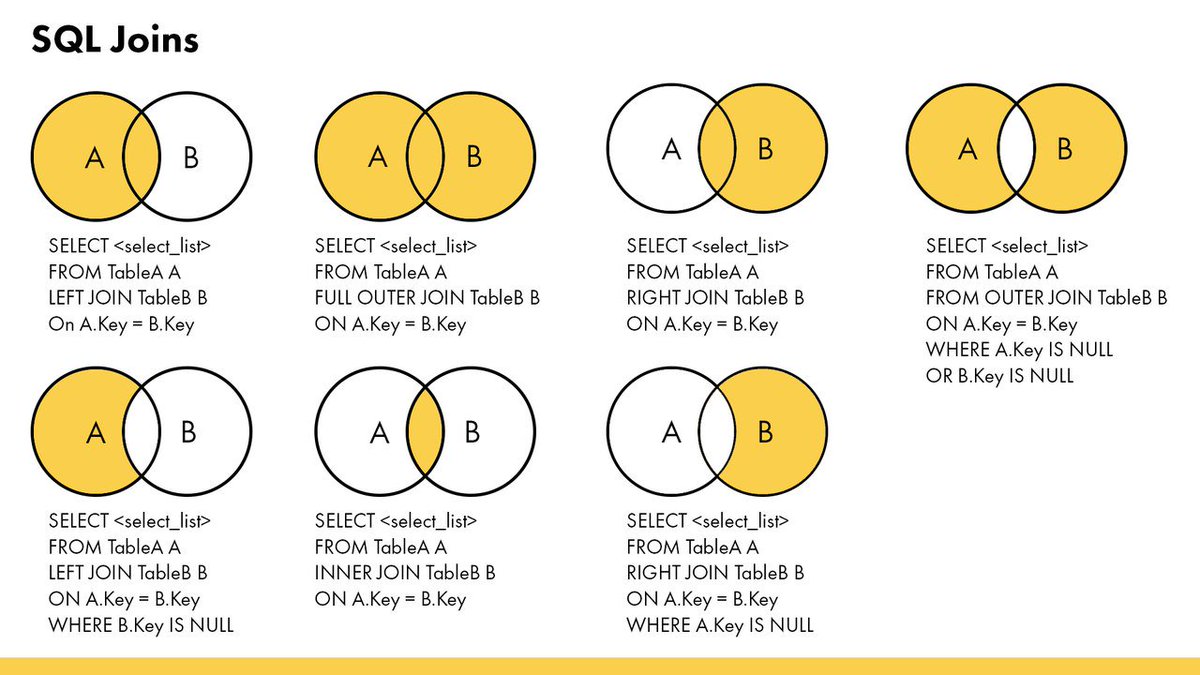 Это реальная история, которая произошла с моим реальным клиентом и настоящим администратором баз данных у их реального клиента. Никакие имена или отрасли не будут делиться здесь. Это забавно, и это, возможно, один из самых забавных обменов мнениями, в которых я участвовал в этом году на работе. (Это было только забавно, потому что это было очень быстро исправлено, и ни один отчет не был поврежден в процессе)..
Это реальная история, которая произошла с моим реальным клиентом и настоящим администратором баз данных у их реального клиента. Никакие имена или отрасли не будут делиться здесь. Это забавно, и это, возможно, один из самых забавных обменов мнениями, в которых я участвовал в этом году на работе. (Это было только забавно, потому что это было очень быстро исправлено, и ни один отчет не был поврежден в процессе)..
Итак.. У меня был клиент, которому я пару раз помогал с консультационной работой. Отличный клиент. Отличный продукт и сервис. Они размещают для подавляющего большинства своих клиентов и предлагают свой продукт как услугу. Пара клиентов, тем не менее, сам хозяин. Они наняли меня, чтобы помочь с настройкой SQL и проверкой работоспособности, чтобы помочь их продукту работать как можно лучше. В процессе этой проверки я заметил, что они время от времени использовали некоторые внешние соединения в старом стиле, которые устарели и вскоре перестанут поддерживаться. Я включил это в список некоторых вещей, над которыми нужно работать. Это было не самым критичным, но я сказал им, что это влияет на читабельность их кода, и поддержка этого синтаксиса ослабевает. Они согласились исправить этот материал и в итоге исправили почти все его экземпляры, но они еще не провели тщательного тестирования 2012 года, поэтому у них была пара здесь или там, которые они оставили без дела..
Это было не самым критичным, но я сказал им, что это влияет на читабельность их кода, и поддержка этого синтаксиса ослабевает. Они согласились исправить этот материал и в итоге исправили почти все его экземпляры, но они еще не провели тщательного тестирования 2012 года, поэтому у них была пара здесь или там, которые они оставили без дела..
Перенесемся на эту неделю… Они позвонили с просьбой о помощи, и это была проблема, связанная с клиентом, поэтому я сказал им, что посмотрю, что я могу сделать. Оказывается, один из их собственных клиентов был обновлен до SQL Server 2012. Им посоветовали тщательно протестировать и убедиться, что все выглядит хорошо, потому что они еще не тестировали приложение на SQL Server 2012. Ну, каким-то образом клиент в конечном итоге выполнил обновление и несколько отчетов начали давать сбой после того, как они успешно работали в течение нескольких дней на SQL Server 2012. Они попросили меня посмотреть, и я быстро просмотрел определения отчетов и нашел «ГДЕ столбец * = столбец» и сказал АГА! Этот синтаксис JOIN не будет работать! И сказал им. Они согласились и начали работать над изменением тех парных отчетов, которые все еще использовали старый синтаксис.
Они согласились и начали работать над изменением тех парных отчетов, которые все еще использовали старый синтаксис.
Я «исправил» опечатки!
Но… Пока я искал проблему, они получили электронное письмо от администратора базы данных/разработчика своего клиента, в котором говорилось, что они нашли и устранили проблему. Клиентские администраторы баз данных оценили ситуацию так: [highlight]В вашем коде была опечатка… Я обнаружил несколько случаев, когда знак «=» заменялся на «*=». Я исправил опечатку и превратил их обратно в знаки «=», и все работает![/highlight]
Сейчас. Поскольку я знал, что у нас есть реальное решение, и скоро все станет лучше, я подумал, что короткий приступ смеха в моем офисе будет нормальным, когда я прочитаю эту записку. Так я и сделал. Я имею в виду.. Это забавно. Если бы это случилось со мной, и я был администратором баз данных, я бы оглянулся назад и тоже подумал бы, что это забавно. Я имею в виду.. Да ладно.. Это смешно. Эти исправления опечаток были тем же самым, что и переписывание «LEFT OUTER JOIN» как «INNER JOIN» — полное изменение поведения и другие результаты определенно могут произойти.
Эти исправления опечаток были тем же самым, что и переписывание «LEFT OUTER JOIN» как «INNER JOIN» — полное изменение поведения и другие результаты определенно могут произойти.
Присоединение к SQL Server — уроки из этого…
Повторюсь — мы исправили ситуацию, все довольны и с той ситуацией все в порядке. Однако после этой ситуации я получил несколько уроков. Я думаю, что они важны (и я также думаю, что они помогают извинить администратора баз данных, который искренне подумал, что это опечатка):
- Существует новое поколение — Не все начинали с этих систем баз данных, когда все начинали с этих систем баз данных. их соединения в предложении WHERE. На самом деле сейчас в наших офисах работает поколение, которое никогда не сталкивалось ни с одним из этих типов соединений. Ни в колледже, ни в поле, ни в книге.
- Кто-то другой поддерживает ваш код – Послушайте. Ваш код не является самодокументируемым. Комментарии не бесполезны. Если вы что-то строите, стройте так, чтобы те, кто придет после вас, могли это взять и работать с этим. Не будьте разработчиком . Это может быть даже вы , который должен получить ваш код позже. Облегчить жизнь следующему человеку…
- Обратите внимание на устаревшие списки — Корпорация Майкрософт ведет их список. Пройдите его, посмотрите, что вы делаете, что не входит в долгосрочный план игры, и адаптируйтесь … Они не просто выдергивают что-то, они, как правило, заранее уведомляют вас о 3 версиях! Если вы планировали поддерживать свой код в будущем, вам не следует делать то, что Microsoft предупредила вас об удалении. Теперь этот мой клиент не знал об этом, и они работали над тем, чтобы приспособиться, но ты?
- Устранение неполадок с дробовиком сложно — Теперь я не слишком сильно виню этого администратора баз данных. Для меня это выглядело бы как опечатка, если бы оно было выделено красными волнистыми линиями, а SSMS сказала бы «недопустимый синтаксис», а запрос прямо над ним имел знак «=», и это сработало. Но… я большой поклонник точного и информированного устранения неполадок, когда ваши данные находятся на линии. Я много веду блог об устранении неполадок, и в этом посте рассказывается о некоторых шагах. Один из них — исследовать решение и понять его.
- Старые левые внешние соединения действительно больше не работают. – Хорошее напоминание. Эти соединения *= не работают в 2012 году. Независимо от того, находитесь ли вы в режиме совместимости с 2008 годом или нет. Приготовьтесь к этому, если вы еще этого не сделали..
- <бессовестная самореклама> Если вы продавец – проверьте свои «вещи» – Одна из вещей, которую мы в Straight Path Solutions делаем хорошо, – помогать поставщикам приложений максимально эффективно использовать их продукты. Мы можем убедиться, что вы делаете все возможное, и мы поможем найти эти потенциальные проблемы до того, как ваши клиенты позвонят нам, и мы поможем им с ними. Независимый взгляд на вашу производительность, рекомендации по обслуживанию и код могут помочь мне не писать подобные сообщения в блоге, а вместо этого писать подобные сообщения.
 Комментарии не бесполезны. Если вы что-то строите, стройте так, чтобы те, кто придет после вас, могли это взять и работать с этим. Не будьте разработчиком . Это может быть даже вы , который должен получить ваш код позже. Облегчить жизнь следующему человеку…
Комментарии не бесполезны. Если вы что-то строите, стройте так, чтобы те, кто придет после вас, могли это взять и работать с этим. Не будьте разработчиком . Это может быть даже вы , который должен получить ваш код позже. Облегчить жизнь следующему человеку… Но… я большой поклонник точного и информированного устранения неполадок, когда ваши данные находятся на линии. Я много веду блог об устранении неполадок, и в этом посте рассказывается о некоторых шагах. Один из них — исследовать решение и понять его.
Но… я большой поклонник точного и информированного устранения неполадок, когда ваши данные находятся на линии. Я много веду блог об устранении неполадок, и в этом посте рассказывается о некоторых шагах. Один из них — исследовать решение и понять его.
Вот и все. Синтаксис соединения SQL Server изменился на , это было совсем недавно и только сейчас (SQL Server 2012) внешние соединения старого стиля больше не являются соединениями SQL Server…
Как использовать SQL Anti-Joins в вашей карьере в науке о данных | by Andreas Martinson
Data Science
И почему вы должны знать о них
Andreas Martinson
·
Follow
Published in
·
5 min читать
·
15 марта 2022 г.
Изображение автора
Слишком часто в социальных сетях я вижу изображения, похожие на показанное выше. Они содержат короткое сообщение о том, что это «обычно используемые соединения SQL». Проблема в том, что эти сообщения обычно не содержат анти-объединений. Я считаю, что анти-объединения важно изучить в начале вашей карьеры, чтобы вы знали о них, когда они вам неизбежно понадобятся. В этом посте я хочу показать вам, как эффективно использовать анти-объединения, чтобы быстро получить необходимые данные.
Я буду использовать эту базу данных песочницы SQLite для своих примеров кода: https://www.sql-practice.com/.
Что такое Anti-Join?
Изображение автора
Вы можете увидеть визуальное представление анти-объединения на изображении выше. Анти-объединение — это когда вы хотите сохранить все записи в исходной таблице, кроме тех записей, которые соответствуют другой таблице. Я никогда не использовал правое анти-соединение в своей работе, левое анти-соединение обычно работает для ваших случаев использования. На самом деле, я обычно вообще не использую правые соединения, поскольку вы можете выполнить то же самое, что и левое соединение, просто изменив порядок таблиц.
Пример антисоединения с использованием кода
Это пример левого антисоединения. Это то же самое, что и левое соединение, за исключением предложения WHERE . Это то, что отличает его от типичного левого соединения.
Вышеприведенный запрос находит все госпитализации, у которых нет соответствующего идентификатора doctor_id в таблице врачей. Если в приведенном выше примере установить для столбца doctor_id значение null, будут найдены все строки в левой таблице, для которых не было соответствующей записи (нулевое значение) в таблице справа.
Если в приведенном выше примере установить для столбца doctor_id значение null, будут найдены все строки в левой таблице, для которых не было соответствующей записи (нулевое значение) в таблице справа.
В данном случае возвращается 0 строк, так как в таблицах одни и те же врачи.
Когда следует использовать анти-соединение?
Описание приведенного выше примера запроса должно прояснить вариант использования. В приведенном выше коде вы можете видеть, что первое CTE (общее табличное выражение) фильтрует таблицу врачей только для общих хирургов.
Эта таблица затем объединяется (используя антисоединение) с таблицей госпитализаций, чтобы найти все госпитализации, в которых не участвовали врачи общей хирургии. Из этого примера вы можете видеть, что этот тип соединения полезен, когда вы хотите найти все те записи, которые не совпадают между двумя соединяемыми таблицами.
Чтобы увидеть эти несовпадения, мы можем изменить приведенный выше запрос, чтобы он был просто левым соединением и отображал все столбцы. Вы увидите, что все несовпадения будут иметь нулевые значения для столбцов таблицы справа.
Вы увидите, что все несовпадения будут иметь нулевые значения для столбцов таблицы справа.
Краткое примечание: вы можете ссылаться на любой столбец в предложении WHERE , он не обязательно должен совпадать со столбцами, которые вы используете для объединения.
Например, вы можете заменить id_терапевта на столбец first_name и получить тот же результат для запроса, показанного в antijoin_example2.sql.
При этом рекомендуется использовать тот же столбец, что и столбец в соединении — я просто подумал, что укажу на это, чтобы помочь вам понять, что делает соединение.
Когда вместо этого следует использовать оператор EXCEPT
Если вы используете Oracle SQL, этот раздел по-прежнему применим, просто замените все ссылки на оператор EXCEPT на оператор МИНУС Вместо оператора .
Я уже слышу, как некоторые люди спрашивают: «Но подождите, оператор , КРОМЕ , уже делает именно это.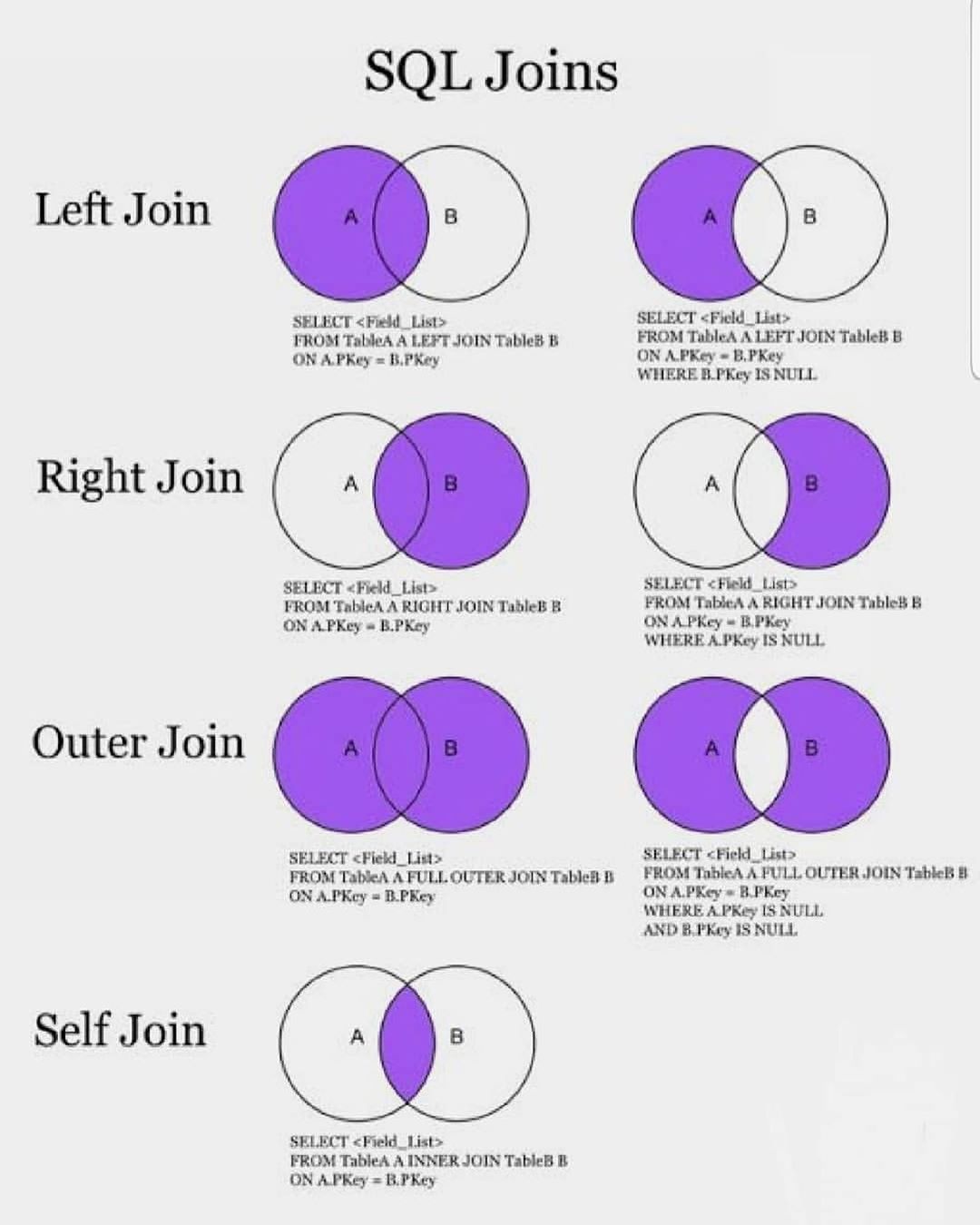 Почему бы мне просто не использовать этот оператор?»
Почему бы мне просто не использовать этот оператор?»
Если вы не знаете, что такое оператор EXCEPT , то, по сути, он берет таблицу и находит все записи в первой таблице, которых нет во второй таблице. Это точно такая же цель, как и анти-объединение, но они используются в разных сценариях:
- Используйте
, ЗА ИСКЛЮЧЕНИЕМ, когда вам нужны только столбцы, которые вы сравниваете между двумя таблицами - Используйте антиобъединение, когда вам нужно больше столбцов, чем вы бы сравнили при использовании оператора
EXCEPT
Если бы мы использовали оператор EXCEPT в этом примере, нам пришлось бы просто соединить таблицу с самой собой. чтобы получить то же количество столбцов, что и исходная таблица допусков.
Как видите, это просто приводит к дополнительному шагу с кодом, который труднее понять и менее эффективен. Вы почти всегда хотите избежать присоединения таблицы к самой себе.
При этом оператор EXCEPT по-прежнему полезен, но не в тех ситуациях, когда вам нужно получить дополнительные столбцы помимо столбцов, которые вы сравниваете при использовании оператора EXCEPT .